| 编辑推荐: |
本文系统性地阐述了如何将原始业务数据提纯为高价值的“高质量数据集”,并提供了从理论定义、成熟度模型、工程流水线到商业化变现的完整方法论,希望对你的学习有帮助。
本文来自于大鱼的数据人生,由Alice编辑、推荐。 |
|
你的数据能直接喂AI吗?
老板拍桌子:"我们攒了十年的业务流水,PB级的体量,为什么接上大模型后,回答问题还是像个智障?"
因为你们存的只是"流水账",不是"知识"。
企业AI转型的第一步,90%的团队掉进同一个坑:把传统大数据等同于大模型需要的高质量数据集。
先做三道快速自测
问题1: 两个数据集,A有100亿字原始日志,B只有1000万字专家问答对。哪个能让AI更聪明?
典型错误回答:数据越多越好,选A。——错。 B的价值可能是A的百倍。
问题2: 数仓里清洗得干干净净、字段完整率99%的销售明细表,算不算高质量数据集?
典型错误回答:当然算。——不算。"高质量数据"和"高质量数据集" 不是一回事 。前者看单点准确,后者看整体能不能用。
问题3: 用大模型自己生成海量对话再喂给自己训练,能解决数据短缺吗?
典型错误回答:很多论文都这么干。——没有人类高质量数据做种子, 左脚踩右脚,很快会模式崩溃 。
如果这三个问题你都答得上来,直接跳到第6章看变现路径和避坑清单。如果不能,这篇文章会帮你彻底搞清楚。
读完这篇,你至少能做到
- 一句话向老板讲清"高质量数据集"到底是什么
- 区分"数据质量管理"和"数据集工程"这两件完全不同的事
- 判断你们公司的数据有没有"数据集化"的变现潜力
- 拿到一段能直接跑的质量评估代码
阅读路线图
- 读完第1-2章,你能向别人 准确定义 什么是高质量数据集(超过80%的同行做不到)
- 读完第3-4章,你能画出数据集的成熟度演进图,看懂提纯流水线
- 读完第5-7章,你能判断自己的数据该怎么建设、怎么变现、哪些坑绝对不能踩
到底什么是"高质量数据集"
一句话定义
高质量数据集是一组经过系统化采集、清洗、标注、校验,并针对特定任务目标进行质量优化的结构化数据集合。
注意这句话里的四个关键动作——采集、清洗、标注、校验,以及一个限定条件—— 针对特定任务 。
没有"通用的"高质量数据集,质量永远是相对于用途而言的。
在大模型场景下,这个定义还要叠加三个特殊要求:
- 信息密度高 ——废话会稀释算力智商
- 逻辑连贯 ——前后矛盾会让模型"精神分裂"
- 意图对齐 ——不只记录"是什么",还要编码"该怎么回答"
七个核心维度
把"高质量"拆开,至少有七个维度:
准确性 ——数据是否正确反映了真实世界。一张猫的图片标注成"狗",准确性就是零。
完整性 ——不只是字段不空,更是任务闭环完整。做客服问答数据集,只有"问题"和"答案"不够,你还需要上下文、用户意图、是否解决。
一致性 ——同一个客户在A表叫"华为技术有限公司",B表叫"华为",一致性就出了问题。
