| �༭�Ƽ�: |
���±������ݼ�¼����ѧC++�����в�ͬ��C��һЩ֪ʶ�㣬�ʺ�����C���Ի�����ͬѧ�Ķ���ϣ����������������
����������csdn���ɻ�����Delores�༭�Ƽ��� |
|
��һ���� ����֪ʶ
һ��HelloWorld�������ռ�
#include <iostream>
using namespace::std;
cout << "Hello World!" <<
endl;
namespace One {
int M = 200;
int inf = 10;
}
namespace Two {
int x;
int inf = 100;
}
int main(int argc, char *argv[])
{
using Two::x;
cout << x << endl;
cout << One:inf << endl;
} |
�������ú����ò���
�����DZ���������ʱ�����ʼ����ʵ�ʴ����ж������������βΣ�ͨ�������ñ�������������������ʹ��ԭʼ���ݣ��������丱����
2.1���õĶ���
int intOne;
int& rInt = intOne;
intOne = 5;
cout << rInt << endl; // 5
rInt = 7; //�����õ�ֵ��
Ҳ������intOne
cout << intOne << endl; // 7 |
2.2 ������������������
void swap(int
&x, int &y) {
int tmp;
tmp = x;
x = y;
y = tmp;
}
//���ã�
int a = 10;
int b = 2;
swap(a, b); |
2.3 ���������������
double price_count(const
Pen &p1,
const Pen &p2);
//�β�ʹ��ָ������������
result = price_count(pen1, pen2);
//���ú���ʱ��������ɣ�
������ָ������������ |
price_count�����������βζ���const���ã����Խ���const�ͷ�const Pen�������ڲ��ܶ�ʵ�ν����ģ�ֻ�ܶ�ȡ��
2.4 ���úͼ̳�
�������ÿ���ָ������������������ǿ������ת����ʵ�ʽ���ǣ����Զ���һ�����ܻ���������Ϊ�����ĺ��������øú���ʱ�����Խ����������Ϊ������Ҳ���Խ������������Ϊ������
2.5 ��ʱʹ�����ò���
һ����ԣ��������������ı���ʽ���ǰ����ô��ݡ�
����-------->ֻ��ʹ��ָ��
�ṹ-------->����ʹ��ָ�롢����
�����------>ʹ������
2.6 ���ú�ָ�������
ָ���DZ������������¸�ֵָ���ı�������ַ��
�����ڶ���ʱ������г�ʼ�������Ҳ����ٹ�������������
�пյ�ָ�룬û�пյ����ã���void�����Dz��Ϸ��ģ�
void &a = 3; //void�����ϲ������ͣ�û��void�����á�
������������
�ڶ��������һ������ʱ����inline��inline����Ӧ�þ����ܼ�̣��Ҳ�Ҫ�����ӵIJ������縡������ȡ�
�ġ�Ĭ�ϲ����ĺ���
4.1 Ĭ�ϲ�����ʹ����ʽ
ֻ������������ʱʹ�����µ���ʽ��ָ��Ĭ��ֵ������ʱ����ָ������
int add(int x
= 5,
int y = 6, int z = 3);
int main()
{
add(); //����������ʹ��
Ĭ��ֵ�������14
add(1,5); //����������ʹ��Ĭ��ֵ
add(1,2,3); //������Ĭ��ֵ
} |
4.2 Ĭ�ϲ�����˳��涨
Ĭ�ϲ������ҵ������壻���ú���ʱ��Ҳֻ�ܴ��ҵ���ƥ��Ĭ�ϲ�������������ʹ���Զ����ֵ����
void func(int
a=1, int b,
int c=3, int d=4); //error
void func(int a, int b=2,
int c=3, int d=4); //ok |
���ڵڶ�����������������õķ����涨Ϊ��
func(10,20);
//ok: c��dʹ��Ĭ��ֵ
func(10,20,30,40);
//ok: ������Ĭ��ֵ
func();
//error: aû��Ĭ��ֵ���������һ��ֵ
func(10,20,,40);
//error: ֻ�ܴ��ҵ���ƥ��Ĭ�ϲ��� |
�塢�������أ���̬��
5.1 �������صĶ���
���������ϵĺ�������������ͬ���βε���Ŀ�����Ͳ�ͬ�����������ݲ��������ͺ����Զ�ƥ�䲢���ã����������ء�
int abs(int);
long abs(long);
double abs(double); |
ע�⣺
���������������ú����ͱ�����Ϊͬһ�����꣬����������������ԭ�Ͳ������أ�
double cube(double
x);
double cube(double &x); |
