| Apache顶级项目介绍之8,我们重新恢复Apache顶级项目系列,较之前介绍系列,我们本文直入代码分析,原因有二,Geode即上文我们分析的Gemfire的开源版本,其二被逼无奈,阅读源码查找问题。
1. Geode
2016年11月21日,Apache 软件基金会(ASF)宣布 Apache? Geode? 已从 Apache
孵化器毕业成为顶级项目(TLP),表明该项目的社区和产品已根据 ASF 的精英流程和原则得到良好管理。
Apache Geode 是一个数据管理平台,提供实时的、一致的、贯穿整个云架构地访问数据关键型应用,最初由
GemStone Systems 公司开发,商标为 GemFire。 此项技术初期被广泛应用在金融领域,用于华尔街交易平台,作为事务性、
低延时的数据引擎。2015年4月将代码提交给 Apache 孵化器作为孵化项目。目前 Apache Geode
有超过600家大中型企业级用户, 主要是必须满足低延时和24x7 高可靠要求的,高可扩展的关键业务应用系统。
2. 适用场景
可以参考上文,分布式缓存利器-Gemfire.
4个主要使用场景:
高可用性的分布式缓存
网格计算
事件通知和处理(CEP类似)
交易处理(Transaction),采用最终一致性
Geode 池化了服务器上的内存, CPU, 网络资源, 和本地磁盘,跨多个进程来管理应用对象和行为.
它使用了动态数据复制和分区技术来实现高可用, 高性能, 高可扩展性, 和容错. 另外, 对于一个分布式数据容器,
Apache Geode 是一个基于内存的数据管理系统, 提供了可靠的异步事件通知和可靠的消息投递.
3. 数据结构源码
如上文所说,系统目前遇到一个分布式系统异常复杂之难题,难到不遍历源码无法解开谜题的地步。注意,笔者写此文时,此难题尚无答案,我们希望当此文发布时,已有解药。
另外,强烈建议看官先自行了解Gemfire功能以及部分原理,否则此文较为吃力。
