| БрМЭЦМі: |
БОЮФжївЊНщЩмCheckpointЕФЪЕЯжЫуЗЈЃЌcheckpointЖдадФмЕФгАЯьЃЌвдМАШчКЮЪЙгУcheckpointЕШЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкCSDNЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂCheckpointЃЌвЛжТадМьВщЕу
flinkЙЪеЯЛжИДЛњжЦЕФКЫаФОЭЪЧcheckpoint
газДЬЌЕФСїгІгУЕФвЛжТадМьВщЕуЃЌЦфЪЕОЭЪЧЫљгаШЮЮёЕФзДЬЌЃЌдкФГИіЪБМфЕуЕФвЛЗнПьееЃЌетИіЪБМфЕуЪЧжИЫљгаШЮЮёЖМЧЁКУДІРэЭъвЛИіЯрЭЌЕФЪфШыЪ§ОнЕФЪБКђ
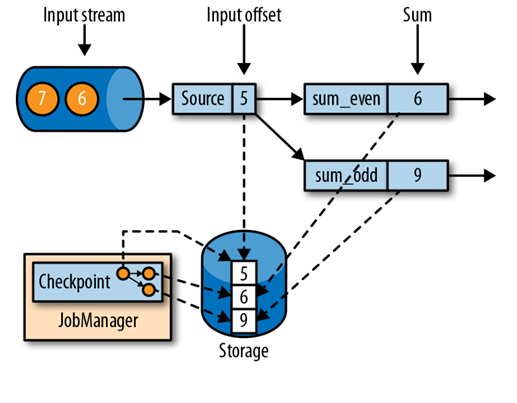
ШчЩЯЭМЫљЪОЃКДЫгІгУгавЛИіsource taskЃЌЯћЗбвЛИіЕндіЪ§ЕФСїЃЌШч1ЃЌ2ЃЌ3ЕШЕШЁЃСїжаЕФЪ§ОнБЛЗжЧјЕНвЛИіЦцЪ§СїЃЌвЛИіХМЪ§СїЁЃдквЛИіsum operatorжаЃЌгаСНИіtaskЃЌЗжБ№гУгкРлМгЦцЪ§гыХМЪ§ЁЃSource task ДцДЂЕБЧАЪфШыСїЕФЦЋвЦСПзїЮЊstateЁЃSum task НЋЕБЧАЕФРлМгКЭзїЮЊstateВЂДцДЂЁЃЭМжаЃЌдкЪфШыЦЋвЦСПЮЊ5ЪБЃЌFlinkзіСЫвЛИіМьВщЕуЃЌДЫЪБСНИіtaskЕФРлМгКЭЗжБ№ЮЊ6КЭ9ЁЃШчЙћШЮЮёДІРэЕН6/7ЪБЗЂЩњЙЪеЯЃЌдђжиЦєШЮЮёКѓПЩвдДгcheckponintжаФУЕН5ЪБЫљгћШЮЮёЕФзДЬЌЃЌДг5ПЊЪМжиаТМЦЫу
FlinkЕФExactly-onceашвЊДгзюНќЕФвЛЗнПьееПЊЪМжиЗХЪ§Он, вђДЫетвВКЭЪ§ОндДЕФФмСІгаЙи, ВЛЪЧЫљгаЕФЪ§ОндДЖМПЩвдЬсЙЉExactly-onceгявхЕФ. вдЯТЪЧapacheЙйЭјСаГіЕФЪ§ОндДКЭExactly-onceгявхБЃеЯФмСІСаБэ.
