| БрМЭЦМі: |
БОЮФНЋЛљгкCRISP-DMЃЈCross-Industry Standard Process
for Data MiningЃЉЗНЗЈТлЃЌВћЪіЙЄвЕДѓЪ§ОнГЁОАЯТЕФЬєеНМАзіЗЈЃЌвдЦкЖдЙЄвЕДѓЪ§ОнЪЕМљЬсЙЉвЛЕуВЮПМЁЃЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкЮЂаХЙЋжкКХРЅТиЪ§ОнK2DataЃЌгЩLindaБрМЁЂЭЦМіЁЃ |
|
ЧАгЩ
дкгыЙЄвЕНчНЛСїжаЃЌЖрДЮБЛЮЪЕНЙЄвЕДѓЪ§ОнЕФЪЕМљЗНЗЈТлЁЃОЭЮвИіШЫЖјбдЃЌВЛЯВЛЖЙ§ЖрЬИТлЗНЗЈТлЃЈаавЕЖДВь/ЪЕМљОбщ/ФкШнЛ§Рл/ЮЪЬтРэНтБШЗНЗЈИќживЊЃЉЃЌИќВЛдИвтдйЬсГівЛжжаТЕФЗНЗЈТлЁЃдкгыЭѕНЈУёЁЂЙљГЏъЭЕШзЈМвЕФНЛСїжаЩюЪмДЅЖЏЃЌБивЊЕФСїГЬЪсРэЖдаЕїДѓМвЕФШЯЪЖКЭааЖЏЛЙЪЧКмживЊЃЌЫфШЛУЛгаБивЊдйЁАДДдьЁБвЛЬзШЋаТЕФЗНЗЈТлЁЃвђДЫЃЌБОЮФНЋЛљгкCRISP-DMЃЈCross-Industry
Standard Process for Data MiningЃЉЗНЗЈТлЃЌВћЪіЙЄвЕДѓЪ§ОнГЁОАЯТЕФЬєеНМАзіЗЈЃЌвдЦкЖдЙЄвЕДѓЪ§ОнЪЕМљЬсЙЉвЛЕуВЮПМЁЃ
дкCRISP-DMКЭДЋЭГЩЬвЕЪ§ОнЗжЮіжаЃЌЗжЮіЬтФПМйЩшЪЧЪТЯШИјЖЈЕФЃЌзїЮЊвЕЮёРэНтНзЖЮЕФЧАжУЪфШыЃЌМДЗжЮіЬтФПЭЈГЃгЩвЕЮёЗжЮіЪІЃЈBusiness
AnalystЃЉЛђвЕЮёВПУХЖЈвхЬсЙЉИјЪ§ОнЗжЮіЪІ(Data Analyst)ЁЃЕЋдкЙЄвЕЪЕМљжаЃЌЭЈГЃКмФбЪЕЯжетбљЧхЮњЕФЗжЙЄЁЃдкЬжТлCRISP-DMжЎЧАЃЌЯШзмНсвЛЯТЙЄвЕЦѓвЕЖдДѓЪ§ОнЕФвЛаЉГЃМћЮЪЬтЃЌЛљгкетаЉЮЪЬтЃЌЬНЬжДѓЪ§ОнЗжЮіПЮЬтЪЖБ№ЮЪЬтЃЌШЛКѓдйЬжТлCRISP-DMЕФ6ИіНзЖЮжаЙЄвЕДѓЪ§ОнСьгђЕФЬєеНЁЂашЧѓгызіЗЈЁЃ
ЙЄвЕДѓЪ§ОнЗжЮіД№вЩ
ЫцзХЪ§ОнВЩМЏФмСІКЭМЦЫуФмСІЕФЗЂеЙЃЌЪ§ОнММЪѕдкЦѓвЕОгЊ/ЩњВњвЕЮёзЊаЭКЭЬсЩ§жаЗЂЛгзХживЊзїгУЁЃДѓЪ§ОнЗжЮізїЮЊЪ§ОнМлжЕБфЯжЕФКЫаФММЪѕЪжЖЮжЎвЛЃЌЦфзїгУЕУЕНГфЗжШЯПЩЁЃЕЋКмЖрМђНрЃЈЛђВЛДјЧАЬсЕФЃЉЕФаћДЋвВИјвЕНчДјРДСЫвЛаЉЮѓНтЁЃ

ДѓЪ§ОндкЩЬвЕСьгђвбОгаСЫВЛЩйКмКУЕФгІгУЁЃЙЄвЕзїЮЊвЛИіжиЩшМЦКЭЛњРэЕФСьгђЃЌДѓЪ§ОнШчКЮгІгУЃЌДѓМвЛЙгаВЛЩйвЩЮЪЁЃетРяСаОйСЫвЛаЉГЃМћЕФЮЪЬтКЭМђвЊНтЮіЃЌКѓУцНЋЯъЯИЬжТлЁЃ
Q
ашвЊЖрЩйЪ§ОнВХФмзіДѓЪ§ОнЗжЮіЃП
A
Ъ§ОнСПЕФПЭЙлашЧѓСПЃКЪ§ОнгыЮЪЬтЕФЦЅХфЃЈЖШСПжИБъЁЂЙиМќвђЫиЭъБИадЁЂЪ§ОнжЪСПЁЂе§/ИКбљБОЦНКтадЁЂЯШОжЊЪЖЕШЃЉ
вЕЮёШЫдБЖдЪ§ОнЛљДЁгаИіРэзЈвЕЕФШЯЪЖЃКЪ§ОнСПДѓВЛвтЮЖзХаХЯЂСПДѓ
Ъ§ОнЗжЮіЪІвЊШЯецЮёЪЕЃКШЯЪЖКЫЪЕЪ§ОнЃЌЕЋВЛвЊвЛЮЖвЊЧѓЪ§ОнСП
Q
ДѓЪ§ОнЗжЮіШчКЮЭЦНјЃП
A
ЙцЛЎЃКвЕЮёМлжЕЧ§ЖЏ+Ъ§ОнЛљДЁжЇГХ
жДааЃКвЕЮёзЈМвгыЪ§ОнЗжЮіЕФаЭЌ
Q
ДѓЪ§ОнЗжЮіЪЧВЛЪЧВЛашвЊвЕЮёКЭСьгђжЊЪЖЃП
A
ЙЄвЕДѓЪ§ОнИќашвЊСьгђжЊЪЖ
СЫНтЪ§ОнДгФФЖљРДЃПШчКЮВЩЕФЃПЪВУДЪБКђПЩаХЃП
СьгђжЊЪЖШЅЯИЛЏНтПеМфЃЌНЕЕЭЖдЪ§ОнСПЕФвЊЧѓ
