| БрМЭЦМі: |
| БОЮФРДздгкcnblogsЃЌЮФеТжївЊЖдCUDAЗНАИЯТЕФИпВЂааЕФМЦЫуЕФЯъЯИВћЪіЃЌЭЌЪБЖдЦфЫћМИжжЗНАИНјааСЫУшЪіЁЃ |
|
етИідТ6КХПЊЪМЃЌзХЪжНтОівЛИіОпгаЪЕМЪвтвхЕФМЦЫуШЮЮёЁЃШЮЮёЪ§Онга9879896ЬѕЃЌУПЬѕАќКЌ30ИіећЪ§ЃЌШЮЮёЪЧМЦЫуУПСНЬѕЪ§ОнжЎМфЕФЫЙЦЄЖћЯрЙиЯЕЪ§МАЦфPжЕЁЃдЪМЪ§ОнжЛга500+MBЃЌвђДЫЮвВЂВЛШЯЮЊетЪЧИіЖрУДДѓЕФМЦЫуШЮЮёЁЃЫцКѓЩдМгМЦЫуЃЌЮвЛЙЪЧКмОЊДєЕФЃЌвЊМЦЫу(9879896ЁС9879895)ЁТ2Ёж4.88вквкзщЪ§ОнЃЌЕЋДЫЪБетЛЙжЛЪЧИіЪ§зжИХФюЃЌЮввВУЛвтЪЖЕНЪБМфИДдгЖШКЭПеМфИДдгЖШЕФЮЪЬтЁЃ
1. МЦЫуЙцФЃГѕЬхбщ
Ъ§ОнИёЪНЃК9879896ааЃЌ30СаЃЌУПСажЎМфвдПеИёЗћИєПЊЃЌР§ШчЃК
0 2 0 2 0 0
0 0 0 0 0 40 0 0 35 0 0 53 0 44 0 0 0 0 0 0 0
0 0 0
0 0 1 148 0 0 0 0 0 0 0 0 0 0 1133 0 1 0 0 1820
0 0 0 2 0 0 0 1 0 0
0 0 0 33 1 0 0 0 0 0 0 0 0 0 231 0 0 0 0 402 0
0 0 0 0 0 0 0 0 0
0 0 6 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 1 0 6
0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0
... ...
... ... |
ПеМфИДдгЖШЃКЕЅДПМЦЫуЯТНсЙћДѓИХгаЖрДѓАЩЃЌУПзщМЦЫуНсЙћАќКЌЯрЙиЯЕЪ§КЭPжЕЃЌШєЖМвдfloatЃЈеМ4зжНкЃЉОЋЖШДцДЂЃЌашвЊеМгУФкДцЃК4.88вквкЁС8BЁж400TBЃЌЕБШЛЃЌЮвУЧВЛОпБИетУДДѓФкДцЃЌвђДЫЮоТлвдКЮжжЗНЪНМЦЫуЃЌЖМашвЊвЛХњХњЕижиИДНЋЪ§ОндиШыФкДцЁЂМЦЫуЁЂДцШыгВХЬетИіЙ§ГЬЃЌжБЕНдЫЫуЭъГЩЁЃФЧУДЃЌДцШыгВХЬЕФНсЙћЛсга400TBТ№ЃПВЛШЛЃЌPжЕаЁгкЛђЕШгк0.05ЕФНсЙћВХЛсашвЊЪфГіЃЌвђДЫЪЕМЪЩЯЛсдЖдЖаЁгкетИіжЕЃЌОпЬхЛсаЁЖрЩйЃЌЯШдЫаавЛХњЪ§ОнКѓВХФмзіГіЙРЫуЁЃ
ЪБМфИДдгЖШЃКМЦЫуЕФзщЪ§ЙцФЃЪЧ(nЁС(n-1))ЁТ2ЃЌФЧУДОЭПДГЬађФмХмЖрПьСЫЁЃЮвЯыЯШПДПДMATLABЖрЯпГЬЁЂPythonЖрЯпГЬЁЂSparkЗжВМЪНМЦЫуФмХмЖрПьЃЌЪЧЗёФмдкзюПьЪБМфФкНтОіЮЪЬтЁЃ
2. MATLABЖрЯпГЬ
MATLABаДЦ№РДзюМђЕЅЃЌМЦЫуЯрЙиЯЕЪ§КЭPжЕЖМВЛгУВйаФЃЌвЛааздДјЕФКЏЪ§ЕїгУОЭЭъГЩЁЃДђПЊMATLABзѓЯТНЧЕФВЂааГиЃЌMATLABНЋЛсздЖЏбАевЕНЛњзгЩЯгаЕФЮяРэКЫаФЃЌВЂЗжХфгыЮяРэКЫаФЪ§ЯрЭЌЕФworkerЁЃБШШчЮвЕФЕчФдЪЧ4КЫ8ЯпГЬЃЌЫќжЛФмПЊ4ИіworkerЃЌВЛЪЖБ№ащФтКЫаФЁЃ
ДњТыШчЯТЃК
t1 = clock;
disp('>> loading ...');
A = importdata('D:/MASTER2016/5.CUDA/data-ID-top30-kv3.txt');
b = A'; %гЩгкMATLABжЛМЦЫуСагыСажЎМфЕФЯрЙиЯЕЪ§ЃЌвђДЫашвЊзЊжУВйзї
disp(etime(clock,t1));
num = size(b, 2);
disp('>> calculating ...');
fid = fopen('D:/MASTER2016/5.CUDA/result-matlab.txt',
'wt');
for i = 1 : num
for j = i+1 : num
[m, n] = corr(b(:, i), b(:, j), 'type', 'Spearman',
'tail', 'both');
if isnan(n) || n>0.05
continue;
end
fprintf(fid, 'X%d\tX%d\t%d\t%d\n', i, j, m, n);
end
end
fclose(fid);
disp('>> OK!'); |
етРяЮвВЂУЛгаПМТЧФкДцПеМфВЛЙЛЕФЮЪЬтЃЌвђЮЊЮвжЛЪЧЯыЫЕУїMATLABЕФМЦЫуЫйЖШЁЃПЊСЫЖрПХКЫаФЕФЧщПіЯТЃЌMATLABВЂУЛФмЭъШЋбЙеЅГіЫљгаЕФCPUадФмЃЌМЦЫуЫйЖШЛКТ§ЮоБШЃЌИќвЊУќЕФЪЧЃЌЫќЛсдНЫудНТ§ЁЃОнЮвЙРЫуЃЌМДЪЙПеМфИДдгЖШзуЙЛЃЌMATLABвВвЊгУГЌЙ§20ФъЕФЪБМфВХФмЫуЭъЃЌетЛЙЪЧВЛПМТЧдНЫудНТ§ЕФЧщПіЁЃ
КУСЫЃЌДЫЗНАИНіЪЧДђНДгЭЁЃ
3. PythonЖрЯпГЬ
