| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФЪзЯШеЙЪОНјГЬЕФФкКЫБэЪОвдМАЫќУЧЪЧШчКЮдкФкКЫФкБЛЙмРэЕФЃЌШЛКѓРДПДПДНјГЬДДНЈКЭЕїЖШЕФИїжжЗНЪНЃЈдквЛИіЛђЖрИіДІРэЦїЩЯЃЉЃЌзюКѓНщЩмНјГЬЕФЯњЛйЁЃ |
|
Linux ЪЧвЛжжЖЏЬЌЯЕЭГЃЌФмЙЛЪЪгІВЛЖЯБфЛЏЕФМЦЫуашЧѓЁЃlinux
МЦЫуашЧѓЕФБэЯжЪЧвдНјГЬЕФЭЈгУГщЯѓЮЊжааФЕФЁЃНјГЬПЩвдЪЧЖЬЦкЕФЃЈДгУќСюаажДааЕФвЛИіУќСюЃЉЃЌвВПЩвдЪЧГЄЦкЕФЃЈвЛжжЭјТчЗўЮёЃЉЁЃвђДЫЃЌЖдНјГЬМАЦфЕїЖШНјаавЛАуЙмРэОЭЯдЕУМЋЮЊживЊЁЃ
дкгУЛЇПеМфЃЌНјГЬЪЧгЩНјГЬБъЪЖЗћЃЈPIDЃЉБэЪОЕФЁЃДггУЛЇЕФНЧЖШРДПДЃЌвЛИі PID ЪЧвЛИіЪ§зжжЕЃЌПЩЮЉвЛБъЪЖвЛИіНјГЬЁЃвЛИі
PID дкНјГЬЕФећИіЩњУќЦкМфВЛЛсИќИФЃЌЕЋ PID ПЩвддкНјГЬЯњЛйКѓБЛжиаТЪЙгУЃЌЫљвдЖдЫќУЧНјааЛКДцВЂВЛМћЕУзмЪЧРэЯыЕФЁЃдкгУЛЇПеМфЃЌДДНЈНјГЬПЩвдВЩгУМИжжЗНЪНЁЃПЩвджДаавЛИіГЬађЃЈетЛсЕМжТаТНјГЬЕФДДНЈЃЉЃЌвВПЩвддкГЬађФкЃЌЕїгУвЛИіforkЛђexecЯЕЭГЕїгУЁЃforkЕїгУЛсЕМжТДДНЈвЛИізгНјГЬЃЌЖјexecЕїгУдђЛсгУаТГЬађДњЬцЕБЧАНјГЬЩЯЯТЮФЁЃетРяНЋЖдетМИжжЗНЗЈНјааЬжТлвдБуФњФмКмКУЕиРэНтЫќУЧЕФЙЄзїдРэЁЃ
етРяНЋАДееЯТУцЕФЫГађеЙПЊЖдНјГЬЕФНщЩмЃЌЪзЯШеЙЪОНјГЬЕФФкКЫБэЪОвдМАЫќУЧЪЧШчКЮдкФкКЫФкБЛЙмРэЕФЃЌШЛКѓРДПДПДНјГЬДДНЈКЭЕїЖШЕФИїжжЗНЪНЃЈдквЛИіЛђЖрИіДІРэЦїЩЯЃЉЃЌзюКѓНщЩмНјГЬЕФЯњЛйЁЃФкКЫЕФАцБОЮЊ2.6.32.45ЁЃ
1. НјГЬУшЪіЗћ
дк Linux ФкКЫФкЃЌНјГЬЪЧгЩЯрЕБДѓЕФвЛИіГЦЮЊ task_struct ЕФНсЙЙБэЪОЕФЁЃДЫНсЙЙАќКЌЫљгаБэЪОДЫНјГЬЫљБиашЕФЪ§ОнЃЌДЫЭтЃЌЛЙАќКЌСЫДѓСПЕФЦфЫћЪ§ОнгУРДЭГМЦЃЈaccountingЃЉКЭЮЌЛЄгыЦфЫћНјГЬЕФЙиЯЕЃЈШчИИКЭзгЃЉЁЃtask_struct
ЮЛгк ./linux/include/linux/sched.hЃЈзЂвт./linux/жИЯђФкКЫдДДњТыЪїЃЉЁЃЯТУцЪЧtask_structНсЙЙЃК
struct task_struct
{
volatile long state; /* -1 ВЛПЩдЫаа, 0 ПЩдЫаа, >0
вбЭЃжЙ */
void *stack; /* ЖбеЛ */
atomic_t usage;
unsigned int flags; /* вЛзщБъжО */
unsigned int ptrace;
/* Ё */
int prio, static_prio, normal_prio; /* гХЯШМЖ */
/* Ё */
struct list_head tasks; /* жДааЕФЯпГЬЃЈПЩвдгаКмЖрЃЉ */
struct plist_node pushable_tasks;
struct mm_struct *mm, *active_mm; /* ФкДцвГЃЈНјГЬЕижЗПеМфЃЉ
*/
/* НјаазДЬЌ */
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* ЕБИИНјГЬЫРЭіЪБвЊЗЂЫЭЕФаХКХ */ |
| <span style=ЁАfont-family:
Arial, Helvetica, sans-serif;ЁБ>/* Ё */ </span>
|
pid_t pid; /*
НјГЬКХ */
pid_t tgid;
/* Ё */
struct task_struct *real_parent; /* ЪЕМЪИИНјГЬreal
parent process */
struct task_struct *parent; /* SIGCHLDЕФНгЪмепЃЌгЩwait4()БЈИц
*/
struct list_head children; /* згНјГЬСаБэ */
struct list_head sibling; /* ажЕмНјГЬСаБэ */
struct task_struct *group_leader; /* ЯпГЬзщЕФleader
*/
/* Ё */
char comm[TASK_COMM_LEN]; /* ПЩжДааГЬађЕФУћГЦЃЈВЛАќКЌТЗОЖЃЉ */
/* ЮФМўЯЕЭГаХЯЂ */
int link_count, total_link_count;
/* Ё */
/* ЬиЖЈCPUМмЙЙЕФзДЬЌ */
struct thread_struct thread;
/* НјГЬЕБЧАЫљдкЕФФПТМУшЪі */
struct fs_struct *fs;
/* ДђПЊЕФЮФМўУшЪіаХЯЂ */
struct files_struct *files;
/* Ё */
}; |
дкtask_structНсЙЙжаЃЌПЩвдПДЕНМИИідЄСЯжЎжаЕФЯюЃЌБШШчжДааЕФзДЬЌЁЂЖбеЛЁЂвЛзщБъжОЁЂИИНјГЬЁЂжДааЕФЯпГЬЃЈПЩвдгаКмЖрЃЉвдМАПЊЗХЮФМўЁЃstate
БфСПЪЧвЛаЉБэУїШЮЮёзДЬЌЕФБШЬиЮЛЁЃзюГЃМћЕФзДЬЌгаЃКTASK_RUNNING БэЪОНјГЬе§дкдЫааЃЌЛђЪЧХХдкдЫааЖгСажае§вЊдЫааЃЛTASK_INTERRUPTIBLE
БэЪОНјГЬе§дканУпЁЂTASK_UNINTERRUPTIBLEБэЪОНјГЬе§дканУпЕЋВЛФмНаабЃЛTASK_STOPPED
БэЪОНјГЬЭЃжЙЕШЕШЁЃетаЉБъжОЕФЭъећСаБэПЩвддк ./linux/include/linux/sched.h
ФкевЕНЁЃ
flags ЖЈвхСЫКмЖржИЪОЗћЃЌБэУїНјГЬЪЧЗёе§дкБЛДДНЈЃЈPF_STARTINGЃЉЛђЭЫГіЃЈPF_EXITINGЃЉЃЌЛђЪЧНјГЬЕБЧАЪЧЗёдкЗжХфФкДцЃЈPF_MEMALLOCЃЉЁЃПЩжДааГЬађЕФУћГЦЃЈВЛАќКЌТЗОЖЃЉеМгУ
commЃЈУќСюЃЉзжЖЮЁЃУПИіНјГЬЖМЛсБЛИГгшгХЯШМЖЃЈГЦЮЊ static_prioЃЉЃЌЕЋНјГЬЕФЪЕМЪгХЯШМЖЪЧЛљгкМгдивдМАЦфЫћМИИівђЫиЖЏЬЌОіЖЈЕФЁЃгХЯШМЖжЕдНЕЭЃЌЪЕМЪЕФгХЯШМЖдНИпЁЃtasksзжЖЮЬсЙЉСЫСДНгСаБэЕФФмСІЁЃЫќАќКЌвЛИі
prev жИеыЃЈжИЯђЧАвЛИіШЮЮёЃЉКЭвЛИі next жИеыЃЈжИЯђЯТвЛИіШЮЮёЃЉЁЃ
НјГЬЕФЕижЗПеМфгЩmm КЭ active_mm зжЖЮБэЪОЁЃmmДњБэЕФЪЧНјГЬЕФФкДцУшЪіЗћЃЌЖј active_mm
дђЪЧЧАвЛИіНјГЬЕФФкДцУшЪіЗћЃЈЮЊИФНјЩЯЯТЮФЧаЛЛЪБМфЕФвЛжжгХЛЏЃЉЁЃthread_struct threadНсЙЙдђгУРДБъЪЖНјГЬЕФДцДЂзДЬЌЃЌДЫдЊЫивРРЕгкLinuxдкЦфЩЯдЫааЕФЬиЖЈМмЙЙЁЃР§ШчЖдгкx86МмЙЙЃЌдк./linux/arch/x86/include/asm/processor.hЕФthread_structНсЙЙжаПЩвдевЕНИУНјГЬзджДааЩЯЯТЮФЧаЛЛКѓЕФДцДЂЃЈгВМўзЂВсБэЁЂГЬађМЦЪ§ЦїЕШЃЉЁЃДњТыШчЯТЃК
struct thread_struct
{
/* Cached TLS descriptors: */
struct desc_struct tls_array[GDT_ENTRY_TLS_ENTRIES];
unsigned long sp0;
unsigned long sp;
#ifdef CONFIG_X86_32
unsigned long sysenter_cs;
#else
unsigned long usersp; /* Copy from PDA */
unsigned short es;
unsigned short ds;
unsigned short fsindex;
unsigned short gsindex;
#endif
#ifdef CONFIG_X86_32
unsigned long ip;
#endif
/* Ё */
#ifdef CONFIG_X86_32
/* Virtual 86 mode info */
struct vm86_struct __user *vm86_info;
unsigned long screen_bitmap;
unsigned long v86flags;
unsigned long v86mask;
unsigned long saved_sp0;
unsigned int saved_fs;
unsigned int saved_gs;
#endif
/* IO permissions: */
unsigned long *io_bitmap_ptr;
unsigned long iopl;
/* Max allowed port in the bitmap, in bytes: */
unsigned io_bitmap_max;
/* MSR_IA32_DEBUGCTLMSR value to switch in if
TIF_DEBUGCTLMSR is set. */
unsigned long debugctlmsr;
/* Debug Store context; see asm/ds.h */
struct ds_context *ds_ctx;
}; |
2. НјГЬЙмРэ
дкКмЖрЧщПіЯТЃЌНјГЬЖМЪЧЖЏЬЌДДНЈВЂгЩвЛИіЖЏЬЌЗжХфЕФ task_struct БэЪОЁЃвЛИіР§ЭтЪЧinit
НјГЬБОЩэЃЌЫќзмЪЧДцдкВЂгЩвЛИіОВЬЌЗжХфЕФtask_structБэЪОЃЌВЮПД./linux/arch/x86/kernel/init_task.cЃЌДњТыШчЯТЃК
static struct
signal_struct init_signals = INIT_SIGNALS(init_signals);
static struct sighand_struct init_sighand = INIT_SIGHAND(init_sighand);
/*
* ГѕЪМЛЏЯпГЬНсЙЙ
*/
union thread_union init_thread_union __init_task_data
=
{ INIT_THREAD_INFO(init_task) };
/*
* ГѕЪМЛЏinitНјГЬЕФНсЙЙЁЃЫљгаЦфЫћНјГЬЕФНсЙЙНЋгЩfork.cжаЕФslabsРДЗжХф
*/
struct task_struct init_task = INIT_TASK(init_task);
EXPORT_SYMBOL(init_task);
/*
* per-CPU TSS segments.
