| БрМЭЦМі: |
БОЮФжївЊЗжЮіЬжТлСЫbeansDBЕФЩшМЦКЭЪЕЯжЩЯЕФвЛаЉЙиМќММЪѕЃЌАќРЈЪ§ОнЮФМўзщжЏЁЂФкДцhash treeЫїв§ЕШ
ЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгк
жЊКѕ
ЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
ЫЕУї
BitcaskЪЧгЩBashoЬсГіЕФКЃСПаЁЮФМўДцДЂГЁОАЯТЕФНтОіЗНАИЃЌжївЊНтОівдЯТЮЪЬт:
1.ЖСаДЕЭбгГй
2.ЫцЛњаДЧыЧѓЕФДХХЬИпЭЬЭТСП
3.ЙЪеЯЪБЕФПьЫйЛжИДЧвВЛЖЊЪ§Он
4.ЪЙгУМђЕЅ
дкbitcaskЕФТлЮФЃЈЛђепЫЕИХвЊЩшМЦИќКЯЪЪЃЉжажївЊУшЪіСЫBitcaskЖдЮФМўДцДЂИёЪНЕФЖЈвхвдМАвЛаЉгХЛЏДыЪЉЁЃ
BeansDBЪЧDoubanВЮПМbitcaskТлЮФПЊЗЂЕФЪЪКЯгкdoubanЪЙгУГЁОАЕФКЃСПаЁЮФМўДцДЂЯЕЭГЁЃзїепDaviesЭЈЙ§НГаФЖРОпЕФЩшМЦКЭЩюКёЕФММЪѕЫЎЦННЋетвЛИДдгЕФЮЪЬтНтОіЕФБШНЯгХбХЃЌжЕЕУзаЯИЦЗЮЖвЛЗЌЁЃ
зїепдкИХвЊдФЖСbitcaskТлЮФКЭbeansDBдДТыЕФЛљДЁЩЯЗжЮіЬжТлСЫbeansDBЕФЩшМЦКЭЪЕЯжЩЯЕФвЛаЉЙиМќММЪѕЃЌАќРЈЪ§ОнЮФМўзщжЏЁЂФкДцhash treeЫїв§ЕШЁЃзюКѓЃЌзїепЬсГіздМКЕФПДЗЈвдМАздМКЕФвЛаЉвЩЛѓЃЌЯЃЭћгыИїЮЛФмвЛЦ№ЩюШыЬНЬжЁЃ
Ъ§ОнДцДЂ
змЬхМмЙЙ
BitcaskжївЊзХблНтОіКЃСПаЁЮФМўДцДЂЕФДцДЂадФмЕЭЯТЮЪЬтЃЌbeansDBзїЮЊЦфПЊдДАцБОЃЌЪЕЯжСЫbitcaskТлЮФжаЬсГіЕФНтОіЗНАИЁЃзїепDaviesНЋЦфЪЕЯжЕФИќгХбХЁЃ
ДгећЬхЩЯРДПДЃЌвЛИіBeansDBНјГЬНЋЙмРэЕФДцДЂПеМфЃЈПЩвдЪЧвЛПщДХХЬЛђепДХХЬЩЯФГИіФПТМЃЉзщжЏГЩвЛПУЪїзДНсЙЙЃЈЪїЕФЩюЖШПЩзїЮЊЦєЖЏВЮЪ§ЃЉЁЃЪ§ОнЮФМўБЛДцДЂдкзюЕзВуЕФФПТМЯТЃЌШчЯТЪЧВтЪдЛЗОГжавЛИіЕфаЭДцДЂХфжУЃК
hzdingkai2013@inspur1:~/workspace/beansdb-0.6/bin/bin/bean4/data$ tree
.
ЉРЉЄЉЄ 0
ЉІ ЉРЉЄЉЄ 0
ЉІ ЉРЉЄЉЄ 1
...
ЉІ ЉРЉЄЉЄ e
ЉІ ЉИЉЄЉЄ f
ЉРЉЄЉЄ 1
ЉІ ЉРЉЄЉЄ 0
ЉІ ЉРЉЄЉЄ 1
...
