| 编辑推荐: |
本文主要系统性地讲透湖仓一体:它的第一性原理是什么?核心技术架构如何运作?三大开放表格式怎么选?主流厂商方案有何差异?如何从0到1落地?希望对你的学习有帮助。
本文来自于微信公众号大鱼的数据人生,由Alice编辑、推荐。 |
|
过去十年,企业数据架构的演进可以用一句话概括:
先建数据仓库做BI,再建数据湖存大数据,然后花大量时间在两套系统之间搬运数据。
讽刺的是:
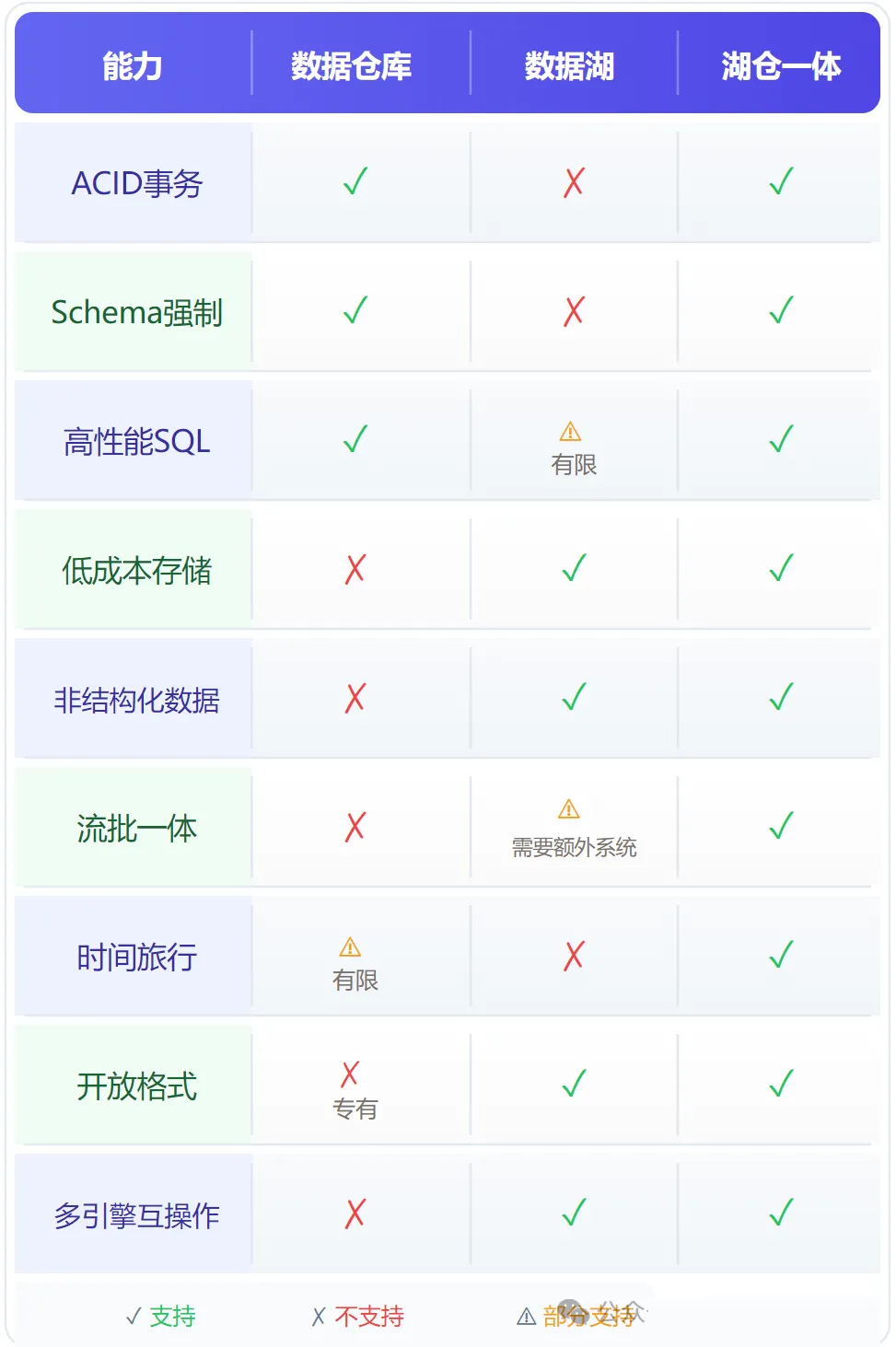
- 数据仓库说:我能提供ACID事务、高性能查询、严谨的治理,但我存不了非结构化数据,扩展太贵
- 数据湖说:我能存一切,便宜又弹性,但我没有事务保证,数据质量全靠人肉
于是,企业不得不同时维护两套系统,数据在湖和仓之间来回"搬家"。一份数据存两份,ETL链路套三层,数据口径永远对不上,分析结果至少是T+1。
湖仓一体(Data Lakehouse)的出现,就是为了终结这种"精神分裂"式的数据架构。
它的本质很简单:在数据湖的廉价存储之上,通过开放表格式(Delta Lake/Iceberg/Hudi)加一层"元数据魔法",让数据湖也能拥有数据仓库级别的事务能力和查询性能。
一份数据,一个真相源(Single Source of Truth),同时支撑BI报表、实时分析、机器学习、数据共享——这就是湖仓一体的终极承诺。
据Databricks调研,74%的全球CIO已在数据架构中部署湖仓一体。市场规模预计从2023年的89亿美元增长至2033年的664亿美元,年复合增长率22.9%。
本文将系统性地讲透湖仓一体:它的第一性原理是什么?核心技术架构如何运作?三大开放表格式怎么选?主流厂商方案有何差异?如何从0到1落地?
通过这些讨论,希望能为你的数据架构决策打下坚实的基础。
第0章:先做一个"3问测试"——你的数据架构到底有多"分裂"?
在深入探讨之前,请先回答下面三个问题:
问题1:你的数据从源头到可用,要经过几次"搬家"?
典型路径:业务数据库 → 数据湖(Raw Zone)→ 数据湖(Curated Zone)→ 数据仓库
→ 数据集市 → BI报表
答案普遍是:4-5次。
每一次"搬家"都意味着:ETL代码要写、调度要配、数据要校验、口径要对齐。而且,每一层都可能出问题,排查时你要一层层往上翻。
问题2:你的分析数据是T+几?
业务方问:"昨天大促的GMV是多少?"
答案:"明天给你。"
因为数据要从OLTP系统抽取、清洗、加载到数据仓库,再跑报表——全流程最快也是T+1。如果遇到数据质量问题,可能T+2、T+3。
问题3:你的数据湖现在是"湖"还是"沼泽"?
数据湖最初的承诺是"先存后用",但三年下来:
- 没人知道湖里到底有什么数据
- 没人敢动老数据,因为不知道谁在用
- 没有Schema强制,数据质量全凭良心
- 想删除一条历史记录?不好意思,整个Parquet文件要重写
如果这三个问题你一个都答不上来满意答案,那么恭喜你——你的企业正处于"湖仓分裂"的痛苦之中。
湖仓一体时代的第一原则很简单:
一份数据、一个真相源、一套治理体系——如果你的数据需要"搬家"才能用,你就一定在浪费时间和金钱。
|
第一章:初识湖仓一体
欢迎来到湖仓一体的世界!在数据驱动决策和AI大模型兴起的今天,湖仓一体已成为企业数据架构的新范式。无论你是数据架构师、数据工程师,还是希望深刻理解技术趋势的决策者,掌握湖仓一体的本质,都将是你知识体系中不可或缺的一环。
1.1 从一个定义开始
在探索任何一个复杂概念时,我们最好从一个简洁的定义开始。
湖仓一体(Data Lakehouse) 是一种新型数据管理架构,它在数据湖的低成本对象存储之上,通过开放表格式(如Delta
Lake、Apache Iceberg、Apache Hudi)添加元数据层,实现数据仓库级别的ACID事务、Schema管理和查询性能。
这个定义包含了湖仓一体的三个基本要素:
存储基座(Storage Foundation):以云对象存储(S3、Azure Blob、GCS、OSS)或HDFS为底座,成本低、扩展性强、可存储任意类型数据。
元数据魔法(Metadata Layer):通过开放表格式在文件之上构建"表"的抽象,提供事务日志、快照管理、Schema演进等数据库级能力。
开放性(Openness):数据以开放格式(Parquet、ORC)存储,元数据协议开源开放,任何计算引擎都可以读写,避免厂商锁定。
真正的湖仓一体,是存储 + 元数据 + 开放性的三位一体。
1.2 第一性原理:湖仓一体解决了什么本质问题?