*/
DEFINE_PER_CPU_SHARED_ALIGNED(struct tss_struct,
init_tss) = INIT_TSS; |
зЂвтНјГЬЫфШЛЖМЪЧЖЏЬЌЗжХфЕФЃЌЕЋЛЙЪЧашвЊПМТЧзюДѓНјГЬЪ§ЁЃдкФкКЫФкзюДѓНјГЬЪ§ЪЧгЩвЛИіГЦЮЊmax_threadsЕФЗћКХБэЪОЕФЃЌЫќПЩвддк
./linux/kernel/fork.c ФкевЕНЁЃПЩвдЭЈЙ§/proc/sys/kernel/threads-max
ЕФ proc ЮФМўЯЕЭГДггУЛЇПеМфИќИФДЫжЕЁЃ
Linux ФкЫљгаНјГЬЕФЗжХфгаСНжжЗНЪНЁЃЕквЛжжЗНЪНЪЧЭЈЙ§вЛИіЙўЯЃБэЃЌгЩPID жЕНјааЙўЯЃМЦЫуЕУЕНЃЛЕкЖўжжЗНЪНЪЧЭЈЙ§ЫЋСДбЛЗБэЁЃбЛЗБэЗЧГЃЪЪКЯгкЖдШЮЮёСаБэНјааЕќДњЁЃгЩгкСаБэЪЧбЛЗЕФЃЌУЛгаЭЗЛђЮВЃЛЕЋЪЧгЩгк
init_task змЪЧДцдкЃЌЫљвдПЩвдНЋЦфгУзїМЬајЯђЧАЕќДњЕФвЛИіУЊЕуЁЃШУЮвУЧРДПДвЛИіБщРњЕБЧАШЮЮёМЏЕФР§згЁЃШЮЮёСаБэЮоЗЈДггУЛЇПеМфЗУЮЪЃЌЕЋИУЮЪЬтКмШнвзНтОіЃЌЗНЗЈЪЧвдФЃПщаЮЪНЯђФкКЫФкВхШыДњТыЁЃЯТУцИјГівЛИіКмМђЕЅЕФГЬађЃЌЫќЛсЕќДњШЮЮёСаБэВЂЛсЬсЙЉгаЙиУПИіШЮЮёЕФЩйСПаХЯЂЃЈnameЁЂpidКЭ
parent УћЃЉЁЃзЂвтЃЌдкетРяЃЌДЫФЃПщЪЙгУ printk РДЗЂГіНсЙћЁЃвЊВщПДОпЬхЕФНсЙћЃЌПЩвдЭЈЙ§
cat ЪЕгУЙЄОпЃЈЛђЪЕЪБЕФ tail -f/var/log/messagesЃЉВщПД /var/log/messages
ЮФМўЁЃnext_taskКЏЪ§ЪЧ sched.h ФкЕФвЛИіКъЃЌЫќМђЛЏСЫШЮЮёСаБэЕФЕќДњЃЈЗЕЛиЯТвЛИіШЮЮёЕФ
task_struct в§гУЃЉЁЃШчЯТЃК
#define next_task(p)
\
list_entry_rcu((p)->tasks.next, struct task_struct,
tasks) |
ВщбЏШЮЮёСаБэаХЯЂЕФМђЕЅФкКЫФЃПщЃК
<pre name=ЁАcodeЁБ
class=ЁАcppЁБ>#include <linux/kernel.h>
#include <linux/module.h>
#include <linux/sched.h>
int init_module(void)
{
/* Set up the anchor point */
struct task_struct *task=&init_task;
/* Walk through the task list, until we hit the
init_task again */
do {
printk(KERN_INFO ЁБ=== %s [%d] parent %s\nЁБ,
task->comm,task->pid,task->parent->comm);
} while((task=next_task(task))!=&init_task);
printk(KERN_INFO ЁБCurrent task is %s [%d]\nЁБ,
current->comm,current->pid);
return 0;
}
void cleanup_module(void)
{
return;
} |
БрвыДЫФЃПщЕФMakefileЮФМўШчЯТЃК
obj-m += procsview.o
KDIR := /lib/modules/(shell uname -r)
/build </span></li><li><span>PWD
:= (shell uname -r)/build &
nbsp;</span></li><li><span>
PWD := (shell
pwd)
default:
(MAKE) -C (MAKE) -C (KDIR)
SUBDIRS=$(PWD) modules |
дкБрвыКѓЃЌПЩвдгУinsmod procsview.ko ВхШыФЃПщЖдЯѓЃЌвВПЩвдгУ rmmod procsview
ЩОГ§ЫќЁЃВхШыКѓЃЌ/var/log/messagesПЩЯдЪОЪфГіЃЌШчЯТЫљЪОЁЃДгжаПЩвдПДЕНЃЌетРягавЛИіПеЯаШЮЮёЃЈГЦЮЊ
swapperЃЉКЭinit ШЮЮёЃЈpid 1ЃЉЁЃ
Dec 28 23:18:16 ubuntu kernel: [12128.910863]=== swapper
[0] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910934]=== init
[1] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910945]=== kthreadd
[2] parent swapper
Dec 28 23:18:16 ubuntu kernel: [12128.910953]=== migration/0
[3] parent kthreadd
ЁЁ
Dec 28 23:24:12 ubuntu kernel: [12485.295015]Current
task is insmod [6051]
Linux ЮЌЛЄвЛИіГЦЮЊcurrentЕФКъЃЌБъЪЖЕБЧАе§дкдЫааЕФНјГЬЃЈРраЭЪЧ task_structЃЉЁЃФЃПщЮВВПЕФФЧааprinkгУгкЪфГіЕБЧАНјГЬЕФдЫааУќСюМАНјГЬКХЁЃзЂвтЕНЕБЧАЕФШЮЮёЪЧ
insmodЃЌетЪЧвђЮЊ init_module КЏЪ§ЪЧдкinsmod УќСюжДааЕФЩЯЯТЮФдЫааЕФЁЃcurrent
ЗћКХЪЕМЪжИЕФЪЧвЛИіКЏЪ§ЃЈget_currentЃЉЃЌПЩдквЛИігы arch гаЙиЕФЭЗВПжаевЕНЫќЁЃБШШч ./linux/arch/x86/include/asm/current.hЃЌШчЯТЃК
#include <linux/compiler.h>
#include <asm/percpu.h>
#ifndef __ASSEMBLY__
struct task_struct;
DECLARE_PER_CPU(struct task_struct *, current_task);
static __always_inline struct task_struct *get_current(void)
{
return percpu_read_stable(current_task);
}
#define current get_current()
#endif /* __ASSEMBLY__ */
#endif /* _ASM_X86_CURRENT_H */ |
3. НјГЬДДНЈ
гУЛЇПеМфФкПЩвдЭЈЙ§жДаавЛИіГЬађЁЂЛђепдкГЬађФкЕїгУforkЃЈЛђexecЃЉЯЕЭГЕїгУРДДДНЈНјГЬЃЌforkЕїгУЛсЕМжТДДНЈвЛИізгНјГЬЃЌЖјexecЕїгУдђЛсгУаТГЬађДњЬцЕБЧАНјГЬЩЯЯТЮФЁЃвЛИіаТНјГЬЕФЕЎЩњЛЙПЩвдЗжБ№ЭЈЙ§vfork()КЭclone()ЁЃforkЁЂvforkКЭcloneШ§ИігУЛЇЬЌКЏЪ§ОљгЩlibcПтЬсЙЉЃЌЫќУЧЗжБ№ЛсЕїгУLinuxФкКЫЬсЙЉЕФЭЌУћЯЕЭГЕїгУfork,vforkКЭcloneЁЃЯТУцвдforkЯЕЭГЕїгУЮЊР§РДНщЩмЁЃ
ДЋЭГЕФДДНЈвЛИіаТНјГЬЕФЗНЪНЪЧзгНјГЬПНБДИИНјГЬЫљгазЪдДЃЌетЮовЩЪЙЕУНјГЬЕФДДНЈаЇТЪЕЭЃЌвђЮЊзгНјГЬашвЊПНБДИИНјГЬЕФећИіЕижЗПеМфЁЃИќдуИтЕФЪЧЃЌШчЙћзгНјГЬДДНЈКѓгжСЂТэШЅжДааexecзхКЏЪ§ЃЌФЧУДИеИеВХДгИИНјГЬФЧРяПНБДЕФЕижЗПеМфгжвЊБЛЧхГ§вдБузАШыаТЕФНјГЬгГЯёЁЃЮЊСЫНтОіетИіЮЪЬтЃЌФкКЫжаЬсЙЉСЫЩЯЪіШ§жжВЛЭЌЕФЯЕЭГЕїгУЁЃ
ЃЈ1ЃЉФкКЫВЩгУаДЪБИДжЦММЪѕЖдДЋЭГЕФforkКЏЪ§НјааСЫЯТУцЕФгХЛЏЁЃМДзгНјГЬДДНЈКѓЃЌИИзгвджЛЖСЕФЗНЪНЙВЯэИИНјГЬЕФзЪдДЃЈВЂВЛАќРЈИИНјГЬЕФвГБэЯюЃЉЁЃЕБзгНјГЬашвЊаоИФНјГЬЕижЗПеМфЕФФГвЛвГЪБЃЌВХЮЊзгНјГЬИДжЦИУвГЁЃВЩгУетбљЕФММЪѕПЩвдБмУтЖдИИНјГЬжаФГаЉЪ§ОнВЛБивЊЕФИДжЦЁЃ
ЃЈ2ЃЉЪЙгУvforkКЏЪ§ДДНЈЕФзгНјГЬЛсЭъШЋЙВЯэИИНјГЬЕФЕижЗПеМфЃЌЩѕжСЪЧИИНјГЬЕФвГБэЯюЁЃИИзгНјГЬШЮвтвЛЗНЖдШЮКЮЪ§ОнЕФаоИФЪЙЕУСэвЛЗНЖМПЩвдИажЊЕНЁЃЮЊСЫЪЙЕУЫЋЗНВЛЪметжжгАЯьЃЌvforkКЏЪ§ДДНЈСЫзгНјГЬКѓЃЌИИНјГЬБуБЛзшШћжБжСзгНјГЬЕїгУСЫexec()Лђexit()ЁЃгЩгкЯждкforkКЏЪ§в§ШыСЫаДЪБИДжЦММЪѕЃЌдкВЛПМТЧИДжЦИИНјГЬвГБэЯюЕФЧщПіЯТЃЌvforkКЏЪ§МИКѕВЛЛсБЛЪЙгУЁЃ
ЃЈ3ЃЉcloneКЏЪ§ДДНЈзгНјГЬЪБСщЛюЖШБШНЯДѓЃЌвђЮЊЫќПЩвдЭЈЙ§ДЋЕнВЛЭЌЕФcloneБъжОВЮЪ§РДбЁдёадЕФИДжЦИИНјГЬЕФзЪдДЁЃ
ДѓВПЗжЯЕЭГЕїгУЖдгІЕФР§ГЬЖМБЛУќУћЮЊ sys_* ВЂЬсЙЉФГаЉГѕЪМЙІФмвдЪЕЯжЕїгУЃЈР§ШчДэЮѓМьВщЛђгУЛЇПеМфЕФааЮЊЃЉЃЌЪЕМЪЕФЙЄзїГЃГЃЛсЮЏХЩИјСэЭтвЛИіУћЮЊ
do_* ЕФКЏЪ§ЁЃ
дк./linux/include/asm-generic/unistd.hжаМЧТМСЫЫљгаЕФЯЕЭГЕїгУКХМАУћГЦЁЃзЂвтforkЪЕЯжгыЬхЯЕНсЙЙЯрЙиЃЌЖд32ЮЛЕФx86ЯЕЭГЛсЪЙгУ./linux/arch/x86/include/asm/unistd_32.hжаЕФЖЈвхЃЌforkЯЕЭГЕїгУБрКХЮЊ2ЁЃforkЯЕЭГЕїгУдкunistd.hжаЕФКъЙиСЊШчЯТЃК
#define __NR_fork
1079
#ifdef CONFIG_MMU
__SYSCALL(__NR_fork, sys_fork)
#else
__SYSCALL(__NR_fork, sys_ni_syscall)
#endif |
дкunistd_32.hжаЕФЕїгУКХЙиСЊЮЊЃК #define __NR_fork 2
дкКмЖрЧщПіЯТЃЌгУЛЇПеМфШЮЮёКЭФкКЫШЮЮёЕФЕзВуЛњжЦЪЧвЛжТЕФЁЃЯЕЭГЕїгУforkЁЂvforkКЭcloneдкФкКЫжаЖдгІЕФЗўЮёР§ГЬЗжБ№ЮЊsys_fork()ЃЌsys_vfork()КЭsys_clone()ЁЃЫќУЧзюжеЖМЛсвРРЕгквЛИіУћЮЊdo_fork
ЕФКЏЪ§РДДДНЈаТНјГЬЁЃР§ШчдкДДНЈФкКЫЯпГЬЪБЃЌФкКЫЛсЕїгУвЛИіУћЮЊ kernel_thread ЕФКЏЪ§ЃЈЖд32ЮЛЯЕЭГ
ВЮМћ./linux/arch/x86/kernel/process_32.cЃЌзЂвтprocess.cЪЧАќКЌ32/64bitЖМЪЪгУЕФДњТыЃЌprocess_32.c
ЪЧЬиЖЈгк32ЮЛМмЙЙЃЌprocess_64.cЪЧЬиЖЈгк64ЮЛМмЙЙЃЉЃЌДЫКЏЪ§жДааФГаЉГѕЪМЛЏКѓЛсЕїгУ do_forkЁЃДД
НЈгУЛЇПеМфНјГЬЕФЧщПігыДЫРрЫЦЁЃдкгУЛЇПеМфЃЌвЛИіГЬађЛсЕїгУforkЃЌЭЈЙ§int $0x80жЎРрЕФШэжаЖЯЛсЕМжТ
ЖдУћЮЊsys_forkЕФФкКЫКЏЪ§ЕФЯЕЭГЕїгУЃЈВЮМћ ./linux/arch/x86/kernel/process_32.cЃЉЃЌШчЯТЃК
int sys_fork(struct
pt_regs *regs)
{
return do_fork(SIGCHLD, regs->sp, regs, 0,
NULL, NULL);
} |
зюжеЖМЪЧжБНгЕїгУdo_forkЁЃНјГЬДДНЈЕФКЏЪ§ВуДЮНсЙЙШчЯТЭМЃК 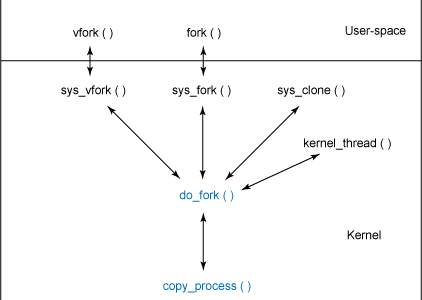
ЭМ1 НјГЬДДНЈЕФКЏЪ§ВуДЮНсЙЙ
ДгЭМжаПЩвдПДЕН do_fork ЪЧНјГЬДДНЈЕФЛљДЁЁЃПЩвддк ./linux/kernel/fork.c
ФкевЕН do_fork КЏЪ§ЃЈвдМАКЯзїКЏЪ§ copy_processЃЉЁЃ
ЕБгУЛЇЬЌЕФНјГЬЕїгУвЛИіЯЕЭГЕїгУЪБЃЌCPUЧаЛЛЕНФкКЫЬЌВЂПЊЪМжДаавЛИіФкКЫКЏЪ§ЁЃдкX86ЬхЯЕжаЃЌПЩвдЭЈЙ§СНжжВЛЭЌЕФЗНЪННјШыЯЕЭГЕїгУЃКжДааint
0ЁС80ЛуБрУќСюКЭжДааsysenterЛуБрУќСюЁЃКѓепЪЧIntelдкPentiumIIжав§ШыЕФжИСюЃЌФкКЫДг2.6АцБОПЊЪМжЇГжетЬѕУќСюЁЃетРяНЋМЏжаЬжТлвдint0ЁС80ЛуБрУќСюКЭжДааsysenterЛуБрУќСюЁЃКѓепЪЧIntelдкPentiumIIжав§ШыЕФжИСюЃЌФкКЫДг2.6АцБОПЊЪМжЇГжетЬѕУќСюЁЃетРяНЋМЏжаЬжТлвдint0ЁС80ЗНЪННјШыЯЕЭГЕїгУЕФЙ§ГЬЁЃ
ЭЈЙ§int 0ЁС80ЗНЪНЕїгУЯЕЭГЕїгУЪЕМЪЩЯЪЧгУЛЇНјГЬВњЩњвЛИіжаЖЯЯђСПКХЮЊ0ЁС80ЕФШэжаЖЯЁЃЕБгУЛЇЬЌfork()ЕїгУЗЂЩњЪБЃЌгУЛЇЬЌНјГЬЛсБЃДцЕїгУКХвдМАВЮЪ§ЃЌШЛКѓЗЂГіint0ЁС80ЗНЪНЕїгУЯЕЭГЕїгУЪЕМЪЩЯЪЧгУЛЇНјГЬВњЩњвЛИіжаЖЯЯђСПКХЮЊ0ЁС80ЕФШэжаЖЯЁЃЕБгУЛЇЬЌfork()ЕїгУЗЂЩњЪБЃЌгУЛЇЬЌНјГЬЛсБЃДцЕїгУКХвдМАВЮЪ§ЃЌШЛКѓЗЂГіint0ЁС80жИСюЃЌЯнШы0x80жаЖЯЁЃCPUНЋДггУЛЇЬЌЧаЛЛЕНФкКЫЬЌВЂПЊЪМжДааsystem_call()ЁЃетИіКЏЪ§ЪЧЭЈЙ§ЛуБрУќСюРДЪЕЯжЕФЃЌЫќЪЧ0ЁС80КХШэжаЖЯЖдгІЕФжаЖЯДІРэГЬађЁЃЖдгкЫљгаЯЕЭГЕїгУРДЫЕЃЌЫќУЧЖМБиаыЯШНјШыsystem_call()ЃЌвВОЭЪЧЫљЮНЕФЯЕЭГЕїгУДІРэГЬађЁЃдйЭЈЙ§ЯЕЭГЕїгУКХЬјзЊЕНОпЬхЕФЯЕЭГЕїгУЗўЮёР§ГЬДІЁЃ32ЮЛx86ЯЕЭГЕФЯЕЭГЕїгУДІРэГЬађдк./linux/arch/x86/kernel/entry_32.SжаЃЌДњТыШчЯТЃК
.macro SAVE_ALL
cld
PUSH_GS
pushl %fs
CFI_ADJUST_CFA_OFFSET 4
/*CFI_REL_OFFSET fs, 0;*/
pushl %es
CFI_ADJUST_CFA_OFFSET 4
/*CFI_REL_OFFSET es, 0;*/
pushl %ds
CFI_ADJUST_CFA_OFFSET 4
/*CFI_REL_OFFSET ds, 0;*/
pushl %eax
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET eax, 0
pushl %ebp
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET ebp, 0
pushl %edi
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET edi, 0
pushl %esi
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET esi, 0
pushl %edx
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET edx, 0
pushl %ecx
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET ecx, 0
pushl %ebx
CFI_ADJUST_CFA_OFFSET 4
