| 编辑推荐: |
|
本文对内存排序的工作原理以及如何在 C++ 中使用原子操作与内存排序来构建无锁队列做些介绍。
希望能为大家提供一些参考或帮助。
文章来自于CSDN,由火龙果软件Elaine编辑推荐。 |
|
想象一下,你有一些并发代码在内存中操作一些共享数据。你有两个线程或进程,一个写入,一个读取一些共享状态。
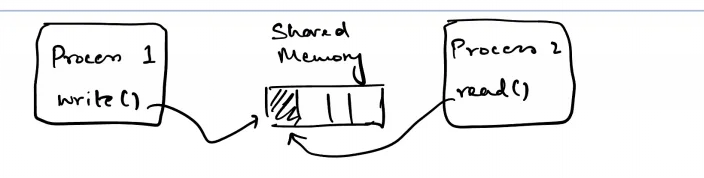
“安全”的处理方式是互斥锁。但是,互斥锁往往会增加开销。原子操作是一种处理并发操作的方式,性能更高,但更为复杂。


原子操作
这一部分非常简单。原子操作指的是不能被编译器或 CPU 拆分或以任何方式重新排序的操作或指令。
C++中最简单的原子操作示例是使用原子标志。

如上,我们定义了一个原子布尔值,首先初始化,然后再调用 store() 方法。这个方法设置了标志的值。接下来,你就可以从内存中加载标志,并断言它的值。
原子操作
你可以执行的原子操作很简单:
1.你可以使用 store() 方法将某个值存储到原子值中。这是一个写操作。
2.你可以使用 load() 方法加载原子值。这是一个读操作。
3.你可以使用 compare_exchange_weak() 或 compare_exchange_strong()
方法,比较并设置原子值。这是一个读取-修改-写入操作。
重点在于,你必须记住这些操作都不能分成单独的指令。
注意:其实还有很多可用的方法,但在文本中,我们只使用这些方法。
C++ 中有各种各样的原子操作,你可以结合内存排序一起使用。

内存排序
这一部分要复杂得多,但也是这个问题的核心。
为什么重要?
编译器和 CPU 能够重新排列程序指令,通常这些指令之间是彼此独立的。也就是说,编译器可以重新排列指令,然后
CPU 可以再次重新排列指令。
然而,只有在编译器可以完全确信两组指令之间无法建立关系时,才允许这样做。
举个例子,下面这两条语句可以被重新排序,因为 x 的赋值和 y 的赋值之间没有任何关系。也就是说,编译器或
CPU 有可能先分配 y,然后再分配 x。但是,这并不会改变程序的语义含义。

然而,下面的代码不能被重新排序,因为编译器无法确定 x 和 y 之间是否存在某种关系。此处可以看到,很明显
y 的取值依赖于 x 的值。

虽然看似不是什么大问题,但在多线程的代码中情况就大为不同了。
排序
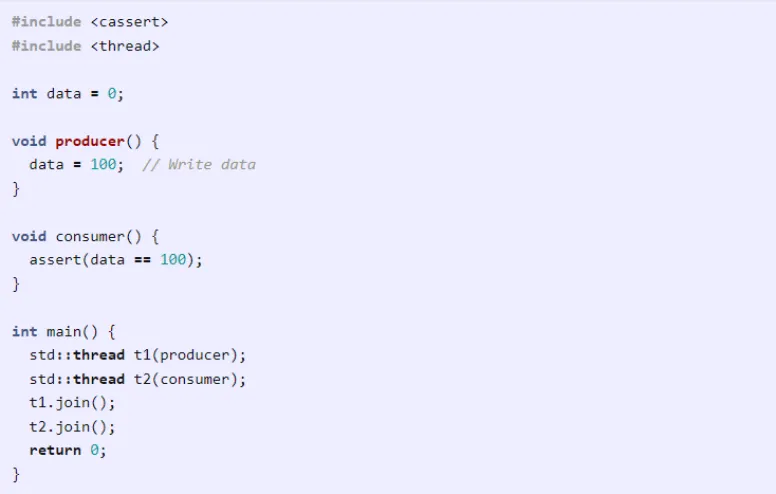
上面的这个多线程示例将无法通过 TSan 编译,因为在线程 1 尝试设置数据的值,线程 2 在同一时间尝试读取数据的值时,二者之间存在明显的数据竞争。为了解决这个问题,简单的方法是使用互斥锁来保护数据的写入和读取,但我们也可以使用原子布尔值来实现。
我们可以循环访问原子布尔值,直到其它被设置为我们要查找的值,然后检查数据的值。

