| 编辑推荐: |
本文重点阐述鸟瞰图描述的整体软件架构中跟智能驾驶相关的部分。也就是“智能驾驶软件框架和基础组件”
部分。深入描述了这一部分的两个核心框架,“环境模型框架”和“EPX-SA模型的实现框架”。希望对您的学习有所帮助。
本文来自搜狐,由火龙果软件Linda编辑、推荐。 |
|
01算法执行的上下文
现在我们来讨论 L.FW 层的架构。前面说到,从这一层开始才有了“智能驾驶”这个语义。这个语义会在
D 轴的实时域和性能域都有体现,同时要能支持 A 轴各个切面要求的特性。
第1章说到,自动驾驶的核心是各种类型的“算法”。L.FW 层要提供的就是算法运行的载体,那么如何能让承载算法的运行呢?如下图,我们从时间(T)、资源(R)和数据流(F)三个维度来对一个算法的运行的上下文进行分析。
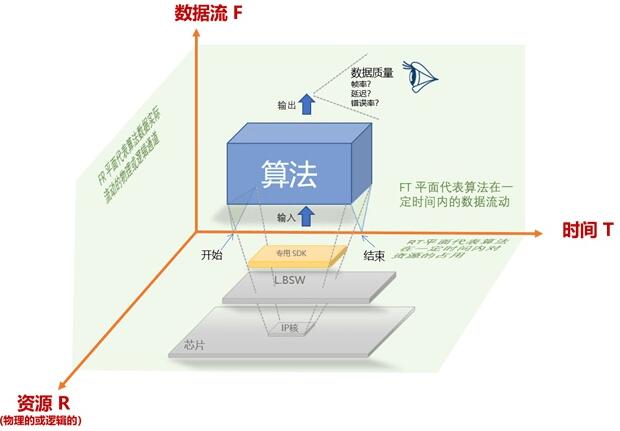
图2 算法执行的上下文
1.1 资源维度
任何算法运行最终需要落实到物理设备上。这在自动驾驶相关的算法中尤为突出。算法运行在哪个物理设备上由以下几个因素约束:
算法的性能要求和实时性要求
物理设备自身或其 SDK 的限制
有些算法必须要运行在实时域,比如雷达处理算法,它要控制电磁波的发送,并接收回波,根据收发的时间差来做分析。算法要求执行周期的时间调度精度非常高,所以一般运行在
MCU 的RTOS之上。如果 MCU主CPU 算力不够,就增加 DSP 芯片来加速。
使用深度学习的视觉算法运行在哪里,跟硬件物理设备及其 SDK 有关系。多数情况下其专用的硬件模块(芯片内的
IP 核心)只能在 Linux/QNX 等OS 上访问,算法需要使用的SDK依赖Linux/QNX
上的软件生态, 因为那就只能运行在性能域。
一般高级程度的 SoC芯片会提供各种用于算法加速的资源,包括用于图像信号处理的ISP模块,用于数字信号处理的
DSP模块,用于执行深度学习推理算法的 AI模块,用于支持图形渲染的GPU等等。芯片厂商同时也会提供对应的专用SDK。这些专用
SDK 是平台强相关的,并不属于“自动驾驶软件框架(L.FW)”的一部分。
“自动驾驶软件框架(L.FW)”需要能为算法分配和管理其所需的硬件计算资源。这又分为“硬件平台无关”与“硬件平台相关”两部分。
如果L.FW 只是使用下层 L.BSW 层提供的服务或API接口,那么基本上就是“硬件平台无关”的。因为
L.BSW层已经屏蔽掉了一部分平台相关的底层细节。
如果某个硬件平台提供能某个算法加速的硬件模块,而两个算法都需要使用它,那么就需要在 L.FW 层做出管理。或者L.FW
成开发出相应的抽象接口来屏蔽硬件相关性。
无论是平台相关还是平台无关,当多个算法竞争同一个资源的时候,L.FW 需要作出仲裁。
1.2 时间维度
前面说到多个算法可能会竞争同一个资源。最基础的就是要安排算法合理的在时间上避免冲突。每一个算法都应该有其合理的开始时间和结束时间。然而这恰恰是最难的部分。大多数的智能驾驶原型系统一般都是让所有算法都一起跑起来。这对简单的单一场景是可以的。L2及以下单一功能的ECU中,因为涉及的算法不多,根据单一功能的状态机确定算法的启用或停止还是可以做到的。
到 Level 3 及以上时,不同场景下需要的各种算法有很大差别。所以算法的执行时间管理就非常重要。更准确的说法,“自动驾驶软件框架(L.FW)”要管理算法的生命周期。
1.3 数据流维度
自动驾驶中的各种算法不是孤立的,相互之间有数据上的交互。某一个算法的输出是另外一个或多个算法的输入。多个算法级联起来形成一个数据流管道。
但是否是所有算法都以数据流的形式被组装还需要根据实际情况进行分析。一般来说,感知类的算法容易呈现出多级级联的数据管道形式。但是对于其他算法,是否数据流是最合适的模式还值得商榷。比如同一个EPX-SA
分形递归层级的 "规划(P)+执行(X)"算法,会形成一个反馈回路, P时刻会监控X的执行结果做重新规划。调度算法(S)需要识别场景,对算法管道进行调整,更像是算法管道之外的控制机制。
无论如何,在这个维度,“自动驾驶软件框架(L.FW)”要管理算法在数据处理流程中的装配与卸载,监督单个算法的输入输出数据质量.