3.1 Region
进入正题,先来看一下核心类Region。
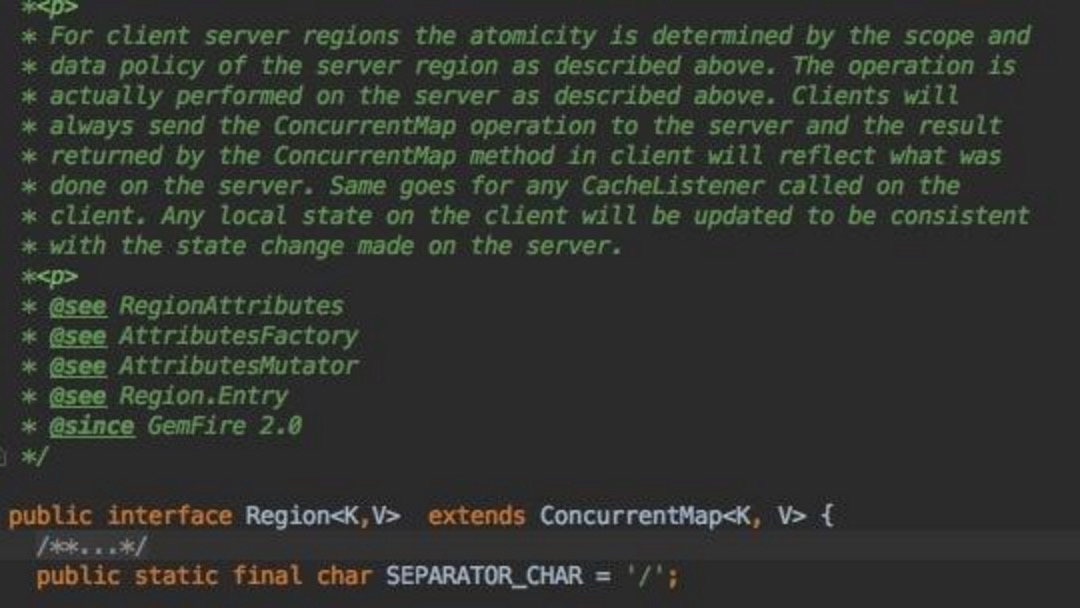
Region继承Java的ConcurrentMap,实现了分布式K,V的HashMap,并提供了高阶的事务,Persistence,分区等分布式功能。
接口继承Map的get, put无须多说,看几个比较重要的。
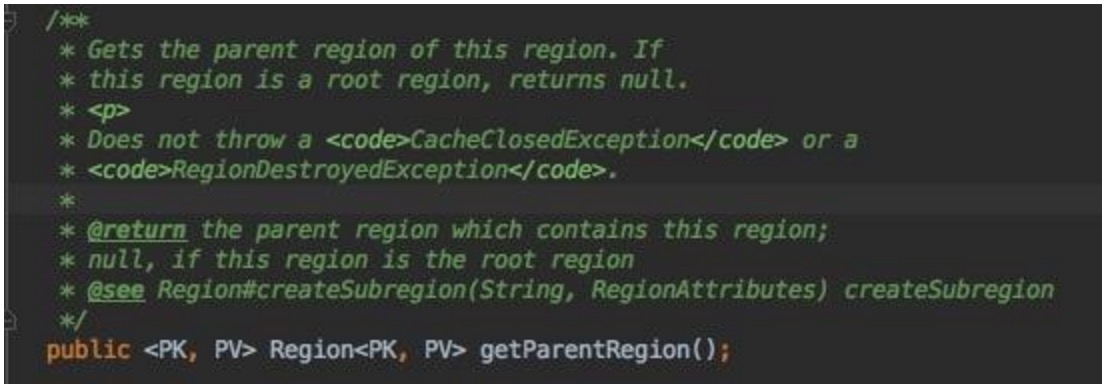
Geode的Region可以像树形一样,形成一种Hierarchy结构嵌套,使用”/”来分隔多个子Region.所以有向上获取父亲,自然也有向下导航获取子女:getSubregion(String
path)
RegionDistributedLock
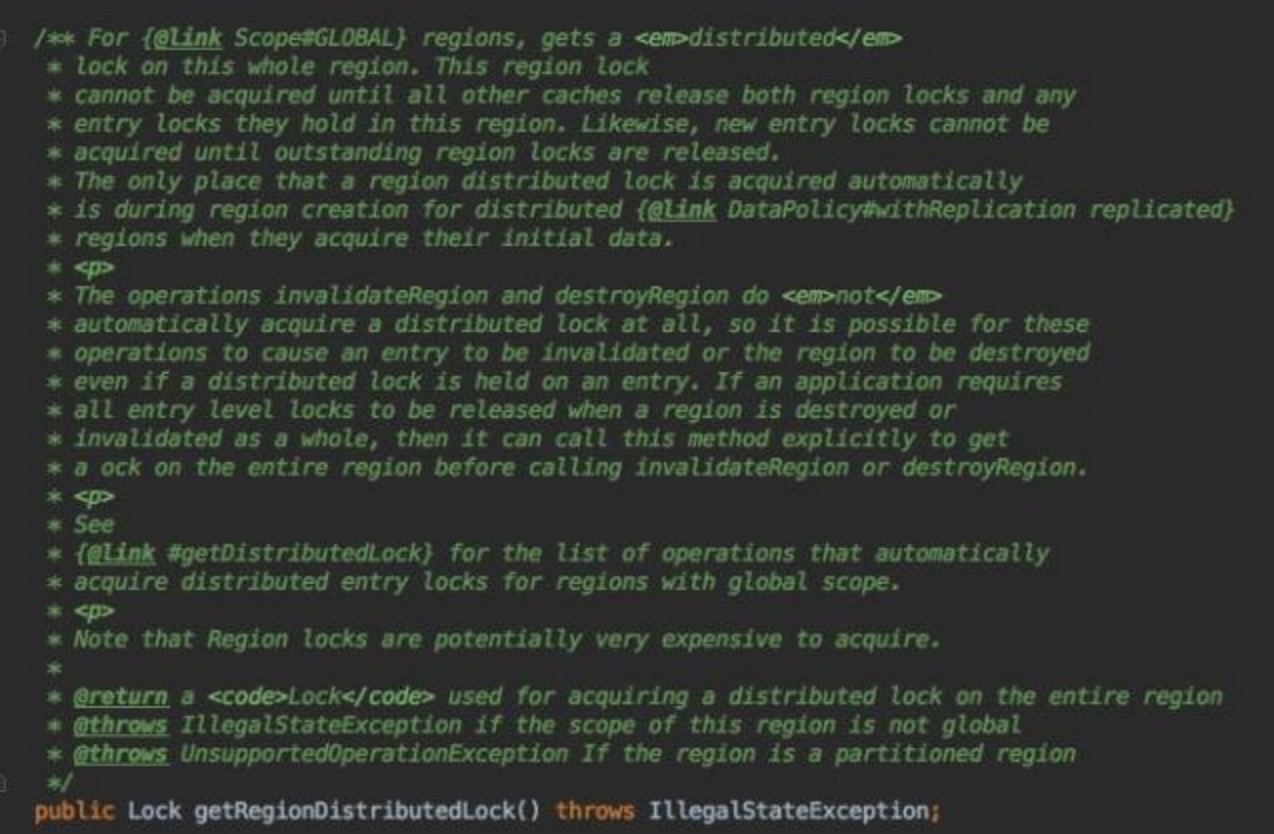
第一个分布式锁,全局Region。注释写很到位,其中提到当region创建时会自动开启全局region锁,所有对region级别的操作,如invalidateRegion,
destroyRegion也可能会自动用到region级别锁,这个么可以理解,毕竟是重量级操作。
getDistributedLock(key)
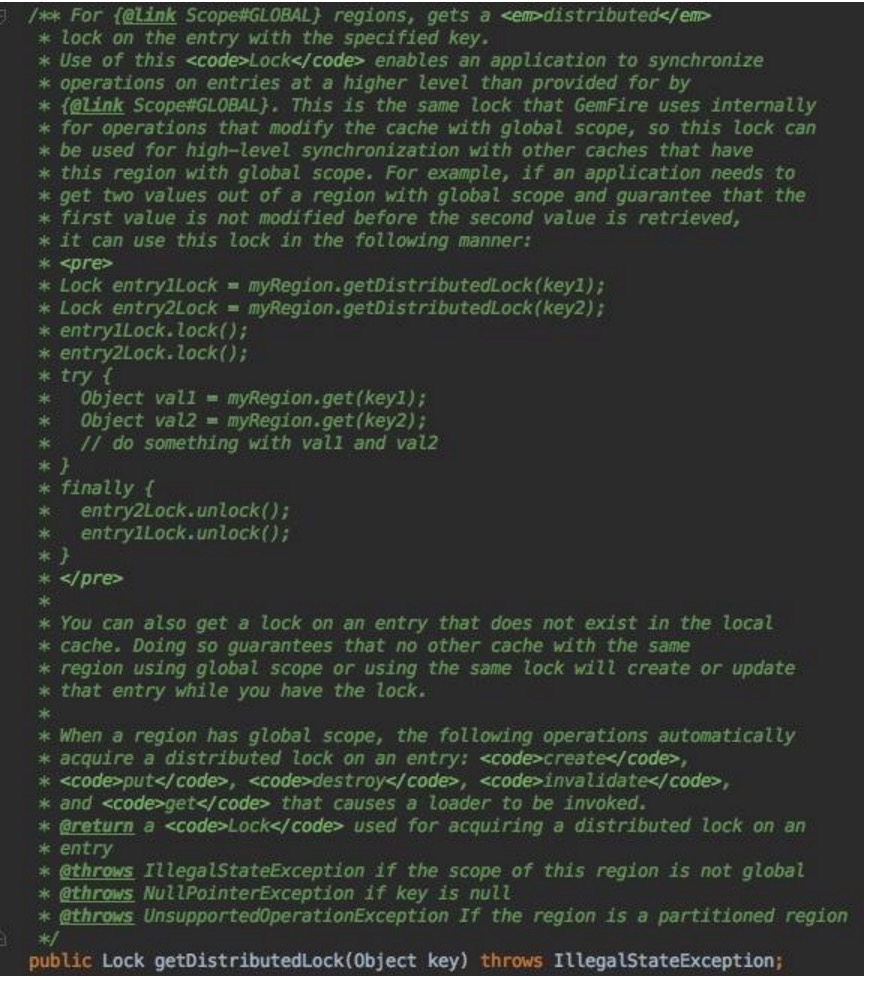
提供了更细粒度的region级别分布式锁控制。
然而,除非必要,所有分布式操作不建议用如此之重的锁,否则后患无穷。
public void writeToDisk();
当然,支持持久化到磁盘,分布式的一种表现形式,相对于普通的HashMap。
public void becomeLockGrantor();
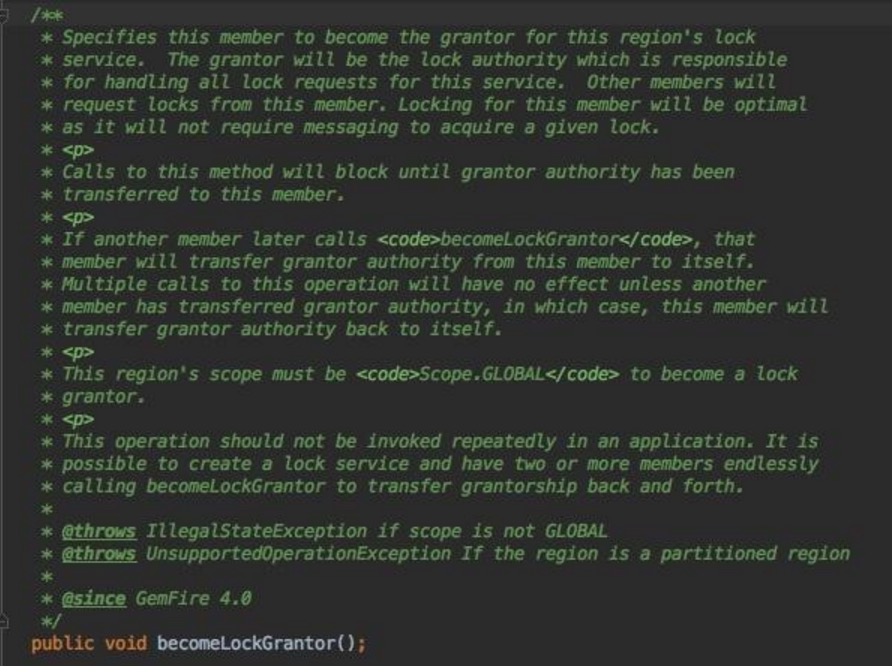
