| БрМЭЦМі: |
| БОЮФРДздгкcsdnЃЌБОЮФжївЊНщЩмДгЪВУДЪЧВЂЗЂвдМАВЂЗЂБрГЬЕФддђШыЪжЯъЯИНВЪіДгJava
5ЕНJava 7ЕФВЂЗЂБрГЬМАОЕфАИР§ембЇМвНјВЭЕШЁЃ |
|
ЮЊЪВУДашвЊВЂЗЂЃП
ВЂЗЂЪЧвЛжжНтёюВпТдЃЌЫќАяжњЮвУЧАбзіЪВУД(ФПЕФ)КЭКЮЪБЃЈЪБЛњЃЉзіЗжНтПЊЁЃдкЕЅЯпГЬгІгУжаЃЌФПЕФгыЪБЛњНєУмёюКЯЃЌКмЖрЪБКђжЛвЊВщПДЖбеЛзЗзйМДПЩЖЯЖЈгІгУГЬађЕФзДЬЌЁЃЖјНтёюФПЕФгыЪБЛњФмУїЯдЕиИФНјгІгУГЬађЕФЭЬЭТСПКЭНсЙЙЁЃДгНсЙЙЕФНЧЖШПДЃЌгІгУГЬађПДЦ№РДИќЯёЪЧаэЖрЬЈаЭЌЙЄзїЕФМЦЫуЛњ,ЖјВЛЪЧвЛИіДѓбЛЗЁЃ
ВЂЗЂЪЧвЛжжЪБМф(When)КЭФПЕФ(What)ЕФНтёюЃЌЬсИпгІгУГЬађЕФЭЬЭТСПЃЌЬсИпcpuРћгУТЪЃЛЕЋЪЧВЂЗЂБрТыВЛЪЧФЧУДШнвзЃЌдйМгЩЯСйНчзЪдДОКељЫРЫјЁЃБраДгХжЪЕФВЂЗЂДњТыЪЧвЛМўФбЖШМЋИпЕФЪТЧщЁЃJavaгябдДгЕквЛАцБОПЊЪМФкжУСЫЖдЖрЯпГЬЕФжЇГжЃЌетвЛЕудкЕБФъЪЧЗЧГЃСЫВЛЦ№ЕФЃЌЕЋЪЧЕБЮвУЧЖдВЂЗЂБрГЬгаСЫИќЩюПЬЕФШЯЪЖКЭИќЖрЕФЪЕМљКѓЃЌЪЕЯжВЂЗЂБрГЬОЭгаСЫИќЖрЕФЗНАИКЭИќКУЕФбЁдёЁЃ
ЖдВЂЗЂЕФЮѓНтКЭПЭЙлШЯЪЖ
зюГЃМћЕФЖдВЂЗЂБрГЬЕФЮѓНтгавдЯТетаЉЃК
-ВЂЗЂзмФмИФНјадФмЃЈВЂЗЂдкCPUгаКмЖрПеЯаЪБМфЪБФмУїЯдИФНјГЬађЕФадФмЁЃЕЋЖрЯпГЬЪЧгаЖюЭтПЊЯњЕФЃЌЕБЯпГЬЪ§СПНЯЖрЕФЪБКђЃЌЯпГЬМфЦЕЗБЕФЕїЖШЧаЛЛЗДЖјЛсШУЯЕЭГЕФадФмЯТНЕЃЉЁЃ
-БраДВЂЗЂГЬађЮоашаоИФдгаЕФЩшМЦЃЈФПЕФгыЪБЛњЕФНтёюЭљЭљЛсЖдЯЕЭГНсЙЙВњЩњОоДѓЕФгАЯьЃЉЁЃ
-дкЪЙгУWebЛђEJBШнЦїЪБВЛгУЙизЂВЂЗЂЮЪЬтЃЈжЛгаСЫНтСЫШнЦїдкзіЪВУДЃЌВХФмИќКУЕФЪЙгУШнЦїЃЉЁЃ
ЯТУцЕФетаЉЫЕЗЈВХЪЧЖдВЂЗЂПЭЙлЕФШЯЪЖЃК
-БраДВЂЗЂГЬађЛсдкДњТыЩЯдіМгЖюЭтЕФПЊЯњЁЃ
-е§ШЗЕФВЂЗЂЪЧЗЧГЃИДдгЕФЃЌМДЪЙЖдгкКмМђЕЅЕФЮЪЬтЁЃ
-ВЂЗЂжаЕФШБЯнвђЮЊВЛвзжиЯжвВВЛШнвзБЛЗЂЯжЁЃ
-ВЂЗЂЭљЭљашвЊЖдЩшМЦВпТдДгИљБОЩЯНјаааоИФЁЃ
ВЂЗЂБрГЬЕФддђ
1. ЕЅвЛжАд№ЃКВЂЗЂвбОзуЙЛИДдгЃЌЮвУЧИќашвЊДњТыЗжРыЃЌЗжРыЯпГЬЯрЙиДњТыКЭЗЧЯпГЬЯрЙиДњТыЃЌЕЅвЛШЈд№ЃЌОЁПЩФмНЕЕЭЦфИДдгЖШЁЃ
2. ЯожЦСйНчзЪдДЕФзїгУгђЃКЮЊСйНчзЪдДМгЫјЪЧЗРжЙВЂЗЂЕФВпТдЃЌЕЋЪЧБиаые§ШЗЕФМгЫјЃЌШчЙћаЮГЩЕШД§ЛЗЃЌОЭЕМжТЫРЫјЁЃЫјЪЧЁААКЙѓЁБЕФЃЌДњМлКмИпЁЃ
3. РћгУЪ§ОнИББОЃЈжЕЖдЯѓЛђепПЫТЁЃЉдкЯпГЬжЎМфДЋЕнЪ§ОнЃКБмУтЯпГЬжЎЧАВйзїЕФВЂЗЂгАЯьЃЛЯпГЬЖРСЂЃЌЪЙЦфдкздМКЕФЛЗОГжадЫааЃЌВЛФмЦфЫћЯпГЬЙВЯэЪ§ОнЁЃ
4. ЯпГЬОЁПЩФмЖРСЂЃКШУЯпГЬДцдкгкздМКЕФЪРНчжаЃЌВЛгыЦфЫћЯпГЬЙВЯэЪ§ОнЁЃгаЙ§Java WebПЊЗЂОбщЕФШЫЖМжЊЕРЃЌServletОЭЪЧвдЕЅЪЕР§ЖрЯпГЬЕФЗНЪНЙЄзїЃЌКЭУПИіЧыЧѓЯрЙиЕФЪ§ОнЖМЪЧЭЈЙ§ServletзгРрЕФserviceЗНЗЈЃЈЛђепЪЧdoGetЛђdoPostЗНЗЈЃЉЕФВЮЪ§ДЋШыЕФЁЃжЛвЊServletжаЕФДњТыжЛЪЙгУОжВПБфСПЃЌServletОЭВЛЛсЕМжТЭЌВНЮЪЬтЁЃSpring
MVCЕФПижЦЦївВЪЧетУДзіЕФЃЌДгЧыЧѓжаЛёЕУЕФЖдЯѓЖМЪЧвдЗНЗЈЕФВЮЪ§ДЋШыЖјВЛЪЧзїЮЊРрЕФГЩдБЃЌКмУїЯдStruts
2ЕФзіЗЈОЭе§КУЯрЗДЃЌвђДЫStruts 2жазїЮЊПижЦЦїЕФActionРрЖМЪЧУПИіЧыЧѓЖдгІвЛИіЪЕР§ЁЃ
5. ЖдгкСйНчзЪдДМгЫјгІОЁСПБЃГжМгЫјЗЖЮЇОЁПЩФмЕФаЁЁЃ
Java 5вдЧАЕФВЂЗЂБрГЬ
JavaЕФЯпГЬФЃаЭНЈСЂдкЧРеМЪНЯпГЬЕїЖШЕФЛљДЁЩЯЃЌвВОЭЪЧЫЕЃК
ЁЄ 1.ЫљгаЯпГЬПЩвдКмШнвзЕФЙВЯэЭЌвЛНјГЬжаЕФЖдЯѓЁЃ
ЁЄ 2.ФмЙЛв§гУетаЉЖдЯѓЕФШЮКЮЯпГЬЖМПЩвдаоИФетаЉЖдЯѓЁЃ
ЁЄ 3.ЮЊСЫБЃЛЄЪ§ОнЃЌЖдЯѓПЩвдБЛЫјзЁЁЃ
JavaЛљгкЯпГЬКЭЫјЕФВЂЗЂЙ§гкЕзВуЃЌЖјЧвЪЙгУЫјКмЖрЪБКђЖМЪЧКмЭђЖёЕФЃЌвђЮЊЫќЯрЕБгкШУЫљгаЕФВЂЗЂЖМБфГЩСЫХХЖгЕШД§ЁЃ
дкJava 5вдЧАЃЌПЩвдгУsynchronizedЙиМќзжРДЪЕЯжЫјЕФЙІФмЃЌЫќПЩвдгУдкДњТыПщКЭЗНЗЈЩЯЃЌБэЪОдкжДааећИіДњТыПщЛђЗНЗЈжЎЧАЯпГЬБиаыШЁЕУКЯЪЪЕФЫјЁЃЖдгкРрЕФЗЧОВЬЌЗНЗЈЃЈГЩдБЗНЗЈЃЉЖјбдЃЌетвтЮЖетвЊШЁЕУЖдЯѓЪЕР§ЕФЫјЃЌЖдгкРрЕФОВЬЌЗНЗЈЃЈРрЗНЗЈЃЉЖјбдЃЌвЊШЁЕУРрЕФClassЖдЯѓЕФЫјЃЌЖдгкЭЌВНДњТыПщЃЌГЬађдБПЩвджИЖЈвЊШЁЕУЕФЪЧФЧИіЖдЯѓЕФЫјЁЃ