TSan 不会在编译时抱怨任何竞争条件。后面我们会详细介绍为什么 TSan 不会抱怨。
下面,我们来添加内存顺序。即,将 ready.store(true); 替换为 ready.store(true,
std::memory_order_relaxed);,并将 while (!ready.load())
替换为 while (!ready.load(std::memory_order_relaxed))。
接着,TSan 就会抱怨存在数据竞争了。为什么会出现这种情况?
问题在于,两个线程操作之间没有顺序了。因此,编译器或 CPU 可以自由地重新排序两个线程中的指令了。我们可以用如下简单的图形来表示。
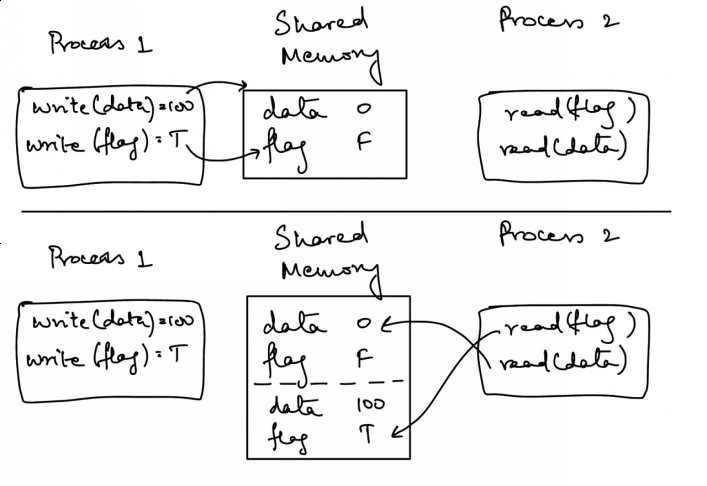
上图展示了两个进程(线程)无法就当前状态或状态更改的顺序达成一致。
一旦进程 2 确定标志已设置为 true,它就会尝试读取 data 的值。但是,线程 2 认为 data
的值尚未变更,即便它认为标志的值已设置为 true。
这让我们感到很迷惑,因为经典的交错并发操作模型并不适用此处。在经典的并发操作模型中,你总是可以建立某种顺序。例如,我们可以认为如下是操作可能出现的一种情况。
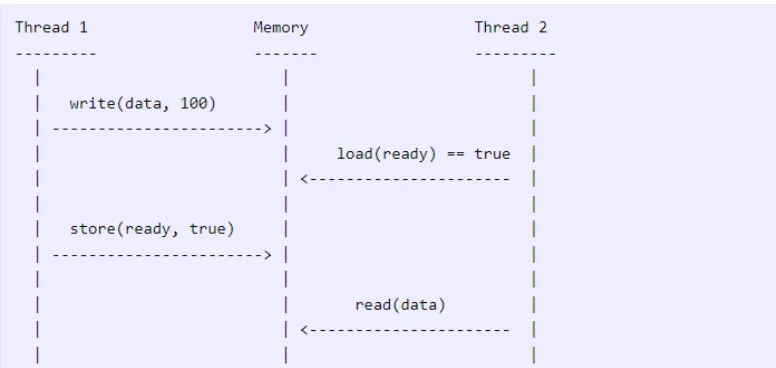
但是,上图假设两个线程已经就事件的某种全局顺序达成了一致,而实际情况并非如此。
在 memory_order_relaxed 模式下,两个线程无法就共享变量的操作顺序达成一致。在线程
1 看来,它执行的操作如下:

然而,在线程 2 看来,线程 1 执行操作的顺序为:

由于没有就共享变量上的操作执行生顺序达成一致,因此跨线程对这些变量进行更改是不安全的。
下面,为了修复这段代码,我们将 std::memory_order_relaxed 替换为 std::memory_order_seq_cst。
也就是说,ready.store(true, std::memory_order_relaxed);
变成了 ready.store(true, std::memory_order_seq_cst);,而
while (!ready.load(std::memory_order_relaxed)) 变成了
while (!ready.load(std::memory_order_seq_cst))。
再次使用 TSan 运行此代码,就不会有数据竞争了。但是,为什么这样就能修复代码呢?
内存屏障
如上,我们看到了一个问题,两个线程无法就事件的单一视图达成一致,而我们希望防止这种情况发生。因此,我们引入了一个屏障,确保顺序的一致性。
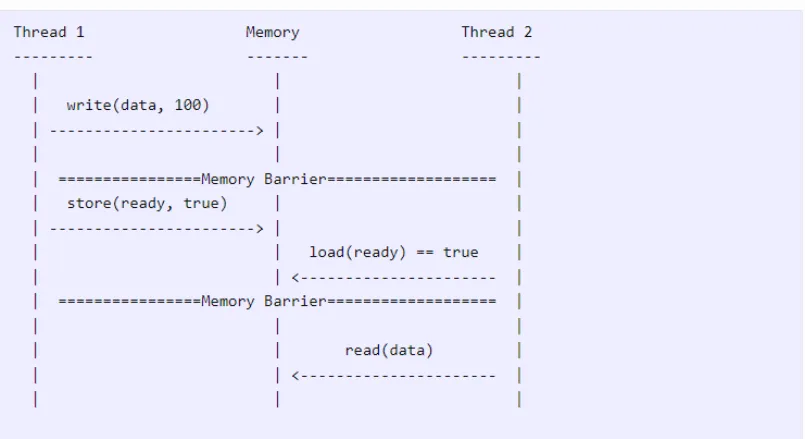
此处,内存屏障表示存储操作之前和加载操作之后的任何内容都不会被重新排序。也就是说,现在线程 2 有了一个保证,即编译器或
CPU 不会将线程 1 中标志的写入放在数据的写入之后。类似地,线程 2 中的读取操作不能被重新排序到内存屏障之上。
内存屏障内的区域类似于一个线程需要通过互斥锁才能进入的临界区域。现在我们有了一种方法来同步两个线程上的事件顺序。
这样,我们就回到了并发中的经典交错模型,因为现在我们有了两个线程都认同的事件顺序。
内存顺序的类型
内存顺序主要有三种类型:
松散内存模型(std::memory_order_relaxed)
释放-获取型内存模型(std::memory_order_release 和 std::memory_order_acquire)
顺序一致型内存模型(std::memory_order_seq_cst)
如上示例涵盖了第1种和第3种。第二种内存模型的一致性处理处于二者之间。

这个示例与前面的相同,只不过此处 ready.store() 中使用了 std::memory_order_release,而
read.load() 中使用了 memory_order_acquire。此处的顺序与之前的内存屏障示例类似。
不同的是,此次内存屏障是在 ready.store() 和 ready.load() 操作上建立的,并且只有在跨线程使用相同的原子变量时才起作用。假设有一个变量
x 在两个线程之间被修改,你可以在线程 1 中执行 x.store(std::memory_order_release),并在线程
2 中执行 x.load(std::memory_order_acquire),这样这个变量就可以在两个线程之间建立了一个同步点。
顺序一致型模型和释放-获取型内存模型的区别在于,前者会强制执行所有线程之间的全局操作顺序,而后者仅在释放和获取操作之间强制执行顺序。
下面,我们来谈论为什么在没有指定内存顺序时,TSan 没有抱怨数据竞争。这是因为 C++在 默认情况下假定没有指定内存顺序时使用
std::memory_order_seq_cst。由于这是最强的内存模型,因此不存在数据竞争。