PythonгябдгЩгкБОЩэЕФЬхжЪЮЪЬтЃЌCythonЯТВЛФмЕїгУЖрКЫЃЌжЛФмгУЖрЯпГЬЁЃРэТлЩЯЪЧетбљЃЌЕЋЛЙЪЧгаКмЖрРЉеЙАќФмЙЛГфЗжбЙеЅГіЖрКЫCPUадФмЃЌР§ШчmultiprocessingЪЧЦфжаЕФйЎйЎепЁЃmultiprocessingгУЦ№РДвВЗЧГЃМђЕЅЃЌПМТЧЕНCPUЕФЖрКЫдЫЫуЯТЃЌУППХКЫаФЕФЫуСІЛЙЪЧКмПЩЙлЕФЃЌЫљгаВЛФмАбУПИіМЦЫузщЖМВ№ГЩВЂааЯпГЬЃЌФЧбљФкДцЕФЖСаДПЊЯњЗДЖјЛсЪЙCPUвЛжБдкЕШД§зДЬЌЃЌВЛФмвЛжБТњИКдиЙЄзїЁЃМјгкДЫЃЌЮвЩшМЦ9879895зщЯпГЬЃЌУПзщДњБэФГИіЬиЖЈаагыЪЃЯТЕФИїИіЪ§ОнаааЮГЩЕФЪ§ОнзщЁЃетбљУПзщЯпГЬЯТЕФдЫЫуСПЛЙЪЧБШНЯДѓЕФЃЌФмЪЙCPUОЁПЩФмШЋдкТњИКдизДЬЌЁЃ
ДњТыШчЯТЃК
# coding=utf-8
import math
import multiprocessing
import time
import scipy.stats as stats
def calculate2(i, X, all_glb, data_array_glb):
all = all_glb.value
result = []
for j in range(i + 1, all):
x = X
y = data_array_glb[j]
if math.fsum(x) == 0 or math.fsum(y) == 0:
continue
corr, p = stats.spearmanr(x, y)
if p > 0.05:
continue
result.append([i + 1, j + 1, corr, p])
return result
if __name__ == "__main__":
multiprocessing.freeze_support()
input_file = 'D:/MASTER2016/5.CUDA/data-ID-top30-kv3.txt'
output_file = 'D:/MASTER2016/5.CUDA/result-python.txt'
print '>> loading ...'
start = time.clock()
data = open(input_file)
data_array = []
for line in data:
data_array.append(map(int, line.strip().split('
')))
data.close()
print time.clock()-start, 's'
print '>> calculating ...'
results = []
pool_size = 8
pool = multiprocessing.Pool(processes=pool_size)
all = len(data_array)
manager = multiprocessing.Manager()
all_share = manager.Value('i', int(all))
data_array_share = manager.list(data_array)
for i in range(all):
data_X = data_array[i]
results.append(pool.apply_async(calculate2, args=(i,
data_X, all_share, data_array_share)))
pool.close()
pool.join()
print time.clock() - start, 's'
data_array = None
print '>> saving ...'
data2 = open(output_file, 'w')
for res in results:
temp_list = res.get()
for temp in temp_list:
data2.write('X'+str(temp[0])+'\t'+'X'+str(temp[1])
+'\t'+str(temp[2])+'\t'+str(temp[3])+'\n')
print time.clock()-start, 's'
data2.close() |
етРяЃЌЮввРШЛУЛгаПМТЧПеМфИДдгЖШЮЪЬтЃЌвђЮЊвЊЯШПДПДМЦЫуФмСІЪЧЗёФмТњзуШЮЮёвЊЧѓЁЃPythonЕФетИіЖрЯпГЬЯТЃЌШЗЪЕФмГфЗжеЅИЩCPUадФмЃЌЗчЩШКєКєЯьЃЌвЊУќЕФЪЧвВДцдкдНЫудНТ§ЕФЮЪЬтЁЃЕЋЪЧЃЌМДЪЙCPUвЛжБетУДТњИКдидЫЫуЃЌЮвДжТдЙРЫуСЫЯТЃЌвВЕУвЊИі14Фъ+ВХФмЫуЭъЃЌвВВЛЫудНЫудНТ§ЕФЧщПіЁЃ
ЫљвдЃЌДЫЗНАИЪЧДђНДгЭ2КХЁЃ
4. SparkЗНАИ
SparkЗНАИЮвВЂУЛгааДЭъЃЌвђЮЊаДзХаДзХОЭИаОѕЕНЁЃЁЃЁЃПЯЖЈЛЙЪЧВЛааЃЌCPUЕФЫуСІвВОЭФЧбљСЫЁЃОЭЫуЕї12ЬЈЛњЦївЛЦ№ХмЃЌвВВЛЪЪКЯгУCPUЯТЕФЯпГЬФЃаЭНтОіЮЪЬтСЫЁЃ
етжжИпВЂааЕФМЦЫуЃЌвЊЯыШЁЕУзюПьМЦЫуЫйЖШЃЌЗЧGPUФЊЪєЁЃ
5. CUDAЗНАИ
CUDAЗНАИЯТЃЌЪзЯШБиаыЧхЮњЕиЩшМЦКУЯпГЬФЃаЭЃЌМДЃКЮвашвЊгУЕНМИПщGPUЃПЮвашвЊдкУППщGPUЩЯЩшМЦЖрЩйИіblockЃПУПИіblockЩшМЦЖрЩйИіЯпГЬЃПУПИіЯпГЬЗжХфЖрЩйдЫЫуСПЃПетЫФИіЮЪЬтЛљБООіЖЈСЫCUDAГЬађЕФадФмКЭИДдгЖШЁЃ
CUDAЪЧвЛжжвьЙЙВЂааНтОіЗНАИЃЌМДCPUгУгкПижЦЃЌGPUгУгкжїдЫЫуЕФЗНАИЁЃвЛИіGPUгавЛИіgridЃЌУПИіgridРягаДѓСПblockЃЌУПИіblockРягаДѓСПthreadЁЃдкдЫЫуЪБЃЌУПИіthreadЖМЪЧЭъШЋЖРСЂВЂааЕидЫЫуЃЌУПИіЯпГЬРяЕФдЫЫуППФкКЫКЏЪ§ПижЦЃЌетвВЪЧCUDAБрГЬЕФКЫаФЃЌФПЧАжЛФмгУCUDA
CБраДЁЃвђДЫJCUDAКЭPyCUDAзіЕФжЛЪЧФкДцЗжХфетаЉCPUЖЫПижЦЕФЪТЧщЃЌЛЙВЛФмДњЬцGPUЖЫЕФCUDA