代表性 ——最容易被低估的一项。一个质检数据集95%是标准件、异常件极少——数据量很大,但模型根本学不会识别异常。 数据多不等于代表性强。
标注可信 ——标签从哪来、谁标的、规则是什么、是否复核。你可以把标注理解成老师批改答案——答案标准本身不稳,学生学得再认真也会被带偏。
可追溯 ——一条数据从哪来、经过哪些处理、版本怎么变化,都要能追。真正解决的是:当结果不好时,你能 快速定位问题 在数据、规则、标注还是模型。
可演化 ——高质量不是一次性交付。业务在变,用户行为也在变。要有版本迭代、增量补充和持续评测机制。
七个维度缺一个,数据集就像一桌菜少了一味调料——看着像那么回事,吃起来不对劲。
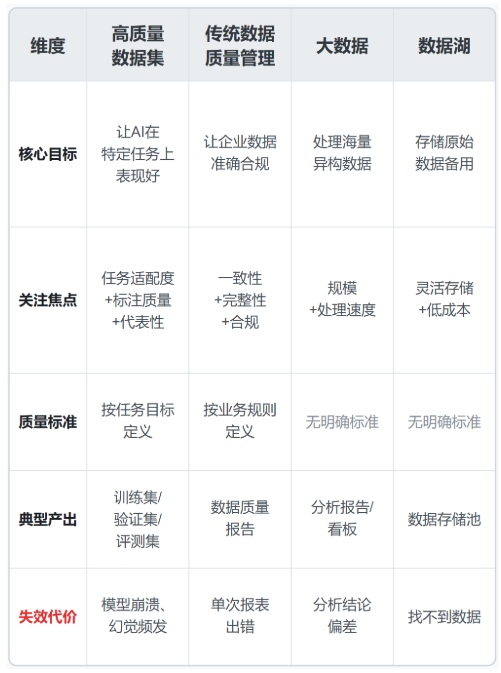
最容易搞混的概念
很多人分不清这四件事,我列张表帮你理清:
数据质量管理是"让已有数据不出错",高质量数据集是"为特定目标设计最优数据"。一个是纠错,一个是设计。
这里有一个行业里传播很广但 极具误导性 的说法:"高质量数据集就是把现有数据再治理一遍。"
实际上,治理是必要前提,但远非充分条件。你把车间零件擦得再亮,也不等于它们自动变成了上架商品。
中间还差:任务定义、样本筛选、结构重组、标注增强、质量验证和迭代维护。
核心类比
记住这个贯穿全文的类比——
- 原始数据 = 菜市场里的散装食材,新鲜度参差不齐
- 数据清洗 = 把食材洗净、去掉烂叶子、切好备用
- 数据标注 = 给每份食材贴上标签:这是西红柿、200克、用于番茄炒蛋
- 高质量数据集 = 米其林餐厅的食材供应链——从种子选育到冷链运输,每个环节都有标准
- 模型训练 = 大厨用这些食材做菜
"你们公司有PB级数据"和"你们公司有高质量数据集"的差距,就是"冰箱里堆满了带泥土豆"和"你有一套米其林供应链"的差距。前者能填饱肚子,后者能拿星。
带泥的土豆怎么一步步变成米其林供应链?这正是下一章要拆解的进化路径。
数据集成熟度5级模型:从散装到飞轮
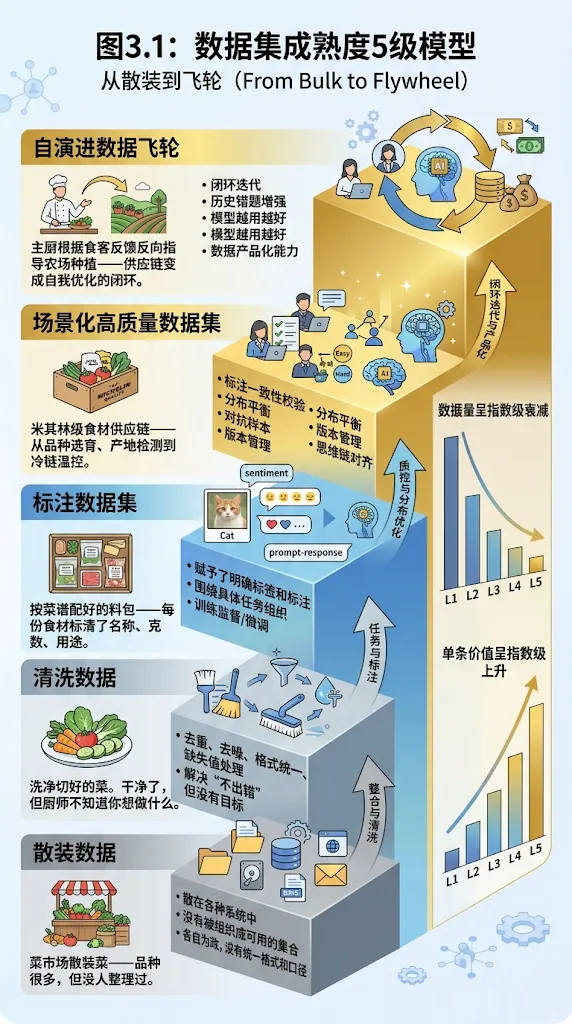
为了把"高质量"这个模糊概念变得可判断、可操作,我提出一个"数据集成熟度5级模型"。你的数据资产处于哪一级,决定了你能用它做什么事。
Level 1:散装数据
特征: 数据散在各种系统中,没有被组织成可用的集合。
企业场景:CRM里有客户信息,ERP里有订单,邮件服务器里有沟通记录——各自为政,没有统一格式和口径。
食材类比:菜市场散装菜——品种很多,但没人整理过。
能做什么:基本的报表和统计。 不能用于任何模型训练。
Level 2:清洗数据
特征: 去重、去噪、格式统一、缺失值处理后的数据。
但这还不够。清洗解决的是"不出错",没有解决"能用来做什么"。一堆洗好切好的蔬菜,没告诉厨师哪些做沙拉、哪些做汤,还是一堆原料。
