| БрМЭЦМі: |
БОЮФжївЊНВНтСЫЪ§ОнжЪСПЁЂГЩБОгХЛЏЁЂЪ§ОнЗўЮёЕФЮЪЬтЁЂЪ§ОнЗўЮёгІИУОпБИЕФЦпДѓЙІФмМАЪ§ОнЗўЮёЯЕЭГМмЙЙЩшМЦЁЃ
БОЮФРДздВЉПЭдА ЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
Ъ§ОнжЪСП
ДгФЃаЭЩшМЦВуУцЃЌж№ВННЋЗжЩЂЁЂдгТвЁЂбЬДбЪНЕФаЁЪ§ВжећКЯГЩСЫПЩИДгУЁЂПЩЙВЯэЕФЪ§ОнжаЬЈЃЌЪ§ОнбаЗЂаЇФмЬсЩ§СЫвЛБЖЁЃФЧЪЧВЛЪЧНЛИЖЪ§ОнзуЙЛПьЃЌЪЙгУЪ§ОнЕФШЫОЭТњвтСЫЃПЙтПьЛЙВЛЙЛЃЌЛЙвЊБЃжЄжЪСПЁЃдкЪ§ОнжаЬЈжаГЃГЃЛсгіЕНвЛЯТРрЫЦЕФЮЪЬтЃК
Ъ§ОнВПУХЭэгквЕЮёЗНЗЂЯжЪ§ОнвьГЃЃЌБЛЭЖЫпКѓВХЗЂЯжЮЪЬтЁЃ
ГіЯжЮЪЬтКѓЃЌЪ§ОнВПУХЮоЗЈПьЫйЖЈЮЛЕНЪ§ОнвьГЃЕФИљдДЃЌХХВщгУСЫНЯГЄЕФЪБМфЁЃ
ЙЪеЯГіЯждкЪ§ОнМгЙЄСДТЗЕФЩЯгЮЖЅЖЫЃЌГіЯжЮЪЬтУЛгаЕквЛЪБМфБЈОЏДІРэЃЌЕМжТЮЪЬтаоИДЪБЃЌЫљгаЯТгЮСДТЗЩЯЕФШЮЮёЖМвЊдЫааЃЌаоИДЪБМфГЩБОЗЧГЃИпЁЃ
етаЉЮЪЬтзюжеЕМжТСЫЪ§ОнГЄЪБМфВЛПЩгУЁЃФЧШчКЮНтОіетаЉЮЪЬтЃЌШЗБЃЪ§ОнИпжЪСПЕФНЛИЖФиЃП ЪзЯШЃЌФувЊСЫНтВњЩњетаЉЮЪЬтЕФИљдДЃЌБЯОЙШЯЪЖЮЪЬтВХФмНтОіЮЪЬтЁЃ
Ъ§ОнжЪСПЮЪЬтЕФИљдД
ЮвУЧЖдЪТМўЕФдвђНјааСЫЙщФЩЃЌжївЊгаЯТУцМИРрЁЃетРяЖрЫЕвЛОфЃЌШчЙћФуЯыИФНјЪ§ОнжЪСПЃЌВЛЗСвВЖдЙ§ШЅВШЙ§ЕФПгзівЛДЮИДХЬЃЌЙщвЛЯТРрЃЌПДПДЮЪЬтЖМГідкФФРяЃЌШЛКѓжЦЖЈеыЖдадЕФИФНјМЦЛЎЁЃ
вЕЮёдДЯЕЭГБфИќ
Ъ§ОнжаЬЈЕФЪ§ОнРДдДгквЕЮёЯЕЭГЃЌЖјдДЯЕЭГБфИќвЛАуЛсв§ЗЂ 3 РрвьГЃЧщПіЃЌ
