| 最大化
AIX 上的 Java 性能,第 1 部分: 基础
这个由五个部分组成的系列提供了若干技巧和技术,这些技巧和技术通常用于优化
Java? 应用程序,以便在 AIX? 上实现最佳的性能。其中还提供了有关每个技巧的适用性讨论。使用这些技巧,您应该能够快速优化
Java 环境,以适合应用程序的需要。
引言
存在若干可用于运行 AIX 的 IBM eServer pSeries 平台的性能优化工具。运行在 AIX
上 IBM 的 Java 实现还包含若干调整,其中大多数调整都有相当清楚的文档说明。尽管如此,IBM 支持团队仍然遇到了多种情况,其中性能优化工作受到这两组工具之间的分离影响。
本系列文章向您展示了如何结合使用 AIX 和 Java 工具,以最大化基于 AIX 的 Java 应用程序的性能。第
1 部分(“基础”)讨论了实现成功的优化工作的先决条件,并概述了可用于协助此类工作的工具。强烈建议您完整阅读此文,因为它可以在以后为您减少大量的麻烦。
本系列中的接下来三篇文章主要集中于性能优化的特定方面。第 2 部分(“速度需求”)讨论了如何改进执行速度和吞吐量。第
3 部分(“更多就是更好”)着眼于大小调整工作,并阐述了如何能够有利地操作内存。第 4 部分(“监视流量”)研究了作为性能优化目标的网络和磁盘
I/O。编写这三篇文章是为了便于快速查找,因此欢迎您将这些文章作为快速参考,而不是从头到尾地阅读。其中每篇文章还讨论了我们认为在实际工作中非常有用的一般技巧和调整。
请注意,本文仅限于 J2SE 信息;有关特定于 J2EE 的优化,请参考 J2EE 组件的配套文档。如果您在使用绑定
Java 的应用程序,应该参考应用程序文档以确保所做的任何更改不会影响应用程序功能。
开始之前
任何类型的优化工作都必须考虑到若干事项,其中有些事项在性质上是对立的。尽管每一项此类工作都是独特的,但是存在一些通用并且几乎始终有帮助的步骤。下面是在考虑性能优化前需要准备好的事项的简要清单。如果存在任何不能在优化开始之前完成的步骤,就应该存在这样做的充分理由。
迁移到最新版本
有关 AIX 上的最新可用 Java 版本列表,请参阅 IBM developer kits for AIX,
Java technology edition。较新版本的 Java 包含通常具有重要意义的性能增强。例如,与以前版本相比,Java
1.4 具有强大得多的垃圾收集实现。
即使受到使用特定 Java 版本要求的约束,也应该迁移到最新的可用服务更新(Service
Refresh,SR)。这是从功能和性能修复中获益的快速方法。此外,如果遇到任何类型的问题,您将需要迁移到最新的
SR 才能获得支持。对最新 SR 的升级的另一个示例是在 Java 1.3.1 已发布之后添加的诸如 -Xdisableexplicitgc
等开关,因此除非您迁移到特定的版本,否则无法使用这些开关。
本文着重以 Java 1.4 和 Java 1.3.1 环境为例,因为较旧的版本要么已经结束服务,要么很快就要结束服务了。由于同样的原因,我们将以
AIX 5L(明确地说是 AIX 5.1 和 AIX 5.2)环境为例,而不是 AIX 4.3.3 或更低版本。
如果应用程序的配置可行,您可能还希望考虑迁移到 64 位版本的 Java。这一主题超出了本系列的范围;除非特别说明,否则我们将把讨论限制到
32 位 Java。请继续关注 ESDD 上不久将推出的一篇有关 64 位 Java 的文章。
在优化之前修复问题
如果遇到诸如崩溃、内存泄漏或应用程序挂起等问题,那么您还没有为优化工作做好准备。这包括您禁用了 Just-In-Time
(JIT) 编译器的部分或全部的情况。如果环境中指定了 JAVA_COMPILER 或 JITC_COMPILEOPT
环境变量,则应用程序可能已经遭受到性能损失(请注意,您也可以使用 JITC_COMPILEOPT 来优化应用程序性能。在开始性能优化之前,您应该已经修复了问题,无论是通过升级到最新的服务刷新,还是通过与
IBM Java Service 团队接洽。IBM developer kits - diagnosis
documentation 上的 Java Diagnostics Guide 提供了有关如何调试 IBM
Java 遇到的任何问题的出色建议。
验证您的环境
您通常不需要担心任何特定的环境设置(前一部分中提到的 JIT 设置,以及用于堆大小修改所需要的 LDR_CNTRL
设置,是一些值得注意的例外),因为 Java 启动程序会自己设置环境。但是,如果应用程序使用 JNI,则必须为
JNI 组件设置正确的环境。每个 Java 版本配套的 SDK 指南或自述文件都提供了需要设置为特定值的变量列表,这其中某个变量不匹配会导致性能和(或)功能问题。
您希望优化的是否为 Java?