不赘述,如注释所描述,LockService的担保,前提当前region必须是Global类型,有点类似对于分布式全局变量加锁,所以每当调用此方法,线程将阻塞直到担保被转移到当前member。
超级重量级方法,请自保。注释强调了,相互调用可能造成死锁,说的比较委婉,back and force。
public void registerInterest(K key);
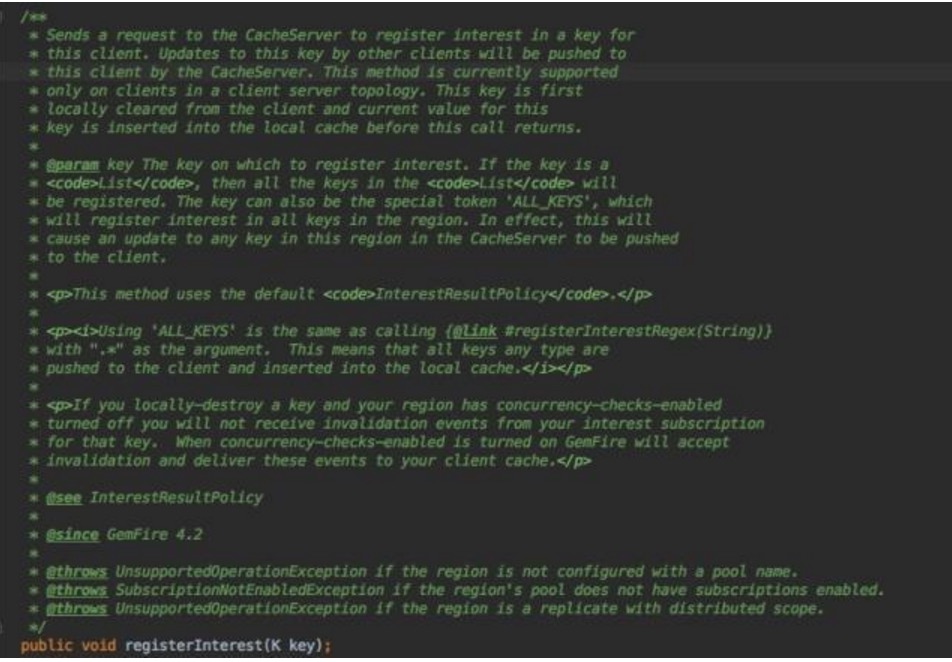
后续很多分布式,多个member交互的入口之一。
注释提到用于向CacheServer提交注册一个感兴趣的key,后续还有按照正则表达式注册,或者注册所有key。其注册目的是用于被通知,类似ems
queue的subscription功能,或者回调通知。
public List getInterestList();
返回当前region已经注册的所有感兴趣key。
对了,每个类代码小于500行都是骗人的,随便看看这些开源代码,少则1000,多则6-7千行代码。
3.2 AbstractRegion
AbstractRegion抽象类,主要封装实现了关于RegionAttributes, AttributesMutator,
and some no-brainer method implementations。

其中,主要cache操作的读写则由上面loader与writer代理实现。Usually there
will be only one CacheWriter in the distributed system.所以,通常整个分布式系统只有一个cache
writer,其它特殊情况暂时不提。
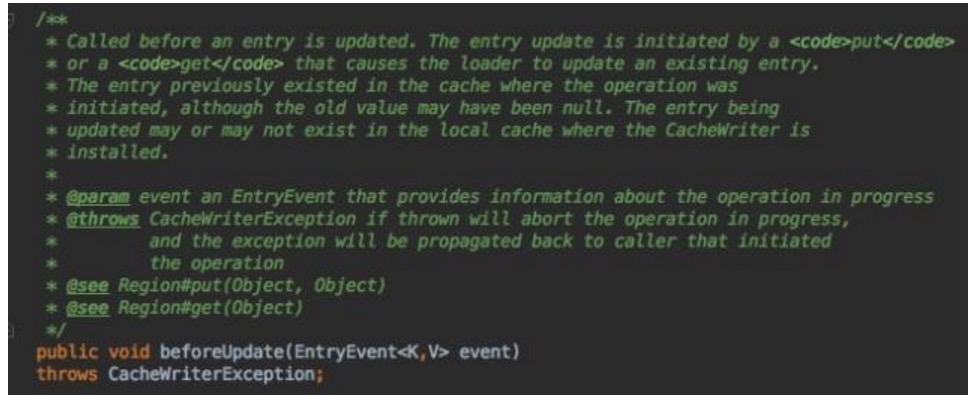
截获entry更新事件,其中entryEvent包含了整个操作的信息,如KeyInfo, EventID,
newValue, oldValue, Operation, originated member等。BTW,