ЪзЯШЪЧдДЯЕЭГЪ§ОнПтБэНсЙЙБфИќЁЃР§ШчвЕЮёЯЕЭГаТАцБОЗЂВМЩЯЯпЃЌЖдЪ§ОнПтНјааСЫБэНсЙЙБфИќЃЌдіМгСЫвЛИізжЖЮЃЌЭЌЪБЖдВПЗжзжЖЮЕФРраЭЁЂУЖОйжЕНјааСЫЕїећЁЃетжжБэНсЙЙБфИќУЛгаЭЈжЊЕНЪ§ОнЭХЖгЃЌЕМжТЪ§ОнЭЌВНШЮЮёЛђепЪ§ОнЧхЯДШЮЮёвьГЃЃЌНјЖјгАЯьСЫЯТгЮЪ§ОнВњГіЁЃ
ЕкЖўИіЪЧдДЯЕЭГЛЗОГБфИќЁЃЮвОГЃдкДѓДйЦкМфМћЕНетжжЧщПіЃЌЦфжаЕФЕфаЭЪЧЧАЖЫгУЛЇааЮЊТёЕуШежОСПБЉдіЃЌЯЕЭГЙмРэдБНєМБЖдЗўЮёЦїНјааРЉШнЃЌЩЯЯпСЫ
5 ЬЈаТЕФЗўЮёЦїЃЌЕЋЪЧУЛгаХфжУет 5 ЬЈЗўЮёЦїЕФШежОЭЌВНШЮЮёЃЌНсЙћЕМжТЪ§ОнВрЩйСЫет 5 ЬЈЗўЮёЦїЕФЪ§ОнЃЌзюжегАЯьСЫЪ§ОнМЦЫуНсЙћЕФзМШЗадЁЃ
зюКѓвЛИіЪЧдДЯЕЭГШежОЪ§ОнИёЪНвьГЃЁЃетжжЧщПіЭЈГЃГіЯждкЧАКѓЖЫТёЕуШежОжаЁЃвЕЮёЯЕЭГЗЂВМЩЯЯпв§ШыТёЕу BUGЃЌЕМжТ
IP ИёЪНГіЯжСЫВЛЗћКЯдМЖЈЕФИёЪНЃЈБШШчЃЌЮвУЧвЛАудМЖЈЕФ IP ИёЪНЪЧ 166.111.4.129ЃЌНсЙћГіЯжСЫ
166.111.4.nullЃЉЃЌзюжевВЛсЕМжТМЦЫуНсЙћДэЮѓЁЃ
Ъ§ОнПЊЗЂШЮЮёБфИќ
етжжЧщПідкЪ§ОнжЪСПЪТМўжаеМЕНСЫ 60% вдЩЯЃЌЖјЫќДѓЖрЪ§ЪЧгЩгкЪ§ОнПЊЗЂЕФчЂТЉв§ЗЂЕФЃЌРДПДМИИіФуБШНЯЪьЯЄЕФР§згЃК
ШЮЮёЗЂВМЩЯЯпЃЌДњТыжав§гУЕФВтЪдПтУЛгааоИФЮЊЯпЩЯПтЃЌНсЙћЮлШОСЫЯпЩЯЪ§ОнЃЛ
ШЮЮёЗЂВМЩЯЯпЃЌДњТыжаЪЙгУСЫЙЬЖЈЗжЧјЃЌУЛгаЧаЛЛЮЊЁА${azkaban.flow.1.days.ago}ЁБЃЌЕМжТЪ§ОнвьГЃЃЛ
ЧАУцР§згжаЃЌЪ§ОнИёЪНДІРэДэЮѓЃЌДњТыКіТдСЫвьГЃЃЌЕМжТЪ§ОнДэЮѓЃЛ