ЖўЁЂCheckpointЕФЪЕЯжЫуЗЈ
ЛљгкChandy-LamportЫуЗЈЕФЗжВМЪНПьеедРэ
НЋМьВщЕуЕФБЃДцКЭЪ§ОнДІРэЗжПЊЃЌВЛднЭЃећИігІгУ
FlinkЕФМьВщЕуЫуЗЈЪЙгУСЫвЛИіЬиЪтЕФrecordРраЭЃЌГЦЮЊвЛИіМьВщЕуЗжНчЃЈcheckpoint barrierЃЉЁЃРрЫЦгкЫЎгЁЃЌМьВщЕуbarriersгЩsource operatorзЂШыЕНГЃЙцЕФСїМЧТМжаЃЌВЂЧвЮоЗЈБЛЦфЫћrecords ИЯГЌЁЃУПИіМьВщЕуbarrierЛсаЏДјвЛИіМьВщЕуIDЃЌгУгкБцБ№ЫќЪєгкФФИіМьВщЕуЃЌВЂЧвНЋвЛИіСїдкТпМЩЯЗжГЩСНВПЗжЁЃдквЛИіbarrierжЎЧАЃЌЖдstateЕФЫљгааоИФЃЌАќКЌгкДЫbarrierЕФМьВщЕуЁЃШєЪЧдквЛИіbarrierжЎКѓЖдstateЕФЫљгааоИФЃЌдђАќКЌгкЯТвЛИіМьВщЕуЁЃ
ЮвУЧвРШЛгУжЎЧАЕФЦцХМЪ§sumР§згРДЫЕУїЃК
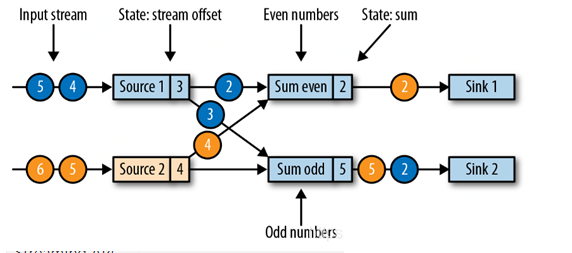
JobManager ЯђУПИіsource taskЗЂЫЭвЛЬѕАќКЌвЛИіаТcheckpointIDЕФЯћЯЂЃЌвдГѕЪМЛЏвЛИіМьВщЕуЃЌШчЯТЭМЃК
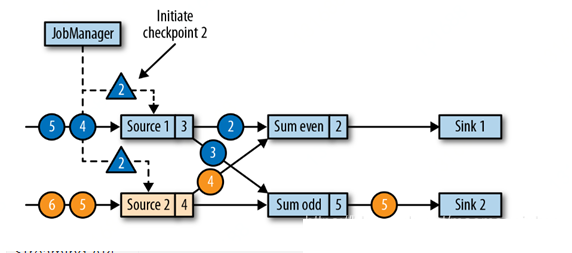
ЕБвЛИіsource task ЪеЕНетЬѕcheckpointЯћЯЂЪБЃЌЫќЛсЭЃжЙЪЭЗХЪ§ОнЃЌНЋoffsetБЃДцЕНcheckpointВЂЭЈжЊJobManagerЃЌЙуВЅМьВщЕуbarrierИјЯТгЮЕФЫљгаШЮЮё ЁЃдкЙуВЅЯћЯЂЗЂГіКѓЃЌsourceМЬајЫќЕФГЃЙцВйзїЁЃbarrierдђБЛзЂШыЬэМгЕНЫќКѓајЕФЪфГіСїЁЃ

МьВщЕуbarrierБЛЙуВЅЕНЫљгаЯрСЌЕФВЂааtasksжаЁЃЕБвЛИіtaskЪеЕНвЛИіаТМьВщЕуЕФbarrierЪБЃЌЫќЛсЕШД§barriersДгЫќЫљгаЕФЪфШыЗжЧјЕНДяЃЈЭМжаЕШД§ЛЦЩЋКЭРЖЩЋЕФШ§НЧ2ЖМЕНДяЃЉЁЃдкЫќЕШД§ЪБЃЌаТРДЕФЪ§ОнРЖЩЋЕФ4ВЛЛсБЛСЂМДДІРэЃЌЖјЪЧБЛЗХШыЛКДцЁЃ
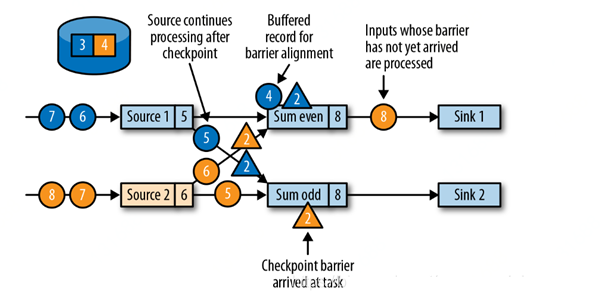
вЛЕЉвЛИіtaskДгЫќЫљгаЪфШыЗжЧјжаЃЌЪеЕНСЫШЋВПЕФbarriersЁЃЫќПЊЪМдкstate backendГѕЪМЛЏМьВщЕуЃЌВЂЙуВЅМьВщЕуbarrierЕНЫќЫљгаЕФЯТгЮtasksЃЌШчЯТЭМЃК8ЃЌ8БЃДцЕНcheckpoint
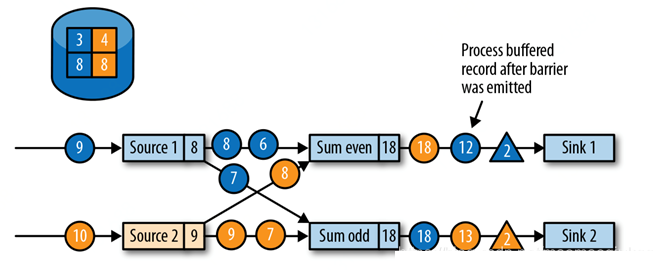
дкЫљгаМьВщЕуbarriersвбОБЛЪЭЗХКѓЃЌtaskПЊЪМДІРэБЛЛКДцЕФМЧТМЁЃдкЫљгаБЛЛКДцЕФМЧТМБЛЪЭЗХКѓЃЌtask МЬајДІРэЫќЕФЪфШыСїЁЃЯТЭМЯдЪОСЫгІгУдкетИіЪБМфЕуЕФдЫаазДПіЃК