虽然研究各个技巧并调整 Java 应用程序环境是个不错的主意,但是只有在消除其他瓶颈之后才能看到性能影响。例如,如果
Java 没有出现在消耗内存最多的前 5 个进程中,如果系统上的其他进程的 CPU 使用率保持在 100%,您对
Java 做出的更改很可能不会起作用。
它能运行得更快吗?
性能 这个措词是多方面的,每个角落都需要做出权衡决策。要从任何此类决策中排除猜测成分,必须充分了解预期行为,从而为您提供支持。您还必须拥有任由自己支配的良好定义的机制来测定所做的任何更改的影响。无论优化工作的规模如何,这里描述的步骤都将使优化工作更加高效。
了解您的应用程序特征
在开始优化应用程序之前,必须了解应用程序预期将如何工作。除了诸如客户机-服务器拓扑或图形用户界面(Graphical
User Interface,GUI)应用程序等广义分类以外,您还应该了解应用程序代码在内部是如何工作以实现其尝试完成的任务的。举例来说,我们可以向您演示如何计算某次特定运行期间使用的
CPU 百分比值,但是对观察到的数字的解释则是每个应用程序所特有的。您应该能够区分“正常”和“异常”的观察行为,以便决定要优化什么对象。
请注意,您不需要访问 Java 源代码即可执行这些文档中描述的大多数优化。这并不意味着您应该将应用程序视为黑盒。您的应用程序是设计为快速完成工作并退出,还是继续运行很长一段时间(例如作为服务器)?它是在启动期间大量地分配内存,还是在启动时仅占用少量内存空间?它是否执行大量的回收,或者它是否占有已分配的对象?诸如此类的问题将决定您的优化工作。
选择优秀的测试套件
我们强烈建议准备某种方法来量化您已实现的收益。使用这其中任何工具的先决条件是存在一个可重复、可验证和可靠的测试套件,此套件允许您检查尽可能多的应用程序功能。记住,在某些情况下,调整运行时行为的一个方面可能会对另一部分造成负面影响。只有优秀的测试套件才使您能够了解运行时性能和内存占用空间(举例而言)之间的权衡。
建立基准
在对系统做出任何更改之前,应该花时间建立清楚和明确的方法来测定所做的任何更改的效果。此方法可以像使用“time”命令一样简单,或者更加精细,例如使用模拟一千个用户的脚本来测量响应时间。无论是哪种方法,用于测定性能调整效果的工作负载都应该足够多样化,以检查尽可能多的不同场景。除了任何类型的外部度量之外,我们建议使用
AIX 性能 PMR 数据收集工具 (PerfPMR)。
PerfPMR 工具实际上是 AIX 和其他服务团队使用的一个数据收集工具。它创建指定时间段内的系统快照,从而提供系统在该时间段内“做”什么的清楚指示。与单独运行每个
AIX 工具不同,您可以直接要求 PerfPMR 为您运行那些工具。由于创建这些快照的方法经过了良好的定义,您可以在优化周期中的不同时点创建多个快照,以跟踪优化进度。请注意,我们在本系列中提供了特定工具而不是
PerfPMR 的示例。
用于完成优化的工具
存在一组丰富的工具可用于监视 AIX 系统的所有方面。表 1 提供了各个工具的简述。这些工具可用于仅监视单个进程或监视整个系统。AIX
5L Performance Tools Handbook 和 Understanding IBM eServer
pSeries Performance and Sizing 及其参考资料是了解下面提到的各个工具的很好起点。
表 1:AIX 上的系统监视工具
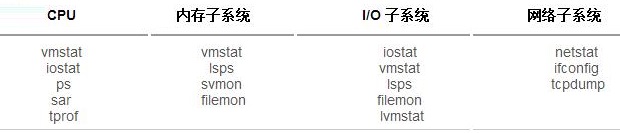
后续的文章将对这其中每个工具进行简要介绍。还有一些工具无法归入某个特定类别,下面将对它们进行简要的讨论。
topas
topas 是一个有用的图形界面,可以为您提供系统上正在发生的事情的即时结果。当您不带任何命令行参数运行此工具时,屏幕将显示如下内容:
Topas Monitor for host: aix4prt EVENTS/QUEUES FILE/TTYMon Apr 16 16:16:50 2001 Interval: 2 Cswitch 5984 Readch 4864 Syscall 15776 Writech 34280 Kernel 63.1 |################## | Reads 8 Rawin 0 User 36.8 |########## | Writes 2469 Ttyout 0 Wait 0.0 | | Forks 0 Igets 0 Idle 0.0 | | Execs 0 Namei 4 Runqueue 11.5 Dirblk 0 Network KBPS I-Pack O-Pack KB-In KB-Out Waitqueue 0.0 lo0 213.9 2154.2 2153.7 107.0 106.9 tr0 34.7 16.9 34.4 0.9 33.8 PAGING MEMORY Faults 3862 Real,MB 1023 Disk Busy% KBPS TPS KB-Read KB-Writ Steals 1580 % Comp 27.0 hdisk0 0.0 0.0 0.0 0.0 0.0 PgspIn 0 % Noncomp 73.9 PgspOut 0 % Client 0.5 Name PID CPU% PgSp Owner PageIn 0 java 16684 83.6 35.1 root PageOut 0 PAGING SPACE java 12192 12.7 86.2 root Sios 0 Size,MB 512 lrud 1032 2.7 0.0 root % Used 1.2 aixterm 19502 0.5 0.7 root NFS (calls/sec) % Free 98.7 topas 6908 0.5 0.8 root ServerV2 0 ksh 18148 0.0 0.7 root ClientV2 0 Press: gil 1806 0.0 0.0 root ServerV3 0 "h" for help |
左下侧的信息显示了最活跃的进程;这里,Java 消耗了 83.6% 的 CPU。中间的右侧区域显示了总的物理内存(在此例中为
1 GB)和分页空间 (512 MB),以及正在使用的容量。因此您可以在单个屏幕中获得有关系统正在做什么的清楚概况,然后您可以基于其中显示的信息选择各个要集中的方面。
trace
trace 捕获带时间戳的系统事件的顺序流。trace 是用于观察系统和应用程序执行的宝贵工具。许多其他工具提供了诸如
CPU 和 I/O 利用率等抽象信息,而 trace 工具则帮助详述了有关事件在何处发生、哪个进程对事件负责、事件何时发生以及它们如何影响系统的信息。两个能够从
trace 提取信息的后期处理工具为 utld(在 AIX 4 中)和 curt (在 AIX 5 中)。这些工具提供了有关
CPU 利用率和进程/线程活动的统计信息。第三个后期处理工具是 splat,此工具表示“简单性能锁分析工具”(Simple
Performance Lock Analysis Tool)。此工具用于分析简单锁在 AIX 内核和内核扩展中的锁活动。
nmon
nmon 是一个免费的软件工具,并提供许多与 topas 相同的信息,不过是将信息保存为 Lotus 123
和 Excel 格式的文件。此工具的下载站点为 http://www.ibm.com/developerworks/eserver/articles/analyze_aix/。所收集的信息包括
CPU、磁盘、网络、适配器统计、内核计数器、内存和“最忙”进程信息。
平台无关的 Java 性能监视
Java 虚拟机监视程序接口(Java Virtual Machine Profiling Interface,JVMPI)受
IBM Java 支持,并且对于性能监视的所有方面都非常有用。您可以使用第三方概要或使用 IBM Java
概要接口,以执行 Java 性能监视。有关更多详细信息,请参阅位于 IBM developer kits
- diagnosis documentation 的 Java Diagnostics Guide 中的
-Xhprof。有关特定于 AIX 上的概要分析的信息,您还应该参阅位于 IBM developer kits
for AIX, Java technology edition 的自述文件/SDK 指南。例如,除非您设置了环境变量
AIXTHREAD_ENRUSG=ON,否则在概要分析期间不会报告线程 CPU 时间。所有 Java 版本的自述文件/SDK
指南都对此作了文档记录。
也许最常用类型的 Java 性能监视是 verbosegc 日志。有关如何分析 verbosegc 日志的更多详细信息可以在
Fine-tuning Java garbage collection performance 中找到。虽然启用
verbosegc 跟踪的确会导致较小的性能影响,但是所获得的用于事后分析检查的优点无疑会胜过性能损失。Fine-tuning
Java garbage collection performance 提到了如何基于 verbosegc
输出执行优化。
AIX 上的缺省 Java 行为
本部分描述各个设置的当前现状。这些设置在大多数情况下将会随时间推移而更改。SDK 的配套自述文件和 SDK
指南始终是此类设置的最新参考资料。
Java 使用了下列环境设置:
AIXTHREAD_SCOPE=S
此设置用于确保每个 Java 线程一对一地映射到某个内核线程。可以在多种场合看到此方法的优点;一个显著的示例就是
Java 如何利用动态逻辑分区(Dynamic Logical Partitioning,DLPAR);当将新的
CPU 添加到该分区时,可以将某个 Java 线程调度到该 CPU 上。在正常情况下不应该更改此设置。
AIXTHREAD_COND_DEBUG、AIXTHREAD_MUTEX_DEBUG 和 AIXTHREAD_RWLOCK_DEBUG