CFI_REL_OFFSET ebx, 0
movl (__USER_DS), %edx </span></li>
<li
class="alt"><span> movl
%edx, %ds </span></li><li><span> &
nbsp; movl %edx, %es
</span></li><li
class="alt"><span>
movl (__USER_DS), %edx
</span></li><li
class="alt"><span>
movl %edx, %ds </span>
</li><li><span> movl
%edx, %es </span></li><li
class="alt"><
span> movl (__KERNEL_PERCPU),
%edx
movl %edx, %fs
SET_KERNEL_GS %edx
.endm
/* Ё */
ENTRY(system_call)
RING0_INT_FRAME # ЮоТлШчКЮВЛФмНјШыгУЛЇПеМф
pushl %eax # НЋБЃДцЕФЯЕЭГЕїгУБрКХбЙШыеЛжа
CFI_ADJUST_CFA_OFFSET 4
SAVE_ALL
GET_THREAD_INFO(%ebp)
# МьВтНјГЬЪЧЗёБЛИњзй
testl TIFWORKSYSCALLENTRY,TIflags(TIFWORKSYSCALLENTRY,
TIflags((nr_syscalls),
%eax
jae syscall_badsys
syscall_call:
call *sys_call_table(,%eax,4) # ЬјШыЖдгІЗўЮёР§ГЬ
movl %eax,PT_EAX(%esp) # БЃДцНјГЬЕФЗЕЛижЕ
syscall_exit:
LOCKDEP_SYS_EXIT
DISABLE_INTERRUPTS(CLBR_ANY) # ВЛвЊЭќСЫдкжаЖЯЗЕЛиЧАЙиБежаЖЯ
TRACE_IRQS_OFF
movl TI_flags(%ebp), %ecx
testl _TIF_ALLWORK_MASK, %ecx #
current->work </span></li><li><span>
jne syscall_exit_work
</span></li><li
class="alt"><span>
</span></li><li><span>restore_all:
</span></li><li
class="alt"><span>
TRACE_IRQS_IRET </span></li><li>
<span>restore_all_notrace: </span></li>
<li
class="alt"><span>
movl PT_EFLAGS(%esp), %eax
# mix EFLAGS, SS and
CS </span></li><li><span><span
class="preprocessor">  
;# Warning: PT_OLDSS(%esp)
contains the wrong/random values
if we</span><span>
</span></span></li><li
class="alt"><span>
<span
class="preprocessor">
# are returning to
the kernel.</span><span>
</span></span></li><li><span><span
class="preprocessor">
# See comments in
process.c:copy_thread() for details
.</span><span> </span></span></li>
<li
class="alt"><span>
movb PT_OLDSS(%esp), %ah
</span></li><li><span>
movb PT_CS(%esp), %al
</span></li><li
class="alt"><span>
andl _TIF_ALLWORK_MASK,
%ecx # current->work
</span></li><li><span>
jne syscall_exit_work
</span></li><li
class="alt"><span>
</span></li><li><span>restore_all:
</span></li><li
class="alt"><span>
TRACE_IRQS_IRET </span>
</li><li><span>restore_all_notrace:
</span></li><li
class="alt"><span>
movl PT_EFLAGS(%esp),
%eax # mix
EFLAGS, SS and CS
</span></li><li><span><span
class="preprocessor">
# Warning:
PT_OLDSS(%esp) contains
the wrong/random values
if we</span><span> </span>
</span></li><li
class="alt"><span><span
class="preprocessor">
# are returning to
the kernel.</span><span>
</span></span></li><li>
<span><span
class="preprocessor">
# See comments
in process.c:copy_thread() for
details.</span><span>
</span></span></li><li
class="alt"><span>
movb PT_OLDSS(%esp),
%ah </span></li><li>
<span>
movb PT_CS(%esp), %al
</span></li><li
class="alt"><span>
andl
(X86_EFLAGS_VM
| (SEGMENT_TI_MASK << 8)
| SEGMENT_RPL_MASK),
%eax
cmpl $((SEGMENT_LDT << 8) | USER_RPL), %eax
CFI_REMEMBER_STATE
je ldt_ss # returning to user-space with LDT SS
restore_nocheck:
RESTORE_REGS 4 # skip orig_eax/error_code
CFI_ADJUST_CFA_OFFSET -4
irq_return:
INTERRUPT_RETURN
.section .fixup,ЁБaxЁБ |
ЗжЮіЃК
ЃЈ1ЃЉдкsystem_callКЏЪ§жДаажЎЧАЃЌCPUПижЦЕЅдЊвбОНЋeflagsЁЂcsЁЂeipЁЂssКЭespМФДцЦїЕФжЕздЖЏБЃДцЕНИУНјГЬЖдгІЕФФкКЫеЛжаЁЃЫцжЎЃЌдк
system_callФкВПЪзЯШНЋДцДЂдкeaxМФДцЦїжаЕФЯЕЭГЕїгУКХбЙШыеЛжаЁЃНгзХжДааSAVE_ALLКъЁЃИУКъдкеЛжаБЃДцНгЯТРДЕФЯЕЭГЕїгУПЩФмвЊгУЕНЕФЫљгаCPUМФДцЦїЁЃ
ЃЈ2ЃЉЭЈЙ§GET_THREAD_INFOКъЛёЕУЕБЧАНјГЬЕФthread_inofНсЙЙЕФЕижЗЃЛдйМьВтЕБЧАНјГЬЪЧЗёБЛЦфЫћНјГЬЫљИњзй(Р§ШчЕїЪдвЛИіГЬађЪБЃЌБЛЕїЪдЕФГЬађОЭДІгкБЛИњзйзДЬЌ)ЃЌвВОЭЪЧthread_infoНсЙЙжаflagзжЖЮЕФ_TIF_ALLWORK_MASKБЛжУ1ЁЃШчЙћЗЂЩњБЛИњзйЕФЧщПідђзЊЯђsyscall_trace_entryБъМЧЕФДІРэУќСюДІЁЃ
ЃЈ3ЃЉЖдгУЛЇЬЌНјГЬДЋЕнЙ§РДЕФЯЕЭГЕїгУКХЕФКЯЗЈадНјааМьВщЁЃШчЙћВЛКЯЗЈдђЬјШыЕНsyscall_badsysБъМЧЕФУќСюДІЁЃ
ЃЈ4ЃЉШчЙћЯЕЭГЕїгУКУКЯЗЈЃЌдђИљОнЯЕЭГЕїгУКХВщев./linux/arch/x86/kernel/syscall_table_32.SжаЕФЯЕЭГЕїгУБэsys_call_tableЃЌевЕНЯргІЕФКЏЪ§ШыПкЕуЃЌЬјШыsys_forkетИіЗўЮёР§ГЬЕБжаЁЃгЩгк
sys_call_tableБэЕФБэЯюеМ4зжНкЃЌвђДЫЛёЕУЗўЮёР§ГЬжИеыЕФОпЬхЗНЗЈЪЧНЋгЩeaxБЃДцЕФЯЕЭГЕїгУКХГЫвд4дйгыsys_call_tableБэЕФЛљжЗЯрМгЁЃsyscall_table_32.SжаЕФДњТыШчЯТЃК
ENTRY(sys_call_table)
.long sys_restart_syscall /* 0 - old ЁАsetup()ЁБ
system call, used for restarting */
.long sys_exit
.long ptregs_fork
.long sys_read
.long sys_write
.long sys_open /* 5 */
.long sys_close
/* Ё */ |
sys_call_tableЪЧЯЕЭГЕїгУЖрТЗЗжНтБэЃЌЪЙгУ eax жаЬсЙЉЕФЫїв§РДШЗЖЈвЊЕїгУИУБэжаЕФФФИіЯЕЭГЕїгУЁЃ
ЃЈ5ЃЉЕБЯЕЭГЕїгУЗўЮёР§ГЬНсЪјЪБЃЌДгeaxМФДцЦїжаЛёЕУЕБЧАНјГЬЕФЕФЗЕЛижЕЃЌВЂАбетИіЗЕЛижЕДцЗХдкдјБЃДцгУЛЇЬЌeaxМФДцЦїжЕЕФФЧИіеЛЕЅдЊЕФЮЛжУЩЯЁЃетбљЃЌгУЛЇЬЌНјГЬОЭПЩвддкeaxМФДцЦїжаевЕНЯЕЭГЕїгУЕФЗЕЛиТыЁЃ
ОЙ§ЕФЕїгУСДЮЊfork()ЁЊ>int$0ЁС80ШэжаЖЯЁЊ>ENTRY(system_call)ЁЊ>ENTRY(sys_call_table)ЁЊ>sys_fork()ЁЊ>do_fork()ЁЃЪЕМЪЩЯforkЁЂvforkКЭcloneШ§ИіЯЕЭГЕїзюжеЖМЪЧЕїгУdo_fork()ЁЃжЛВЛЙ§дкЕїгУЪБЫљДЋЕнЕФВЮЪ§гаЫљВЛЭЌЃЌЖјВЮЪ§ЕФВЛЭЌе§КУЕМжТСЫзгНјГЬгыИИНјГЬжЎМфЖдзЪдДЕФЙВЯэГЬЖШВЛЭЌЁЃвђДЫЃЌЗжЮіdo_fork()ГЩЮЊЮвУЧЕФЪзвЊШЮЮёЁЃдкНјШыdo_forkКЏЪ§НјааЗжЮіжЎЧАЃЌКмгаБивЊСЫНтвЛЯТЫќЕФВЮЪ§ЁЃ
clone_flagsЃКИУБъжОЮЛЕФ4ИізжНкЗжЮЊСНВПЗжЁЃзюЕЭЕФвЛИізжНкЮЊзгНјГЬНсЪјЪБЗЂЫЭИјИИНјГЬЕФаХКХДњТыЃЌЭЈГЃЮЊSIGCHLDЃЛЪЃгрЕФШ§ИізжНкдђЪЧИїжжcloneБъжОЕФзщКЯЃЈБОЮФЫљЩцМАЕФБъжОКЌвхЯъМћЯТБэЃЉЃЌвВОЭЪЧШєИЩИіБъжОжЎМфЕФЛђдЫЫуЁЃЭЈЙ§
cloneБъжОПЩвдгабЁдёЕФЖдИИНјГЬЕФзЪдДНјааИДжЦЁЃБОЮФЫљЩцМАЕНЕФcloneБъжОЯъМћЯТБэЁЃ
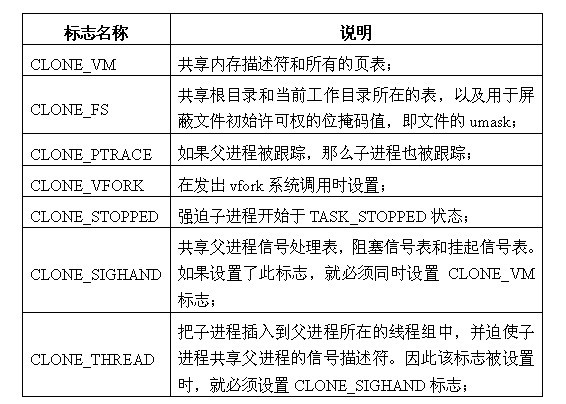
Бэ1 cloneБъжОКЌвх
stack_startЃКзгНјГЬгУЛЇЬЌЖбеЛЕФЕижЗЁЃ
regsЃКжИЯђpt_regsНсЙЙЬхЕФжИеыЁЃЕБЯЕЭГЗЂЩњЯЕЭГЕїгУЃЌМДгУЛЇНјГЬДггУЛЇЬЌЧаЛЛЕНФкКЫЬЌЪБЃЌИУНсЙЙЬхБЃДцЭЈгУМФДцЦїжаЕФжЕЃЌВЂБЛДцЗХгкФкКЫЬЌЕФЖбеЛжаЁЃ
stack_sizeЃКЮДБЛЪЙгУЃЌЭЈГЃБЛИГжЕЮЊ0ЁЃ
parent_tidptrЃКИИНјГЬдкгУЛЇЬЌЯТpidЕФЕижЗЃЌИУВЮЪ§дкCLONE_PARENT_SETTIDБъжОБЛЩшЖЈЪБгавтвхЁЃ
child_tidptrЃКзгНјГЬдкгУЛЇЬЌЯТpidЕФЕижЗЃЌИУВЮЪ§дкCLONE_CHILD_SETTIDБъжОБЛЩшЖЈЪБгавтвхЁЃ
do_forkКЏЪ§дк./linux/kernel/fork.cжаЃЌжївЊЙЄзїОЭЪЧИДжЦдРДЕФНјГЬГЩЮЊСэвЛИіаТЕФНјГЬЃЌЫќЭъГЩСЫећИіНјГЬДДНЈжаЕФДѓВПЗжЙЄзїЁЃДњТыШчЯТЃК
long do_fork(unsigned
long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr)
{
struct task_struct *p;
int trace = 0;
long nr;
/*
* зівЛаЉдЄЯШЕФВЮЪ§КЭШЈЯоМьВщ
*/
if (clone_flags & CLONE_NEWUSER) {
if (clone_flags & CLONE_THREAD)
return -EINVAL;
/* ЯЃЭћЕБгУЛЇУћГЦБЛжЇГжЪБЃЌетРяЕФМьВщПЩШЅЕє
*/
if (!capable(CAP_SYS_ADMIN) || !capable(CAP_SETUID)
||
!capable(CAP_SETGID))
return -EPERM;
}
/*
* ЯЃЭћдк2.6.26жЎКѓетаЉБъжОФмЪЕЯжбЛЗ
*/
if (unlikely(clone_flags & CLONE_STOPPED))
{
static int __read_mostly count = 100;
if (count > 0 && printk_ratelimit())
{
char comm[TASK_COMM_LEN];
countЈC;
printk(KERN_INFO ЁБfork(): process `%sЁЏ used deprecated
ЁБ
ЁБclone flags 0x%lx\nЁБ,
get_task_comm(comm, current),
clone_flags & CLONE_STOPPED);
}
}
/*
* ЕБДгkernel_threadЕїгУБОdo_forkЪБЃЌВЛЪЙгУИњзй
*/
if (likely(user_mode(regs))) /* ШчЙћДггУЛЇЬЌНјШыБОЕїгУЃЌдђЪЙгУИњзй
*/
trace = tracehook_prepare_clone(clone_flags);
p = copy_process(clone_flags, stack_start, regs,
stack_size,
child_tidptr, NULL, trace);
/*
* дкЛНабаТЯпГЬжЎЧАзіЯТУцЕФЙЄзїЃЌвђЮЊаТЯпГЬЛНабКѓБОЯпГЬжИеыЛсБфГЩЮоаЇЃЈШчЙћЭЫГіКмПьЕФЛАЃЉ
*/
if (!IS_ERR(p)) {
struct completion vfork;
trace_sched_process_fork(current, p);
nr = task_pid_vnr(p);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
}
audit_finish_fork(p);
tracehook_report_clone(regs, clone_flags, nr,
p);
/*
* ЮвУЧдкДДНЈЪБЩшжУPF_STARTINGЃЌвдЗРжЙИњзйНјГЬЯыЪЙгУетИіБъжОРДЧјЗжвЛИіЭъШЋЛюзХЕФНјГЬ
* КЭвЛИіЛЙУЛгаЛёЕУtrackhook_report_clone()ЕФНјГЬЁЃЯждкЮвУЧЧхГ§ЫќВЂЧвЩшжУзгНјГЬдЫаа
*/
p->flags &= ~PF_STARTING;
if (unlikely(clone_flags & CLONE_STOPPED))
{
/*
* ЮвУЧНЋСЂПЬЦєЖЏвЛИіМДЪБЕФSIGSTOP
*/
sigaddset(&p->pending.signal, SIGSTOP);
set_tsk_thread_flag(p, TIF_SIGPENDING);
__set_task_state(p, TASK_STOPPED);
} else {
wake_up_new_task(p, clone_flags);
}
tracehook_report_clone_complete(trace, regs,
clone_flags, nr, p);
if (clone_flags & CLONE_VFORK) {
freezer_do_not_count();
wait_for_completion(&vfork);
freezer_count();
tracehook_report_vfork_done(p, nr);
}
} else {
nr = PTR_ERR(p);
}
return nr;
} |
ЃЈ1ЃЉдквЛПЊЪМЃЌИУКЏЪ§ЖЈвхСЫвЛИіtask_structРраЭЕФжИеыpЃЌгУРДНгЪеМДНЋЮЊаТНјГЬЃЈзгНјГЬЃЉЫљЗжХфЕФНјГЬУшЪіЗћЁЃtraceБэЪОИњзйзДЬЌЃЌnrБэЪОаТНјГЬЕФpidЁЃНгзХзівЛаЉдЄЯШЕФВЮЪ§КЭШЈЯоМьВщЁЃ