ВЛЙмЪЧЭЌВНДњТыПщЛЙЪЧЭЌВНЗНЗЈЃЌУПДЮжЛгавЛИіЯпГЬПЩвдНјШыЃЌШчЙћЦфЫћЯпГЬЪдЭМНјШыЃЈВЛЙмЪЧЭЌвЛЭЌВНПщЛЙЪЧВЛЭЌЕФЭЌВНПщЃЉЃЌJVMЛсНЋЫќУЧЙвЦ№ЃЈЗХШыЕНЕШЫјГижаЃЉЁЃетжжНсЙЙдкВЂЗЂРэТлжаГЦЮЊСйНчЧјЃЈcritical
sectionЃЉЁЃетРяЮвУЧПЩвдЖдJavaжагУsynchronizedЪЕЯжЭЌВНКЭЫјЕФЙІФмзівЛИізмНсЃК
ЁЄ жЛФмЫјЖЈЖдЯѓЃЌВЛФмЫјЖЈЛљБОЪ§ОнРраЭ
ЁЄ БЛЫјЖЈЕФЖдЯѓЪ§зщжаЕФЕЅИіЖдЯѓВЛЛсБЛЫјЖЈ
ЁЄ ЭЌВНЗНЗЈПЩвдЪгЮЊАќКЌећИіЗНЗЈЕФsynchronized(this) { Ё }ДњТыПщ
ЁЄ ОВЬЌЭЌВНЗНЗЈЛсЫјЖЈЫќЕФClassЖдЯѓ
ЁЄ ФкВПРрЕФЭЌВНЪЧЖРСЂгкЭтВПРрЕФ
ЁЄ synchronizedаоЪЮЗћВЂВЛЪЧЗНЗЈЧЉУћЕФзщГЩВПЗжЃЌЫљвдВЛФмГіЯждкНгПкЕФЗНЗЈЩљУїжа
ЁЄ ЗЧЭЌВНЕФЗНЗЈВЛЙиаФЫјЕФзДЬЌЃЌЫќУЧдкЭЌВНЗНЗЈдЫааЪБШдШЛПЩвдЕУвддЫаа
ЁЄ synchronizedЪЕЯжЕФЫјЪЧПЩжиШыЕФЫјЁЃ
дкJVMФкВПЃЌЮЊСЫЬсИпаЇТЪЃЌЭЌЪБдЫааЕФУПИіЯпГЬЖМЛсгаЫќе§дкДІРэЕФЪ§ОнЕФЛКДцИББОЃЌЕБЮвУЧЪЙгУsynchronziedНјааЭЌВНЕФЪБКђЃЌеце§БЛЭЌВНЕФЪЧдкВЛЭЌЯпГЬжаБэЪОБЛЫјЖЈЖдЯѓЕФФкДцПщЃЈИББОЪ§ОнЛсБЃГжКЭжїФкДцЕФЭЌВНЃЌЯждкжЊЕРЮЊЪВУДвЊгУЭЌВНетИіДЪЛуСЫАЩЃЉЃЌМђЕЅЕФЫЕОЭЪЧдкЭЌВНПщЛђЭЌВНЗНЗЈжДааЭъКѓЃЌЖдБЛЫјЖЈЕФЖдЯѓзіЕФШЮКЮаоИФвЊдкЪЭЗХЫјжЎЧАаДЛиЕНжїФкДцжаЃЛдкНјШыЭЌВНПщЕУЕНЫјжЎКѓЃЌБЛЫјЖЈЖдЯѓЕФЪ§ОнЪЧДгжїФкДцжаЖСГіРДЕФЃЌГжгаЫјЕФЯпГЬЕФЪ§ОнИББОвЛЖЈКЭжїФкДцжаЕФЪ§ОнЪгЭМЪЧЭЌВНЕФ
ЁЃ
дкJavaзюГѕЕФАцБОжаЃЌОЭгавЛИіНаvolatileЕФЙиМќзжЃЌЫќЪЧвЛжжМђЕЅЕФЭЌВНЕФДІРэЛњжЦЃЌвђЮЊБЛvolatileаоЪЮЕФБфСПзёбвдЯТЙцдђЃК
ЁЄ БфСПЕФжЕдкЪЙгУжЎЧАзмЛсДгжїФкДцжадйЖСШЁГіРДЁЃ
ЁЄ ЖдБфСПжЕЕФаоИФзмЛсдкЭъГЩжЎКѓаДЛиЕНжїФкДцжаЁЃ
ЪЙгУvolatileЙиМќзжПЩвддкЖрЯпГЬЛЗОГЯТдЄЗРБрвыЦїВЛе§ШЗЕФгХЛЏМйЩшЃЈБрвыЦїПЩФмЛсНЋдквЛИіЯпГЬжажЕВЛЛсЗЂЩњИФБфЕФБфСПгХЛЏГЩГЃСПЃЉЃЌЕЋжЛгааоИФЪБВЛвРРЕЕБЧАзДЬЌЃЈЖСШЁЪБЕФжЕЃЉЕФБфСПВХгІИУЩљУїЮЊvolatileБфСПЁЃ
ВЛБфФЃЪНвВЪЧВЂЗЂБрГЬЪБПЩвдПМТЧЕФвЛжжЩшМЦЁЃШУЖдЯѓЕФзДЬЌЪЧВЛБфЕФЃЌШчЙћЯЃЭћаоИФЖдЯѓЕФзДЬЌЃЌОЭЛсДДНЈЖдЯѓЕФИББОВЂНЋИФБфаДШыИББОЖјВЛИФБфдРДЕФЖдЯѓЃЌетбљОЭВЛЛсГіЯжзДЬЌВЛвЛжТЕФЧщПіЃЌвђДЫВЛБфЖдЯѓЪЧЯпГЬАВШЋЕФЁЃJavaжаЮвУЧЪЙгУЦЕТЪМЋИпЕФStringРрОЭВЩгУСЫетбљЕФЩшМЦЁЃШчЙћЖдВЛБфФЃЪНВЛЪьЯЄЃЌПЩвддФЖСбжКъВЉЪПЕФЁЖJavaгыФЃЪНЁЗвЛЪщЕФЕк34еТЁЃЫЕЕНетРяФуПЩФмвВЬхЛсЕНfinalЙиМќзжЕФживЊвтвхСЫЁЃ
Java 5ЕФВЂЗЂБрГЬ
ВЛЙмНёКѓЕФJavaЯђзХКЮжжЗНЯђЗЂеЙЛђепУ№УІЃЌJava 5ОјЖдЪЧJavaЗЂеЙЪЗжавЛИіМЋЦфживЊЕФАцБОЃЌетИіАцБОЬсЙЉЕФИїжжгябдЬиадЮвУЧВЛдкетРяЬжТлЃЈгааЫШЄЕФПЩвддФЖСЮФеТЁЖJavaЕФЕк20ФъЃКДгJavaАцБОбнНјПДБрГЬММЪѕЕФЗЂеЙЁЗЃЉЃЌЕЋЪЧЮвУЧБиаывЊИааЛDoug
LeaдкJava 5жаЬсЙЉСЫЫћРяГЬБЎЪНЕФНмзїjava.util.concurrentАќЃЌЫќЕФГіЯжШУJavaЕФВЂЗЂБрГЬгаСЫИќЖрЕФбЁдёКЭИќКУЕФЙЄзїЗНЪНЁЃDoug
LeaЕФНмзїжївЊАќРЈвдЯТФкШнЃК
ЁЄ 1.ИќКУЕФЯпГЬАВШЋЕФШнЦї
ЁЄ 2.ЯпГЬГиКЭЯрЙиЕФЙЄОпРр
ЁЄ 3.ПЩбЁЕФЗЧзшШћНтОіЗНАИ
ЁЄ 4.ЯдЪОЕФЫјКЭаХКХСПЛњжЦ
ЯТУцЮвУЧЖдетаЉЖЋЮїНјаавЛвЛНтЖСЁЃ
дзгРр
Java 5жаЕФjava.util.concurrentАќЯТУцгавЛИіatomicзгАќЃЌЦфжагаМИИівдAtomicДђЭЗЕФРрЃЌР§ШчAtomicIntegerКЭAtomicLongЁЃЫќУЧРћгУСЫЯжДњДІРэЦїЕФЬиадЃЌПЩвдгУЗЧзшШћЕФЗНЪНЭъГЩдзгВйзїЃЌДњТыШчЯТЫљЪОЃК

ЯдЪОЫј
ЛљгкsynchronizedЙиМќзжЕФЫјЛњжЦгавдЯТЮЪЬтЃК
ЁЄ ЫјжЛгавЛжжРраЭЃЌЖјЧвЖдЫљгаЭЌВНВйзїЖМЪЧвЛбљЕФзїгУ
ЁЄ ЫјжЛФмдкДњТыПщЛђЗНЗЈПЊЪМЕФЕиЗНЛёЕУЃЌдкНсЪјЕФЕиЗНЪЭЗХ
ЁЄ ЯпГЬвЊУДЕУЕНЫјЃЌвЊУДзшШћЃЌУЛгаЦфЫћЕФПЩФмад
Java 5ЖдЫјЛњжЦНјааСЫжиЙЙЃЌЬсЙЉСЫЯдЪОЕФЫјЃЌетбљПЩвддквдЯТМИИіЗНУцЬсЩ§ЫјЛњжЦЃК
ЁЄ ПЩвдЬэМгВЛЭЌРраЭЕФЫјЃЌР§ШчЖСШЁЫјКЭаДШыЫј
