| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФНщЩмСЫЧЖШыЪНCБрТыЙцЗЖжаЕФБъЪОЗћУќУћЙцдђЁЂЭтЙлВМОжЁЂзЂЪЭвдМАЧЖШыЪНШэМўАВШЋадЯрЙиЙцЗЖЕШЯрЙиФкШнЁЃ |
|
0ЙцЗЖжЦЖЈЫЕУї
0.1ѓ№бд
ММЪѕШЫдБЩшМЦГЬађЕФЪзвЊФПЕФЪЧгУгкММЪѕШЫдБЙЕЭЈКЭНЛСїЃЌЦфДЮВХЪЧгУгкЛњЦїжДааЁЃГЬађЕФЩњУќСІдкгкгУЛЇЪЙгУЃЌГЬађЕФГЩГЄдкгкКѓЦкЕФЮЌЛЄМАИљОнгУЛЇашЧѓИќаТКЭЩ§МЖЙІФмЁЃШчЙћФуЕФГЬађжЛФмгЩФуРДЮЌЛЄЃЌЕБФуРыПЊетИіГЬађЪБЃЌФуЕФГЬађвВКЭФувЛЦ№РыПЊСЫЃЌетНЋИјЙЋЫОКЭКѓРДНгЪжЕФММЪѕШЫдБДјРДОоДѓЕФЭДПрКЭЫ№ЪЇЁЃвђДЫЃЌЮЊСЫГЬађПЩЖСЁЂвзРэНтЁЂКУЮЌЛЄЃЌФуЕФГЬађашвЊзёЪивЛЖЈЕФЙцЗЖЃЌФуЕФГЬађашвЊЩшМЦЁЃ
ЁАГЬађБиаыЮЊдФЖСЫќЕФШЫЖјБраДЃЌжЛЪЧЫГБугУгкЛњЦїжДааЁЃЁБ
ЁЊЁЊHarold Abelson КЭ Gerald Jay Sussman
ЁАБраДГЬађгІИУвдШЫЮЊБОЃЌМЦЫуЛњЕкЖўЁЃЁБ
ЁЊЁЊSteve McConnell
0.2МђНщЃК
ЮЊЬсИпВњЦЗДњТыжЪСПЃЌжИЕМвЧБэЧЖШыЪНШэМўПЊЗЂШЫдББраДГіМђНрЁЂПЩЮЌЛЄЁЂПЩППЁЂПЩВтЪдЁЂИпаЇЁЂПЩвЦжВЕФДњТыЃЌБраДСЫБОЙцЗЖЁЃ
БОЙцЗЖНЋЗжЮЊЭъећАцКЭОЋМђАцЃЌЭъећАцНЋАќРЈИќЖрЕФбљР§ЁЂЙцЗЖЕФНтЪЭвдМАВЮПМВФСЯ(what
& why)ЃЌЖјОЋМђАцНЋжЛАќКЌЙцдђВПЗж(what)вдБуВщдФЁЃ
дкБОЙцЗЖЕФзюКѓЃЌСаГіСЫвЛаЉвЕНчБШНЯгХауЕФБрГЬЙцЗЖЃЌзїЮЊбгЩьдФЖСВЮПМВФСЯЁЃ
БОЙцЗЖжївЊАќКЌвдЯТСНИіЗНУцЕФФкШнЃК
вЛЃКЮЊаЮГЩЭГвЛБрГЬЙцЗЖЃЌДгБрТыаЮЪННЧЖШГіЗЂЃЌБОЙцЗЖЖдБъЪОЗћУќУћЁЂИёЪНгыХХАцЁЂзЂЪЭЕШЗНУцНјааСЫЯъЯИВћЪіЁЃ
ЖўЃКЮЊБраДГіИпжЪСПЧЖШыЪНШэМўЃЌДгЧЖШыЪНШэМўАВШЋМАПЩППадГіЗЂЃЌБОЙцЗЖЖдгЩгкCгябдБъзМЁЂCгябдБОЩэЁЂCБрвыЦїМАИіШЫРэНтЕМжТЕФЧБдкЮЃЯеНјааЫЕУїМАЙцБмЁЃ
0.3ЪЪгУЗЖЮЇЃК
БОЙцЗЖЖдЧЖШыЪНШэМўПЊЗЂЦ№вЛЖЈЕФжИЕМзїгУЁЃ
0.4ЪѕгяЖЈвх
0.4.1 ЙцЗЖЪѕгя
ддђЃКБрГЬЪББиаыМсГжЕФжИЕМЫМЯыЁЃ
ЙцдђЃКБрГЬЪБашвЊзёбЕФдМЖЈЃЌЗжЮЊЧПжЦКЭНЈвщЃЈЧПжЦЪЧБиаызёЪиЕФЃЌНЈвщЪЧвЛАуЧщПіЯТашвЊзёЪиЃЌЕЋУЛгаЧПжЦадЃЉЁЃ
ЫЕУїЃКЖдддђ/ЙцдђНјааБивЊЕФНтЪЭЁЃ
ЪЕР§ЃКЖдДЫддђ/ЙцдђДге§ЁЂЗДСНИіЗНУцИјГіР§згЁЃ
ВФСЯЃКРЉеЙЁЂбгЩьЕФдФЖСВФСЯЁЃ
UnspecifiedЃКЮДЯъЯИЫЕУїЕФааЮЊЃЌетаЉЪЧБиаыГЩЙІБрвыЕФгябдНсЙЙЃЌЕЋЙигкНсЙЙЕФааЮЊЃЌБрвыЦїЕФБраДепгаФГаЉздгЩЁЃР§ШчCгябджаЕФЁАдЫЫуДЮађЁБЮЪЬтЁЃетбљЕФЮЪЬтга
22 ИіЁЃ дкФГжжЗНЪНЩЯЭъШЋЯраХБрвыЦїЕФааЮЊЪЧВЛУїжЧЕФЁЃБрвыЦїЕФааЮЊЩѕжСВЛЛсдкЫљгаПЩФмЕФНсЙЙжаЖМЪЧвЛжТЕФЁЃ
UndefinedЃКЮДЖЈвхааЮЊЃЌетаЉЪЧБОжЪЕФБрГЬДэЮѓЃЌЕЋБрвыЦїЕФБраДепВЛвЛЖЈЮЊДЫИјГіДэЮѓаХЯЂЁЃЯргІЕФР§згЪЧЮоаЇВЮЪ§ДЋЕнИјКЏЪ§ЃЌЛђКЏЪ§ЕФВЮЪ§гыЖЈвхЪБЕФВЮЪ§ВЛЦЅХфЁЃДгАВШЋадНЧЖШетЪЧЬиБ№живЊЕФЮЪЬтЃЌвђЮЊЫќУЧДњБэСЫФЧаЉВЛвЛЖЈФмБЛБрвыЦїВЖзНЕНЕФДэЮѓЁЃ
Implementation-definedЃКЪЕЯжЖЈвхЕФааЮЊЃЌетгааЉРрЫЦгкЁАunspecified
ЁБЮЪЬтЃЌЦфжївЊЧјБ№дкгкБрвыЦївЊЬсЙЉвЛжТЕФааЮЊВЂМЧТМГЩЮФЕЕЁЃЛЛОфЛАЫЕЃЌВЛЭЌЕФБрвыЦїжЎМфЙІФмПЩФмЛсгаВЛЭЌЃЌЪЙЕУДњТыВЛОпгаПЩвЦжВадЃЌЕЋдкШЮвЛБрвыЦїФкЃЌааЮЊгІЕБЪЧСМКУЖЈвхЕФЁЃБШШчгУдквЛИіе§ећЪ§КЭвЛИіИКећЪ§ЩЯЕФећГ§дЫЫуЁА/
ЁБКЭЧѓФЃдЫЫуЗћЁА% ЁБЁЃДцдк76ИіетбљЕФЮЪЬтЁЃДгАВШЋадНЧЖШЃЌМйШчБрвыЦїЭъШЋЕиМЧТМСЫЫќЕФЗНЗЈВЂМсГжЫќЕФЪЕЯжЃЌФЧУДЫќПЩФмВЛЪЧФЧбљжСЙиживЊЁЃОЁПЩФмЕФЧщПіЯТвЊБмУтетаЉЮЪЬтЁЃ
0.4.2 CгябдЯрЙиЪѕгя
ЩљУї(declaration)ЃКжИЖЈСЫвЛИіБфСПЕФБъЪЖЗћЃЌгУРДУшЪіБфСПЕФРраЭЃЌЪЧРраЭЛЙЪЧЖдЯѓЃЌ
епКЏЪ§ЕШЁЃЩљУїЃЌгУгкБрвыЦї(compiler)ЪЖБ№БфСПУћЫљв§гУЕФЪЕЬхЁЃвдЯТетаЉОЭЪЧЩљУїЃК
extern int bar;
extern int g(int,int);
double f(int,double);[ЖдгкКЏЪ§ЩљУїЃЌexternЙиМќзжЪЧПЩвдЪЁТдЕФЁЃ]
ЖЈвх(definition)ЃКЪЧЖдЩљУїЕФЪЕЯжЛђепЪЕР§ЛЏЁЃСЌНгЦї(linker)ашвЊЫќЃЈЖЈвхЃЉРДв§гУФкДцЪЕЬхЁЃгыЩЯУцЕФЩљУїЯргІЕФЖЈвхШчЯТЃК
int bar;
int g(int lhs,int rhs) {returnlhs*rhs;}
double f(int i,double d) {returni+d;}
0.5ЙцдђЕФаЮЪН
Йцдђ/ддђ<ађКХ>(ЙцдђРраЭ)ЃКЙцдђФкШнЁЃ
[дЪМВЮПМ]
<ађКХ>ЃКУПЬѕЙцдђЖМгавЛИіађКХЃЌађКХЪЧАДеееТНкФПТМ-**ЕФаЮЪНЃЌДгЪ§зж1ПЊЪМЁЃР§ШчЃЌШєдкДЫеТНкгаИіЙцдђЕФЛАЃЌађКХЮЊ0.5-1ЁЃ
(ЙцдђРраЭ)ЃКЛђепЪЧЁЎЧПжЦЁЏЃЌЛђепЪЧЁЎНЈвщЁЏЁЃ
ЙцдђФкШнЃКДЫЬѕЙцдђЕФОпЬхФкШнЁЃ
[дЪМВЮПМ]ЃКжИЪОСЫВњЩњБОЬѕПюЛђБОзщЬѕПюЕФПЩгІгУЕФжївЊРДдДЁЃ
1БъЪОЗћУќУћЙцдђ
1.1БъЪОЗћУќУћзмдђ
Йцдђ1.1-1(ЧПжЦ)ЃКБъЪЖЗћЃЈФкВПЕФКЭЭтВПЕФЃЉЕФгааЇзжЗћВЛФмЖргк31ЁЃ
[UndefinedImplementation-defined]
ЫЕУїЃКISO БъзМвЊЧѓдкФкВПБъЪЖЗћжЎМфЧА31 ИізжЗћБиаыЪЧВЛЭЌЕФЃЌЭтВПБъЪЖЗћжЎМфЧА6
ИізжЗћБиаыЪЧВЛЭЌЕФЃЈКіТдДѓаЁаДЃЉвдБЃжЄПЩвЦжВадЁЃЮвУЧетРяЗХПэСЫДЫвЊЧѓЃЌвЊЧѓФкВПЁЂЭтВПБъЪОЗћЕФгааЇзжЗћВЛФмЖргк31МДПЩЁЃетбљжївЊЪЧБугкБрвыЦїЪЖБ№ЃЌДњТыЧхЮњвзЖСЃЌВЂБЃжЄПЩвЦжВадЁЃ
Йцдђ1.1-2(ЧПжЦ)ЃКОпгаФкВПзїгУгђЕФБъЪЖЗћВЛгІЪЙгУгыОпгаЭтВПзїгУгђЕФБъЪЖЗћЯрЭЌЕФ
УћГЦЃЌдкФкВПзїгУгђРяОпгаФкВПБъЪОЗћЛсвўВиЭтВПБъЪЖЗћЁЃ
ЫЕУїЃКЭтВПзїгУгђКЭФкВПзїгУгђЕФЖЈвхШчЯТЁЃЮФМўЗЖЮЇФкЕФБъЪЖЗћПЩвдПДзіЪЧОпгазюЭтВП
ЃЈoutermost ЃЉЕФзїгУгђЃЛПщЗЖЮЇФкЕФБъЪЖЗћПДзіЪЧОпгаИќФкВПЃЈmore
innerЃЉЕФзїгУгђЃЌСЌајЧЖЬзЕФПщЃЌЦфзїгУгђИќЩюШыЁЃШчЙћФкВПзїгУгђБъЪОЗћКЭЭтВПзїгУгђБъЪОЗћЭЌУћЃЌФкВПзїгУгђБъЪОЗћЛсИВИЧЭтВПзїгУгђБъЪОЗћЃЌЕМжТГЬађЛьТвЁЃ
ЪЕР§ЃК
INT8U test;
{
INT8U test; /*ЖЈвхСЫСНИіtest */
test = 3; /*етНЋВњЩњЛьЯ§ */
} |
Йцдђ1.1-3(НЈвщ)ЃКОпгаОВЬЌДцДЂЦкЕФЖдЯѓЛђКЏЪ§БъЪЖЗћВЛФмжигУЁЃ
ЫЕУїЃКВЛЙмзїгУгђШчКЮЃЌОпгаОВЬЌДцДЂЦкЕФБъЪЖЗћЖМВЛгІдкЯЕЭГФкЕФЫљгадДЮФМўжажигУЁЃЫќАќКЌДјгаЭтВПСДНгЕФЖдЯѓЛђКЏЪ§ЃЌМАДјгаОВЬЌДцДЂРрБъЪЖЗћЕФШЮКЮЖдЯѓЛђКЏЪ§ЁЃдквЛИіЮФМўжаДцдквЛИіОпгаФкВПСДНгЕФБъЪЖЗћЃЌЖјдкСэЭтвЛИіЮФМўжаДцдкзХОпгаЭтВПСДНгЕФЯрЭЌУћзжЕФБъЪЖЗћЃЌЛђепДцдкСНИіБъЪОЗћЯрЭЌЕФЭтВПБъЪОЗћЁЃЖдгУЛЇРДЫЕЃЌетгаПЩФмЕМжТЛьЯ§ЁЃ
ЪЕР§ЃК
test1.c
/**ЖЈвхСЫвЛИіОВЬЌЮФМўгђБфСПtest1*/
static INT8U test1;
void test_fun(void)
{
INT8U test1; /*ЖЈвхСЫвЛИіЭЌУћЕФОжВПБфСПtest1*/
} |
test2.c
/**дкСэвЛИіЮФМўгжЖЈвхСЫвЛИіОпгаЭтВПСДНгЕФЮФМўгђБфСПtest1*/
INT8U test1; |