ЃЈ2ЃЉНгЯТРДМьВщclone_flagsЪЧЗёЩшжУСЫCLONE_STOPPEDБъжОЁЃШчЙћЩшжУСЫЃЌдђзіЯргІДІРэЃЌДђгЁЯћЯЂЫЕУїНјГЬвбЙ§ЪБЁЃЭЈГЃетбљЕФЧщПіКмЩйЗЂЩњЃЌвђДЫдкХаЖЯЪБЪЙгУСЫunlikelyаоЪЮЗћЁЃЪЙгУИУаоЪЮЗћЕФХаЖЯгяОфжДааНсЙћгыЦеЭЈХаЖЯгяОфЯрЭЌЃЌжЛВЛЙ§дкжДаааЇТЪЩЯгаЫљВЛЭЌЁЃе§ШчИУЕЅДЪЕФКЌвхЫљБэЪОЕФФЧбљЃЌЕБЧАНјГЬКмЩйЮЊЭЃжЙзДЬЌЁЃвђДЫЃЌБрвыЦїОЁСПВЛЛсАбifФкЕФгяОфгыЕБЧАгяОфжЎЧАЕФДњТыБрвыдквЛЦ№ЃЌвддіМгcacheЕФУќжаТЪЁЃгыДЫЯрЗДЃЌlikelyаоЪЮЗћдђБэЪОЫљаоЪЮЕФДњТыКмПЩФмЗЂЩњЁЃtracehook_prepare_cloneгУгкЩшжУзгНјГЬЪЧЗёБЛИњзйЁЃЫљЮНИњзйЃЌзюГЃМћЕФР§згОЭЪЧДІгкЕїЪдзДЬЌЯТЕФНјГЬБЛdebuggerНјГЬЫљИњзйЁЃНјГЬЕФptraceзжЖЮЗЧ0ЫЕУїdebuggerГЬађе§дкИњзйЫќЁЃШчЙћЕїгУЪЧДггУЛЇЬЌНјРДЕФЃЈЖјВЛДгkernel_threadНјРДЕФЃЉЃЌЧвЕБЧАНјГЬЃЈИИНјГЬЃЉБЛСэЭтвЛИіНјГЬЫљИњзйЃЌФЧУДзгНјГЬвВвЊЩшжУЮЊБЛИњзйЃЌВЂЧвНЋИњзйБъжОCLONE_PTRACEМгШыБъжОБфСПclone_flagsжаЁЃШчЙћИИНјГЬВЛБЛИњзйЃЌдђзгНјГЬвВВЛЛсБЛИњзйЃЌЩшжУКУКѓЗЕЛиtraceЁЃ
ЃЈ3ЃЉНгЯТРДЕФетЬѕгяОфвЊзіЕФЪЧећИіДДНЈЙ§ГЬжазюКЫаФЕФЙЄзїЃКЭЈЙ§copy_process()ДДНЈзгНјГЬЕФУшЪіЗћЃЌЗжХфpidЃЌВЂДДНЈзгНјГЬжДааЪБЫљашЕФЦфЫћЪ§ОнНсЙЙЃЌзюжедђЛсЗЕЛиетИіДДНЈКУЕФНјГЬУшЪіЗћpЁЃИУКЏЪ§жаЕФВЮЪ§втвхгыdo_forkКЏЪ§ЯрЭЌЁЃзЂвтдРДФкКЫжаЮЊзгНјГЬЗжХфpidЕФЙЄзїЪЧдкdo_forkжаЭъГЩЃЌЯждкаТЕФФкКЫвбОвЦЕНcopy_processжаСЫЁЃ
ЃЈ4ЃЉШчЙћcopy_processКЏЪ§жДааГЩЙІЃЌФЧУДНЋМЬајжДааif(!IS_ERR(p))ВПЗжЁЃЪзЯШЖЈвхСЫвЛИіЭъГЩСПvforkЃЌгУtask_pid_vnr(p)ДгpжаЛёШЁаТНјГЬЕФpidЁЃШчЙћclone_flagsАќКЌCLONE_VFORKБъжОЃЌФЧУДНЋНјГЬУшЪіЗћжаЕФvfork_doneзжЖЮжИЯђетИіЭъГЩСПЃЌжЎКѓдйЖдvforkЭъГЩСПНјааГѕЪМЛЏЁЃЭъГЩСПЕФзїгУЪЧЃЌжБЕНШЮЮёAЗЂГіаХКХЭЈжЊШЮЮёBЗЂЩњСЫФГИіЬиЖЈЪТМўЪБЃЌШЮЮёBВХЛсПЊЪМжДааЃЌЗёдђШЮЮёBвЛжБЕШД§ЁЃЮвУЧжЊЕРЃЌШчЙћЪЙгУvforkЯЕЭГЕїгУРДДДНЈзгНјГЬЃЌФЧУДБиШЛЪЧзгНјГЬЯШжДааЁЃОПЦфдвђОЭЪЧДЫДІvforkЭъГЩСПЫљЦ№ЕНЕФзїгУЁЃЕБзгНјГЬЕїгУexecКЏЪ§ЛђЭЫГіЪБОЭЯђИИНјГЬЗЂГіаХКХЃЌДЫЪБИИНјГЬВХЛсБЛЛНабЃЌЗёдђвЛжБЕШД§ЁЃДЫДІЕФДњТыжЛЪЧЖдЭъГЩСПНјааГѕЪМЛЏЃЌОпЬхЕФзшШћгяОфдђдкКѓУцЕФДњТыжагаЫљЬхЯжЁЃ
ЃЈ5ЃЉШчЙћзгНјГЬБЛИњзйЛђепЩшжУСЫCLONE_STOPPEDБъжОЃЌФЧУДЭЈЙ§sigaddsetКЏЪ§ЮЊзгНјГЬдіМгЙвЦ№аХКХЃЌВЂНЋзгНјГЬЕФзДЬЌЩшжУЮЊTASK_STOPPEDЁЃsignalЖдгІвЛИіunsignedlongРраЭЕФБфСПЃЌИУБфСПЕФУПИіЮЛЗжБ№ЖдгІвЛжжаХКХЁЃОпЬхЕФВйзїЪЧНЋSIGSTOPаХКХЫљЖдгІЕФФЧвЛЮЛжУ1ЁЃШчЙћзгНјГЬВЂЮДЩшжУCLONE_STOPPEDБъжОЃЌФЧУДЭЈЙ§wake_up_new_taskНЋНјГЬЗХЕНдЫааЖгСаЩЯЃЌДгЖјШУЕїЖШЦїНјааЕїЖШдЫааЁЃwake_up_new_task()дк./linux/kernel/sched.cжаЃЌгУгкЛНабЕквЛДЮаТДДНЈЕФНјГЬЃЌЫќНЋЮЊаТНјГЬзівЛаЉГѕЪМЕФБиаыЕФЕїЖШЦїЭГМЦВйзїЃЌШЛКѓАбНјГЬЗХЕНдЫааЖгСажаЁЃвЛЕЉЕБШЛе§дкдЫааЕФНјГЬЪБМфЦЌгУЭъЃЈЭЈЙ§ЪБжгtickжаЖЯРДПижЦЃЉЃЌОЭЛсЕїгУschedule()ЃЌДгЖјНјааНјГЬЕїЖШ(ЯТвЛеТНкЮФеТжаНјааЯъЯИНВНт)ЁЃДњТыШчЯТЃК
void wake_up_new_task(struct
task_struct *p, unsigned long clone_flags)
{
unsigned long flags;
struct rq *rq;
int cpu = get_cpu();
#ifdef CONFIG_SMP
rq = task_rq_lock(p, &flags);
p->state = TASK_WAKING;
/*
* Fork balancing, do it here and not earlier because:
* - cpus_allowed can change in the fork path
* - any previously selected cpu might disappear
through hotplug
*
* We set TASK_WAKING so that select_task_rq()
can drop rq->lock
* without people poking at ->cpus_allowed.
*/
cpu = select_task_rq(rq, p, SD_BALANCE_FORK, 0);
set_task_cpu(p, cpu);
p->state = TASK_RUNNING;
task_rq_unlock(rq, &flags);
#endif
rq = task_rq_lock(p, &flags);
update_rq_clock(rq);
activate_task(rq, p, 0);
trace_sched_wakeup_new(rq, p, 1);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken)
p->sched_class->task_woken(rq, p);
#endif
task_rq_unlock(rq, &flags);
put_cpu();
} |
етРяЯШгУget_cpu()ЛёШЁCPUЃЌШчЙћЪЧЖдГЦЖрДІРэЯЕЭГЃЈSMPЃЉЃЌЯШЩшжУЮвЮЊTASK_WAKINGзДЬЌЃЌгЩгкгаЖрИіCPUЃЈУПИіCPUЩЯЖМгавЛИідЫааЖгСаЃЉЃЌашвЊНјааИКдиОљКтЃЌбЁдёвЛИізюМбCPUВЂЩшжУЮвЪЙгУетИіCPUЃЌШЛКѓЩшжУЮвЮЊTASK_RUNNINGзДЬЌЁЃетЖЮВйзїЪЧЛЅГтЕФЃЌвђДЫашвЊМгЫјЁЃзЂвтTASK_RUNNINGВЂВЛБэЪОНјГЬвЛЖЈе§дкдЫааЃЌЮоТлНјГЬЪЧЗёе§дкеМгУCPUЃЌжЛвЊОпБИдЫааЬѕМўЃЌЖМДІгкИУзДЬЌЁЃ
LinuxАбДІгкИУзДЬЌЕФЫљгаPCBзщжЏГЩвЛИіПЩдЫааЖгСаrun_queueЃЌЕїЖШГЬађДгетИіЖгСажабЁдёНјГЬдЫааЁЃЪТЪЕЩЯЃЌLinuxЪЧНЋОЭаїЬЌКЭдЫааЬЌКЯВЂЮЊСЫвЛжжзДЬЌЁЃ
ШЛКѓгУ./linux/kernel/sched.c:activate_task()АбЕБЧАНјГЬВхШыЕНЖдгІCPUЕФrunqueueЩЯЃЌзюжеЭъГЩШыЖгЕФКЏЪ§ЪЧactive_task()ЁЊ>enqueue_task()ЃЌЦфжаКЫаФДњТыааЮЊЃК
p->sched_class->enqueue_task(rq, p,wakeup, head);
sched_classдк./linux/include/linux/sched.hжаЃЌЪЧЕїЖШЦївЛЯЕСаВйзїЕФУцЯђЖдЯѓГщЯѓЃЌетИіРрАќРЈНјГЬШыЖгЁЂГіЖгЁЂНјГЬдЫааЁЂНјГЬЧаЛЛЕШНгПкЃЌгУгкЭъГЩЖдНјГЬЕФЕїЖШдЫааЁЃ
ЃЈ6ЃЉtracehook_report_clone_completeКЏЪ§гУгкдкНјГЬИДжЦПьвЊЭъГЩЪББЈИцИњзйЧщПіЁЃШчЙћИИНјГЬБЛИњзйЃЌдђНЋзгНјГЬЕФpidИГжЕИјИИНјГЬЕФНјГЬУшЪіЗћЕФpstrace_messageзжЖЮЃЌВЂЯђИИНјГЬЕФИИНјГЬЗЂЫЭSIGCHLDаХКХЁЃ
ЃЈ7ЃЉШчЙћCLONE_VFORKБъжОБЛЩшжУЃЌдђЭЈЙ§waitВйзїНЋИИНјГЬзшШћЃЌжБжСзгНјГЬЕїгУexecКЏЪ§ЛђепЭЫГіЁЃ
ЃЈ8ЃЉШчЙћcopy_process()дкжДааЕФЪБКђЗЂЩњДэЮѓЃЌдђЯШЪЭЗХвбЗжХфЕФpidЃЌдйИљОнPTR_ERR()ЕФЗЕЛижЕЕУЕНДэЮѓДњТыЃЌБЃДцгкnrжаЁЃ
4. copy_process: НјГЬУшЪіЗћЕФДІРэ
copy_processКЏЪ§вВдк./linux/kernel/fork.cжаЁЃЫќЛсгУЕБЧАНјГЬЕФвЛИіИББОРДДДНЈаТНјГЬВЂЗжХфpidЃЌЕЋВЛЛсЪЕМЪЦєЖЏетИіаТНјГЬЁЃЫќЛсИДжЦМФДцЦїжаЕФжЕЁЂЫљгагыНјГЬЛЗОГЯрЙиЕФВПЗжЃЌУПИіcloneБъжОЁЃаТНјГЬЕФЪЕМЪЦєЖЏгЩЕїгУепРДЭъГЩЁЃ
ЖдгкУПвЛИіНјГЬЖјбдЃЌФкКЫЮЊЦфЕЅЖРЗжХфСЫвЛИіФкДцЧјгђЃЌетИіЧјгђДцДЂЕФЪЧФкКЫеЛКЭИУНјГЬЫљЖдгІЕФвЛИіаЁаЭНјГЬУшЪіЗћthread_infoНсЙЙЁЃдк./linux/arch/x86/include/asm/thread_info.hжаЃЌШчЯТЃК
struct thread_info
{
struct task_struct *task; /* жїНјГЬУшЪіЗћ */
struct exec_domain *exec_domain; /* жДаагђ */
__u32 flags; /* ЕЭМЖБ№БъжО */
__u32 status; /* ЯпГЬЭЌВНБъжО */
__u32 cpu; /* ЕБЧАCPU */
int preempt_count; /* 0 => ПЩЧРеМ, <0 =>
BUG */
mm_segment_t addr_limit;
struct restart_block restart_block;
void __user *sysenter_return;
#ifdef CONFIG_X86_32
unsigned long previous_esp; /* ЯШЧАеЛЕФESPЃЌвдЗРЧЖШыЕФЃЈIRQЃЉеЛ
*/
__u8 supervisor_stack[0];
#endif
int uaccess_err;
};
/* Ё */
/* дѕбљДгCЛёШЁЕБЧАеЛжИеы */
register unsigned long current_stack_pointer asm(ЁАespЁБ)
__used;
/* дѕбљДгCЛёШЁЕБЧАЯпГЬаХЯЂНсЙЙ */
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
} |
жЎЫљвдНЋЯпГЬаХЯЂНсЙЙГЦжЎЮЊаЁаЭЕФНјГЬУшЪіЗћЃЌЪЧвђЮЊдкетИіНсЙЙжаВЂУЛгажБНгАќКЌгыНјГЬЯрЙиЕФзжЖЮЃЌЖјЪЧЭЈЙ§taskзжЖЮжИЯђОпЬхФГИіНјГЬУшЪіЗћЁЃЭЈГЃетПщФкДцЧјгђЕФДѓаЁЪЧ8KBЃЌвВОЭЪЧСНИівГЕФДѓаЁЃЈгаЪБКђвВЪЙгУвЛИівГРДДцДЂЃЌМД4KBЃЉЁЃвЛИіНјГЬЕФФкКЫеЛКЭthread_infoНсЙЙжЎМфЕФТпМЙиЯЕШчЯТЭМЫљЪОЃК
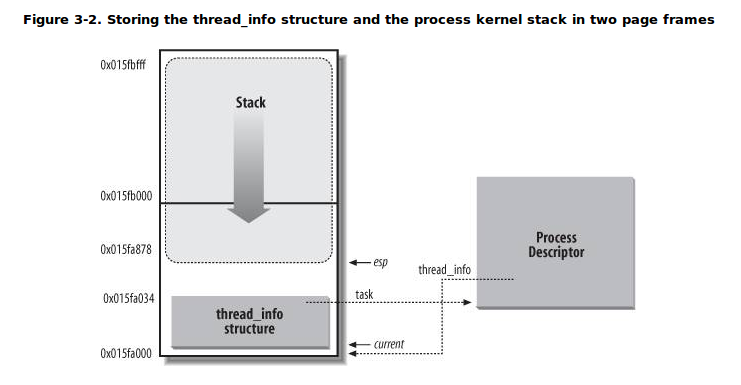
ЭМ НјГЬФкКЫеЛКЭthread_infoНсЙЙЕФДцДЂ
ДгЩЯЭМПЩжЊЃЌФкКЫеЛЪЧДгИУФкДцЧјгђЕФЖЅВуЯђЯТЃЈДгИпЕижЗЕНЕЭЕижЗЃЉдіГЄЕФЃЌЖјthread_infoНсЙЙдђЪЧДгИУЧјгђЕФПЊЪМДІЯђЩЯЃЈДгЕЭЕижЗЕНИпЕижЗЃЉдіГЄЁЃФкКЫеЛЕФеЛЖЅЕижЗДцДЂдкespМФДцЦїжаЁЃЫљвдЃЌЕБНјГЬДггУЛЇЬЌЧаЛЛЕНФкКЫЬЌКѓЃЌespМФДцЦїжИЯђетИіЧјгђЕФФЉЖЫЁЃДгДњТыЕФНЧЖШРДПДЃЌФкКЫеЛКЭthread_infoНсЙЙЪЧБЛЖЈвхдк./linux/include/linux/sched.hжаЕФвЛИіСЊКЯЬхЕБжаЕФЃК
union thread_union
{
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
}; |
ЦфжаЃЌTHREAD_SIZEЕФжЕШЁ8192ЪБЃЌstackЪ§зщЕФДѓаЁЮЊ2048ЃЛTHREAD_SIZEЕФжЕШЁ4096ЪБЃЌstackЪ§зщЕФДѓаЁЮЊ1024ЁЃ
ЯждкЮвУЧгІИУЫМПМЃЌЮЊКЮвЊНЋФкКЫеЛКЭthread_infoЃЈЦфЪЕвВОЭЯрЕБгкtask_structЃЌжЛВЛЙ§ЪЙгУthread_infoНсЙЙИќНкЪЁПеМфЃЉНєУмЕФЗХдквЛЦ№ЃПзюжївЊЕФдвђОЭЪЧФкКЫПЩвдКмШнвзЕФЭЈЙ§espМФДцЦїЕФжЕЛёЕУЕБЧАе§дкдЫааНјГЬЕФthread_infoНсЙЙЕФЕижЗЃЌНјЖјЛёЕУЕБЧАНјГЬУшЪіЗћЕФЕижЗЁЃдкЩЯУцЕФcurrent_thread_infoКЏЪ§жаЃЌЖЈвхcurrent_stack_pointerЕФетЬѕФкСЊЛуБргяОфЛсДгespМФДцЦїжаЛёШЁФкКЫеЛЖЅЕижЗЃЌКЭ~(THREAD_SIZE
- 1)зігыВйзїНЋЦСБЮЕєЕЭ13ЮЛЃЈЛђ12ЮЛЃЌЕБTHREAD_SIZEЮЊ4096ЪБЃЉЃЌДЫЪБЫљжИЕФЕижЗОЭЪЧетЦЌФкДцЧјгђЕФЦ№ЪМЕижЗЃЌвВОЭИеКУЪЧthread_infoНсЙЙЕФЕижЗЁЃЕЋЪЧЃЌthread_infoНсЙЙЕФЕижЗВЂВЛЛсЖдЮвУЧжБНггагУЁЃЮвУЧЭЈГЃПЩвдЧсЫЩЕФЭЈЙ§
currentКъЛёЕУЕБЧАНјГЬЕФtask_structНсЙЙЃЌЧАУцвбОСаГіЙ§get_current()КЏЪ§ЕФДњТыЁЃcurrentКъЗЕЛиЕФЪЧthread_infoНсЙЙtaskзжЖЮЃЌЖјtaskе§КУжИЯђгыthread_infoНсЙЙЙиСЊЕФФЧИіНјГЬУшЪіЗћЁЃЕУЕН
currentКѓЃЌЮвУЧОЭПЩвдЛёЕУЕБЧАе§дкдЫааНјГЬЕФУшЪіЗћжаШЮКЮвЛИізжЖЮСЫЃЌБШШчЮвУЧЭЈГЃЫљзіЕФcurrent->pidЁЃ
ЯТУцПДcopy_processЕФЪЕЯжЁЃ
static struct
task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
struct pt_regs *regs,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
int cgroup_callbacks_done = 0;
if ((clone_flags & (CLONE_NEWNS|CLONE_FS))
== (CLONE_NEWNS|CLONE_FS))
return ERR_PTR(-EINVAL);
/*
* Thread groups must share signals as well, and
detached threads
* can only be started up within the thread group.
