| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌНщЩмСЫCUDAБрГЬФЃаЭЛљДЁЃЌЯђСПМгЗЈЪЕР§ЃЌОиеѓГЫЗЈЪЕР§ЕШЁЃ |
|
ЧАбд
2006ФъЃЌNVIDIAЙЋЫОЗЂВМСЫCUDAЃЈhttp://docs.nvidia.com/cuda/ЃЉЃЌCUDAЪЧНЈСЂдкNVIDIAЕФCPUsЩЯЕФвЛИіЭЈгУВЂааМЦЫуЦНЬЈКЭБрГЬФЃаЭЃЌЛљгкCUDAБрГЬПЩвдРћгУGPUsЕФВЂааМЦЫув§ЧцРДИќМгИпаЇЕиНтОіБШНЯИДдгЕФМЦЫуФбЬтЁЃНќФъРДЃЌGPUзюГЩЙІЕФвЛИігІгУОЭЪЧЩюЖШбЇЯАСьгђЃЌЛљгкGPUЕФВЂааМЦЫувбОГЩЮЊбЕСЗЩюЖШбЇЯАФЃаЭЕФБъХфЁЃФПЧАЃЌзюаТЕФCUDAАцБОЮЊCUDA
9ЁЃ
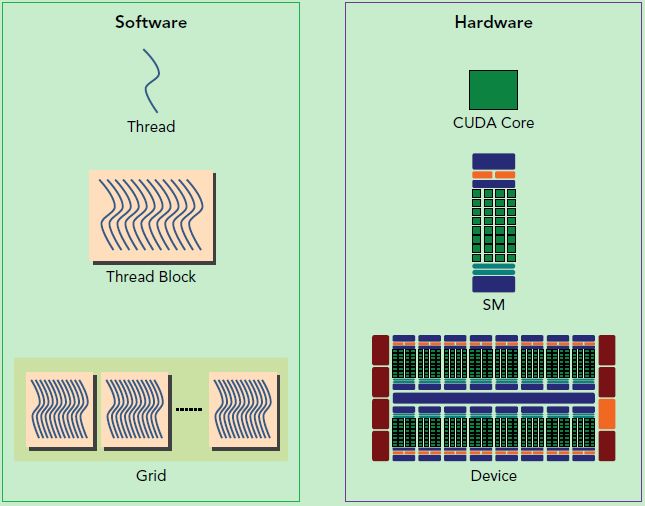
GPUВЂВЛЪЧвЛИіЖРСЂдЫааЕФМЦЫуЦНЬЈЃЌЖјашвЊгыCPUаЭЌЙЄзїЃЌПЩвдПДГЩЪЧCPUЕФаДІРэЦїЃЌвђДЫЕБЮвУЧдкЫЕGPUВЂааМЦЫуЪБЃЌЦфЪЕЪЧжИЕФЛљгкCPU+GPUЕФвьЙЙМЦЫуМмЙЙЁЃдквьЙЙМЦЫуМмЙЙжаЃЌGPUгыCPUЭЈЙ§PCIeзмЯпСЌНгдквЛЦ№РДаЭЌЙЄзїЃЌCPUЫљдкЮЛжУГЦЮЊЮЊжїЛњЖЫЃЈhostЃЉЃЌЖјGPUЫљдкЮЛжУГЦЮЊЩшБИЖЫЃЈdeviceЃЉЃЌШчЯТЭМЫљЪОЁЃ
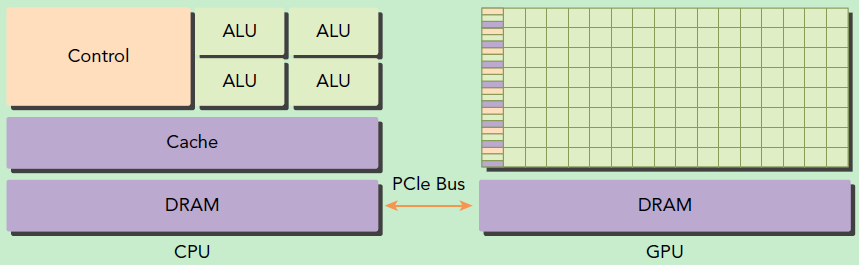
ЛљгкCPU+GPUЕФвьЙЙМЦЫу. РДдДЃКPreofessional
CUDA? C Programming
ПЩвдПДЕНGPUАќРЈИќЖрЕФдЫЫуКЫаФЃЌЦфЬиБ№ЪЪКЯЪ§ОнВЂааЕФМЦЫуУмМЏаЭШЮЮёЃЌШчДѓаЭОиеѓдЫЫуЃЌЖјCPUЕФдЫЫуКЫаФНЯЩйЃЌЕЋЪЧЦфПЩвдЪЕЯжИДдгЕФТпМдЫЫуЃЌвђДЫЦфЪЪКЯПижЦУмМЏаЭШЮЮёЁЃСэЭтЃЌCPUЩЯЕФЯпГЬЪЧжиСПМЖЕФЃЌЩЯЯТЮФЧаЛЛПЊЯњДѓЃЌЕЋЪЧGPUгЩгкДцдкКмЖрКЫаФЃЌЦфЯпГЬЪЧЧсСПМЖЕФЁЃвђДЫЃЌЛљгкCPU+GPUЕФвьЙЙМЦЫуЦНЬЈПЩвдгХЪЦЛЅВЙЃЌCPUИКд№ДІРэТпМИДдгЕФДЎааГЬађЃЌЖјGPUжиЕуДІРэЪ§ОнУмМЏаЭЕФВЂааМЦЫуГЬађЃЌДгЖјЗЂЛгзюДѓЙІаЇЁЃ
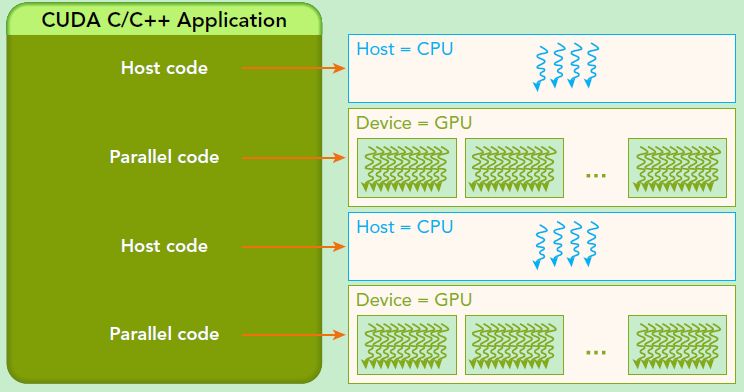
ЛљгкCPU+GPUЕФвьЙЙМЦЫугІгУжДааТпМ.
