| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌНщЩмСЫCUDAДгШыУХЕНОЋЭЈЛЗОГДюНЈЃЌCUDAГЬађЃЌМгЩюЖдЩшБИЕФШЯЪЖЃЌЯпГЬВЂааЕШЁЃ |
|
CUDAДгШыУХЕНОЋЭЈЃЈвЛЃЉЃКЛЗОГДюНЈ
NVIDIAгк2006ФъЭЦГіCUDAЃЈCompute Unified Devices ArchitectureЃЉЃЌПЩвдРћгУЦфЭЦГіЕФGPUНјааЭЈгУМЦЫуЃЌНЋВЂааМЦЫуДгДѓаЭМЏШКРЉеЙЕНСЫЦеЭЈЯдПЈЃЌЪЙЕУгУЛЇжЛашвЊвЛЬЈДјгаGeforceЯдПЈЕФБЪМЧБООЭФмХмНЯДѓЙцФЃЕФВЂааДІРэГЬађЁЃ
ЪЙгУЯдПЈЕФКУДІЪЧЃЌКЭДѓаЭМЏШКЯрБШЙІКФЗЧГЃЕЭЃЌГЩБОвВВЛИпЃЌЕЋадФмКмЭЛГіЁЃвдЮвЕФБЪМЧБОЮЊР§ЃЌGeforce
610MЃЌгУDeviceQueryГЬађВтЪдЃЌПЩЕУЕНШчЯТгВМўВЮЪ§ЃК
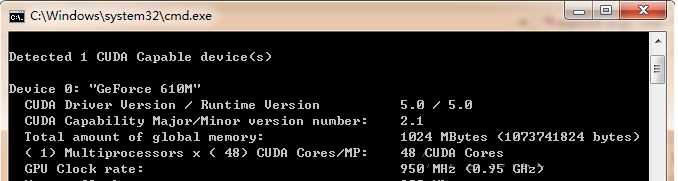
МЦЫуФмСІДя48X0.95 = 45.6 GFLOPSЁЃЖјБЪМЧБОЕФCPUВЮЪ§ШчЯТЃК
CPUМЦЫуФмСІЮЊЃЈ4КЫЃЉЃК2.5G*4 = 10GFLOPSЃЌПЩМћЃЌЯдПЈМЦЫуадФмЪЧ4КЫi5 CPUЕФ4~5БЖЃЌвђДЫЮвУЧПЩвдГфЗжРћгУетвЛзЪдДРДЖдвЛаЉКФЪБЕФгІгУНјааМгЫйЁЃ
КУСЫЃЌЙЄгћЩЦЦфЪТБиЯШРћЦфЦїЃЌЮЊСЫЪЙгУCUDAЖдGPUНјааБрГЬЃЌЮвУЧашвЊзМБИвдЯТБиБИЙЄОпЃК
1. гВМўЦНЬЈЃЌОЭЪЧЯдПЈЃЌШчЙћФугУЕФВЛЪЧNVIDIAЕФЯдПЈЃЌФЧУДжЛФмЫЕБЇЧИЃЌЦфЫћЖМВЛжЇГжCUDAЁЃ
2. ВйзїЯЕЭГЃЌЮвгУЙ§windows XPЃЌWindows 7ЖМУЛЮЪЬтЃЌБОВЉПЭгУWindows7ЁЃ
3. CБрвыЦїЃЌНЈвщVS2008ЃЌКЭБОВЉПЭвЛжТЁЃ
4. CUDAБрвыЦїNVCCЃЌПЩвдУтЗбУтзЂВсУтlicenseДгЙйЭјЯТдиCUDA ToolkitCUDAЯТдиЃЌзюаТАцБОЮЊ5.0ЃЌБОВЉПЭгУЕФОЭЪЧИУАцБОЁЃ
5. ЦфЫћЙЄОпЃЈШчVisual AssistЃЌИЈжњДњТыИпССЃЉ
зМБИЭъБЯЃЌПЊЪМАВзАШэМўЁЃVS2008АВзАБШНЯЗбЪБМфЃЌНЈвщАВзАЭъећАцЃЈNVIDIAЙйЭјЫЕExpressАцвВПЩвдЃЉЃЌЙ§ГЬВЛБиЯъЪіЁЃCUDA
Toolkit 5.0РяУцАќКЌСЫNVCCБрвыЦїЁЂЩшМЦЮФЕЕЁЂЩшМЦР§ГЬЁЂCUDAдЫааЪБПтЁЂCUDAЭЗЮФМўЕШБиБИЕФдВФСЯЁЃ
АВзАЭъБЯЃЌЮвУЧдкзРУцЩЯЗЂЯжетИіЭМБъЃК
ВЛДэЃЌОЭЪЧЫќЃЌЫЋЛїдЫааЃЌПЩвдПДЕНвЛДѓЖбР§ГЬЁЃЮвУЧевЕНSimple OpenGLетИідЫааПДПДаЇЙћЃК
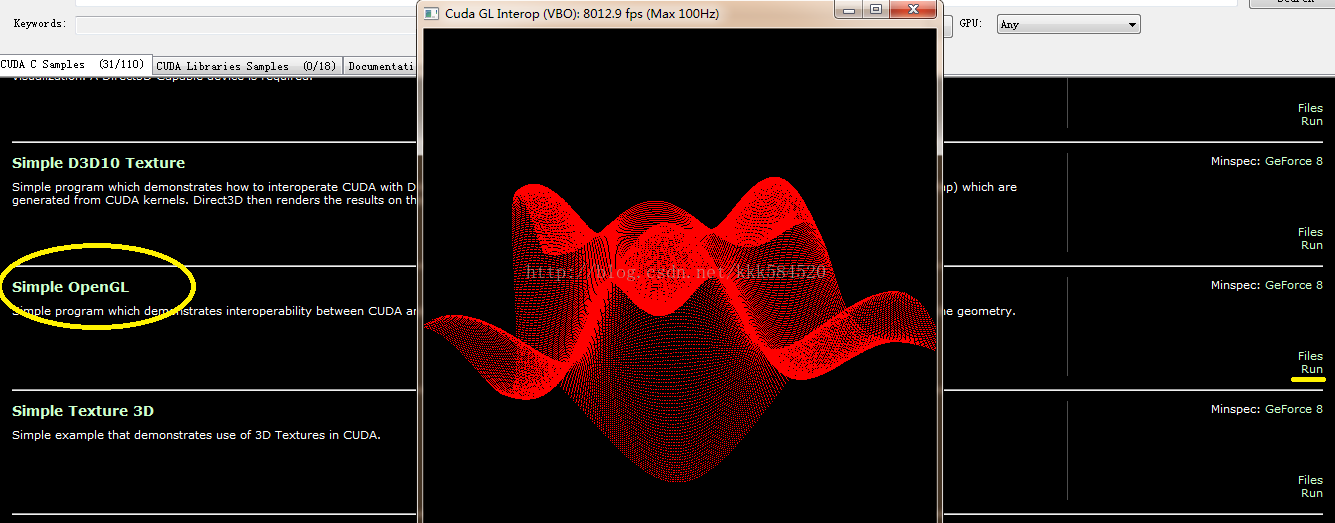
ЕугвБпЛЦЯпБъМЧДІЕФRunМДПЩПДЕНУРУюЕФШ§ЮЌе§ЯвЧњУцЃЌЪѓБъзѓМќЭЯЖЏПЩвдзЊЛЛНЧЖШЃЌгвМќЭЯЖЏПЩвдЫѕЗХЁЃШчЙћетИідЫааГЩЙІЃЌЫЕУїФуЕФЛЗОГЛљБОДюНЈГЩЙІЁЃ
ГіЯжЮЪЬтЕФПЩФмЃК
1. ФуЪЙгУдЖГЬзРУцСЌНгЕЧТМЕНСэвЛЬЈЗўЮёЦїЃЌИУЗўЮёЦїЩЯгаЯдПЈжЇГжCUDAЃЌЕЋФудЖГЬжеЖЫВЛФмдЫааCUDAГЬађЁЃетЪЧвђЮЊдЖГЬЕЧТМЪЙгУЕФЪЧФуБОЕиЯдПЈзЪдДЃЌдкдЖГЬЕЧТМЪБПДВЛЕНЗўЮёЦїЖЫЕФЯдПЈЃЌЫљвдЛсБЈДэЃКУЛгажЇГжCUDAЕФЯдПЈЃЁНтОіЗНЗЈЃК1.
дЖГЬЗўЮёЦїзАСНПщЯдПЈЃЌвЛПщжЛгУгкЯдЪОЃЌСэвЛПщгУгкМЦЫуЃЛ2.ВЛвЊгУЭМаЮНчУцЕЧТМЃЌЖјЪЧгУУќСюааНчУцШчtelnetЕЧТМЁЃ
2.гаСНИівдЩЯЯдПЈЖМжЇГжCUDAЕФЧщПіЃЌШчКЮЧјЗжЪЧдкФФИіЯдПЈЩЯдЫааЃПетИіашвЊФудкГЬађРяПижЦЃЌбЁдёЗћКЯвЛЖЈЬѕМўЕФЯдПЈЃЌШчНЯИпЕФЪБжгЦЕТЪЁЂНЯДѓЕФЯдДцЁЂНЯИпЕФМЦЫуАцБОЕШЁЃЯъЯИВйзїМћКѓУцЕФВЉПЭЁЃ
КУСЫЃЌЯШЫЕетУДЖрЃЌЯТвЛНкЮвУЧНщЩмШчКЮдкVS2008жаИјGPUБрГЬЁЃ
CUDAДгШыУХЕНОЋЭЈЃЈЖўЃЉЃКЕквЛИіCUDAГЬађ
ЪщНгЩЯЛиЃЌЮвУЧМШШЛжБНгдЫааР§ГЬГЩЙІСЫЃЌНгЯТРДОЭЪЧСЫНтШчКЮЪЕЯжР§ГЬжаЕФУПИіЛЗНкЁЃЕБШЛЃЌЮвУЧЯШДгМђЕЅЕФзіЦ№ЃЌвЛАуБрГЬгябдЖМЛсевИіhelloworldР§згЃЌЖјЮвУЧЕФЯдПЈЪЧВЛЛсЫЕЛАЕФЃЌжЛФмзівЛаЉМђЕЅЕФМгМѕГЫГ§дЫЫуЁЃЫљвдЃЌCUDAГЬађЕФhelloworldЃЌЮвЯыгІИУзюКЯЪЪВЛЙ§ЕФОЭЪЧЯђСПМгСЫЁЃ
ДђПЊVS2008ЃЌбЁдёFile->New->ProjectЃЌЕЏГіЯТУцЖдЛАПђЃЌЩшжУШчЯТЃК
жЎКѓЕуOKЃЌжБНгНјШыЙЄГЬНчУцЁЃ
ЙЄГЬжаЃЌЮвУЧПДЕНжЛгавЛИі.cuЮФМўЃЌФкШнШчЯТЃК
#include "cuda_runtime.h"
#include "device_ launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda (int *c, const int *a,
const int *b, size_t size);
__ global __ void addKernel(int *c, const int
*a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50
};
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b,
arraySize);
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "addWithCuda failed!");
return 1;
}
printf ("{1,2,3,4,5} + {10,20,30,40,50} =
{%d ,%d ,%d, %d, %d }\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaThreadExit must be called before exiting
in order for profiling and
// tracing tools such as Nsight and Visual Profiler
to show complete traces.
cudaStatus = cudaThreadExit();
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaThreadExit failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors
in parallel.
cudaError_ t addWithCuda(int *c, const int *a,
const int *b, size_t size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on
a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaSetDevice failed! Do
you have a CUDA- capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two
input, one output) .
cudaStatus = cudaMalloc ((void**)&dev_c, size
* sizeof (int));
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size
* sizeof (int) );
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size
* sizeof (int));
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU
buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread
for each element.
addKernel <<<1, size>>> (dev_c,
dev_a, dev_b);
// cudaThreadSynchronize waits for the kernel
to finish , and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaThreadSynchronize returned
error code %d after launching addKernel!\n",
cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host
memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int),
cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf (stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
} |
ПЩвдПДГіЃЌCUDAГЬађКЭCГЬађВЂЮоЧјБ№ЃЌжЛЪЧЖрСЫвЛаЉвд"cuda"ПЊЭЗЕФвЛаЉПтКЏЪ§КЭвЛИіЬиЪтЩљУїЕФКЏЪ§ЃК
__global__
void addKernel(int *c, const int *a, const int
*b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
} |
етИіКЏЪ§ОЭЪЧдкGPUЩЯдЫааЕФКЏЪ§ЃЌГЦжЎЮЊКЫКЏЪ§ЃЌгЂЮФУћKernel FunctionЃЌзЂвтвЊКЭВйзїЯЕЭГФкКЫКЏЪ§ЧјЗжПЊРДЁЃ
ЮвУЧжБНгАДF7БрвыЃЌПЩвдЕУЕНШчЯТЪфГіЃК
1>------
Build started : Project: cuda_helloworld, Configuration:
Debug Win32 ------
1> Compiling with CUDA Build Rule...