ддђ1.1-4(ЧПжЦ)ЃКБъЪЖЗћЕФУќУћвЊЧхЮњЁЂУїСЫЃЌгаУїШЗКЌвхЃЌЭЌЪБЪЙгУЭъећЕФЕЅДЪЛђДѓМвЛљБОПЩвдРэНтЕФЫѕаДЃЌБмУтЪЙШЫВњЩњЮѓНтЁЃ
ЫЕУїЃКБъЪОЗћЕФУќУћОЁСПзіЕНМћУћжЊвтЃЌОЁСПШУБ№ШЫПьЫйРэНтФуЕФДњТыЁЃ
ЪЕР§ЃК
КУЕФУќУћЗНЗЈЃК
INT8U debug_message;
INT16U err_num; |
ВЛКУЕФУќУћЗНЗЈЃК
ддђ1.1-5(ЧПжЦ)ЃКГЃМћЭЈгУЕФЕЅДЪЫѕаДОЁСПЭГвЛЃЌВЛЕУЪЙгУККгяЦДвєЁЂгЂгяЛьгУЁЃ
ЫЕУїЃКМђЖЬЕФЕЅДЪПЩвдЪЙгУТдШЅЁЎдЊвєЁЏзжФИаЮГЩЫѕаДЃЌНЯГЄЕФЕЅДЪПЩвдЪЙгУвєНкЪззжФИ
епЕЅДЪЧАМИИізжФИаЮГЩЫѕаДЃЌеыЖдДѓМвЙЋШЯЕФЕЅДЪЫѕаДвЊЭГвЛЁЃЖдгкЬиЖЈЕФЯюФПвЊЪЙ
гУЕФзЈгаЫѕаДгІИУзЂУїЛђепзіЭГвЛЫЕУїЁЃ
ЪЕР§ЃКГЃМћЕЅДЪЫѕаДБэ(НЈвщ)ЃК
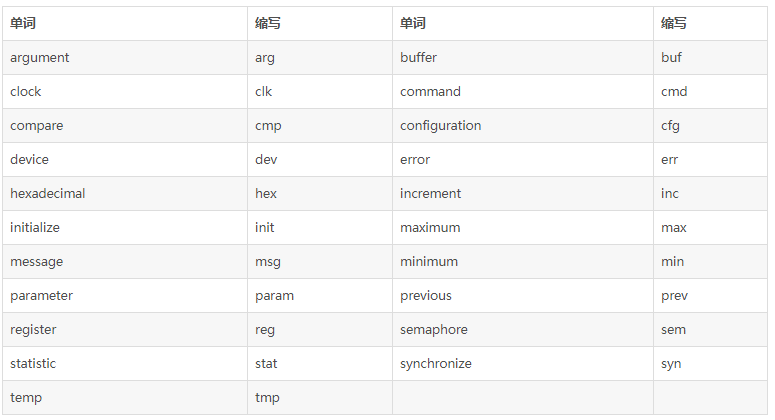
ддђ1.1-6(НЈвщ)ЃКгУе§ШЗЕФЗДвхДЪзщУќУћОпгаЛЅГтвтвхЕФБфСПЛђЯрЗДЖЏзїЕФКЏЪ§ЕШЁЃ
ЪЕР§ЃКГЃМћЗДвхДЪБэЃК
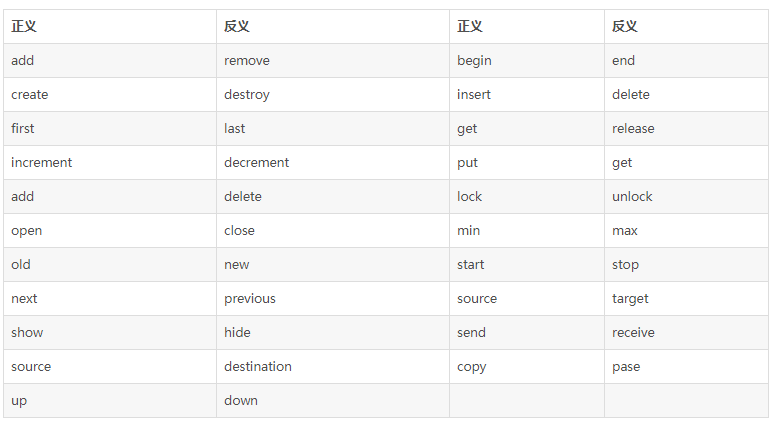
ддђ1.1-7(НЈвщ)ЃКБъЪОЗћОЁСПБмУтЪЙгУЪ§зжБрКХЃЌГ§ЗЧТпМЩЯашвЊЁЃ
ЪЕР§ЃК
#define DEBUG_0_MSG
#define DEBUG_1_MSG |
гІИФЮЊИќгавтвхЕФЖЈвхЃК
#define DEBUG_WARN_MSG
#define DEBUG_ERR_MSG |
ВФСЯЃКЁЖДњТыДѓШЋЕк2АцЁЗЃЈSteve McConnell жј Н№Иъ/ЬРСш/ГТЫЖ/еХЗЦ
вы ЕчзгЙЄвЕГіАцЩч
2006Фъ3дТЃЉ"Ек11еТБфСПУќЕФСІСП"ЁЃ
1.2ЮФМўУќУћМАДцДЂЙцдђ
Йцдђ1.2-1(ЧПжЦ)ЃКЮФМўУћЪЙгУаЁаДзжФИЁЃ
ЫЕУїЃКгЩгкВЛЭЌЯЕЭГЖдЮФМўУћДѓаЁаДДІРэВЛЭЌЃЌWindowsВЛЧјЗжЮФМўУћДѓаЁаДЃЌЖјLinuxЧјЗжЁЃЫљвдЮФМўУћУќУћОљВЩгУаЁаДзжФИЃЌЖрИіЕЅДЪжЎМфПЩЪЙгУЁБ_ЁБЗжИєЗћЁЃ
ЪЕР§ЃКdisp.h os_sem.c
Йцдђ1.2-2(НЈвщ)ЃКЙЄГЬдДТыЪЙгУGB2312БрТыЗНЪНЁЃ
ЫЕУїЃКГЬађРяЕФзЂЪЭПЩФмЛсЪЙгУжаЮФЃЌGB2312ЪЧМђЬхжаЮФБрТыЃЌДѓВПЗжЕФБрМЙЄОпКЭМЏГЩIDEЛЗОГЖМжЇГжGB2312БрТыЃЌЮЊБмУтжаЮФТвТыЃЌНЈвщЪЙгУGB2312ЖддДТыНјааБрТыЁЃШєашвЊзЊЛЛГЩЦфЫћБрТыИёЪНЃЌПЩЪЙгУЮФБОБрТызЊЛЛЙЄОпНјаазЊЛЛЁЃ
Йцдђ1.2-3(ЧПжЦ)ЃКЙЄГЬдДТыЪЙгУАцБОЙмРэЙЄОпНјааАцБОЙмРэЁЃ
ЫЕУїЃКГЬађвЛАуашвЊДѓСПИќаТЁЂаое§ЁЂЮЌЛЄЙЄзїЃЌЧвгаЪБашвЊЖрШЫКЯзїЁЃЪЙгУАцБОЙмРэЙЄОпПЩвдАяжњФуЬсИпЙЄзїаЇТЪЁЃНЈвщЪЙгУЁАGitЁБАцБОЙмРэЙЄОпЁЃ
1.3БфСПУќУћЙцдђ
ддђ1.3-1(ЧПжЦ)ЃКБфСПУќУћгІУїШЗЫљДњБэЕФКЌвхЛђепзДЬЌЁЃ
ЫЕУїЃКБфСПУћГЦПЩвдЪЙгУУћДЪБэЪіЧхГўЕФОЁСПЪЙгУУћДЪЃЌЪЙгУУћДЪЮоЗЈУшЪіЧхГўЪБЃЌЪЙгУаЮ
ШнДЪЛђепУшЪіадЕФЕЅДЪ+УћДЪЕФаЮЪНЁЃБфСПвЛАуЮЊЪЕЬхЕФЪєадЁЂзДЬЌЕШаХЯЂЃЌЪЙгУЩЯ
ЪіЗНАИвЛАуПЩвдНтОіБфСПУћЕФУќУћЮЪЬтЃЌШчЙћГіЯжУќУћКмРЇФбЛђепЮоЗЈИјГіКЯРэЕФУќ
УћЗНЪНЪБЃЌЮЪЬтПЩФмГіЯждкећЬхЩшМЦЩЯЃЌЧыжиаТЩѓЪгЩшМЦЁЃ
Йцдђ1.3-2(ЧПжЦ)ЃКШЋОжБфСПЬэМгЁБG_ЁБЧАзКЃЌШЋОжОВЬЌБфСПЬэМгЁБ
S_ ЁБЃЌОжВПОВЬЌБфСПЬэМгЁБs_ЁБЧАзКЁЃЪЙгУДѓаЁаДЛьКЯЗНЪНУќУћЃЌДѓаДзжФИгУгкЗжИюВЛЭЌЕЅДЪЁЃ
ЫЕУїЃКЬэМгЧАзКЕФдвђгаСНИіЁЃЪзЯШЃЌЪЙШЋОжБфСПБфЕУИќабФПЃЌЬсабММЪѕПЊЗЂШЫдБЪЙгУетаЉБфСПЪБвЊаЁаФЁЃЦфДЮЃЌЬэМгЧАзКЪЙШЋОжБфСПКЭОВЬЌБфСПБфЕУКЭЦфЫћБфСПВЛвЛжТЃЌЬсабММЪѕПЊЗЂШЫдБОЁСПЩйгУШЋОжБфСПЁЃ
ЪЕР§ЃК
/**ГіДэаХЯЂ */
INT8U G_ErrMsg;
/**УПУыжгзЊЖЏШІЪ§ */
static INT32U S_CirclePerSec; |
Йцдђ1.3-3(ЧПжЦ)ЃКОжВПБфСПЪЙгУаЁаДзжФИЃЌШєБъЪОЗћБШНЯИДдгЃЌЪЙгУЁЏ_ЁЏЗжИєЗћЁЃ
ЫЕУїЃКОжВПБфСПШЋВПЪЙгУаЁаДзжФИЃЌКЭШЋОжБфСПгаУїЯдЧјЗжЃЌЪЙЖСепПДЕНБъЪОЗћОЭжЊЕРЪЧКЮ
жжзїгУгђЕФБфСПЁЃ
ЪЕР§ЃК
| INT32U download_program_address; |
Йцдђ1.3-4(ЧПжЦ)ЃКЖЈвхжИеыБфСП*НєАЄБфСПУћЃЌШЋОжжИеыБфСПЪЙгУДѓаДPЧАзКЁБP_ЁБЃЌОжВПжИеыБфСПЪЙгУаЁаДpЧАзКЁБp
_ЁБЁЃ
ЪЕР§ЃК
INT8U *P_MsgAddress;
/*ШЋОжБфСП*/
INT8U *p_msg; /*ОжВПБфСП*/ |
1.4КЏЪ§УќУћЙцдђ
ддђ1.4-1(ЧПжЦ)ЃККЏЪ§УќУћгІИУУїШЗеыЖдЪВУДЖдЯѓзіГіСЫЪВУДВйзїЁЃ
ЫЕУїЃККЏЪ§ЕФЙІФмЪЧЛёШЁЁЂаоИФЪЕЬхЕФЪєадЁЂзДЬЌЕШЃЌВЩгУЁАЖЏДЪ+УћДЪЁБЕФЗНЪНПЩвдТњзуЩЯЪіашЧѓЃЌШєГіЯжЪЙгУДЫЗНЪНУќУћКЏЪ§КмРЇФбЛђВЛФмУќУћЕФЧщПіЃЌЮЪЬтПЩФмГіЯждкећЬхЩшМЦЩЯЃЌЧыжиаТЩѓЪгЩшМЦЗНАИЁЃ
Йцдђ1.4-2(ЧПжЦ)ЃКОпгаЭтВПСДНгЕФКЏЪ§УќУћЪЙгУДѓаЁаДЛьКЯЕФЗНЪНЃЌЪззжФИДѓаДЃЌгУгкЗжИюВЛЭЌЕЅДЪЁЃ
ЫЕУїЃККЏЪ§ОпгаЭтВПСДНгЪєадЕФКЌвхЪЧКЏЪ§ЭЈЙ§ЭЗЮФМўЖдЭтЩљУїКѓЃЌЖдЦфЫћЮФМўЛђФЃПщРД
ЫЕЪЧПЩМћЕФЁЃШчЙћвЛИіКЏЪ§вЊдкЦфЫћФЃПщЛђепЮФМўжаЪЙгУЃЌашвЊдкЭЗЮФМўжаЩљУїИУКЏ
Ъ§ЁЃСэЭтЃЌдкЭЗЮФМўЩљУїКЏЪ§ЃЌЛЙПЩвдДйЪЙБрвыЦїМьВщКЏЪ§ЩљУїКЭЕїгУЕФвЛжТадЁЃ
ЪЕР§ЃК
| char *GetErrMsg(ErrMsg
*msg); |
Йцдђ1.4-3(ЧПжЦ)ЃКОпгаЮФМўФкВПСДНгЪєадЕФКЏЪ§УќУћЪЙгУаЁаДзжФИЃЌЪЙгУЁЏ_ЁЏЗжИєЗћЗжИюВЛЭЌЕЅДЪЃЌЧвЪЙгУstaticЙиМќзжЯожЦКЏЪ§зїгУгђЁЃ
ЫЕУїЃККЏЪ§ОпгаФкВПСДНгЪєадЕФКЌвхЪЧКЏЪ§жЛФмдкФЃПщЛђЮФМўФкВПЕїгУЃЌЖдЮФМўЛђФЃПщЭтРД
ЫЕЪЧВЛПЩМћЕФЁЃШчЙћвЛИіКЏЪ§НідкФЃПщФкВПЛђепЮФМўФкВПЪЙгУЃЌашвЊЯожЦКЏЪ§СДНгЮЇЃЌ
ЪЙгУstaticаоЪЮЗћаоЪЮКЏЪ§ЃЌЪЙЦфжЛОпгаФкВПСДНгЪєадЁЃдкдДЮФМўжаЩљУївЛБщОпгаФк
ВПСДНгЕФКЏЪ§ЭЌбљОпгаДйЪЙБрвыЦїМьВщКЏЪ§ЩљУїКЭЕїгУЕФвЛжТадЁЃ
ЪЕР§ЃК
| static char
get_key(void); |
Йцдђ1.4-4(ЧПжЦ)ЃККЏЪ§ВЮЪ§ЪЙгУаЁаДзжФИЃЌИїЕЅДЪжЎМфЪЙгУЁА_ЁБЗжИюЃЌОЁСПБЃГжВЮЪ§ЫГађДгзѓЕНгвЮЊЃКЪфШыЁЂаоИФЁЂЪфГіЁЃ
ЫЕУїЃККЏЪ§ВЮЪ§ЫГађЮЊашЪфШыВЮЪ§жЕЃЈетИіжЕвЛАуВЛаоИФЃЌШєВЛашвЊаоИФЪЙгУconstЙиМќзж
аоЪЮЃЉЃЌашаоИФЕФВЮЪ§ЃЈетИіВЮЪ§ЪфШыКѓгУгкЬсЙЉЪ§ОнЃЌКЏЪ§ФкВППЩвдаоИФДЫВЮЪ§ЃЉЃЌ
ЪфГіВЮЪ§ЃЈетИіВЮЪ§ЪЧКЏЪ§ЪфГіжЕЃЉЁЃ
1.5ГЃСПЕФУќУћЙцдђ
Йцдђ1.5-1(ЧПжЦ)ЃКГЃСПЃЈ#defineЖЈвхЕФГЃСПЁЂУЖОйЁЂconstЖЈвхЕФГЃСПЃЉЕФЖЈвхЪЙгУШЋДѓаДзжФИЃЌЕЅДЪжЎМфМг
ЁЏ_ЁЏЗжИюЕФУќУћЗНЪНЁЃ
ЪЕР§ЃК
#define PI_ROUNDED
3.14
const double PI_ROUNDED = 3.14;
enum weekday{ SUN,MON,TUE,WED,THU,FRI,SAT }; |
Йцдђ1.5-2(НЈвщ)ЃКГЃЪ§КъЖЈвхЪБЃЌЪЎСљНјжЦЪ§ЕФБэЪОЗНЗЈЮЊ0xFFЁЃ
ЫЕУїЃКЧАУц0xжаЕФxаЁаДЃЌЪ§ОнжаЕФЁБA-FЁБДѓаДЁЃ
1.6аТЖЈвхЕФРраЭУќУћЙцЗЖ
Йцдђ1.6-1(ЧПжЦ)ЃКаТЖЈвхРраЭУћЕФУќУћгІИУУїШЗГщЯѓЖдЯѓЕФКЌвхЃЌаТРраЭУћЪЙгУДѓаДзжФИЃЌЕЅДЪжЎМфМгЁЏ_ЁЏЗжИюЃЌаТРраЭжИеыдкРраЭУћЧАдіМгЧАзКЁБP_ЁБЁЃГЩдББфСПБъЪОЗћЧАМгРраЭУћГЦЧАзКЃЌЪззжФИДѓаДгУгкЧјЗжИїИіЕЅДЪЁЃ
ЪЕР§ЃК
typedef struct
_STUDENT
{
StudentName;
StudentAge ;
......
