| Tips��
��man��ѯ����ʱ����Щ������ֱ��man + �������鵽�����磺man fopen man 2 open
���Կ�����man+����+�����������ԣ���������ݿ��Բ鿴 /usr/local/share/man/�����Ӧ��Ŀ¼
Linux man �ֲ��ά����2010-10 Oreilly ����һ������<<The
Linux Programming Interface>>����,�ҿ������ǹ���ϵͳ���ú�C�⺯����.��Ϊ��man�Ĺٷ���վ(http://www.kernel.org/doc/man-pages/index.html)�϶�man�����µ�����
1:The Linux man-pages project documents
the Linux kernel and C library interfaces that are employed
by user programs. It provides manual pages in the following
sections:
2: System calls, documenting the system
calls provided by the Linux kernel.
3: Library functions, documenting the
functions provided by the standard C library (with particular
focus on glibc, the GNU C library).
4: Devices, which documents details
of various devices, most of which reside in /dev.
5: Files, which describes various file
formats, and includes proc(5), which documents the /proc
file system.
6: Overviews, conventions, and miscellaneous.
�����Ͽ��Կ���man���������˭��:Linuxϵͳ����,kernel,C��.
���еڶ����ֶ�Ӧ����System calls(ϵͳ����),�����ں��ṩ��;
�������ֶ�Ӧ����Library functions,�ⲿ�����ɱ�C��(һ��ָ����GNU��glibc)�ṩ��.
����֮ǰʹ�õ����� man 2 ���е�2����ָ��man�ֲ�ĵڶ�����,ͬ������ָ�������IJ���,�����ϵͳ���úͿ⺯��ͬ���Ļ�,����Ҫ�ֶ�ָ����,����������Ļ�,����������ǿ���ʡ�Ե�.
���������open��fopen�IJ��.
OPEN(2) Linux Programmer's Manual OPEN(2)
�����(2)ָ�ľ���open�����ں��ṩ��,��fopen
FOPEN(3) Linux Programmer's Manual FOPEN(3)
���Կ���һ����ϵͳ����,һ����C�⺯��,��ôϵͳ���úͿ⺯��������ʲô��ϵ��?������csdn��һ������,�����м��仰�����е�����
1.ϵͳ������Ϊ�˷���Ӧ��ʹ�ò���ϵͳ�Ľӿڣ����⺯����Ϊ�˷������DZ�дӦ�ó���������ģ��������Լ���дһ��������ʵҲ����˵����һ���⺯����
2.ϵͳ���ÿ�������Ϊ�ں��ṩ���������û�̬�õĽӿں�����������Ϊ��ij���ں˵Ŀ⺯����
3.read����ϵͳ����,��fread����C���⺯��.
4.�ܶ�c�������еĺ�������ϵͳ���õ�����һ������Ϊ�ú���������ʵ���ǵ��õ�ϵͳ���ã��ŵ�c���������Ϊ���û�̬��ʹ��
5.д����ֱ��ʹ�õ��ǿ⺯�������⺯���ڲ����ܾ��ǵ��õ�ͬ��ϵͳ����
6.���ȣ����ڵ�OS�ں���Ҫ��������ģʽ������ĵ��ں�ģʽ(linux)�ͷֲ���ں�ģʽ(Windows)�����ں�ģʽ���ص���Ǵ�����գ�ִ���ٶȿ죬����ģ��֮����ֱ�ӵĵ��ù�ϵ������˵���һ������ŵ㣬Ҳ��ȱ��...�е����ִ���ٶȿ죬ȱ�����ں˿��������ң�ά���������ѡ�
�����ǵ��ںˣ������ںˣ��������ϵ�ṹ���µ��ϴ�Ŷ��Ƿֳ��������㣺����Ӳ����OS�ںˣ�OS����Ӧ�ó������IJ�ṹ�У�OS�ں���һ�����������¡������ã����¹�������Ӳ��������ΪOS�����Ӧ�ó����ṩ�ӿڡ����⣬����Ľӿ�ʵ������ָϵͳ����(System
Call)��
ͨ��OS�ں�Ϊ�˿���ʵ���������ѶȺ����ڹ�����ֻ�ṩ�ٲ��ֱ�Ҫ��ϵͳ���ã���Щϵͳ����ͨ������C�ͻ������ʵ�ֵġ��ӿ���C���壬ʵ�����û����д���������ĺô��ǣ�ִ��Ч�ʸߣ����Ҽ���ķ������ϲ�ĵ��á�
��˵�⺯��(��API)���⺯�����Ը����ķ�Ϊ���࣬һ������OS�ṩ�ģ���һ���ǵ������ġ���ϵͳ�ṩ�Ŀ⺯����һ����װ�����ϵͳ���ã�ʵ�ָ���Ĺ��ܣ�������C���Ե�����ܵ�һ��С������ʵ�ֺܶ�ܶ�����ܸ��ӵĴ���һ����������API�ܹ�ִ��һЩ����ں���˵�ܸ��ӵIJ��������磬read()�������ݲ�����ֱ�Ӿ��ܶ��ļ������������صı����ļ���Ӳ�̵��ĸ��ŵ����ĸ����������ص��ڴ���ĸ�λ�õȵ���Щ����������Ա�Dz��ع��ĵģ���Щ����������ȻҲ������ϵͳ���á������ڵ������Ŀ⣬����ʵ��ϵͳ��һ����ֻ����ֱ������ϵͳ���õĿ�����ҪСһЩ����������ϵͳ�ṩ��API�ӿ���ʵ�ֹ��ܡ�(API�Ľӿ��ǿ��ŵ�)��
7.�����Կ⺯����ȷ�ǵ���ϵͳ������ʵ�ֵģ�����˵ϵͳ���ò���������Ӳ�������ġ����Ǵ�ҿ���ע���Ϊʲô�⺯��Ϊʲô��ͨ�õģ�ͬ�������������Ǹ����Բ��������ض���Ӳ������ʵ�����DZ�����������⺯����ϵͳ����֮���ת���ġ�����˵VC����ͨ����fopen������Ӧ��windows�Ĵ�ӡϵͳ����XXX����֪���������ĸ�����ȥ�ˣ���linux�ı�����gccͨ����fopen������Ӧ��linux��ϵͳ����open��ȥ�ˡ�
8.ϵͳ����û�п⺯����Ч�ʸ�����Ϊ�����õĻ���ش�С�йذɣ�����أ���֪���û��Ļ����ں˵ģ�С�Ļ���ϵͳ���õIJ�����Ƶ��������أ���֪���û��Ļ����ںˣ���ĵĻ����⺯���͵���ϵͳ���õĴ������١�
9.Ӧ�ó������ֱ�ӵ��ÿ⺯������������ôlinux��Դ����C���Dz�Ӧ��ʹ�ÿ⺯���İɣ����롣�������ӳ��ں˾����װ������ϣ��������л�����û��ôϵͳ���ð����е��˻�˵��ϵͳ�����ڱ������ӵ�ʱ���Ѿ���ϵͳ����Ū��ȥ�ˣ���ô����˵�������еĶ�̬������ֱ��������Ҫʱ��ȥ������
��̳���˻����������ϵĹ۵�.