这些标志用于内核调试目的。这些标志有时可能设置为 OFF。如果不是这样,则关闭它们会提供很好的性能提升。
LDR_CNTRL=MAXDATA=0x80000000
这是 Java 1.3.1 上的缺省设置,并控制如何允许大型 Java 堆增长。Java 1.4 基于所请求的堆来决定
LDR_CNTRL 设置。有关如何操作此变量的详细信息,请参阅 Getting more memory
in AIX for your Java applications。
JAVA_COMPILER
此设置决定将要使用的 Just-In-Time 编译器。缺省设置为 jitc,并指向 IBM JIT 编译器。可以将其更改为
jitcg,表示 JIT 编译器的调试版本;或者更改为 NONE,表示关闭 JIT 编译器(这样做在大多数情况下对性能来说绝对是最糟糕的)。
IBM_MIXED_MODE_THRESHOLD
此设置决定 JVM JIT 在编译某个方法前该方法的调用次数。此设置视平台和版本而异;例如,对于 AIX
上的 Java 1.3.1,此设置为 600。
请注意,上述任何一个设置都不会覆盖现有的设置。例如,如果将 LDR_CNTRL=MAXDATA 更改为某个其他值,则会使用您指定的值而不是使用上面提到的缺省值。
IBM Java SDK 的配套自述文件/SDK 指南解释了任何 Java 本机接口(Java Native
Interface,JNI)库都必须具有的环境设置。如果修改了该列表中指定的任何环境设置,您必须确保也使用相应的设置来生成
JNI 库。
总结
本文介绍了一些基本步骤,可作为开始优化工作的清单。接下来的三个部分将研究 CPU、内存、网络和磁盘 I/O
优化。
最大化 AIX 上的 Java 性能,第 2 部分: 速度需求
引言
这是由五部分组成的有关 AIX 上的 Java 性能优化的系列中的第 2 部分。强烈建议您在进一步继续之前阅读本系列中的第
1 部分(如果您还没有这样做的话)。
本文研究用于最大化系统执行速度和吞吐量的方法。对于涉及用户界面的程序,我们还将研究如何确保系统的响应能力保持在可接受的级别内。
您应该查看本文第一部分,以了解适用于大多数情况的一般技巧。我们还提供了对于 CPU 瓶颈检测和研究非常有用的工具的快速参考。下一部分将描述各种类型的应用程序以及如何优化它们。此讨论将利用您的应用程序知识来决定哪些技巧最适合您。第三部分将描述各种技巧。本文在结束时将讨论一下本系列中的下一篇文章。
CPU 瓶颈
本文将讨论如何使您的应用程序更快或响应能力更高,或者同时实现这两个目的。
通过将实际与预期的性能数字进行比较,您通常可以确定应用程序是否运行得太慢。或者,应用程序的用户界面可能定期地定住,或者到应用程序的网络连接可能由于应用程序忙而超时。使用
topas 或 tprof 将显示 CPU 利用率是否达到 100%。您需要能够区分异常活动和大小设置不当的情况;如果您需要更快的
CPU 或更高规格的计算机,则没有多少调整空间可以执行。
作为第一步,您应该使用 topas 或其他类似工具来确定 Java 是否为最大的 CPU 用户。如果看到
Java 处在 CPU 用户列表中的较低位置,则执行特定于 CPU 的优化可能没有多大用处。我们在第 1
部分中提供了 topas 的简单概述。
理想的情况是应用程序的 CPU 利用率达到或高于 90%。如果您已经达到该阶段并且仍然对吞吐量不满意,也许是您使用的计算机的规格不够高。如果使用
DLPAR,可以尝试添加另外一个或两个 CPU 并测量差异。
vmstat
vmstat 可用于提供有关系统的多种统计信息。对于特定于 CPU 的工作,可以尝试以下命令:
此命令执行 3 次采样,每次相隔 1 秒钟,并带有时间戳 (-t)。您当然可以随心所欲地更改参数。下面显示了此命令的输出:
kthr memory page faults cpu time----- ----------- ------------------------ ------------ ----------- -------- r b avm fre re pi po fr sr cy in sy cs us sy id wa hr mi se 0 0 45483 221 0 0 0 0 1 0 224 326 362 24 7 69 0 15:10:22 0 0 45483 220 0 0 0 0 0 0 159 83 53 1 1 98 0 15:10:23 2 0 45483 220 0 0 0 0 0 0 145 115 46 0 9 90 1 15:10:24 |
此输出中需要观察的一些内容包括:
列 r(运行队列)和 b(被阻塞)开始上升,尤其是高于 10。这通常是有太多进程在争用 CPU 的迹象。
如果 cs(上下文切换)与进程数量相比上升得非常高,您可能需要使用 vmtune 来优化系统。此主题超出了本系列的范围。
在 cpu 部分,us(用户时间)指示在程序中所花的时间。假设 Java 在 tprof 中位于列表顶部,您可能需要优化
