|
|
|
|
企业系统的性能与扩展
|
| |
|
作者:Vlad Mihalcea 来源:CSDN 发布于 2016-5-30 |

|
|
|
企业应用需要以尽可能快的速度来存储并检索尽可能多的数据,在应用的性能管理中有两个重要的指标,它们分别是响应时间与吞吐量。
其中响应时间越短,应用的响应度就越高,因此响应时间是衡量性能的指标;而扩展则指的是在保持响应时间较短的同时,提升系统的负载能力,因此吞吐量是可扩展性的衡量指标。
响应时间与吞吐量
“事务响应时间”是根据系统完成一个事务所花费的时间来计算的,因此包含下面这些种类的分段时间:
1.获取数据库连接的时间;
2.将所有数据库语句通过无线发送完毕的时间;
3.执行所有输入语句的时间;
4.将结果发回数据库客户端所花费的时间;
5.在释放数据库连接前,由于执行应用级计算而导致事务呈空闲状态的时间。
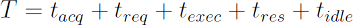
吞吐率是根据输入工作的完成速率来定义的。在数据库概念中,吞吐量可以根据指定时间间隔内所执行的事务数量来计算。
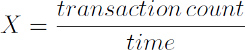
从这个定义我们能够推断出:只要减少事务在执行时所花费的时间,系统就能处理更多的请求。
减少响应时间会让释放数据库连接的速度变得更快,因此每秒能处理的事务就越多。但在高并发环境中,只减少响应时间是不够的。为了保持响应时间有一个固定的最大值,必须根据输入请求的吞吐量相应地增加系统的容量。增加更多的资源可以在一定程度内提升可扩展性,直到容量增益开始下降为止。
容量规划使用了反馈驱动机制,需要持续对应用进行监控,因此任何优化都必须通过应用的性能指标来执行。
向上扩展与横向扩展
扩展就是通过增加更多资源以提高容量。垂直扩展(即向上扩展)指的是在单台机器上增加更多资源,而水平扩展(即横向扩展)指的是增加可用机器的数量。
传统上来说,为数据库服务器增加更多的硬件资源是增加数据库容量的最佳方案。关系数据库是在70年代末出现的,25年之后根据摩尔定律的发展趋势,数据库供应商搭上了硬件发展的东风。
分布式系统比集中式系统更难管理,复杂度大大增加,这就是为什么水平扩展比垂直扩展更具有挑战性的原因。另一方面,配置一台专用的高性能服务器,其价格足以购买多台商品机——而后者可用资源(CPU、内存、硬盘存储器)加起来远比单个专用服务器要多得多。在决定哪种扩展方法更适合指定的企业系统时,价格(包括硬件与证书授权)与固有的开发运营费用都要纳入考量。
构建在许多开源项目(比如PHP,MySQL)之上的Facebook就使用了水平扩展的架构,以适应它那巨大的流量。而StackOverflow则是垂直扩展架构的最佳范例,在一篇博文里,Jeff Atwood解释道:Windows与SQL Server授权的价格也是他们不选择水平扩展方式的原因之一。
无论效果有多强大,一个专用的服务器仍只是一个单独的故障点,若系统可用性出了问题,吞吐量就会降到零。因此在大多企业系统中,对数据库复制是有强制要求的。
主从复制
主从复制方案很适合读写比例较高的企业系统,可以提高其可用性。
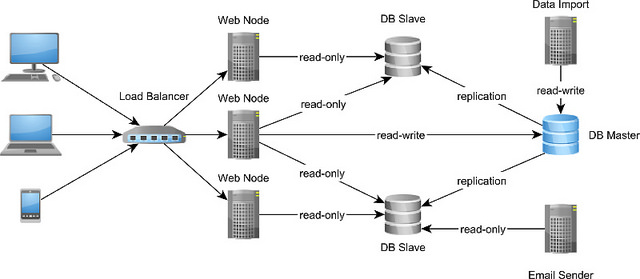
主节点负责记录,它也是唯一接受写入的节点,在主节点上执行的所有记录修改会复制到从节点上。二进制复制使用了主节点预写式日志(WAL),而基于SQL语句的复制则在从节点上完全重演主节点的操作。
异步复制非常常见——特别是在有许多从节点要更新的情况下。虽然从节点的更新速度可能会落后于主节点,但最终结果是一致的。在主节点崩溃的情况下,整个集群会从可用的从节点中选出新的主节点(一般是更新记录最新的那个节点)。
因为主节点不会立刻进行选举,因此异步复制拓扑结构也被称为热备用。
