|
用科学实验来衡量哪些代码异味最难维护。
如何处理有异味的代码?
前辈曾经教导我们,作为开发人员,我们最主要的职责就是不要写烂代码。除非你是单兵作战并且只是写几行很快就会弃用的Perl脚本而已,否则最重要的一点,就是你写的代码必须易于阅读和理解。在软件产品的整个生命周期中,可维护的代码通常会免除你和你的同事们呆坐在电脑前痛苦绝望的很多时间。
然而,导致代码可读性差的原因却不总是那么清晰,这就是为什么像代码编写标准、准则、代码模式和编程语言箴言之类的东西存在的原因之一。一条众所周知的准则是Martin
Fowler【1】写的《重构》这本书,书里描述了一系列的代码异味以及去掉这些异味的重构策略。尽管拥有这个无可估价的资源,我们依然面临挑战――除了要学习很多重构策略,还需要决定哪些的优先级比较高。显然,它们不可能同样重要!我们如何得知现在做的代码重构工作会有长期正面效益呢?
问题在于Martin Fowler的重构书没有提及哪些代码异味是关键的,哪些不是。Fowler他自己也提到,没有哪个标准或指标能够比得上人的直觉。我们作为开发人员来说只能依靠直觉和经验去决定是否需要重构。这可能是一场噩梦。面对一个有数千个代码异味的系统,你要从何处入手?除此之外,任何对代码的改动都可能带来意向不到的副作用。就算有高质量的自动化测试,修改代码常常蕴含高风险而且代价昂贵。如果知道哪些代码异味是最具破坏性,先把它们处理掉就好了。另外,我们希望向管理层展示,我们并不是浪费时间在为了写漂亮代码而写漂亮代码上,而是我们当前的努力能够在未来为项目带来长期效益。
【补充】:在软件开发领域,代码中的任何可能导致深层次问题的症状都可以叫做代码异味。
通常,在对代码做简短的反馈迭代时,代码异味会暴露出一些深层次的问题,这里的反馈迭代,是指以一种小范围的、可控的方式重构代码。基于这些暴露的问题,人们会进一步的检查设计和代码中是否还存在别的代码异味,然后再做进一步的重构。从负责重构的开发者的角度来看,代码异味可以启发何时重构,如何重构。因此,可以说代码异味推动着重构的进行。(摘自维基百科)
收集关于代码异味的事实
2009年,挪威Simula研究所需要把一个内部系统改造成一个新的内容管理系统。这个项目被外包给6个Java开发人员。这个项目被认为是深入研究代码异味对可维护性造成影响的机会。
在这个项目持续的三个月中,他们使用了一些工具来衡量代码异味,每天跟那些开发人员面谈,并且每个开发人员的Eclipse
IDE上都安装了一个日志记录工具。这个日志记录工具不但记录修改每个文件花了多长时间,而且记录了花在搜索,浏览以及翻阅代码所花费的时间。
在这个项目过程中,他们使用一个问题追踪工具登记下那些开发人员所面临的问题,然后反向追踪到那些引起问题的源代码文件。除此之外,所有的开发人员都要接受面谈。这个过程中收集到的数据远远多于常规的仅仅分析代码仓库的方法。以下是所得到的观察结果:
观察结果1:万能类其实很糟糕!