要真正理解湖仓一体,我们需要回到数据架构演进的第一性原理。
数据仓库的本质能力:事务一致性(ACID)、Schema强制执行、高性能SQL查询、精细化治理。这些能力的代价是:只能存结构化数据、存储成本高、扩展困难。
数据湖的本质能力:存储任意类型数据、成本极低、弹性扩展、Schema-on-Read灵活性。这些能力的代价是:没有事务保证、没有一致性快照、数据质量难以管控。
传统架构下,企业不得不"鱼和熊掌不可兼得",只能同时运营两套系统。
湖仓一体的第一性原理,是在开放存储之上,用元数据层"注入"数据库能力,从而打破这个二元对立。
关键洞察在于:数据库的很多能力,本质上是元数据管理能力,而不是存储格式能力。ACID事务靠事务日志实现,快照隔离靠版本管理实现,Schema强制靠元数据校验实现——这些都可以在文件系统之上"软件定义"出来,而不需要专有的存储引擎。
1.3 湖仓一体不是什么
为了让你更清晰地理解湖仓一体的边界,我们需要明确区分几个容易混淆的概念:
核心误区:把"在数据湖上跑SQL"当成"湖仓一体"。
如果你只是在S3上放了一堆Parquet文件,然后用Athena/Presto查询,这不是湖仓一体。因为你没有:ACID事务保证、一致性快照、增量更新能力、Schema演进机制、时间旅行功能。
湖仓一体的本质是"表格式",是把一堆文件变成可治理的"表"。
1.4 一个类比:从"文件夹"到"数据库表"
我们可以用一个类比来理解湖仓一体的核心创新:
想象你有一个共享文件夹,里面放着几千个Excel文件。这就是传统数据湖的状态:
- 可见性:你知道有哪些文件
- 但不知道:这些文件之间的关系是什么?谁在什么时候修改了什么?删除一行数据要怎么操作?两个人同时修改会发生什么?
现在,湖仓一体通过开放表格式,在这堆文件之上加了一层"数据库管理系统":
- 事务日志:每次修改都记录在案,可以知道谁在什么时候做了什么
- 快照机制:每次变更产生新版本,历史版本可追溯、可回滚
- Schema注册:表结构有定义、有校验、有演进规则
- 并发控制:多人同时操作不会冲突,读写互不阻塞
湖仓一体 = 数据湖的存储 + 数据库的管理
本章小结
用5句话把湖仓一体的"正确姿势"收束:
1.湖仓一体是架构范式,不是单一产品——它是存储层+元数据层+计算层的组合。
2.核心创新是开放表格式——Delta Lake/Iceberg/Hudi把文件变成表。
3.本质是在开放存储上"软件定义"数据库能力——ACID、快照、Schema都是元数据层实现的。
4.目标是Single Source of Truth——一份数据服务所有工作负载,消除数据搬运。
5.关键价值是开放性——数据不被厂商锁定,多引擎可以互操作。
第二章:数据架构的三次革命——从数据仓库到湖仓一体
上一章,我们明确了湖仓一体的定义与本质。但要真正理解它的价值,我们需要回顾数据架构的演进历史。每一次架构变革,都是对前一代局限性的回应。
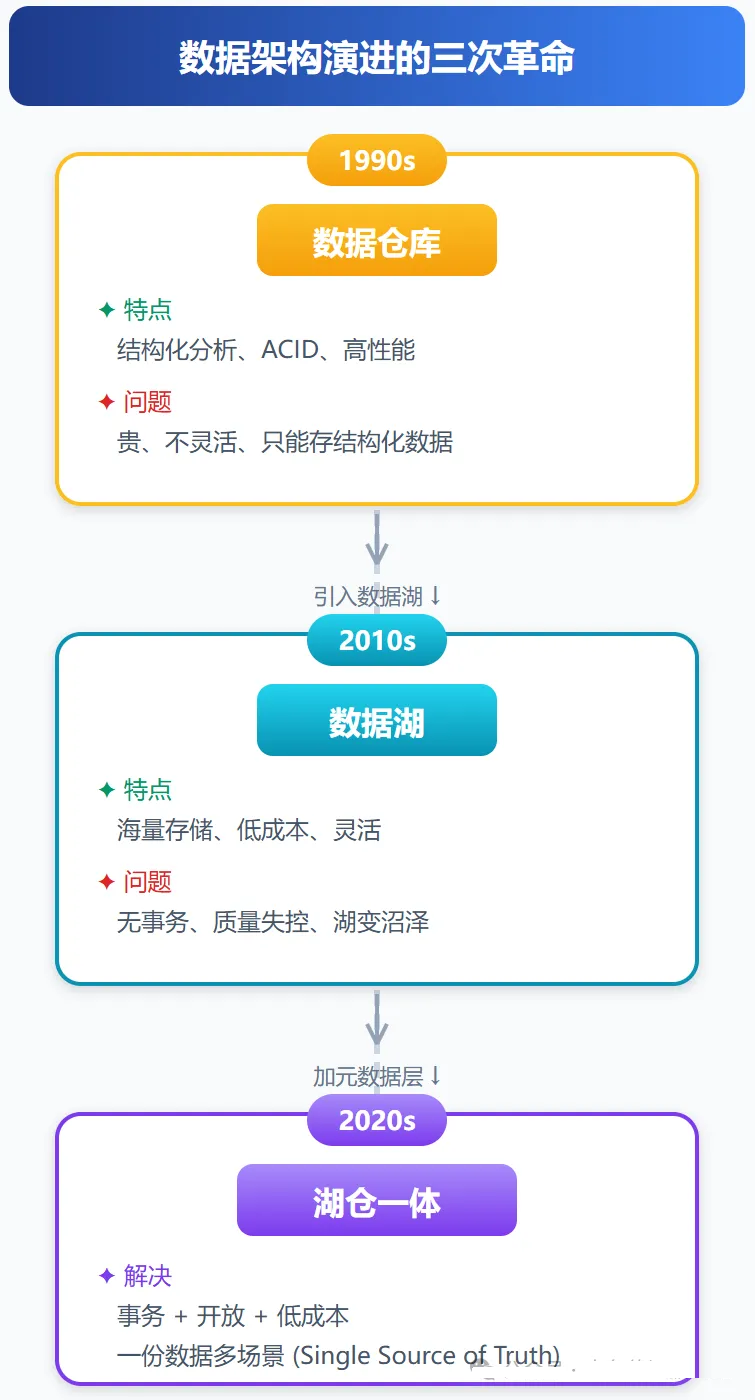
2.1 第一次革命:数据仓库(1990s)
背景:1990年代,企业开始意识到事务型数据库(OLTP)无法满足复杂分析需求。Bill Inmon提出"数据仓库"概念,开创了企业级分析的先河。
核心思想:把分散在各业务系统的数据抽取出来,清洗转换后加载到专门的分析型数据库中,用于支持报表和决策。
技术特征:
- 采用关系型数据库,支持ACID事务
- 星型/雪花型数据建模(维度建模)
- ETL流程:Extract-Transform-Load
- SQL作为统一查询语言
代表产品:Teradata、Oracle Exadata、IBM Netezza、传统MPP数据库
核心价值:让企业第一次有了"分析型系统"与"事务型系统"的分离,可以在不影响业务运营的情况下做复杂分析。
致命局限:
- 成本高昂:专有硬件+软件授权,每TB存储成本数万美元
- 扩展困难:垂直扩展为主,容量有天花板
- 数据类型受限:只能存储结构化数据,非结构化数据无法纳入
- 灵活性差:Schema-on-Write要求数据入库前必须定义好结构
2.2 第二次革命:数据湖(2010s)
背景:2006年Google发布MapReduce论文,Hadoop生态崛起。2010年前后,企业开始面临"大数据"挑战——日志、点击流、传感器数据、社交媒体数据呈爆发式增长,传统数据仓库无法承载。
核心思想:用廉价的分布式存储(HDFS、后来是云对象存储)先把数据"存下来",以后再想怎么用。Schema-on-Read,灵活处理各种数据类型。
技术特征:
- 基于Hadoop/Spark的分布式计算
- 文件格式:Parquet、ORC、Avro
- 存储与计算分离开始萌芽
- 支持结构化、半结构化、非结构化数据