��Щ����,����ο�����<>�ĵ�����,����ϵͳ���õ�һЩ����,����:
��5�� ϵͳ����
�ֽ���Linux�ں˵��鼮��û����ϸ˵��ϵͳ���ã���Ӧ������һ��ʧ���ں˷�չ�����ڣ�����ʵ����Ҫ��ϵͳ���������Ѿ�ʮ���������������������˵���ٺķѱ����ʱ��ȥ�о�ϵͳ���õ�ʵ���Ǻ�����������顣
Ȼ��������ϣ���ܹ����ں��и��������������˵����ϸ�о�����ϵͳ��������ʮ��ֵ�õġ��������л�������˽�һЩ��������Գû���ϸ�˽�һ���ں˱�̵��ص㣬����ϵͳ���ñ�����Ӧ�ó�����ں˼����������һ����ѧϰ��������Ҳ�����������ں˵�һ���ܺõĹ��ɡ�
5.1 ϵͳ���ø���
һ���ȶ����е�Linux����ϵͳ��Ҫ�ں˺��û�Ӧ�ó���֮���������ϣ��ں��ṩ���ָ����ķ���Ȼ���û�Ӧ�ó���ͨ��ij��;��ʹ����Щ�����������û��IJ�ͬ����
�û�Ӧ�ó�����ʲ�ʹ���ں����ṩ�ĸ��ַ����;������ϵͳ���á����ں˺��û�Ӧ�ó����ཻ��ĵط����ں��ṩ��һ��ϵͳ���ýӿڣ�ͨ������ӿڣ�Ӧ�ó�����Է���ϵͳӲ�����ֲ���ϵͳ��Դ�������û�����ͨ���ļ�ϵͳ��ص�ϵͳ���ã�����ϵͳ���ļ����ر��ļ����д�ļ�������ͨ��ʱ����ص�ϵͳ���ã����ϵͳʱ������ö�ʱ���ȡ�
�ں��ṩ������ϵͳ����ͨ��Ҳ����֮Ϊϵͳ���ýӿڲ㡣ϵͳ���ýӿڲ���Ϊ�ں˺��û�Ӧ�ó���֮����м�㣬������һ������������˵�м��˵Ľ�ɫ��ϵͳ���ð�Ӧ�ó����������ںˣ����ں˴�����������ٽ�����������ظ�Ӧ�ó���
5.1.1 ϵͳ���á�POSIX��C�⡢ϵͳ������ں˺���
��1��ϵͳ���ú�POSIX��
ϵͳ������Ȼ���ں˺��û�Ӧ�ó���֮��Ĺ�ͨ���������û�Ӧ�ó�������ں˵���ڵ㣬��ͨ������£�Ӧ�ó�����ͨ������ϵͳ�ṩ��Ӧ�ñ�̽ӿڣ�API��������ֱ��ͨ��ϵͳ��������̡�
����ϵͳAPI����Ҫ�����ǰѲ���ϵͳ�Ĺ�����ȫչʾ�������ṩ��Ӧ�ó����ڸò���ϵͳ�����ļ����ڴ桢ʱ�ӡ����硢ͼ�Ρ���������Ȼ����������������⣬����ϵͳAPIͨ�����ṩ�������Ĺ��ܣ���������ַ����������������͡�ʱ�����ڵȡ�
��UNIX�������ͨ�õIJ���ϵͳAPI����POSIX��Portable
Operating System Interface of UNIX������ֲ����ϵͳ�ӿڣ�����POSIX�ĵ�����UNIX�ķ�չ�ܲ��ɷ֣�UNIX��20����70���������Bell
lab������20����80������������У�ַ�V7���Դ�������о���UC Berkeley��V7�Ļ����Ͽ�����BSD
UNIX��
�����ܶ���ҵ������ʶ��UNIX�ļ�ֵҲ����Bell Lab��System
V��BSDΪ�����������Լ���UNIX������������Sun OS��AIX��VMS�ȡ���Ȼ�������UNIX�ķ��٣������ڸ����Ҷ�UNIX�Ŀ�������Ϊ����UNIX�İ汾�൱���ң��������Ŀ���ֲ�Դ����ܴ����ѣ���UNIX�ķ�չ��Ϊ������
Ϊ�������־��棬IEEE�ƶ���POSIX����Ŀ�����ṩһ�״����ϻ���UNIX�Ŀ���ֲ����ϵͳ�������UNIX������Ӧ�ó���Ŀ���ֲ�ԡ�Ȼ����POSIX����������UNIX�����������IJ���ϵͳ������DEC
OpenVMS��Microsoft Windows NT����֧��POSIX��
POSIX��������"POSIX����"�IJ���ϵͳ�������ṩ�ķ���Linux������POSIX�����ṩ�˸���POSIX�������API��������ЩAPI������ϵͳ����֮������ֱ�ӵĹ�ϵ��һ��API����������һ��ϵͳ����ʵ�֣�Ҳ����ͨ�����ö��ϵͳ������ʵ�֣���������ȫ��ʹ���κ�ϵͳ���á�
��2��ϵͳ���ú�C�⡣
����ϵͳAPIͨ������C��ķ�ʽ�ṩ��LinuxҲ����ˡ�C���ṩ��POSIX�ľ���API��ͬʱ���ں��ṩ��ÿ��ϵͳ������C���ж�������Ӧ�ķ�װ������ϵͳ��������C���װ���������Ƴ�����ͬ�����磬readϵͳ������C���еķ�װ������Ϊread������
C���е�ϵͳ���÷�װ���������յ��õ���Ӧϵͳ����֮ǰ�������������ٶ���Ĺ�����������ijЩ����»���Щ���⣬�������������ص�ϵͳ����truncate��truncate64��C���еķ�װ����truncate��������Ҫ���������е��ĸ�Ӧ�����ձ����á�
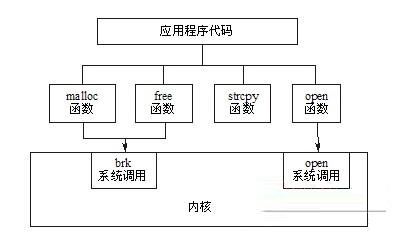
��Ȼ����ͼ5.1��ʾ��ϵͳ���ú�C�⺯��֮�䲢����һһ��Ӧ�Ĺ�ϵ�����ܼ�����ͬ�ĺ�������õ�ͬһ��ϵͳ���ã�����malloc������free��������ͨ��brkϵͳ�������������С���̵Ķ�ջ��execl��execlp��execle��execv��execvp��execve��������ͨ��execveϵͳ������ִ��һ����ִ���ļ���
Ҳ�п���һ���������ö��ϵͳ���á�����Щ���������������κ�ϵͳ���ã�����strcpy�����������ַ�������atoi������ת��ASCIIΪ����������Ϊ���Dz�����Ҫ���ں������κη���
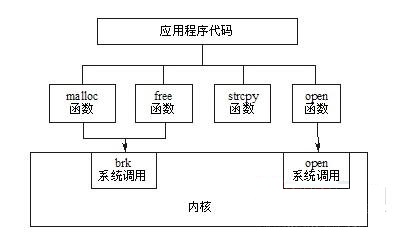
ͼ5.1 C�⺯����ϵͳ����
ʵ���ϣ����û��ĽǶȿ���ϵͳ���ú�C��֮���������Ҫ������ֻ��ͨ��C�⺯��������蹦�ܡ��෴�����ں˵ĽǶȿ�����Ҫ���ǵ������ṩ��Щ���ȷ��Ŀ�ĵ�ϵͳ���ã�������Ҫ��ע������α�ʹ�á�
��3��ϵͳ������ϵͳ���
ϵͳ����λ��C��ĸ��ϲ㣬������C��ʵ�ֵĿ�ִ�г�������Ϊ���õ�ls��cd�����
strace���߿��Ը��������ִ�У�ʹ��ϣ�����ٵ�����Ϊ����������ʾ��������ִ�й�������ʹ�õ�������ϵͳ���á����磬���ϣ���˽���ִ��pwd����ʱ����������Щϵͳ���ã�����ʹ����������
����������������Ϣ����ʾ��pwd����ִ�й����������õ��ĸ���ϵͳ���ã�
����
write(1, "/usr/src/linux-2.6.23/n", 22/usr/src/linux-2.6.23)
= 22
close(1) = 0
munmap(0xb7f5a000, 4096) = 0
exit_group(0) |
��4��ϵͳ���ú��ں˺�����
�ں˺�����C�⺯��������������ں˺������ں�ʵ�֣���˱��������ں˱�̵Ĺ���
ϵͳ�������ձ��������ȷ�IJ������û�Ӧ�ó���ͨ��ϵͳ���ý����ں˺�ִ�и���ϵͳ���ö�Ӧ���ں˺�������ϵͳ���÷������̣�����ϵͳ����getpid�ķ����������ں˺���sys_getpid��
