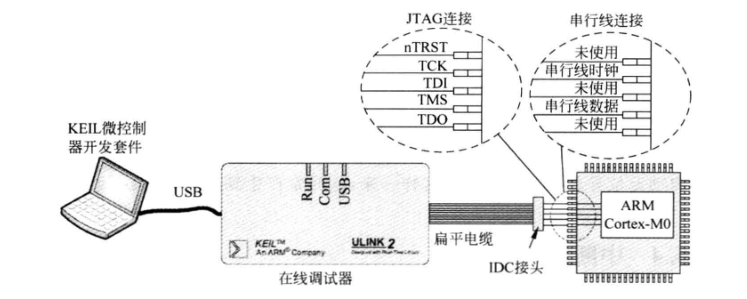
| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌБОЮФжївЊЖдM0ЃЌM0+,M3,M4ЃЌM7ЃЌarm7ЃЌarm9ЃЌCORTEX-AЯЕСаЕФМђНщКЭЬиЕуЕШЯрЙиФкШнзіСЫЯъЯИНщЩмЁЃ |
|
КмЖрЪБКђЮвУЧЖМЛсЖдM0ЃЌM0+,M3,M4ЃЌM7ЃЌarm7ЃЌarm9ЃЌCORTEX-AЯЕСаЃЌЛђепЫЕAVR,51ЃЌPICЕШЃЌвЛЭЗЮэЫЎЃЌжЛжЊЕРЪЧМмЙЙЃЌВЛжЊЕРОпЬхЪЧЪВУДЃЌгаФФаЉВЛЭЌЃПНёЬьВщСЫаЉзЪСЯЃЌРДНтНтЛѓЃЌВЛЪЧКмЯъЯИЃЌЕЋЖдДЫгаИіДѓЬхСЫНтЁЃдлЯШРДЕБЯТзюЛ№ЕФARMАЩ
1.ARM
ARMМДвдгЂЙњARMЃЈAdvanced RISC MachinesЃЉЙЋЫОЕФФкКЫаОЦЌзїЮЊCPUЃЌЭЌЪБИНМгЦфЫћЭтЮЇЙІФмЕФЧЖШыЪНПЊЗЂАхЃЌгУвдЦРЙРФкКЫаОЦЌЕФЙІФмКЭбаЗЂИїПЦММРрЦѓвЕЕФВњЦЗ.
ARM ЮЂДІРэЦїФПЧААќРЈЯТУцМИИіЯЕСаЃЌвдМАЦфЫќГЇЩЬЛљгк ARM ЬхЯЕНсЙЙЕФДІРэЦїЃЌГ§СЫОпгаARM ЬхЯЕНсЙЙЕФЙВЭЌЬиЕувдЭтЃЌУПвЛИіЯЕСаЕФ
ARM ЮЂДІРэЦїЖМгаИїздЕФЬиЕуКЭгІгУСьгђЁЃ
Ѓ ARM7 ЯЕСа
Ѓ ARM9 ЯЕСа
Ѓ ARM9E ЯЕСа
Ѓ ARM10E ЯЕСа
Ѓ ARM11ЯЕСа
Ѓ Cortex ЯЕСа
Ѓ SecurCore ЯЕСа
Ѓ OptimoDE Data Engines
Ѓ IntelЕФXscale
Ѓ IntelЕФStrongARM ARM11ЯЕСа
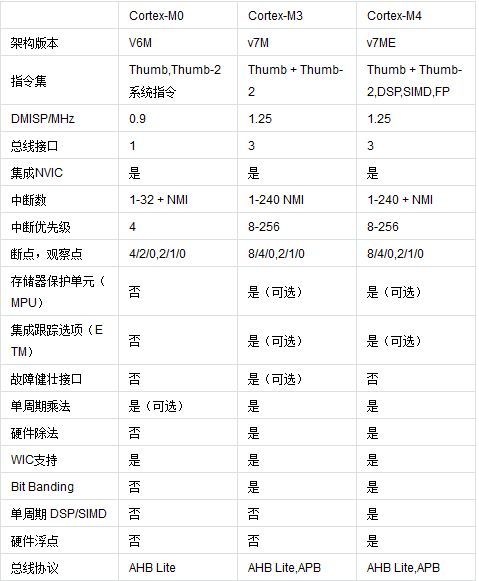
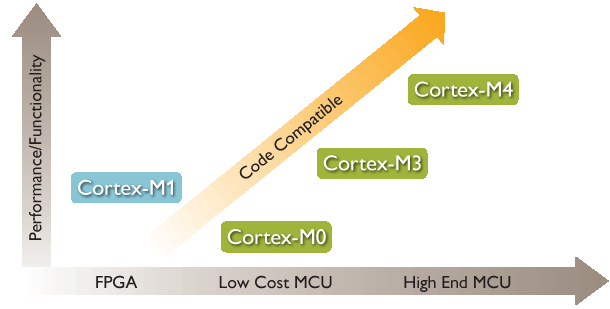
2. Cortex ЯЕСа
32ЮЛRISCCPUПЊЗЂСьгђжаВЛЖЯШЁЕУЭЛЦЦЃЌЦфЩшМЦЕФЮЂДІРэЦїНсЙЙвбОДгv3ЗЂеЙЕНЯждкЕФv7ЁЃCortexЯЕСаДІРэЦїЪЧЛљгкARMv7МмЙЙЕФЃЌ
ЗжЮЊCortex-MЁЂCortex-RКЭCortex-AШ§РрЁЃгЩгкгІгУСьгђЕФВЛЭЌЃЌЛљгкv7МмЙЙЕФCortexДІРэЦїЯЕСаЫљВЩгУЕФММЪѕвВВЛЯрЭЌЁЃЛљгкv7AЕФГЦЮЊЁАCortex-AЯЕСаЁЃ
ИпадФмЕФCortex-A15ЁЂПЩЩьЫѕЕФCortex-A9ЁЂОЙ§ЪаГЁбщжЄЕФCortex-A8ДІРэЦївдМАИпаЇЕФCortex-A7КЭCortex-A5ДІРэЦїОљЙВЯэЭЌвЛЬхЯЕНсЙЙЃЌвђДЫОпгаЭъећЕФгІгУМцШнадЃЌжЇГжДЋЭГЕФARMЁЂThumbжИСюМЏ
КЭаТдіЕФИпадФмНєДеаЭThumb-2жИСюМЏЁЃ
1Cortex-MЯЕСа
Cortex-MЯЕСагжПЩЗжЮЊCortex-M0ЁЂCortex-M0+ЁЂCortex-M3ЁЂCortex-M4ЃЛ
2Cortex-RЯЕСа
Cortex-RЯЕСаЗжЮЊCortex-R4ЁЂCortex-R5ЁЂCortex-R7ЃЛ
3Cortex-A ЯЕСа
Cortex-AЯЕСаЗжЮЊCortex-A5ЁЂCortex-A7ЁЂCortex-A8ЁЂCortex-A9ЁЂCortex-A15ЁЂCortex-A50ЕШ
ЃЌЭЌбљвВОЭгаСЫЖдгІФкКЫЕФCortex-M0ПЊЗЂАхЁЂCortex-A5ПЊЗЂАхЁЂCortex-A8ПЊЗЂАхЁЂCortex-A9ПЊЗЂАхЁЂ
Cortex-R4ПЊЗЂАхЕШЕШЁЃ
4АыЕМЬх
гЩгкARMЙЋЫОжЛЖдЭтЬсЙЉARMФкКЫЃЌИїДѓГЇЩЬдкЪкШЈИЖЗбЪЙгУARMФкКЫЕФЛљДЁЩЯбаЗЂЩњВњИїздЕФаОЦЌЃЌаЮГЩСЫЧЖШыЪНARM
CPUЕФДѓМвЭЅЃЌЬсЙЉетаЉФкКЫаОЦЌЕФГЇЩЬгаAtmelЁЂTIЁЂЗЩЫМПЈЖћЁЂNXPЁЂSTЁЂКЭШ§аЧЕШЁЃ
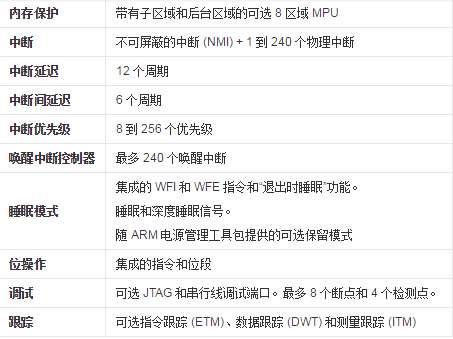
Cortex-MМцШнЬиад
ЮЊСЫФмзіЕНCortex-MШэМўжигУЃЌARMЙЋЫОдкЩшМЦCortex-MДІРэЦїЪБЮЊЦфИГгшСЫДІРэЦїЯђЯТМцШнЁЂШэМўЖўНјжЦЯђЩЯМцШнЬиадЁЃ
ЪзЯШПДЪВУДЪЧЖўНјжЦМцШнЃЌетИіЬиаджївЊЪЧеыЖдШэМўЖјбдЃЌетРяжИЕФЪЧЕБФГШэМў(ГЬађ)вРРЕЕФЭЗЮФМўЛђПтЮФМўЗжБ№Щ§МЖЪБЃЌШэМўЙІФмВЛЪмгАЯьЁЃвЊзіЕНЖўНјжЦМцШнЃЌБЛШэМўЫљвРРЕЕФЭЗЮФМўЛђПтЮФМўЩ§МЖЪББиаыЪЧЖўНјжЦМцШнЕФЁЃ
ФЧУДЪВУДгжЪЧЯђЩЯМцШнЃЌЯђЩЯМцШнгжНаЯђЧАМцШнЃЌжИЕФЪЧдкНЯЕЭАцБОДІРэЦїЩЯБрвыЕФШэМўПЩвддкНЯИпАцБОДІРэЦїЩЯжДааЁЃ
ИњЯђЩЯМцШнЯрЖдЕФСэвЛИіИХФюНаЯђЯТМцШнЃЌЯђЯТМцШнгжНаЯђКѓМцШнЃЌжИЕФЪЧНЯИпАцБОДІРэЦїПЩвде§ШЗдЫаадкНЯЕЭАцБОДІРэЦїЩЯБрвыЕФШэМўЁЃ
ЫљвдЦфЪЕМШПЩвдгУЯђЩЯМцШнЃЌвВПЩвдгУЯђЯТМцШнРДаЮШнCortex-MЬиадЃЌжЛВЛЙ§УшЪіЕФжїгяВЛвЛбљЃЌЮвУЧПЩвдЫЕCortex-MГЬађЪЧЯђЩЯМцШнЕФЃЌвВПЩвдЫЕCortex-MДІРэЦїЪЧЯђЯТМцШнЕФЁЃ
ОпЬхЕНCortex-MДІРэЦїЪБЃЌетИіМцШнЬиадБэЯжЮЊЃК
ДгДІРэЦїНЧЖШПДЃКCM0жИСюМЏКЭЙІФмФЃПщЪЧзюОЋМђЕФЃЌCM7жИСюМЏКЭЙІФмФЃПщЪЧзюЗсИЛЕФЁЃВЛДцдкЕЭАцБОДІРэЦїЩЯДцдкЕФЬиадЪЧИпАцБОДІРэЦїЫљУЛгаЕФЁЃ
ДгШэМўНЧЖШРДПДЃКCMSISЬсЙЉЕФЭЗЮФМўКЭЙІФмКЏЪ§ЪЧЖўНјжЦЯђЩЯМцШнЕФЃЌБШШчФГCM0ШэМўAppЪЙгУЕФЪЧcore_cm0.hЭЗЮФМўЃЌЖјетИіAppвЊдкCM7ЩЯдЫааЪБЃЌВЛашвЊЪЙгУcore_cm7.hдйжиаТБрвывЛДЮЃЈЕБШЛЪЙгУаТЭЗЮФМўБрвыКѓЕФAppвВЪЧе§ГЃЕФЁЃЃЉ
ДгMCUФкКЫЕНMCUЪЕМЪгІгУЪЧвЛИіЭъећЕФВњвЕСДЃЌетИіВњвЕСДЗжЮЊЮхИіВПЗжЃК
ЦфЪЕЖМЪЧетбљЃЌЧАШ§ИіВПЗжгааОЦЌГЇМвКЭМмЙЙФкКЫЙЋЫОИКд№ПЊаОЦЌЃЌКѓСНИіВПЗжгЩбаЗЂЙЋЫОИљОнаОЦЌЩшМЦЃЌПЊЗЂЁЃ
ОЭФУSTЮЊР§ЃЌARMЙЋЫОЮЊзюПЊЪМЕФВПЗжЃЌSTЃЈвтЗЈАыЕМЬхЃЉЮЊаОЦЌЩшМЦгыжЦдьЙЋЫОЃЌвдARMФкКЫЮЊдиЬхЃЌЭЈЙ§НјвЛВНЕФЩшМЦПЊЗЂЃЌЮЊARMХфБИЭтЮЇЕФжЇГжЃЌЮЊНЋМЦЫуПижЦФмСІгІгУЕНЕчзгВњЦЗжаЬсЙЉаОЦЌЗўЮё
Cortex-M0 ДІРэЦїМђНщ
ARMЙЋЫОЕФCortex-M0гІгУгкИїжжЮЂПижЦЦїЃЈMCUЃЉжаЃЌВЂПЩШУбаЗЂЙЄГЬЪІвд8ЮЛЕФМлЮЛДДдь32ЮЛЕФЕФаЇФмЃЌВЂНЋДЋЭГЕФ8ЮЛКЭ16ЮЛЕФДІРэЦїЩ§МЖЕНИќИпаЇЁЂИќЕЭЙІКФЕФ32ЮЛДІРэЦїЁЃ
Cortex-M0ЪЧCortex-MМвзхжаЕФM0ЯЕСаЁЃзюДѓЬиЕуЪЧЕЭЙІКФЕФЩшМЦЁЃCortex-M0ЮЊ32ЮЛЁЂ3МЖСїЫЎЯпRISCДІРэЦїЃЌЦфКЫаФШдЮЊЗы.ХЕвРТќНсЙЙЃЌЪЧжИСюКЭЪ§ОнЙВЯэЭЌвЛзмЯпЕФМмЙЙЁЃзїЮЊаТвЛДњЕФДІРэЦїЃЌCortex-M0ЕФЩшМЦНјааСЫаэЖрЕФИФИягыДДаТЃЌШчЯЕЭГДцДЂЦїЕижЗгГЯё(system
address map)ЁЂИФЩЦаЇТЪВЂдіЧПШЗЖЈадЕФЧЖЬзЯђСПжаЖЯЯЕЭГ(NVIC)гыВЛПЩЦСБЮжаЖЯ(NMI)ЁЂШЋаТЕФгВМўГ§ДэЕЅдЊЕШЕШЃЌЖМДјИјСЫЪЙгУепШЋаТЕФЬхбщКЭИќБуРћЁЂ
ИќгааЇТЪЕФВйзїЁЃ
ММЪѕМмЙЙ
CortexM0ЦфКЫаФМмЙЙЮЊARMv6MЃЌЦфдЫЫуФмСІПЩвдДяЕН0.9 DMIPS/MHzЃЌЖјгыЦфЫћЕФ16ЮЛгы8ЮЛДІРэЦїЯрБШЃЌгЩгкCortexM0ЕФдЫЫуадФмДѓЗљЬсИпЃЌЫљвддкЭЌбљШЮЮёЕФжДааЩЯCortexM0жЛашНЯЕЭЕФдЫааЫйЖШЃЌЖјДѓЗљНЕЕЭСЫећЬхЕФЖЏЬЌЙІКФЁЃ
CortexЁЊM0ЪєгкARMv6-MМмЙЙЃЌАќРЈ1ПХзЈЮЊЧЖШыЪНгІгУЖјЩшМЦЕФARMКЫЁЂНєёюКЯЕФПЩЧЖЬзжаЖЯЮЂПижЦЦїNVICЁЂПЩбЁЕФЛНабжаЖЯПижЦЦїWICЃЌЖдЭтЬсЙЉСЫЛљгкAMBAНсЙЙЃЈИпМЖЮЂПижЦЦїзмЯпМмЙЙЃЉЕФAHB-liteзмЯпКЭЛљгкCoreSightММЪѕЕФSWDЛђJTAGЕїЪдНгПкЃЌШчЭМЫљЪОЁЃCortex-M0ЮЂПижЦЦїЕФгВМўЪЕЯжАќКЌЖрИіПЩХфжУбЁЯюЃКжаЖЯЪ§СПЁЂWICЁЂЫЏУпФЃЪНКЭНкФмДыЪЉЁЂДцДЂЯЕЭГДѓаЁЖЫФЃЪНЁЂЯЕЭГЕЮД№ЪБжгЕШЃЌАыЕМЬхГЇЩЬПЩвдИљОнгІгУашвЊбЁдёКЯРэЕФХфжУЁЃ
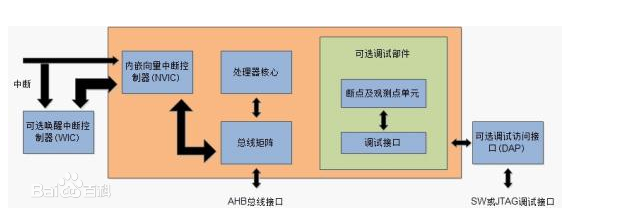
ЯЕЭГзмЯпЛљгкAHB_LiteИпМЖИпадФмзмЯпавщЁЃЭтЩшзмЯпЛљгкAPBИпМЖЭтЩшзмЯпавщЃЌЭЈЙ§вЛИізЊЛЛЧХСЌНгЕНAHBЩЯ,етжЛЪЧCortex-M0ФкКЫЕФДѓИХФЃЪН.