}STUDENT , *P_ STUDENT;/* STUDENT ЮЊаТРраЭУћГЦЃЌP_ STUDENT
ЮЊаТРраЭжИеыУћ*/ |
2ЭтЙлВМОж
2.1ХХАцгыИёЪН
2.1.1 ЭЗЮФМўХХАц
Йцдђ2.1.1-1(ЧПжЦ)ЃКЭЗЮФМўХХАцФкШнвРДЮЮЊАќКЌЕФЭЗЮФМўЁЂКъЖЈвхЁЂРраЭЖЈвхЁЂЩљУїБфСПЁЂЩљУїКЏЪ§ЁЃЧвИїИіжжРрЕФФкШнМфПеШ§ааЁЃ
ЫЕУїЃКЭЗЮФМўЪЧФЃПщЖдЭтЕФЙЋгУНгПкЁЃдкЭЗЮФМўжаЖЈвхЕФКъЃЌПЩвдБЛЦфЫћФЃПщв§гУЁЃProject
жаВЛНЈвщЪЙгУШЋВПБфСПЃЌШєЪЙгУдђашдкЭЗЮФМўРяЖдЭтЩљУїЁЃФЃПщЖдЭтЕФКЏЪ§НгПкдкФЃ
ПщЭЗЮФМўРяЩљУїЁЃ
2.1.2 дДЮФМўХХАц
Йцдђ2.1.2-1(ЧПжЦ)ЃКдДЮФМўХХАцФкШнвРДЮЮЊАќКЌЕФЭЗЮФМўЁЂКъЖЈвхЁЂОпгаЭтВПСДНгЪєадЕФШЋОжБфСПЖЈвхЁЂФЃПщФкВПЪЙгУЕФstaticБфСПЁЂОпгаФкВПСДНгЕФКЏЪ§ЩљУїЁЂКЏЪ§ЪЕЯжДњТыЁЃЧвИїИіжжРрЕФФкШнМфПеШ§ааЁЃ
ЫЕУїЃКФЃПщФкВПЖЈвхЕФКъЃЌжЛФмдкИУФЃПщФкВПЪЙгУЁЃжЛдкФЃПщФкВПЪЙгУЕФКЏЪ§ЃЌашдкдДТыЮФ
МўжаЩљУїЃЌгУгкДйЪЙБрвыЦїМьВщКЏЪ§ЩљУїКЭЕїгУЕФвЛжТадЁЃ
Йцдђ2.1.2-2(ЧПжЦ)ЃКГЬађПщВЩгУЫѕНјЗчИёБраДЃЌУПМЖЫѕНј4ИіПеИёЁЃ
ЫЕУїЃКЕБЧАжїСїIDEЖМжЇГжTabЫѕНјЃЌЪЙгУTabЫѕНјашвЊДђПЊКЭЩшжУЯрЙибЁЯюЁЃКъЖЈвхЁЂБрвыПЊЙиЁЂЬѕМўдЄДІРэгяОфПЩвдЖЅИёЁЃ
Йцдђ2.1.2-3(ЧПжЦ)ЃКifЁЂforЁЂdoЁЂwhileЁЂcaseЁЂswitchЁЂdefaulЁЂtypedefЕШгяОфЖРеМвЛааЃЌЧветаЉЙиМќзжКѓашПевЛИёЁЃ
ЫЕУїЃКжДаагяОфБиаыгУЫѕНјЗчИёаДЃЌЪєгкifЁЂforЁЂdoЁЂwhileЁЂcaseЁЂswitchЁЂdefaultЁЂtypedef
ЕШЕФЯТвЛИіЫѕНјМЖБ№ЁЃвЛАуаДifЁЂforЁЂdoЁЂwhileЕШгяОфЖМЛсгаГЩЖдГіЯжЕФ{}?ЃЌifЁЂ
forЁЂdoЁЂwhileЕШгяОфКѓЕФжДаагяОфНЈвщдіМгГЩЖдЕФЁА{}ЁБЃЛ
ШчЙћif/elseгяОфПщжажЛ
гавЛЬѕгяОфЃЌвВашдіМгЁА{}ЁБЁЃ
ЪЕР§ЃК
for (i = 0;
i < max_num; i++)
{
for (j = 0; j < max_num; j++)
{
If (name_found)
{
гяОф
}
else
{
гяОф
}
}
} |
Йцдђ2.1.2-4(ЧПжЦ)ЃКНјааЫЋФПдЫЫуЁЂИГжЕЪБЃЌВйзїЗћжЎЧАЁЂжЎКѓвЊМгПеИёЃЛНјааЗЧЖдЕШВйзїЪБЃЌШчЙћЪЧЙиЯЕУмЧаЕФСЂМДВйзїЗћЃЈШчЃ>ЃЉЃЌКѓВЛгІМгПеИёЁЃ
ЫЕУїЃКВЩгУетжжЗНЪНЪщаДДњТыЃЌжївЊФПЕФЪЧЪЙДњТыИќЧхЮњЃЌЪЙЙиМќВйзїЗћИќЭЛГіЁЃ
ЪЕР§ЃК
(1) БШНЯВйзїЗћ, ИГжЕВйзїЗћ"="ЁЂ "+="ЃЌЫуЪѕВйзїЗћ"+"ЁЂ"%"ЃЌТпМВйзїЗћ"&&"ЁЂ"&"ЃЌ
ЮЛгђВйзїЗћ"<<"ЁЂ"^"ЕШЫЋФПВйзїЗћЕФЧАКѓМгПеИёЁЃ
If (a > b)
a += 2;
b = a ^ 3; |
(2) "!"ЁЂ"~"ЁЂ"++"ЁЂ"--"ЁЂ"&"ЃЈЕижЗВйзїЗћЃЉ
Search_dowm
= !true;
a++; |
(3) "->"ЁЂ"."ЁЂЁБ[]ЁБЧАКѓВЛМгПеИёЁЃ
Weight = G_Car->weight;
eye = People.eye;
array[8] = 8; |
Йцдђ2.1.2-5(НЈвщ)ЃКвЛаажЛЖЈвхвЛИіБфСПЃЌвЛаажЛЪщаДвЛЬѕжДаагяОфЃЌЖрааЭЌРрВйзїЪБВйзїЗћОЁСПБЃГжЖдЦыЁЃ
ЫЕУїЃКвЛааЖЈвхвЛИіБфСПЃЌвЛаажЛЪщаДвЛЬѕжДаагяОфЃЌЗНБузЂЪЭЃЌЖрааЭЌРрВйзїЖдЦыУРЙлЁЂећНрЁЃ
ЪЕР§ЃК
events_rdy =
OS_FALSE;
events_rdy_nbr = 0;
events_stat = OS_STAT_RDY;
pevents = pevents_pend;
pevent = *pevents; |
Йцдђ2.1.2-6(НЈвщ)ЃККЏЪ§ФкВПОжВПБфСПЖЈвхКЭКЏЪ§гяОфжЎМфгІПеШ§ааЁЃ
ЫЕУїЃКОжВПБфСПЖЈвхКЭКЏЪ§гяОфЪЧЯрЖдЖРСЂЕФЃЌЖјЧвПеШ§ааПЩвдИќЧхЮњЕиБэЪОГіетжжЖРСЂадЁЃ
3зЂЪЭ
3.1зЂЪЭддђ
ддђ3.1-1(ЧПжЦ)ЃКзЂЪЭЕФФкШнвЊЧхГўЁЂУїСЫЃЌКЌвхзМШЗЃЌдкДњТыЕФЙІФмЁЂвтЭМВуДЮЩЯНјаазЂЪЭЁЃ
ЫЕУїЃКзЂЪЭЕФФПЕФЪЧШУЖСепПьЫйРэНтДњТыЕФвтЭМЁЃзЂЪЭВЛЪЧЮЊСЫУћДЪНтЪЭЃЈwhatЃЉЃЌЖјЪЧЫЕ
УїгУЭОЃЈwhyЃЉЁЃ
ЪЕР§ЃК
ШчЯТзЂЪЭДПЪєЖргрЃК
++i; // iдіМг1
if (data_ready) /* ШчЙћdata_readyЮЊец
*/
ШчЯТзЂЪЭЮоШЮКЮВЮПММлжЕЃК
// ЪБМфгаЯоЃЌЯждкЪЧ:04ЃЌИљБОРДВЛМАЯыЮЊЪВУДЃЌвВУЛШЫФмАяЮвЫЕЧхГў
ддђ3.1-2(ЧПжЦ)ЃКзЂЪЭгІЗжЮЊСНИіНЧЖШНјааЃЌЪзЯШЪЧгІгУНЧЖШЃЌжївЊЪЧИцЫпЪЙгУепШчКЮЪЙгУНгПкЃЈМДФуЬсЙЉЕФКЏЪ§ЃЉЃЌЦфДЮЪЧЪЕЯжНЧЖШЃЌжївЊЪЧИцЫпКѓЦкЩ§МЖЁЂЮЌЛЄЕФММЪѕШЫдБЪЕЯжЕФдРэКЭЯИНкЁЃ
ЫЕУїЃКУПвЛИіВњЦЗЖМПЩвдЗжЮЊШ§ИіВуДЮЃЌВњЦЗБОЩэЪЧвЛИіВуДЮЃЌетИіВуДЮжЎЯТЕФЪЧФуЪЙгУ
ЕФИќаЁЕФзщМўЃЌетИіВуДЮжЎЩЯЕФЪЧФуЮЊБ№ШЫЬсЙЉЕФЗўЮёЁЃФуетИіВњЦЗЕФДцдкЕФМлжЕ
ОЭдкгкАбзюЕзВуЕФаЁВПМўЕФЪЙгУЯИНквўВиЃЌЭЌЪБИјзюЩЯВуЕФгУЛЇЬсЙЉЗНБуЁЂМђНрЕФ
ЪЙгУНгПкЃЌТњзугУгкашЧѓЁЃДгетИіНЧЖШРДПДШэМўЕФзЂЪЭЃЌФугІИУЪБПЬЯызХФуаДЕФзЂЪЭ
ЪЧИјФЧвЛВуДЮЕФШЫдБПДЕФЃЌШчЙћЪЧгУЛЇЃЌФЧУДФугІИУзЂжиУшЪіШчКЮЪЙгУЃЌШчЙћЪЧКѓЦк
ЮЌЛЄепЃЌФЧУДФугІИУзЂжидРэКЭЪЕЯжЯИНкЁЃ
ддђ3.1-3(ЧПжЦ)ЃКаоИФДњТыЪБЃЌгІЮЌЛЄДњТыжмБпЕФзЂЪЭЃЌЪЙЦфДњТыКЭзЂЪЭвЛжТЃЌВЛдйЪЙгУЕФзЂЪЭгІЩОГ§ЁЃ
ЫЕУїЃКзЂЪЭЕФФПЕФдкгкАяжњЖСепПьЫйРэНтДњТыЪЙгУЗНЗЈЛђепЪЕЯжЯИНкЃЌШєзЂЪЭКЭДњТыВЛвЛ
жТЃЌЛсЦ№ЕНЯрЗДЕФзїгУЁЃНЈвщдкаоИФДњТыЧАгІИУЯШаоИФзЂЪЭЁЃ
Йцдђ3.1-4(НЈвщ)ЃКДњТыЖЮВЛгІБЛЁАзЂЪЭЕєЁБЃЈcomment out
ЃЉЁЃ
ЫЕУїЃКЕБдДДњТыЖЮВЛашвЊБЛБрвыЪБЃЌгІИУЪЙгУЬѕМўБрвыРДЭъГЩЃЈШчДјгазЂЪЭЕФ#ifЛђ#ifdef
Нс
ЙЙЃЉЁЃЮЊетжжФПЕФЪЙгУзЂЪЭЕФПЊЪМКЭНсЪјБъМЧЪЧЮЃЯеЕФЃЌвђЮЊC ВЛжЇГж/**/ЧЖЬзЕФзЂ
ЪЭЃЌЖјЧввбОДцдкгкДњТыЖЮжаЕФШЮКЮзЂЪЭНЋгАЯьжДааЕФНсЙћЁЃ
3.2ЮФМўзЂЪЭ
Йцдђ3.2-1(ЧПжЦ)ЃКЮФМўзЂЪЭашЗХЕНЮФМўПЊЭЗЃЌОпЬхИёЪНМћЪЕР§ЁЃ
ЪЕР§ЃК
stm32f10x_dac.h
/**
**********************************************
* @file stm32f10x_dac.h
* @brief Thisfile contains all the functions prototypes
for the DAC firmware
* library.