РДдДЃКPreofessional CUDA? C Programming
CUDAЪЧNVIDIAЙЋЫОЫљПЊЗЂЕФGPUБрГЬФЃаЭЃЌЫќЬсЙЉСЫGPUБрГЬЕФМђвзНгПкЃЌЛљгкCUDAБрГЬПЩвдЙЙНЈЛљгкGPUМЦЫуЕФгІгУГЬађЁЃCUDAЬсЙЉСЫЖдЦфЫќБрГЬгябдЕФжЇГжЃЌШчC/C++ЃЌPythonЃЌFortranЕШгябдЃЌетРяЮвУЧбЁдёCUDA
C/C++НгПкЖдCUDAБрГЬНјааНВНтЁЃПЊЗЂЦНЬЈЮЊWindows 10 + VS 2013ЃЌWindowsЯЕЭГЯТЕФCUDAАВзАНЬГЬПЩвдВЮПМетРяhttp:
//docs.nvidia.com /cuda / cuda-installation-guide-
microsoft-windows/index.html
1
CUDAБрГЬФЃаЭЛљДЁ
дкИјГіCUDAЕФБрГЬЪЕР§жЎЧАЃЌетРяЯШЖдCUDAБрГЬФЃаЭжаЕФвЛаЉИХФюМАЛљДЁжЊЪЖзіИіМђЕЅНщЩмЁЃCUDAБрГЬФЃаЭЪЧвЛИівьЙЙФЃаЭЃЌашвЊCPUКЭGPUаЭЌЙЄзїЁЃдкCUDAжаЃЌhostКЭdeviceЪЧСНИіживЊЕФИХФюЃЌЮвУЧгУhostжИДњCPUМАЦфФкДцЃЌЖјгУdeviceжИДњGPUМАЦфФкДцЁЃCUDAГЬађжаМШАќКЌhostГЬађЃЌгжАќКЌdeviceГЬађЃЌЫќУЧЗжБ№дкCPUКЭGPUЩЯдЫааЁЃЭЌЪБЃЌhostгыdeviceжЎМфПЩвдНјааЭЈаХЃЌетбљЫќУЧжЎМфПЩвдНјааЪ§ОнПНБДЁЃЕфаЭЕФCUDAГЬађЕФжДааСїГЬШчЯТЃК
1.ЗжХфhostФкДцЃЌВЂНјааЪ§ОнГѕЪМЛЏЃЛ
2.ЗжХфdeviceФкДцЃЌВЂДгhostНЋЪ§ОнПНБДЕНdeviceЩЯЃЛ
3.ЕїгУCUDAЕФКЫКЏЪ§дкdeviceЩЯЭъГЩжИЖЈЕФдЫЫуЃЛ
4.НЋdeviceЩЯЕФдЫЫуНсЙћПНБДЕНhostЩЯЃЛ
5.ЪЭЗХdeviceКЭhostЩЯЗжХфЕФФкДцЁЃ
ЩЯУцСїГЬжазюживЊЕФвЛИіЙ§ГЬЪЧЕїгУCUDAЕФКЫКЏЪ§РДжДааВЂааМЦЫуЃЌkernelЃЈhttp:
//docs. nvidia.com /cuda /cuda-c -programming-guide/index.html#kernelsЃЉЪЧCUDAжавЛИіживЊЕФИХФюЃЌkernelЪЧдкdevice
ЩЯЯпГЬжаВЂаажДааЕФКЏЪ§ЃЌКЫКЏЪ§гУ__global__ЗћКХЩљУїЃЌдкЕїгУЪБашвЊгУ<<<grid,
block>>> РДжИЖЈkernel вЊжДааЕФЯпГЬЪ§СПЃЌдкCUDAжаЃЌУПвЛИіЯпГЬЖМвЊжДааКЫКЏЪ§ЃЌВЂЧвУПИіЯпГЬЛсЗжХфвЛИіЮЈвЛЕФЯпГЬКХthread
IDЃЌетИіIDжЕПЩвдЭЈЙ§КЫКЏЪ§ЕФФкжУБфСПthreadIdxРДЛёЕУЁЃ
гЩгкGPUЪЕМЪЩЯЪЧвьЙЙФЃаЭЃЌЫљвдашвЊЧјЗжhostКЭdeviceЩЯЕФДњТыЃЌдкCUDAжаЪЧЭЈЙ§КЏЪ§РраЭЯоЖЈДЪПЊЧјБ№hostКЭdeviceЩЯЕФКЏЪ§ЃЌжївЊЕФШ§ИіКЏЪ§РраЭЯоЖЈДЪШчЯТЃК
__global__ЃКдкdeviceЩЯжДааЃЌДгhostжаЕїгУЃЈвЛаЉЬиЖЈЕФGPUвВПЩвдДгdeviceЩЯЕїгУЃЉЃЌЗЕЛиРраЭБиаыЪЧvoidЃЌВЛжЇГжПЩБфВЮЪ§ВЮЪ§ЃЌВЛФмГЩЮЊРрГЩдБКЏЪ§ЁЃзЂвтгУ__global__ЖЈвхЕФkernelЪЧвьВНЕФЃЌетвтЮЖзХhostВЛЛсЕШД§kernelжДааЭъОЭжДааЯТвЛВНЁЃ
__device__ЃКдкdeviceЩЯжДааЃЌНіПЩвдДгdeviceжаЕїгУЃЌВЛПЩвдКЭ__global__ЭЌЪБгУЁЃ
__host__ЃКдкhostЩЯжДааЃЌНіПЩвдДгhostЩЯЕїгУЃЌвЛАуЪЁТдВЛаДЃЌВЛПЩвдКЭ__global__ЭЌЪБгУЃЌЕЋПЩКЭ__
device __ЃЌДЫЪБКЏЪ§ЛсдкdeviceКЭhostЖМБрвыЁЃ