ЬиЕу
1ЃЉФмКФаЇТЪ
CortexM0ЕФдЫаааЇТЪКмИпЃЈ0.9DMIPS/MHzЃЉЃЌФмдкНЯЩйЕФжмЦкРяЭъГЩвЛЯюШЮЮёЁЃетвтЮЖзХCortexM0ПЩвддкДѓВПЗжЕФЪБМфРяДІгканУпзДЬЌЃЌЯћКФКмЩйЕФФмСПЃЌОпгаСМКУЕФФмКФаЇТЪЁЃЭЌбљНЯаЁЕФТпМУХЪ§вВНЕЕЭСЫД§ЛњЕчСїЁЃЖјИпаЇЕФжаЖЯПижЦЦїЃЈNVICЃЉашвЊКмаЁЕФжаЖЯПЊЯњЁЃ
2ЃЉДњТыУмЖШ
Cortex-M0ЛљгкThumb-2ЕФжИСюМЏЃЌБШгУ8ЮЛЛђеп16ЮЛМмЙЙЪЕЯжЕФДњТыЛЙвЊЩйЃЌвђДЫгУЛЇПЩвдбЁдёОпгаНЯаЁFlashПеМфЕФаОЦЌЁЃПЩвдНЕЕЭЯЕЭГЙІКФЁЃ[1]
3ЃЉ взгкЪЙгУ
Cortex-M0ЪЪгУгкCгябдБрГЬЃЌВЂЧвБЛаэЖрБрвыЦїжЇГжЁЃПЩвдгУCгябджБНгБрГЬжаЖЯР§ГЬЃЌЖјЮоашЪЙгУЛуБргябдЁЃЭЌЪБCortex-M0ЛЙБЛЖржжПЊЗЂЙЄОпжЇГжЁЃАќРЈКмЖрПЊдДЕФЧЖШыЪНВйзїЯЕЭГЭЌбљжЇГжCortex-M0ЁЃ
ЁЁ
Cortex-M0 ДІРэЦїМђНщ
1. Cortex-M0 ДІРэЦїЛљгкЗыХЕвРТќМмЙЙЃЈЕЅзмЯпНгПкЃЉЃЌЪЙгУ32ЮЛОЋМђжИСюМЏЃЈRISCЃЉЃЌИУжИСюМЏБЛГЦЮЊThumbжИСюМЏЁЃгыжЎЧАЯрБШЃЌаТЕФжИСюМЏдіМгСЫМИЬѕARMv6МмЙЙЕФжИСюЃЌВЂЧвМгШыСЫeThumb-2жИСюМЏЕФВПЗжжИСюЁЃThumb-2ММЪѕРЉеЙСЫThumbЕФгІгУЃЌдЪаэЫљгаЕФВйзїЖМПЩвддкЭЌвЛжжCPUзДЬЌЯТжДааЁЃThumbжИСюМЏМШАќРЈ16ЮЛжИСюЃЌвВАќРЈ32ЮЛжИСюЁЃCБрвыЦїЩњГЩЕФжИСюДѓВПЗжЪЧ16ЮЛЕФЃЌЕБ16ЮЛЕФжИСюЮоЗЈЪЕЯжЫљашвЊЕФВйзїЪБЃЌ32ЮЛжИСюОЭЛсЗЂЛгзїгУЁЃетбљвдРДЃЌдкДњТыУмЖШЕУЕНЬсЩ§ЕФЭЌЪБЃЌЛЙБмУтСЫСНЬзжИСюМЏжЎМфНјааЧаЛЛДјРДЕФПЊЯњ
ЁЁ2. Cortex-M0змЙВжЇГж56ИіЛљБОжИСюЃЌЦфжаФГаЉжИСюПЩФмЛсгаЖржжаЮЪНЁЃЯрЖдгкCortex-M0НЯаЁЕФжИСюМЏЃЌЦфДІРэЦїЕФФмСІПЩВЛвЛАуЃЌвђЮЊThumbЪЧОЙ§ИпЖШгХЛЏЕФжИСюМЏЁЃДгРэТлРДЫЕЃЌгЩгкЖСаДДцДЂЪЧЕФжИСюЪЧЯрЛЅЖРСЂЕФЃЌЖјЧвЫуЪ§ЛђТпМВйзїЕФжИСюЪЙгУМФДцЦїЃЌCortex-M0ДІРэЦїПЩвдБЛЙщЕНМгди-ДцДЂЃЈload-storeЃЉНсЙЙжаЁЃ
ЁЁ
3. ДІРэЦїКЫаФАќРЈЃК
МФДцЦїзщ АќКЌ16Иі32ЮЛМФДцЦїЃЌЦфжагавЛаЉЬиЪтМФДцЦї
ЫуЪѕТпМЕЅдЊ
Ъ§ОнзмЯп
ПижЦТпМ
СїЫЎЯпИљОнЩшМЦПЩЗжЮЊШ§жжзДЬЌЃК ШЁжИЁЂвыТыЁЂжДааЁЃ
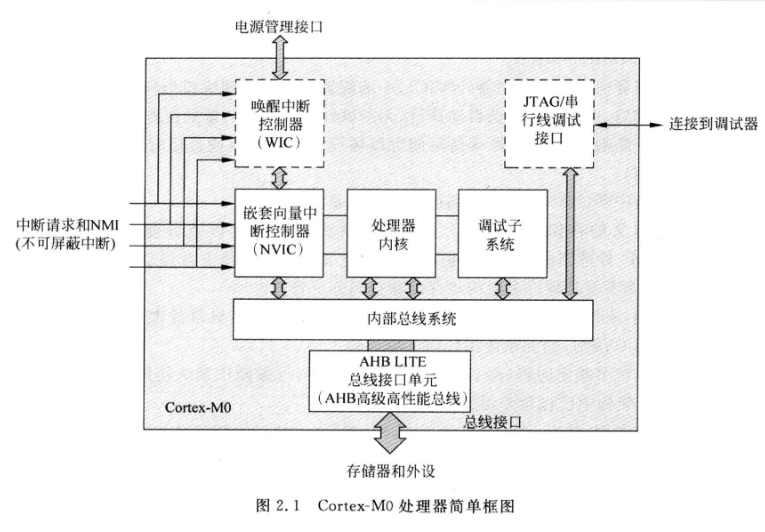
4. ЧЖЬзЯђСПжаЖЯПижЦЦїЃЈNVICЃЉПЩвдДІРэзюЖр32ИіжаЖЯЧыЧѓКЭвЛИіВЛПЩЦСБЮжаЖЯЃЈNMIЃЉЪфШыЁЃ
5. NVICашвЊБШНЯетИідкжДаажаЖЯКЭЧыЧѓжаЖЯЕФгХЯШМЖЃЌЃЌШЛКѓздЖЏжДааИпгХЯШМЖЕФжаЖЯЁЃ
6. ШчЙћвЊДІРэвЛИіжаЖЯЃЌNVICЛсКЭДІРэЦїНјааЭЈаХЃЌЭЈжЊДІРэЦїжДаажаЖЯДІРэГЬађЁЃ
7. ЛНабжаЖЯПижЦЦї(WIC)ЮЊПЩбЁЕФЕЅдЊЃЌдкЕЭЙІКФгІгУжаЃЌдкЙиБеСЫДІРэЦїДѓВПЗжФЃПщКѓЃЌЮЂПижЦЦїЛсНјШыД§ЛњзАЬюЃЌДЫЪБЃЌWICПЩвддкNVICКЭДІРэЦїДІгканУпЕФЧщПіЯТЃЌжДаажаЖЯЦСБЮЙІФмЁЃЕБWICМьВтЕНвЛИіжаЖЯЪБЃЌЛсЭЈжЊЕчдДЙмРэВПЗжИјЯЕЭГЩЬЕъЃЌШУNVICКЭДІРэЦїФкКЫжДааЪЃгрЕФжаЖЯДІРэЁЃ
8. ЙигкЕїЪдзгЯЕЭГЃЌЕБЕїЪдЪТМўЗЂЩњЪБЃЌДІРэЦїФкКЫЛсБЛжУгкднЭЃзДЬЌЃЌетЪЧПЊЗЂШЫдБПЩвдМьВщЕБЧАДІРэЦїЕФзДЬЌЁЃгВМўЕїЪдЙЄОпгаJTAGКЭSWDЃЈДЎааЯпЕїЪдЃЉЁЃ
ARM Cortex-M0 ДІРэЦїЕФЬиад
ЯЕЭГЬиад
thumbжИСюМЏЃЌОпгаИпаЇКЭИпДњТыУмЖШ
ИпадФмЃЌзюИпДяЕН0.9DMIPS/MHz
ФкжУЕФЧЖЬзЯђСПжаЖЯПижЦЦїЃЈNVICЃЉЃЌжаЖЯХфжУКЭвьГЃДІРэШнвз
ШЗЖЈЕФжаЖЯЯьгІЪТМўЃЌжаЖЯЕШД§ЪТМўПЩвдБЛЩшЖЈЮЊЙЬЖЈжЕЛђзюЖЬЪТМўЃЈзюаЁ16ИіЪБжгжмЦкЃЉ
ВЛПЩЦСБЮжаЖЯЃЈNMIЃЉЃЌЖдИпПЩППадЯЕЭГЗЧГЃживЊ
ФкжУЕФЯЕЭГНкХФЖЈЪБЦїЃЈsystickЃЉЁЃ24ЮЛЖЈЪБЦїЃЌПЩБЛВйзїЯЕЭГЪЙгУЃЌЛђепгУзїЭЈгУЖЈЪБЦїЃЌМмЙЙжавбОАќКЌзЈгУЕФвьГЃРраЭ
ЧыЧѓЙмРэЕїгУЃЌОпгаSVCвьГЃКЭPendSVвьГЃЃЈПЩЙвЦ№ЕФЙмРэЗўЮёЃЉЃЌжЇГжЧЖШыЪНosЕФЖржжВйзї
МмЙЙЖЈвхЕФанУпФЃЪНКЭНјШыанУпЕФжИСюЃЌанУпЬиадФмДѓДѓНЕЕЭФмСПЕФЯћКФЁЃгЩгкНјШыанУпзДЬЌашвЊЪЙгУЬиЖЈЕФжИСюЃЌЖјВЛЪЧЪЙгУМФДцЦїЃЌМмЙЙЖЈвхЕФанУпФЃЪНвВЬсИпСЫШэМўЕФПЩвЦжВадЁЃ
вьГЃДІРэПЩвдВЖЛёЕНЯЕЭГжаЕФЖржжДэЮѓЁЃ
гІгУЬиад
жаЖЯЪ§СППЩХфжУ
жЇГжДѓЖЫЛђаЁЖЫДцДЂЦї
ПЩбЁдёЕФЛНабжаЖЯПижЦЦїЃЈWICЃЉЃЌДІРэЦїПЩвддканУпзДЬЌЯТЕєЕчвдНЕЕЭЙІКФЃЌЖјWICПЩвддкжаЖЯЗЂЩњЪБЛНабЯЕЭГ
Cortex-M3
Cortex-M3ЪЧвЛИі32ЮЛЕФКЫЃЌдкДЋЭГЕФЕЅЦЌЛњСьгђжаЃЌгавЛаЉВЛЭЌгкЭЈгУ32ЮЛCPUгІгУЕФвЊЧѓЁЃдкЙЄПиСьгђЃЌгУЛЇвЊЧѓОпгаИќПьЕФжаЖЯЫйЖШЃЌCortex-M3ВЩгУСЫTail-ChainingжаЖЯММЪѕЃЌЭъШЋЛљгкгВМўНјаажаЖЯДІРэЃЌзюЖрПЩМѕЩй12ИіЪБжгжмЦкЪ§ЃЌдкЪЕМЪгІгУжаПЩМѕЩй70%жаЖЯЁЃ
ИХЪі
Cortex-M3ЪЧвЛИі32ЮЛДІРэЦїФкКЫЁЃФкВПЕФЪ§ОнТЗОЖЪЧ32ЮЛЕФЃЌМФДцЦїЪЧ32ЮЛЕФЃЌДцДЂЦїНгПквВЪЧ32ЮЛЕФЁЃCM3ВЩгУСЫЙўЗ№НсЙЙЃЌгЕгаЖРСЂЕФжИСюзмЯпКЭЪ§ОнзмЯпЃЌПЩвдШУШЁжИгыЪ§ОнЗУЮЪВЂааВЛуЃЁЃетбљвЛРДЪ§ОнЗУЮЪВЛдйеМгУжИСюзмЯпЃЌДгЖјЬсЩ§СЫадФмЁЃЮЊЪЕЯжетИіЬиадЃЌCM3ФкВПКЌгаКУМИЬѕзмЯпНгПкЃЌУПЬѕЖМЮЊздМКЕФгІгУГЁКЯгХЛЏЙ§ЃЌВЂЧвЫќУЧПЩвдВЂааЙЄзїЁЃЕЋЪЧСэвЛЗНУцЃЌжИСюзмЯпКЭЪ§ОнзмЯпЙВЯэЭЌвЛИіДцДЂЦїПеМфЃЈвЛИіЭГвЛЕФДцДЂЦїЯЕЭГЃЉЁЃЛЛОфЛАЫЕЃЌВЛЪЧвђЮЊгаСНЬѕзмЯпЃЌПЩбАжЗПеМфОЭБфГЩ8GBСЫЁЃ
БШНЯИДдгЕФгІгУПЩФмашвЊИќЖрЕФДцДЂЯЕЭГЙІФмЃЌЮЊДЫCM3ЬсЙЉвЛИіПЩбЁЕФMPUЃЌЖјЧвдкашвЊЕФЧщПіЯТвВПЩвдЪЙгУЭтВПЕФcacheЁЃСэЭтдкCM3жаЃЌBothаЁЖЫФЃЪНКЭДѓЖЫФЃЪНЖМЪЧжЇГжЕФЁЃ
CM3ФкВПЛЙИНдљСЫКУЖрЕїЪдзщМўЃЌгУгкдкгВМўЫЎЦНЩЯжЇГжЕїЪдВйзїЃЌШчжИСюЖЯЕуЃЌЪ§ОнЙлВьЕуЕШЁЃСэЭтЃЌЮЊжЇГжИќИпМЖЕФЕїЪдЃЌЛЙгаЦфЫќПЩбЁзщМўЃЌАќРЈжИСюИњзйКЭЖржжРраЭЕФЕїЪдНгПкЁЃ
ФкКЫМмЙЙ
ARMCortex-M3ВЩгУЙўЗ№НсЙЙЃЌВЂбЁдёСЫЪЪКЯгкЮЂПижЦЦїгІгУЕФШ§МЖСїЫЎЯпЃЌЕЋдіМгСЫЗжжЇдЄВтЙІФмЁЃ
ЯжДњДІРэЦїДѓЖрВЩгУжИСюдЄШЁКЭСїЫЎЯпММЪѕЃЌвдЬсИпДІРэЦїЕФжИСюжДааЫйЖШЁЃСїЫЎЯпДІРэЦїдке§ГЃжДаажИСюЪБЃЌШчЙћХіЕНЗжжЇЃЈЬјзЊЃЉжИСюЃЌгЩгкжИСюжДааЕФЫГађПЩФмЛсЗЂЩњБфЛЏЃЌжИСюдЄШЁЖгСаКЭСїЫЎЯпжаЕФВПЗжжИСюОЭПЩФмзїЗЯЃЌЖјашвЊДгаТЕФЕижЗжиаТШЁжИЁЂжДааЃЌетбљОЭЛсЪЙСїЫЎЯпЁАЖЯСїЁБЃЌДІРэЦїадФмвђДЫЖјЪмЕНгАЯьЁЃЬиБ№ЪЧЯжДњCгябдГЬађЃЌОБрвыЦїгХЛЏЩњГЩЕФФПБъДњТыжаЃЌЗжжЇжИСюЫљеМЕФБШР§ПЩДя10-20%ЃЌЖдСїЫЎЯпДІРэЦїЕФгАЯьЛсЕФИќДѓЁЃЮЊДЫЃЌЯжДњИпадФмСїЫЎЯпДІРэЦїжавЛАуЖММгШыСЫЗжжЇдЄВтВПМўЃЌОЭЪЧдкДІРэЦїДгДцДЂЦїдЄШЁжИСюЪБЃЌЕБгіЕНЗжжЇЃЈЬјзЊЃЉжИСюЪБЃЌФмздЖЏдЄВтЬјзЊЪЧЗёЛсЗЂЩњЃЌдйДгдЄВтЕФЗНЯђНјааШЁжИЃЌДгЖјЬсЙЉИјСїЫЎЯпСЌајЕФжИСюСїЃЌСїЫЎЯпОЭПЩвдВЛЖЯЕижДаагааЇжИСюЃЌБЃжЄСЫЦфадФмЕФЗЂЛгЁЃ
ARMCortex-M3ФкКЫЕФдЄШЁВПМўОпгаЗжжЇдЄВтЙІФмЃЌПЩвддЄШЁЗжжЇФПБъЕижЗЕФжИСюЃЌЪЙЗжжЇбгГйМѕЩйЕНвЛИіЪБжгжмЦкЁЃ
еыЖдвЕНчЖдARMДІРэЦїжаЖЯЯьгІЕФЮЪЬтЃЌCortex-M3ЪзДЮдкФкКЫЩЯМЏГЩСЫЧЖЬзЯђСПжаЖЯПижЦЦїЃЈNVICЃЉЁЃCortex-M3ЕФжаЖЯбгГйжЛга12ИіЪБжгжмЦк(ARM7ашвЊ24-42ИіжмЦк)ЃЛCortex-M3ЛЙЪЙгУЮВСДММЪѕЃЌЪЙЕУБГППБГЃЈback-to-backЃЉжаЖЯЕФЯьгІжЛашвЊ6ИіЪБжгжмЦк(ARM7ашвЊДѓгк30ИіжмЦк)ЁЃCortex-M3ВЩгУСЫЛљгкеЛЕФвьГЃФЃЪНЃЌЪЙЕУаОЦЌГѕЪМЛЏЕФЗтзАИќЮЊМђЕЅЁЃ
