由于本学期好多神都选了Cisco网络课,
而我这等弱渣没选, 去蹭了一节发现讲的内容虽然我不懂但是还是无爱. 我想既然都本科就出来工作还是按照自己爱好来点技能吧,
于是我就不去了. 一个人在宿舍没有点计划好的事情做就会很容易虚度, 正好这个学期主打网络与数据库开发,
那就先学学Python开发爬虫吧. 我失散多年的好朋友Jay Loong突然说他会爬虫了, 我感到真棒,
我也要学 :D 因为一个星期有两节Cisco课, 所以本系列博文也就一周两更.
选择一门语言
爬虫可以用各种语言写, C++, Java都可以, 为什么要Python?
首先用C++搞网络开发的例子不多(可能是我见得太少), 然后由于Oracle收购了Sun, Java目前虽然在Android开发上很重要,
但是如果Google官司进展不顺利, 那么很有可能用Go语言替代掉Java来做Android开发. 在这计算机速度高速增长的年代里,
选语言都要看他爹的业绩, 真是稍不注意就落后于时代. 随着计算机速度的高速发展, 某种语言开发的软件运行的时间复杂度的常数系数已经不像以前那么重要,
我们可以越来越偏爱为程序员打造的而不是为计算机打造的语言. 比如Ruby这种传说中的纯种而又飘逸的的OOP语言,
或者Python这种稍严谨而流行库又非常多的语言, 都大大弱化了针对计算机运行速度而打造的特性, 强化了为程序员容易思考而打造的特性.
所以我选择Python.
选择Python版本
有2和3两个版本, 3比较新, 听说改动大. 根据我在知乎上搜集的观点来看,
我还是倾向于使用”在趋势中将会越来越火”的版本, 而非”目前已经很稳定而且很成熟”的版本. 这是个人喜好,
而且预测不一定准确. 但是如果Python3无法像Python2那么火, 那么整个Python语言就不可避免的随着时间的推移越来越落后,
因此我想其实选哪个的最坏风险都一样, 但是最好回报却是Python3的大. 其实两者区别也可以说大也可以说不大,
最终都不是什么大问题. 我选择的是Python 3.
一个简单的伪代码
以下这个简单的伪代码用到了set和queue这两种经典的数据结构, 集与队列.
集的作用是记录那些已经访问过的页面, 队列的作用是进行广度优先搜索.
queue Q
set S
StartPoint = "http://jecvay.com"
Q.push(StartPoint) # 经典的BFS开头
S.insert(StartPoint) # 访问一个页面之前先标记他为已访问
while (Q.empty() == false) # BFS循环体
T = Q.top() # 并且pop
for point in PageUrl(T) # PageUrl(T)是指页面T中所有url的集合, point是这个集合中的一个元素.
if (point not in S)
Q.push(point)
S.insert(point)
|
这个伪代码不能执行, 我觉得我写的有的不伦不类, 不类Python也不类C++.. 但是我相信看懂是没问题的,
这就是个最简单的BFS结构. 我是看了知乎里面的那个伪代码之后, 自己用我的风格写了一遍. 你也需要用你的风格写一遍.
这里用到的Set其内部原理是采用了Hash表, 传统的Hash对爬虫来说占用空间太大,
因此有一种叫做Bloom Filter的数据结构更适合用在这里替代Hash版本的set. 我打算以后再看这个数据结构怎么使用,
现在先跳过, 因为对于零基础的我来说, 这不是重点.
代码实现(一): 用Python抓取指定页面
我使用的编辑器是Idle, 安装好Python3后这个编辑器也安装好了,
小巧轻便, 按一个F5就能运行并显示结果. 代码如下:
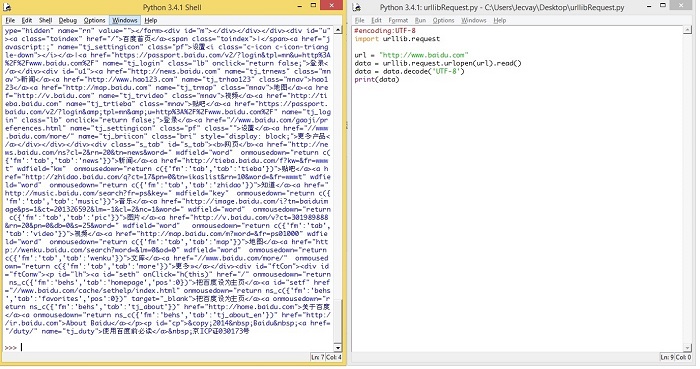
#encoding:UTF-8
import urllib.request
url = "http://www.baidu.com"
data = urllib.request.urlopen(url).read()
data = data.decode('UTF-8')
print(data)
|
urllib.request是一个库, 隶属urllib. 点此打开官方相关文档.
官方文档应该怎么使用呢? 首先点刚刚提到的这个链接进去的页面有urllib的几个子库, 我们暂时用到了request,
所以我们先看urllib.request部分. 首先看到的是一句话介绍这个库是干什么用的:
The urllib.request module defines functions
and classes which help in opening URLs (mostly HTTP)
in a complex world ― basic and digest authentication,
redirections, cookies and more.