*/
if ((clone_flags & CLONE_THREAD) &&
!(clone_flags & CLONE_SIGHAND))
return ERR_PTR(-EINVAL);
/*
* Shared signal handlers imply shared VM. By way
of the above,
* thread groups also imply shared VM. Blocking
this case allows
* for various simplifications in other code.
*/
if ((clone_flags & CLONE_SIGHAND) &&
!(clone_flags & CLONE_VM))
return ERR_PTR(-EINVAL);
/*
* Siblings of global init remain as zombies on
exit since they are
* not reaped by their parent (swapper). To solve
this and to avoid
* multi-rooted process trees, prevent global and
container-inits
* from creating siblings.
*/
if ((clone_flags & CLONE_PARENT) &&
current->signal->flags & SIGNAL_UNKILLABLE)
return ERR_PTR(-EINVAL);
retval = security_task_create(clone_flags);
if (retval)
goto fork_out;
retval = -ENOMEM;
p = dup_task_struct(current);
if (!p)
goto fork_out;
ftrace_graph_init_task(p);
rt_mutex_init_task(p);
#ifdef CONFIG_PROVE_LOCKING
DEBUG_LOCKS_WARN_ON(!p->hardirqs_enabled);
DEBUG_LOCKS_WARN_ON(!p->softirqs_enabled);
#endif
retval = -EAGAIN;
if (atomic_read(&p->real_cred->user->processes)
>=
p->signal->rlim[RLIMIT_NPROC].rlim_cur)
{
if (!capable(CAP_SYS_ADMIN) && !capable(CAP_SYS_RESOURCE)
&&
p->real_cred->user != INIT_USER)
goto bad_fork_free;
}
retval = copy_creds(p, clone_flags);
if (retval < 0)
goto bad_fork_free;
/*
* If multiple threads are within copy_process(),
then this check
* triggers too late. This doesnЁЏt hurt, the check
is only there
* to stop root fork bombs.
*/
retval = -EAGAIN;
if (nr_threads >= max_threads)
goto bad_fork_cleanup_count;
if (!try_module_get(task_thread_info(p)->exec_domain->module))
goto bad_fork_cleanup_count;
p->did_exec = 0;
delayacct_tsk_init(p); /* Must remain after dup_task_struct()
*/
copy_flags(clone_flags, p);
INIT_LIST_HEAD(&p->children);
INIT_LIST_HEAD(&p->sibling);
rcu_copy_process(p);
p->vfork_done = NULL;
spin_lock_init(&p->alloc_lock);
init_sigpending(&p->pending);
p->utime = cputime_zero;
p->stime = cputime_zero;
p->gtime = cputime_zero;
p->utimescaled = cputime_zero;
p->stimescaled = cputime_zero;
p->prev_utime = cputime_zero;
p->prev_stime = cputime_zero;
p->default_timer_slack_ns = current->timer_slack_ns;
task_io_accounting_init(&p->ioac);
acct_clear_integrals(p);
posix_cpu_timers_init(p);
p->lock_depth = -1; /* -1 = no lock */
do_posix_clock_monotonic_gettime(&p->start_time);
p->real_start_time = p->start_time;
monotonic_to_bootbased(&p->real_start_time);
p->io_context = NULL;
p->audit_context = NULL;
cgroup_fork(p);
#ifdef CONFIG_NUMA
p->mempolicy = mpol_dup(p->mempolicy);
if (IS_ERR(p->mempolicy)) {
retval = PTR_ERR(p->mempolicy);
p->mempolicy = NULL;
goto bad_fork_cleanup_cgroup;
}
mpol_fix_fork_child_flag(p);
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
p->irq_events = 0;
#ifdef __ARCH_WANT_INTERRUPTS_ON_CTXSW
p->hardirqs_enabled = 1;
#else
p->hardirqs_enabled = 0;
#endif
p->hardirq_enable_ip = 0;
p->hardirq_enable_event = 0;
p->hardirq_disable_ip = _THIS_IP_;
p->hardirq_disable_event = 0;
p->softirqs_enabled = 1;
p->softirq_enable_ip = _THIS_IP_;
p->softirq_enable_event = 0;
p->softirq_disable_ip = 0;
p->softirq_disable_event = 0;
p->hardirq_context = 0;
p->softirq_context = 0;
#endif
#ifdef CONFIG_LOCKDEP
p->lockdep_depth = 0; /* no locks held yet
*/
p->curr_chain_key = 0;
p->lockdep_recursion = 0;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
p->blocked_on = NULL; /* not blocked yet */
#endif
p->bts = NULL;
/* Perform scheduler related setup. Assign this
task to a CPU. */
sched_fork(p, clone_flags);
retval = perf_event_init_task(p);
if (retval)
goto bad_fork_cleanup_policy;
if ((retval = audit_alloc(p)))
goto bad_fork_cleanup_policy;
/* copy all the process information */
if ((retval = copy_semundo(clone_flags, p)))
goto bad_fork_cleanup_audit;
if ((retval = copy_files(clone_flags, p)))
goto bad_fork_cleanup_semundo;
if ((retval = copy_fs(clone_flags, p)))
goto bad_fork_cleanup_files;
if ((retval = copy_sighand(clone_flags, p)))
goto bad_fork_cleanup_fs;
if ((retval = copy_signal(clone_flags, p)))
goto bad_fork_cleanup_sighand;
if ((retval = copy_mm(clone_flags, p)))
goto bad_fork_cleanup_signal;
if ((retval = copy_namespaces(clone_flags, p)))
goto bad_fork_cleanup_mm;
if ((retval = copy_io(clone_flags, p)))
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start,
stack_size, p, regs);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
if (clone_flags & CLONE_NEWPID) {
retval = pid_ns_prepare_proc(p->nsproxy->pid_ns);
if (retval < 0)
goto bad_fork_free_pid;
}
}
p->pid = pid_nr(pid);
p->tgid = p->pid;
if (clone_flags & CLONE_THREAD)
p->tgid = current->tgid;
if (current->nsproxy != p->nsproxy) {
retval = ns_cgroup_clone(p, pid);
if (retval)
goto bad_fork_free_pid;
}
p->set_child_tid = (clone_flags & CLONE_CHILD_SETTID)
? child_tidptr : NULL;
/*
* Clear TID on mm_release()?
*/
p->clear_child_tid = (clone_flags & CLONE_CHILD_CLEARTID)
? child_tidptr: NULL;
#ifdef CONFIG_FUTEX
p->robust_list = NULL;
#ifdef CONFIG_COMPAT
p->compat_robust_list = NULL;
#endif
INIT_LIST_HEAD(&p->pi_state_list);
p->pi_state_cache = NULL;
#endif
/*
* sigaltstack should be cleared when sharing the
same VM
*/
if ((clone_flags & (CLONE_VM|CLONE_VFORK))
== CLONE_VM)
p->sas_ss_sp = p->sas_ss_size = 0;
/*
* Syscall tracing should be turned off in the
child regardless
* of CLONE_PTRACE.
*/
clear_tsk_thread_flag(p, TIF_SYSCALL_TRACE);
#ifdef TIF_SYSCALL_EMU
clear_tsk_thread_flag(p, TIF_SYSCALL_EMU);
#endif
clear_all_latency_tracing(p);
/* ok, now we should be set up.. */
p->exit_signal = (clone_flags & CLONE_THREAD)
? -1 : (clone_flags & CSIGNAL);
p->pdeath_signal = 0;
p->exit_state = 0;
/*
* Ok, make it visible to the rest of the system.
* We dont wake it up yet.
*/
p->group_leader = p;
INIT_LIST_HEAD(&p->thread_group);
/* Now that the task is set up, run cgroup callbacks
if
* necessary. We need to run them before the task
is visible
* on the tasklist. */
cgroup_fork_callbacks(p);
cgroup_callbacks_done = 1;
/* Need tasklist lock for parent etc handling!
*/
write_lock_irq(&tasklist_lock);
/* CLONE_PARENT re-uses the old parent */
if (clone_flags & (CLONE_PARENT|CLONE_THREAD))
{
p->real_parent = current->real_parent;
p->parent_exec_id = current->parent_exec_id;
} else {
p->real_parent = current;
p->parent_exec_id = current->self_exec_id;
}
spin_lock(Ёшt->sighand->siglock);
/*
* Process group and session signals need to be
delivered to just the
* parent before the fork or both the parent and
the child after the
* fork. Restart if a signal comes in before we
add the new process to
* itЁЏs process group.
* A fatal signal pending means that current will
exit, so the new
* thread canЁЏt slip out of an OOM kill (or normal
SIGKILL).
*/
recalc_sigpending();
if (signal_pending(current)) {
spin_unlock(Ёшt->sighand->siglock);
write_unlock_irq(&tasklist_lock);
retval = -ERESTARTNOINTR;
goto bad_fork_free_pid;
}
if (clone_flags & CLONE_THREAD) {
atomic_inc(Ёшt->signal->count);
atomic_inc(Ёшt->signal->live);
p->group_leader = current->group_leader;
list_add_tail_rcu(&p->thread_group, &p->group_leader->thread_group);
}
if (likely(p->pid)) {
list_add_tail(&p->sibling, &p->real_parent->children);
tracehook_finish_clone(p, clone_flags, trace);
if (thread_group_leader(p)) {
if (clone_flags & CLONE_NEWPID)
p->nsproxy->pid_ns->child_reaper = p;
p->signal->leader_pid = pid;
tty_kref_put(p->signal->tty);
p->signal->tty = tty_kref_get(current->signal->tty);
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__get_cpu_var(process_counts)++;
}
attach_pid(p, PIDTYPE_PID, pid);
nr_threads++;
}
total_forks++;
spin_unlock(Ёшt->sighand->siglock);
write_unlock_irq(&tasklist_lock);
proc_fork_connector(p);
cgroup_post_fork(p);
perf_event_fork(p);
return p;
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
put_io_context(p->io_context);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
__cleanup_signal(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_policy:
perf_event_free_task(p);
#ifdef CONFIG_NUMA
mpol_put(p->mempolicy);
bad_fork_cleanup_cgroup:
#endif
cgroup_exit(p, cgroup_callbacks_done);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
} |
ЃЈ1ЃЉЖЈвхЗЕЛижЕврЪЧretvalКЭаТЕФНјГЬУшЪіЗћtask_structНсЙЙpЁЃ