Cortex-M3МгШыСЫРрЫЦгк8ЮЛДІРэЦїЕФФкКЫЕЭЙІКФФЃЪНЃЌжЇГж3жжЙІКФЙмРэФЃЪНЃКЭЈЙ§вЛЬѕжИСюСЂМДЫЏУпЃЛвьГЃ/жаЖЯЭЫГіЪБЫЏУпЃЛЩюЖШЫЏУпЁЃЪЙећИіаОЦЌЕФЙІКФПижЦИќЮЊгааЇЁЃ
ЬиЕу
ИпадФм
аэЖржИСюЖМЪЧЕЅжмЦкЕФЁЊЁЊАќРЈГЫЗЈЯрЙижИСюЁЃВЂЧвДгећЬхадФмЩЯЃЌCortex-M3БШЕУЙ§ОјДѓЖрЪ§ЦфЫќЕФМмЙЙЁЃ
жИСюзмЯпКЭЪ§ОнзмЯпБЛЗжПЊЃЌШЁжЕКЭЗУФкПЩвдВЂааВЛуЃ
Thumb-2ЕФЕНРДИцБ№СЫзДЬЌЧаЛЛЕФОЩЪРДњЃЌдйвВВЛашвЊЛЈЪБМфРДЧаЛЛгк32ЮЛARMзДЬЌКЭ16ЮЛThumbзДЬЌжЎМфСЫЁЃетМђЛЏСЫШэМўПЊЗЂКЭДњТыЮЌЛЄЃЌЪЙВњЦЗУцЪаИќПьЁЃ
Thumb-2жИСюМЏЮЊБрГЬДјРДСЫИќЖрЕФСщЛюадЁЃаэЖрЪ§ОнВйзїЯждкФмгУИќЖЬЕФДњТыИуЖЈЃЌетвтЮЖзХCortex-M3ЕФДњТыУмЖШИќИпЃЌвВОЭЖдДцДЂЦїЕФашЧѓИќЩйЁЃ
ШЁжИЖМАД32ЮЛДІРэЁЃЭЌвЛжмЦкзюЖрПЩвдШЁГіСНЬѕжИСюЃЌСєЯТСЫИќЖрЕФДјПэИјЪ§ОнДЋЪфЁЃ
Cortex-M3ЕФЩшМЦдЪаэЕЅЦЌЛњИпЦЕдЫааЃЈЯжДњАыЕМЬхжЦдьММЪѕФмБЃжЄ100MHzвдЩЯЕФЫйЖШЃЉЁЃМДЪЙдкЯрЭЌЕФЫйЖШЯТдЫааЃЌCM3ЕФУПжИСюжмЦкЪ§(CPI)вВИќЕЭЃЌгкЪЧЭЌбљЕФMHzЯТПЩвдзіИќЖрЕФЙЄзїЃЛСэвЛЗНУцЃЌвВЪЙЭЌвЛИігІгУдкCM3ЩЯашвЊИќЕЭЕФжїЦЕЁЃ
ЯШНјЕФжаЖЯДІРэЙІФм
ФкНЈЕФЧЖЬзЯђСПжаЖЯПижЦЦїжЇГжЖрДя240ЬѕЭтВПжаЖЯЪфШыЁЃЯђСПЛЏЕФжаЖЯЙІФмОчСвЕиЫѕЖЬСЫжаЖЯбгГйЃЌвђЮЊВЛдйашвЊШэМўШЅХаЖЯжаЖЯдДЁЃжаЖЯЕФЧЖЬзвВЪЧдкгВМўЫЎЦНЩЯЪЕЯжЕФЃЌВЛашвЊШэМўДњТыРДЪЕЯжЁЃ
Cortex-M3дкНјШывьГЃЗўЮёР§ГЬЪБЃЌздЖЏбЙеЛСЫR0-R3, R12, LR, PSRКЭPCЃЌВЂЧвдкЗЕЛиЪБздЖЏЕЏГіЫќУЧЃЌетЖрЧхЫЌЃЁМШМгЫйСЫжаЖЯЕФЯьгІЃЌвВдйВЛашвЊЛуБргябдДњТыСЫЁЃ
NVICжЇГжЖдУПвЛТЗжаЖЯЩшжУВЛЭЌЕФгХЯШМЖЃЌЪЙЕУжаЖЯЙмРэМЋИЛЕЏадЁЃзюДжЯпЬѕЕФЪЕЯжвВжСЩйвЊжЇГж8МЖгХЯШМЖЃЌЖјЧвЛЙФмЖЏЬЌЕиБЛаоИФЁЃ
гХЛЏжаЖЯЯьгІЛЙгаСНеаЃЌЫќУЧЗжБ№ЪЧЁАвЇЮВжаЖЯЛњжЦЁБКЭЁАЭэЕНжаЖЯЛњжЦЁБЁЃ
гааЉашвЊНЯЖржмЦкВХФмжДааЭъЕФжИСюЃЌЪЧПЩвдБЛжаЖЯЃМЬајЕФЁЊЁЊОЭКУБШЫќУЧЪЧвЛДЎжИСювЛбљЁЃетаЉжИСюАќРЈМгдиЖрИіМФДцЦїЃЈLDMЃЉЃЌДцДЂЖрИіМФДцЦїЃЈSTMЃЉЃЌЖрИіМФДцЦїВЮгыЕФPUSHЃЌвдМАЖрИіМФДцЦїВЮгыЕФPOPЁЃ
Г§ЗЧЯЕЭГБЛГЙЕзЕиЫјЖЈЃЌNMIЃЈВЛПЩЦСБЮжаЖЯЃЉЛсдкЪеЕНЧыЧѓЕФЕквЛЪБМфгшвдЯьгІЁЃЖдгкКмЖрАВШЋ-ЙиМќ(safety-critical)ЕФгІгУЃЌNMIЖМЪЧБиВЛВЛПЩЩйЕФЃЈШчЛЏбЇЗДгІМДНЋЪЇПиЪБЕФНєМБЭЃЛњЃЉЁЃ
ЕЭЙІКФ
Cortex-M3ашвЊЕФТпМУХЪ§ЩйЃЌЫљвдЯШЬьОЭЪЪКЯЕЭЙІКФвЊЧѓЕФгІгУЃЈЙІТЪЕЭгк0.19mW/MHzЃЉдкФкКЫЫЎЦНЩЯжЇГжНкФмФЃЪНЃЈSLEEPINGКЭSLEEPDEEPЮЛЃЉЁЃЭЈЙ§ЪЙгУЁАЕШД§жаЖЯжИСюЃЈWFIЃЉЁБКЭЁАЕШД§ЪТМўжИСюЃЈWFEЃЉЁБЃЌФкКЫПЩвдНјШыЫЏУпФЃЪНЃЌВЂЧввдВЛЭЌЕФЗНЪНЛНабЁЃСэЭтЃЌФЃПщЕФЪБжгЪЧОЁПЩФмЕиЗжПЊЙЉгІЕФЃЌЫљвддкЫЏУпЪБПЩвдАбCM3ЕФДѓЖрЪ§ЁАЙйФмЭХЁБИјЭЃЕєЁЃ
CM3ЕФЩшМЦЪЧШЋОВЬЌЕФЁЂЭЌВНЕФЁЂПЩзлКЯЕФЁЃШЮКЮЕЭЙІКФЕФЛђЪЧБъзМЕФАыЕМЬхЙЄвеОљПЩЗХаФвћгУЁЃ
ЯЕЭГЬиад
ЯЕЭГжЇГжЁАЮЛбАжЗДјЁБВйзїЃЈ8051ЮЛбАжЗЛњжЦЕФЁАЭўСІДѓЗљМгЧПАцЁБЃЉЃЌзжНкВЛБфЕФДѓЖЫФЃЪНЃЌВЂЧвжЇГжЗЧЖдЦыЕФЪ§ОнЗУЮЪЁЃ
гЕгаЯШНјЕФfaultДІРэЛњжЦЃЌжЇГжЖржжРраЭЕФвьГЃКЭfaultsЃЌЪЙЙЪеЯеяЖЯИќШнвзЁЃ
ЭЈЙ§в§ШыbankedЖбеЛжИеыЛњжЦЃЌАбЯЕЭГГЬађЪЙгУЕФЖбеЛКЭгУЛЇГЬађЪЙгУЕФЖбеЛЛЎЧхНчЯпЁЃШчЙћдйХфЩЯПЩбЁЕФMPUЃЌДІРэЦїОЭФмГЙЕзТњзуЖдШэМўНЁзГадКЭПЩППадгабЯИёвЊЧѓЕФгІгУЁЃ
ЕїЪджЇГж
дкжЇГжДЋЭГЕФJTAGЛљДЁЩЯЃЌЛЙжЇГжИќаТИќКУЕФДЎааЯпЕїЪдНгПкЁЃ
ЛљгкCoreSightЕїЪдНтОіЗНАИЃЌЪЙЕУДІРэЦїФФХТЪЧдкдЫааЪБЃЌвВФмЗУЮЪДІРэЦїзДЬЌКЭДцДЂЦїФкШнЁЃ
ФкНЈСЫЖдЖрДя6ИіЖЯЕуКЭ4ИіЪ§ОнЙлВьЕуЕФжЇГжЁЃ
ПЩвдбЁХфвЛИіETMЃЌгУгкжИСюИњзйЁЃЪ§ОнЕФИњзйПЩвдЪЙгУDWT
дкЕїЪдЗНУцЛЙМгШыСЫвдЯТЕФаТЬиадЃЌАќРЈfaultзДЬЌМФДцЦїЃЌаТЕФfaultвьГЃЃЌвдМАЩСДцаоВЙ ЃЈpatchЃЉВйзїЃЌЪЙЕУЕїЪдДѓЗљМђЛЏЁЃ
ПЩбЁITMФЃПщЃЌВтЪдДњТыПЩвдЭЈЙ§ЫќЪфГіЕїЪдаХЯЂЃЌЖјЧвЁАСрАќМДПЩШызЁЁБАуЕиЗНБуЪЙгУЁЃ
БрГЬФЃЪН
CortexЃM3ДІРэЦїВЩгУARMv7-MМмЙЙЃЌЫќАќРЈЫљгаЕФ16ЮЛThumbжИСюМЏКЭЛљБОЕФ32ЮЛThumb-2жИСюМЏМмЙЙЃЌCortex-M3ДІРэЦїВЛФмжДааARMжИСюМЏЁЃ
Thumb-2дкThumbжИСюМЏМмЙЙЃЈISAЃЉЩЯНјааСЫДѓСПЕФИФНјЃЌЫќгыThumbЯрБШЃЌОпгаИќИпЕФДњТыУмЖШВЂЬсЙЉ16/32ЮЛжИСюЕФИќИпадФмЁЃ
ЙигкЙЄзїФЃЪН
Cortex-M3ДІРэЦїжЇГж2жжЙЄзїФЃЪНЃКЯпГЬФЃЪНКЭДІРэФЃЪНЁЃдкИДЮЛЪБДІРэЦїНјШыЁАЯпГЬФЃЪНЁБЃЌвьГЃЗЕЛиЪБвВЛсНјШыИУФЃЪНЃЌЬиШЈКЭгУЛЇЃЈЗЧЬиШЈЃЉФЃЪНДњТыФмЙЛдкЁАЯпГЬФЃЪНЁБЯТдЫааЁЃ
ГіЯжвьГЃФЃЪНЪБДІРэЦїНјШыЁАДІРэФЃЪНЁБЃЌдкДІРэФЃЪНЯТЃЌЫљгаДњТыЖМЪЧЬиШЈЗУЮЪЕФЁЃ
ЙигкЙЄзїзДЬЌ
Cortex-M3ДІРэЦїга2жжЙЄзїзДЬЌЁЃ
ThumbзДЬЌЃКетЪЧ16ЮЛКЭ32ЮЛЁААызжЖдЦыЁБЕФThumbКЭThumb-2жИСюЕФжДаазДЬЌЁЃ
ЕїЪдзДЬЌЃКДІРэЦїЭЃжЙВЂНјааЕїЪдЃЌНјШыИУзДЬЌЁЃ
Cortex-M4
ЛљБОМђНщ
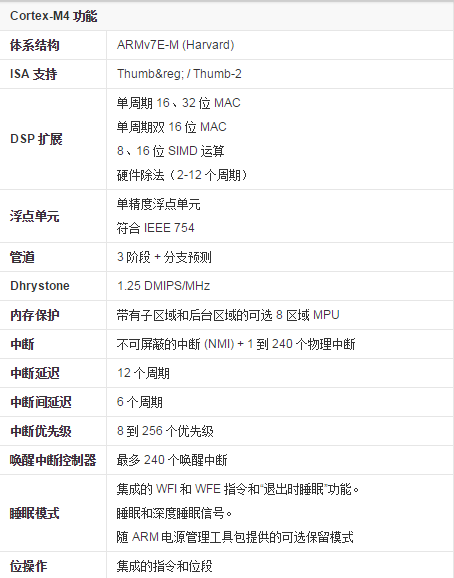
ARMCortex-M4ДІРэЦїЪЧгЩARMзЈУХПЊЗЂЕФзюаТЧЖШыЪНДІРэЦїЃЌдкM3ЕФЛљДЁЩЯЧПЛЏСЫдЫЫуФмСІЃЌаТМгСЫИЁЕуЁЂDSPЁЂВЂааМЦЫуЕШЃЌгУвдТњзуашвЊгааЇЧввзгкЪЙгУЕФПижЦКЭаХКХДІРэЙІФмЛьКЯЕФЪ§зжаХКХПижЦЪаГЁЁЃЦфИпаЇЕФаХКХДІРэЙІФмгыCortex-MДІРэЦїЯЕСаЕФЕЭЙІКФЁЂЕЭГЩБОКЭвзгкЪЙгУЕФгХЕуЕФзщКЯЃЌжМдкТњзузЈУХУцЯђЕчЖЏЛњПижЦЁЂЦћГЕЁЂЕчдДЙмРэЁЂЧЖШыЪНвєЦЕКЭЙЄвЕздЖЏЛЏЪаГЁЕФаТаЫРрБ№ЕФСщЛюНтОіЗНАИЁЃ
Ьиад
ARMCortex-M4ДІРэЦїФкКЫЪЧдкCortex-M3ФкКЫЛљДЁЩЯЗЂеЙЦ№РДЕФЃЌЦфадФмБШCortex-M3ЬсИпСЫ20%ЁЃаТдіМгСЫИЁЕуЁЂDSPЁЂВЂааМЦЫуЕШЁЃгУвдТњзуашвЊгааЇЧввзгкЪЙгУЕФПижЦКЭаХКХДІРэЙІФмЛьКЯЕФЪ§зжаХКХПижЦЪаГЁЁЃЦфИпаЇЕФаХКХДІРэЙІФмгыCortex-MДІРэЦїЯЕСаЕФЕЭЙІКФЁЂЕЭГЩБОКЭвзгкЪЙгУЕФгХЕуЯрНсКЯЁЃ
Cortex-M4ЬсЙЉСЫЮоПЩБШФтЕФЙІФмЃЌНЋ32ЮЛПижЦгыСьЯШЕФЪ§зжаХКХДІРэММЪѕМЏГЩРДТњзуашвЊКмИпФмаЇМЖБ№ЕФЪаГЁЁЃ
Cortex-M4ДІРэЦїВЩгУвЛИіРЉеЙЕФЕЅЪБжгжмЦкГЫЗЈРлМгЃЈMACЃЉЕЅдЊЁЂгХЛЏЕФЕЅжИСюЖрЪ§ОнЃЈSIMDЃЉжИСюЁЂБЅКЭдЫЫужИСюКЭвЛИіПЩбЁЕФЕЅОЋЖШИЁЕуЕЅдЊЃЈFPU)ЁЃетаЉЙІФмвдБэЯж
ARMCortex-MЯЕСаДІРэЦїЬиеїЕФДДаТММЪѕЮЊЛљДЁЁЃАќРЈ
ЁЄRISCДІРэЦїФкКЫЃЌИпадФм32ЮЛCPUЁЂОпгаШЗЖЈадЕФдЫЫуЁЂЕЭбгГй3НзЖЮЙмЕРЃЌПЩДя1.25DMIPS/MHzЃЛ
ЁЄThumb-2жИСюМЏЃЌ16/32ЮЛжИСюЕФзюМбЛьКЯЁЂаЁгк8ЮЛЩшБИ3БЖЕФДњТыДѓаЁЁЂЖдадФмУЛгаИКУцгАЯьЃЌЬсЙЉзюМбЕФДњТыУмЖШЃЛ
ЁЄЕЭЙІКФФЃЪНЃЌМЏГЩЕФЫЏУпзДЬЌжЇГжЁЂЖрЕчдДгђЁЂЛљгкМмЙЙЕФШэМўПижЦЃЛ
ЁЄЧЖЬзЪИСПжаЖЯПижЦЦїЃЈNVICЃЉЃЌЕЭбгГйЁЂЕЭЖЖЖЏжаЖЯЯьгІЁЂВЛашвЊЛуБрБрГЬЁЂвдДПCгябдБраДЕФжаЖЯЗўЮёР§ГЬЃЌФмЭъГЩГіЩЋЕФжаЖЯДІРэЃЛ
ЁЄЙЄОпКЭRTOSжЇГжЃЌЙуЗКЕФЕкШ§ЗНЙЄОпжЇГжЁЂCortexЮЂПижЦЦїШэМўНгПкБъзМЃЈCMSISЃЉЁЂзюДѓЯоЖШЕидіМгШэМўГЩЙћжигУ;
ЁЄCoreSightЕїЪдКЭИњзйЃЌJTAGЛђ2еыДЎааЯпЕїЪдЃЈSWDЃЉСЌНгЁЂжЇГжЖрДІРэЦїЁЂжЇГжЪЕЪБИњзйЁЃ