1> "C:\Program Files\NVIDIA GPU Computing
Toolkit \CUDA\ v5.0\ \bin \nvcc.exe" -G -gencode=
arch= compute_ 10,code= \"sm_10 ,compute_
10\" - gencode= arch= compute_ 20,code =
\"sm_20 ,compute_20 \" --machine 32
-ccbin "C :\Program Files (x86)\ Microsoft
Visual Studio 9.0 \VC \bin" -Xcompiler "
/EHsc /W3 /nologo /O2 / Zi /MT " -I"C:
\Program Files \NVIDIA GPU Computing Toolkit \CUDA
\v5.0\\include" -maxrregcount= 0 -- compile
-o "Debug /kernel. cu.obj " kernel.cu
1>tmpxft_ 000000ec_00000000- 8_kernel. compute_
10 . cudafe1 .gpu
1>tmpxft_ 000000ec_00000000- 14_kernel. compute_
10. cudafe2.gpu
1>tmpxft_ 000000ec_00000000- 5_kernel. compute_
20. cudafe1.gpu
1>tmpxft_ 000000ec_00000000 -17_kernel .compute_
20. cudafe2.gpu
1>kernel.cu
1>kernel.cu
1>tmpxft_ 000000ec_ 00000000-8_kernel.compute_
10. cudafe1 .cpp
1>tmpxft_ 000000ec_ 00000000-24_kernel.compute
_10.ii
1>Linking...
1>Embedding manifest...
1>Performing Post-Build Event...
1>copy "C :\Program Files\NVIDIA GPU Computing
Toolkit \CUDA\ v5 .0 \\ bin\cudart *.dll"
"C:\Users \ DongXiaoman \Documents \Visual
Studio 2008\Projects\cuda_ helloworld \Debug"
1>C: \ Program Files \NVIDIA GPU Computing
Toolkit\ CUDA \ v5.0 \\ bin\ cudart32_50_35.dll
1> C:\ Program Files\NVIDIA GPU Computing Toolkit
\ CUDA \v5.0\ \bin\ cudart64_ 50_35.dll
1>вбИДжЦ 2 ИіЮФМўЁЃ
1>Build log was saved at "file ://c:\
Users\ DongXiaoman \ Documents \ Visual Studio
2008\Projects \cuda_helloworld \cuda_ helloworld
\Debug\BuildLog.htm"
1> cuda_helloworld - 0 error(s), 105 warning(s)
========== Build: 1 succeeded, 0 failed, 0 up-to-date,
0 skipped ========== |
ПЩМћЃЌБрвы.cuЮФМўашвЊРћгУnvccЙЄОпЁЃИУЙЄОпЕФЯъЯИЪЙгУМћКѓУцВЉПЭЁЃ
жБНгдЫааЃЌПЩвдЕУЕННсЙћЭМШчЯТЃК
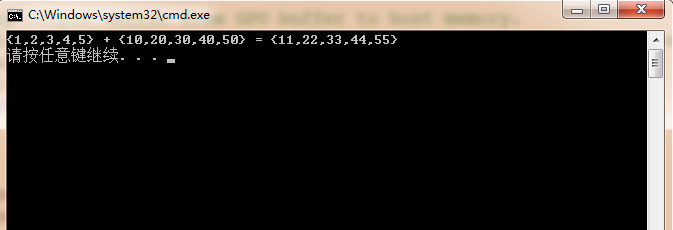
ШчЙћЯдЪОе§ШЗЃЌФЧУДЮвУЧЕФЕквЛИіГЬађаћИцГЩЙІЃЁ
CUDAДгШыУХЕНОЋЭЈЃЈШ§ЃЉЃКБиБИзЪСЯ
ИеШыУХCUDAЃЌХмЙ§МИИіЙйЗНЬсЙЉЕФР§ГЬЃЌПДСЫПДШЫМвЕФДњТыЃЌОѕЕУВЂВЛФбЃЌЕЋздМКЖЏЪжаДДњТыЪБЃЌзмЪЧВЛжЊЕРвЊЯШИЩЪВУДЃЌКѓИЩЪВУДЃЌвВВЛжЊЕРДгФФИіжЊЪЖЕубЇЦ№ЁЃетЪБОЭашвЊгавЛБОФмЬсЙЉжИЕМЕФЪщМЎЛђепНЬГЬЃЌвЛВНВНИњзХзіЯТШЅЃЌжБЕНеце§еЦЮеЁЃ
вЛАуНВЪіCUDAЕФЪщЃЌЮвШЯЮЊВЛДэЕФгаЯТУцетМИБОЃК

ГѕбЇепПЩвдЯШПДУРЙњШЫаДЕФетБОЁЖGPUИпадФмБрГЬCUDAЪЕеНЁЗЃЌПЩВйзїадКмЧПЃЌЕЋВЛвЊЦкЭћФмШЋПДЖЎЃЈPsЃКРяУцгааЉИХФюЦфЪЕЮвЯждкЛЙЪЧВЛдѕУДЖЎЃЉЃЌЕЋВЛгАЯьФуНјвЛВНбЇЯАЁЃШчЙћЯыИќШЋУцЕибЇЯАCUDAЃЌЁЖGPGPUБрГЬММЪѕЁЗБШНЯПЭЙлЯъЯИЕиНщЩмСЫЭЈгУGPUБрГЬЕФВпТдЃЌПДЙ§етБОЪщЃЌПЩвдЖдЯдПЈгаИќЩюШыЕФСЫНтЃЌНвПЊGPUЕФЩёУиУцЩДЁЃКѓУцЁЖOpenGLБрГЬжИФЯЁЗЭъШЋЪЧЮЊСЫЬхбщЭМаЮНЛЛЅДјРДЕФРжШЄЃЌПЩвдгабЁдёЕиПДЃЛЁЖGPUИпадФмдЫЫужЎCUDAЁЗетБОЪЧЪІажИјЕФЃЌЪЪКЯПьЫйВщбЏЃЈИаОѕЪЧНЋЙйЗНБрГЬЪжВсЗвыСЫвЛБщЃЉвЛаЉЙиМќММЪѕКЭИХФюЁЃ
гаСЫетаЉжИЕМВФСЯЛЙВЛЙЛЃЌЮвУЧдкзіЯюФПЕФЪБКђЃЌгіЕНЕФЮЪЬтдкетаЉЪщЩЯПЯЖЈевВЛЕНЃЌЫљвдЛЙашвЊгаЯТУцетаЉРћЦїЃК
етРяУцгаКмЖрЙЄОпЕФЪЙгУЪжВсЃЌШчCUDA_GDBЃЌNsightЃЌCUDA_ProfilerЕШЃЌЗНБуЕїЪдГЬађЃЛЛЙгавЛаЉгагУЕФПтЃЌШчCUFFTЪЧзЈУХгУРДзіПьЫйИЕРявЖБфЛЛЕФЃЌCUBLASЪЧзЈгУгкЯпадДњЪ§ЃЈОиеѓЁЂЯђСПМЦЫуЃЉЕФЃЌCUSPASEЪЧзЈгУгкЯЁЪшОиеѓБэЪОКЭМЦЫуЕФПтЁЃетаЉПтЕФЪЙгУПЩвдНЕЕЭЮвУЧЩшМЦЫуЗЈЕФФбЖШЃЌЬсИпПЊЗЂаЇТЪЁЃСэЭтЛЙгааЉШыУХНЬГЬвВЪЧжЕЕУвЛЖСЕФЃЌФуЛсЖдNVCCБрвыЦїгаИќНќОрРыЕФНгДЅЁЃ
КУСЫЃЌЧАбдОЭетУДЖрЃЌБОВЉжїМЦЛЎАДШчЯТЫГађРДНВЪіCUDAЃК
1.СЫНтЩшБИ
2.ЯпГЬВЂаа
3.ПщВЂаа
4.СїВЂаа
5.ЯпГЬЭЈаХ
6.ЯпГЬЭЈаХЪЕР§ЃКЙцдМ
7.ДцДЂФЃаЭ
8.ГЃЪ§ФкДц
9.ЮЦРэФкДц
10.жїЛњвГЫјЖЈФкДц
11.ЭМаЮЛЅВйзї
12.гХЛЏзМдђ
13.CUDAгыMATLABНгПк
14.CUDAгыMFCНгПк
CUDAДгШыУХЕНОЋЭЈЃЈЫФЃЉЃКМгЩюЖдЩшБИЕФШЯЪЖ
ЧАУцШ§НквбОЖдCUDAзіСЫвЛИіМђЕЅЕФНщЩмЃЌетвЛНкПЊЪМеце§НјШыБрГЬЛЗНкЁЃ
ЪзЯШЃЌГѕбЇепгІИУЖдздМКЪЙгУЕФЩшБИгаНЯЮЊдњЪЕЕФРэНтКЭеЦЮеЃЌетбљЖдКѓУцбЇЯАВЂааГЬађгХЛЏКмгаАяжњЃЌСЫНтгВМўЯъЯИВЮЪ§ПЩвдЭЈЙ§ЩЯНкНщЩмЕФМИБОЪщКЭЙйЗНзЪСЯЛёЕУЃЌЕЋШчЙћШдШЛОѕЕУВЛЙЛжБЙлЃЌФЧУДЮвУЧПЩвдздМКЖЏЪжЛёЕУетаЉФкШнЁЃ
вдЕкЖўНкР§ГЬЮЊФЃАхЃЌЮвУЧЩдМгИФЖЏЕФВПЗжДњТыШчЯТЃК
// Add vectors
in parallel.
cudaError_t cudaStatus;
int num = 0;
cudaDeviceProp prop;
cudaStatus = cudaGetDeviceCount(&num);
for(int i = 0;i<num;i++)
{
cudaGetDeviceProperties(&prop,i);
}
cudaStatus = addWithCuda(c, a, b, arraySize);
|
етИіИФЖЏЕФФПЕФЪЧШУЮвУЧЕФГЬађздЖЏЭЈЙ§ЕїгУcuda APIКЏЪ§ЛёЕУЩшБИЪ§ФПКЭЪєадЃЌЫљЮНЁАжЊМКжЊБЫЃЌАйеНВЛДљЁБЁЃ
cudaError_t ЪЧcudaДэЮѓРраЭЃЌШЁжЕЮЊећЪ§ЁЃ
cudaDevicePropЮЊЩшБИЪєадНсЙЙЬхЃЌЦфЖЈвхПЩвдДгcuda ToolkitАВзАФПТМжаевЕНЃЌЮвЕФТЗОЖЮЊЃКC:\Program
Files \NVIDIA GPU Computing Toolkit \CUDA\v5.0 \include\driver_types.hЃЌевЕНЖЈвхЮЊЃК
/**
* CUDA device properties
*/
struct __device_builtin__ cudaDeviceProp
{
char name[256]; /**< ASCII string identifying
device */
size_t totalGlobalMem; /**< Global memory available
on device in bytes */
size_t sharedMemPerBlock; /**< Shared memory
available per block in bytes */
int regsPerBlock; /**< 32-bit registers available
per block */
int warpSize; / **< Warp size in threads */
size_t memPitch; / **< Maximum pitch in bytes
allowed by memory copies */
int maxThreadsPerBlock; /**< Maximum number
of threads per block */
int maxThreadsDim[3]; /**< Maximum size of
each dimension of a block */
int maxGridSize[3]; /**< Maximum size of each
dimension of a grid */
int clockRate; /**< Clock frequency in kilohertz
*/
size_ t totalConstMem; /**< Constant memory
available on device in bytes */
int major; /**< Major compute capability */
int minor; /**< Minor compute capability */
size_t textureAlignment; /**< Alignment requirement
for textures */
size_t texturePitchAlignment; /**< Pitch alignment
requirement for texture references bound to pitched
memory */
int deviceOverlap; /**< Device can concurrently
copy memory and execute a kernel. Deprecated.