CДњТыЁЃ
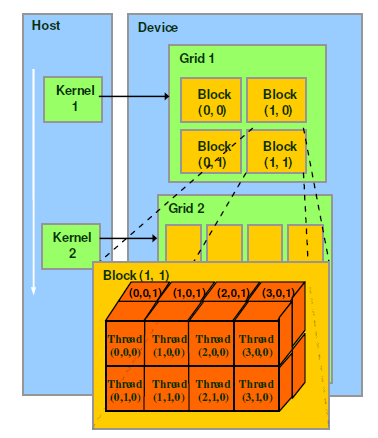
ШчЩЯЭМЃЌзѓБпСаЪЧHostЖЫЃЌМДCPUЩЯжДааЕФПижЦЖЫЃЌгУгкЗжХфGPUФкДцПеМфЃЌПНБДФкДцЪ§ОнЕНGPUЯдДцЕШЕШВйзїЁЃгвБпСаЪЧDeviceЖЫЃЌМДGPUЩЯЕФВЂааФЃаЭЃЌгЩgridЃЌblockЃЌthreadШ§епЙЙГЩЁЃВЛЭЌаЭКХGPUЕФзюДѓblockЪ§КЭУПИіblockжаЕФзюДѓthreadВЛЭЌЃЌЕЋЪЧПЩвдВщбЏЁЃдкАВзАКУCUDA
ToolkitКѓЃЌwindowsгУЛЇПЩвдНјШыC:\ProgramData\NVIDIA Corporation\CUDA
Samples\v8.0\1_Utilities\deviceQueryФПТМЃЌДђПЊЯргІАцБОЕФЯюФПЃЌжДаадЫааВщбЏЁЃ
БШШчЮвЕФЛњЦїЃК
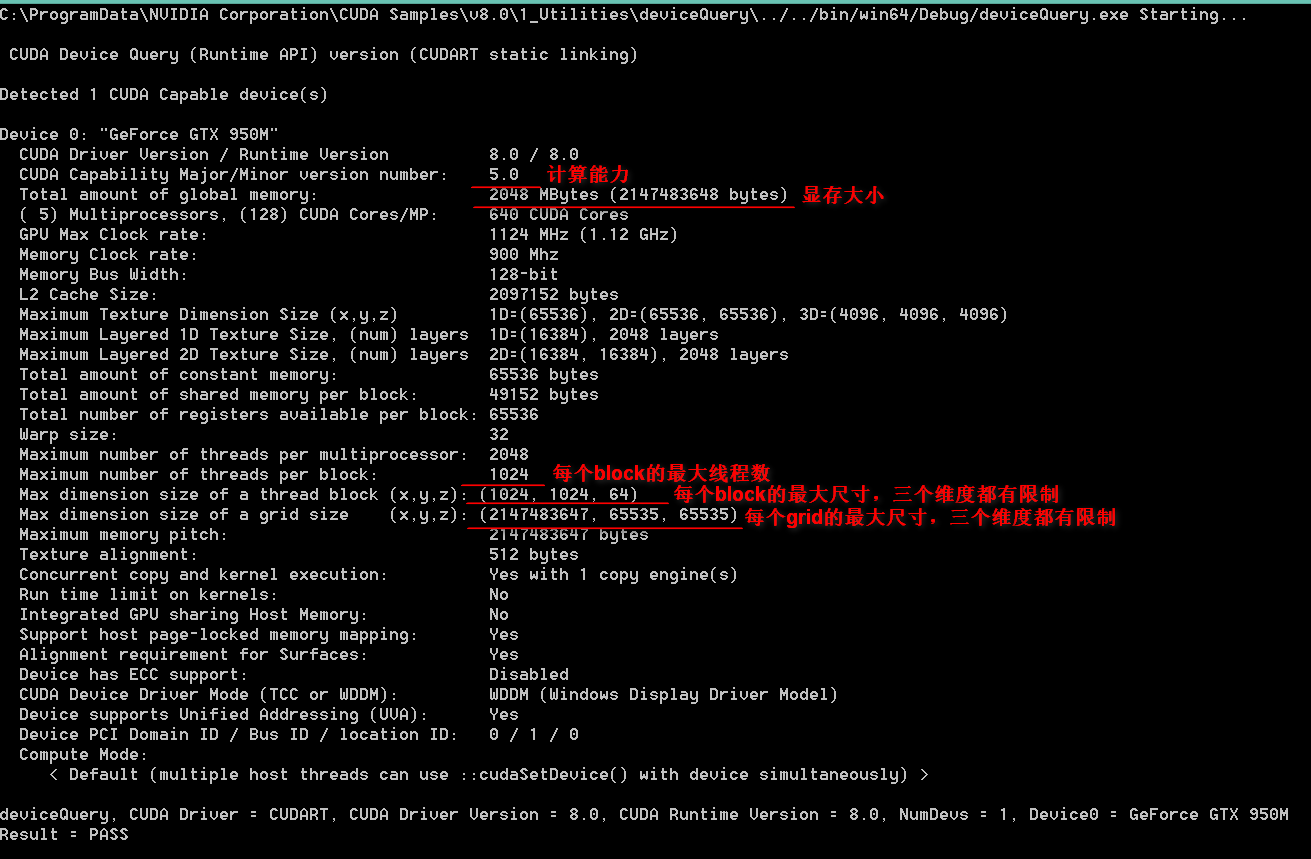
ЛљгкДЫЃЌЮвЩшМЦЕФЯпГЬФЃаЭЪЧЃКБШШчЪ§ОнЪЧROWSааЃЌCOLSСаЃЌФЧУДга((ROWS-1)ЁСROWS)ЁТ2зщМЦЫуЃЌУПвЛааЖМвЊгыДгетааПЊЪМКѓУцЕФУПвЛааНјааМЦЫуЁЃПЊБй(ROWS-1)ИіblockЃЌБрКХ0~(ROWS-1)ЖдгІзХЪ§ОнЕФааКХЁЃЫљвдЃЌЖдгкЕквЛааЃЌааКХЪЧ0ЃЌвЊгы1~(ROWS-1)ЕФУПвЛааНјааМЦЫуЃЌвЛЙВга(ROWS-1)зщЃЌетаЉМЦЫуШЮЮёЗжХфИјЕквЛПщblockЕФ1024ИіЯпГЬЩЯМЦЫуЁЃвРДЫРрЭЦЁЃетбљзіВЂВЛЪЧзюМбЕФШЮЮёЗжХфЗНАИЃЌвђЮЊВЛЪЧЙЋЦНЗжХфЃЌБрКХдНППКѓЕФblockЗжХфЕФШЮЮёдНЩйЁЃЕЋЪЧЃЌетбљзіЕФКУДІЪЧБугкРћгУЙВЯэФкДцЃЌМгЫйУПвЛИіblockФкЕФМЦЫуЁЃ
БШШчЕквЛааЃЌНЋЪ§ОнЕквЛааДцШыЙВЯэФкДцЃЌФЧУДЫќдкгыЦфЫћааЗжБ№МЦЫуЕФЪБКђЃЌжБНгДгУПИіblockФкЕФЙВЯэФкДцЖСШЁЪ§ОнЃЌдЖдЖБШДгЯдДцЩЯЕФШЋОжФкДцЖСШЁЫйЖШПьЕУЖрЁЃашвЊзЂвтЕФЪЧЃЌУППщblockФкЕФЙВЯэФкДцЕФДѓаЁвВгагВМўЯожЦЃЌЩЯУцНиЭМжаПЩвдПДЕНЃЌGTX
950MЕФЙВЯэФкДцЪЧ49152BЁЃ
Talk is cheap. Show me the code:
#include <time.h>
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
// ЖЈвхзмЪ§ОнОиеѓЕФааЪ§КЭСаЪ§
#define ROWS 15000
#define COLS 30
// ЖЈвхУПвЛПщФкЕФЯпГЬИіЪ§ЃЌGT720зюЖрЪЧ1024ЃЈБиаыДѓгкзмОиеѓЕФСаЪ§ЃК30ЃЉ
#define NUM_THREADS 1024
bool InitCUDA()
{
int count;
cudaGetDeviceCount(&count);
if (count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++) {
cudaDeviceProp prop;
if (cudaGetDeviceProperties(&prop, i) ==
cudaSuccess) {
if (prop.major >= 1) {
break;
}
}
}
if (i == count) {
fprintf(stderr, "There is no device supporting
CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
__device__ float meanForRankCUDA(int num)
{
float sum = 0;
for (int i = 0; i <= num; i++) {
sum += i;
}
return sum / (num + 1);
}
__device__ float meanForArrayCUDA(float array[],
int len)
{
float sum = 0;
for (int i = 0; i < len; i++) {
sum += array[i];
}
return sum / len;
}
__device__ float spearmanKernel(int Xarray[],
int Yarray[])
{
//1ЃЌЖддЯШЕФЪ§ОнНјааХХађЃЌЯрЭЌЕФжЕШЁЦНОљжЕ
float Xrank[30];
float Yrank[30];
int col = 30;
for (int i = 0; i < col; i++) {
int bigger = 1;
int equaer = -1;
for (int j = 0; j < col; j++) {
if (Xarray[i] < Xarray[j]) {
bigger = bigger + 1;
}
else if (Xarray[i] == Xarray[j]) {
equaer = equaer + 1;
}
}
Xrank[i] = bigger + meanForRankCUDA(equaer);
}
for (int i = 0; i < col; i++) {
int bigger = 1;
int equaer = -1;
for (int j = 0; j < col; j++) {
if (Yarray[i] < Yarray[j]) {
bigger = bigger + 1;
}
else if (Yarray[i] == Yarray[j]) {
equaer = equaer + 1;
}
}