ДЫЭтЃЌИУДІРэЦїЛЙЬсЙЉСЫвЛИіПЩбЁЕФФкДцБЃЛЄЕЅдЊЃЈMPUЃЉЃЌЬсЙЉЕЭГЩБОЕФЕїЪд/зЗзйЙІФмКЭМЏГЩЕФанУпзДЬЌЃЌвддіМгСщЛюадЁЃЧЖШыЪНПЊЗЂепНЋЕУвдПьЫйЩшМЦВЂЭЦГіСюШЫжѕФПЕФжеЖЫВњЦЗЃЌОпБИзюЖрЕФЙІФмвдМАзюЕЭЕФЙІКФКЭГпДчЁЃ
ДІРэММЪѕ
Cortex-M4 ДІРэЦївбЩшМЦЮЊОпгаЪЪгУгкЪ§зжаХКХПижЦЪаГЁЕФЖржжИпаЇаХКХДІРэЙІФмЁЃCortex-M4
ДІРэЦїВЩгУРЉеЙЕФЕЅжмЦкГЫЗЈРлМг (MAC) жИСюЁЂгХЛЏЕФ SIMD дЫЫуЁЂБЅКЭдЫЫужИСюКЭвЛИіПЩбЁЕФЕЅОЋЖШИЁЕуЕЅдЊ
(FPU)ЁЃетаЉЙІФмвдБэЯж ARM Cortex-M ЯЕСаДІРэЦїЬиеїЕФДДаТММЪѕЮЊЛљДЁЁЃ

жївЊЙІФм
ДгЭМЩЯПЩвдПДГіШ§епЙІФмЩЯЕФвьЭЌЕуЁЃЫќУЧЕФВЛЭЌЕувВОіЖЈСЫШ§епЕФВЛЭЌгІгУГЁКЯЁЃM4ЯрБШНЯЧАСНепжївЊЕФБфЛЏдкгкЪ§зждЫЫуФмСІЩЯЕФдіЧПЃЌдіМгСЫDSPдЫЫужИСюЁЂSIMDЃЈSingle
Instruction Multiple DataЃЌЕЅжИСюЖрЪ§ОнСїЃЉжИСюМЏЁЂFPUЃЈИЁЕудЫЫуЕЅдЊЃЌПЩбЁЃЉЁЃ
ДгЭМжазувдПДГіM4ФкКЫЕФЧПДѓЃЌЭЌЪБCortex-M ЯЕСаДІРэЦїЖМЪЧЖўНјжЦЯђЩЯМцШнЕФЃЌетЪЙЕУШэМўжигУвдМАДгвЛИі
Cortex-M ДІРэЦїЮоЗьЗЂеЙЕНСэвЛИіГЩЮЊПЩФм(ЭМ3)ЃК
ЯТУцОЭдіЧПЕФШ§ИіЙІФмНјааЫЕУїЃК
1ЁЂDSPжИСюМЏ
ЫљЮНМЏГЩDSPЙІФмВЂВЛЪЧЫЕM4ФкКЫЪЧвЛИіM3+DSPЕФЫЋКЫДІРэЦїЃЈФПЧАИіШЫжЊЕРЕФетРрДІРэЦїЪЧTIЕФДяЗвЦцЯЕСаЃЌжївЊгІгУгкгявєЁЂЪгЦЕЭМЯёгаЙиЕФЪ§зжЖрУНЬхСьгђЃЉЁЃЖјЪЧжЛЪЧдіМгСЫDSPЙІФмЕФжИСюМЏ(ЕЅжмЦкЕФдЫЫужИСю)ЃЌФмдквЛИіжмЦкФкЭъГЩжИСюВйзїЁЃдкЙйЗНЕФCMSISБъзМЙЄГЬПтжавбОМЏГЩЃЌПЩвджБНгЪЙгУЃЈгаЙиФкШндквдКѓЮФеТжаНщЩмЃЉЁЃ
ЭМБэеЙЪОСЫДІРэЦїдЫаадкЯрЭЌЕФЫйЖШЯТCortex - M3КЭCortex - M4дкЪ§зжаХКХДІРэФмСІЗНУцЕФЯрЖдадФмБШНЯЁЃ
дкЯТУцЕФЪ§зжЃЌYжсДњБэжДааИјГіЕФМЦЫугУЕФЯрЖдЕФжмЦкЪ§ЁЃ вђДЫЃЌбЛЗЪ§дНаЁЃЌадФмдНКУЁЃвдCortex
- M3зїЮЊВЮПМЃЌCortex - M4ЕФадФмМЦЫуЃЌадФмБШДѓИХЮЊЦфжмЦкМЦЪ§ЕФЕЙЪ§ЁЃОйР§ЫЕУїЃЌPIDЙІФмЃЌCortex
- M4ЕФжмЦкЪ§ЪЧгыCortex - M3ЕФдМ0.7БЖЃЌвђДЫЯрЖдадФмЪЧ1/0.7ЃЌМД1.4БЖЁЃ
Cortex - MЯЕСа16ЮЛбЛЗМЦЪ§ЙІФм
Cortex - MЯЕСа32ЮЛбЛЗМЦЪ§ЙІФм
етКмЧхГўЕФБэУїЃЌCortex - M4дкЪ§зжаХКХДІРэЗНУцЖдБШCortex - M3ЕФ16ЮЛЛђ32ЮЛВйзїгазХКмДѓЕФгХЪЦЁЃ
Cortex-M4жДааЕФЫљгаЕФDSPжИСюМЏЖМПЩвддквЛИіжмЦкЭъГЩЃЌCortex - M3ашвЊЖрИіжИСюКЭЖрИіжмЦкВХФмЭъГЩЕФЕШаЇЙІФмЁЃМДЪЙЪЧPIDЫуЗЈЁЊЁЊЭЈгУDSPдЫЫужазюКФЗбзЪдДЕФЙЄзїЃЌCortex
- M4вВФмЬсЙЉСЫвЛИі1.4БЖЕФадФмЕУИФЩЦ ЁЃСэвЛИіР§згЃЌMP3НтТыдкCortex-M3ашвЊ20-25MhzЃЌЖјдкCortex-M4жЛашвЊ10-12MHzЁЃ
2. 32ЮЛГЫЗЈРлМгЃЈMACЃЉ
32ЮЛГЫЗЈРлМгЃЈMACЃЉАќРЈаТЕФжИСюМЏКЭеыЖдCortex - M4гВМўжДааЕЅдЊЕФгХЛЏЫќЪЧФмЙЛдкЕЅжмЦкФкЭъГЩвЛИі
32 ЁС 32 + 64 - > 64 ЕФВйзї Лђ СНИі16 ЁС 16 ЕФВйзїЁЃШчЯТБэСаГіСЫетИіЕЅдЊЕФМЦЫуФмСІЁЃ
3 .SIMD
(Single Instruction Multiple DataЃЌЕЅжИСюЖрЪ§ОнСї)ФмЙЛИДжЦЖрИіВйзїЪ§ЃЌВЂАбЫќУЧДђАќдкДѓаЭМФДцЦїЕФвЛзщжИСюМЏЃЌР§ЃК3DNow!ЁЂSSEЁЃвдЭЌВНЗНЪНЃЌдкЭЌвЛЪБМфФкжДааЭЌвЛЬѕжИСюЁЃ
SIMDдкадФмЩЯЕФгХЪЦЃК
вдМгЗЈжИСюЮЊР§ЃЌЕЅжИСюЕЅЪ§ОнЃЈSISDЃЉЕФCPUЖдМгЗЈжИСювыТыКѓЃЌжДааВПМўЯШЗУЮЪФкДцЃЌШЁЕУЕквЛИіВйзїЪ§ЃЛжЎКѓдйвЛДЮЗУЮЪФкДцЃЌШЁЕУЕкЖўИіВйзїЪ§ЃЛЫцКѓВХФмНјааЧѓКЭдЫЫуЁЃЖјдкSIMDаЭЕФCPUжаЃЌжИСювыТыКѓМИИіжДааВПМўЭЌЪБЗУЮЪФкДцЃЌвЛДЮадЛёЕУЫљгаВйзїЪ§НјаадЫЫуЁЃетИіЬиЕуЪЙSIMDЬиБ№ЪЪКЯгкЖрУНЬхгІгУЕШЪ§ОнУмМЏаЭдЫЫуЁЃ
ШчЃКAMDЙЋЫОв§вдЮЊКРЕФ3D NOW! ММЪѕЪЕжЪОЭЪЧSIMDЃЌетЪЙK6-2ЁЂРзФёЁЂЖОСњДІРэЦїдквєЦЕНтТыЁЂЪгЦЕЛиЗХЁЂ3DгЮЯЗЕШгІгУжаЯдЪОГігХвьЕФадФмЁЃ
4.FPU
FPUЪЧCortex - M4ИЁЕудЫЫуЕФПЩбЁЕЅдЊЁЃвђДЫЫќЪЧвЛИізЈгУгкИЁЕуШЮЮёЕФЕЅдЊЁЃетИіЕЅдЊЭЈЙ§гВМўЬсЩ§адФмЃЌФмДІРэЕЅОЋЖШИЁЕудЫЫуЃЌВЂгыIEEE
754БъзМ МцШнЁЃетЭъГЩСЫARMv7 - MМмЙЙЕЅОЋЖШБфСПЕФИЁЕуРЉеЙЁЃFPUРЉеЙСЫМФДцЦїЕФГЬађФЃаЭгыАќКЌ32ИіЕЅОЋЖШМФДцЦїЕФМФДцЦїЮФМўЁЃетаЉПЩвдБЛПДзїЪЧЃК
ЁЄ16Иі64ЮЛЫЋзжМФДцЦїЃЌD0 - D15
ЁЄ32Иі32ЮЛЕЅзжМФДцЦїЃЌS0 - S31 ИУFPUЬсЙЉСЫШ§жжФЃЪНдЫзїЃЌвдЪЪгІИїжжгІгУ
ЁЄШЋМцШнФЃЪНЃЈдкШЋМцШнФЃЪНЃЌFPUДІРэЫљгаЕФВйзїЖМзёбIEEE754ЕФгВМўБъзМЃЉ
ЁЄFlush-to-zero ГхЯДЕНСуФЃЪНЃЈЩшжУFZЮЛИЁЕузДЬЌКЭПижЦМФДцЦїFPSCR [24]ЕНflush-to-zero
ФЃЪНЁЃдкДЫФЃЪНЯТЃЌFPU дкдЫЫужаНЋЫљгаВЛе§ГЃЕФЪфШыВйзїЪ§ЕФЫуЪѕCDPВйзїЕБзі0.Г§СЫЕБДгСуВйзїЪ§ЕФНсЙћЪЧКЯЪЪЕФЧщПіЁЃVABSЃЌVNEGЃЌVMOV
ВЛЛсБЛЕБзіЫуЪѕCDPЕФдЫЫуЃЌЖјЧвВЛЪмflush-to-zero ФЃЪНгАЯьЁЃНсЙћЪЧЮЂаЁЕФЃЌОЭЯёдкIEEE
754 БъзМЕФУшЪіЕФФЧбљЃЌдкФПБъОЋЖШдіМгЕФЗљЖШаЁгкЫФЩсЮхШыКѓзюЕЭе§ГЃжЕЃЌБЛСуШЁДњЁЃIDCЕФБъжОЮЛЃЌFPSCR
[7]ЃЌБэЪОЕБЪфШыFlushЪББфЛЏЁЃUFCБъжОЮЛЃЌFPSCR [3]ЃЌБэЪОЕБFlushНсЪјЪББфЛЏЃЉ
ЁЄФЌШЯЕФNaNФЃЪНЃЈDNЮЛЕФЩшжУЃЌFPSCR [25]ЃЌЛсНјШыNaNЕФФЌШЯФЃЪНЁЃдкетжжФЃЪНЯТЃЌШчЖдШЮКЮЫуЪѕЪ§ОнДІРэВйзїЕФНсЙћЃЌЩцМАвЛИіЪфШыNaNЃЌЛђВњЩњвЛИіNaNНсЙћЃЌЛсЗЕЛиФЌШЯЕФNaNЁЃНіЕБVABSЃЌVNEGЃЌVMOVдЫЫуЪБЃЌЗжЪ§ЮЛдіМгБЃГжЁЃЫљгаЦфЫћЕФCDPдЫЫуЛсКіТдЫљгаЪфШыNaNЕФаЁЪ§ЮЛЕФаХЯЂЃЉЁЃОпЬхжИСюЧыздааВщПДЪжВсЁЃ
Cortex-MЙІФмФЃПщВювь
ЁЁЁЁгЩгкCM1жївЊЪЧгУдкFPGAВњЦЗжаЃЌЙЪЯТУцЖдБШКіТдCM1ЁЃЮвУЧжЊЕРCMДІРэЦїЪЧЯђЯТМцШнЕФЃЌЙЪCMЙІФмФЃПщЪЧЫцзХАцБОЕФЩ§МЖЖјж№ВНдіМгЕФЃЌЮвУЧж№ВНДгзюЕЭАцБОПЊЪМЖдБШЁЃ
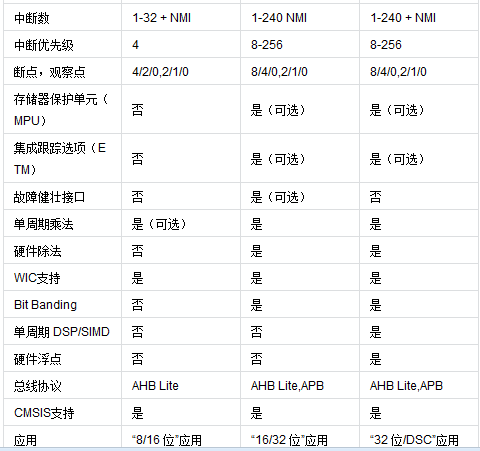
2.1 CM0 vs CM0+
ЯШРДСФСФCM0гыCM0+ЃЌДгзюЛљзМЕФCM0ФЃПщПДЦ№ЃК

ARMv6-M CPUФкКЫЃКARMЙЋЫОгк2007ФъЭЦГіЕФФкКЫЁЃЗыЁЄХЕвРТќЬхЯЕНсЙЙЃЌ3МЖСїЫЎЯпЃЌжЇГжДѓВПЗжThumbКЭаЁВПЗжThumb-2жИСюМЏЃЌЫљгажИСювЛЙВ57ЬѕЁЃДЫЭтЛЙФкЧЖ32-bitЗЕЛиНсЙћЕФгВМўГЫЗЈЦїЁЃ
NVICЧЖЬзЯђСПжаЖЯПижЦЦїЃКгУгкCPUдке§ГЃRunФЃЪНЯТжаЖЯЙмРэЁЃзюДѓжЇГж32ИіЭтВПжаЖЯЃЌЭтВПжаЖЯПЩЩш4МЖЧРеМгХЯШМЖЃЈ2bitЃЉЁЃ
WICЛНабжаЖЯПижЦЦїЃКгУгкCPUдкЕЭЙІКФSleepФЃЪНЯТжаЖЯЙмРэЁЃ
AHB-LiteзмЯпЃКвЛЬѕ32bit AMBA-3БъзМЕФИпадФмsystemзмЯпИКд№ЫљгаFlashЁЂSRAMжажИСюКЭЪ§ОнДцШЁЁЃ
ЕїЪдФЃПщЃК0-4ИігВМўЖЯЕуBreakpointЃЌ0-2ИіЪ§ОнМрВтЕуWatchpointЁЃ
DAPЕїЪдНгПкЃКЭЈЙ§DAPФЃПщжЇГжJTAGКЭSWDНгПкЁЃ

ФЧУДCM0+ЕНЕзИФНјСЫЪВУДЃП
ARMv6-M CPUФкКЫЃКСїЫЎЯпИФЮЊ2МЖЃЈКмЖр8bit MCUЖМЪЧ2МЖСїЫЎЯпЃЌжївЊгУгкНЕЕЭЙІКФЃЉ
NVICЧЖЬзЯђСПжаЖЯПижЦЦїЃКдіМгСЫVTORМДжаЖЯжиЖЈЯђЙІФмЁЃ
ФЧУДCM0+ЕНЕздіМгСЫЪВУДЃП
MPUДцДЂЦїБЃЛЄЕЅдЊЃКЬсЙЉгВМўЗНЪНЙмРэКЭБЃЛЄФкДцЃЌПижЦЗУЮЪШЈЯоЃЌзюДѓПЩНЋФкДцЗжЮЊ8*8ИіregionЁЃФкДцдНШЈЗУЮЪЃЌНЋЗЕЛиMemManage
FaultЁЃ
MTBЦЌЩЯИњзйЕЅдЊЃКгУЛЇЬхбщИќКУЕФЕФИњзйЕїЪдЃЌгХЛЏЕФвьГЃВЖЛёЛњжЦЃЌПЩвдИќПьЕиЖЈЮЛbugЁЃ
Fast I/OЃКПЩЕЅжмЦкЗУЮЪЕФПьЫйI/OПкЃЌИќвзгкBit-bangingЃЈБШШчGPIOФЃФтSPIЁЂIICавщЃЉЁЃ
2.2 CM0+ vs CM3