Java 应用程序。
在 cpu 部分,如果 sys(系统时间)高于预期,并且您仍然还剩有 id(空闲)时间,这可能表示锁争用。检查
tprof 以了解内核时间中与锁相关的调用。您可能希望尝试运行 JVM 的多个实例。还可以在 javacore
文件中查找死锁。
在 cpu 部分,如果 wa(I/O 等待)非常高,这可能指示磁盘瓶颈,并且您应该使用 iostat 和其他工具来查看磁盘使用情况。
pi、po(页面调入/调出)列中的值不为零可能指示系统在使用分页,您可能需要更多的内存。也许您设置的堆栈大小对于某些
JVM 实例来说可能太高了。这还可能意味着您分配的堆大于系统上的内存量。当然,您可能还有其他使用内存的应用程序,或者文件页可能占据了太多的内存。
iostat
可以使用 iostat 获取 vmstat 所提供的相同 CPU 信息,此外还可以获取磁盘 I/O 等信息。
ps
ps 是一个非常灵活的工具,用于确定正在系统上运行的程序和那些程序正在使用的资源。它显示有关系统上的进程的统计和状态信息,例如进程或线程
ID、I/O 活动、CPU 和内存使用。
此命令将允许您确定所有活动 Java 进程的 ID。许多其他命令要求您首先确定进程 ID;使用 -ef
将通过显示其命令行参数来帮助您区分多个 Java 进程。
使用感兴趣的 Java 进程的 PID(进程 ID),您可以检查已创建了多少个线程。这对于希望监视某个大型应用程序的情况尤其非常有用;您可以通过
wc -l 对上述输出进行管道传输,以获得 JVM 创建的线程数量。这可以在一个循环中进行,以便您能够检测某些线程是否在不应该启动或终止的时候启动或终止了。
对于获取 %CPU 和 %Memory 数据(按使用量最多的用户排序)非常有用。这对于快速定位系统上的瓶颈非常有用。
显示虚拟内存使用情况。请注意,监视本机和 Java 堆的首选方法是使用 svmon。本系列的第 3 部分将对此进行详细阐述。
使用 PID(进程 ID),您可以获取进程的环境设置的输出。例如,这将显示所执行的 Java 的完整文件路径,而普通的
ps 清单中可能不会显示此信息。请注意,为了获得完整的环境清单,建议您改为创建一个 javadump 文件(有关详细信息,请参见
IBM developer kits - diagnosis documentation)。
sar
sar -u -P ALL x y 可用于检查多个 CPU 之间的 CPU 使用平衡。如果使用情况分布不平衡,这可能指示应用程序没有线程化,并且您可能需要创建该应用程序的多个实例。下面的示例在一个达到
80% 利用率的双处理器系统上,相隔五秒钟进行了两次采样。
# sar -u -P ALL 5 2
AIX aix4prt 0 5 000544144C00 02/09/01
15:29:32 cpu %usr %sys %wio %idle
15:29:37 0 34 46 0 20
1 32 47 0 21
- 33 47 0 20
15:29:42 0 31 48 0 21
1 35 42 0 22
- 33 45 0 22
Average 0 32 47 0 20
1 34 45 0 22
- 33 46 0 21 |
您还可能看到所有 CPU 都达到 100% 利用率,或者只是单个 CPU 达到 100% 的利用率(当
JVM 在执行压缩的时候)。
tprof
tprof 是 AIX 遗留工具之一,可以提供每个 AIX 进程 ID 和名称的详细 CPU 使用情况分析。AIX
5.2 对其进行了完全的改写,下面的示例使用了 AIX 5.1 语法。您应该参阅 AIX 5.2 Performance
Tools update:Part 3,以了解新的语法。
调用此命令的最简单方法是使用:
# tprof -kse -x "sleep 10" |
十秒钟后,将生成一个新文件 __prof.all,其中包含有关什么命令正在使用系统上的 CPU 的信息。搜索
FREQ,该信息应该与下面的示例类似:
Process FREQ Total Kernel User Shared Other======= === ===== ====== ==== ====== ===== oracle 244 10635 3515 6897 223 0 java 247 3970 617 0 2062 1291 wait 16 1515 1515 0 0 0 ... ======= === ===== ====== ==== ====== ===== Total 1060 19577 7947 7252 3087 1291 |
此示例表明,超过半数的 CPU 时间都与 Oracle 应用程序关联,并且 Java 正在使用大约 3970/19577
或 1/5 的 CPU。wait 通常意味着空闲时间,但是也可以包括 CPU 使用量的 I/O 等待部分。
要确定是否存在大量的锁争用,您还应该检查 KERNEL 部分:
Total Ticks For All Processes (KERNEL) = 7787
Subroutine Ticks % Source Address Bytes
============= ===== ==== ======== ======== ======
.unlock_enable_mem 2286 11.7 low.s 930c 1f4
.waitproc_find_run_queue 1372 7.0 ../../../../../src/bos/kernel/proc/dispatc
h.c 2a6ec 2b0
.e_block_thread 893 4.6 ../../../../../src/bos/kernel/proc/sleep2. |
对于 Shared Objects 部分,查找 libjvm.a,特别是 gc_* 或与任何 GC 短语(Mark、Sweep、Compact)接近的名称。如果发现大量的此类内容,则
JVM 进程可能需要 GC 优化。
您还应该查找占用大量 CPU 时钟周期百分比的重要子例程。例如,某个 tprof 输出显示 clProgramCounter2Method
的值相当高:
Subroutine Ticks % Source Address Bytes============= ===== ==== ======== ======== ====== .clProgramCounter2Method 3551 14.8 /userlvl/ca131/src/jvm/sov/cl/clloadercache.c |
在检查多个此类示例之后,我们发现删除 Throwable.printStackTrace 调用可以带来重要的性能改进。得出这个特定方法是从分析
tprof 输出开始的。
特定于 Java 的技巧
在几乎所有情况下(请参见相关技巧以了解例外情况),JIT 编译器都必须打开,因为这样导致的性能差异相当于执行字节代码与执行本机代码的差异。JIT
能够提供高达 25 倍的改进,因此它对 Java 来说是至关重要的性能组件。
垃圾收集也是另一个至关重要的组件,因此必须根据需要对其进行检查和调整。请注意,虽然启用 GC 跟踪(使用
-verbosegc)具有轻微的负面影响,但是能够监视和分析堆的优点显然胜过负面影响。另一种考虑方式在于,良好状况的堆会最小化通过
-verbosegc 打印的信息量,因此通过调整堆,您还可以最小化执行附加跟踪的开销。
基于特征的优化技巧
下面让我们看一下典型应用程序的不同特征。您应该定位到与您的应用程序类似的行为(无论是设计上的还是观察到的),并应用对应的技巧。
应用程序的长期性
IBM Java 旨在为诸如服务器代码等长期运行的应用程序提供更好的特征。如果由于某种原因要尝试运行持续时间不到
5 分钟左右的测试用例,您可能发现 IBM Java 为长期运行而做的准备会影响启动时间。如果应用程序的快速启动比长期运行更重要,请查看
技巧 CPU001:快速启动应用程序和 技巧 CPU004:完全去掉 GC。如果 技巧 CPU004:完全去掉
GC 不适用于您,可以改为考虑 技巧 CPU012:避免堆大小调整。在严格的情况下,如果您的测试用例是如此的短,以致
JIT 初始化也开销太大,您可能希望在关闭 JIT 的情况下进行测试。请注意,我们没有将禁用 JIT 作为一项独立的性能技巧提出来,这是因为,正如在上一篇文章中所提到的,这可能是影响应用程序性能的最糟糕的事情。
如果应用程序能够承受启动时间的轻微延迟,您应该参阅 技巧 CPU003:在第一次调用时编译所有内容和 技巧
CPU008:使用小型堆。对于具有明显的“初始化”和“运行”阶段的长时间运行的应用程序,技巧 CPU003:在第一次调用时编译所有内容是非常便利的。
交互级别
基于您的代码是否为计算密集型,JVM 的响应能力可以具有从非常关键到不相关的不同重要性。如果您要尝试优化的
JVM 在运行 GUI,则长时间的 GC 暂停将是不可接受的。与此同时,如果您在运行多个允许负载共享的
JVM 实例,或者如果正在执行批处理模式的处理,则长时间的暂停也许是可接受的。
对于无法承受长时间暂停的应用程序,请参见 技巧 CPU002:使用并发 GC、技巧 CPU004:完全去掉
GC、技巧 CPU007:禁用显式的 System.gc() 调用、技巧 CPU008:使用小型堆、技巧
CPU009:消除“标记堆栈溢出”和 技巧 CPU012:避免堆大小调整。技巧 CPU004 在大多数情况下仅适用于短时间运行的应用程序。请注意,必须将技巧
CPU008 与应用程序的内存特征结合起来考虑,因为如果应用不当,可能会带来相反的效果。
对于能够承受更长时间暂停的应用程序,应该考虑 技巧 CPU003:在第一次调用时编译所有内容。请注意,长时间暂停在大多数情况下都不是好事情,因此即使应用程序能够承受,也应该考虑并纠正该问题,因为您无法通过错误配置的
JVM 实例获得任何好处。
CPU 消耗