ЁЄ ПЩвддквЛИіЗНЗЈжаМгЫјЃЌдкСэвЛИіЗНЗЈжаНтЫј
ЁЄ ПЩвдЪЙгУtryLockЗНЪНГЂЪдЛёЕУЫјЃЌШчЙћЕУВЛЕНЫјПЩвдЕШД§ЁЂЛиЭЫЛђепИЩЕуБ№ЕФЪТЧщЃЌЕБШЛвВПЩвддкГЌЪБжЎКѓЗХЦњВйзї
ЯдЪОЕФЫјЖМЪЕЯжСЫjava.util.concurrent.LockНгПкЃЌжївЊгаСНИіЪЕЯжРрЃК
ЁЄ ReentrantLock - БШsynchronizedЩдЮЂСщЛювЛаЉЕФжиШыЫј
ЁЄ ReentrantReadWriteLock - дкЖСВйзїКмЖраДВйзїКмЩйЪБадФмИќКУЕФвЛжжжиШыЫј
ЖдгкШчКЮЪЙгУЯдЪОЫјЃЌПЩвдВЮПМJavaУцЪдЯЕСаЮФеТЁЖJavaУцЪдЬтМЏ51-70ЁЗжаЕк60ЬтЕФДњТыЁЃжЛгавЛЕуашвЊЬсабЃЌНтЫјЕФЗНЗЈunlockЕФЕїгУзюКУФмЙЛдкfinallyПщжаЃЌвђЮЊетРяЪЧЪЭЗХЭтВПзЪдДзюКУЕФЕиЗНЃЌЕБШЛвВЪЧЪЭЗХЫјЕФзюМбЮЛжУЃЌвђЮЊВЛЙме§ГЃвьГЃПЩФмЖМвЊЪЭЗХЕєЫјРДИјЦфЫћЯпГЬвддЫааЕФЛњЛсЁЃ
CountDownLatch
CountDownLatchЪЧвЛжжМђЕЅЕФЭЌВНФЃЪНЃЌЫќШУвЛИіЯпГЬПЩвдЕШД§вЛИіЛђЖрИіЯпГЬЭъГЩЫќУЧЕФЙЄзїДгЖјБмУтЖдСйНчзЪдДВЂЗЂЗУЮЪЫљв§ЗЂЕФИїжжЮЪЬтЁЃЯТУцНшгУБ№ШЫЕФвЛЖЮДњТыЃЈЮвЖдЫќзіСЫвЛаЉжиЙЙЃЉРДбнЪОCountDownLatchЪЧШчКЮЙЄзїЕФЁЃ
import java.util.concurrent.CountDownLatch;
/**
* ЙЄШЫРр
*
*/
class Worker {
private String name; // Ућзж
private long workDuration; // ЙЄзїГжајЪБМф
/**
* ЙЙдьЦї
*/
public Worker(String name, long workDuration)
{
this.name = name;
this.workDuration = workDuration;
}
/**
* ЭъГЩЙЄзї
*/
public void doWork() {
System.out.println(name + " begins to
work...");
try {
Thread.sleep(workDuration); // гУанУпФЃФтЙЄзїжДааЕФЪБМф
} catch(InterruptedException ex) {
ex.printStackTrace();
}
System.out.println(name + " has finished
the job...");
}
}
/**
* ВтЪдЯпГЬ
* @author ТцъЛ
*
*/
class WorkerTestThread implements Runnable
{
private Worker worker;
private CountDownLatch cdLatch;
public WorkerTestThread(Worker worker, CountDownLatch
cdLatch) {
this.worker = worker;
this.cdLatch = cdLatch;
}
@Override
public void run() {
worker.doWork(); // ШУЙЄШЫПЊЪМЙЄзї
cdLatch.countDown(); // ЙЄзїЭъГЩКѓЕЙМЦЪБДЮЪ§Мѕ1
}
}
class CountDownLatchTest {
private static final int MAX_WORK_DURATION
= 5000; // зюДѓЙЄзїЪБМф
private static final int MIN_WORK_DURATION
= 1000; // зюаЁЙЄзїЪБМф
// ВњЩњЫцЛњЕФЙЄзїЪБМф
private static long getRandomWorkDuration(long
min, long max) {
return (long) (Math.random() * (max - min)
+ min);
}
public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(2);
// ДДНЈЕЙМЦЪБуХВЂжИЖЈЕЙМЦЪБДЮЪ§ЮЊ2
Worker w1 = new Worker("ТцъЛ", getRandomWorkDuration(MIN_WORK_DURATION,
MAX_WORK_DURATION));
Worker w2 = new Worker("ЭѕДѓДИ", getRandomWorkDuration(MIN_WORK_DURATION,
MAX_WORK_DURATION));
new Thread(new WorkerTestThread(w1, latch)).start();
new Thread(new WorkerTestThread(w2, latch)).start();
try {
latch.await(); // ЕШД§ЕЙМЦЪБуХМѕЕН0
System.out.println("All jobs have been
finished!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} |
ConcurrentHashMap
ConcurrentHashMapЪЧHashMapдкВЂЗЂЛЗОГЯТЕФАцБОЃЌДѓМвПЩФмвЊЮЪЃЌМШШЛвбОПЩвдЭЈЙ§Collections.synchronizedMapЛёЕУЯпГЬАВШЋЕФгГЩфаЭШнЦїЃЌЮЊЪВУДЛЙашвЊConcurrentHashMapФиЃПвђЮЊЭЈЙ§CollectionsЙЄОпРрЛёЕУЕФЯпГЬАВШЋЕФHashMapЛсдкЖСаДЪ§ОнЪБЖдећИіШнЦїЖдЯѓЩЯЫјЃЌетбљЦфЫћЪЙгУИУШнЦїЕФЯпГЬЮоТлШчКЮвВЮоЗЈдйЛёЕУИУЖдЯѓЕФЫјЃЌвВОЭвтЮЖзХвЊвЛжБЕШД§ЧАвЛИіЛёЕУЫјЕФЯпГЬРыПЊЭЌВНДњТыПщжЎКѓВХгаЛњЛсжДааЁЃЪЕМЪЩЯЃЌHashMapЪЧЭЈЙ§ЙўЯЃКЏЪ§РДШЗЖЈДцЗХМќжЕЖдЕФЭАЃЈЭАЪЧЮЊСЫНтОіЙўЯЃГхЭЛЖјв§ШыЕФЃЉЃЌаоИФHashMapЪБВЂВЛашвЊНЋећИіШнЦїЫјзЁЃЌжЛашвЊЫјзЁМДНЋаоИФЕФЁАЭАЁБОЭПЩвдСЫЁЃHashMapЕФЪ§ОнНсЙЙШчЯТЭМЫљЪОЁЃ
