软件指标可以帮助您寻找代码中隐藏的设计元素,让它们能够成为惯用模式。
演化架构与紧急设计 的这一期讲解如何使用指标和可视化发现被复杂性掩盖的重要代码元素。
紧急设计的难题之一是寻找隐藏在代码中的惯用模式和其他设计元素。指标和可视化有助于识别代码的重要部分,从而提取出一些设计元素。本文主要讨论两个指标,圈复杂度(cyclomatic
complexity) 和传入耦合(afferent coupling)。圈复杂度度量方法的相对复杂度。传入耦合表示有多少个其他类使用当前类。本文要介绍显示和理解这两个指标的一些工具,以及如何通过组合指标帮助发现设计特征。
我在 “测试驱动设计,第
2 部分” 中讨论过圈复杂度,但是有一些细节没有讨论。通过 Java™ 工具度量圈复杂度的一个难点是工作单元。圈复杂度是方法级度量,但是
Java 编程中的工作单元是类。因此,圈复杂度指标通常表示为类中所有方法的总复杂度或平均复杂度。这两种形式都是有意义的。
例如,可能会出现以下情况。假设一个类包含一个非常复杂的方法 (CC = 40),但是还有许多非常小的方法(比如
Java 代码中常见的 get/set 方法对)。JavaNCSS(见 参考资料)等工具报告所有方法的总复杂度,因此整个类的圈复杂度很高。如果使用
Cobertura 等工具(它们报告类的平均圈复杂度),那么这个类看起来并不糟糕,因为大量简单方法掩盖了那个复杂方法的复杂度。由于工作单元不匹配,所以同时观察圈复杂度的总值和平均值是有意义的。如果单独考虑它们,可能会得出错误的结论。同时使用这两个指标有助于消除这种可能性。
对于设计有意义的其他指标是两个耦合数:传出(efferent) 和传入 耦合。传出耦合度量当前类引用的类的数量。很容易通过简单的检查判断传出耦合:打开要检查的类,统计(字段和参数中)对其他类的引用。传入耦合比较难判断,但是更有价值。它度量使用当前类的其他类的数量。可以使用命令行
fu 判断它,也可以使用理解这个指标的其他工具。这种工具包括 ckjm,这是一个用于运行 Chidamber
& Kemerer 面向对象指标集的开放源码工具(见 参考资料)。尽管
ckjm 的设置和运行有点儿复杂,但是能够提供圈复杂度(报告类中所有方法的圈复杂度总和)以及传出和传入耦合数。
但是,获得了这些数字之后,如何发挥它们的作用呢(尤其在设计方面)?指标数字只提供关于代码的一个信息维,数字本身往往意义不大。可以以两种方式通过指标获得有用的信息。一种方式是观察数值随时间的变化和趋势。还可以把指标组合起来,提供更丰富的信息,本文介绍这种方式。
我在本系列的几篇文章中以 Struts 代码库作为示例,这不是因为我偏爱 Struts,而是因为它是一个著名的开放源码项目。相信我:在世界上的大多数代码中都能够找到隐藏的设计特征!既然前面使用
Struts,本文继续使用它说明我的观点。
ckjm 的输出是文本,这些文本可以转换为 XML(也可以使用 XSLT 转换为其他格式)。图
1 显示几个 ckjm 指标的组合,其中的 WMC (Weight Methods
per Class) 是类的方法的圈复杂度,Ca 是传入耦合。
图 1. 表格形式的 ckjm 指标结果
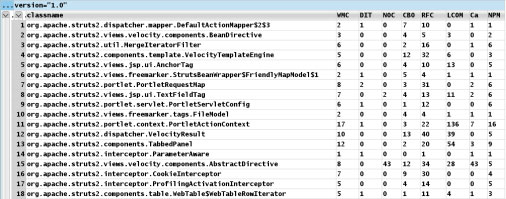
图 2 显示按
WMC 排序的同一个表:
图 2. 按 WMC 排序的 ckjm 指标
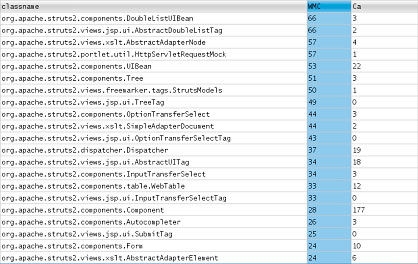
通过观察这个结果可以发现,DoubleListUIBean
是 Struts 代码库中最复杂的类。这说明应该考虑对它进行重构,消除一定的复杂性,寻找可提取出的重复的模式。但是,WMC