如果您在运行其线程数量超过已安装的 CPU 数量的应用程序,则观察到总体 CPU 利用率保持在 90%
或更高是很正常的,任何类型的后台处理都会损害您的应用程序的吞吐量。另一方面,如果您的应用程序是服务器,并且其线程在大多数时间都处于睡眠状态,只有在响应传入的请求时才会醒来,那么您也许能够使用后台处理来减小长时间
GC 暂停所导致的影响。
对于属于 CPU 密集型从而希望最小化后台处理的应用程序,可以考虑 技巧 CPU007:禁用显式的 System.gc()
调用、技巧 CPU008:使用小型堆和 技巧 CPU009:消除“标记堆栈溢出”。正如前面提到过的,您应该将
技巧 CPU008:使用小型堆与内存特征结合起来考虑。
对于非 CPU 密集型应用程序,强烈建议考虑 技巧 CPU002:使用并发 GC。这将通过减少 GC 周期到达时的总体暂停时间来获益。
定义良好的引用局域性
如果应用程序有一些经常执行的方法,而其他方法则很少执行,则 技巧 CPU003:在第一次调用时编译所有内容将是非常好的性能增强方法。
并行度
如果应用程序运行多个线程以完成工作,则会从具有大量 CPU 的系统中获益。对于动态分区,添加更多 CPU
会立即表现出改进,因为可以立即将 Java 线程调度到新添加的 CPU 上。技巧 CPU005:使用大量线程、技巧
CPU006:减少锁争用和 技巧 CPU011:超过 24 个 CPU 的系统讨论了可尝试的其他优化。
但是如果应用程序只有单个执行线程,则会受到单个 CPU 的处理能力的限制。在此情况下,您可能希望尝试 技巧
CPU002:使用并发 GC 和 技巧 CPU010:单 CPU 系统。如果您要尝试在某个系统上运行多个
JVM 实例(例如,在集群环境中),则 技巧 CPU010:单 CPU 系统特别有帮助。
一般技巧集合
下文将把 Java 的命令行参数(在 class/jar 文件名称之前指定)称为“开关”。例如,命令行“java
-mx2g hello”具有单个开关“-mx2g”。
技巧 CPU001:快速启动应用程序
可以使用非标准开关 -Xquickstart 缩短应用程序的启动时间。此开关将 JIT 优化级别降至最低,并且仅当适用的方法再次变得活动时才重新应用优化。对于其执行不是集中于少数方法的应用程序,这样做的结果是启动时间要快得多。
请注意:由于多阶段的优化方法,此开关可能对长期运行的应用程序具有负面影响。请注意:
技巧 CPU002:使用并发 GC
可以指定“并发标记垃圾收集策略”(Concurrent Mark Garbage Collection
Policy),以便减少 GC 周期引入的暂停时间量。这是使用 -Xgcpolicy:optavgpause
开关来指定的。
请注意:在某些情况下,CPU 密集型应用程序可能会在指定了并发标记的情况下表现出吞吐量下降。
技巧 CPU003:在第一次调用时编译所有内容(或选定的方法)
可以将环境变量 IBM_MIXED_MODE_THRESHOLD 设置为 0,从而关闭混合模式的解释器
(Mixed-Mode interpreter)。其结果是所有方法都将在第一次调用时进行 JIT 编译。将下面这一行内容添加到环境设置中,或者简单地在启动
Java 前运行此行命令:
export IBM_MIXED_MODE_THRESHOLD=0 |
还可以对非零值进行试验,以确定是否有某个特定的 MMI 阈值可以比零值提供更好的性能。对于 AIX,Java
1.3.1 使用 600 作为阈值,而 Java 1.4 则使用一个大于 1000 的值(请注意,这些值可能会更改)。IBM
developer kits - diagnosis documentation 在“JIT Diagnostics”一章下面的“Selecting
the MMI Threshold”小节中提供了更多信息。
如果您只希望影响某些类,可以改为使用 JITC_COMPILEOPT=FORCE(0){classname}{methodname}。示例:
export JITC_COMPILEOPT=FORCE(0){com/myapp/*}{*} |
此示例在第一次加载时编译 com.myapp.* 包中的所有类的所有方法。
export JITC_COMPILEOPT=FORCE(0){*}{uniqueName} |
此示例在第一次加载时编译所有名为“uniqueName”的方法。
export JITC_COMPILEOPT=FORCE(0){com/myapp/special}{SpecialMethod} |
此示例仅在第一次加载时编译这个特定的方法。除了 *(表示零个或多个字符)以外,还可以使用“?”作为单个字符的通配符。
可以使用以下语法指定多个类和/或方法:
export JITC_COMPILEOPT=FORCE(0){class1}{method1}{class2}{method2} |
确保用文档清楚地说明这是一个优化而不是修复!
