| 编辑推荐: |
| 本文来自于csdn,OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制. |
|
1.OpenMP基本概念
OpenMP是一种用于共享内存并行系统的多线程程序设计方案,支持的编程语言包括C、C++和Fortran。OpenMP提供了对并行算法的高层抽象描述,特别适合在多核CPU机器上的并行程序设计。编译器根据程序中添加的pragma指令,自动将程序并行处理,使用OpenMP降低了并行编程的难度和复杂度。当编译器不支持OpenMP时,程序会退化成普通(串行)程序。程序中已有的OpenMP指令不会影响程序的正常编译运行。在VS中启用OpenMP很简单,很多主流的编译环境都内置了OpenMP。在项目上右键->属性->配置属性->C/C++->语言->OpenMP支持,选择“是”即可。
2.OpenMP执行模式
OpenMP采用fork-join的执行模式。开始的时候只存在一个主线程,当需要进行并行计算的时候,派生出若干个分支线程来执行并行任务。当并行代码执行完成之后,分支线程会合,并把控制流程交给单独的主线程。
一个典型的fork-join执行模型的示意图如下:
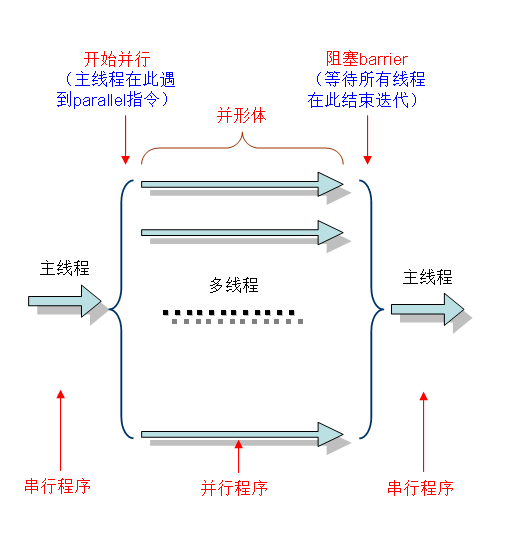
OpenMP编程模型以线程为基础,通过编译制导指令制导并行化,有三种编程要素可以实现并行化控制,他们分别是编译制导、API函数集和环境变量。
3.编译器指令
OpenMP的编译器指令的目标主要有:
1)产生一个并行区域;
2)划分线程中的代码块;
3)在线程之间分配循环迭代;
4)序列化代码段;
5)同步线程间的工作。编译制导指令以#pragma omp 开始,后边跟具体的功能指令,格式如:#pragma
omp 指令[子句],[子句]…]。
常用的功能指令如下:
parallel :用在一个结构块之前,表示这段代码将被多个线程并行执行;
for:用于for循环语句之前,表示将循环计算任务分配到多个线程中并行执行,以实现任务分担,必须由编程人员自己保证每次循环之间无数据相关性;
parallel for :parallel和for指令的结合,也是用在for循环语句之前,表示for循环体的代码将被多个线程并行执行,它同时具有并行域的产生和任务分担两个功能;
sections :用在可被并行执行的代码段之前,用于实现多个结构块语句的任务分担,可并行执行的代码段各自用section指令标出(注意区分sections和section);
parallel sections:parallel和sections两个语句的结合,类似于parallel?for;
single:用在并行域内,表示一段只被单个线程执行的代码;
critical:用在一段代码临界区之前,保证每次只有一个OpenMP线程进入;
flush:保证各个OpenMP线程的数据影像的一致性;
barrier:用于并行域内代码的线程同步,线程执行到barrier时要停下等待,直到所有线程都执行到barrier时才继续往下执行;
atomic:用于指定一个数据操作需要原子性地完成;
master:用于指定一段代码由主线程执行;
threadprivate:用于指定一个或多个变量是线程专用,后面会解释线程专有和私有的区别。
相应的OpenMP子句为:
private:指定一个或多个变量在每个线程中都有它自己的私有副本;
firstprivate:指定一个或多个变量在每个线程都有它自己的私有副本,并且私有变量要在进入并行域或任务分担域时,继承主线程中的同名变量的值作为初值;
lastprivate:是用来指定将线程中的一个或多个私有变量的值在并行处理结束后复制到主线程中的同名变量中,负责拷贝的线程是for或sections任务分担中的最后一个线程;
reduction:用来指定一个或多个变量是私有的,并且在并行处理结束后这些变量要执行指定的归约运算,并将结果返回给主线程同名变量;
nowait:指出并发线程可以忽略其他制导指令暗含的路障同步;