Yrank[i] = bigger + meanForRankCUDA(equaer);
}
//2ЃЌМЦЫуЫЙЦЄЖћТќЯрЙиадЯЕЪ§
float numerator = 0;
float denominatorLeft = 0;
float denominatorRight = 0;
float meanXrank = meanForArrayCUDA(Xrank, col);
float meanYrank = meanForArrayCUDA(Yrank, col);
for (int i = 0; i < col; i++) {
numerator += (Xrank[i] - meanXrank) * (Yrank[i]
- meanYrank);
denominatorLeft += powf(Xrank[i] - meanXrank,
2);
denominatorRight += powf(Yrank[i] - meanYrank,
2);
}
float corr = 0;
if ((denominatorLeft != 0) && (denominatorRight
!= 0)) {
corr = numerator / sqrtf(denominatorLeft * denominatorRight);
}
return corr;
}
__global__ static void spearCUDAShared(const
int* a, size_t lda, float* c, size_t ldc, float*
d, size_t ldd)
{
extern __shared__ int data[];
const int tid = threadIdx.x;
const int row = blockIdx.x;
int i, j;
// ЭЌВНЕк1аа~ЕЙЪ§ЕкЖўааЕНЙВЯэФкДцЃЌааЪ§гЩblockИіЪ§ЃЈзмЪ§ОнОиеѓЕФааЪ§-1ЃЉПижЦЃЌУПИіblockЙВЯэвЛааЪ§Он
if (tid < 30) {
data[tid] = a[row * lda + tid];
}
__syncthreads();
int cal_per_block = gridDim.x - row; // УПИіПщЗжЕЃЕФМЦЫуСП
int cal_per_thread = cal_per_block / blockDim.x
+ 1; // УПИіЯпГЬЗжЕЃЕФМЦЫуСП
// ЗжХфИїЯпГЬМЦЫуШЮЮёЃЌЭЈЙ§forбЛЗПижЦдквЛИіЯпГЬашвЊМЦЫуЕФзщЪ§
for (i = row + cal_per_thread * tid; i <
(row + cal_per_thread * (tid + 1)) &&
i < gridDim.x; i++) {
int j_row[30]; // ДцЗХзмЪ§ОнОиеѓЕФЕкjаа
for (j = 0; j < 30; j++) {
j_row[j] = a[(i + 1)*lda + j];
}
float corr = spearmanKernel(data, j_row);
c[row * ldc + (i + 1)] = corr;
float t_test = 0;
if (corr != 0) t_test = corr*(sqrtf((30 - 2)
/ (1 - powf(corr, 2))));
d[row * ldd + (i + 1)] = t_test;
//printf("blockКХЃК%d, ЯпГЬКХЃК%d, МЦЫузщЃК%d-%d,
idКХЃК%d, blockИіЪ§ЃК%d, УППщЯпГЬИіЪ§ЃК%d, ИУПщзмМЦЫуСПЃК%d, ИУПщжаУПИіЯпГЬМЦЫуСПЃК%d,
corr: %lf, %d, %d, %d - %d, %d, %d\n",
row, tid, row, i + 1, (row*blockDim.x + tid),
gridDim.x, blockDim.x, cal_per_block, cal_per_thread,
corr, data[0], data[1], data[29], j_row[0],
j_row[1], j_row[29]);
}
}
clock_t matmultCUDA(const int* a, float* c,
float* d)
{
int *ac;
float *cc, *dc;
clock_t start, end;
start = clock();
size_t pitch_a, pitch_c, pitch_d;
// ПЊБйaЁЂcЁЂdдкGPUжаЕФФкДц
cudaMallocPitch((void**)&ac, &pitch_a,
sizeof(int)* COLS, ROWS);
cudaMallocPitch((void**)&cc, &pitch_c,
sizeof(float)* ROWS, ROWS);
cudaMallocPitch((void**)&dc, &pitch_d,
sizeof(float)* ROWS, ROWS);
// ИДжЦaДгCPUФкДцЕНGPUФкДц
cudaMemcpy2D(ac, pitch_a, a, sizeof(int)* COLS,
sizeof(int)* COLS, ROWS, cudaMemcpyHostToDevice);
spearCUDAShared << <ROWS - 1, NUM_THREADS,
sizeof(int)* COLS >> > (ac, pitch_a
/ sizeof(int), cc, pitch_c / sizeof(float),
dc, pitch_d / sizeof(float));
cudaMemcpy2D(c, sizeof(float)* ROWS, cc, pitch_c,
sizeof(float)* ROWS, ROWS, cudaMemcpyDeviceToHost);
cudaMemcpy2D(d, sizeof(float)* ROWS, dc, pitch_d,
sizeof(float)* ROWS, ROWS, cudaMemcpyDeviceToHost);