ЃЈ2ЃЉБъжОКЯЗЈадМьВщЁЃЖдclone_flagsЫљДЋЕнЕФБъжОзщКЯНјааКЯЗЈадМьВщЁЃЕБГіЯжвдЯТШ§жжЧщПіЪБЃЌЗЕЛиГіДэДњКХЃК
1ЃЉCLONE_NEWNSКЭCLONE_FSЭЌЪББЛЩшжУЁЃЧАепБъжОБэЪОзгНјГЬашвЊздМКЕФУќУћПеМфЃЌЖјКѓепБъжОдђДњБэзгНјГЬЙВЯэИИНјГЬЕФИљФПТМКЭЕБЧАЙЄзїФПТМЃЌСНепВЛПЩМцШнЁЃдкДЋЭГЕФUnixЯЕЭГжаЃЌећИіЯЕЭГжЛгавЛИівбОАВзАЕФЮФМўЯЕЭГЪїЁЃУПИіНјГЬДгЯЕЭГЕФИљЮФМўЯЕЭГПЊЪМЃЌЭЈЙ§КЯЗЈЕФТЗОЖПЩвдЗУЮЪШЮКЮЮФМўЁЃдк2.6АцБОжаЕФФкКЫжаЃЌУПИіНјГЬЖМПЩвдгЕгаЪєгкздМКЕФвбАВзАЮФМўЯЕЭГЪїЃЌвВБЛГЦЮЊУќУћПеМфЁЃЭЈГЃДѓЖрЪ§НјГЬЖМЙВЯэinitНјГЬЫљЪЙгУЕФвбАВзАЮФМўЯЕЭГЪїЃЌжЛгадкclone_flagsжаЩшжУСЫCLONE_NEWNSБъжОЪБЃЌВХЛсЮЊДЫаТНјГЬПЊБйвЛИіаТЕФУќУћПеМфЁЃ
2ЃЉCLONE_THREADБЛЩшжУЃЌЕЋCLONE_SIGHANDЮДБЛЩшжУЁЃШчЙћзгНјГЬКЭИИНјГЬЪєгкЭЌвЛИіЯпГЬзщЃЈCLONE_THREADБЛЩшжУЃЉЃЌФЧУДзгНјГЬБиаыЙВЯэИИНјГЬЕФаХКХЃЈCLONE_SIGHANDБЛЩшжУЃЉЁЃ
3ЃЉCLONE_SIGHANDБЛЩшжУЃЌЕЋCLONE_VMЮДБЛЩшжУЁЃШчЙћзгНјГЬЙВЯэИИНјГЬЕФаХКХЃЌФЧУДБиаыЭЌЪБЙВЯэИИНјГЬЕФФкДцУшЪіЗћКЭЫљгаЕФвГБэЃЈCLONE_VMБЛЩшжУЃЉЁЃ
ЃЈ3ЃЉАВШЋадМьВщЁЃЭЈЙ§ЕїгУsecurity_task_create()КЭКѓУцЕФsecurity_task_alloc()жДааЫљгаИНМгЕФАВШЋадМьВщЁЃбЏЮЪ
Linux Security Module (LSM) ПДЕБЧАШЮЮёЪЧЗёПЩвдДДНЈвЛИіаТШЮЮёЁЃLSMЪЧSELinuxЕФКЫаФЁЃ
ЃЈ4ЃЉИДжЦНјГЬУшЪіЗћЁЃЭЈЙ§dup_task_struct()ЮЊзгНјГЬЗжХфвЛИіФкКЫеЛЁЂthread_infoНсЙЙКЭtask_structНсЙЙЁЃзЂвтЃЌетРяНЋЕБЧАНјГЬУшЪіЗћжИеызїЮЊВЮЪ§ДЋЕнЕНДЫКЏЪ§жаЁЃКЏЪ§ДњТыШчЯТЃК
int __attribute__((weak))
arch_dup_task_struct(struct task_struct *dst,
struct task_struct *src)
{
*dst = *src;
return 0;
}
static struct task_struct *dup_task_struct(struct
task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
unsigned long *stackend;
int err;
prepare_to_copy(orig);
tsk = alloc_task_struct();
if (!tsk)
return NULL;
ti = alloc_thread_info(tsk);
if (!ti) {
free_task_struct(tsk);
return NULL;
}
err = arch_dup_task_struct(tsk, orig);
if (err)
goto out;
tsk->stack = ti;
err = prop_local_init_single(&tsk->dirties);
if (err)
goto out;
setup_thread_stack(tsk, orig);
stackend = end_of_stack(tsk);
*stackend = STACK_END_MAGIC; /* гУгквчГіМьВт */
#ifdef CONFIG_CC_STACKPROTECTOR
tsk->stack_canary = get_random_int();
#endif
/* One for us, one for whoever does the ЁАrelease_task()ЁБ
(usually parent) */
atomic_set(&tsk->usage,2);
atomic_set(&tsk->fs_excl, 0);
#ifdef CONFIG_BLK_DEV_IO_TRACE
tsk->btrace_seq = 0;
#endif
tsk->splice_pipe = NULL;
account_kernel_stack(ti, 1);
return tsk;
out:
free_thread_info(ti);
free_task_struct(tsk);
return NULL;
} |
ЪзЯШЃЌИУКЏЪ§ЗжБ№ЖЈвхСЫжИЯђtask_structКЭthread_infoНсЙЙЬхЕФжИеыЁЃНгзХЃЌprepare_to_copyЮЊе§ЪНЕФЗжХфНјГЬУшЪіЗћзівЛаЉзМБИЙЄзїЁЃжївЊЪЧНЋвЛаЉБивЊЕФМФДцЦїЕФжЕБЃДцЕНИИНјГЬЕФthread_infoНсЙЙжаЁЃетаЉжЕЛсдкЩдКѓБЛИДжЦЕНзгНјГЬЕФthread_infoНсЙЙжаЁЃжДааalloc_task_structКъЃЌИУКъИКд№ЮЊзгНјГЬЕФНјГЬУшЪіЗћЗжХфПеМфЃЌНЋИУЦЌФкДцЕФЪзЕижЗИГжЕИјtskЃЌЫцКѓМьВщетЦЌФкДцЪЧЗёЗжХфе§ШЗЁЃжДааalloc_thread_infoКъЃЌЮЊзгНјГЬЛёШЁвЛПщПеЯаЕФФкДцЧјЃЌгУРДДцЗХзгНјГЬЕФФкКЫеЛКЭthread_infoНсЙЙЃЌВЂНЋДЫЛсФкДцЧјЕФЪзЕижЗИГжЕИјtiБфСПЃЌЫцКѓМьВщЪЧЗёЗжХфе§ШЗЁЃ
ЩЯУцвбОЫЕУїЙ§origЪЧДЋНјРДЕФcurrentКъЃЌжИЯђЕБЧАНјГЬУшЪіЗћЕФжИеыЁЃarch_dup_task_structжБНгНЋorigжИЯђЕФЕБЧАНјГЬУшЪіЗћФкШнИДжЦЕНЕБЧАРяГЬУшЪіЗћtskЁЃНгзХЃЌгУatomic_setНЋзгНјГЬУшЪіЗћЕФЪЙгУМЦЪ§ЦїЩшжУЮЊ2ЃЌБэЪОИУНјГЬУшЪіЗће§дкБЛЪЙгУВЂЧвДІгкЛюЖЏзДЬЌЁЃзюКѓЗЕЛижИЯђИеИеДДНЈЕФзгНјГЬУшЪіЗћФкДцЧјЕФжИеыЁЃ
ЭЈЙ§dup_task_structПЩвдПДЕНЃЌЕБетИіКЏЪ§ГЩЙІВйзїжЎКѓЃЌзгНјГЬКЭИИНјГЬЕФУшЪіЗћжаЕФФкШнЪЧЭъШЋЯрЭЌЕФЁЃдкЩдКѓЕФcopy_processДњТыжаЃЌЮвУЧНЋЛсПДЕНзгНјГЬж№ВНгыИИНјГЬЧјЗжПЊРДЁЃ
ЃЈ5ЃЉвЛаЉГѕЪМЛЏЁЃЭЈЙ§жюШчftrace_graph_init_taskЃЌrt_mutex_init_taskЭъГЩФГаЉЪ§ОнНсЙЙЕФГѕЪМЛЏЁЃЕїгУcopy_creds()ИДжЦжЄЪщЃЈгІИУЪЧИДжЦШЈЯоМАЩэЗнаХЯЂЃЉЁЃ
ЃЈ6ЃЉМьВтЯЕЭГжаНјГЬЕФзмЪ§СПЪЧЗёГЌЙ§СЫmax_threadsЫљЙцЖЈЕФНјГЬзюДѓЪ§ЁЃ
ЃЈ7ЃЉИДжЦБъжОЁЃЭЈЙ§copy_flagsЃЌНЋДгdo_fork()ДЋЕнРДЕФЕФclone_flagsКЭpidЗжБ№ИГжЕИјзгНјГЬУшЪіЗћжаЕФЖдгІзжЖЮЁЃ
ЃЈ8ЃЉГѕЪМЛЏзгНјГЬУшЪіЗћЁЃГѕЪМЛЏЦфжаЕФИїИізжЖЮЃЌЪЙЕУзгНјГЬКЭИИНјГЬж№НЅЧјБ№ГіРДЁЃетВПЗжЙЄзїАќКЌГѕЪМЛЏзгНјГЬжаЕФchildrenКЭsiblingЕШЖгСаЭЗЁЂГѕЪМЛЏзда§ЫјКЭаХКХДІРэЁЂГѕЪМЛЏНјГЬЭГМЦаХЯЂЁЂГѕЪМЛЏPOSIXЪБжгЁЂГѕЪМЛЏЕїЖШЯрЙиЕФЭГМЦаХЯЂЁЂГѕЪМЛЏЩѓМЦаХЯЂЁЃЫќдкcopy_processКЏЪ§жаеМОнСЫЯрЕБГЄЕФвЛЖЮЕФДњТыЃЌВЛЙ§ПМТЧЕНtask_structНсЙЙБОЩэЕФИДдгадЃЌвВОЭВЛзуЮЊЦцСЫЁЃ
ЃЈ9ЃЉЕїЖШЦїЩшжУЁЃЕїгУsched_forkКЏЪ§жДааЕїЖШЦїЯрЙиЕФЩшжУЃЌЮЊетИіаТНјГЬЗжХфCPUЃЌЪЙЕУзгНјГЬЕФНјГЬзДЬЌЮЊTASK_RUNNINGЁЃВЂНћжЙФкКЫЧРеМЁЃВЂЧвЃЌЮЊСЫВЛЖдЦфЫћНјГЬЕФЕїЖШВњЩњгАЯьЃЌДЫЪБзгНјГЬЙВЯэИИНјГЬЕФЪБМфЦЌЁЃ
ЃЈ10ЃЉИДжЦНјГЬЕФЫљгааХЯЂЁЃИљОнclone_flagsЕФОпЬхШЁжЕРДЮЊзгНјГЬПНБДЛђЙВЯэИИНјГЬЕФФГаЉЪ§ОнНсЙЙЁЃБШШчcopy_semundo()ЁЂИДжЦПЊЗХЮФМўУшЪіЗћЃЈcopy_filesЃЉЁЂИДжЦЗћКХаХЯЂЃЈcopy_sighand
КЭcopy_signalЃЉЁЂИДжЦНјГЬФкДцЃЈcopy_mmЃЉвдМАзюжеИДжЦЯпГЬЃЈcopy_threadЃЉЁЃ
ЃЈ11ЃЉИДжЦЯпГЬЁЃЭЈЙ§copy_threads()КЏЪ§ИќаТзгНјГЬЕФФкКЫеЛКЭМФДцЦїжаЕФжЕЁЃдкжЎЧАЕФdup_task_struct()жажЛЪЧЮЊзгНјГЬДДНЈвЛИіФкКЫеЛЃЌжСДЫВХЪЧеце§ЕФИГгшЫќгавтвхЕФжЕЁЃ
ЕБИИНјГЬЗЂГіcloneЯЕЭГЕїгУЪБЃЌФкКЫЛсНЋФЧИіЪБКђCPUжаМФДцЦїЕФжЕБЃДцдкИИНјГЬЕФФкКЫеЛжаЁЃетРяОЭЪЧЪЙгУИИНјГЬФкКЫеЛжаЕФжЕРДИќаТзгНјГЬМФДцЦїжаЕФжЕЁЃЬиБ№ЕФЃЌФкКЫНЋзгНјГЬeaxМФДцЦїжаЕФжЕЧПжЦИГжЕЮЊ0ЃЌетвВОЭЪЧЮЊЪВУДЪЙгУfork()ЪБзгНјГЬЗЕЛижЕЪЧ0ЁЃЖјдкdo_forkКЏЪ§жадђЗЕЛиЕФЪЧзгНјГЬЕФpidЃЌетвЛЕудкЩЯЪіФкШнжаЮвУЧвбОгаЫљЗжЮіЁЃСэЭтЃЌзгНјГЬЕФЖдгІЕФthread_infoНсЙЙжаЕФespзжЖЮЛсБЛГѕЪМЛЏЮЊзгНјГЬФкКЫеЛЕФЛљжЗЁЃ
ЃЈ12ЃЉЗжХфpidЁЃгУalloc_pidКЏЪ§ЮЊетИіаТНјГЬЗжХфвЛИіpidЃЌLinuxЯЕЭГФкЕФpidЪЧбЛЗЪЙгУЕФЃЌВЩгУЮЛЭМЗНЪНРДЙмРэЁЃМђЕЅЕФЫЕЃЌОЭЪЧгУУПвЛЮЛЃЈbitЃЉРДБъЪОИУЮЛЫљЖдгІЕФpidЪЧЗёБЛЪЙгУЁЃЗжХфЭъБЯКѓЃЌХаЖЯpidЪЧЗёЗжХфГЩЙІЁЃГЩЙІдђИГИјp->pidЁЃ
ЃЈ13ЃЉИќаТЪєадКЭНјГЬЪ§СПЁЃИљОнclone_flagsЕФжЕМЬајИќаТзгНјГЬЕФФГаЉЪєадЁЃНЋ nr_threadsМгвЛЃЌБэУїаТНјГЬвбОБЛМгШыЕННјГЬМЏКЯжаЁЃНЋtotal_forksМгвЛЃЌвдМЧТМБЛДДНЈНјГЬЪ§СПЁЃ
ЃЈ14ЃЉШчЙћЩЯЪіЙ§ГЬжаФГвЛВНГіЯжСЫДэЮѓЃЌдђЭЈЙ§gotoгяОфЬјЕНЯргІЕФДэЮѓДњТыДІЃЛШчЙћГЩЙІжДааЭъБЯЃЌдђЗЕЛизгНјГЬЕФУшЪіЗћpЁЃ
жСДЫЃЌcopy_process()ЕФДѓжТжДааЙ§ГЬЗжЮіЭъБЯЁЃ
copy_process()жДааЭъКѓЗЕЛиdo_fork()ЃЌdo_fork()жДааЭъБЯКѓЃЌЫфШЛзгНјГЬДІгкПЩдЫаазДЬЌЃЌЕЋЪЧЫќВЂУЛгаСЂПЬдЫааЁЃжСгкзгНјГЬКЮЪБжДааетЭъШЋШЁОігкЕїЖШГЬађЃЌвВОЭЪЧschedule()ЕФЪТСЫЁЃ
5. НјГЬЕїЖШ
ДДНЈКУЕФНјГЬзюКѓБЛВхШыЕНдЫааЖгСажаЃЌЫќЛсЭЈЙ§ Linux ЕїЖШГЬађРДЕїЖШЁЃLinuxЕїЖШГЬађЮЌЛЄСЫеыЖдУПИігХЯШМЖБ№ЕФвЛзщСаБэЃЌЦфжаБЃДцСЫ
task_struct в§гУЁЃЕБе§дкдЫааЕФНјГЬЪБМфЦЌгУЭъЪБЃЌЪБжгtickВњЩњжаЖЯЃЌЕїгУkernel/sched.c:scheduler_tick()НјГЬЕїЖШЦїЕФжаЖЯДІРэЃЌжаЖЯЗЕЛиКѓОЭЛсЕїгУschedule()ЁЃдЫааЖгСажаЕФШЮЮёЭЈЙ§
schedule КЏЪ§ЃЈдк./linux/kernel/sched.c ФкЃЉРДЕїгУЃЌЫќИљОнМгдиМАНјГЬжДааРњЪЗОіЖЈзюМбНјГЬЁЃетРяВЂВЛЩцМАДЫКЏЪ§ЕФЗжЮіЁЃ
6. НјГЬЯњЛй
НјГЬЯњЛйПЩвдЭЈЙ§МИИіЪТМўЧ§ЖЏЁЂЭЈЙ§е§ГЃЕФНјГЬНсЪјЃЈЕБвЛИіCГЬађДгmainКЏЪ§ЗЕЛиЪБstartuproutineЕїгУexitЃЉЁЂЭЈЙ§аХКХЛђЪЧЭЈЙ§ЯдЪНЕиЖд
exit КЏЪ§ЕФЕїгУЁЃВЛЙмНјГЬШчКЮЭЫГіЃЌНјГЬЕФНсЪјЖМвЊНшжњЖдФкКЫКЏЪ§ do_exitЃЈдк./linux/kernel/exit.c
ФкЃЉЕФЕїгУЁЃКЏЪ§ЕФВуДЮНсЙЙШчЯТЭМЃК
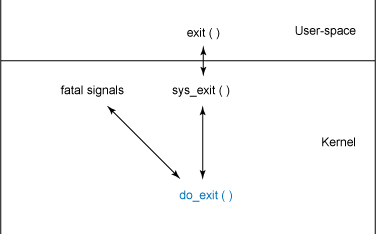
ЭМ НјГЬЯњЛйЕФКЏЪ§ВуДЮНсЙЙ
exit()ЕїгУЭЈЙ§0x80жаЖЯЬјЕНsys_exitФкКЫР§ГЬДІЃЌетИіР§ГЬУћГЦПЩвддк./linux/include/linux/syscalls.hжаевЕНЃЈsyscalls.hжаЕМГіЫљгаЦНЬЈЮоЙиЕФЯЕЭГЕїгУУћГЦЃЉЃЌЖЈвхЮЊasmlinkage
long sys_exit(int error_code); ЫќЛсжБНгЕїгУdo_exitЁЃДњТыШчЯТЃК
NORET_TYPE void
do_exit(long code)
{
struct task_struct *tsk = current;
int group_dead;
profile_task_exit(tsk);
WARN_ON(atomic_read(&tsk->fs_excl));
if (unlikely(in_interrupt()))
panic(ЁБAiee, killing interrupt handler!ЁБ);
if (unlikely(!tsk->pid))
panic(ЁБAttempted to kill the idle task!ЁБ);
/*
* If do_exit is called because this processes
oopsed, itЁЏs possible
* that get_fs() was left as KERNEL_DS, so reset
it to USER_DS before
* continuing. Amongst other possible reasons,
this is to prevent
* mm_release()->clear_child_tid() from writing
to a user-controlled
* kernel address.
*/
set_fs(USER_DS);
tracehook_report_exit(&code);
validate_creds_for_do_exit(tsk);
/*
* WeЁЏre taking recursive faults here in do_exit.
Safest is to just
* leave this task alone and wait for reboot.
*/
if (unlikely(tsk->flags & PF_EXITING))
{
printk(KERN_ALERT
ЁБFixing recursive fault but reboot is needed!\nЁБ);
/*
* We can do this unlocked here. The futex code
uses
* this flag just to verify whether the pi state
* cleanup has been done or not. In the worst case
it
* loops once more. We pretend that the cleanup
was
* done as there is no way to return. Either the
* OWNER_DIED bit is set by now or we push the
blocked
* task into the wait for ever nirwana as well.
*/
tsk->flags |= PF_EXITPIDONE;
set_current_state(TASK_UNINTERRUPTIBLE);
schedule();
}
exit_irq_thread();
exit_signals(tsk); /* sets PF_EXITING */
/*
* tsk->flags are checked in the futex code
to protect against
* an exiting task cleaning up the robust pi futexes.