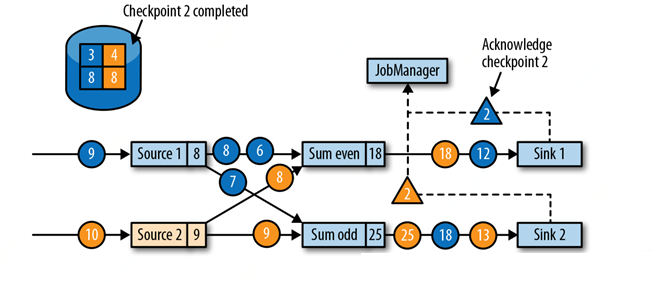
зюжеЃЌМьВщЕуbarriers ЕНДявЛИіsink taskЁЃЕБвЛИіsink task ЪеЕНвЛИіbarrierЪБЃЌЫќЛсзівЛИіbarrier ЕїећЃЈalignmentЃЉЃЌИјЫќздМКЕФзДЬЌзіМьВщЕуЃЌВЂЯђJobManagerШЗШЯЃЈacknowledgeЃЉЫќвбЪеЕНbarrierЁЃJobManagerдкЪеЕНвЛИіapplicationЕФЫљгаtaskЗЂЫЭЕФcheckpoint acknowledgeКѓЃЌЫќЛсМЧТМЃКДЫapplicationЕФМьВщЕуЭъГЩЁЃЯТЭМЯдЪОСЫМьВщЕуЫуЗЈЕФзюКѓвЛВНЃЌЭъГЩЕФМьВщЕуПЩвдгУгкДгЙЪеЯжаЛжИДвЛИіapplicationЁЃ
Ш§ЁЂcheckpointЖдадФмЕФгАЯь
FlinkЕФМьВщЕуЫуЗЈПЩвддкВЛЭЃжЙећИіapplicationЕФЧщПіЯТЃЌДгСїгІгУжаЩњГЩвЛжТадЗжВМЪНЕФМьВщЕуЁЃШЛЖјЃЌЫќЛсдіМгapplicationЕФДІРэбгЪБЃЈprocessing latencyЃЉЁЃFlink ЪЕЯжСЫЧсЮЂЕїећЃЌвддкФГаЉЬиЖЈЬѕМўЯТЛКНтадФмгАЯьЁЃ
дквЛИіtaskЖдЫќЕФзДЬЌзіМьВщЕуЪБЃЌЫќЛсзшШћЃЌВЂЛКДцЫќЕФЪфШыЁЃвђЮЊstateПЩвдБфЕФКмДѓЃЌВЂЧвМьВщЕуЕФВйзїашвЊЭЈЙ§ЭјТчаДШыЪ§ОнЕНвЛИідЖЖЫДцДЂЯЕЭГЃЌЫљвдзіМьВщЕуЕФВйзїПЩФмЛсКмШнвзОЭЛЈЗбМИУыЕНМИЗжжгЃЌетЖдгкбгЪБУєИаЕФapplicationРДЫЕЃЌбгЪБЙ§ГЄСЫЁЃдкFlinkЕФЩшМЦжаЃЌзівЛИіМьВщЕуЪЧгЩstate backendИКд№ЕФЁЃвЛИіtaskЕФstateШчКЮОЋШЗЕФБЛИДжЦЃЌШЁОігкstate backendЕФЪЕЯжЁЃР§ШчЃЌFileSystem state backendгыRocksDB state backendжЇГжвьВНзіМьВщЕуЁЃЕБвЛИіМьВщЕуБЛДЅЗЂЪБЃЌstate backendдкБОЕиДДНЈвЛИіМьВщЕуЕФИББОЁЃдкБОЕиИББОДДНЈЭъГЩКѓЃЌtaskМЬајЫќЕФе§ГЃДІРэЁЃвЛИіКѓЖЫЯпГЬЛсвьВНЕиИДжЦБОЕиПьееЕНдЖЖЫДцДЂЃЌВЂдкЫќЭъГЩМьВщЕуКѓЬсабtaskЁЃвьВНМьВщЕуПЩвдЯджјЕиНЕЕЭвЛИіtaskДгднЭЃЕНМЬајДІРэЪ§ОнЃЌетжаМфЕФЪБМфЁЃСэЭтЃЌRocksDB state backendвВгадіСПМьВщЕуЕФЙІФмЃЌПЩвдМѕЩйЪ§ОнЕФДЋЪфСПЁЃ