食材类比:洗净切好的菜。干净了,但厨师不知道你想做什么。
能做什么:传统BI分析。但不能直接用于AI训练—— 因为没有标注,也没有任务目标。
Level 3:标注数据集
特征: 数据被赋予了明确的标签和标注信息,围绕具体任务组织,可以直接用于模型训练。
这是 质的飞跃 。一张图片不再只是像素——被标注为"猫"或"狗"。一段客服对话不再只是字符串——被标注了意图类别和情绪标签。
在大模型语境下,这一级对应SFT指令微调数据——每条数据被改写成"问→答"的格式,模型开始"懂规矩"。
食材类比:按菜谱配好的料包——每份食材标清了名称、克数、用途。厨师拿到就能开始做菜。
能做什么:训练监督学习模型、微调大模型。但质量上限取决于标注质量和数据分布。
微测试:你能说出Level 2和Level 3的核心区别吗?核心就一个字:目标。从"数据被整理了"进化到"数据围绕任务被设计了"。这一步,超过了大多数只会喊"数据质量"口号的人。
Level 4:场景化高质量数据集
特征: 在标注基础上进行了多维质量控制和任务目标优化。
跨越是从"有标注"到" 标注质量极高+数据分布精心设计 ":
- 标注一致性校验 ——多个标注员对同一数据的标注一致率达到特定阈值
- 分布平衡 ——刻意控制各类别、各难度的样本比例,避免模型偏科
- 对抗样本 ——加入容易让模型犯错的"陷阱数据",锻炼鲁棒性
- 版本管理 ——像管理代码一样管理数据集的每次变更
在大模型语境下,这一级还包含 思维链对齐数据 ——数据不仅有答案,还写入了专家完整的推理和自我纠错过程。它教AI如何像专家一样思考,而不只是模仿结论。
食材类比:米其林级食材供应链——从品种选育、产地检测到冷链温控,每个环节都有标准和检验。
能做什么:训练出高精度、高鲁棒性的AI模型。头部团队的标准做法。
Level 5:自演进数据飞轮
特征: 数据集不再是静态的。模型上线后的表现数据被自动收集、筛选、回流到数据集中,形成 闭环迭代 。
模型线上预测错误的案例,被自动收集回来,人工校验后加入训练集。下一版模型在这些"历史错题"上表现更好。如此循环。
这一级还具备了数据产品化能力——标准化包装、持续更新机制、价值评估逻辑。数据集不再只是项目交付物,而是可复用、甚至 可交易的供给单元 。
食材类比:主厨根据食客反馈反向指导农场种植——供应链变成自我优化的闭环。
能做什么:数据壁垒的终极形态。模型越用越好,数据越用越优,竞争对手追不上。
高质量数据集的升级路径,不是"数据越来越干净",而是"数据越来越像一个可交付、可复用、可经营的产品"。理解了这条主线,你就理解了为什么"把数据洗干净"只是Level 2——离真正的高质量还差三级。
五级阶梯看清楚了。一个操作性更强的问题来了——从Level 1到Level 4的提纯过程,在工程层面到底是怎么跑的?