ЧАУцБШНЯЭъСЫCM0гыCM0+ЃЌдйРДПДПДCM3БШCM0+діЧПдкСЫФФРяЃК
ФЧУДCM3ЕНЕзИФНјСЫЪВУДЃП
ARMv7-M CPUФкКЫЃКARMЙЋЫОгк2004ФъЭЦГіЕФФкКЫЁЃЙўЗ№ЬхЯЕНсЙЙЃЌ3МЖСїЫЎЯп+ЗжжЇдЄВтЃЌжЇГжШЋВПЕФThumbКЭThumb-2жИСюМЏЁЃФкЧЖ32-bitгВМўГЫЗЈЦїПЩЗЕЛи64-bitдЫЫуНсЙћЃЌЧваТді32-bitгВМўГ§ЗЈЦїЁЃ
NVICЧЖЬзЯђСПжаЖЯПижЦЦїЃКзюДѓжЇГж240ИіЭтВПжаЖЯЃЌжаЖЯгХЯШМЖПЩЗжзщЃЈЧРеМгХЯШМЖЁЂЯьгІгХЯШМЖЃЉЃЌ8bitгХЯШМЖЩшжУЃЈзюДѓ128МЖЧРеМгХЯШМЖ(ЖдгІзюаЁ2МЖЯьгІгХЯШМЖ)ЃЌзюДѓ256МЖЯьгІгХЯШМЖ(ЖдгІЮоЧРеМгХЯШМЖ)ЃЉЁЃ
3x AHB-LiteзмЯпЃКГ§СЫдsystemзмЯпИКд№SRAMДцШЁЭтЃЌЛЙаТдіСНЬѕICodeЁЂDCodeзмЯпЗжБ№ЭъГЩFlashЩЯжИСюКЭЪ§ОнДцШЁЁЃ
ЕїЪдФЃПщЃК0-8ИігВМўЖЯЕуBreakpointЃЌ0-4ИіЪ§ОнМрВтЕуWatchpointЁЃ
ITM/ETMИњзйЕЅдЊЃКITMИќКУЕижЇГжprintfЗчИёdebugЃЌETMЬсЙЉЪЕЪБжИСюКЭЪ§ОнИњзйЁЃ
ФЧУДCM3ЕНЕздіМгСЫЪВУДЃП
ЖюЃЌCM3ЯрБШCM0+ВЂУЛгадіМгЪВУДЖРгаФЃПщЃЌЗДЕЙЪЧЩйСЫFast I/O
PortЃЌЪЕМЪЩЯFast I/O PortЪЧCMМвзхРяCM0+ЫљЖРгаЕФФЃПщЁЃ
2.3 CM3 vs CM4

ЧАУцБШНЯЭъСЫCM0+гыCM3ЃЌдйРДПДПДCM4БШCM3діЧПдкСЫФФРяЃК
ФЧУДCM4ЕНЕзИФНјСЫЪВУДЃП
ARMv7E-M CPUФкКЫЃКдіМгСЫDSPЯрЙижИСюжЇГжЁЃ
ФЧУДCM4ЕНЕздіМгСЫЪВУДЃП
DSPЪ§зжаХКХДІРэЕЅдЊЃКаТдіжЇГжЕЅжмЦк16/32-bit MACЁЂdual 16-bit MAC,
8/16-bit SIMDЫуЗЈЕФЪ§зжаХКХДІРэЕЅдЊЁЃ
FPUИЁЕудЫЫуЕЅдЊЃКаТдіЕЅОЋЖШЃЈfloatаЭЃЉМцШнIEEE-754БъзМЕФИЁЕудЫЫуЕЅдЊЃЈVFPv4-SPЃЉЁЃ
2.4 CM4 vs CM7
ЧАУцБШНЯЭъСЫCM3гыCM4ЃЌдйРДПДПДCM7БШCM4діЧПдкСЫФФРяЃК
ФЧУДCM7ЕНЕзИФНјСЫЪВУДЃП
ARMv7E-M CPUФкКЫЃК6МЖСїЫЎЯп+ЗжжЇдЄВтЁЃ
2x AHB-LiteзмЯпЃКОЋМђЮЊ2ЬѕAHBзмЯпЃЌЦфжаAHB-PЭтЩшНгПкЭъГЩдРДsystemзмЯпЙІФм,
AHB-SДгЪєНгПкИКд№ЭтВПзмЯпПижЦЦїЃЈШчDMAЃЉЙІФмвдМАгыTCMНгПкЙІФмЁЃ
MPUДцДЂЦїБЃЛЄЕЅдЊЃКзюДѓПЩНЋФкДцЗжЮЊ16*8ИіregionЁЃ
FPUИЁЕудЫЫуЕЅдЊЃКаТдіЫЋОЋЖШЃЈdoubleаЭЃЉМцШнIEEE-754БъзМЕФИЁЕудЫЫуЕЅдЊЃЈVFPv5ЃЉЁЃ

ФЧУДCM7ЕНЕздіМгСЫЪВУДЃП
I/D-CacheЛКДцЧјЃКМДЪЧЮвУЧЭЈГЃРэНтЕФL1 CacheЃЌУПИіCacheДѓаЁЮЊ4-64KBЁЃ
I/D-TCMНєУмёюКЯДцДЂЦїЃКНєУмЕФгыДІРэЦїФкКЫЯрёюКЯЕФRAMЃЌЬсЙЉгыCacheЯрЕБЕФадФмЃЌЕЋБШCacheИќОпШЗЖЈадЃЌmemoryзюДѓОљЮЊ16MBЁЃ
ECCЬиадЃКЖдL1 CacheЬсЙЉДэЮѓаЃе§КЭЛжИДЙІФмЃЌЬсИпЯЕЭГЕФПЩППадЁЃ
AXI-MзмЯпЃКЛљгкAMBA 4ЕФ64bit AXIзмЯпЃЌгУгкжЇГжЙвдкЯЕЭГЩЯЕФL2 memoryЁЃ
зюНќдкЙизЂCortex-MДІРэЦїЃЌеыЖдФПЧАНјШыДѓжкЪгвАЕФM0ЁЂM3ЁЂM4зіСЫШчЯТМђЕЅЖдБШЃЌФкШнРДздARMЕШЙйЭјЃЌетРяНіНіЪЧећРэСЫЯТЃЌПДЦ№РДИќжБЙлЕуЃЌКЧКЧЁЃ
Cortex-M ЯЕСаеыЖдГЩБОКЭЙІКФУєИаЕФ MCU КЭжеЖЫгІгУЃЈШчжЧФмВтСПЁЂШЫЛњНгПкЩшБИЁЂЦћГЕКЭЙЄвЕПижЦЯЕЭГЁЂДѓаЭМвгУЕчЦїЁЂЯћЗбадВњЦЗКЭвНСЦЦїаЕЃЉЕФЛьКЯаХКХЩшБИНјааЙ§гХЛЏЁЃ.
вЛЁЂБШНЯCortex-M ДІРэЦї
Cortex-M ЯЕСаДІРэЦїЖМЪЧЖўНјжЦЯђЩЯМцШнЕФЃЌетЪЙЕУШэМўжигУвдМАДгвЛИі Cortex-M ДІРэЦїЮоЗьЗЂеЙЕНСэвЛИіГЩЮЊПЩФмЁЃ
M Cortex-M ММЪѕ
CMSIS
ARM Cortex ЮЂПижЦЦїШэМўНгПкБъзМ (CMSIS)ЪЧ Cortex-M ДІРэЦїЯЕСаЕФгыЙЉгІЩЬЮоЙиЕФгВМўГщЯѓВуЁЃ
ЪЙгУ CMSISЃЌПЩвдЮЊНгПкЭтЩшЁЂЪЕЪБВйзїЯЕЭГКЭжаМфМўЪЕЯжвЛжТЧвМђЕЅЕФШэМўНгПкЃЌДгЖјМђЛЏШэМўЕФжигУЁЂЫѕЖЬаТЮЂПижЦЦїПЊЗЂШЫдБЕФбЇЯАЙ§ГЬЃЌВЂЫѕЖЬаТВњЦЗЕФЩЯЪаЪБМфЁЃ
ЩюШыЃКЧЖЬзЪИСПжаЖЯПижЦЦї (NVIC)
NVIC ЪЧ Cortex-M ДІРэЦїВЛПЩЛђШБЕФВПЗжЃЌЫќЮЊДІРэЦїЬсЙЉСЫзПдНЕФжаЖЯДІРэФмСІЁЃ
Cortex-M ДІРэЦїЪЙгУвЛИіЪИСПБэЃЌЦфжаАќКЌвЊЮЊЬиЖЈжаЖЯДІРэГЬађжДааЕФКЏЪ§ЕФЕижЗЁЃНгЪмжаЖЯЪБЃЌДІРэЦїЛсДгИУЪИСПБэжаЬсШЁЕижЗЁЃ
ЮЊСЫМѕЩйУХЪ§ВЂдіЧПЯЕЭГСщЛюадЃЌCortex-M ДІРэЦїЪЙгУвЛИіЛљгкЖбеЛЕФвьГЃФЃаЭЁЃГіЯжвьГЃЪБЃЌЯЕЭГЛсНЋЙиМќЭЈгУМФДцЦїЭЦЫЭЕНЖбеЛЩЯЁЃЭъГЩШыеЛКЭжИСюЬсШЁКѓЃЌНЋжДаажаЖЯЗўЮёР§ГЬЛђЙЪеЯДІРэГЬађЃЌШЛКѓздЖЏЛЙдМФДцЦївдЪЙжаЖЯЕФГЬађЛжИДе§ГЃжДааЁЃЪЙгУДЫЗНЗЈЃЌБуЮоашБраДЛуБрЦїАќзАЦїСЫЃЈЖјетЪЧЖдЛљгк
C гябдЕФДЋЭГжаЖЯЗўЮёР§ГЬжДааЖбеЛВйзїЫљБиашЕФЃЉЃЌДгЖјЪЙЕУгІгУГЬађЕФПЊЗЂБфЕУЗЧГЃШнвзЁЃNVICжЇГжжаЖЯЧЖЬзЃЈШыеЛЃЉЃЌДгЖјдЪаэЭЈЙ§дЫгУНЯИпЕФгХЯШМЖРДНЯдчЕиЮЊФГИіжаЖЯЬсЙЉЗўЮёЁЃ
дкгВМўжаЭъГЩЖджаЖЯЕФЯьгІ
Cortex-M ЯЕСаДІРэЦїЕФжаЖЯЯьгІЪЧДгЗЂГіжаЖЯаХКХЕНжДаажаЖЯЗўЮёР§ГЬЕФжмЦкЪ§ЁЃЫќАќРЈЃК
МьВтжаЖЯ
БГЖдБГЛђГйЕНжаЖЯЕФзюМбДІРэЃЈВЮМћЯТЮФЃЉ
ЬсШЁЪИСПЕижЗ
НЋвзЫ№ЛЕЕФМФДцЦїШыеЛ
ЬјзЊЕНжаЖЯДІРэГЬађ
етаЉШЮЮёдкгВМўжажДааЃЌВЂЧвАќКЌдкЮЊ Cortex-M ДІРэЦїБЈГіЕФжаЖЯЯьгІжмЦкЪБМфжаЁЃдкЦфЫћаэЖрЬхЯЕНсЙЙжаЃЌетаЉШЮЮёБиаыдкШэМўЕФжаЖЯДІРэГЬађжажДааЃЌДгЖјв§Ц№бгГйВЂЪЙЕУЙ§ГЬЪЎЗжИДдгЁЃ
NVIC жаЕФЮВСД
дкБГЖдБГжаЖЯЕФЧщПіЯТЃЌДЋЭГЯЕЭГЛсжиИДЭъећЕФзДЬЌБЃДцКЭЛЙджмЦкСНДЮЃЌДгЖјЕМжТИќИпЕФбгГйЁЃCortex-MДІРэЦїЭЈЙ§дк
NVIC гВМўжаЪЕЯжЮВСДММЪѕМђЛЏСЫЛюЖЏжаЖЯКЭЙвЦ№ЕФжаЖЯжЎМфЕФзЊЛЛЁЃДІРэЦїзДЬЌЛсдкБШШэМўЪЕЯжЪБМфИќЩйЕФжмЦкФкздЖЏБЃДцдкжаЖЯЬѕФПЩЯВЂдкжаЖЯЭЫГіЪБЛЙдЃЌДгЖјЯджјЬсЩ§ЕЭ
MHz ЯЕЭГЕФадФмЁЃ
NVIC ЖдГйЕНЕФНЯИпгХЯШМЖжаЖЯЕФЯьгІ
ШчЙћдкЮЊЩЯвЛИіжаЖЯжДааЖбеЛЭЦЫЭЦкМфНЯИпгХЯШМЖЕФжаЖЯГйЕНЃЌNVIC ЛсСЂМДЬсШЁаТЕФЪИСПЕижЗРДЮЊЙвЦ№ЕФжаЖЯЬсЙЉЗўЮёЃЌШчЩЯЫљЪОЁЃCortex-M
NVIC ЖдетаЉПЩФмадЬсЙЉОпгаШЗЖЈадЕФЯьгІВЂжЇГжГйЕНКЭЧРеМЁЃ
NVIC НјааЕФЖбеЛЕЏГіЧРеМ
ЭЌбљЃЌШчЙћвьГЃЕНДяЃЌNVIC НЋЗХЦњЖбеЛЕЏГіВЂСЂМДЮЊаТЕФжаЖЯЬсЙЉЗўЮёЃЌШчЩЯЫљЪОЁЃЭЈЙ§ЧРеМВЂЧаЛЛЕНЕкЖўИіжаЖЯЖјВЛЭъГЩзДЬЌЛЙдКЭБЃДцЃЌNVIC
вдОпгаШЗЖЈадЕФЗНЪНЪЕЯжСЫЫѕЖЬбгГйЁЃ
дйРДЫЕЫЕARM7ЃЌARM9ЯЕСаЃЌ
ARM9
ARM9ЯЕСаДІРэЦїЪЧгЂЙњARMЙЋЫОЩшМЦЕФжїСїЧЖШыЪНДІРэЦїЃЌжївЊАќРЈARM9TDMIКЭARM9E-SЕШЯЕСаЁЃ
ЛљБОИХЪі
ARM9ВЩгУЙўЗ№ЬхЯЕНсЙЙЃЌжИСюКЭЪ§ОнЗжЪєВЛЭЌЕФзмЯпЃЌПЩвдВЂааДІРэЁЃдкСїЫЎЯпЩЯЃЌARM7ЪЧШ§МЖСїЫЎЯпЃЌARM9ЪЧЮхМЖСїЫЎЯпЁЃгЩгкНсЙЙВЛЭЌЃЌARM7ЕФжДаааЇТЪЕЭгкARM9ЁЃЦНЪБЫљЫЕЕФARM7ЁЂARM9ЪЕМЪЩЯжИЕФЪЧARM7TDMIЁЂARM9TDMIШэКЫЃЌетжжДІРэЦїШэКЫВЂВЛДјгаMMUКЭcacheЃЌВЛФмЙЛдЫаажюШчlinuxетбљЕФЧЖШыЪНВйзїЯЕЭГЁЃЖјARMЙЋЫОЖдетжжМмЙЙНјааСЫРЉеЙЃЌЫљвдгаСЫARM710TЁЂARM720TЁЂARM920TЁЂARM922TЕШДјгаMMUКЭcacheЕФДІРэЦїФкКЫЁЃ
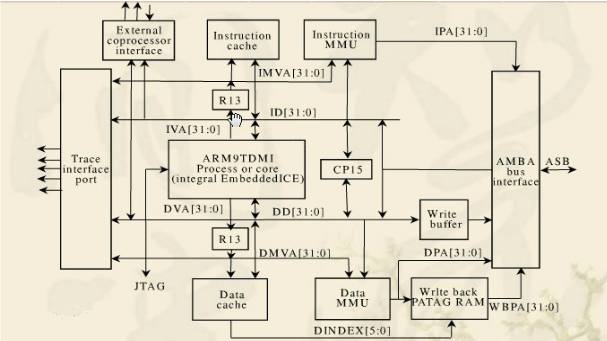
жївЊЬиадБрМ
ШкКЯСЫARM920T ARM Thumb ДІРэЦї
ЈC ЙЄзїгк180 MHzЪБадФмИпДя200 MIPSЃЌДцДЂЦїЙмРэЕЅдЊ
ЈC 16-K зжНкЕФЪ§ОнЛКДцЃЌ16-KзжНкЕФжИСюЛКДцЃЌаДЛКГхЦї
ЈC КЌгаЕїЪдаХЕРЕФФкВПЗТецЦї
ЈC жаЕШЙцФЃЕФЧЖШыЪНКъЕЅдЊНсЙЙ( НіеыЖд256 BGA ЗтзА)
ЁЄ ЕЭЙІКФЃКVDDCOREЕчСїЮЊ30.4 mA Д§ЛњФЃЪНЕчСїЮЊ3.1 mA
ЁЄ ИНМгЕФЧЖШыЪНДцДЂЦї
ЈC SRAMЮЊ16K ЃЛROMЮЊ128K