СьгђОбщжИЕМЬиеїЬсШЁЃЌЬсИпЫуЗЈЕФЧѓНтаЇТЪЃЌЬсИпФЃаЭЕФПЩНтЪЭад
ИќШЋУцПЭЙлЦРЙРФЃаЭЕФЪЪгУЗЖЮЇ
Q
ЪВУДбљЕФФЃаЭЪЧвЛИіКУФЃаЭ
A
ПЩБЛвЕЮёгУЛЇЯћЗб(consumable)
МЋМђддђЃКдкБЃжЄадФмТњзуЕФЧАЬсЯТЃЌЫуЗЈдНМђЕЅдНКУ
ПЩПиадЃКУїШЗИјГіЪВУДЪБКђФЃаЭВЛЪЪгУ
Q
ЮЊЪВУДКмЖрЁАПЊЯфМДгУЁБЫуЗЈУЛгааћДЋЕУФЧУДКУгУ
A
дкЗжЮіЪЕеНжаЕФживЊЖШХХађЃКЖЈвхвЛИіКУЮЪЬт>ећРэЭъБИПЩППЕФЪ§Он>МгЙЄКУЕФЬиеїБфСП>ЫуЗЈ
ШЮКЮЫуЗЈЖМгавЛЖЈЪЪгУЧАЬсЃЈСЫНтЪВУДЪБКђФЃаЭВЛЪЪгУБШС§ЭГЕФадФмжИБъгаЪБКђЛЙживЊЃЉЃЌашвЊбЯИёЕФВтЪдбщжЄ
Q
ЙЄвЕДѓЪ§ОнЗжЮіашвЊЪВУДбљЕФДѓЪ§ОнЦНЬЈ
A
ПЊЗЂНзЖЮЃК
1ЃЉЬсЙЉШЋЮЌЖШЪ§ОнЙиСЊВщбЏЃЈЪБађЪ§ОнЁЂвЕЮёЪ§ОнЁЂЗЧНсЙЙЛЏЪ§ОнЕШЃЉЃЛ
2ЃЉжЇГжПьЫйЕќДњЃЈжЇГХR/Python/MatlabЕШЙЄвЕНчГЃгУЙЄОпЃЌжЇГжвбгаЕЅЛњЗжЮіГЬађЕФжигУЃЉ
ВПЪ№НзЖЮЃК
вЕЮёБеЛЗЃЌЖдЗжЮіФЃаЭНјааШЋЩњУќжмЦкЙмРэ
ЗжЮіЬтФПЕФЪЖБ№гыЙцЛЎ
ЗжЮіЬтФПЪЖБ№ЕФЧАЬсЪЧЖдаавЕКЭЦѓвЕЕФЛљБОУцгавЛИіШЋУцАбЮеЃЌГфЗжРћгУаавЕвбгаЕФВЮПМФЃаЭЃЈБШШчжЪСПЙмРэжаПЩвдВЮдФPDCAЁЂ6-sigmaЕШвбгаЕФВЮПМФЃаЭЃЉЁЃЯТУцДгЙЄвЕДѓЪ§ОнЗжЮіФмзіЪВУДКЭШчКЮНјаагХЯШМЖХХађСНИіЗНУцНјааЬжТлЁЃ
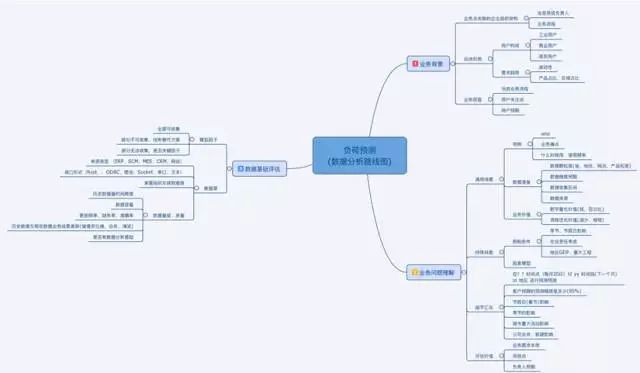
ЙЄвЕДѓЪ§ОнЗжЮіГЁОА
ЙЄвЕДѓЪ§ОнЕФЕфаЭЗжЮіГЁОАШчЯТБэЫљЪОЁЃ
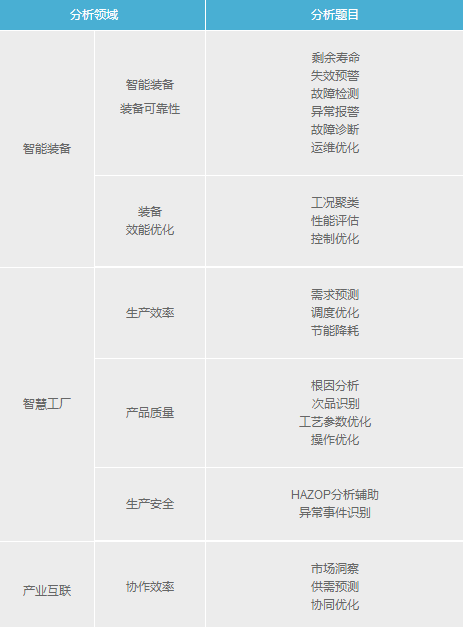
ВЛЭЌаавЕЕФВржиЕугаЫљВЛЭЌЃЌИпЖЫзАБИжЦдьвЕЖрЧПЕїЁАЗўЮёаджЦдьЁБКЭЁАжЧФмзАБИЁБЃЌЛЏЙЄаавЕдђЧПЕїЁААВЮШГЄТњгХЁАЃЌЕчзгаавЕвдВњЦЗжЪСПЮЊКЫаФЃЌЪЏгЭЪЏЛЏдђзЂжизЪВњЙмРэКЭЩњВњаЇТЪЬсЩ§ЁЃ
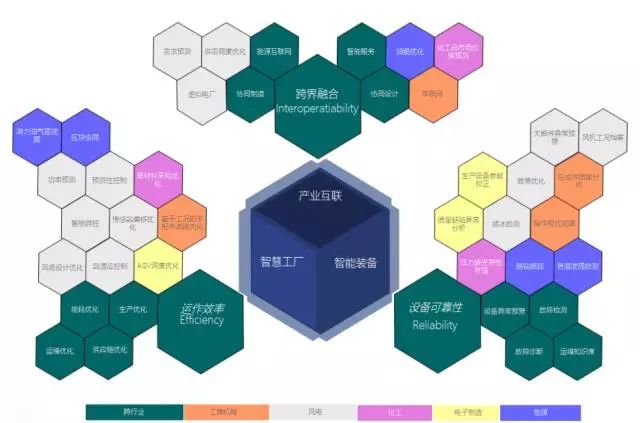
ДѓЪ§ОнЗжЮіЙцЛЎ
ДѓЪ§ОнЗжЮіЙцЛЎвЫВЩгУЁАвЕЮёЕМЯђ+Ъ§ОнЧ§ЖЏЁБЕФЗНЪНЃЈШчЯТЭМЫљЪОЃЉЁЃДгЙиМќвЕЮёФПБъЗжНтГіЗЂЃЌЙиСЊЕНОпЬхЕФвЕЮёСьгђЃЈбаЗЂЁЂНЈЩшЁЂдЫааЁЂдЫЮЌЁЂАВШЋЛЗБЃЁЂЯњЪлЁЂВЩЙКЕШЃЉЃЌДгживЊЖШКЭНєЦШЖШЕФНЧЖШЃЌЖдПЩФмЕФвЕЮёЗжЮіЮЪЬтНјааЦРЙРЁЃШЛКѓЃЌНсКЯГѕВНЕФвђзгЗжНтЃЌЦРЙРУПИіЬтФПЕФЫљашЪ§ОнЕФЭъБИЖШЃЈReadinessЃЉЁЃзлКЯвЕЮёМлжЕКЭЪ§ОнЭъБИЖШЃЌНјааЖрИіЯюФПЕФгХЯШХХађЁЃ

вЕЮёРэНтНзЖЮЃЈBusiness UnderstandingЃЉ
дкCRISP-DMЗНЗЈТлжаЃЌетвЛНзЖЮДгвЕЮёЕФНЧЖШРэНтЯюФПЕФФПБъКЭашЧѓЃЌВЂНЋЦфзЊЮЊвЛИіПЩНтЕФЪ§ОнЗжЮіЮЪЬтЃЌПЩВЩгУвЕЮёСїГЬНЈФЃЁЂОіВпНЈФЃЕШЗНЗЈЃЌЗжНтвЕЮёФПБъЃЌЗжЮівЕЮёгУР§ЃЈuse
caseЃЉЃЌРхЧхЙиМќвђЫиЃЌШЗЖЈЗжЮіЮЪЬтЕФЗЖЮЇ(scope)ЁЃ