ϵͳ���÷�������֮�⣬�ں��д����Ŵ������ں˺�������Щ������ij���ں��ļ��Լ�ʹ�ã���Щ����export�������ں��������ֹ�ͬʹ�á�����export�������ں˺���������ʹ��ksyms�����ͨ��/proc/ksyms�ļ��鿴��
5.1.2 ϵͳ���ñ�
ϵͳ���ñ�sys_call_table�洢������ϵͳ���ö�Ӧ�ķ������̵ĺ�����ַ����arch/i386/kernel/syscall_table.S�ļ��б����壺
001 ENTRY(sys_call_table) 002 .long sys_restart_syscall
/* 0 - old "setup()" system call, used for
restarting */ 003 .long sys_exit 004 .long sys_fork
005 .long sys_read 006 .long sys_write 007 .long sys_open
/* 5 */ ?-?- 320 .long sys_getcpu 321 .long sys_epoll_pwait
322 .long sys_utimensat /* 320 */ 323 .long sys_signalfd
324 .long sys_timerfd 325 .long sys_eventfd 326 .long
sys_fallocate |
���пɷ��������ر�֮�������ȣ�����ϵͳ���÷������̵�����������һ���Ĺ�����ϵͳ��������֮ǰ����"sys_"ǰ������openϵͳ���ö�Ӧsys_open������
��Σ��ں��ṩ��ϵͳ������Ŀ�dz����ޣ���2.6.23�汾���ں�Ҳ�����Ŵﵽ����325����ʹ��"man
2 syscalls"����������������ϵͳ���õ�������ʷ����Ҳ��ϵͳ������C�⺯��������֮һ��ϵͳ����ͨ��ֻ�ṩ��С�Ľӿڣ�C�⺯�����ڴ˻���֮���ṩ���ิ�ӵĹ��ܡ�
5.1.3 ϵͳ���ú�
��Ȼϵͳ���ñ����д��������ϵͳ���÷������̵ĵ�ַ����ôϵͳ�������ں��е�ִ�оͿ���ת��Ϊ�Ӹñ���ȡ��Ӧ�ķ������̲�ִ�еĹ��̡�
���������һ������Ҫ�Ļ��ھ���ϵͳ���úš�ÿ��ϵͳ���ö�ӵ��һ����һ����ϵͳ���úţ��û�Ӧ��ͨ������������ϵͳ���õ����ƣ���ָ��Ҫִ���ĸ�ϵͳ���á�
ϵͳ���úŵĶ�����include/asm-i386/unistd.h�ļ���
#define __NR_restart_syscall 0 #define __NR_exit 1
#define __NR_fork 2 #define __NR_read 3 #define __NR_write
4 #define __NR_open 5 ...... #define __NR_getcpu 318
#define __NR_epoll_pwait 319 #define __NR_utimensat
320 #define __NR_signalfd 321 #define __NR_timerfd 322
#define __NR_eventfd 323 #define __NR_fallocate 324 |
������sys_call_table�Ķ�����ȽϿ��Է��֣�ÿ��ϵͳ���úŶ����ζ�Ӧ��sys_call_table�е�ijһ��ں����ǽ�ϵͳ���ú���Ϊ�±�ȥ��ȡsys_call_table�еķ������̺�����ַ��
ϵͳ���ú���ϵͳ����Ϊ���������Ĺ�ϵ��һ������Ͳ��������κα������ʹ��ϵͳ���ñ�ɾ��������ӵ�е�ϵͳ���ú�Ҳ���ܱ��������á�
5.1.4 ϵͳ���÷�������
ϵͳ����������ϵͳ���÷������������ȷ�IJ��������е�ϵͳ���÷������̼���������include/linux/syscalls.h�ļ�������ɢ
�����ںܶͬ���ļ�������getpidϵͳ�������ڻ�ȡ��ǰ���̵�PID�����ķ�������sys_getpid��kernel/timer.c�ļ��ж���Ϊ��
asmlinkage long sys_getpid(void) { return current->tgid; } |
���˶�����"sys_"ǰ֮�⣬���е�ϵͳ���÷������������붨�廹��������������һЩ�������ȣ����������б�������asmlinkage��ǣ�֪ͨ���������Ӷ�ջ�л�ȡ�ú����IJ�����
��Σ����뷵��һ��long���͵ķ���ֵ��ʾ�ɹ������ͨ������0��ʾ�ɹ������ظ�ֵ��ʾ����Ȼ��getpidϵͳ���÷dz��������ܻ�ʧ�ܣ�ͨ������"man
2 getpid"���Բ鿴�����ֲᣬ����Ҳ��ȷָ������һ�㡣
ÿ��ϵͳ���õ�ϵͳ���úš������Լ�����Ŀ�Ķ��ǹ̶��ģ����ں����ȥʵ�ֲ�û����ȷ�涨����ͬ�汾����ͬ�ܹ����ں�ʵ�ֶ��п��ܻ������仯��
5.1.5 ���ʹ��ϵͳ����
��ͼ5.2��ʾ���û�Ӧ�ÿ���ͨ�����ַ�ʽʹ��ϵͳ���á���һ�ַ�ʽ��ͨ��C�⺯��������ϵͳ������C���еķ�װ������������ͨ������
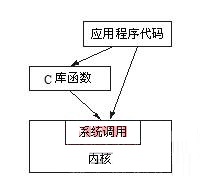
ͼ5.2 ʹ��ϵͳ���õ����ַ�ʽ
�ڶ��ַ�ʽ��ʹ��_syscall�ꡣ2.6.18�汾֮ǰ���ںˣ���include/asm-i386/unistd.h�ļ��ж�����7��_syscall�꣬�ֱ��ǣ�
_syscall0(type,name); _syscall1(type,name,type1,arg1);
_syscall2(type,name,type1,arg1,type2,arg2); _syscall3(type,name,type1,arg1,type2,arg2,type3,arg3);
_syscall4(type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4);
syscall5type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4,type5,arg5);
syscall6type,name,type1,arg1,type2,arg2,type3,arg3,type4,arg4,type5,arg5,type6,arg6); |
���У�type��ʾ������ϵͳ���õķ���ֵ���ͣ�name��ʾ��ϵͳ���õ����ƣ�typeN��argN�ֱ��ʾ��N�����������ͺ����ƣ����ǵ���Ŀ
��_syscall���������һ������Щ��������Ǵ�����Ϊname�ĺ�����_syscall�����������ָ���˸ú����IJ����ĸ�����
����sysinfoϵͳ�������ڻ�ȡϵͳ����ͳ����Ϣ��ʹ��_syscall�궨��Ϊ:
_syscall1(int, sysinfo, struct sysinfo *, info); |
չ�������ʽΪ��
int sysinfo(struct sysinfo * info) { long __res; __asm__
volatile("int $0x80" : "=a" (__res)
: ""(116),"b" ((long)(info))); do
{ if((unsigned long)(__res) >= (unsigned long)(-(128
+ 1))) { errno = -(__res); __res = -1; } return (int)
(__res); } while (0); } |
���Կ�����_syscall1(int, sysinfo, struct
sysinfo *, info)չ����һ����Ϊsysinfo�ĺ�����ԭ����int���Ǻ����ķ������ͣ�ԭ����struct
sysinfo *��info�ֱ��º����IJ�����
�ڳ����ļ���ʹ��_syscall�궨����Ҫ��ϵͳ���ã��Ϳ����ڽ������Ĵ�����ͨ��ϵͳ��������ֱ�ӵ��ø�ϵͳ���á�������һ��ʹ��sysinfoϵͳ���õ�ʵ����
�����嵥5.1 sysinfoϵͳ����ʹ��ʵ��
#include #include #include #include #include /* for
struct sysinfo */ _syscall1(int, sysinfo,struct sysinfo
*, info); int main(void) { struct sysinfo s_info; int
error; error = sysinfo(&s_info); printf("code
error = %d/n", error); printf("Uptime = %lds/nLoad:
1 min %lu / 5 min %lu / 15 min %lu/n" "RAM:
total %lu / free %lu / shared %lu/n" "Memory
in buffers = %lu/nSwap: total %lu / free %lu/n"
"Number of processes = %d/n", s_info.uptime,
s_info.loads[0], s_info.loads[1], s_info.loads[2], s_info.totalram,
s_info.freeram, s_info.sharedram, s_info.bufferram,
s_info.totalswap, s_info.freeswap, s_info.procs); exit(EXIT_SUCCESS);
} |
������2.6.19�汾��ʼ��_syscall�걻�ϳ���������Ҫʹ��syscall������ͨ��ָ��ϵͳ���úź�һ�����������ϵͳ���á�
syscall����ԭ��Ϊ��
int syscall(int number, ...); |
����number��ϵͳ���úţ�number����Ӧ˳����ϸ�ϵͳ���õ����в�����������gettidϵͳ���õĵ���ʵ����
�����嵥5.2 gettidϵͳ����ʹ��ʵ��
| #include
#include #include #define __NR_gettid 224 int main(int
argc, char *argv[]) { pid_t tid;tid = syscall(__NR_gettid);
} |
��ϵͳ���ö�������һ��SYS_���ų�����ָ���Լ���ϵͳ���úŵ�ӳ�䣬���������ɫ�IJ��ֿ���дΪ��
|
tid = syscall(SYS_gettid);
|
5.1.6 Ϊʲô��Ҫϵͳ����
Ϊʲô��Ҫϵͳ���ã���Ҫ������������ԭ��
��1��ϵͳ���ÿ���Ϊ�û��ռ��ṩ����Ӳ����Դ��ͳһ�ӿڣ�������Ӧ�ó���ȥ��ע�����Ӳ�����ʲ��������磬��д�ļ�ʱ��Ӧ�ó�����ȥ�ܴ������ͣ������ڲ��ù����������ļ�ϵͳ��
��2��ϵͳ���ÿ��Զ�ϵͳ���б�������֤ϵͳ���ȶ��Ͱ�ȫ��ϵͳ���õĴ��ڹ涨���û����̽����ں˵ľ��巽ʽ�����仰˵���û������ں˵�·�������ȹ涨�õģ�ֻ�ܴӹ涨λ�ý����ںˣ����������������ںˡ����������Ľ����ں˵�ͳһ����·�����Ʋ��ܱ�֤�ں˵İ�ȫ��
���ǿ���������������ֻ��ƣ���Ϊһ���οͣ��������ƱҪ�����Ұ�������������������ʵʵ�����ڹ۹�ϣ����չ涨��·�߹۹���������Ȼ�����³�����Ϊ����̫Σ�գ��������㶪��С�������������Ż���Ұ�����
5.2 ϵͳ����ִ�й���
ϵͳ���õ�ִ�й�����Ҫ������ͼ5.3��ͼ5.4��ʾ�������Σ��û��ռ䵽�ں˿ռ��ת���Σ��Լ�ϵͳ���ô�������system_call������ϵͳ���÷������̵ĽΡ�
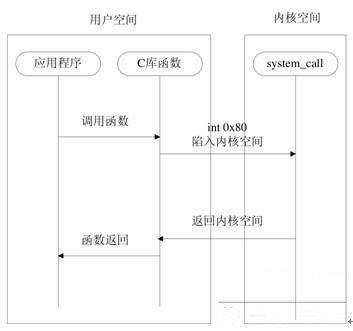
ͼ5.3 �û��ռ䵽�ں˿ռ�
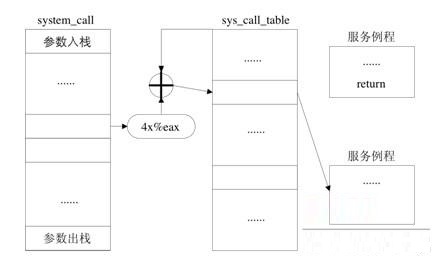
ͼ5.4 system_call������ϵͳ���÷�������
��1���û��ռ䵽�ں˿ռ䡣
��ͼ5.3��ʾ��ϵͳ���õ�ִ����Ҫһ���û��ռ䵽�ں˿ռ��״̬ת������ͬ��ƽ̨���в�ͬ��ָ������������ת��������ָ��Ҳ����������ϵͳ���루operating
system trap��ָ�
Linuxͨ�����ж���ʵ���������룬�������X86�ܹ���˵�������ж�0x80��Ҳ��int
$0x80���ָ����жϺ����dz�˵���жϣ�Ӳ���жϣ���֮ͬ������-��������ָ�����������Ӳ������������
int 0x80ָ���װ��C���У������û�Ӧ����˵�����ڿ���ֲ�ԵĿ��ǣ���Ӧ��ֱ�ӵ���int
$0x80ָ�����ָ���ƽ̨�����ԣ�Ҳ����ϵͳ������Ҫ��C����з�װ��ԭ��֮һ��
ͨ�����ж�0x80��ϵͳ����ת��һ��Ԥ����ں˿ռ��ַ����ָ����ϵͳ���ô�������Ҫ��ϵͳ���÷��������������������arch/i386/kernel/entry.S�ļ���ʹ�û�����Ա�д��system_call������
��2��system_call������ϵͳ���÷������̡�
����Ȼ�����е�ϵͳ���ö���ͳһ��ת�������ַ����ִ��system_call������������ǰ����������2.6.23��Ϊֹ���ں��ṩ��ϵͳ�����Ѿ��ﵽ��325������ôsystem_call�����ָ�����ɷ����ǵ����Եķ��������أ�
���ж�ָ��int 0x80ִ��ʱ��ϵͳ���úŻᱻ����eax�Ĵ�����ͬʱ��sys_call_tableÿһ��ռ��4���ֽڡ���������ͼ5.5��
ʾ��system_call�������Զ�ȡeax�Ĵ�����õ�ǰϵͳ���õ�ϵͳ���úţ��������4����ƫ�Ƶ�ַ��Ȼ����sys_call_tableΪ��
ַ����ַ����ƫ�Ƶ�ַ��ָ������ݼ���Ӧ��ִ�е�ϵͳ���÷������̵ĵ�ַ��
���⣬���˴���ϵͳ���úŵ�eax�Ĵ����������Ҫ�����ᴫ��һЩ�������ںˣ�����writeϵͳ���õķ�������ԭ��Ϊ��
| sys_write(unsigned
int fd, const char * buf, size_t count); |
����writeϵͳ����ʱ����Ҫ�����ļ�������fd��Ҫд�������buf�Լ�д���ֽ���count�ȼ������ݵ��ںˡ�ebx��ecx��edx��esi�Լ�edi�Ĵ����������ڴ�����Щ����IJ�����
����֮ǰ������ϵͳ���÷������̶����е�asmlinkage��DZ�ʾ�����������Ӷ�ջ�л�ȡ�ú����IJ�����������Ҫ�ӼĴ����л���κβ���������
system_call����ǰ���û�Ӧ�ý�������ŵ���Ӧ�Ĵ����У�system_call����ִ��ʱ�����Ƚ���Щ�Ĵ���ѹ���ջ��
����ϵͳ���÷������̣�����ֱ�Ӵ�system_call����ѹ��Ķ�ջ�л�ò������Բ�������Ҳ����һֱ�ڶ�ջ�н��С���system_call�����˳����û�Ӧ�ÿ���ֱ�ӴӼĴ����л�ñ��Ĺ��IJ�����
���������е�ϵͳ���÷������̶���ʵ�ʵ����ݣ���һ����������sys_ni_syscall���˷���-ENOSYS�ⲻ���κ�������������kernel/sys_ni.c�ļ��ж��塣
| asmlinkage
