|
������ƪ����˵�����Ѿ����ϰ汾������
Ubuntu 16.04 �������ȫ�°�װ���ڰ�װ�� Ubuntu 16.04 LTS ֮��������������
15 ���¡��������Ǹռ��� Ubuntu ���е����û��������о�������û����㶼�ᷢ��һЩ�dz����õĵ����ͽ��顣
1.�˽�Ubuntu 16.04 LTS������
ע�������Ƕ��ڶ�͵�ѧϰ���ܽᣬ���ܴ��������������Ż��ɵ��۹⣬ͬʱ����д���ϣ����ָ����
ͬ��IO���첽IO������IO�ͷ�����IO�ֱ���ʲô��������ʲô���𣿲�ͬ�����ڲ�ͬ���������¸����Ĵ��Dz�ͬ�ġ���������һ�±��ĵ������ġ�
�������۵ı�����Linux�����µ�network IO��
һ ����˵��
�ڽ��н���֮ǰ������Ҫ˵���������
- �û��ռ���ں˿ռ�
- �����л�
- ���̵�����
- �ļ�������
- ���� I/O
�û��ռ����ں˿ռ�
���ڲ���ϵͳ���Dz�������洢������ô��32λ����ϵͳ���ԣ�����Ѱַ�ռ䣨����洢�ռ䣩Ϊ4G��2��32�η���������ϵͳ�ĺ������ںˣ���������ͨ��Ӧ�ó����Է����ܱ������ڴ�ռ䣬Ҳ�з��ʵײ�Ӳ���豸������Ȩ�ޡ�Ϊ�˱�֤�û����̲���ֱ�Ӳ����ںˣ�kernel������֤�ں˵İ�ȫ������ϵͳ������ռ仮��Ϊ�����֣�һ����Ϊ�ں˿ռ䣬һ����Ϊ�û��ռ䡣���linux����ϵͳ���ԣ�����ߵ�1G�ֽڣ��������ַ0xC0000000��0xFFFFFFFF�������ں�ʹ�ã���Ϊ�ں˿ռ䣬�����ϵ͵�3G�ֽڣ��������ַ0��00000000��0xBFFFFFFF��������������ʹ�ã���Ϊ�û��ռ䡣
�����л�
Ϊ�˿��ƽ��̵�ִ�У��ں˱�����������������CPU�����еĽ��̣����ָ���ǰ�����ij�����̵�ִ�С�������Ϊ����Ϊ�����л�����˿���˵���κν��̶����ڲ���ϵͳ�ں˵�֧�������еģ������ں˽�����صġ�
��һ�����̵�����ת����һ�����������У���������о���������Щ�仯��
1. ���洦���������ģ���������������������Ĵ�����
2. ����PCB��Ϣ��
3. �ѽ��̵�PCB������Ӧ�Ķ��У����������ij�¼������ȶ��С�
4. ѡ����һ������ִ�У���������PCB��
5. �����ڴ���������ݽṹ��
6. �ָ������������ġ� ע���ܶ���֮���Ǻܺ���Դ
���̵�����
����ִ�еĽ��̣������ڴ���ijЩ�¼�δ������������ϵͳ��Դʧ�ܡ��ȴ�ij�ֲ�������ɡ���������δ��������¹������ȣ�����ϵͳ�Զ�ִ������ԭ��(Block)��ʹ�Լ�������״̬��Ϊ����״̬���ɼ������̵������ǽ���������һ��������Ϊ��Ҳ���ֻ�д�������̬�Ľ��̣����CPU�����ſ��ܽ���תΪ����״̬�������̽�������״̬���Dz�ռ��CPU��Դ�ġ�
�ļ�������fd
�ļ���������File descriptor���Ǽ������ѧ�е�һ�������һ�����ڱ���ָ���ļ������õij����
�ļ�����������ʽ����һ���Ǹ�������ʵ���ϣ�����һ������ֵ��ָ���ں�Ϊÿһ��������ά���ĸý��̴��ļ��ļ�¼�����������һ�������ļ����ߴ���һ�����ļ�ʱ���ں�����̷���һ���ļ����������ڳ�������У�һЩ�漰�ײ�ij����д������Χ�����ļ�������չ���������ļ���������һ��������ֻ������UNIX��Linux�����IJ���ϵͳ��
���� I/O
