|
|
|
|
Swift 2���ַ�����Ƶı���˼�� |
| |
|
���ߣ� Apple ��Դ��Apple Developer's Blog ���������� ������ 2015-08-18 |

|
|
|
ժҪ��Swift�ṩ�����ܡ�����Unicode��String��Ϊ�����һ���֡���Swift 2.0�У�String���Ͳ��ٷ���CollectionTypeЭ�飬ת���ṩһ�������ַ�����ͼ��charactes���ԡ�Ϊʲô��䣿ƻ������Swift�ٷ������и����˴𰸡�
Swift�ṩ�����ܡ�����Unicode��String��Ϊ�����һ���֣���Swift 2.0�У�String���Ͳ��ٷ���CollectionTypeЭ�飬����String���ַ��ļ��ϣ�������array�����ڣ�String�ṩ��һ�������ַ�����ͼ��charactes���ԡ�
Ϊʲô��䣿��Ȼģ��һ���ַ�����Ϊ�ַ����Ͽ���������Ȼ������String���͵���Ϊ������Array��Set��Dictionary���ּ��������кܴ��������һֱ�����ţ���������Swift 2Э����չ�����ӣ���Щ����ʹ���б�Ҫ����һЩ�����ĸı䡣
��֮��ͬ��Sum
��������һ��Ԫ�ص������У����������Ͻ��������Ԫ�ء�����˵�����㽫һ��ֵ���ӵ�������ʱ�������������ֵ������Ӧ��dictionary��set��Ȼ����������һ��string������һ����ϱ���ַ������ַ������������ݱ����ġ�
�����ַ���cafe���������ĸ��ַ�����c��a��f��e��
var letters: [Character] = ["c", "a", "f", "e"]
var string: String = String(letters)
print(letters.count) // 4
print(string) // cafe
print(string.characters.count) // 4 |
���������һ������ַ�U+0301�͡䣬�ַ�����Ȼ���ĸ��ַ��������������һλ�Ǩ���
let acuteAccent: Character = "\u{0301}" // �� COMBINING ACUTE ACCENT' (U+0301)
string.append(acuteAccent)
print(string.characters.count) // 4
print(string.characters.last!) // �� |
�ڸո�����ַ������ַ����Բ�����ԭʼ��Сд��ĸe��Ҳ������ֻ�Ǹ��ӵġ䡣�෴���ַ��������ڰ���һ��Сд��e�������Ш���
string.characters.contains("e") // false
string.characters.contains("��") // false
string.characters.contains("��") // true |
��������������������������ַ��������������������Ǿ��ȣ�����UIColor.redColor()��UIColor.greenColor()��Ȼ������������UIColor.yellowColor()��
�������������ж�
�ַ����ͼ���֮�����һ������������ȷ����ȵķ�ʽ��
- �������array������ͬ����Ŀ������ÿ��Ԫ������Ӧ��ָ������ȵģ�����array��ȡ�
-
�������sets������ͬ����Ŀ������ÿ��Ԫ�ذ����ڵ�һ��Ԫ��Ҳ�����ڵڶ�����
-
�������dictionaries����ͬ��key��value��������dictionaries��ȡ�
Ȼ��string��������ȼ�ƽ�ȡ��������ͬ��������˼�����������������������ɲ�ͬ��Unicode��ɣ����ʾ��Ч��
�����º���Э��ϵͳ����24����ĸ��ɣ�����Jamo����������ĸ�����Ԫ����������Щ��ĸд������ʱ��ÿ�����ڶ�����ĸ��������ġ��ַ���?����[GA]��������ĸ��?����[ ]���͡�?��[һ]����Swift�У��ַ�������ͬ�ģ��������ɷֽ��Ԥ���ַ����У�
string.characters.contains("e") // false
string.characters.contains("��") // false
string.characters.contains("��") // true |
ͬ����������Ϊ���κο��ٵ��ռ������кܴ�IJ�ͬ���⽫�����˾��ȵļ�ֵ�ͱ���Ϊ�������С�
ȡ������Ĺ۵�
-
characters is a collection of Character values, or extended grapheme clusters.
- unicodeScalars is a collection of Unicode scalar values.
- utf8 is a collection of UTF�C8 code units.
- utf16 is a collection of UTF�C16 code units.
������ǰѡ�CAF����ǰ������ӣ��ɷֽ������[C��A��F��E ]��[��]�������и����ַ�������ͼ��������
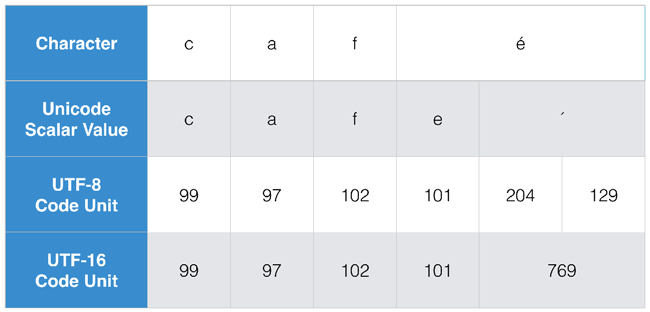
-
characters���Զε��ı���չ���μ�Ⱥ������һ�����Ƶ��û���֪���ַ�������������£�c, a, f, and ��������Ϊһ���ַ��������������ÿһ��λ�ã�ÿ��λ�ó�Ϊһ������㣩��Ϊ��ȷ���ַ��߽�.���ʴ����Ե��������O(n)ʱ�䡣�������ַ�����������ɶ����ı��������Ի������е�Unicode�����㷨������ʹ��localizedstandardcompare�ã�_����������localizedlowercasestring�Ʋ���Ӧ���Ȳ����ַ��������ص㡣
- UTF8��UTF16����ΪUTF 8��16��ʾ�Cutf�C�ṩ����.��Щֵ��Ӧ�ڽ�ʵ�ʵ��ֽ�д�뵽һ���ļ��������뵽�ʹ�һ���ض��ı��롣UTF-8���뵥Ԫ������POSIX�ַ�������API.��UTF-16���뵥Ԫ��ʹ�õ�Cocoa & Cocoa Touch��ʾ�ַ����ij��Ⱥ�ƫ������
|
|
|
|
|