硬件考虑
不同的内存模型在不同硬件上有不同的性能损失。
举个例子,x86 架构指令集实现了“总线存储排序”( total store ordering,TSO)。其核心思想是所有线程都读写共享内存的模型。这意味着,x86
处理器可以提供计算开销相对较低的顺序一致性。
另一方面,ARM 处理器系列具有弱顺序的指令集架构。这是因为每个线程或进程都读写自己的内存。这意味着,ARM
处理器为更高的计算开销提供了顺序一致性。

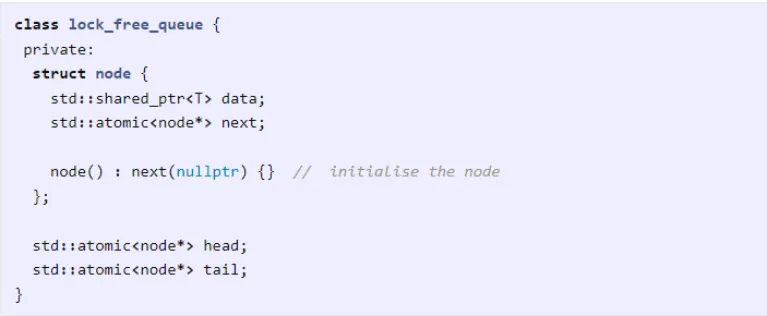
构建并发队列
下面,我将使用截止到目前为止讨论过的操作来构建一个基本的无锁并发队列的基本操作。下列代码并不是完整的实现,只不过是我尝试使用原子来重新创建一些基本操作。
我将使用链表来表示队列,并将每个节点包装在原子内。
下面是入队操作的实现:
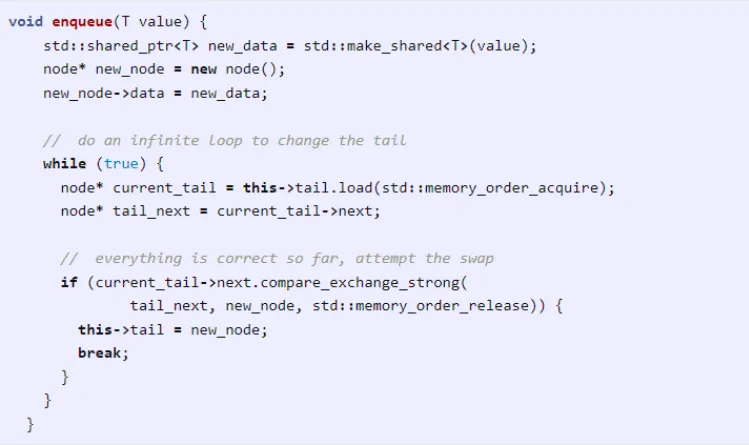
请注意 load 和 compare_exchange_strong 操作。load 操作使用了
acquire,而 compare_exchange_strong 操作使用了 release,以确保末尾的读写是同步的。
出队操作与之类似:
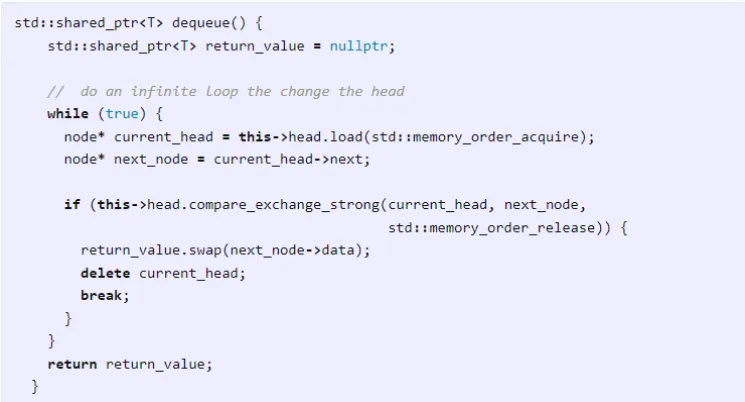
注意,此队列没有处理 ABA 问题。
以上就是关于 C++ 中的原子操作的介绍。非常复杂,我绝对不会把这段代码放到生产环境中,因为我确信我的这个并发队列会出问题。
|






 订阅
订阅