вЊЩюПЬРэНтkernelЃЌБиаывЊЖдkernelЕФЯпГЬВуДЮНсЙЙгавЛИіЧхЮњЕФШЯЪЖЁЃЪзЯШGPUЩЯКмЖрВЂааЛЏЕФЧсСПМЖЯпГЬЁЃkernelдкdeviceЩЯжДааЪБЪЕМЪЩЯЪЧЦєЖЏКмЖрЯпГЬЃЌвЛИіkernelЫљЦєЖЏЕФЫљгаЯпГЬГЦЮЊвЛИіЭјИёЃЈgridЃЉЃЌЭЌвЛИіЭјИёЩЯЕФЯпГЬЙВЯэЯрЭЌЕФШЋОжФкДцПеМфЃЌgridЪЧЯпГЬНсЙЙЕФЕквЛВуДЮЃЌЖјЭјИёгжПЩвдЗжЮЊКмЖрЯпГЬПщЃЈblockЃЉЃЌвЛИіЯпГЬПщРяУцАќКЌКмЖрЯпГЬЃЌетЪЧЕкЖўИіВуДЮЁЃЯпГЬСНВузщжЏНсЙЙШчЯТЭМЫљЪОЃЌетЪЧвЛИіgirdКЭblockОљЮЊ2-dimЕФЯпГЬзщжЏЁЃgridКЭblockЖМЪЧЖЈвхЮЊdim3РраЭЕФБфСПЃЌdim3ПЩвдПДГЩЪЧАќКЌШ§ИіЮоЗћКХећЪ§ЃЈxЃЌyЃЌzЃЉГЩдБЕФНсЙЙЬхБфСПЃЌдкЖЈвхЪБЃЌШБЪЁжЕГѕЪМЛЏЮЊ1ЁЃвђДЫgridКЭblockПЩвдСщЛюЕиЖЈвхЮЊ
1- dimЃЌ2-dimвдМА3-dim НсЙЙЃЌЖдгкЭМжаНсЙЙЃЈжївЊЫЎЦНЗНЯђЮЊxжсЃЉЃЌЖЈвхЕФgridКЭblockШчЯТЫљЪОЃЌkernelдкЕїгУЪБвВБиаыЭЈЙ§жДааХфжУ
ЃЈhttp://docs.nvidia.com/ cuda/cuda-c-programming-
guide / index .html #execution-configuration ЃЉ<<<grid,
block>>>РДжИЖЈkernelЫљЪЙгУЕФЯпГЬЪ§МАНсЙЙЁЃ
dim3 grid(3,
2);
dim3 block(4, 3);
kernel_fun<<< grid, block >>>(prams...); |
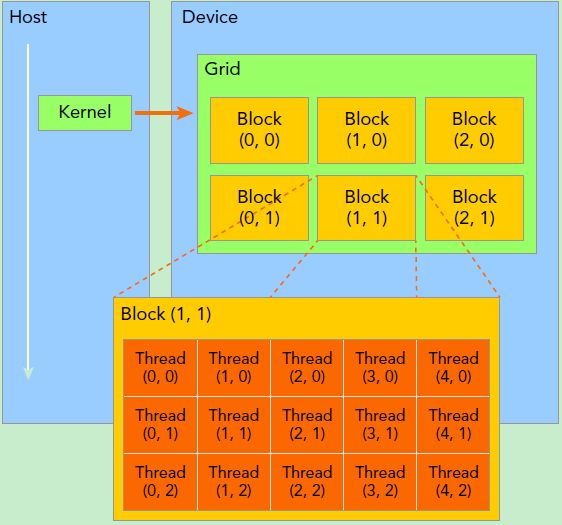
ЫљвдЃЌвЛИіЯпГЬашвЊСНИіФкжУЕФзјБъБфСПЃЈblockIdxЃЌthreadIdxЃЉРДЮЈвЛБъЪЖЃЌЫќУЧЖМЪЧdim3РраЭБфСПЃЌЦфжаblockIdxжИУїЯпГЬЫљдкgridжаЕФЮЛжУЃЌЖјthreaIdxжИУїЯпГЬЫљдкblockжаЕФЮЛжУЃЌШчЭМжаЕФThread
(1,1)ТњзуЃК
threadIdx.x
= 1
threadIdx.y = 1
blockIdx.x = 1
blockIdx.y = 1 |
вЛИіЯпГЬПщЩЯЕФЯпГЬЪЧЗХдкЭЌвЛИіСїЪНЖрДІРэЦїЃЈSM)ЩЯЕФЃЌЕЋЪЧЕЅИіSMЕФзЪдДгаЯоЃЌетЕМжТЯпГЬПщжаЕФЯпГЬЪ§ЪЧгаЯожЦЕФЃЌЯжДњGPUsЕФЯпГЬПщПЩжЇГжЕФЯпГЬЪ§ПЩДя1024ИіЁЃгаЪБКђЃЌЮвУЧвЊжЊЕРвЛИіЯпГЬдкblcokжаЕФШЋОжIDЃЌДЫЪБОЭБиаыЛЙвЊжЊЕРblockЕФзщжЏНсЙЙЃЌетЪЧЭЈЙ§ЯпГЬЕФФкжУБфСПblockDimРДЛёЕУЁЃЫќЛёШЁЯпГЬПщИїИіЮЌЖШЕФДѓаЁЁЃЖдгквЛИі2-dimЕФblock640?wx_fmt=pngЃЌЯпГЬЃЈx,y)ЕФIDжЕЮЊ640?wx_fmt=png,ШчЙћЪЧ3-dimЕФblock640?wx_fmt=png,ЯпГЬ(x,y,z)ЕФIDжЕЮЊ640?wx_fmt=pngЁЃСэЭтЯпГЬЛЙгаФкжУБфСПgridDimЃЌгУгкЛёЕУЭјИёПщИїИіЮЌЖШЕФДѓаЁЁЃ