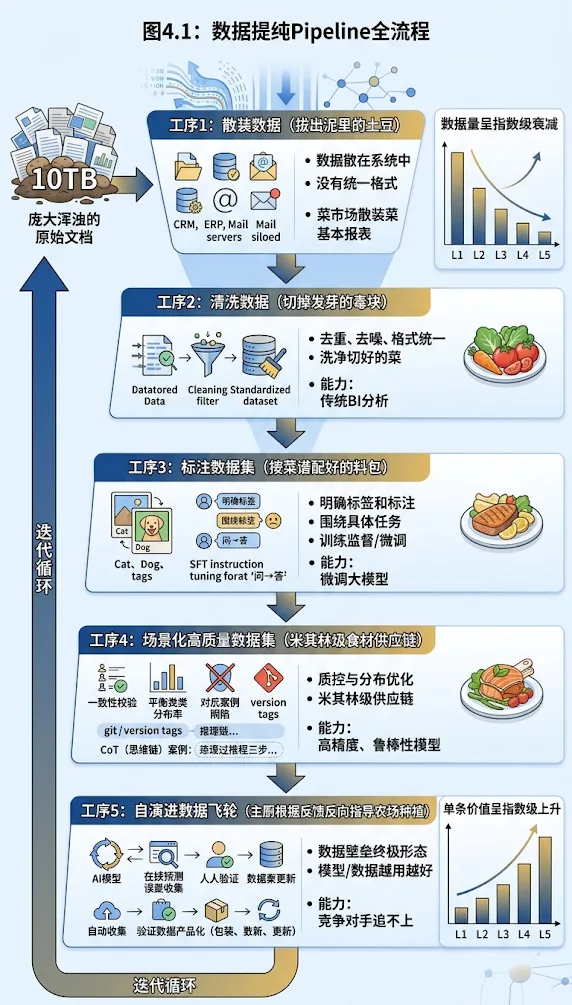
提纯流水线:一个高质量数据集是怎么做出来的
别指望几条正则表达式就能搞定。一条成熟的数据提纯流水线, 复杂度不亚于大模型本身 。
我们以一个真实场景来走全流程:假设你的团队要为公司的智能客服构建一个意图识别数据集——让模型判断客户的每句话是"查订单""退货""投诉"还是"咨询产品"。
工序1:数据采集与格式解析
食材类比:拔出泥里的土豆。
从历史客服记录中提取对话文本。关键决策:
- 时间窗口只用最近12个月(太旧的表述习惯已变)
- 8个意图类别每个至少500条原始样本
- 脱敏处理必须在采集阶段就完成
同时,把企业大量排版错乱的PDF、内部wiki精准还原成纯文本,剥离页眉页脚和系统时间戳。
工序2:启发式规则过滤
食材类比:切掉发芽的毒块。
用几百条硬性规则筛掉劣质内容:连续出现20个特殊符号的句子、通篇只有两三个字的废话、明显的广告—— 直接丢弃 ,防止污染模型词表。
工序3:MinHash精准去重
食材类比:扔掉重复食材。
防范模型崩溃的关键步骤。知识库里有1万份高度相似的"报销制度"文档,模型训练后会严重 过拟合 (把训练数据背得太死,遇到新数据就翻车)。
用MinHash局部敏感哈希把文本转化为高维指纹,找出相似度超过阈值的文本对,强行只保留一份。
工序4:标注与质量校验
食材类比:核心环节,成本最高。
标注不是"找几个人打标签"那么简单。一个严谨的流程包含:
- 标注规范制定 ——十几页的手册,定义每个类别的边界、歧义处理规则和示例
- 试标注与校准 ——先标200条,计算一致率,发现理解偏差后修订规范
- 正式标注 ——多人标注同一条数据,取多数一致结果
- 质检抽查 ——专家抽样审核,拒绝率超阈值的标注员再培训
LIMA定律——全文最重要的一条规律
这里有一个反直觉的事实——
2023年Meta发表的LIMA论文提出了一个颠覆性结论,被称为 LIMA定律 (Less Is More for Alignment):
在AI微调阶段,仅用1000条精心构造的专家标注数据微调的模型,效果碾压使用10万条粗糙数据训练的版本。
这直接回答了第1章的问题1:为什么1000万字专家问答对比100亿字原始日志更有价值。