*/
smp_mb();
spin_unlock_wait(&tsk->pi_lock);
if (unlikely(in_atomic()))
printk(KERN_INFO ЁБnote: %s[%d] exited with preempt_count
%d\nЁБ,
current->comm, task_pid_nr(current),
preempt_count());
acct_update_integrals(tsk);
group_dead = atomic_dec_and_test(&tsk->signal->live);
if (group_dead) {
hrtimer_cancel(&tsk->signal->real_timer);
exit_itimers(tsk->signal);
if (tsk->mm)
setmax_mm_hiwater_rss(&tsk->signal->maxrss,
tsk->mm);
}
acct_collect(code, group_dead);
if (group_dead)
tty_audit_exit();
if (unlikely(tsk->audit_context))
audit_free(tsk);
tsk->exit_code = code;
taskstats_exit(tsk, group_dead);
exit_mm(tsk);
if (group_dead)
acct_process();
trace_sched_process_exit(tsk);
exit_sem(tsk);
exit_files(tsk);
exit_fs(tsk);
check_stack_usage();
exit_thread();
cgroup_exit(tsk, 1);
if (group_dead && tsk->signal->leader)
disassociate_ctty(1);
module_put(task_thread_info(tsk)->exec_domain->module);
proc_exit_connector(tsk);
/*
* Flush inherited counters to the parent - before
the parent
* gets woken up by child-exit notifications.
*/
perf_event_exit_task(tsk);
exit_notify(tsk, group_dead);
#ifdef CONFIG_NUMA
mpol_put(tsk->mempolicy);
tsk->mempolicy = NULL;
#endif
#ifdef CONFIG_FUTEX
if (unlikely(current->pi_state_cache))
kfree(current->pi_state_cache);
#endif
/*
* Make sure we are holding no locks:
*/
debug_check_no_locks_held(tsk);
/*
* We can do this unlocked here. The futex code
uses this flag
* just to verify whether the pi state cleanup
has been done
* or not. In the worst case it loops once more.
*/
tsk->flags |= PF_EXITPIDONE;
if (tsk->io_context)
exit_io_context();
if (tsk->splice_pipe)
__free_pipe_info(tsk->splice_pipe);
validate_creds_for_do_exit(tsk);
preempt_disable();
exit_rcu();
/* causes final put_task_struct in finish_task_switch().
*/
tsk->state = TASK_DEAD;
schedule();
BUG();
/* Avoid ЁАnoreturn function does returnЁБ. */
for (;;)
cpu_relax(); /* For when BUG is null */
}
EXPORT_SYMBOL_GPL(do_exit); |
ЃЈ1ЃЉЮЊНјГЬЯњЛйзівЛЯЕСазМБИЁЃгУset_fsЩшжУUSER_DSЁЃзЂвтШчЙћdo_exitЪЧвђЮЊЕБЧАНјГЬГіЯжВЛПЩдЄжЊЕФДэЮѓЖјБЛЕїгУЃЌетЪБget_fs()гаПЩФмЕУЕНЕФШдШЛЪЧKERNEL_DSзДЬЌЃЌвђДЫЮвУЧвЊжижУЫќЮЊUSER_DSзДЬЌЁЃЛЙгавЛИіПЩФмдвђЪЧетПЩвдЗРжЙmm_release()->clear_child_tid()аДвЛИіБЛгУЛЇПижЦЕФФкКЫЕижЗЁЃ
ЃЈ2ЃЉЧхГ§ЫљгааХКХДІРэКЏЪ§ЁЃexit_signalsКЏЪ§ЛсЩшжУPF_EXITINGБъжОРДБэУїНјГЬе§дкЭЫГіЃЌВЂЧхГ§ЫљгааХЯЂДІРэКЏЪ§ЁЃФкКЫЕФЦфЫћЗНУцЛсРћгУPF_EXITINGРДЗРжЙдкНјГЬБЛЩОГ§ЪБЛЙЪдЭМДІРэДЫНјГЬЁЃ
ЃЈ3ЃЉЧхГ§вЛЯЕСаЕФНјГЬзЪдДЁЃБШШчБШШч exit_mmЩОГ§ФкДцвГЁЂexit_filesЙиБеЫљгаДђПЊЕФЮФМўУшЪіЗћЃЌетЛсЧхРэI/OЛКДцЃЌШчЙћЛКДцжагаЪ§ОнЃЌОЭЛсНЋЫќУЧаДШыЯргІЕФЮФМўЃЌвдЗРжЙЮФМўЪ§ОнЕФЖЊЪЇЁЃexit_fsЧхГ§ЕБЧАФПТМЙиСЊЕФinodeЁЂexit_threadЧхГ§ЯпГЬаХЯЂЁЂЕШЕШЁЃ
ЃЈ4ЃЉЗЂГіЭЫГіЭЈжЊЁЃЕїгУexit_notifyжДаавЛЯЕСаЭЈжЊЁЃР§ШчЭЈжЊИИНјГЬЮве§дкЭЫГіЁЃШчЯТЃК
static void
exit_notify(struct task_struct *tsk, int group_dead)
{
int signal;
void *cookie;
/*
* This does two things:
*
* A. Make init inherit all the child processes
* B. Check to see if any process groups have become
orphaned
* as a result of our exiting, and if they have
any stopped
* jobs, send them a SIGHUP and then a SIGCONT.
(POSIX 3.2.2.2)
*/
forget_original_parent(tsk);
exit_task_namespaces(tsk);
write_lock_irq(&tasklist_lock);
if (group_dead)
kill_orphaned_pgrp(tsk->group_leader, NULL);
/* Let father know we died
*
* Thread signals are configurable, but you arenЁЏt
going to use
* that to send signals to arbitary processes.
* That stops right now.
*
* If the parent exec id doesnЁЏt match the exec
id we saved
* when we started then we know the parent has
changed security
* domain.
*
* If our self_exec id doesnЁЏt match our parent_exec_id
then
* we have changed execution domain as these two
values started
* the same after a fork.
*/
if (tsk->exit_signal != SIGCHLD &&
!task_detached(tsk) &&
(tsk->parent_exec_id != tsk->real_parent->self_exec_id
||
tsk->self_exec_id != tsk->parent_exec_id))
tsk->exit_signal = SIGCHLD;
signal = tracehook_notify_death(tsk, &cookie,
group_dead);
if (signal >= 0)
signal = do_notify_parent(tsk, signal);
tsk->exit_state = signal == DEATH_REAP ? EXIT_DEAD
: EXIT_ZOMBIE;
/* mt-exec, de_thread() is waiting for us */
if (thread_group_leader(tsk) &&
tsk->signal->group_exit_task &&
tsk->signal->notify_count < 0)
wake_up_process(tsk->signal->group_exit_task);
write_unlock_irq(&tasklist_lock);
tracehook_report_death(tsk, signal, cookie, group_dead);
/* If the process is dead, release it - nobody
will wait for it */
if (signal == DEATH_REAP)
release_task(tsk);
} |
exit_notifyНЋЕБЧАНјГЬЕФЫљгазгНјГЬЕФИИНјГЬIDЩшжУЮЊ1(init)ЃЌШУinitНгЙмЫљгаетаЉзгНјГЬЁЃШчЙћЕБЧАНјГЬЪЧФГИіНјГЬзщЕФзщГЄЃЌЦфЯњЛйЕМжТНјГЬзщБфЮЊЁАЮоСьЕМзДЬЌЁАЃЌдђЯђУПИізщФкНјГЬЗЂЫЭЙвЦ№аХКХSIGHUPЃЌШЛКѓЗЂЫЭSIGCONTЁЃетЪЧзёбPOSIX3.2.2.2БъзМЁЃНгзХЯђздМКЕФИИНјГЬЗЂЫЭSIGCHLDаХКХ,ШЛКѓЕїгУdo_notify_parentЭЈжЊИИНјГЬЁЃШєЗЕЛиDEATH_REAP(етИівтЫМЪЧВЛЙмЪЧЗёгаЦфЫћНјГЬЙиаФБОНјГЬЕФЭЫГіаХЯЂЃЌздЖЏЭъГЩНјГЬЭЫГіКЭPCBЯњЛй)ЃЌОЭжБНгНјШыEXIT_DEADзДЬЌЃЌШчЙћВЛЪЧЃЌдђОЭашвЊБфЮЊEXIT_ZOMBIEзДЬЌЁЃ
зЂвтдкзюГѕИИНјГЬДДНЈзгНјГЬЪБЃЌШчЙћЕїгУСЫwaitpid()ЕШД§згНјГЬНсЪјЃЈБэЪОЫќЙиаФзгНјГЬЕФзДЬЌЃЉЃЌзгНјГЬНсЪјЪБИИНјГЬЛсДІРэЫќЗЂРДЕФSIGCHILDаХКХЁЃШчЙћВЛЕїгУwaitЃЈБэЪОЫќВЛЙиаФзгНјГЬЕФЫРЛюзДЬЌЃЉЃЌдђВЛЛсДІРэзгНјГЬЕФSIGCHILDаХКХЁЃВЮПД./linux/kernel/signal.c:do_notify_parent()ЃЌДњТыШчЯТЃК
int do_notify_parent(struct
task_struct *tsk, int sig)
{
struct siginfo info;
unsigned long flags;
struct sighand_struct *psig;
int ret = sig;
BUG_ON(sig == -1);
/* do_notify_parent_cldstop should have been called
instead. */
BUG_ON(task_is_stopped_or_traced(tsk));
BUG_ON(!task_ptrace(tsk) &&
(tsk->group_leader != tsk || !thread_group_empty(tsk)));
info.si_signo = sig;
info.si_errno = 0;
/*
* we are under tasklist_lock here so our parent
is tied to
* us and cannot exit and release its namespace.
*
* the only it can is to switch its nsproxy with
sys_unshare,
* bu uncharing pid namespaces is not allowed,
so weЁЏll always
* see relevant namespace
*
* write_lock() currently calls preempt_disable()
which is the
* same as rcu_read_lock(), but according to Oleg,
this is not
* correct to rely on this
*/
rcu_read_lock();
info.si_pid = task_pid_nr_ns(tsk, tsk->parent->nsproxy->pid_ns);
info.si_uid = __task_cred(tsk)->uid;
rcu_read_unlock();
info.si_utime = cputime_to_clock_t(cputime_add(tsk->utime,
tsk->signal->utime));
info.si_stime = cputime_to_clock_t(cputime_add(tsk->stime,
tsk->signal->stime));
info.si_status = tsk->exit_code & 0x7f;
if (tsk->exit_code & 0x80)
info.si_code = CLD_DUMPED;
else if (tsk->exit_code & 0x7f)
info.si_code = CLD_KILLED;
else {
info.si_code = CLD_EXITED;
info.si_status = tsk->exit_code >> 8;
}
psig = tsk->parent->sighand;
spin_lock_irqsave(&psig->siglock, flags);
if (!task_ptrace(tsk) && sig == SIGCHLD
&&
(psig->action[SIGCHLD-1].sa.sa_handler == SIG_IGN
||
(psig->action[SIGCHLD-1].sa.sa_flags &
SA_NOCLDWAIT))) {
/*
* We are exiting and our parent doesnЁЏt care.
POSIX.1
* defines special semantics for setting SIGCHLD
to SIG_IGN
* or setting the SA_NOCLDWAIT flag: we should
be reaped
* automatically and not left for our parentЁЏs
wait4 call.
* Rather than having the parent do it as a magic
kind of
* signal handler, we just set this to tell do_exit
that we
* can be cleaned up without becoming a zombie.
Note that
* we still call __wake_up_parent in this case,
because a
* blocked sys_wait4 might now return -ECHILD.
*
* Whether we send SIGCHLD or not for SA_NOCLDWAIT
* is implementation-defined: we do (if you donЁЏt
want
* it, just use SIG_IGN instead).
