| 编辑推荐: |
| 本文来自于csdn,介绍了CPU和GPU的区别、GPU适合的工作内容,Win-10
安装 TensorFlow-GPU等。 |
|
先来看看第一部分
为什么GPU比CPU更diao呢?
这里就需要从他么的区别入手
那他么的区别是什么呢?
这里就需要从他的原理出发了,由于其设计目标的不同,它们分别针对了两种不同的应用场景
CPU 需要很强的通用性
为了处理各种不同的数据类型,同时又要逻辑判断又会引入大量的分支跳转和中断的处理。这些都使得CPU的内部结构异常复杂。
While GPU 面对的是类型高度统一的、互相无依赖的大规模数据和不需要被打断的纯净的计算环境
于是乎:CPU和GPU就呈现出非常不同的架构(看图)
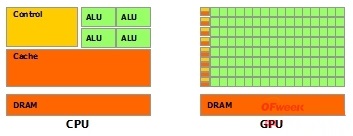
鲜绿色:计算单元ALU(Arithmetic Logic Unit)
橙红色:存储单元(cache)
橙黄色:控制单元(control)
GPU:数量众多的计算单元和超长的流水线,只有简单的控制逻辑并省去了Cache
CPU:被Cache占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路。
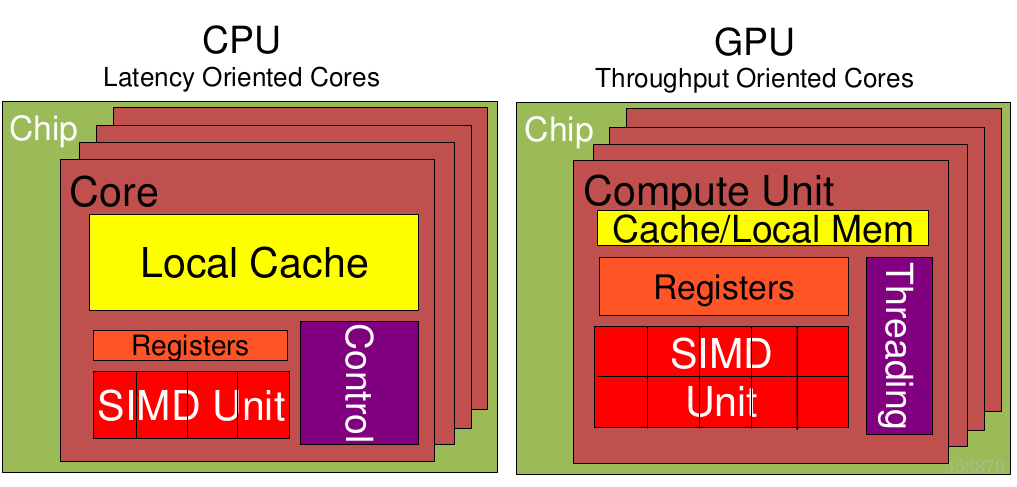
*结果可想而知:看这个更详细的图片*
来,小明,你说你看出什么区别了
我看到了黄色的东西,一个大一个小。
就看不到深层的东西?
老师,我饿了。
滚出去。
我给大家说一下啊!
1.Cache, local memory: CPU > GPU
2.Threads(线程数): GPU > CPU
3.Registers(寄存器): GPU > CPU 多寄存器可以支持非常多的Thread
4.thread需要用到register,thread数目大register也必须得跟着很大才行。
5.SIMD Unit(单指令多数据流,以同步方式,在同一时间内执行同一条指令):
GPU > CPU。
文字很麻烦吧,可以形象的看[这个视频 挺有意思的]
1.CPU有强大的ALU, 可以在很少的时钟周期内完成算术计算,可以达到64bit
双精度,执行双精度浮点源算的加法和乘法只需要1~3个[时钟周期]
2.CPU的时钟周期的频率非常高,达到1.532~3gigahertz(千兆HZ,
10的9次方).