数据质量的回报曲线是 对数型 的:从1000条到1万条,效果提升巨大;从100万条到1000万条,提升肉眼不可见。而成本曲线是线性的。过了拐点之后,加数据量是最差的投资。
与其给厨师运来十吨带泥土豆,不如给他一公斤米其林认证的顶级食材。顶级食材做出来的菜,十吨土豆永远追不上。
工序5:质量评估与迭代
食材类比:主厨试菜后说"番茄酸度不够,换一批;洋葱切得太粗,重新处理"。
数据集做完不是终点。用它训练一版模型,看哪些类别表现差,反过来检查:是标注有问题,还是样本不够多、不够多样?
针对性补充数据、修正标注、调整分布,再训练、再评估。 这个循环走2-3轮,质量才能达标。
微测试:现在你能说出"高质量数据集构建"和"数据清洗"最大的区别了吗?数据清洗只是5道工序中的一个环节。就像"洗菜"只是做一桌菜的一道工序——你不会说"菜洗好了"就等于"一桌菜做好了"。
这套流水线的代码层面长什么样?第7章会给你一段能直接跑的脚本。在那之前,先把分类体系理清楚。
三个维度看分类
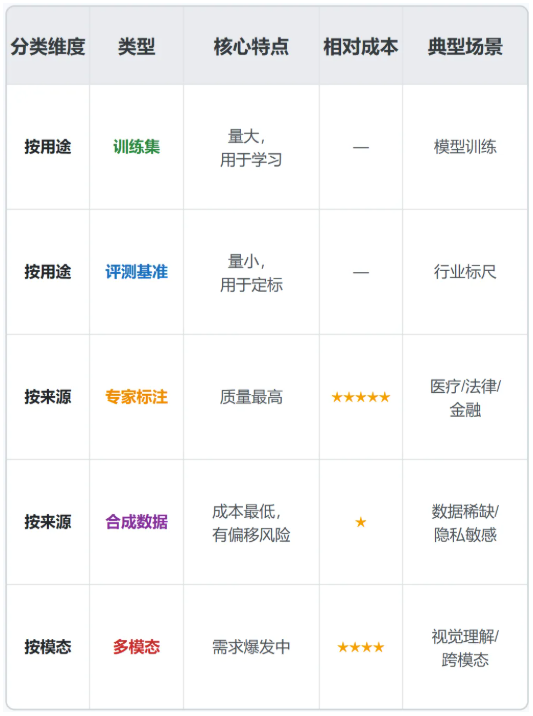
按用途分
- 训练集 ——模型的"教科书",体量最大,占70%-80%
- 验证集 ——模型的"月考卷",用来调参防过拟合,占10%-15%
- 测试集 ——模型的"高考真题",模型在训练过程中绝对不能看到,占10%-15%
- 评测基准(Benchmark) ——行业的"标准考试",不用于训练,用于定标。谁的benchmark被广泛采用,谁就掌握了 评判模型好坏的话语权
按来源分
- 专家采集+专家标注 ——质量天花板最高,成本也最高。医疗、法律、金融等高风险场景必选
- 自动采集+人工标注 ——最常见组合,规模和质量的最佳平衡点
- 合成数据 ——用算法或大模型生成。成本低、不涉及隐私,但可能存在分布偏移。 没有高质量人类数据做种子,"左脚踩右脚"很快会崩溃
按模态分
文本、图像、音频、视频、以及多模态数据集。GPT-4V、Gemini等模型的训练需要大量图文配对数据, 多模态数据集需求正在爆发 。
分类体系理清了。最实际的问题来了:这些数据集在企业里怎么用、怎么赚钱、哪些坑不能踩?
