| 编辑推荐: |
本文是数据湖的概览,包括诞生背景,数据糊本质,与数仓的关系以及行业实践等内容。
本文来自于知乎,由Linda编辑、推荐。
|
|
诞生背景
数据领域,已经有了数据库以及数据仓库了,为何还需要数据湖了?数据湖是解决什么问题了?在什么背景下诞生的了?
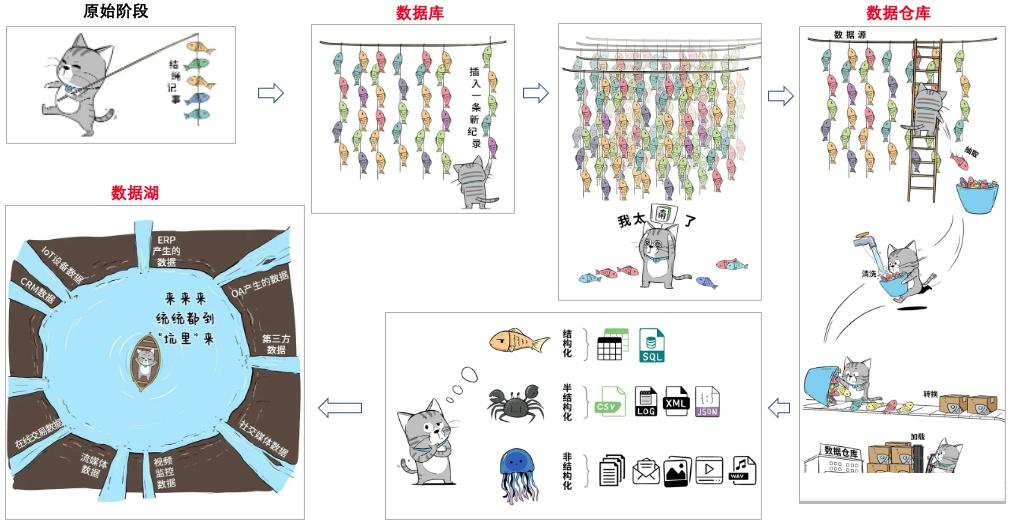
图片参考:Data Lake, how to dig? - Jason Feng's blog
小猫咪最喜欢吃鱼了,每天都去捕鱼,开始就几条,问题不大,怎么样都行,大不了采用结绳记事。随着鱼的数量的增多,一会儿存,一会取的,快忙不过来了,科技改变生活,数据库出现,小猫咪用数据库来对鱼进行快速的增删改查,方便了不少。
日子久了,库里的鱼更多了,这时候,猫咪想着不能一味的光吃呀,得分析下近一年近一个季度的捕鱼的情况,以及不同河流的捕鱼数量情况等等。但是,传统数据库一般是事务性的数据系统,存取还好,这种以读取大量数据为特征的分析业务并不适合。这个时候就需要数据仓库了。数据仓库,在现有的数据库基础上,对鱼进行加工,这个加工过程,被称为ETL(抽取、转换和加载),最终数据进入数仓,以便后续分析。
随着江河治理的成效不断体现,捕到的水产越来越多了,不仅仅是鱼,还有螃蟹等其他东西。这些也很美味,也很有分析研究价值,不能扔了呀,但是这些五花八门的水产,该怎么存了?索性挖个大坑吧,统统装进来,好了,进入数据湖阶段。
好了,言归正传,说白了,企业在持续发展,企业的数据也不断堆积,虽然“含金量”最高的数据都存在数据库和数仓里,支撑着企业的运转。但是,企业希望把生产经营中的所有相关数据,历史的、实时的,在线的、离线的,内部的、外部的,结构化的、非结构化的,都能完整保存下来,方便“沙中淘金”,然后就出现了数据湖。
这里大家有没有思考过,为何是叫数据湖,而不是其他的名字,比如Data River等,来,一起看看:
为什么不是数据河Data River?因为,数据要能存,而不是一江春水向东流。
为什么不是数据池Data Pool?因为,要足够大,大数据太大,一池存不下。
为什么不是数据海Data Sea?因为,企业的数据要有边界,可以流通和交换,但更注重隐私和安全,“海到无边天作岸”,那可不行。
So,叫Data lake数据湖最合适,就问你讲不讲究,哈哈!