ЙЄвЕЪ§ОнЗжЮіГЃГЃЪЧвЛИіжЊЪЖбЯжиЖўЗжЕФЧщаЮЁЃЪ§ОнЗжЮіЪІЖдЙЄвЕЙ§ГЬШБЗІЩюШыСЫНтЃЌЖјвЕНчШЫдБЖдЪ§ОнЗжЮіЕФСЫНтЯрЖдШБЗІЁЃПЩВЩгУШчЯТЫљЪіЕФШ§РраЮЪНЛЏФЃаЭЬсИпЙЕЭЈаЕїаЇТЪЁЃ
ЯЕЭГЩЯЯТЮФФЃаЭ(System Context)
дкЙиМќвЊЫиЗжЮіЩЯЃЌЙЄвЕЗжЮіЮЪЬтЕФЩЯЯТЮФЃЈContextЃЉФЃаЭКмживЊЃЌАќРЈЩњВњЁЂдЫзїЁЂЛЗОГЁЂЪБПеЕШЖрИіЗНУцЩЯЯТЮФЁЃжЛгаетбљЃЌЪ§зжПеМфВХПЩФмВПЗжЗДгІЮяРэПеМфЁЃ
дкзАБИжЦдьвЕЃЌBOMЃЈBill of MaterialЃЉЪЧСЫНтЩЯЯТЮФЕФвЛИіКУЕФЦ№ЕуЁЃР§ШчЃЌдкЗчЕчзАБИжЦдьвЕЃЌашвЊСЫНтЗчЛњЙЄзїЛњРэЁЂЗчЕчГЁвЕЮёдЫзїЛњжЦЁЂЩшБИЙиМќЖЏзїзДЬЌЃЈБШШчЦЋКНЖдЗчЁЂНтРТЁЂНЕЙІТЪдЫааЁЂБЃбјЁЂЙЪеЯЭЃЛњЕШЃЉЁЃжЛгаетбљЪ§зжПЩФмаЮГЩЖдЮяРэЪРНчЕФвЛИіЯрЖдЭъећЕФУшЪігыПЬЛЁЃ
дкСїГЬаавЕЃЌPFDЃЈProcess & Flowing DiagramЃЉЁЂPIDЃЈPiping
& Instrument DiagramЃЉетСНРрЭМКмживЊЃЌПЩвдАяЮвУЧСЫНтЯрЙиЛЏбЇ/ЮяРэЙ§ГЬЃЌвдМАЧАКѓЛЗНкЕФЯрЛЅгАЯьЃЈБШШчЃЌКѓУцЛЗНкЕФЗДгІЫйЖШЛсЭЈЙ§ЙмЕРбЙСІЗДЙ§РДгАЯьЧАжУЙЄађЕФЗДгІЬѕМўЃЉЁЃ
ЯЕЭГЖЏСІбЇФЃаЭ(System Dynamics)
ЯжЪЕжаВЂЗЧЫљгавђЫиЖМгаЪ§ОнжЇГХЛђжБНгПЩвдВйПиЕФЁЃДгПЩВйПиадКЭПЩЙлВтадСНИіЮЌЖШНЋContext modelжавђЫиНјааПЬЛЃЌШчЯТБэЫљЪОЃК

ЛљгкетбљЕФЗжРрЃЌаЮГЩЗжЮіЮЪЬтЙ§ГЬЕФвђзгЖЏСІбЇЙиЯЕЭМЃЌШчЯТЭМЫљЪОЃЈЮЊЭЛГіЗжЮіФПБъЃЌЬиБ№НЋФПБъСПБъГіЃЉЁЃЖдгкЭтЩњБфСПЃЈЬиБ№ЪЧВЛПЩЙлВтЕФЃЉЫфШЛЮвУЧЮоЗЈжБНггХЛЏЃЌЕЋжСЩйЧхЮњЬсабСЫЗжЮіФЃаЭЕФЪЪгУЧАЬсЁЃ
вЕЮёгУР§ЃЈUse Case/ScenarioЃЉ
ЙЄвЕЗжЮіЮЪЬтЖЈвхЕФвЛИіживЊФкШнОЭЪЧЛиД№ЫРДгУЁЂЪВУДЪБКђгУЁЂШчКЮгУЁЃЯЕЭГгУР§ОЭЪЧетЗНУцЕФвЛИіКУЙЄОпЁЃдкПЬЛвЕЮёгУЛЇЁЂвЕЮёСїГЬЕФЛљДЁЩЯЃЌЗжЮівЕЮёЖдЗжЮіФЃаЭЕФКЫаФашЧѓЃЌДгЖјШЗЖЈЗжЮіФЃаЭЕФЖШСПжИБъЁЃБШШчЃЌдкГщгЭЛњЙЪеЯМьВтжаЃЌХаЖЯЛњЦїзДЬЌЪЧЗёе§ГЃЃЌШєвьГЃЃЌИјГіЙЪеЯРраЭЁЃвЕЮёашЧѓЪЧНЕЕЭвЛЯпМрВтШЫдБЕФЙЄзїСПЃЌЖјВЛЪЧМђЕЅЕФОіВпжЇГжЁЃОЋЖШДяЕН99%ЕФЗжЮіФЃаЭвВУЛгаЖрДѓгУЃЌЮоЗЈжИУїФФ1%ЪЧДэЮѓЕФЃЌЛЙЪЧашвЊШЋЪБЕФШЫЙЄЩѓВщЃЌЛЙВЛШчвЛИіФЃаЭПЩвдЭъШЋзМШЗЕФХХГ§30%ЕФбљБОЃЌЦфгрЕФ70%СєИјШЫШЅХаЖЯЃЌЛђЬсЙЉГѕХаНсЙћЃЌжСЩйНкЪЁСЫ30%ЕФЙЄзїСПЁЃ
етвВОЭЪЧЪ§ОнЗжЮіжаГЃЬИЕФЮѓБЈЁЂТЉБЈЕФЮЪЬтЃЌЕЋКЭОЕфNЗжРрЮЪЬтЃЈNжжзДЬЌРраЭЃЌАќРЈе§ГЃзДЬЌКЭN-1РрЙЪеЯзДЬЌЃЉДцдквЛЕуЮЂУюЧјБ№ЃЌЯжГЁдЫзїдЪаэЗжЮіФЃаЭЪфГі(N+1)РрзДЬЌЃЈЕкN+1РрЪЧВЛШЗЖЈзДЬЌЃЉЃЌНЋЧАNРрХаБ№ГЩN+1РрЕФГЭЗЃКмаЁЃЈПЩвдСєИјШЫШЅДІРэЃЉЃЌЕЋЧАNРрМфЕФЮѓХаЪЧВЛдЪаэЕФЃЈФЃаЭИјГіЕФНсЙћвЛЖЈЪЧе§ШЗЕФЃЉЁЃ
