| �༭�Ƽ�: |
���±������ݼ�¼Э�̣�Coroutine����ʲô��Libco
ʹ�ü�飬Libco Э�̵��������ڣ��ʺ�����C���Ի�����ͬѧ�Ķ���ϣ����������������
����������csdn���ɻ�����Delores�༭�Ƽ��� |
|
1 ����
ʹ�� C++ ����д�����ܵ���������������������Ǽ����������顣��û��Ӧ���κ������ܣ��� epoll/kqueue ֱ�������ʱ��������ˡ�����ʹ�� libevent, libev�����¼�������������ȥ������ķ�����ṹ��Ȼ����ܼ�Ϊ�λ���������Ϊ�������ṩ�Ķ��Ƿ�����ʽ�ġ��첽�ı�̽ӿڣ��첽�ı�̷�ʽ������Ҫ˼ά��ʽ��ת�䡣Ϊʲô golang �������ܹ����ģ���������أ���Ϊ���ⷽ����ͻ����һ��������������� API����ȫͬ������ʽ�Ľӿڡ�Ҫ������go ��һ��Э�̾ͺ��ˡ����Ŷ��ںܶ�����˵���ʼ�Ӵ����ֱ�̷�ʽ�����е�����ġ������е�������ͬ������ʽ�ĵ��ã�����������ܺ��𣿴��ǣ��ã����ҷdz��á���ô golang ������������أ��ؾ����������Э�̻������ go ���Ե� API ����Ҳ����� epoll/kqueue ֮��� I/O ��·���ã�I/O multiplexing���ӿڣ���������ô��������֧����������ʮ����߲��������� IO ���أ��� Linux �������� Unix ϵͳ�֧�� I/O ��·�����¼�֪ͨ��ϵͳ���ã�System Call�������epoll/kqueue�����ѵ������뿪��Щϵͳ�ӿ�����¯������Ȼ�Dz����ܵġ������Ķ��ߣ�Ӧ�ô����뵽���ⱳ������ô��ԭ���ˡ��������õ�Э�̲���ģʽ��ͬ������ʽ�� IO �ӿڣ�ʹ�� golang ������ʮ�����ס���ô C++ �ɲ��������������أ�����Ҫ���ܵĿ�ԴЭ�̿� libco���������������һ����Դ�⣬����ĸ����������������̲������ѡ�Libco ���ź�̨���ģʹ�õ� C++ Э�̿⣬�� 2013 ���ʱ����Ϊ��Ѷ����Դ��Ŀ�״ο�Դ����˵ 2013 �������ȶ��������ź�̨������̨�����ϡ��ӱ���ArchSummit �������������Ѷ�ڲ��ķ�������������������Ѷ�ڲ�ʹ��ȷʵ�DZȽϹ㷺�ġ�ͬ go ����һ����libco Ҳ���ṩ��ͬ�������ģʽ��ͬʱ���ܱ�֤ϵͳ�ĸ߲���������
2 ��֪ʶ
2.1 Э�̣�Coroutine����ʲô��
Э������������⼸������൱�������ˡ����� go ��������֮�����õ�Э�����ԣ���ȫ�����˲���ϵͳ�̵߳ĸ���ϸ�ڣ�����ʹ go �����ߡ�ֻ֪��Э�̣���֪���̡߳��ˡ���Ȼ C++, Java Ҳ�������������й�ע�� C++ ���Ե����¶�̬������Ҳ��ע������겻�������ڸ� C++ ��ί����Э�̵�֧�ַ�����Java Ҳͬ����һЩ�����ԵĽ����������������� go ���Դ�������Ľ��죬û��˵��Э������ʵij���ԱӦ�ú����ˣ�����ֱ�ӽӴ���Э�̱�̵ģ�golang, lua, python �ȣ�Ҳ���������������Ϊ���Ǹ��Ƚ��µĶ���������ʵЭ����������ڼ���������Ѿ��൱�ع����ˡ�������ʮ�����Donald Knuth ���������� The Art of Computer Programming �н� Coroutine ��������� Conway Melvin��ͬʱ��Knuth ���ᵽ��coroutines ������һ������� subroutines��Subroutine �����̵��ã��ںܶ��������Ҳ�к�����Ϊ�˷���������������ǽ�����Ϊ������������������һ������ʱ������Ӻ�����ͷ����ʼִ�У��������˳�ʱ�������������������Ҳ�ͽ����ˡ�һ�������������������У�ֻ���ܷ���һ�Ρ���Э����ͬ��Э����ִ�й����У����Ե��ñ��Э���Լ�����;�˳�ִ�У�֮���ִӵ��ñ��Э�̵ĵط��ָ�ִ�С����е������ϵͳ���̣߳�ִ�й����п��ܱ�������λ�ڱ���߳�ִ�У��Ժ��ִӹ���ĵط��ָ�ִ�С�����������У�Э����Э��֮��ʵ���ϲ�����ͨ���������뱻���ߡ��Ĺ�ϵ������֮��Ĺ�ϵ�ǶԳƵģ�symmetric����ʵ���ϣ�Э�̲�һ�������ֶԳƵĹ�ϵ����������һ�ַǶԳƵ�Э��ģʽ��asymmetric coroutines�����ǶԳ�Э����ʵҲ�Ƚϳ���������Ҫ���ܵ� libco ��ʵ����һ�ַǶԳ�Э�̣�Boost C++ ��Ҳ�ṩ�˷ǶԳ�Э�̡������������ǶԳ�Э�̣�asymmetric coroutines���Ǹ�һ���ض��ĵ����߰ģ�Э���ó� CPU ʱ��ֻ���ûظ�ԭ�����ߡ��ǵ�����ʲô���������Գơ��أ���ʵ���ǶԳ����ڳ��������ת�Ƶ�����Э��ʱʹ�õ��� call/resume ��������������Э���ó� CPUʱʹ�õ�ȴ�� return/yield ���������⣬Э�̼�ĵ�λҲ���Եȣ�caller �� callee ��ϵ��ȷ���ģ����ɸ��ĵģ��ǶԳ�Э��ֻ�ܷ��������������Э�̡��Գ�Э�̣�symmetric coroutines����һ��������֮�������֮ǰ��Э��û���κι�ϵ�ˡ�Э�̵��л�������һ�����ֻ��һ��������yield�����ڽ����������ת�Ƹ������Э�̡��Գ�Э�̻���һ����Ҫһ����������֧�֣���һ�� t�������㷨ȥѡ�� yield��Ŀ��Э�̡�Go �����ṩ��Э�̣���ʵ���ǵ��͵ĶԳ�Э�̡������Գƣ�goroutines �������ڶ���߳���Ǩ�ơ�����Э�̸�����ϵͳ�е��̷߳dz����ƣ��������Խ������û����̡߳��ˡ��� libco �ṩ��Э�̣���Ȼ��̽ӿڸ� pthread �е����ƣ����� pthread �Ľӿ���ơ��������߳̿�һ�����ɡ���������ȴ��һ�ַǶԳ�Э�̡���һ�㲻Ҫ���������ˡ���ʵ�ϣ�libco �ڲ���Ϊ����Э�̵ĵ���������һ�� stack �ṹ������� stack ��Сֻ�й̶��� 128��ʹ�� libco��������ϵ���һ��Э�����й�����������һ��Э�̣�����Ƕ��������ӾͿ��ܻ�������ջ�ռ������
3 Libco ʹ�ü��
3.1 һ��������
�ڶ��̱߳�̳̽��У���һ����������ӣ����������������⡣��ʵ�ϣ�����������������Ҳ�����ʺ�Э�̵�Ӧ�ó�������ô���Ǿʹ�������������֣�����һ��ʹ�� libco ��д�������������߳���
struct stTask_t
{
int id;
};
struct stEnv_t {
stCoCond_t* cond;
queue<stTask_t*> task_queue;
};
void* Producer(void* args) {
co_enable_hook_sys();
stEnv_t* env = (stEnv_t*)args;
int id = 0;
while (true) {
stTask_t* task = (stTask_t*)calloc
(1, sizeof(stTask_t));
task->id = id++;
env->task_queue.push(task);
printf("%s:%d produce task %d\n",
__func__, __LINE__, task->id);
co_cond_signal(env->cond);
poll(NULL, 0, 1000);
}
return NULL;
}
void* Consumer(void* args) {
co_enable_hook_sys();
stEnv_t* env = (stEnv_t*)args;
while (true) {
if (env->task_queue.empty()) {
co_cond_timedwait(env->cond, 1);
continue;
}
stTask_t* task = env->task_queue.front();
env->task_queue.pop();
printf("%s:%d consume task %d\n",
__func__, __LINE__, task->id);
free(task);
}
return NULL;
} |