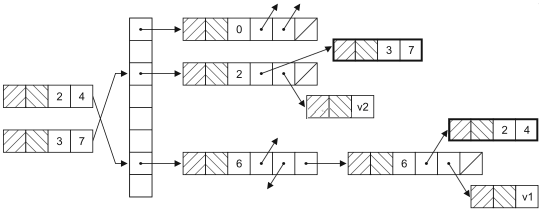
ДЫЭтЃЌConcurrentHashMapЛЙЬсЙЉСЫдзгВйзїЕФЗНЗЈЃЌШчЯТЫљЪОЃК
1.putIfAbsentЃКШчЙћЛЙУЛгаЖдгІЕФМќжЕЖдгГЩфЃЌОЭНЋЦфЬэМгЕНHashMapжаЁЃ
2.removeЃКШчЙћМќДцдкЖјЧвжЕгыЕБЧАзДЬЌЯрЕШЃЈequalsБШНЯНсЙћЮЊtrueЃЉЃЌдђгУдзгЗНЪНвЦГ§ИУМќжЕЖдгГЩф
3.replaceЃКЬцЛЛЕєгГЩфжадЊЫиЕФдзгВйзї
CopyOnWriteArrayList
CopyOnWriteArrayListЪЧArrayListдкВЂЗЂЛЗОГЯТЕФЬцДњЦЗЁЃCopyOnWriteArrayListЭЈЙ§діМгаДЪБИДжЦгявхРДБмУтВЂЗЂЗУЮЪв§Ц№ЕФЮЪЬтЃЌвВОЭЪЧЫЕШЮКЮаоИФВйзїЖМЛсдкЕзВуДДНЈвЛИіСаБэЕФИББОЃЌвВОЭвтЮЖзХжЎЧАвбгаЕФЕќДњЦїВЛЛсХіЕНвтСЯжЎЭтЕФаоИФЁЃетжжЗНЪНЖдгкВЛвЊбЯИёЖСаДЭЌВНЕФГЁОАЗЧГЃгагУЃЌвђЮЊЫќЬсЙЉСЫИќКУЕФадФмЁЃМЧзЁЃЌвЊОЁСПМѕЩйЫјЕФЪЙгУЃЌвђЮЊФЧЪЦБиДјРДадФмЕФЯТНЕЃЈЖдЪ§ОнПтжаЪ§ОнЕФВЂЗЂЗУЮЪВЛвВЪЧШчДЫТ№ЃПШчЙћПЩвдЕФЛАОЭгІИУЗХЦњБЏЙлЫјЖјЪЙгУРжЙлЫјЃЉЃЌCopyOnWriteArrayListКмУїЯдвВЪЧЭЈЙ§ЮўЩќПеМфЛёЕУСЫЪБМфЃЈдкМЦЫуЛњЕФЪРНчРяЃЌЪБМфКЭПеМфЭЈГЃЪЧВЛПЩЕїКЭЕФУЌЖмЃЌПЩвдЮўЩќПеМфРДЬсЩ§аЇТЪЛёЕУЪБМфЃЌЕБШЛвВПЩвдЭЈЙ§ЮўЩќЪБМфРДМѕЩйЖдПеМфЕФЪЙгУЃЉЁЃ
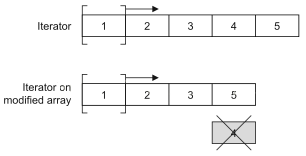
ПЩвдЭЈЙ§ЯТУцСНЖЮДњТыЕФдЫаазДПіРДбщжЄвЛЯТCopyOnWriteArrayListЪЧВЛЪЧЯпГЬАВШЋЕФШнЦїЁЃ
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class AddThread implements Runnable {
private List<Double>list;
public AddThread(List<Double>list) {
this.list =list;
}
@Override
public void run() {
for(int i = 0;i < 10000; ++i) {
list.add(Math.random());
}
}
}
public class Test05 {
private static final int THREAD_POOL_SIZE
= 2;
public static void main(String[]args) {
List<Double> list = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
es.execute(new AddThread(list));
es.execute(new AddThread(list));
es.shutdown();
}
} |
ЩЯУцЕФДњТыЛсдкдЫааЪБВњЩњArrayIndexOutOfBoundsExceptionЃЌЪдвЛЪдНЋЩЯУцДњТы25ааЕФArrayListЛЛГЩCopyOnWriteArrayListдйжиаТдЫааЁЃ
| List<Double>list
=new CopyOnWriteArrayList<>(); |
Queue
ЖгСаЪЧвЛИіЮоДІВЛдкЕФУРУюИХФюЃЌЫќЬсЙЉСЫвЛжжМђЕЅгжПЩППЕФЗНЪННЋзЪдДЗжЗЂИјДІРэЕЅдЊЃЈвВПЩвдЫЕЪЧНЋЙЄзїЕЅдЊЗжХфИјД§ДІРэЕФзЪдДЃЌетШЁОігкФуПДД§ЮЪЬтЕФЗНЪНЃЉЁЃЪЕЯжжаЕФВЂЗЂБрГЬФЃаЭКмЖрЖМвРРЕЖгСаРДЪЕЯжЃЌвђЮЊЫќПЩвддкЯпГЬжЎМфДЋЕнЙЄзїЕЅдЊЁЃ
Java 5жаЕФBlockingQueueОЭЪЧвЛИідкВЂЗЂЛЗОГЯТЗЧГЃКУгУЕФЙЄОпЃЌдкЕїгУputЗНЗЈЯђЖгСажаВхШыдЊЫиЪБЃЌШчЙћЖгСавбТњЃЌЫќЛсШУВхШыдЊЫиЕФЯпГЬЕШД§ЖгСаЬкГіПеМфЃЛдкЕїгУtakeЗНЗЈДгЖгСажаШЁдЊЫиЪБЃЌШчЙћЖгСаЮЊПеЃЌШЁГідЊЫиЕФЯпГЬОЭЛсзшШћЁЃ
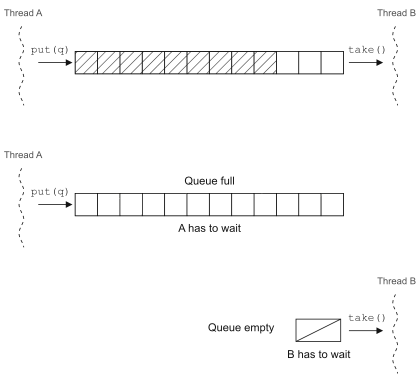
ПЩвдгУBlockingQueueРДЪЕЯжЩњВњеп-ЯћЗбепВЂЗЂФЃаЭЃЈЯТвЛНкжагаНщЩмЃЉЃЌЕБШЛдкJava
5вдЧАвВПЩвдЭЈЙ§waitКЭnotifyРДЪЕЯжЯпГЬЕїЖШЃЌБШНЯвЛЯТСНжжДњТыОЭжЊЕРЛљгквбгаЕФВЂЗЂЙЄОпРрРДжиЙЙВЂЗЂДњТыЕНЕзКУдкФФРяСЫЁЃ
ЛљгкwaitКЭnotifyЕФЪЕЯж
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* ЙЋЙВГЃСП
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE =
10;
public static final int NUM_OF_PRODUCER =
2;
public static final int NUM_OF_CONSUMER =
3;
}
/**
* ЙЄзїШЮЮё
*
*/
class Task {