kernelЕФетжжЯпГЬзщжЏНсЙЙЬьШЛЪЪКЯvector,matrixЕШдЫЫуЃЌШчЮвУЧНЋРћгУЩЯЭМ2-dimНсЙЙЪЕЯжСНИіОиеѓЕФМгЗЈЃЌУПИіЯпГЬИКд№ДІРэУПИіЮЛжУЕФСНИідЊЫиЯрМгЃЌДњТыШчЯТЫљЪОЁЃЯпГЬПщДѓаЁЮЊ(16,
16)ЃЌШЛКѓНЋN*NДѓаЁЕФОиеѓОљЗжЮЊВЛЭЌЕФЯпГЬПщРДжДааМгЗЈдЫЫуЁЃ
// KernelЖЈвх
__global__ void MatAdd (float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel ЯпГЬХфжУ
dim3 threadsPerBlock(16, 16);
dim3 numBlocks (N / threadsPerBlock.x, N / threadsPerBlock
.y);
// kernelЕїгУ
MatAdd <<<numBlocks, threadsPerBlock>>>(A,
B, C);
...
} |
ДЫЭтетРяМђЕЅНщЩмвЛЯТCUDAЕФФкДцФЃаЭЃЌШчЯТЭМЫљЪОЁЃПЩвдПДЕНЃЌУПИіЯпГЬгаздМКЕФЫНгаБОЕиФкДцЃЈLocal
MemoryЃЉЃЌЖјУПИіЯпГЬПщгаАќКЌЙВЯэФкДцЃЈShared MemoryЃЉ,ПЩвдБЛЯпГЬПщжаЫљгаЯпГЬЙВЯэЃЌЦфЩњУќжмЦкгыЯпГЬПщвЛжТЁЃДЫЭтЃЌЫљгаЕФЯпГЬЖМПЩвдЗУЮЪШЋОжФкДцЃЈGlobal
MemoryЃЉЁЃЛЙПЩвдЗУЮЪвЛаЉжЛЖСФкДцПщЃКГЃСПФкДцЃЈConstant MemoryЃЉКЭЮЦРэФкДцЃЈTexture
MemoryЃЉЁЃФкДцНсЙЙЩцМАЕНГЬађгХЛЏЃЌетРяВЛЩюШыЬНЬжЫќУЧЁЃ
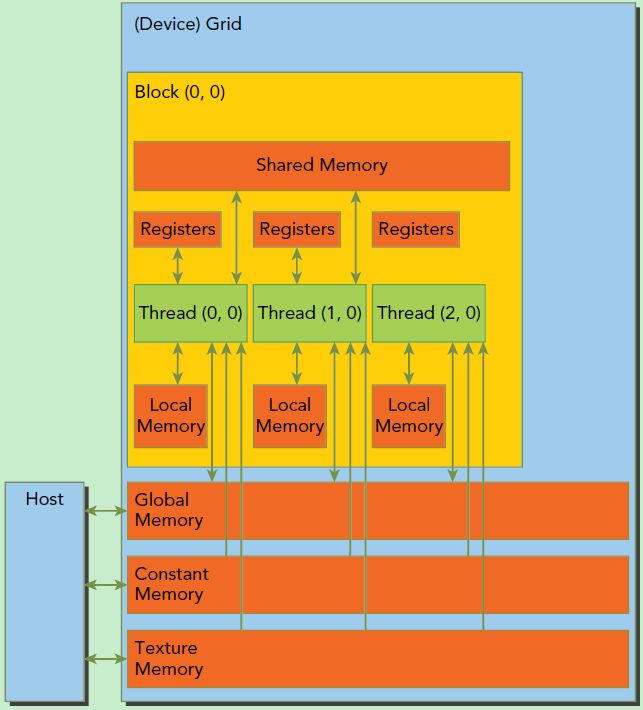
CUDAФкДцФЃаЭ
ЛЙгаживЊвЛЕуЃЌФуашвЊЖдGPUЕФгВМўЪЕЯжгавЛИіЛљБОЕФШЯЪЖЁЃЩЯУцЫЕЕНСЫkernelЕФЯпГЬзщжЏВуДЮЃЌФЧУДвЛИіkernelЪЕМЪЩЯЛсЦєЖЏКмЖрЯпГЬЃЌетаЉЯпГЬЪЧТпМЩЯВЂааЕФЃЌЕЋЪЧдкЮяРэВуШДВЂВЛвЛЖЈЁЃетЦфЪЕКЭCPUЕФЖрЯпГЬгаРрЫЦжЎДІЃЌЖрЯпГЬШчЙћУЛгаЖрКЫжЇГжЃЌдкЮяРэВувВЪЧЮоЗЈЪЕЯжВЂааЕФЁЃЕЋЪЧКУдкGPUДцдкКмЖрCUDAКЫаФЃЌГфЗжРћгУCUDAКЫаФПЩвдГфЗжЗЂЛгGPUЕФВЂааМЦЫуФмСІЁЃGPUгВМўЕФвЛИіКЫаФзщМўЪЧSMЃЌЧАУцвбОЫЕЙ§ЃЌSMЪЧгЂЮФУћЪЧ
Streaming MultiprocessorЃЌЗвыЙ§РДОЭЪЧСїЪНЖрДІРэЦїЁЃSMЕФКЫаФзщМўАќРЈCUDAКЫаФЃЌЙВЯэФкДцЃЌМФДцЦїЕШЃЌSMПЩвдВЂЗЂЕижДааЪ§АйИіЯпГЬЃЌВЂЗЂФмСІОЭШЁОігкSMЫљгЕгаЕФзЪдДЪ§ЁЃЕБвЛИіkernelБЛжДааЪБЃЌЫќЕФgirdжаЕФЯпГЬПщБЛЗжХфЕНSMЩЯЃЌвЛИіЯпГЬПщжЛФмдквЛИіSMЩЯБЛЕїЖШЁЃSMвЛАуПЩвдЕїЖШЖрИіЯпГЬПщЃЌетвЊПДSMБОЩэЕФФмСІЁЃФЧУДгаПЩФмвЛИіkernelЕФИїИіЯпГЬПщБЛЗжХфЖрИіSMЃЌЫљвдgridжЛЪЧТпМВуЃЌЖјSMВХЪЧжДааЕФЮяРэВуЁЃSMВЩгУЕФЪЧSIMTЃЈСДНгЃКhttp://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#simt-architectureЃЉ(Single-Instruction,
