| 编辑推荐: |
| 本文来自于csdn,讲解了CISC体系结构和RISC体系结构,典型的ARM
CPU Core体系结构,ARM编程模型,ARM异常与中断等。 |
|
CISC体系结构和RISC体系结构
计算机体系结构
计算机体系结构是指从用户角度看到的计算机属性,其中包括计算机的指令集、可见存储器、存储器管理单元和异常处理模式等。
CISC体系结构
CISC(Complex Instruction Set Computer),指的是复杂指令集计算机。其顺应的是上世纪80年代之前的增加指令集的复杂程度提升计算机的综合性能的整体思路,但是其自身却有着许多的缺点。
主要有:
设计周期延长,资金耗费增加;
20%与80%的问题。复杂指令集计算机中仅有五分之一的指令是被经常调用的,而另外的指令实际上相对而言是一种冗余,或者说这一部分实际上是完全没有必要存在的;
指令复杂度对处理器的VLSI实现性能的影响—暂时不是太明白
软硬件的协同设计问题。指令集的增加,必然带来了软硬件协同设计上的难度增加;
RISC体系结构
RISC(Reduced Instruction Set Computer), 顾名思义,其是精简指令集计算机。RISC体系结构具有的优点是
指令类型少;
指令格式和长度固定
优化编译效率高
大多数指令单周期完成
分开的Load/Store结构的存取指令
基于多个通用寄存器堆操作
(注:)暂时对于后面三点不是太理解
RISC的历史贡献
流水线
高时钟频率和单周期执行
注: 有时嵌入式系统会限制RISC的高时钟频率,因为时钟频率的增加直接伴随着耗电量的增加。
特别值得注意的是,RISC结构不能够执行X86代码,同时给优化编译程序带来了较大的困难,其优点都是相对于CISC而言的。
ARM是第一个为商业用途而开发的RISC微处理器。
ARM体系结构的发展概述
关于ARM体系结构详细的发展历程,具体可以参看PPT相关资料。以下介绍几个比较有意思而PPT中基本没有提到的内容。
ARM–Advanced RISC Machines
ARM公司只卖关于产品架构的授权,而不卖具体的产品。
一般在移动设备上使用较多的都是Cortex-A型处理器,与此同时,由于竞争等原因,因此相对而言奇数位的ARM处理器市场占有率更高。
典型的ARM CPU Core体系结构
ARM7TDMI
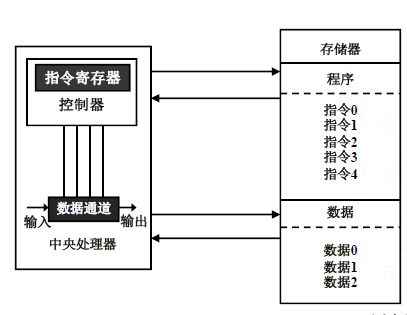
ARM7处理器采用冯诺依曼结构,指令和数据公用一条32位总线。只有装载、存储和交换指令可以对存储器中的数据进行访问。
ARM7采用的是“冯·诺依曼结构”,而ARM9则采用的是“哈佛”结构。
首先来谈一谈冯诺依曼结构:
冯诺依曼结构就是将程序和数据都存储在同一个存储器中,其优点是结构简单,但是由于其不能同时进行取址和取数据的操作,因此其处理速度相对较慢。
三级流水线
ARM7处理器使用的是三级流水线来提高运行的效率。其后,流水线技术在ARM系列产品以及其他处理器中得到了广泛的运用。
ARM7流水线可以分为三级,分别为取指–>译码–>执行。
如下概念图所示: 
其中ARM7具有两套指令集,一套是32位的ARM指令集,一套是16位的Thumb指令集。
流水线冲突
流水线冲突的情况主要有如下几点:
资源冲突。一个指令需要使用一个已经被另外一个指令占据的资源;