cudaFree(ac);
cudaFree(cc);
end = clock();
return end - start;
}
void print_int_matrix(int* a, int row, int col)
{
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
printf("%d\t", a[i * col + j]);
}
printf("\n");
}
}
void print_float_matrix(float* c, int row, int
col) {
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
printf("%f\t", c[i * col + j]);
}
printf("\n");
}
}
void read_ints(int* a) {
FILE* file = fopen("D:\\MASTER2016\\5.CUDA\\data-ID-top30-kv.txt",
"r");
int i = 0;
int count = 0;
fscanf(file, "%d", &i);
while (!feof(file))
{
a[count] = i;
count++;
if (count == ROWS*COLS) break;
fscanf(file, "%d", &i);
}
fclose(file);
}
int main()
{
int *a; // CPUФкДцжаЕФзмЪ§ОнОиеѓЃЌROWSааЃЌCOLSСа
float *c; // CPUФкДцжаЕФЯрЙиЯЕЪ§НсЙћОиеѓЃЌROWSааЃЌROWSСа
float *d; // CPUФкДцжаЕФTжЕНсЙћОиеѓЃЌROWSааЃЌROWSСа
a = (int*)malloc(sizeof(int)* COLS * ROWS);
c = (float*)malloc(sizeof(float)* ROWS * ROWS);
d = (float*)malloc(sizeof(float)* ROWS * ROWS);
clock_t start = clock();
printf(">> loading ... rows: %d,
cols: %d", ROWS, COLS);
read_ints(a);
clock_t end = clock() - start;
printf("\nTime used: %.2f s\n", (double)(end)
/ CLOCKS_PER_SEC);
//print_int_matrix(a, ROWS, COLS);
//printf("\n");
printf(">> calculating ... ");
printf("\n---------------------------------------");
printf("\ntotal groups: %lld", (long
long)ROWS*(ROWS - 1) / 2);
printf("\ntotal threads: %d (blocks) *
1024 = %d", (ROWS - 1), (ROWS - 1) * 1024);
printf("\ntotal space complexity: %lld
MB", (long long)((ROWS / 1024) * (ROWS
/ 1024) * 8));
printf("\n---------------------------------------");
if (!InitCUDA()) return 0;
clock_t time = matmultCUDA(a, c, d);
double sec = (double)(time + end) / CLOCKS_PER_SEC;
printf("\nTime used: %.2f s\n", sec);
printf(">> saving ... ");
FILE *f = fopen("D:\\MASTER2016\\5.CUDA\\result-c-2.txt",
"w");
for (int i = 0; i < ROWS; i++) {
for (int j = i + 1; j < ROWS; j++) {
float t_test = d[i * ROWS + j];
if (t_test >= 2.042) {
fprintf(f, "X%d\tX%d\t%f\t%lf\n",
i + 1, j + 1, c[i * ROWS + j], t_test);
}
}
}
fclose(f);
end = clock() - start;
printf("OK\nTime used: %.2f s\n",
(double)(end) / CLOCKS_PER_SEC);
//printf(">> ЯрЙиЯЕЪ§НсЙћОиеѓ: \n");
//print_float_matrix(c, ROWS, ROWS);
//printf(">> TжЕНсЙћОиеѓ: \n");
//print_float_matrix(d, ROWS, ROWS);
getchar();
return 0;
}
CUDAЕквЛАц |
ашвЊжИГіЕФЪЧЃЌЩЯУцГЬађБЃДцЮЊfilename.cuЮФМўЃЌжДааnvcc
-o filename filename.cuБрвыЃЌжДааfilenameМДПЩдЫааЁЃЦфжаROWSЪЧДгзмЪ§ОнЮФМўжаЖСШЁЕФааЪ§ЃЌгУгкПижЦЪ§ОнЙцФЃЕїЪдГЬађЃЌШчЙћROWSДѓгкЛђЕШгкзмЪ§ОнааЪ§ЃЌФЧУДОЭЪЧЖСШЁећИіЮФМўСЫЁЃ
гЩгкПеМфИДдгЖШЬЋИпЃЌвВОЭЪЧзюПЊЪМЬсЕНЕФЃЌФЧУДЯТУцзіаЉЕїећЃЌМгИіПижЦВЮЪ§ЃЌУПДЮжЛМЦЫувЛЖЈЕФааЪ§ЃЌЪЙЯдДцТњдиЕЋВЛГЌГіМДПЩЁЃЯргІЕиЃЌФкКЫКЏЪ§жаЕФЫїв§КХЃЌБЃДцЮФМўЕФКЏЪ§ЖМашвЊзіаЉЮЂЕїЃЌДњТыШчЯТЃК
#include <time.h>