private String id; // ШЮЮёЕФБрКХ
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" +id + "]";
}
}
/**
* ЯћЗбеп
*
*/
class Consumer implements Runnable {
private List<Task>buffer;
public Consumer(List<Task>buffer) {
this.buffer =buffer;
}
@Override
public void run() {
while(true) {
synchronized(buffer) {
while(buffer.isEmpty()) {
try {
buffer.wait();
} catch(InterruptedExceptione) {
e.printStackTrace();
}
}
Task task = buffer.remove(0);
buffer.notifyAll();
System.out.println("Consumer[" +
Thread.currentThread().getName() +"] got
" + task);
}
}
}
}
/**
* ЩњВњеп
*
*/
class Producer implements Runnable {
private List<Task>buffer;
public Producer(List<Task>buffer) {
this.buffer =buffer;
}
@Override
public void run() {
while(true) {
synchronized (buffer) {
while(buffer.size() >= Constants.MAX_BUFFER_SIZE)
{
try {
buffer.wait();
} catch(InterruptedExceptione) {
e.printStackTrace();
}
}
Task task = new Task();
buffer.add(task);
buffer.notifyAll();
System.out.println("Producer[" +
Thread.currentThread().getName() +"] put
" + task);
}
}
}
}
public class Test06 {
public static void main(String[]args) {
List<Task> buffer = new ArrayList<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER
+ Constants.NUM_OF_PRODUCER);
for(int i = 1;i <= Constants.NUM_OF_PRODUCER;
++i) {
es.execute(new Producer(buffer));
}
for(int i = 1;i <= Constants.NUM_OF_CONSUMER;
++i) {
es.execute(new Consumer(buffer));
}
}
} |
ЛљгкBlockingQueueЕФЪЕЯж
import java.util.UUID;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
/**
* ЙЋЙВГЃСП
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE =
10;
public static final int NUM_OF_PRODUCER =
2;
public static final int NUM_OF_CONSUMER =
3;
}
/**
* ЙЄзїШЮЮё
*
*/
class Task {
private String id; // ШЮЮёЕФБрКХ
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" +id + "]";
}
}
/**
* ЯћЗбеп
*
*/
class Consumer implements Runnable {
private BlockingQueue<Task>buffer;
public Consumer(BlockingQueue<Task>buffer)
{
this.buffer =buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = buffer.take();
System.out.println("Consumer[" +
Thread.currentThread().getName() +"] got
" + task);
} catch (InterruptedExceptione) {
e.printStackTrace();
}
}
}
}
/**
* ЩњВњеп
*
*/
class Producer implements Runnable {
private BlockingQueue<Task>buffer;
public Producer(BlockingQueue<Task>buffer)
{
this.buffer =buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = new Task();
buffer.put(task);
System.out.println("Producer[" +
Thread.currentThread().getName() +"] put
" + task);
} catch (InterruptedExceptione) {
e.printStackTrace();
}
}
}
}
public class Test07 {
public static void main(String[]args) {
BlockingQueue<Task> buffer =new LinkedBlockingQueue<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER
+ Constants.NUM_OF_PRODUCER);
for(int i = 1;i <= Constants.NUM_OF_PRODUCER;
++i) {
es.execute(new Producer(buffer));
}
for(int i = 1;i <= Constants.NUM_OF_CONSUMER;
++i) {
es.execute(new Consumer(buffer));
