| 编辑推荐: |
本文主要讲述了抽象语法树 AST 从零入门的相关内容。 希望能为大家提供一些参考或帮助。
文章来自于知乎,由火龙果Linda编辑推荐。 |
|
抽象语法树从零入门(翻译)
在我开始学习计算机科学的旅程之前,有一些术语和短语让我想润到别的研究方向。
但我并没有润,而是假装了解这些知识,在谈话中点头哈腰,假装我知道别人指的是什么,尽管事实是我根本不知道,而且当我听到那个超级可怕的计算机科学术语时,实际上已经完全糊涂了。在这个系列的过程中,我已经成功地覆盖了很多地方(指作者写的系列),其中许多术语实际上已经变得不那么可怕了!但是,有一个重要的术语......还没有说道。
不过,那个术语,我已经回避了一段时间了。直到现在,每当我听到这个术语时,我都会觉得人都麻了。它出现在闲聊中,有时也出现在会议的会谈中。每一次,我都会想到机器在转圈,电脑在吐出一串串无法解读的代码,只是我周围的人其实都能解读这些代码,所以实际上只有我不知道发生了什么(哎呀,怎么会这样!)。
也许我不是唯一有这种感觉的人。但是,我想我应该告诉你这个术语到底是什么,对吗?好吧,准备好了,因为我指的是永远难以捉摸的、似乎令人困惑的抽象语法树,或者简称AST。在被吓唬了许多年之后,我很高兴终于不再害怕这个术语,并真正理解它到底是什么。
现在是时候直面抽象语法树的根源,并提高我们的 parse(解析) 水平了!
从具体到抽象
每一个优秀的研究都是从一个坚实的基础开始的,而我们揭开这个结构的神秘面纱的任务也应该以完全相同的方式开始:当然是以一个定义开始的。
抽象语法树实际上不过是解析树(就是指直接 tokenize 后解析得到的树)的一个简化、浓缩版本。在编译器设计中,AST
一词与语法树(Syntax Tree)可以互换使用。
我们经常会把语法树(以及它们是如何构建的)与我们已经相当熟悉的对应的解析树相比较来思考。我们知道,解析树是包含我们代码语法结构的树状数据结构;换句话说,它们包含所有出现在代码
"句子 "中的句法信息,并直接从编程语言本身的语法中得到。
另一方面,一个抽象的语法树忽略了大量的语法信息,但是解析树就会包含这些信息。
相比之下,一个 AST 只包含与分析源文本有关的信息,而跳过任何其他在解析文本时使用的额外内容(例如什么分号,函数参数中的逗号之类的对程序没有意义的东西)。
如果我们把注意力集中在 AST 的 "抽象性 "上,这种区别就开始变得更有意义了。