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
// ЖЈвхзмЪ§ОнОиеѓЕФааЪ§КЭСаЪ§
#define ROWS 1000
#define COLS 30
// ПижЦвЛДЮМЦЫуеМгУЯдДцЕФДѓаЁЃКCONTROL_ROWS*ROWS*8ЃЈзжНкЃЉ<
ЯдДц
#define CONTROL_ROWS 45
// ЖЈвхУПвЛПщФкЕФЯпГЬИіЪ§ЃЌGT720зюЖрЪЧ1024
#define NUM_THREADS 1024
bool InitCUDA()
{
int count;
cudaGetDeviceCount(&count);
if (count == 0) {
fprintf(stderr, "There is no device.\n");
return false;
}
int i;
for (i = 0; i < count; i++) {
cudaDeviceProp prop;
if (cudaGetDeviceProperties(&prop, i) ==
cudaSuccess) {
if (prop.major >= 1) {
break;
}
}
}
if (i == count) {
fprintf(stderr, "There is no device supporting
CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
return true;
}
__device__ float meanForRankCUDA(int num)
{
float sum = 0;
for (int i = 0; i <= num; i++) {
sum += i;
}
return sum / (num + 1);
}
__device__ float meanForArrayCUDA(float array[],
int len)
{
float sum = 0;
for (int i = 0; i < len; i++) {
sum += array[i];
}
return sum / len;
}
__device__ float spearmanKernel(int Xarray[],
int Yarray[])
{
//1ЃЌЖддЯШЕФЪ§ОнНјааХХађЃЌЯрЭЌЕФжЕШЁЦНОљжЕ
float Xrank[30];
float Yrank[30];
int col = 30;
for (int i = 0; i < col; i++) {
int bigger = 1;
int equaer = -1;
for (int j = 0; j < col; j++) {
if (Xarray[i] < Xarray[j]) {
bigger = bigger + 1;
}
else if (Xarray[i] == Xarray[j]) {
equaer = equaer + 1;
}
}
Xrank[i] = bigger + meanForRankCUDA(equaer);
}
for (int i = 0; i < col; i++) {
int bigger = 1;
int equaer = -1;
for (int j = 0; j < col; j++) {
if (Yarray[i] < Yarray[j]) {
bigger = bigger + 1;
}
else if (Yarray[i] == Yarray[j]) {
equaer = equaer + 1;
}
}
Yrank[i] = bigger + meanForRankCUDA(equaer);
}
//2ЃЌМЦЫуЫЙЦЄЖћТќЯрЙиадЯЕЪ§
float numerator = 0;
float denominatorLeft = 0;
float denominatorRight = 0;
float meanXrank = meanForArrayCUDA(Xrank, col);
float meanYrank = meanForArrayCUDA(Yrank, col);
for (int i = 0; i < col; i++) {
numerator += (Xrank[i] - meanXrank) * (Yrank[i]
- meanYrank);
denominatorLeft += powf(Xrank[i] - meanXrank,
2);
denominatorRight += powf(Yrank[i] - meanYrank,
2);
}
float corr = 0;
if ((denominatorLeft != 0) && (denominatorRight
!= 0)) {
corr = numerator / sqrtf(denominatorLeft * denominatorRight);
}
return corr;
}
__global__ static void spearCUDAShared(const
int* a, size_t lda, float* c, size_t ldc, float*
d, size_t ldd, int cols, int start)
{
extern __shared__ int data[];
const int tid = threadIdx.x;
const int row = blockIdx.x;
int i, j;
// ЭЌВНЕк1аа~ЕЙЪ§ЕкЖўааЕНЙВЯэФкДцЃЌааЪ§гЩblockИіЪ§ПижЦЃЌУПИіblockЙВЯэвЛааЪ§Он
if (tid < 30) {
data[tid] = a[(start + row) * lda + tid];
}
__syncthreads();
int cal_per_block = cols - (start + row);
// УПИіПщЗжЕЃЕФМЦЫуСП
int cal_per_thread = cal_per_block / blockDim.x
+ 1; // УПИіЯпГЬЗжЕЃЕФМЦЫуСП
// ЗжХфИїЯпГЬМЦЫуШЮЮёЃЌЭЈЙ§forбЛЗПижЦдквЛИіЯпГЬашвЊМЦЫуЕФзщЪ§