�β���Ŀ��������ͬ��ֻ�к������Ͳ�ͬʱ�����ԶԺ����������ء�
5.2 extern "C"
extern "C"����Ҫ���þ���Ϊ���ܹ���ȷʵ��C++�����������C���Դ��롣����extern "C"��ָʾ�������ⲿ�ִ��밴C���ԵĽ��б��룬������C++�ġ�
����C++֧�ֺ������أ���˱��������뺯���Ĺ����лὫ�����IJ�������Ҳ�ӵ������Ĵ����У����������Ǻ���������C���Բ���֧�ֺ������أ���˱���C���Դ���ĺ���ʱ������Ϻ����IJ������ͣ�һ��ֻ������������
#ifdef __cplusplus
extern "C" {
#endif
int foo(char, int);
#ifdef __cplusplus
}
#endif |
��������ģ�����ģ��
�� C++ �У�ģ���Ϊ����ģ�����ģ�����֡�����ģ�����������ɺ����ģ���ģ����������������ġ�
6.1 ����ģ��
����ģ��ʹ�÷��������庯�������еķ��Ϳ����þ�������ͣ���int��double���滻�������ʱҲ��Ϊͨ�ñ�̡�
6.1.1 һ�����Ͳ����ĺ���ģ��
template<typename
T>
void Swap(T &x, T &y)
{
T tmp = x;
x = y;
y = tmp;
} |
typename������class�滻��
int main
(int
argc, char *argv[])
{
//����ģ��
int a = -10;
int b = 23;
double c = -12.34;
double d = 56.789;
cout << "Swap(a, b) =
" <<
Swap(a, b) << endl;
cout << "Swap(c, d) =
" <<
Swap(c, d) << endl;
}
|
�������ڱ��뵽Swap(a, b);ʱ�Ҳ������� Swap �Ķ��壬���Ƿ���ʵ��a��b����int���͵ģ���int�����滻Swapģ���е�T�ܵõ������ģ�庯����
void Swap(int &x, int &y)
{
int tmp = x;
x = y;
y = tmp;
} |
ͬ�����������ڱ��뵽Swap(c, d)ʱ������ģ�庯����
void Swap(double
&x, double &y)
{
double tmp = x;
x = y;
y = tmp;
} |
6.1.2 ������Ͳ����ĺ���ģ��
����ģ��Ҳ�����ж�����͵IJ�����
template<typename T1,
typename T2>
T2 print(T1 arg1, T2 arg2)
{
cout << arg1 << �� ��
<< arg2
<< endl;
return arg1;
} |
6.1.3 ����ģ�����
������ģ���������غ���ͨ������
����ģ�岻�����Զ�����ת������ͨ��������ԣ�
������������ѡ����ͨ�������������ģ���ܲ������õIJ�������ƥ�䣬��ѡ����ģ�壻����ģ��Ҳ�������ء�
����ͨ����ģ��ʵ���б������������ֻͨ��ģ��ƥ�䣺Swap<>(a, b);
6.2 ��ģ��
6.2.1 ������ģ��
template<typename
T>
class ClassModule {
public:
ClassModule(T n) {
this->num = n;
}
T getnum() {
return num;
}
private:
T num;
}
void main()
{
ClassModule<int> myclass(100);
//ʹ����ģ����Ҫ�ò����б�
ָ������IJ�������
cout << myclass.getnum() << endl;
return;
} |
6.2.2 �̳��е���ģ��
�������ģ����̳�ʱ����Ҫ�ñ�����ָ������ľ����������ͣ�����Ҫָ������IJ������ͣ�class B: public A< int >
//�̳��е���ģ��
template<typename T>
class A {
public:
A(T n) {
this->t = n;
}
void printA() {
cout << "A:" << t <<
endl;
}
public:
T t;
};
class B : public A<int> {
public:
B(int m) : A(m){};
//ʹ�û���Ĺ��캯��
void printB() {
cout << "B:" << t <<
endl;
}
};
int main(int argc, char *argv[])
{
B b(88);
b.printA(); //88
b.printB(); //88
return 0;
} |
�ߡ��ࡢ����װ
7.1 ����
���Ǵ��������ģ��
���Ƕ���Ķ��壬���������ʵ����������IJ����벻�������ģ��
������������ԣ���Ϊ��״̬����ʶ
7.2 ����һ����
class Car {
public:
void run() { //�����
...
}
void stop() {
...