num_threads:指定并行域内的线程的数目;
schedule:指定for任务分担中的任务分配调度类型;
shared:指定一个或多个变量为多个线程间的共享变量;
ordered:用来指定for任务分担域内指定代码段需要按照串行循环次序执行;
copyprivate:配合single指令,将指定线程的专有变量广播到并行域内其他线程的同名变量中;
copyin n:用来指定一个threadprivate类型的变量需要用主线程同名变量进行初始化;
default:用来指定并行域内的变量的使用方式,缺省是shared。
4.API函数
除上述编译制导指令之外,OpenMP还提供了一组API函数用于控制并发线程的某些行为,下面是一些常用的OpenMP
API函数以及说明:
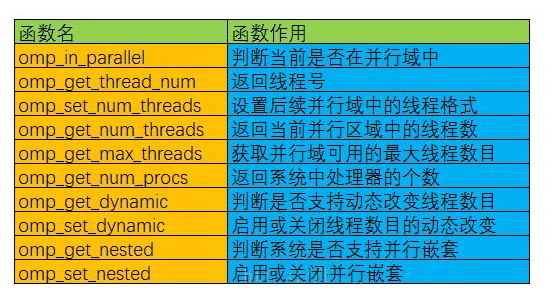
5.环境变量
OpenMP提供了一些环境变量,用来在运行时对并行代码的执行进行控制。这些环境变量可以控制:1)设置线程数;2)指定循环如何划分;3)将线程绑定到处理器;4)启用/禁用嵌套并行,设置最大的嵌套并行级别;5)启用/禁用动态线程;6)设置线程堆栈大小;7)设置线程等待策略。常用的环境变量:
OMP_SCHEDULE:用于for循环并行化后的调度,它的值就是循环调度的类型;
OMP_NUM_THREADS:用于设置并行域中的线程数;
OMP_DYNAMIC:通过设定变量值,来确定是否允许动态设定并行域内的线程数;
OMP_NESTED:指出是否可以并行嵌套。
(1).OpenMP指令及子句用法
(2).parallel
parallel 是用来构造一个并行块的,也可以使用其他指令如for、sections等和它配合使用。parallel指令是用来为一段代码创建多个线程来执行它的。parallel块中的每行代码都被多个线程重复执行。和传统的创建线程函数比起来,相当于为一个线程入口函数重复调用创建线程函数来创建线程并等待线程执行完。程序示例如下:
void fun1()
{
#pragma omp parallel num_threads(6) //定义6个线程,每个线程都将运行{}内代码,运行结果:输出6次Test
{
cout << "Test" << endl;
}
system("pause");
}
|
(3)for
for指令则是用来将一个for循环分配到多个线程中执行。for指令一般可以和parallel指令合起来形成parallel
for指令使用,也可以单独用在parallel语句的并行块中。parallel for用于生成一个并行域,并将计算任务在多个线程之间分配,用于分担任务。程序示例如下:
void fun2()
{
#pragma omp parallel for num_threads(6) {
printf("OpenMP Test, 线程编号为: %d\n", omp_get_thread_num());
} //指定了6个线程,迭代量为12,每个线程都分到了12/6=2次的迭代量。
system("pause");
}
|
(4)sections & section
section语句是用在sections语句里用来将sections语句里的代码划分成几个不同的段,每段都并行执行。语法格式如下:
#pragma omp [parallel]
sections [子句]
{
#pragma omp section
{
代码块
}
#pragma omp section
{
代码块
}
}
|
说明各个section里的代码都是并行执行的,并且各个section被分配到不同的线程执行。
使用section语句时,需要注意的是这种方式需要保证各个section里的代码执行时间相差不大,否则某个section执行时间比其他section过长就达不到并行执行的效果了。用for语句来分摊是由系统自动进行,只要每次循环间没有时间上的差距,那么分摊是很均匀的,使用section来划分线程是一种手工划分线程的方式。