ЁЄ ЭтВПзмЯпНгПк(EBI)
ЈC жЇГжSDRAMЃЌОВЬЌДцДЂЦїЃЌ Burst FlashЃЌЮоЗьСЌНгЕФCompactFlashЃЌ
SmartMediaМАNAND Flash
ЁЄ ЬсИпадФмЖјЪЙгУЕФЯЕЭГЭтЩшЃК
ЈC діЧПЕФЪБжгЗЂЩњЦїгыЕчдДЙмРэПижЦЦї
ЈC СНИігаЫЋPLLЕФЦЌЩЯеёЕДЦї
ЈC ЕЭЫйЕФЪБжгВйзїФЃЪНгыШэМўЙІКФгХЛЏФмСІ
ЈC ЫФИіПЩБрГЬЕФЭтВПЪБжгаХКХ
ЈC АќРЈжмЦкаджаЖЯЁЂПДУХЙЗМАЕкЖўМЦЪ§ЦїЕФЯЕЭГЖЈЪБЦї
ЈC гаБЈОЏжаЖЯЕФЪЕЪБЪБжг
ЈC ЕїЪдЕЅдЊЁЂСНЯпUARTВЂжЇГжЕїЪдаХЕР
ЈC га8 ИігХЯШМЖЕФИпМЖжаЖЯПижЦЦїЃЌЖРСЂЕФПЩЦСБЮжаЖЯдДЃЌЮБжаЖЯБЃЛЄ
ЈC 7ИіЭтВПжаЖЯдДМА1 ИіПьЫйжаЖЯдД
ЈC га122ИіПЩБрГЬI/OПкЯпЕФЫФИі32 ЮЛPIOПижЦЦїЃЌИїЯпОљгаЪфШыБфЛЏжаЖЯМАПЊТЉФмСІ
ЈC 20ЭЈЕРЕФЭтЩшЪ§ОнПижЦЦї(DMA)
ЁЄ 10/100 Base-T аЭвдЬЋЭјПЈНгПк
ЈC ЖРСЂЕФУНЬхНгПк(MII)ЛђМђЛЏЕФЖРСЂУНЬхНгПк(RMII)
ЈC ЖдгкНгЪегыЗЂЫЭгаМЏГЩЕФ28 зжНкFIFOМАзЈгУЕФDMA ЭЈЕР
ЁЄ USB 2.0 ШЋЫй(12 MБШЬи/Уы) жїЛњЫЋЖЫПк
ЈC ЫЋЦЌЩЯЪеЗЂЦї(208в§НХPQFPЗтзАжаНіЮЊвЛИі)
ЈC МЏГЩЕФFIFOМАзЈгУЕФDMA ЭЈЕР
ЁЄ USB 2.0 ШЋЫй(12 MБШЬи/Уы) ЦїМўЖЫПк
ЈC ЦЌЩЯЪеЗЂЦїЃЌ 2-KзжНкПЩХфжУЕФМЏГЩFIFO
ЁЄ ЖрУНЬхПЈНгПк(MCI)
ЈC здЖЏавщПижЦМАПьЫйздЖЏЪ§ОнДЋЪф
ЈC гыMMCМАSDДцДЂЦїПЈМцШнЃЌжЇГжСНИіSDДцДЂЦї
ЁЄ 3ИіЭЌВНДЎааПижЦЦї(SSC)
ЈC УПИіНгЪеЦїгыЗЂЫЭЦїгаЖРСЂЕФЪБжгМАжЁЭЌВНаХКХ
ЈC жЇГжI2SФЃФтНгПкЃЌЪБЗжИДгУ
ЈC 32БШЬиЕФИпЫйЪ§ОнСїДЋЪфФмСІ
ЁЄ 4ИіЭЈгУЭЌВН/вьВННгЪе/ЗЂЫЭЦї(USART)
ЈC жЇГжISO7816 T0/T1 жЧФмПЈ
ЈC гВШэМўЮеЪж
ЈC жЇГжRS485 МАИпДя115 KbpsЕФIrDA змЯп
ЈC USART1ЮЊШЋЕїжЦНтЕїПижЦЯп
ЁЄ жїЛњ/ДгЛњДЎааЭтЩшНгПк(SPI)
ЈC 8ЁЋ 16 ЮЛПЩБрГЬЪ§ОнГЄЖШЃЌПЩСЌНг4ИіЭтЩш
ЁЄ СНИі 3 ЭЈЕР16 ЮЛЖЈЪБ/МЦЪ§Цї(TC)
ЈC 3ИіЭтВПЪБжгЪфШыЃЌУПЬѕЭЈЕРга2 ИіЖрЙІФмI/Oв§НХ
ЈC ЫЋPWM ВњЩњЦїЃЌВЖЛё/ВЈаЮФЃЪНЃЌЩЯМг/ЯТМѕМЦЪ§ФмСІ
ЁЄ СНЯпНгПк(TWI)
ЈC жїЛњФЃЪНжЇГжЃЌЫљгаСНЯпAtmel EEPROM жЇГж
ЁЄ ЫљгаЪ§зжв§НХЕФIEEE 1149.1 JTAGБпНчЩЈУш
ЁЄ ЕчдДЙЉгІ
ЈC VDDCOREЃЌVDDOSCМАVDDPLLЕчбЙЮЊЃК1.65V ЁЋ1.95V
ЈC VDDIOP (ЭтЩшI/O) МАVDDIOM (ДцДЂЦїI/O)ЕчбЙЮЊЃК1.65VЁЋ 3.6V
ЬхЯЕЬиЕу
НсЙЙЬиЕу
вдARM9E-SЮЊР§НщЩмARM9ДІРэЦїЕФжївЊНсЙЙМАЦфЬиЕуЁЃARM9E-SЕФНсЙЙШчЭМ4ЫљЪОЁЃЦфжївЊЬиЕуШчЯТЃК
ЂХ32bitЖЈЕуRISCДІРэЦїЃЌИФНјаЭARM/ThumbДњТыНЛжЏЃЌдіЧПадГЫЗЈЦїЩшМЦЁЃжЇГжЪЕЪБЃЈreal-timeЃЉЕїЪдЃЛ
ЂЦЦЌФкжИСюКЭЪ§ОнSRAMЃЌЖјЧвжИСюКЭЪ§ОнЕФДцДЂЦїШнСППЩЕїЃЛ
ЂЧЦЌФкжИСюКЭЪ§ОнИпЫйЛКГхЦїЃЈcacheЃЉШнСПДг4KзжНкЕН1MзжНкЃЛ
ЂШЩшжУБЃЛЄЕЅдЊЃЈprotection unitЃЉЃЌЗЧГЃЪЪКЯЧЖШыЪНгІгУжаЖдДцДЂЦїНјааЗжЖЮКЭБЃЛЄЃЛ
ЂЩВЩгУAMBA AHBзмЯпНгПкЃЌЮЊЭтЩшЬсЙЉЭГвЛЕФЕижЗКЭЪ§ОнзмЯпЃЛ
ЂЪжЇГжЭтВПаДІРэЦїЃЌжИСюКЭЪ§ОнзмЯпгаМђЕЅЕФЮеЪжаХСюжЇГжЃЛ
ЂЫжЇГжБъзМЛљБОТпМЕЅдЊЩЈУшВтЪдЗНЗЈбЇЃЌЖјЧвжЇГжBIST(built-in-self-testЃЉЃЛ
ЂЬжЇГжЧЖШыЪНИњзйКъЕЅдЊЃЌжЇГжЪЕЪБИњзйжИСюКЭЪ§ОнЁЃ
ARM920TдЫааФЃЪН
ARM920TжЇГж7жждЫааФЃЪНЃЌЗжБ№ЮЊЃК
(1)гУЛЇФЃЪН(usr)ЃЌ
ARMДІРэЦїе§ГЃЕФГЬађжДаазДЬЌЃЛ
(2)ПьЫйжаЖЯФЃЪН (fiq)ЃЌ
гУгкИпЫйЪ§ОнДЋЪфЛђЭЈЕРДІРэЃЛ
(3)ЭтВПжаЖЯФЃЪН(irq)ЃЌ
гУгкЭЈгУЕФжаЖЯДІРэЃЛ
(4)ЙмРэФЃЪН(svc)ЃЌ
ВйзїЯЕЭГЪЙгУЕФБЃЛЄФЃЪНЃЛ
(5)Ъ§ОнЗУЮЪжежЙФЃЪН(abt)ЃЌ
ЕБЪ§ОнЛђжИСюдЄШЁжежЙЪБНјШыИУФЃЪНЃЌПЩгУгкащФтДцДЂМАДцДЂБЃЛЄЃЛ
(6)ЯЕЭГФЃЪН(sys)ЃЌ
дЫааОпгаЬиШЈЕФВйзїЯЕЭГШЮЮёЃЛ
(7)ЮДЖЈвхжИСюжажЙФЃЪН(und)
ЕБЮДЖЈвхЕФжИСюжДааЪБНјШыИУФЃЪНЃЌПЩгУгкжЇГжгВМўаДІРэЦїЕФШэМўЗТецЁЃ
ARMЮЂДІРэЦїЕФдЫааФЃЪНПЩвдЭЈЙ§ШэМўИФБфЃЌвВПЩвдЭЈЙ§ЭтВПжаЖЯЛђвьГЃДІРэИФБфЁЃДѓЖрЪ§ЕФгІгУГЬађдЫаадкгУЛЇФЃЪНЯТЃЌЕБДІРэЦїдЫаадкгУЛЇФЃЪНЯТЪБЃЌФГаЉБЛБЃЛЄЕФЯЕЭГзЪдДЪЧВЛФмБЛЗУЮЪЕФЁЃГ§гУЛЇФЃЪНвдЭтЃЌЦфгрЕФ6жжФЃЪНГЦЮЊЬиШЈФЃЪН;ЦфжаГ§ШЅгУЛЇФЃЪНКЭЯЕЭГФЃЪНвдЭтЕФ5жжгжГЦЮЊвьГЃФЃЪНЃЌГЃгУгкДІРэжаЖЯЛђвьГЃЃЌвдМАЗУЮЪЪмБЃЛЄЕФЯЕЭГзЪдДЕШЧщПіЁЃ
ARM920TЕФЙЄзїзДЬЌ
ДгБрГЬЕФНЧЖШПДЃЌARM920TЮЂДІРэЦїЕФЙЄзїзДЬЌвЛАугаСНжжЃК
(1)ARMзДЬЌЃЌДЫЪБДІРэЦїжДаа32ЮЛЕФЁЂзжЖдЦыЕФARMжИСюЃЛ
(2)ThumbзДЬЌЃЌДЫЪБДІРэЦїжДаа16ЮЛЕФЁЂАызжЖдЦыЕФThumbжИСюЁЃ
ARMжИСюМЏКЭThumbжИСюМЏОљгаЧаЛЛДІРэЦїзДЬЌЕФжИСюЃЌдкГЬађЕФжДааЙ§ГЬжаЃЌЮЂДІРэЦїПЩвдЫцЪБдкСНжжЙЄзїзДЬЌжЎМфЧаЛЛЃЌВЂЧвЃЌДІРэЦїЕФЙЄзїзДЬЌЕФзЊБфВЂВЛгАЯьДІРэЦїЕФЙЄзїФЃЪНКЭЯргІМФДцЦїжаЕФФкШнЁЃЕЋARMЮЂДІРэЦїдкПЊЪМжДааДњТыЪБЃЌгІИУДІгкARM
зДЬЌЁЃ
ЕБВйзїЪ§МФДцЦїЕФзДЬЌЮЛ(ЮЛ0)ЮЊ1ЪБЃЌПЩвдВЩгУжДааBXжИСюЕФЗНЗЈЃЌЪЙЮЂДІРэЦїДг
ARMзДЬЌЧаЛЛЕНThumbзДЬЌЁЃДЫЭтЃЌЕБДІРэЦїДІгкThumbзДЬЌЪБЗЂЩњвьГЃ(ШчIRQЁЂFIQЁЂUndefЁЂAbortЁЂSWIЕШ)ЃЌЕБвьГЃДІРэЗЕЛиЪБЃЌздЖЏЧаЛЛЛиThumbзДЬЌЁЃЕБВйзїЪ§МФДцЦїЕФзДЬЌЮЛЮЊ0ЪБЃЌжДааBXжИСюПЩвдЪЙЮЂДІРэЦїДгThumbзДЬЌЧаЛЛЕНARMзДЬЌЁЃДЫЭтЃЌдкДІРэЦїНјаавьГЃДІРэЪБЃЌНЋPCжИеыЗХШывьГЃФЃЪНСДНгМФДцЦїжаЃЌВЂДгвьГЃЯђСПЕижЗПЊЪМжДааГЬађЃЌвВПЩвдЪЙДІРэЦїЧаЛЛЕНARMзДЬЌЁЃ
ARM920TЬхЯЕНсЙЙЕФДцДЂЦїИёЪН
ARM920TЬхЯЕНсЙЙНЋДцДЂЦїПДзіЪЧДгСуЕижЗПЊЪМЕФзжНкЕФЯпадзщКЯЁЃДг0зжНкЕН3зжНкЗХжУЕк1ИіДцДЂЕФзжЪ§ОнЃЌДгЕк4ИізжНкЕНЕк7ИізжНкЗХжУЕк2ИіДцДЂЕФзжЪ§ОнЃЌвРДЮХХСаЁЃзїЮЊ32ЮЛЕФЮЂДІРэЦїЃЌARM92OTЬхЯЕНсЙЙЫљжЇГжЕФзюДѓбАжЗПеМфЮЊ4GBЁЃ
ARM92OTЬхЯЕНсЙЙПЩвдгУСНжжЗНЗЈДцДЂзжЪ§ОнЃЌЗжБ№ГЦЮЊДѓЖЫИёЪНКЭаЁЖЫИёЪНЁЃДѓЖЫИёЪНжазжЪ§ОнЕФИпзжНкДцДЂдкЕЭЕижЗжаЃЌЖјзжЪ§ОнЕФЕЭзжНкдђДцЗХдкИпЕижЗжа
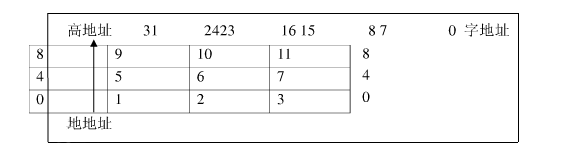
вдДѓЖЫИёЪНДцДЂЪ§Он

вдаЁЖЫИёЪНДцДЂЪ§Он
жИСю
ЂБloads жИСюгыn storesжИСю
жИСюжмЦкЪ§ЕФИФНјзюУїЯдЕФЪЧloadsжИСюКЭstoresжИСюЁЃДгARM7ЕНARM9етСНЬѕжИСюЕФжДааЪБМфМѕЩйСЫ30%ЁЃжИСюжмЦкЕФМѕЩйЪЧгЩгкARM7КЭARM9СНжжДІРэЦїФкЕФСНИіЛљБОЕФЮЂДІРэНсЙЙВЛЭЌЫљдьГЩЕФЁЃ
ЂХARM9гаЖРСЂЕФжИСюКЭЪ§ОнДцДЂЦїНгПкЃЌдЪаэДІРэЦїЭЌЪБНјааШЁжИКЭЖСаДЪ§ОнЁЃетНазїИФНјаЭЙўЗ№НсЙЙЁЃЖјARM7жЛгаЪ§ОнДцДЂЦїНгПкЃЌЫќЭЌЪБгУРДШЁжИСюКЭЪ§ОнЗУЮЪЁЃ
ЂЦ5МЖСїЫЎЯпв§ШыСЫЖРСЂЕФДцДЂЦїКЭаДЛиСїЫЎЯпЃЌЗжБ№гУРДЗУЮЪДцДЂЦїКЭНЋНсЙћаДЛиМФДцЦїЁЃ
вдЩЯСНЕуЪЕЯжСЫвЛИіжмЦкЭъГЩloadsжИСюКЭstoresжИСюЁЃ
ЂВЛЅЫј(interlocksЃЉММЪѕ
ЕБжИСюашвЊЕФЪ§ОнвђЮЊвдЧАЕФжИСюУЛгажДааЭъЖјУЛгазМБИКУОЭЛсВњЩњЙмЕРЛЅЫјЁЃЕБЙмЕРЛЅЫјЗЂЩњЪБЃЌгВМўЛсЭЃжЙетИіжИСюЕФжДааЃЌжБЕНЪ§ОнзМБИКУЮЊжЙЁЃЫфШЛетжжММЪѕЛсдіМгДњТыжДааЪБМфЃЌЕЋЪЧЮЊГѕЦкЕФЩшМЦепЬсЙЉСЫОоДѓЕФЗНБуЁЃБрвыЦївдМАЛуБрГЬађдБПЩвдЭЈЙ§жиаТЩшМЦДњТыЕФЫГађЛђепЦфЫћЗНЗЈРДМѕЩйЙмЕРЛЅЫјЕФЪ§СПЁЃ
ЂГЗжжІжИСю