* @author MCD Application Team
* @version V3.5.0
* @date 11-March-2014
* @par Modification:ЬэМгКЏЪ§ЃЌжЇГж********<br>
* History
* VersionЃКV3.0.1 <br>
* AuthorЃК***<br>
* Modification:ЬэМгКЏЪ§ЃЌжЇГж********<br>
* VersionЃКV3.0.0 <br>
* AuthorЃК***<br>
* Modification:ЬэМгКЏЪ§ЃЌжЇГж********<br>
***********************************************
* @attention
***********************************
*/ |
ЫЕУїЃКзЂЪЭИёЪНПЩБЛdoxygenЙЄОпЪЖБ№ЃЌЦфжа@fileЁЂ@briefЁЂ@authorЕШЪЧdoxygenЙЄОпЪЖБ№ЕФЙиМќзжЃЌзЂЪЭФкШнПЩвдЮЊжаЮФЁЃ
3.3КЏЪ§зЂЪЭ
Йцдђ3.3-1(ЧПжЦ)ЃККЏЪ§зЂЪЭЗжЮЊЭЗЮФМўжаКЏЪ§даЭЩљУїЪБЕФзЂЪЭКЭдДЮФМўжаКЏЪ§ЪЕЯжЪБЕФзЂЪЭЁЃЭЗЮФМўжаЕФзЂЪЭзЂжиКЏЪ§ЪЙгУЗНЗЈКЭзЂвтЪТЯюЃЌдДЮФМўжаЕФзЂЪЭзЂжиКЏЪ§ЪЕЯждРэКЭЗНЗЈЁЃОпЬхИёЪНМћЪЕР§ЁЃ
ЫЕУїЃККЏЪ§даЭЩљУїЕФзЂЪЭАДееdoxygenЙЄОпПЩвдЪЖБ№ЕФИёЪННјаазЂЪЭЃЌгУгкdoxygenЙЄОп
ЩњГЩЭЗЮФМўаХЯЂвдМАКЏЪ§МфЕФЕїгУЙиЯЕаХЯЂЁЃдДДњТыЪЕЯжжївЊЪЧзЂЪЭКЏЪ§ЪЕЯждРэМА
аоИФМЧТМЃЌВЛашАДееdoxygenЙЄОпвЊЧѓЕФзЂЪЭИёЪННјаазЂЪЭЁЃ
ЪЕР§ЃК
ЭЗЮФМўКЏЪ§даЭЩљУїзЂЪЭЃК
/**
**************************************
* @brief Configures the discontinuous mode for
theselected ADC regular
* group channel.
* @param ADCx:where x can be 1, 2 or 3 to select
the ADC peripheral.
* @param Number:specifies the discontinuous mode
regular channel
* count value. This number must be between 1 and8.
* @retval None
* @par UsageЃК
* ADC_DiscModeChannelCountConfig(ADC1,6);<br>
* @par Tag:
* ДЫКЏЪ§ВЛФмдкжаЖЯРяЕїгУЁЃ
***************************************
*/
void ADC_DiscModeChannelCountConfig(ADC_TypeDef*
ADCx, INT8U_tNumber); |
дДЮФМўКЏЪ§ЪЕЯжзЂЪЭЃК
/*
***************************************
* @brief Configures the discontinuousmode for
the selected ADC regular
* group channel.
* @param ADCx: where x can be 1, 2 or 3 toselect
the ADC peripheral.
* @param Number: specifies the discontinuousmode
regular channel
* count value. This number must bebetween 1 and
8.
* @retval None
* @par Modification:аоИФСЫ********<br>
* History
* Modified byЃК***<br>
* DateЃК 2013-10-10
* Modification:аоИФСЫ********<br>
***************************************
*/
void ADC_DiscModeChannelCountConfig(ADC_TypeDef*ADCx,
INT8U_t Number)
{
ИГжЕгяОф*********; /*ЙиМќгяОфЕФзЂЪЭ */
гяОф***********; /*ЙиМќгяОфЕФзЂЪЭИёЪН */
гяОф*******; /*ЪЕЯж*****************ЙІФм*/
} |
3.4ГЃСПМАШЋОжБфСПзЂЪЭ
Йцдђ3.3-1(ЧПжЦ)ЃКГЃСПЁЂШЋОжБфСПашвЊзЂЪЭЃЌзЂЪЭИёЪНМћЪЕР§ЁЃ
ЪЕР§ЃК
/** Description
of the macro */
#define XXXX_XXX_XX 0
/**Description of global variable */
INT8U G_xxx = 0; |
ЫЕУїЃКШєШЋОжБфСПдк.cЮФМўжаЖЈвхЃЌгждк.hЮФМўжаЩљУїЃЌдђдкЭЗЮФМўжаЪЙгУdoxygen
ИёЪНзЂЪЭЃЌдкдДТыЮФМўжаЪЙгУ /* Description of the
globalvariable */ЕФаЮЪНЁЃЗРжЙdoxygenЩњГЩСНБщзЂЪЭЮФЕЕаХЯЂЁЃ
3.5ОжВПБфСПМАгяОфзЂЪЭ
Йцдђ3.3-1(ЧПжЦ)ЃКОжВПБфСПЃЌКЏЪ§ЪЕЯжЙиМќгяОфашвЊзЂЪЭЃЌзЂЪЭИёЪНМћЪЕР§ЁЃ
ЪЕР§ЃК
*pq->OSQIn++
= pmsg; /* Insert message into queue */
pq->OSQEntries++; /* Update the nbr of entries
in the queue*/
if (pq->OSQIn== pq->OSQEnd)
{
pq->OSQIn = pq->OSQStart; /* Wrap IN ptr
if we are at end of queue */
} |
ЫЕУїЃКОжВПБфСПЃЌЙиМќгяОфашвЊзЂЪЭЃЌДгЙІФмКЭвтЭМЩЯНјаазЂЪЭЃЌЖјВЛЪЧДњТыЕФжиИДЁЃЖрЬѕзЂЪЭгяОфОЁСПБЃГжЖдЦыЃЌЪЕЯжУРЙлЃЌећНрЁЃ
ВФСЯЃК
1. ЁЖДњТыећНржЎЕРЁЗЃЈRobertC.Martin жј КЋРк вы
ШЫУёгЪЕчГіАцЩч2010Фъ1дТЃЉЕкЫФеТ"зЂЪЭЁБЁЃ
2. ЁЖDoxygenжаЮФЪжВсЁЗ
4ЯюФПАцБОКХУќУћЙцЗЖ
ЯюФПАцБОКХЙмРэЪЧЯюФПЙмРэЕФживЊЗНУцЃЌЮвУЧИљОнЯюФПВЛЭЌЕФПЊЗЂНзЖЮжЦЖЈСЫВЛЭЌЕФАцБОКХУќУћЙцЗЖЁЃЯюФППЊЗЂЙ§ГЬвЛАуЗжЮЊЧАЦкПЊЗЂВтЪдНзЖЮЁЂЗЂВМНзЖЮЁЂЮЌЛЄНзЖЮетШ§ИіжївЊНзЖЮЃЌЮвУЧЗжБ№жЦЖЈСЫУќУћЙцЗЖЁЃ
4.1ПЊЗЂЁЂВтЪдНзЖЮАцБОКХУќУћ
Йцдђ4.1-1(ЧПжЦ)ЃКДІгкПЊЗЂЁЂЕїЪдНзЖЮЕФЯюФПЃЌАцБОКХЪЙгУЁАV0.yzЁБЕФаЮЪНЁЃ
ЫЕУїЃКДІгкаТПЊЗЂЁЂЕїЪдНзЖЮЕФЯюФПЃЌАцБОКХЪЙгУЁАV0.yzЁБ ЕФаЮЪНЃЌБШШчаТПЊЗЂЕФЯюФПе§ДІдкПЊЗЂЁЂЕїЪдНзЖЮЃЌетЪБПЩвдЪЙгУЁА
V0.10 ЁБетбљЕФАцБОКХЁЃФуШЯЮЊЭъГЩСЫаТЕФЙІФмФЃПщЛђећЬхМмЙЙзіСЫКмДѓЕФаоИФЃЌПЩвдИљОнЧщПідіМг Y
Лђеп ZЕФжЕЁЃБШШчЃЌФуПЊЗЂНзЖЮдкЁА V0.10 ЁБЛљДЁЩЯаТдіМгСЫвЛИіЙІФмФЃПщФуПЩвдНЋАцБОКХИФЮЊЁАV0.11ЁБЃЌзіСЫБШНЯДѓЕФаоИФЃЌФуПЩвдНЋАцБОКХЖЈЮЊЁАV0.20ЁБЁЃ
4.2е§ЪНЗЂВМНзЖЮАцБОКХУќУћ
Йцдђ4.2-1(ЧПжЦ)ЃКДІгке§ЪНЗЂВМНзЖЮЕФЯюФПЃЌАцБОКХЪЙгУЁАVx.yЁБЕФаЮЪНЁЃ
ЫЕУїЃКДІгке§ЪНЗЂВМЕФЯюФПАцБОКХЪЙгУЁАVx.yЁБЕФаЮЪНЁЃБШШчЃЌФуЗЂВМСЫвЛИіе§ЪНУцЯђЪаГЁЕФЯюФПЃЌФуПЩвдЪЙгУЁАV1.0ЁБзїЮЊе§ЪНЕФАцБОКХЁЃдкЁАV1.0ЁБЛљДЁЩЯдіМгЙІФмЕФе§ЪНАцБОЃЌФуПЩвдЪЙгУЁАV1.1ЁБзїЮЊЯТвЛДЮе§ЪНАцБОЕФАцБОКХЃЌдкЁАV1.0ЁБЛљДЁЩЯаое§СЫДѓЕФBUGЛђепзіСЫКмДѓЕФИФЖЏЃЌФуПЩвдЪЙгУЁАV2.0ЁБзїЮЊЯТвЛДЮе§ЪНАцБОКХЁЃ
4.3ЮЌЛЄНзЖЮАцБОКХУќУћ
Йцдђ4.3-1(ЧПжЦ)ЃКДІгкЮЌЛЄНзЖЮЕФЯюФПЃЌАцБОКХЪЙгУЁАVx.yzЁБЕФаЮЪНЁЃ
ЫЕУїЃКДІгкЮЌЛЄНзЖЮЕФЯюФПАцБОКХЪЙгУЁАVx.yzЁБЕФаЮЪНЁЃБШШчдк"V1.1"ЕФЛљДЁЩЯаоИФСЫвЛИіЙІФмЪЕЯжЫуЗЈвдЪЕЯжИпаЇТЪЃЌдђПЩвдЪЙгУ"V1.11"
РДБэЪОетЪЧдке§ЪНЗЂВМАцБОЁАV1.1ЁБЕФЛљДЁЩЯНјааЕФвЛДЮаое§ЃЌдйДЮаое§ПЩвдЪЙгУЁАV1.12ЁБЁЃ
5ЧЖШыЪНШэМўАВШЋадЯрЙиЙцЗЖ
5.1ЭЗЮФМў
ддђ5.1-1(ЧПжЦ)ЃКЭЗЮФМўгУгкЩљУїФЃПщЖдЭтНгПкЃЌАќРЈОпгаЭтВПСДНгЕФКЏЪ§даЭЩљУїЁЂШЋОжБфСПЩљУїЁЂЖЈвхЕФРраЭЩљУїЕШЁЃ