Multiple-ThreadЃЌЕЅжИСюЖрЯпГЬ)МмЙЙЃЌЛљБОЕФжДааЕЅдЊЪЧЯпГЬЪјЃЈwraps)ЃЌЯпГЬЪјАќКЌ32ИіЯпГЬЃЌетаЉЯпГЬЭЌЪБжДааЯрЭЌЕФжИСюЃЌЕЋЪЧУПИіЯпГЬЖМАќКЌздМКЕФжИСюЕижЗМЦЪ§ЦїКЭМФДцЦїзДЬЌЃЌвВгаздМКЖРСЂЕФжДааТЗОЖЁЃЫљвдОЁЙмЯпГЬЪјжаЕФЯпГЬЭЌЪБДгЭЌвЛГЬађЕижЗжДааЃЌЕЋЪЧПЩФмОпгаВЛЭЌЕФааЮЊЃЌБШШчгіЕНСЫЗжжЇНсЙЙЃЌвЛаЉЯпГЬПЩФмНјШыетИіЗжжЇЃЌЕЋЪЧСэЭтвЛаЉгаПЩФмВЛжДааЃЌЫќУЧжЛФмЫРЕШЃЌвђЮЊGPUЙцЖЈЯпГЬЪјжаЫљгаЯпГЬдкЭЌвЛжмЦкжДааЯрЭЌЕФжИСюЃЌЯпГЬЪјЗжЛЏЛсЕМжТадФмЯТНЕЁЃЕБЯпГЬПщБЛЛЎЗжЕНФГИіSMЩЯЪБЃЌЫќНЋНјвЛВНЛЎЗжЮЊЖрИіЯпГЬЪјЃЌвђЮЊетВХЪЧSMЕФЛљБОжДааЕЅдЊЃЌЕЋЪЧвЛИіSMЭЌЪБВЂЗЂЕФЯпГЬЪјЪ§ЪЧгаЯоЕФЁЃетЪЧвђЮЊзЪдДЯожЦЃЌSMвЊЮЊУПИіЯпГЬПщЗжХфЙВЯэФкДцЃЌЖјвВвЊЮЊУПИіЯпГЬЪјжаЕФЯпГЬЗжХфЖРСЂЕФМФДцЦїЁЃЫљвдSMЕФХфжУЛсгАЯьЦфЫљжЇГжЕФЯпГЬПщКЭЯпГЬЪјВЂЗЂЪ§СПЁЃзмжЎЃЌОЭЪЧЭјИёКЭЯпГЬПщжЛЪЧТпМЛЎЗжЃЌвЛИіkernelЕФЫљгаЯпГЬЦфЪЕдкЮяРэВуЪЧВЛвЛЖЈЭЌЪБВЂЗЂЕФЁЃЫљвдkernelЕФgridКЭblockЕФХфжУВЛЭЌЃЌадФмЛсГіЯжВювьЃЌетЕуЪЧвЊЬиБ№зЂвтЕФЁЃЛЙгаЃЌгЩгкSMЕФЛљБОжДааЕЅдЊЪЧАќКЌ32ИіЯпГЬЕФЯпГЬЪјЃЌЫљвдblockДѓаЁвЛАувЊЩшжУЮЊ32ЕФБЖЪ§ЁЃ
CUDAБрГЬЕФТпМВуКЭЮяРэВу
дкНјааCUDAБрГЬЧАЃЌПЩвдЯШМьВщвЛЯТздМКЕФGPUЕФгВМўХфжУЃЌетбљВХПЩвдгаЕФЗХЪИЃЌПЩвдЭЈЙ§ЯТУцЕФГЬађЛёЕУGPUЕФХфжУЪєадЃК
int dev = 0;
cudaDeviceProp devProp;
CHECK (cudaGetDeviceProperties (&devProp,
dev));
std : :cout << "ЪЙгУGPU device "
<< dev << ": " <<
devProp .name << std::endl;
std::cout << "SMЕФЪ§СПЃК" <<
devProp.multiProcessorCount << std::endl;
std::cout << "УПИіЯпГЬПщЕФЙВЯэФкДцДѓаЁЃК" <<
devProp.sharedMemPerBlock / 1024.0 << "
KB" << std ::endl;
std ::cout << "УПИіЯпГЬПщЕФзюДѓЯпГЬЪ§ЃК" <<
devProp .maxThreadsPerBlock << std::endl;
std ::cout << "УПИіEMЕФзюДѓЯпГЬЪ§ЃК" <<
devProp . maxThreadsPerMultiProcessor <<
std::endl;
std ::cout << "УПИіEMЕФзюДѓЯпГЬЪјЪ§ЃК" <<
devProp.maxThreadsPerMultiProcessor / 32 <<
std::endl;
// ЪфГіШчЯТ
ЪЙгУGPU device 0: GeForce GT 730
SMЕФЪ§СПЃК2
УПИіЯпГЬПщЕФЙВЯэФкДцДѓаЁЃК48 KB
УПИіЯпГЬПщЕФзюДѓЯпГЬЪ§ЃК1024
УПИіEMЕФзюДѓЯпГЬЪ§ЃК2048
УПИіEMЕФзюДѓЯпГЬЪјЪ§ЃК64 |
КУАЩЃЌGT 730ЯдПЈШЗЪЕгаЕудќЃЌжЛга2ИіSMЃЌЮиЮи......