数据冲突。一个指令所需要的数据还没有计算出来,或者是一个指令需要的寄存器内容还没有被调入寄存器。
控制流冲突。流水线必须等待一个有条件Goto指令是否会被执行。
减少冲突的办法
调整代码顺序:将带有与邻近指令不相关的寄存器插到带有相关寄存器的指令之间;
合并循环:将两个循环合并成一个循环,或者在一定程度上去降低程序的循环次数(这是一种牺牲时间资源换取空间资源的方法)
ARM9TDMI
哈佛结构
哈佛结构是相对于冯诺依曼结构的改进而提出的,现在的笔记本电脑大多使用的是哈佛结构。
哈佛结构具有的突出特点就是指令总线和数据总线及其存储区是相互分开、独立的。取指操作和取数操作可以在同一个时间周期内进行,提高了处理速度。
以下是哈佛结构的模式图: 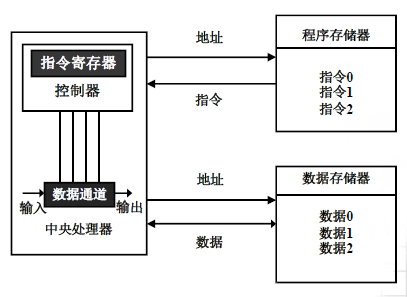
ARM9流水线
ARM9流水线为5级流水线,其增加了存储器访问段和回写段,一定程度上提升了处理器的性能。
Fetch –> Decode –> Execute –> Memory –>
Write
(预取–>译码–>执行–>访存–>写入)
在此之后,随着ARM的版本的提高,ARM处理器的流水线级数也随之不断增加。
ARM编程模型
ARM数据类型
ARM支持的数据类型:
字节–8位
半字–16位
字–32位
各种操作使用的数据类型
所有数据操作,例如ADD,都以字为单位;
装载和保存指令可以对字节、半字和字进行操作;
ARM指令的长度为一个字,而Thumble指令的长度刚好为半字
我们知道ARM处理器有ARM状态和Thumb状态,那么计算机是如何分辨当前应该是以半字执行还是以字执行呢?
实际上,对于任何一段ARM程序代码,ARM处理器将其默认为ARM状态进行执行,然后根据指令的指导合理地进行状态的切换。因此,绝对意义上而言是没有一套完整的存粹的Thumb指令的,该指令的初始指令一定为ARM指令。
处理器状态
ARM处理器有两种状态,分别为ARM状态和Thumb状态,通过之前内容的分析我们可以很明确两者之间的区别。
那么状态之间是如何进行切换的呢?
从ARM状态切换到Thumb状态
LDR R0,= Lable+1,
BX R0
其中,LDR指令是赋值操作,表示将 Lable 这一地址变量+1后将地址值给 R0,然后 BX
指令是状态切换指令 |
从Thumb状态切换到ARM状态
LDR R0, =Lable
BX R0
其基本情况同上。 |
通过比较上述两个状态切换指令,那么我们肯定会问的一个问题是,为什么Lable加不加一的操作就可以决定状态怎样转换呢?
原因是ARM状态是以4字节来运行的,因此其为0Xnnn00, 而Thumb状态是以半字来运行的,因此其为0Xnnn0。通过在ARM状态下+1的操作,就可以实现状态的跳转。
思考:状态的跳转与其末尾有几位零之间存在什么关系?
处理器模式
c处理器共有其中不同的模式,具体内容如下: 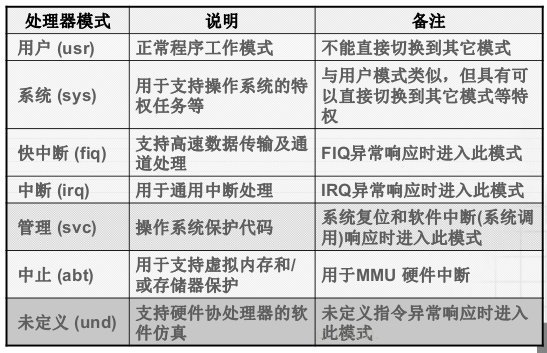
其中Fiq以及irq都是硬中断,是引脚(硬件)引起的中断,而软件引起的中断则被称之为软中断,其可以进入管理模式。
其中未定义模式实际上就是CPU的一种报错模式,是CPU对于自身不清楚的指令的一种处理方式。