我们记得,解析树是一个句子语法结构的图解版本。换句话说,我们可以说解析树完全代表了一个表达式、句子或文本的样子。它基本上是文本本身的直接翻译;我们把句子的每一小部分--从标点符号到表达式再到标记--都变成一个树形数据结构。它揭示了文本的具体语法,这就是为什么它也被称为具体语法树,或CST(Concrete
Syntax Tree)。我们用 "具体 "一词来描述这种结构,因为它是我们的代码的语法拷贝,以树状格式逐个标记。
但是,是什么让一些东西变得具体而又抽象呢?好吧,抽象语法树并不像解析树那样向我们展示一个表达式的确切面貌。
相反,抽象的语法树向我们展示了 "重要 "的部分--那些我们真正关心的东西,它们赋予了我们的代码
"句子 "本身以意义。语法树向我们展示了一个表达式的重要部分,或者我们源文本的抽象语法。因此,与具体的语法树相比,这些结构是我们代码的抽象表示(在某些方面,不那么精确),这正是它们的名字的由来。
既然我们已经了解了这两种数据结构的区别,以及它们表示代码的不同方式,那么就值得提出这样的问题:抽象语法树在编译器中的位置?首先,列出我们所知道的关于编译过程的一切。
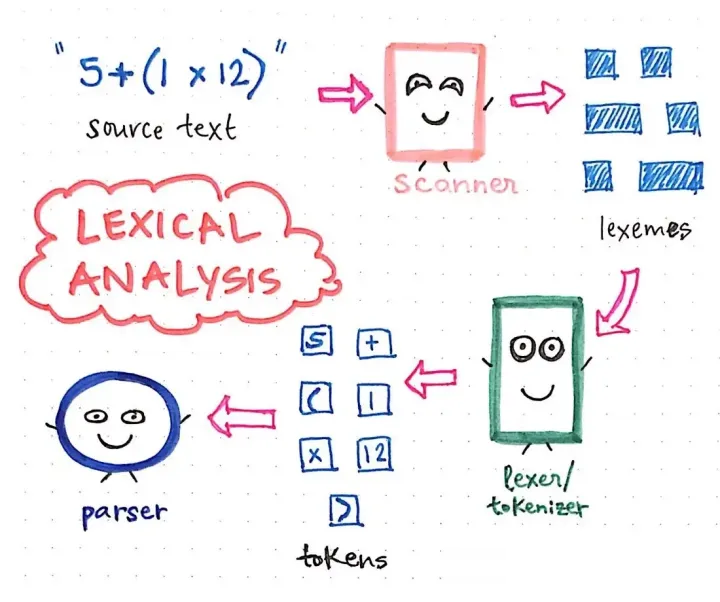
源文本->扫描器(Scanner)->Tokenizer->解析器(Parser)
假设我们有一个超级短小精悍的源文本,它看起来像这样。5 + (1 x 12). 我们记得,在编译过程中发生的第一件事是对文本进行扫描,这项工作由扫描器(Scanner)完成,其结果是文本被分解成其尽可能小的部分,这些部分被称为词素。这一部分将与语言无关,我们最终会得到我们源文本的剥离版本。
接下来,这些词素会被传递给词法/符号化器(Tokenizer/Lexer),它将我们源文本的这些小的表现形式转化为token,这将是我们的语言所特有的。我们的token将看起来像这样。[5,
+, (, 1, x, 12, )]. 扫描器和标记器的共同努力构成了编译的词法分析。 然后,一旦我们的输入被标记化,它所产生的标记就会被传递给我们的Parser,然后它就会从源文本中构建一个解析树。下面的图例说明了我们的标记化代码在解析树格式中的样子。
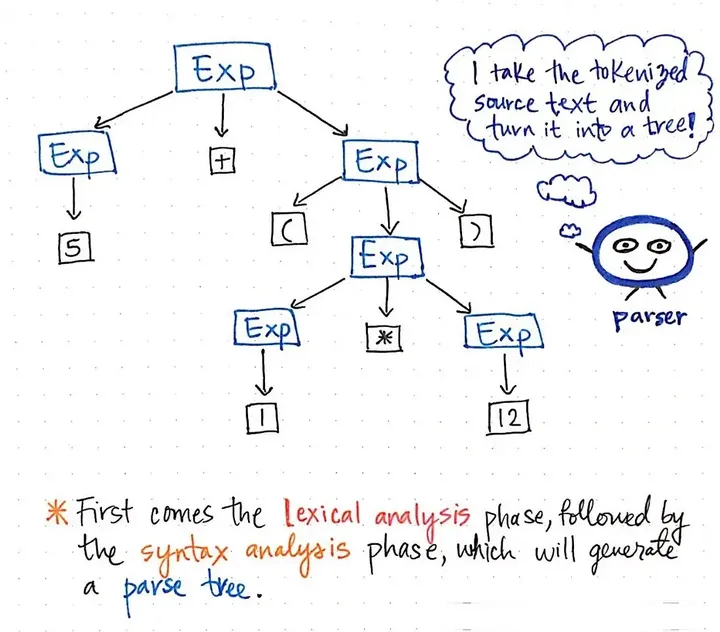
语法分析阶段生成解析树
将标记变成解析树的工作也被称为解析,被称为语法分析阶段。语法分析阶段直接依赖于 tokenize 阶段;因此,在编译过程中,tokenize
必须永远是第一位的,因为我们的编译器的解析器只有在 tokenizer 完成它的工作后才能完成它的工作!