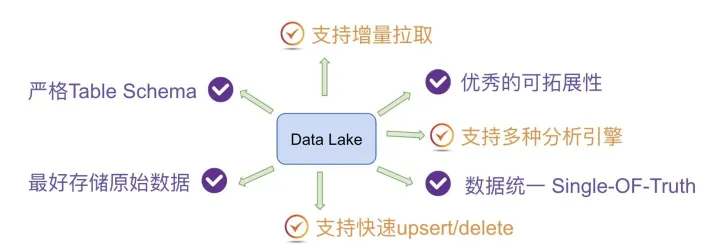
数据湖的本质
关于数据湖的定义其实很多,但是基本上都围绕着以下几个特性展开。
数据湖需要提供足够用的数据存储能力,这个存储保存了一个企业/组织中的所有数据。
数据湖可以存储海量的任意类型的数据,包括结构化、半结构化和非结构化数据。
数据湖中的数据是原始数据,是业务数据的完整副本。数据湖中的数据保持了他们在业务系统中原来的样子。
数据湖需要具备完善的数据管理能力(完善的元数据),可以管理各类数据相关的要素,包括数据源、数据格式、连接信息、数据schema、权限管理等。
数据湖需要具备多样化的分析能力,包括但不限于批处理、流式计算、交互式分析以及机器学习;同时,还需要提供一定的任务调度和管理能力。
数据湖需要具备完善的数据生命周期管理能力。不光需要存储原始数据,还需要能够保存各类分析处理的中间结果,并完整的记录数据的分析处理过程,能帮助用户完整详细追溯任意一条数据的产生过程。
数据湖需要具备完善的数据获取和数据发布能力。数据湖需要能支撑各种各样的数据源,并能从相关的数据源中获取全量/增量数据;然后规范存储。数据湖能将数据分析处理的结果推送到合适的存储引擎中,满足不同的应用访问需求。
对于大数据的支持,包括超大规模存储以及可扩展的大规模数据处理能力。
综上,个人认为数据湖应该是一种不断演进中、可扩展的大数据存储、处理、分析的基础设施;以数据为导向,实现任意来源、任意速度、任意规模、任意类型数据的全量获取、全量存储、多模式处理与全生命周期管理;并通过与各类外部异构数据源的交互集成,支持各类企业级应用。简单来讲,就是由“数据存储架构+数据处理工具”组成的解决方案,而不是某个单一独立产品。
数据存储架构
数据存储架构,要有足够的扩展性和可靠性,要满足企业能把所有原始数据都“囤”起来,存得下、存得久。一般来讲,各大云厂商都喜欢用对象存储来做数据湖的存储底座。
数据处理工具
数据处理工具,则分为两大类:
第一类工具,解决的问题是如何把数据“搬到”湖里,包括定义数据源、制定数据访问策略和安全策略,并移动数据、编制数据目录等等。
第二类工具,就是要从湖里的海量数据中“淘金”。
数据入湖

如果没有这些数据管理/治理工具,元数据缺失,湖里的数据质量就没法保障,“泥石俱下”,各种数据倾泻堆积到湖里,最终好好的数据湖,慢慢就变成了数据沼泽。

因此,在一个数据湖方案里,数据移动和管理的工具非常重要。比如,Amazon Web Services提供“Lake
Formation”这个工具,帮助客户自动化地把各种数据源中的数据移动到湖里,同时还可以调用Amazon
Glue来对数据进行ETL,编制数据目录,进一步提高湖里数据的质量。
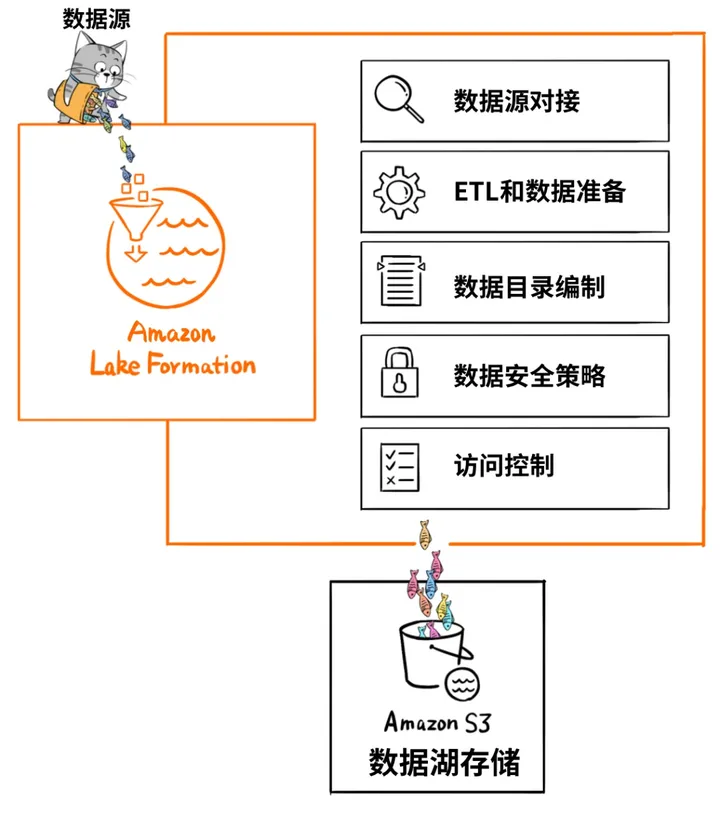
湖中淘金
数据并不是存进数据湖里就万事大吉,要对数据进行分析、挖掘、利用,比如要对湖里的数据进行查询,同时要把数据提供给机器学习、数据科学类的业务,便于“点石成金”。

继续拿Amazon Web Services来举例子,基于Amazon Athena这个服务,就可以使用标准的SQL来对S3(数据湖)中的数据进行交互式查询。再比如使用Amazon
SageMaker机器学习服务,导入数据湖中的数据进行模型训练,这些都是常规操作。