long sys_ni_syscall(void) { return -ENOSYS; } |
sys_ni_syscall��ȷ�����ϵͳ���÷������̣������Ͽ��������ܲ�û��ʲô�ô������ǣ�����sys_call_table��ռ���˺ܶ�λ�á�����λ���ϵ�sys_ni_syscal����������Щ�Ѿ����ں�����̭��ϵͳ���ã����磺
| .long
sys_ni_syscall /* old stty syscall holder */ .long
sys_ni_syscall /* old gtty syscall holder */ |
�ͷֱ�������Ѿ�������stty��gttyϵͳ���á����һ��ϵͳ���ñ���̭��������Ӧ�ķ������̾�Ҫ��ָ��Ϊsys_ni_syscall��
���Dz����ܽ����ǵ�λ�÷����������ϵͳ���ã���ΪһЩ�ϵĴ�����ܻ���ʹ�õ����ǡ��������ij���û�Ӧ����ͼ������Щ�Ѿ�����̭��ϵͳ���ã����õ��Ľ�����������һ���ļ����ͻ���Ԥ����ȫ��ͬ���⽫���˸е��dz���֡�
��ʵ��sys_ni_syscall�е�"ni"����ʾ"not
implemented��û��ʵ�֣�"��
ϵͳ����ͨ�����ж�0x80�����ںˣ���ת��ϵͳ���ô�������system_call��������ִ����Ӧ�ķ������̣��������Ǵ����û����̣��������ִ�й��̲��������ж������ģ����Ǵ��ڽ��������ġ�
��ˣ�ϵͳ����ִ�й����У����Է����û����̵�������Ϣ�����Ա�����������ռ����Ϊ�µĽ��̿���ʹ����ͬ��ϵͳ���ã����Ա��뱣֤ϵͳ���ÿ����룩���������ߣ�������ϵͳ��������ʱ����ʽ����schedule����ʱ����
��Щ�ص��漰���̵��ȵ����⣬�ڴ˲����������ֻ��Ҫ���ϵͳ������ɺѿ���Ȩ���ص�������õ��û�����ǰ���ں˻���һ�ε��ȡ�������������ȼ����ߵĽ��̻�ǰ���̵�ʱ��Ƭ���꣬��ô�ͻ�ѡ������ȼ��Ľ��̻�����ѡ��������С�
5.3 ϵͳ����ʾ��
����ͨ���Լ���ϵͳ���õ��������������ǵĹ�����ʽ��
5.3.1 sys_dup
dupϵͳ���õķ�������Ϊsys_dup��������fs/fcntl.c�ļ��ж������¡�
�����嵥5.3 dupϵͳ���õķ�������
asmlinkage long sys_dup(unsigned int fildes) 193 {
int ret = -EBADF; struct file * file = fget(fildes);
if (file) ret = dupfd(file, 0); return ret; } |
����sys_ni_call()���⣬sys_dup()�Ƶ�������ķ�������֮һ��������ȴ��Linux����/����ض���Ļ�����
��Linux�У�ִ��һ��shell����ʱͨ�����Զ���3�����ļ����������ļ���stdin����ͨ����Ӧ�ն˵ļ��̣�������ļ�
��stdout���� ����������ļ���stderr����ͨ����Ӧ�ն˵���Ļ��shell����ӱ������ļ��еõ��������ݣ���������������������ļ�������������Ϣ���
���������ļ��С�
������������
����cpuinfo�ļ���������ʾ����Ļ�ϣ��������cat���������������stdin�ж�ȡ���ݣ������������stdout�����磺
�û������ÿһ�ж������̱��������Ļ�ϡ�
�����ض�����ָ������ı������ض���ָ�����ļ��У���������Բ����Լ��̣�������һ��ָ�����ļ�������˵�������ض�����Ҫ���ڸı�һ�����������Դ��
����ض�����ָ������ı�����������������¶���ָ���ļ��С������������������Ͳ���ʾ����Ļ�ϣ�����д�뵽ָ���ļ��С����Ǿ�������������ض�����������log���浽ָ�����ļ��С�
��ôsys_dup()��������������/������ض����أ�����ͨ��һ�����ӽ���˵����
��������shell�ն�������"echo hello"����ʱ������Ҫ��shell����ִ��һ����ִ���ļ�echo������Ϊ"hello"����shell���̽��յ�����֮������/binĿ¼����
��echo�ļ������ǿ���ʹ��which�������������ڵ�λ�ã���Ȼ��һ���ӽ���ȥִ��/bin/echo�������������ݸ�����������ӽ��̴�
shell���̼̳���3��������/����ļ�����stdin��stdout��stderr���ļ��ŷֱ�Ϊ0��1��2�����Ĺ����ܼ����ǽ���
��"hello"д��stdout�ļ��У�ͨ���������ǵ���Ļ�ϡ�
����������ǽ�����ij�"echo hello > txt"������ִ��ʱ������ᱻ�ض������ļ�txt�С��ٶ�֮ǰ��shell����ֻ������3�����ļ�������������������ִ�С�
��1�����ļ�txt�����txt��ԭ�������ݣ������ԭ�������ݣ����ļ���Ϊ3��
��2��ͨ��dupϵͳ���ø����ļ�stdout��������ݽṹ���ļ���4��
��3���ر�stdout����������4���ļ�Ҳͬʱ����stdout������stdout�ļ���δ�����رգ�ֻ���ڳ�1���ļ���λ�á�
��4��ͨ��dupϵͳ���ã�����3���ļ������ļ�txt��������1���ļ��رգ���λ�ÿ�ȱ����3���ļ������Ƶ�1�ţ���������ԭ��ָ��stdout��ָ��ָ����txt��
��5��ͨ��ϵͳ����fork��exec�����ӽ��̲�ִ��echo���ӽ�����ִ��catǰ�ر�3�ź�4���ļ���ֻ����0��1��2�����ļ�����ע�⣬��
ʱ��1���ļ��Ѿ�����stdout�����ļ�txt�ˡ���cat����stdout�ļ�д��"hello"ʱ��Ȼ��д�뵽��txt�С�
��6���ص�shell���̺ر�ָ��txt��1����3���ļ��ļ�������dup��closeϵͳ���ý�2�Żָ���stdout������shell�ͻָ���0��1��2����������/����ļ���
5.3.2 sys_reboot
Linux���йعػ���������������Ҫ��shutdown��reboot��halt��poweroff��telinit��init�����Ƕ����Դﵽ�ػ���������Ŀ�ģ�����ÿ������Ĺ������̲���һ����
��Щ��������ǻ�������ģ����磬poweroff��reboot����halt�ķ������ӣ������������ն���ͨ��rebootϵͳ��������ɹػ�������������
rebootϵͳ���õķ�������Ϊsys_reboot��������kernel/sys.c�ļ��ж������¡�
�����嵥5.4 rebootϵͳ���õķ�������
asmlinkage long sys_reboot(int magic1, int magic2,
unsigned int cmd, void __user * arg) { charbuffer[256];
/* We only trust the superuser with rebooting the system.