我们可以把编译器的各个部分看作是好朋友,他们都相互依赖,以确保我们的代码能够正确地从文本或文件转化为解析树。
但回到我们最初的问题:抽象语法树在这个朋友圈中的地位如何?嗯,为了回答这个问题,首先要理解对 AST
的需求。
将一棵树“浓缩”成另一棵树
好了,现在我们有两棵树在我们的脑子里。我们已经有了一个解析树,现在又有一个数据结构需要学习了!显然,这个AST数据结构只是一个简化的解析树。那么,我们为什么需要它呢?它的意义何在?
好吧,让我们看一下我们的解析树。
我们已经知道,解析树代表了我们的程序中最独特的部分;事实上,这就是为什么 Scanner 和 Tokenizer
有如此重要的工作,将我们的表达式分解成最小的部分!这就是为什么我们要用解析树来代表我们的程序。事实证明,有时一个程序的所有不同部分实际上并不总是对我们那么有用。
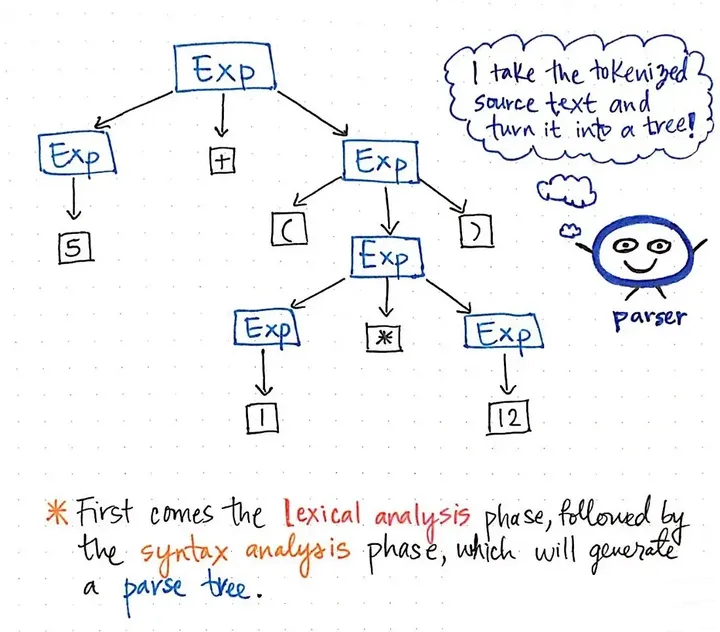
让我们看一下这里的插图,它以解析树的格式表示我们的原始表达式,5+(1×12)。如果我们用批判的眼光仔细观察这棵树,我们会发现有几个例子,其中一个节点正好有一个子节点,这也被称为单继承者节点,因为它们只有一个子节点源于它们。
在我们的解析树例子中,单继承者节点的父节点是一个表达式,即Exp,它有一个单一的继承者,比如5、1或12的值。然而,这里的Exp父节点实际上并没有给我们增加任何有价值的东西啊,不是吗?我们可以看到它们包含一些
Token 或者最终的子节点,但是我们并不真正关心这个 Exp 父节点;我们真正想知道的是这个表达式到底是什么。
一旦我们解析了我们的树,这个 Exp 父节点根本不会给我们任何额外的信息。相反,我们真正关心的是单一子节点、单一继承者节点。事实上,这才是给我们提供重要信息的节点,对我们有意义的部分:数字和数值本身!这也是我们的目标。考虑到这些父节点对我们来说是一种不必要的事实,很明显,这个解析树是一种冗长的。
所有这些单一的继承节点对我们来说都是相当多余的,对我们一点帮助都没有。所以,让我们把它们去掉吧!
