|
1.ʲô���ڴ���룿
�ִ���������ڴ�ռ䶼�ǰ���byte���ֵģ��������Ͻ��ƺ����κ����͵ı����ķ��ʿ��Դ��κε�ַ��ʼ����ʵ��������ڷ����ض�������ʱ�����ض����ڴ��ַ���ʣ��������Ҫ���������ݰ���һ���Ĺ����ڿռ������У�������˳���һ����һ�����ŷţ�����Ƕ��롣
2.Ϊʲô�ڴ�Ҫ���룿
�ֵIJο����϶�������˵�ģ�
�١�ƽ̨ԭ��(��ֲԭ��)���������е�Ӳ��ƽ̨���ܷ��������ַ�ϵ��������ݵģ�ijЩӲ��ƽֻ̨����ijЩ��ַ��ȡijЩ�ض����͵����ݣ������׳�Ӳ���쳣��
�ڡ�����ԭ�����ݽṹ(������ջ)Ӧ�þ����ܵ�����Ȼ�߽��϶��롣ԭ�����ڣ�Ϊ�˷���δ������ڴ棬��������Ҫ�������ڴ���ʣ���������ڴ���ʽ���Ҫһ�η��ʡ�
������Щƽ̨ÿ�ζ����Ǵ�ż����ַ��ʼ�����һ��int�ͣ�����Ϊ32λ����������ż����ʼ�ĵط�����ôһ�������ھͿ��Զ������������������ַ��ʼ�ĵط����Ϳ��ܻ���Ҫ2�������ڣ��������ζ����Ľ���ĸߵ��ֽڽ���ƴ�ղ��ܵõ���int���ݡ���Ȼ�ڶ�ȡЧ�����½��ܶࡣ
3.�ڴ���������ʵ�ֵģ�
ͨ������д�����ʱ����Ҫ���Ƕ������⣬��������������ѡ���ʺ�Ŀ��ƽ̨�Ķ�����ԡ���Ȼ������Ҳ����֪ͨ������������Ԥ����ָ����ı���ƶ����ݵĶ��뷽����ȱʡ����£�������Ϊ�ṹ���ÿ����Ա������Ȼ������������ռ䡣������Ա�������DZ�������˳�����ڴ���˳��洢����һ����Ա�ĵ�ַ�������ṹ�ĵ�ַ��ͬ����Ȼ���缴Ĭ�϶��뷽ʽ����ָ���ṹ��ij�Ա��size���ij�Ա���롣
4.�ڴ����Ĺ���
ÿ���ض�ƽ̨�ϵı����������Լ���Ĭ�ϡ�����ϵ����(Ҳ�ж���ģ��)������Ա����ͨ��Ԥ��������#pragma
pack(n)��n=1,2,4,8,16���ı���һϵ�������е�n������Ҫָ���ġ�����ϵ������
����
1�����ݳ�Ա������ṹ(struct)(������(union))�����ݳ�Ա����һ�����ݳ�Ա����offsetΪ0�ĵط����Ժ�ÿ�����ݳ�Ա�Ķ��밴��#pragma
packָ������ֵ��������ݳ�Ա
���������У��Ƚ�С���Ǹ����С�
2���ṹ(������)�����������������ݳ�Ա��ɸ��Զ���֮�ṹ(������)����ҲҪ���ж��룬���뽫����#pragma
packָ������ֵ�ͽṹ(������)������ݳ�Ա�����У��Ƚ�С���Ǹ����С�
3�����1��2���ƶϣ���#pragma pack��nֵ���ڻ��������ݳ�Ա���ȵ�ʱ�����nֵ�Ĵ�С���������κ�Ч����
5.�ڴ�������
ͨ��#pragma pack(n)�ı䡰����ϵ������Ȼ��쿴sizeof(struct
test_t)��ֵ��
1��1�ֽڶ���(#pragma pack(1))
��������sizeof(struct test_t) = 8 [�������������һ��]
�������̣�
1) ��Ա���ݶ���
#pragma pack(1)
struct test_t {
int a; /* ����4 > 1 ��1���룻��ʼoffset=0 0%1=0�����λ������[0,3] */
char b; /* ����1 = 1 ��1���룻��ʼoffset=4 4%1=0�����λ������[4] */
short c; /* ����2 > 1 ��1���룻��ʼoffset=5 5%1=0�����λ������[5,6] */
char d; /* ����1 = 1 ��1���룻��ʼoffset=7 7%1=0�����λ������[7] */
};
#pragma pack() |
��Ա�ܴ�С=8
2) �������
�������ϵ�� = min((max(int,short,char), 1)