*/ if(!capable(CAP_SYS_BOOT)) return -EPERM; /* For
safety, we require "magic" arguments. */ if
(magic1 != LINUX_REBOOT_MAGIC1 ||(magic2 != LINUX_REBOOT_MAGIC2
&& magic2 != LINUX_REBOOT_MAGIC2A &&
magic2 != LINUX_REBOOT_MAGIC2B && magic2 !=
LINUX_REBOOT_MAGIC2C)) return -EINVAL; /* Instead of
trying to make the power_off code look like * halt when
pm_power_off is not set do it the easy way.*/ if((cmd
== LINUX_REBOOT_CMD_POWER_OFF) && !pm_power_off)
cmd = LINUX_REBOOT_CMD_HALT; lock_kernel();switch (cmd)
{ case LINUX_REBOOT_CMD_RESTART: kernel_restart(NULL);
break; caseLINUX_REBOOT_CMD_CAD_ON: C_A_D = 1; break;
case LINUX_REBOOT_CMD_CAD_OFF: C_A_D = 0; break; caseLINUX_REBOOT_CMD_HALT:
kernel_halt(); unlock_kernel(); do_exit(0); break; caseLINUX_REBOOT_CMD_POWER_OFF:
kernel_power_off(); unlock_kernel(); do_exit(0); break;
caseLINUX_REBOOT_CMD_RESTART2: if (strncpy_from_user(&buffer[0],
arg,sizeof(buffer) - 1) < 0) { unlock_kernel(); return
-EFAULT; } buffer[sizeof(buffer) - 1] = '/0'; kernel_restart(buffer);break;
case LINUX_REBOOT_CMD_KEXEC: kernel_kexec(); unlock_kernel();
return -EINVAL; #ifdef CONFIG_HIBERNATION case LINUX_REBOOT_CMD_SW_SUSPEND:
{ int ret = hibernate(); unlock_kernel();return ret;
} #endif default: unlock_kernel(); return -EINVAL; }
unlock_kernel(); return 0; } |
����˼�壬rebootϵͳ���ÿ���������������ϵͳ�����������ṩ�IJ�����ͬ�������ܹ���ɹػ�������ϵͳ���������ֹʹ��
Ctrl+Alt+Del��ϼ������Ȳ�ͬ�IJ��������ǻ�Ҫ�ر�ע���ں����sys_reboot()��ע�ͣ���ʹ����֮ǰ����Ҫʹ��sync����ͬ����
�̣���������ϵ��ļ�ϵͳ���ܻ�������
��901�м��������Ƿ��кϷ�Ȩ�ޡ�capable�������ڼ���Ƿ��в���ָ����Դ��Ȩ�ޣ���������ط���ֵ�����������Ȩ���в�����������Ȩ���������磬��һ�е�capable(CAP_SYS_BOOT)�����������Ƿ���Ȩ��ʹ��rebootϵͳ���á�
��905�С���910��ͨ������������magic1��magic2�ļ�⣬�ж�rebootϵͳ�����Dz��DZ�żȻ���õ��ġ����rebootϵͳ�����DZ�żȻ���õģ���ô����magic1��magic2����������ͬʱ����Ԥ������⼸�����ֵļ��ϡ�
�ӵ�919�п�ʼ��sys_reboot()�Ե����ߵĸ���ʹ������������֡�ΪLINUX_REBOOT_CMD_RESTART
ʱ��kernel_restart()����ӡ��"Restarting system."��Ϣ��Ȼ�����machine_restart������������ϵͳ��
ΪLINUX_REBOOT_CMD_CAD_ON��LINUX_REBOOT_CMD_CAD_OFFʱ���ֱ��������ֹ
Ctrl+Alt+Del��ϼ������ǻ�������/etc/inittab�ļ�ָ���Ƿ����ʹ��Ctrl+Alt+Del��ϼ����رղ�����ϵͳ�����ϣ��
��ȫ��ֹ������ܣ���Ҫ��/etc/inittab�ļ��е�����һ��ע�͵���
ca:12345:ctrlaltdel:/sbin/shutdown -t1 -a -r now |
ΪLINUX_REBOOT_CMD_HALTʱ����ӡ��"System
halted."��Ϣ����LINUX_REBOOT_CMD_RESTART��������ƣ���ֻ����ͣϵͳ�����ǽ�������������
ΪLINUX_REBOOT_CMD_POWER_OFFʱ����ӡ��"Power
down."��Ϣ��Ȼ��رջ�����Դ��
ΪLINUX_REBOOT_CMD_RESTART2ʱ�����������ַ��������ַ���˵����ϵͳӦ����ιرա�
���LINUX_REBOOT_CMD_SW_SUSPEND����ʹϵͳ���ߡ�
5.4 ϵͳ���õ�ʵ��
һ��ϵͳ���õ�ʵ�ֲ�����Ҫȥ������δ��û��ռ�ת�����ں˿ռ䣬�Լ�ϵͳ���ô����������ȥִ�У�����Ҫ����ֻ����ѭ�����̶��IJ��衣
5.4.1 ���ʵ��һ���µ�ϵͳ����
ΪLinux�����µ�ϵͳ�����Ǽ�����������飬��Ҫ������4�����裺��дϵͳ���÷������̣�����ϵͳ���úţ���ϵͳ���ñ������±����ں˲����������ӵ�ϵͳ���á�
������һ������ʵ���ô���helloϵͳ����Ϊ��������ʾ�����������衣
��1����дϵͳ���÷������̡�
��ѭǰ�������ļ���ԭ��helloϵͳ���õķ�������ʵ��Ϊ��
asmlinkage long sys_hello(void) { printk("Hello!/n"); return 0; } |
ͨ����Ӧ��Ϊ�µ�ϵͳ���÷������̴���һ���µ��ļ����д�ţ���Ҳ���Խ��䶨���������ļ�֮�в�����ע������Ҫ˵����ͬʱ����Ҫ��include/linux/syscalls.h�ļ�������ԭ��������
asmlinkage long sys_hello(void); |
sys_hello�����dz���������ӡһ����䣬��û��ʹ���κβ������������ϣ��helloϵͳ���ò����ܴ�ӡ"hello!"��ӭ��Ϣ�����ܹ���ӡ�����Ǵ��ݹ�ȥ�����ƣ�����������һЩ������Ϣ����sys_hello��������ʵ��Ϊ��
asmlinkage long sys_hello(const char __user *_name)
02 { char *name; long ret; name = strndup_user(_name,
PAGE_SIZE); 07 if (IS_ERR(name)) { ret = PTR_ERR(name);
goto error; } printk("Hello, %s!/n", name);
return 0; error: return ret; } |
�ڶ���sys_hello����ʹ����һ���������������в������ݷ���������£���дϵͳ���÷�������ʱ������ϸ������еIJ����Ƿ�Ϸ���Ч����Ϊϵͳ�������ں˿ռ�ִ�У�����������������û�Ӧ�ô�����������ںˣ���ϵͳ�İ�ȫ���ȶ����ܵ�Ӱ�졣