处理器启动时进入的模式是管理模式(或者称之为监督模式),其主要是对处理器以及硬件进行初始化。类似于CPU的频率初始化,避免频率过低达不到运行要求,也避免频率过高,大量发热耗电。又如关闭所有中断,以此来防止系统初始化时候被用户进行误操作。
然后进入处理管理模式之外的多种特权模式,其主要完成的是各个模式的堆栈的初始化设置,主要完成的是堆栈位置以及大小的设定。特别注意的是,用户模式没有权限进入特权模式,因此主要在此第二个阶段不要进入用户模式。
最后是用户程序的运行模式。其一般指的是用户模式。
ARM处理器的寄存器
ARM处理器一共有37个32位寄存器。其中包括一个PC寄存器,一个CPSR(current program
state register–当前状态寄存器), 5个SPSR(saved program state
register状态保存寄存器)和30个通用寄存器。
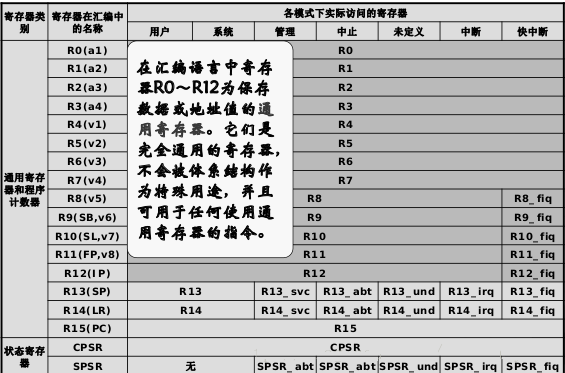
从图中可以看到快中断之所以为“快”的一个重要原因是在快中断之下有一组独立的寄存器,因此其不需要在通用寄存器之上进行压栈和弹栈操作。
同时可以看到,五个CPSR(状态保存寄存器)对应着除了系统模式之外的五中特权模式。图中,管理模式的状态保存寄存器的编写存在笔误。
R14寄存器与子程序调用
R14(LR–Link Register),顾名思义是连接寄存器, 其一般是返回程序调用的入口处地址。
最典型的就是在子程序的调用之中,如果程序A调用了子程序B,如图所示:
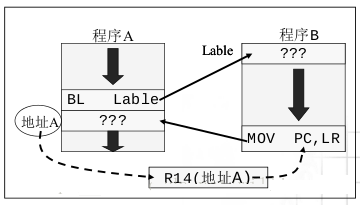
其具体的流程是,程序A在执行过程中调用B,当程序跳转至标号Lable时,执行程序B。同时硬件将BL
Lable指令的下一条指令所在地址存入R14。当程序B执行完成之后,将R14寄存器的内容放入PC,返回程序A。
而当进行子程序嵌套调用时,会出现无限循环嵌套问题,因此在R14链接寄存器的设计上需要采用堆栈的方式进行存储。在子程序调用之前以及子子程序调用完成之后分别进行压栈和弹栈操作。
R14寄存器与异常发生
异常发生时,程序要跳转至异常服务程序,对返回地址的处理与子程序的调用类似,都是由硬件来完成的,主要区别是有些异常存在一个小的常量的偏移。而且异常发生时会引起IRQ中断。
值得注意的是,异常处理的时候R14与R14_irq由于是两个不同的寄存器,因此相互独立,不能彼此之间相互联系,因此在执行完中断程序之后得到一个返回值,将该返回值减去一个小的常量之后就将地址返回源程序对应处执行。
程序计数器PC(程序指针)(R15)
R15指向的是正在取址的地址。
z在进行正常操作时,从R15读取的值是处理器正在取指的地址,即当前正在执行指令的地址加上8个字节(两条ARM指令的长度)。
z值得注意的是,在使用STR或者STM指令保存R15时,这些指令可能会将当前指令加上8字节或者是12个字节进行保存,其与计算机本身有关,但是一旦计算机硬件确定之后其是8还是12就已经确定了。
偏移量的计算代码
0x300000 SUB
R1. PC, #4 ;将PC值-4 然后加上移位8,因此R1= PC+4
0x300004 STR PC, [R0] ;将R0 的地址值存入 PC中
0x300008 LDR R0. [R0] ;将R0 的地址值附给 R0
0x30000c SUB R0, R0, R1 ;通过加法得到 offset的值