Use instead asyncEngineCount. */
int multiProcessorCount; /**< Number of multiprocessors
on device */
int kernelExecTimeoutEnabled; /**< Specified
whether there is a run time limit on kernels */
int integrated; /**< Device is integrated as
opposed to discrete */
int canMapHostMemory; /**< Device can map host
memory with cudaHostAlloc/cudaHostGetDevicePointer
*/
int computeMode; /**< Compute mode (See ::cudaComputeMode)
*/
int maxTexture1D; /**< Maximum 1D texture size
*/
int maxTexture1DMipmap; /**< Maximum 1D mipmapped
texture size */
int maxTexture1DLinear; /**< Maximum size for
1D textures bound to linear memory */
int maxTexture2D[2]; /**< Maximum 2D texture
dimensions */
int maxTexture2DMipmap[2]; /**< Maximum 2D
mipmapped texture dimensions */
int maxTexture2DLinear[3]; /**< Maximum dimensions
(width, height, pitch) for 2D textures bound to
pitched memory */
int maxTexture2DGather[2]; /**< Maximum 2D
texture dimensions if texture gather operations
have to be performed */
int maxTexture3D[3]; /**< Maximum 3D texture
dimensions */
int maxTextureCubemap; /**< Maximum Cubemap
texture dimensions */
int maxTexture1DLayered[2]; /**< Maximum 1D
layered texture dimensions */
int maxTexture2DLayered[3]; /**< Maximum 2D
layered texture dimensions */
int maxTextureCubemapLayered[2];/**< Maximum
Cubemap layered texture dimensions */
int maxSurface1D; /**< Maximum 1D surface size
*/
int maxSurface2D[2]; /**< Maximum 2D surface
dimensions */
int maxSurface3D[3]; /**< Maximum 3D surface
dimensions */
int maxSurface1DLayered[2]; /**< Maximum 1D
layered surface dimensions */
int maxSurface2DLayered[3]; /**< Maximum 2D
layered surface dimensions */
int maxSurfaceCubemap; /**< Maximum Cubemap
surface dimensions */
int maxSurfaceCubemapLayered[2];/**< Maximum
Cubemap layered surface dimensions */
size_t surfaceAlignment; /**< Alignment requirements
for surfaces */
int concurrentKernels; /**< Device can possibly
execute multiple kernels concurrently */
int ECCEnabled; /**< Device has ECC support
enabled */
int pciBusID; /**< PCI bus ID of the device
*/
int pciDeviceID; /**< PCI device ID of the
device */
int pciDomainID; /**< PCI domain ID of the
device */
int tccDriver; /**< 1 if device is a Tesla
device using TCC driver, 0 otherwise */
int asyncEngineCount; /**< Number of asynchronous
engines */
int unifiedAddressing; /**< Device shares a
unified address space with the host */
int memoryClockRate; /**< Peak memory clock
frequency in kilohertz */
int memoryBusWidth; /**< Global memory bus
width in bits */
int l2CacheSize; /**< Size of L2 cache in bytes
*/
int maxThreadsPerMultiProcessor;/**< Maximum
resident threads per multiprocessor */
}; |
КѓУцЕФзЂЪЭвбОЫЕУїСЫЦфзжЖЮДњБэвтвхЃЌПЩФмгааЉЪѕгяЖдгкГѕбЇепРэНтЦ№РДЛЙЪЧгавЛЖЈРЇФбЃЌУЛЙиЯЕЃЌЮвУЧЯждкжЛашвЊЙизЂвдЯТМИИіжИБъЃК
nameЃКОЭЪЧЩшБИУћГЦЃЛ
totalGlobalMemЃКОЭЪЧЯдДцДѓаЁЃЛ
major,minorЃКCUDAЩшБИАцБОКХЃЌга1.1, 1.2, 1.3, 2.0, 2.1ЕШЖрИіАцБОЃЛ
clockRateЃКGPUЪБжгЦЕТЪЃЛ
multiProcessorCountЃКGPUДѓКЫЪ§ЃЌвЛИіДѓКЫЃЈзЈвЕЕуГЦЮЊСїЖрДІРэЦїЃЌSMЃЌStream-MultiprocessorЃЉАќКЌЖрИіаЁКЫЃЈСїДІРэЦїЃЌSPЃЌStream-ProcessorЃЉ
БрвыЃЌдЫааЃЌЮвУЧдкVS2008ЙЄГЬЕФcudaGetDeviceProperties()КЏЪ§ДІЗХвЛИіЖЯЕуЃЌЕЅВНжДааетвЛКЏЪ§ЃЌШЛКѓгУWatchДАПкЃЌЧаЛЛЕНAutoвГЃЌеЙПЊ+ЃЌдкЮвЕФБЪМЧБОЩЯЕУЕНШчЯТНсЙћЃК
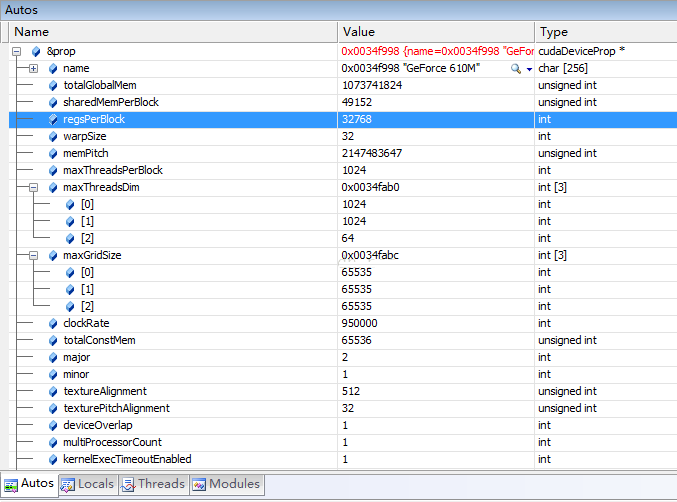
ПЩвдПДЕНЃЌЩшБИУћЮЊGeForce 610MЃЌЯдДц1GBЃЌЩшБИАцБО2.1ЃЈБШНЯИпЖЫСЫЃЌЙўЙўЃЉЃЌЪБжгЦЕТЪЮЊ950MHzЃЈзЂвт950000ЕЅЮЛЮЊkHzЃЉЃЌДѓКЫЪ§ЮЊ1ЁЃдквЛаЉИпадФмGPUЩЯЃЈШчTeslaЃЌKeplerЯЕСаЃЉЃЌДѓКЫЪ§ПЩФмДяЕНМИЪЎЩѕжСЩЯАйЃЌПЩвдзіИќДѓЙцФЃЕФВЂааДІРэЁЃ
PSЃКНёЬьПДSDKДњТыЪБЗЂЯждкhelp_cuda.hжагаИіКЏЪ§ЪЕЯжДгCUDAЩшБИАцБОВщбЏЯргІДѓКЫжааЁКЫЕФЪ§ФПЃЌОѕЕУКмгагУЃЌвдКѓБрГЬађПЩвдНшМјЃЌеЊГШчЯТЃК
// Beginning
of GPU Architecture definitions
inline int _ ConvertSMVer2Cores(int major, int
minor)
{
// Defines for GPU Architecture types (using the
SM version to determine the # of cores per SM
typedef struct
{
int SM; // 0xMm (hexidecimal notation), M = SM
Major version, and m = SM minor version
int Cores;
} sSMtoCores;
sSMtoCores nGpuArchCoresPerSM[] =
{
{ 0x10, 8 }, // Tesla Generation (SM 1.0) G80
class
{ 0x11, 8 }, // Tesla Generation (SM 1.1) G8x
class
{ 0x12, 8 }, // Tesla Generation (SM 1.2) G9x
class
{ 0x13, 8 }, // Tesla Generation (SM 1.3) GT200
class
{ 0x20, 32 }, // Fermi Generation (SM 2.0) GF100
class
{ 0x21, 48 }, // Fermi Generation (SM 2.1) GF10x
class
{ 0x30, 192}, // Kepler Generation (SM 3.0) GK10x
class
{ 0x35, 192}, // Kepler Generation (SM 3.5) GK11x
class
{ -1, -1 }
};
int index = 0;
while (nGpuArchCoresPerSM[index].SM != -1)
{
if (nGpuArchCoresPerSM[index].SM == ((major <<
4) + minor))
{
return nGpuArchCoresPerSM[index].Cores;
}
index++;
}
// If we don't find the values, we default use
the previous one to run properly
printf ("MapSMtoCores for SM %d.%d is undefined.
Default to use %d Cores/SM\n", major, minor,
nGpuArch CoresPerSM [7].Cores);
return nGpuArchCoresPerSM [7].Cores;
}
// end of GPU Architecture definitions |
ПЩМћЃЌЩшБИАцБО2.1ЕФвЛИіДѓКЫга48ИіаЁКЫЃЌЖјАцБО3.0вдЩЯЕФвЛИіДѓКЫга192ИіаЁКЫЃЁ
ЧАЮФЫЕЕНЙ§ЃЌЕБЮвУЧгУЕФЕчФдЩЯгаЖрИіЯдПЈжЇГжCUDAЪБЃЌдѕУДРДЧјЗждкФФИіЩЯдЫааФиЃПетРяЮвУЧПДвЛЯТadd
WithCuda етИіКЏЪ§ЪЧдѕУДзіЕФЁЃ
cudaError_t
cudaStatus;
// Choose which GPU to run on, change this on
a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do
you have a CUDA-capable GPU installed?");
goto Error;
} |
ЪЙгУСЫcudaSetDevice(0)етИіВйзїЃЌ0БэЪОФмЫбЫїЕНЕФЕквЛИіЩшБИКХЃЌШчЙћгаЖрИіЩшБИЃЌдђБрКХЮЊ0,1,2...ЁЃ
дйПДЮвУЧБОНкЬэМгЕФДњТыЃЌгаИіКЏЪ§cudaGetDeviceCount(&num)ЃЌетИіКЏЪ§гУРДЛёШЁЩшБИзмЪ§ЃЌетбљЮвУЧбЁдёдЫааCUDAГЬађЕФЩшБИКХШЁжЕОЭЪЧ0,1,...num-1ЃЌгкЪЧПЩвдвЛИіИіУЖОйЩшБИЃЌРћгУcudaGetDeviceProperties(&prop)ЛёЕУЦфЪєад,ШЛКѓРћгУвЛЖЈХХађЁЂЩИбЁЫуЗЈЃЌевЕНзюЗћКЯЮвУЧгІгУЕФФЧИіЩшБИКХoptЃЌШЛКѓЕїгУcudaSetDevice(opt)МДПЩбЁдёИУЩшБИЁЃбЁдёБъзМПЩвдДгДІРэФмСІЁЂАцБОПижЦЁЂУћГЦЕШИїИіНЧЖШГіЗЂЁЃКѓУцНВЪіСїВЂЗЂЙ§ГЬЪБЃЌЛЙвЊгУЕНетаЉAPIЁЃ
ШчЙћЯЃЭћСЫНтИќЖргВМўФкШнПЩвдНсКЯhttp://www.geforce.cn/hardwareЛёШЁЁЃ
CUDAДгШыУХЕНОЋЭЈЃЈЮхЃЉЃКЯпГЬВЂаа
ЖрЯпГЬЮвУЧгІИУЖМВЛФАЩњЃЌдкВйзїЯЕЭГжаЃЌНјГЬЪЧзЪдДЗжХфЕФЛљБОЕЅдЊЃЌЖјЯпГЬЪЧCPUЪБМфЕїЖШЕФЛљБОЕЅдЊЃЈетРяМйЩшжЛга1ИіCPUЃЉЁЃ
НЋЯпГЬЕФИХФюв§ЩъЕНCUDAГЬађЩшМЦжаЃЌЮвУЧПЩвдШЯЮЊЯпГЬОЭЪЧжДааCUDAГЬађЕФзюаЁЕЅдЊЃЌЧАУцЮвУЧНЈСЂЕФЙЄГЬДњТыжаЃЌгаИіКЫКЏЪ§ИХФюВЛжЊИїЮЛЭЏаЌЛЙМЧЕУУЛгаЃЌдкGPUЩЯУПИіЯпГЬЖМЛсдЫаавЛДЮИУКЫКЏЪ§ЁЃ
ЕЋGPUЩЯЕФЯпГЬЕїЖШЗНЪНгыCPUгаКмДѓВЛЭЌЁЃCPUЩЯЛсгагХЯШМЖЗжХфЃЌДгИпЕНЕЭЃЌЭЌбљгХЯШМЖЕФПЩвдВЩгУЪБМфЦЌТжзЊЗЈЪЕЯжЯпГЬЕїЖШЁЃGPUЩЯЯпГЬУЛгагХЯШМЖИХФюЃЌЫљгаЯпГЬЛњЛсОљЕШЃЌЯпГЬзДЬЌжЛгаЕШД§зЪдДКЭжДааСНжжзДЬЌЃЌШчЙћзЪдДЮДОЭаїЃЌФЧУДОЭЕШД§ЃЛвЛЕЉОЭаїЃЌСЂМДжДааЁЃЕБGPUзЪдДКмГфдЃЪБЃЌЫљгаЯпГЬЖМЪЧВЂЗЂжДааЕФЃЌетбљМгЫйаЇЙћКмНгНќРэТлМгЫйБШЃЛЖјGPUзЪдДЩйгкзмЯпГЬИіЪ§ЪБЃЌгавЛВПЗжЯпГЬОЭЛсЕШД§ЧАУцжДааЕФЯпГЬЪЭЗХзЪдДЃЌДгЖјБфЮЊДЎааЛЏжДааЁЃ
ДњТыЛЙЪЧгУЩЯвЛНкЕФАЩЃЌИФЖЏКмЩйЃЌдйЬљвЛБщЃК
#include "cuda_runtime.h"
//CUDAдЫааЪБAPI
#include "device_ launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a,
const int *b, size_t size);
__global__ void addKernel (int *c, const int *a,
const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50
};
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus;
int num = 0;
cudaDeviceProp prop;
cudaStatus = cudaGetDeviceCount(&num);
for(int i = 0;i<num;i++)
{
cudaGetDeviceProperties(&prop,i);
}
cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} =
{%d, %d, %d, %d, %d}\ n",c[0],c[1], c[2],c[3],c[4]);
// cudaThreadExit must be called before exiting
in order for profiling and
// tracing tools such as Nsight and Visual Profiler
to show complete traces.