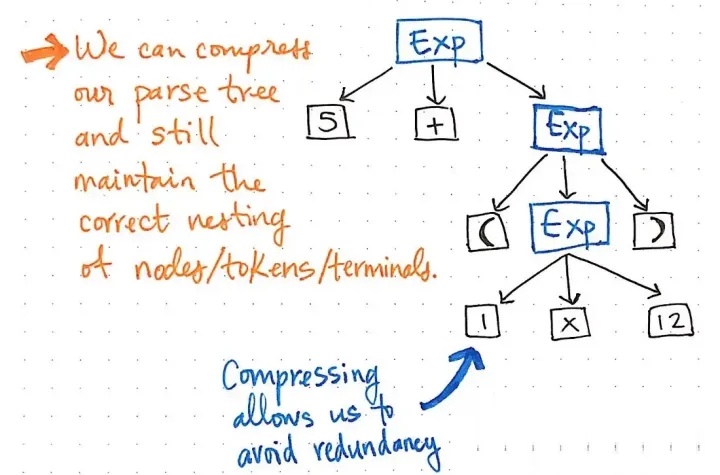
压缩解析树可以避免冗余。
如果我们对解析树中的只有一个子节点的节点进行压缩删除,我们最终会得到一个完全相同结构的压缩版本。看一下上面的插图,我们会发现我们仍然保持着和以前完全一样的嵌套,我们的节点/
Token 仍然出现在树中的正确位置。但是,我们已经设法把它缩小了一点。
而且,我们也可以对我们的树进行一些修剪。例如,如果我们看一下我们目前的解析树,我们会发现其中有一个镜像结构。(1
x 12)的子表达式嵌套在小括号()内,而小括号本身就是 Token。
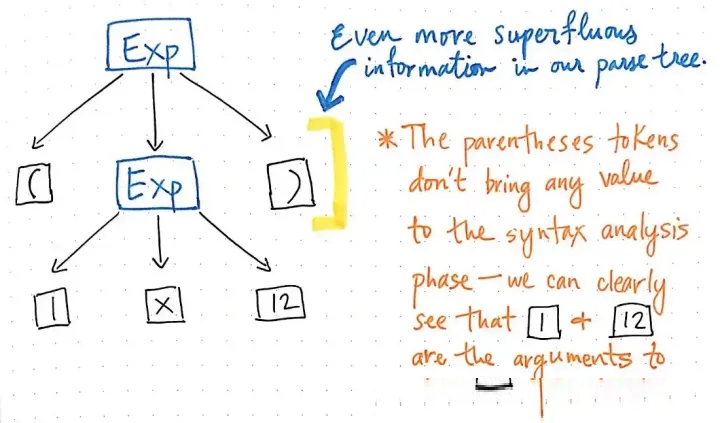
对我们没有用处的多余的信息可以从解析树中删除。
然而,从这个树来看,这些括号并没有真正帮助我们。我们已经知道,1和12是将被传递给乘法操作的参数,所以括号在这一点上并没有任何意义。所以说,我们可以进一步压缩我们的解析树,去掉这些多余的叶子节点。
一旦我们压缩和简化了我们的解析树,摆脱了多余的句法鸡肋,我们最终得到的结构在这一点上看起来明显不同。事实上,这个结构就是我们新的、备受期待的朋友:抽象语法树。
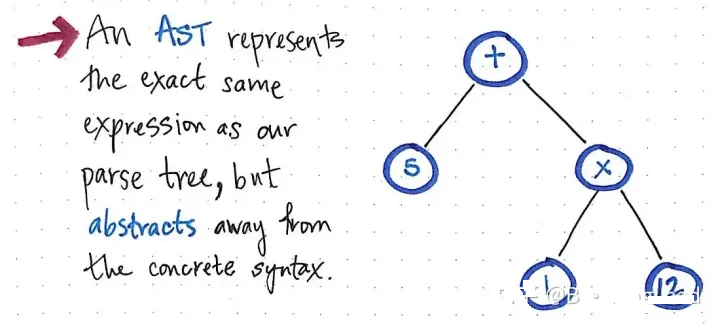
一个 AST 和解析树表示的是完全相同的,只不过它从实际语法中抽象出来了而已
上面的图片说明了与我们的解析树完全相同的表达。5 + (1 x 12). 不同的是,它把表达式从具体的语法中抽象出来了。我们在这棵树上看不到任何括号(),因为它们没有改变运算顺序,所以不是必须的。同样,我们也看不到像
Exp 这样的非终子节点(这翻译的怪怪的),因为我们已经弄清楚了 "表达式 "是什么,而且我们能够取出对我们真正重要的值,例如,数字5。
这正是区分 AST 和 CST 的因素。我们知道,抽象语法树忽略了解析树所包含的大量的语法信息,并跳过了解析中使用的
"额外内容"。但现在我们可以确切地看到这一点是如何发生的!