然后把我们代码中用到的urlopen()函数部分阅读完.
urllib.request.urlopen(url, data=None,
[timeout, ]*, cafile=None, capath=None, cadefault=False)
重点部分是返回值, 这个函数返回一个 http.client.HTTPResponse
对象, 这个对象又有各种方法, 比如我们用到的read()方法, 这些方法都可以根据官方文档的链接链过去.
根据官方文档所写, 我用控制台运行完毕上面这个程序后, 又继续运行如下代码, 以更熟悉这些乱七八糟的方法是干什么的.
>>> a = urllib.request.urlopen(full_url)
>>> type(a)
<class ‘http.client.HTTPResponse’>
>>> a.geturl()
‘http://www.baidu.com/s?word=Jecvay’
>>> a.info()
<http.client.HTTPMessage object at 0x03272250>
>>> a.getcode()
200
|
代码实现(二): 用Python简单处理URL
如果要抓取百度上面搜索关键词为Jecvay Notes的网页, 则代码如下
import urllib
import urllib.request
data={}
data['word']='Jecvay Notes'
url_values=urllib.parse.urlencode(data)
url="http://www.baidu.com/s?"
full_url=url+url_values
data=urllib.request.urlopen(full_url).read()
data=data.decode('UTF-8')
print(data)
|
data是一个字典, 然后通过urllib.parse.urlencode()来将data转换为 ‘word=Jecvay+Notes’的字符串,
最后和url合并为full_url, 其余和上面那个最简单的例子相同. 关于urlencode(), 同样通过官方文档学习一下他是干什么的.
通过查看
1.urllib.parse.urlencode(query, doseq=False, safe=”, encoding=None, errors=None)
2.urllib.parse.quote_plus(string, safe=”, encoding=None, errors=None)
|
大概知道他是把一个通俗的字符串, 转化为url格式的字符串.
这一回, 开始用Python将伪代码中的所有部分实现. 由于文章的标题就是”零基础”,
因此会先把用到的两种数据结构队列和集合介绍一下. 而对于”正则表达式“部分, 限于篇幅不能介绍, 但给出我比较喜欢的几个参考资料.
Python的队列
在爬虫程序中, 用到了广度优先搜索(BFS)算法. 这个算法用到的数据结构就是队列.
Python的List功能已经足够完成队列的功能, 可以用 append() 来向队尾添加元素, 可以用类似数组的方式来获取队首元素,
可以用 pop(0) 来弹出队首元素. 但是List用来完成队列功能其实是低效率的, 因为List在队首使用
pop(0) 和 insert() 都是效率比较低的, Python官方建议使用collection.deque来高效的完成队列任务.
from collections import deque
queue = deque(["Eric", "John", "Michael"])
queue.append("Terry") # Terry 入队
queue.append("Graham") # Graham 入队
queue.popleft() # 队首元素出队
#输出: 'Eric'
queue.popleft() # 队首元素出队
#输出: 'John'
queue # 队列中剩下的元素
#输出: deque(['Michael', 'Terry', 'Graham'])
|
Python的集合
在爬虫程序中, 为了不重复爬那些已经爬过的网站, 我们需要把爬过的页面的url放进集合中, 在每一次要爬某一个url之前,
先看看集合里面是否已经存在. 如果已经存在, 我们就跳过这个url; 如果不存在, 我们先把url放入集合中,
然后再去爬这个页面.
Python提供了set这种数据结构. set是一种无序的, 不包含重复元素的结构. 一般用来测试是否已经包含了某元素,
或者用来对众多元素们去重. 与数学中的集合论同样, 他支持的运算有交, 并, 差, 对称差.
创建一个set可以用 set() 函数或者花括号 {} . 但是创建一个空集是不能使用一个花括号的,
只能用 set() 函数. 因为一个空的花括号创建的是一个字典数据结构. 以下同样是Python官网提供的示例.
>>> basket = {'apple', 'orange', 'apple', 'pear', 'orange', 'banana'}
>>> print(basket) # 这里演示的是去重功能
{'orange', 'banana', 'pear', 'apple'}
>>> 'orange' in basket # 快速判断元素是否在集合内
True
>>> 'crabgrass' in basket
False
>>> # 下面展示两个集合间的运算.
...
>>> a = set('abracadabra')
>>> b = set('alacazam')
>>> a
{'a', 'r', 'b', 'c', 'd'}
>>> a - b # 集合a中包含元素
{'r', 'd', 'b'}
>>> a | b # 集合a或b中包含的所有元素
{'a', 'c', 'r', 'd', 'b', 'm', 'z', 'l'}
>>> a & b # 集合a和b中都包含了的元素
{'a', 'c'}
>>> a ^ b # 不同时包含于a和b的元素
{'r', 'd', 'b', 'm', 'z', 'l'}
|
其实我们只是用到其中的快速判断元素是否在集合内的功能, 以及集合的并运算.