cudaStatus = cudaThreadExit();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaThreadExit failed!");
return 1;
}
return 0;
}
// жиЕуРэНтетИіКЏЪ§
cudaError_t addWithCuda (int *c, const int *a,
const int * b, size_t size)
{
int *dev_a = 0; //GPUЩшБИЖЫЪ§ОнжИеы
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus; //зДЬЌжИЪО
// Choose which GPU to run on, change this on
a multi-GPU system.
cudaStatus = cudaSetDevice(0); //бЁдёдЫааЦНЬЈ
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaSetDevice failed! Do
you have a CUDA-capable GPU installed?");
goto Error;
}
// ЗжХфGPUЩшБИЖЫФкДц
cudaStatus = cudaMalloc ((void**)&dev_c, size
* sizeof (int ));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size
* sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size
* sizeof (int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// ПНБДЪ§ОнЕНGPU
cudaStatus = cudaMemcpy (dev_a, a, size * sizeof(int),
cudaMemcpyHost ToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// дЫааКЫКЏЪ§
<span style= "BACKGROUND-COLOR: #ff6666">
<strong> addKernel <<<1, size>>>
(dev_c, dev_a, dev_b) ; </ strong>
</span> // cudaThreadSynchronize waits
for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize(); //ЭЌВНЯпГЬ
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaThreadSynchronize returned
error code %d after launching addKernel!\n",
cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host
memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int),
cudaMemcpyDeviceToHost); //ПНБДНсЙћЛижїЛњ
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c); //ЪЭЗХGPUЩшБИЖЫФкДц
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
} |
КьЩЋВПЗжМДЦєЖЏКЫКЏЪ§ЕФЕїгУЙ§ГЬЃЌетРяПДЕНЕїгУЗНЪНКЭCВЛЬЋвЛбљЁЃ<<<>>>БэЪОдЫааЪБХфжУЗћКХЃЌРяУц1БэЪОжЛЗжХфвЛИіЯпГЬзщЃЈгжГЦЯпГЬПщЁЂBlockЃЉЃЌsizeБэЪОУПИіЯпГЬзщгаsizeИіЯпГЬЃЈThreadЃЉЁЃБОГЬађжаsizeИљОнЧАУцДЋЕнВЮЪ§ИіЪ§гІИУЮЊ5ЃЌЫљвддЫааЕФЪБКђЃЌКЫКЏЪ§дк5ИіGPUЯпГЬЕЅдЊЩЯЗжБ№дЫааСЫвЛДЮЃЌзмЙВдЫааСЫ5ДЮЁЃет5ИіЯпГЬЪЧШчКЮжЊЕРздМКЁАЩэЗнЁБЕФЃПЪЧППthreadIdxетИіФкжУБфСПЃЌЫќЪЧИіdim3РраЭБфСПЃЌНгЪм<<<>>>жаЕкЖўИіВЮЪ§ЃЌЫќАќКЌx,y,z
3ЮЌзјБъЃЌЖјЮвУЧДЋШыЕФВЮЪ§жЛгавЛЮЌЃЌЫљвджЛгаxжЕЪЧгааЇЕФЁЃЭЈЙ§КЫКЏЪ§жаint i = threadIdx.x;етвЛОфЃЌУПИіЯпГЬПЩвдЛёЕУздЩэЕФidКХЃЌДгЖјевЕНздМКЕФШЮЮёШЅжДааЁЃ
CUDAДгШыУХЕНОЋЭЈЃЈСљЃЉЃКПщВЂаа
ЭЌвЛАцБОЕФДњТыгУСЫетУДЖрДЮЃЌгаЕуЙ§втВЛШЅЃЌгкЪЧетДЮЮввЊзіНЯДѓЕФИФЖЏДѓаІЃЌДѓМввЊВСССблОІЃЌЪУФПвдД§ЁЃ
ПщВЂааЯрЕБгкВйзїЯЕЭГжаЖрНјГЬЕФЧщПіЃЌЩЯНкЫЕЕНЃЌCUDAгаЯпГЬзщЃЈЯпГЬПщЃЉЕФИХФюЃЌНЋвЛзщЯпГЬзщжЏЕНвЛЦ№ЃЌЙВЭЌЗжХфвЛВПЗжзЪдДЃЌШЛКѓФкВПЕїЖШжДааЁЃЯпГЬПщгыЯпГЬПщжЎМфЃЌКСЮоЙЯИ№ЁЃетгаРћгкзіИќДжСЃЖШЕФВЂааЁЃЮвУЧНЋЩЯвЛНкЕФДњТыИФЮЊПщВЂааАцБОШчЯТЃК
ЯТНкЮвУЧНщЩмПщВЂааЁЃ
#include "cuda_runtime.h"
#include " device_launch_parameters.h"
#include <stdio.h>
cudaError_ t addWithCuda(int *c, const int *a,
const int *b, size_t size);
__global__ void addKernel(int *c, const int *a,
const int *b)
{
<span style="BACKGROUND-COLOR: #ff0000">
int i = blockIdx .x;
</span>
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50
};
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus;
int num = 0;
cudaDeviceProp prop;
cudaStatus = cudaGetDeviceCount(&num);
for(int i = 0;i<num;i++)
{
cudaGetDeviceProperties (&prop,i);
}
cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf ("{1,2,3,4,5} + {10,20,30,40,50} =
{%d, %d, %d, %d, %d} \n",c[0],c[1] ,c[2],c[3],c[4]);
// cudaThreadExit must be called before exiting
in order for profiling and
// tracing tools such as Nsight and Visual Profiler
to show complete traces.
cudaStatus = cudaThreadExit();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaThreadExit failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors
in parallel.
cudaError_t addWithCuda (int *c, const int *a,
const int *b, size_t size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on
a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaSetDevice failed! Do
you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two
input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size
* sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size
* sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size
* sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU
buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy (dev_b, b, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread
for each element.
<span style = "BACKGROUND-COLOR: #ff0000">
addKernel <<<size,1 >>> (dev_c,
dev_a, dev_b);
</span>
// cudaThreadSynchronize waits for the kernel
to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize();
if (cudaStatus != cudaSuccess)
{
fprintf( stderr, "cudaThreadSynchronize returned
error code %d after launching addKernel! \n",
cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host
memory.
cudaStatus = cudaMemcpy (c, dev_c, size * sizeof(int),
cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
} |
КЭЩЯвЛНкЯрБШЃЌжЛгаетСНаагаИФБфЃЌ<<<>>>РяЕквЛИіВЮЪ§ИФГЩСЫsizeЃЌЕкЖўИіИФГЩСЫ1ЃЌБэЪОЮвУЧЗжХфsizeИіЯпГЬПщЃЌУПИіЯпГЬПщНіАќКЌ1ИіЯпГЬЃЌзмЙВЛЙЪЧга5ИіЯпГЬЁЃет5ИіЯпГЬЯрЛЅЖРСЂЃЌжДааКЫКЏЪ§ЕУЕНЯргІЕФНсЙћЃЌгыЩЯвЛНкВЛЭЌЕФЪЧЃЌУПИіЯпГЬЛёШЁidЕФЗНЪНБфЮЊint
i = blockIdx.xЃЛетЪЧЯпГЬПщIDЁЃ
гкЪЧгаЭЏаЌЬсЮЪСЫЃЌЯпГЬВЂааКЭПщВЂааЕФЧјБ№дкФФРяЃП
ЯпГЬВЂааЪЧЯИСЃЖШВЂааЃЌЕїЖШаЇТЪИпЃЛПщВЂааЪЧДжСЃЖШВЂааЃЌУПДЮЕїЖШЖМвЊжиаТЗжХфзЪдДЃЌгаЪБзЪдДжЛгавЛЗнЃЌФЧУДЫљгаЯпГЬПщЖМжЛФмХХГЩвЛЖгЃЌДЎаажДааЁЃ