���� I/O �ֱ������� I/O��������ļ�ϵͳ��Ĭ�� I/O �������ǻ��� I/O���� Linux �Ļ��� I/O �����У�����ϵͳ�Ὣ I/O �����ݻ������ļ�ϵͳ��ҳ���棨 page cache ���У�Ҳ����˵�����ݻ��ȱ�����������ϵͳ�ں˵Ļ������У�Ȼ��Ż�Ӳ���ϵͳ�ں˵Ļ�����������Ӧ�ó���ĵ�ַ�ռ䡣
���� I/O ��ȱ�㣺
�����ڴ����������Ҫ��Ӧ�ó����ַ�ռ���ں˽��ж�����ݿ�����������Щ���ݿ��������������� CPU �Լ��ڴ濪���Ƿdz���ġ�
�� IOģʽ
�ղ�˵�ˣ�����һ��IO���ʣ���read�����������ݻ��ȱ�����������ϵͳ�ں˵Ļ������У�Ȼ��Ż�Ӳ���ϵͳ�ں˵Ļ�����������Ӧ�ó���ĵ�ַ�ռ䡣����˵����һ��read��������ʱ�����ᾭ�������Σ�
1. �ȴ������� (Waiting for the data to be ready)
2. �����ݴ��ں˿����������� (Copying the data from the kernel to the process)
��ʽ��Ϊ�������Σ�linuxϵͳ������������������ģʽ�ķ����� - ���� I/O��blocking IO��
- ������ I/O��nonblocking IO��
- I/O ��·���ã� IO multiplexing��
- �ź����� I/O�� signal driven IO��
- �첽 I/O��asynchronous IO�� ע������signal driven IO��ʵ���в������ã���������ֻ�ἰʣ�µ�����IO Model��
���� I/O��blocking IO��
��linux�У�Ĭ����������е�socket����blocking��һ�����͵Ķ��������̴����������
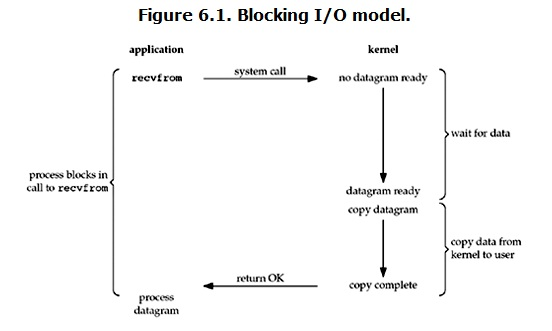
���û����̵�����recvfrom���ϵͳ���ã�kernel�Ϳ�ʼ��IO�ĵ�һ���Σ������ݣ���������IO��˵���ܶ�ʱ��������һ��ʼ��û�е�����磬��û���յ�һ��������UDP�������ʱ��kernel��Ҫ�ȴ��㹻�����ݵ����������������Ҫ�ȴ���Ҳ����˵���ݱ�����������ϵͳ�ں˵Ļ�����������Ҫһ�����̵ġ������û�������ߣ��������̻ᱻ��������Ȼ���ǽ����Լ�ѡ�������������kernelһֱ�ȵ����������ˣ����ͻὫ���ݴ�kernel�п������û��ڴ棬Ȼ��kernel���ؽ�����û����̲Ž��block��״̬����������������
���ԣ�blocking IO���ص������IOִ�е������ζ���block�ˡ�
������ I/O��nonblocking IO��
linux�£�����ͨ������socketʹ���Ϊnon-blocking������һ��non-blocking socketִ�ж�����ʱ��������������ӣ�
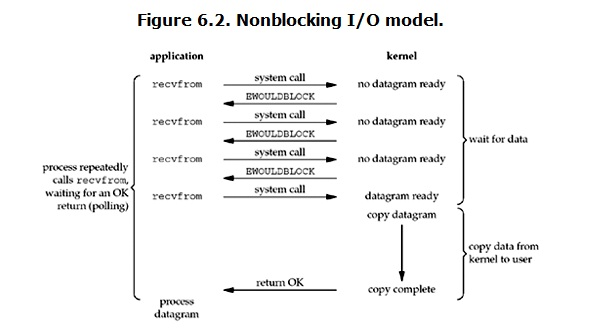
���û����̷���read����ʱ�����kernel�е����ݻ�û�����ã���ô��������block�û����̣��������̷���һ��error�����û����̽ǶȽ� ��������һ��read����������Ҫ�ȴ����������Ͼ͵õ���һ��������û������жϽ����һ��errorʱ������֪�����ݻ�û�����ã������������ٴη���read������һ��kernel�е����������ˣ��������ٴ��յ����û����̵�system call����ô�����Ͼͽ����ݿ��������û��ڴ棬Ȼ�ء�
���ԣ�nonblocking IO���ص����û�������Ҫ���ϵ�����ѯ��kernel���ݺ���û�С�
I/O ��·���ã� IO multiplexing��
IO multiplexing��������˵��select��poll��epoll����Щ�ط�Ҳ������IO��ʽΪevent driven IO��select/epoll�ĺô������ڵ���process�Ϳ���ͬʱ��������������ӵ�IO�����Ļ���ԭ������select��poll��epoll���function��ϵ���ѯ�����������socket����ij��socket�����ݵ����ˣ���֪ͨ�û����̡�
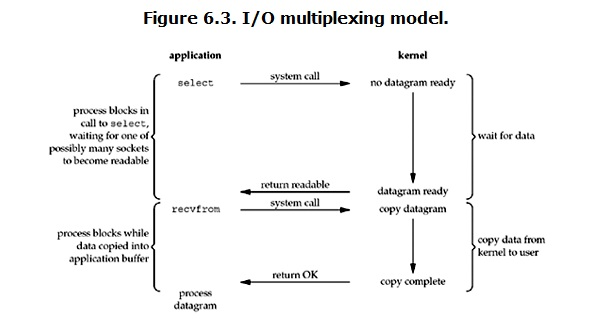
���û����̵�����select����ô�������̻ᱻblock����ͬʱ��kernel�ᡰ���ӡ�����select�����socket�����κ�һ��socket�е����������ˣ�select�ͻ᷵�ء����ʱ���û������ٵ���read�����������ݴ�kernel�������û����̡�
���ԣ�I/O ��·���õ��ص���ͨ��һ�ֻ���һ��������ͬʱ�ȴ�����ļ�������������Щ�ļ������������������������е�����һ�����������״̬��select()�����Ϳ��Է��ء�
���ͼ��blocking IO��ͼ��ʵ��û��̫��IJ�ͬ����ʵ�ϣ�������һЩ����Ϊ������Ҫʹ������system call (select �� recvfrom)����blocking IOֻ������һ��system call (recvfrom)�����ǣ���select����������������ͬʱ�������connection�� ���ԣ�������������������ǺܸߵĻ���ʹ��select/epoll��web server��һ����ʹ��multi-threading + blocking IO��web server���ܸ��ã������ӳٻ�����select/epoll�����Ʋ����Ƕ��ڵ��������ܴ����ø��죬���������ܴ�����������ӡ���
��IO multiplexing Model�У�ʵ���У�����ÿһ��socket��һ�㶼���ó�Ϊnon-blocking�����ǣ�����ͼ��ʾ�������û���process��ʵ��һֱ��block�ġ�ֻ����process�DZ�select�������block�������DZ�socket IO��block��
�첽 I/O��asynchronous IO��
inux�µ�asynchronous IO��ʵ�õú��١��ȿ�һ���������̣�
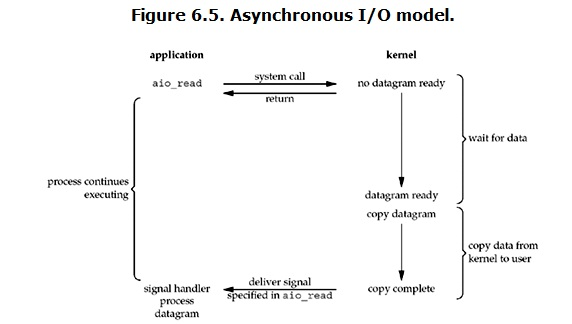
�û����̷���read����֮�����̾Ϳ��Կ�ʼȥ���������¡�����һ���棬��kernel�ĽǶȣ������ܵ�һ��asynchronous read֮�������������̷��أ����Բ�����û����̲����κ�block��Ȼ��kernel��ȴ���������ɣ�Ȼ�����ݿ������û��ڴ棬����һ�ж����֮��kernel����û����̷���һ��signal��������read��������ˡ�
�ܽ�
blocking��non-blocking������
����blocking IO��һֱblockס��Ӧ�Ľ���ֱ��������ɣ���non-blocking IO��kernel�������ݵ�����»����̷��ء�
synchronous IO��asynchronous IO������
��˵��synchronous IO��asynchronous IO������֮ǰ����Ҫ�ȸ������ߵĶ��塣POSIX�Ķ����������ӵģ�
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
- An asynchronous I/O operation does not cause the requesting process to be blocked; ���ߵ����������synchronous IO����IO operation����ʱ��Ὣprocess����������������壬֮ǰ������blocking IO��non-blocking IO��IO multiplexing������synchronous IO��
���˻�˵��non-blocking IO��û�б�block���������и��dz����ƻ����ĵط�����������ָ�ġ�IO operation����ָ��ʵ��IO���������������е�recvfrom���system call��non-blocking IO��ִ��recvfrom���system call��ʱ�����kernel������û�����ã���ʱ��block���̡����ǣ���kernel���������õ�ʱ��recvfrom�Ὣ���ݴ�kernel�������û��ڴ��У����ʱ������DZ�block�ˣ������ʱ���ڣ������DZ�block�ġ�
��asynchronous IO��һ���������̷���IO ����֮��ֱ�ӷ�����Ҳ�������ˣ�ֱ��kernel����һ���źţ����߽���˵IO��ɡ��������������У�������ȫû�б�block��
����IO Model�ıȽ���ͼ��ʾ��

ͨ�������ͼƬ�����Է���non-blocking IO��asynchronous IO�������Ǻ����Եġ���non-blocking IO�У���Ȼ���̴�ʱ�䶼���ᱻblock����������ȻҪ�����ȥ������check�����ҵ�����������Ժ�Ҳ��Ҫ�����������ٴε���recvfrom�������ݿ������û��ڴ档��asynchronous IO����ȫ��ͬ�����������û����̽�����IO�������������ˣ�kernel����ɣ�Ȼ������������ź�֪ͨ���ڴ��ڼ䣬�û����̲���Ҫȥ���IO������״̬��Ҳ����Ҫ������ȥ�������ݡ�
�� I/O ��·����֮select��poll��epoll���
select��poll��epoll����IO��·���õĻ��ơ�I/O��·���þ���ͨ��һ�ֻ��ƣ�һ�����̿��Լ��Ӷ����������һ��ij��������������һ���Ƕ���������д���������ܹ�֪ͨ���������Ӧ�Ķ�д��������select��poll��epoll�����϶���ͬ��I/O����Ϊ���Ƕ���Ҫ�ڶ�д�¼��������Լ�������ж�д��Ҳ����˵�����д�����������ģ����첽I/O�������Լ�������ж�д���첽I/O��ʵ�ֻḺ������ݴ��ں˿������û��ռ䡣��������£�
select
int select (int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); |
select �������ӵ��ļ���������3�࣬�ֱ���writefds��readfds����exceptfds�����ú�select������������ֱ���������������������� �ɶ�����д��������except�������߳�ʱ��timeoutָ���ȴ�ʱ�䣬�������������Ϊnull���ɣ����������ء���select�������غ��� ͨ������fdset�����ҵ���������������
selectĿǰ���������е�ƽ̨��֧�֣������ÿ�ƽ̨֧��Ҳ������һ���ŵ㡣select��һ ��ȱ�����ڵ��������ܹ����ӵ��ļ�����������������������ƣ���Linux��һ��Ϊ1024������ͨ���ĺ궨���������±����ں˵ķ�ʽ������һ���ƣ��� ������Ҳ�����Ч�ʵĽ��͡�
poll
int poll (struct pollfd *fds, unsigned int nfds, int timeout); |
��ͬ��selectʹ������λͼ����ʾ����fdset�ķ�ʽ��pollʹ��һ�� pollfd��ָ��ʵ�֡�
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events to watch */
short revents; /* returned events witnessed */
}; |
pollfd�ṹ������Ҫ���ӵ�event�ͷ�����event������ʹ��select������-ֵ�����ݵķ�ʽ��ͬʱ��pollfd��û������������ƣ������������������Ҳ�ǻ��½����� ��select����һ����poll���غ���Ҫ��ѯpollfd����ȡ��������������
�����濴��select��poll����Ҫ�ڷ��غ�ͨ�������ļ�����������ȡ�Ѿ�������socket����ʵ�ϣ�ͬʱ���ӵĴ����ͻ�����һʱ�̿���ֻ�к��ٵĴ��ھ���״̬��������ż��ӵ���������������������Ч��Ҳ�������½���
epoll
epoll����2.6�ں�������ģ���֮ǰ��select��poll����ǿ�汾�������select��poll��˵��epoll������û�����������ơ�epollʹ��һ���ļ�������������������������û���ϵ���ļ����������¼���ŵ��ں˵�һ���¼����У��������û��ռ���ں˿ռ��copyֻ��һ�Ρ�
һ epoll��������
epoll����������Ҫ�����ӿڣ��ֱ����£�
int epoll_create(int size)��//����һ��epoll�ľ����size���������ں������������Ŀһ���ж��
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)��
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
|
1. int epoll_create(int size);
����һ��epoll�ľ����size���������ں������������Ŀһ���ж�����������ͬ��select()�еĵ�һ��������������������fd+1��ֵ������size������������epoll���ܼ�������������������ֻ�Ƕ��ں˳�ʼ�����ڲ����ݽṹ��һ�����顣
��������epoll��������ͻ�ռ��һ��fdֵ����linux������鿴/proc/����id/fd/�����ܹ��������fd�ģ�������ʹ����epoll�������close()�رգ�������ܵ���fd���ľ���
2. int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)��
�����Ƕ�ָ��������fdִ��op������
- epfd����epoll_create()�ķ���ֵ��
- op����ʾop������������������ʾ������EPOLL_CTL_ADD��ɾ��EPOLL_CTL_DEL����EPOLL_CTL_MOD���ֱ����ӡ�ɾ�����Ķ�fd�ļ����¼���
- fd������Ҫ������fd���ļ���������
- epoll_event���Ǹ����ں���Ҫ����ʲô�£�struct epoll_event�ṹ���£�
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
|
//events���������¼�����ļ��ϣ�
EPOLLIN ����ʾ��Ӧ���ļ����������Զ��������Զ�SOCKET�����رգ���
EPOLLOUT����ʾ��Ӧ���ļ�����������д��
EPOLLPRI����ʾ��Ӧ���ļ��������н��������ݿɶ�������Ӧ�ñ�ʾ�д������ݵ�������
EPOLLERR����ʾ��Ӧ���ļ���������������
EPOLLHUP����ʾ��Ӧ���ļ����������Ҷϣ�
EPOLLET�� ��EPOLL��Ϊ��Ե����(Edge Triggered)ģʽ�����������ˮƽ����(Level Triggered)��˵�ġ�
EPOLLONESHOT��ֻ����һ���¼���������������¼�֮���������Ҫ�����������socket�Ļ�����Ҫ�ٴΰ����socket���뵽EPOLL������
3. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
�ȴ�epfd�ϵ�io�¼�������maxevents���¼���
����events�������ں˵õ��¼��ļ��ϣ�maxevents��֮�ں����events�ж�����maxevents��ֵ���ܴ��ڴ���epoll_create()ʱ��size������timeout�dz�ʱʱ�䣨���룬0���������أ�-1����ȷ����Ҳ��˵��˵���������������ú���������Ҫ�������¼���Ŀ���緵��0��ʾ�ѳ�ʱ��
�� ����ģʽ
epoll���ļ��������IJ���������ģʽ��LT��level trigger����ET��edge trigger����LTģʽ��Ĭ��ģʽ��LTģʽ��ETģʽ���������£�
LTģʽ����epoll_wait���������¼������������¼�֪ͨӦ�ó���Ӧ�ó�����Բ������������¼����´ε���epoll_waitʱ�����ٴ���ӦӦ�ó���֪ͨ���¼���
ETģʽ����epoll_wait���������¼������������¼�֪ͨӦ�ó���Ӧ�ó�����������������¼���������������´ε���epoll_waitʱ�������ٴ���ӦӦ�ó���֪ͨ���¼���
1. LTģʽ
LT(level triggered)��ȱʡ�Ĺ�����ʽ������ͬʱ֧��block��no-block socket.�����������У��ں˸�����һ���ļ��������Ƿ�����ˣ�Ȼ������Զ����������fd����IO����������㲻���κβ������ں˻��ǻ����֪ͨ��ġ�
2. ETģʽ
ET(edge-triggered)�Ǹ��ٹ�����ʽ��ֻ֧��no-block socket��������ģʽ�£�����������δ������Ϊ����ʱ���ں�ͨ��epoll�����㡣Ȼ�����������֪���ļ��������Ѿ����������Ҳ�����Ϊ�Ǹ��ļ�������������ľ���֪ͨ��ֱ��������ijЩ���������Ǹ��ļ�����������Ϊ����״̬��(���磬���ڷ��ͣ����ջ��߽��������߷��ͽ��յ���������һ����ʱ������һ��EWOULDBLOCK ����������ע�⣬���һֱ�������fd��IO����(�Ӷ��������ٴα��δ����)���ں˲��ᷢ�����֪ͨ(only once) ETģʽ�ںܴ�̶��ϼ�����epoll�¼����ظ������Ĵ��������Ч��Ҫ��LTģʽ�ߡ�epoll������ETģʽ��ʱ����ʹ�÷������ӿڣ��Ա�������һ���ļ������������/����д�����Ѵ�������ļ������������������
3. �ܽ�
����������һ�����ӣ�
1. �����Ѿ���һ�������ӹܵ��ж�ȡ���ݵ��ļ����(RFD)���ӵ�epoll������
2. ���ʱ��ӹܵ�����һ�˱�д����2KB������
3. ����epoll_wait(2)���������᷵��RFD��˵�����Ѿ����ö�ȡ����
4. Ȼ�����Ƕ�ȡ��1KB������
5. ����epoll_wait(2)����
LTģʽ��
�����LTģʽ����ô�ڵ�5������epoll_wait(2)֮����Ȼ���ܵ�֪ͨ��
ETģʽ��
��������ڵ�1����RFD���ӵ�epoll��������ʱ��ʹ����EPOLLET��־����ô�ڵ�5������epoll_wait(2)֮���п��ܻ������Ϊʣ������ݻ��������ļ������뻺�����ڣ��������ݷ����˻��ڵȴ�һ������Ѿ��������ݵķ�����Ϣ��ֻ���ڼ��ӵ��ļ�����Ϸ�����ij���¼���ʱ�� ET ����ģʽ�Ż�㱨�¼�������ڵ�5����ʱ�����߿��ܻ�����ȴ����ڴ������ļ����뻺�����ڵ�ʣ�����ݡ�
��ʹ��epoll��ETģ��������ʱ����������һ��EPOLLIN�¼���
�����ݵ�ʱ����Ҫ���ǵ��ǵ�recv()���صĴ�С�����������Ĵ�С����ô���п����ǻ�������������δ���꣬Ҳ��ζ�Ÿô��¼���û�д����꣬���Ի���Ҫ�ٴζ�ȡ��
while(rs){
buflen = recv(activeevents[i].data.fd, buf, sizeof(buf), 0);
if(buflen < 0){
// �����Ƿ�������ģʽ,���Ե�errnoΪEAGAINʱ,��ʾ��ǰ�������������ݿɶ�
// ������͵����Ǹô��¼��Ѵ�����.