СэЭтЃЌвЕЮёгУР§ЕФЗжНтвВПЩвдАяжњДѓМвРэадЕФЫМПМвЕЮёЮЪЬтЃЌБмУтШЫЮЊЕФЁАДДдьЁБММЪѕЬєеНЁЃКмЖрдРДПДЦ№РДЪєгкЁАЙЪеЯдЄВтЁАЕФвЕЮёашЧѓЃЌвВаэЁБЙЪеЯЕФМАЪБМьВтЁАОЭПЩвдТњзуЃЌЕЋСНепдкММЪѕФбЖШЩЯВюБ№ПЩФмКмДѓЁЃ
БШШчЃЌЖдгкЗчЛњЗЂЕчЛњНсБљЮЪЬтЃЌНсБљдЄВташвЊаЁГпЖШЕФЬьЦјдЄБЈЃЌШєзіЕНЗчЛњВуУцЕФдЄВтЛЙашвЊвЖЦЌБэУцЙтНрЖШЕШаХЯЂЃЈЗёдђЃЌНтЪЭВЛСЫЦНдЗчГЁЕФ3ЬЈЯрСкЕФЗчЛњЃЌжЛга1ЬЈНсБљЃЌСэЭт2ЬЈУЛгаНсБљЕФЯжЯѓЃЌет3ЬЈЗчЛњЭЌаЭКХЭЌЪБЦкНЈЩшЃЌЕиаЮКЭжмБпЛЗОГвВМИКѕвЛбљЃЉЁЃЕЋзіЕННсБљМьВтЛљгкSCADAЗчЛњзДЬЌЪ§ОнОЭПЩвдзіЕУБШНЯзМШЗЁЃДгвЕЮёгУР§ЗжЮіРДПДЃЌЗчГЁдЫЮЌашвЊЪЧЃКФмдкЗчЛњбЯжиНсБљЧАВЩШЁЪЪЕБДыЪЉЃЌБмУтИпдиКЩЯТдЫааЖдЗчЛњдьГЩЫ№КІЁЃМАЪБЕФНсБљМьВтБЈОЏвВПЩвдТњзувЕЮёашЧѓЁЃ
ЗжЮіЮЪЬтЕФЙцдМ
Ъ§ОнЗжЮіЪЧЪжЖЮЃЌЖјВЛЪЧФПЕФЃЌАбЪ§ОнЗжЮіЗНЗЈгІгУдквЛИіЧЁЕБЕФЮЛжУНтОівЛИігаМлжЕЕФЪЕМЪЮЪЬтВХгавтвхЁЃИљОнЩЯУцЕФЗжНтЃЌПЩГѕВНАбЮЪЬтЙцдМЕНЫФжжРраЭЮЪЬтЃЌВЛЭЌЮЪЬтЕФгІгУЧАЬсКЭашвЊНтОіЕФЬєеНвВТдгаВЛЭЌЁЃ
БОЮФжиЕуЬжТлЪ§ОнЭкОђРрЃЈМДЯСвхЕФЪ§ОнЗжЮіЗЖГыЃЉЃЌвВЪЧCRISP-DMЗНЗЈТлЕФВржиЕуЁЃ
Ёё ЭГМЦРрКЭзЈМвжЊЪЖздЖЏЛЏЕФашЧѓЃЌжївЊЪЧЖдЙЄвЕДѓЪ§ОнЦНЬЈЕФвЊЧѓЃЈЖрРраЭЪ§ОнЕФгаЛњШкКЯЁЂвдЩшБИ/ЙЄвеЮЊжааФЕФШЋЮЌЖШЪ§ОнВщбЏв§ЧцЁЂЗЧЧжШыЪНЕФЪ§ОнЗжЮіВЂааЛЏЕШЃЉЃЌПЩВЮдФЮФЯз3ЃЌ4
ЁЃвЕЮёШЫдБИјГівЕЮёТпМЃЌЭЈГЃВЛЭъБИЁЂВЛШЗЖЈЃЌашвЊРћгУДѓЪ§ОнНјааОЋЯИЛЏЃЌБШШчЃЌЁАДцдк2HzЕФжїеёЖЏЗжСПЁБЕФвЕЮёТпМвбОЗЧГЃУїШЗЃЌЕЋдкБфГЩПЩздЖЏЛЏжДааЕФв§ЧцЧАЃЌвЊЯИЛЏЁА2HzЁБЕФЗЖЮЇЧјМфЁЂЁАжїЗжСПЁАЃЈеМзмФмСПЕФ15%жЎЩЯЃПЛЙЪЧБШЕкЖўИпЗжСПИп5БЖЃПЃЉЕФЖЈвхЁЃ
Ёё ДѓЪ§ОнЧщаЮЯТЕФдЫГягХЛЏКЭОЕфЕїЖШдкММЪѕЬєеНЩЯУЛгаБОжЪЧјБ№ЃЌЙиМќЪЧШчКЮЖЈвхвЛИіКЯЪЪЕФЗЖЮЇЃЌКмЖрвЕЮёвђЫиШБЗІЪ§ОнжЇГХЁЂКмЖрвЕЮёТпМгУЪ§бЇЙцЛЎгябдУшЪіЬЋИДдгЃЈПЩвдгУЙцдђЃЉЁЂдМЪјЫЩГкТпМИДдгЃЌЪЕМЪжаГЃВЩгУЁАЙцдђ+Ъ§ОнЙцЛЎЁБЕФЗНЪНШЅЧѓНтЁЃДѓЪ§ОнЮЊдЫГягХЛЏЬсЙЉСЫИќЖрЕФЛљДЁЪ§ОнЃЈБШШчЃЌГЩБОНсЙЙЁЂЬьЦјаХЯЂЁЂЕРТЗНЛЭЈСїСПЃЉКЭдЄВтадаХЯЂЃЈШчашЧѓдЄВтЃЉЕФжЇГжЃЌЖјетаЉКЭЪ§ОнЭкОђРрЮЪЬтЪЧвЛжТЕФЁЃ

зюКѓЃЌгІИУГфЗжШЯЪЖЕНЪ§ОнЗжЮіЕФЕќДњадЁЃдкдчЦкЃЌЖдЮЪГЁОАЁЂвђЫиЕФШЯЪЖКмФбЭъБИЃЌЪЕМЪЪ§ОнгыМйЩшЪЧЗёЯрЗћгаД§бщжЄЁЃетаЉВЛШЗЖЈадЖМСєИјКѓУцЕФНзЖЮЃЌжЛгаОЙ§ЖрДЮЕќДњВХгаПЩФмаЮГЩЯрЖдЭъБИЕФЮЪЬтРэНтЁЃ
Ъ§ОнРэНтЃЈData UnderstandingЃЉ
Ъ§ОнРэНтЕФФПБъЪЧШЗШЯЕБЧАЪ§ОнЪЧЗёжЇГХЗжЮіЮЪЬтЃЌжївЊШЮЮёАќРЈЪ§ОнжЪСПЩѓВщЁЂЪ§ОнЗжВМЃЌаЮГЩЪ§ОнЕФГѕВНЖДВьКЭжБОѕХаЖЯСІЁЃЯТУцОЭЙЄвЕДѓЪ§ОнЗжЮіжаЕФЫФИіЬиБ№жЎДІНјааЬжТлЁЃ