ЉІ ЉРЉЄЉЄ f
...
ЉРЉЄЉЄ f
ЉІ ЉРЉЄЉЄ 0
ЉІ ЉРЉЄЉЄ 1
...
ЉІ ЉРЉЄЉЄ f |
Цфжага256ИізгФПТМЃЈХфжУЕФЪїЩюЖШЮЊ2ЃЉПЩвдДцДЂЪЕМЪЮФМўЪ§ОнЁЃУПИізгФПТМЖдгІСЫвЛИіbitcaskЪЕР§ЃЌећИіbeansDBНјГЬдђгЩЖрИіbitcaskЪЕР§зщжЏЖјГЩЁЃЯТЭМФмНЯКУЕиЗДгГhstoreгыbitcaskЪЕР§жЎМфЕФЙиЯЕЃК

ЮФМўИёЪН
дкУПИіbitcaskЪЕР§ФкВПЃЌBeansDBВЩШЁСЫbitcaskТлЮФЖЈвхЕФЮФМўДцДЂИёЪНЃЌШчЯТЃК
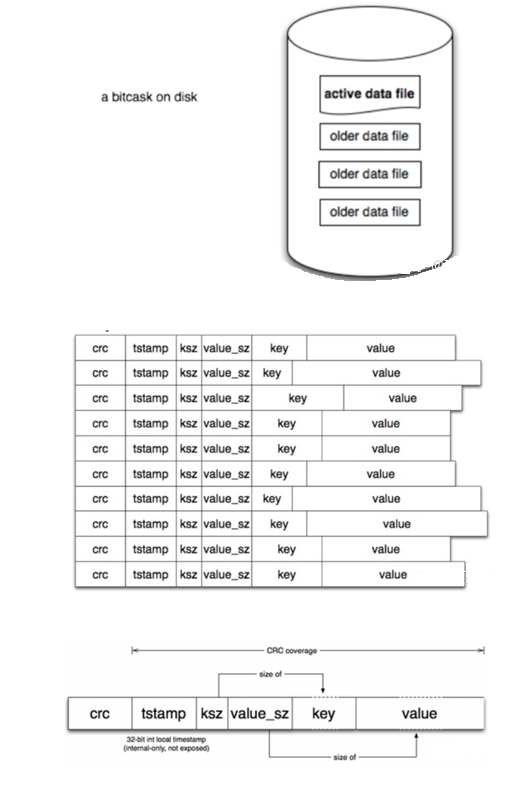
bitcaskЪЕР§ЬиЕу
УПИіФПТМЯТжЛгавЛИіЛюдОЮФМўЃЈЕБЧАПЩаДШыЃЉЃЌГЦЮЊ active data file ЃЌЦфЫћЮФМўГЦЮЊ older data file ЃЌжЛЖСВЛаД
УПИіЮФМўзїЮЊМЧТМБЛзЗМгаДШы active data file
ЮФМўЕФЩОГ§вВБЛзїЮЊвЛЬѕ record зЗМгжСactive data fileКѓУц
дЊЪ§ОнДцДЂ
bitcaskЩшМЦГѕждвтдкНтОіаЁЮФМўДцДЂЕФаЇТЪЕЭЯТЮЪЬтЃЌЖјаЁЮФМўДцДЂаЇТЪЕЭЯТЕФдвђГ§СЫЮФМўЫцЛњIOНЯЖрЭтЃЌЛЙШнвзгЩгкЮФМўЪ§СПЕФБЉеЧЖјЕМжТдЊЪ§Он(dentry/inode)ПЊЯњЕФдіДѓЃЌжБНггАЯьЖСаДаЇТЪЁЃ
ЮЊСЫНтОіИУЮЪЬтЃЌbitcaskНЋЮФМўвдШежОЗНЪНзЗМгжСbitcaskЪЕР§(ФПТМ)ЕФДѓЮФМўжаЃЌздМКЙмРэЮФМўЫїв§ЃЌМДЮФМўkeyжСдкДХХЬЮФМўЮЛжУвдМАЮФМўФкЦЋвЦЁЃbeansDBЮФМўдЊЪ§ОнИёЪНЮЊЃК

ЮЊНјвЛВНЬсИпадФмЃЌbitcaskЛсНЋЫљгадЊЪ§ОнЛКДцдкФкДцжаЃЌдкЖСЮФМўЪБжЛашвЊвЛДЮIOМДПЩЁЃ