代表产品:Hadoop生态(HDFS+Hive+Spark)、AWS S3+EMR、Azure
Data Lake
核心价值:
- 存储成本下降10-100倍(从每TB数万美元降到几十美元)
- 可存储任意类型数据
- 水平扩展,PB级数据不在话下
- 为机器学习提供了原始数据基础
致命局限:
- 没有ACID事务:并发读写可能产生脏数据
- 没有一致性快照:查询过程中数据可能变化,结果不可复现
- 没有增量更新:想更新一条记录,必须重写整个文件
- 数据质量失控:没有Schema强制,数据湖很容易变成"数据沼泽"
结果:大多数企业被迫采用"数据湖+数据仓库"的双层架构——数据先落湖,再ETL到仓库供分析。数据在两套系统之间来回搬运,冗余存储、链路复杂、口径不一致。
2.3 第三次革命:湖仓一体(2020s)
背景:2020年1月,Databricks发布博客《What is a Data Lakehouse?》,正式提出湖仓一体概念。2021年1月,Databricks联合创始人Matei
Zaharia(Apache Spark创始人)等人在CIDR学术会议发表里程碑论文,系统阐述湖仓一体的技术原理。
核心思想:在数据湖的低成本存储之上,通过开放表格式添加元数据层,实现数据仓库级别的能力,同时保持开放性和灵活性。
技术特征:
- 存储层:云对象存储(S3/ADLS/GCS/OSS)
- 元数据层:开放表格式(Delta Lake/Iceberg/Hudi)
- 计算层:多引擎支持(Spark/Flink/Trino/Presto)
- 完全的存算分离,弹性伸缩
核心价值:
关键突破:
Delta Lake(Databricks,2019年开源)通过事务日志实现ACID
Apache Iceberg(Netflix,2017年开源)通过三层元数据架构实现跨引擎互操作
Apache Hudi(Uber,2016年开源)通过Copy-on-Write/Merge-on-Read支持高频更新
2.4 为什么是现在?——三个结构性变化
湖仓一体在2020年代爆发,不是偶然,而是三个结构性变化的汇聚:
变化1:云对象存储成熟
云对象存储(S3、ADLS、GCS)的成本、可靠性、扩展性已经达到企业级要求。每TB每月几美元的存储成本,11个9的可用性,无限扩展——这让"先存后算"成为可能。
变化2:开放表格式技术成熟
Delta Lake、Iceberg、Hudi经过多年发展,已经在Netflix、Uber、阿里、工商银行等顶级企业大规模验证。它们不再是实验性技术,而是生产就绪的基础设施。
变化3:AI时代对数据架构提出新要求
大模型和机器学习需要"数据湖+数据仓库"两边的数据:训练需要海量原始数据(湖),推理需要实时特征数据(仓)。传统双层架构在这种场景下链路太长、延迟太高。湖仓一体让训练和推理可以共享同一份数据。
本章小结
用一张图总结数据架构的三次革命:
第三章:核心技术架构——湖仓一体的六层体系
上一章,我们梳理了湖仓一体的历史演进。本章将深入技术内核,拆解湖仓一体的完整架构。
3.1 架构总览:六层体系
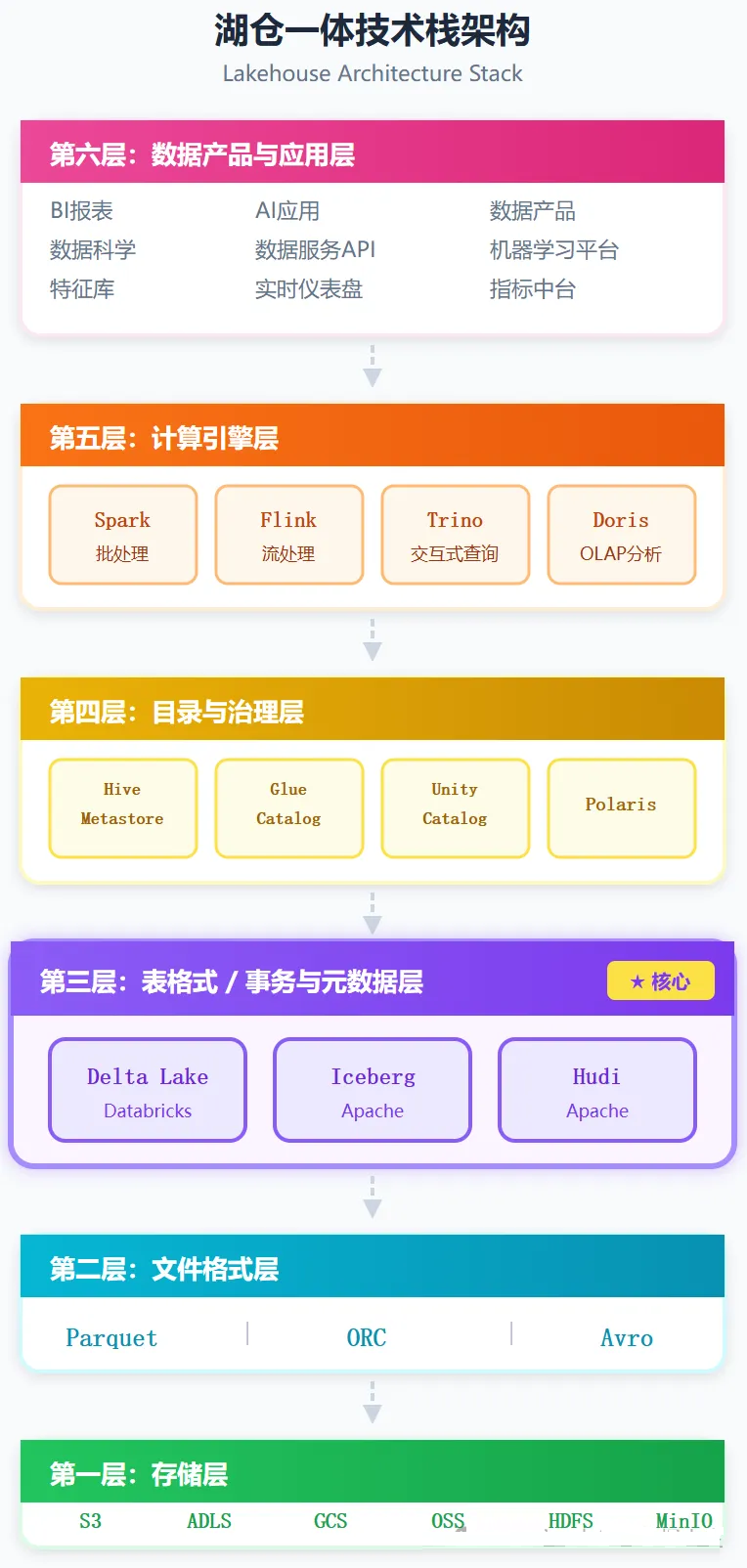
湖仓一体架构可以分为六层,自底向上分别是:
关键洞察:第三层(表格式层)是湖仓一体的核心创新层。 它把第一、二层的"文件集合"组织成"表",提供事务、快照、Schema演进等能力,同时向上暴露标准接口供第四、五层使用。
3.2 第一层:存储层——成本与规模的基座
核心组件:云对象存储(S3、Azure Blob Storage、Google Cloud Storage、阿里云OSS)或HDFS
核心能力:
- 极低成本:S3标准存储约$0.023/GB/月,归档存储更便宜
- 极高可靠性:11个9的数据持久性
- 无限扩展:EB级数据无压力
- 存算分离:存储和计算独立扩展,按需付费
关键认知:存储层只解决"存得下"的问题,不解决"用得好"的问题。它是湖仓一体的地基,但不是全部。
3.3 第二层:文件格式层——高效存储的编码方式
核心组件:Parquet(主流)、ORC、Avro
Parquet为什么是主流?
Parquet的列式存储天然适合分析型查询:只读需要的列(列裁剪),同类数据压缩效率高,支持谓词下推。
关键认知:文件格式层决定了数据如何编码存储,但它不提供"表"的事务与一致性——这需要第三层来解决。
3.4 第三层:表格式层——湖仓一体的灵魂 ★
这是湖仓一体最关键的创新层。
传统数据湖的问题是:它只有"文件"的概念,没有"表"的概念。你可以读写Parquet文件,但你没有:
- 事务保证(两个人同时写会怎样?)
- 一致性快照(查询过程中数据变了怎么办?)
- 增量更新(想改一行数据怎么操作?)
- 时间旅行(想看昨天的数据版本怎么办?)