Ъ§ОнЗжЮіЕФИљЛљЃКвдШЯецИКд№ЕФЬЌЖШШЅЩѓЪгЪ§ОнжЪСП
дкЙЄвЕСьгђЃЌвЛжжГЃМћЪ§ОнРраЭЪЧДЋИаЦїМрВтЛђМьВтЪ§ОнЃЌГ§СЫЪ§жЕжЪСПБОЩэЭтЃЌЛЙвЊПМТЧДЋИаЦїБОЩэЕФПЩППадКЭАВзАЗНЪНЃЌЗжЮіДЋИаЦїЕФR&R
(Gage Repeatability and Reproducibility)ЁЃдкЗчЕчСьгђЃЌЗчЛњВтЗчвЧВтЕФЗчЫйжЕЪЧЮВСїЗчЫйЃЌЖјВЛЪЧТжьБЗчЫйЃЌСэЭтЃЌВтЗчвЧЕФАВзАЮЛжУБОЩэвВПЩФмДцдкЦЋВюЃЌвВПЩФмНсБљЁЃ
дкЛЏЙЄСьгђЃЌЦјЬхВњСПВЛНівЊЙизЂЦфСїСПЃЈЬхЛ§ЃЉЃЌЛЙвЊЙизЂЖдгІЕФЦјбЙКЭЮТЖШЃЌЗёдђПЩФмЛсБЛЁАащМйБэеїЁБЮѓЕМЁЃ
дкЙЄГЬЛњаЕГЕСЊЭјЗжЮіжаЃЌвђЮЊЪЉЙЄЖЏЬЌадЃЈШчДЋЭГгЭЮЛДЋИаЦїЪ§ОндыЩљЬЋДѓЃЉЁЂЪЉЙЄЛЗОГЃЈЪ§ОнДЋЪфДцдкШБЪЇЃЉЁЂШЫЮЊЦЦЛЕЁЂВПМўИќЛЛЁЂДЋИаЦїМАНтЮіГЬађЕФЩ§МЖЛЛДњЕШЖржжЭтВПвђЫиЕФЙВЭЌзїгУЃЌдьГЩЪ§ОнжЪСПЩѓВщЗЧГЃЗБдгЃЌгааЉДцСПЪ§ОнЕФжЪСПЮЪЬтЩѕжСЮоЗЈНтЪЭЃЈР§ШчЃЌдТПЊЙЄЪБГЄЩѕжСГЌЙ§744аЁЪБЃЉЁЃЕЋетаЉМшПрЛљДЁадЕФЪ§ОнжЮРэЙЄзїБиВЛПЩЩйЃЌЗёдђЗжЮіНсЙћПЩаХЖШКмФбБЃжЄЁЃ
дкЪЕМљжаЃЌПЩвдВЩгУОЕфЕФЭГМЦЗНЗЈШЅЗЂЯжЪ§жЕвьГЃЃЌШЛКѓВЛЖЯЩюШыРэНтФФаЉЁАвьГЃЁБЪЧЯЕЭГЕФЖЏСІбЇЬиеїЃЈБШШчТЏЮТЪЧвЛИіДѓЙпЁЂИпЪБжЭЕФЙ§ГЬЃЉЁЂФФаЉЪЧПижЦТпМааЮЊЃЈБШШчФЅУКЛњГіПкЮТЖШЕФБеЛЗПижЦЃЉЁЂФФаЉЪЧВтСПЯЕЭГЮЪЬтЁЂФФаЉЪЧЭтВПИЩШХЕШЁЃжЛгаАбЪ§ОнГдЭИЃЌКѓУцЕФЫуЗЈФЃаЭВХгаКУЕФЛљДЁЁЃ
ФувдЮЊФувдЮЊЕФВЛЪЧФувдЮЊЕФЃКЭИЙ§вЕЮёГЁОАЛЙдЃЌЗЂЯжвўаджЪСПЮЪЬт
ИќЮЊЬєеНЕФЪЧЃЌКмЖрЪ§ОнжЪСПЮЪЬтВЂЗЧГЃЙцЪжЖЮПЩвдЗЂЯжЕФЃЌгаЕФЩѕжССЌвЕЮёШЫдБвВУЛгавтЪЖЕНЁЃдкЪЕеНжаЃЌПЩРћгУЪ§ОнШЅЛЙдЕфаЭЙ§ГЬЃЌЗЂОђЪ§ОнжаБэЯжГіЕФЁАвьГЃЁБГЁОАЃЌШЅЭъЩЦвЕЮёЩЯЯТЮФЕФРэНтЁЃ
Р§ШчЃЌЦјЛЏТЏТЏФкЮТЖШШэВтСПЕФвЛИіЧАЬсМйЩшЪЧCH4ХЈЖШЯрЖдЮШЖЈЃЌЧвгыТЏФкЮТЖШУмЧаЯрЙиЁЃЕЋЪЕМЪЪ§ОнЬНЫїжаЗЂЯжЦфжавЛЬЈЦјЛЏТЏВЂВЛТњзуетбљЕФМйЩшЃЈCH4ХЈЖШж№ФъЩЯЩ§ЃЌЙЄвеЖдДЫЕФВТЯыЪЧТЏзгФкБкВЛЖЯРЉДѓдьГЩЕФЃЉЃЌЖјетбљЕФЯжЯѓЙ§ШЅЫвВУЛгавтЪЖЕНЁЃ
дЫгЊКЭдЫзїЪ§ОнвВгаРрЫЦЮЪЬтЃЌБШШчЃЌБИМўЯњСПДѓВЛвЛЖЈЗДгГеце§ЕФЪаГЁашЧѓЃЌвВПЩФмЪЧДњРэЩЬЖкЛѕЃЈГхвЕМЈЃЉЁЃжЛгаАбгАЯьЪ§ОнжЪСПЕФжївЊвђЫиПМТЧШЋУцЃЌВХПЩФмзіГігавтвхЕФЗжЮіЁЃ
Ъ§ОнСПЕФРЇОГЃКЁАДѓЪ§ОнЁБСПЯТЕФЁАаЁЪ§ОнЁБаХЯЂ
СэЭтвЛИіБЛОГЃзЗЮЪЕФОЭЪЧЪ§ОнЗжЮіашвЊЕФЪ§ОнСПЁЃЙЄвЕЗжЮіЮЪЬтМДЪЙзіЙ§ЖРСЂадЗжЮіКѓЃЌЯрЙивђзгвВЭЈГЃГЩАйЩЯЧЇЃЌШєбЯИёАДееШЋзщКЯИВИЧЃЌашЧѓСПдЖдЖГЌЙ§ЯжЪЕжаПЩвдВЩМЏЕФЪ§СПЁЃ