这个看起来普通的EntryEvent类也有2856行,此处省略无数。。。
protected Set asyncEventQueueIds;
隐隐觉得,其分布式的消息事件处理会放到queue中,这里用了set结构,我们继续看下去。
protected booleanenableSubscriptionConflation;
这个参数对于高频写region非常有用,主要是同一个key高速写,类似实时报价。这个参数效果类似于Leaky
Bucke。
漏桶算法(Leaky Bucket)是网络世界中流量整形(Traffic Shaping)或速率限制(Rate
Limiting)时经常使用的一种算法,它的主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。漏桶可以看作是一个带有常量服务时间的单服务器队列,如果漏桶(包缓存)溢出,那么数据包会被丢弃。
3.3 Regions UML
当我们越加深入,发现代码越来越复杂,很多类少则几千,多则上万行,类也有上千万个,对于大型开源项目,还是来一张类图吧,掌握整体宏观很重要。
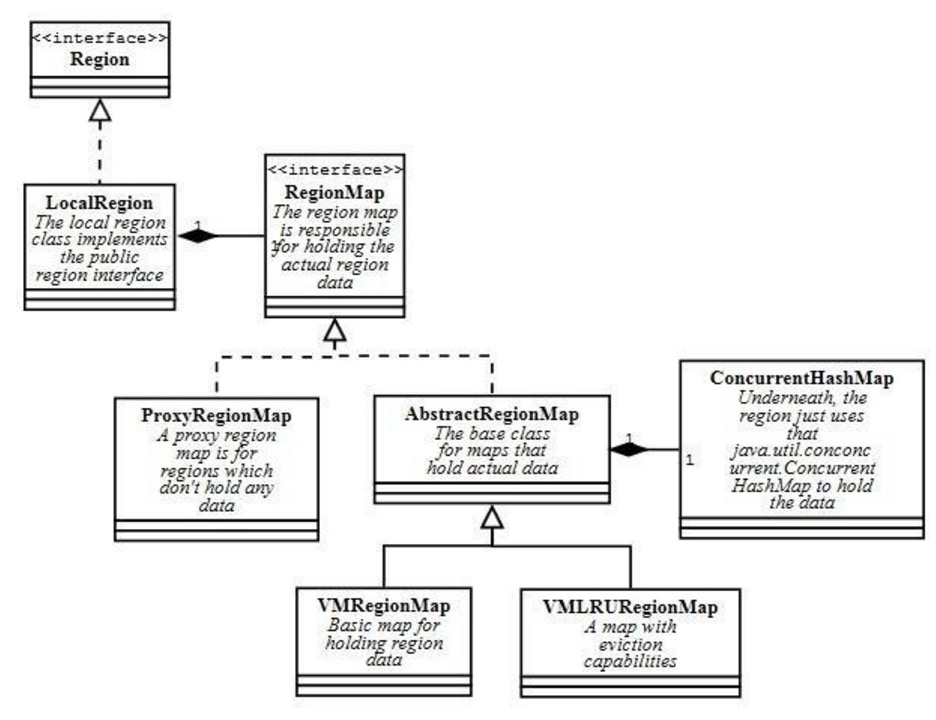
可以看到LocalRegion继承自AbstractRegion,最重要的是内部封装了Region的数据结构。
了解HashMap内部数据结构的朋友应该知道,其内部为数组+链表组合的二维空间;同理,Geode的Region内部数据结构则由RegionMap来抽象,持有真正的数据,而究其内部则是内置了一个ConcurrentHashMap,想想让我们来设计的话也大概如此吧。
3.4 AbstractRegionMap
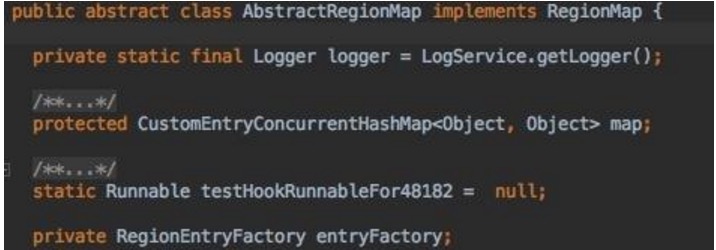
可以看到里面内置一个CustomEntryConcurrentHashMap map;应该是这个map,
这是什么神器?