AST 是源文本的一个抽象表示。
AST 是源文本的一个抽象表示。他们通常在一下几点看起来和解析树不太一样。
一些诸如逗号啊,括号啊,分号之类的句法细节,AST 没有。
节点链通常会被折叠起来(类似语言学中的NP-N直接写成N)只有一个继承者的节点不会出现。
像加减乘除之类的运算符可以作为父节点出现,而不是子节点。
用人眼看起来,AST总是比解析树更紧凑,因为根据定义,它是解析树的压缩版本,语法细节更少。
因此,因为 AST 是解析树的压缩版本,所以我们只有在有了构建解析树的 Token 等东西之后,才能创建一个抽象的语法树。
事实上,这就是抽象语法树在更大的编译过程中的作用。语法树与我们已经学过的解析树有直接的联系,同时,在创建语法树之前,还要依靠词法分析器来完成它的工作。

语法分析阶段的最终结果就是个 AST。解析器有可能,或者不会生成(?大脑过载)在生成 AST 之前先搞一个
CST(这取决于编译器的设计),但是最后它还是会生成一个 AST 的。(看下面是机翻)
抽象的语法树是作为语法分析阶段的最终结果而创建的。语法分析过程中,作为主要 "角色 "的解析器,可能会也可能不会总是生成一棵解析树,即
CST。根据编译器本身以及它的设计方式,解析器可能会直接构建一个语法树,或 AST 。但是,分析器总是会生成一个
AST 作为它的输出,不管它在这中间是否创建了一个 CST,或者它可能需要经过多少次才能做到这一点。
AST “解剖”
现在我们知道了抽象语法树的重要性(起码*不会*让你造成恐慌),我们就可以开始对它进行更多的剖析了。关于如何构建
AST 的一个有意思的方面是与该树的节点有关的。
下面的图片展示了抽象语法树中单个节点的解剖结构。
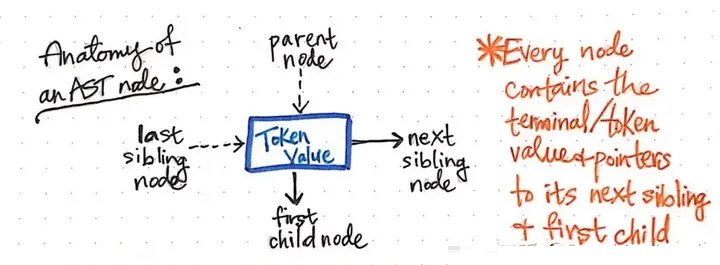
我们会注意到,这个节点与我们之前看到的其他节点类似,它包含一些数据(一个 Token 和它的值)。然而,它还包含一些非常具体的指针。AST中的每个节点都包含对其下一个同级节点的指针以及第一个子节点的指针。
例如,我们的5 + (1 x 12)的简单表达式可以被构造成一个AST的可视化图示,就像下面这个。
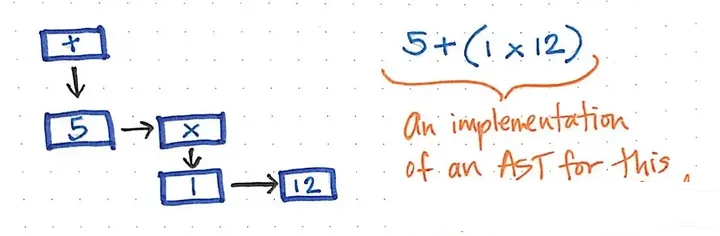
这个表达式的 AST 的一个可能实现的可视化版本(译者头脑已爆炸,果然我不适合学CS)(
We can imagine that reading, traversing, or “interpreting”
this AST might start from the bottom levels of the
tree, working its way back up to build up a value
or a returnresultby the end.(看不懂放弃)
看到解析器输出的代码版本也会有所帮助,以帮助补充我们的可视化。我们可以依靠各种工具和使用预先存在的解析器来快速查看我们的表达式在解析器中运行时可能出现的例子。下面是我们的源文本,5
+ (1 * 12),通过 ECMAScript 解析器 Esprima 运行的例子,以及其产生的抽象语法树,后面是其不同标记的列表。
// Using Esprima, a ECMAScript parser
written in ECMAScript
// var esprima = require('esprima');
// var program = 'const answer = 42';
// 注释不写了(不懂js
// Syntax
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "result"
},
"init": {
"type": "BinaryExpression",
"operator": "+",