МйЩшга20ИіБфСПЃЌИљОнОжВПСЌајадМйЖЈЃЌУПИіБфСПШЁ4ИіЪ§жЕОЭПЩвдКмКУЕФФтКЯећИіВЮЪ§ПеМфЃЌШЋзщКЯвтЮЖдђашвЊЬѕЪ§Он(дМ1ЧЇвк)ЃЌМДЪЙВЩМЏЦЕТЪПЩДя1000HzЃЌвВашвЊНќ35ФъЕФРњЪЗЪ§ОнЁЃСэЭтЃЌЙЄвЕЙ§ГЬЭЈГЃвЛИідЫаадкОЋаФЩшМЦЙцТЩЯТЕФЮШЬЌЙ§ГЬЃЈЪЕМЪЩњВњжаВЂУЛгаБщРњећИіВЮЪ§ПеМфЃЉЃЌетвВОЭвтЮЖзХДѓЪ§ОнжавўКЌЕФаХЯЂСПЦфЪЕЪЧЁАКмаЁЁБЕФЁЃвђДЫЃЌЙигкЪ§ОнСПЕФЮЪЬтЃЌЮвУЧЭЈГЃЕФЛиД№ЃКШчЙћВЛШкШыСьгђШЯЪЖШЅЯћМѕвђзгЪ§СПЃЌЭЈГЃФуЪЧЮоЗЈЬсЙЉЁАзуЙЛЁБЕФРњЪЗЪ§ОнШЅИВИЧЫљгазщКЯЧщаЮЁЃ
Ъ§ОнЕФГЩБОвтЪЖЃКЪ§ОнЗжЮіЪІВЛвЊЬЋШЮад
ЫфШЛзмЦкЭћЫљгаЕФживЊвђзгЪ§ОнЖМФмБЛШЋСПВЩМЏЃЌЕЋЯжЪЕжаЪ§ОнВЩМЏЪЧгаГЩБОЕФЃЌЭЌЪБвВЪмжЦгкЕБЧАЕФММЪѕЫЎЦНЃЈБШШчЃЌЦјЛЏТЏФкЮТЖШЪЧКмживЊЕФзДЬЌСПЃЌЕЋФПЧАЕФШШЕчХМЕШДЋИаЦїММЪѕЛЙЮоЗЈГЄЦкПЩППЙЄзїЃЉКЭАВШЋ/ЛЗОГПМТЧЃЈБШШчЃЌГЄЪфгЭЦјЙмЕРЕФбЙСІДЋИаЦїжЛФмдкЗЇЪвЛђГЁеОВПЪ№ЃЉЁЃ
СэЭтЃЌдкЩшБИЙЪеЯдЄОЏЛђМьВтЗжЮіжаЃЌЙЪеЯЪ§ОнЪЧЗЧГЃЯЁШБЕФЃЌРњЪЗЕФдЫЮЌЪ§ОнЭЈГЃвВЪЧВЛЭъећЕФЁЃетаЉИјЪ§ОнЗжЮіДјРДСЫКмДѓЬєеНЃЌЕЋЭЌЪБвВгІШЯЪЖЕНетОЭЪЧЯжЪЕЃЈвВаэгРдЖЖМВЛЭъУРЃЉЃЌЮвУЧЕФЙЄзїОЭЪЧдкЯжЪЕЕФЪ§ОнЬѕМўЯТНјааЕФЃЈИљОнЪ§ОнЛљДЁЃЌаоИФЗжЮіЮЪЬтЕФЬсЗЈЃЌЛђЭЈЙ§ЦфЫћаХЯЂВЙГЅЙиМќвђзгЕФШБЪЇЃЌЛђЯоЖЈЗжЮіФЃаЭЕФЪЪгУЗЖЮЇЕШЃЉЃЌЖјВЛЪЧШЮадЕФвЛЮЖвЊЧѓЪ§ОнЁЃ
Ъ§ОнзМБИЃЈDataPreparationЃЉ
БОНзЖЮФПБъЪЧНЈФЃЗжЮіЫљашЕФЪ§ОнМгЙЄЃЌАќРЈдЪМЪ§ОнГщШЁЁЂЖрЪ§ОндДШкКЯЁЂЪ§ОнЧхЯДгыжЪСПЬсЩ§ЁЂЬиеїЬсШЁЁЃЪЕМЪЗжЮіЯюФПжаЃЌЬиеїМгЙЄЛсеМећИіЯюФПЪБМфЕФ40ЁЋ60%ЁЃ
еыЖдвЛаЉЬиЖЈСьгђЮЪЬтЃЌЬиеїЬсШЁгІГфЗжРћгУвбгаЕФзЈвЕжЊЪЖЃЈВЛвЊРЫЗбЪБМфгУЪ§ОнЗжЮіЪжЖЮЭкОђГіИУСьгђдчвбЪьжЊЕФЙцТЩЃЉЁЃвд2009ФъЙњМЪPHM
Data ChallengeЕФГнТжЯфЙЪеЯФЃЪНбаХаЬтФПЮЊР§ЃЌзЈвЕзщЙкОќРћгУСЫа§зЊЩшБИЕФЕфаЭЙЪеЯФЃЪНЃЈИїжжБЖЦЕЃЉЕФСьгђжЊЪЖЃЌНјааЬиеїМгЙЄЃЌдйгУЪ§ОнЭкОђЫуЗЈЃЌШЁЕУСЫКмКУЕФНсЙћЃЌФЃаЭЕФЮяРэКЌвхЖдЯжГЁЪЕВйШЫдБвВБШНЯШнвзРэНтЁЃНќФъРДЃЌЩюЖШбЇЯАЕФЗЂеЙЃЌдквЛаЉЬиЖЈРраЭЕФЮЪЬтЩЯПЩвдНЕЕЭЗжЮіШЫдБЕФЬиеїЬсШЁЙЄзїСПЃЌЕЋЖдЙиМќЬиеїБфСПЕФРэНтдкЙЄвЕЗжЮіШдБиВЛПЩЩйЁЃ
НЈФЃЃЈModelingЃЉ
ЛњЦїбЇЯАЃЈЛђЭГМЦбЇЯАЁЂЪ§ОнЭкОђЃЉЗжЮіРэТлЗЂеЙГЩЪьЃЌвВгаКмЖрУїШЗЕФжИЕМддђКЭЗсИЛЕФЫуЗЈЙЄОпЃЌвђЖјЃЌНЈФЃЙ§ГЬдкЪЕМЪЗжЮіЯюФПжаЛЈЕФЪБМфЗДЖјВЛЖрЃЌвђДЫетРяВЛдйзИЪіЁЃЮЊБЃжЄФЃаЭЕФПЩЯћЗбадЃЈConsumabilityЃЉЖјЗЧММЪѕЩЯЕФздгщздРжЃЌЯТУцНіНіЬИШ§ЕуЁАаЮЖјЩЯЁБЕФддђЁЃ
Ёё НсЙћвЊгаЁАаТвтЁАЃКБмУтЭкОђГЃЪЖЃЈcommon senseЃЉЃЌГЃЪЖгІЕБзїЮЊЧАДІРэЛђЬиеїБфСПШкШыЪ§ОнЗжЮіФЃаЭ