ФЧЪЧВЛЪЧЮвУЧЫљгаЪБКђЖМгІИУгУЯпГЬВЂааЃЌОЁПЩФмВЛгУПщВЂааЃП
ЕБШЛВЛЪЧЃЌЮвУЧЕФШЮЮёгаЪБПЩвдВЩгУЗжжЮЗЈЃЌНЋвЛИіДѓЮЪЬтЗжНтЮЊМИИіаЁЙцФЃЮЪЬтЃЌНЋетаЉаЁЙцФЃЮЪЬтЗжБ№гУвЛИіЯпГЬПщЪЕЯжЃЌЯпГЬПщФкПЩвдВЩгУЯИСЃЖШЕФЯпГЬВЂааЃЌЖјПщжЎМфЮЊДжСЃЖШВЂааЃЌетбљПЩвдГфЗжРћгУгВМўзЪдДЃЌНЕЕЭЯпГЬВЂааЕФМЦЫуИДдгЖШЁЃЪЪЕБЗжНтЃЌНЕЕЭЙцФЃЃЌдквЛаЉОиеѓГЫЗЈЁЂЯђСПФкЛ§МЦЫугІгУжаПЩвдЕУЕНГфЗжЕФеЙЪОЁЃ
ЪЕМЪгІгУжаЃЌГЃГЃЪЧЖўепЕФНсКЯЁЃЯпГЬПщЁЂЯпГЬзщжЏЭМШчЯТЫљЪОЁЃ
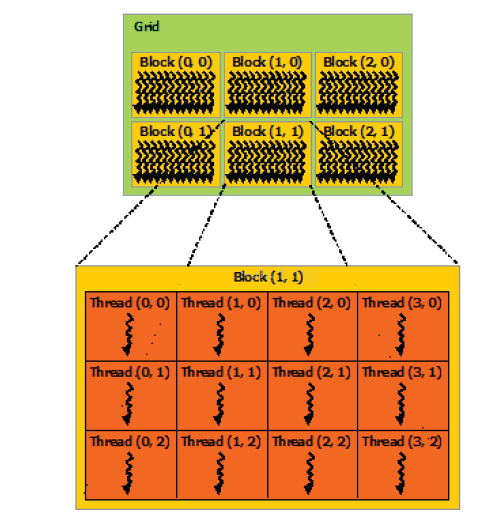
ЖрИіЯпГЬПщзщжЏГЩСЫвЛИіGridЃЌГЦЮЊЯпГЬИёЃЈОРњСЫДгвЛЮЛЯпГЬЃЌЖўЮЌЯпГЬПщЕНШ§ЮЌЯпГЬИёЕФЙ§ГЬЃЌСЂЬхИаКмЧПАЁЃЉЁЃ
КУСЫЃЌЯТвЛНкЮвУЧНщЩмСїВЂааЃЌЪЧИќИпВуДЮЕФВЂааЁЃ
CUDAДгШыУХЕНОЋЭЈЃЈЦпЃЉЃКСїВЂаа
ЧАУцЮвУЧУЛгаНВГЬађЕФНсЙЙЃЌЮвЯыгааЉЭЏаЌПЩФмЦШВЛМАД§ЯыжЊЕРCUDAГЬађЕНЕзЪЧдѕУДвЛИіжДааЙ§ГЬЁЃКУЕФЃЌетвЛНкдкНщЩмСїжЎЧАЃЌЯШАбCUDAГЬађНсЙЙМђвЊЫЕвЛЯТЁЃ
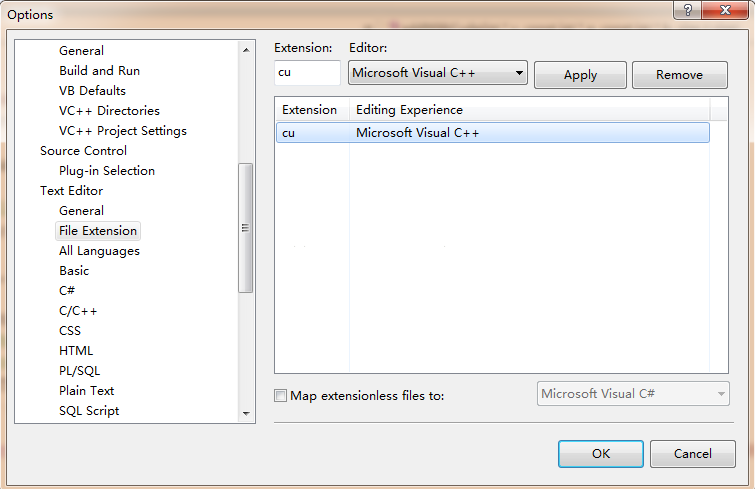
CUDAГЬађЮФМўКѓзКЮЊ.cuЃЌгааЉБрвыЦїПЩФмВЛШЯЪЖетИіКѓзКЕФЮФМўЃЌЮвУЧПЩвддкVS2008ЕФTools->
Options -> Text Editor-> File ExtensionРяЬэМгcuКѓзКЕНVC++жаЃЌШчЯТЭМЃК
вЛИі.cuЮФМўФкМШАќКЌCPUГЬађЃЈГЦЮЊжїЛњГЬађЃЉЃЌвВАќКЌGPUГЬађЃЈГЦЮЊЩшБИГЬађЃЉЁЃШчКЮЧјЗжжїЛњГЬађКЭЩшБИГЬађЃПИљОнЩљУїЃЌЗВЪЧЙвгаЁА__global__ЁБЛђепЁА__device__ЁБЧАзКЕФКЏЪ§ЃЌЖМЪЧдкGPUЩЯдЫааЕФЩшБИГЬађЃЌВЛЭЌЕФЪЧ__global__ЩшБИГЬађПЩБЛжїЛњГЬађЕїгУЃЌЖј__device__ЩшБИГЬађдђжЛФмБЛЩшБИГЬађЕїгУЁЃ
УЛгаЙвШЮКЮЧАзКЕФКЏЪ§ЃЌЖМЪЧжїЛњГЬађЁЃжїЛњГЬађЯдЪОЩљУїПЩвдгУ__host__ЧАзКЁЃЩшБИГЬађашвЊгЩNVCCНјааБрвыЃЌЖјжїЛњГЬађжЛашвЊгЩжїЛњБрвыЦїЃЈШчVS2008жаЕФcl.exeЃЌLinuxЩЯЕФGCCЃЉЁЃжїЛњГЬађжївЊЭъГЩЩшБИЛЗОГГѕЪМЛЏЃЌЪ§ОнДЋЪфЕШБиБИЙ§ГЬЃЌЩшБИГЬађжЛИКд№МЦЫуЁЃ
жїЛњГЬађжаЃЌгавЛаЉЁАcudaЁБДђЭЗЕФКЏЪ§ЃЌетаЉЖМЪЧCUDA Runtime
APIЃЌМДдЫааЪБКЏЪ§ЃЌжївЊИКд№ЭъГЩЩшБИЕФГѕЪМЛЏЁЂФкДцЗжХфЁЂФкДцПНБДЕШШЮЮёЁЃЮвУЧЧАУцЕкШ§НкгУЕНЕФКЏЪ§cudaGetDeviceCount()ЃЌcudaGet
DeviceProperties ()ЃЌcudaSetDevice()ЖМЪЧдЫааЪБAPIЁЃетаЉКЏЪ§ЕФОпЬхВЮЪ§ЩљУїЮвУЧВЛБивЛвЛМЧЯТРДЃЌФУГіЕкШ§НкЕФЙйЗНРћЦїОЭПЩвдЧсЫЩВщбЏЃЌШУЮвУЧДђПЊетИіЮФМўЃК
ДђПЊКѓЃЌдкpdfЫбЫїРИжаЪфШывЛИідЫааЪБКЏЪ§ЃЌР§ШчcudaMemcpyЃЌВщЕНЕФНсЙћШчЯТЃК
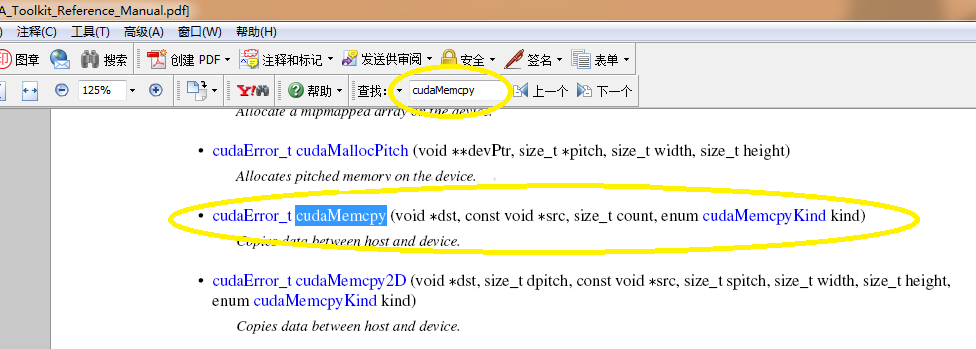
ПЩвдПДЕНЃЌИУAPIКЏЪ§ЕФВЮЪ§аЮЪНЮЊЃЌЕквЛИіБэЪОФПЕФЕиЃЌЕкЖўИіБэЪОРДдДЕиЃЌЕкШ§ИіВЮЪ§БэЪОзжНкЪ§ЃЌЕкЫФИіБэЪОРраЭЁЃШчЙћЖдРраЭВЛСЫНтЃЌжБНгЕуЛїГЌСДНгЃЌЕУЕНЯъЯИНтЪЭШчЯТЃК

ПЩМћЃЌИУAPIПЩвдЪЕЯжДгжїЛњЕНжїЛњЁЂжїЛњЕНЩшБИЁЂЩшБИЕНжїЛњЁЂЩшБИЕНЩшБИЕФФкДцПНБДЙ§ГЬЁЃЭЌЪБПЩвдЗЂЯжЃЌРћгУИУAPIЪжВсПЩвдКмЗНБуЕиВщбЏЮвУЧашвЊгУЕФетаЉAPIКЏЪ§ЃЌЫљвдвдКѓБрCUDAГЬађвЛЖЈвЊАбЫќДђПЊЃЌЫцЪБзМБИВщбЏЃЌетбљПЩвдДѓДѓЬсИпБрГЬаЇТЪЁЃ
КУСЫЃЌНјШыНёЬьЕФжїЬтЃКСїВЂааЁЃ
ЧАУцвбОНщЩмСЫЯпГЬВЂааКЭПщВЂааЃЌжЊЕРСЫЯпГЬВЂааЮЊЯИСЃЖШЕФВЂааЃЌЖјПщВЂааЮЊДжСЃЖШЕФВЂааЃЌЭЌЪБвВжЊЕРСЫCUDAЕФЯпГЬзщжЏЧщПіЃЌМДGrid-Block-ThreadНсЙЙЁЃвЛзщЯпГЬВЂааДІРэПЩвдзщжЏЮЊвЛИіblockЃЌЖјвЛзщblockВЂааДІРэПЩвдзщжЏЮЊвЛИіGridЃЌКмздШЛЕиЯыЕНЃЌGridжЛЪЧвЛИіЭјИёЃЌЮвУЧЪЧЗёПЩвдРћгУЖрИіЭјИёРДЭъГЩВЂааДІРэФиЃПД№АИОЭЪЧРћгУСїЁЃ
СїПЩвдЪЕЯждквЛИіЩшБИЩЯдЫааЖрИіКЫКЏЪ§ЁЃЧАУцЕФПщВЂаавВКУЃЌЯпГЬВЂаавВКУЃЌдЫааЕФКЫКЏЪ§ЖМЪЧЯрЭЌЕФЃЈДњТывЛбљЃЌДЋЕнВЮЪ§вВвЛбљЃЉЁЃЖјСїВЂааЃЌПЩвджДааВЛЭЌЕФКЫКЏЪ§ЃЌвВПЩвдЪЕЯжЖдЭЌвЛИіКЫКЏЪ§ДЋЕнВЛЭЌЕФВЮЪ§ЃЌЪЕЯжШЮЮёМЖБ№ЕФВЂааЁЃ
CUDAжаЕФСїгУcudaStream_tРраЭЪЕЯжЃЌгУЕНЕФAPIгавдЯТМИИіЃКcudaStreamCreate(cudaStream_t
* s)гУгкДДНЈСїЃЌcudaStreamDestroy(cudaStream_t s)гУгкЯњЛйСїЃЌcudaStreamSynchronize()гУгкЕЅИіСїЭЌВНЃЌcudaDeviceSynchronize()гУгкећИіЩшБИЩЯЕФЫљгаСїЭЌВНЃЌcudaStreamQuery()гУгкВщбЏвЛИіСїЕФШЮЮёЪЧЗёвбОЭъГЩЁЃОпЬхЕФКЌвхПЩвдВщбЏAPIЪжВсЁЃ
ЯТУцЮвУЧНЋЧАУцЕФСНИіР§згжаЕФШЮЮёИФгУСїЪЕЯжЃЌШдШЛЪЧ{1,2,3,4,5}+{10,20,30,40,50}
= {11, 22, 33, 44, 55} етИіР§згЁЃДњТыШчЯТЃК
#include "cuda_runtime.h"
#include "device_ launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda (int *c, const int *a,
const int *b, size_t size);
__global__ void addKernel(int *c, const int *a,
const int *b)
{
int i = blockIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50
};
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_ t cudaStatus;
int num = 0;
cudaDeviceProp prop;
cudaStatus = cudaGetDeviceCount (&num);
for(int i = 0;i<num;i++)
{
cudaGetDeviceProperties(&prop,i);
}
cudaStatus = addWithCuda (c, a, b, arraySize);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} =
{%d, %d, %d, %d, %d}\n",c[0] ,c[1],c[2],c[3],c[4]);
// cudaThreadExit must be called before exiting
in order for profiling and
// tracing tools such as Nsight and Visual Profiler
to show complete traces.
cudaStatus = cudaThreadExit();
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaThreadExit failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors
in parallel.
cudaError_t addWithCuda (int *c, const int *a,
const int * b, size_t size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on
a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaSetDevice failed! Do
you have a CUDA- capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two
input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size
* sizeof (int));
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size
* sizeof (int));
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size
* sizeof (int));
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU
buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
<span style= "BACKGROUND-COLOR : #ff6666">
cudaStream _ t stream[5];
for (int i = 0;i<5;i++)
{
cudaStreamCreate (&stream[i]); //ДДНЈСї
}
</span> // Launch a kernel on the
GPU with one thread for each element.