开放表格式的核心思想:在文件之上加一层元数据,用"元数据+协议"的方式定义"表"的行为。
打个比方:文件格式是"砖块",表格式是"建筑图纸"。有了图纸,一堆砖块才能组成有结构的房子。
ACID事务的实现原理
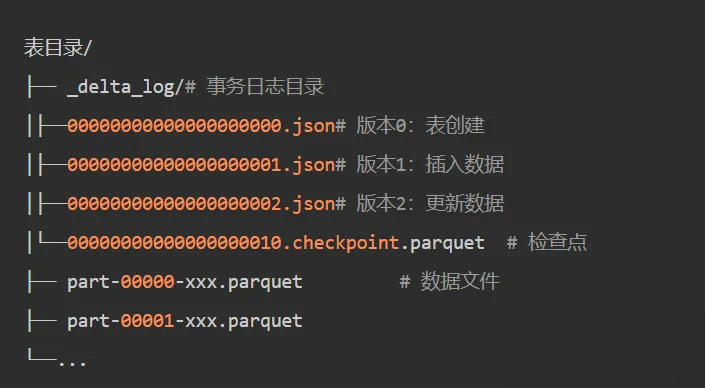
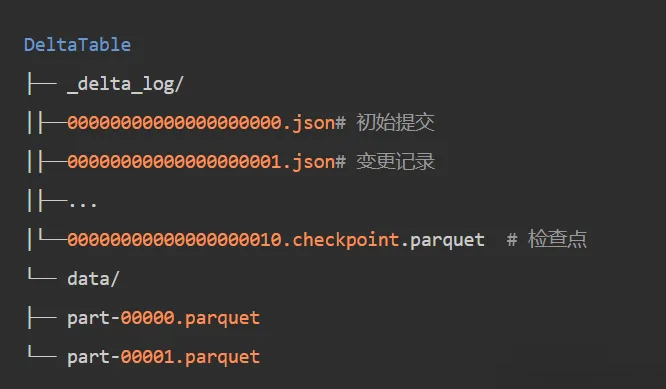
以Delta Lake为例,ACID事务通过事务日志实现:
1.每张表有一个 _delta_log/目录
2.每次提交生成一个JSON日志文件(如 00000000000000000001.json)
3.日志记录了这次提交添加/删除了哪些数据文件
4.读取时,先读日志,构建当前有效文件列表,再读数据
5.写入时,先写数据文件,最后原子性提交日志
关键洞察:事务日志是湖仓一体的"账本"。有了它,任何一次数据变更都有迹可循,可追溯、可回滚、可审计。
时间旅行的实现原理
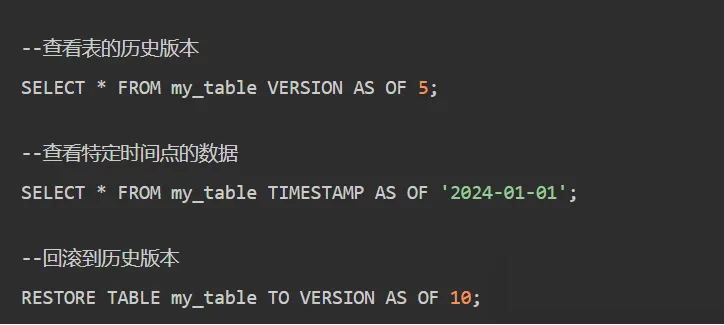
时间旅行(Time Travel)是湖仓一体的杀手级功能之一:
实现原理:
- 每次提交创建新快照,快照引用当时有效的数据文件集合
- 历史快照保留(直到显式清理)
- 查询历史版本时,根据日志重建该版本的文件列表
应用场景:
- 数据审计:监管要求追溯"这个报表数字是怎么来的"
- 错误回滚:ETL跑错了,一键恢复到上个版本
- ML可复现:模型训练时用的是哪个版本的数据?
3.5 第四层:目录与治理层——数据资产的"户籍系统"
核心问题:表格式解决了"单张表"的事务和一致性,但企业有成千上万张表。这些表在哪里?属于谁?有什么Schema?谁有权限访问?——这需要统一的目录和治理体系。
核心组件:
- Hive Metastore:Hadoop生态的事实标准,被称为"de facto
metadata hub"
- AWS Glue Data Catalog:AWS托管的元数据服务
- Databricks Unity Catalog:2024年开源,统一治理数据和AI资产
- Apache Polaris:Snowflake开源,实现Iceberg REST Catalog标准
- Project Nessie:Git-like的数据版本控制目录
目录层要回答的问题:
- 这张表的owner是谁?
- 哪些引擎在读写这张表?
- 表的Schema是什么?可以演进吗?
- 谁有权限读?谁有权限写?
关键认知:没有统一目录,湖仓一体就是一堆散落的表;有了统一目录,湖仓一体才是可治理的企业级数据平台。
3.6 第五层:计算引擎层——多引擎协同
湖仓一体的一大价值是"多引擎互操作":同一份数据,不同引擎各取所长。
关键认知:湖仓一体的目标是"同一份数据,不同引擎各取所长",而不是"一个引擎包打天下"。选型时要根据工作负载特点匹配合适的引擎。
3.7 第六层:数据产品与应用层——价值兑现
湖仓一体的终极价值,不在于"架构更先进",而在于"同一份可信数据服务更多业务场景":
- BI与报表:PowerBI、Tableau、Superset直连湖仓
- 数据科学:Jupyter Notebook直接读取生产数据
- 特征库:AI模型的特征存储与服务
- 数据服务API:向外部系统提供数据接口
- 数据共享:Delta Sharing、Iceberg跨组织数据交换
3.8 Medallion架构:数据分层的最佳实践
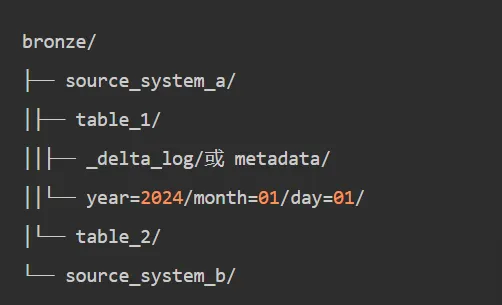
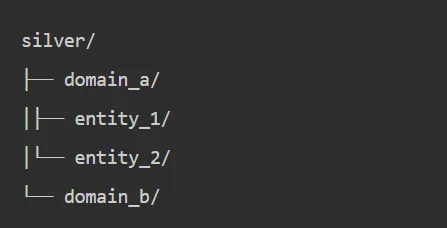
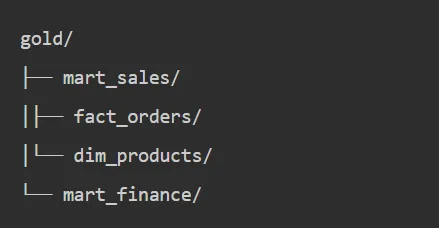
在湖仓一体内部,数据如何组织?业界最广泛采用的是Medallion架构(也叫Bronze-Silver-Gold三层架构):
Bronze层(原始层):
- 只做可靠接入,保留原貌
- 数据格式与源系统一致(可能是JSON、CSV、Parquet)
- 支持审计追溯和数据重放
- 例:CDC原始事件、日志原始记录
Silver层(标准层):
- 清洗、去重、主键对齐、维表拉齐
- 统一时间格式、编码标准
- 数据质量校验
- 形成"可复用的标准明细"
Gold层(服务层):
- 围绕业务主题域输出
- 指标宽表、汇总表、特征表
- 强调SLA与语义稳定
- 直接服务BI、AI等应用
关键洞察:Medallion架构让数据"逐层精炼",Bronze保证不丢数据,Silver保证质量统一,Gold保证业务可用。每层都有明确的职责边界。
本章小结
湖仓一体的六层架构,每一层解决一类问题:
1.存储层:解决"存得下、存得便宜"——云对象存储
2.文件格式层:解决"存得高效"——Parquet列式存储
3.表格式层:解决"用得可靠"——Delta/Iceberg/Hudi提供事务
★核心
4.目录治理层:解决"管得住"——统一元数据与权限