}
protected:
private:
int price; //˽�����ݳ�Ա
int carNum;
}; |
�����ж����Ա������
���ж���ij�Ա����һ��Ϊ������������ʹû����ȷ��inline��ʶ
�ඨ��ͨ������ͷ�ļ���
����֮�����Ա������
���ඨ������Ա��������ֿ�
�ඨ�壨ͷ�ļ���������ⲿ�ӿڣ���ij�Ա��������������ڲ�ʵ��
7.3 ��Ա����
7.3.1 ��Ա�����Ķ����ʹ�ã�
���Ա���������أ�
���Ա������������ͨ����һ�����أ�����ͬ���ͬ��������������
���Ա������Ĭ�ϲ�����
���Ա������������ͨ����һ��ʹ��Ĭ�ϲ���
��Ա����һ����.cpp��ʵ�֣��ڶ�����ʱֻ�ṩһ���ӿڹ��ⲿʹ�ã�
car.h:
class Car {
public:
void run();
private:
int price;
int carnum;
}
---------------------------
car.cpp:
void Car::run() {
cout << "Car run..." <<
endl;
}
---------------------------
main.cpp:
int main() {
Car a;
a.run();
} |
7.3.2 thisָ��
���ڶ���ĵ�ַ
7.3.3 ����������
7.4 ��װ
OOP�������ԣ���װ���̳С���̨
�����࣬���������ݳ�Ա����Ա�����Ĺ��̳�Ϊ��װ��
��ķ������η���
public���౾��(����Ա����)�����ࡢ����
protected���౾��(����Ա����)������
private�� �౾��(����Ա����)
�ˡ����캯��
��ɶ����ʼ���ĺ�����������ij�Ա������
���캯������������ͬ�����������ͣ�����void�ͣ���
class Car {
public:
Car(int pri=100000, int num=0);
int setProperty(int pri, int num);
private:
int price;
int carnum;
}
Car::Car() {
setProperty(int pri, int num);
} |
����һ���࣬��������˴������Ĺ��캯�������Ҳ������е��βζ���Ĭ��ֵ����ô�ͱ��붨��һ�����������Ĺ��캯���������ò��������Ĺ��캯��ʱ�ᱨ�������磺
class Person
{
public:
Person(const string & name,
const int age)
:
m_name(name), m_age(age);
private:
string m_name;
int m_age;
} |
�ඨ�����ϣ�
1�������ʹ��Person person01����������ʱ�ᱨ�������붨��һ�����������Ĺ��캯����Person(){ };
2��������캯����һ���β�name��Ĭ��ֵ����ʹ��Person person01����������ʱ���ᱨ������ʱ����ô������Ĺ��캯�������ң���ʱҲ�����ٶ���һ�����������Ĺ��캯��������ʹ��Person person01����������ʱ����������ͬʱƥ�����������캯�����ᱨ���ơ�warning C4520: ��Person��: ָ���˶��Ĭ�Ϲ��캯���������Ĵ���
�š���������
����ͷŶ���ռ�ĺ�����������ij�Ա������
����������Ϊ����ǰ�ӡ�~���������βΡ��������ͣ�����void�ͣ���
������������������ã�Ҳ�������أ�ֻ����������������ڽ�����ʱ����ϵͳ�Զ����á�
�������������麯���������������Ӧд���麯��������������ֻ����û������������
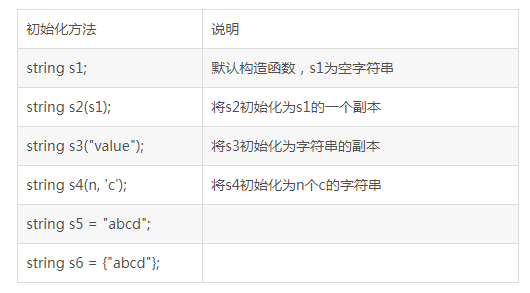
ʮ����������string
10.1 �ַ�������ij�ʼ��
10.2 �ַ�������
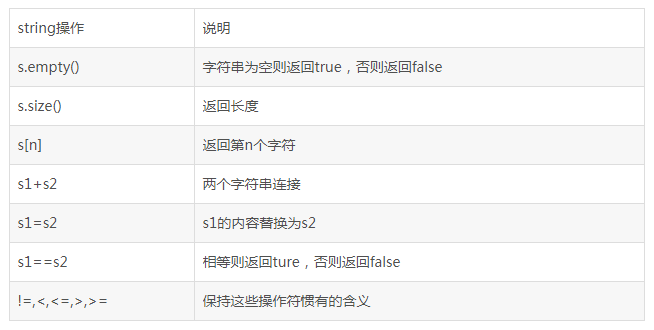
ʮһ��static���ݳ�Ա�ͳ�Ա����
static�������г�Ա����ʾ��Ĺ�������
11.1 static���ݳ�Ա
static���ݳ�Ա������ͨ�������ݳ�Ա��static�����ݳ�Ա������һ�������static�����ݳ�Ա����������ģ���������ඨ��Ķ������κι�ϵ����static��������ͨ�����ݳ�Աһ��ÿһ���������һ�ݣ�ȫ��������ǹ���һ��static���Ա�ġ�static ��Ա������ռ�ö�����ڴ棬���������ж���֮����ڴ棬��ʹ����������Ҳ���Է��ʡ�
����A���������static��ԱΪ1����ôB�����Ӧ��static������Ա��ֵҲ����1��
ʹ��static��Ա����������������г�ʼ������̬��Ա�����ڳ�ʼ��ʱ�����ټ� static��������Ҫ���������͡��� private��protected��public ���εľ�̬��Ա���������������ַ�ʽ��ʼ����
| int Martain::martain_count
= 2; |
ʹ��static���ݳ�Ա�ĺô���
��static���εij�Ա�����ڶ������Dz�ռ�ڴ�ģ���Ϊ�����Ǹ�����һ���ڶѻ���ջ�����ɣ���static���εı����ھ�̬�洢�����ɵġ�������static����һ����ĺô��ǿ��Խ�ʡ������ڴ�ռ䡣��ͬ�㴴��100��Person������100�������й��е�һ������������й�������������Person����Ĺ���������ͬ�ġ�
���������������static���εĻ�����ʹ��100��Person����Ҳ���ᴴ��100������������ֻ��Ҫ��һ��static���εĹ��������Ϳ����ˡ���100������Ҫ�õ�ʱ�ͻ�ȥ����static���εĹ���������������100��Person�������ͻᴴ��100�������������ڹ�������������ͬ������£��͵����˷ѿռ��ˡ�
11.2 static��Ա����
����static���ε����Ա�����࣬�����ڶ������static���Ա������û��thisָ��ģ�thisָ����ָ�����ָ�룩������Ϊû��thisָ�룬����static���Ա�������ܷ��ʷ�static�����Ա��ֻ�ܷ��� static���εľ�̬���Ա��
��ͨ��Ա��������ͨ�����������е��ã���static��Ա��������ͨ���������е��ã���Ϊ�������������
class Martain
{
plubic:
int func1();
static int func2();
}
main(){
Martain m1;
m1.func1();
Martain::func2();
} |
ע�������������ݼ����Դ���"004-static"
ʮ������̬�ڴ����
new/delete����������ؼ��֣���malloc/free�Ǻ�������
int *p1 = new
int;
int *p2 = new int[10];
//����10��int�͵��ڴ�ռ�
Student *pstu1 = new Student;
//����һ��Student����ڴ�ռ�
Student *pstu2 = new Student();
//�������÷����ǿ��Ե�
delete p1;
delete[] p2;
|
ʮ�����������캯��
Student(const
Student& s);
//�������캯���Ĺ̶���ʽ |
13.1 ����ʱ��
1������һ���¶�����һ��ͬ���͵Ķ�����г�ʼ��ʱ
2��������Ϊʵ�λ������ض���ʱ
ʵ�����룺
Student s1("Jame");
printf("&s1 = %x\n", &s1);
//����ʱ��1����һ�������ʼ����һ������
Student s2 = s1;
printf("&s2 = %x\n", &s2);
//����ʱ��2��������Ϊʵ�λ������ض���
foo(s1);
Student s4 = zoo();
printf("&s4 = %x\n", &s4); |
13.2 dz���������
dz����
��������忽�����캯�������������ʹ��Ĭ�Ͽ������캯������dz������dz�����������£�
dz������������ָ��Ķ�������ʱ�����׳����⣬��Ϊdz���������Ķ����ԭ�����
ָ�붼ָ��ͬһ���ڴ�ռ䣬������һ��������������һ��������ʹ��ʱ�ͻᷢ���ڴ������
���
�������ָ��ʱ�������·���һ��ռ䣬��˲��������⡣
13.3 ʲôʱ����Ҫ���忽�����캯��
1�������ݳ�Ա��ָ��
2�������ݳ�Ա������Դ�����һ���ļ���
3��һ������Ҫ���������ͷ���Դʱ������Ҳ��Ҫһ���������캯��
ijЩ��������ֹ���ÿ������캯������ֵ���������ô���Խ������������ŵ�private�С����£�
class Uncopyable
{
private:
Uncopyable(const Uncopyable &);
//��ֹ��������
Uncopyable &operator=
(const Uncopyable &);
//��ֹ��ֵ�����
}; |
ʮ�ġ�const�ؼ���
14.1 ��ʼ���б�
���캯���ij�ʼ���б�
��ʼ�� const ��Ա������Ψһ��������ʹ�ó�ʼ���б�
14.2 const ��ָ��
const Ҳ���Ժ�ָ�����һ��ʹ�ã�������������ָ�����������Ҳ��������ָ��ָ������ݡ�
const ��ָ��һ��ʹ�û��м��ֲ�ͬ��˳��������ʾ��
1. const int *p1;
2. int const *p2;
3. int * const p3;
�����һ������£�ָ����ֻ���ģ�Ҳ���� p3 ������ֵ���ܱ��ģ�
��ǰ����������£�ָ����ָ���������ֻ���ģ�Ҳ���� p1��p2 ������ֵ�����ģ�ָ��ͬ�����ݣ���������ָ������ݲ��ܱ��ġ�
��Ȼ��ָ�뱾������ָ������ݶ��п�����ֻ���ģ����������д���ܹ�������һ�㣺
1. const int * const p4;
2. int const * const p5;
const ��ָ���ϵ�д���������䣺�����������*�ű��ָ�������const���ε���[������]