}
}
} |
ЪЙгУBlockingQueueКѓДњТыгХбХСЫКмЖрЁЃ
ВЂЗЂФЃаЭ
дкМЬајЯТУцЕФЬНЬжжЎЧАЃЌЮвУЧЛЙЪЧжиЮТвЛЯТМИИіИХФюЃК
|
ИХФю
|
НтЪЭ
|
|
СйНчзЪдД
|
ВЂЗЂЛЗОГжагазХЙЬЖЈЪ§СПЕФзЪдД
|
|
ЛЅГт
|
ЖдзЪдДЕФЗУЮЪЪЧХХЫћЪНЕФ
|
|
МЂЖі
|
вЛИіЛђвЛзщЯпГЬГЄЪБМфЛђгРдЖЮоЗЈШЁЕУНјеЙ
|
|
ЫРЫј
|
СНИіЛђЖрИіЯпГЬЯрЛЅЕШД§ЖдЗННсЪј
|
|
ЛюЫј
|
ЯывЊжДааЕФЯпГЬзмЪЧЗЂЯжЦфЫћЕФЯпГЬе§дкжДаавджСгкГЄЪБМфЛђгРдЖЮоЗЈжДаа
|
жиЮТСЫетМИИіИХФюКѓЃЌЮвУЧПЩвдЬНЬжвЛЯТЯТУцЕФМИжжВЂЗЂФЃаЭЁЃ
ЩњВњеп-ЯћЗбеп
вЛИіЛђЖрИіЩњВњепДДНЈФГаЉЙЄзїВЂНЋЦфжУгкЛКГхЧјЛђЖгСажаЃЌвЛИіЛђЖрИіЯћЗбепЛсДгЖгСажаЛёЕУетаЉЙЄзїВЂЭъГЩжЎЁЃетРяЕФЛКГхЧјЛђЖгСаЪЧСйНчзЪдДЁЃЕБЛКГхЧјЛђЖгСаЗХТњЕФЪБКђЃЌЩњВњетЛсБЛзшШћЃЛЖјЛКГхЧјЛђЖгСаЮЊПеЕФЪБКђЃЌЯћЗбепЛсБЛзшШћЁЃЩњВњепКЭЯћЗбепЕФЕїЖШЪЧЭЈЙ§ЖўепЯрЛЅНЛЛЛаХКХЭъГЩЕФЁЃ
ЖСеп-аДеп
ЕБДцдквЛИіжївЊЮЊЖСепЬсЙЉаХЯЂЕФЙВЯэзЪдДЃЌЫќХМЖћЛсБЛаДепИќаТЃЌЕЋЪЧашвЊПМТЧЯЕЭГЕФЭЬЭТСПЃЌгжвЊЗРжЙМЂЖіКЭГТОЩзЪдДЕУВЛЕНИќаТЕФЮЪЬтЁЃдкетжжВЂЗЂФЃаЭжаЃЌШчКЮЦНКтЖСепКЭаДепЪЧзюРЇФбЕФЃЌЕБШЛетИіЮЪЬтжСНёЛЙЪЧвЛИіБЛШШвщЕФЮЪЬтЃЌПжХТБиаыИљОнОпЬхЕФГЁОАРДЬсЙЉКЯЪЪЕФНтОіЗНАИЖјУЛгаФЧжжЗХжЎЫФКЃЖјНдзМЕФЗНЗЈЃЈВЛЯёЮвдкЙњФкЕФПЦбаЮФЯзжаПДЕНЕФФЧбљЃЉЁЃ
ембЇМвНјВЭ
1965ФъЃЌКЩРММЦЫуЛњПЦбЇМвЭМСщНБЕУжїEdsger Wybe DijkstraЬсГіВЂНтОіСЫвЛИіЫћГЦжЎЮЊембЇМвНјВЭЕФЭЌВНЮЪЬтЁЃетИіЮЪЬтПЩвдМђЕЅЕиУшЪіШчЯТЃКЮхИіембЇМвЮЇзјдквЛеХдВзРжмЮЇЃЌУПИіембЇМвУцЧАЖМгавЛХЬЭЈаФЗлЁЃгЩгкЭЈаФЗлКмЛЌЃЌЫљвдашвЊСНАбВцзгВХФмМазЁЁЃЯрСкСНИіХЬзгжЎМфЗХгавЛАбВцзгШчЯТЭМЫљЪОЁЃембЇМвЕФЩњЛюжагаСНжжНЛЬцЛюЖЏЪБЖЮЃКМДГдЗЙКЭЫМПМЁЃЕБвЛИіембЇМвОѕЕУЖіСЫЪБЃЌЫћОЭЪдЭМЗжСНДЮШЅШЁЦфзѓБпКЭгвБпЕФВцзгЃЌУПДЮФУвЛАбЃЌЕЋВЛЗжДЮађЁЃШчЙћГЩЙІЕиЕУЕНСЫСНАбВцзгЃЌОЭПЊЪМГдЗЙЃЌГдЭъКѓЗХЯТВцзгМЬајЫМПМЁЃ
АбЩЯУцЮЪЬтжаЕФембЇМвЛЛГЩЯпГЬЃЌАбВцзгЛЛГЩОКељЕФСйНчзЪдДЃЌЩЯУцЕФЮЪЬтОЭЪЧЯпГЬОКељзЪдДЕФЮЪЬтЁЃШчЙћУЛгаОЙ§ОЋаФЕФЩшМЦЃЌЯЕЭГОЭЛсГіЯжЫРЫјЁЂЛюЫјЁЂЭЬЭТСПЯТНЕЕШЮЪЬтЁЃ
ЯТУцЪЧгУаХКХСПдгяРДНтОіембЇМвНјВЭЮЪЬтЕФДњТыЃЌЪЙгУСЫJava 5ВЂЗЂЙЄОпАќжаЕФSemaphoreРрЃЈДњТыВЛЙЛЦЏССЕЋЪЧвбОзувдЫЕУїЮЪЬтСЫЃЉЁЃ
//import java.util.concurrent.ExecutorService;
//import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* ДцЗХЯпГЬЙВЯэаХКХСПЕФЩЯЯТЮЪ
*
*/
class AppContext {
public static final int NUM_OF_FORKS = 5;
// ВцзгЪ§СП(зЪдД)
public static final int NUM_OF_PHILO = 5;
// ембЇМвЪ§СП(ЯпГЬ)
public static Semaphore[]forks; // ВцзгЕФаХКХСП
public static Semaphorecounter; // ембЇМвЕФаХКХСП
static {
forks = new Semaphore[NUM_OF_FORKS];
for (int i = 0,len = forks.length;i < len;
++i) {
forks[i] =new Semaphore(1); // УПИіВцзгЕФаХКХСПЮЊ1
}
counter = new Semaphore(NUM_OF_PHILO - 1);
// ШчЙћгаNИіембЇМвЃЌзюЖржЛдЪаэN-1ШЫЭЌЪБШЁВцзг
}
/**
* ШЁЕУВцзг
* @param index ЕкМИИіембЇМв
* @param leftFirst ЪЧЗёЯШШЁЕУзѓБпЕФВцзг
* @throws InterruptedException
*/
public static void putOnFork(int index,boolean
leftFirst)throws InterruptedException {
if(leftFirst) {
forks[index].acquire();
forks[(index + 1) %NUM_OF_PHILO].acquire();
}
else {
forks[(index + 1) %NUM_OF_PHILO].acquire();
forks[index].acquire();
}
}
/**
* ЗХЛиВцзг
* @param index ЕкМИИіембЇМв
* @param leftFirst ЪЧЗёЯШЗХЛизѓБпЕФВцзг
* @throws InterruptedException
*/