怎么用,怎么赚钱,哪些坑不能踩
四种主流应用模式
模式1:RAG检索增强知识库。
不改模型权重,外挂高质量参考资料库。代表框架LangChain、LlamaIndex。优势是 部署快、数据更新即时生效 。
模式2:垂直领域SFT微调。
用内部专家的脑力成果改变模型的说话习惯。医疗问诊、合同审查、金融风控——领域壁垒高、标注需要专业知识的数据集, 价值远高于通用数据 。
模式3:RLHF偏好数据集。
同一个问题两个回答,人类判断哪个更好。标注成本极高,但决定了模型是"正确但冷冰冰"还是"正确且友好"。
模式4:经营分析与知识沉淀。
不直接用于AI训练,但往往比做大模型更容易见效。围绕"利润波动""客户流失""内部SOP"组织的数据集,让散在多个系统的数据变成 可重复使用的分析供给包 。
四层变现逻辑
第一层:省钱。
很多企业每做一个项目都重新找数、洗数、对齐口径。高质量数据集把这种重复劳动沉淀下来—— 一次建设,多次复用 。如果同类数据每年被3次以上重复使用,投入当年就回本。
第二层:提效。
没有成型数据集,每做一个场景都从头来。有了数据集,从"先找数"变成"直接试"。
第三层:增收。
数据集足够标准化,就能衍生对外服务——行业研究数据、训练样本服务、评测服务、数据订阅。 卖原料难,卖经过整理验证包装的数据产品,空间更大。
第四层:壁垒。
模型和算力会越来越普及。但围绕业务沉淀的高质量数据集, 复制难度极高 ——它背后是业务场景、组织流程、经验规则和持续迭代机制的叠加。这就是Level 5数据飞轮的终极价值。
高危反模式——这些坑不要踩
① 用微调做SQL能搞定的精确核算。
大模型基于概率生成文本,算加减法准确率可能只有85%。一条SQL准确率100%。别用几十万条销售流水去"微调"大模型学算账。
② 未经专家归因的系统日志直接灌。
满篇IP地址和报错码对语言模型来说全是噪音。没有人工翻译成"故障→排查→解决方案",灌进去 只会制造幻觉 。
③ 没想清楚任务目标就先攒数据。
"先攒起来以后总有用"是最常见的资源浪费。产出的是Level 1的散装数据,不是数据集。
④ 为了汇报申报而做"展示型数据集"。
好看不好用,做完没人维护。高质量数据集是 持续供给工程 ,不是一次性包装动作。
一句话拆穿行业话术
动手体验:亲手评估一份数据的质量
做完这一节,你会得到:一段可直接运行的Python脚本,输入一个CSV数据集,输出 多维质量评分报告 。
准备工作
Python 3.8+,安装pandas:
质量评估脚本
import pandas as pd
import re
import json
def evaluate_dataset_quality(file_path, label_column=None):
"""评估CSV数据集的多维质量指标"""
df = pd.read_csv(file_path)
total_rows = len(df)
total_cells = df.size
report = {}
# 维度1:完整性(非空值比例)
missing_ratio = df.isnull().sum().sum() / total_cells
report['completeness_pct'] = round((1 - missing_ratio) * 100, 2)
# 维度2:唯一性(去重后保留率)
duplicate_ratio = df.duplicated().sum() / total_rows
report['uniqueness_pct'] = round((1 - duplicate_ratio) * 100, 2)
# 维度3:信息密度(文本列有效字符占比)
text_cols = df.select_dtypes(include='object').columns
if len(text_cols) > 0:
def info_density(text):
if pd.isna(text): return0
text = str(text)
if len(text) == 0: return0
useful = len(re.findall(r'[\w\u4e00-\u9fa5]', text))
return useful / len(text)
densities = df[text_cols[0]].apply(info_density)
report['avg_info_density'] = round(densities.mean(), 3)
report['low_density_rows'] = int((densities < 0.6).sum())
# 维度4:一致性(同一列大小写变体检测)
consistency_issues = 0
for col in text_cols:
lower_unique = df[col].dropna().str.lower().nunique()
original_unique = df[col].dropna().nunique()
if original_unique > lower_unique:
consistency_issues += (original_unique - lower_unique)
report['consistency_issues'] = consistency_issues
# 维度5:代表性——标签分布平衡度
if label_column and label_column in df.columns:
label_counts = df[label_column].value_counts()
imbalance = label_counts.max() / label_counts.min()
report['label_imbalance_ratio'] = round(imbalance, 2)
report['label_distribution'] = label_counts.to_dict()
if imbalance > 10:
report['warning'] = "类别严重不平衡,代表性不足"
report['total_rows'] = total_rows
report['total_columns'] = len(df.columns)
return report
# 使用示例
# result = evaluate_dataset_quality("your_data.csv", label_column="intent")
# print(json.dumps(result, indent=2, ensure_ascii=False))
|
运行结果示例
{
"completeness_pct": 94.5,
"uniqueness_pct": 98.2,
"avg_info_density": 0.82,
"low_density_rows": 47,
"consistency_issues": 12,
"label_imbalance_ratio": 3.5,
"label_distribution": {
"查订单": 1200,
"退货": 800,
"投诉": 340,
"咨询": 660
},
"total_rows": 3000,
"total_columns": 5
}
|
你能立刻看出:完整性94.5%(5.5%缺失值需处理);有47行信息密度低于0.6(大概率是乱码,Pipeline第2道工序要淘汰的); 标签分布比3.5 (代表性偏弱但不致命)。
零代码体验路径
如果你不写代码,直接打开Hugging Face网站,搜索 databricks-dolly-15k ,点击预览。
你会看到工整的"指令(instruction)"和带推导的"回答(response)"——这就是 Level 3级别的指令微调数据 在真实世界里的样子。
现实边界
这个脚本只评估基础维度。标注一致率、对抗样本覆盖率、与真实分布的匹配度——这些更深层的评估需要专业工具和人工参与。
把它当作"体检快筛",不是"全面诊断"。
前沿:三个正在改变游戏的方向
方向1:高质量人类文本见底
研究机构测算,可用于训练的高质量互联网文本可能在未来几年被耗尽。
应对方向是用顶级模型批量生成带推理过程的合成教学语料,反哺小模型。但核心约束没变—— 合成数据的天花板取决于种子数据的质量 。
方向2:专家标注成本失控
让三甲医院主任医师天天打标数据不现实。
未来方向是AI反馈强化学习(RLAIF)——由预先注入规则的"裁判模型"自动打分,替代部分人工标注。但 高风险场景短期内仍离不开人类专家 。
方向3:数据集像代码一样被管理和交易
DVC、Hugging Face Datasets等工具让数据集有了版本号和分支。
数据价值取决于稀缺性、替代成本和对模型性能的边际贡献。未来可能出现类似资本市场的 数据集定价机制 。
当数据集开始像代码一样做版本管理、像资产一样做定价估值——"数据集工程师"将成为一个独立的职业方向。
总结
高质量数据集是什么?
不是"干净的数据",不是"大量的数据"。是针对特定任务、经过系统化构建和多维质量控制的结构化数据集合—— 米其林供应链,不是带泥土豆 。
它和数据质量管理有什么区别?
数据质量管理是"纠错",数据集工程是"设计"。治理是前提,但不是全部。
它有几级成熟度?
散装数据→清洗数据→标注数据集→场景化高质量数据集→自演进数据飞轮。 LIMA定律告诉你:1000条顶级数据碾压10万条粗糙数据。
怎么赚钱?
四层递进:先省钱→再提效→再增收→最终变壁垒。
企业该不该做?
判断标准:这批数据会被反复使用吗?任务目标清楚吗?有持续维护机制吗? 三个"是"就值得投。
| 






 订阅
订阅