ЮЊСЫФмНЋШчДЫжкЖрЕФЮФМўдЊЪ§ОнШЋВПЛКДцдкФкДцжаЃЌБиаыЕУОЁСПбЙЫѕУПИіЮФМўЕФдЊЪ§ОнзжНкЪ§ЃЌbeansDBдкетЗНУцПЩЮНПраФЙТвшЃК
struct t_item {
uint32_t pos; // Ъ§ОнМЧТМдкШежОЮФМўЦ№ЪМЦЋвЦ
int32_t ver; // Ъ§ОнМЧТМАцБОКХ
uint16_t hash; // Ъ§ОнМЧТМhash
uint8_t length; // keyЕФГЄЖШ
char key[1]; // keyЕФЪЕМЪжЕ
}; |
етРяПДЕНвЛИіКмЦцЙжЯжЯѓОЭЪЧетРяУЛгаМЧТМЮФМўБЛДцДЂЫљдкЕФДѓЮФМўidЃЈдкbeansDBФкгазЈУХГЦКєЮЊ bucket ЃЉЁЃетЦфЪЕЪЧбЙЫѕдЊЪ§ОнДцДЂПеМфЕФМЋКУР§згЃК beansDBНЋposЕФЕЭ8ЮЛгУРДДцДЂbucket id ЁЃ
етбљУПИіbitcaskЪЕР§ФкБуПЩвдзюЖрДцДЂ256ИіbucketЁЃИп24ЮЛБугУРДДцДЂbucketФкЦЋвЦЁЃУПИіbucketДѓаЁвЛАуЖЈвхЮЊ2GBЃЌетбљУПИіbitcaskЪЕР§зюДѓжЇГжЕФДцДЂПеМфЮЊ512GBЃЌЭзЭзЕФЃЁ
ИљОнЩЯУцЕФЖЈвхЮвУЧДѓжТПЩвдМЦЫуГіУПИіЮФМўдЊЪ§ОнеМОнЕФзмДцДЂПеМфsize = 4B + 4B + 2B + 1B + size(key) = 11B + size(key)ЃЌПЩвдЫЕвбОКмаЁСЫЃЌАДее20B/ЮФМўМЦЫуЃЌ100MBИіЮФМўвВжЛеМгУдМ2GBФкДцЁЃ
Hash tree
BeansDBЪЙгУСЫhash treeРДДцДЂbitcaskЪЕР§ЕФдЊЪ§ОнЁЃЪЙгУЪ§зщЪЕЯжСЫ16Вцhash tree
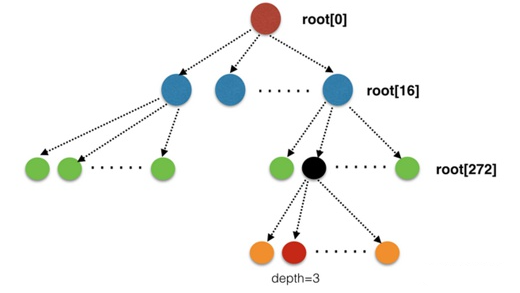
жЎЫљвдЪЙгУhash treeЕФжївЊдвђгаЖўЃК
РрЫЦгкЦеЭЈЕФЙўЯЃзжЕф, БЃДц key вдМАЫќдкДХХЬжаЕФЮЛжУ, ЗНУцПьЫйЗУЮЪ.