= 1
�����С(size)=$(��Ա�ܴ�С) �� $(�������ϵ��) Բ�� =
8 /* 8%1=0 */ [ע1]
2��2�ֽڶ���(#pragma pack(2))
��������sizeof(struct test_t) = 10 [�������������һ��]
�������̣�
1) ��Ա���ݶ���
#pragma pack(2)
struct test_t {
int a; /* ����4 > 2 ��2���룻��ʼoffset=0 0%2=0�����λ������[0,3] */
char b; /* ����1 < 2 ��1���룻��ʼoffset=4 4%1=0�����λ������[4] */
short c; /* ����2 = 2 ��2���룻��ʼoffset=6 6%2=0�����λ������[6,7] */
char d; /* ����1 < 2 ��1���룻��ʼoffset=8 8%1=0�����λ������[8] */
};
#pragma pack() |
��Ա�ܴ�С=9
2) �������
�������ϵ�� = min((max(int,short,char), 2)
= 2
�����С(size)=$(��Ա�ܴ�С) �� $(�������ϵ��) Բ�� =
10 /* 10%2=0 */
3��4�ֽڶ���(#pragma pack(4))
��������sizeof(struct test_t) = 12 [�������������һ��]
�������̣�
1) ��Ա���ݶ���
#pragma pack(4)
struct test_t {
int a; /* ����4 = 4 ��4���룻��ʼoffset=0 0%4=0�����λ������[0,3] */
char b; /* ����1 < 4 ��1���룻��ʼoffset=4 4%1=0�����λ������[4] */
short c; /* ����2 < 4 ��2���룻��ʼoffset=6 6%2=0�����λ������[6,7] */
char d; /* ����1 < 4 ��1���룻��ʼoffset=8 8%1=0�����λ������[8] */
};
#pragma pack() |
��Ա�ܴ�С=9
2) �������
�������ϵ�� = min((max(int,short,char), 4)
= 4
�����С(size)=$(��Ա�ܴ�С) �� $(�������ϵ��) Բ�� =
12 /* 12%4=0 */
4��8�ֽڶ���(#pragma pack(8))
��������sizeof(struct test_t) = 12 [�������������һ��]
�������̣�
1) ��Ա���ݶ���
#pragma pack(8)
struct test_t {
int a; /* ����4 < 8 ��4���룻��ʼoffset=0 0%4=0�����λ������[0,3] */
char b; /* ����1 < 8 ��1���룻��ʼoffset=4 4%1=0�����λ������[4] */
short c; /* ����2 < 8 ��2���룻��ʼoffset=6 6%2=0�����λ������[6,7] */
char d; /* ����1 < 8 ��1���룻��ʼoffset=8 8%1=0�����λ������[8] */
};
#pragma pack() |
2) �������
�������ϵ�� = min((max(int,short,char), 8)
= 4
�����С(size)=$(��Ա�ܴ�С) �� $(�������ϵ��) Բ�� =
12 /* 12%4=0 */
5��16�ֽڶ���(#pragma pack(16))
��������sizeof(struct test_t) = 12 [�������������һ��]
�������̣�
1) ��Ա���ݶ���
#pragma pack(16)
struct test_t {
int a; /* ����4 < 16 ��4���룻��ʼoffset=0 0%4=0�����λ������[0,3] */
char b; /* ����1 < 16 ��1���룻��ʼoffset=4 4%1=0�����λ������[4] */
short c; /* ����2 < 16 ��2���룻��ʼoffset=6 6%2=0�����λ������[6,7] */