ШЮЮёХфжУвьГЃЃЌЫќЭЈГЃБэЯждкШЮЮёУЛгаХфжУвРРЕЃЌЧАвЛИіШЮЮёУЛгадЫааЭъЃЌКѓвЛИіШЮЮёОЭПЊЪМдЫааЃЌЪфШыЪ§ОнВЛЭъећЃЌЕМжТЯТгЮЪ§ОнВњГіДэЮѓЁЃ
ЮяРэзЪдДВЛзу
дкЖрзтЛЇЯТЃЌHadoop ЩњЬЌЕФДѓЪ§ОнШЮЮёЃЈMRЃЌHiveЃЌSparkЃЉвЛАудЫаадк yarn ЙмРэЕФЖрИіЖгСаЩЯЃЈЕїЖШЦїЮЊ
CapacityScheduluerЃЉЃЌУПИіЖгСаЖМЪЧЗжХфСЫвЛЖЈДѓаЁЕФМЦЫузЪдДЃЈCPUЁЂФкДцЃЉЁЃ
ЛљДЁЩшЪЉВЛЮШЖЈ
ДгЪ§СПЩЯРДПДЃЌетРрвьГЃВЛЫуЖрЃЌЕЋгАЯьШДЪЧШЋОжадЕФЁЃЮвУЧдјОдкДѓДйЦкМфЃЌХіЕНСЫвЛИіHadoop 2.7
NameNode ЕФ BUGЃЌдьГЩ HDFS ећИіЗўЮёЖМЭЃжЙЖСаДЃЌзюжеЭЈЙ§СйЪБВЙЖЁЕФЗНЪНВХаоИДЁЃзмЕФРДЫЕЃЌГіЯжЮЪЬтВЂВЛПЩХТЃЌПЩХТЕФЪЧЃЌЮвУЧУЛгаМАЪБЗЂЯжЮЪЬтЃЌОЁПьЛжИДЗўЮёЃЌОйвЛЗДШ§ЕиЭЈЙ§СїГЬКЭММЪѕЪжЖЮЃЌНЕЕЭЮЪЬтГіЯжЕФИХТЪЁЃЫљвдНгЯТРДЮвУЧОЭРДПДвЛПДЃЌШчКЮЬсИпЪ§ОнжЪСПЃП
ШчКЮЬсИпЪ§ОнжЪСПЃП
ЮвШЯЮЊЃЌвЊЯыЬсЩ§Ъ§ОнжЪСПЃЌзюживЊЕФОЭЪЧЁАдчЗЂЯжЃЌдчЛжИДЁБЃК
дчЗЂЯжЃЌЪЧвЊФмЙЛЯШгкЪ§ОнЪЙгУЗНЗЂЯжЪ§ОнЕФЮЪЬтЃЌОЁПЩФмдкГіЯжЮЪЬтЕФдДЭЗЗЂЯжЮЪЬтЃЌетбљОЭЮЊЁАдчЛжИДЁБељШЁЕНСЫДѓСПЕФЪБМфЁЃ
дчЛжИДЃЌОЭЪЧвЊЫѕЖЬЙЪеЯЛжИДЕФЪБМфЃЌНЕЕЭЙЪеЯЖдЪ§ОнВњГіЕФгАЯьЁЃ
ФЧОпЬхШчКЮзіЕНетСНИідчФиЃПЮвзмНсСЫвЛЬзЪ§ОнжЪСПНЈЩшЕФЗНЗЈЃЌАќРЈетбљМИИіФкШнЁЃ
ЬэМгЛќКЫаЃбщШЮЮё