����ָ�룩��ָ��ֻ�������û�б��ָ�������ε���[*������]����ָ��ָ��ı�������
Ҳ����ָ��ָ��ı���ֻ����
14.3 const��Ա����
��ʼ��const��Ա������Ψһ������ʹ�ó�ʼ���б��������ڹ��캯���ĺ������г�ʼ������
class Demo {
private:
const int m_len;
int *m_arr;
public:
Demo(int len) : m_len(len)
{ //ͨ����ʼ���б���ʼ��const��Ա����
m_arr = new int[len];
};
}
class Demo {
private:
const int m_len;
int *m_arr;
public:
Demo(int len){}��
}
Demo:Demo(int len) {
m_len = len; //����
�����ں������ڳ�ʼ��
m_arr = new int[len];
} |
14.4 const��Ա����������Ա������
const ��Ա��������ʹ�����е����г�Ա���������Dz��������ǵ�ֵ�����ִ�ʩ��Ҫ����Ϊ
�˱������ݶ����õġ�const ��Ա����Ҳ��Ϊ����Ա������
����Ա������Ҫ�������Ͷ����ʱ���ں���ͷ���Ľ�β���� const �ؼ���
14.5 const��������
�� C++ �У�const Ҳ�����������ζ���Ϊ������һ����������Ϊ������֮��
��ֻ�ܵ������ const ��Ա������ const ��Ա������ const ��Ա�������ˡ�
���峣�������Ͷ��峣��������ƣ�
const classnameobject(params);
classnameconst object(params); |
���ַ�ʽ��������Ķ����dz�����
��ȻҲ���Զ��� const ָ�룺
const classname
*p =
new classname (params);
classname const *p =
new classname (params); |
classnameΪ������objectΪ��������paramsΪʵ���б���pΪָ������
ʮ�������������
����������ĸ�ʽ��operator op(argument-list);
Time operator+
(const Time & t) const; |
��������ؿ���ѡ��ʹ�ó�Ա������dz�Ա������ʵ�֡�
16.1 ��Ա�����汾
16.2 �dz�Ա�����汾
�dz�Ա����Ӧ����Ԫ�����������ſ���ֱ�ӷ������˽�����ݡ�
friend Time
operator+
(const Time & t1, const Time &
t2); |
ע�⣺��Ԫ�����ڶ���ʱ��Ҫ�ùؼ���friend��������ʱ���á�
16.3 ��������ص�ʹ�÷���
total = coding.operator+(fixing);
total = coding + fixing; |
�������ֱ�ʾ����������operator+()������
���⣬Ҳ���������ã�
| total = coding
+ fixing + morefixing; |
���ͣ�����+�Ǵ������ҽ�ϵ�����������Ի��ȱ�ת����total = coding.operator+(fixing + morefixing);��Ȼ����������ת����һ���������ã�������ǣ�total = coding.operator+( fixing.operator+(morefixing) );
16.4 ��������ص�����
1�����غ�����������������һ�����������û���������ͣ������ܽ��ӷ���������س�
����int����ӣ�����������Ϊ�˰�ȫ���ǣ�
2������Υ�������ԭ���ľ䷨�����粻��������������ȼ���
3�����ܴ����µ��������
4���������أ�sizeof . .* :: : typeid const_cast synamic_cast
reinterpret_cast static_cast��
5������������������ͨ����Ա��dz�Ա�����������أ�������Щ�����ֻ��ͨ��
��Ա�����������أ�=? ()? []? ->
ʮ�ߡ��̳�
OOP��������
��װ�� �̳У� ��̬
17.1 ��֮���ϵ
is-a�̳�����
has-a�������
17.2 �̳е�����
��������
���ֲ�ͬ������
17.3 C++�м̳����ַ�ʽ
���м̳�
˽�м̳�
���ؼ̳�
���м̳���ʽ:
class Teacher: public Person {
}
UML astah
���� ����
���� �̳���
����ֻ�ܷ��ʸ����public��protected��Ա�����ܷ���private��Ա��
�ڹ���һ������ʱ�����ಿ���ɸ���Ĺ��캯����ɣ�����IJ���������Ĺ��캯����ɡ�
����һ������ʱ���ȹ��츸�࣬Ȼ�������࣬����ʱ�෴��
ʮ�ˡ���̬
OOP�������ԣ���װ���̳С���̬
��̬��ͬ���ķ������ö�ִ�в�ͬ���������в�ͬ���롣
LSP�����ϴ���ԭ�������ͱ����ܹ��滻���ǵĻ��ࡣ
18.1 �麯���������
�麯��?���ڻ�����ʹ�ùؼ���?virtual?�����ĺ������������������¶�������ж���
���麯��ʱ������߱�������Ҫ��̬���ӵ��ú�����
�麯���Ǽ̳еģ�����������Ϊ�麯���ĺ������������в�����������Ϊ���麯����
������Ҫ�����ڳ������������Ը��������õĶ���������ѡ����õĺ�����
���ֲ�������Ϊ��̬���ӣ�����ڰ�
��һ�����к����麯��ʱ�������г����ࡣ
Class Animal
{
virtual ~Animal();
virtual void makeSound();
} |
��չ��
class Pet {
eat();
}
class Dog : public Pet {
eat();
}
int main() {
Pet * p = new Dog;
//���ָ��ΪPet���ͣ�
��eat����Ϊ�鷽����
�����Dog���ͣ�����Ҫ��
p->eat();
} |
p->eat()��������Pet��eat������������Dog�ġ�Ϊ��ʹ��������ȷ�����ӵ�Dog��eat������
��Ҫ�ڻ����eat()ǰ����Virtural�����֡�
18.2 ���麯����ӿ���
��������Ҫ�ڻ����ж����麯�����Ա��������������¶���ú������õ������ڶ���
�������ڻ������ֲ��ܶ��麯�������������ʵ�֣����ʱ��ͻ��õ����麯����
���麯�������=0���Ǵ��麯�������麯��û�����塣
Class Animal
{
virtual ~Animal() = 0;
virtual void makeSound() = 0;
} |
�������һ���ӿ��࣬�ӿ����ʵ�������������ɶ���ʵ����
����Ϊ��̬��������virtual��������������ֻ��������������������������
����ʱ�Ķ�̬�ԣ�ͨ������ʵ��
����ʱ�Ķ�̬�ԣ�ͨ���麯��ʵ��
��ʮ��STL
STL��һЩ�������Լ�����Щ���ݼ����ϲ������㷨���ɣ����������������������㷨����������
����(Container)������ij�����ļ���
������(Iterator)���ڶ����Ͻ��б���
�㷨(Algorithm)�����������ڵ�Ԫ��
��C++���У�STL������Щͷ�ļ���< algorithm > < vector >
< list > < map > < set > < memory > < functional > �ȡ�
���������:
����ʽ������vector��
����ʽ����
20.1 Vector
��̬���飬�Զ������ڴ�
API��push_back ��pop_back��begin��end��capacity��size
����������iterator���±귨
20.2 Iterator
���������������汾��ָ�룬����������ָ�������е�һ��λ�ã���������STL������
�����������ṩ���ֵ�������
1��Container::iterator �Զ�дģʽ����Ԫ��
vector<int>::iterator
iter;
//����һ��������
*iter = 10; //ok |
2��Container::const_interator ��ֻ��ģʽ����Ԫ��
vector<int>::const_iterator iter;
//����һ��ֻ���ĵ�����
*iter = 10; //error |
API��begin��end��
20.3 list
ʹ��˫����������Ԫ�أ�ʱ˳����ʵ�������
����������iterator
API��push_back��push_front��pop_back��begin��end��erase��size��sort
20.4 map
���Ϻ�ӳ��ʱ������Ҫ�ķ����������࣬�ڲ�ʵ��һ��Ϊƽ���������
map�ǹ���������
����������iterator
API��insert��begin��end
ʾ����
map<int,string>
mymap;
//����Ԫ�صķ�����
mymap.insert(pair<int,
string>(1,"one"));
mymap.insert(make_pair(2, "two"));
mymap.insert(map<int, string>
::value_type(9,
"nine"));
mymap[0] = "Zero";
//���ʷ���1(map�ĵ�����)��
map<int, string>::iterator iter_map;
for (iter_map = mymap.begin();
iter_map != mymap.end();
++iter_map)
{
cout << iter_map->first
<< "
" << iter_map->second << endl;
}
//���ʷ���2(map�±�)��
cout << mymap[0] << endl; |
��ʮһ�����ģʽ
���������Ƶĵ�һԭ����Խӿڱ�̣����������ʵ�ֱ�̡�
���������Ƶĵڶ�ԭ������ʹ�ö�����ϣ���������̳С�
�̳кͶ�����ϳ�һ��ʹ�á�
21.1 �۲���ģʽ
�۲���ģʽ�����˶�����һ�Զ�������ϵ����һ���Ķ���ı�״̬ʱ��
���е������߶��ᱻ֪ͨ���Զ������¡���������һ����Ŀ�������(Subject����
�������й۲���(Observers����
�۲���ģʽҲ�С�����-����ģʽ��(Publish-Subscribe)��
21.2 ����ģʽ
�ڶ����� ����֪ʶ
һ������ << ������
operator << ()������ԭ�ͣ�
std::ostream& operator<<(std::ostream &os, Score s);
��һ���������ǽ�Ҫ����д�����ݵ��Ǹ����������ò������ݣ�
�ڶ�����������Ҫд������ݡ����õ�operator<<()���غ���������Ϊ��������������ģ�
����ֵ��һ��͵�һ������һ�����ɣ�����д����Ǹ�����
class Score {
public:
Score(unsigned int score) :
m_score(score) {};
friend std::ostream&
operator<<
(std::ostream
& os, Score &s);
private:
unsigned int m_score;
};
std::ostream& operator<<
(std::ostream
& os, Score &s);
std::ostream& operator<<
(std::ostream
& os, Score &s)
{
os << s.m_score;
return os;
}
int main(int argc, char *argv[])
{
Score Fang(80);
cout << "Score:" << Fang
<< endl;
return 0;
} |
���������쳣
2.1 �����
int exception_func(int
num)
{
if (num == 0) {
cout << "before throw -1 " <<
endl;
throw -1;
cout << "after throw -1 " <<
endl;
}
else if (num == 1) {
throw -1.1;
}
else if (num == 2) {
throw string("a string exception");
}
else {
cout << "num = " << num
<< endl;
}
return num;
}
int main(int argc, char *argv[])
{
//�����쳣
try {
exception_func(2);
}
catch (int i) {
cout << "capture a
exception: "
<< i << endl;
}
catch (double d) {
cout << "capture a
exception: "
<< d << endl;
}
catch (string s) {
cout << "capture a exception:
"
<< s << endl;
}
catch (...) {
cout << "capture a unknown
exception.
" << endl;
}
}
|
ʹ���쳣��ԭ���ǣ�Ӧ��ֻ��������ȷʵ���ܲ������������
����������������Ӧ��ʹ���쳣��
���try�������ҵ���֮ƥ���catch���飬�����׳����쳣����ֹ�����ִ�С�
���ʹ�ö�����Ϊ�쳣���ԡ�ֵ���ݡ���ʽ�׳������ԡ����ô��ݡ���ʽ�������
2.2 �������쳣�����б�
Ϊ����ǿ����Ŀɶ��ԺͿ�ά���ԣ�ʹ����Ա��ʹ��һ������ʱ���ܿ����������
���ܻᒁ����Щ�쳣��C++ �����ں��������Ͷ���ʱ�����������ܒ������쳣���б���
����д�����£�
void func()
throw
(int, double, A, B, C); |
��
void func()
throw
(int, double, A, B, C){...} |
�����д������ func ���ܒ��� int �͡�double ���Լ� A��B��C �������͵��쳣��
�쳣�����б������ں�������ʱд��Ҳ�����ں�������ʱд�����������д��������Ӧһ�¡�
����쳣�����б����±�д����˵�� func �������ᒁ���κ��쳣��
void func() throw ();
һ����������������ܒ�����Щ���͵��쳣���Ϳ��Ԓ����κ����͵��쳣��
����������������쳣�����б���û�е��쳣���ڱ���ʱ������������������ʱ��
Dev C++ ��������ij����������� Visual Studio 2010 ��������ij����������
�쳣�����б�����ʵ�����á�
2.3 C++���쳣��
C++ ��������һЩ������쳣����Щ��Ǵ� exception �����������ģ�
ʾ����
int main(int
argc, char *argv[])
{
try {
vector<int> vec_int(10);
vec_int.at(11) = 1; //���׳��쳣
//vec_int.assign(11, 1);
//�����׳��쳣
}
catch (out_of_range & e) {
cout << e.what() << endl;
}
catch (...) {
cout <<
"capture a unknown
exception2.
" << endl;
}
try {
char * p = new char[0x7fffffff];
}
catch (bad_alloc & e) {
cout << e.what() << endl;
}
catch (...) {
cout << "capture a unknown
exception3.