请注意:应用程序的启动时间可能由于此设置而延长。
技巧 CPU004:完全去掉 GC
可以将启动和最大堆大小设置为非常大的值,以便在运行期间不会发生任何分配故障。应该为这些运行启用 verbosegc,以确保该策略有效!
请注意:当 GC 发生时,其周期可能会相当长,因此只能在极少的情况下使用此技巧。
技巧 CPU005:使用大量线程
对于扩展到更大数量的线程,您应该使用 -Xss 开关来指定一个小于缺省值(通常为 512 K,但是可能随
Java 版本而异)的值。这将使您可以扩展到更大数量的线程,同时减小应用程序的本机内存占用空间。
请注意:如果堆栈大小太小,您可能会遇到堆栈溢出 (Stack Overflow) 异常。
技巧 CPU006:减少锁争用
如果应用程序体系结构允许的话,您可以尝试运行多个 Java 实例,以减少锁争用。这是通过允许此类配置的应用程序服务器来促进的;例如,WebSphere
允许您在同一台物理计算机上使用多个节点。
请注意:这只能掩盖问题;您应该复查导致过多锁争用的代码部分。可以使用 tprof 或 Java 分析来定位需要复查的区域。
技巧 CPU007:禁用显式的 system.gc() 调用
使用非标准开关 -Xdisableexplicitgc,您可以减少对删除代码中的 System.gc()
调用的需要。删除这些调用将把 GC 管理工作返还给 JVM。
请注意:如果需要通过功能来实现 System.gc() 调用(例如,通过应用程序屏幕上的按钮),这将是个坏主意,因为按钮将变得无法工作。也许有
System.gc() 调用可以存在于代码中的其他合理理由。
技巧 CPU008:使用小型堆
使用决不允许压缩时间变得不可忍受的堆大小。如果由于某种原因,应用程序最终导致大量的压缩,则使用 256
MB 的堆所花的压缩时间要比 1 GB 的堆少得多。
请注意:如果由于较小的堆而触发更多的压缩,则此优化就事与愿违了。只能在要创建大量临时对象的情况下使用此技巧。
技巧 CPU009:消除标记堆栈溢出
如果在 verbosegc 日志中观察到“标志堆栈溢出 (Mark Stack Overflow)”消息,可以减少堆中保持活动的对象数量,以便这些消息消失。较新版本的
Java 具有好得多的 MSO 处理功能。这里包括此技巧是因为 MSO 会严重损害应用程序的性能,必须将其视为缺陷而不是优化。
技巧 CPU010:单 CPU 系统
可以使用 bindprocessor 命令将 Java 进程绑定到某个特定的处理器。可以考虑使用此技巧以避免多个
JVM 实例争夺 CPU 调度。如果系统不是单处理器计算机,您可能希望设置 -Xgcthreads0。
如果您是在不会进行重新配置以动态添加更多 CPU 的单 CPU 的 LPAR 上运行应用程序,则还可以导出
NO_LPAR_RECONFIGURATION=1,以在某些情况下获得更好的性能。
请注意:您是在通过迫使 Java 在单 CPU 配置中运行,从而禁用其最佳的性能特性。NO_LPAR_RECONFIGURATION
还将禁用 Java 适应 DLPAR 的动态可配置性,因此应该慎用。
技巧 CPU0011:超过 24 个 CPU 的系统
对于 24 至 32 路系统,您应该使用 -Xgcpolicy:subpool 进行测试,因为此 GC
策略是为了给较大型配置交付更好的性能而优化的。
技巧 CPU012:避免堆大小调整
可以保持固定大小的堆,以避免在空闲空间百分比低于(或高于)某个值时花时间去调整堆的大小。
请注意:即使堆使用率为其最高水平的 10%,应用程序的内存占用空间也将保持在指定的堆大小。
总结
本文介绍了如何使用 AIX 工具进行 Java 性能监视,并提供了可用来优化应用程序的
CPU 使用的常用调整列表。本系列中的下一篇文章将讨论 AIX 上的 Java 应用程序的内存调整。
|