r如果以偏移量8为例,R1= 0X300004, [R0]= 0X30000c, R0= 0
x 30000c, R0= 8 |
ARM异常与中断
异常的基本概念及分类
异常是指任何打断处理器正常执行的操作,并且迫使处理器进入一个由有特权的特殊指令执行的事件。
异常可以分为同步异常和异步异常两类。其中,同步异常是指由内部时间引起的异常情况,而异步异常是指由外部事件引起的异常。其中,内部事件主要指的是处理器指令本身运行时产生的事件吗,而外部事件则是处理器指令执行不相关的事件。
其中,异步异常又被称之为中断。
异步中断的优先级
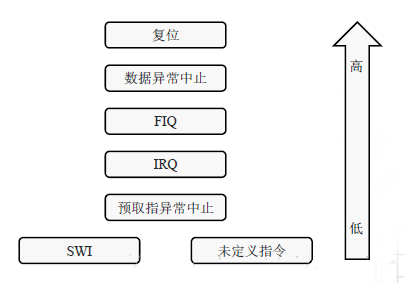
从上述的表格形式可以看到各种异常情况的优先级。其中,我们可以看到,很让人不可思议的是软中断和未定义指令的优先级是一样的,同时其也是从硬件和软件两个角度来分析的。那么我们不由得会思考一个问题,那就是一般而言CPU同一时间只能够执行一条指令,那么发生了这种两种中断方式优先级相同的情况如何去指导计算机执行。经过细致的分析,我们不难发现,实际上软中断和未定义指令一般而言是不可能同时发生的,因此可以将其置于同一优先级。
但是,就需要明确的一点是,异常中断的多种情况中,接收的是不同的信息源,因此如果发生不同中断源的干扰而导致两种异常发生的情况怎么处理?
异常向量表
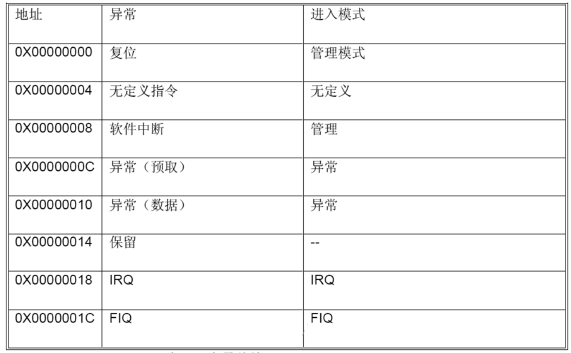
从上述异常向量表中我们可以得到很多的信息。
从异常到处理
我们从向量表中可以看到,每个异常状态的存储空间只有4个字节,也就是刚好为一个ARM指令的长度,但是我们对于异常的处理基本上很难在一个指令内完成,因此在进行异常处理时,需要进行Goto跳转。这在ARM模式之下,一般执行的是“B”指令,一般很少使用“BL”指令,因为BL指令需要记录返回地址的值,但是实际上我们从异常中进行操作之后,不需要再次重复进入异常。
FIQ相对于IRQ称之为”快”中断的原因?
FIQ模式有一组从R8-R12的独立的LR寄存器,因此在存储地址时相对于其他模式不需要进行弹栈和压栈操作,因此速度相对较快。
在异常向量表中,FIQ模式的优先级大于IRQ模式的优先级,因此其是优先执行的;
在异常向量表中,FIQ模式置于异常向量表的最尾部,因此其不需要在处理异常时执行Goto语句进行相关的异常处理
低位地址与操作系统执行代码的冲突
我们知道,操作系统完成必须任务所需要执行的代码一般都是低位地址的序列,而我们异常向量表中的异常模式的模式指定地址也都是低位地址,因此如果在嵌入式设备中使用操作系统,就产生了操作系统与异常向量表在低位地址处的冲突。
而我们在嵌入式系统开发时,解决此问题的方法有两种,一种是还是将异常向量表交给操作系统进行接管,但是我们将操作系统的低位地址执行异常向量表的序列;另外一种解决方法就是我们可以通过编写程序的方式,将异常向量表的存储位置置为高位地址处。
异常的入口和出口
进入异常
在进入异常之后,ARM内核会进行以下操作:
首先是保存地址,然后执行相关异常处理操作。其中保存地址有两部分内容,一是程序执行状态的地址,二是返回地址。
1.将CPSR复制到适当的SPSR中;(复制状态现场)
2.将返回地址保存到对应模式下的LR_寄存器中;(记录返回地址)