ПЩПьЫйБШНЯСНИіДцДЂНкЕужаЕФФкШнЪЧЗёвЛжТ, НЋЫљга key АДееЦфЙўЯЃзщжЏГЩЪї, ЭЌЪБ НкЕуЕФЙўЯЃЪЧзгНкЕуЕФЙўЯЃЕФЙўЯЃ , етбљПЩвдПьЫйБШНЯВЂевГіВювь.
ЙиМќСїГЬ
дкетРяВЂВЛДђЫувЛвЛУЖОйAPIЪЕЯжЃЌжЛвдBeansDBЮЊР§ДѓжТУшЪіЦфКЫаФAPIЕФФкВПСїГЬЁЃ
Put
1.ИљОнkeyЖЈЮЛИУЗЂЭљФФИіДцДЂФПТМЃЈbitcask instanceЃЉЃЛ
2.дкbitcaskЕФhash treeжаИљОнkeyВщевЖдгІЕФItemЪЧЗёДцдкЃЌШчЙћДцдкЃЌЫЕУїЪЧupdateЃЌМЧТМЯТдЪМАцБОКХ(oldv)ЃЛ
3.ИљОндЪМАцБОКХвдМАИќаТРраЭОіЖЈаТАцБОКХЃЛ
4.ЮЊвЊаДШыЕФЪ§ОнМЦЫуhashЃК uint16_t hash = gen_hash(value, vlen) ЃЛ
5.ШчЙћВНжш2ЕУЕНЕФitemВЛЮЊnullВЂЧвЕБЧАаДШыЪ§ОнКЭвбОДцдкЪ§ОнЃЈИљОнВНжш4МЦЫуЕФhashжЕЖдБШЃЉЪЧвЛбљЕФЃЌФЧЦфЪЕЪВУДвВВЛгУзіЃЌжБНгЗЕЛиМДПЩЃЛ
6.ЗжХфаТЕФDataRecordВЂГѕЪМЛЏЃЌвдШнФЩвЊаДШыЕФаТЪ§ОнЃЛ
7.НЋ6ЗжХфЕФDataRecordаДШыbitcaskЕФЛКДцbufferЃЌ ЕШД§КѓајЖЈЦкsyncЕНШежОЮФМў(bucket)ЃЛ
8.дкbitcaskЕФhash treeжаВхШыЛђИќаТИУМЧТМЕФдЊЪ§ОнаХЯЂВЂЗЕЛиГЩЙІ
ЫЕУїЃК
дкbeansdbЕФЪЕЯжжаЃЌУПИіbitcaskЪЕР§гаСНИіhash treeЃЌШЋОжЕФhash treeКЭЕБЧАе§дкаДШыbucketЕФhash treeЁЃетУДзіЕФдвђЪЧЮЊСЫМгПьЩњГЩhint fileЕФЫйЖШЁЃПЩВЮПМ bc_rotate ЕФДњТыЁЃвђДЫЃЌдк8ЕФВхШыhash treeЪБКђашвЊЗжБ№ВхШыетСНПУЪї
ЩЯУцЕФаДЙ§ГЬЖМЪЧдкbitcaskЕФаДЫјБЃЛЄжЎЯТЭъГЩЕФ pthread_mutex_lock(&bc->write_lock) ЁЃетЛсВЛЛсГЩЮЊадФмЦПОБЃПгІИУВЛжСгкЃЌвђЮЊШЋЪЧФкДцВйзїЃЁ
ВНжш7жаПЩФмаДШыBitcaskЪЕР§ЕФФкДцЛКГхЧјПЩФмОЭЗЕЛиСЫЃЌ ЧБдкЗчЯеЃЁ
Get
ИљОнkeyЖЈЮЛДцДЂФПТМ(bitcask instance)ЃЛ
дкbitcaskЕФhash treeжаВщИУkeyЖдгІЕФItemЪЧЗёДцдкЃЌВЛДцдкдђЗЕЛиnull
ХаЖЯitemжаМЧТМЕФbucket id(pos & 0xff)ЪЧЗёЪЧЕБЧАе§дкаДШыЕФbucketЃЌШчЙћЪЧЯШХаЖЯвЊЖСШЁЕФЪ§ОнЪЧЗёдкФкДцЛКГхЧјЃЛ