2 ЯђСПМгЗЈЪЕР§
жЊЕРСЫCUDAБрГЬЛљДЁЃЌЮвУЧОЭРДИіМђЕЅЕФЪЕеНЃЌРћгУCUDAБрГЬЪЕЯжСНИіЯђСПЕФМгЗЈЃЌдкЪЕЯжжЎЧАЃЌЯШМђЕЅНщЩмвЛЯТCUDAБрГЬжаФкДцЙмРэAPIЁЃЪзЯШЪЧдкdeviceЩЯЗжХфФкДцЕФcudaMallocКЏЪ§ЃК
| cudaError_t cudaMalloc(void** devPtr,
size_t size); |
етИіКЏЪ§КЭCгябджаЕФmallocРрЫЦЃЌЕЋЪЧдкdeviceЩЯЩъЧывЛЖЈзжНкДѓаЁЕФЯдДцЃЌЦфжаdevPtrЪЧжИЯђЫљЗжХфФкДцЕФжИеыЁЃЭЌЪБвЊЪЭЗХЗжХфЕФФкДцЪЙгУcudaFreeКЏЪ§ЃЌетКЭCгябджаЕФfreeКЏЪ§ЖдгІЁЃСэЭтвЛИіживЊЕФКЏЪ§ЪЧИКд№hostКЭdeviceжЎМфЪ§ОнЭЈаХЕФcudaMemcpyКЏЪ§ЃК
| cudaError_t cudaMalloc(void** devPtr,
size_t size); |
ЦфжаsrcжИЯђЪ§ОндДЃЌЖјdstЪЧФПБъЧјгђЃЌcountЪЧИДжЦЕФзжНкЪ§ЃЌЦфжаkindПижЦИДжЦЕФЗНЯђЃКcudaMemcpy
HostToHost , cudaMemcpyHostToDevice,
cudaMemcpyDeviceToHost МАcudaMemcpyDeviceToDeviceЃЌШч
cudaMemcpyHostToDeviceНЋhost ЩЯЪ§ОнПНБДЕНdeviceЩЯЁЃ
ЯждкЮвУЧРДЪЕЯжвЛИіЯђСПМгЗЈЕФЪЕР§ЃЌетРяgridКЭblockЖМЩшМЦЮЊ1-dimЃЌЪзЯШЖЈвхkernelШчЯТЃК
// СНИіЯђСПМгЗЈkernelЃЌgridКЭblockОљЮЊвЛЮЌ
__global__ void add(float* x, float * y, float*
z, int n)
{
// ЛёШЁШЋОжЫїв§
int index = threadIdx.x + blockIdx.x * blockDim.x;
// ВНГЄ
int stride = blockDim.x * gridDim.x;
for (int i = index; i < n; i += stride)
{
z[i] = x[i] + y[i];
}
} |
ЦфжаstrideЪЧећИіgridЕФЯпГЬЪ§ЃЌгаЪБКђЯђСПЕФдЊЫиЪ§КмЖрЃЌетЪБКђПЩвдНЋдкУПИіЯпГЬЪЕЯжЖрИідЊЫиЃЈдЊЫизмЪ§/ЯпГЬзмЪ§ЃЉЕФМгЗЈЃЌЯрЕБгкЪЙгУСЫЖрИіgridРДДІРэЃЌетЪЧвЛжжgrid-stride
loopЃЈСДНгЃКhttps://devblogs.nvidia.com/cuda-pro-tip-write-flexible-kernels-grid-stride-loops/ЃЉЗНЪНЃЌВЛЙ§ЯТУцЕФР§згвЛИіЯпГЬжЛДІРэвЛИідЊЫиЃЌЫљвдkernelРяУцЕФбЛЗЪЧВЛжДааЕФЁЃЯТУцЮвУЧОпЬхЪЕЯжЯђСПМгЗЈЃК
int main()
{
int N = 1 << 20;
int nBytes = N * sizeof(float);
// ЩъЧыhostФкДц
float *x, *y, *z;
x = (float*)malloc(nBytes);
y = (float*)malloc(nBytes);
z = (float*)malloc(nBytes);
// ГѕЪМЛЏЪ§Он
for (int i = 0; i < N; ++i)
{
x[i] = 10.0;
y[i] = 20.0;
}
// ЩъЧыdeviceФкДц
float *d_x, *d_y, *d_z;
cudaMalloc((void**)&d_x, nBytes);
cudaMalloc((void**)&d_y, nBytes);
cudaMalloc((void**)&d_z, nBytes);
// НЋhostЪ§ОнПНБДЕНdevice
cudaMemcpy ((void*)d_x, (void*)x, nBytes, cudaMemcpyHostToDevice
);
cudaMemcpy ((void*)d_y, (void*)y, nBytes, cudaMemcpyHostToDevice);
// ЖЈвхkernelЕФжДааХфжУ
dim3 blockSize(256);
dim3 gridSize((N + blockSize.x - 1) / blockSize.x);
// жДааkernel
add << < gridSize, blockSize >>
>(d_x, d_y, d_z, N);
// НЋdeviceЕУЕНЕФНсЙћПНБДЕНhost
cudaMemcpy((void*)z, (void*)d_z, nBytes, cudaMemcpyHostToDevice);
// МьВщжДааНсЙћ
float maxError = 0.0;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "зюДѓЮѓВю: " <<
maxError << std::endl;
// ЪЭЗХdeviceФкДц
cudaFree(d_x);
cudaFree(d_y);
cudaFree(d_z);
// ЪЭЗХhostФкДц
free(x);
free(y);
free(z);
return 0;
} |
етРяЮвУЧЕФЯђСПДѓаЁЮЊ1<<20ЃЌЖјblockДѓаЁЮЊ256ЃЌФЧУДgridДѓаЁЪЧ4096ЃЌ
kernelЕФЯпГЬВуМЖНсЙЙШчЯТЭМЫљЪОЃК
kernelЕФЯпГЬВуДЮНсЙЙ. РДдДЃКhttps://devblogs.nvidia.com/even-easier-introduction-cuda/
ЪЙгУnvprofЙЄОпПЩвдЗжЮіkernelдЫааЧщПіЃЌНсЙћШчЯТЫљЪОЃЌПЩвдПДЕНkernelКЏЪ§ЗбЪБдМ1.5msЁЃ