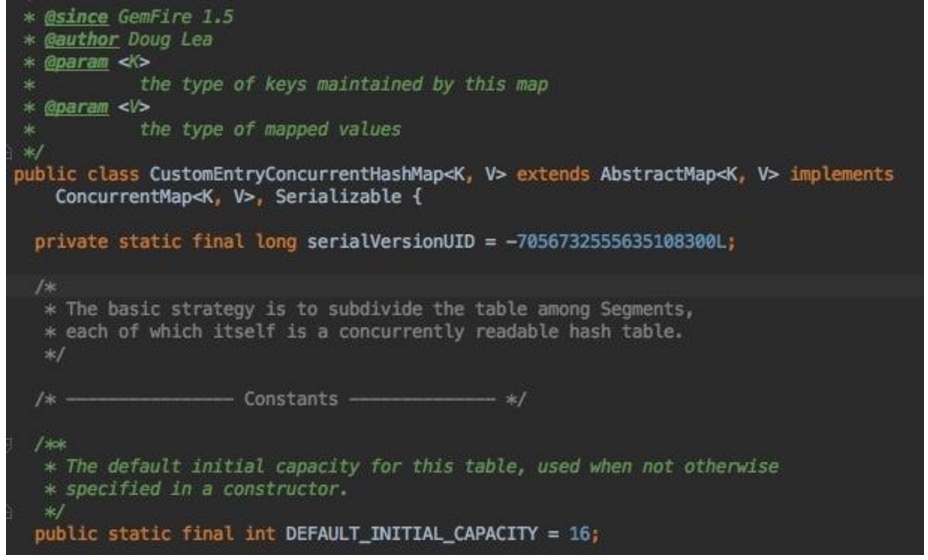
如果你看到了Doug Lea的大名,不要惊奇,难道Doug也为Gemfire/Geode操刀?非也。
Gemfire/Geode当年直接copy Doug老人家的ConcurrentHashMap, 你可以去比较一下源码,当然,GemStone也进行了一些定制化,如读锁等。
了解完其真实内部存储数据结构后,心中略有一二,而然这也是预期之中,我们继续看如何实现分布式的精髓。
3.5 DistributedRegion
我们还是先上UML图吧。
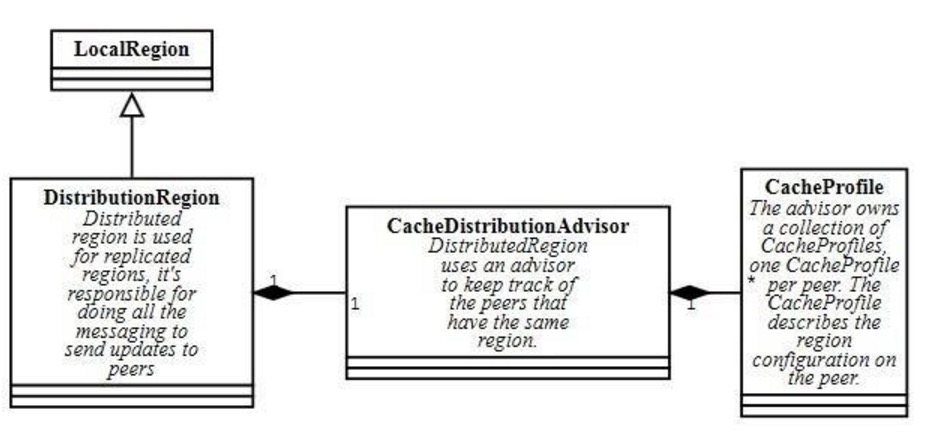
DistributinRegion代表了分布式的ReplicatedRegion, 而其中则是靠CacheDistributionAdvisor来帮忙跟踪保持数据同步的。
3.6 Partitioned Regions
Partitioned Region为PatitionedRegion的实例化,内部则基于key的hash
code来检测定位Bucket。
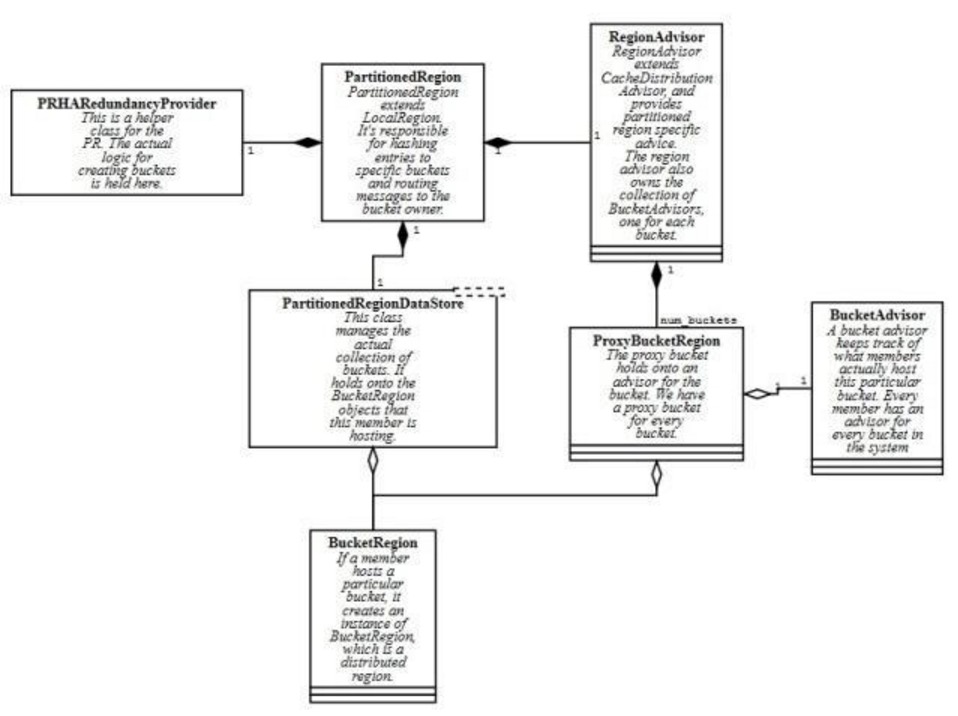
PartitionedRegion,Geode中的核心分布式结构。通过hash算法(可以自定义)来把key映射到相应的bucket从而达到分布式存储,并提供routing消息到相应的bucket。
PartionedRegion中的PartitionedRegionDataStore则实际负责分布式管理bucket,以及存储。