ЫЕУїЃКЭЗЮФМўЪЧФЃПщЃЈModuleЃЉЛђЕЅдЊЃЈUnitЃЉЕФЖдЭтНгПкЁЃЭЗЮФМўжагІЗХжУЖдЭтВПЕФЩљ
УїЃЌШчЖдЭтЬсЙЉЕФКЏЪ§ЩљУїЁЂКъЖЈвхЁЂРраЭЖЈвхЕШЁЃФкВПЪЙгУЕФКЏЪ§ЩљУїВЛгІЗХдк
ЭЗЮФМўжаЁЃ ФкВПЪЙгУЕФКъЁЂУЖОйЁЂНсЙЙЖЈвхВЛгІЗХШыЭЗЮФМўжаЁЃБфСПЖЈвхВЛгІЗХ
дкЭЗЮФМўжаЃЌгІЗХдк.cЮФМўжаЁЃ БфСПЕФЩљУїОЁСПВЛвЊЗХдкЭЗЮФМўжаЃЌврМДОЁСПВЛвЊ
ЪЙгУШЋОжБфСПзїЮЊНгПкЁЃБфСПЪЧФЃПщЛђЕЅдЊЕФФкВПЪЕЯжЯИНкЃЌВЛгІЭЈЙ§дкЭЗЮФМўжа
ЩљУїЕФЗНЪНжБНгБЉТЖИјЭтВПЃЌгІЭЈЙ§КЏЪ§НгПкЕФЗНЪННјааЖдЭтБЉТЖЁЃМДЪЙБиаыЪЙгУ
ШЋОжБфСПЃЌвВжЛгІЕБдк.cжаЖЈвхШЋОжБфСПЃЌдк.hжаНіЩљУїБфСПЮЊШЋОжЕФЁЃ
ВФСЯЃКЁЖCгябдНгПкгыЪЕЯжЁЗЃЈDavid R. Hansonжј ИЕШи
жмХє еХРЅчїШЈЭў вы ЛњаЕЙЄвЕГі
АцЩч 2004Фъ1дТЃЉЃЈгЂЮФАцЃК "C Interfaces
and Implementations"ЃЉ
Йцдђ5.1-2(ЧПжЦ)ЃКжЛФмЭЈЙ§АќКЌЭЗЮФМўЕФЗНЪНЪЙгУЦфЫћ.cЬсЙЉЕФНгПкЃЌНћжЙдк.cжаЭЈЙ§externЕФЗНЪНЪЙгУЭтВПКЏЪ§НгПкЁЂБфСПЁЃ
ЫЕУїЃКШєa.cЪЙгУСЫb.cЖЈвхЕФfoo()КЏЪ§ ЃЌдђгІЕБдкb.hжаЩљУїexternint
foo(int input);ВЂ
дкa.cжаЭЈЙ§#include <b.h>РДЪЙгУfooЁЃНћжЙЭЈЙ§дкa.cжааДexternint
foo(int input);
РДЪЙгУfooЃЌКѓУцетжжаДЗЈШнвздкfooИФБфЪБПЩФмЕМжТЩљУїКЭЖЈвхВЛвЛжТЁЃ
Йцдђ5.1-3(ЧПжЦ)ЃКЪЙгУ#defineЖЈвхБЃЛЄЗћЃЌЗРжЙЭЗЮФМўжиИДАќКЌЁЃ
ЫЕУїЃКЖрДЮАќКЌвЛИіЭЗЮФМўПЩвдЭЈЙ§ШЯецЕФЩшМЦРДБмУтЁЃШчЙћВЛФмзіЕНетвЛЕуЃЌОЭашвЊВЩШЁ
зшжЙЭЗЮФМўФкШнБЛАќКЌЖргквЛДЮЕФЛњжЦЁЃЭЈГЃЕФЪжЖЮЪЧЮЊУПИіЮФМўХфжУвЛИіКъЃЌЕБЭЗ
ЮФМўЕквЛДЮБЛАќКЌЪБОЭЖЈвхетИіКъЃЌВЂдкЭЗЮФМўБЛдйДЮАќКЌЪБЪЙгУЫќвдХХГ§ЮФМўФк
ШнЁЃЫљгаЭЗЮФМўЖМгІЕБЪЙгУ#define ЗРжЙЭЗЮФМўБЛЖржиАќКЌЃЌУќУћИёЪНFILENAME_H_ЃЌ
ЦфжаFILENAME ЮЊЭЗЮФМўЕФУћГЦЁЃ
ЪЕР§ЃК
ШєЮФМўУћЮЊЃКstm32f10x_adc.hЁЃ
#ifndef STM32F10x_DAC_H_
#define STM32F10x_DAC_H_
ЁЁЁЁ
ЪмБЃЛЄЕФДњТы
#endif |
5.2дЄДІРэУќСю
Йцдђ5.2-1(ЧПжЦ)ЃКCЕФКъжЛФмРЉеЙЮЊгУДѓРЈКХРЈЦ№РДЕФГѕЪМЛЏЁЂГЃСПЁЂаЁРЈКХРЈЦ№РДЕФ
БэДяЪНЁЂРраЭЯоЖЈЗћЁЂДцДЂРрБъЪЖЗћЛђdo-while-zero НсЙЙЁЃ
ЫЕУїЃКетаЉЪЧКъЕБжаЫљгаПЩдЪаэЪЙгУЕФаЮЪНЁЃДцДЂРрБъЪЖЗћКЭРраЭЯоЖЈЗћАќРЈжюШчextern
ЁЂ
staticКЭconstетбљЕФЙиМќзжЁЃЪЙгУШЮКЮЦфЫћаЮЪНЕФ#define
ЖМПЩФмЕМжТЗЧдЄЦкЕФааЮЊЃЌ
ЛђепЪЧЗЧГЃФбЖЎЕФДњТыЁЃЬиБ№ЕФЃЌКъВЛФмгУгкЖЈвхгяОфЛђВПЗжгяОфЃЌГ§СЫdo-while
Нс
ЙЙЁЃКъвВВЛФмжиЖЈвхгябдЕФгяЗЈЁЃКъЕФЬцЛЛСаБэжаЕФЫљгаРЈКХЃЌВЛЙмФФжжаЮЪНЕФ
()ЁЂ
{} ЁЂ[] ЖМгІИУГЩЖдГіЯжЁЃ do-while-zero НсЙЙЃЈМћЯТУцЪЕР§ЃЉЪЧдкКъгяОфЬхжаЮЈвЛПЩНгЪмЕФОпгаЭъећгяОфЕФаЮЪНЁЃdo-while-zero
НсЙЙгУгкЗтзАгяОфађСаВЂШЗБЃЦфЪЧе§ШЗЕФЁЃ
зЂвтЃКдкКъгяОфЬхЕФФЉЮВБиаыЪЁТдЗжКХЁЃ
ЪЕР§ЃК
вдЯТЪЧКЯРэЕФКъЖЈвхЃК
#define PI 3.14159F
/*Constant */
#define XSTAL 10000000 /*Constant */
#define CLOCK (XSTAL / 16) /*Constant expression
*/
#define PLUS2(X) ( (X) + 2 ) /* Macro expanding
to expression */
#define STOR extern /*storage class specifier
*/
#define INIT(value) { (value), 0, 0 } /*braced
initialiser */
#define READ_TIME_32() \
do { \
DISABLE_INTERRUPTS(); \
time_now = (INT32U) TIMER_HI << 16; \
time_now = time_now | (INT32U) TIMER_LO; \
ENABLE_INTERRUPTS(); \
} while(0) /* example of do-while-zero */ |
вдЯТЪЧВЛКЯРэЕФКъЖЈвхЃК
#define unsigned
int long /* use typedef instead */
#defineSTARTIF if( /* unbalanced () and languageredefinition
*/ |
Йцдђ5.2-2(ЧПжЦ)ЃКдкЖЈвхКЏЪ§КъЪБЃЌУПИіВЮЪ§ЪЕР§ЖМгІИУвдаЁРЈКХРЈЦ№РДЁЃ
ЪЕР§ЃК
вЛИіabs КЏЪ§ПЩвдЖЈвхГЩЃК
#define abs (x) ( ( (x) >= 0 )
? (x) : -(x) )
ВЛФмЖЈвхГЩЃК
#define abs(x) ( ( (x) >= 0 )
? x : -x )
ШчЙћВЛМсГжБОЙцдђЃЌФЧУДЕБдЄДІРэЦїЬцДњКъНјШыДњТыЪБЃЌВйзїЗћгХЯШЫГађНЋВЛЛсИјГівЊ
ЧѓЕФНсЙћЁЃ
ПМТЧЧАУцЕкЖўИіВЛе§ШЗЕФЖЈвхБЛЬцДњЪБЛсЗЂЩњЪВУДЃК
z = abs ( a ЈC b );
НЋИјГіШчЯТНсЙћЃК
z = ( ( a ЈC b >= 0 ) ? a ЈC b :
-a ЈC b );
згБэДяЪН ЈC a - b ЯрЕБгк (-a)-b ЃЌЖјВЛЪЧЯЃЭћЕФ ЈC(a-b)
ЁЃАбЫљгаВЮЪ§ЖМРЈНјаЁРЈКХжаОЭПЩвдБмУтетбљЕФЮЪЬтЁЃ
Йцдђ5.2-3(НЈвщ)ЃКЪЙгУКъЪБЃЌВЛдЪаэВЮЪ§Ъ§жЕЗЂЩњБфЛЏЁЃ
ЪЕР§ЃК
ШчЯТгУЗЈПЩФмЕМжТДэЮѓЁЃ
#define SQUARE(a)
((a) * (a))
int a = 5;
int b;
b = SQUARE(a++); /*НсЙћЃКa = 7ЃЌМДжДааСЫСНДЮдіЁЃ |
е§ШЗЕФгУЗЈЪЧЃК
b = SQUARE(a);
a++; /*НсЙћЃКa = 6ЃЌМДжЛжДааСЫвЛДЮді*/ |
ЭЌбљНЈвщдкЕїгУКЏЪ§ЪБЃЌВЮЪ§вВВЛвЊБфЛЏЃЌШчЙћФГДЮШэМўЩ§МЖНЋЦфжавЛИіНгПкгЩКЏЪ§ЪЕЯжзЊЛЛГЩКъЃЌФЧВЮЪ§Ъ§жЕЗЂЩњБфЛЏЕФЕїгУНЋВњЩњЗЧдЄЦкаЇЙћЁЃ
Йцдђ5.2-4(НЈвщ)ЃКГ§ЗЧБивЊЃЌгІОЁПЩФмЪЙгУКЏЪ§ДњЬцКъЁЃ
ЫЕУїЃККъФмЬсЙЉБШКЏЪ§гХдНЕФЫйЖШЃЌЕЋЪЧУЛгаВЮЪ§МьВщЛњжЦЃЌВЛЕБЕФЪЙгУПЩФмВњЩњЗЧдЄЦкКѓЙћЁЃ
5.3РраЭМАРраЭзЊЛЛ
Йцдђ5.3-1(ЧПжЦ)ЃКгІИУЪЙгУБъУїСЫДѓаЁКЭЗћКХЕФtypedefДњЬцЛљБОЪ§ОнРраЭЁЃВЛгІЪЙгУЛљБОЪ§жЕРраЭcharЁЂintЁЂshortЁЂlongЁЂfloatКЭdoubleЃЌЖјгІЪЙгУtypedefНјааРраЭЕФЖЈвхЁЃ
ЫЕУїЃКЮЊСЫГЬађЕФПчЦНЬЈвЦжВадЃЌЮвУЧЪЙгУtypedefЖЈвхжИУїСЫДѓаЁКЭЗћКХЕФЪ§ОнРраЭЁЃ
ЪЕР§ЃК
ДЫЪЕР§ЪЧИљОнkeil for ARMЕФЪ§ОнРраЭДѓаЁНјааЕФЖЈвхЁЃ
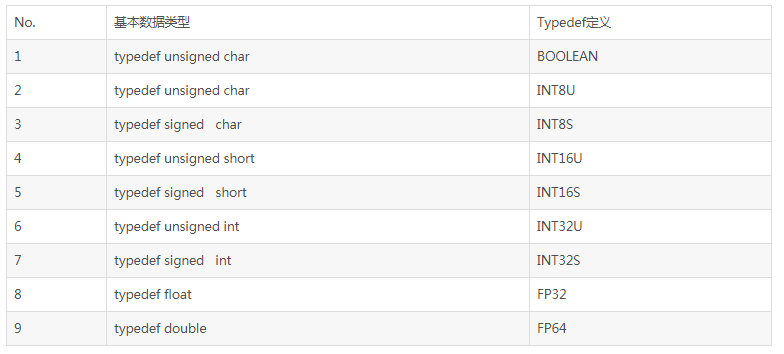
гІИљОнгВМўЦНЬЈКЭБрвыЦїЕФаХЯЂЖдЛљБОРраЭНјааЖЈвхЁЃ
Йцдђ5.3-2(НЈвщ)ЃКИЁЕугІгУгІИУЪЪгІгквбЖЈвхЕФИЁЕуБъзМЁЃ
ЫЕУїЃКИЁЕудЫЫуЛсДјРДаэЖрЮЪЬтЃЌвЛаЉЮЪЬтЃЈЖјВЛЪЧШЋВПЃЉПЩвдЭЈЙ§ЪЪгІвбЖЈвхЕФБъзМРДПЫЗўЁЃЦфжавЛИіКЯЪЪЕФБъзМЪЧ
ANSI/IEEE Std 754 [1] ЁЃ
5.3.1 ЯдЪНЪ§ОнРраЭзЊЛЛ
C гябдИјГЬађдБЬсЙЉСЫЯрЕБДѓЕФздгЩЖШВЂдЪаэВЛЭЌЪ§жЕРраЭПЩвдздЖЏзЊЛЛЁЃгЩгкФГаЉЙІФм
адЕФдвђПЩвдв§ШыЯдЪНЕФЧПжЦзЊЛЛЃЌР§ШчЃК
1. гУвдИФБфРраЭЪЙЕУКѓајЕФЪ§жЕВйзїПЩвдНјаа
2. гУвдНиШЁЪ§жЕ