дкЪ§ОнМгЙЄШЮЮёжаЃЌЖдВњГіБэАДеевЕЮёЙцдђЃЌЩшМЦвЛаЉаЃбщТпМЃЌШЗБЃЪ§ОнЕФЭъећадЁЂвЛжТадКЭзМШЗадЃЌетЪЧЬсЩ§Ъ§ОнжЪСПзюаажЎгааЇЕФЗНЗЈЁЃЭЈГЃНЈвщФудкЪ§ОнВњГіШЮЮёдЫааНсЪјКѓЃЌЦєЖЏЛќКЫаЃбщШЮЮёЖдЪ§ОнНсЙћНјааЩЈУшМЦЫуЃЌХаЖЯЪЧЗёЗћКЯЙцдђдЄЦкЁЃШчЙћВЛЗћКЯЃЌОЭИљОнЬсЧАЩшЖЈЕФЧПШѕЙцдђЃЌДЅЗЂВЛЭЌЕФДІРэСїГЬЁЃШчЙћЪЧЧПЙцдђЃЌОЭСЂМДжежЙШЮЮёМгЙЄСДТЗЃЌКѓајЕФШЮЮёВЛЛсжДааЃЌВЂЧвСЂМДЗЂГіЕчЛАБЈОЏЃЌЩѕжСЮвУЧвЊЧѓЃЌЙиМќШЮЮёЛЙвЊПЊЦєбЛЗЕчЛАБЈОЏЃЌжБЕНЙЪеЯБЛШЯСьЃЛШчЙћЪЧШѕЙцдђЃЌШЮЮёЛсМЬајжДааЁЃЕЋЪЧДцдкЗчЯеЃЌетаЉЗчЯеЛсЭЈЙ§гЪМўЛђепЖЬаХЕФЗНЪНЃЌЭЈжЊЕНЪ§ОнПЊЗЂЃЌгЩШЫРДНјвЛВНХаЖЯЗчЯебЯжиГЬЖШЁЃ
ФЧОпЬхвЊМгФФаЉЛќКЫЙцдђФиЃПЭъећадЙцдђЁЃжївЊФПЕФЪЧШЗБЃЪ§ОнМЧТМЪЧЭъећЕФЃЌВЛЖЊЪЇЁЃГЃМћЕФЛќКЫЙцдђгаБэЪ§ОнСПЕФОјЖджЕМрПиКЭВЈЖЏТЪЕФМрПиЃЈБШШчБэВЈЖЏГЌЙ§
20%ЃЌОЭШЯЮЊЪЧвьГЃЃЉЁЃЛЙгажїМќЮЈвЛадЕФМрПиЃЌЫќЪЧХаЖЯЪ§ОнЪЧЗёгажиИДМЧТМЕФМрПиЙцдђЃЌБШНЯЛљДЁЁЃГ§СЫБэМЖБ№ЕФМрПиЃЌЛЙгазжЖЮМЖБ№ЕФМрПиЃЈБШШчзжЖЮЮЊ
0ЁЂЮЊ NULL ЕФМЧТМЃЉЁЃвЛжТадЙцдђЁЃжївЊНтОіЯрЙиЪ§ОндкВЛЭЌФЃаЭжавЛжТадЕФЮЪЬтЁЃЩЬЦЗЙКТђТЪЪЧЭЈЙ§ЩЬЦЗЙКТђгУЛЇЪ§Г§вдЩЬЦЗЗУЮЪ
uv МЦЫуЖјРДЕФЃЌШчЙћдкВЛЭЌЕФФЃаЭжаЃЌЩЬЦЗЙКТђгУЛЇЪ§ЪЧ 1WЁЂЩЬЦЗЗУЮЪ uv10WЃЌЩЬЦЗЙКТђТЪ 20%ЃЌФЧетШ§ИіжИБъОЭДцдкВЛвЛжТЁЃзМШЗадЙцдђЁЃжївЊНтОіЪ§ОнМЧТМе§ШЗадЕФЮЪЬтЁЃГЃМћЕФЛќКЫЙцдђгаЃЌвЛИіЩЬЦЗжЛФмЙщЪєдквЛИіРрФПЃЌЪ§ОнИёЪНЪЧВЛЪЧе§ШЗЕФ