PRHARedundancyProvider
类如其名:
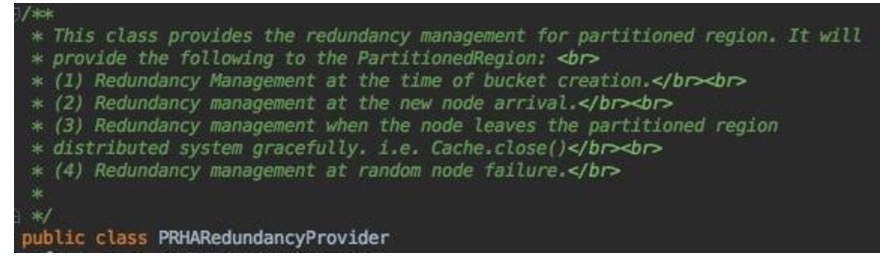
主要提供针对Reduancy Copy的管理,包括:
bucket创建,以及node的管理。
当创建并配bucket的时候,其内部创建出BucketRegion的实例, 来看一下BucketRegion中经典的virtualPut:
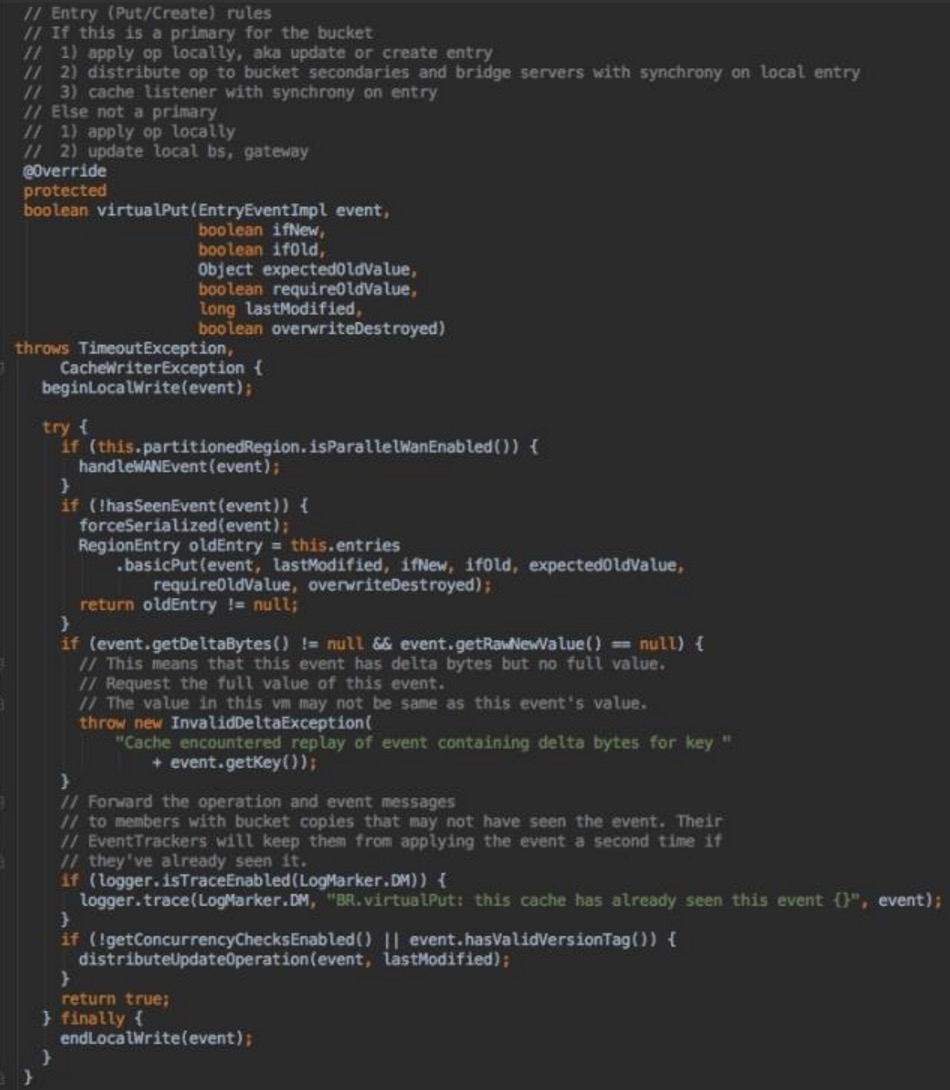
注释很好,
如果当前是Primary, 则op locally, 之后分发操作op到secondaries及bridge
server,同时cache listerner同步其结果;
反之,则首先op locally,之后更新local bridge server, gateway
来个序列图吧: 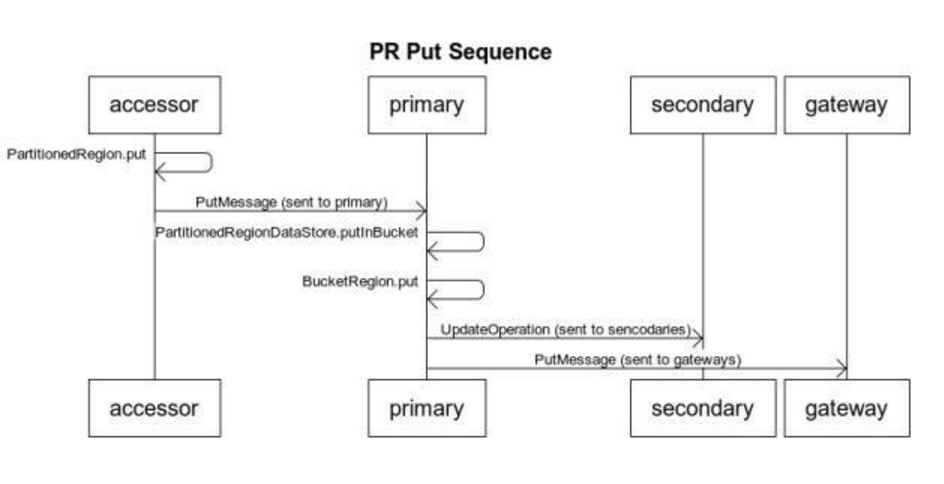
4. 分布式管理Client + Server
Geode的分布式消息通信分为主要两大类,一类是Peer to Peer,主要使用了InternalDistributedMember。
4.1 Peer to Peer 消息机制
InternalDistributedMember封装了分布式member的信息,当需要发送p2p消息时,需要用该对象表明目标。