3. ГігкЧхЮњЕФНЧЖШЃЌгУвджДааЯдЪНЕФРраЭзЊЛЛ
ЮЊСЫДњТыЧхЮњЕФФПЕФЖјВхШыЕФЧПжЦзЊЛЛЭЈГЃЪЧгагУЕФЃЌЕЋШчЙћЙ§ЖрЪЙгУОЭЛсЕМжТГЬађЕФ
ПЩЖСадЯТНЕЁЃе§ШчЯТУцЫљУшЪіЕФЃЌвЛаЉвўЪНзЊЛЛЪЧПЩвдАВШЋЕиКіТдЕФЃЌЖјСэвЛаЉдђВЛФмЁЃ
Йцдђ5.3.1-1(ЧПжЦ)ЃКЧПжЦзЊЛЛжЛФмЯђБэЪОЗЖЮЇИќеЕФЗНЯђзЊЛЛЃЌЧвгыБЛзЊЛЛЖдЯѓЕФРр
аЭОпгаЯрЭЌЕФЗћКХЁЃИЁЕуРраЭжЕжЛФмЧПжЦзЊЛЛЕНИќеЕФИЁЕуРраЭЁЃ
ЫЕУїЃКетЬѕЙцдђжївЊЪЧвЊЧѓашвЊЧПжЦзЊЛЛЪБЃЌаыУїШЗБЛзЊЛЛЖдЯѓЕФБэЪОЗЖЮЇМАзЊЛЛКѓЕФБэЪО
ЗЖЮЇЁЃзЊЛЛЪБОЁСПБЃГжЗћКХвЛжТЃЌВЛЭЌЗћКХЖдЯѓжЎМфВЛгІГіЯжЧПжЦзЊЛЛЁЃЯђИќПэЪ§Он
ЗЖЮЇзЊЛЛВЂВЛФмЬсИпЪ§ОнОЋШЗЖШЃЌВЂУЛгаЪЕМЪвтвхЁЃдкГЬађжаОЁСПЙцЛЎКУБфСПЗЖЮЇЃЌ
ОЁСПЩйЪЙгУЧПжЦзЊЛЛЁЃ
Йцдђ5.3.1-2(ЧПжЦ)ЃКШчЙћЮЛдЫЫуЗћ ~ КЭ <<
гІгУдкЛљБОРраЭЮЊunsigned charЛђunsigned
short ЕФВйзїЪ§ЃЌНсЙћгІИУСЂМДЧПжЦзЊЛЛЮЊВйзїЪ§ЕФЛљБОРраЭЁЃ
ЫЕУїЃКЕБетаЉВйзїЗћЃЈ~ КЭ<<ЃЉгУдк small integer
РраЭЃЈunsigned char Лђunsigned short ЃЉЪБЃЌдЫЫужЎЧАвЊЯШНјааећЪ§ЬсЩ§ЃЌНсЙћПЩФмАќКЌВЂЗЧдЄЦкЕФИпЖЫЪ§ОнЮЛЁЃ
Р§ШчЃК
INT8U port=
0x5aU;
INT8U result_8;
INT16U result_16;
INT16U mode;
result_8 = (~port) >> 4; /* ВЛКЯЙцЗЖ */ |
~portЕФжЕдк16ЮЛЛњЦїЩЯЪЧ 0xffa5 ЃЌЖјдк 32 ЮЛЛњЦїЩЯЪЧ
0xffffffa5 ЁЃдкУПжжЧщПіЯТЃЌresultЕФжЕЪЧ0xfa ЃЌШЛЖјЦкЭћжЕПЩФмЪЧ0x0a ЁЃетбљЕФЮЃЯеПЩвдЭЈЙ§ШчЯТЫљЪОЕФЧПжЦзЊЛЛРДБмУтЃК
result_8 = (
(INT8U) (~port )) >> 4; /* ЗћКЯЙцЗЖ */
result_16 = ( (INT16U ) (~(INT16U) port ) ) >>
4 ; /*ЗћКЯЙцЗЖ */ |
ЕБ<<ВйзїЗћгУдк smallinteger РраЭЪБЛсгіЕНРрЫЦЕФЮЪЬтЃЌИпЖЫЪ§ОнЮЛБЛБЃСєЯТРДЁЃ
Р§ШчЃК
| result_16 = (
( port << 4 ) & mode ) >> 6 ;
/*ВЛЗћКЯЙцЗЖ */ |
result_16 ЕФжЕНЋвРРЕгк int ЪЕЯжЕФДѓаЁЁЃИНМгЕФЧПжЦзЊЛЛПЩвдБмУтШЮКЮФЃК§адЁЃ
| result_16 =
( ( INT16U) ( ( INT16U ) port << 4 ) &
mode )>> 6 ; /* ЗћКЯЙцЗЖ */ |
5.3.2вўЪНРраЭзЊЛЛ
Йцдђ5.3.2-1(ЧПжЦ)ЃКвдЯТРраЭжЎМфВЛгІИУДцдквўЪНРраЭзЊЛЛЁЃ
1) гаЗћКХКЭЮоЗћКХжЎМфУЛгавўЪНзЊЛЛ
2) ећаЭКЭИЁЕуРраЭжЎМфУЛгавўЪНзЊЛЛ
3) УЛгаДгПэРраЭЯђеРраЭЕФвўЪНзЊЛЛ
4) КЏЪ§ВЮЪ§УЛгавўЪНзЊЛЛ
5) КЏЪ§ЕФЗЕЛиБэДяЪНУЛгавўЪНзЊЛЛ
6) ИДдгБэДяЪНУЛгавўЪНзЊЛЛ
5.3.3 ећЪ§КѓзК
Йцдђ5.3.3-1(ЧПжЦ)ЃККѓзКЁАUЁБгІИУгУдкЫљгаunsigned
РраЭЕФГЃСПЩЯЁЃ
ећаЭГЃСПЕФРраЭЪЧЛьЯ§ЕФЧБдкРДдДЃЌвђЮЊЫќвРРЕгкаэЖрвђЫиЕФИДдгзщКЯЃЌАќРЈЃК
1) ГЃЪ§ЕФСПМЖ
2) ећЪ§РраЭЪЕЯжЕФДѓаЁ
3) ШЮКЮКѓзКЕФДцдк
4) Ъ§жЕБэДяЕФНјжЦЃЈМДЪЎНјжЦЁЂАЫНјжЦЛђЪЎСљНјжЦЃЉ
Р§ШчЃЌећаЭГЃСПЁА40000ЁБдк32ЮЛЛЗОГжаЪЧ int РраЭЃЌЖјдк 16ЮЛЛЗОГжадђЪЧlong
РраЭЁЃ
жЕ0x8000 дк16ЮЛЛЗОГжаЪЧ unsigned int РраЭЃЌЖјдк
32 ЮЛЛЗОГжадђЪЧЃЈsigned ЃЉint РраЭЁЃ
зЂвтЃК
1) ШЮКЮДјгаЁАUЁБКѓзКЕФжЕЪЧunsigned РраЭ
2) вЛИіВЛДјКѓзКЕФаЁгк231ЕФЪЎНјжЦжЕЪЧsigned РраЭ
ЕЋЪЧЃК
1) ВЛДјКѓзКЕФДѓгкЛђЕШгк215ЕФЪЎСљНјжЦЪ§ПЩФмЪЧ signed Лђunsigned
РраЭ
2) ВЛДјКѓзКЕФДѓгкЛђЕШгк231ЕФЪЎНјжЦЪ§ПЩФмЪЧ signed Лђunsigned
РраЭ
ГЃСПЕФЗћКХгІИУУїШЗЁЃЗћКХЕФвЛжТадЪЧЙЙНЈСМКУаЮЪНЕФБэДяЪНЕФживЊддђЁЃШчЙћвЛИіГЃ
Ъ§ЪЧunsigned РраЭЃЌЮЊЦфМгЩЯЁАUЁБКѓзКНЋгажњгкБмУтЛьЯ§ЁЃЕБгУдкНЯДѓЪ§жЕЩЯЪБЃЌКѓзКвВаэЪЧЖргрЕФЃЈдкФГжжвтвхЩЯЫќВЛЛсгАЯьГЃСПЕФРраЭЃЉЃЛШЛЖјКѓзКЕФДцдкЖдДњТыЕФЧхЮњадЪЧжжгаМлжЕЕФАяжњЁЃ
5.3.4 жИеыРраЭзЊЛЛ
жИеыРраЭПЩвдЙщЮЊШчЯТМИРрЃК
1) ЖдЯѓжИеы
2) КЏЪ§жИеы
3) void жИеы
4) ПеЃЈnull ЃЉжИеыГЃСПЃЈМДгЩЪ§жЕ 0 ЧПжЦзЊЛЛЮЊ void*РраЭЃЉ
ЩцМАжИеыРраЭЕФзЊЛЛашвЊУїШЗЕФЧПжЦЃЌГ§ЗЧдквдЯТЪБПЬЃК
1) зЊЛЛЗЂЩњдкЖдЯѓжИеыКЭvoid жИеыжЎМфЃЌЖјЧвФПБъРраЭГадиСЫдДРраЭЕФЫљгаРраЭБъЪЖЗћЁЃ
2) ЕБПежИеыГЃСПЃЈvoid*ЃЉБЛИГжЕИјШЮКЮРраЭЕФжИеыЛђгыЦфзіЕШжЕБШНЯЪБЃЌПежИеыГЃСПБЛздЖЏзЊЛЏЮЊЬиЖЈЕФжИеыРраЭЁЃ
C ЕБжажЛЖЈвхСЫвЛаЉЬиЖЈЕФжИеыРраЭзЊЛЛЃЌЖјвЛаЉзЊЛЛЕФааЮЊЪЧЪЕЯжЖЈвхЕФЁЃ
Йцдђ5.3.9-1(ЧПжЦ)ЃКзЊЛЛВЛФмЗЂЩњдкКЏЪ§жИеыКЭЦфЫћГ§СЫећаЭжЎЭтЕФШЮКЮРраЭжИеыжЎМфЁЃ
[Undefined]
ЫЕУїЃК
КЏЪ§жИеыЕНВЛЭЌРраЭжИеыЕФзЊЛЛЛсЕМжТЮДЖЈвхЕФааЮЊЁЃетвтЮЖзХвЛИіКЏЪ§жИ
еыВЛФмзЊЛЛГЩжИЯђВЛЭЌРраЭКЏЪ§ЕФжИеыЁЃ
Йцдђ5.3.9-2(ЧПжЦ)ЃКЖдЯѓжИеыКЭЦфЫћГ§ећаЭжЎЭтЕФШЮКЮРраЭжИеыжЎМфЁЂЖдЯѓжИеыКЭЦфЫћРр
аЭЖдЯѓЕФжИеыжЎМфЁЂЖдЯѓжИеыКЭvoidжИеыжЎМфВЛФмНјаазЊЛЛЁЃ
[Undefined]
Йцдђ5.3.9-3(ЧПжЦ)ЃКВЛгІдкФГРраЭЖдЯѓжИеыКЭЦфЫћВЛЭЌРраЭЖдЯѓжИеыжЎМфНјааЧПжЦзЊЛЛЁЃ
ЫЕУїЃКШчЙћаТЕФжИеыРраЭашвЊИќбЯИёЕФЗжХфЪБетбљЕФзЊЛЛПЩФмЪЧЮоаЇЕФЁЃ
ЪЕР§ЃК
INT8U *p1;
INT32U *p2;
p2= (INT32U *) p1; /*ВЛЗћЙцЗЖ*/ |
5.4ГѕЪМЛЏЁЂЩљУїгыЖЈвх
Йцдђ5.4-1(ЧПжЦ)ЃКЫљгаздЖЏБфСПдкЪЙгУЧАЖМгІБЛИГжЕЁЃ
[Undefined]
ЫЕУїЃКзЂвтЃЌИљОнISO C[2] БъзМЃЌОпгаОВЬЌДцДЂЦкЕФБфСПШБЪЁЕиБЛздЖЏИГгшСужЕЃЌГ§ЗЧОЙ§СЫЯдЪНЕФГѕЪМЛЏЁЃЪЕМЪжаЃЌвЛаЉЧЖШыЪНЛЗОГУЛгаЪЕЯжетбљЕФШБЪЁааЮЊЁЃОВЬЌДцДЂЦкЪЧЫљгавдstaticДцДЂРраЮЪНЩљУїЕФБфСПЛђОпгаЭтВПСДНгЕФБфСПЕФЙВЭЌЪєадЃЌздЖЏДцДЂЦкБфСПЭЈГЃВЛЪЧздЖЏГѕЪМЛЏЕФЁЃ
Йцдђ5.4-2(ЧПжЦ)ЃКгІИУЪЙгУДѓРЈКХвджИЪОКЭЦЅХфЪ§зщКЭНсЙЙЕФЗЧСуГѕЪМЛЏЙЙдьЁЃ
[Undefined]
ЫЕУїЃК
ISO C[2]вЊЧѓЪ§зщЁЂНсЙЙКЭСЊКЯЕФГѕЪМЛЏСаБэвЊвдвЛЖдДѓРЈКХРЈЦ№РДЃЈОЁЙмВЛетбљзіЕФааЮЊЪЧЮДЖЈвхЕФЃЉЁЃБОЙцдђИќНјвЛВНЕивЊЧѓЃЌЪЙгУИНМгЕФДѓРЈКХРДжИЪОЧЖЬзЕФНсЙЙЁЃЫќЦШЪЙГЬађдБЯдЪНЕиПМТЧКЭУшЪіИДдгЪ§ОнРраЭдЊЫиЃЈБШШчЃЌЖрЮЌЪ§зщЃЉЕФГѕЪМЛЏДЮађЁЃ
Р§ШчЃЌЯТУцЕФР§згЪЧЖўЮЌЪ§зщГѕЪМЛЏЕФгааЇЃЈдкISO C [2]жаЃЉаЮЪНЃЌЕЋЕквЛИігыБОЙц
дђЯрЮЅБГЃК
дкНсЙЙжавдМАдкНсЙЙЁЂЪ§зщКЭЦфЫћРраЭЕФЧЖЬззщКЯжаЃЌЙцдђРрЫЦЁЃ
ЛЙвЊзЂвтЕФЪЧЃЌЪ§зщЛђНсЙЙЕФдЊЫиПЩвдЭЈЙ§жЛГѕЪМЛЏЦфЪздЊЫиЕФЗНЪНГѕЪМЛЏЃЈЮЊ
0 Лђ