值不能指出花时间重构这个类是否值得。注意,这个类的 Ca 是 3。只有 3 个其他类使用这个类,这说明不值得花费大量时间改进这个类的设计。
图 3 显示按
Ca 排序的 ckjm 结果:
图 3. 按传入耦合排序的 ckjm 结果
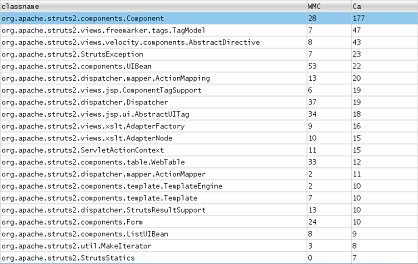
这个组合视图表明,Struts 中最常用的类是 Component(由于 Struts
是 Web 框架,这是很正常的)。尽管 Component 并不复杂,但是有
177 个类使用它,所以它是改进设计的好目标。改进 Component 的设计会影响其他许多类。
WMC 和 Ca 的组合是了解 图
3 提供的信息的最佳方法。这在一个视图中同时指出代码库中最重要和最复杂的部分。即使您以前并不了解这个代码库,也可以通过这个视图了解在哪些方面进行改进会产生最好的结果。尽管这不一定准确,但是与只查看代码相比现在掌握了关于代码库的更多信息。
数字指标提供关于代码的信息,但是它们处于相当低的层次上;它们提供特定类的信息,而不提供代码库的全局视图。现在,有许多工具可以通过可视化把指标提高到下一个层次。
指标的可视化为特定的维提供替代视图,包括单一维和多个维的聚合。Smalltalk 社区开发了许多指标可视化工具(甚至创建了支持这些可视化的
Moose 平台;见 参考资料)。Smalltalk
开发的许多指标技术已经迁移到了 Java 语言。
iPlasma 和行业标准
与圈复杂度相关的常见问题包括 “我的代码与别人的代码相比怎么样?” 和 “对于一个类,多大的数值是合适的?”
iPlasma 项目能够回答这些问题(见 参考资料)。iPlasma
是一个用于面向对象设计的质量评估的平台,是罗马尼亚的一个大学项目。它为项目生成许多重要的指标,并与行业标准范围进行比较。
在运行 iPlasma 时,指定一个源代码目录,它就会生成一个指标金字塔,见 图
4(这是 Struts 2.0.11 代码库的结果):
图 4. iPlasma 指标金字塔
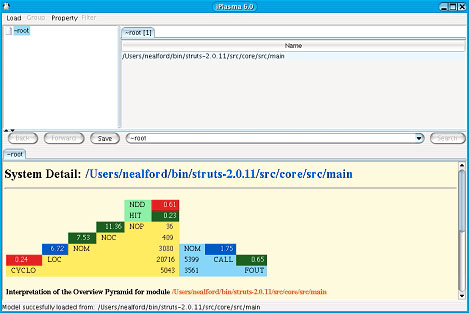
这个金字塔包含大量信息,您要学会如何理解它。每行包含一个彩色的百分数;这个百分数是这一行上的数字和下一行上的数字的比值。表
1 按从上到下的次序说明数字的含义:
表 1. iPlasma 金字塔的含义
| 编码 |
说明 |
| NDD |
直接后代的数量 |
| HIT |
继承树的高度 |
| NOP |
包的数量 |
| NOC |
类的数量 |
| NOM |
方法的数量 |
| LOC |
代码行数 |
| CYCLO |
圈复杂度 |
| CALL |
每个方法的调用数 |
| FOUT |
分散调用(给定的方法调用的其他方法数量) |
数字表示比值;颜色表示比值是否在行业标准范围内(行业标准范围来自大量开放源码项目)。比值是绿色(处于范围内)、蓝色(低于范围)或红色(在范围之外)的。对于
Struts 代码库,NDD 和 CYCLO 的值处于行业标准范围之外,LOC 和 NOM 低于标准范围。表
2 列出使用的范围:
表 2. iPlasma 的行业指标范围
| |
低 |
中等 |
高 |
| CYCLO / 行 |
0.16 |
0.20 |
0.24 |
| LOC / 方法 |
7 |
10 |
13 |
| NOM / 类 |
4 |
7 |
10 |
| NOC / 包 |
6 |
17 |
26 |
| CALLS / 方法 |
2.01 |
2.62 |
3.20 |
| FANOUT / 调用 |
0.56 |
0.62 |
0.68 |
iPlasma 还根据金字塔提供建议,见金字塔下面显示的内容。图 5 显示针对 Struts 的建议:
图 5. iPlasma 建议