5.计算引擎层:解决"算得快"——多引擎各取所长
6.应用层:解决"用得上"——服务BI、AI、数据产品
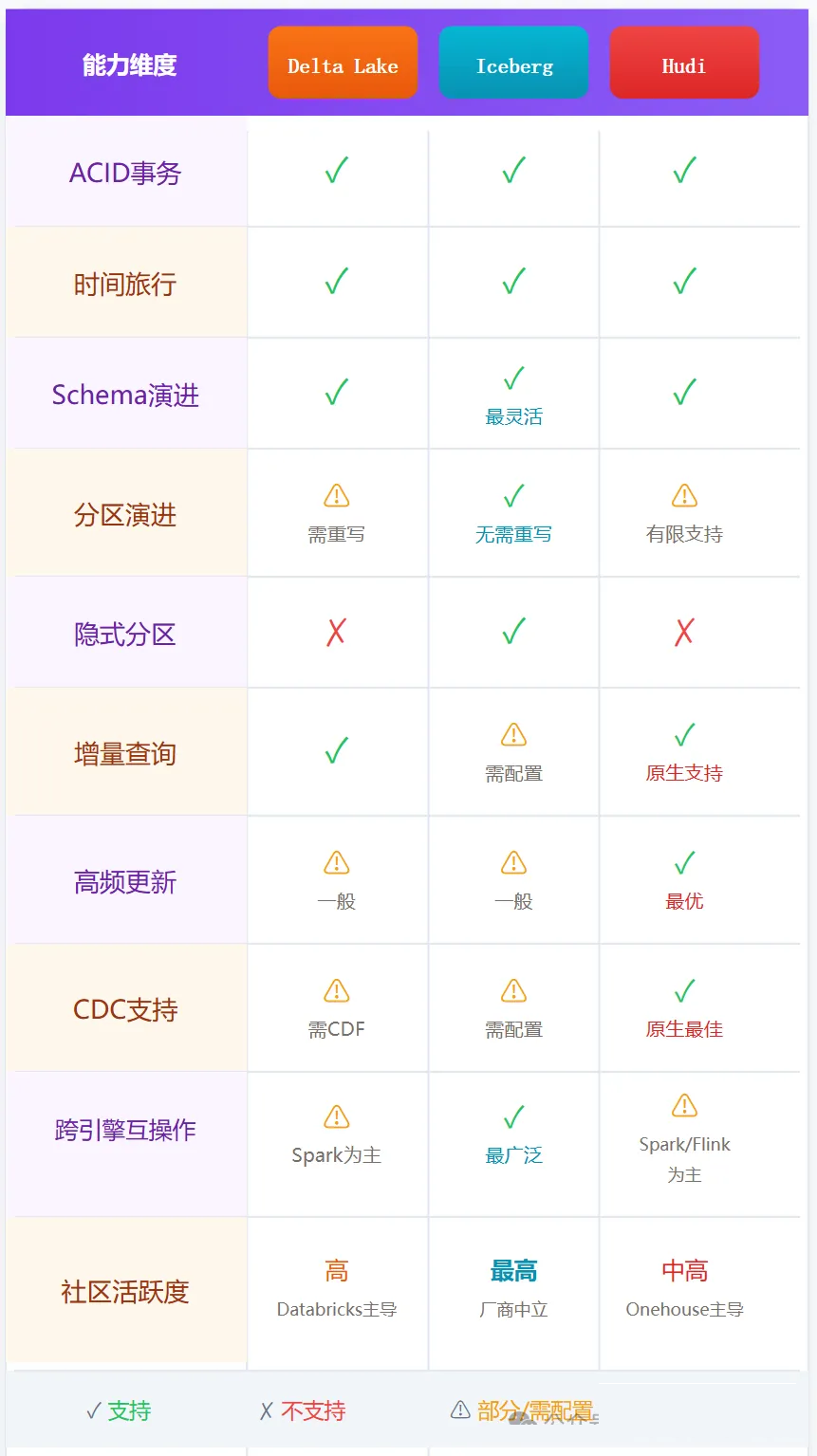
第四章:三大开放表格式深度对比——Delta Lake vs Iceberg vs Hudi
上一章,我们知道开放表格式是湖仓一体的"灵魂"。目前业界有三大主流表格式:Delta
Lake、Apache Iceberg、Apache Hudi。它们各有特点,适用于不同场景。本章将深入对比,帮你做出正确选型。
4.1 三大表格式的诞生背景
关键洞察:三种格式的设计初衷不同,导致它们在不同场景下各有优势。
4.2 技术架构对比
Delta Lake:事务日志驱动
核心机制:
- 每次操作写入JSON日志文件记录变更
- 定期生成Parquet格式的Checkpoint汇总
- 采用乐观并发控制
- 读操作使用快照隔离,写操作使用写序列化隔离
架构图示:
Delta Lake 3.0重要创新:
- UniForm:自动生成Iceberg和Hudi元数据,一张表三种格式读取
- Liquid Clustering:无需预定义分区,智能调整数据布局
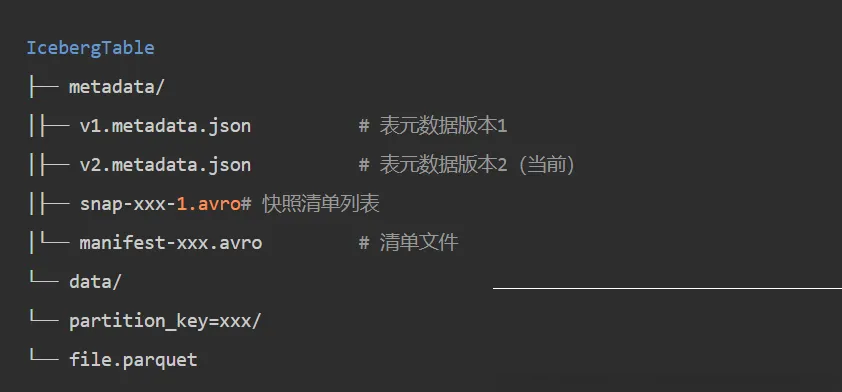
Apache Iceberg:三层元数据架构
核心机制:
- Metadata File:跟踪表Schema、分区规格、当前快照
- Manifest List:指向清单文件列表
- Manifest Files:包含数据文件位置和统计信息
架构图示:
Iceberg独特优势:
- 隐式分区:分区定义基于元数据而非物理文件夹,用户无需在查询中指定分区
- 分区演进:可在现有表上更新分区规格而无需重写数据
- 跨引擎互操作:支持的计算引擎最广泛(Spark、Flink、Trino、DuckDB、Snowflake、BigQuery等)
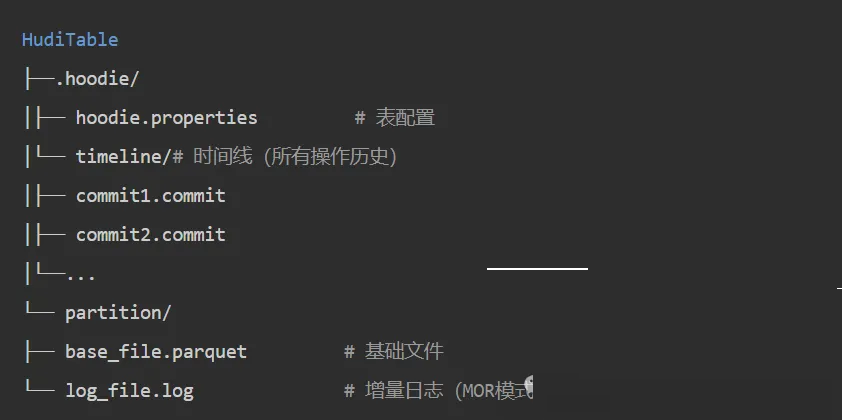
Apache Hudi:为高频更新而生
核心机制:
- Copy-on-Write (COW):每次更新重写整个文件,读取性能最优,适合读密集型场景
- Merge-on-Read (MOR):写入增量日志,读取时合并,适合写密集型场景
架构图示:
Hudi独特优势:
- 增量查询:原生支持"从某次commit后的新数据"查询
- 多模态索引:提供10-100倍点查性能提升
- DeltaStreamer:托管摄入工具,简化CDC场景
4.3 能力矩阵对比
4.4 选型决策框架
选择Delta Lake的情况:
- 你是Databricks用户,或主力引擎是Spark
- 需要与Databricks生态(Unity Catalog、MLflow等)深度集成
- 批流混合处理场景
选择Apache Iceberg的情况:
- 需要多引擎互操作(Spark + Flink + Trino + 云数仓)
- 超大规模表(PB级、百万分区)
- 希望避免厂商锁定,追求最大开放性
- 2025年推荐默认选项——已成为事实上的行业标准
选择Apache Hudi的情况:
- 高频更新/Upsert场景(如用户画像实时更新)
- CDC变更数据捕获场景
- 需要分钟级数据新鲜度
- 对增量消费有强诉求
4.5 Apache XTable:格式互操作的终极方案
如果你担心选错格式被锁定,Apache XTable(原OneTable,2024年成为Apache孵化项目)提供了跨格式元数据翻译能力:
- 无需复制数据,只翻译元数据
- 支持Delta↔Iceberg↔Hudi任意双向转换
- 一张表可以被三种格式的引擎同时读取
这意味着:你可以先选一种格式落地,未来有需要时再通过XTable实现互操作。
4.6 格式战争已经结束
2025年的行业共识:格式战争基本结束,Apache Iceberg正成为事实标准。
- Snowflake、AWS、Google Cloud、Databricks全面支持Iceberg
- Delta Lake通过UniForm自动生成Iceberg元数据
- 行业焦点从"选哪个格式"转向"如何建设数据湖管理系统(DLMS)"
务实建议:
- 新项目优先选择Iceberg(最大开放性、最广泛引擎支持)
- Databricks深度用户可继续使用Delta Lake(通过UniForm兼容Iceberg)
- CDC/高频更新场景评估Hudi
- 不要同时引入多种格式——运维复杂度会爆炸
本章小结
三大表格式的核心定位:
1.Delta Lake:Databricks生态的事务层,Spark亲和度最高,UniForm实现格式兼容
2.Apache Iceberg:厂商中立的开放标准,跨引擎互操作最强,2025年事实标准
3.Apache Hudi:为高频更新设计,CDC和增量消费场景最优
选型原则:"一主一辅"甚至"一主到底",避免多格式并存带来的运维地狱。
第五章:主流厂商方案对比——谁的湖仓一体适合你?