СэвЛИігУгкМѕЩйМьВщЕуЫуЗЈЖдДІРэбгЪБгАЯьЕФММЪѕЪЧЃКЮЂЕїbarrierХХСаВНжшЁЃШєЪЧвЛИігІгУашвЊЗЧГЃЖЬЕФбгЪБЃЌВЂЧвПЩвдШнШЬat-least-once зДЬЌБЃжЄЁЃFlinkПЩвдБЛХфжУЮЊдкbuffer alignmentЪБЖдЫљгаЕНДяЕФМЧТМзіДІРэЃЌЖјВЛЪЧНЋетаЉМЧТМЮЊвбОЕНДяЕФbarrierЛКДцЯТРДЁЃЖдгквЛИіМьВщЕуЃЌдкЫќЫљгаЕФbarriersЖМЕНДяКѓЃЌoperatorЮЊЫќЕФзДЬЌзіМьВщЕуЃЌЯждкетРяПЩФмвВЛсАќРЈЃКБОгІЪєгкЯТвЛИіМьВщЕуЕФrecordsЖдstate зіЕФаоИФЁЃдкДэЮѓЗЂЩњЪБЃЌетаЉrecordsЛсБЛдйДЮДІРэЃЌвВОЭЪЧЫЕЃЌетРяМьВщЕуЬсЙЉЕФЪЧat-least-once вЛжТадБЃжЄЃЌЖјВЛЪЧexcatly-once вЛжТадБЃжЄЁЃ
ЫФЁЂБЃДцЕуЃЈSavepointsЃЉ
дРэЩЯЃЌБЃДцЕугыМьВщЕугУЕФЪЧЯрЭЌЕФЫуЗЈДДНЈЕФЃЌЫљвдБЃДцЕуЦфЪЕОЭЪЧЃКМьВщЕуМгЩЯвЛаЉЖюЭтЕФдЊЪ§ОнЁЃFlinkВЛЛсздЖЏзівЛИіБЃДцЕуЃЌЫљвдвЛИігУЛЇЃЈЛђЪЧЭтВПЕїЖШЦїЃЉашвЊУїШЗЕиДЅЗЂДДНЈБЃДцЕуЁЃFlinkвВВЛЛсздЖЏЧхРэБЃДцЕуЁЃ
БЃДцЕуПЩвдзіКмЖрЪТЧщЃЌБШШчЖЈЦкЪжЖЏБИЗнЃЌИќаТгІгУГЬађЃЈИФbugЃЉЃЌflinkАцБОЩ§МЖЃЌМЏШКЧЈвЦЃЌднЭЃКЭжиЦєгІгУЕШ
ЮхЁЂЪЙгУcheckpoint
object CheckPointTest {
def main(args: Array[String]) {
//ДДНЈжДааЛЗОГ
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
//ПЊЦєcheckpointУПЗжжгcheckpointвЛДЮ
env.enableCheckpointing(60000)
//бЁдёcheckpointЕФзДЬЌКѓЖЫ
env.setStateBackend(new FsStateBackend("hdfs:// namenode: 9000 / flink/ checkpoints"))
//ЩшжУжиЦєВпТдЃЌвВПЩвддкХфжУЮФМўХф,зюДѓШ§ДЮжиЦєЃЌУПДЮМфИє10s
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(3,
org.apache.flink.api.common.time.Time.seconds(10)))
//ЩшжУжиЦєВпТдЃЌвВПЩвддкХфжУЮФМўХф,10sФкШ§ДЮжиЦєЃЌУПДЮМфИє1s
env.setRestartStrategy(RestartStrategies.failureRateRestart(3,
org.apache.flink.api.common.time.Time.seconds(10),
org.apache.flink.api.common.time.Time.seconds(1)))
//ФЌШЯEXACTLY_ONCE
env.getCheckpointConfig.setCheckpointingMode ( CheckpointingMode . EXACTLY_ONCE)
//ЩшжУcheckpointГЌЪБЪБМфГЌЪБКѓЗХЦњБОДЮcheckpoint