�������������Ҫ��һ����Ǽ���û�Ӧ���ṩ���û��ռ�ָ���Ƿ���Ч����������sys_hello��������Ϊchar����ָ�룬����ʹ����__user��ǽ������Ρ�__user��DZ�ʾ�����ε�ָ��Ϊ�û��ռ�ָ�룬�������ں˿ռ�ֱ�����ã�ԭ����Ҫ���¡�
�û��ռ�ָ�����ں˿ռ��������Ч�ġ�
�û��ռ���ڴ��Ƿ�ҳ�ģ���������ҳ����
���ֱ�������ܹ��ɹ������൱���û��ռ����ֱ�ӷ����ں˿ռ䣬������ȫ���⡣
��ˣ�Ϊ���ܹ���ɱ���ļ�飬�Լ����û��ռ���ں˿ռ�֮�䰲ȫ�ش������ݣ�����Ҫʹ���ں��ṩ�ĺ�����������sys_hello�����ĵ�6�У���ʹ�����ں��ṩ��strndup_user��������mm/util.c�ļ��ж��壩���û��ռ临���ַ���name�����ݡ�
��2������ϵͳ���úš�
ÿ��ϵͳ���ö���ӵ��һ����һ����ϵͳ���úţ����Խ�������Ҫ����include/asm-i386/unistd.h�ļ���Ϊhelloϵͳ��������һ��ϵͳ���úš�
#define __NR_utimensat 320 329 #define __NR_signalfd
321 330 #define __NR_timerfd 322 331 #define __NR_eventfd
323 332 #define __NR_fallocate 324 333 #define __NR_hello
325 /*����helloϵͳ���ú�Ϊ325*/ #ifdef __KERNEL__ #define NR_syscalls
326 /*��ϵͳ������Ŀ��1��Ϊ326*/ |
��3����ϵͳ���ñ���
Ϊ����ϵͳ���ô�������system_call�����ܹ��ҵ�helloϵͳ���ã����ǻ���Ҫ��ϵͳ���ñ�sys_call_table�������������sys_hello�����ĵ�ַ��
.long sys_utimensat /* 320 */ .long sys_signalfd 324
. .long sys_timerfd 325 .long sys_eventfd 326 .long
sys_fallocate 327 .long sys_hello /*helloϵͳ���÷�������*/ |
�µ�ϵͳ����hello�ķ������̱����ӵ���sys_call_table��ĩβ�����ǿ���ע���sys_call_tableÿ��5������ͻ���һ��ע�ͣ����������ϵͳ���úţ������ϰ�߿����ڲ���ϵͳ���ö�Ӧ��ϵͳ���ú�ʱ�ṩ���㡣
��4�����±����ں˲����ԡ�
Ϊ���ܹ�ʹ�������ӵ�ϵͳ���ã���Ҫ���±����ںˣ���ʹ�����ں���������ϵͳ��Ȼ�����ǻ���Ҫ��д���Գ�����µ�ϵͳ���ý��в��ԡ����helloϵͳ���õIJ��Գ������£�
#include #include #include #define __NR_hello 325 int
main(int argc, char *argv[]) { syscall(__NR_hello);
return 0; } |
Ȼ��ʹ��gcc���벢ִ�У�
$gcc -o hello hello.c
$./hello
Hello! |
��ִ�н���ɼ���ϵͳ�������ӳɹ���
5.4.2 ʲôʱ����Ҫ�����µ�ϵͳ����
��˵����һ���µ�ϵͳ���÷dz������Ⲣ����ζ���û��б�Ҫ��ô��������ϵͳ������Ҫ���ں�Դ���롢���±����ںˣ��������һ��ϣ���Լ����ӵ�
ϵͳ�����ܹ��õ��㷺��Ӧ�ã�����Ҫ�õ��ٷ����Ͽɲ�����һ���̶���ϵͳ���úţ�����Ҫ����ϵͳ������ÿ����Ҫ֧�ֵ���ϵ�ṹ��ʵ�֡�����������ʹ����
������������ں˽�����Ϣ��������ʾ��
ʹ���豸����������һ���豸�ڵ㣬ͨ��read��write�������ж�д���ʣ�ʹ��ioctl�����������ò����ͻ�ȡ�ض���Ϣ�����ַ������ĺô����ڿ���ģ��ʽ����ж�أ������˱����ں˵ȹ��̣����ҵ��ýӿڹ̶������ײ�����
ʹ��proc�����ļ�ϵͳ������proc�ӿڻ�ȡϵͳ������Ϣ����ϵͳ״̬��һ�ֺܳ������ֶΣ������ȡ/proc/cpuinfo���Ի�õ�ǰϵͳ��CPU��Ϣ��ͨ���豸�����ṩ��proc�ӿڻ���������Ӳ���Ĵ�����
sysfs�ļ�ϵͳ��sysfs�ļ�ϵͳ��2.6�ں˱����룬��һ��������proc�ļ�ϵͳ�������ļ�ϵͳ�����ڶ�ϵͳ���豸���й���������ʵ�����ӵ�ϵͳ�ϵ��豸��������֯�ɲ�νṹ�������û��ṩ��ϸ���ں����ݽṹ��Ϣ���û�����������Щ��Ϣ��ʵ�ֺ��ں˵Ľ�����
��UNIX ��������̡�һ�������˵��
���в���ϵͳ���ṩ���ַ������ڵ㣬�ɴ˳�����ϵͳ�ں���������ְ汾��Unix���ṩ�����ö����������Ŀ����ڵ㣬������Щ��ڵ����ϵͳ�ںˣ���Щ��ڵ㱻��֮Ϊϵͳ����(system
call)��ϵͳ���������Dz��ܸ��ĵ�һ��Unix������Unix�汾7�ṩ��Լ50��ϵͳ���ã�4 3+BSD�ṩ��Լ110������SVR4���ṩ��Լ120����
ϵͳ���ý���������Unix����Ա�ֲ�ĵڶ�������˵�����䶨��Ҳ������C�����С�����ܶ�����ڵIJ���ϵͳ�Dz�ͬ�ģ���Щϵͳ����ͳ���ڻ����Ļ�������ж���ϵͳ����ڵ㡣
Unix��ʹ�õļ�����Ϊÿ��ϵͳ�����ڱ�C��������һ������ͬ�����ֵĺ������û������ñ�C����������������Щ������Ȼ������ϵͳ��Ҫ��ļ���������Ӧ��ϵͳ�˷������纯���ɽ�һ����C��������ͨ�üĴ�����Ȼ��ִ��ij���������жϽ���ϵͳ�˵Ļ���ָ���Ӧ�ýǶȿ��ǣ����ǿɽ�ϵͳ��������ΪC������
Unix����Ա�ֲ�ĵ������ֶ����˳���Ա����ʹ�õ�ͨ�ú�������Ȼ��Щ�������ܻ����һ����ϵͳ�˵�ϵͳ���ã��������Dz�����ϵͳ�˵���ڵ㡣���磬printf���������writeϵͳ�����Խ������������������strcpy(����һ�ַ���)��atoi(�任ASCIIΪ����)����ʹ���κ�ϵͳ���á�
��ʵʩ�ߵĽǶȣ�ϵͳ���úͿ⺯��֮�����ش����𣬵����û��Ƕ��������dz���Ҫ���ӱ����Ŀ�ij�����ϵͳ���úͿ⺯���ڱ����ж���������C��������ʽ���֡����߶���Ӧ�ó����ṩ�����ǣ�����Ӧ�����⣬���ϣ���Ļ������ǿ��Դ����⺯��������ͨ������ȴ���ܴ���ϵͳ����
�Դ洢�����亯��mallocΪ�����ж��ַ������Խ��д洢�����估������ص��������ռ�����(�����Ӧ���״���Ӧ��)���������ڶ����г�����ѵ�һ�ּ�����Unixϵͳ�����д����洢���������sbrk(2)��������һ��ͨ�õĴ洢���������������ӻ����ָ���ֽ����Ľ��̵�ַ�ռ䡣��ι����õ�ַ�ռ�ȴȡ���ڽ��̡��洢�����亯��malloc(3)ʵ��һ���ض����͵ķ��䡣������Dz�ϲ���������ʽ�������ǿ��Զ����Լ���malloc������������ܣ�������Ҫ����sbrkϵͳ���á���ʵ�ϣ��кܶ�������������ʵ���Լ��Ĵ洢�������㷨������ʹ��sbrkϵͳ���á�ͼ1.1��ʾ��Ӧ�ó���
malloc�����Լ�sbrkϵͳ����֮��Ĺ�ϵ��
ͼ1.2��malloc������sbrkϵͳ����
���пɼ�������ְ��ͬ����ֿ���Ҫ���е�ϵͳ���÷�������һ��ռ�����̣����⺯��malloc��������ֿռ䡣
��һ����˵��ϵͳ���úͿ⺯��֮��IJ��������ǣ�Unix�ṩ������ǰʱ������ڵĽ��档ijЩ����ϵͳ�ṩһ��ϵͳ�����Է���ʱ�䣬����һ�������ڡ��κ�����Ĵ�������������ʱ�ƺ��չ��Լʱ��֮���ת������ϵͳ�˴�����Ҫ���˵ĸ��衣Unix��ͬ����ֻ�ṩһ��ϵͳ���ã���ϵͳ���÷��ع��ʱ�ʱ��Ԫһ��������һ��һ����ҹ�����Ծ������������Ը�ֵ���κν��ͣ����罫��任�����ǿɶ��ģ�ʹ�ñ���ʱ����ʱ������ڣ��������û��������С��ڱ�C���У��ṩ�����������Դ���������������Щ�⺯����������ϸ�ڣ���������չ��Լʱ�㷨��
Ӧ�ó�����Ի��ߵ���ϵͳ���ã����߿⺯�������ܶ�⺯��������ϵͳ���á�����ͼ1.3����ʾ��
ͼ1.3��C�⺯����ϵͳ����֮��IJ��
��һ��ϵͳ���úͿ⺯��֮��IJ���ǣ�ϵͳ����ͨ���ṩһ����С�ӿڣ����⺯��ͨ���ṩ�Ƚϸ��ӵĹ��ܡ����Ǵ�sbrkϵͳ���ú�malloc�⺯��֮��IJ���п�������һ�㣬���ԺȽϲ��������I/O����(��3��)�Լ���I/O��(�ڵ�5��)ʱ�����ǻ����������ֲ��
���̿���ϵͳ����(fork,exec��wait)ͨ�����û���Ӧ�ó���ֱ�ӵ��á�(��������1.5�еĻ���shell)����Ϊ�˼�ijЩ�����������UNIXϵͳҲ�ṩ��һЩ�⺯��������system��popen����8.12���У����ǽ�˵��system������һ��ʵ�֣���ʹ�û����Ľ��̿���ϵͳ���á���10.18�У����ǻ���ǿ����һʵ������ȷ�ش����źš�
Ϊʹ�����˽���������ԱӦ�õ�Unixϵͳ���棬���Dz��ò���˵��ϵͳ���ã��ֽ���ijЩ�⺯��������������ֻ˵��sbrkϵͳ���ã���ô�ͻ���Ժܶ�Ӧ�ó���ʹ�õ�malloc�⺯����
�ڱ����У�����һ��Ҫ������������ʱ�����Ƕ���ʹ������"����"���漰ϵͳ���úͿ⺯�����ߡ�
��The Linux Kernel Module Programming
Guide���������������
�⺯���Ǹ߲�ģ���ȫ�������û��ռ䣬 Ϊ����Ա�ṩ������������Ļ�����ʵ�������ϵͳ���õĸ�����Ľӿڡ�ϵͳ�������ں�̬���в������ں��Լ��ṩ����C�⺯��printf()���Ա�������һ��ͨ�õ������䣬����ʵ�������ǽ�����ת��Ϊ���ϸ�ʽ���ַ������ҵ���ϵͳ����
write()�����Щ�ַ�����
�Ƿ��뿴һ��printf()����ʹ������Щϵͳ����? ������ף���������Ĵ��롣
#include int main(void) { printf("hello"); return 0; } |
ʹ������gcc -Wall -o hello hello.c���롣������
strace hello ���ٸÿ�ִ���ļ����Ƿ�ܾ��ȣ� ÿһ�ж���һ��ϵͳ�������Ӧ�� strace��һ���dz����õij��������Ը��������ʹ������Щϵͳ���ú���Щϵͳ���õIJ���������ֵ��
����һ�����м�ֵ�IJ鿴�����ڸ�ʲô�Ĺ��ߡ��������ĩβ����Ӧ�ÿ����������Ƶ�һ��write(1, "hello",
5hello)�����������Ҫ�ҵġ��������printf() ����ʵ��Ŀ����Ȼ���������ʹ�ÿ⺯�������ļ�I/O���в���(��
fopen, fputs, fclose)�� ����Բ鿴man˵���ĵڶ�����ʹ������man 2 write
��man˵���ĵڶ�����ר�Ž���ϵͳ����(��kill()��read())�� man˵���ĵ���������ר�Ž�������ܸ���Ϥ�Ŀ⺯��(��cosh()��random())��
���������Ա�д����ȥ����ϵͳ���ã��������Dz���Ҫ���ġ����ͳ���������Ϊϵͳ��װ���Ż�ľ����
����������������һЩ��������£������ں���ÿ��ij��ɾ���ļ�ʱ��� �� Tee hee, that tickles!��
����Ϣ��
�Լ��ܽ
�ӳ�����ɵĹ����������������ṩ�ĺ���ͨ���Dz���Ҫ����ϵͳ�ķ����������û��ռ���ִ�еģ����Ǻ����漰��I/O�����ȣ�һ���Dz����е�����̬�ġ�ϵͳ������Ҫ�����ϵͳΪ�û��ṩ���̣��ṩij�ַ���ͨ�����漰ϵͳ��Ӳ����Դ��һЩ���е�������Դ�ȡ�
������ĺ��������������������صĺ�����������ͨ��Linux��ϵͳ��������ɡ�������ǿ��Խ�������ĺ�������Ӧ�ó��������Ա��ϵͳ���ó���֮��
�� һ���м�㣬ͨ������м�㣬���ǿ�����һ�µĽӿ�����ȫ�ĵ���ϵͳ���á���������Ա����ֻҪдһ�δ�����ܹ��ڲ�ͬ�汾��linuxϵͳ��ʹ�û�ѹ�־�
��ʵ����ȫ��ͬ��ϵͳ���á��������ʵ�ֶԲ�ͬ��ϵͳ���õļ��������⣬���Ǻ�������������ĵ����⡣
�ӳ���ִ��Ч��������ϵͳ���õ�ִ��Ч�ʴ��Ҫ�Ⱥ����ߣ������Ǵ�����������ĺ��������������������Ƚ�Сʱ��������ĺ���ִ��Ч�ʿ��ܱȽϺã���Ϊ����
��������ǽ�Ҫ�����������ȴ��� �������ڣ��ȵ�������װ���ˣ��ٽ�����һ��д����߶��������ַ�ʽ����С������ʱЧ�ʱȽϸߣ������ڽ���ϵͳ����ʱ����Ϊ�û����̴��û�ģʽ����ϵͳ����
ģʽ���м��漰����������������л���������Щ������Ϊ�������л�������Ķ������Ӱ��ϵͳ��ִ��Ч�ʡ����ǵ�Ҫ�������������Ƚϴ�ʱ�����統������
���������������ļ�ϵͳ����ľ���ʱ������ϵͳ���ÿɻ�ýϸߵ�Ч�ʡ�
�ӳ���Ŀ���ֲ�ԵĽǶ������������ϵͳ���ã�C���Եı��������⣨ANSI
C�� �߱��ϸߵĿ���ֲ�ԣ��ڲ�ͬ��ϵͳ�����£�ֻҪ�����ٵ��ģ�ͨ������Dz���Ҫ�ĵġ�
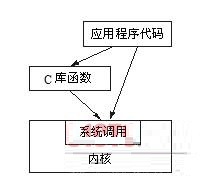
1.ϵͳ�������ں��ṩ���û���API,�⺯���ǿ��ṩ���û���API.��ʹ�ýǶ��Ͽ�,������һ�µ�:��������д,����ʵ��.
2.ϵͳ�������ں˼����,�⺯�����û��㼶���
3.ϵͳ������ijЩ�⺯����ʵ��,���⺯��Ҳ��δʹ��ϵͳ���þ��ܹ�ʵ�ֵ�
4.ϵͳ���õ�Ч�ʸ��ڿ⺯��
5.ϵͳ���õ���ֲ�Ը��ڿ⺯��
|