Ёё ФЃаЭгІзёбЁАМЋМђЁБддђЃКгУзюМђЕЅЕФЫуЗЈШЅНтОіЮЪЬтЃЌВЛвЊЮЊСЫЮЂВЛзуЕРЕФадФмжИБъЬсЩ§ЖјЪЙгУПДЦ№РДЁАИпДѓЩЯЁБЕФИДдгФЃаЭЁЃЮЊДЫЃЌОЭашвЊзЅзЁЮЪЬтЕФжївЊУЌЖмЃЌЕНЕзЪЧcensored
dataЮЪЬтЁЂбљБОВЛОљКтЁЂФЃаЭЕФТГАєадЮЪЬтЃЈгІЖдИіБ№МЋЖЫвьГЃЪ§ОнЃЉЁЂЙ§ФтКЯЃЈбљБОСПЯрЖдФЃаЭВЮЪ§ПеМфВЛзуЃЉЁЂФЃаЭЕФздЪЪгІадКЭЬсЧАадЃЈБШШчеыЖдКъЙлЪаГЁЕФБфЛЏЃЌЪЧЗёвЊЧѓЬсЧАдЄЙРЛЙЪЧЪТКѓМАЪБЪЪгІИњзйЃЉЁЂФЃаЭзЗЧѓЕФжИБъЃЈБШШчЃЌЛиЙщЮЪЬтзЗЧѓЪЧЦНОљОЋЖШЛЙЪЧзюВюЕзЯпЃПЗжРрЮЪЬтЖдТЉБЈЁЂЮѓБЈЕФВржиЕуЃЉЁЂФЃаЭЕФПЩНтЪЭадЃЈЖдгкИљвђЗжЮіЃЌЪЖБ№ФФаЉвђЫидкЪВУДЧщаЮЯТживЊЖдИФНјЙЄвеИќгаЪЕВйадЃЉЁЃ
Ёё ФЃаЭЕФПЩПиадКЭПЩНтЪЭадЃКШЮКЮФЃаЭЖМЪЧдквЛЖЈЧАЬсМйЩшЯТЖдЮяРэЪРНчЕФМђЛЏЃЌЗжЮіФЃаЭдкНЈФЃЪБКђВЛНівЊЙиаФЦНОљадФмЃЌЛЙгІЙиаФЁБworst-caseЁБЃЈзюЛЕЧщаЮЃЉЃЌзюКУФмЙЛЧхЮњИјГіЪВУДЪБКђГЁОАФЃаЭВЛЪЪгУЃЈвдМАЖдгІЕФДІРэДыЪЉЃЉЁЃЖдгкадФмЬсЩ§ЃЌПЩвдНтЪЭЧхГўЦфдвђЁЃ
ШчЧАЫљЪіЃЌЪ§ОнЗжЮіЪЧвЛИіЕќДњЙ§ГЬЁЃКмЖрФЃаЭадФмЦПОБВЂЗЧРДздгкЫуЗЈЃЌЖјЪЧРДздгквЕЮёЖЈвхЁЂЪ§ОнРэНтЁЂЪ§ОнзМБИЃЌР§ШчвЛаЉКмЩйЗЂЩњЕЋживЊЕФвЕЮё/ЩњВњГЁОАУЛгаПМТЧЕНЃЌвЛаЉживЊвђЫиЩѕжСУЛгаАќКЌдкЕБЧАЪ§ОнМЏЃЌвЛаЉбЯжиЕФЪ§ОнжЪСПУЛгавтЪЖЕНЁЃвђЮЊЙЄвЕДѓЪ§ОнЗжЮіММФмЕФЖўЗжЛЏЃЌЪ§ОнЗжЮіШЫдБЮоЗЈЖРСЂЧюОЁвЕЮёУшЪіКЭЪ§ОнМЏЗЖЮЇжЎЭтЕФЧщаЮЃЌЖјвЕЮёзЈМввВВЛПЩФмЫМТЧЭђШЋЁЃ
Р§ШчЃЌдкгывЛИіЙњМЪПЭЛЇКЯзїЕиЯТЙмЕРЪЇаЇЗчЯеЦРЙРЯюФПжаЃЌИљОнвЕЮёзЈМвКЭСьгђЕїбаЃЌЮвУЧФУЕНЯрЖдЭъБИЕФЪ§ОнМЏЃЌЕквЛЦкФЃаЭЕФзмЬхадФмЛЙВЛДэЃЌЕЋОЭдкМИИіЧјгђЮвУЧЗЂЯжФЃаЭБэЯжВЛКУЁЃ
ЕБАбетаЉЧјгђвдGISЕФаЮЪНПЩЪгЛЏЕНвЕЮёзЈМвУцЧАЃЌЫћУЧКмПьвтЪЖЕНвЛИіживЊвђзгЕФШБЪЇЃЈетаЉЧјгђЪЧЮЇКЃдьЬяЃЌЮЇКЃдьЬяЧјЕФВЛОљдШГСНЕБШЦфЫћЧјгђвЊДѓКмЖрЃЌетдкЕБЧАЪ§ОнМЏжаУЛгаЬхЯжЃЉЃЌетаЉЕФаХЯЂЖдвЛИіЗЧБОЕиШЫЪП/ЗЧзЈвЕШЫЪПРДЫЕМИКѕЪЧВЛПЩФмЯыЯѓЕНЕФЁЃ
дкНЈФЃЙ§ГЬжаЃЌВЛЪЧЗКЗКЬИФЃаЭЕФадФмЛђЪ§ОнжЪСПЃЌЖјЪЧВЩгУЁБworst-caseЁБЧ§ЖЏЕФЗНЪНШЅКЭвЕЮёзЈМвНЛСїЃЌИцЫпвЕЮёзЈМвдкЪВУДЧщаЮЯТЗжЮіФЃаЭЙЄзїВЛКУЃЈИјГіОпЬхЕФР§згЃЉЃЌДЅЗЂвЕЮёзЈМвЕФЫМПМЃЌНшжњзЈвЕЭтФдШЅЗЂЯжЮЪЬтЕФИљвђКЭНтОіЪжЖЮЁЃ
ЦРЙРЃЈEvaluationЃЉ
НЈФЃНзЖЮвбОЖдЗжЮіФЃаЭДгЪ§ОнКЭММЪѕЕФНЧЖШЕФНјааГфЗжМьбщЁЃЦРЙРНзЖЮдйДЮДгвЕЮёЕФНЧЖШЩѓЪгФЃаЭЕФвЕЮёПЩгУад(Actionable)ЃЌЬиБ№вЊЖЈвхЧхГўФЃаЭдкЪВУДЧщаЮЯТВЛЪЪгУЃЌЪ§ОнФЃаЭгывЕЮёСїГЬЕФШкКЯЗНЪН(Consumable)ЁЃ