for (i = row + cal_per_thread * tid; i <
(row + cal_per_thread * (tid + 1)) &&
i < cols; i++) {
int j_row[30]; // ДцЗХзмЪ§ОнОиеѓЕФЕкjаа
for (j = 0; j < 30; j++) {
j_row[j] = a[(start + i + 1)*lda + j];
}
float corr = spearmanKernel(data, j_row);
c[row * ldc + (start + i + 1)] = corr;
float t_test = 0;
if (corr != 0) t_test = corr*(sqrtf((30 - 2)
/ (1 - powf(corr, 2))));
d[row * ldd + (start + i + 1)] = t_test;
//printf("blockКХЃК%d, ЯпГЬКХЃК%d, МЦЫузщЃК%d-%d,
idКХЃК%d, blockИіЪ§ЃК%d, УППщЯпГЬИіЪ§ЃК%d, ИУПщзмМЦЫуСПЃК%d, ИУПщжаУПИіЯпГЬМЦЫуСПЃК%d,
corr: %lf, %d, %d, %d - %d, %d, %d\n",
row, tid, row, i + 1, (row*blockDim.x + tid),
gridDim.x, blockDim.x, cal_per_block, cal_per_thread,
corr, data[0], data[1], data[29], j_row[0],
j_row[1], j_row[29]);
}
}
clock_t matmultCUDA(const int* a, float* c,
float* d, int start_index, int control_rows)
{
int *ac;
float *cc, *dc;
clock_t start, end;
start = clock();
size_t pitch_a, pitch_c, pitch_d;
// ПЊБйaЁЂcЁЂdдкGPUжаЕФФкДц
cudaMallocPitch((void**)&ac, &pitch_a,
sizeof(int)* COLS, ROWS);
cudaMallocPitch((void**)&cc, &pitch_c,
sizeof(float)* ROWS, control_rows);
cudaMallocPitch((void**)&dc, &pitch_d,
sizeof(float)* ROWS, control_rows);
// ИДжЦaДгCPUФкДцЕНGPUФкДц
cudaMemcpy2D(ac, pitch_a, a, sizeof(int)* COLS,
sizeof(int)* COLS, ROWS, cudaMemcpyHostToDevice);
spearCUDAShared << <control_rows,
NUM_THREADS, sizeof(int)* COLS >> >
(ac, pitch_a / sizeof(int), cc, pitch_c / sizeof(float),
dc, pitch_d / sizeof(float), ROWS - 1, start_index);
cudaMemcpy2D(c, sizeof(float)* ROWS, cc, pitch_c,
sizeof(float)* ROWS, control_rows, cudaMemcpyDeviceToHost);
cudaMemcpy2D(d, sizeof(float)* ROWS, dc, pitch_d,
sizeof(float)* ROWS, control_rows, cudaMemcpyDeviceToHost);
cudaFree(ac);
cudaFree(cc);
cudaFree(dc);
end = clock();
return end - start;
}
void print_int_matrix(int* a, int row, int col)
{
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
printf("%d\t", a[i * col + j]);
}
printf("\n");
}
}
void print_float_matrix(float* c, int row, int
col) {
for (int i = 0; i < row; i++) {
for (int j = 0; j < col; j++) {
printf("%f\t", c[i * col + j]);
}
printf("\n");
}
}
void read_ints(int* a, char *input_file) {
FILE* file = fopen(input_file, "r");
int i = 0;
int count = 0;
fscanf(file, "%d", &i);
while (!feof(file))
{
a[count] = i;
count++;
if (count == ROWS*COLS) break;
fscanf(file, "%d", &i);
}
fclose(file);
}
void clear_ints(char * out_file) {
FILE *f = fopen(out_file, "w");
fclose(f);
}
void cal_and_save(int i, int *a, char *out_file,
int control_rows) {
float *c; // CPUФкДцжаЕФЯрЙиЯЕЪ§НсЙћОиеѓЃЌROWSааЃЌROWSСа
float *d; // CPUФкДцжаЕФTжЕНсЙћОиеѓЃЌROWSааЃЌROWSСа
c = (float*)malloc(sizeof(float)* control_rows
* ROWS);
d = (float*)malloc(sizeof(float)* control_rows
* ROWS);