再看看GPU
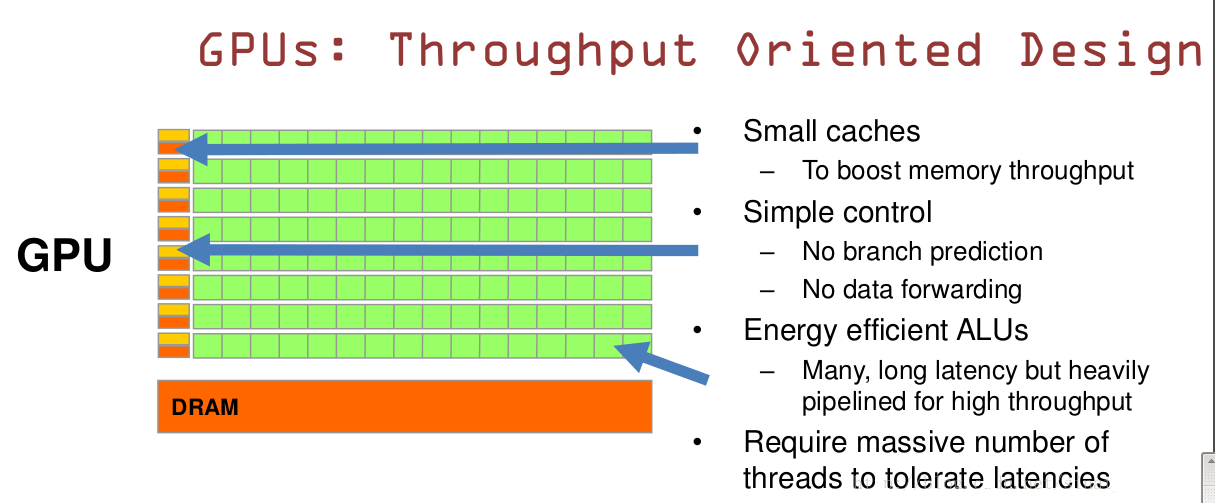
GPU是基于大的吞吐量
特点:很多的ALU和很少的cache
缓存的目的不是保存后面需要访问的数据,这点和CPU不同,而是为thread提高服务
如果有很多线程需要访问同一个相同的数据?
缓存会合并这些访问,然后再去访问dram(因为需要访问的数据保存在dram中而不是cache里面)
获取数据后cache会转发这个数据给对应的线程,这个时候是数据转发的角色,由于需要访问dram,自然会带来延时的问题。
GPU的控制单元(左边黄色区域块)可以把多个的访问合并成少的访问。
总的来说:有一个例子说的很好
GPU的工作大部分就是这样,计算量大,而且要重复很多很多次。就像你有个工作需要算几亿次一百以内加减乘除一样,最好的办法就是雇上几十个小学生一起算,一人算一部分
CPU就像老教授,积分微分都会算,就是工资高,一个老教授资顶二十个小学生,你要是富士康你雇哪个
CPU和GPU因为最初用来处理的任务就不同,所以设计上有不小的区别,而某些任务和GPU最初用来解决的问题比较相似,所以用GPU来算了
GPU的运算速度取决于雇了多少小学生,CPU的运算速度取决于请了多么厉害的教授。教授处理复杂任务的能力是碾压小学生的,但是对于没那么复杂的任务,还是顶不住人多。
当然现在的GPU也能做一些稍微复杂的工作了,相当于升级成初中生高中生的水平。但还需要CPU来把数据喂到嘴边才能开始干活,究竟还是靠CPU来管的。
GPU适合干什么活?
(1)计算密集型的程序
所谓计算密集型(Compute-intensive)的程序,就是其大部分运行时间花在了寄存器运算上,寄存器的速度和处理器的速度相当,从寄存器读写数据几乎没有延时。
可以做一下对比,读内存的延迟大概是几百个时钟周期;读硬盘的速度就不说了,即便是SSD, 也实在是太慢了。
(2)易于并行的程序。
GPU其实是一种SIMD(Single Instruction Multiple
Data)架构, 他有成百上千个核,每一个核在同一时间最好能做同样的事情。
可能用到的链接(参考链接)
RAM
RRAM DRAM三者有什么区别?
DRAM
第二部分: 操作
Win-10 安装 TensorFlow-GPU
0x00. 缘由
Q:为什么要写(这么低级的)配置教程?
A:(其实并不低级),鉴于以后(或许)会有多篇关于TensorFlow的文章(花式挖坑),所以在这里有必要介绍一下其安装方法
Q:TensorFlow是什么?
A:TensorFlow is an Open Source Software Library for
Machine Intelligence
由Google开源的深度学习库,可以对定义在 Tensor(张量)上的函数自动求导。
Tensor意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow即为张量从图的一端流动到另一端。
它的一大亮点是支持异构设备分布式计算,它能够在各个平台上自动运行模型,从电话、单个CPU/GPU到成百上千GPU卡组成的分布式系统。
支持CNN、RNN和LSTM算法,是目前在Image、NLP最流行的深度神经网络模型。
Q:为什么要研究这个?
A:深度学习通常意味着建立具有很多层的大规模的神经网络。
除了输入X,函数还使用一系列参数,其中包括标量值、向量以及最昂贵的矩阵和高阶张量。
在训练网络之前,需要定义一个代价函数,常见的代价函数包括回归问题的方差以及分类时候的交叉熵。
训练时,需要连续的将多批新输入投入网络,对所有的参数求导后,代入代价函数,从而更新整个网络模型。
这个过程中有两个主要的问题:1. 较大的数字或者张量在一起相乘百万次的处理,使得整个模型代价非常大。2.