env.getCheckpointConfig.setCheckpointTimeout(600000)
//checkpointГіЯжвьГЃЪБЪЧЗёжїЖЏАбгІгУГЬађjob failЕєЃЌ
ФЌШЯЪЧ true ОЭЪЧ checkpointЪЇАмШЫЮявВЛсЪЇАм
env.getCheckpointConfig.setFailOnCheckpointingErrors(false)
//зюДѓВЂааcheckpointШЮЮёЪ§ЃЌcheckpointЬЋЦЕЗБЛсгАЯьадФм
env.getCheckpointConfig.setMaxConcurrentCheckpoints(1)
//СНДЮcheckpointЕФзюаЁЪБМфМфИєms
env.getCheckpointConfig.setMinPauseBetweenCheckpoints(10000)
//ЪЧЗёПЊЦєcheckpointЭтВПГжОУЛЏЃЌ
ФЌШЯШЮЮёЪЇАмМьВщЕу БЃДцЕФЪ§ОнЛсБЛЩОГ§
//ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:
МДЪЙЪжЖЏШЁЯћШЮЮёвВВЛвЊЩОГ§БЃДцЕу
//ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATIONЃК
ЪжЖЏШЁЯћШЮЮёЩОГ§БЃДцЕу
env.getCheckpointConfig.enableExternalizedCheckpoints
( ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
}
}
|
СљЁЂstate backend зДЬЌКѓЖЫ
flinkЕФзДЬЌКѓЖЫИКд№СНМўЪТЃЌstate backendЃЌИКд№БОЕизДЬЌЙмРэЃЌзДЬЌЕФДцДЂЗУЮЪМАЮЌЛЄЃЛвдМАНЋМьВщЕуЃЈcheckpointЃЉзДЬЌаДШыдЖГЬДцДЂ
ПЩвдЭЈЙ§вдЯТДњТыЩшжУЃЈвЛАуЪЧдкЙЋЫОFlinkМЏШКЖЫЭГвЛХфжУЃЉЃК
//бЁдёcheckpointЕФзДЬЌКѓЖЫ
env.setStateBackend(new FsStateBackend
("hdfs://namenode:9000/flink/checkpoints")) |
зДЬЌКѓЖЫбЁдёЃК
MemoryStateBackendЃЌФкДцМАЕФзДЬЌКѓЖЫЃЌЛсНЋНЁПизДЬЌДцДЂдкTaskManagerЕФjvmЖбЩЯЃЌЖјНЕcheckpointДцДЂдкJobManagerЕФjvmЖбЩЯ
ЬиЕуЃКПьЫйЁЂЕЭбгЪБЁЂЕЋВЛЮШЖЈЃЌЩњВњВЛгУ
FsStateBackendЃКБОЕизДЬЌКЭЩЯвЛИівЛбљЃЌcheckpointДцДЂдкдЖГЬЕФГжОУЛЏЮФМўЯЕЭГЩЯ
ЬиЕуЃЌПьЫйЕЭбгЪБИќКУЕФЮШЖЈадЃЌВЛЪЧГЌДѓаЭЪ§ОнвЛАуЪЙгУетжжМДПЩ
RocksDBStateBackendЃКНЋЫљгаЪ§ОнађСаЛЏКѓДцШыБОЕиЕФRocksDBжаДцДЂ
ИќМгжиСПМЖЃЌВЛЛсЪмЗўЮёЦїФкДцКЭgcгАЯь
ХфжУзДЬЌКѓЖЫЃК