算法的装配可是静态的也可以是动态的。静态装配是在配置文件中描述,修改后需要重新启动才能生效。在汽车内就是要OTA更新配置。动态装配是根据运行的状态动态决定算法模块的安装和卸载,甚至在不同的硬件资源上动态迁移。
静态装配的好处是可测试性强,能够通过完全覆盖的测试保证系统的可靠性。动态装配的好处是灵活性强。一般汽车软件为了可靠性都倾向于静态配置。自动驾驶的算法模块必然要动态的启用和停止,但是动态和静态也是相对的,我们需要的动态切换的功能也许就可以通过某种静态的配置去支持呢。这都需要在具体的设计开发中去找具体的实现办法。也要看
L.BSW这一层提供了哪些可用的能力。
1.4 三个平面的含义
上图中 ,F T R 三个轴每两个轴形成一个平面。
FT 平面代表算法在一定时间内的数据流动
FR 平面代表算法数据实际流动的物理或逻辑通道
RT平面代表算法在一定时间内对资源的占用
这从另一个角度阐释了 L.FW 需要做的工作。
总结前面所述,我们必须清楚一点:“自动驾驶软件框架(L.FW)”不做具体的算法实现,但它为算法准备好上下文,即算法执行所需的资源,时间,数据,它是算法执行的容器。另外别忘了,L.FW
包括实时域和性能域,在两个域应该有对等的实现,还要有合适的通讯机制。当然,两个域的具体实现架构是不一样的,但做的事情都是上面说的范畴,不过实时域在架构上可以简化很多。
02感知算法的目标是构建环境模型
前文已经提出了环境模型的概念。环境模型是 L.FW 层的重要产品,这里进一步详细说明。
当我们只做一个单一场景的原型系统时,可以只谈感知,感知的结果被用于后续的规划,基本上是一个线性的模型。这个线性模型可以支持到
Level2 以下的大多数自动驾驶功能的实现。因为每个Level2 功能单独实现时,涉及到的传感器数量不多,需要感知数据的软件模块也比较单一。
2.3 节中的“驾驶辅助域控制器”就已经可以接收多种类型的感知数据。这些感知数据集中被集中表达与处理时,就已经开始有了环境模型的雏形。
2.1 环境模型的探索
下图是 Mobileye EyeQ4 目标识别结果信息的 UML 类图表示。内容根据 EyeQ4输出信息的
DBC 文件反向分析整理而来。
图3 EyeQ4 的数据语义

EyeQ4属于 Smart Sensor, 将视觉算法与执行算法的硬件集成在了一起。算法加速使用了
Mobile 自己的专用芯片。EyeQ4通过 Can 总线输出视觉算法检测到的结果。从上图中可以看出,EyeQ4
输出的信息主要是三类:
1. Object 代表所有的目标,ObjectClass 对目标的分类,包括,小汽车,卡车,自行车,行人,动物等。MotionStatus
表示了目标的状态,有停止,移动等,没有移动的速度方向等更具体的信息。
2. Lane 代表车道线。更进一步有车道线的类型(实现、虚线、双线等等)、颜色的描述。
3. TSR 是交通标识牌识别,详细信息包括标识牌的类型和语义等。
这里有一个 LaneAssigment 有特别的意义,它表示目标在哪个车道。将两类信息结合在了一起。
EyeQ4 也需要输入的信息,它需要当前车辆状态信息来帮助更好的获取和利用前面的三类信息。比如指出哪个目标是前方车辆。
EyeQ4 是一个商业产品,上图是其明确的对外感知数据接口协议。它内部的或许还有更细节的数据格式没有对外公布。比如它的算法也会是多级算法级联,每级之间的数据接口并没有公布。公开的接口数据已经对一部分环境的描述了。
下图是华为与国汽智联联合发布的《自动驾驶功能软件接口标准》。定义了定位(Localtion)、感知融合(Enviroment)、预测(predict)、决策规划(Plan)四个服务方面的数据接口。Common
包含一些公共概念,会被其它部分引用。括号中的英文是该标准中的用语。标准接口以 Protobuf 的格式定义。下图是根据
Protobuf 反向分析整理出来的UML类图。
图4 自动驾驶功能软件接口标准
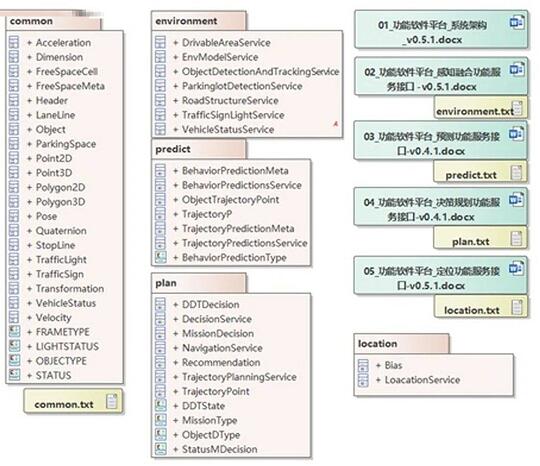
EyeQ4 输出的信息在《自动驾驶功能软件接口标准》中是放在了 Common 部分。Common
还包含了从 2D点,3D点开始的基础数据格式,停车位,可行驶区域等信息,这已经是与环境相关的内容了。详细信息如下图。
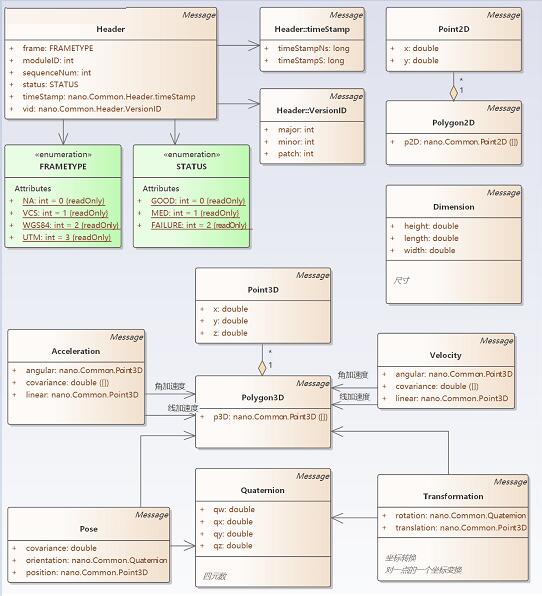
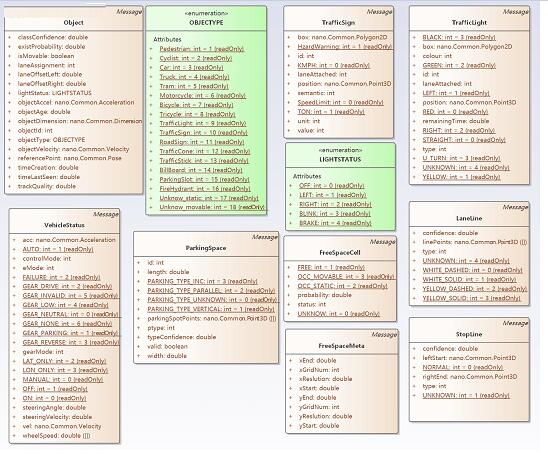
图5 智能驾驶功能软件接口标准环境语义
另外,上述接口标准中还包含了,预测和定位的内容。定位是指自车信息的一部分,自车信息包括位置、速度、姿态以及车内装置(如油门和刹车)的状态等等。狭义的"环境"不包括自车信息,只包含自车之外的环境。本文中提到的"环境"或者"环境模型"都包含自车信息。