char d; /* ����1 < 16 ��1���룻��ʼoffset=8 8%1=0�����λ������[8] */
};
#pragma pack() |
��Ա�ܴ�С=9
2) �������
�������ϵ�� = min((max(int,short,char), 16)
= 4
�����С(size)=$(��Ա�ܴ�С) �� $(�������ϵ��) Բ�� =
12 /* 12%4=0 */
8�ֽں�16�ֽڶ�������֤���ˡ����ĵ�3�㣺����#pragma pack��nֵ���ڻ��������ݳ�Ա���ȵ�ʱ�����nֵ�Ĵ�С���������κ�Ч������
6.�ڴ����ͼ
#include <iostream>
2 using namespace std;
3
4 struct X1
5 {
6 int i;//4���ֽ�
7 char c1;//1���ֽ�
8 char c2;//1���ֽ�
9 };
10
11 struct X2
12 {
13 char c1;//1���ֽ�
14 int i;//4���ֽ�
15 char c2;//1���ֽ�
16 };
17
18 struct X3
19 {
20 char c1;//1���ֽ�
21 char c2;//1���ֽ�
22 int i;//4���ֽ�
23 };
24 int main()
25 {
26 cout<<"long "<<sizeof(long)<<"\n";
27 cout<<"float "<<sizeof(float)<<"\n";
28 cout<<"int "<<sizeof(int)<<"\n";
29 cout<<"char "<<sizeof(char)<<"\n";
30
31 X1 x1;
32 X2 x2;
33 X3 x3;
34 cout<<"x1 �Ĵ�С "<<sizeof(x1)<<"\n";
35 cout<<"x2 �Ĵ�С "<<sizeof(x2)<<"\n";
36 cout<<"x3 �Ĵ�С "<<sizeof(x3)<<"\n";
37 return 0;
38 } |
��γ���Ĺ��ܼܺ����Ƕ����������ṹX1,X2,X3,�������ṹ����Ҫ��������ڴ����ݰڷŵ�˳����������һ���ģ�������������˼��ֻ���������ռ�õ��ֽ������Լ���������������ṹ��ռ�õ��ֽ�����
��γ�������н��Ϊ��
long 4
2 float 4
3 int 4
4 char 1
5 x1 �Ĵ�С 8
6 x2 �Ĵ�С 12
7 x3 �Ĵ�С 8 |
�ڴ���һ�������Ŀ飬���ǿ����������ͼ����ʾ, ������4���ֽڶ�һ�����뵥λ�ģ�

�����ǿ��������ṹ���ڴ��еIJ��֣�
������ X1������ͼ��ʾ
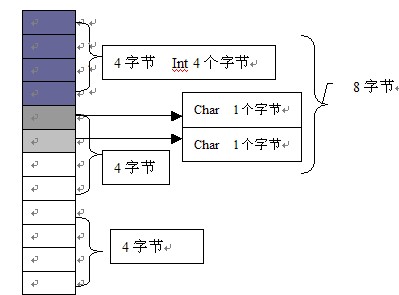
X1 �е�һ���� Int���ͣ���ռ��4�ֽڣ�����ǰ��4��������ˣ�Ȼ��ڶ�����char���ͣ���������ֻռһ���ֽڣ�������ռ���˵ڶ���4�ֽ�����еĵ�һ������Ҳ��char���ͣ�������Ҳռ��һ���ֽڣ����������˵ڶ������ĵڶ�����Ϊ���Ǽ���һ���СҲ������һ���飬�������������������ڴ��еĽṹ���������ģ���Ϊ���ڴ�ֿ���룬�����������Ľ����8��������6����Ϊ��������������ʵҲ���DZ����ˡ�
�ٴο���X2����ͼ��ʾ

X2�е�һ��������Char���ͣ���ռ��һ���ֽڣ��������������ڵ�һ���ĵ�һ���������棬�ڶ�����Int���ͣ���ռ��4���ֽڣ���һ����Ѿ��õ�һ��ʣ3�϶��������µڶ�Int���͵ģ���ΪҪ���ǵ����룬���Բ��ò������ŵ��ڶ�����飬������������Char���ͣ�����һ�����ơ�����Ϊ���ڴ�ֿ���룬���ǵ��ڴ�Ͳ���8�������ˣ�����12���ˡ�
�ٿ���X3������ͼ��ʾ��

����X3��˵����ʵ��X1�����Ƶģ�ֻ������������1���ֽڵķŵ���ǰ�棬���ſ���ǰ�����������˵������Ҳ�Ǻ���������ġ�
|