" << endl;
}
} |
�������� ��������֪ʶ��
const���ò�������ʱ����
���������β�Ϊconst����ʱ��������������ʱ�����������������
ʵ�ε�������ȷ����������ֵ������(x+0.3)�Ͳ�����ֵ��
ʵ�ε����Ͳ���ȷ��������ת������ȷ�����͡�
����λ���������еĺ������Զ���Ϊ����������
��������Ҫ����ÿ��ʹ�������ļ��ж�������ж��壬���Խ�����������ڶ������ͷ�ļ��С�
����������
���ֲ�����������ʱ��ϵͳ��������ʼ�������������ж����ʼ����
�ڳ����У��ֲ�������ȫ�ֱ��������ƿ�����ͬ�������ں����ڣ��ֲ�������ֵ�Ḳ��ȫ�ֱ�����ֵ��
��һ���������ڿ��Դ��������ı�����ǰ�������ǵ�������ͬ��
#include < iostream>
using namespace std;
int main()
{
int b = 2;
{
int b = 1;
cout << "b = " << b << endl;// 1
}
cout << "b = " << b << endl; // 2
}
�洢�ھ�̬�������ı������ڳ���տ�ʼ����ʱ����ɳ�ʼ����Ҳ��Ψһ��һ�γ�ʼ����
�������ֱ����洢�ھ�̬�洢����ȫ�ֱ����� static ������
ȫ�ֱ����ͺ;ֲ�����ͬ��ʱ����ͨ�������ں��������õ�ȫ�ֱ�����
�����������������þֲ�����
#include< iostream >
using namespace std;
int a = 10;
int main()
{
int a = 20;
cout << ::a << endl;// 10
cout << a << endl;// 20
return 0;
}
�� VS2013 ��������ȫ�ֱ����������Լ����¸�ֵ��ֱ����ȫ�ֱ���������֣�
count ��������ȷ�����⡣
�ڱ�����ǰ���� :: ���ż��ɡ�
#include < iostream >
using namespace std;
int count = 10; //ȫ�ֱ�����ʼ��
int main()
{
::count = 1; //ȫ�ֱ������¸�ֵ
for (;::count <= 10; ++::count)
{
cout <<"ȫ�ֱ���count="<< ::count << endl;
}
return 0;
}
�������ڴ��е�λ��
��1����������text segment�����ֳ�ֻ������ͨ����ָ������ų���ִ�д����һ���ڴ������ⲿ������Ĵ�С�ڳ�������ǰ���Ѿ�ȷ���������ڴ�����ͨ������ֻ����ijЩ�ܹ�Ҳ���������Ϊ��д���������ij����ڴ�����У�Ҳ�п��ܰ���һЩֻ���ij��������������ַ��������ȡ�
��2��ȫ�ֳ�ʼ��������/��̬��������Data Segment����������ų����Ѿ���ʼ����ȫ�ֱ������Ѿ���ʼ���ľ�̬������λ��λ�ڿ�ִ�д���κ��棬�����Dz������ġ��ڳ�������֮����Ϊ���ݶ������˿ռ䣬�����˳���ʱ���ͷſռ䣬�������������������������ʱ�ڡ�
��3��δ��ʼ����������BSS����������ų�����δ��ʼ����ȫ�ֱ����;�̬������λ�������ݶ�֮���Բ����������������ں����ݶ�һ������2���ͣ�3��ͳ��Ϊ��̬�洢����
��4��ջ����Stack�����ֳƶ�ջ����ų�����ʱ�����ľֲ��������纯���IJ���ֵ������ֵ���ֲ������ȡ�Ҳ�������Ǻ�������{}�ж���ı�������������static�����ľ�̬������static��ζ�������ݶ��д�ŵı�����������֮�⣬�ں���������ʱ�������Ҳ�ᱻѹ�뷢����õĽ���ջ�У����ҵȵ����ý��������ķ���ֵҲ�ᱻ��Ż�ջ�С��������Զ������ͷţ�������������չ�ġ�
��5��������Heap����λ��ջ�������棬������������չ�ġ����ڴ�Ž��������ж�̬������ڴ�Σ����Ĵ�С�����̶����ɶ�̬���Ż������������̵���malloc�Ⱥ��������ڴ��ʱ���·�����ڴ�ͱ���̬���ӵ����ϣ��ѱ����ţ���������free�Ⱥ����ͷ��ڴ��ʱ���ͷŵ��ڴ�Ӷ��б������ѱ���������һ���ɳ���Ա���з�����ͷţ������ͷţ��ڳ��������ʱ����OS������ա�
const���ε�ȫ�ֱ��������ڴ������У�const���εľֲ�����������ջ���С�
|