上述接口标准中还包括了"预测"部分,包括行为预测和轨迹预测。行为预测指的是被检测到的“目标”在未来一段时间可能发生的行为语义,比如启动、减速、加速、左转等等。轨迹预测是对“目标”在一定时间内可能行驶(或行走)的轨迹的预估。上述接口标准中没有把这两个预测算作环境的一部分。
我们认为环境不仅仅包括空间属性,也应该包括时间属性。“预测”是环境模型在时间维度上“未来”的可能结果,对应还应该有环境模型在时间维度上的“历史”。也就是说“历史轨迹”和“历史行为”也是环境模型的一部分。其实在
EQ4的环境数据中,Object 有一个字段“ObjectAge”,代表的是改目标出现了多少帧。这里就已经有了一点时间属性。感知算法中有一类跟踪算法,也是属于时间语义。本文中的环境模型概念包括时间属性上的“预测”与“历史”。
2.2 环境模型的多级语义
两种层级关系
环境模型有两种类型的层级关系,一种是分形递归的 EPX-SA 模型的层级。这个类比的层级关系体现在场景粒度上。假设有以下三种粒度:
粒度1. 我们关注的是一个城市范围的场景,关心的环境信息是路网的拥堵状况,用于规划城市范围从A点到B点的行驶路径。对当前旁边有什么车不感兴趣。这些路网信息可能是通过车联网云端获取。
粒度2:我们关注的是街道级别(500米内)的场景,关心的环境信息是前方几个车道的拥堵状况,和前方两个路口的红绿灯的状况。这个信息可以是车路云协同的路侧单元(RSU)提供过来。这个粒度下也不用关心旁边是否有车。
粒度3:当根据粒度2 的信息我们确定我们需要变道来避免拥堵。这时候就需要关心周边车辆信息,车道信息。这个信息可以通过本车的传感器获取,也可以通过
RSU 获取。
另一种是在粒度3情况下的,由低级(浅)到高级(深)的不同的语义层级。这里所谓的“语义”,是指有特定领域含义的结构化信息。比如一张照片,没有语义信息的情况下它就是一堆无意义的像素点。从像素点中识别出“这是人,这是车,那是路”就是语义信息,而判断出“人在车上”就是更深一层的语义信息。
语义层级
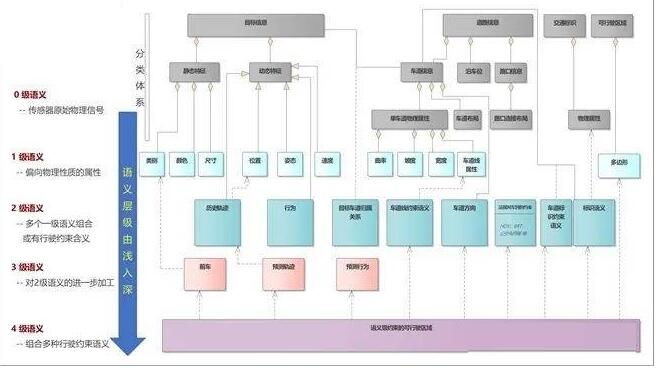
我们把语义层级从低到高分成 0-4 共5级。
0 级就是没有语义的原始物理信号。如摄像头的原始像素点集合,激光雷达的点云,雷达收到的电磁波形状。
1 级是根据原始物理信号计算出来的属性特征,偏向物理属性(有计量单位或量纲)。比如速度,位置,颜色等。不具有与车辆行驶相关的语义信息。
2 级就开始有与车辆行驶相关的语义,比如限速,左转弯道,停车位等。一般没有物理量纲。几何可行驶区域。
3 级语言是在2级语义上的进一步加工,有一下几种可能情况
两个2级语义的组合,如车在某个车道。
时空两个维度同时具备,如历史轨迹,轨迹预测。
对意图的识别与判断,如当前行为,行为预测。
4 级语义就是多个二三级语义的组合,比如加上了交通规程,其它目标的行为和轨迹预测之后,得出的可行驶区域。到这一级已经是最接近规划的部分了。
如下图所示,列举了一些语义层级的例子。不过,本节的重点是阐述的基于语义层级的环境模型分析方法,具体的层级划分标准,以及图中每个语义所属的层级有待商榷,需要进一步研究分析。
图6 分级的环境语义
为什么要定义语义层级:
1. 语义层级本身就是感知算法的自然逻辑,明确定义语义层级可以更清晰的界定不同类型算法的分工界面。让各段算法更清晰的关注并解决本领域的问题
2. 方便多路感知来源的协同工作,互为备份。Level2以下自动驾驶使用的传感器数量较少,重叠度也不高。Level3+逐步装备了更多的传感器,各传感器可能有功能重叠的部分。同时
V2X技术让我们可以直接从云端或路侧单元收到感知数据,这些经过云端或路侧单元的算力处理后的感知数据直接就是2级或级语义。清晰的语义分级有利于定义不同语义等级直接的接口形式,不同来源的语义可以直接注入到环境模型中的对应位置。
3. 低级的环境模型语义可以被用于计算多个高级语义,清晰的语义分级可以复用低级语义的技术,避免各自高级语义重复计算低级语义。
4. 高级的环境语义能让规划算法的更简单合理。目前多数感知算法的实现是做到1级语义和部分2级语义。更高级的语义经常在规划算法中实现。在
EPX-SA模型中,每一个分形递归层级的 EPX 可能被调度算法替换掉。每个 P(规划) 组件都要做高级语义的计算就会让
P 组件复杂度提高。高层级的语义由专门的算法直接提供,每个P组件按需取用。这这样能让感知和规划的分工更清晰,各自算法更专注于自己本领域的工作。
2.3 理想模型与现实模型