IP ИёЪНЃЌЖЉЕЅЕФЯТЕЅШеЦкЪЧЛЙУЛгаЗЂЩњЕФШеЦкЕШЕШЁЃ
ЫќУЧЪЧЧПЙцдђЛЙЪЧШѕЙцдђЃЌШЁОігквЕЮёЖдЩЯЪівьГЃЕФШнШЬЖШЃЈБШШчЩцМАЕННЛвзЁЂжЇИЖИњЧЎЯрЙиЕФЃЌвЛАуЖМЛсЩшжУЮЊЧПЙцдђЃЌЖдгквЛаЉЦЋааЮЊЗжЮіЕФЃЌвЛАуЖМЪЧШѕЙцдђЃЉЁЃ
НЈСЂШЋСДТЗМрПи
Ъ§ОнжаЬЈЕФФЃаЭЩшМЦЪЧЗжВуЕФЃЌШЗБЃжаМфНсЙћПЩвдБЛЖрИіФЃаЭИДгУЁЃВЛЙ§етЛсЕМжТЪ§ОнМгЙЄЕФСДТЗБфГЄЃЌМгЙЄСДТЗЕФвРРЕЙиЯЕЛсЗЧГЃИДдгЃЌзюжеЕБЯТгЮБэЩЯЕФФГИіжИБъГіЯжЮЪЬтЃЌХХВщЖЈЮЛЮЪЬтЕФЪБМфЖМЛсБШНЯГЄЁЃЫљвдЃЌЮвУЧгаБивЊЛљгкЪ§ОнбЊдЕЙиЯЕЃЌНЈСЂШЋСДТЗЪ§ОнжЪСПМрПиЁЃ
ДгетИіЭМжаФуПЩвдПДЕНЃЌвЕЮёЯЕЭГЕФдДЪ§ОнПтБэЪЧЦ№ЕуЃЌОЙ§Ъ§ОнжаЬЈЕФЪ§ОнМгЙЄСДТЗЃЌВњГіжИБъЁАКкПЈЛсдБЙКТђгУЛЇЪ§ЁБЃЌЪ§ОнгІгУЪЧСДТЗЕФжеЕуЁЃЖдСДТЗжаУПИіБэдіМгЛќКЫаЃбщЙцдђжЎКѓЃЌЕБЦфжаШЮКЮвЛИіНкЕуВњГіЕФЪ§ОнГіЯжвьГЃЪБЃЌФуФмЙЛЕквЛЪБМфЗЂЯжЃЌВЂСЂМДаоИДЃЌзіЕНдчЗЂЯжЁЂдчаоИДЁЃСэЭтЃЌМДЪЙЪЧЪЙгУЗНЗДРЁОгЊЗжЮіЩЯЕФКкПЈЛсдБЙКТђгУЛЇЪ§ЃЌЯрНЯгкзђЬьЪ§ОнДѓЗљЯТНЕГЌЙ§
30%ЃЌФувВПЩвдПьЫйХаЖЈећИіжИБъМгЙЄСДТЗЩЯНкЕуЪЧЗёдЫаае§ГЃЃЌВњГіШЮЮёЪЧЗёгаИќаТЃЌЬсИпСЫЮЪЬтХХВщЫйЖШЁЃ
ЭЈЙ§жЧФмдЄОЏЃЌШЗБЃШЮЮёАДЪБВњГі
дкЪ§ОнжЪСПЮЪЬтжаЃЌЮвЬсЕНЛсДцдкЮяРэзЪдДВЛзуЃЌЕМжТШЮЮёВњГібгГйЕФЧщПіЁЃдкЭјвзЃЌЫљгаЪ§ОнжаЬЈВњГіЕФжИБъвЊЧѓ