���νӴ� libco �Ķ��ߣ�Ӧ������Դ����룬��������һ��������ӿ�����������ʲô��ʵ���ϣ�������ӵ������������߳�ʵ�ַ��������Ƶģ�Producer ��Consumer �����ӡ������������Ϣ�����������룬�� main() �����У����ǿ�������һ��Э�̵Ľṹ���� stCoRoutine_t������һ��Э��ʹ�� co_create() ����������ע�������� co_create() �Ľӿ���Ƹ�pthread ��pthread_create() �Ƿdz����Ƶġ��� pthread ��̫һ���ǣ�������һ��Э��֮��û��������������������Ҫ����Э�̣�������� co_resume() ���������pthread �����߳�֮�����߳������� pthread_join() �ȵ����߳��˳��������������û�С�co_join()�������Ƶĺ��������ǵ�����һ�� co_eventloop() ��������Щ�����ԭ�����Ǻ��Ļ���ϸ������Ȼ���ٿ� Producer �� Consumer ��ʵ�֣�ϸ�ĵĶ��߿��ܻᷢ�֣������� Producer���� Consumer�������ڲ��������Ķ���ʱ��û�м�����û�л��Ᵽ������ô�������Ƿ�ȫ�أ���ʵ�ǰ�ȫ�ġ��������������ʱ�������� ps ����ῴ�������ʵ����ֻ��һ���̡߳�������κ�ʱ�̴�������ֻ����һ��Э�������У����Բ����� race conditions������Ҫ�κλ��Ᵽ��������һ�����⡣��������Ȼֻ��һ���̣߳���ô Producer �� Consumer ������Э�̺�����������������ִ�е��أ��������Ϥ pthread �Ͳ���ϵͳ���̵߳�ԭ����Ӧ�úܿ��ܷ��ֳ����� co_cond_signal()��poll() �� co_cond_timedwait() �⼸���ؼ��㡣����
��һ�� pthread ��д�������������߳�����ֻ�е��� CPU �Ļ�����ִ�У�����Dz���һ���ģ���֮��������Ӹ� pthread ʵ�ֵ������������߳����Ƿdz����Ƶġ�ͨ��������ӣ�����Ҳ���¶� libco ��Э�̽ӿ����˳������˽⡣Ϊ���ܿ������Ľ����������ݣ�����������������ӵĴ���Ҳ�����һ�¡��������ǽ�����ֱ���г� libco �����еĴ��룬��������õ��������вο���ش��롣
4. libco����
ͨ����һ�ڵ����ӣ������Ѿ��� libco �е�Э�����˳�����ӡ��������ȫ����������һ���û�̬�߳������������������Ǿʹ��̵߳ĽǶ�����ʼ̽������������ʵ�ֻ��ơ��� Linux Ϊ�����ڲ���ϵͳ�ṩ���̻߳����У�һ���߳�һ��߱�����Ҫ�أ�
(1) ��һ�γ�����ִ�У��������Ȼ�DZ���ġ����⣬��ͬ�߳̿��Թ���ͬһ�γ������Ҳ����Ȼ�ģ��������dz�������ᆳ���õ����̳߳ء������̣߳���ͬ�Ĺ����߳̿���ִ����ȫһ���Ĵ��롣
(2) ������ġ�˽�вƲ��������߳�ר����ϵͳ��ջ�ռ䡣
(3) �С����ڡ�������ϵͳ�̿���������������ߣ��̿��ƿ顱��Ӣ����д�� PCB����Linux �ں����Ϊ task_struct ��һ���ṹ�塣����������ݽṹ���̲߳��ܳ�Ϊ�ں˵��ȵ�һ��������λ�����ں˵��ȡ�����ṹҲ��¼���߳�ռ�еĸ�����Դ�����⣬ֵ��һ����ǣ�����ϵͳ�Ľ��̻����Լ�ר�����ڴ�ռ䣨�û�̬�ڴ�ռ䣩����ͬ���̼���ڴ�ռ�����������������ŵġ���ͬ��һ�����̵ĸ��̣߳����ǹ����ڴ�ռ�ġ���Ȼ��Э��Ҳ�ǹ����ڴ�ռ�ġ����ǿ��Խ������ϵͳ�̵߳�ʵ��˼�룬�� OS ֮��ʵ���û����̣߳�Э�̣�����OS �߳�һ�����û����߳�ҲӦ�þ߱�������Ҫ�ء�����ͬ��ֻ�ǵڶ��㣬�û����̣߳�Э�̣�û���Լ�ר���Ķѿռ䣬ֻ��ջ�ռ䡣���ȣ����ǵ���һ�γ���Э��ִ�У��⼴�� co_create() �����ڴ���Э�̵�ʱ����ĵ��������������β�Ϊ void*������ֵΪ void ��һ����������Σ���ҪΪ������Э����һ��ջ�ڴ�ռ䡣ջ�ڴ����ڱ�����ú��������е���ʱ�������Լ�������������ջ֡������ Intel �� x86 �Լ� x64 ��ϵ�ṹ�У�ջ����ESP��RSP���Ĵ���ȷ��������һ������һ��Э�̣�������ʱ��Ҫ�� ESP��RSP���е������ջ�ڴ��ϣ����Ľ��Դ�����ϸ������co_create() ���óɹ�������һ�� stCoRoutine_t �Ľṹָ�루��һ������������������Ҳ���Կ��������ýṹ�������� libco ��Э�̣���¼��һ��Э��ӵ�еĸ�����Դ�����Dz�����֮Ϊ��Э�̿��ƿ顱������������һ��Э����Ҫ�ء���ִ�еĺ�����ջ�ڴ棬Э�̿��ƿ飬�� co_create() ������ɺ�㶼�������ˡ�
5. �ؼ����ݽṹ�����ϵ
struct stCoRoutine_t
{
stCoRoutineEnv_t *env;
pfn_co_routine_t pfn;
void *arg;
coctx_t ctx;
char cStart;
char cEnd;
char cIsMain;
char cEnableSysHook;
char cIsShareStack;
void *pvEnv;
//char sRunStack[ 1024 * 128 ];
stStackMem_t* stack_mem;
//save satck buffer while
confilct on same
stack_buffer;
char* stack_sp;
unsigned int save_size;
char* save_buffer;
stCoSpec_t aSpec[1024];
}; |
�����������������һ�� stCoRoutine_t �ṹ�еĸ����Ա�����ȿ��� 2 �е� env��Э��ִ�еĻ�����������һ�£���ͬ�� go ���ԣ�libco ��Э��һ������֮��������ʱ���Ǹ��̰߳��˵ģ��Dz�֧���ڲ�ͬ�̼߳�Ǩ�ƣ�migrate���ġ���� env����ͬ����һ���߳�����Э�̵�ִ�л����������˵�ǰ����Э�̡��ϴ��л������Э�̡�Ƕ���õ�Э��ջ����һ�� epoll �ķ�װ�ṹ��TBD������ 3��4 �зֱ�Ϊʵ�ʴ�ִ�е�Э�̺����Լ��������� 5 �У�ctx ��һ�� coctx_t ���͵Ľṹ������Э���л�ʱ���� CPU �����ģ�context���ģ���ν�������ģ���esp��ebp��eip������ͨ�üĴ�����ֵ���� 7 �� 11 ����һЩ״̬�ͱ�־����������Ҳ�����ˡ��� 13 �� pvEnv�����ֿ������е�ѽ⣬��������֪������һ�����ڱ������ϵͳ����������ָ��ͺ��ˡ�16 ����� stack_mem��Э������ʱ��ջ�ڴ档ͨ��ע������֪�����ջ�ڴ��ǹ̶��� 128KB �Ĵ�С�����ǿ��Լ���һ�£�ÿ��Э�� 128K �ڴ棬��ôһ�������� 100 ���Э������Ҫռ�øߴ� 122GB���ڴ档���ߴ�Żỳ�ɣ����dz���˵Э�̺�����������ô��ռ����ô����ڴ棿�𰸾��ڽ����� 19 �� 21 �еļ�����Ա�����С�����Ҫ�ᵽʵ�� stackful Э�̣���֮��ԵĻ���һ�� stackless Э�̣������ּ�����Separate coroutine stacks �� Copying the stack���ֽй���ջ����ʵ��ϸ���ϣ�ǰ��Ϊÿһ��Э�̷���һ�������ġ��̶���С��ջ�����������Ϊ�������е�Э�̷���ջ�ڴ棬��Э�̱������л���ȥʱ���Ͱ���ʵ��ռ�õ�ջ�ڴ� copy ���浽һ����������Ļ������������г�ȥ��Э���ٴε���ִ��ʱ����һ�� copy ��ԭ�������ջ�ڴ�ָ����Ǹ������ġ��̶���С��ջ�ڴ�ռ䡣ͨ������£�һ��Э��ʵ��ռ�õģ��� esp ��ջ�ף�ջ�ռ䣬���Ԥ��������ջ��С������ libco�� 128KB����С�öࣻ����һ����copying stack ��ʵ�ַ�����ռ�õ��ڴ����ٺܶࡣ��Ȼ��Э���л�ʱ�����ڴ�Ŀ�����Щ������Ҳ�Ǻܴ�ġ�������ַ����������ף���libco ��ͬʱʵ�������ַ�����Ĭ��ʹ��ǰ�ߣ�Ҳ�����û��ڴ���Э��ʱָ��ʹ�ù���ջ��
struct coctx_t
{
#if defined(__i386__)
void *regs[8];
#else
void *regs[14];
#endif
size_t ss_size;
char *ss_sp;
}; |
ǰ�Ļ��ᵽ��Э�̿��ƿ� stCoRoutine_t �ṹ���һ���ֶ� env�����ڱ���Э�̵����С���������ǰ��Ҳָ��������ṹ�Ǹ����е��̰߳��˵ģ�������ͬһ���߳��ϵĸ�Э���ǹ����ýṹ�ģ��Ǹ�ȫ���Ե���Դ����ô��� stCoRoutineEnv_t ���װ���ʲô��Ҫ��Ϣ�أ��뿴���룺
struct stCoRoutineEnv_t
{
stCoRoutine_t *pCallStack[128];
int iCallStackSize;
stCoEpoll_t *pEpoll;
// for copy stack log lastco and nextco
stCoRoutine_t* pending_co;
stCoRoutine_t* ocupy_co;
}; |
���ǿ��� stCoRoutineEnv_t �ڲ���һ������ CallStack �ġ�ջ�������и� stCoPoll_t �ṹ
ָ�롣���⣬�������� stCoRoutine_t ָ�����ڼ�¼Э���л�ʱռ�й���ջ�ĺͽ�Ҫ��
�����е�Э�̡��ڲ�ʹ�ù���ջģʽʱ pending_co �� ocupy_co ���ǿ�ָ�룬��������
�������ǣ��ȵ���������ջ��ʱ����˵��stCoRoutineEnv_t �ṹ��� pCallStack ������ͨ���������ǽ����Ǹ���������ջ���Ǹ� ESP��RSP���Ĵ���ָ���ջ�������������������й����оֲ������Լ��������ù�ϵ�ġ����ǣ���� pCallStack �ָ� ESP��RSP��ָ���ջ������֮���������Э�̿���һ������ĺ�������ô��� pCallStack ��ʱ������Щ�����ĵ�������ջ�������Ѿ��������ǶԳ�Э������ص����Э�̼������ȷ�ĵ��ù�ϵ����������Щ�����У�����Э�̱����� call������Э�̽� return���ǶԳ�Э�̻����µı���Э��ֻ�ܷ��ص�������Э�̣����ֵ��ù�ϵ�����ң���˱��뽫�����������������⼴�� pCallStack �����ã���������Ϊ������ջ��ʵ����ǡ����֡�ÿ��������resume��һ��Э��ʱ���ͽ�����Э�̿��ƿ� stCoRoutine_t �ṹָ�뱣���� pCallStack �ġ�ջ������Ȼ��ջָ�롱iCallStackSize �� 1������л� context ��������Э�����С���Э��Ҫ�ó���yield��CPU ʱ���ͽ����� stCoRoutine_t �� pCallStack ��������ջָ�롱iCallStackSize �� 1��Ȼ���л� context ����ǰջ����Э�̣�ԭ��������ĵ����ߣ��ָ�ִ�С������ѹջ���͡���ջ���Ĺ��������� co_resume() �� co_yield() �����н����ٴν�������ô������һ�����⣬libco ����ĵ�һ��Э���أ������һ��Э�� yield ʱ��CPU����Ȩ�ø�˭�أ�����������⣬��������Ҫ�����⡰��һ����Э����ʲô��ʵ���ϣ�libco �ĵ�һ��Э�̣���ִ�� main ������Э�̣���һ�������Э�̡����Э���ֿ��Գ�����Э�̣�������Э������Э�̵ĵ���ִ�У��������ǻῴ������������ I/O �Լ���ʱ�¼��������������Լ�����Զ���� yield�����������ó� CPU�����ó���yield��CPU��������˵��һֱ��ռ�� CPU������֪�� CPU ִ��Ȩ������ת��;����һ��ͨ�� yield �ø������ߣ�������� resume ��������Э�����С��������ǿ�������ؿ�����co_resume()�� co_yield() ���������������л����� CPU��������ת�ơ������ڳ����е�һ�ε���co_resume() ʱ��CPU ִ��Ȩ�ʹ���Э��ת�Ƶ��� resume Ŀ��Э�����ˡ��ᵽ��Э�̣���ô����һ�����������ˣ���Э������ʲôʱ���������أ�ʲô
ʱ�� resume ���أ���ʵ�ϣ���Э���Ǹ� stCoRoutineEnv_t һ���ġ���Э��Ҳ������� resume �������������dz����������� main ��������Э����һ������Ĵ��ڣ�������Ϊ��ֻ��һ���ṹ����ѡ��ڳ����״ε��� co_create() ʱ���˺����ڲ����жϵ�ǰ���̣��̣߳��� stCoRoutineEnv_t �ṹ�Ƿ��ѷ��䣬���δ���������һ����ͬʱ����һ�� stCoRoutine_t �ṹ������ pCallStack[0] ָ����Э�̡��˺������ co_resume() ����Э�̣��ֻὫ resume ��Э��ѹ�� pCallStack ջ�������������̿�����ͼ1����ʾ��
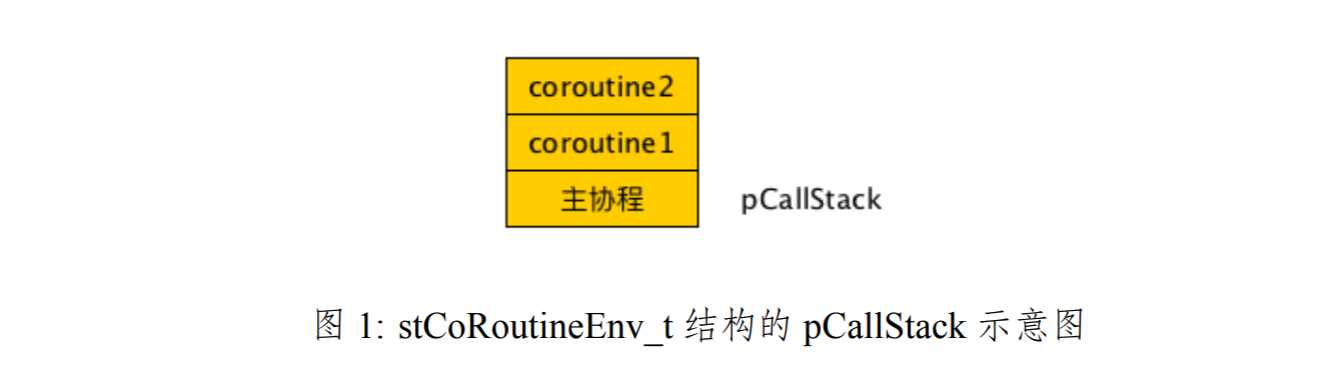
��ͼ1�У�coroutine2 ������ջ����Ҳ����˵����ǰ���� CPU �� running ��Э����coroutine2���� coroutine2 �ĵ�������˭�أ���˭ resume �� coroutine2 �أ��� coroutine1��coroutine1 ������Э�������ģ����� main ������ resume �ġ��� coroutine2 �ó� CPU ʱ��ֻ���ø� coroutine1����� coroutine1 ���ó� CPU����ô�ֻص�����Э�̵Ŀ��������ˡ����������ص���Э����ʱ����Э���ڸ�Щʲô�أ��ع�ͷ�����������������Ǹ����ӡ��Ǹ������У�main �����г������յ����� co_eventloop()���ú�����һ������epoll/kqueue ���¼�ѭ���������������Э�����У�����ϸ����ʱ��ȥ����������ֻ��֪����stCoRoutineEnv_t �ṹ�е� pEpoll ��ʹ�������õľ��ˡ����ˣ������Ѿ����������� stCoRoutineEnv_t �ṹ�����á������䡣
6. Libco Э�̵���������
6.1 ����Э�̣�Creating coroutines��
ǰ�����ᵽ��libco �д���Э���� co_create() �����������������£�
1 int co_create(stCoRoutine_t**
co,
const stCoRoutineAttr_t* attr, void* (routine)(
void), void* arg); |
ͬ pthread_create һ�����ú������ĸ�������
@co: stCoRoutine_t** ���͵�ָ�롣���������co_create �ڲ���Ϊ��Э�̷��� ����Э�̿��ƿ顱��co ��ָ����������Э�̿��ƿ顣
@attr: stCoRoutineAttr_t ���͵�ָ�롣�� ����������ָ��Ҫ����Э�̵����ԣ���Ϊ NULL��ʵ���Ͻ����������ԣ�ջ С��ָ����ջ��ָ�루ʹ�ù���ջģʽ����
@routine: void* (*)(void ) ���͵ĺ���ָ�룬ָ��Э�̵������������������Э�̺�Ҫ���ʲô��������routine ����Ϊ����ָ�롣
@arg: void ����ָ�룬���ݸ��������IJ����������� pthread ���ݸ��̵߳IJ��������� co_create ��Э�̴�����������ʱ������û��������Ҳ����˵���Ǵ��ݵ�routine ������û�б����á�ʵ���ϣ���������ڲ������Ƿ��䲢��ʼ�� stCoRoutine_t�ṹ�塢����������ָ�롢����һ�Ρ�ջ���ڴ棬�Լ�����ͳ�ʼ�� coctx_t��Ϊʲô����ġ�ջ��Ҫ�Ӹ������أ���Ϊ�����ջ�ڴ棬������ʹ��Ԥ�ȷ���Ĺ���ջ������co_create �ڲ����������ջ����ʵ���ǵ��� malloc �ӽ��̵Ķ��ڴ��������ġ�����Э�̶��ԣ�����ǡ�ջ���������ڵײ�Ľ��̣��̣߳���˵��ֻ��������ͨ�Ķ��ڴ���ѡ�
�����ϣ�co_create �����ڲ����Ĺ����ܼ�����Ͳ����������ˡ�
6.2 ����Э�̣�Resume a coroutine��
�ڵ��� co_create ����Э�̷��سɹ�����Ե��� co_resume �������������ˡ��ú����������£�
| void co_resume(stCoRoutine_t*
co); |
������������ˣ������� co ָ��ָ���Э�̡�ֵ��ע����ǣ�Ϊʲô����������� co_start ���� co_resume �أ�ǰ�����ᵽ��libco ��Э���ǷǶԳ�Э�̣�Э�����ó�CPU ��Ҫ�ָ�ִ�е�ʱ����Ҫ�ٴε���һ�� co_resume ���������ȥ��������Э�����еġ���������������co_start ֻ��һ�Σ��� co_resume ��������֮ͣ��ָ����������Զ�ε��ã�����ô������ʵ���ϣ������ڹ���Э�̵����ף������ǶԳ�Э�̣�һ���á�resume���롰yield�����������Э��Ҫ��� CPU ִ��Ȩ�á�resume�������ó� CPU ִ���á�yield��������������������ͬ�ģ����ԳƵģ����̣�������ֻ��Ʋű���Ϊ�ǶԳ�Э�̣�asymmetric coroutines�������Խ��� resume һ��Э�̣�����һ����ע�⣬������ǵ�һ��������Э�̣�Ҳ������Ҫ���������й����Э�̡����ǿ�����Ϊ�� libco ����Э��ֻ������״̬����running �� pending��������һ��Э�̲����� resume ֮�������� running ״̬��֮��Э�̿���ͨ�� yield �ó� CPU����ͽ����� pending ״̬��������������״̬��ѭ��������ֱ��Э���˳���ִ�е������� routine ���أ�����ͼ2��ʾ��TBD ��״̬������
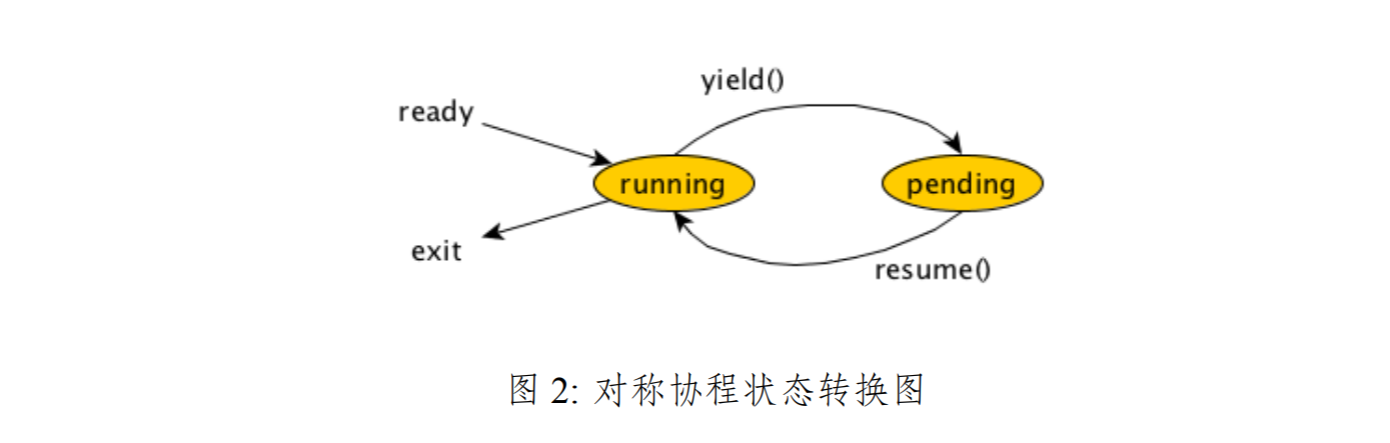
��Ҫָ�����ǣ���ͬ�� go ���ԣ����� co_resume() ����һ��Э�̵ĺ��壬���ǡ�����һ�������������� co_resume() ��������Э�̵��������л���Э�̵��������������ͻᱻִ�еģ��������ִ�й��̲��Dz����ģ�Concurrent����Ϊʲô���Dz������أ���Ϊ co_resume() �����ڲ������ coctx_swap() ����ǰЭ�̹���Ȼ��Ϳ�ʼִ��Ŀ��Э�̵Ĵ����ˣ�������̼�����Э���л���һ�ڵķ���������������������Ǵ��еģ���һ������ϵͳ�̣߳����̣��Ϸ����ģ���������˵��һ�� CPU ���Ϸ����ģ��ٶ�û�з��� CPU migration����������վ�� Knuth �ĽǶȣ��� coroutine ����һ�������subroutine ������������Եø������A Э�̵��� co_resume(B) ������ B Э�̣���������һ������Ĺ��̵��ù�ϵ��A ���� B ������ B �����ڲ��������Ȼ��һ�ִ���ִ�еĹ�ϵ����ô����Ȼ co_resume() ���ú�����˱���Э��ִ�п���������ô co_resume()����������ʱ���أ����Ҫ�ȱ���Э�������ó� CPU �ˡ�(TDB ����ͼ)
void co_resume(stCoRoutine_t
*co) {
stCoRoutineEnv_t *env = co->env;
stCoRoutine_t *lpCurrRoutine
= env->pCallStack[env->iCallStackSize 1];
if (!co->cStart) {
coctx_make(&co->ctx,
(coctx_pfn_t)CoRoutineFunc,
co, 0);
co->cStart = 1;
}
env->pCallStack[env->iCallStackSize++]
= co;
co_swap(lpCurrRoutine, co);
} |
������߶� co_resume() �����������ʣ������ٿ�һ�����Ĵ���ʵ�֡��� 5��6 �е� if ������֧�����ҽ���Э���ǵ�һ������ʱ�Ż�ִ�е����״�����Э�̹����е����⣬��Ҫ���� coctx_make() Ϊ��Э���� context��Ϊ���� co_swap() ������ת��Э�̵��������������� cStart ��־������ 1�����Ե� 4~7 ���״�����Э�̵�����������ôco_resume() ���� 4 �д�����ѡ��� 3 ��ȡ��ǰЭ�̿��ƿ�ָ�룬�� 8 �н���������Э�� co ѹ�� pCallStack ջ��Ȼ��� 9 �о͵��� co_swap() �л��� co ָ�����Э����ȥִ���ˡ�ǰ��Ҳ�Ѿ��ᵽ��co_swap() ����ʹ˷��أ�����Ҫ��� resume �� co Э������yield �ó� CPU ʱ�Ż᷵�ص� co_resume() ������ֵ��ָ�����ǣ����イ co_swap() ����ʹ˷��أ�����˵�������������������ȴ� co ���Э�� yield �ó� CPU��ʵ���ϣ��������ǽ��ῴ����co_swap() �ڲ��Ѿ��л��� CPU ִ�������ģ����� co Э�̵Ĵ���·��ȥִ���ˡ��������̲��Dz����ģ����Ǵ��еģ���һ�������Ѿ�����ǿ�����ˡ�
6.3 Э�̵Ĺ���Yield to another coroutine��
�ڷǶԳ�Э�����ۣ�yield �� resume �Ǹ���ԵIJ�����A Э�� resume ������ B Э�̣���ôֻ�е� B Э��ִ�� yield ����ʱ�Ż᷵�ص� A Э�̡�����һ������Э���������� co_resume() ʱ��Ҳ�ᵽ�˸ú����ڲ� co_swap() ��ִ�б���Э�̵Ĵ��롣ֻ�б���Э�� yield �ó� CPU��������Э�̵�co_swap() �������ܷ��ص�ԭ�㣬�����ص�ԭ��co_resume() �ڵ�λ�á���ǰ�Ľ���stCoRoutineEnv_t �ṹ pCallStack ���������ջ����ʱ�������Ѿ���Ҫ���ᵽ�� yield �������ڲ������ڱ���Э��Ҫ�ó� CPU ʱ���Ὣ���� stCoRoutine_t ��pCallStack ��������ջ�롱iCallStackSize �� 1��Ȼ�� co_swap() �л� CPU �����ĵ�ԭ��������ĵ�����Э�ָ̻�ִ�С����������ĵ�����Э�̡������ǵ����� co_resume()���л� CPU �����ı�������Ǹ�Э�̡�������������һ�� co_yield_env() �������룺
void co_yield_env(stCoRoutineEnv_t
*env) {
stCoRoutine_t *last = env->pCallStack
[env->iCallStackSize
- 2];
stCoRoutine_t *curr = env->pCallStack
[env->iCallStackSize
- 1];
env->iCallStackSize ;
co_swap(curr, last);
} |
co_yield_env() �������� 4 �д��룬��ʵ�����������д�ø����Щ����������Ű�������������� 3 �У������������ɶ��ԡ�ע��������Ϊʲô�� co_yield_env ������ co_yield �أ����Ҳ�ܼ�����֪�� co_resume ������ȷĿ�Ķ���ģ����ҿ���ͨ�� resume �� CPU ��������Э�̡��� yield ��һ������ֻ�� yield ����ǰЭ�̵ĵ����ߡ�����ǰЭ�̵ĵ����ߣ������ resume ��ǰЭ�̵�Э�̣��DZ����� stCoRoutineEnv_t�� pCallStack �еġ������ֻ�� yield ����env����yield ��������Э�̣����������� yield������Э�̣�CPU ���������ø�˭�����ø�˭�ġ���ʵ�ϣ�libco �ṩ��һ�� co_yield(stCoRoutine_t*) �ĺ��������������ƺ����Խ�
CPU �ø�����Э�̡�ʵ���ϲ�����ˣ�
void co_yield(stCoRoutine_t
*co) {
co_yield_env(co->env);
} |
����֪����ͬһ���߳�������Э���ǹ���һ�� stCoRoutineEnv_t �ṹ�ģ��������Э�̵� co->env ָ��Ľṹ����ͬ���������� co_yield(co)������Ϊ�� CPU �ø� co Э���ˣ��Ǿʹ��ˡ�����ͨ�� co_yield_env() ���ǻὫ CPU �ø�ԭ��������ǰЭ�̵ĵ����ߡ������еĶ��������ʣ�ͬһ���߳�������Э�̹��� stCoRoutineEnv_t����ô��co_yield() �������߳��ϵ�Э���أ��Բ����������ô������ô��ij�����ˡ�libco��Э���Dz�֧���̼߳�Ǩ�ƣ�migration���ģ��������ͼ��ô��������һ����ҵ������ co_yield() ��ʵ�������˲������ġ��ٲ���˵��һ�£�Э�̿�����Ȼ�ṩ�� co_yield(stCoRoutine_t*) ����������û���κεط��е��ù��ú����������������룩��ʹ�õĽ϶��������һ����������co_yield_ct()����ʵ���������ö���һ���ġ�
6.4 Э�̵��л���Context switch��
ǰ���������۵� co_yield_env() �� co_resume()����������ȫ�෴�Ĺ��̣������ǵĺ�������ȴ��һ���ġ����л� CPU ִ�������ģ������Э�̵��л����� co_resume()�У�����л��Ǵӵ�ǰЭ���л�������Э�̣����� co_yield_env() �У����Ǵӵ�ǰЭ���л���������Э�̡����յ��������л����������� co_swap() �����ڡ��ϸ��������ﲻ����Э����������һ���֣���ֻ������Э�̿�ʼִ�����ó� CPUʱ��һ���ٽ�㡣��Ȼ���л����Ǿ��漰������Э�̡�Ϊ�˱������㣬���ǰѵ�ǰ���ó� CPU ��Э�̽��� current Э�̣��Ѽ�������ִ�еĽ��� pending Э�̡�
.globl coctx_swap
#if !defined( __APPLE__ )
.type coctx_swap, @function
#endif
coctx_swap:
#if defined(__i386__)
leal 4(%esp), %eax //sp
movl 4(%esp), %esp
leal 32(%esp), %esp
//parm a : ®s[7]
+ sizeof(void*)
pushl %eax //esp ->parm a
pushl %ebp
pushl %esi
pushl %edi
pushl %edx
pushl %ecx
pushl %ebx
pushl -4(%eax)
movl 4(%eax), %esp //parm b -> ®s[0]
popl %eax //ret func addr
popl %ebx
popl %ecx
popl %edx
popl %edi
popl %esi
popl %ebp
popl %esp
pushl %eax //set ret func addr
xorl %eax, %eax
ret
#elif defined(__x86_64__) |
�����ȡ����coctx_swap.S �ļ������ x86 ��ϵ�ṹ��һ�δ��룬x64 �µ�ԭ��������һ���ģ�����Ҳ����ͬһ���ļ��С��Ӻ�۽Ƕȿ������ﶨ����һ����Ϊ coctx_swap�ĺ����������� C ���ĺ�������ΪҪ�� C++ ������ã����ӵ��÷��������ǿ��Խ�������һ����ͨ�� C ����������ԭ�����£�
void coctx_swap
(coctx_t*
curr, coctx_t* pending)
asm(��coctx_swap��); |
coctx_swap ������������������ֵ�����У���һ������ curr Ϊ��ǰЭ�̵� coctx_t�ṹָ�룬��ʵ�Ǹ�����������������ù����лὫ��ǰЭ�̵� context �������������ָ����ڴ���ڶ������� pending�����������Э�̵� coctx_t ָ�룬�Ǹ����������coctx_swap ������ȡ�ϴα���� context���ָ����Ĵ�����ֵ��ǰ�����ǽ��� coctx_t �ṹ���������ڱ�����Ĵ���ֵ��context���ġ������������֮�������ڵ���֮ǰ�����ڵ�һ��Э�̵Ļ������ú������غ���ǰ���е�Э�̾��Ѿ���ȫ�ǵڶ���Э���ˡ���� Linux �ں˵������� switch_to �����Ƿdz����Ƶģ�ֻ�����ں����̵߳��л����Ҫ���ӵöࡣ����ν��������ȥ������ͳ���������Ȼ������Ҳ�����ǡ�����ͽ�ȥ���������������Թ����⣬���������Ȼ��Ҫֱ�Ӳ����Ĵ������ǵ�Ȼ�ǻ����ˡ�������Զ��������ˣ���Ҳ��Ҫ���������õ��Ķ��dz��õ�ָ�ֵ��һ����ǣ��������ѧУ���̳�ʹ�õĶ��� Intel �����ʽ���������õ����� AT&T ��ʽ����������ֻ��֪�����ߵ���Ҫ������ڲ�������˳���Ƿ������ģ����㹻�ˡ��� AT&T ���ָ������ָ������������������ô��һ����Դ���������ڶ�����ΪĿ�IJ����������⣬����ǰ���ᵽ�����Ǹ� C ���ĺ�����ʲô��˼�أ��� x86 ƽ̨�£�����C ��������ʹ��һ�̶ֹ��ķ��������������IJ����뷵��ֵ�������IJ���ʹ��ջ���ݣ���Լ���˲���˳����ͼ3��ʾ���ڵ��ú���֮ǰ���������Ὣ���������Է���˳��ѹջ����ͼ3�к�����������������ô���� 3 ���� push ��ջ������Dz��� 2�������� 1�����ò������� CALL ָ��ʱ CPU �Զ��� IP �Ĵ������������ص�ַ��push ��ջ������ڽ��뱻������֮���γ�����ͼ3��ջ��֡��������ý���ǰ����ʹ�� EAX �Ĵ������ݷ���ֵ����� 32 λ���õĻ�����64 λ��ʹ�� EDX:EAX������Ǹ���ֵ��ʹ��FPU ST(0) �Ĵ������ݡ�
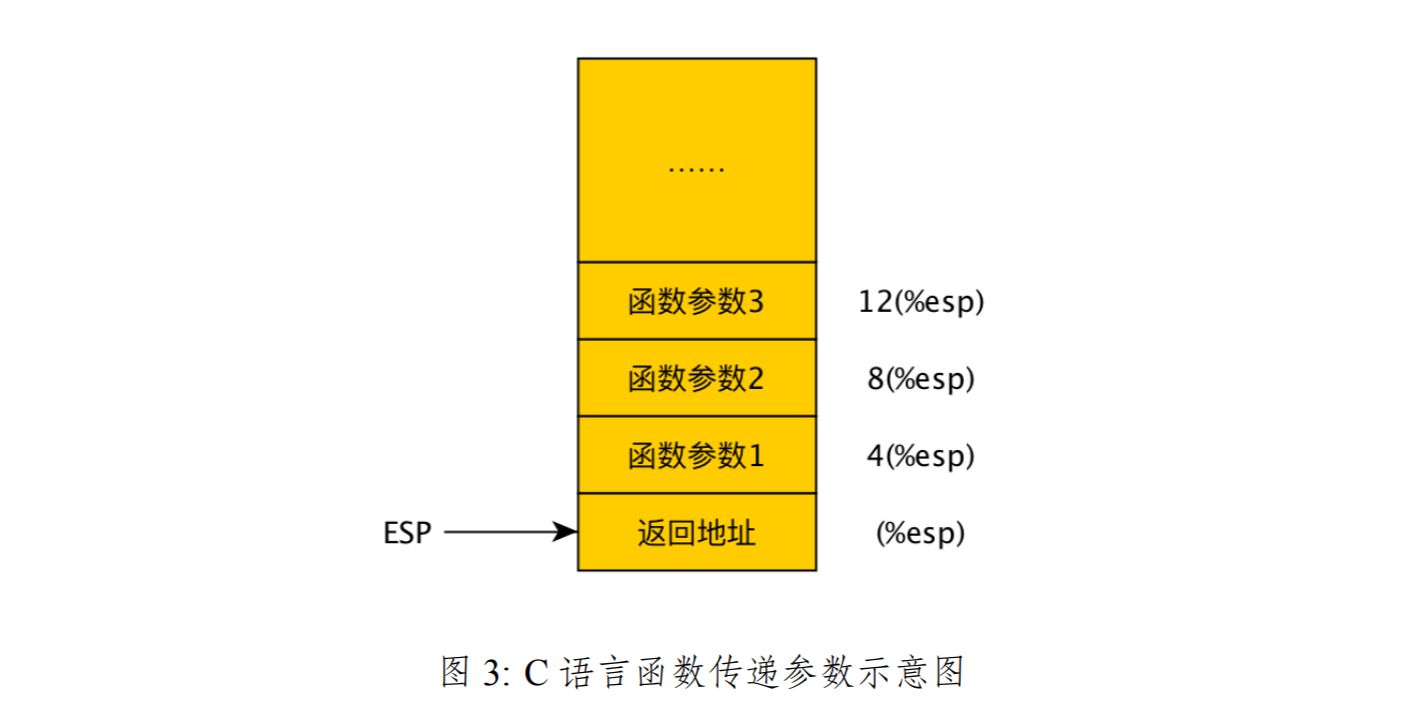
�ڸ�ϰ����Щ�������֪ʶ������������ coctx_swap ����������������������ô���뺯������� 4(%esp) �����ȡ����һ����������ǰЭ�� context ָ�룩��8(%esp)����ȡ���ڶ�������������������Э�̵� context ָ�룩����ǰջ�������ݣ�(%esp) ���� coctx_swap �ķ��ص�ַ�������ջ���ݲ��������� coctx_swap �����Ĺؼ������������� coctx_swap ��ÿ��ָ�����Ҫʱ������ǰ��ջ�����ջ������������һ���ֲ������ǰ� coctx_swap ��Ϊ�����֣��Ե� 21 ������ MOVL ָ��Ϊ�硣��һ���������ڱ��� current Э�̵ĸ����Ĵ������ڶ��������ǻָ� pending Э�̵ļĴ������������������н��з�����
�� 8 ��LEA ָ� Load Effective Address ����д������ָ��� 4(%esp) ��Ч��ַ���浽 eax �Ĵ�����������Ϊ�ǽ���ǰ��ջ����ַ����������ʵ�ʱ���ĵ�ַ��ջ����Ҫ 4 �ֽڣ�Ϊ�� �����Ǿͳ�֮Ϊջ������ΪʲôҪ����ջָ���أ���Ϊ�����ž�Ҫ�� ջ�л��ˡ�
�� 9~10 �������� 9 ����������ǰ�潲���� C ����������ջ�е�λ�ã���ʱ4(%esp) ������ָ�� current Э�� coctx_t ��ָ�룬����������� esp �Ĵ�������������10 �ֽ� coctx_t ָ��ָ��ĵ�ַ���� 32 ���ֽڵ��ڴ�λ�ü��ص� esp �С�������ô
13
���ڣ�esp �Ĵ���ʵ����ָ���˵�ǰЭ�� coctx_t �ṹ�� ss_size ��Աλ�ã�����֮���и���Ϊ regs �����飬�պ����������� 8 ���Ĵ���ֵ�ġ�ע�����ǵ� ��ջ�л�����������ʱ�Եģ�Ŀ��ֻ�� �������ʹ�� push ָ�����Ĵ���ֵ��
�� 12 ��eax �Ĵ�������ѹջ����ȷ�Ľ����ǽ� eax �Ĵ������浽�� coctx_t->regs[7] ��λ��ע��ڵ� 8 eax �Ĵ����Ѿ�������ԭջ���ĵ�ַ���������ʵ�����ǽ���ǰЭ��ջ�������������Ա��´ε��Ȼ���ʱ�ָ�ջ��ַ��
�� 13~18 �������ͨ�üĴ�����ֵ���� coctx_t �ṹ�� regs[1]~regs[6] ��λ�á�
�� 19 ���� ���е���˼�ˡ�eax ��ֵ���ӵ� 8 ֮��ͱ�������ô-4(%eax)ʵ������ָ��ԭ�� coctx_swap �ս���ʱ��ջ�������ǽ���ջ����ֵ�� call ָ���Զ�ѹ �ĺ������ص�ַ�����ʵ���Ͼ��ǽ� coctx_swap �ķ��ص�ַ�����������ˣ�����coctx_t->regs[0] ��λ�á�
�� 21 �� �ˣ�current Э�̵ĸ���Ҫ�Ĵ������ѱ�������ˣ���ʼ���Է� �ؽ���� pending Э���ˡ�������������Ҫ�� pending Э�̵��������� ������ҪΪ���ָ�context�����ָ���ͨ�üĴ�����ֵ�Լ�ջָ�롣����� ��ջָ���е� pending Э�̵� coctx_t �ṹ�忪ʼ���� regs[0] ��λ�ã�Ϊ�ָ��Ĵ���ֵ����������
�� 23 ������ regs[0] ��ֵ�� eax �Ĵ�����regs[0] ����Э���ϴα��л���ȥʱ�ڵ�19 �����ֵ���� coctx_swap �ķ��ص�ַ��
�� 24~29 ���� regs[1]~regs[6] �ָ����Ĵ�����ֵ����֮��Ӧ����ǰ��� 13~18 ��ѹջ��������
�� 30 ���� pending Э���ϴ��л���ȥʱ��ջָ��ָ�����֮��Ӧ���ǵ� 12 ѹջ����������˼�� �£�ջ�����Ѿ���ȫ�ָ�����ע��� 8 ���ǽ�������ʱ����ġ�ջ������������ջ������ �� 4 �ֽڵ�ƫ�ơ� �� 4 �ֽ�����ջ�������ݣ�����coctx_swap �ķ��ص�ַ�������ʱ�����ִ ret ָ��أ��dz���Ͳ�֪�����ܵ���ȥ�ˡ�
�� 31 ��Ϊ�˳�������ȷ�ط���ԭ���� coctx_swap ���õĵ� ���� eax ���ݣ���19 ���� regs[7]���� 23 ȡ������ eax��ѹջ��
�� 33~34 ������ eax �Ĵ�����ִ ����ָ�
���ˣ��� 32 λƽ̨�� coctx_swap �����͵��˽����ˡ�ϸ�ĵĶ��ᷢ��һ���л��� 3 ��ջָ�룬����������һЩע�ͣ�����δ�����ںܶ�����˵���»�����������ġ����Ľ��������� 32 λ�������x64 �µĴ����������Ƶģ������漰�ļĴ�������һЩ�����Һ�������ʱ��������������������Ȥ�Ķ��߿������з����£����⣬�����Խ�� glibc �� ucontext Դ��Աȷ���һ�¡�ucontext Ҳ�ṩ��֧���û����̵߳Ľӿڣ�Ҳ�����ƹ��ܵ� swapcontext() ����������Ļ�����Ƚ�������Щ����������Ч�ʱȽϵ͡�
6.5 Э�̵��˳�
���イ���˳����б���Э�̵Ĺ�����υ�������� Ї�� ָЭ�̵�������ִ�н��������Ĺ��̡�����˵������Э����������ִ����return��䣬�����������������ڡ�����ijЩ���������õġ�ͬЭ�̹���һ����Э���˳�ʱҲӦ��CPU����Ȩ�������ĵ����ߣ���Ҳ�ǵ���co_yield_env() ��������ɵġ�������ƺܼ�����ƪ�����������Ͳ��������ˡ�
ֵ��ע����ǣ����ǵ��� co_create()��co_resume()����Э��ִ��һ�����������������Ҫ�ǵõ���co_free()�� co_release()���������ʱ�Ե�Э�̣����������ڴ�й©��
7 �¼�������Э�̵���
7.1 Э�̵ġ����������̵߳ġ���������
�����Ѿ������� libco ��Э�̴Ӵ������������������Լ�����˳��Ĺ��̡�ͬʱ������Ҳ������һ���߳��ϵ�����Э�̱���������δ���ִ�еġ���������ʱ�ص�3.1�ڵ����ӡ��� Producer Э�̺��������ǻῴ������ poll �����ȴ� 1 �룬Consumer��Ҳ�ῴ������ co_cond_timedwait �����ȴ��������źš�ע�⣬��Э�̵ĽǶȿ�����Щ�ȴ�����������ͬ���ģ�synchronous���������ģ�blocking�������ӵײ��̵߳ĽǶ����������Ƿ������ģ�non-blocking������3.1������������Ҳ��������� pthread ʵ�ֵ�ԭ����һ���ġ��� pthread ʵ�ֵ��������У�������� pthread_cond_timedwait ����ȥͬ���ȴ������ߵ��źţ����������У�������� poll �� sleep ����ȥ��ʱ�ȴ������̵߳ĽǶȿ�����Щ���������õ�ǰ�߳������������ں˵ĽǶȿ�����������û���������ں˿���Ҫ����æ�ŵ��ȱ���߳����С���ô����Э��Ҳ��һ���ĵ�������Э�̵ĽǶȿ�����ǰ�ij��������ˣ����������µ��߳��������Լ�������æ��ִ�б��Э�̺���������������У��� Consumer Э�̵��� co_cond_timedwait ���������������߳̿����Ѿ��� Producer ���Ȼָ�ִ�У���֮��Ȼ����ô�������Э�̡����ȡ����߳������أ�����������Э�̱���������̡߳�
7.2 ��Э����Э�̵ġ����ȡ�
���ǵ�ǰ������ġ���Э�̡��ĸ����������ٴΰ���������������������Э�̵ġ��������롰���ȡ����ܸ��а��������ǽ�����libco ������һ����Э�̣����������״ε���co_create() ��ʽ������һ��Э�̵�Э�̡���3.1�������У���Ϊ main ��������� co_eventloop() �����Э�̡��� Consumer �� Producer ������CPU �� yield ����Э�̣���ʱ��Э���ڸ�ʲô�أ���Э���� co_eventloop() ������ͷæ���� co_eventloop() �������������ĺ������ڡ���Ҫ����˵�����ǣ����イ�ġ������������ϸ��������㲻�������ĵ�������ֻ��Ϊ�˱����ķ��㡣libco ��Э�̻����ǷǶԳƵģ�û��ʲô�����㷨����ִ�� yield ʱ����ǰЭ��ֻ�ܽ�����Ȩ����������Э�̣�û���κοɵ��ȵ���ء�resume �������ǿһ�㣬����Ҳ���㲻�õ��ȡ������Ҫ˵��ʲô�������㷨���Ļ����Ǿ�ֻ��˵�ǡ����� epoll/kqueue �¼��������ĵ����㷨���������������� epoll/kqueue ���¼�ѭ��������֪������ go �����У��û�ֻ��ʹ��ͬ������ʽ�ı�̽ӿڼ��ɿ����������ܵķ�������epoll/kqueue ������ I/O �¼�֪ͨ���ƣ�I/O event notification mechanism����ȫ���������������� libco ��Ҳ��һ���ģ���ֻ��Ҫʹ����ͨ C �⺯�� read()��write()�ȵ�ͬ���ض�д���ݾͺ��ˡ���ô epoll �������أ��Ͳ�����Э�̵� co_eventloop() �С�Э�̵ĵ������¼������ǽ�����ϵ��һ��ģ��������˵ libco ��һ��Э�̿⣬������˵����һ������⡣�ں�̨�����������У�һ��������Χ������ I/O ת�ģ�libco ����������������ĺ����ԡ�
7.3 stCoEpoll_t �ṹ�붨ʱ��
�ڷ��� stCoRoutineEnv_t �ṹ�������嵥5����ʱ����һ�� stCoEpoll_t ���͵�pEpoll ָ���Աû�н�������Ϊ stCoRoutineEnv_t �ij�Ա������ṹҲ��һ��ȫ���Ե���Դ����ͬһ���߳�������Э�̹�����������Ҳ���ó�����stCoEpoll_t �Ǹ� epoll ���¼�ѭ����صġ��������ǿ�һ�������ڲ��ֶΣ�
struct stCoEpoll_t
{
int iEpollFd;
static const int _EPOLL_SIZE = 1024 * 10;
struct stTimeout_t *pTimeout;
struct stTimeoutItemLink_t *pstTimeoutList;
struct stTimeoutItemLink_t *pstActiveList;
co_epoll_res *result;
}; |
@iEpollFd: ��Ȼ�� epoll ʵ���� ����������
@_EPOLL_SIZE: ֵΪ 10240 �����ͳ�������Ϊ epoll_wait() ϵͳ���õĵ������������� �� epoll_wait ���صľ����¼�������
@pTimeout: ����Ϊ stTimeout_t �Ľṹ��ָ�롣�ýṹʵ������ ��ʱ���֣�Timingwheel����ʱ����ֻ�������ȽϹ֣��� ������ͷ�ԡ�
@pstTimeoutList: ָ�� stTimeoutItemLink_t ���͵Ľṹ��ָ�롣��ָ��ʵ������ ������ͷ������������ʱ��ų�ʱ�¼��� item��
@pstActiveList: ָ�� stTimeoutItemLink_t ���͵Ľṹ��ָ�롣Ҳ��ָ�� �����������������ڴ�� epoll_wait �õ��ľ����¼��Ͷ�ʱ����ʱ�¼���
@result: �� epoll_wait()�� �������ķ�װ���� �� epoll_wait �õ��Ľ����������֪������ʱ�����¼�����ģ�͵�������һ���ز����ٵĹ��ܡ����� I/O �ij�ʱ����ʱ��������ʱ�ȴ���poll �� timedwait���������ڴˡ�һ����ԣ�ʹ�ö�ʱ����ʱ������������ʱ����ע��һ����ʱ�¼���Timer Event������ע�ᶨʱ�¼�ʱ��Ҫָ������¼���δ���Ĵ���ʱ�䡣�ڵ��˴���ʱ�������ǻ��յ���ʱ����֪ͨ����������Ķ�ʱ�����Կ�������������ɣ���һ�����DZ�����ע�� timer events�����ݽṹ���ڶ��������Ƕ�ʱ֪ͨ���ơ�������ע��� timer events��һ��ѡ�ú���������� nginx������һ�ֳ��������ݽṹ����ʱ���֣�libco ��ʹ�������ֽṹ����Ȼ��Ҳ����ֱ����������ʵ�֣�ֻ��ʱ�临�ӶȱȽϸߣ��ڶ�ʱ����ܶ�ʱ������׳�Ϊ��ܵ�����ƿ����
��ʱ���ĵڶ����֣��߾��ȵĶ�ʱ����ȷ���뼶��֪ͨ���ƣ�һ��ʹ��getitimer/setitimer ����ӿڣ���Ҫ�����źţ��Ǹ��Ƚ��鷳���¡�������һ���Ӧ�ö��ԣ���ȷ��������ˡ����ȷſ������뼶ʱ������˳���� epoll/kqueue ������ϵͳ��������ɶ�ʱ֪ͨ������һ�������� I/O �¼�֪ͨ�붨ʱ�¼�֪ͨ��������ͳһ�����ˡ�����֮ǰʵ�ֹ���һ������ libcurl ���첽 HTTP client�����еĶ�ʱ�����ܾ����� epoll ��Ϻ����ʵ�ֵġ�libco �ڲ�Ҳֱ��ʹ���� epoll �����ж�ʱ����ͬ��ֻ�DZ��� timer events ���õ���ʱ���ֶ��ѡ�
ʹ�� epoll ��ʱ���ֵ�ʵ�ֶ�ʱ�����㷨���£�
Step 1 [epoll_wait]���� epoll_wait() �ȴ� I/O �����¼����� �ȴ�ʱ������Ϊ 1 ���루�� epoll_wait() �ĵ� 4 ����������
Step 2 [���� I/O �����¼�] ѭ������ epoll_wait() �õ��� I/O ���� ����������
Step 3 [��ʱ����ȡ��ʱ�¼�] ��ʱ����ȡ��ʱ�¼����ŵ� timeout ���С�
Step 4 [������ʱ�¼�] ��� Step 3 ȡ���ij�ʱ�¼���Ϊ�գ���ôѭ������ timeout�����еĶ�ʱ��������ת�� Step 1 �����¼�ѭ����
Step 5 [����ѭ��] ��ת�� Step 1�������¼�ѭ����
7.4 ����Э����ָ���ִ��
��ǰ�ĵĵ�6.2���6.3С�ڣ�������ϸ�ط�����Э�̵� resume �� yield ���̡���ôЭ�̾�����ʲôʱ����Ҫ yield �ó� CPU������ʲôʱ��ָ�ִ���أ������� yield��ʵ������ libco �й��� 3 �ֵ��� yield �ij�����
�û��������������� co_yield_ct()��
��������� poll() �� co_cond_timedwait() �� ���������ȴ���
��������� connect(), read(), write(), recv(), send() ��ϵͳ������ ���������ȴ�����Ӧ�أ����� resume ����һ��Э��Ҳ�� 3 �������
��Ӧ�û��������� yield ��������������Ҳ�������û�����������Э��co_resume() ������
poll() ��Ŀ�� ���������¼�������ʱ��co_cond_timedwait() �ȵ�������Э�̵� co_cond_signal() ֪ͨ�źŻ�ȴ���ʱ��
read(), write() �� I/O �ӿڳɹ�������д�����ݣ����߶�д��ʱ���ڵ�һ������£����û�����
yield �� resume Э�̣��൱�� libco ��ʹ���߳е��˲��ֵ�Э�̡����ȡ����������������ʵҲ�ܳ�������
libco Դ�����example_echosvr.cpp�����о��С���Ҳ�Ƿ����ʹ�� libco
�ĵ���ģ�ͣ������ֶ������ȡ�Э�̵����ӡ��ڶ��������ǰ���3.1���е������������߾��Ǹ����͵����ӡ����Ǹ����������ǿ������û�������������
yield��Ҳֻ�����������Э��ʱ������ resume�������ߺ�������Э�����������л����أ��� poll()
�� co_cond_timedwait() �����С��������������ߡ���������Э����������ʱ�����ᷢ����������ǿյģ����ǵ���
co_cond_timedwait() ���������� cond �ϡ��������ȴ���ͬ����ϵͳ�̵߳������ȴ�ԭ��һ����������������stCoCond_t
�����ڲ�Ҳ��һ�����ȴ����С���co_cond_timedwait() �����ڲ��Ὣ��ǰЭ�̹������������ĵȴ������ϣ�������һ���ص��������ûص�����������δ�������ѡ���ǰЭ�̵ģ���
resume �����Э�̣������⣬��� wait �� timeout �������� 0 �Ļ�����Ҫ��ǰִ�л����Ķ�ʱ����ע��һ����ʱ�¼������ҵ�ʱ�����ϣ�������������У�������Э��co_cond_timedwait
�� timeout ����Ϊ-1���� indefinitly �صȴ���ȥ��ֱ���ȵ���������������������
signal �źš� Ȼ�����������������ߡ���������Э�����������������������Ͷ��һ��������co_cond_signal()
֪ͨ�����ߣ�Ȼ���ٵ��� poll() ��ԭ�ء��������ȴ� 1000 ���롣����co_cond_signal
�����ڲ���ʵҲ�����ǽ����������ĵȴ��������Э���ó�����Ȼ��ҵ���ǰִ�л����� pstActiveList����
7.3 �� stCoEpoll_t �ṹ����co_cond_signal������û������ resume
���������ϵĵȴ�Э�̣��Ͼ���������� CPU ��ʱ������ôʲôʱ�� CPU ����Ȩ��ʲôʱ��
resume ������Э���أ��������¿������������������߷������źš�֮�����ű���� poll()
�����ˡ��������ȴ����ȴ� 1 ���ӡ����poll �����ڲ�ʵ�������������¡����ȣ����Լ���Ϊһ����ʱ�¼�ע�ᵽ��ǰִ�л����Ķ�ʱ����ע���ʱ��������
1 ���ӵij�ʱʱ���һ���ص�����������һ������δ�������ѡ��Լ��Ļص�����Ȼ�͵��� co_yield_env()
�� CPU �ø���Э���ˡ����ڣ�CPU ����Ȩ�ֻص�����Э�����С���Э�̴�ʱҪ��ʲô�أ������Ѿ���������Э�̾����¼�ѭ��
co_eventloop() �������� co_eventloop() �У���Э���ܶ���ʼ�ص���epoll_wait()�����о�����
I/O �¼��ʹ��� I/O �¼�������ʱ�����г�ʱ���¼��ʹ�����ʱ�¼���pstActiveList
���������л�Ծ�¼��ʹ�����Ծ�¼���������ν�ġ������¼�������ʵ���ǵ�����������Э��ע��ĸ��ֻص��������ѡ���ôǰ�����ǽ�����������Э�̺�������Э�̵Ļص��������ǡ����ѡ��Լ����ѡ�����Э�̵���
co_cond_timedwait()�� poll() ���롰�������ȴ��������ϼ���ͨ�� co_yield_env
�����ó��� CPU������Э���������¼�ѭ���С����ѡ���Щ����������Э�̣���ν�����ѡ����������ù���Э��ע��Ļص���������Щ�ص��ڲ�ʹ��
co_resume() ���»ָ�����Ĺ���Э�̡����Э�� yield �� resume �ĵ����������������
read(), write() �� I/O ���������롰������������ָֻ�ִ�еĹ��̡�����������ڶ��ֹ��̻������ơ���Ҫע����ǣ�����ġ���������Ȼ���û�̬ʵ�ֵĹ��̡�����֪����libco