环境模型“理想模型与现实模型”是与“语义层级”正交的另一个维度。
理想的环境模型是假设所有得到的环境数据的各级语义是全角度、无延迟、绝对正确的。然而现实情况并非如此。现实的环境模型与理想的环境模型至少有几方面的不同:
1、覆盖范围小于理想模型。
前面提到过,每一个传感器可以看做是环境模型在“角度、距离、光谱区间”的一个过滤器。如下图。一个传感器组合就是多个过滤器的并集。但无论多少传感器,其并集也只是整个理想环境模型的子集。
图7 传感器是理想环境模型的过滤器
2、数据存在延迟
任何传感器都有延迟,数据在多级传输、计算的过程中,延迟逐步累加。一张 1080p 的图片经过目前最快的传输线路GMSL2(~6Gbps)需要约7毫秒的传输时间,然后经过多级感知算法,规划算法,到控制输出,需要的时间至少在30-50毫秒之间。车辆以60km/h的速度,已经走出去
0.5 到 0.8 米。
Level2 以下自动驾驶功能开发中,一般会在系统设计阶段定义好线缆及各级算法要求达到的性能及延迟,以控制总的延迟。性能开销最大的算法会独占相关的计算加速资源,开发时努力优化到设计要求。相当于在整体系统中静态要求了一个最大的延迟范围,各处理层级级保障达到对自己的静态要求。整体的环境语义中没有延迟相关的信息。
Level3~Level4 的自动驾驶实现中,各级粒度的场景会按情况进行切换,各种算法依次轮流使用计算资源,有的算法会竞争使用计算资源。那么这种数据处理的延迟会是动态的。有必要把数据延迟相关的信息内置与环境模型中,作为现实模型的一部分。
3、数据准确度存在一个置信区间,而且置信区间会随着环境(日夜、天气)等因素改变。
任何算法的结果的准确度都是一个概率上的置信区间范围。环境模型数据中如果能包含各级语义的置信区间数据,可以为规划提供更多的依据。
2.4 环境模型作为产品边界的定义及对开发方式的影响
环境模型还定义了 L.FW(智能驾驶软件框架) 层内部的产品边界。这句话有两层含义。首先,L.FW
内部可以有多个产品的组合,第二,环境模型定义了一类产品的边界。
我们以 Mobile 的 EyeQ 系列产品为例来说明。EyeQ 本身是一个独立的软硬一体的产品,很多
ADAS 解决方案都采用它做为感知的解决方案。
如下图: 可以把它输出的感知数据理解为一种环境模型的表达形式。环境模型左边是模型数据的生产者,环境模型右边是模型数据的消费者。EyeQ
作为独立产品,扮演了模型数据的生产者角色。它使用专用的芯片和算法获取可以量产的感知结果,以它定义的环境模型形式供其它模型数据消费者使用。
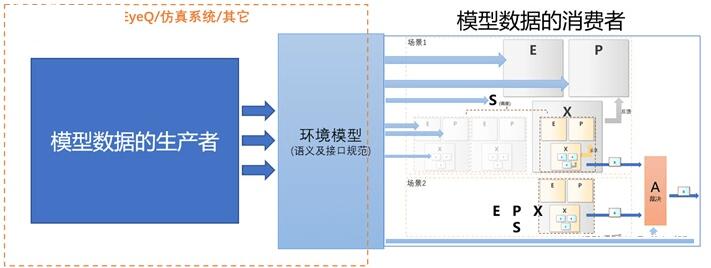
图8 环境模型对开发方式的影响
环境模型定义了模型数据的“生产者”和“消费者”之间的边界。有了这个边界,我们可以替换掉左侧“模型生产者”的实现方式。
支持Level3智能驾驶的域控器集成了感知算法加速的硬件模块,可以自己完成构建环境模型需要的计算。也可以用仿真软件来作为环境模型数据的生产者,这样及时在算法能力还不具备的情况下,也可以直接开始右侧“模型数据消费者”的功能开发。这也是环境模型作为产品边界的意义,通过产品级别的区分,可以让不同的团队完成各自专业的产品定义。不同的开发团队能同时进行各自产品的开发。
2.5 环境模型模块与接口要求
“环境模型”可以作为 FW 层提供的服务(FW:ENV:Mod)。它保存着实时的1-4级环境语义,也会保留一段时间内的历史信息。
FW:ENV:Mod 需要提供语义注入的接口,格式符合环境模型语义规范,能够支持多种不同层级的语义注入。FW:ENV:Pipe
是环境模型相关算法的执行管道,负责装配算法模块(FW:ENV:Algo),提供算法模块的执行环境。FW:ENV:Pipe
会在合适的语义生成时,注入到 FW:ENV:Mod 服务中。
ENV:Mod, ENV:Pipe和 ENV:Algo 一起构成了 L.FW 层的 FW:ENV
模块。
图9 环境模型服务及接口
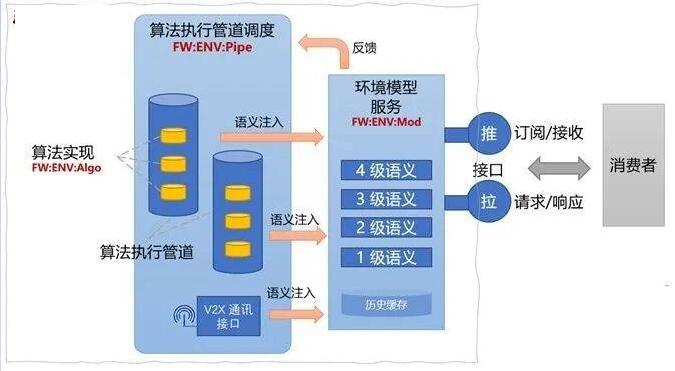
FW:ENV 模块整体需要对外提供环境模型的访问接口,接口格式执行多级语义,支持现实模型的含义表达。接口需要支持
“推”和“拉”两种形式。“接口”即请求响应接口,可选实现 Restful 形式。消费者使用"推"接口需要先向
FW:ENV 发起订阅,数据到达后获得通知。或者结合使用,即消费者先订阅,收到推送的通知后,主动调用“拉”接口请求数据。
FW:ENV 模块还有一个重要的特性,就是要能够根据消费者当前对环境模型数据要求,动态调整算法执行管道的装配。FW:ENV:Mod
是有所有对环境语义需求的信息,这个信息可以反馈到 FW:ENV:Pipe 来调整算法的装配。