理解了技术架构和表格式之后,落地时还要选择具体的厂商方案。本章对比国内外主流厂商的湖仓一体解决方案,帮你做出适合自己的选择。
5.1 国际厂商方案
Databricks:湖仓一体的定义者
核心架构:Delta Lake存储 + Photon向量化引擎 + Unity Catalog统一治理
差异化优势:
- Photon引擎:C++向量化执行,相比传统云数仓提供最高12倍性价比提升
- Unity Catalog:统一治理结构化/非结构化数据、AI模型和指标
- Mosaic AI:向量搜索、Agent开发,AI原生
- MLflow:机器学习全生命周期管理,月下载量超3000万
适用场景:机器学习与AI驱动的企业、多云策略、需要统一平台做AI训练+商业智能
定价参考:DBU(Databricks Unit)模式,SQL Compute约$0.22-0.88/DBU-小时
Snowflake:从云数仓到开放湖仓
核心架构:三层解耦(存储→计算→云服务)+ 微分区专有格式 + Iceberg Tables
差异化优势:
- 易用性:SQL分析强大,几乎零运维
- Internal Iceberg Tables:2024年发布,Snowflake管理的原生Iceberg表
- Snowpark:支持Python/Java/Scala在Snowflake内执行数据工程和ML
- Data Sharing:跨组织数据共享能力业界领先
适用场景:SQL分析为主的企业、重视易用性和低运维、需要数据共享能力
定价参考:Credit模式,X-Small仓库1 Credit/小时,On-Demand约$2-4/credit
AWS:组件化的灵活方案
核心架构:S3 + Glue Catalog + Lake Formation + Athena/Redshift
Spectrum + EMR
2024年重大创新:
- S3 Tables:首个内置Apache Iceberg支持的云对象存储,比自管理Iceberg快3倍查询、10倍TPS
- SageMaker Lakehouse:统一访问S3数据湖、Redshift仓库和第三方源
- Zero-ETL:Aurora/DynamoDB数据自动同步到Redshift,无需ETL
适用场景:AWS深度用户、需要组件灵活组合、已有大量S3数据资产
定价参考:Athena $5/TB扫描,Redshift按节点计费
Google Cloud:无服务器优先
核心架构:BigQuery(无服务器数仓)+ BigLake(数据湖统一访问)+ Dataproc(Spark/Flink)
差异化优势:
- 完全无服务器:BigQuery几乎零冷启动,无需管理集群
- BigLake:将Parquet、Iceberg等开放格式作为一等公民
- 内置AI:BigQuery ML、Vertex AI深度集成
适用场景:超大规模数据分析、需要内置AI能力、GCP用户
定价参考:按需模式$5-6.25/TB扫描,1TB/月免费额度
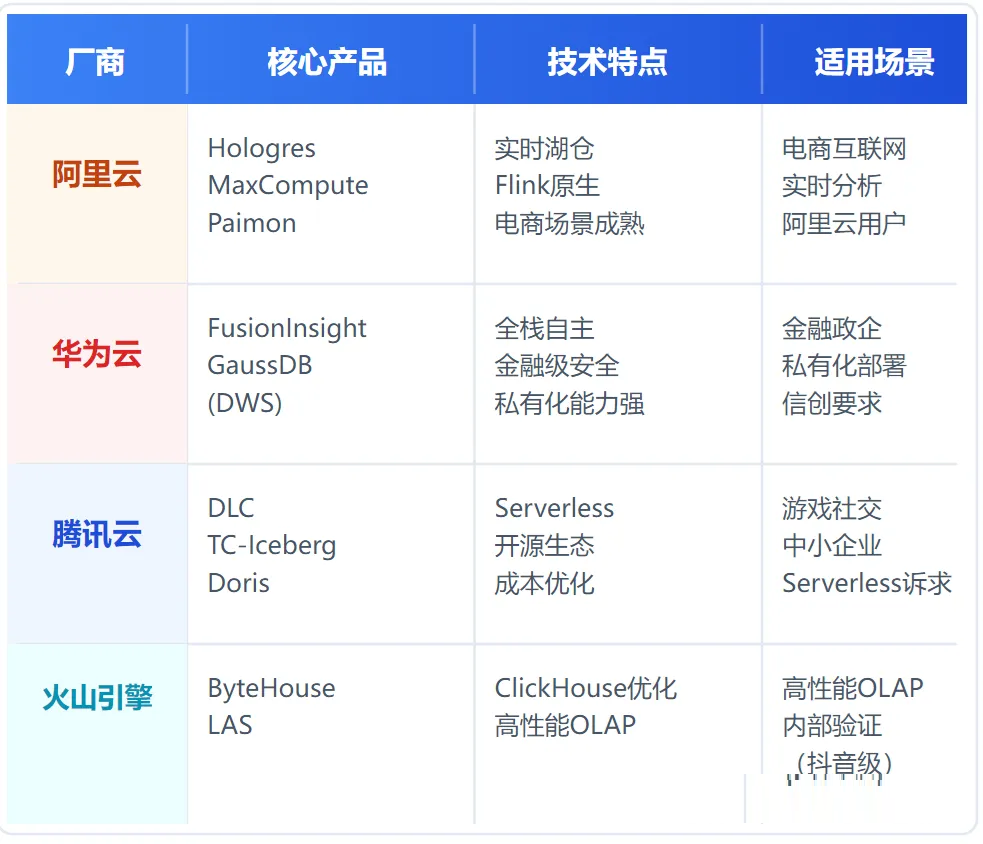
5.2 国内厂商方案
阿里云:实时湖仓的领跑者
核心架构:Hologres 3.0(实时分析)+ MaxCompute(批处理)+ Apache
Paimon(湖格式)+ Flink
差异化优势:
- Hologres 3.0:一份数据同时支撑OLAP、即席查询、在线服务、向量检索
- Paimon深度集成:查询性能达内表60%,TPC-H比Trino快6倍以上
- "Flink + Paimon + Hologres"黄金组合:实时湖仓最佳实践
典型客户:37手游、Lazada、淘菜菜、中信建投证券
定价参考:Hologres 64CU约¥170/CU/月
华为云:政企市场的绝对领先者
核心架构:FusionInsight(数据湖)+ GaussDB(DWS)(数仓)+ DataArts(治理)
差异化优势:
- 全栈自主可控:满足金融、政企的自主可控要求
- IDC市场份额:据IDC报告,政企市场份额大于第2-4名总和
- 金融级安全:异地多活容灾、安全隔离
典型客户:工商银行(2000+节点)、交通银行(报送效率从8小时降至2小时)
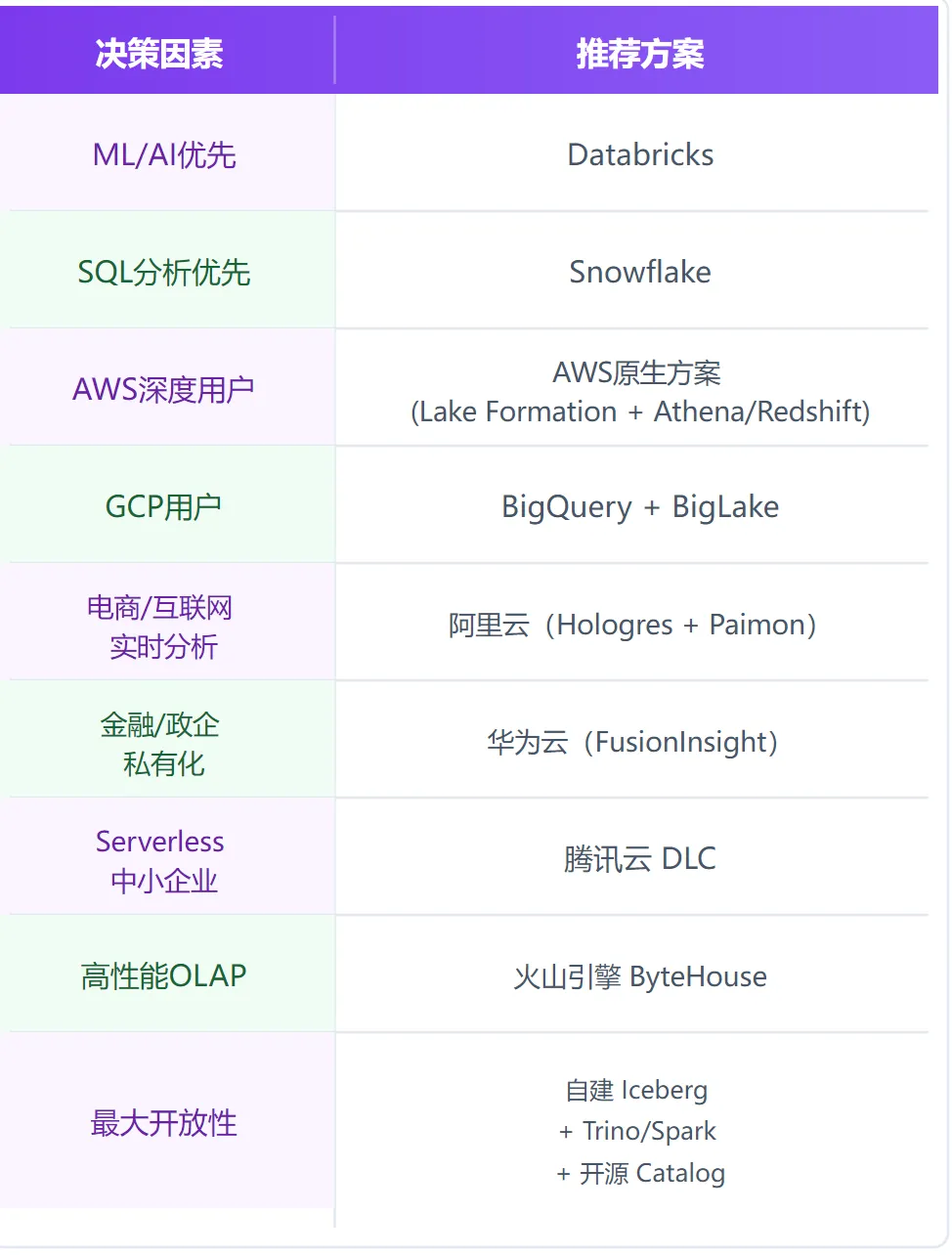
5.3 选型决策矩阵
本章小结
厂商选型的核心原则:
1.业务场景匹配:ML/AI选Databricks,SQL分析选Snowflake,实时选阿里云,政企选华为云
2.云平台绑定:如果已深度使用某云,优先选该云的原生方案
3.开放性考量:担心锁定选开源方案(Iceberg + 多引擎),接受锁定选商业方案
4.成本结构:按查询量付费选Serverless,稳定负载选预留资源
第六章:行业落地案例——湖仓一体的真实效果
技术架构和厂商方案讲了很多,但企业决策最终看的是"别人用得怎么样"。本章精选金融、零售、制造、医疗四个行业的落地案例,展示湖仓一体的真实效果。