NULLЃЉЁЃШчЙћбЁдёСЫетбљЕФГѕЪМЛЏЗНЗЈЃЌФЧУДЪздЊЫигІИУБЛГѕЪМЛЏЮЊ0ЃЈЛђNULLЃЉЃЌ
ДЫЪБВЛашвЊЪЙгУЧЖЬзЕФДѓРЈКХЁЃ
ЪЕР§ЃК
INT16U test[3][2]
= { 1, 2, 3, 4, 5, 6 }; /* ВЛЗћКЯДЫЙцдђ */
INT16U test[3][2] = { { 1, 2 }, { 3, 4 }, { 5,
6 } }; /* ЗћКЯДЫЙцдђ */ |
Йцдђ5.4-3(ЧПжЦ)ЃКдкУЖОйСаБэжаЃЌЁА= ЁБВЛФмЯдЪНгУгкГ§ЪздЊЫижЎЭтЕФдЊЫиЩЯЃЌГ§ЗЧЫљга
ЕФдЊЫиЖМЪЧЯдЪНГѕЪМЛЏЕФЁЃ
ЫЕУїЃК
ШчЙћУЖОйСаБэЕФГЩдБУЛгаЯдЪНЕиГѕЪМЛЏЃЌФЧУДC НЋЮЊЦфЗжХфвЛИіДг0 ПЊЪМЕФећЪ§ађСаЃЌЪздЊЫиЮЊ0
ЃЌКѓајдЊЫивРДЮМг 1 ЁЃ
ШчЩЯЙцдђдЪаэЕФЃЌЪздЊЫиЕФЯдЪНГѕЪМЛЏЦШЪЙећЪ§ЕФЗжХфДгетИіИјЖЈЕФжЕПЊЪМЁЃЕБВЩгУетжжЗНЗЈЪБЃЌживЊЕФЪЧШЗБЃЫљгУГѕЪМЛЏжЕвЛЖЈвЊзуЙЛаЁЃЌетбљСаБэжаЕФКѓајжЕОЭВЛЛсГЌГіИУУЖОйГЃСПЫљгУЕФint
ДцДЂСПЁЃ
СаБэжаЫљгаЯюФПЕФЯдЪНГѕЪМЛЏвВЪЧдЪаэЕФЃЌЫќЗРжЙСЫвзВњЩњДэЮѓЕФздЖЏгыЪжЖЏЗжХфЕФЛьКЯЁЃШЛЖјЃЌГЬађдБОЭИУЕЃИКжАд№вдБЃжЄЫљгажЕЖМДІдквЊЧѓЕФЗЖЮЇФквдМАжЕВЛЪЧБЛЮовтИДжЦЕФЁЃ
ЪЕР§ЃК
enum colour
{ red = 3, blue, green, yellow = 5 }; /* ВЛЗћКЯДЫЙцдђ
*/
enum colour { red = 3, blue = 4, green = 5, yellow=
5 }; /* ЗћКЯДЫЙцдђ */ |
ЫфШЛgreenКЭyellowЕФжЕЖМЪЧ5ЃЌЕЋетЗћКЯЙцдђЁЃ
| enum colour
{ red = 1, blue, green, yellow }; /* ЗћКЯДЫЙцдђ */ |
Йцдђ5.4-4(ЧПжЦ)ЃККЏЪ§гІЕБОпгадаЭЩљУїЃЌЧвдаЭдкКЏЪ§ЕФЖЈвхКЭЕїгУЗЖЮЇФкЖМЪЧПЩМћ
ЕФЁЃ
[Undefined]
ЫЕУїЃКдаЭЕФЪЙгУЪЙЕУБрвыЦїФмЙЛМьВщКЏЪ§ЖЈвхКЭЕїгУЕФЭъећадЁЃШчЙћУЛгадаЭЃЌОЭВЛЛсЦШЪЙБрвыЦїМьВщГіКЏЪ§ЕїгУЕБжаЕФвЛЖЈДэЮѓЃЈБШШчЃЌКЏЪ§ЬхОпгаВЛЭЌЕФВЮЪ§Ъ§ФПЃЌЕїгУКЭЖЈвхжЎМфВЮЪ§РраЭЕФВЛЦЅХфЃЉЁЃЪТЪЕжЄУїЃЌКЏЪ§НгПкЪЧЯрЕБЖрЮЪЬтЕФеивђЃЌвђДЫБОЙцдђЪЧЯрЕБживЊЕФЁЃЖдЭтВПКЏЪ§РДЫЕЃЌЮвУЧНЈвщВЩгУШчЯТЗНЗЈЃЌдкЭЗЮФМўжаЩљУїКЏЪ§ЃЈврМДИјГіЦфдаЭЃЉЃЌВЂдкЫљгаашвЊИУКЏЪ§даЭЕФДњТыЮФМўжаАќКЌетИіЭЗЮФМўЃЌдкЪЕЯжКЏЪ§ЙІФмЕФ.cЮФМўжавВАќКЌОпгадаЭЩљУїЕФЭЗЮФМўЁЃ
ЮЊОпгаФкВПСДНгЕФКЏЪ§ИјГіЦфдаЭвВЪЧСМКУЕФБрГЬЪЕМљЁЃ
Йцдђ5.4-5(ЧПжЦ)ЃКЖЈвхЛђЩљУїЖдЯѓЁЂКЏЪ§ЪБЖМгІИУЯдЪОжИУїЦфРраЭЁЃ
Йцдђ5.4-6(ЧПжЦ)ЃККЏЪ§ЕФУПИіВЮЪ§РраЭдкЩљУїКЭЖЈвхжаБиаыЪЧЕШЭЌЕФЃЌКЏЪ§ЕФЗЕЛиРраЭ
вВИУЪЧЕШЭЌЕФЁЃ
[Undefined]
Йцдђ5.4-6(ЧПжЦ)ЃККЏЪ§гІИУЩљУїЮЊОпгаЮФМўзїгУгђЁЃ
[Undefined]
ЫЕУїЃКдкПщзїгУгђжаЩљУїКЏЪ§Лсв§Ц№ЛьЯ§ВЂПЩФмЕМжТЮДЖЈвхЕФааЮЊЁЃ
Йцдђ5.4-7(ЧПжЦ)ЃКдкЮФМўЗЖЮЇФкЩљУїКЭЖЈвхЕФЫљгаЖдЯѓЛђКЏЪ§гІИУОпгаФкВПСДНгЃЌГ§ЗЧ
ЪЧдкашвЊЭтВПСДНгЕФЧщПіЯТЃЌОпгаФкВПСДНгЪєадЕФЖдЯѓЛђКЏЪ§гІИУЪЙгУstaticЙиМќзжаоЪЮЁЃ
ЫЕУїЃКШчЙћвЛИіБфСПжЛЪЧБЛЭЌвЛЮФМўжаЕФКЏЪ§ЫљЪЙгУЃЌФЧУДОЭгУstaticЁЃРрЫЦЕиЃЌШчЙћвЛИіКЏЪ§жЛЪЧдкЭЌвЛЮФМўжаЕФЦфЫћЕиЗНЕїгУЃЌФЧУДОЭгУ
staticЁЃЪЙгУ staticДцДЂРрБъЪЖЗћНЋШЗБЃБъЪЖЗћжЛЪЧдкЩљУїЫќЕФЮФМўжаЪЧПЩМћЕФЃЌВЂЧвБмУтСЫКЭЦфЫћЮФМўЛђПтжаЕФЯрЭЌБъЪЖЗћЗЂЩњЛьЯ§ЕФПЩФмадЁЃОпгаЭтВПСДНгЪєадЕФЖдЯѓЛђКЏЪ§дкЯргІФЃПщЕФЭЗЮФМўжаЩљУїЃЌдкашвЊЪЙгУетаЉНгПкЕФФЃПщжаАќКЌДЫЭЗЮФМўЁЃ
Йцдђ5.4-8(ЧПжЦ)ЃКЕБвЛИіЪ§зщЩљУїЮЊОпгаЭтВПСДНгЃЌЫќЕФДѓаЁгІИУЯдЪНЩљУїЛђепЭЈЙ§Гѕ
ЪМЛЏНјаавўЪНЖЈвхЁЃ
[Undefined]
ЪЕР§ЃК
INT8U array[10]
; /* ЗћКЯЙцЗЖ */
extern INT8U array[] ; /* ВЛЗћКЯЙцЗЖ*/
INT8U array[] = { 0, 10, 15}; /* ЗћКЯЙцЗЖ */ |
ОЁЙмПЩвддкЪ§зщЩљУїВЛЭъЩЦЪБЗУЮЪЦфдЊЫиЃЌШЛЖјШдШЛЪЧдкЪ§зщЕФДѓаЁПЩвдЯдЪНШЗЖЈЕФЧщ
ПіЯТЃЌетбљзіВХЛсИќЮЊАВШЋЁЃ
5.5ПижЦгяОфКЭБэДяЪН
Йцдђ5.5-1(НЈвщ)ЃКВЛвЊЙ§ЗжвРРЕC БэДяЪНжаЕФдЫЫуЗћгХЯШЙцдђЁЃ
ЫЕУїЃКРЈКХЕФЪЙгУГ§СЫПЩвдИВИЧШБЪЁЕФдЫЫуЗћгХЯШМЖвдЭтЃЌЛЙПЩвдгУРДЧПЕїЫљЪЙгУЕФдЫЫуЗћЁЃЪЙгУЯрЕБИДдгЕФC
дЫЫуЗћгХЯШМЖЙцдђКмШнвзв§Ц№ДэЮѓЃЌФЧУДетжжЗНЗЈОЭПЩвдАяжњБмУтетбљЕФДэЮѓЃЌВЂЧвПЩвдЪЙЕУДњТыИќЮЊЧхЮњПЩЖСЁЃШЛЖјЃЌЙ§ЖрЕФРЈКХЛсЗжЩЂДњТыЪЙЦфНЕЕЭСЫПЩЖСадЁЃвђДЫЃЌЧыКЯРэЪЙгУРЈКХРДЬсИпГЬађЧхЮњЖШКЭПЩЖСадЁЃ
Йцдђ5.5-1(ЧПжЦ)ЃКВЛФмдкОпгаИБзїгУЕФБэДяЪНжаЪЙгУsizeof
дЫЫуЗћЁЃ
ЫЕУїЃКЕБвЛИіБэДяЪНЪЙгУСЫsizeofдЫЫуЗћЃЌВЂЦкЭћМЦЫуБэДяЪНЕФжЕЪБЃЌБэДяЪНЪЧВЛЛсБЛМЦЫуЕФЁЃsizeofжЛЖдБэДяЪНЕФРраЭгагУЁЃ
ЪЕР§ЃК
INT32S i;
INT32S j;
j = sizeof (i = 1234); /* jЕФжЕЪЧiРраЭЕФДѓаЁЃЌЕЋiЕФжЕВЂУЛгаИГжЕГЩ1234
*/ |
Йцдђ5.5-2(ЧПжЦ)ЃКТпМдЫЫуЗћ && Лђ ||
ЕФгвЪжВйзїЪ§ВЛФмАќКЌИБзїгУЁЃ
ЫЕУїЃКCгябджаДцдкБэДяЪНЕФФГаЉВПЗжВЛЛсБЛМЦЫуЕНЃЌетШЁОігкБэДяЪНжаЕФЦфЫћВПЗжЁЃТпМВйзїЗћ&&Лђ||дкНјааТпМХаЖЯЪБЃЌШєНіХаБ№зѓВйзїЪ§ОЭФмШЗЖЈtrue
or falseЕФЧщПіЯТЃЌТпМВйзїЗћЕФгвВйЪ§НЋБЛКіТдЁЃ
ЪЕР§ЃК
| if ( high &&
( x == i++ ) ) /* ВЛЗћКЯЙцдђ */ |
ШєhighЮЊfalseЃЌдђећИіБэДяЪНЕФВМЖћжЕвВМДЮЊfalseЃЌВЛгУдйШЅжДааКЭХаЖЯгвВйзїЪ§ЁЃ
Йцдђ5.5-3(НЈвщ)ЃКТпМдЫЫуЗћЃЈ&&ЁЂ| | КЭ
! ЃЉЕФВйзїЪ§гІИУЪЧгааЇЕФВМЖћЪ§ЁЃгааЇВМЖћ
РраЭЕФБэДяЪНВЛФмгУзіЗЧТпМдЫЫуЗћЃЈ&&ЁЂ| | КЭ
! ЃЉЕФВйзїЪ§ЁЃ
ЫЕУїЃКгааЇВМЖћРраЭЪЧБэЪОецЁЂМйЕФвЛжжЪ§ОнРраЭЃЌВњЩњВМЖћРраЭЕФПЩвдЪЧБШНЯЃЌТпМдЫЫуЃЌЕЋВМЖћРраЭЪ§ОнжЛФмНјааТпМдЫЫуЁЃ
Йцдђ5.5-4(ЧПжЦ)ЃКЮЛдЫЫуЗћВЛФмгУгкЛљБОРраЭЃЈunderlying
type ЃЉЪЧгаЗћКХЕФВйзїЪ§ЩЯЁЃ
[Implementation-defined]
ЫЕУїЃКЮЛдЫЫуЃЈ~ ЁЂ<<ЁЂ>>ЁЂ&ЁЂ^
КЭ | ЃЉЖдгаЗћКХећЪ§ЭЈГЃЪЧЮовтвхЕФЁЃБШШчЃЌШчЙћгввЦдЫЫуАбЗћКХЮЛвЦЖЏЕНЪ§ОнЮЛЩЯЛђепзѓвЦдЫЫуАбЪ§ОнЮЛвЦЖЏЕНЗћКХЮЛЩЯЃЌОЭЛсВњЩњЮЪЬтЁЃ
Йцдђ5.5-6(НЈвщ)ЃКдквЛИіБэДяЪНжаЃЌзддіЃЈ++ЃЉКЭздМѕЃЈ- -
ЃЉдЫЫуЗћВЛгІЭЌЦфЫћдЫЫуЗћ
ЛьКЯдквЛЦ№ЁЃ
ЫЕУїЃКВЛНЈвщЪЙгУЭЌЦфЫћЫуЪѕдЫЫуЗћЛьКЯдквЛЦ№ЕФзддіКЭздМѕдЫЫуЗћЪЧвђЮЊ
1ЃЉЫќЯджјЯїШѕСЫДњТыЕФПЩЖСад;
2ЃЉдкВЛЭЌЕФБфвьЛЗОГЯТЃЌЛсжДааВЛЭЌЕФдЫЫуДЮађЃЌВњЩњВЛЭЌНсЙћЁЃ
ЪЕР§ЃК
| u8a = ++u8b
+u8c--; /* ВЛЗћКЯЙцЗЖ */ |
ЯТУцЕФађСаИќЮЊЧхЮњКЭАВШЋЃК
++u8b;
u8a = u8b + u8c;
u8c--; |