2.6 FW:ENV 的实现以及对上层的接口
L.FW 层包括实时域和性能域两部分。FW:ENV 需要在两个域都有实现。实时域的实现可能会适当简化,主要是
Pipe 部分,可能没有明确的 Pipe 形式,只是以独立的 Algo 存在。但是 FW:ENV:Mod
在实时域和性能域都需要存在,并且能支持数据的同步。比如性能域的深度学习视觉算法发布的环境语义信息,运行在实时域的规划算法可以得到。反之亦然。为了避免多余的数据传输,某一个域不需要的数据可以不同步,但这是优化传输的问题,基本的数据同步逻辑亦然不变。
FW:ENV 为上层 L.APK 层提供一些接口及SDK:
l 环境模型的语义定义标准
l FW:ENV 的"推""拉"接口说明及 SDK
l FW:ENV:Pipe 的定制开发说明及SDK,支持L.APK层开发自定义的 Pipe.
l FW:ENV:Algo 定制开发说明及SDK,支持 L.APK 层开发自定义的 Algo 被装配到已有的
Pipe.
03深入EPX-SA 模型
3.1 EPX的抽象语义
EPX-SA 是一个抽象模型,它对复杂自动驾驶场景进行分解,并提供一致性的表达方式。下图描述了一个3层
EPX 的协作关系。首先我们来定义一下符号表示法。
图10 深入 EPX-SA 模型
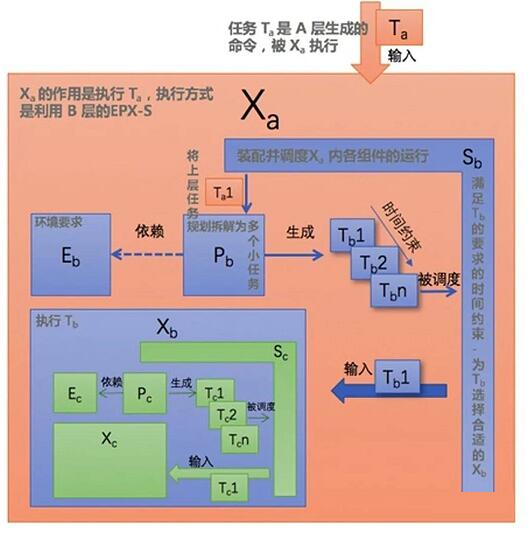
因为EPX 的分形递归特性,我们在使用 EPX 标识符时,需要对其层次进行标注,不然很容易表述不清楚。我们使用下标来表达分形递归的层级。相对层级使用数字下标
“-1”“+1”分别表示下一层和上一层,比如 E-1 表所示下一层的E,P+1 表示上一层的P. 没有下标表示当前层。绝对层级使用字母下标,如
Xa,Xb,Xc 表示逐个递进层级的 X。每一组 EPXS 都是在 X+1内。
我们明确定义一下EPX-S 的概念。
E 是对环境的感知需求,当我们有环境模型服务提供感知能力后,就不需要E来具备实际的感知能力,只需要要描述对感知的需求,并不实际执行感知动作。
P 是抽象意义的规划,会将上一层的任务 T+1拆解为一系列的小任务序列(T1,T2,.. ,Tn),表示为Seq<T>,Seq<T>
被送给S 进行调度。Seq<T>有时间约束属性,下文详述。P 会根据E的变化重新规划新的
Seq<T>,重新被 S调度。
S 是抽象的调度器。它有几个作用:
1. 负责X+1内所有组件的装配
2. 调度 Seq<T>中每一个T的执行,需要满足Seq<T>的时间约束要求,当时间约束不能满足时需要做出响应
3. 为每一个T选择合适的 X
Seq<T> 是由P 产生的任务序列。这里的任务是一个抽象的概念,代表需要“在一定约束下需要达到的某种目标”。约束可以是对单个任务T,比如要求在一定时间内完成,或者在一定空间内完成。约束也可以是对任务序列
Seq<T>,比如要求必须按照顺序完成,或者某些任务可以并行,即有不同的 X 同时执行。这将会导致仲裁机制的引入。
X 是同层次T 执行器。它要么直接完成实际的任务执行动作,或者调用其内部的下一层 E-1P-1X-1
来执行。X 每次执行完成一个T,要向通知 S ,S会检查Seq<T>是否为空,不为空就执行下一个T,如果为空就要求P生成新的Seq<T>,
P 如果根据 E 的信息发现 T+1 已经完成,将会输出空任务序列,S将认为 X+1 已完成。
下图用 UML 序列图描述了一个典型的EPX 执行过程。
X+1 被创建时,其内部先创建 S,再由S创建了 E、P,E会向环境模型服务订阅需要的环境信息
外部将 T+1 交给 X+1执行,被交给 S进行调度,S 将 T+1交给 P做规划
P 创建了任务T1,交由S进行调度。S 创建 X,将 T1 交给X 进行执行
X 执行完成T1后销毁 T1,通知 S 执行完成。S通知 P 重新规划
第3,4步 重复执行,直到P 没有新的 T 产生,通知S无新任务
S 通知X+1任务完成,X+1 通知外部
图11 典型的EPX 执行过程
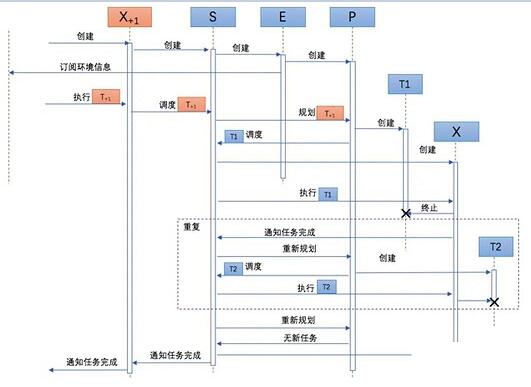
最内层的 X 是会是非常简单的执行机制,不需要进一步被分解为下一层的 EPX。这相当于递归的终止条件。
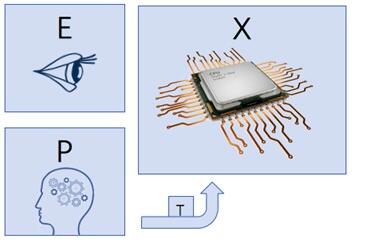
图12 最外层的 EPX
最外层的 EPX 往往并不是三者都属于计算机系统。如上图,人自身的感知完成 E 的工作,人脑完成
P 的工作,产生的任务 T 交给计算机系统X去执行。所以对于计算机系统而言,X是分形递归的起点。
3.2 EPX 示例
以上说的内容都非常抽象,下面我们举具体的例子。