小结一下,数据湖不只是个“囤积”数据的“大水坑”,除了用存储技术构建的湖底座以外,还包含一系列的数据入湖、数据出湖、数据管理、数据应用工具集,共同组成了数据湖解决方案。
开源数据湖方案
开源数据湖方案,目前主要是三个框架:DeltaLake、Hudi、Iceberg。
Delta Lake
背景
Databricks推出的delta,它要解决的核心问题基本上集中在下图:
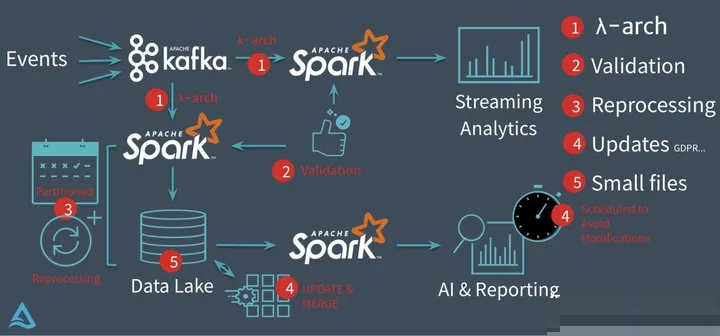
在没有delta数据湖之前,Databricks的客户一般会采用经典的lambda架构来构建他们的流批处理场景。以用户点击行为分析为例,点击事件经Kafka被下游的Spark
Streaming作业消费,分析处理(业务层面聚合等)后得到一个实时的分析结果,这个实时结果只是当前时间所看到的一个状态,无法反应时间轴上的所有点击事件。所以为了保存全量点击行为,Kafka还会被另外一个Spark
Batch作业分析处理,导入到文件系统上(一般就是parquet格式写HDFS或者S3,可以认为这个文件系统是一个简配版的数据湖),供下游的Batch作业做全量的数据分析以及AI处理等。
这套方案其实存在很多问题 :
第一、批量导入到文件系统的数据一般都缺乏全局的严格schema规范,下游的Spark作业做分析时碰到格式混乱的数据会很麻烦,每一个分析作业都要过滤处理错乱缺失的数据,成本较大;
第二、数据写入文件系统这个过程没有ACID保证,用户可能读到导入中间状态的数据。所以上层的批处理作业为了躲开这个坑,只能调度避开数据导入时间段,可以想象这对业务方是多么不友好;同时也无法保证多次导入的快照版本,例如业务方想读最近5次导入的数据版本,其实是做不到的。
第三、用户无法高效upsert/delete更新历史数据,parquet文件一旦写入HDFS文件,要想改数据,就只能全量重新写一份的数据,成本很高。事实上,这种需求是广泛存在的,例如由于程序问题,导致错误地写入一些数据到文件系统,现在业务方想要把这些数据纠正过来;线上的MySQL
binlog不断地导入update/delete增量更新到下游数据湖中;某些数据审查规范要求做强制数据删除,例如欧洲出台的GDPR隐私保护等等。
第四、频繁地数据导入会在文件系统上产生大量的小文件,导致文件系统不堪重负,尤其是HDFS这种对文件数有限制的文件系统。
所以,在Databricks看来,以下四个点是数据湖必备的。
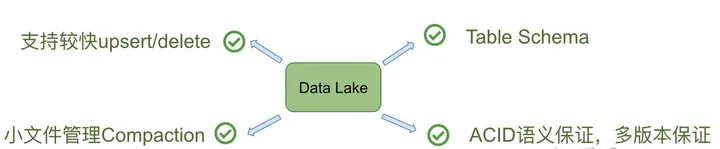
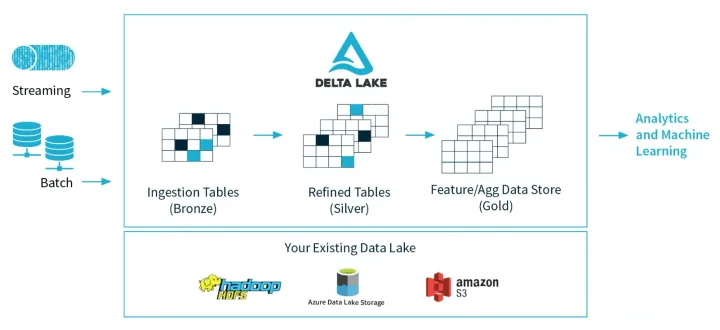
事实上, Databricks在设计delta时,希望做到流批作业在数据层面做到进一步的统一(如下图)。业务数据经过Kafka导入到统一的数据湖中(无论批处理,还是流处理),上层业务可以借助各种分析引擎做进一步的商业报表分析、流式计算以及AI分析等等。
架构
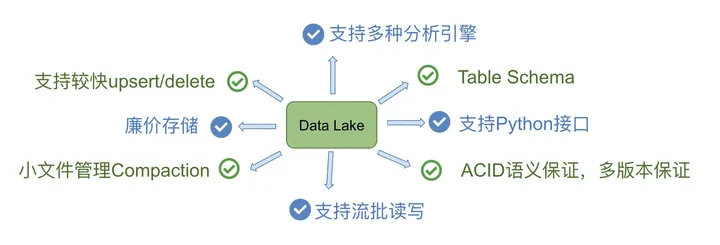
特性
所以,总结起来,我认为databricks设计delta时主要考虑实现以下核心功能特性:
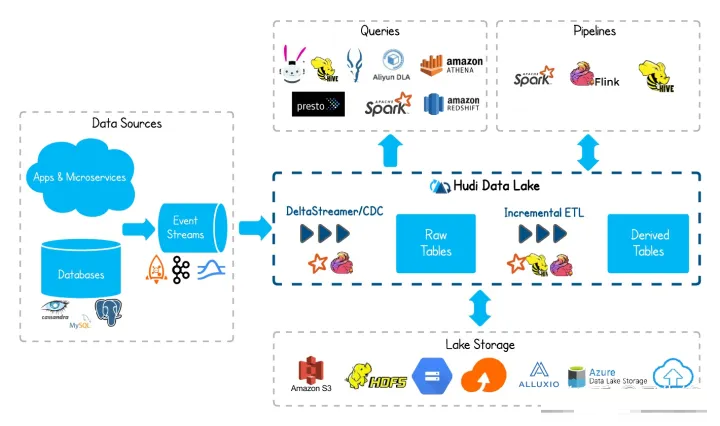
Hudi
背景