public static void putDownFork(int index,boolean
leftFirst)throws InterruptedException {
if(leftFirst) {
forks[index].release();
forks[(index + 1) %NUM_OF_PHILO].release();
}
else {
forks[(index + 1) %NUM_OF_PHILO].release();
forks[index].release();
}
}
}
/**
* ембЇМв
*
*/
class Philosopher implements Runnable {
private int index; // БрКХ
private String name; // Ућзж
public Philosopher(int index, Stringname)
{
this.index =index;
this.name =name;
}
@Override
public void run() {
while(true) {
try {
AppContext.counter.acquire();
boolean leftFirst =index % 2 == 0;
AppContext.putOnFork(index,leftFirst);
System.out.println(name +"е§дкГдвтДѓРћУцЃЈЭЈаФЗлЃЉ...");
// ШЁЕНСНИіВцзгОЭПЩвдНјЪГ
AppContext.putDownFork(index,leftFirst);
AppContext.counter.release();
} catch (InterruptedExceptione) {
e.printStackTrace();
}
}
}
}
public class Test04 {
public static void main(String[]args) {
String[] names = { "ТцъЛ", "ЭѕДѓДИ",
"еХШ§Зс", "бюЙ§", "РюФЊГю"
}; // 5ЮЛембЇМвЕФУћзж
// ExecutorService es = Executors.newFixedThreadPool(AppContext.NUM_OF_PHILO);
// ДДНЈЙЬЖЈДѓаЁЕФЯпГЬГи
// for(int i = 0,len = names.length; i <len;
++i) {
// es.execute(new Philosopher(i, names[i]));
// ЦєЖЏЯпГЬ
// }
// es.shutdown();
for(int i = 0,len = names.length; i < len;
++i) {
new Thread(new Philosopher(i,names[i])).start();
}
}
} |
ЯжЪЕжаЕФВЂЗЂЮЪЬтЛљБОЩЯЖМЪЧетШ§жжФЃаЭЛђепЪЧетШ§жжФЃаЭЕФБфЬхЁЃ
ВтЪдВЂЗЂДњТы
ЖдВЂЗЂДњТыЕФВтЪдвВЪЧЗЧГЃМЌЪжЕФЪТЧщЃЌМЌЪжЕНЮоашЫЕУїДѓМввВКмЧхГўЕФГЬЖШЃЌЫљвдетРяЮвУЧжЛЪЧЬНЬжвЛЯТШчКЮНтОіетИіМЌЪжЕФЮЪЬтЁЃЮвУЧНЈвщДѓМвБраДвЛаЉФмЙЛЗЂЯжЮЪЬтЕФВтЪдВЂОГЃадЕФдкВЛЭЌЕФХфжУКЭВЛЭЌЕФИКдиЯТдЫааетаЉВтЪдЁЃВЛвЊКіТдЕєШЮКЮвЛДЮЪЇАмЕФВтЪдЃЌЯпГЬДњТыжаЕФШБЯнПЩФмдкЩЯЭђДЮВтЪджаНіНіГіЯжвЛДЮЁЃОпЬхРДЫЕгаетУДМИИізЂвтЪТЯюЃК
ЁЄ ВЛвЊНЋЯЕЭГЕФЪЇаЇЙщНсгкХМЗЂЪТМўЃЌОЭЯёРВЛГіЪКЕФЪБКђВЛФмЙжЕиЧђУЛгав§СІЁЃ
ЁЄ ЯШШУЗЧВЂЗЂДњТыЙЄзїЦ№РДЃЌВЛвЊЪдЭМЭЌЪБевЕНВЂЗЂКЭЗЧВЂЗЂДњТыжаЕФШБЯнЁЃ
ЁЄ БраДПЩвддкВЛЭЌХфжУЛЗОГЯТдЫааЕФЯпГЬДњТыЁЃ
ЁЄ БраДШнвзЕїећЕФЯпГЬДњТыЃЌетбљПЩвдЕїећЯпГЬЪЙадФмДяЕНзюгХЁЃ
ЁЄ ШУЯпГЬЕФЪ§СПЖргкCPUЛђCPUКЫаФЕФЪ§СПЃЌетбљCPUЕїЖШЧаЛЛЙ§ГЬжаЧБдкЕФЮЪЬтВХЛсБЉТЖГіРДЁЃ
ЁЄ ШУВЂЗЂДњТыдкВЛЭЌЕФЦНЬЈЩЯдЫааЁЃ
ЁЄ ЭЈЙ§здЖЏЛЏЛђепгВБрТыЕФЗНЪНЯђВЂЗЂДњТыжаМгШывЛаЉИЈжњВтЪдЕФДњТыЁЃ
Java 7ЕФВЂЗЂБрГЬ
Java 7жав§ШыСЫTransferQueueЃЌЫќБШBlockingQueueЖрСЫвЛИіНаtransferЕФЗНЗЈЃЌШчЙћНгЪеЯпГЬДІгкЕШД§зДЬЌЃЌИУВйзїПЩвдТэЩЯНЋШЮЮёНЛИјЫќЃЌЗёдђОЭЛсзшШћжБжСШЁзпИУШЮЮёЕФЯпГЬГіЯжЁЃПЩвдгУTransferQueueДњЬцBlockingQueueЃЌвђЮЊЫќПЩвдЛёЕУИќКУЕФадФмЁЃ
ИеВХЭќМЧСЫвЛМўЪТЧщЃЌJava 5жаЛЙв§ШыСЫCallableНгПкЁЂFutureНгПкКЭFutureTaskНгПкЃЌЭЈЙ§ЫћУЧвВПЩвдЙЙНЈВЂЗЂгІгУГЬађЃЌДњТыШчЯТЫљЪОЁЃ
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Test07 {
private static final int POOL_SIZE = 10;
static class CalcThreadimplements Callable<Double>
{
private List<Double>dataList = new ArrayList<>();
public CalcThread() {
for(int i = 0;i < 10000; ++i) {
dataList.add(Math.random());
}
}
@Override
public Double call()throws Exception {
double total = 0;
for(Doubled : dataList) {
total += d;
}
return total /dataList.size();
}