手动求导耗时非常久。
所以TensorFlow的对函数自动求导以及分布式计算,可以帮我们节省很多时间来训练模型。
Q:它有什么优点?
A:1. 基于python,写的很快并且具有可读性;
2. 在多GPU系统上的运行更为顺畅;
3. 代码编译效率较高;
4. 社区发展的非常迅速并且活跃;
5. 能够生成显示网络拓扑结构和性能的可视化图。
0x01. 环境
a. Microsoft Windows [版本 10.0.15063](Win 10 x64 Pro
1703 15063.483)
b. Python 3.6.1 (v3.6.1:69c0db5, Mar 21 2017, 18:41:36)
[MSC v.1900 64 bit (AMD64)] on win32
c. JetBrains Pycharm 2017.2 x64 Professional
d. GeForce GTX 965M
0x02. 安装
1. 安装python 36
一路下一步打钩环境变量设置即可。不建议python 27,因为好像不支持,所以最后一步会报Could
not find a version that satisfies the requirement
tensorflow-gpu (from versions: ) No matching distribution
found for tensorflow-gpu
2. 更改pip默认源
默认源服务器在国外,国内下载较慢,有必要换为国内阿里源。
对于Win来说,直接在当前用户目录下新建一个pip.ini文件,例:C:\Users\yuangezhizao\pip.ini
内容如下:
1.[global]
2.index-url = http://mirrors.aliyun.com/pypi/simple/
3.[install]
4.trusted-host=mirrors.aliyun.com
3. 升级pip
py -2 -m pip install --upgrade pip
由于我电脑安装了两个版本,所以用 py -2 选择 2 版本的解释器,同理 py -3 即是选择 3
版本的解释器
TensorFlow有两个版本:CPU版本和GPU版本。
如果你的电脑没有NVIDIA显卡的话,你就必须选择安装这个版本,不过这个版本的安装要比GPU版的简单,官方也推荐先用CPU版的来体验。TensorFlow在GPU上运行要比CPU上快很多,如果你的GPU能够达到要求就可以选择安装GPU版。GPU版本需要CUDA和cuDNN的支持,要安装GPU版本,需确认显卡是否支持CUDA,查看
GPU 是否支持 CUDA,计算能力大于3.5的N卡一般都支持的说……
另,网上多建议安装Anaconda,因为这个集成了很多科学计算所必需的库,能够避免很多依赖问题,这个Pycharm党就先不安了(其实我安了但是可能是因为我用习惯了感觉没有Pycharm舒服)
4. 安装 CUDA
Windows→x86_64→10→exe (local)
下载如下两个文件,按照先后顺序安装:
Base Installer Download (1.3 GB)
Patch 2 (Released Jun 26, 2017) Download (43.1 MB)
安装完之后,在命令行输入nvcc -V,会有正常回显……
5. 安装 cuDNN
cuDNN可以在前面GPU加速基础上大概再提升1.5倍的速度,同样由nVIDIA开发。官网注册账号,下载
cuDNN v6.0 Library for Windows 10
压缩包,解压完将对应文件夹(bin、include、lib)覆盖至CUDA的安装目录,即C:\Program
Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0,然后把C:\Program
Files\NVIDIA GPU Computing Toolkit\CUDA\v8.0\bin加入环境变量,并将bin文件夹里的cudnn64_6.dll重命名为cudnn64_5.dll(此处参考
tensorflow/issues/7705,其实换旧版本也可以解决 stackoverflow,因为重下安装包较大故采用前一方法),才算完成。
https://developer.nvidia.com/compute/machine-learning/cudnn
/secure/v7.0.5 /prod/9.1_20171129 / cudnn- 9.1- windows10-x64-v7
http://developer2.download.nvidia.com/compute/machine-learning
/cudnn /secure /v7.0.5 /prod /9.1_20171129 /cudnn-9.1-windows10
-x64-v7.zip?ZLrypQyS9qaPi2V24ZffXps- WqZnYaTOsPUaA5O9BY-LV-
bJlHkijvtQkvNn -SPFVTDbAGqc0UhtSt5e70qbF66G4mCzvo9BLs3-fAGYNo0afIsTeQ6YwVbARA1
yzss WExLzEgOm FeGOv7AscZCeepaNlc3 - OdFeUb2s72BF-dXNV8VQx_
u7nc2vgWRQypNmFCTeTXZxo-FpoE-t
话说注册账号要求好麻烦,大小写包含特殊符号且不少于6位……
6. pip安装TensorFlow-GPU(最后一步)
pip3 install -- upgrade tensorflow-gpu
万一在线pip安装失败了,就离线安装,到 http://www.lfd.uci.edu
/~gohlke/pythonlibs/ 下载python 的whl 包tensorflow_gpu?1.1.0?cp36?cp36m?win_amd64.whl,然后命令提示符运行pip
install < 此处填写 .whl 所在位置 >(可以将.whi文件拖入命令提示符中即生成其位置)
0x03. 测试
1.#! python3
2.# coding: utf-8
3.import tensorflow as tf
4.hello = tf.constant('Hello, TensorFlow!')