(5) private
private子句用于将一个或多个变量声明成线程私有的变量,变量声明成私有变量后,指定每个线程都有它自己的变量私有副本,其他线程无法访问私有副本。即使在并行区域外有同名的共享变量,共享变量在并行区域内不起任何作用,并且并行区域内不会操作到外面的共享变量。程序示例如下:
int k = 100;
#pragma omp parallel for private(k)
for( k=0; k < 3; k++)
{
printf("k=%d/n", k);
}
printf("last k=%d/n", k);
|
上面程序执行后打印的结果如下:
k=0
k=1
k=2
k=3
last k=100 |
从打印结果可以看出,for循环前的变量k和循环区域内的变量k其实是两个不同的变量。用private子句声明的私有变量的初始值在并行区域的入口处是未定义的,它并不会继承同名共享变量的值。
private声明的私有变量不能继承同名变量的值,但实际情况中有时需要继承原有共享变量的值,OpenMP提供了firstprivate子句来实现这个功能。若上述程序使用firstprivate(k),则并行区域内的私有变量k继承了外面共享变量k的值100作为初始值,并且在退出并行区域后,共享变量k的值保持为100未变。
有时在并行区域内的私有变量的值经过计算后,在退出并行区域时,需要将它的值赋给同名的共享变量,前面的private和firstprivate子句在退出并行区域时都没有将私有变量的最后取值赋给对应的共享变量,lastprivate子句就是用来实现在退出并行区域时将私有变量的值赋给共享变量。程序示例如下:
int k = 100;
#pragma omp parallel for firstprivate(k),lastprivate(k)
for( i=0; i < 4; i++)
{
k+=i;
printf("k=%d/n",k);
}
printf("last k=%d/n", k);
|
上面代码执行后的打印结果如下:
| k=100
k=101
k=103
k=102
last k=103
|
从打印结果可以看出,退出for循环的并行区域后,共享变量k的值变成了103,而不是保持原来的100不变。OpenMP规范中指出,如果是循环迭代,那么是将最后一次循环迭代中的值赋给对应的共享变量;如果是section构造,那么是最后一个section语句中的值赋给对应的共享变量。注意这里说的最后一个section是指程序语法上的最后一个,而不是实际运行时的最后一个运行完的。如果是类(class)类型的变量使用在lastprivate参数中,那么使用时有些限制,需要一个可访问的,明确的缺省构造函数,除非变量也被使用作为firstprivate子句的参数;还需要一个拷贝赋值操作符,并且这个拷贝赋值操作符对于不同对象的操作顺序是未指定的,依赖于编译器的定义。
(6) threadprivate
threadprivate指令用来指定全局的对象被各个线程各自复制了一个私有的拷贝,即各个线程具有各自私有的全局对象。threadprivate和private的区别在于threadprivate声明的变量通常是全局范围内有效的,而private声明的变量只在它所属的并行构造中有效。用作threadprivate的变量的地址不能是常数。对于C++的类(class)类型变量,用作threadprivate的参数时有些限制,当定义时带有外部初始化时,必须具有明确的拷贝构造函数。程序示例如下:
int g;
#pragma omp threadprivate(g) //一定要先声明
int main(int argc, char *argv[])
{
/* Explicitly turn off dynamic threads */
omp_set_dynamic(0);
#pragma omp parallel
{
g = omp_get_thread_num();? ?