6.1 金融行业:风控与合规双突破
案例1:某全球支付机构——欺诈检测提效65%
背景:从传统Hadoop迁移至湖仓架构,处理700TB数据
方案:MinIO AIStor + Trino湖仓架构
效果:
- 欺诈模型运行时间从20小时降至6-7小时(降低65%)
- 工作负载容量提升5倍
- 存储成本大幅下降
关键洞察:湖仓一体让欺诈检测模型可以用更新鲜的数据训练,更快发现新型欺诈模式。
案例2:工商银行——AI风控平台
背景:构建"AI风控平台",融合多源数据
方案:湖仓融合架构,整合行为数据、交易流水、社交网络、舆情数据
效果:
- 欺诈识别率提升40%
- 误判率下降30%
- 每年减少数亿元损失
案例3:J.P. Morgan Payments——3PB级数据统一
背景:日处理近10万亿美元支付,整合50+银行系统
方案:湖仓一体架构,统一3PB数据
效果:
- 服务3000+下游分析师
- 数据口径统一,报告一致性显著提升
6.2 零售电商:从T+1到实时决策
案例1:某头部电商——ETL效率提升4倍
背景:双11等大促期间,T+1的数据延迟无法支撑实时运营决策
方案:数据湖仓融合 + LLM自动特征工程
效果:
- ETL效率提升4倍
- 存储成本下降35%
- 模型训练效率提升3倍
- 实时推理支持每秒10万次推荐请求,延迟控制在200ms以内
案例2:某母婴品牌——库存周转优化
背景:传统BI系统无法支撑精细化库存管理
方案:湖仓一体 + LSTM神经网络销售预测
效果:
- 库存周转天数减少2.3天
- 滞销品占比下降18%
- 订单处理周期从72小时缩短至4小时
案例3:菜鸟物流——分钟级查询响应
背景:25+集群、3个地域、日常上万核规模
方案:Apache Doris + Paimon湖仓方案
效果:
- 点查QPS达1000-2000
- RT在几十到100-200毫秒
- 多表join聚合查询一般1秒内返回
6.3 制造业:预测性维护降本增效
案例:某全球制造企业——非计划停机减少28%
背景:设备故障导致生产线停机,损失巨大
方案:Microsoft Fabric湖仓平台,整合传感器读数、维护日志、质量指标(15TB)
效果(90天POC):
- 为200+资产生成每日风险评分
- 非计划停机减少28%
- 单位维护成本降低22%
- 设备综合效率(OEE)提升3个百分点
- 备件库存减少18%
关键洞察:湖仓一体打通了设备传感器数据、维护记录、质量数据的壁垒,使预测性维护模型能够获得完整的数据视图。
6.4 医疗健康:加速药物研发
案例1:Regeneron——基因组分析从3周到5小时
背景:处理150万外显子组基因组分析
方案:湖仓一体架构
效果:
- 数据处理时间从3周降至5小时
- 基因型-表型查询从30分钟降至3秒
案例2:武田制药——跨临床研究数据整合
背景:12个临床研究项目数据分散,覆盖肿瘤、胃肠病学、神经科学、疫苗领域
方案:湖仓一体统一数据平台
效果:
- 跨项目数据分析成为可能
- 研发成本显著降低
- 临床洞察速度提升
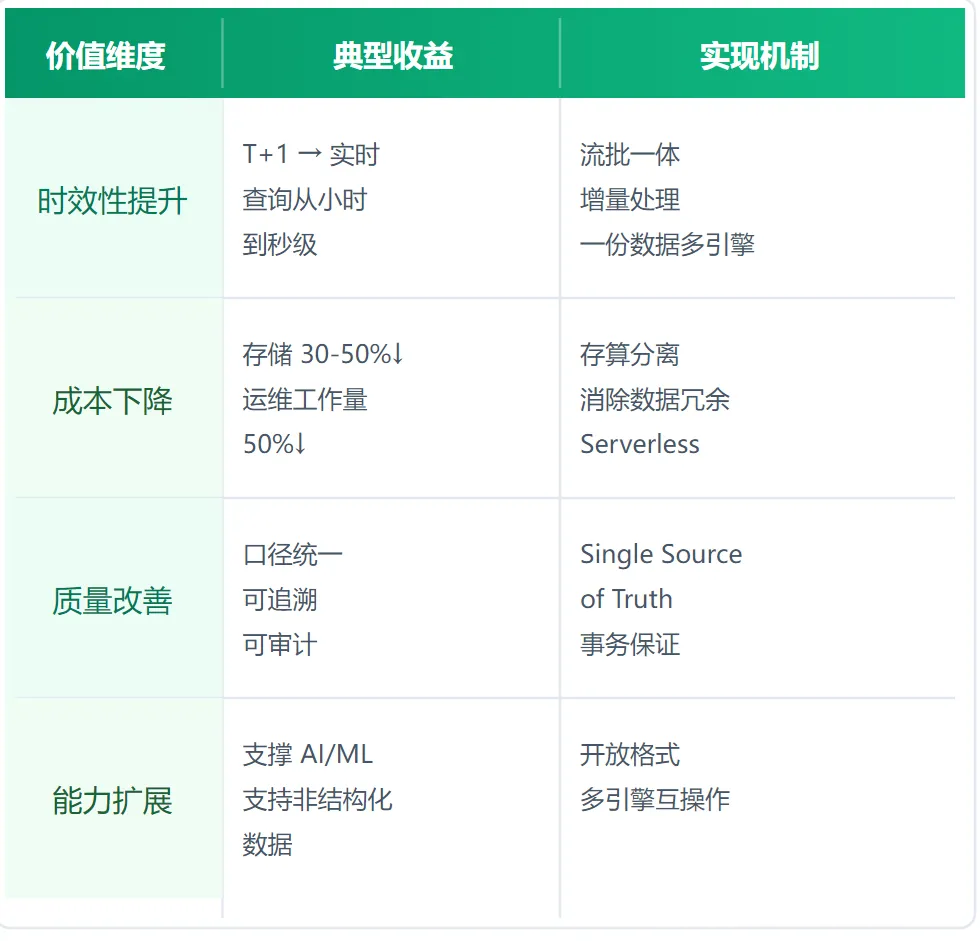
6.5 案例总结:价值兑现的共性规律
从上述案例中,我们可以提炼出湖仓一体价值兑现的共性规律:
第七章:从0到1落地指南——如何不踩坑地实施湖仓一体
理论和案例讲了很多,但落地才是硬道理。本章提供一套经过验证的落地方法论,帮你避开常见的坑。
7.1 落地的三个阶段
湖仓一体落地建议分三个阶段,循序渐进:
阶段一:基础设施搭建(1-2个月)
- 建立云存储(S3/OSS等)
- 配置统一元数据目录(Glue/Hive Metastore)
- 建立治理框架和权限体系
- 选定表格式(建议Iceberg)
- 完成技术选型和POC验证
阶段二:增量验证(3-6个月)
- 选择1-2个非核心业务场景试点
- 实现Bronze-Silver-Gold三层架构
- 验证数据质量、性能、成本
- 建立监控和运维体系
- 沉淀最佳实践文档
阶段三:全面推广(6-12个月)
- 扩展至所有工作负载
- 迁移存量数据
- 性能调优和成本优化
- 建立数据产品化体系
- 培训和组织能力建设
7.2 技术选型Checklist
在开始之前,回答以下问题,指导你的技术选型:
关于表格式:
- 你的主力计算引擎是什么?(Spark选Delta/Iceberg,多引擎选Iceberg,CDC选Hudi)
- 你对厂商锁定的容忍度如何?(低容忍选Iceberg)
- 你有大量高频更新/Upsert场景吗?(有则评估Hudi)
关于计算引擎:
- 你的主要工作负载是什么?(批处理选Spark,流处理选Flink,交互式选Trino)
- 你需要实时Dashboard吗?(需要则加Doris/StarRocks)
- 你的团队熟悉什么技术栈?