5.sess = tf.Session()
6.print(sess.run(hello)) |
我的输出较长:
C:\Python36\python.exe
C:/Users /yuangezhizao /PycharmProjects /deeplearning
/helloworld.py
2017- 08- 03 14:53:23.258570: W c:\tf_jenkins
\home\workspace \release-win \m \windows-gpu\py\36
\tensorflow \core \platform \cpu_feature_guard
.cc:45] The TensorFlowlibrary wasn't compiled
to use SSE instructions, but these are available
on your machine and could speed up CPU computations.
2017-08-03 14:53:23.258819: W c:\tf_jenkins \home\workspace
\release-win \m\ windows-gpu\py\36 \tensorflow\
core\platform \cpu_ feature_guard.cc:45] The TensorFlow
library wasn't compiled to use SSE2 instructions,
but these are available on your machine and could
speed up CPU computations.
2017-08-03 14:53:23.259063: W c:\tf_jenkins \home\workspace
\release -win \ m\windows-gpu\py\36 \tensorflow\
core\platform \cpu_feature_ guard.cc:45] The TensorFlow
library wasn't compiled to use SSE3 instructions,
but these are available on your machine and could
speed up CPU computations.
2017-08-03 14:53:23.259307: W c:\tf_jenkins \home\workspace
\ release- win \m\windows-gpu\py\36 \tensorflow
\core \platform \cpu_feature_guard.cc:45] The
TensorFlow library wasn't compiled to use SSE4.1
instructions, but these are available on your
machine and could speed up CPU computations.
2017-08-03 14:53:23.259552: W c:\tf_jenkins \home\workspace
\ release- win \m\windows-gpu\py\36 \tensorflow
\core\platform \ cpu_ feature_guard.cc:45] The
TensorFlow library wasn't compiled to use SSE4.2
instructions, but these are available on your
machine and could speed up CPU computations.
2017-08-03 14:53:23.259790: W c:\tf_jenkins \home\workspace
\ release - win \m\windows-gpu\py \36\tensorflow
\core\platform \ cpu_feature_ guard.cc:45] The
TensorFlow library wasn't compiled to use AVX
instructions, but these are available on your
machine and could speed up CPU computations.
2017-08-03 14:53:23.260028: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py
\36 \ tensorflow\core\platform\cpu_feature_guard.cc:45]
The TensorFlow library wasn't compiled to use
AVX2 instructions, but these are available on
your machine and could speed up CPU computations.
2017-08-03 14:53:23.260264: W c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py
\36\ tensorflow\core\platform\cpu_feature_guard.cc:45]
The TensorFlow library wasn't compiled to use
FMA instructions, but these are available on your
machine and could speed up CPU computations.
2017-08-03 14:53:24.103495: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py
\36 \t ensorflow\core\common_runtime\gpu\gpu_device.cc:940]
Found device 0 with properties:
name: GeForce GTX 965M
major: 5 minor: 2 memoryClockRate (GHz) 0.9495
pciBusID 0000:01:00.0
Total memory: 2.00GiB
Free memory: 1.64GiB
2017-08-03 14:53:24.103772: I c:\tf_ jenkins\home
\workspace\ release -win \ m\windows-gpu\py\36\
tensorflow\ core\common_ runtime \gpu \gpu_device.cc:961]
DMA: 0
2017-08-03 14:53:24.103900: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36
\tensorflow \core\common_runtime\gpu\gpu_device.cc:971]
0: Y
2017-08-03 14:53:24.104045: I c:\tf_jenkins\home\workspace\release-win\m\windows-gpu\py\36\
tensorflow \core\common_runtime\gpu\gpu_device.cc:1030]
Creating TensorFlow device (/gpu:0) -> (device:
0, name: GeForce GTX 965M, pci bus id: 0000:01:00.0)
b'Hello, TensorFlow!' |
这里之所以会出红字提示是因为没有在本机编译,尝试编译(实在是不会……),于是重启进Mac里…… 未完待续
0x04. 参考
http://www.jianshu.com/p/6766fbcd43b9
http://www.jianshu.com/p/c245d46d43f0
http://blog.csdn.net/u010099080/article/details/53418159
http://blog.csdn.net/wx7788250/article/details/60877166
http://www.cnblogs.com/leoking01/p/6913408.html |