3.2.1 OKR的设定与逐级分解
OKR(Objectives and Key Results)即目标与关键成果法,是一套明确和跟踪目标及其完成情况的管理工具和方法,由英特尔公司创始人安迪·葛洛夫(AndyGrove)发明。并由约翰·道尔(JohnDoerr)引入到谷歌使用,1999年OKR在谷歌发扬光大,在Facebook、Linked
in等企业广泛使用。2014年,OKR传入中国。2015年后,百度、华为、字节跳动等企业都逐渐使用和推广OKR。详细内容参见百度百科的相关词条(baike.baidu.com/item/OK
一个企业的 OKR 是自顶向下逐层制定的。一般来说,公司制定几个顶级的目标(Objectives),以及达成这个目标后的关键结果(key
results)。然后各部门根据公司级的OKR,指定自己的OKR,然后部门内各组,到个人依次逐层制定各自的OKR。
我们可以用 EPX 模型来对OKR进行解释。企业要对自己的业务状况、业务数据进行了解,对市场进行分析这是企业级“E”的部分,即对企业所在的市场环境和自身状态进行感知。基于这个感知结果,企业进行业务分析和规划,这是“P”的部分,“P”的结果就是公司级别的OKR(目标和关键结果),这是
“T”。也可以把 “KR”(关键结果)当做 “T”, O 是 “T”的分组。公司级的领导会把这个OKR分配到各个业务部门去完成,某个部门可能只是完成一个或多个
“KR”。在这里每个业务部门就是“X”。哪个部门完成哪个“KR”,就是 S 的工作。
业务部门(X) 领到自己需要完成的“KR”(T)后,会根据自己的情况(E-1)进行分析,规划(P-1)出自己部门的OKR(T-1),然后交由部门内的各组(X-1)去进一步制定下一级的OKR。各组的职能不一样,能够完成的
T-1的类型也不一样,这由 S-1 进行分配。
组一级就是 E-2X-2P-2,到每一个人就是E-3X-3P-3。然后就不再进一步分解了。
整个逐层递归的分解过程就是一个完整的EPX模型的实施。这个过程将一个抽象的任务逐层落实到了具体的执行层并完成。
3.2.2 “自适应巡航”(ACC)
“ACC”作为“定速巡航”的升级功能,相对于“定速巡航”的最大优点在于不仅能够保持驾驶人预先设定的车速,还能够根据前方车辆的状态自适应的调整本车的车速,甚至自动停车,并在合适的时机自动起步。
ACC的几个典型的功能:
(l)当前方无车辆时,ACC车辆将处于普通的巡航驾驶状态,按照驾驶员设定的车速行驶,驾驶员只需要控制方向(横向控制)
(2)当ACC车辆前方出现目标车辆时,如果目标车辆的速度小于ACC车辆时,ACC车辆将自动开始进行减速控制,确保两车的距离为所设定的安全距离,并以与前车相同的速度自动跟随行驶。
(3)当前方车辆停止时,本车也会刹停,待前方车辆启动后自动起步、加速,跟随前车。
(4)为了更好的用户体验,ACC开启过程中,驾驶员依旧可以和ACC系统进行少量的交互。比如车辆快停止时主动刹停,“轻踩油门”通知ACC系统随时准备启动等。
一般ACC功能逻辑可以以一个状态机来表示。
我们以EPX模型来设计ACC功能的软件架构。
首先需要确定 EPX 的递归层级。
如下图,我们把 ACC 的EPX 递归层级分为 0-3 共四级。E0和P0存在于系统之外,X0 代表ACC系统,它能完成的任务就是按照用户的设定速度实现自适应巡航功能。X0内部有
E1、P1、X1。E1对环境的要求包括车辆信息,车道信息,本车信息,需要知道本车道前方是否有车,前方车的速度距离,还需要知道本车道的限速。P1
根据从 E1获得的信息,决定一段时间内需要达到的车速(0~用户设置的循环速度),交由 X1执行。X1内部的E2已经不关心,只需关心当前的自车车速,P2计算出一段时间内需要达到的加速度交由
X2执行。同理 X2内部的P2产生油门开度信息,交由 X3执行。X3可以是汽车VCU(车辆控制单元)。这里把X3作为递归的终止点,也就是说,我们认为
X3内部的执行机制对我们是透明的,对于ACC应用不需要了解其细节。当然,X3内部也可能有进一步的EPX机制,只是在这里我们不关心。
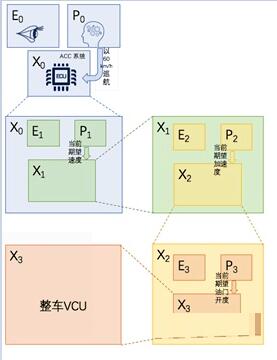
图13 ACC 到EPX概念模型的映射
通过0~3共4级的分形递归,我们把问题逐步简化。需要注意的是,X0~X3,它们执行任务的时间周期是不一样的。
X0是启用ACC的一个完整过程,其时间周期可以是10分钟以上。
X1需要让车达到某个速度,一般我们期望在保证安全和舒适的前提下,这个过程在10秒内完成。
X2 需要让车达到某个加速度,一般这会在200~1000毫秒内完成。