关于云平台:
- 你是否已深度绑定某个云?(是则优先选该云原生方案)
- 你是否需要私有化部署?(需要则选华为云或自建)
- 你的预算结构是什么?(按量付费选Serverless,稳定负载选预留)
7.3 Medallion架构实施规范
Bronze-Silver-Gold三层架构的具体实施规范:
Bronze层规范:
-
命名规则: bronze.{source_system}.{table_name}
- 数据格式:保留源系统原始格式,或统一转为Parquet
- 分区策略:按时间分区(年/月/日)
- 保留策略:至少保留N天原始数据(根据审计要求)
- 数据质量:只做基础校验(非空、格式),不做业务校验
Silver层规范:
- 命名规则: silver.{domain}.{entity_name}
- 数据格式:统一Parquet + 选定的表格式
- 数据处理:去重、清洗、类型转换、主键对齐、维表关联
- 数据质量:Schema强制、完整性校验、一致性校验
- SLA:T+N小时(根据业务需求)
Gold层规范:
-
命名规则: gold.{mart_name}.{table_name}
- 数据格式:高度优化(聚合、预计算、分区优化)
- 面向:直接服务BI、API、AI应用
- SLA:明确的数据新鲜度和可用性承诺
- 治理:语义层定义、指标口径文档、变更管理流程
7.4 性能优化清单
湖仓一体的性能不是"天然好",需要持续优化:
文件治理(最重要):
- 小文件合并(目标每文件128MB-1GB)
- 定期Compaction
- 控制分区数量(避免分区爆炸)
- 设置快照过期策略(Time Travel历史不能无限保留)
分区与布局:
- 选择正确的分区键(高基数字段不适合做分区键)
- 使用Iceberg的隐式分区(避免用户感知分区逻辑)
- 考虑Z-Ordering/Liquid Clustering优化多维查询
统计信息:
- 确保表统计信息及时更新
- 配置Data Skipping(基于min/max统计跳过无关文件)
- 高频查询字段考虑Bloom Filter索引
缓存策略:
- 热数据配置本地缓存(如Alluxio)
- 配置结果集缓存(Query Result Cache)
7.5 治理体系建设
湖仓一体越强调复用,越要把治理前置。
元数据管理:
- 统一目录(选择Glue/Unity Catalog/Polaris之一)
- Schema注册与演进规则
- 自动化血缘追踪
权限控制:
- RBAC(角色级权限)
- 列级、行级权限(敏感字段脱敏)
- 审计日志(谁在什么时候访问了什么)
数据质量:
- 入湖校验(Bronze层)
- 转换校验(Silver层)
- 服务校验(Gold层SLA监控)
- 质量评分和告警
数据契约:
- 明确Schema兼容性规则(只加列不删列,或通过语义层隔离)
- 变更审批流程
- 下游影响评估
7.6 常见误区与避坑指南
误区1:把"湖上跑SQL"当成"湖仓一体"
问题:只是在S3上放Parquet文件+Athena查询,没有表格式、没有治理
后果:没有事务保证、没有Schema演进、没有时间旅行,本质还是数据湖
解法:引入开放表格式(Delta/Iceberg/Hudi),建立元数据管理
误区2:同时引入多种表格式
问题:Delta用于A场景,Iceberg用于B场景,Hudi用于C场景
后果:运维复杂度爆炸,引擎兼容性问题频发,人才培养成本高
解法:"一主一辅"甚至"一主到底",用XTable解决互操作
误区3:忽视文件治理
问题:写入很爽,从不做Compaction,小文件堆积
后果:查询性能断崖式下降,元数据膨胀,成本失控
解法:建立自动化文件治理机制,定期合并、清理快照
误区4:治理后置
问题:"先用起来再说,治理以后再做"
后果:Bronze层放了大量敏感数据,权限粗放,数据沼泽形成
解法:治理前置,从第一张表开始就有owner、有权限、有质量校验
误区5:把湖仓一体当银弹
问题:期望湖仓一体解决所有数据问题
后果:忽视组织变革、流程改进、人才培养,技术落地但价值没实现
解法:湖仓一体是技术底座,不是业务解决方案;需要配套的数据战略和组织能力
本章小结
湖仓一体落地的核心原则:
1.分阶段推进:基础设施→增量验证→全面推广,不要一步到位
2.技术选型要匹配场景:没有最好的方案,只有最适合的方案
3.Medallion架构是最佳实践:Bronze保原貌、Silver保质量、Gold保可用
4.性能优化是持续工程:文件治理、分区布局、统计信息要长期关注
5.治理必须前置:从第一张表开始就要有owner、有权限、有质量要求
6.避开常见误区:不要把"湖上SQL"当湖仓,不要多格式并存,不要忽视文件治理
第八章:未来趋势——湖仓一体的下一步
技术不会停滞,湖仓一体也在持续演进。本章展望2025-2027年的关键趋势,帮你提前布局。
8.1 趋势一:Iceberg成为事实标准
2025年共识:格式战争基本结束,Apache Iceberg正成为行业标准。
证据:
- Snowflake、AWS、Google Cloud、Databricks全面支持Iceberg
- Delta Lake通过UniForm自动生成Iceberg元数据
- Iceberg REST Catalog成为跨引擎元数据访问的标准协议
影响:选型焦虑降低,"选Iceberg不会错"成为共识
8.2 趋势二:实时湖仓突破分钟级延迟
问题:传统湖仓受文件系统架构限制,存在固有的分钟级延迟
突破方向:
- Apache Fluss(2025年孵化):热层(NVMe/SSD)毫秒级 + 冷层(Iceberg)成本优化
- Apache Paimon:Flink原生表格式,分钟级数据新鲜度
- Redpanda Iceberg Topics:Kafka Topic自动物化为Iceberg表
影响:Lambda/Kappa架构终结,真正的"流批一体"成为可能
8.3 趋势三:AI与湖仓深度融合
AI湖仓架构(AI Lakehouse)正在成为新范式:
- 特征库(Feature Store):实时特征服务集成到湖仓
- 向量索引:非结构化数据(图片、文本)的向量化存储
- MLOps集成:模型训练、注册、服务与数据平台统一
Databricks的Mosaic AI、Snowflake的Cortex AI、阿里云的PAI都在朝这个方向演进。
影响:湖仓一体从"数据基础设施"升级为"AI基础设施"
8.4 趋势四:数据湖管理系统(DLMS)兴起
问题:表格式解决了"表"的问题,但企业需要管理的是"整个数据湖"
DLMS概念:像数据库有DBMS一样,数据湖需要DLMS来统一管理表、目录、权限、血缘、质量
代表产品:
- Databricks Unity Catalog
- Apache Polaris
- Apache Gravitino
- 各云厂商的托管目录服务
影响:竞争焦点从"表格式"转向"湖管理系统"
8.5 趋势五:开源Catalog生态繁荣
2024-2025年重要事件:
- Databricks开源Unity Catalog
- Snowflake开源Apache Polaris
- Apache Gravitino提供多目录联邦
意义:目录层不再是厂商锁定的工具,开放目录让多云、混合云架构更容易实现
本章小结
湖仓一体的未来发展方向:
1.标准化:Iceberg成为事实标准,格式战争结束
2.实时化:Streamhouse架构突破分钟级延迟限制
3.AI原生:特征库、向量索引、MLOps深度集成
4.管理系统化:从表格式竞争转向DLMS竞争
5.开放生态:开源Catalog繁荣,多云互操作成为可能
本文小结:湖仓一体的10条核心认知
在本文中,我们系统性地讲透了湖仓一体:从它的第一性原理到技术架构,从表格式对比到厂商选型,从行业案例到落地指南,从常见误区到未来趋势。
最后,用10条核心认知收束全文,这是你做出湖仓一体决策时最需要牢记的:
1.湖仓一体是架构范式,不是单一产品——它是存储层+元数据层+计算层的组合,不要被某个产品名词绑架。
2.核心创新是开放表格式——Delta Lake/Iceberg/Hudi把"文件集合"变成"可治理的表",这是湖仓一体的灵魂。
3.本质是在开放存储上"软件定义"数据库能力——ACID事务、快照隔离、Schema演进都是元数据层实现的,不需要专有存储引擎。
4.目标是Single Source of Truth——一份数据服务所有工作负载,消除数据搬运和冗余存储。
5.2025年选Iceberg不会错——格式战争基本结束,Iceberg已成为事实标准,获得所有主流厂商支持。
6.治理必须前置,不能后补——从第一张表开始就要有owner、有权限、有质量校验,否则湖仓会变成沼泽。
7.性能不是天然好,需要持续优化——文件治理、分区布局、统计信息是长期工程,不是一次性配置。
8.厂商选型要匹配场景——ML/AI选Databricks,SQL分析选Snowflake,实时选阿里云,政企选华为云,没有银弹。
9.落地要分阶段推进——基础设施→增量验证→全面推广,不要一步到位,先跑通再优化。
10.湖仓一体的价值不在架构先进,而在业务价值兑现——"同一份可信数据服务更多业务场景"才是终极目标,不要为了架构而架构。
| 






 订阅
订阅