3.将CPSR模式位强制设置为与异常类型相对应的值;(修改当前状态)
4.强制PC重相关的异常向量处取址 (从状态表中执行相应的异常处理跳转)
异常总是在ARM状态中进行处理,即使当处理器在Thumb状态发生了异常,但是仍然会跳转为ARM状态进行异常处理。
退出异常
由上述的复制现场的情况,我们知道,退出异常需要返还所有的现场。也就是上述四步操作中的前两步。
将SPSR的值复制回CPSR
将对应LR中的值减去偏移量后存入PC,偏移量根据异常类型而有所不同
通过分析,我们可以得知,这两个步骤是同时执行的,否则会存在许多的问题。
原因主要如下:
1. 如果首先执行步骤一然后执行步骤二,那么将状态发生改变之后,由于LR对应的值发生了改变,也就是说如果初始时为用户模式,然后异常进入的是快速中断模式,那么此时用户模式就不能够使用快速中断模式的LR了,因此其返还的地址值就不能够一一对应了;
2. 如果首先执行步骤二然后执行步骤一,由于我们知道LR向PC的跳转是无条件的,因此SPSR值复制到CPSR这一过程就不会被执行。
综上所述,退出异常时这两个现场的返回是同时进行的。
异常返回地址修正
异常返回地址修正的根本原因是ARM处理器的流水线技术
计算返回地址需要把握两点:
1. 发生异常时PC寄存器的值是否已经更新
2. 异常返回后被打断的当前指令的值是否还会被执行
从异常中断处理程序中返回
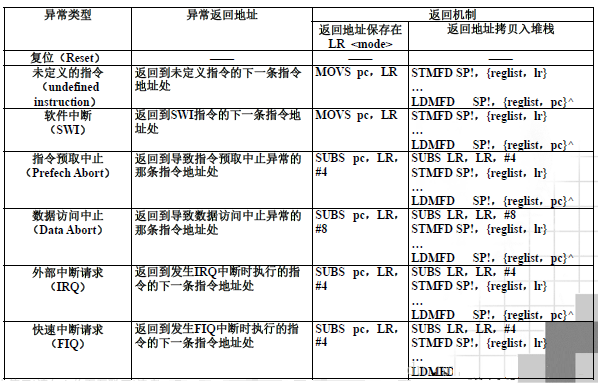
不同异常模式偏移量的计算
未定义异常和软件中断异常的偏移量为0;以上两种指令都是需要在中断处理完成之后执行待处理指令的下一条指令。而本身我们存储LR时,对应地址存储的LR的值实际上-4,但是由于ARM7的三级流水线结构设计,因此以上两者的偏移量为0;
外部中断请求和快速中断请求的偏移量为4: 以上两种命令都需返回到发生TRQ中断或者是FIQ中断的下一条指令地址,由于完成了当前指令的执行,因此PC的值发生了更新,故此处需要进行减4操作;
指令预取终止和数据访问中止,前者的偏移量为4,后者的偏移量为8.因为进行指令预取异常时,程序需要重新回到预取指令处,但是PC没有进行更新,因此偏移量为4,而数据访问终止PC更新了,同时也需要回到之前的操作,则其偏移量为8.
退出异常操作的实时性
我们使用的MOVS其中MOV后加S,而且操作对象为PC,则在进行LR减去偏移量存入PC的操作同时,需要进行SPSR状态值返回到CPSR的操作。这是解决实时性的关键方式。
内存和I/O
内存系统–大端和小端
在大端存储中,高地址位存储的是重要性相对较差的内容,而对于小端存储而言,低地址位存储的是重要性相对较差的内容。另外,对于一个数据本身而言,一般数据的高位对于数据本身影响较大。
在默认模式之下,通常被认为是小端、但是可以被配置为大端。
在使用小端ARM系统时,一个双精度的字将以大端顺序存储,而每个字的每个字节都以小端顺序存储。
I/O端口编址方式
I/O端口编址方式有两种,一种是存储器映射编址,其是I/O端口的地址与内存地址统一编址,即I/O单元与内存单元在同一个地址空间。另外一种是I/O映射编址,其是I/O端口地址与内存地址分开编址,即I/O单元与内存单元都有自己独立的空间。
ARM CPU的I/O端口都是存储器映射的编制方式,也就是其I/O端口的地址与内存的地址统一编址。
|