ЦѓвЕЩњВњгыЙмРэЪЧвдЙЄвеСїГЬЛђвЕЮёСїГЬЮЊЧ§ЖЏЕФЛюЖЏЃЌОЕфаХЯЂЛЏДѓЖрОЭСїГЬЃЈЛђИФдьКѓЕФСїГЬЃЉНјааЪ§ОнВЩМЏ/ећКЯКЭСїзЊЃЌвдЬсЩ§СЫвЕЮёаЇТЪЃЛЪ§ОнЧ§ЖЏЕФДѓЪ§ОнЗНЗЈГЂЪдДгЪ§ОнВњЩњ/ЯћЗбЙ§ГЬКЭЖрЮЌЖШЙиСЊЕФаТЪгНЧдйДЮЩѓЪгЦфжаЕФдЬКЌЕФвЕЮёМлжЕЁЃЕЋЪ§ОнЗжЮіЕФНсЙћШєВЛФмТфЕНЦѓвЕСїГЬЃЈЯжгаЕФЛђаТДДНЈЕФЃЉЃЌЗжЮіФЃаЭОЭгЮРыдкЦѓвЕЯжгаЯЕЭГжЎЭтЃЌКмФбЪЕЯжМлжЕТфЕиЁЃ
ЖдгкВЩгУвбгаЕФГЩЪьФЃаЭЃЌБОНзЖЮгШЮЊживЊЁЃШЮКЮФЃаЭЖМгавЛЖЈЕФЪЪгУЧАЬсЃЌгааЉдкЖдЭтаћДЋЪБКђБЛКіТдЃЌгааЉЧАЬсдкФЃаЭПЊЗЂЪБУЛгавтЪЖЕНЃЌвђДЫЃЌетаЉФЃаЭЪЧЗёЪЪгУгкЕБЯТГЁОАашвЊДѓСПЕФбЯНїЕФВтЪдЁЃ
ВПЪ№ЃЈDeploymentЃЉ
ВПЪ№ЕФФПЕФЪЧБЃжЄФЃаЭЕФНсЙћПЩБЛвЕЮёГжОУздЖЏЕиЯћЗб(Consume)ЃЌГ§СЫДѓЪ§ОнЦНЬЈЕФМЦЫуадФмЮЪЬтЃЌЛЙгІИУзЂвтЗжЮіФЃаЭЕФШЋЩњУќжмЦкЙмРэЁЃвђЮЊЃЌдкЙЄвЕгІгУжаЃЌВФСЯ/ЙЄве/зАБИ/ДЋИаММЪѕЕФВЛЖЯИќаТЁЃОЁПЩФмЖдВПЪ№ФЃаЭНјааУмЧаЕФадФмМрПиЃЌЭЈЙ§БеЛЗЗДРЁНјааФЃаЭГЩЪьЖШЦРЙРКЭзДЬЌЙмРэЃЈЪдгУЁЂе§ЪНгІгУЁЂашИќаТЁЂЭЫвлЕШЃЉЃЌБЃжЄЩњВњЕФГжајадКЭПЩППадЁЃ
КѓМЧ
БОЮФвдCRISP-DMЗНЗЈТлЮЊЛљДЁЃЌЬжТлЙЄвЕДѓЪ§ОнЗжЮідкВЛЭЌНзЖЮЕФЬєеНЁЂашЧѓгызіЗЈЁЃCRISP-DMЗНЗЈТлЪЧжкЖрЪ§ОнЗжЮіЗНЗЈТлЕФвЛжжЁЃШЮКЮЪ§ОнЗжЮіЗНЗЈТлЕФвЊжМВЛЭтКѕвдЯТШ§ЕуЃК1ЃЉЖЈвхвЛИіКУЮЪЬтЃЈгавЕЮёМлжЕЃЌММЪѕПЩНтЃЌЪ§ОнПЩжЇГХЃЉЃЛ2ЃЉећРэГіжЕЕУаХРЕЕФЪ§ОнЃЛ3ЃЉЙЙНЈвЛИіПЩБЛЯћЗб(consumable)ЕФФЃаЭЁЃвЛИіШЯецИКд№ЁЂНХЬЄЪЕЕиЕФЙЄвЕЪ§ОнЗжЮіЪІгІз№жиСьгђжЊЪЖЃЌСЫНтЪ§ОнЕФРДдДКЭвЕЮёвтвхЃЌАбЮеЗжЮіЯюФПЕФжївЊУЌЖмЃЌвдЁАМЋМђжївхЁБЕФЫМТЗШЅНЈФЃЃЌНЋЗжЮіММЪѕгывЕЮёСїГЬгаЛњНсКЯЁЃ
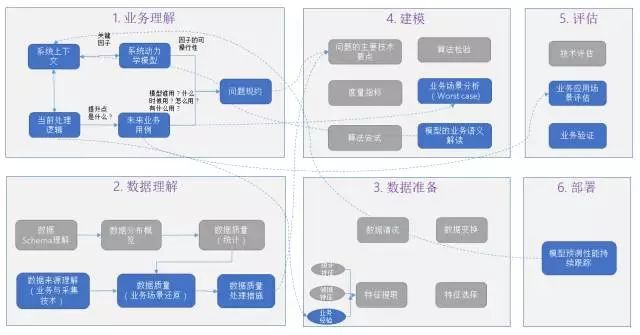
CRISP-DMЗНЗЈТлЕФСљИіНзЖЮдкВЛЭЌЮЪЬтжаЕФживЊЖШвВВЛЭЌЁЃР§ШчЃЌгаКмЖрОЕфЪ§ОнЗжЮіЮЪЬтЃЈШчШЫСГЪЖБ№ЁЂгявєЪЖБ№ЁЂЮФБОЗжЮіЃЉБОЩэОЭКмОпЬхЃЌетЪБжївЊЕФОЋСІдкЪ§ОндЄДІРэКЭЫуЗЈОЋЖШЩЯЁЃ
ДгКъЙлВуУцРДНВЃЌЙЄвЕДѓЪ§ОнКЭЩЬвЕДѓЪ§ОндкЗжЮіЗНЗЈТлЩЯУЛгаБОжЪЧјБ№ЃЌжЛВЛЙ§ЗжЮіЖдЯѓЁЂЪ§ОнЬиЕуЁЂЯжгаЛљДЁЁЂгІгУЦкЭћЕШЗНУцДцдкНЯДѓВювьЖјвбЃЈЯъЯИВћЪіЧыВЮдФ5ЃЉЁЃдйМгЩЯвЛаЉМђНрЕФДѓЪ§ОнЫМЮЌЃЈШчДгбљБОЕНШЋСПЫМЮЌЃЛгЩОЋШЗЕНФЃК§ЫМЮЌЃЛгЩвђЙћЕНЙиСЊЫМЮЌЃЉЁЂAIЕШаћДЋЃЌШєЭбРыСЫЩЯЯТЮФКЭгІгУГЁОАЯоЖЈЃЌКмШнвзЮѓЕМЙЄвЕДѓЪ§ОнЕФЪЕМљЁЃ
ЗНЗЈТлЮЊЗжЮіЯюФПЭЦНјЬсЙЉСЫКмКУЕФЗНЯђаджИЕМЃЌЗжЮіЯюФПЕФГЩЙІИќРыВЛПЊЪ§ОнЗжЮіЪІКЭвЕЮёШЫдБЕФзЈвЕОЋЩёКЭЮёЪЕЬЌЖШЃЌвдМАаавЕЩюШыРэНтЁЂЯрЙиЕФАИР§жЊЪЖЁЂЗсИЛЕФЪЕМљОбщЁЂаавЕЫуЗЈПтвдМАКЯЪЪЕФДѓЪ§ОнЗжЮіЦНЬЈжЇГХЁЃ
|