ЗёдђИљОнpos & 0xffffff00ДгЯргІЕФbucketжаЖСГіЪ§ОнВЂЗЕЛиЁЃ
Delete
deleteЕФСїГЬгыputвЛжТЃЌжЛЪЧЦфversionЩшжУЮЊ-1ЁЃБъМЧЮЊЩОГ§ЃЌгые§ГЃЕФputЧјБ№дкгкЃК
valueжЕЮЊПеЃЛ
аТЕФDataRecordЕФАцБОЮЊ-oldversion - 1ЃЌЮЊИКжЕЃЛ
ЫЕУї
deleteЕФЪБКђВЂУЛгаНЋМЧТМЕФдЊЪ§Он(Item)Дгhash treeжаЩОГ§ЃЛЖјЪЧгаИіКѓЬЈЯпГЬЛсзіЖЈЦкбЙЫѕЃЈНЋversion<0ЕФЕФдЊЪ§ОнМЧТМЩОЕєЃЉЁЃетбљЩшМЦЕФжївЊРэгЩЮвЯыПЩФмЪЧБмУтдкЩОГ§ЕФЪБКђЖдhash treeзїЕїећАЩЁЃКѓЬЈбЙЫѕЕФЪЕЯжПЩВЮПМ bc_optimize ЁЃ
МИИіЙиМќЮЪЬт
ФкДцЪЙгУ
етИіЮвУЧдкЧАУцДѓжТЙРЫуЙ§ЃЌ2GBЕФФкДцПЩДѓдМДцДЂ100MИіЮФМўЃЌгыbeansDBзїепЕФЩшМЦФПБъВюВЛЖрЃЌБШBitcaskФкДцРћгУаЇТЪИпЁЃ
вьГЃЛжИД
ЮЊСЫНтОіBeansDBЩшМЦдкНјГЬвьГЃЭЫГіЪБУПИіbitcakЪЕР§ЖМашвЊДгДХХЬЛжИДФкДцЮФМўгГЩфБэЃЈkey->дЊЪ§ОнЃЉЖјВЛЕУВЛЖСШЁДѓСПЪ§ОнЕФЮЪЬтЁЃbitcaskЛсНЋУПИіДѓЮФМў(bucket)ЩњГЩвЛИіЫїв§ЮФМўhintfileЃЌЦфЪЕЪЧИУbucketФкЫљгаЮФМўдЊЪ§ОнЕФвЛЗнДХХЬdumpЁЃ
ЧАУцЮвУЧПДЕНдкаДШыbitcaskЪЕР§ЪБГ§СЫаДШыbitcaskШЋОжЕФhash treeЭтЛЙаДШыСЫвЛПУcurrent hash treeЃЌетБуЪЧЕБЧАЛюдОbucketЕФдЊЪ§ОнЪїЃЌдкbucketаДТњЙиБеЪБдкКѓЬЈгЩФкДцdumpжСДХХЬжаЁЃЯыЗЈЗЧГЃздШЛЃЌЪЕЯжЗЧГЃгХбХЁЃ
МДБуШчДЫЃЌгЩгкУПИіbitcaskЪЕР§жаЫїв§ЮФМўПЩФмвВБШНЯЖрЃЈМйШчАДееУПИіbitcaskЙмРэ256GBДХХЬПеМфЃЌЖјУПИіЮФМўЦНОљДѓаЁЮЊ128KBМЦЫуЃЌУПИіbitcaskзмЕФЮФМўЪ§СПдМЮЊ2MЃЌЖјУПИіЮФМўдЊЪ§ОнСПдМЮЊ20BЃЌдђУПИіbitcaskЪЕР§ЕФдЊЪ§ОнзмСПдМЮЊ40MBЃЌМДУПИіbitcaskЕФдЊЪ§ОнЛжИДЪБМфвВБШНЯПьЃЌШЁОігкдЊЪ§ОнIOЫйЖШЃЉЃЌМДЪЙгаЖрИіbitcaskЪЕР§ЃЌЮвУЧвВПЩвдВЩШЁВЂааЛжИДЃЈУПИіbitcaskЪЕЧ€ааЕиЖСГідЊЪ§ОнЃЌЙЙНЈhash treeЃЉЕФВпТдРДЬсЩ§ЛжИДаЇТЪЁЃ
Ъ§ОнПЩППадвдМАгЩДЫв§ГіЕФвЛжТадЬжТл