<span style= "BACKGROUND-COLOR : #ff6666">
for (int i = 0;i<5;i++)
{
addKernel <<<1,1,0,stream[i]>>>
(dev_ c+i, dev_ a+i, dev_ b+i); //жДааСї
}
cudaDeviceSynchronize();
</span> // cudaThreadSynchronize waits for
the kernel to finish , and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize();
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaThreadSynchronize returned
error code %d after launching addKernel!\n",
cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host
memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int),
cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
<span style= "BACKGROUND-COLOR : #ff6666">
for(int i = 0;i<5;i++)
{
cudaStreamDestroy(stream[i]); //ЯњЛйСї
}
</span> cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
} |
зЂвтЕНЃЌЮвУЧЕФКЫКЏЪ§ДњТыШдШЛКЭПщВЂааЕФАцБОвЛбљЃЌжЛЪЧдкЕїгУЪБзіСЫИФБфЃЌ<<<>>>жаЕФВЮЪ§ЖрСЫСНИіЃЌЦфжаЧАСНИіКЭПщВЂааЁЂЯпГЬВЂаажаЕФвтвхЯрЭЌЃЌШдШЛЪЧЯпГЬПщЪ§ЃЈетРяЮЊ1ЃЉЁЂУПИіЯпГЬПщжаЯпГЬЪ§ЃЈетРявВЪЧ1ЃЉЁЃЕкШ§ИіЮЊ0БэЪОУПИіblockгУЕНЕФЙВЯэФкДцДѓаЁЃЌетИіЮвУЧКѓУцдйНВЃЛЕкЫФИіЮЊСїЖдЯѓЃЌБэЪОЕБЧАКЫКЏЪ§дкФФИіСїЩЯдЫааЁЃЮвУЧДДНЈСЫ5ИіСїЃЌУПИіСїЩЯЖМзАдиСЫвЛИіКЫКЏЪ§ЃЌЭЌЪБДЋЕнВЮЪ§гааЉВЛЭЌЃЌвВОЭЪЧУПИіКЫКЏЪ§зїгУЕФЖдЯѓвВВЛЭЌЁЃетбљОЭЪЕЯжСЫШЮЮёМЖБ№ЕФВЂааЃЌЕБЮвУЧгаМИИіЛЅВЛЯрЙиЕФШЮЮёЪБЃЌПЩвдаДЖрИіКЫКЏЪ§ЃЌзЪдДдЪаэЕФЧщПіЯТЃЌЮвУЧНЋетаЉКЫКЏЪ§зАдиЕНВЛЭЌСїЩЯЃЌШЛКѓжДааЃЌетбљПЩвдЪЕЯжИќДжСЃЖШЕФВЂааЁЃ
КУСЫЃЌСїВЂааОЭетУДМђЕЅЃЌЮвУЧДІРэШЮЮёЪБЃЌПЩвдИљОнашвЊЃЌбЁдёзюЪЪКЯЕФВЂааЗНЪНЁЃ
UDAДгШыУХЕНОЋЭЈЃЈАЫЃЉЃКЯпГЬЭЈаХ
ЮвУЧЧАУцМИНкжївЊНщЩмСЫШ§жжРћгУGPUЪЕЯжВЂааДІРэЕФЗНЪНЃКЯпГЬВЂааЃЌПщВЂааКЭСїВЂааЁЃдкетаЉЗНЗЈжаЃЌЮвУЧвЛдйЧПЕїЃЌИїИіЯпГЬЫљНјааЕФДІРэЪЧЛЅВЛЯрЙиЕФЃЌМДСНИіЯпГЬВЛЛиВњЩњНЛМЏЃЌУПИіЯпГЬЖМжЛЙизЂздМКЕФвЛФЖШ§ЗжЕиЃЌЖдЦфЫћЯпГЬКСЮоаЫШЄЃЌОЭЕБВЛДцдкЁЃЁЃЁЃЁЃ
ЕБШЛЃЌЪЕМЪгІгУжаЃЌетбљЕФР§згЬЋЩйСЫЃЌвВОЭЪЧгіЕНЯђСПЯрМгЁЂЯђСПЖдгІЕуГЫетРрВХЛсгаШчДЫИпЕФВЂааЖШЃЌЖјЦфЫћвЛаЉгІгУЃЌШчвЛзщЪ§ЧѓКЭЃЌЧѓзюДѓЃЈаЁЃЉжЕЃЌИїИіЯпГЬВЛдйЪЧЯрЛЅЖРСЂЕФЃЌЖјЪЧВњЩњвЛЖЈЙиСЊЃЌЯпГЬ2ПЩФмЛсгУЕНЯпГЬ1ЕФНсЙћЃЌетЪБОЭашвЊРћгУБОНкЕФЯпГЬЭЈаХММЪѕСЫЁЃ
ЯпГЬЭЈаХдкCUDAжагаШ§жжЪЕЯжЗНЪНЃК
1. ЙВЯэДцДЂЦїЃЛ
2. ЯпГЬ ЭЌВНЃЛ
3. дзгВйзїЃЛ
зюГЃгУЕФЪЧЧАСНжжЗНЪНЃЌЙВЯэДцДЂЦїЃЌЪѕгяShared MemoryЃЌЪЧЮЛгкSMжаЕФЬиЪтДцДЂЦїЁЃЛЙМЧЕУSMТ№ЃЌОЭЪЧСїЖрДІРэЦїЃЌДѓКЫЪЧвВЁЃвЛИіSMжаВЛНіАќКЌШєИЩИіSPЃЈСїДІРэЦїЃЌаЁКЫЃЉЃЌЛЙАќРЈвЛВПЗжИпЫйCacheЃЌМФДцЦїзщЃЌЙВЯэФкДцЕШЃЌНсЙЙШчЭМЫљЪОЃК
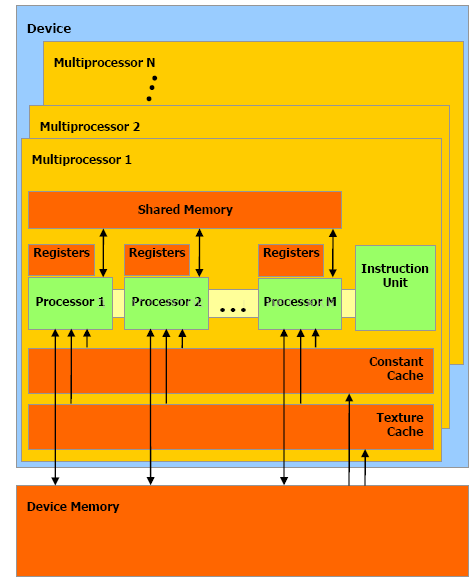
ДгЭМжаПЩПДГіЃЌвЛИіSMФкгаMИіSPЃЌShared MemoryгЩетMИіSPЙВЭЌеМгаЁЃСэЭтжИСюЕЅдЊвВБЛетMИіSPЙВЯэЃЌМДSIMTМмЙЙЃЈЕЅжИСюЖрЯпГЬМмЙЙЃЉЃЌвЛИіSMжаЫљгаSPдкЭЌвЛЪБМфжДааЭЌвЛДњТыЁЃ
ЮЊСЫЪЕЯжЯпГЬЭЈаХЃЌНіНіППЙВЯэФкДцЛЙВЛЙЛЃЌашвЊгаЭЌВНЛњжЦВХФмЪЙЯпГЬжЎМфЪЕЯжгаађДІРэЁЃЭЈГЃЧщПіЪЧетбљЃКЕБЯпГЬAашвЊЯпГЬBМЦЫуЕФНсЙћзїЮЊЪфШыЪБЃЌашвЊШЗБЃЯпГЬBвбОНЋНсЙћаДШыЙВЯэФкДцжаЃЌШЛКѓЯпГЬAдйДгЙВЯэФкДцжаЖСГіЁЃЭЌВНБиВЛПЩЩйЃЌЗёдђЃЌЯпГЬAПЩФмЖСЕНЕФЪЧЮоаЇЕФНсЙћЃЌдьГЩМЦЫуДэЮѓЁЃЭЌВНЛњжЦПЩвдгУCUDAФкжУКЏЪ§ЃК__syncthreads()ЃЛЕБФГИіЯпГЬжДааЕНИУКЏЪ§ЪБЃЌНјШыЕШД§зДЬЌЃЌжБЕНЭЌвЛЯпГЬПщЃЈBlockЃЉжаЫљгаЯпГЬЖМжДааЕНетИіКЏЪ§ЮЊжЙЃЌМДвЛИі__syncthreads()ЯрЕБгквЛИіЯпГЬЭЌВНЕуЃЌШЗБЃвЛИіBlockжаЫљгаЯпГЬЖМДяЕНЭЌВНЃЌШЛКѓЯпГЬНјШыдЫаазДЬЌЁЃ
злЩЯСНЕуЃЌЮвУЧПЩвдаДвЛЖЮЯпГЬЭЈаХЕФЮБДњТыШчЯТЃК
//Begin
if this is thread B
write something to Shared Memory;
end if
__syncthreads();
if this is thread A
read something from Shared Memory;
end if
//End |
ЩЯУцДњТыдкCUDAжаЪЕЯжЪБЃЌгЩгкSIMTЬиадЃЌЫљгаЯпГЬЖМжДааЭЌбљЕФДњТыЃЌЫљвддкЯпГЬжаашвЊХаЖЯздМКЕФЩэЗнЃЌвдУтЮѓВйзїЁЃ
зЂвтЕФЪЧЃЌЮЛгкЭЌвЛИіBlockжаЕФЯпГЬВХФмЪЕЯжЭЈаХЃЌВЛЭЌBlockжаЕФЯпГЬВЛФмЭЈЙ§ЙВЯэФкДцЁЂЭЌВННјааЭЈаХЃЌЖјгІВЩгУдзгВйзїЛђжїЛњНщШыЁЃ
ЖдгкдзгВйзїЃЌШчЙћИааЫШЄПЩвдЗдФЁЖGPUИпадФмБрГЬCUDAЪЕеНЁЗЕкОХеТЁАдзгадЁБЁЃ
БОНкЭъЁЃЯТНкЮвУЧИјГівЛИіЪЕР§РДПДЯпГЬЭЈаХЕФДњТыдѕУДЩшМЦЁЃ
CUDAДгШыУХЕНОЋЭЈЃЈОХЃЉЃКЯпГЬЭЈаХЪЕР§
НгзХЩЯвЛНкЃЌЮвУЧРћгУИебЇЕНЕФЙВЯэФкДцКЭЯпГЬЭЌВНММЪѕЃЌРДзівЛИіМђЕЅЕФР§згЁЃЯШПДЯТаЇЙћАЩЃК
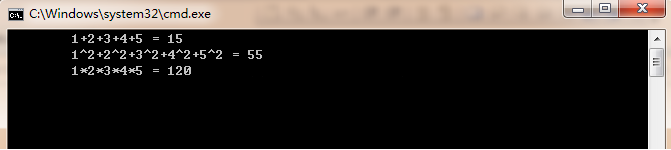
КмМђЕЅЃЌОЭЪЧЗжБ№ЧѓГі1~5ет5ИіЪ§зжЕФКЭЃЌЦНЗНКЭЃЌСЌГЫЛ§ЁЃЯраХбЇЙ§CгябдЕФЭЏаЌЖМФмгУforбЛЗзіГіЭЌЩЯУцвЛбљЕФаЇЙћЃЌЕЋЮЊСЫбЇЯАCUDAЙВЯэФкДцКЭЭЌВНММЪѕЃЌЮвУЧЛЙЪЧвЊАбМђЕЅЕФЖЋЮїИДдгЛЏ(^_^)ЁЃ
МђвЊЗжЮівЛЯТЃЌЩЯУцР§згЕФЪфШыЖМЪЧвЛбљЕФЃЌ1,2,3,4,5ет5ИіЪ§ЃЌЕЋМЦЫуЙ§ГЬгааЉБфЛЏЃЌЖјЧвУПИіЪфГіКЭЫљгаЪфШыЖМЯрЙиЃЌВЛЪЧЧАМИНкР§згжаФЧбљЃЌвЛИіЪфГіжЛКЭвЛИіЪфШыгаЙиЁЃЫљвдЮвУЧдкРћгУCUDAБрГЬЪБЃЌашвЊеыЖдЬиЪтЮЪЬтзіаЉШУВНЃЌАбвЛаЉВНжшДЎааЛЏЪЕЯжЁЃ
ЪфШыЪ§ОндБОЮЛгкжїЛњФкДцЃЌЭЈЙ§cudaMemcpy APIвбОПНБДЕНGPUЯдДцЃЈЪѕгяЮЊШЋОжДцДЂЦїЃЌGlobal
MemoryЃЉЃЌУПИіЯпГЬдЫааЪБашвЊДгGlobal MemoryЖСШЁЪфШыЪ§ОнЃЌШЛКѓЭъГЩМЦЫуЃЌзюКѓНЋНсЙћаДЛиGlobal
MemoryЁЃЕБЮвУЧМЦЫуашвЊЖрДЮЯрЭЌЪфШыЪ§ОнЪБЃЌДѓМвПЩФмЯыЕНЃЌУПДЮЖМЗжБ№ШЅGlobal MemoryЖСЪ§ОнКУЯёгаЕуРЫЗбЃЌШчЙћЪ§ОнКмДѓЃЌФЧУДЗДИДЖрДЮЖСЪ§ОнЛсЯрЕБКФЪБМфЁЃЫїадЮвУЧАбЫќДгGlobal
MemoryвЛДЮадЖСЕНSMФкВПЃЌШЛКѓдкФкВПНјааДІРэЃЌетбљПЩвдНкЪЁЗДИДЖСШЁЕФЪБМфЁЃ
гаСЫетИіЫМТЗЃЌНсКЯЩЯНкПДЕНЕФSMНсЙЙЭМЃЌПДЕНгавЛЦЌДцДЂЦїНазіShared MemoryЃЌЫќЮЛгкSMФкВПЃЌДІРэЪБЗУЮЪЫйЖШЯрЕБПьЃЈВюВЛЖрУПИіЪБжгжмЦкЖСвЛДЮЃЉЃЌЖјШЋОжДцДЂЦїЖСвЛДЮашвЊКФЗбМИЪЎЩѕжСЩЯАйИіЪБжгжмЦкЁЃгкЪЧЃЌЮвУЧОЭжЦЖЈAМЦЛЎШчЯТЃК
ЯпГЬПщЪ§ЃК1ЃЌПщКХЮЊ0ЃЛЃЈжЛгавЛИіЯпГЬПщФкЕФЯпГЬВХФмНјааЭЈаХЃЌЫљвдЮвУЧжЛЗжХфвЛИіЯпГЬПщЃЌОпЬхЙЄзїНЛИјУПИіЯпГЬЭъГЩЃЉ
ЯпГЬЪ§ЃК5ЃЌЯпГЬКХЗжБ№ЮЊ0~4ЃЛЃЈЯпГЬВЂааЃЌЧАУцНВЙ§ЃЉ
ЙВЯэДцДЂЦїДѓаЁЃК5ИіintаЭБфСПДѓаЁЃЈ5 * sizeof(intЃЉЃЉЁЃ
ВНжшвЛЃКЖСШЁЪфШыЪ§ОнЁЃНЋGlobal MemoryжаЕФ5ИіећЪ§ЖСШыЙВЯэДцДЂЦїЃЌЮЛжУвЛвЛЖдгІЃЌКЭЯпГЬКХвВвЛвЛЖдгІЃЌЫљвдПЩвдЭЌЪБЭъГЩЁЃ
ВНжшЖўЃКЯпГЬЭЌВНЃЌШЗБЃЫљгаЯпГЬЖМЭъГЩСЫЙЄзїЁЃ
ВНжшШ§ЃКжИЖЈЯпГЬЃЌЖдЙВЯэДцДЂЦїжаЕФЪфШыЪ§ОнЭъГЩЯргІДІРэЁЃ
ДњТыШчЯТЃК
#include "cuda_
runtime.h"
#include "device_ launch_parameters.h"
#include <stdio.h>
cudaError_ t addWithCuda (int *c, const int *a,
size_t size);
__global__ void addKernel (int *c, const int *a)
{
int i = threadIdx.x;
<span style="font-size:24px;">
<strong> extern __ shared __ int smem[];</strong>
</span> smem[i] = a[i];
__ syncthreads();
if(i == 0) // 0КХЯпГЬзіЦНЗНКЭ
{
c[0] = 0;
for (int d = 0; d < 5; d++)
{
c[0] += smem[d] * smem[d];
}
}
if(i == 1)//1КХЯпГЬзіРлМг
{
c[1] = 0;
for (int d = 0; d < 5; d++)
{
c[1] += smem[d];
}
}
if (i == 2) //2КХЯпГЬзіРлГЫ
{
c[2] = 1;
for(int d = 0; d < 5; d++)
{
c[2] *= smem[d];
}
}
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
int c [arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda (c, a, arraySize
);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf(" \t1+2+3+4+5 = %d\n\t1^2+2^2+3^2+4^2+5^2
= %d \n\ t1*2*3*4*5 = %d\n\n\n\n\n\n", c[1],
c[0], c[2]);
// cudaThreadExit must be called before exiting
in order for profiling and
// tracing tools such as Nsight and Visual Profiler
to show complete traces.