大多数据库系统允许有一个同步的从节点,代价是增加响应时间(主节点必须无停顿地同步通知从节点进行复制)。在主节点发生故障的情况下,自动故障转移机制可以将同步的从节点提升为新的主节点。
拥有一个同步的从节点可以在主节点发生故障的情况下确保系统数据一致,因为这个同步从节点是完全复制主节点的。同步主从复制也被称为热备份拓扑,因为同步从节点时刻准备着顶上主节点的位置。
如果只有异步从节点可用,新选举出来的从节点可能会比发生故障的主节点更新速度慢,在这种情况下系统用一致性与持久性换取了更低的延迟与更高的吞吐量。
除了解决单点故障的问题之外,数据库复制也能增加事务的吞吐量。在主从拓扑中,从节点可以接受只读事务,因此可以分流读取的流量。增加从节点的可用只读连接,可以减少主节点的资源竞争,反过来也能减少读写事务的响应时间。如果主节点不能再与一直增加的读写流量同步,使用多个主节点进行复制也许是更好的选择。
多个主节点复制
在多个主节点的复制方案中,所有节点都是平等的,都可以接受只读与读写事务。这样一来将负载量分配到多个节点上,就可以只增加事务的吞吐量,并减少响应时间了。
然而,由于分布式系统都是与权衡相关的,在多主节点复制方案中想要确保数据的一致性是很有挑战性的,因为单一可信的来源可不止一个。由于同样的数据可以在不同节点上同时修改,因此可能会造成更新冲突的问题。在这种复制方案中,可以考虑采用避免冲突的方式,或者在检测到冲突发生后,自动应用冲突解决算法的方式来解决问题。
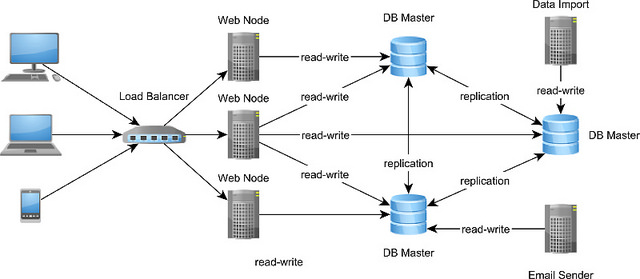
为了避免冲突,可以使用两阶段提交协议,以确保在分布式事务中,要么所有的参与进程都提交事务成功,要么都取消事务。这种设计允许所有节点随时执行同步,不过相对的,也会造成事务响应的时间增加(由于降低了写入操作的速度)。
如果节点分布在广域网(WAN)上,同步延迟可能会大幅增加。如果由于某个节点变得不可访问而造成同步失败,那么所有主节点上的事务都会执行回滚。
尽管从数据一致性的角度来看,避免冲突是更好的办法,但同步复制可能会导致事务响应的时间很长。而异步复制在吞吐量方面更为优秀,前提是必须要解决更新冲突的问题。异步多主节点复制需要有检测冲突的机制以及自动解决冲突的算法,一旦检测到冲突,自动解决方案就会尝试合并这两个冲突分支,在失败的情况下会请求人工介入。
分片
如果数据的规模超出了复制多节点环境的总容量,切分数据就会变得无可避免。分片指的是将数据分布到多个节点上,这样每个实例就只包含整体数据的一个子集。
一般来讲,关系数据库提供了水平分区的方式,即在同一个数据库服务器上将数据分布到多个表格中。与水平分区相反,分片则需要一个分布式的系统拓扑结构,以便数据可以分布在多台机器上。
每个分片必须是独立的,因为用户事务只能使用单个分片内的数据。跨分片连接一般是不允许的,因为分布式加锁和网络开销的成本都可能会导致事务的响应时间很长。
通过减少每个节点的数据大小,就能减少索引所占的空间。请求的数据越少,事务的响应时间也就越短。
典型的分片拓扑结构至少包括两个单独分开的数据中心:
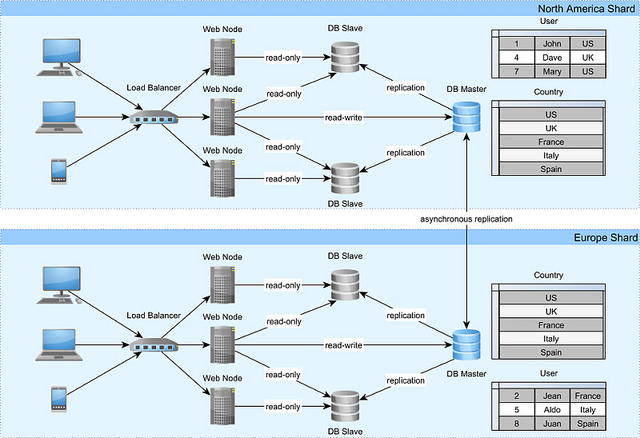
每个数据中心都可以提供一个专门的地理区域,这样就可以跨地理区域来平衡负载。并非所有表格都需要执行跨分片分区,较小的那些会复制到每个分区上。为了保持分片同步,需要采用异步复制机制。
在之前的图表中,系统将国家表格从一个数据中心镜像到另一个,分区只在用户表格中实现。为了避免对跨分片处理数据产生需求,每个用户及其相关的所有数据都只会存放在同一个数据中心上。
在寻求增加系统容量的解决方案中,分片一般是在其他选项都不可用时的最后选择——其他选项包括:
1.优化数据层,缩短事务响应时间;
2.在成本合算的配置前提下,对每个复制节点进行扩展;
3.增加更多复制节点,直到同步延迟开始降到可接受阈值之下。
|
|
|
|
|