Йцдђ5.5-7(ЧПжЦ)ЃКИЁЕуБэДяЪНВЛФмзіЯёЁЎ>ЁЏ ЁЎ<ЁЏ
ЁЎ==ЁЏ ЁЎ!=ЁЏЕШ ЙиЯЕдЫЫуЁЃ
ЫЕУїЃКfloatЁЂdoubleРраЭЕФЪ§ОнЖМгавЛЖЈЕФОЋШЗЖШЯожЦЃЌЪЙгУВЛЭЌИЁЕуЪ§БэЪОЙцЗЖЛђепВЛЭЌгВМўЦНЬЈПЩФмЕМжТЙиЯЕдЫЫуЕФНсЙћВЛвЛжТЁЃ
Йцдђ5.5-8(ЧПжЦ)ЃКforгяОфЕФШ§ИіБэДяЪНгІИУжЛЙизЂбЛЗПижЦЃЌforбЛЗжагУгкМЦЪ§ЕФБфСПВЛгІдкбЛЗЬхжааоИФЁЃ
ЫЕУїЃКfor гяОфЕФШ§ИіБэДяЪНЖМИјГіЪБЫќУЧгІИУжЛгУгкШчЯТФПЕФЃК
ЕквЛИіБэДяЪНГѕЪМЛЏбЛЗМЦЪ§ЦїЃЛ
ЕкЖўИіБэДяЪНАќКЌЖдбЛЗМЦЪ§ЦїКЭЦфЫћПЩбЁЕФбЛЗПижЦБфСПЕФВтЪдЃЛ
ЕкШ§ИіБэДяЪНбЛЗМЦЪ§ЦїЕФЕндіЛђЕнМѕЁЃ
Йцдђ5.5-9(ЧПжЦ)ЃКзщГЩswitchЁЂwhileЁЂdo...while
Лђfor НсЙЙЬхЕФгяОфгІИУЪЧИДКЯгяОфЁЃМДЪЙИУИДКЯгяОфжЛАќКЌвЛЬѕгяОфвВвЊРЉдк{}РяЁЃ
ЪЕР§ЃК
for ( i = 0
; i< N_ELEMENTS ; ++i )
{
buffer[i] = 0; /* НігавЛЬѕгяОфвВашЪЙгУ{} */
} |
Йцдђ5.5-10(ЧПжЦ)ЃКif /elseгІИУГЩЖдГіЯжЁЃЫљгаЕФif
... else if НсЙЙгІИУгЩelse згОфНсЪјЁЃ
Йцдђ5.5-11(ЧПжЦ)ЃКswitch гяОфжаШчЙћcase ЗжжЇЕФФкШнВЛЮЊПеЃЌФЧУДБиаывдbreak
зїЮЊНсЪјЃЌзюКѓЗжжЇгІИУЪЧdefaultЗжжЇЁЃ
5.6КЏЪ§
ддђ5.6-1(ЧПжЦ)ЃКБраДећНрКЏЪ§ЃЌЭЌЪБАбДњТыгааЇзщжЏЦ№РДЁЃ
ЫЕУїЃКДњТыМђЕЅжБНгЁЂВЛвўВиЩшМЦепЕФвтЭМЁЂгУИЩОЛРћТфЕФГщЯѓКЭжБНиСЫЕБЕФПижЦгяОфНЋКЏЪ§гаЛњзщжЏЦ№РДЁЃДњТыЕФгааЇзщжЏАќРЈЃКТпМВузщжЏКЭЮяРэВузщжЏСНИіЗНУцЁЃТпМВуЃЌжївЊЪЧАбВЛЭЌЙІФмЕФКЏЪ§ЭЈЙ§ФГжжСЊЯЕзщжЏЦ№РДЃЌжївЊЙизЂФЃПщМфЕФНгПкЃЌвВОЭЪЧФЃПщЕФМмЙЙЁЃЮяРэВуЃЌЮоТлЪЙгУЪВУДбљЕФФПТМЛђепУћзжПеМфЕШЃЌашвЊАбКЏЪ§гУвЛжжБъзМЕФЗНЗЈзщжЏЦ№РДЁЃР§ШчЃКЩшМЦСМКУЕФФПТМНсЙЙЁЂКЏЪ§УћзжЁЂЮФМўзщжЏЕШЃЌетбљПЩвдЗНБуВщевЁЃ
Йцдђ5.6-2(ЧПжЦ)ЃКвЛЖЈвЊЯдЪОЩљУїКЏЪ§ЕФЗЕЛижЕРраЭЃЌМАЫљДјЕФВЮЪ§ЁЃШчЙћУЛгавЊЩљУїЮЊvoidЁЃ
ЫЕУїЃКCгябджаВЛМгРраЭЫЕУїЕФКЏЪ§ЃЌвЛТЩздЖЏАДећаЭДІРэЁЃ
Йцдђ5.6-3(НЈвщ)ЃКВЛНЈвщЪЙгУЕнЙщКЏЪ§ЕїгУЁЃ
ЫЕУїЃКгааЉЫуЗЈЪЙгУЗжЖјжЮжЎЕФЕнЙщЫМЯыЃЌЕЋдкЧЖШыЪНжаеЛПеМфгаЯоЃЌЕнЙщБОЩэГадизХПЩ
гУЖбеЛПеМфЙ§ЖШЕФЮЃЯеЃЌетФмЕМжТбЯжиЕФДэЮѓЁЃГ§ЗЧЕнЙщОЙ§СЫЗЧГЃбЯИёЕФПижЦЃЌ
ЗёдђВЛПЩФмдкжДаажЎЧАШЗЖЈЪВУДЪЧзюЛЕЧщПіЃЈworst-caseЃЉЕФЖбеЛЪЙгУЁЃ
5.7жИеыгыЪ§зщ
Йцдђ5.7-1(ЧПжЦ)ЃКГ§СЫжИЯђЭЌвЛЪ§зщЕФжИеыЭтЃЌВЛФмгУжИеыНјааЪ§бЇдЫЫуЃЌВЛФмНјааЙиЯЕдЫЫуЁЃ
ЫЕУїЃКетбљзіЕФФПЕФвЛЪЧЪЙДњТыЧхЮњвзЖСЃЌСэЭтБмУтЗУЮЪЮоаЇЕФФкДцЕижЗЁЃ
Йцдђ5.7-2(ЧПжЦ)ЃКжИеыдкЪЙгУЧАвЛЖЈвЊИГжЕЃЌБмУтВњЩњвАжИеыЁЃ
Йцдђ5.7-3(ЧПжЦ)ЃКВЛвЊЗЕЛиОжВПБфСПЕФЕижЗЁЃ
ЫЕУїЃКОжВПБфСПЪЧдкеЛжаЗжХфЕФЃЌКЏЪ§ЗЕЛиКѓеМгУЕФФкДцЛсЪЭЗХЃЌМЬајЪЙгУетбљЕФФкДцЪЧ
ЮЃЯеЕФЁЃвђДЫЃЌгІИУБмУтГіЯжетбљЕФЮЃЯеЁЃ
ЪЕР§ЃК
INT8U *foobar
(void)
{
INT8U local_auto;
return(&local_auto); /* ВЛЗћКЯЙцЗЖ */
} |
5.8НсЙЙгыСЊКЯ
ддђ5.8-1(ЧПжЦ)ЃКНсЙЙЙІФмЕЅвЛЃЌВЛвЊЩшМЦУцУцОуЕНЕФЪ§ОнНсЙЙЁЃ
ЫЕУїЃКЯрЙиЕФвЛзщаХЯЂВХЪЧЙЙГЩвЛИіНсЙЙЬхЕФЛљДЁЃЌНсЙЙЕФЖЈвхгІИУПЩвдУїШЗЕФУшЪівЛИіЖдЯѓЃЌЖјВЛЪЧвЛзщЯрЙиадВЛЧПЕФЪ§ОнЕФМЏКЯЁЃЩшМЦНсЙЙЪБгІСІељЪЙНсЙЙДњБэвЛжжЯжЪЕЪТЮёЕФГщЯѓЃЌЖјВЛЪЧЭЌЪБДњБэЖржжЁЃНсЙЙжаЕФИїдЊЫигІДњБэЭЌвЛЪТЮёЕФВЛЭЌВрУцЃЌЖјВЛгІАбУшЪіУЛгаЙиЯЕЛђЙиЯЕКмШѕЕФВЛЭЌЪТЮёЕФдЊЫиЗХЕНЭЌвЛНсЙЙжаЁЃ
5.9БъзМПт
Йцдђ5.9-1(ЧПжЦ)ЃКБъзМПтжаБЃСєЕФБъЪЖЗћЁЂКъКЭКЏЪ§ВЛФмБЛЖЈвхЁЂжиЖЈвхЛђШЁЯћЖЈвхЁЃ
[Undefined]
ЫЕУїЃКЭЈГЃ #undef вЛИіЖЈвхдкБъзМПтжаЕФКъЪЧМўЛЕЪТЁЃЭЌбљВЛКУЕФЪЧЃЌ#define
вЛИіКъУћзжЃЌЖјИУУћзжЪЧC ЕФБЃСєБъЪЖЗћЛђепБъзМПтжазіЮЊКъЁЂЖдЯѓЛђКЏЪ§УћзжЕФC ЙиМќзжЁЃР§ШчЃЌДцдквЛаЉЬиЪтЕФБЃСєзжКЭКЏЪ§УћзжЃЌЫќУЧЕФзїгУЮЊШЫЫљЪьжЊЃЌШчЙћЖдЫќУЧжиаТЖЈвхЛђШЁЯћЖЈвхОЭЛсВњЩњвЛаЉЮДЖЈвхЕФааЮЊЁЃетаЉУћзжАќРЈdefinedЁЂ__LINE__ЁЂ__FILE__ЁЂ__DATE__
ЁЂ__TIME__ЁЂ__STDC__ЁЂerrnoКЭassertЁЃ
Йцдђ5.9-2(ЧПжЦ)ЃКДЋЕнИјПтКЏЪ§ЕФжЕБиаыМьВщЦфгааЇадЁЃ
ЫЕУїЃКC БъзМПтжаЕФаэЖрКЏЪ§ИљОнISO [2] БъзМ ВЂВЛашвЊМьВщДЋЕнИјЫќУЧЕФВЮЪ§ЕФгааЇадЁЃМДЪЙБъзМвЊЧѓетбљЃЌЛђепБрвыЦїЕФБраДепЩљУївЊетУДзіЃЌвВВЛФмБЃжЄЛсзіГіГфЗжЕФМьВщЁЃвђДЫЃЌГЬађдБгІИУЮЊЫљгаДјгабЯИёЪфШыгђЕФПтКЏЪ§ЃЈБъзМПтЁЂЕкШ§ЗНПтМАздМКЖЈвхЕФПтЃЉЬсЙЉЪЪЕБЕФЪфШыжЕМьВщЛњжЦЁЃ
ОпгабЯИёЪфШыгђВЂашвЊМьВщЕФКЏЪ§Р§згЮЊЃК
math.h жаЕФаэЖрЪ§бЇКЏЪ§ЃЌБШШчЃК
ИКЪ§ВЛФмДЋЕнИјsqrt ЛђlogКЏЪ§ЃЛ
fmod КЏЪ§ЕФЕкЖўИіВЮЪ§ВЛФмЮЊСу
toupper КЭtolowerЃКЕБДЋЕнИјtoupperКЏЪ§ЕФВЮЪ§ВЛЪЧаЁаДзжЗћЪБЃЌФГаЉЪЕЯжФмВњЩњВЂЗЧдЄЦкЕФНсЙћЃЈtolower
КЏЪ§ЧщПіРрЫЦЃЉ
ШчЙћЮЊctype.h жаЕФзжЗћВтЪдКЏЪ§ДЋЕнЮоаЇЕФжЕЪБЛсИјГіЮДЖЈвхЕФааЮЊ
гІгУгкДѓЖрЪ§ИКећЪ§ЕФabs КЏЪ§ИјГіЮДЖЈвхЕФааЮЊ дкmath.h
жаЃЌОЁЙмДѓЖрЪ§Ъ§бЇПтКЏЪ§ЖЈвхСЫЫќУЧдЪаэЕФЪфШыгђЃЌЕЋдкгђЗЂЩњДэЮѓЪБЫќУЧЕФЗЕЛижЕШдПЩФмЫцБрвыЦїЕФВЛЭЌЖјВЛЭЌЁЃвђДЫЃЌЖдетаЉКЏЪ§РДЫЕЃЌдЄЯШМьВщЦфЪфШыжЕЕФгааЇадОЭБфЕУжСЙиживЊЁЃ
ГЬађдБдкЪЙгУКЏЪ§ЪБЃЌгІИУЪЖБ№гІгУгкетаЉКЏЪ§жЎЩЯЕФШЮКЮЕФгђЯожЦЃЈетаЉЯожЦПЩФм
ЛсвВПЩФмВЛЛсдкЮФЕЕжаЫЕУїЃЉЃЌВЂЧввЊЬсЙЉЪЪЕБЕФМьВщвдШЗШЯетаЉЪфШыжЕЮЛгкИїздгђ
жаЁЃЕБШЛЃЌдкашвЊЪБЃЌетаЉжЕЛЙПЩвдИќНјвЛВНМгвдЯожЦЁЃ
гааэЖрЗНЗЈПЩвдТњзуБОЙцдђЕФвЊЧѓЃЌАќРЈЃК
1. ЕїгУКЏЪ§ЧАМьВщЪфШыжЕ
2. ЩшМЦЩюШыКЏЪ§ФкВПЕФМьВщЪжЖЮЁЃетжжЗНЗЈгШЦфЪЪгІгкЪЕбщЪвФкПЊЗЂЕФПтЃЌзнШЛЫќвВПЩвдгУгкТђНјЕФЕкШ§ЗНПтЃЈШчЙћЕкШ§ЗНПтЕФЙЉгІЩЬЩљУїЫћУЧвбФкжУСЫМьВщЕФЛАЃЉЁЃ
3. ВњЩњКЏЪ§ЕФЁАЗтзАЁБЃЈwrappedЃЉАцБОЃЌдкИУАцБОжаЪзЯШМьВщЪфШыЃЌШЛКѓЕїгУдЪМЕФКЏЪ§ЁЃ
4. ОВЬЌЕиЩљУїЪфШыВЮЪ§гРдЖВЛЛсВЩШЁЮоаЇЕФжЕЁЃ
зЂвтЃЌдкМьВщКЏЪ§ЕФИЁЕуВЮЪ§ЪБЃЈИЁЕуВЮЪ§дкСуЕуЩЯЮЊЦцЕуЃЉЃЌЪЪЕБЕФзіЗЈЪЧжДааЦфЪЧЗёЮЊСуЕФМьВщЁЃШЛЖјШчЙћЕБВЮЪ§ЧїНќгкСуЪБЃЌКЏЪ§жЕЕФСПМЖЧїНќЮоЧюЕФЛАЃЌШдШЛгаБивЊМьВщЦфдкСуЕуЃЈЛђЦфЫћШЮКЮЦцЕуЃЉЩЯЕФШнЯоЃЌетбљПЩвдБмУтвчГіЕФЗЂЩњЁЃ
|