cudaStatus = cudaThreadExit();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaThreadExit failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors
in parallel.
cudaError_t addWithCuda (int *c, const int *a,
size_t size)
{
int *dev_a = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on
a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaSetDevice failed! Do
you have a CUDA -capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two
input, one output) .
cudaStatus = cudaMalloc ((void**)&dev_c, size
* sizeof (int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size
* sizeof (int));
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU
buffers.
cudaStatus = cudaMemcpy (dev_a, a, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread
for each element.
<span style ="font-size:24px;">
<strong> addKernel <<< 1, size,
size * sizeof (int), 0>>> (dev_c, dev_a);
</ strong>
</span>
// cudaThreadSynchronize waits for the kernel
to finish , and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize();
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaThreadSynchronize returned
error code %d after launching addKernel!\n",
cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host
memory.
cudaStatus = cudaMemcpy (c, dev_c, size * sizeof(int),
cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
return cudaStatus;
} |
ДгДњТыжаПДЕНжДааХфжУ<<<>>>жаЕкШ§ИіВЮЪ§ЮЊЙВЯэФкДцДѓаЁЃЈзжНкЪ§ЃЉЃЌетбљЮвУЧОЭжЊЕРСЫШЋВП4ИіжДааХфжУВЮЪ§ЕФвтвхЁЃЙЇЯВЃЌФуЕФCUDAжегкШыУХСЫЃЁ
CUDAДгШыУХЕНОЋЭЈЃЈЪЎЃЉЃКадФмЦЪЮіКЭVisual Profiler
ШыУХКѓЕФНјвЛВНбЇЯАЕФФкШнЃЌОЭЪЧШчКЮгХЛЏздМКЕФДњТыЁЃЮвУЧЧАУцЕФР§згУЛгаПМТЧШЮКЮадФмЗНУцгХЛЏЃЌЪЧЮЊСЫИќКУЕибЇЯАЛљБОжЊЪЖЕуЃЌЖјВЛЪЧЦфЫћЯИНкЮЪЬтЁЃДгБОНкПЊЪМЃЌЮвУЧвЊДгадФмГіЗЂПМТЧЮЪЬтЃЌВЛЖЯгХЛЏДњТыЃЌЪЙжДааЫйЖШЬсИпЪЧВЂааДІРэЕФЮЈвЛФПЕФЁЃ
ВтЪдДњТыдЫааЫйЖШгаКмЖрЗНЗЈЃЌCгябдРяЬсЙЉСЫРрЫЦгкSystemTime()етбљЕФAPIЛёЕУЯЕЭГЪБМфЃЌШЛКѓМЦЫуСНИіЪТМўжЎМфЕФЪБГЄДгЖјЭъГЩМЦЪБЙІФмЁЃдкCUDAжаЃЌЮвУЧгазЈУХВтСПЩшБИдЫааЪБМфЕФAPIЃЌЯТУцвЛвЛНщЩмЁЃ
ЗПЊБрГЬЪжВсЁЖCUDA_Toolkit_Reference_ManualЁЗЃЌЫцЪБзМБИВщбЏВЛЖЎЕУAPIЁЃЮвУЧдкдЫааКЫКЏЪ§ЧАКѓЃЌзіШчЯТВйзїЃК
cudaEvent_t
start, stop; <span style= "white-space
: pre "> </span> //ЪТМўЖдЯѓ
cudaEventCreate(&start); <span style= "white-space
: pre"> </span>//ДДНЈЪТМў
cudaEventCreate (&stop); <span style ="white-space:
pre"> </span>//ДДНЈЪТМў
cudaEventRecord (start, stream); <span style=
"white-space: pre"> </span>//МЧТМПЊЪМ
myKernel <<<dimg,dimb,size_ smem ,stream>>>
( parameter list);//жДааКЫКЏЪ§
cudaEventRecord (stop,stream);<span style=
"white-space:pre"> </span>//МЧТМНсЪјЪТМў
cudaEventSynchronize (stop);<span style= "white-space
: pre"> </span>//ЪТМўЭЌВНЃЌЕШД§НсЪјЪТМўжЎЧАЕФЩшБИВйзїОљвбЭъГЩ
float elapsedTime;
cudaEventElapsedTime(&elapsedTime,start,stop);//МЦЫуСНИіЪТМўжЎМфЪБГЄЃЈЕЅЮЛЮЊmsЃЉ
|
КЫКЏЪ§жДааЪБМфНЋБЛБЃДцдкБфСПelapsedTimeжаЁЃЭЈЙ§етИіжЕЮвУЧПЩвдЦРЙРЫуЗЈЕФадФмЁЃЯТУцИјвЛИіР§згЃЌРДПДдѕУДЪЙгУМЦЪБЙІФмЁЃ
ЧАУцЕФР§згЙцФЃКмаЁЃЌжЛга5ИідЊЫиЃЌДІРэСПЬЋаЁВЛзувдМЦЪБЃЌЯТУцНЋЙцФЃРЉДѓЮЊ1024ЃЌДЫЭтНЋЗДИДдЫаа1000ДЮМЦЫузмЪБМфЃЌетбљЙРМЦВЛШнвзЪмЫцЛњШХЖЏгАЯьЁЃЮвУЧЭЈЙ§етИіР§згЖдБШЯпГЬВЂааКЭПщВЂааЕФадФмШчКЮЁЃДњТыШчЯТЃК
#include "cuda_
runtime.h"
#include "device_ launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda (int *c, const int *a,
const int *b, size _t size);
__global__ void addKernel_blk (int *c, const int
*a, const int *b)
{
int i = blockIdx.x;
c[i] = a[i]+ b[i];
}
__global__ void addKernel_thd (int *c, const int
*a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i]+ b[i];
}
int main()
{
const int arraySize = 1024;
int a[arraySize] = {0};
int b[arraySize] = {0};
for(int i = 0;i<arraySize;i++)
{
a[i] = i;
b[i] = arraySize-i;
}
int c[arraySize] = {0};
// Add vectors in parallel.
cudaError_t cudaStatus;
int num = 0;
cudaDeviceProp prop;
cudaStatus = cudaGetDeviceCount(&num);
for(int i = 0;i<num;i++)
{
cudaGetDeviceProperties (&prop,i);
}
cudaStatus = addWithCuda (c, a, b, arraySize);
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "addWithCuda failed!");
return 1;
}
// cudaThreadExit must be called before exiting
in order for profiling and
// tracing tools such as Nsight and Visual Profiler
to show complete traces.
cudaStatus = cudaThreadExit();
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaThreadExit failed!");
return 1;
}
for(int i = 0;i<arraySize;i++)
{
if(c[i] != (a[i]+b[i]))
{
printf("Error in %d\n",i);
}
}
return 0;
}
// Helper function for using CUDA to add vectors
in parallel.
cudaError_t addWithCuda(int *c, const int *a,
const int *b, size_t size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on
a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaSetDevice failed! Do
you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two
input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size
* sizeof(int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size
* sizeof (int));
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size
* sizeof (int));
if (cudaStatus != cudaSuccess)
{
fprintf (stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU
buffers.
cudaStatus = cudaMemcpy (dev_a, a, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy (dev_b, b, size * sizeof(int),
cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaEvent_t start,stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start,0);
for(int i = 0;i<1000;i++)
{
// addKernel_ blk <<<size,1>>>
(dev_c, dev_a, dev_b);
addKernel _thd<<<1,size>>> (dev_c,
dev_a, dev_b);
}
cudaEventRecord (stop,0);
cudaEventSynchronize (stop);
float tm;
cudaEventElapsedTime (&tm,start,stop);
printf ("GPU Elapsed time :%.6f ms.\n",tm);
// cudaThreadSynchronize waits for the kernel
to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize();
if (cudaStatus != cudaSuccess)
{
fprintf( stderr, "cudaThreadSynchronize returned
error code %d after launching addKernel!\n",
cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host
memory.