"left": {
"type": "Literal",
"value": 5,
"raw": "5"
},
"right": {
"type": "BinaryExpression",
"operator": "*",
"left": {
"type": "Literal",
"value": 1,
"raw": "1"
},
"right": {
"type": "Literal",
"value": 12,
"raw": "12"
}
}
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
// Token List
[
{
"type": "Keyword",
"value": "var"
},
{
"type": "Identifier",
"value": "result"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "Numeric",
"value": "5"
},
{
"type": "Punctuator",
"value": "+"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Numeric",
"value": "1"
},
{
"type": "Punctuator",
"value": "*"
},
{
"type": "Numeric",
"value": "12"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": ";"
}
]
|
在这种格式中,如果我们看一下嵌套的对象,我们就可以看到树的嵌套情况。我们会注意到,包含 1 和 12
的值分别是父运算 * 的左子和右子。我们还将看到,乘法运算构成了整个表达式本身的右小节,这就是为什么它被嵌套在更大的二元表达式对象中,位于
"右 "键之下。同样地,5 的值是大 BinaryExpression 对象的单一左边的子节点。

有时搞出 AST 是很难的!
然而,抽象语法树最耐人寻味的地方是,尽管它们是如此紧凑和干净,但它们并不总是一个容易尝试和构建的数据结构。事实上,构建一个AST可能是相当复杂的,这取决于分析器所处理的语言。
大多数解析器通常会先构建一个解析树(CST),然后将其转换为 AST ,因为这有时会更容易--尽管这意味着更多的步骤,而且一般来说,更多地通过源文本。一旦解析器知道了它要解析的语言的语法,建立一个
CST 实际上是非常容易的。它不需要做任何复杂的工作来确定一个标记是否要怎么怎么操作,或者是不是“重要“节点;相反,它只需要按照它看到的特定顺序,准确地记录看到它的内容,并将其全部搞到一个树中。
但是,有一些分析器会试图将所有这些作为一个单步过程,直接构建一个 AST。
直接构建AST是很棘手的,因为解析器不仅要找到标记并正确表示它们,还要决定哪些标记对我们重要,哪些不重要。
在编译器设计中,AST最终是超级重要的,原因不止一个,就是上面提到的那些。是的,它的构造特别麻烦(而且可能很容易一怒而下摔键盘),但同时它也是词法和语法分析阶段的最后和最终结果。词法和句法分析阶段通常被合称为分析阶段,或编译器的前端。

我们可以把抽象的语法树看作是编译器前端的最终项目。这是最重要的部分,因为它是前端必须为自己展示的最后一件事。这个技术术语被称为中级代码表示结构或IR(intermediate
code representation)(不知道这个词怎么翻译?),因为它成为最终被编译器用来表示源文本的数据结构。
抽象语法树是最常见的IR形式,但有时也是最容易被误解的。但是,现在我们对它有了一点了解,我们可以开始改变对这种有些厄厄的可怕结构的看法了,希望现在它对我们的“威慑力“有所降低。
|







 订阅
订阅