clock_t time = matmultCUDA(a, c, d, i, control_rows);
FILE *f = fopen(out_file, "a");
for (int m = 0; m < control_rows; m++) {
for (int n = i + m + 1; n < ROWS; n++) {
float t_test = d[m * ROWS + n];
if (t_test >= 2.042) {
fprintf(f, "X%d\tX%d\t%f\t%lf\n",
i + m + 1, n + 1, c[m * ROWS + n], t_test);
}
}
}
fclose(f);
//printf(">> ЯрЙиЯЕЪ§НсЙћОиеѓ: \n");
//print_float_matrix(c, CONTROL_ROWS, ROWS);
//printf(">> TжЕНсЙћОиеѓ: \n");
//print_float_matrix(d, CONTROL_ROWS, ROWS);
free(c);
free(d);
}
int main()
{
int *a; // CPUФкДцжаЕФзмЪ§ОнОиеѓЃЌROWSааЃЌCOLSСа
a = (int*)malloc(sizeof(int)* COLS * ROWS);
char *input_file = "D:\\MASTER2016\\5.CUDA\\data-ID-top30-kv.txt";
char *out_file = "D:\\MASTER2016\\5.CUDA\\result-c.txt";
clock_t start = clock();
printf(">> loading ... rows: %d,
cols: %d", ROWS, COLS);
read_ints(a, input_file);
clear_ints(out_file);
clock_t end = clock() - start;
printf("\nTime used: %.2f s\n", (double)(end)
/ CLOCKS_PER_SEC);
//print_int_matrix(a, ROWS, COLS);
//printf("\n");
printf(">> calculating ... ");
printf("\n---------------------------------------");
printf("\ntotal groups: %lld", (long
long)ROWS*(ROWS - 1) / 2);
printf("\ntotal threads: %d (blocks) *
1024 = %d", (ROWS - 1), (ROWS - 1) * 1024);
printf("\ntotal space complexity: %lld
MB", (long long)((CONTROL_ROWS / 1024)
* (ROWS / 1024) * 8));
printf("\n---------------------------------------");
if (!InitCUDA()) return 0;
int i;
for (i = 0; i < ROWS - 1; i += CONTROL_ROWS)
{
printf("\n>> calculating and saving
... id: %d ... ", i);
cal_and_save(i, a, out_file, CONTROL_ROWS);
end = clock() - start;
printf("Time used: %.2f s", (double)(end)
/ CLOCKS_PER_SEC);
}
// ВЛФмећГ§ЕФЗЧећЪ§ВПЗжашвЊМЦЫу
//i -= CONTROL_ROWS;
//int control_rows = ROWS - 1 - i;
//printf("\n%d", control_rows);
//if (control_rows > 0) {
// printf("\n>> calculating and saving
... id: %d ... ", i);
// cal_and_save(i, a, out_file, control_rows);
// end = clock() - start;
// printf("Time used: %.2f s", (double)(end)
/ CLOCKS_PER_SEC);
//}
printf("\nFinished.\n");
getchar();
return 0;
}
CUDAЕкЖўАц |
ЕНЯждкЃЌгЩгкПеМфИДдгЖШЙ§ИпЖјЯдДцВЛЙЛЕФЮЪЬтЭЈЙ§діМгЪБМфИДдгЖШЕФЗНЗЈЛљБОНтОіСЫЁЃЕБШЛдкЯдДцзуЙЛЕФЧщПіЯТЃЌЛЙЪЧвЛДЮадЫуЭъЪЧзюПьЕФЃЌЪЕВтCUDAЬсЫй100+БЖЃЌЪ§ОнСПдНДѓЬсЫйдНУїЯдЁЃдвђвЛЪЧФуБиаыБЛБЦзХАДееCUDAЕФВЂааФЃаЭРДаДГЬађЃЌЖўЪЧGPUЕФМмЙЙЩшМЦШЗЪЕИќЪЪКЯГЌДѓВЂааГЬађЕФМгЫйЁЃгЮЯЗЛУцфжШООЭЪЧетбљЃЌФуПЩвдЯыГЩвЛИіblockПижЦвЛПщЦСФЛЕФфжШОЃЌУППщblockЕФУПИіЯпГЬПижЦМИИіЯёЫиИёЕФфжШОЃЌЖјетаЉЭМЯёфжШОЭъШЋПЩвдЪЧЖРСЂВЂааЕФЃЌGPUЕФЩшМЦГѕждЃЌМДЪЧдіМгКЫаФЪ§ЃЌВЛЭцУќЩ§ЦЕТЪЃЌдіМгЯдДцДјПэЃЌЪЙГЩАйЩЯЧЇЕФКЫаФЪ§ЕФВЂааМЦЫуФмСІЕУЕНГфЗжЪЭЗХЁЃ
ЕЋЪЧФПЧАЕФГЬађЕБШЛвВВЛЪЧЭъУРЕФЃЌЮвУЛгаПМТЧШчКЮвўВиФкДцгыЯдДцжЎМфЪ§ОнЕФДЋЪфбгГйЃЌУЛгаПМТЧЖрПщGPUШчКЮСЊЖЏдЫЫуЁЃКѓУцЮвЛсЫМПМетаЉЁЃ
ВЂааМЦЫуЪЧМЦЫуЕФЮДРДЁЃвьЙЙВЂааМЦЫуЃЌвВНЋЪЧЫљгаМмЙЙЪІБиаыдіМгЕФбЇЯАПтЁЃ
|