ЕквЛжжЃКЕЅШЮЮёЕїећ
аоИФЕБЧАШЮЮёДњТы
env.setStateBackend(new FsStateBackend(ЁА hdfs://namenode:9000/flink/checkpointsЁБ));
Лђепnew MemoryStateBackend()
Лђепnew RocksDBStateBackend(filebackend, true);ЁОашвЊЬэМгЕкШ§ЗНвРРЕЁП
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.7.0</version>
</dependency> |
ЕкЖўжжЃКШЋОжЕїећ
аоИФflink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs: // namenode : 9000/flink/checkpoints
зЂвтЃКstate.backendЕФжЕПЩвдЪЧЯТУцМИжжЃКjobmanager (MemoryStateBackend), filesystem(FsStateBackend), rocksdb(RocksDBStateBackend)
ЦпЁЂБЃДцЖрИіCheckpoint
ФЌШЯЧщПіЯТЃЌШчЙћЩшжУСЫCheckpointбЁЯюЃЌдђFlinkжЛБЃСєзюНќГЩЙІЩњГЩЕФ1ИіCheckpointЃЌЖјЕБFlinkГЬађЪЇАмЪБЃЌПЩвдДгзюНќЕФетИіCheckpointРДНјааЛжИДЁЃЕЋЪЧЃЌШчЙћЮвУЧЯЃЭћБЃСєЖрИіCheckpointЃЌВЂФмЙЛИљОнЪЕМЪашвЊбЁдёЦфжавЛИіНјааЛжИДЃЌетбљЛсИќМгСщЛюЃЌБШШчЃЌЮвУЧЗЂЯжзюНќ4ИіаЁЪБЪ§ОнМЧТМДІРэгаЮЪЬтЃЌЯЃЭћНЋећИізДЬЌЛЙдЕН4аЁЪБжЎЧАЁЃ
FlinkПЩвджЇГжБЃСєЖрИіCheckpointЃЌашвЊдкFlinkЕФХфжУЮФМўconf/flink-conf.yamlжаЃЌЬэМгШчЯТХфжУЃЌжИЖЈзюЖрашвЊБЃДцCheckpointЕФИіЪ§ЃК
state.checkpoints.num-retained: 20
дкHDFSЕФЯргІЮФМўМаЯТУцЛсВњЩњЖрИіcheckpointЮФМўЁЃ
АЫЁЂДгCheckpointНјааЛжИД
ШчЙћFlinkГЬађвьГЃЪЇАмЃЌЛђепзюНќвЛЖЮЪБМфФкЪ§ОнДІРэДэЮѓЃЌЮвУЧПЩвдНЋГЬађДгФГвЛИіCheckpointЕуЃЌБШШчchk-860НјааЛиЗХЃЌжДааШчЯТУќСюЃК
bin/flink run -s hdfs://namenode01.td.com/flink-1.5.3 / flink-checkpoints / 582e17d2cc343e6c56255d111bae0191 / chk-860/_metadata flink-app-jobs.jar