Python的正则表达式
在爬虫程序中, 爬回来的数据是一个字符串, 字符串的内容是页面的html代码. 我们要从字符串中, 提取出页面提到过的所有url.
这就要求爬虫程序要有简单的字符串处理能力, 而正则表达式可以很轻松的完成这一任务.
虽然正则表达式功能异常强大, 很多实际上用的规则也非常巧妙, 真正熟练正则表达式需要比较长的实践锻炼.
不过我们只需要掌握如何使用正则表达式在一个字符串中, 把所有的url都找出来, 就可以了. 如果实在想要跳过这一部分,
可以在网上找到很多现成的匹配url的表达式, 拿来用即可.
Python网络爬虫Ver 1.0 alpha
有了以上铺垫, 终于可以开始写真正的爬虫了. 我选择的入口地址是Fenng叔的Startup News,
我想Fenng叔刚刚拿到7000万美金融资, 不会介意大家的爬虫去光临他家的小站吧. 这个爬虫虽然可以勉强运行起来,
但是由于缺乏异常处理, 只能爬些静态页面, 也不会分辨什么是静态什么是动态, 碰到什么情况应该跳过, 所以工作一会儿就要败下阵来.
import re
import urllib.request
import urllib
from collections import deque
queue = deque()
visited = set()
url = 'http://news.dbanotes.net' # 入口页面, 可以换成别的
queue.append(url)
cnt = 0
while queue:
url = queue.popleft() # 队首元素出队
visited |= {url} # 标记为已访问
print('已经抓取: ' + str(cnt) + ' 正在抓取 <--- ' + url)
cnt += 1
urlop = urllib.request.urlopen(url)
if 'html' not in urlop.getheader('Content-Type'):
continue
# 避免程序异常中止, 用try..catch处理异常
try:
data = urlop.read().decode('utf-8')
except:
continue
# 正则表达式提取页面中所有队列, 并判断是否已经访问过, 然后加入待爬队列
linkre = re.compile('href=\"(.+?)\"')
for x in linkre.findall(data):
if 'http' in x and x not in visited:
queue.append(x)
print('加入队列 ---> ' + x)
|
这个版本的爬虫使用的正则表达式是
所以会把那些.ico或者.jpg的链接都爬下来. 这样read()了之后碰上decode(‘utf-8′)就要抛出异常.
因此我们用getheader()函数来获取抓取到的文件类型, 是html再继续分析其中的链接.
if 'html' not in urlop.getheader('Content-Type'):
continue
|
但是即使是这样, 依然有些网站运行decode()会异常. 因此我们把decode()函数用try..catch语句包围住,
这样他就不会导致程序中止. 程序运行效果图如下:
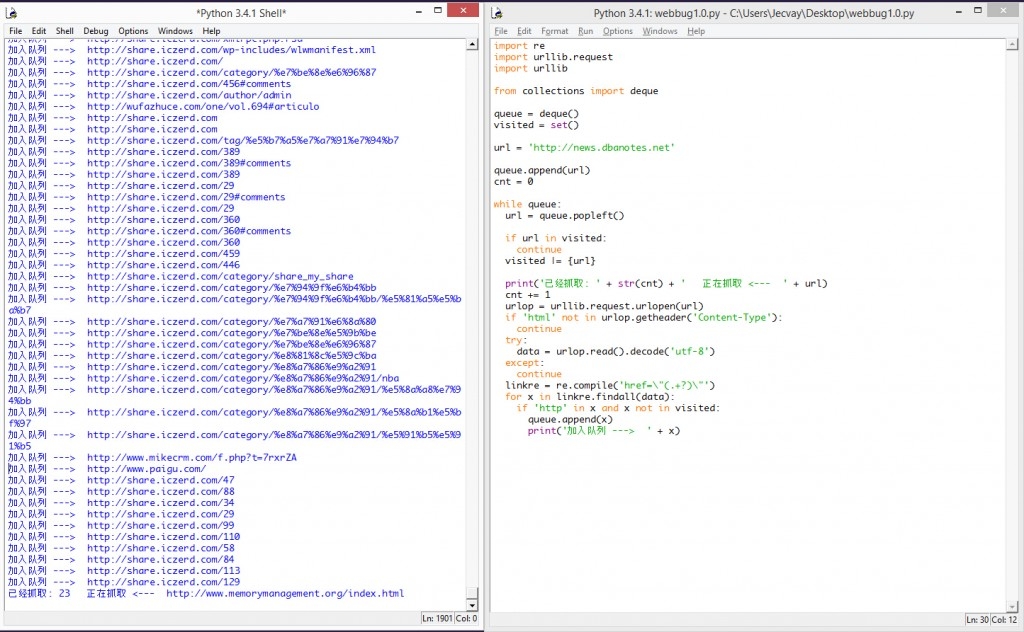
下回预告
爬虫是可以工作了,但是在碰到连不上的链接的时候,它并不会超时跳过。而且爬到的内容并没有进行处理,没有获取对我们有价值的信息,也没有保存到本地。下次我们可以完善这个alpha版本。
|