6 ЕуЧАВњГіЁЃЮЊСЫЪЕЯжетИіФПБъЃЌЮвУЧашвЊЖджИБъМгЙЄСДТЗжаЕФУПИіШЮЮёЕФВњГіЪБМфНјааМрПиЃЌЛљгкШЮЮёЕФдЫааЪБМфКЭЪ§ОнбЊдЕЃЌЖдЯТгЮжИБъВњГіЪБМфНјааЪЕЪБдЄВтЃЌвЛЕЉЗЂЯжжИБъЮоЗЈАДЪБВњГіЃЌдђСЂМДБЈОЏЃЌЪ§ОнПЊЗЂПЩвджежЙвЛаЉЕЭгХЯШМЖЕФШЮЮёЃЌШЗБЃКЫаФШЮЮёАДЪБВњГіЁЃ
ЭЈЙ§гІгУЕФживЊадЧјЗжЪ§ОнЕШМЖЃЌМгПьЛжИДЫйЖШ
ЛќКЫаЃбщЛсЯћКФДѓСПЕФзЪдДЃЌЫљвджЛгаКЫаФШЮЮёВХашвЊЁЃКЫаФШЮЮёЕФЖЈвхЪЧКЫаФгІгУЃЈЪЙгУЗЖЮЇЙуЁЂЪЙгУепЙмРэМЖБ№ИпЃЉЪ§ОнСДТЗЩЯЕФЫљгаШЮЮёЁЃ
ЙцЗЖЛЏЙмРэжЦЖШ
НВЕНетЖљЃЌФуПЩФмЛсЮЪЃКЪ§ОнжЪСПШЁОігкЛќКЫЙцдђЕФЭъЩЦадЃЌШчЙћЪ§ОнПЊЗЂУЛгаЬэМгЃЌЛђепЬэМгЕФЙцдђВЛШЋЃЌЪЧВЛЪЧОЭДяВЛЕНдчЗЂЯжЁЂдчЛжИДЃПетИіЮЪЬтДСжаСЫвЊКІЃЌОЭЪЧЙцдђЕФЭъБИадШчКЮРДБЃеЯЁЃдкЮвПДРДЃЌетВЛНіНіЪЧвЛИіММЪѕЮЪЬтЃЌвВЩцМАЙмРэЁЃдкЭјвзЃЌЮвУЧЛсжЦЖЈвЛаЉЭЈгУЕФжИЕМЙцдђЃЈБШШчЃЌЫљгаЪ§ОнжаЬЈЮЌЛЄЕФБэЖМашвЊЬэМгжїМќЮЈвЛадЕФМрПиЙцдђЃЉЃЌЕЋетаЉЭЈгУЙцдђЭљЭљгывЕЮёЙиЯЕВЛДѓЁЃШчЙћЩцМАвЕЮёВуУцЃЌОЭвЊгЩЪ§ОнМмЙЙЪІЧЃЭЗЃЌАДеежїЬтгђЁЂвЕЮёЙ§ГЬЃЌЖдУПИіБэЕФЙцдђНјааЦРЩѓЃЌОіЖЈетаЉЙцдђЙЛВЛЙЛЁЃФЧЮвЯыНЈвщФуЃЌШчЙћвЊзіЛќКЫаЃбщЃЌПЩвдЭЈЙ§зщНЈЪ§ОнМмЙЙЪІЭХЖгЃЌгЩетИіЭХЖгИКд№КЫаФБэЕФЙцдђЩѓКЫЃЌШЗБЃЙцдђЕФЭъБИадЁЃФЧУДЕБФуАДееетМИИіЗНЗЈНЈСЂСЫЪ§ОнжЪСПЬхЯЕжЎКѓЃЌвЊШчКЮбщжЄЬхЯЕЪЧЗёгааЇФи?