��Э�����ڵײ��߳��ϴ���ִ�еġ�������� read �� write ��ϵͳ���������������������õ�ǰ�̱߳��ں˹���
�Ļ�����ô���ǰЭ�̱������ˣ�����Э��Ҳ�ò���ִ�еĻ��ᡣ��ˣ��������Э�������������ں�̬��������ô
libco ����ͻ���ȫֹͣ��ת������Ǻ����صġ�Ϊ�˱��������ں�̬���������DZ���������ں��ṩ�ķ�����
I/O ���ƣ��� socket�ļ�����������Ϊ non-blocking �ġ�Ϊ���� libco ��ʹ���߸����㣬���ǻ��ý�����non-blocking
�Ĺ��̸���װ������αװ�ɡ�ͬ������ʽ���ĵ��ã��� co_cond_timedwait()һ��������ʵ�ϣ�go
���Ծ�����ô���ġ��� libco ���������αװ�ø��ӳ��ף����Ӿ�����ƭ�ԡ���ͨ��dlsym����
hook �˸������� I/O ��ص�ϵͳ���ã�ʹ���û������ԡ�ͬ�����ķ�ʽֱ��ʹ������read()��write()��connect()��ϵͳ���á���ˣ����ǻῴ��3.1�������������������Э�����������һ��͵�����һ��
co_enable_hook_sys()�ĺ����������� co_enable_hook_sys �����ŻῪ��
hook ϵͳ���ù��ܣ�������Ҫ���Ƚ�Ҫ��д���ļ�����������Ϊ non-blocking
���ԣ�������Э�̾Ϳ��������������ں�̬��������һ����Ӧ����Ҫ�ر����ע�⡣ �� read() Ϊ������������������һ����Щ��αװ����ͬ������ʽϵͳ���õ��ڲ�ԭ�������ȣ��������
accept ��һ�������ӣ���ô�������ǽ�������ӵ� socket �ļ�����������Ϊ������ģʽ��Ȼ������һ������Э��ȥ����������ӡ�����Э�̵���
read()��ͼ�Ӹ��������϶�ȡ���ݡ���ʱ������ϵͳ read() �����Ѿ��� hook������ʵ���ϻ���õ�
libco �ڲ����õ�read() ��������������ڲ�ʵ�������� 4 ���£���һ������ǰЭ��ע�ᵽ��ʱ���ϣ����ڽ�������
read() �����Ķ���ʱ���ڶ��������� epoll_ctl()���Լ�ע�ᵽ��ǰִ�л����� epoll
ʵ���ϡ�������ע����̶���Ҫָ��һ���ص��������������ڡ����ѡ���ǰЭ�̡������������� co_yield_env
�����ó� CPU�����IJ�Ҫ�ȵ���Э�̱���Э�����¡����ѡ�����ܼ����������Э�� epoll_wait()
��֪ read �������ļ��������ɶ������ִ��ԭ read Э��ע��Ļ�ص��������ѣ���ʱ��ͬ����������Ҫ���ó�ʱ��־��������Э�̱����Ѻ��ڵ���ԭ
glibc �ڱ� hook �滻���ġ������� read() ϵͳ���á���ʱ����������� epoll_wait
��֪�ļ������� I/O �����ͻ�������ݣ�����dz�ʱ�ͻ᷵��-1����֮�����ⲿʹ���߿�������� read()
������ʽ��ϵͳ���ñ��ֳ�������ȫһ�µ���Ϊ�ˡ�
7.5 ��Э���¼�ѭ��Դ�����
ǰ���Ѿ�����ᵽ����Э���¼�ѭ������Э������Ρ����ȡ�����Э�����еġ�����������������������Ĵ��루Ϊ�˽�ʡƪ�����ڲ��������������乤��ԭ����ǰ���£��Ѿ���ȥ�����в���صĴ��룩��
void co_eventloop(stCoEpoll_t
*ctx,
pfn_co_eventloop_t pfn, void *arg)
{
co_epoll_res *result = ctx->result;
for (;;) {
int ret= co_epoll_wait
(ctx->iEpollFd, result,
stCoEpoll_t::_EPOLL_SIZE, 1);
stTimeoutItemLink_t *active
= (ctx->pstActiveList);
stTimeoutItemLink_t *timeout
= (ctx->pstTimeoutList);
memset(timeout, 0, sizeof
(stTimeoutItemLink_t));
for (int i=0; i<ret; i++) {
stTimeoutItem_t *item =
(stTimeoutItem_t*)result->events[i].data.ptr;
if (item->pfnPrepare) {
item->pfnPrepare
(item, result->events[i],
active);
} else {
AddTail(active, item);
}
}
unsigned long long now = GetTickMS();
TakeAllTimeout(ctx->pTimeout, now, timeout);
stTimeoutItem_t *lp = timeout->head;
while (lp) {
lp->bTimeout = true;
lp = lp->pNext;
}
Join<stTimeoutItem_t, stTimeoutItemLink_t>
(active,
timeout);
lp = active->head;
while (lp) {
PopHead<stTimeoutItem_t,
stTimeoutItemLink_t>(active);
if (lp->pfnProcess) {
lp->pfnProcess(lp);
}
lp = active->head;
}
}
} |
�� 6 ������ epoll_wait() �ȴ� I/O �����¼���Ϊ�����ʱ���� ��������� timeout����Ϊ 1 ���롣
�� 8~10 ��active ָ��ָ��ǰִ ������ pstActiveList ���У�ע������������Ѿ��С���Ծ���Ĵ������¼���timeout ָ��ָ�� pstTimeoutList �б�����ʵ��� timeout ȫ�Ǹ���ʱ�Ե�������pstTimeoutList ��ԶΪ�ա�
�� 12~19 ������������ ��������������û�������Ԥ�����ص��������pfnPrepare ��Ԥ������15 ��������ֱ�ӽ������¼� item �� active ���С�ʵ���ϣ�pfnPrepare() Ԥ���������ڲ�Ҳ�Ὣ���� item �� active ���У����ն��Ǽ� �� active���еȵ� 32~40 ͳ ������
�� 21~22 ����ʱ������ȡ���ѳ�ʱ���¼����ŵ� timeout ���С�
�� 24~28 ������ timeout ���У������¼��ѳ�ʱ��־��bTimeout ��Ϊ true����
�� 30 ���� timeout �������¼��ϲ��� active ���С�
�� 32~40 ������ active ���У����� ��Э�����õ� pfnProcess() �ص����� resume����� ��Э�̣�������Ӧ�� I/O ��ʱ�¼����������Э�̵��¼�ѭ���������̣����ǿ������ܶ���ʼ�� epoll_wait()�����ѹ���Ĺ���Э��ȥ������ʱ���� I/O �¼���������������������л��� epoll ʵ�ֵ��¼����������ܲ�û��ʲô�ر�֮������û���漰���κ�Э�̵����㷨���ɴ�Ҳ���Կ��� libco ��ʵ��һ���ܵ��͵ķǶԳ�Э�̻��ơ��������� call/return �ĽǶȳ����������� resume/yield ȥ��������Э�̵����л������������и���������
8 ��������
�����¡�����
8.1 echo ʵ����
TBD
8.2 �����������
TBD: ��ȷ����ƽ��ÿ��Э���������л��Ŀ�������ʱ�������� CPU ʱ������������ �� boost��libtask �ĶԱȡ�
��
���ͨ�����ĵķ�����ϣ������Ӧ�������� libco �����л���������ϲ������ʵս��ͬѧ��˵������������δ����ʵ����Ŀ��ʹ�����Ļ����ܹ����������еף����ƹ�һЩ���ԵĿӣ���һ��������ʱҲ�ܿ��ٵؽ����������Щϣ���������������Э�̹���ԭ����ͬѧ��˵��ϣ�����ĵķ���������ש��������ã��Ժ���ѧϰ boost Э�̻� golang Э��ԭ��Ҳ�ܸ����ץסҪ�㡣����ʱ��ִ٣����ĵķ��������˼·���Ǻ�������������ڳ��νӴ� libco �������������ܸ��ӳ������������Զ��֣�����Դ����룬�Ķ����Ӵ��벢����һ�£���Ҫʱֱ���Ķ�Դ������ܻ���а�����
|