Uber的业务场景主要为:将线上产生的行程订单数据,同步到一个统一的数据中心,然后供上层各个城市运营同事用来做分析和处理。在2014年的时候,Uber的数据湖架构相对比较简单,业务日志经由Kafka同步到S3上,上层用EMR做数据分析;线上的关系型数据库以及NoSQL则会通过ETL(ETL任务也会拉去一些Kakfa同步到S3的数据)任务同步到闭源的Vertica分析型数据库,城市运营同学主要通过Vertica
SQL实现数据聚合。当时也碰到数据格式混乱、系统扩展成本高(依赖收Vertica商业收费软件)、数据回填麻烦等问题。后续迁移到开源的Hadoop生态,解决了扩展性问题等问题,但依然碰到Databricks上述的一些问题,其中最核心的问题是无法快速upsert存量数据。
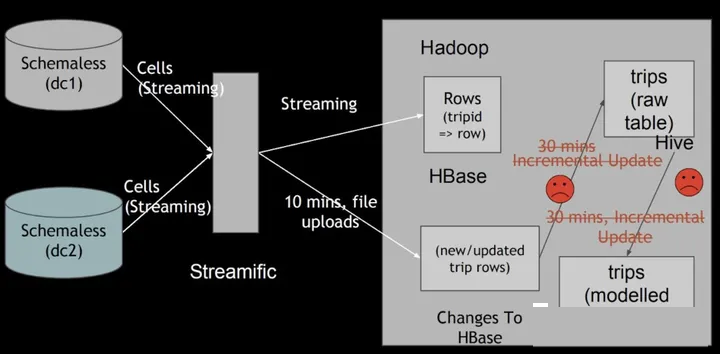
如上图所示,ETL任务每隔30分钟定期地把增量更新数据同步到分析表中,全部改写已存在的全量旧数据文件,导致数据延迟和资源消耗都很高。此外,在数据湖的下游,还存在流式作业会增量地消费新写入的数据,数据湖的流式消费对他们来说也是必备的功能。所以,他们就希望设计一种合适的数据湖方案,在解决通用数据湖需求的前提下,还能实现快速的upsert以及流式增量消费。
架构
特性
hudi主要有八大特性,具体如下所示:

Uber团队在Hudi上同时实现了Copy On Write和Merge On Read 的两种数据格式,其中Merge
On Read就是为了解决他们的fast upsert而设计的。简单来说,就是每次把增量更新的数据都写入到一批独立的delta文件集,定期地通过compaction合并delta文件和存量的data文件。同时给上层分析引擎提供三种不同的读取视角:仅读取delta增量文件、仅读取data文件、合并读取delta和data文件。满足各种业务方对数据湖的流批数据分析需求。
最终,我们可以提炼出Uber的数据湖需求为如下图,这也正好是Hudi所侧重的核心特性。
Iceberg
背景
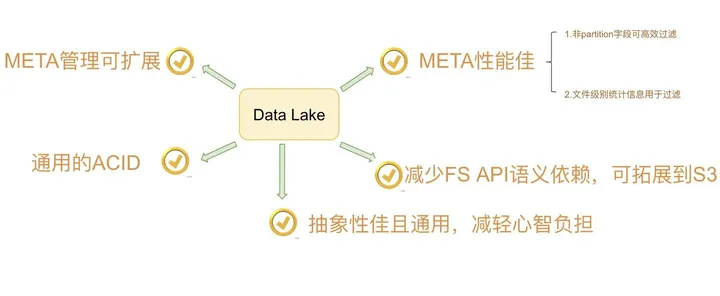
Netflix的数据湖原先是借助Hive来构建,但发现Hive在设计上的诸多缺陷之后,开始转为自研Iceberg,并最终演化成Apache下一个高度抽象通用的开源数据湖方案。Netflix用内部的一个时序数据业务的案例来说明Hive的这些问题,采用Hive时按照时间字段做partition,他们发现仅一个月会产生2688个partition和270万个数据文件。他们执行一个简单的select查询,发现仅在分区裁剪阶段就耗费数十分钟。

他们发现Hive的元数据依赖一个外部的MySQL和HDFS文件系统,通过MySQL找到相关的parition之后,需要为每个partition去HDFS文件系统上按照分区做目录的list操作。在文件量大的情况下,这是一个非常耗时的操作。同时,由于元数据分属MySQL和HDFS管理,写入操作本身的原子性难以保证。即使在开启Hive
ACID情况下,仍有很多细小场景无法保证原子性。另外,Hive Memstore没有文件级别的统计信息,这使得filter只能下推到partition级别,而无法下推到文件级别,对上层分析性能损耗无可避免。最后,Hive对底层文件系统的复杂语义依赖,使得数据湖难以构建在成本更低的S3上。
于是,Netflix为了解决这些痛点,设计了自己的轻量级数据湖Iceberg。在设计之初,作者们将其定位为一个通用的数据湖项目,所以在实现上做了高度的抽象。虽然目前从功能上看不如前面两者丰富,但由于它牢固坚实的底层设计,一旦功能补齐,将成为一个非常有潜力的开源数据湖方案。