“人人都知道”万能类是不好的,可是到底不好到什么程度?如下图所示:
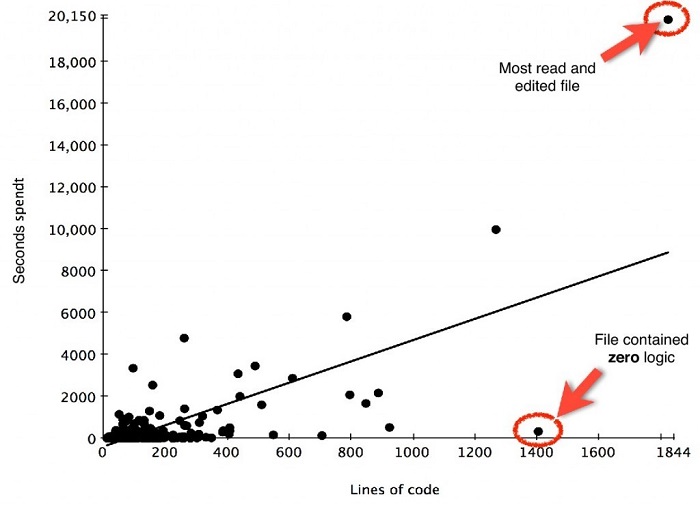
Y轴代表在项目维护期间花费在阅读修改一个文件上的时间;X轴代表文件的大小。
请注意,阅读和修改最大的文件(1844行代码)要花的时间是大部分文件(少于600行代码)的10倍以上。这个文件就是一个万能类。另外请注意,20000秒差不多是5个小时的工作(对于一个文件来说太长了!)。我们还可以看到编辑另一个大文件(大约1400行代码)没有花掉很多时间。这个大文件包含了很多的访问器和修改器,没有包含任何逻辑(相对于全能类)。这解释了为什么开发人员没有在上面花太多时间。包含复杂逻辑的大文件(即全能类)会显著影响可维护性。
建议:你应该把包含复杂逻辑的大文件分割成小文件。一个推荐的阈值是将文件大小保持在1000行代码内。
观察结果2: 数据团块没有你想得那么糟糕……
“数据团块(Data Clump)”是指一些语义上没有相关性的方法和变量集合。一般情况下,包含数据团块的文件包含了不同类型的变量,后面跟着一系列的访问器和修改器。比如,下图中Person这个类包含了不直接跟一个人相关的信息,因此可以被分割成两个类。Simula的研究人员创建了一个统计模型来解释代码异味的出现是否增加了开发人员在维护过程中遭遇问题的可能性(他们会记录维护过程中面临的所有问题以及那些引起问题的文件)。他们发现,事实上那些包含数据团块的文件引起维护问题的可能性更低!
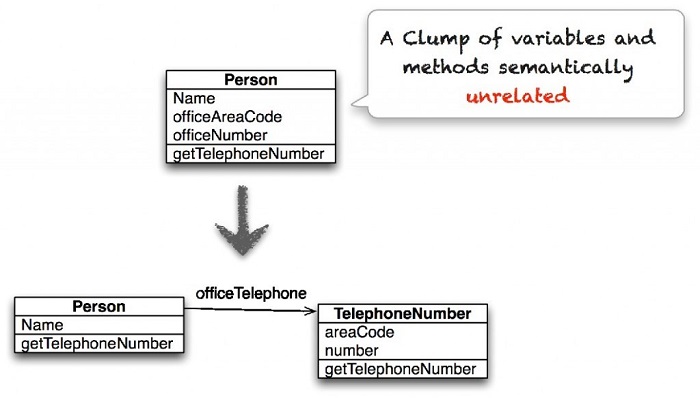
建议:不要去管那些数据团块,除非它们包含了其他代码异味。
观察结果3: 坚持接口分离原则
Robert C. Martin(Bob大叔)介绍了接口分离原则(ISP)作为 SOLID 原则【2】的一部分。
接口分离原则指出,任何软件库的调用者都不应该被强迫依赖于它没有调用的方法。接口分离原则把非常庞大的接口分割成更小更加明确的接口,从而使得调用者只需要知道他们所关心的方法。
软件工程的研究者们【3】提出了如何使用代码量化标准去鉴别一些代码异味。有些商业工具实现了这些量化标准,但是你也可以提出自己的探测策略并且在工具中实现它们,比如Java中的SonarQube或者.Net中的NDepend。下图展示了Simula使用的探测策略,这个策略是基于研究员Radu
Marinescu【4】的工作提出的。
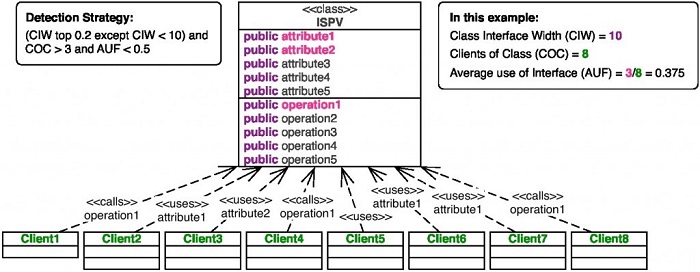
这个类的类“接口宽度”(即公开的方法和属性个数)为10,类的“调用者”数目为8,“平均接口用度”(即调用者所使用的方法或属性个数除以调用者数目)为0.375。根据这个探测策略,这个类可能违反了接口分离原则.