ARM9КЭARM7ЕФЗжжІжИСюжмЦкЪЧЯрЭЌЕФЁЃЖјЧвARM9TDMIКЭARM9E-SВЂУЛгаЖдЗжжІжИСюНјаадЄВтДІРэЁЃ
ДІРэФмСІ
аТвЛДњЕФARM9ДІРэЦїЃЌЭЈЙ§ШЋаТЕФЩшМЦЃЌВЩгУСЫИќЖрЕФОЇЬхЙмЃЌФмЙЛДяЕНСНБЖвдЩЯгкARM7ДІРэЦїЕФДІРэФмСІЁЃетжжДІРэФмСІЕФЬсИпЪЧЭЈЙ§діМгЪБжгЦЕТЪКЭМѕЩйжИСюжДаажмЦкЪЕЯжЕФЁЃ
ЃЈвЛЃЉ ЪБжгЦЕТЪЕФЬсИпЃК
ARM7ДІРэЦїВЩгУ3МЖСїЫЎЯпЃЌЖјARM9ВЩгУ5МЖСїЫЎЯпЁЃдіМгЕФСїЫЎЯпЩшМЦЬсИпСЫЪБжгЦЕТЪКЭВЂааДІРэФмСІЁЃ5МЖСїЫЎЯпФмЙЛНЋУПвЛИіжИСюДІРэЗжХфЕН5ИіЪБжгжмЦкФкЃЌдкУПвЛИіЪБжгжмЦкФкЭЌЪБга5ИіжИСюдкжДааЁЃдкЭЌбљЕФМгЙЄЙЄвеЯТЃЌARM9TDMIДІРэЦїЕФЪБжгЦЕТЪЪЧARM7TDMIЕФ1.8ЁЋ2.2БЖЁЃ
ЃЈЖўЃЉ жИСюжмЦкЕФИФНјЃК
жИСюжмЦкЕФИФНјЖдгкДІРэЦїадФмЕФЬсИпгаКмДѓЕФАяжњЁЃадФмЬсИпЕФЗљЖШвРРЕгкДњТыжДааЪБжИСюЕФжиЕўЃЌетЪЕМЪЩЯЪЧГЬађБОЩэЕФЮЪЬтЁЃЖдгкВЩгУзюИпМЖЕФгябдЃЌвЛАуРДЫЕЃЌадФмЕФЬсИпдк30%зѓгвЁЃ
Cortex-A ЯЕСаДІРэЦї
Cortex-A ЯЕСаДІРэЦїЪЧвЛЯЕСаДІРэЦїЃЌжЇГжARM32Лђ64ЮЛжИСюМЏЃЌЯђКѓЭъШЋМцШндчЦкЕФARMДІРэЦїЃЌАќРЈДг1995ФъЗЂВМЕФARM7TDMIДІРэЦїЕН2002ФъЗЂВМЕФARMllДІРэЦїЯЕСаЁЃ
МђНщ
32ЮЛRISCCPUПЊЗЂСьгђжаВЛЖЯШЁЕУЭЛЦЦЃЌЦфЩшМЦЕФЮЂДІРэЦїНсЙЙвбОДгv3ЗЂеЙЕНЯждкЕФv7ЁЃCortexЯЕСаДІРэЦїЪЧЛљгкARMv7МмЙЙЕФЃЌЗжЮЊCortex-MЁЂCortex-RКЭCortex-AШ§РрЁЃгЩгкгІгУСьгђЕФВЛЭЌЃЌЛљгкv7МмЙЙЕФCortexДІРэЦїЯЕСаЫљВЩгУЕФММЪѕвВВЛЯрЭЌЁЃЛљгкv7AЕФГЦЮЊЁАCortex-AЯЕСаЁЃИпадФмЕФCortex-A15ЁЂПЩЩьЫѕЕФCortex-A9ЁЂОЙ§ЪаГЁбщжЄЕФCortex-A8ДІРэЦївдМАИпаЇЕФCortex-A7КЭCortex-A5ДІРэЦїОљЙВЯэЭЌвЛЬхЯЕНсЙЙЃЌвђДЫОпгаЭъећЕФгІгУМцШнадЃЌжЇГжДЋЭГЕФARMЁЂThumbжИСюМЏКЭаТдіЕФИпадФмНєДеаЭThumb-2жИСюМЏЁЃ
Cortex-A15КЭCortex-A7ЖМжЇГжARMv7AЬхЯЕНсЙЙЕФРЉеЙЃЌДгЖјЮЊДѓаЭЮяРэЕижЗЗУЮЪКЭгВМўащФтЛЏвдМАЦєгУbig.LITTLEДІРэЕФAMBA4ACEвЛжТадЬсЙЉжЇГжЁЃ
ММЪѕЬиЕу
ARMv7АќРЈ3ИіЙиМќвЊЫиЃКNEONЕЅжИСюЖрЪ§Он(SIMD)ЕЅдЊЁЂARMtrustZoneАВШЋРЉеЙЁЂвдМАthumb2жИСюМЏЃЌЭЈЙ§16ЮЛКЭ32ЮЛЛьКЯГЄЖШжИСювдМѕаЁДњТыГЄЖШЁЃ
ИпадФм
Cortex-A ЩшБИПЩЮЊЦфФПБъгІгУСьгђЬсЙЉИїжжПЩЩьЫѕЕФФмаЇадФмЕуЁЃвЛаЉЫЕУїЪОР§ШчЯТЃК
Cortex-A15 ЃЌПЩЮЊаТвЛДњвЦЖЏЛљДЁНсЙЙгІгУКЭвЊЧѓПСПЬЕФЮоЯпЛљДЁНсЙЙгІгУЬсЙЉадФмзюИпЕФНтОіЗНАИ
Cortex-A7ЃЌПЩВЩгУЖРСЂЁЂЖрКЫХфжУЪЕЯжЃЌЬсЙЉ 800 MHz - 1.2 GHz ЕФЕфаЭЦЕТЪЃЌвВПЩвдгы
Cortex-A15 НсКЯгУгк big.LITTLE ДІРэ Cortex-A9 ЪЕЯжЃЌПЩЬсЙЉ 800
MHz - 2 GHz ЕФБъзМЦЕТЪЃЌУПИіФкКЫПЩЬсЙЉ 5000 DMIPS ЕФадФм Cortex-A8
ЕЅКЫНтОіЗНАИЃЌПЩЬсЙЉОМУгааЇЕФИпадФмЃЌдк 600 MHz - 1 GHz ЕФЦЕТЪЯТЃЌЬсЙЉЕФадФмГЌЙ§
2000 DMIPS Cortex-A5 ЕЭГЩБОЪЕЯжЃЌдк 400- 800 MHz ЕФЦЕТЪЯТЃЌЬсЙЉЕФадФмГЌЙ§
1200 DMIPSЁЃ
ЖрКЫММЪѕ
Cortex-A5ЁЂ[1] Cortex-A7ЁЂCortex-A9 КЭ Cortex-A15 ДІРэЦїЖМжЇГж
ARM ЕФЕкЖўДњЖрКЫММЪѕ
ЕЅКЫЕНЫФКЫЪЕЯжЃЌжЇГжУцЯђадФмЕФгІгУСьгђ жЇГжЖдГЦКЭЗЧЖдГЦЕФВйзїЯЕЭГЪЕЯж ЭЈЙ§МгЫйЦївЛжТадЖЫПк (ACP)
дкЕМГіЕНЯЕЭГЕФећИіДІРэЦїжаБЃГжвЛжТад Cortex-A7 КЭ Cortex-A15 НЋЖрКЫвЛжТадРЉеЙжС
AMBA4 ACE ЕФ 1~4 КЫШКМЏвдЩЯЃЈAMBA вЛжТадРЉеЙЃЉ
ИпМЖРЉеЙ
Г§СЫОпгагыЩЯвЛДњОЕф ARM КЭ Thumb® ЬхЯЕНсЙЙЕФЖўНјжЦМцШнадЭтЃЌCortex-A
РрДІРэЦїЛЙЭЈЙ§вдЯТММЪѕРЉеЙЬсЙЉСЫИќЖргХЪЦ
Thumb-2ЃЌЬсЙЉзюМбДњТыДѓаЁКЭадФм TrustZone АВШЋРЉеЙЃЌЬсЙЉПЩаХМЦЫу Jazelle
ММЪѕЃЌЬсИпжДааЛЗОГЃЈШч JavaЁЂ.NetЁЂMSILЁЂPython КЭ PerlЃЉЫйЖШЁЃ
ВњЦЗгІгУ
ARMЙЋЫОЕФCortex-AЯЕСаДІРэЦїЪЪгУгкОпгаИпМЦЫувЊЧѓЁЂдЫааЗсИЛВйзїЯЕЭГвдМАЬсЙЉНЛЛЅУНЬхКЭЭМаЮЬхбщЕФгІгУСьгђЁЃДгзюаТММЪѕЕФвЦЖЏInternetБиБИЩшБИЃЈШчЪжЛњКЭГЌБуаЏЕФЩЯЭјБОЛђжЧФмБОЃЉЕНЦћГЕаХЯЂгщРжЯЕЭГКЭЯТвЛДњЪ§зжЕчЪгЯЕЭГЁЃвВПЩвдгУгкЦфЫћвЦЖЏБуаЏЪНЩшБИЃЌЛЙПЩвдгУгкЪ§зжЕчЪгЁЂЛњЖЅКаЁЂЦѓвЕЭјТчЁЂДђгЁЛњКЭЗўЮёЦїНтОіЗНАИЁЃетвЛЯЕСаЕФДІРэЦїОпгаИпаЇЕЭКФЕШЬиЕуЃЌБШНЯЪЪКЯХфжУгкИїжжвЦЖЏЦНЬЈЁЃ
ЫфШЛCortex-AДІРэЦїе§ГЏзХЬсЙЉЭъШЋЕФInternetЬхбщЕФЗНЯђЗЂеЙЃЌЕЋЦфгІгУвВКмЙуЗКЃЌАќРЈЃК
Cortex-A5 ДІРэЦї
ARM Cortex-A5 ДІРэЦїЪЧФмаЇзюИпЁЂГЩБОзюЕЭЕФДІРэЦїЃЌФмЙЛЯђзюЙуЗКЕФЩшБИЬсЙЉ Internet
ЗУЮЪЃКДгШыУХМЖжЧФмЪжЛњЁЂЕЭГЩБОЪжЛњКЭжЧФмвЦЖЏжеЖЫЕНЦеБщВЩгУЕФЧЖШыЪНЁЂЯћЗбРрКЭЙЄвЕЩшБИЁЃ
Cortex-A5 ДІРэЦїПЩЮЊЯжга ARM926EJ-S КЭ ARM1176JZ-S ДІРэЦїЩшМЦЬсЙЉКмгаМлжЕЕФЧЈвЦЭООЖЁЃЫќПЩвдЛёЕУБШ
ARM1176JZ-S ИќКУЕФадФмЃЌБШ ARM926EJ-S ИќКУЕФЙІаЇКЭФмаЇвдМА 100% ЕФ Cortex-A
МцШнадЁЃ
етаЉДІРэЦїЯђЬиБ№зЂжиЙІКФКЭГЩБОЕФгІгУГЬађЬсЙЉИпЖЫЙІФмЃЌЦфжаАќРЈЃК
ЖржиДІРэЙІФмЃЌПЩвдЛёЕУПЩЩьЫѕЁЂИпФмаЇадФм
гУгкУНЬхКЭаХКХДІРэЕФПЩбЁИЁЕуЛђ NEONЕЅдЊ
гы Cortex-A8ЁЂCortex-A9 КЭОЕф ARM ДІРэЦїЕФЭъШЋгІгУМцШнад
ИпадФмФкДцЯЕЭГЃЌАќРЈИпЫйЛКДцКЭФкДцЙмРэЕЅдЊ
Cortex-A7 ДІРэЦї
ARM Cortex-A7 MPCore ДІРэЦїЪЧ ARM ЦљНёЮЊжЙПЊЗЂЕФзюгааЇЕФгІгУДІРэЦїЃЌЫќЯджјРЉеЙСЫ
ARM дкЮДРДШыУХМЖжЧФмЪжЛњЁЂЦНАхЕчФдвдМАЦфЫћИпМЖвЦЖЏЩшБИЗНУцЕФЕЭЙІКФСьЯШЕиЮЛЁЃ
Cortex-A7 ДІРэЦїЕФЬхЯЕНсЙЙКЭЙІФмМЏгы Cortex-A15 ДІРэЦїЭъШЋЯрЭЌЃЌВЛЭЌетДІдкгкЃЌCortex-A7
ДІРэЦїЕФЮЂЬхЯЕНсЙЙВржигкЬсЙЉзюМбФмаЇЃЌвђДЫетСНжжДІРэЦїПЩдк big.LITTLEХфжУжааЭЌЙЄзїЃЌШэМўПЩвддкИпФмаЇ
Cortex-A7 ДІРэЦїЩЯдЫаа вВПЩвддкашвЊЪБдкИпадФм Cortex-A15 ДІРэЦїЩЯдЫаа ЮоашжиаТБрвы,[2]
ДгЖјЬсЙЉИпадФмгыГЌЕЭЙІКФЕФжеМЋзщКЯЁЃ
зїЮЊЖРСЂДІРэЦїЃЌЕЅИі Cortex-A7 ДІРэЦїЕФФмдДаЇТЪЪЧ ARM Cortex-A8 ДІРэЦїЃЈжЇГжШчНёЕФаэЖрзюСїаажЧФмЪжЛњЃЉЕФ
5 БЖЃЌадФмЬсЩ§ 50%ЃЌЖјГпДчНіЮЊКѓепЕФЮхЗжжЎвЛЁЃ
Cortex-A7 ПЩвдЪЙ 2013-2014 ФъЦкМфЕЭгк 100 УРдЊМлИёЕуЕФШыУХМЖжЧФмЪжЛњгы 2010
Фъ 500 УРдЊЕФИпЖЫжЧФмЪжЛњЯрцЧУРЁЃетаЉШыУХМЖжЧФмЪжЛњдкЗЂеЙжаЪРНчНЋжиаТЖЈвхСЌНгКЭ Internet
ЪЙгУЁЃ
ИУДІРэЦїгыЦфЫћ Cortex-A ЯЕСаДІРэЦїЭъШЋМцШнВЂећКЯСЫИпадФм Cortex-A15 ДІРэЦїЕФЫљгаЙІФмЃЌАќРЈащФтЛЏЁЂДѓЮяРэЕижЗРЉеЙ
(LPAE) NEON ИпМЖ SIMD КЭ AMBA 4 ACE вЛжТадЁЃ
зюМбЕФЙІаЇКЭеМгУПеМфЃЌПЩзїЮЊЖРСЂЕФгІгУДІРэЦї адФмИпгк 2011 ФъжїСїжЧФмЪжЛњ CPU адФмЬсЩ§ИпДя
20% ЖјЙІКФНЕЕЭ 60%AMBA 4 ACE вЛжТадНгПкжЇГжДѓаЁ CPU ШКМЏжЎМф 20us вдЯТЕФЩЯЯТЮФЧЈвЦ
Cortex-A8 ДІРэЦї
ARMCortex-A8ДІРэЦїЪЧвЛПюЪЪгУгкИДдгВйзїЯЕЭГМАгУЛЇгІгУЕФгІгУДІРэЦїЃЌЦфНсЙЙШчЭМЫљЪОЁЃжЇГжжЧФмФмдДЙмРэ(IEMЃЌIntelligentEnergyManger)ММЪѕЕФARMArtisanПтвдМАЯШНјЕФаЙТЉПижЦММЪѕЃЌЪЙЕУCortex-A8ДІРэЦїЪЕЯжСЫЗЧЗВЕФЫйЖШКЭЙІКФаЇТЪдк65nmЩЯвеЯТЃЌARMcortex-A8ДІРэЦїЕФЙІКФВЛЕН300mWЃЌФмЙЛЬсЙЉИпадФмКЭЕЭЙІКФЫќЕквЛДЮЮЊЕЭЗбгУЁЂИпШнСПЕФВњЦЗДјРДСЫЬЈЪНЛњМЖБ№ЕФадФм