}
public static void main(String[]args) {
List<Future<Double>> fList =new
ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(POOL_SIZE);
for(int i = 0;i < POOL_SIZE; ++i) {
fList.add(es.submit(new CalcThread()));
}
for(Future<Double>f : fList) {
try {
System.out.println(f.get());
} catch (Exceptione) {
e.printStackTrace();
}
}
es.shutdown();
}
} |
CallableНгПквВЪЧвЛИіЕЅЗНЗЈНгПкЃЌЯдШЛетЪЧвЛИіЛиЕїЗНЗЈЃЌРрЫЦгкКЏЪ§ЪНБрГЬжаЕФЛиЕїКЏЪ§ЃЌдкJava
8 вдЧАЃЌJavaжаЛЙВЛФмЪЙгУLambdaБэДяЪНРДМђЛЏетжжКЏЪ§ЪНБрГЬЁЃКЭRunnableНгПкВЛЭЌЕФЪЧCallableНгПкЕФЛиЕїЗНЗЈcallЗНЗЈЛсЗЕЛивЛИіЖдЯѓЃЌетИіЖдЯѓПЩвдгУНЋРДЪБЕФЗНЪНдкЯпГЬжДааНсЪјЕФЪБКђЛёЕУаХЯЂЁЃЩЯУцДњТыжаЕФcallЗНЗЈОЭЪЧНЋМЦЫуГіЕФ10000Иі0ЕН1жЎМфЕФЫцЛњаЁЪ§ЕФЦНОљжЕЗЕЛиЃЌЮвУЧЭЈЙ§вЛИіFutureНгПкЕФЖдЯѓЕУЕНСЫетИіЗЕЛижЕЁЃФПЧАзюаТЕФJavaАцБОжаЃЌCallableНгПкКЭRunnableНгПкЖМБЛДђЩЯСЫ@FunctionalInterfaceЕФзЂНтЃЌвВОЭЪЧЫЕЫќПЩвдгУКЏЪ§ЪНБрГЬЕФЗНЪНЃЈLambdaБэДяЪНЃЉДДНЈНгПкЖдЯѓЁЃ
ЯТУцЪЧFutureНгПкЕФжївЊЗНЗЈЃК
ЁЄ 1.get()ЃКЛёШЁНсЙћЁЃШчЙћНсЙћЛЙУЛгазМБИКУЃЌgetЗНЗЈЛсзшШћжБЕНШЁЕУНсЙћЃЛЕБШЛвВПЩвдЭЈЙ§ВЮЪ§ЩшжУзшШћГЌЪБЪБМфЁЃ
ЁЄ 2.cancel()ЃКдкдЫЫуНсЪјЧАШЁЯћЁЃ
ЁЄ 3.isDone()ЃКПЩвдгУРДХаЖЯдЫЫуЪЧЗёНсЪјЁЃ
Java 7жаЛЙЬсЙЉСЫЗжжЇ/КЯВЂЃЈfork/joinЃЉПђМмЃЌЫќПЩвдЪЕЯжЯпГЬГижаШЮЮёЕФздЖЏЕїЖШЃЌВЂЧветжжЕїЖШЖдгУЛЇРДЫЕЪЧЭИУїЕФЁЃЮЊСЫДяЕНетжжаЇЙћЃЌБиаыАДеегУЛЇжИЖЈЕФЗНЪНЖдШЮЮёНјааЗжНтЃЌШЛКѓдйНЋЗжНтГіЕФаЁаЭШЮЮёЕФжДааНсЙћКЯВЂГЩдРДШЮЮёЕФжДааНсЙћЁЃетЯдШЛЪЧдЫгУСЫЗжжЮЗЈЃЈdivide-and-conquerЃЉЕФЫМЯыЁЃЯТУцЕФДњТыЪЙгУСЫЗжжЇ/КЯВЂПђМмРДМЦЫу1ЕН10000ЕФКЭЃЌЕБШЛЖдгкШчДЫМђЕЅЕФШЮЮёИљБОВЛашвЊЗжжЇ/КЯВЂПђМмЃЌвђЮЊЗжжЇКЭКЯВЂБОЩэвВЛсДјРДвЛЖЈЕФПЊЯњЃЌЕЋЪЧетРяЮвУЧжЛЪЧЬНЫївЛЯТдкДњТыжаШчКЮЪЙгУЗжжЇ/КЯВЂПђМмЃЌШУЮвУЧЕФДњТыФмЙЛГфЗжРћгУЯжДњЖрКЫCPUЕФЧПДѓдЫЫуФмСІЁЃ
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
class Calculator extends RecursiveTask<Integer>
{
private static final long serialVersionUID
= 7333472779649130114L;
private static final int THRESHOLD = 10;
private int start;
private int end;
public Calculator(int start,int end) {
this.start =start;
this.end =end;
}
@Override
public Integer compute() {
int sum = 0;
if ((end -start) < THRESHOLD) { // ЕБЮЪЬтЗжНтЕНПЩЧѓНтГЬЖШЪБжБНгМЦЫуНсЙћ
for (int i =start; i <= end; i++) {
sum += i;
}
} else {
int middle = (start +end) >>> 1;
// НЋШЮЮёвЛЗжЮЊЖў
Calculator left = new Calculator(start,middle);
Calculator right = new Calculator(middle +
1,end);
left.fork();
right.fork();
// зЂвтЃКгЩгкДЫДІЪЧЕнЙщЪНЕФШЮЮёЗжНтЃЌвВОЭвтЮЖзХНгЯТРДЛсЖўЗжЮЊЫФЃЌЫФЗжЮЊАЫ...
sum = left.join() + right.join(); // КЯВЂСНИізгШЮЮёЕФНсЙћ
}
return sum;
}
}
public class Test08 {
public static void main(String[]args) throws
Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future<Integer> result = forkJoinPool.submit(new
Calculator(1, 10000));
System.out.println(result.get());
}
} |
АщЫцзХJava 7ЕФЕНРДЃЌJavaжаФЌШЯЕФЪ§зщХХађЫуЗЈвбОВЛдйЪЧОЕфЕФПьЫйХХађЃЈЫЋЪржсПьЫйХХађЃЉСЫЃЌаТЕФХХађЫуЗЈНаTimSortЃЌЫќЪЧЙщВЂХХађКЭВхШыХХађЕФЛьКЯЬхЃЌTimSortПЩвдЭЈЙ§ЗжжЇКЯВЂПђМмГфЗжРћгУЯжДњДІРэЦїЕФЖрКЫЬиадЃЌДгЖјЛёЕУИќКУЕФадФмЃЈИќЖЬЕФХХађЪБМфЃЉЁЃ
|