关于数据团块的分析同样涵盖了违反接口分离原则的文件,结果发现当一个文件违反了接口分离原则时,它存在问题的概率的概率会增加。
如下图所示,违反接口分离原则的文件比没有违反该原则的文件出问题的概率要高(大约30%),这也印证了上述观点。
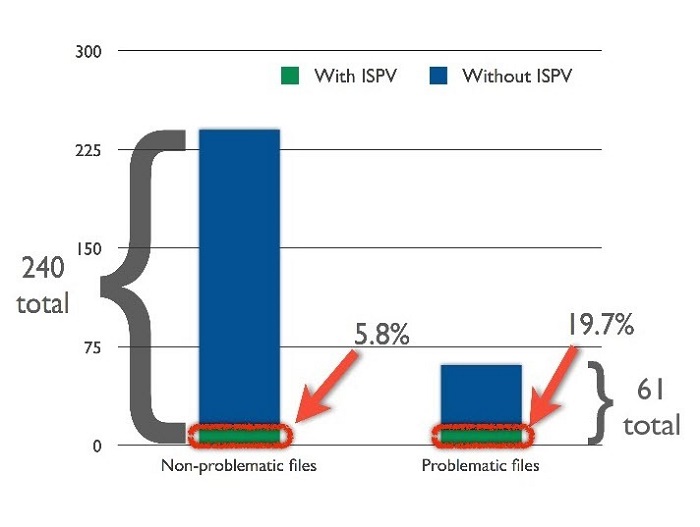
建议:分割那些过于宽泛,用途繁多的接口可以减少维护时出现问题的风险。
观察结果4:代码异味往往成群结队出现
在同一个实验中,某些代码异味表现出在同一个文件中一起出现的趋势。如下图所示,识别出来的代码异味往往出现在同一个文件里。“异味囤积者”本质上就是那些想要囤积所有系统功能的文件。“混乱因素”是那些在文件中引起困惑的代码异味。另外两组,“宽泛接口”和“数据容器”的含义则是不言自明的。
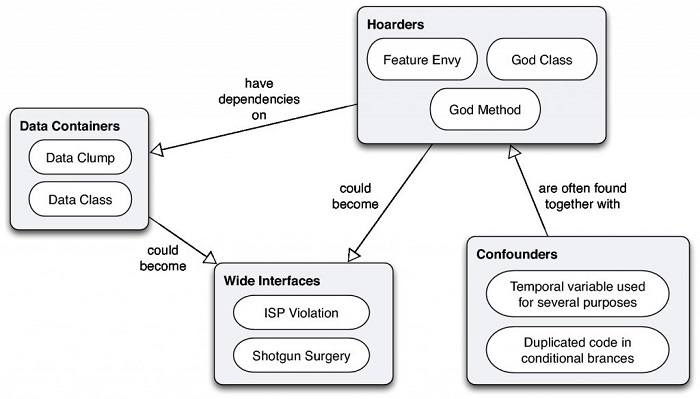
建议:如果你在一个文件中发现了某个类型的代码异味,你大概想要检查它是否包含其他的“异味小伙伴”。同个文件中的代码异味组合会增加风险,减少可维护性!
长文略读
就像Fowler所说,我们要追随自己的直觉,经验和判断来决定哪些需要重构,但是下列根据科学研究得出的准则可以帮助你来区分优先级:
1. 分割那些包含过多逻辑的大文件(多于1000行代码)
2. 关键不在于重构数据团块
3. 把那些宽泛而用途繁多的接口按照用途来分割成不同接口
4. 包含某些代码异味的文件往往同时会有更多的“不受欢迎的小伙伴”,注意识别它们!
快乐地重构吧!
|