if(errno == EAGAIN){
break;
}
else{
return;
}
}
else if(buflen == 0){
// �����ʾ�Զ˵�socket�������ر�.
} if(buflen == sizeof(buf){
rs = 1; // ��Ҫ�ٴζ�ȡ
}
else{
rs = 0;
}
}
|
Linux�е�EAGAIN���� Linux�����¿��������������ܶ����(����errno)������EAGAIN�����бȽϳ�����һ������(�������ڷ�����������)��
������������������ʾ����һ�Ρ�������������ڵ�Ӧ�ó������һЩ������(non-blocking)����(���ļ���socket)��ʱ��
���磬�� O_NONBLOCK�ı�־���ļ�/socket/FIFO�������������read������û�����ݿɶ�����ʱ�������������ȴ��������������أ�read�����᷵��һ������EAGAIN����ʾ���Ӧ�ó�������û�����ݿɶ����Ժ����ԡ�
�����磬��һ��ϵͳ����(����fork)��Ϊû���㹻����Դ(���������ڴ�)��ִ��ʧ�ܣ�����EAGAIN��ʾ���ٵ���һ��(Ҳ���´ξ��ܳɹ�)��
�� ������ʾ
������һ�β������Ĵ����Ҹ�ʽ���ԣ����ڱ�������Ĺ��̣�ȥ����һЩģ����롣 #define IPADDRESS "127.0.0.1"
#define PORT 8787
#define MAXSIZE 1024
#define LISTENQ 5
#define FDSIZE 1000
#define EPOLLEVENTS 100
listenfd = socket_bind(IPADDRESS,PORT);
struct epoll_event events[EPOLLEVENTS];
//����һ��������
epollfd = epoll_create(FDSIZE);
//���Ӽ����������¼�
add_event(epollfd,listenfd,EPOLLIN);
//ѭ���ȴ�
for ( ; ; ){
//�ú��������Ѿ����õ��������¼���Ŀ
ret = epoll_wait(epollfd,events,EPOLLEVENTS,-1);
//�������յ�������
handle_events(epollfd,events,ret,listenfd,buf);
}
//�¼���������
static void handle_events(int epollfd,struct epoll_event *events,int num,int listenfd,char *buf)
{
int i;
int fd;
//���б���;����ֻҪ�����Ѿ����õ�io�¼���num�����ǵ���epoll_createʱ��FDSIZE��
for (i = 0;i < num;i++)
{
fd = events[i].data.fd;
//���������������ͺ��¼����ͽ��д���
if ((fd == listenfd) &&(events[i].events & EPOLLIN))
handle_accpet(epollfd,listenfd);
else if (events[i].events & EPOLLIN)
do_read(epollfd,fd,buf);
else if (events[i].events & EPOLLOUT)
do_write(epollfd,fd,buf);
}
}
//�����¼�
static void add_event(int epollfd,int fd,int state){
struct epoll_event ev;
ev.events = state;
ev.data.fd = fd;
epoll_ctl(epollfd,EPOLL_CTL_ADD,fd,&ev);
}
//�������յ�������
static void handle_accpet(int epollfd,int listenfd){
int clifd;
struct sockaddr_in cliaddr;
socklen_t cliaddrlen;
clifd = accept(listenfd,(struct sockaddr*)&cliaddr,&cliaddrlen);
if (clifd == -1)
perror("accpet error:");