ДгЩЯУцЮвУЧПЩвдПДЕНЃЌЧАУцFlink JobЕФIDЮЊ 582e17d2cc343e6c56255d111bae0191 ЃЌЫљгаЕФ CheckpointЮФМўЖМдквдJob IDЮЊУћГЦЕФФПТМРяУцЃЌЕБJobЭЃЕєКѓЃЌжиаТДгФГИіCheckpointЕуЃЈchk-860ЃЉНјааЛжИДЪБЃЌжиаТЩњГЩJob IDЃЈетРяЪЧ11bbc5d9933e4ff7e25198a760e9792eЃЉЃЌЖјЖдгІЕФCheckpointБрКХЛсДгИУДЮдЫааЛљгкЕФБрКХМЬајСЌајЩњГЩЃКchk-861ЁЂchk-862ЁЂchk-863ЕШЕШЁЃ
ОХЁЂFlink Savepoint
SavepointЛсдкFlink JobжЎЭтДцДЂздАќКЌЃЈself-containedЃЉНсЙЙЕФCheckpointЃЌЫќЪЙгУ Flink ЕФ CheckpointingЛњжЦРДДДНЈвЛИіЗЧдіСПЕФSnapshotЃЌРяУцАќКЌStreamingГЬађЕФзДЬЌЃЌВЂНЋCheckpointЕФЪ§ОнДцДЂЕНЭтВПДцДЂЯЕЭГжаЁЃ
FlinkГЬађжаАќКЌСНжжзДЬЌЪ§ОнЃЌвЛжжЪЧгУЛЇЖЈвхЕФзДЬЌЃЈUser-defined StateЃЉЃЌЫћУЧЪЧЛљгкFlinkЕФTransformationКЏЪ§РДДДНЈЛђепаоИФЕУЕНЕФзДЬЌЪ§ОнЃЛСэвЛжжЪЧЯЕЭГзДЬЌЃЈSystem StateЃЉЃЌЫћУЧЪЧжИзїЮЊOperatorМЦЫувЛВПЗжЕФЪ§ОнBufferЕШзДЬЌЪ§ОнЃЌБШШчдкЪЙгУWindow FunctionЪБЃЌдкWindowФкВПЛКДцStreamingЪ§ОнМЧТМЁЃЮЊСЫФмЙЛдкДДНЈ Savepoint Й§ГЬжаЃЌЮЈвЛЪЖБ№ЖдгІЕФOperatorЕФзДЬЌЪ§ОнЃЌFlinkЬсЙЉСЫAPIРДЮЊГЬађжаУПИіOperatorЩшжУIDЃЌетбљПЩвддкКѓајИќаТ/Щ§МЖГЬађЕФЪБКђЃЌПЩвддкSavepointЪ§ОнжаЛљгкOperator IDРДгыЖдгІЕФзДЬЌаХЯЂНјааЦЅХфЃЌДгЖјЪЕЯжЛжИДЁЃЕБШЛЃЌШчЙћЮвУЧВЛжИЖЈOperator IDЃЌFlinkвВЛсЮвУЧздЖЏЩњГЩЖдгІЕФOperatorзДЬЌIDЁЃ
ЖјЧвЃЌЧПСвНЈвщЪжЖЏЮЊУПИіOperatorЩшжУIDЃЌМДЪЙЮДРДFlinkгІгУГЬађПЩФмЛсИФЖЏКмДѓЃЌБШШчЬцЛЛдРДЕФOperatorЪЕЯжЁЂдіМгаТЕФOperatorЁЂЩОГ§OperatorЕШЕШЃЌжСЩйЮвУЧгаПЩФмгыSavepointжаДцДЂЕФOperatorзДЬЌЖдгІЩЯЁЃСэЭтЃЌБЃДцЕФSavepointзДЬЌЪ§ОнЃЌБЯОЙЪЧЛљгкЕБЪБГЬађМАЦфФкДцЪ§ОнНсЙЙЩњГЩЕФЃЌЫљвдШчЙћЮДРДFlinkГЬађИФЖЏБШНЯДѓЃЌгШЦфЪЧЖдгІЕФашвЊВйзїЕФФкДцЪ§ОнНсЙЙЖМБфЛЏСЫЃЌПЩФмИљБООЭЮоЗЈДгдРДОЩЕФSavepointе§ШЗЕиЛжИДЁЃ
ЯТУцЃЌЮвУЧвдFlinkЙйЭјЮФЕЕжаИјЖЈЕФР§згЃЌРДПДЯТШчКЮЩшжУOperator IDЃЌДњТыШчЯТЫљЪОЃК
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID |
ЪЎЁЂДДНЈSavepoint