БОЦЊжївЊЬжТлbeasdbШчКЮгХбХЪЕЯжСЫbitcaskЖЈвхЕФДцДЂИёЪНЁЃЮвУЧВЂУЛгаЬжТлЮФМўЪ§ОнЕФПЩППадвдМАВЩгУЖрИББОВпТдБЃжЄПЩППадЪБЕФвЛжТадЮЪЬтЁЃзїепДњТыжавВУЛЯрЙиФкШнЁЃ
ДѓИХВТВтЃК
ЪзЯШЩЯВуЩшжУproxyЃЌНЋаДЧыЧѓзЊЗЂжСЖрИББОЃЌЖрИББОШЋВПаДШыВХЫуГЩЙІЃЛ
ШчЙћЗЂЩњаДвьГЃЃЌжБНгЭЈЙ§ЭЌВНhash treeРДзіЪ§ОнЭЌВНМДПЩЃЌПЩВЮПМЧАУцЫЕЕФhash treeЬиадРДРэНтЁЃ
beansDBДцДЂгІгУ
ИљОнзїепЕФВЉПЭЭИТЖЃЌbeansDBФПЧАдкdoubanжївЊгаСНЬзДцДЂМЏШКЃКвЛЬзДцДЂжюШчЭМЦЌЁЂШеМЧЕШМЋаЁЮФМўЃЌЖјСэЭтвЛЬзДцДЂжюШчвєРжЁЂЪгЦЕЕШНЯДѓЮФМўЃЌЮвЕЙЪЧКмКУЦцЖдгквЛаЉГЌДѓЮФМўЃЈШчГЌЙ§зюДѓbucketЕФЯожЦЃЉЃЌbeansDBШчКЮДІРэЃПВТВтДѓИХЪЧгІгУВуЧаЦЌЁЃ
ПЩФмЖЊЪ§Он
гЩгкbeansDBдкаДШыЪБжЛЪЧаДЛКГхЧјМДЗЕЛиЃЌвђДЫЃЌПЭЛЇЖЫМДЪЙЕУЕНаДГЩЙІЕФНсЙћвВВЛвЛЖЈБЃЯеЁЃОнЩчЧјгаШЫЗДгГЃЌШЗЪЕЖЊЪ§ОнСЫЁЃ
гыDaviesНЛСїЙ§етИіЮЪЬтЕУжЊBeansDBжЇГжвьВНЪ§ОнЫЂаТЃЌЧвдкЩњВњЛЗОГжаЭЈЙ§ЖрИББОВпТдРДМѕЩйЖЊЪ§ОнЗчЯеЁЃ
Ъ§Онmerge
гЩгкbeansdbЕФЩОГ§НіЪЧТпМЩОГ§ЃЌЦфЪЕМЪЮяРэЪ§ОнвРШЛДцдкЃЌвђДЫЃЌашвЊКѓЬЈШЮЮёЖЈЦкЖдРЌЛјЪ§ОнНЯЖрЕФbucketзїПеМфЛиЪеЃКmergeЁЃ
beansDBжаЕФmergeвВБШНЯМђЕЅЃКЫГађЩЈУшУПИіbucketЁЃЩЈУшЦфhash treeЕФУПИіМЧТМЃЌВщевЦфдкШЋОжhash treeжаЪЧЗёвРШЛгааЇЃЌШчЙћЮоаЇЃЌИУМЧТМПеМфМДПЩБЛЛиЪеЁЃ
merge ЕФЪБКђ, ЖдЕБЧАmergeЕФbucketЛсЩњВњвЛИіаЁЕФhash tree, ЖдгІаТЩњВњЕФЪ§ОнЮФМўЁЃвЛИіЪ§ОнЮФМў merge ЭъГЩКѓ, ЛсЫјзЁаД, ВЂетИіаЁЕФhash treeЕФФкШнИќаТЕНжїЬх hash tree жа, етИіЙ§ГЬЪЧMlogN ИДдгЖШЕФФкДцВйзї, NЪЧвЛИіbucket ЕФМЧТМЪ§, M ЪЧЕБЧАЪ§ОнЮФМўЕФМЧТМЪ§, MвЛАудк1MвдФк, ИќаТгІИУФмдк 1s зѓгвЕФЪБМфФкЭъГЩЁЃ
Ъ§ОнНсЙЙ
Item
typedef struct t_item Item;
struct t_item {
uint32_t pos; // Ъ§ОнМЧТМдкШежОЮФМўЦ№ЪМЦЋвЦ
int32_t ver; // Ъ§ОнМЧТМАцБОКХ
uint16_t hash; // Ъ§ОнМЧТМhash