printf("tid: %d\n",g); //随机依次输出0~3
} // End of parallel region
#pragma omp parallel
{
int temp = g*g;
printf("tid : %d, tid*tid: %d\n",g,
temp); //不同线程中全局变量值不同
} // End of parallel region
}
|
注意:在使用threadprivate的时候,要用omp_set_dynamic(0)关闭动态线程的属性,才能保证结果正确。
(7) Share
shared子句可以用于声明一个或多个变量为共享变量。所谓的共享变量,是值在一个并行区域的team内的所有线程只拥有变量的一个内存地址,所有线程访问同一地址。所以,对于并行区域内的共享变量,需要考虑数据竞争条件,要防止竞争,需要增加对应的保护。程序示例如下:
#define COUNT
10000
int main(int argc, _TCHAR* argv[])
{
int sum = 0;
#pragma omp parallel for shared(sum)
for(int i = 0; i < COUNT;i++)
{
sum = sum + i;
}
printf("%d\n",sum);
return 0;
}
|
多次运行,结果可能不一样。需要注意的是:循环迭代变量在循环构造区域里是私有的,声明在循环构造区域内的自动变量都是私有的。如果循环迭代变量也是共有的,OpenMP该如何去执行,所以也只能是私有的了。即使使用shared来修饰循环迭代变量,也不会改变循环迭代变量在循环构造区域中是私有的这一特点。程序示例如下:
#define COUNT
10
int main(int argc, _TCHAR* argv[])
{
int sum = 0;
int i = 0;
#pragma omp parallel for shared(sum, i)
for(i = 0; i < COUNT;i++)
{
sum = sum + i;
}
printf("%d\n",i);
printf("%d\n",sum);
return 0;
}
|
上述程序中,循环迭代变量i的输出值为0,尽管这里使用shared修饰变量i。注意,这里的规则只是针对循环并行区域,对于其他的并行区域没有这样的要求。同时在循环并行区域内,循环迭代变量是不可修改的。即在上述程序中,不能再for循环体内对循环迭代变量i进行修改。
(8) Default
default指定并行区域内变量的属性,C++的OpenMP中default的参数只能为shared或none。default(shared):表示并行区域内的共享变量在不指定的情况下都是shared属性
default(none):表示必须显式指定所有共享变量的数据属性,否则会报错,除非变量有明确的属性定义(比如循环并行区域的循环迭代变量只能是私有的)如果一个并行区域,没有使用default子句,那么其默认行为为default(shared)。
(9) Copyin
copyin子句用于将主线程中threadprivate变量的值拷贝到执行并行区域的各个线程的threadprivate变量中,从而使得team内的子线程都拥有和主线程同样的初始值。程序示例如下:
#include <omp.h>
int A = 100;
#pragma omp threadprivate(A)?
int main(int argc, _TCHAR* argv[])
{
#pragma omp parallel for
for(int i = 0; i<10;i++)
{
A++;
printf("Thread ID: %d, %d: %d\n",omp_get_thread_num(),
i, A); // #1
}
|
printf("Global A: %d\n",A);
// 并行区域外的打印的“Globa A”的值总是和前面的thread 0的结果相等,因为退出并行区域后,只有master线程即0号线程运行。
#pragma omp parallel
for copyin(A)
for(int i = 0; i<10;i++)
{
A++;
printf("Thread ID: %d, %d: %d\n",omp_get_thread_num(),
i, A); // #1
}
printf("Global A: %d\n",A); // #2
return 0;
}
|
不使用copyin的情况下,进入第二个并行区域的时候,不同线程的私有副本A的初始值是不一样的,这里使用了copyin之后,发现所有的线程的初始值都使用主线程的值初始化,然后继续运算,输出的值即为本次thread
0的结果。简单理解,在使用了copyin后,所有的线程的threadprivate类型的副本变量都会与主线程的副本变量进行一次“同步”。
另外copyin中的参数必须被声明成threadprivate的,对于类类型的变量,必须带有明确的拷贝赋值操作符。
(10) Copyprivate
copyprivate子句用于将线程私有副本变量的值从一个线程广播到执行同一并行区域的其他线程的同一变量。copyprivate只能用于single指令(single指令:用在一段只被单个线程执行的代码段之前,表示后面的代码段将被单线程执行)的子句中,在一个single块的结尾处完成广播操作。copyprivate只能用于private/firstprivate或threadprivate修饰的变量。程序示例如下:
int counter
= 0;
#pragma omp threadprivate(counter)
int increment_counter()
{
counter++;
return(counter);
}
#pragma omp parallel
{
int count;
#pragma omp single copyprivate(counter)
{
counter = 50;
}
count = increment_counter();
printf("ThreadId: %ld, count = %ld/n",
omp_get_thread_num(), count);
}
|
打印结果为:
| ThreadId: 2,
count = 51
ThreadId: 0, count = 51
ThreadId: 3, count = 51
ThreadId: 1, count = 51
|
如果没有使用copyprivate子句,那么打印结果为:
| ThreadId: 2,
count = 1
ThreadId: 1, count = 1
ThreadId: 0, count = 51
ThreadId: 3, count = 1
|
可以看出,使用copyprivate子句后,single构造内给counter赋的值被广播到了其他线程里,但没有使用copyprivate子句时,只有一个线程获得了single构造内的赋值,其他线程没有获取single构造内的赋值。
6. OpenMP中的任务调度
OpenMP中,任务调度主要用于并行的for循环中,当循环中每次迭代的计算量不相等时,如果简单地给各个线程分配相同次数的迭代的话,会造成各个线程计算负载不均衡,这会使得有些线程先执行完,有些后执行完,造成某些CPU核空闲,影响程序性能。OpenMP提供了schedule子句来实现任务的调度。schedule子句格式:schedule(type,[size])。
参数type是指调度的类型,可以取值为static,dynamic,guided,runtime四种值。其中runtime允许在运行时确定调度类型,因此实际调度策略只有前面三种。
参数size表示每次调度的迭代数量,必须是整数。该参数是可选的。当type的值是runtime时,不能够使用该参数。
( 1) 静态调度static
大部分编译器在没有使用schedule子句的时候,默认是static调度。static在编译的时候就已经确定了,那些循环由哪些线程执行。假设有n次循环迭代,t个线程,那么给每个线程静态分配大约n/t次迭代计算。n/t不一定是整数,因此实际分配的迭代次数可能存在差1的情况。
在不使用size参数时,分配给每个线程的是n/t次连续的迭代,若循环次数为10,线程数为2,则线程0得到了0~4次连续迭代,线程1得到5~9次连续迭代。
当使用size时,将每次给线程分配size次迭代。若循环次数为10,线程数为2,指定size为2则0、1次迭代分配给线程0,2、3次迭代分配给线程1,以此类推。
( 2) 动态调度dynamic
动态调度依赖于运行时的状态动态确定线程所执行的迭代,也就是线程执行完已经分配的任务后,会去领取还有的任务(与静态调度最大的不同,每个线程完成的任务数量可能不一样)。由于线程启动和执行完的时间不确定,所以迭代被分配到哪个线程是无法事先知道的。
当不使用size 时,是将迭代逐个地分配到各个线程。当使用size
时,逐个分配size个迭代给各个线程,这个用法类似静态调度。
(3) 启发式调度guided
采用启发式调度方法进行调度,每次分配给线程迭代次数不同,开始比较大,以后逐渐减小。开始时每个线程会分配到较大的迭代块,之后分配到的迭代块会逐渐递减。迭代块的大小会按指数级下降到指定的size大小,如果没有指定size参数,那么迭代块大小最小会降到1。
size表示每次分配的迭代次数的最小值,由于每次分配的迭代次数会逐渐减少,少到size时,将不再减少。具体采用哪一种启发式算法,需要参考具体的编译器和相关手册的信息。
(4) 调度方式总结
静态调度static:每次哪些循环由那个线程执行时固定的,编译调试。由于每个线程的任务是固定的,但是可能有的循环任务执行快,有的慢,不能达到最优。
动态调度dynamic:根据线程的执行快慢,已经完成任务的线程会自动请求新的任务或者任务块,每次领取的任务块是固定的。
启发式调度guided:每个任务分配的任务是先大后小,指数下降。当有大量任务需要循环时,刚开始为线程分配大量任务,最后任务不多时,给每个线程少量任务,可以达到线程任务均衡。
OpenMP程序设计技巧总结
1.当循环次数较少时,如果分成过多的线程来执行的话,可能会使得总的运行时间高于较少线程或一个线程的执行情况,并且会增加能耗;
2.如果设置的线程数量远大于CPU的核数的话,那么存在着大量的任务切换和调度的开销,也会降低整体的效率。
3.在嵌套循环中,如果外层循环迭代次数较少时,如果将来CPU核数增加到一定程度时,创建的线程数将可能小于CPU核数。另外如果内层循环存在负载平衡的情况下,很难调度外层循环使之达到负载平衡。
|