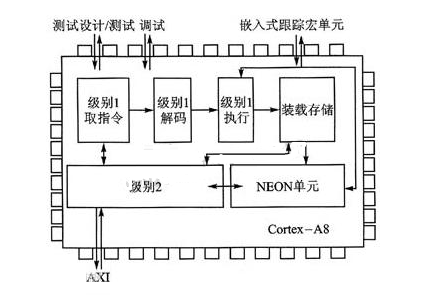
A8ДІРэЦїНсЙЙ
Cortex-A8ДІРэЦїЪЧЕквЛПюЛљгкЯТвЛДњARMv7МмЙЙЕФгІгУДІРэЦїЃЌЪЙгУСЫФмЙЛДјРДИќИпадФмЁЂИќЕЭЙІКФКЭИќИпДњТыУмЖШЕФThumb-2ММЪѕЫќЪзДЮВЩгУСЫЧПДѓЕФNEONаХКХДІРэРЉеЙМЏЃЌЮЊH.264КЭMP3ЕШУНЬхБрНтТыЬсЙЉМгЫй
Cortex-A8ЕФНтОіЗНАИЛЙАќРЈJazelle-RCTJavaМгЫйММЪѕЃЌЖдЪЕЪБ(JIT)КЭЖЏЬЌЕїећБрвы(DAC)ЬсЙЉзюгХЛЏЃЌЭЌЪБМѕЩйФкДцеМгУПеМфИпДя3БЖИУДІРэЦїХфжУСЫЯШНјЕФГЌБъСПЬхЯЕНсЙЙСїЫЎЯпЃЌФмЙЛЭЌЪБжДааЖрЬѕжИСюЃЌВЂЧвЬсЙЉГЌЙ§2.0DMIPS/MHzЕФадФмДІРэЦїМЏГЩСЫвЛИіПЩЕїГпДчЕФЖўМЖИпЫйЛКГхДцДЂЦїЃЌФмЙЛЭЌИпЫйЕФ16KBЛђеп32KBвЛМЖИпЫйЛКГхДцДЂЦївЛЦ№ЙЄзїЃЌДгЖјДяЕНзюПьЕФЖСШЁЫйЖШКЭзюДѓЕФЭЬЭТСПаТДІРэЦїЛЙХфжУСЫгУгкАВШЋНЛвзКЭЪ§зжАцШЈЙмРэЕФTrustZoneММЪѕЃЌвдМАЪЕЯжЕЭЙІКФЙмРэЕФIEMЙІФм
Cortex-A8ДІРэЦїЪЙгУСЫЯШНјЕФЗжжЇдЄВтММЪѕЃЌВЂЧвОпгазЈгУЕФNEONећаЭКЭИЁЕуаЭСїЫЎЯпНјааУНЬхКЭаХКХДІРэдкЪЙгУаЁгк4mm2ЕФЙшЦЌМАЕЭЙІКФЕФ65nmЙЄвеЕФЧщПіЯТЃЌCortex-A8ДІРэЦїЕФдЫааЦЕТЪНЋИпгк600MHz(ВЛАќРЈNEONзЗзйММЪѕКЭЖўМЖИпЫйЛКГхДцДЂЦї)дкИпадФмЕФ90nmКЭ65nmЙЄвеЯТЃЌCortex-A8ДІРэЦїдЫааЦЕТЪзюИпПЩДя1GHzЃЌФмЙЛТњзуИпадФмЯћЗбВњЦЗЩшМЦЕФашвЊЁЃ
Cortex-A9ДІРэЦї
ARM Cortex-A9 ДІРэЦїЬсЙЉСЫЪЗЮоЧАР§ЕФИпадФмКЭИпФмаЇЃЌДгЖјЪЙЦфГЩЮЊашвЊдкЕЭЙІКФЛђЩЂШШЪмЯоЕФГЩБОУєИааЭЩшБИжаЬсЙЉИпадФмЕФЩшМЦЕФРэЯыНтОіЗНАИЁЃ
ЫќМШПЩгУзїЕЅКЫДІРэЦїЃЌвВПЩгУзїПЩХфжУЕФЖрКЫДІРэЦїЃЌЭЌЪБПЩЬсЙЉПЩКЯГЩЛђгВКъЪЕЯжЁЃИУДІРэЦїЪЪгУгкИїжжгІгУСьгђЃЌДгЖјФмЙЛЖдЖрИіЪаГЁНјааЮШЖЈЕФШэМўЭЖзЪЁЃ
гыИпадФмМЦЫуЦНЬЈЯћКФЕФЙІТЪЯрБШЃЌARM Cortex-A9 ДІРэЦїПЩЬсЙЉЙІТЪИќЕЭЕФзПдНЙІФмЃЌЦфжаАќРЈЃК
ЮогыТзБШЕФадФмЃЌ2GHz БъзМВйзїПЩЬсЙЉ TSMC 40G гВКъЪЕЯж
вдЕЭЙІКФЮЊФПБъЕФЕЅКЫЪЕЯжЃЌУцЯђГЩБОУєИааЭЩшБИ
РћгУИпМЖ MPCore ММЪѕЃЌзюЖрПЩРЉеЙЮЊ 4 ИівЛжТЕФФкКЫ
ПЩбЁ NEON УНЬхКЭ/ЛђИЁЕуДІРэв§Чц
Cortex-A15 ДІРэЦї
ARM Cortex-A15 MPCore ДІРэЦїЪЧадФмИпЧвПЩЪкгшаэПЩЕФДІРэЦїЁЃЫќЬсЙЉЧАЫљЮДгаЕФДІРэЙІФмЃЌгыЕЭЙІКФЬиадЯрНсКЯЃЌдкИїжжЪаГЁЩЯГЩОЭСЫзПдНЕФВњЦЗЃЌАќРЈжЧФмЪжЛњЁЂЦНАхЕчФдЁЂвЦЖЏМЦЫуЁЂИпЖЫЪ§зжМвЕчЁЂЗўЮёЦїКЭЮоЯпЛљДЁНсЙЙЁЃCortex-A15
MPCore ДІРэЦїЬсЙЉСЫадФмЁЂЙІФмКЭФмаЇЕФЖРЬизщКЯЃЌНјвЛВНМгЧПСЫ ARM дкетаЉИпМлжЕКЭИпШнСПгІгУЯИЗжЪаГЁжаЕФСьЕМЕиЮЛЁЃ
Cortex-A15 MPCore ДІРэЦїЪЧ Cortex-A ЯЕСаДІРэЦїЕФзюаТГЩдБЃЌШЗБЃдкгІгУЗНУцгыЫљгаЦфЫћЛёЕУИпЖШдогўЕФ
Cortex-A ДІРэЦїЭъШЋМцШнЁЃетбљЃЌОЭПЩвдСЂМДЗУЮЪвбЕУЕНШЯПЩЕФПЊЗЂЦНЬЈКЭШэМўЬхЯЕЃЌАќРЈ AndroidЁЂAdobe®
Flash® PlayerЁЂJava Platform Standard Edition
(Java SE)ЁЂJavaFXЁЂLinuxЁЂMicrosoft Windows EmbeddedЁЂSymbian
КЭ Ubuntu вдМА 700 ЖрИі ARM Connected Community ГЩдБЃЌетаЉГЩдБЬсЙЉгІгУШэМўЁЂгВМўКЭШэМўПЊЗЂЙЄОпЁЂжаМфМўвдМА
SoC ЩшМЦЗўЮёЁЃ
Cortex-A15 MPCore ДІРэЦїОпгаЮоађГЌБъСПЙмЕРЃЌДјгаНєУмёюКЯЕФЕЭбгГй 2 МЖИпЫйЛКДцЃЌИУИпЫйЛКДцЕФДѓаЁзюИпПЩДя
4MBЁЃИЁЕуКЭ NEON УНЬхадФмЗНУцЕФЦфЫћИФНјЪЙЩшБИФмЙЛЮЊЯћЗбепЬсЙЉЯТвЛДњгУЛЇЬхбщЃЌВЂЮЊ Web
ЛљДЁНсЙЙгІгУЬсЙЉИпадФмМЦЫуЁЃ
дЄМЦ Cortex-A15 MPCore ДІРэЦїЕФвЦЖЏХфжУЫљФмЬсЙЉЕФадФмЪЧЕБЧАЕФИпМЖжЧФмЪжЛњадФмЕФЮхБЖЛЙЖрЁЃдкИпМЖЛљДЁНсЙЙгІгУжаЃЌCortex-A15
ЕФдЫааЫйЖШзюИпПЩДя 2.5GHzЃЌетНЋжЇГждкВЛЖЯНЕЕЭЙІКФЁЂЩЂШШКЭГЩБОдЄЫуЗНУцЪЕЯжИпЖШПЩЩьЫѕЕФНтОіЗНАИЁЃ
Cortex-A57
cortex-a57ЪЧARMеыЖд2013ФъЁЂ2014ФъКЭ2015ФъЩшМЦЦ№ЕуЕФCPUВњЦЗЯЕСаЕФЦьНЂМЖCPUЃЌЫќВЩгУarmv8-aМмЙЙЃЌЬсЙЉ64ЮЛЙІФмЃЌЖјЧвЭЈЙ§Aarch32жДаазДЬЌЃЌБЃГжгыARMv7МмЙЙЕФЭъШЋКѓЯђМцШнадЁЃдкИпгк4GBЕФФкДцЙуЗКЪЙгУжЎЧАЃЌ64ЮЛВЂВЛЪЧвЦЖЏЯЕЭГеце§БиашЕФЃЌМДБуЕНФЧЪБвВПЩвдЪЙгУРЉеЙЮяРэбАжЗММЪѕРДНтОіЃЌЕЋОЁдчЭЦГі64ЮЛЃЌПЩвдЪЕЯжИќГЄЁЂИќЫГГЉЕФШэМўЧЈвЦЃЌШУИпадФмгІгУГЬађФмЙЛГфЗжРћгУИќДѓащФтЕижЗЗЖЮЇРДдЫааФкШнДДНЈгІгУГЬађЃЌР§ШчЪгЦЕБрМЁЂееЦЌБрМКЭдіЧПЯжЪЕЁЃаТМмЙЙПЩвддЫаа64ЮЛВйзїЯЕЭГЃЌВЂдкВйзїЯЕЭГЩЯЮоЗьЛьКЯдЫаа32ЮЛКЭ64ЮЛгІгУГЬађЁЃARMv8МмЙЙПЩвдЪЕЯжзДЬЌжЎМфЕФЧсЫЩзЊЛЛЁЃ
Г§СЫARMv8ЕФМмЙЙгХЪЦжЎЭтЃЌCortex-A57ЛЙЬсИпСЫЕЅИіЪБжгжмЦкадФмЃЌБШИпадФмЕФCortex-A15CPUИпГіСЫ20%жС40%ЁЃЫќЛЙИФНјСЫЖўМЖИпЫйЛКДцЕФЕФЩшМЦвдМАФкДцЯЕЭГЕФЦфЫћзщМўЃЌМЋДѓЕФЬсИпСЫФмаЇЁЃCortex-A57НЋЮЊвЦЖЏЯЕЭГЬсЙЉЧАЫљЮДгаЕФИпФмаЇадФмЫЎЦНЃЌЖјНшжњbig.LITTLEЃЌSoCФмвдКмЕЭЕФЦНОљЙІКФзіЕНетвЛЕуЁЃ
Cortex-A72ДІРэЦї

Cortex-A72ЪЧARMадФмзюГіЩЋЁЂзюЯШНјЕФДІРэЦїЁЃгк2015ФъФъГѕе§ЪНЗЂВМЕФCortex-A72ЪЧЛљгкARMv8-AМмЙЙЁЂВЂЙЙНЈгкCortex-A57ДІРэЦїдквЦЖЏКЭЦѓвЕЩшБИСьгђГЩЙІЕФЛљДЁжЎЩЯЁЃдкЯрЭЌЕФвЦЖЏЩшБИЕчГиЪйУќЯожЦЯТЃЌCortex-A72ФмЯрНЯЛљгкCortex-A15ЕФЩшБИЬсЙЉ3.5БЖЕФадФмБэЯжЃЌеЙЯжгХвьЕФећЬхЙІКФаЇТЪЁЃ
Cortex-A72ЕФЧПЛЏадФмКЭЙІКФЫЎЦНжиаТЖЈвхСЫ2016ФъИпЖЫЩшБИЮЊЯћЗбепДјРДЕФЗсИЛСЌНгКЭЧщОГИажЊЃЈcontext-awareЃЉЕФЬхбщЃЌетаЉИпЖЫЩшБИКИЧИпНзЕФжЧФмЪжЛњЁЂжааЭЦНАхЕчФдЁЂДѓаЭЦНАхЕчФдЁЂЗИЧЪНБЪМЧБОЁЂвЛжБЕНЭтаЮЙцИёПЩБфЛЏЕФвЦЖЏЩшБИЁЃЮДРДЕФЦѓвЕЛљеОКЭЗўЮёЦїаОЦЌвВФмЪмЛнгкCortex-A72ЕФадФмЃЌВЂдкЦфгХвьЕФФмаЇЛљДЁЩЯЃЌдкгаЯоЕФЙІКФЗЖЮЇФкдіМгФкКЫЪ§СПЃЌЬсЩ§ЙЄзїИКдиСПЁЃ
Cortex-A72ПЩдкаОЦЌЩЯЕЅЖРЪЕЯжЃЌвВПЩвдДюХфCortex-A53ДІРэЦїгыARMCoreLinkTMCCIИпЫйЛКДцвЛжТадЛЅСЌЃЈCacheCoherentInterconnectЃЉЙЙГЩARMbig.LITTLETMХфжУЃЌНјвЛВНЬсЩ§ФмаЇЁЃ
Cortex-A72ЪЧФПЧАЛљгкARMv8-AМмЙЙДІРэЦїжаадФмзюИпЕФДІРэЦїЁЃЫќдйДЮеЙЯжСЫARMдкДІРэЦїММЪѕЕФСьЯШЕиЮЛЃЌдкЬсЩ§аТЕФадФмБъзМжЎгрЃЌЭЌЪБДѓЗљНЕЕЭЙІКФЃЌПЩЙуЗКЕиРЉеЙгІгУгквЦЖЏгыЦѓвЕЩшБИЁЃ
жЧФмЪжЛњЪЧФПЧАДѓжкжївЊЕФМЦЫуЦНЬЈЃЌЬсЙЉЪЙгУепЫцЪБЫцЕиДДдьЁЂЧПЛЏвдМАЪЙгУФкШнЕФЙІФмЁЃФтецЧвИДдгЕФЭМЯёгыЪгЦЕВЖзНЁЂжїЛњМЖгЮЯЗАуЕФадФмЁЂгУРДНјааЮФЕЕгыАьЙЋгІгУСїГЉДІРэЕФЩњВњСІЬзМўЕШЃЌетаЉашЧѓДйЪЙCortex-A72ШчДЫИпЖЫадФмЕФДІРэЦїУцЪаЃЌжДааетаЉЗўЮёЕФЩшБИБЛвЊЧѓдкИќЧсБЁЁЂИќЪБЩаЕФЭтаЮЩшМЦжЎЯТЃЌБиаыШЋЬьКђДІРэШевцдіГЄЕФCPUКЭGPUЙЄзїИКдиЃЌетЪЙЕУжЦдьЩЬВЛЕУВЛНЋОЋСІгУдкбАевИпФмаЇЕФДІРэЦїФкКЫЁЃдкжЧФмЪжЛњЁЂЦНАхЕчФдЁЂЩѕжСЪЧДѓГпДчЕФвЦЖЏЩшБИЃЌCortex-A72ФмЭЈЙ§ГіЩЋЕФФмаЇгыФкДцЯЕЭГЃЌЬсЙІОјМбЕФгУЛЇЬхбщЁЃНЋCortex-A72гыCortex-A53ДІРэЦївдARMbig.LITTLEЃЈДѓаЁКЫЃЉДІРэЦїНјааХфжУЃЌПЩвдРЉеЙећЬхЕФадФмгыаЇТЪБэЯжЁЃ |