uint8_t length; // keyЕФГЄЖШ
char key[1]; // keyЕФЪЕМЪжЕ
}; |
ItemДњБэСЫУПИіЪ§ОнМЧТМ(ЮФМў)ЕФдЊЪ§ОнаХЯЂЃЌБЛДцДЂдкbeansdbЕФhash treeЕФУПИівЖзгНкЕу(node)ЩЯЁЃ
Node
typedef struct t_node Node;
struct t_node {
uint16_t is_node:1; // ЪЧЗёЪЧжаМфНкЕу
uint16_t valid:1;
uint16_t depth:4; // НкЕуЩюЖШ
uint16_t flag:9;
uint16_t hash; // node hash value ?
uint32_t count; // НкЕужагааЇЪ§ОнЯюИіЪ§
Data *data; // НкЕужаДцДЂЕФЪЕМЪЪ§ОнЯю
}; |
NodeЪЧhash treeжаЕФУПИіНкЕуЕФЪ§ОнНсЙЙЁЃ
Data
typedef struct t_data Data;
struct t_data {
int size;
int used;
int count; // ItemЪ§зщЕФЪЕМЪДѓаЁ
Item head[0];
}; |
DataЪЧНкЕуNodeжаЪЕМЪДцДЂЕФЪ§ОнЁЃИУЪ§ОнЪЧгЩItemзщГЩЕФЪ§зщЁЃ
DataRecord
typedef struct data_record {
char *value; // Ъ§ОндкФкДцжаЕФжИеы
union {
bool free_value; // free value or not
uint32_t crc;
};
int32_t tstamp;
int32_t flag;
int32_t version;
uint32_t ksz;
uint32_t vsz;
char key[0]; // ЪЕМЪkeyжЕ
} DataRecord; |
DataRecordЪЧЪЕМЪДцДЂдкШежОЮФМўЕФЪ§ОнМЧТМЕФИёЪНЁЃУПИіЪ§ОнМЧТМАДееИУИёЪНБЛвЛЬѕЬѕзЗМгжСШежОЮФМўжаЁЃ
bitcask_t
struct bitcask_t {
uint32_t depth, pos;
time_t before;
Mgr *mgr;
// ЕБЧАе§дкаДШыКЭШЋОжЕФhash tree
HTree *tree, *curr_tree;
int last_snapshot;
int curr; // ЕБЧАе§аДШыЕФbucket
uint64_t bytes, curr_bytes;
// аДЛКГхЧјЃЌаДШыМЧТМЯШаДШыЛКГхЧј
// ЛКГхЧјТњЪБдйflushжСШежОЮФМў
char *write_buffer;
time_t last_flush_time;
uint32_t wbuf_size, wbuf_start_pos, wbuf_curr_pos;
pthread_mutex_t flush_lock, buffer_lock, write_lock;
int optimize_flag;
}; |
|