nvprof cuda9.exe
==7244== NVPROF is profiling process 7244, command:
cuda9.exe
зюДѓЮѓВю: 4.31602e+008
==7244== Profiling application: cuda9.exe
==7244== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 67.57% 3.2256ms 2 1.6128ms 1.6017ms
1.6239ms [CUDA memcpy HtoD]
32.43% 1.5478ms 1 1.5478ms 1.5478ms 1.5478ms add(float*,
float*, float*, int) |
ФуЕїећblockЕФДѓаЁЃЌЖдБШВЛЭЌХфжУЯТЕФkernelдЫааЧщПіЃЌЮветРяВтЪдЕФЪЧЕБblockЮЊ128ЪБЃЌkernelЗбЪБдМ1.6msЃЌЖјblockЮЊ512ЪБkernelЗбЪБдМ1.7msЃЌЕБblockЮЊ64ЪБЃЌkernelЗбЪБдМ2.3msЁЃПДРДВЛЪЧblockдНДѓдНКУЃЌЖјвЊЪЪЕБбЁдёЁЃ
дкЩЯУцЕФЪЕЯжжаЃЌЮвУЧашвЊЕЅЖРдкhostКЭdeviceЩЯНјааФкДцЗжХфЃЌВЂЧввЊНјааЪ§ОнПНБДЃЌетЪЧКмШнвзГіДэЕФЁЃКУдкCUDA
6.0в§ШыЭГвЛФкДцЃЈUnified MemoryЃЉЃЈСДНгЃКhttp://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html#um-unified-memory-programming-hdЃЉРДБмУтетжжТщЗГЃЌМђЕЅРДЫЕОЭЪЧЭГвЛФкДцЪЙгУвЛИіЭаЙмФкДцРДЙВЭЌЙмРэhostКЭdeviceжаЕФФкДцЃЌВЂЧвздЖЏдкhostКЭdeviceжаНјааЪ§ОнДЋЪфЁЃCUDAжаЪЙгУcudaMallocManagedКЏЪ§ЗжХфЭаЙмФкДцЃК
| cudaError_t
cudaMallocManaged (void **devPtr, size_t size,
unsigned int flag=0); |
РћгУЭГвЛФкДцЃЌПЩвдНЋЩЯУцЕФГЬађМђЛЏШчЯТЃК
int main()
{
int N = 1 << 20;
int nBytes = N * sizeof(float);
// ЩъЧыЭаЙмФкДц
float *x, *y, *z;
cudaMallocManaged ((void**)&x, nBytes);
cudaMallocManaged ((void**)&y, nBytes);
cudaMallocManaged ((void**)&z, nBytes);
// ГѕЪМЛЏЪ§Он
for (int i = 0; i < N; ++i)
{
x[i] = 10.0;
y[i] = 20.0;
}
// ЖЈвхkernelЕФжДааХфжУ
dim3 blockSize (256);
dim3 gridSize ((N + blockSize.x - 1) / blockSize.x);
// жДааkernel
add << < gridSize, blockSize >>
>(x, y, z, N);
// ЭЌВНdevice БЃжЄНсЙћФме§ШЗЗУЮЪ
cudaDeviceSynchronize();
// МьВщжДааНсЙћ
float maxError = 0.0;
for (int i = 0; i < N; i++)
maxError = fmax(maxError, fabs(z[i] - 30.0));
std::cout << "зюДѓЮѓВю: " <<
maxError << std::endl;
// ЪЭЗХФкДц
cudaFree(x);
cudaFree(y);
cudaFree(z);
return 0;
} |
ЯрБШжЎЧАЕФДњТыЃЌЪЙгУЭГвЛФкДцИќМђНрСЫЃЌжЕЕУзЂвтЕФЪЧkernelжДааЪЧгыhostвьВНЕФЃЌгЩгкЭаЙмФкДцздЖЏНјааЪ§ОнДЋЪфЃЌетРявЊгУcudaDeviceSynchronize()КЏЪ§БЃжЄdeviceКЭhostЭЌВНЃЌетбљКѓУцВХПЩвде§ШЗЗУЮЪkernelМЦЫуЕФНсЙћЁЃ
3
ОиеѓГЫЗЈЪЕР§
зюКѓЮвУЧдйЪЕЯжвЛИіЩдЮЂИДдгвЛаЉЕФР§згЃЌОЭЪЧСНИіОиеѓЕФГЫЗЈЃЌЩшЪфШыОиеѓЮЊAКЭB,вЊЕУЕНC=A*BЁЃЪЕЯжЫМТЗЪЧУПИіЯпГЬМЦЫуCЕФвЛИідЊЫижЕ640?wx_fmt=pngЃЌЖдгкОиеѓдЫЫуЃЌгІИУбЁгУgridКЭblockЮЊ2-DЕФЁЃЪзЯШЖЈвхОиеѓЕФНсЙЙЬхЃК
// ОиеѓРраЭЃЌаагХЯШЃЌM(row,
col) = *(M.elements + row * M.width + col)
struct Matrix
{
int width;
int height;
float *elements;
Matrix(int w, int h, float* e = NULL)
{
width = w;
height = h;
elements = e;
}
}; |
ОиеѓГЫЗЈЪЕЯжФЃЪН
ШЛКѓЪЕЯжОиеѓГЫЗЈЕФКЫКЏЪ§ЃЌетРяЮвУЧЖЈвхСЫСНИіИЈжњЕФ__device__КЏЪ§ЗжБ№гУгкЛёШЁОиеѓЕФдЊЫижЕКЭЮЊОиеѓдЊЫиИГжЕЃЌОпЬхДњТыШчЯТЃК
// ЛёШЁОиеѓAЕФ(row,
col)дЊЫи
__device__ float getElement(const Matrix A, int
row, int col)
{
return A.elements[row * A.width + col];
}
// ЮЊОиеѓAЕФ(row, col)дЊЫиИГжЕ
__device__ void setElement(Matrix A, int row,
int col, float value)
{