ШчКЮКтСПЪ§ОнжЪСПЃП
зіЪ§ОнжЮРэЃЌЮввЛжБЗюааЁАаЇЙћПЩСПЛЏЁБЕФддђЃЌЗёдђетИіжЮРэзіЕНЪВУДГЬЖШЃЌКмФбКтСПЁЃФЧУДШчКЮЦРМлЪ§ОнжЪСПЪЧЗёгаИФНјФиЃПГ§СЫЙЪеЯДЮЪ§ЃЌФуЛЙПЩвдгаетбљМИИіжИБъЁЃ4
ЕуАыЧАЪ§ОнжаЬЈКЫаФШЮЮёВњГіЭъГЩТЪЁЃетИіжИБъЪЧвЛИізлКЯаджИБъЃЌШчЙћШЮЮёвьГЃЃЌШЮЮёбгГйЃЌЧПЛќКЫЙцдђЪЇАмЃЌЖМЛсЕМжТШЮЮёЮоЗЈдкЙцЖЈЪБМфЧАВњГіЁЃЛљгкЛќКЫЙцдђЃЌМЦЫуБэМЖБ№ЕФжЪСПЗжЪ§ЁЃИљОнБэЩЯЛќКЫЙцдђЕФЭЈЙ§ЧщПіЃЌЮЊУПИіБэНЈСЂжЪСПЗжЪ§ЃЌЖдгкЗжЪ§ЕЭЕФБэЃЌБэИКд№ШЫвЊГаЕЃИФНјд№ШЮЁЃашвЊСЂМДНщШыЕФБЈОЏДЮЪ§ЃЌЭЈГЃвдПЊЦєбЛЗБЈОЏЕФЕчЛАБЈОЏДЮЪ§ЮЊзМЁЃЖдгкКЫаФШЮЮёЃЌШЮЮёвьГЃЛсДЅЗЂбЛЗЕчЛАБЈОЏЃЌНгЕНБЈОЏЕФЪ§ОнПЊЗЂашвЊСЂМДНщШыЁЃЪ§ОнВњЦЗ
SLAЁЃУПИіЪ§ОнВњЦЗЩЯЫљгажИБъгаУЛгадк 9 ЕуВњГіЃЌШчЙћУЛгаЃЌПЊЪММЦЫуВЛПЩгУЪБМфЃЌећЬхПЩвдАДееВЛЭЌЪ§ОнВњЦЗЕФживЊадНјааелЫуЃЌ99.8%
ЪЧЪ§ОнВњЦЗвЛИіЯрЖдБШНЯКУЕФ SLAЁЃ
ВЛЙ§ЃЌММЪѕКЭЙцЗЖзюжеашвЊвРППВњЦЗРДАяжњТфЕиЃЌдкЭјвзФкВПЃЌгавЛИіЪ§ОнжЪСПжааФЕФ ВњЦЗЃЌЭЈЙ§НщЩметИіВњЦЗЃЌЮвЯЃЭћФмИјФувЛИіВЮПМЃЌШчКЮШЅЩшМЦвЛИіЪ§ОнжЪСПжааФЃЌЛђепдкбЁаЭЕФЪБКђЃЌЪ§ОнжЪСПжааФБиаыОпБИЕФЙІФмЁЃ
ГЩБОгХЛЏ
дквЛПЊЪМНЈЩшЪ§ОнжаЬЈЪБЃЌФуЭљЭљЛсЙизЂаТвЕЮёЕФНгШыЃЌЪ§ОнЕФећКЯЃЌЪ§ОнМлжЕЕФЭкОђЩЯЃЌКіТдГЩБОЙмПиЕФЮЪЬтЃЌДгЖјТфШыЯнкхжаЃЌдьГЩГЩБОБЌеЈЪНЕФдіГЄЁЃЫљвдЃЌФугаБивЊЩюШыСЫНтвЛЯТгаФФаЉЯнкхЃЌДгЖјОЁСПдкШеГЃПЊЗЂжаБмУтЁЃдкетРяЃЌЮвзмНсСЫ
8 жжЯнкхЃЌЦфжаЃК
1~3 ЪЧЙуЗКДцдкЃЌЕЋЪЧШнвзБЛКіТдЕФЃЌашвЊФуИёЭтзЂвтЃЛ