总体来说,Netflix设计Iceberg的核心诉求可以归纳为如下:
总结对比
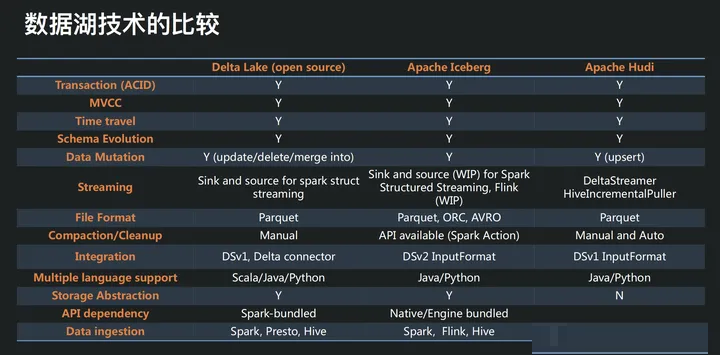
三大方案,简单描述如下:
Delta Lake作为 Databricks 开源的项目,更侧重于在 Spark 层面上解决 Parquet
等存储格式的固有问题,并带来更多的能力提升;高度依赖于 Spark 生态圈,与其他引擎的适配尚需时日。
Iceberg设计初衷更倾向于定义一个标准、开放且通用的数据组织格式,同时屏蔽底层数据存储格式上的差异,向上提供统一的操作
API,使得不同的引擎可以通过其提供的 API 接入;Iceberg 在其格式定义和核心能力上最为完善,但是上游引擎的适配上明显不足,比如
Spark、Hive、Flink 等不同引擎的适配, 而对于 Hive、Flink 的支持尚在开发中。Iceberg
在数据组织方式上充分考虑了对象存储的特性,避免耗时的 listing 和 rename 操作。
Hudi 的设计初衷是为了解决流式数据的快速落地,并能够通过 upsert 语义进行延迟数据修正;Hudi
基于 Spark 打造了完整的流式数据落地方案,但是其核心抽象较弱,与 Spark 耦合较紧。
湖与仓的关系

数据仓库适用于结构化和已处理的数据类型,并提供数据聚合和汇总的只读查询,写入机制和预处理功能使其成为商业分析的完美选择。数据湖系统以原始格式存储数据,可以存储结构化、半结构化(CSV、JSON、日志)、非结构化(电子邮件、文档)和二进制数据(音频、照片等)。不同于数据仓库,数据湖可以完美地处理不同类型的数据,而且因为能提供高性价比的大数据存储而备受赞赏。数据湖与其他数据系统主要区别如下:
易用,数据湖可以存储不同来源、不同类型的数据,方便进一步分析和重新安置
组织和结构化,数据是以原始格式进行实时收集和存储
实惠,能为任何规模的数据提供划算的价格
适用于任何时间框架,可以实时或按需更新
无限存储空间,为大数据存储提供优秀的解决方案。
从数据含金量来比,数据仓库里的数据价值密度更高一些,数据的抽取和Schema的设计,都有非常强的针对性,便于业务分析师迅速获取洞察结果,用与决策支持;而数据湖更有一种“兜底”的感觉,甭管当下有用没有/或者暂时没想好怎么用,先保存着、沉淀着,将来想用的时候,尽管翻牌子就是了,反正都原汁原味的留存了下来。
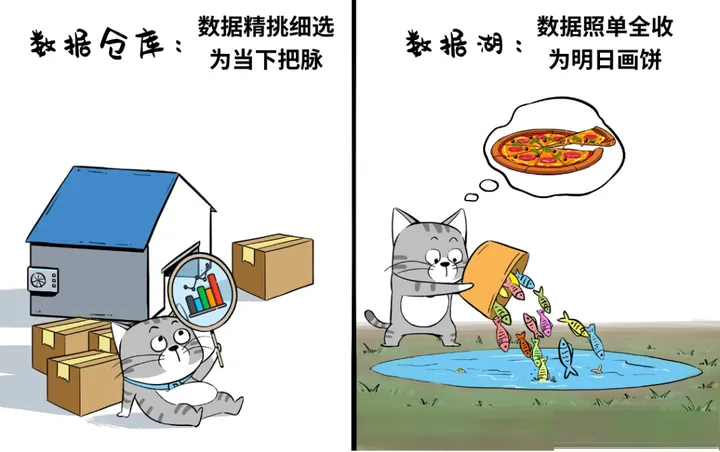
湖仓一体
为何要湖仓一体?
曾经,数据仓库擅长的BI、数据洞察离业务更近、价值更大,而数据湖里的数据,更多的是为了远景画饼。随着大数据和AI的上纲上线,原先的“画的饼”也变得炙手可热起来,为业务赋能,价值被重新定义。而因为数仓和数据库的出发点不同、架构不同,企业在实际使用过程中,“性价比”差异很大。
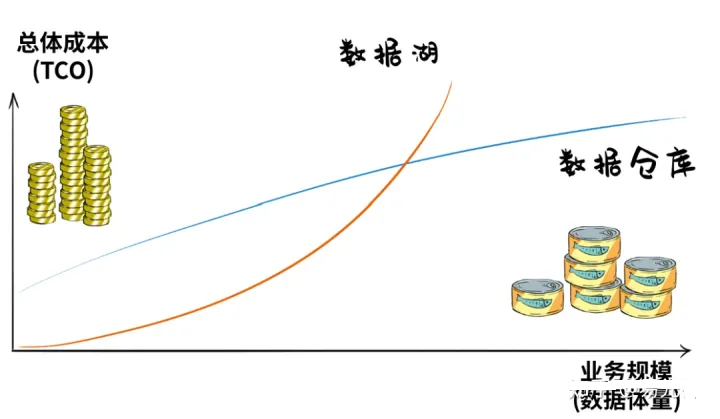
数据湖起步成本很低,但随着数据体量增大,TCO成本会加速飙升,数仓则恰恰相反,前期建设开支很大。总之,一个后期成本高,一个前期成本高,对于既想修湖、又想建仓的用户来说,仿佛玩了一个金钱游戏。于是,人们就想,既然都是拿数据为业务服务,数据湖和数仓作为两大“数据集散地”,能不能彼此整合一下,让数据流动起来,少点重复建设呢?