A.elements[row * A.width + col] = value;
}
// ОиеѓЯрГЫkernelЃЌ2-DЃЌУПИіЯпГЬМЦЫувЛИідЊЫи
__global__ void matMulKernel(const Matrix A,
const Matrix B, Matrix C)
{
float Cvalue = 0.0;
int row = threadIdx.y + blockIdx.y * blockDim.y;
int col = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = 0; i < A.width; ++i)
{
Cvalue += getElement(A, row, i) * getElement(B,
i, col);
}
setElement(C, row, col, Cvalue);
} |
зюКѓЮвУЧВЩгУЭГвЛФкДцБраДОиеѓЯрГЫЕФВтЪдЪЕР§ЃК
int main()
{
int width = 1 << 10;
int height = 1 << 10;
Matrix A(width, height, NULL);
Matrix B(width, height, NULL);
Matrix C(width, height, NULL);
int nBytes = width * height * sizeof(float);
// ЩъЧыЭаЙмФкДц
cudaMallocManaged ((void**)&A.elements, nBytes);
cudaMallocManaged ((void**)&B.elements, nBytes);
cudaMallocManaged ((void**)&C.elements, nBytes);
// ГѕЪМЛЏЪ§Он
for (int i = 0; i < width * height; ++i)
{
A.elements[i] = 1.0;
B.elements[i] = 2.0;
}
// ЖЈвхkernelЕФжДааХфжУ
dim3 blockSize (32, 32);
dim3 gridSize ((width + blockSize.x - 1) / blockSize
. x ,
(height + blockSize.y - 1) / blockSize.y);
// жДааkernel
matMulKernel << < gridSize, blockSize
>> >(A, B, C);
// ЭЌВНdevice БЃжЄНсЙћФме§ШЗЗУЮЪ
cudaDeviceSynchronize();
// МьВщжДааНсЙћ
float maxError = 0.0;
for (int i = 0; i < width * height; i++)
maxError = fmax(maxError, fabs(C.elements[i]
- 2 * width));
std::cout << C.elements[0] << std::endl;
std::cout << "зюДѓЮѓВю: " <<
maxError << std::endl;
return 0;
} |
етРяОиеѓДѓаЁЮЊ1024*1024ЃЌЩшМЦЕФЯпГЬЕФblockДѓаЁЮЊ(32, 32)ЃЌФЧУДgridДѓаЁЮЊ(32,
32)ЃЌзюжеВтЪдНсЙћШчЯТЃК
nvprof cuda9.exe
==2456== NVPROF is profiling process 2456, command:
cuda9.exe
зюДѓЮѓВю: 0
==2456== Profiling application: cuda9.exe
==2456== Profiling result:
Type Time(%) Time Calls Avg Min Max Name
GPU activities: 100.00% 2.67533s 1 2.67533s 2.67533s
2.67533s matMulKernel(Matrix, Matrix, Matrix)
API calls: 92.22% 2.67547s 1 2.67547s 2.67547s
2.67547s cudaDeviceSynchronize
6.06% 175.92ms 3 58.640ms 2.3933ms 170.97ms cudaMallocManaged
1.65% 47.845ms 1 47.845ms 47.845ms 47.845ms cudaLaunch
0.05% 1.4405ms 94 15.324us 0ns 938.54us cuDeviceGetAttribute
0.01% 371.49us 1 371.49us 371.49us 371.49us cuDeviceGetName
0.00% 13.474us 1 13.474us 13.474us 13.474us cuDeviceTotalMem
0.00% 6.9300us 1 6.9300us 6.9300us 6.9300us cudaConfigureCall
0.00% 3.8500us 3 1.2830us 385ns 1.9250us cuDeviceGetCount
0.00% 3.4650us 3 1.1550us 0ns 2.3100us cudaSetupArgument
0.00% 2.3100us 2 1.1550us 385ns 1.9250us cuDeviceGet
==2456== Unified Memory profiling result:
Device "GeForce GT 730 (0)"
Count Avg Size Min Size Max Size Total Size
Total Time Name
2048 4.0000KB 4.0000KB 4.0000KB 8.000000MB 22.70431ms
Host To Device
266 46.195KB 32.000KB 1.0000MB 12.00000MB 7.213048ms
Device To Host |
ЕБШЛЃЌетВЛЪЧзюИпаЇЕФЪЕЯжЃЌКѓУцПЩвдМЬајгХЛЏ...
аЁНс
зюКѓжЛгавЛОфЛАЃКCUDAШыУХШнвзЃЌЕЋЪЧЩюШыФбЃЁЯЃЭћВЛЪЧДгШыУХЕНЗХЦњ.
|