X3 是达到期望的油门开度,其执行周期可能在20~200毫秒区间。
X1、X2、X3的执行时间还与其对应的 P1、P2、P3的具体输出的任务粒度有关。一般P1、P2、P3都可采用PID控制算法,
X的执行时间与对应P的算法实现是的增量区间相关。但X1、X2、X3的执行时间的数量级是逐步递减的。我们需要根据这个数量级来判断某一级别的EPX是否必须在实时域执行。
还有一个问题是,前面所说的ACC状态机在哪里体现。有两种可行的方式。
一是所有状态机逻辑都放在P1中实现。P1中保存状态的变化,根据不同的状态输出不同的速度要求。第二种方式就是引入
S1,并增加多个不同的P1的实现。多种不同的P1实现,处理状态机中的不同场景,这里的场景可能是一个状态,或者多个状态的组合。比如,有的P1处理前方无车的情况,有的P1处理前方有车并且在减速的情况,有的P1处理前方有车,本车已经跟停的情况。由S1负责根据当时的情况选择不同的P1装配到处理流程。这样状态机就实际分布在
S1以及不同的P1实现中。这是另一种对问题进行分解的方式。具体选用哪种看具体的设计而定,哪种更能符合实际情况,简化设计就使用哪种。需要具体问题具体分析。
3.3 仲裁机制
前面说过,S可以同时启动多个并行的X执行不同的任务。如下图:
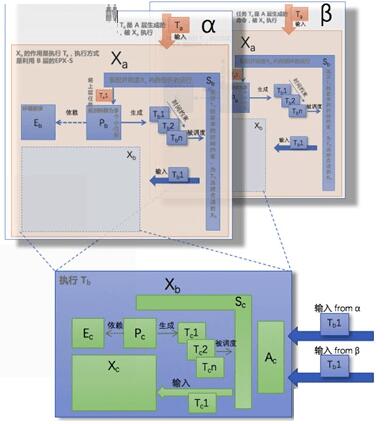
图14 仲裁机制
α 和 β 是被上一层同时启动的两个并行执行的 EPX 运行机制。但是它们在 Xb这一层级,都是引用了同一个
Xb 的实例。这样Xb实例就会同时收到两个不同来源的任务执行请求。这就需要仲裁机制(Arbitration)来对多个来源的输入进行分析,如果不冲突,能否进行合并,如果冲突选择优先级最高的执行。
例如,车道保持辅助(LKA)功能和自动紧急刹车(AEB)功能是可以和 ACC 同时运行的,它们可以有一个独立的EPX分形递归结构,但是在最内层的
X (指向VCU)可以与 ACC的分形递归结构共享同一个实现。这个被共享的X需要有仲裁机制A。因为LKA是输出方向盘的扭矩来进行横向控制,与ACC的纵向控制不冲突,一般来说可以合并一起执行。但AEB也是输出纵向控制信号,需要与ACC的输出进行仲裁,但AEB一般有更高的优先级。这个仲裁逻辑就由A组件来实现。
并不是所有 EPX 层级都有 A 的存在。只有能够被多个次引用的 EPX 才需要。该层级的 A最清楚本层级的能力,它要负责该EPX层级的仲裁逻辑。
04FW:ENV 与FW:EPX-SA在软件架构上的意义
第3章我们提到L.FW层开始有智能驾驶相关的语义,这一层的主要作用是提供智能驾驶的软件框架和基础组件。4.1
节指出:“L.FW不做具体的算法实现,但它为算法准备好上下文,即算法执行所需的资源,时间,数据,它是算法执行的容器“。所以FW层软件架构就就是要为各种智能驾驶相关的算法运行提供良好的组织方式和运行环境。让算法关注与自身逻辑的实现,怎么被装配和执行,交由框架来处理。
FW:ENV与FW:EPX-SA 是L.FW 层最重要的两个框架,对整个L.FW 层的软件架构有如下重要意义:
1. FW:ENV框架为作为构建环境模型的基础框架,为感知提供了可标准化的语义层级,从而可以定义标准化的感知领域的API
接口,将感知能力的开发与智能驾驶的功能开发解耦合。
2. FW:ENV 框架为感知领域的算法提供了运行环境。
3. FW:EPX-SA 提供了三个维度的场景分析与简化的方法论。
4. 这两个框架为L1-L2开发和L3以上功能的开发提供了一致的方法论模型。
5. 让组件式开发成为可能。FW:ENV中每一个 Pipe可以是一个组件集合,每一个算法也可以是一个组件。FW:EPX-SA
中每一个EPX层级可以是一个组件,每个层级中单独的 EPXSA都可以成为一个组件。基于组件进行分析、设计、开发、测试,让智能驾驶这个复杂系统的开发能够被分解成可操作的单元,这对智能驾驶系统软件开发具有重要意义。
6. 可以支持组件的重用机制。能力范围、数据接口定义清楚的组件是可以被重用的。一方面可以在同一个自动驾驶系统的不同功能(或场景)中复用已经经过良好测试的组件。另一方面,积累的可复用组件库可以大大加快新项目的开发。
7. 实质上定义了对应用层(L.APK)的API 接口形式。
05L.FW 在域控制器中的实现
5.1 实时域和性能域都要实现 ENV 和 EPX-SA 框架
前面 ACC的示例中,我们提到,不同EPX 层级的执行的时间要求是不一样的。执行时间周期越小,特别是有确定性的时间周期要求的
X 应该在实时域中完成。通常越是与车辆控制层接近的操作应该在实时域实现。某些感知算法,一般是雷达相关算法,会要求在实时域实现。因为要精确控制雷达脉冲的发送和回波采样时间,这个时间要求一般在毫秒级别。我们应该在实时域和性能域都实现各自的