iPlasma 生成的数字有两个用途。首先,可以通过它们比较自己和别人的代码库。第二,这些数字指出应该在哪些方面改进代码质量和设计。例如,对于
Struts,iPlasma 指出继承树的深度非常大,而且方法往往太复杂了。但是,必须根据上下文理解这些数字。像
Struts 这样的 Web 框架往往具有非常细致的层次结构,这意味着 NDD 值高可能不要紧。但是,CC
值与上下文关系不大,它太高了,就说明方法级的设计不太合理。
为了进行比较,图 6 显示 iPlasma 为 Vuze 项目生成的金字塔,这是一个用 Java 语言编写的开放源码
BitTorrent 客户机(见 参考资料):
图 6. iPlasma 为 Vuze 生成的金字塔
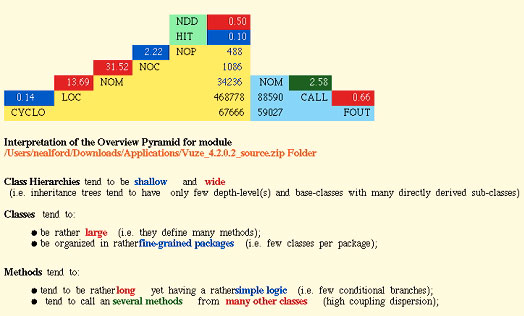
Vuze 是一个大型项目(超过 500,000 行代码),它在继承树的深度、每个类中的方法数量、每个方法的代码行数和每个方法的调用数方面可能有设计问题。
依赖性
紧急设计需要查看代码中的关系和其他高级抽象。试图从源代码调用中看出这些高级概念就像是盲人摸象。这种做法只能了解局部特征,无法获得全局视图。
这种局部化问题使我们很难判断类和对象之间的依赖性。iPlasma 这样的工具可以显示代码的总体特征,但是不能指出哪些部分应该进一步研究。幸运的是,其他工具可以帮助您从不同的角度了解代码。
Smalltalk 社区开发了一个称为 CodeCrawler 的工具(见 参考资料)。它基于
Moose 平台,用图形显示一些代码指标,包括类的大小、方法长度等等。可以让 CodeCrawler 检查
Java 代码,但是很麻烦。幸运的是,因为已经出现了 X-Ray 项目,现在不用费劲儿了(见 参考资料)。
X-Ray 是一个 Eclipse 插件,它生成有助于了解代码总体结构的一些信息,包括类之间依赖性的图形表示,图
7 是 Struts 的依赖性视图:
图 7. X-Ray 类依赖性视图
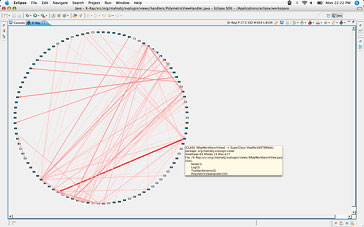
圆周上的每个点是一个类,线表示类之间的依赖性。线的粗细表示依赖性的强度。单击类会显示这个类的相关信息,双击它会在
Eclipse 编辑器中打开它。这个视图包含的信息太多,不容易找到有用的信息。可以放大它以查看各条线。粗线表示类之间的依赖性很强(传出耦合),如果两个类的关系太紧密,可能说明有设计缺陷。
X-Ray 还为包依赖性提供相似的视图,见图 8:
图 8. X-Ray 包依赖性视图
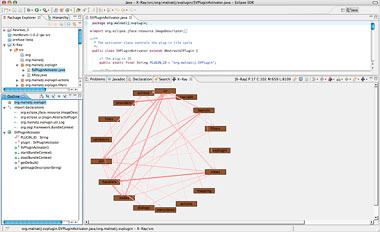
总体结构
还有一个 X-Ray 视图显示有用的代码信息,它也基于 CodeCrawler。系统复杂度视图通过图形显示代码库的情况,继承层次结构显示为自顶向下的树视图,框的大小表示类中的行数,框的宽度表示方法数。图
9 给出系统复杂度视图。
图 9. X-Ray 系统复杂度视图
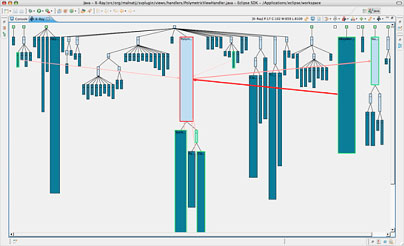
这个视图还把向外调用(传出耦合)显示为粉红线,把向内调用(传入耦合)显示为红线。与前面的视图一样,单击一个框会在
Eclipse 中打开这个类。这个代码视图可以提供独特的视角,仅仅查看代码很难了解到这些信息。如果可以沿着某些维快速地筛选,收缩应该进一步研究的范围,就很容易找到某些方面的设计缺陷。
X-Ray 和 iPlasma 只提供了 Java 代码可用的一小部分可视化特性。适当地使用它们可以快速地收缩关注的范围,有助于找到项目代码中隐藏的设计。寻找惯用模式是紧急设计的关键活动之一,工具有助于轻松地找到模式(包括好的和糟糕的),可以显著降低研究工作量,为重构代码留出更多时间。
学习
获得产品和技术
讨论
| 