cudaStatus = cudaMemcpy (c, dev_c, size * sizeof(int),
cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess)
{
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
} |
addKernel_blkЪЧВЩгУПщВЂааЪЕЯжЕФЯђСПЯрМгВйзїЃЌЖјaddKernel_thdЪЧВЩгУЯпГЬВЂааЪЕЯжЕФЯђСПЯрМгВйзїЁЃЗжБ№дЫааЃЌЕУЕНЕФНсЙћШчЯТЭМЫљЪОЃК
ЯпГЬВЂааЃК

ПщВЂааЃК

ПЩМћадФмОЙШЛЯрВюНќ16БЖЃЁвђДЫбЁдёВЂааДІРэЗНЗЈЪБЃЌШчЙћЮЪЬтЙцФЃВЛЪЧКмДѓЃЌФЧУДВЩгУЯпГЬВЂааЪЧБШНЯКЯЪЪЕФЃЌЖјДѓЮЪЬтЗжЖрИіЯпГЬПщДІРэЪБЃЌУПИіПщФкЯпГЬЪ§ВЛвЊЬЋЩйЃЌЯёБОЮФжаЕФжЛга1ИіЯпГЬЃЌетЪЧЖдгВМўзЪдДЕФМЋДѓРЫЗбЁЃвЛИіРэЯыЕФЗНАИЪЧЃЌЗжNИіЯпГЬПщЃЌУПИіЯпГЬПщАќКЌ512ИіЯпГЬЃЌНЋЮЪЬтЗжНтДІРэЃЌаЇТЪЭљЭљБШЕЅвЛЕФЯпГЬВЂааДІРэЛђЕЅвЛПщВЂааДІРэИпКмЖрЁЃетвВЪЧCUDAБрГЬЕФОЋЫшЁЃ
ЩЯУцетжжЗжЮіГЬађадФмЕФЗНЪНБШНЯДжВкЃЌжЛжЊЕРДѓИХдЫааЪБМфГЄЖШЃЌЖдгкЩшБИГЬађИїВПЗжДњТыжДааЪБМфУЛгавЛИіЩюШыЕФШЯЪЖЃЌетбљЮвУЧОЭгаИіЮЪЬтЃЌШчЙћЖдДњТыНјаагХЛЏЃЌФЧУДгХЛЏФФвЛВПЗжФиЃПЪЧНЋЯпГЬЪ§ЕїНкФиЃЌЛЙЪЧИФгУЙВЯэФкДцЃПетИіЮЪЬтзюКУЕФНтОіЗНАИОЭЪЧРћгУVisual
ProfilerЁЃЯТУцФкШнеЊздЁЖCUDA_Profiler_Users_GuideЁЗ
ЁАVisual ProfilerЪЧвЛИіЭМаЮЛЏЕФЦЪЮіЙЄОпЃЌПЩвдЯдЪОФуЕФгІгУГЬађжаCPUКЭGPUЕФЛюЖЏЧщПіЃЌРћгУЗжЮів§ЧцАяжњФубАевгХЛЏЕФЛњЛсЁЃЁБ
ЦфЪЕГ§СЫПЩЪгЛЏЕФНчУцЃЌNVIDIAЬсЙЉСЫУќСюааЗНЪНЕФЦЪЮіУќСюЃКnvprofЁЃЖдгкГѕбЇепЃЌЪЙгУЭМаЮЛЏЕФЗНЪНБШНЯШнвзЩЯЪжЃЌЫљвдБОНкЪЙгУVisual
ProfilerЁЃ
ДђПЊVisual ProfilerЃЌПЩвдДгCUDA ToolkitАВзАВЫЕЅДІевЕНЁЃжїНчУцШчЯТЃК
ЮвУЧЕуЛїFile->New SessionЃЌЕЏГіаТНЈЛсЛАЖдЛАПђЃЌШчЯТЭМЫљЪОЃК
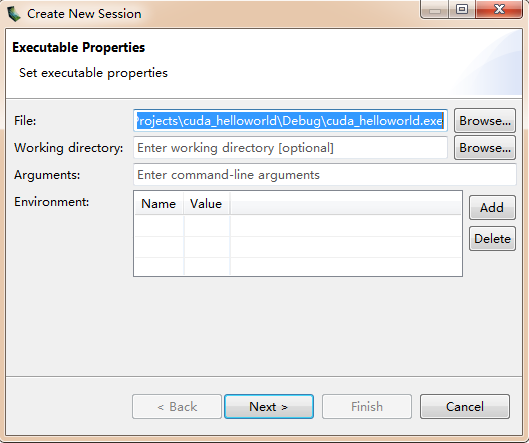
ЦфжаFileвЛРИЬюШыЮвУЧашвЊНјааЦЪЮіЕФгІгУГЬађexeЮФМўЃЌКѓУцПЩвдЖМВЛЬюЃЈШчЙћашвЊУќСюааВЮЪ§ЃЌПЩвддкЕкШ§ааЬюШыЃЉЃЌжБНгNextЃЌМћЯТЭМЃК
ЕквЛааЮЊгІгУГЬађжДааГЌЪБЪБМфЩшЖЈЃЌПЩВЛЬюЃЛКѓУцШ§ИіЕЅбЁПђЖМЙДЩЯЃЌетбљЮвУЧЗжБ№ЪЙФмСЫЦЪЮіЃЌЪЙФмСЫВЂЗЂКЫКЏЪ§ЦЪЮіЃЌШЛКѓдЫааЗжЮіЦїЁЃ
ЕуFinishЃЌПЊЪМдЫааЮвУЧЕФгІгУГЬађВЂНјааЦЪЮіЁЂЗжЮіадФмЁЃ
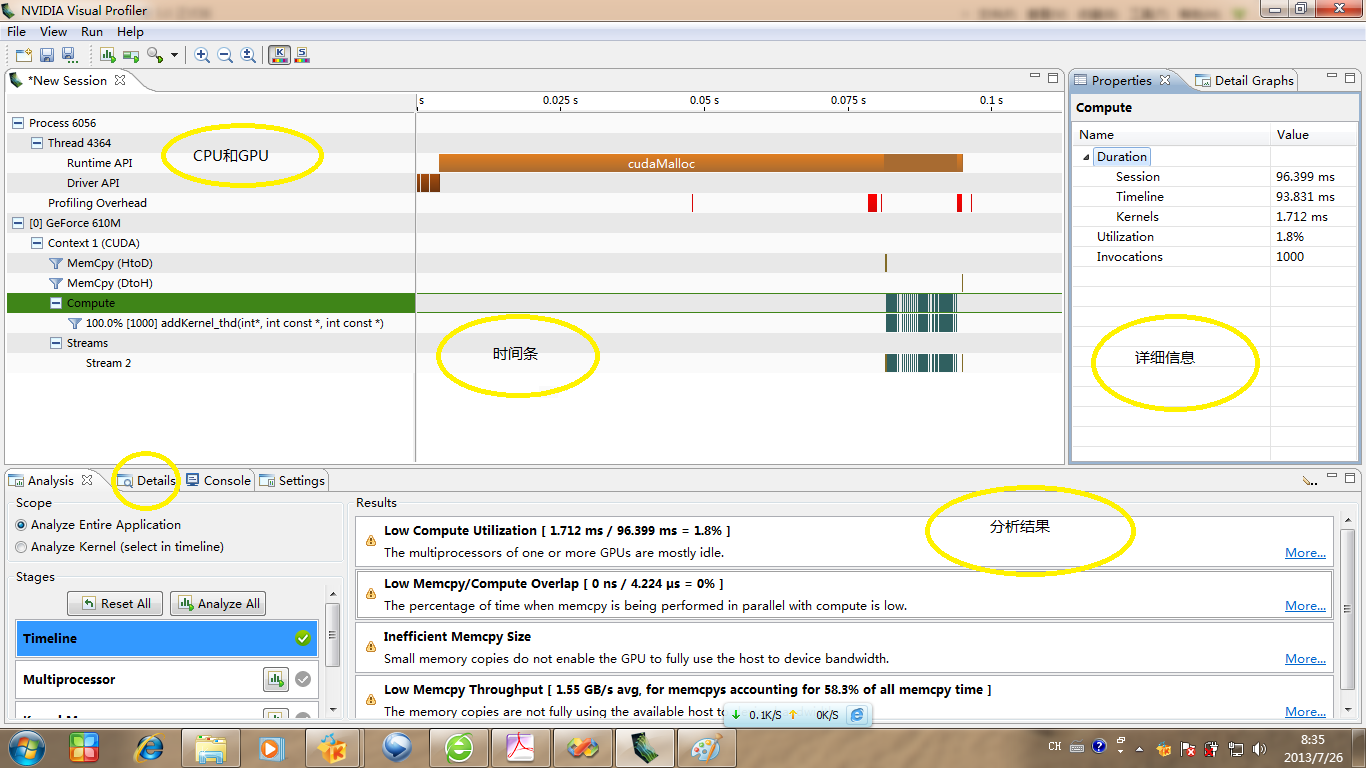
ЩЯЭМжаЃЌCPUКЭGPUВПЗжЯдЪОСЫгВМўКЭжДааФкШнаХЯЂЃЌЕуФГвЛЯюдђНЋЪБМфЬѕЖдгІЕФВПЗжИпССЃЌБугкЙлВьЃЌЭЌЪБгвБпЯъЯИаХЯЂЛсЯдЪОдЫааЪБМфаХЯЂЁЃДгЪБМфЬѕЩЯПДГіЃЌcudaMallocеМгУСЫКмДѓвЛВПЗжЪБМфЁЃЯТУцЗжЮіЦїИјГіСЫвЛаЉадФмЬсЩ§ЕФЙиМќЕуЃЌАќРЈЃКЕЭМЦЫуРћгУТЪЃЈМЦЫуЪБМфжЛеМзмЪБМфЕФ1.8%ЃЌвВФбЙжЃЌМгЗЈМЦЫуИДдгЖШБОРДОЭКмЕЭбНЃЁЃЉЃЛЕЭФкДцПНБД/МЦЫуНЛЕўТЪЃЈвЛЕуЖМУЛгаНЛЕўЃЌЭъШЋЪЧПНБДЁЊЁЊМЦЫуЁЊЁЊПНБДЃЉЃЛЕЭДцДЂПНБДГпДчЃЈЪфШыЪ§ОнСПЬЋаЁСЫЃЌЯрЕБгкФуЬдБІТђСЫИіШеМЧБОЃЌдЫЗбБШЪЕЮяМлИёЛЙИпЃЁЃЉЃЛЕЭДцДЂПНБДЭЬЭТТЪЃЈжЛга1.55GB/sЃЉЁЃетаЉЖдЮвУЧНјвЛВНгХЛЏГЬађЪЧЗЧГЃгаАяжњЕФЁЃ
ЮвУЧЕувЛЯТDetailsЃЌОЭдкAnalysisДАПкХдБпЁЃЕУЕННсЙћШчЯТЫљЪОЃК
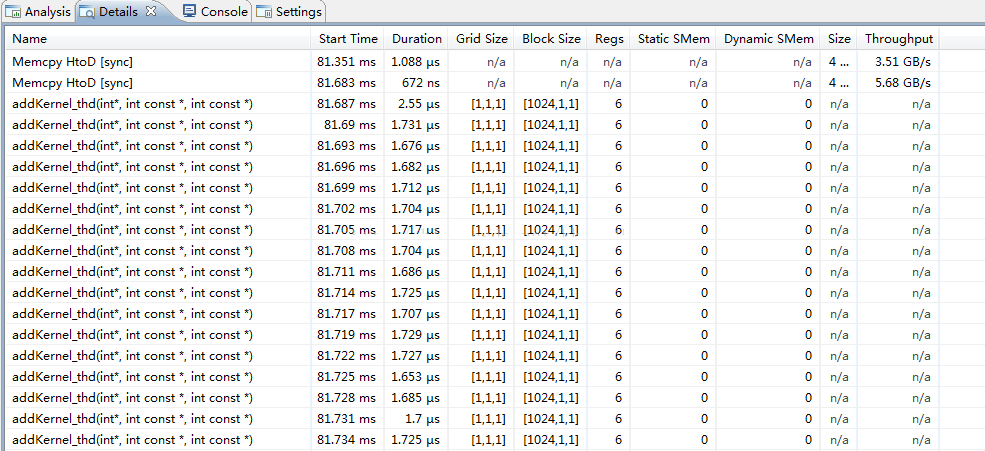
ЭЈЙ§етИіДАПкПЩвдПДЕНУПИіКЫКЏЪ§жДааЪБМфЃЌвдМАЯпГЬИёЁЂЯпГЬПщГпДчЃЌеМгУМФДцЦїИіЪ§ЃЌОВЬЌЙВЯэФкДцЁЂЖЏЬЌЙВЯэФкДцДѓаЁЕШВЮЪ§ЃЌвдМАФкДцПНБДКЏЪ§ЕФжДааЧщПіЁЃетИіЬсЙЉСЫБШЧАУцcudaEventКЏЪ§ВтЪБМфИќОЋШЗЕФЗНЪНЃЌжБНгПДЕНУПвЛВНЕФжДааЪБМфЃЌОЋШЗЕНnsЁЃ
дкDetailsКѓУцЛЙгавЛИіConsoleЃЌЕувЛЯТПДПДЁЃ

етИіЦфЪЕОЭЪЧУќСюааДАПкЃЌЯдЪОдЫааЪфГіЁЃПДЕНМгШыСЫProfilerаХЯЂКѓЃЌзмжДааЪБМфБфГЄСЫЃЈдРДЯпГЬВЂааАцБОЕФГЬађдЫааЪБМфжЛаш4msзѓгвЃЉЁЃетвВЪЧЁАВтВЛзМЖЈРэЁБОіЖЈЕФЃЌШчЙћЮвУЧЯЃЭћВтСПИќЯИЮЂЕФЪБМфЃЌФЧУДзмЪБМфПЯЖЈЪЧВЛзМЕФЃЛШчЙћЮвУЧЯЃЭћВтСПзмЪБМфЃЌФЧУДЯИЮЂЕФЪБМфОЭБЛКіТдЕєСЫЁЃ
КѓУцSettingsОЭЪЧЮвУЧНЈСЂЛсЛАЪБЕФВЮЪ§ХфжУЃЌВЛдйЯъЪіЁЃ
ЭЈЙ§БОНкЃЌЮвУЧгІИУФмЖдCUDAадФмЬсЩ§гаСЫвЛаЉЯыЗЈ |