*/
ret = tsk->exit_signal = -1;
if (psig->action[SIGCHLD-1].sa.sa_handler ==
SIG_IGN)
sig = -1;
}
if (valid_signal(sig) && sig > 0)
__group_send_sig_info(sig, &info, tsk->parent);
__wake_up_parent(tsk, tsk->parent);
spin_unlock_irqrestore(&psig->siglock,
flags);
return ret;
} |
ЮвУЧПЩвдПДЕНЃЌШчЙћИИНјГЬЯдЪОжИЖЈЖдзгНјГЬЕФSIGCHLDаХКХДІРэЮЊSIG_IGNЃЌЛђепБъжОЮЊSA_NOCLDWAITЃЌдђЗЕЛиЕФЪЧret=-1ЃЌМДDEATH_REAPЃЈетИіКъдк./linux/include/tracehook.hжаЖЈвхЮЊЃ1ЃЉЃЌетЪБдкexit_notifyжазгНјГЬТэЩЯБфЮЊEXIT_DEADЃЌБэЪОЮввбЭЫГіВЂЧвЫРЭіЃЌзюКѓБЛКѓУцЕФrelease_taskЛиЪеЃЌНЋВЛЛсдйгаНјГЬЕШД§ЮвЁЃЗёдђЗЕЛижЕгыДЋШыЕФаХКХжЕЯрЭЌЃЌзгНјГЬБфГЩEXIT_ZOMBIEЃЌБэЪОвбЭЫГіЕЋЛЙУЛЫРЁЃВЛЙмгаУЛгаДІРэSIGCHLDЃЌdo_notify_parentзюКѓЖМЛсгУ__wake_up_parentРДЛНабе§дкЕШД§ЕФИИНјГЬЁЃ
ПЩМћзгНјГЬдкНсЪјЧАВЛвЛЖЈЖМашвЊОЙ§вЛИіEXIT_ZOMBIEЙ§ГЬЁЃШчЙћИИНјГЬЕїгУСЫwaitpidЕШД§згНјГЬЃЌдђЛсЯдЪОДІРэЫќЗЂРДЕФSIGCHILDаХКХЃЌзгНјГЬНсЪјЪБЛсздЮвЧхРэЃЈдкdo_exitжаздМКгУrelease_taskЧхРэЃЉЃЛШчЙћИИНјГЬУЛгаЕїгУwaitpidЕШД§згНјГЬЃЌдђВЛЛсДІРэSIGCHLDаХКХЃЌзгНјГЬВЛЛсТэЩЯБЛЧхРэЃЌЖјЪЧБфГЩEXIT_ZOMBIEзДЬЌЃЌГЩЮЊжјУћЕФНЉЪЌНјГЬЁЃЛЙгавЛжжЬиЪтЧщаЮЃЌШчЙћзгНјГЬЭЫГіЪБИИНјГЬЧЁКУе§дкЫЏУпЃЈsleepЃЉЃЌЕМжТУЛРДЕУМБДІРэSIGCHLDЃЌзгНјГЬвВЛсГЩЮЊНЉЪЌЃЌжЛвЊИИНјГЬдкабРДКѓФмЕїгУwaitpidЃЌвВФмЧхРэНЉЪЌзгНјГЬЃЌвђЮЊwaitЯЕЭГЕїгУФкВПгаЧхРэНЉЪЌзгНјГЬЕФДњТыЁЃвђДЫЃЌШчЙћИИНјГЬвЛжБУЛгаЕїгУwaitpidЃЌФЧУДНЉЪЌзгНјГЬОЭжЛФмЕШЕНИИНјГЬЭЫГіЪББЛinitНгЙмСЫЁЃinitНјГЬЛсИКд№ЧхРэетаЉНЉЪЌНјГЬЃЈinitПЯЖЈЛсЕїгУwaitЃЉЁЃ
ЮвУЧПЩвдаДИіМђЕЅЕФГЬађРДбщжЄЃЌИИНјГЬДДНЈ10ИізгНјГЬЃЌзгНјГЬsleepвЛЖЮЪБМфКѓЭЫГіЁЃЕквЛжжЧщПіЃЌИИНјГЬжЛЖд1~9КХзгНјГЬЕїгУwaitpid()ЃЌ1~9КХзгНјГЬЖМе§ГЃНсЪјЃЌЖјдкИИНјГЬНсЪјЧАЃЌpids[0]ЮЊEXIT_ZOMBIEЁЃЕкЖўжжЧщПіЃЌИИНјГЬДДНЈ10ИізгНјГЬКѓЃЌsleep()вЛЖЮЪБМфЃЌдкетЖЮЪБМфФк_exit()ЕФзгНјГЬЖМГЩЮЊEXIT_ZOMBIEЁЃИИНјГЬsleep()НсЪјКѓЃЌвРДЮЕїгУwaitpid()ЃЌзгНјГЬТэЩЯБфЮЊEXIT_DEADБЛЧхРэЁЃ
ЮЊСЫИќКУЕиРэНтдѕУДЧхРэНЉЪЌНјГЬЃЌЮвУЧМђвЊЕиЗжЮівЛЯТwaitЯЕЭГЕїгУЁЃwaitзхЕФЯЕЭГЕїгУШчwaitpid,wait4ЕШЃЌзюКѓЖМЛсНјШы./linux/kernel/exit.c:do_wait()ФкКЫР§ГЬЃЌЖјКѓКЏЪ§СДЮЊdo_wait()ЁЊ>do_wait_thread()ЁЊ>wait_consider_task()ЃЌдкетРяЃЌШчЙћзгНјГЬдкexit_notifyжаЩшжУЕФtsk->exit_stateЮЊEXIT_DEADЃЌОЭЗЕЛи0ЃЌМДwaitЯЕЭГЕїгУЗЕЛиЃЌЫЕУїзгНјГЬВЛЪЧНЉЪЌНјГЬЃЌЛсздМКгУrelease_taskНјааЛиЪеЁЃШчЙћЫќЕФexit_stateЪЧEXIT_ZOMBIEЃЌНјШыwait_task_zombie()ЁЃдкетРяЪЙгУxchgГЂЪдАбЫќЕФexit_stateЩшжУЮЊEXIT_DEADЃЌПЩМћИИНјГЬЕФwait4ЕїгУЛсАбзгНјГЬгЩEXIT_ZOMBIEЩшжУЮЊEXIT_DEADЁЃзюКѓwait_task_zombie()дкФЉЮВЕїгУrelease_task()ЧхРэетИіНЉЪЌНјГЬЁЃ
ЃЈ5ЃЉЩшжУЯњЛйБъжОВЂЕїЖШаТЕФНјГЬЁЃдкdo_exitЕФзюКѓЃЌгУexit_io_contextЧхГ§IOЩЯЯТЮФЁЂpreempt_disableНћгУЧРеМЃЌЩшжУНјГЬзДЬЌЮЊTASK_DEADЃЌШЛКѓЕїгУ./linux/kernel/sched.c:schedule()РДбЁдёвЛИіНЋвЊжДааЕФаТНјГЬЁЃзЂвтНјГЬдкЭЫГіВЂЛиЪежЎКѓЃЌЦфЮЛгкЕїЖШЦїЕФНјГЬСаБэжаЕФНјГЬУшЪіЗћЃЈPCBЃЉВЂУЛгаСЂМДЪЭЗХЃЌБиаыдкЩшжУtask_structЕФstateЮЊTASK_DEADжЎКѓЃЌгЩschedule()жаЕФfinish_task_switch()ЁЊ>put_task_struct()АбЫќЕФPCBжиаТЗХЛиЕНfreelist(ПЩгУСаБэ)жаЃЌетЪБPCBВХЫуЪЭЗХЃЌШЛКѓЧаЛЛЕНаТЕФНјГЬЁЃ
7. exitгы_exitЕФВювь
ЮЊСЫРэНтетСНИіЯЕЭГЕїгУЕФВювьЃЌЯШРДЬжТлЮФМўФкДцЛКДцЧјЕФЮЪЬтЁЃ дкlinuxжаЃЌБъзМЪфШыЪфГіЃЈI/OЃЉКЏЪ§ЖМЪЧзїЮЊЮФМўРДДІРэЁЃЖдгІгкДђПЊЕФУПИіЮФМўЃЌдкФкДцжаЖМгаЖдгІЕФЛКДцЃЌУПДЮЖСШЁЮФМўЪБЃЌЛсЖрЖСвЛаЉМЧТМЕНЛКДцжаЃЌетбљдкЯТДЮЖСЮФМўЪБЃЌОЭдкЛКДцжаЖСШЁЃЛЭЌбљЃЌдкаДЮФМўЪБвВЪЧаДдкЮФМўЖдгІЕФЛКДцжаЃЌВЂВЛЪЧжБНгаДШыгВХЬЕФЮФМўжаЃЌЕШТњзуСЫвЛЖЈЬѕМўЃЈШчДяЕНвЛЖЈЪ§СПЃЌгіЕНЛЛааЗћ\nЛђЮФМўНсЪјБъжОEOFЃЉВХНЋЪ§Онеце§ЕФаДШыЮФМўЁЃетбљзіЕФКУДІОЭЪЧМгПьСЫЮФМўЖСаДЕФЫйЖШЁЃЕЋетбљвВДјРДСЫвЛаЉЮЪЬтЃЌБШШчгавЛаЉЪ§ОнЃЌЮвУЧШЯЮЊвбОаДШыСЫЮФМўЃЌЕЋЪЕМЪЩЯУЛгаТњзувЛЖЈЬѕМўЖјШЮШЛзЄСєдкФкДцЕФЛКДцжаЃЌетбљЃЌШчЙћЮвУЧжБНггУ_exitЃЈЃЉКЏЪ§жБНгжежЙНјГЬЃЌНЋЕМжТЪ§ОнЖЊЪЇЁЃШчЙћИФГЩexitЃЌОЭВЛЛсгаЪ§ОнЖЊЪЇЕФЮЪЬтГіЯжСЫЃЌетОЭЪЧЫќУЧжЎМфЕФЧјБ№СЫ.вЊНтЪЭетИіЮЪЬтЃЌОЭвЊЩцМАЫќУЧЕФЙЄзїВНжшСЫЁЃ
exit()ЃКЭЈЙ§ЧАУцдДДњТыЗжЮіПЩжЊЃЌдкжДааИУКЏЪ§ЪБЃЌНјГЬЛсМьВщЮФМўДђПЊЧщПіЃЌЧхРэI/OЛКДцЃЌШчЙћЛКДцжагаЪ§ОнЃЌОЭЛсНЋЫќУЧаДШыЯргІЕФЮФМўЃЌетбљОЭЗРжЙСЫЮФМўЪ§ОнЕФЖЊЪЇЃЌШЛКѓжежЙНјГЬЁЃ
_exit()ЃКдкжДааИУКЏЪ§ЪБЃЌВЂВЛЧхРэБъзМЪфШыЪфГіЛКДцЃЌЖјЪЧжБНгЧхГ§ФкДцПеМфЃЌЕБШЛвВОЭАбЮФМўЛКДцжаЩаЮДаДШыЮФМўЕФЪ§ОнИјЯњЛйСЫЁЃгЩДЫПЩМћЃЌЪЙгУexit()КЏЪ§ИќМгАВШЋЁЃ
ДЫЭтЃЌЖдгкЫќУЧСНепЕФЧјБ№ЛЙгаИїздЕФЭЗЮФМўВЛЭЌЁЃexit()дкstdlib.hжаЃЌ_exit()дкunistd.hжаЁЃвЛАуЧщПіЯТexit(0)БэЪОе§ГЃЭЫГі,exit(1)ЃЌexit(-1)ЮЊвьГЃЭЫГіЃЌ0ЁЂ1ЁЂ-1ЪЧЗЕЛижЕЃЌОпЬхКЌвхПЩвдздЖЈЁЃЛЙвЊзЂвтreturnЪЧЗЕЛиКЏЪ§ЕїгУЃЌШчЙћЗЕЛиЕФЪЧmainКЏЪ§ЃЌдђЮЊЭЫГіГЬађ
ЁЃexitЪЧдкЕїгУДІЧПааЭЫГіГЬађЃЌдЫаавЛДЮГЬађОЭНсЪјЁЃ
ЯТУцЪЧЭъећЕФLinuxНјГЬдЫааСїГЬЃК
arch/x86/include/asm/unistd_32.h:fork()
гУЛЇПеМфРДЕїгУЃЈШчCГЬађЃЉ
ЁЊ>int $0ЁС80 ВњЩњ0x80ШэжаЖЯ
ЁЊ>arch/x86/kernel/entry_32.S:ENTRY(system_call)
жаЖЯДІРэГЬађsystem_call()
ЁЊ>жДааSAVE_ALLКъ БЃДцЫљгаCPUМФДцЦїжЕ
ЁЊ>arch/x86/kernel/syscall_table_32.S:ENTRY
(sys_call_table)
ЯЕЭГЕїгУЖрТЗЗжНтБэ
ЁЊ>arch/x86/kernel/process_32.c:sys_fork()
ЁЊ>kernel/fork.c:do_fork() ИДжЦдРДЕФНјГЬГЩЮЊСэ
вЛИіаТЕФНјГЬ
ЁЊ>kernel/fork.c:copy_process()
ЁЊ>struct task_struct *p; ЖЈвхаТЕФНјГЬУшЪіЗћЃЈPCBЃЉ
ЁЊ>clone_flagsБъжОЕФКЯЗЈадМьВщ
ЁЊ>security_task_create() АВШЋадМьВщ(SELinuxЛњжЦ)
ЁЊ>kernel/fork.c:dup_task_struct() ИДжЦНјГЬУшЪіЗћ
ЁЊ>struct thread_info *ti; ЖЈвхЯпГЬаХЯЂНсЙЙ
ЁЊ>alloc_task_struct() ЮЊаТЕФPCBЗжХфФкДц
ЁЊ>kernel/fork.c:arch_dup_task_struct() ИДжЦ
ИИНјГЬЕФPCB
ЁЊ>atomic_set(&tsk->usage,2) НЋPCBЪЙгУМЦЪ§
ЦїЩшжУЮЊ2ЃЌБэЪОЛюЖЏзДЬЌ
ЁЊ>copy_creds() ИДжЦШЈЯоМАЩэЗнаХЯЂ
ЁЊ>МьВтНјГЬзмЪ§ЪЧЗёГЌЙ§max_threads
ЁЊ>ГѕЪМЛЏPCBжаИїИізжЖЮ
ЁЊ>sched_fork() ЕїЖШЦїЯрЙиЩшжУ
ЁЊ>ИДжЦНјГЬЫљгааХЯЂcopy_semundo(), copy_files(),
ЁЊ>copy_signal(), copy_mm()
ЁЊ>copy_thread() ИДжЦЯпГЬ
ЁЊ>alloc_pid() ЗжХфpid
ЁЊ>ИќаТЪєадКЭНјГЬЪ§СПМЦЪ§
ЁЊ>kernel/sched.c:wake_up_new_task() АбНјГЬЗХЕНдЫааЖгСаЩЯЃЌШУЕїЖШЦїНјааЕїЖШ
ЁЊ>kernel/sched.c:select_task_rq() бЁдёзюМбЕФCPUЃЈSMPжагаЖрИіCPUЃЉ
ЁЊ>p->state = TASK_RUNNING ЩшжУГЩTASK_RUNNINGзДЬЌ
ЁЊ>activate_task()
ЁЊ>enqueue_task() АбЕБЧАНјГЬВхШыЕНЖдгІCPUЕФrunqueueЩЯ
ЁЊ>гаCLONE_VFORKБъжОЃКwait_for_completion() ШУИИНјГЬзшШћЃЌЕШД§згНјГЬНсЪј
ЁЊ>ЗЕЛиЗжХфЕФpid
kernel/sched.c:schedule() ЕїЖШаТДДНЈЕФНјГЬ
НјГЬдЫаажа
exit() гУЛЇПеМфРДЕїгУЃЈШчCГЬађЃЉ
ЁЊ>0x80жаЖЯЬјзЊЕНinclude/linux/syscalls.h:sys_exit()
ЁЊ>kernel/exit.c:do_exit() ИКд№НјГЬЕФЭЫГі
ЁЊ>struct task_struct *tsk = current; ЛёШЁЮвЕФPCB
ЁЊ>set_fs(USER_DS) ЩшжУЪЙгУЕФЮФМўЯЕЭГФЃЪН
ЁЊ>exit_signals() ЧхГ§аХКХДІРэКЏЪ§ВЂЩшжУPF_EXITINGБъжО
ЁЊ>ЧхГ§НјГЬвЛЯЕСазЪдДexit_mm(), exit_files()
ЁЊ>exit_fs(), exit_thread()
ЁЊ>kernel/exit.c:exit_notify() ЭЫГіЭЈжЊ
ЁЊ>forget_original_parent() АбЮвЕФЫљгазгНјГЬЙ§МЬИјinitНјГЬ
ЁЊ>kill_orphaned_pgrp() ЯђНјГЬзщФкИїНјГЬЗЂЫЭЙвЦ№аХКХSIGHUPМАSIGCONT
ЁЊ>tsk->exit_signal = SIGCHLD; ЯђЮвЕФИИНјГЬЗЂЫЭSIGCHLDаХКХ
ЁЊ>kernel/exit.c:do_notify_parent() ЭЈжЊИИНјГЬ
ЁЊ>ШчЙћИИНјГЬДІРэSIGCHLDаХКХЃЌЗЕЛиDEATH_REAP
ЁЊ>ШчЙћИИНјГЬВЛДІРэSIGCHLDаХКХЃЌЗЕЛиДЋШыЪБЕФаХКХжЕ
ЁЊ>__wake_up_parent() ЛНабИИНјГЬ
ЁЊ>ЭЈжЊЗЕЛиDEATH_REAPЃЌЩшжУexit_stateЮЊEXIT_DEAD ЮвЭЫГіВЂЧвЫРЭі
ЁЊ>ЗёдђЩшжУЮвЮЊEXIT_ZOMBIE ЮвЭЫГіЕЋУЛЫРЭіЃЌГЩЮЊНЉЪЌНјГЬ
ЁЊ>ШчЙћЮЊDEATH_REAPЃКrelease_task() ЮвздМКЧхРэЯрЙизЪдД
ЁЊ>ШчЙћЮЊНЉЪЌЃЌдкЮвЕФИИНјГЬЭЫГіЪБЮвЛсЙ§МЬИјinitНјГЬЃЌгЩinitИКд№ЧхРэ
ЁЊ>exit_io_context() ЧхРэIOЩЯЯТЮФ
ЁЊ>preempt_disable() НћгУЧРеМ
ЁЊ>tsk->state = TASK_DEAD; ЩшжУЮвЮЊНјГЬЫРЭізДЬЌ
ЁЊ>kernel/sched.c:schedule() ЪЭЗХЮвЕФPCBЃЌЕїЖШСэвЛИіаТЕФНјГЬ
ЧхРэНЉЪЌНјГЬЃКwaitЯЕЭГЕїгУ ЕШД§згНјГЬНсЪј
ЁЊ>0x80жаЖЯзюКѓЕНДяkernel/exit.c:do_wait()
ЁЊ>do_wait_thread()
ЁЊ>wait_consider_task()
ЁЊ>ШчЙћзгНјГЬЮЊEXIT_DEADЃЌЗЕЛи0ЃЌwaitЕїгУЗЕЛиЃЌзгНјГЬздМКЧхРэздМК
ЁЊ>ШчЙћзгНјГЬЮЊEXIT_ZOMBIEЃКwait_task_zombie()
ЁЊ>xchg() ЩшжУНЉЪЌзгНјГЬЮЊEXIT_DEAD
ЁЊ>release_task() ЧхРэНЉЪЌзгНјГЬ |
ЯТУцЪЧЛљБОЕФжДааСїГЬЭМЃК
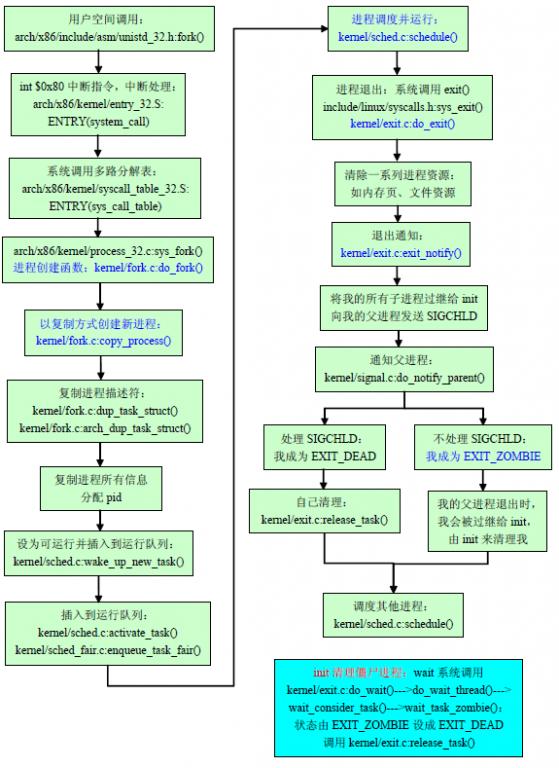
ЭМ LinuxНјГЬЙмРэЕФжДааСїГЬ |