DM提供了获取所有当前cluster中的peers列表,并通过listerners来获取动态信息,而其底层则是通过DistributionAdvisor实现,统一的模式,所以真正筹谋画册的都是幕僚。DM主要封装了相关的网络通信信息,包含netMember,
dcPort(direct channel port), vmPid(member machine’s
process id)等,当然实现特定内部序列化接口(DataSerializableFixedID)是必不可少的。
而消息则是DistributionMessage封装,包含了上述InternalDistributedMember信息的sender与destination,以及多个recipients的InternalDistrbutedMember[]数组,还有万恶的用于direct
ack的ReplySender等。
整个消息通信过程大概是先创建DistributionMessage, 设定recipient(可以多个),之后调用(DistrbutManager
DM) DM.putOutgoing(message)。
如果需要不但发送消息,而且还要确认消息回复response,则要使用著名的ReplyProcessor21,
如果你看到过Gemfire/Geode的ThreadDump, 你就明白我说什么了。
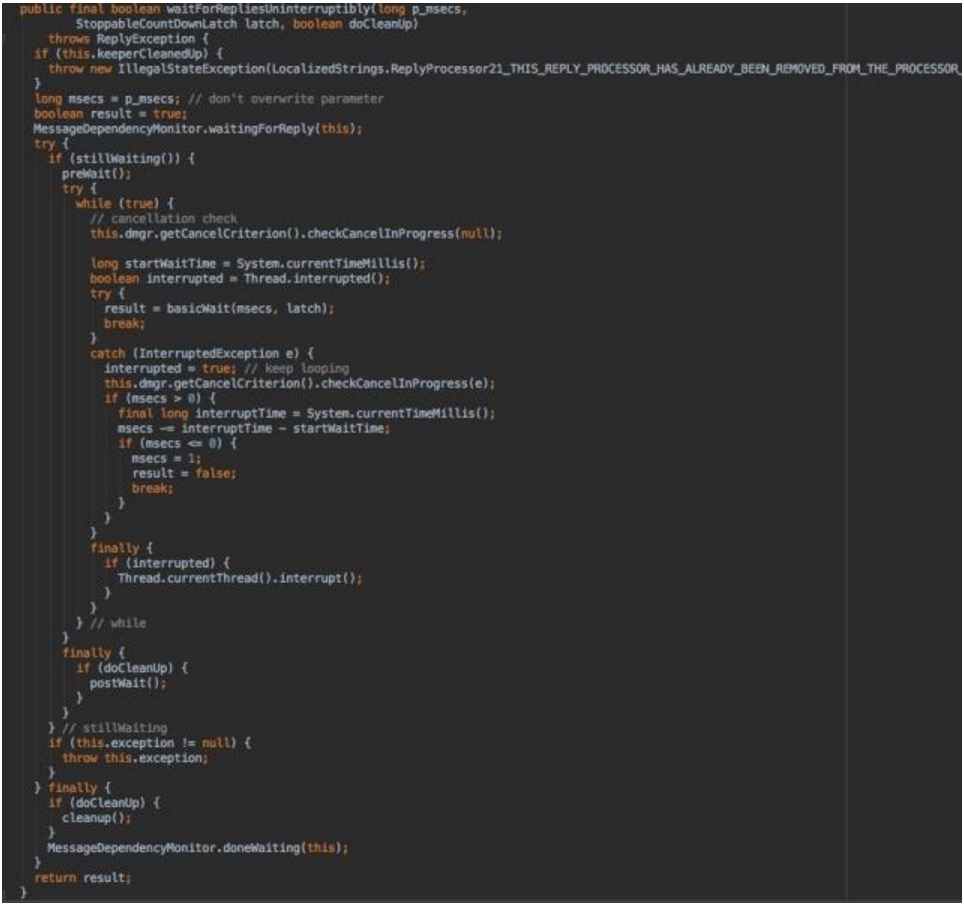
还是来个序列图吧,一图抵千言。
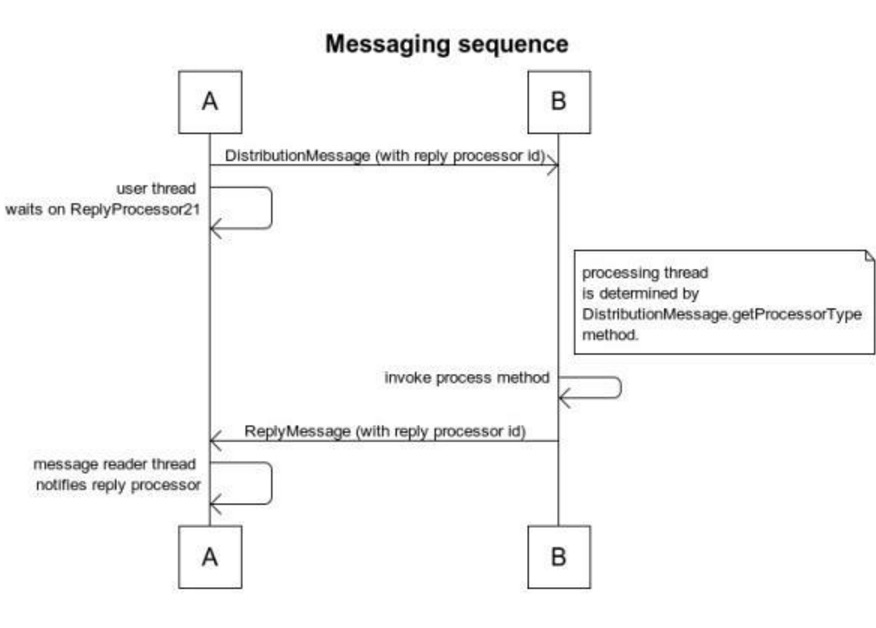
最后在远端则是通用的处理:

最后,远端返回replyMessage,并使用相同的unique id,sender收到消息后,找到ReplyProcessor,并wakeup
thread waitForRepliesUninterrupibly()。
4.2 Client / Server 通信
Client/Server通信机制与p2p略有不同。Server端封装了command,引入智囊团BridgeServerImpl,
AcceptorImpl, Client端则封装了AbstractOp。
Server: 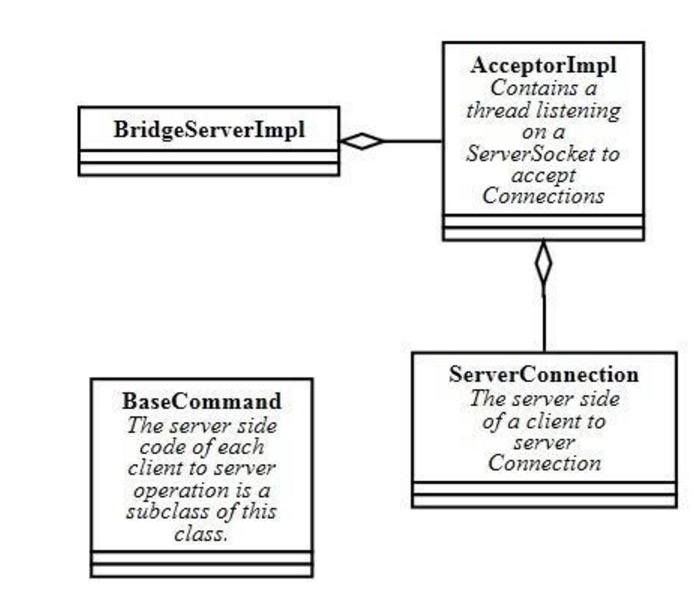
Acceptorimpl主要监听socket端口,接受客户端的链接。而其中又通过区分max-connections,
max-threads而分为使用dedicated thread还是selector模式的NIO处理。
Client:
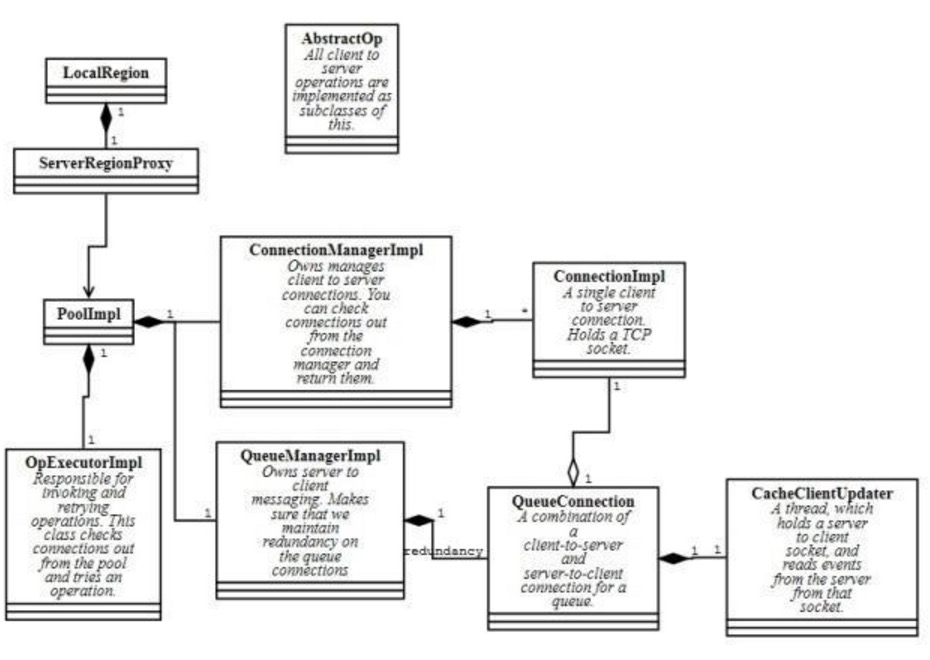
客户端则使用PoolImpl来管理连接connections,client region则持有serverRegionProxy以便实现调用。
值得注意的是,客户端可以通过subscribe events于特定/多个region或者通过内置的continuous
queries,这样当服务器端有数据更新则client端可以受到更新的通知event。
5. 总结
好吧,时间,篇幅受限,我们先到此。我们把核心的数据结构以及分布式通信的核心类大概介绍了一下,详细细节还需要仔细阅读源码。 |