FW:ENV 和 FW:EPX-SA框架,当然实现方式可以有所不同。
5.1.1环境模型的数据同步
性能域的FW:ENV 产生的环境模型数据需要能够被同步的实时域。也就是说,当实时域的某个EPX 中的E订阅的环境信息,实际上是产生于性能域,但实时域的E任然只需要向实时域的FW:ENV订阅。但所需的数据会从性能域自动同步到实时域。如下图:
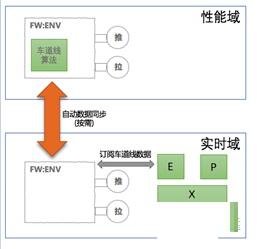
图15 两域的数据同步
实时域需要车道线数据只需要向本域的FW:ENV订阅。至于车道线数据如何从性能域同步到实时域,是由两域的FW:ENV负责实现。同时,要再两域之间同步的数据应该是充分必要的,即不需要的数据(没有被某个E订阅)不应该被同步。数据同步是双向的,比如,自车状态信息也是环境模型的一部分,一般是先从实时域获得,要按需同步到性能域。
类似的两域之间的数据传递几乎在所有划分了“实时域“和”性能域”的智能驾驶系统中都会有实现。那么本文所描述的数据同步机制有什么特别之处?有三点:
1. 环境模型语义的结构化表达与标准化的定义。我们要定义多级环境模型语义的结构化表达形式(使用某种接口定义语言
IDL来描述),形成内部标准。这个结构化标准并不是为特定项目或特定智能驾驶功能设计,它应该是具有一定的通用性。当然可以有逐步的版本演进过程。
2. 两域之间环境模型数据同步的实现机制是通用的。一般来说,不同的项目会为两域之间的环境模型数据传输单独设计项目特定的传输协议。而FW:ENV框架的数据在两域之间的传输不是这样。因为我们已经定义了标准化的环境模型语义格式,所以可以做出特定项目无关的通用实现机制。即使当标准的版本发生变化时,也应该能通过代码生成的方式产生通用的模板代码。
3. 运行时同步机制自动进行的。一旦系统运行起来,两域之间环境模型数据的同步是自动进行的。实时域或性能域的环境数据消费者并不需要知道环境模型数据具体是在哪个域产生的。
5.1.2 EPX 中X的代理模式
一般来说,在EPX多层级递归模型的实现中,越往外层与用户的交互就越近,实时性要求不高,多半会在性能域完成。越往内层实时性要求高,多半会在实时域完成。也就是说同一个EPX多级序列,会发生一部分在性能域,一部分在实时域的情况。这种情况下如何进行跨域的EPX多级递归实现呢?
解决方法就是在性能域实现一个实时域X的代理,装配到性能域的EPX结构中。
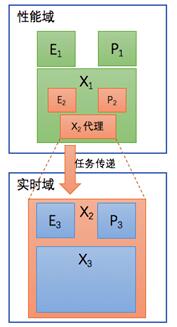
图16 X 的代理机制
如上图,X2对于性能域的EPX递归结构而言,它是最内层,也是递归的终止层,没有更细一层的EPX分解。但实际上,X2只是实时域最外层的一个X结构的代理。这个代理直接将任务发送到实时域的X2实例进行执行。
也就是说,实时域的X要被性能域使用,需要在性能域实现一个它的代理,这个代理与实际的X实例进行跨域的通讯。反之亦然。
5.2 实现方案的技术选型参考
5.2.1 L.FW 对 L.BSW 的强依赖
L. FW 层是需要基于 L.BSW 层进行开发。L.BSW 准备好了作为汽车电子控制器(ECU)所需具备的基础功能。同时为L.FW准备好了执行环境和基础服务。L.FW
层要使用 L.BSW层提供的执行机制,就必须按照它的应用开发规范去编写代码,按照它的配置规范去编写配置文件,使用它提供的
API和服务。这会让L.FW对 L.BSW 层构成强依赖关系。
在实时域,L.BSW 层可行的实现方式有使用 CP AutoSar 或其它RTOS。(有的情况下
实时域也会有多核心,一个核心运行 CP AutoSar , 解决与车辆交互的问题,其他核心使用简单的
RTOS解决部分计算的问题。) 使用 CP AutoSar 那就是编写CP BSW层的配置,生成 RTE,
编写 SWC 使用RTE接口。如果在此基础上是实现 L.FW ,那就是跟CP AutoSar 紧密相关的。
在性能域也是一样的问题,如果基于 AP AutoSar 开发那就是要符合 AP 的一系列规范。当然也得到
AP 带来好处。基于ROS2开发就是使用 ROS2的一系列概念(Node, Topic, Service,
Action),与基于AP开发是完全不一样的方式和实现架构。但是 L.FW 层如果对不同 L.BSW层各开发一套,那倒是有可能让
L.APK层能兼容不同的L.BSW平台。因为 L.FW层的差异化实现实际扮演了中间层的角色,屏蔽了更下一层的差异。
因此,实际开发 L.FW层之前,要先选择好 L.BSW 层的技术方案。
| 






 订阅
订阅