比如,让“数仓”在进行数据分析的时候,可以直接访问数据湖里的数据(Amazon Redshift Spectrum是这么干的)。再比如,让数据湖在架构设计上,就“原生”支持数仓能力(DeltaLake是这么干)。
正是这些想法和需求,推动了数仓和数据湖的打通和融合,也就是当下炙手可热的概念:Lake House。
什么是湖仓一体?
虽然数据仓库和数据湖的应用场景和架构不同,但它们并不是对立关系。数据仓库存储结构化的数据,适用于快速的BI和决策支撑,而数据湖可以存储任何格式的数据,往往通过挖掘能够发挥出数据的更大作为,因此在一些场景上二者的并存可以给企业带来更多收益。
湖仓一体,又被称为Lake House,其出发点是通过数据仓库和数据湖的打通和融合,让数据流动起来,减少重复建设。Lake
House架构最重要的一点,是实现数据仓库和数据湖的数据/元数据无缝打通和自由流动。湖里的“显性价值”数据可以流到仓里,甚至可以直接被数仓使用;而仓里的“隐性价值”数据,也可以流到湖里,低成本长久保存,供未来的数据挖掘使用。
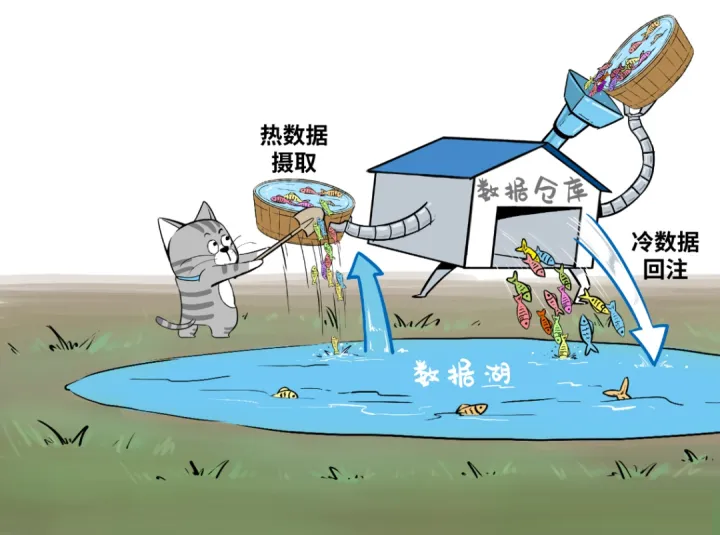
湖里的“新鲜”数据可以流到仓里,甚至可以直接被数仓使用,而仓里的“不新鲜”数据,也可以流到湖里,低成本长久保存,供未来的数据挖掘使用。
为了实现这个目标,Amazon Web Services推出了Redshift Spectrum,打通了数仓对数据湖的直接访问,能够高效查询S3数据湖当中的EB级数据。
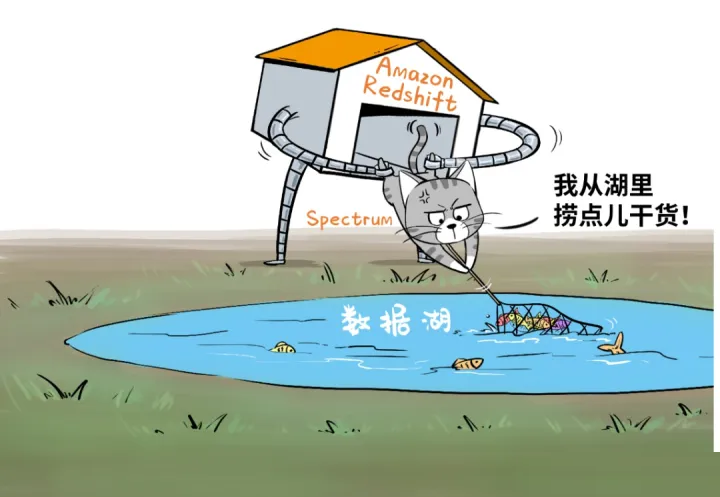
“Spectrum”是智能湖仓的核心组件,被称为“Lake House引擎”,它可以在湖与仓之间架起数据流动的管道;
可以将数据湖中最近几个月的“热数据”摄取到数仓中;
反过来,也可以轻松将大量冷门历史数据从数仓转移至成本更低廉的数据湖内,同时这些移到湖里的数据,仍然可以被Redshift数仓查询使用;
处理数仓内的热数据与数据湖中的历史数据,生成丰富的数据集,全程无需执行任何数据移动操作;
生成的新数据集可以插入到数仓中的表内,或者直接插入由数据湖托管的外部表中。
做到这一步,基本上算是 get 到了Lake House的精髓,“湖仓一体”初见端倪。
但是,在实际业务场景下,数据的移动和访问,不仅限于数仓和数据湖之间,搜索引擎服务、机器学习服务、大数据分析服务……,都涉及到数据在本地(本系统)和数据湖之间的移动,以及数据在不同服务之间的移动。
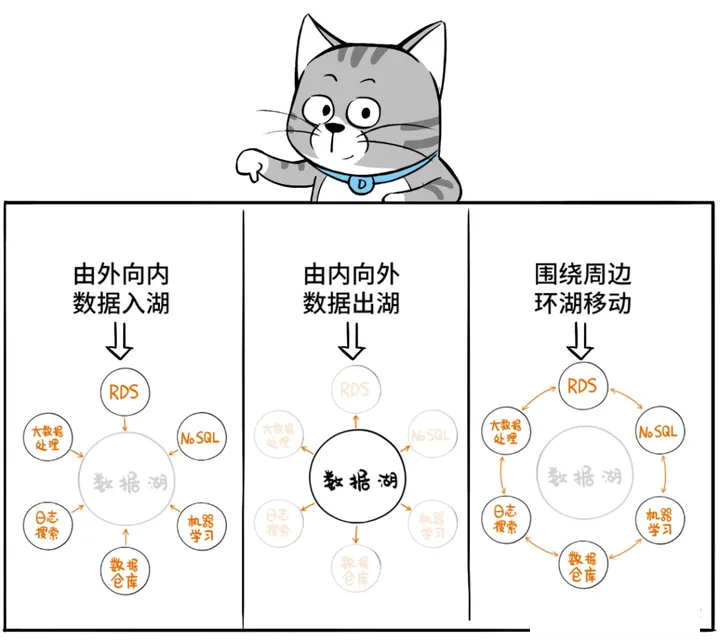
数据积累得越多,移动起来就越困难,这就是所谓的“数据重力”。
所以,Lake House不仅要把湖、仓打通,还要克服“数据重力”,让数据在这些服务之间按需来回移动:入湖、出湖、环湖……
把数据湖和数据仓库集成起来只是第一步,还要把湖、仓以及所有其他数据处理服务组成统一且连续的整体,这就是Amazon
Web Services为何把自家的Lake House架构称为“智能湖仓”,而非“湖仓一体”。
什么是智能湖仓?