ДДНЈвЛИіSavepointЃЌашвЊжИЖЈЖдгІSavepointФПТМЃЌгаСНжжЗНЪНРДжИЖЈЃК
вЛжжЪЧЃЌашвЊХфжУSavepointЕФФЌШЯТЗОЖЃЌашвЊдкFlinkЕФХфжУЮФМў conf/flink-conf.yaml жаЃЌЬэМгШчЯТХфжУЃЌЩшжУSavepointДцДЂФПТМЃЌР§ШчШчЯТЫљЪОЃК
state.savepoints.dir: hdfs://namenode01.td.com /flink-1.5.3/ flink-savepoints
СэвЛжжЪЧЃЌдкЪжЖЏжДааsavepointУќСюЕФЪБКђЃЌжИЖЈSavepointДцДЂФПТМЃЌУќСюИёЪНШчЯТЫљЪОЃК
bin/flink savepoint :jobId [:targetDirectory]
Р§ШчЃЌе§дкдЫааЕФFlink JobЖдгІЕФIDЮЊ 40dcc6d2ba90f13930abce295de8d038ЃЌЪЙгУФЌШЯ state.savepoints.dir ХфжУжИЖЈЕФSavepointФПТМЃЌжДааШчЯТУќСюЃК
bin/flink savepoint 40dcc6d2ba90f13930abce295de8d038
ПЩвдПДЕНЃЌдкФПТМhdfs://namenode01.td.com/flink-1.5.3 /flink-savepoints /savepoint-40dcc6-4790807da3b0 ЯТУцЩњГЩСЫIDЮЊ40dcc6d2ba90f13930abce295de8d038ЕФJobЕФSavepointЪ§ОнЁЃ
ЮЊе§дкдЫааЕФFlink JobжИЖЈвЛИіФПТМДцДЂSavepointЪ§ОнЃЌжДааШчЯТУќСюЃК
bin/flink savepoint 40dcc6d2ba90f13930abce295de8d038 hdfs:// namenode01.td.com / tmp / flink / savepoints
ПЩвдПДЕНЃЌдкФПТМ hdfs://namenode01.td.com/tmp/flink/savepoints/ savepoint-40dcc6-a90008f0f82fЯТУцЩњГЩСЫIDЮЊ40dcc6d2ba90f13930abce295de8d038ЕФJobЕФSavepointЪ§ОнЁЃ
ЪЎвЛЁЂДгSavepointЛжИД
ЯждкЃЌЮвУЧПЩвдЭЃЕєJob 40dcc6d2ba90f13930abce295de8d038ЃЌШЛКѓЭЈЙ§SavepointУќСюРДЛжИДJobдЫааЃЌУќСюИёЪНШчЯТЫљЪОЃК
bin/flink run -s :savepointPath [:runArgs]
вдЩЯУцБЃДцЕФSavepointЮЊР§ЃЌЛжИДJobдЫааЃЌжДааШчЯТУќСюЃК
bin/flink run -s hdfs://namenode01.td.com/tmp/flink/savepoints/ savepoint-40dcc6-a90008f0f82f flink-app-jobs .jar
ПЩвдПДЕНЃЌЦєЖЏвЛИіаТЕФ Flink Job ЃЌIDЮЊ cdbae3af1b7441839e7c03bab0d0eefd ЁЃ
|