else {
printf("accept a new client: %s:%d\n",
inet_ntoa(cliaddr.sin_addr),cliaddr.sin_port);
//����һ���ͻ����������¼�
add_event(epollfd,clifd,EPOLLIN);
}
}
//������
static void do_read(int epollfd,int fd,char *buf){
int nread;
nread = read(fd,buf,MAXSIZE);
if (nread == -1) {
perror("read error:");
close(fd); //��סclose fd
delete_event(epollfd,fd,EPOLLIN); //ɾ������
}
else if (nread == 0) {
fprintf(stderr,"client close.\n");
close(fd); //��סclose fd
delete_event(epollfd,fd,EPOLLIN); //ɾ������
}
else {
printf("read message is : %s",buf);
//����������Ӧ���¼����ɶ���Ϊд
modify_event(epollfd,fd,EPOLLOUT);
}
}
//���
static void do_write(int epollfd,int fd,char *buf) {
int nwrite;
nwrite = write(fd,buf,strlen(buf));
if (nwrite == -1){
perror("write error:");
close(fd); //��סclose fd
delete_event(epollfd,fd,EPOLLOUT); //ɾ������
}else{
modify_event(epollfd,fd,EPOLLIN);
}
memset(buf,0,MAXSIZE);
}
//ɾ���¼�
static void delete_event(int epollfd,int fd,int state) {
struct epoll_event ev;
ev.events = state;
ev.data.fd = fd;
epoll_ctl(epollfd,EPOLL_CTL_DEL,fd,&ev);
}
//���¼�
static void modify_event(int epollfd,int fd,int state){
struct epoll_event ev;
ev.events = state;
ev.data.fd = fd;
epoll_ctl(epollfd,EPOLL_CTL_MOD,fd,&ev);
}
//ע������һ���Ҿ�ʡ��
|
�� epoll�ܽ�
�� select/poll�У�����ֻ���ڵ���һ���ķ������ں˲Ŷ����м��ӵ��ļ�����������ɨ�裬��epoll����ͨ��epoll_ctl()��ע��һ ���ļ���������һ������ij���ļ�����������ʱ���ں˻��������callback�Ļص����ƣ�Ѹ�ټ�������ļ��������������̵���epoll_wait() ʱ��õ�֪ͨ��(�˴�ȥ���˱����ļ�������������ͨ�������ص��ĵĻ��ơ�������epoll���������ڡ�)
epoll���ŵ���Ҫ��һ�¼������棺 1. ���ӵ������������������ƣ�����֧�ֵ�FD�����������Դ��ļ�����Ŀ���������һ��Զ����2048,�ٸ�����,��1GB�ڴ�Ļ����ϴ�Լ��10���� �ң�������Ŀ����cat /proc/sys/fs/file-max�쿴,һ����˵�����Ŀ��ϵͳ�ڴ��ϵ�ܴ�select�����ȱ����ǽ��̴�fd�����������Ƶġ���� �����������Ƚϴ�ķ�������˵�����������㡣��ȻҲ����ѡ�����̵Ľ������( Apache��������ʵ�ֵ�)��������Ȼlinux���洴�����̵Ĵ��۱Ƚ�С�����Ծ��Dz��ɺ��ӵģ����Ͻ��̼�����ͬ��Զ�Ȳ����̼߳�ͬ���ĸ�Ч������Ҳ����һ�������ķ�����
2.IO��Ч�ʲ������ż���fd���������������½���epoll��ͬ��select��poll��ѯ�ķ�ʽ������ͨ��ÿ��fd����Ļص�������ʵ�ֵ�
��ֻ�о�����fd�Ż�ִ�лص����� |