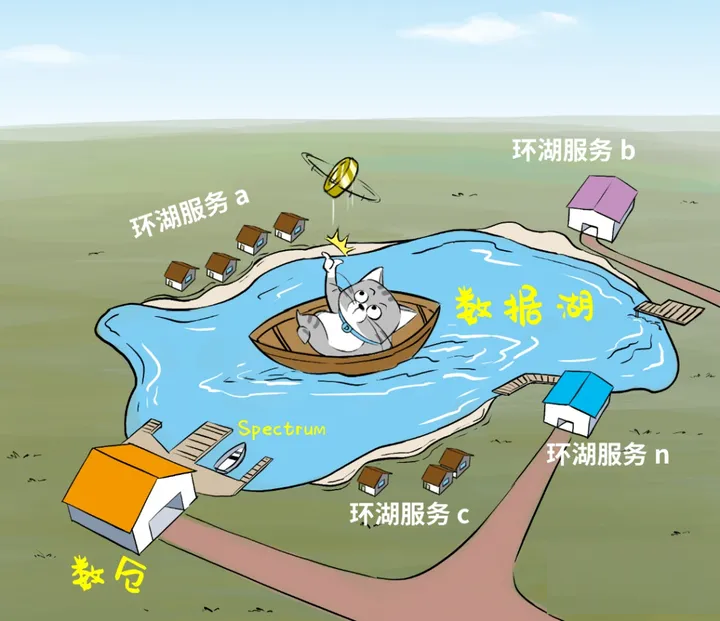
智能湖仓并非单一产品,它描述的是一种架构。这套架构,以数据湖为中心,把数据湖作为中央存储库,再围绕数据湖建立专用“数据服务环”,环上的服务包括了数仓、机器学习、大数据处理、日志分析,甚至RDS和NOSQL服务等等。

大家“环湖而饲”,既可以直接操纵湖内数据,也可以从湖中摄取数据,还可以向湖中回注数据,同时环湖的服务彼此之间也可以轻松交换数据。
任何热门的数据处理服务,都在湖边建好了,任何对口的数据都能召之即来、挥之则去。依靠这种无缝集成和数据移动机制,用户就能从容地用对的工具从对的数据中,挖出干货!
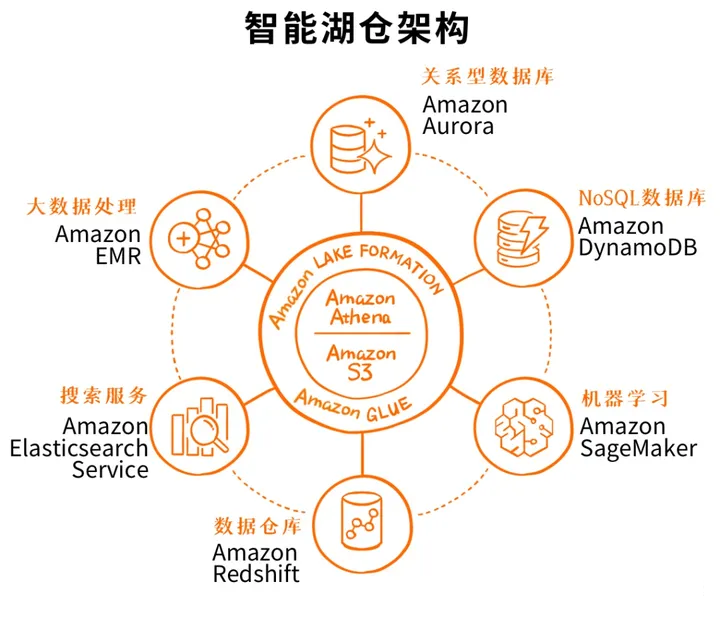
上面这张图看着就更加明白一些,中间是湖,周边集成了全套的云上数据服务,然后还有Lake Formation、Glue、Athena以及前面重点提到的Redshift
Spectrum这些工具,来实现数据湖的构建、数据的管理、安全策略以及数据的移动。
如果我们再从数据获取到数据应用的完整流程来看,这些产品又是如何各司其职的呢?Amazon Web
Services 官方给出了智能湖仓的参考架构:
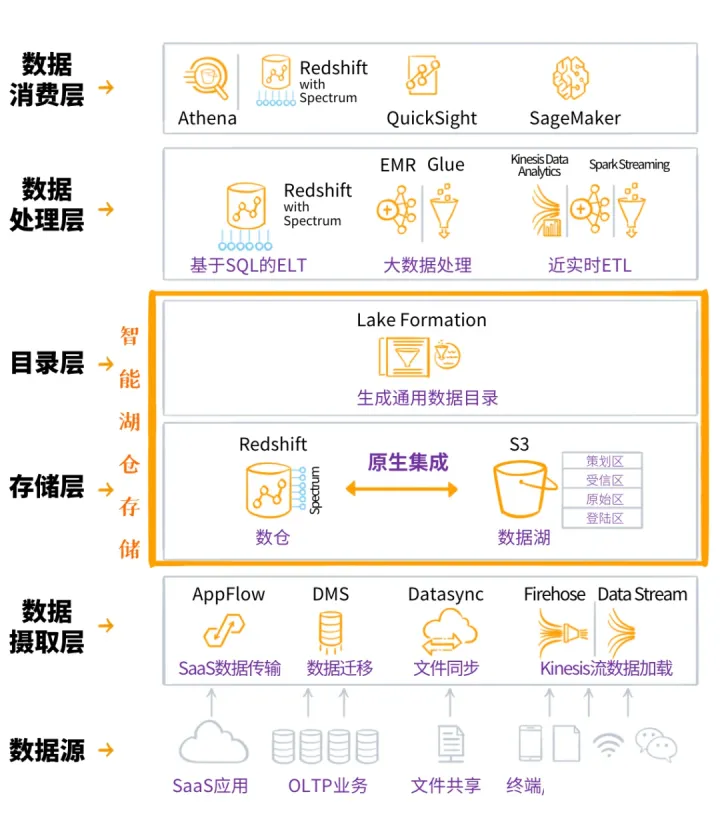
这个六层架构,从数据源定义、数据摄取和入湖入仓,到湖仓打通与集成,再到数据出湖、数据处理和数据消费,一气呵成,各种云上数据服务无缝集成在一起。数据从各种源头“流入”到智能湖仓存储中,又按需流出,被处理、被消费。
在“智能湖仓”架构下,企业可以轻松汇集和保存海量业务数据,并随心所欲地调用各种数据服务,用于BI、可视化分析、搜索、建模、特征提取、流处理等等,未来新的数据源、新的分析方法,也可以快速应对。同时,数据湖的存储底座S3成本低廉并有近乎无限的扩展性,“湖边”大量的数据分析和处理的服务又是无长期成本的Serverless架构,企业“入坑”智能湖仓之后,完全没有后顾之忧。
数据湖行业实践
T3出行存储计算分离的数据湖架构

T3出行数据湖架构分为了两层,一层是计算层,一层是存储层。
计算层用到了 Flink、Spark、Kylin 和 Presto 并且搭配 ES 做任务调度。数据分析和展示方面用到了达芬奇和
Zeppelin。
在存储层,使用了阿里云 OSS 并搭配 HDFS 做数据存储。数据格式方面使用 Hudi 作为主要的存储格式,并配合
Parquet、ORC 和 Json 文件。在计算和存储之前,我们加了一个 Alluxio 来加速提升数据处理性能。资源管理方面我用到了
Yarn,在后期时机成熟的时候也会转向 K8s。
腾讯基于Apache Flink + Iceberg的实时数仓建设实践
当前业界的离线T+1数仓,以及实时数仓的Lamda和kappa架构,均存在不足,如下图所示:

Iceberg 既然能够作为一个优秀的表格式,既支持 Streaming reader,又可以支持
Streaming sink,是否可以考虑将 Kafka 替换成 Iceberg?
Iceberg 底层依赖的存储是像 HDFS 或 S3 这样的廉价存储,而且 Iceberg 是支持
parquet、orc、Avro 这样的列式存储。有列式存储的支持,就可以对 OLAP 分析进行基本的优化,在中间层直接进行计算。例如谓词下推最基本的
OLAP 优化策略,基于 Iceberg snapshot 的 Streaming reader 功能,可以把离线任务天级别到小时级别的延迟大大的降低,改造成一个近实时的数据湖分析系统。
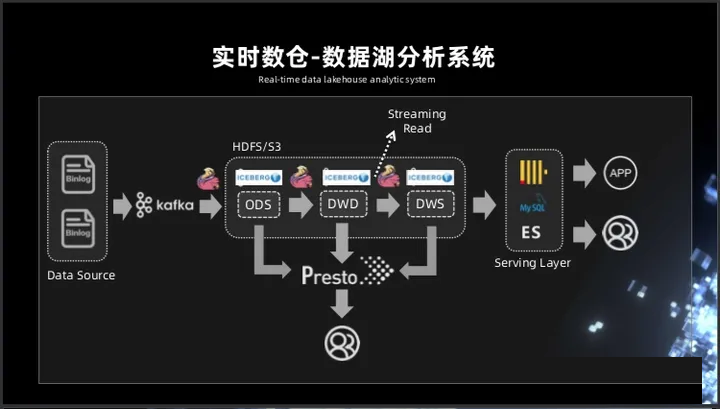
在中间处理层,可以用 presto 进行一些简单的查询,因为 Iceberg 支持 Streaming
read,所以在系统的中间层也可以直接接入 Flink,直接在中间层用 Flink 做一些批处理或者流式计算的任务,把中间结果做进一步计算后输出到下游。 |







 订阅
订阅