4~8 ЩцМАЪ§ОнПЊЗЂжавЛаЉММФмЃЌФудкПЊЗЂЙ§ГЬжазЂвтвЛЯТОЭПЩвдСЫЁЃ
Г§ДЫжЎЭтЃЌдкбЇЯАетВПЗжжЊЪЖЕФЙ§ГЬжаЃЌЮвНЈвщФуЁАжЊЦфШЛЃЌИќвЊжЊЦфЫљвдШЛЁБЃЌетбљВХФмЗЂЯжЮЪЬтЕФБОжЪЃЌДгЖјЩюШыеЦЮеНтОіЮЪЬтЕФЗНЗЈЁЃ
ЕквЛЃЌЪ§ОнЩЯЯпШнвзЯТЯпФбЁЃ
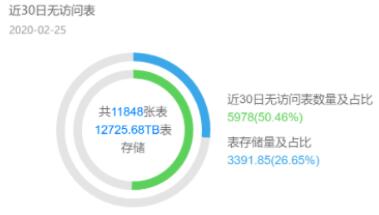
ЯШРДПДвЛзщЭГМЦЪ§ОнЃЌетЪЧФГЪ§ОнжаЬЈЯюФПЃЌБэЯрЙиЕФЪЙгУЭГМЦЁЃДгжаФуПЩвдЗЂЯжЃЌгавЛАыЕФБэдк 30 ЬьФкЖМУЛгаЗУЮЪЃЌЖјетаЉБэеМгУСЫ
26% ЕФДцДЂПеМфЁЃШчЙћЮвУЧАбетаЉБэЕФВњГіШЮЮёЕЅЖРСрГіРДЃЌдкИпЗхЦкашвЊЯћКФ 5000Core CPU
ЕФМЦЫузЪдДЃЌЛЛЫуГЩЗўЮёЦїашвЊ 125 ЬЈЃЈАДеевЛЬЈЗўЮёЦїПЩЗжХф CPU 40Core МЦЫуЃЉЃЌелКЯГЩБОвЛФъНгНќ
500WЁЃЪЧВЛЪЧОѕЕУздМКОЙШЛгаетУДЖрУЛгУЕФЪ§ОнЃПЮвОГЃАбЪ§ОнБШзїЪжЛњжаЕФЭМЦЌЃЌЮвУЧзмЪЧВЛЖЯЕиХФееЃЌЩњГЩЭМЦЌЃЌШДРСЕУЧхРэЃЌзюжеЪжЛњРяУцЕФДцДЂОГЃВЛЙЛгУЁЃЖдгкЮоЗЈМАЪБЧхРэЪ§ОнЃЌЪ§ОнПЊЗЂЦфЪЕвВгаПрждЁЃЫћУЧВЂВЛжЊЕРвЛИіБэЛЙгаФФаЉШЮЮёдкв§гУЃЌЛЙгаФФаЉШЫдкВщбЏЃЌздШЛВЛИвЭЃжЙетИіБэЕФЪ§ОнМгЙЄЃЌФЧдьГЩЕФКѓЙћОЭЪЧЪ§ОнЩЯЯпШнвзЃЌЯТЯпФбЁЃ
ЕкЖўЃЌЕЭМлжЕЕФЪ§ОнгІгУЯћКФСЫДѓСПЕФзЪдДЁЃ
ЮвУЧЕФЪ§ОнПДЩЯШЅУПЬьЖМдкБЛЗУЮЪЃЌЕЋОПОЙВњГіСЫЖрЩйМлжЕЃЌЭЖШыКЭВњГіЪЧЗёЦЅХфФиЃПзїЮЊвЛИіЪ§ОнВПУХЃЌЮвУЧвЊЮЪвЛЮЪздМКЁЃЮвУЧдјОгавЛИіПэБэЃЈгЕгаКмЖрСаЕФБэЃЌОГЃГіЯждкЪ§ОнжаЬЈЯТгЮЕФЛузмВуЪ§ОнжаЃЉЃЌЫуЩЯЩЯгЮМгЙЄСДТЗЕФШЮЮёЃЌУПЬьМгЙЄетеХПэБэвЊЯћКФ
6000 ПщЧЎЃЌвЛФъвЊ 200WЃЌПЩзЗВщКѓЮвУЧЗЂЯжЃЌетеХПэБэЪЕМЪУПЬьжЛгавЛИіШЫдкЪЙгУЃЌЛЙЪЧвЛИідЫгЊЕФЪЕЯАЩњЁЃЯдШЛЃЌЭЖШыКЭВњГіМЋВЛЦЅХфЁЃетЦфЪЕМфНгЫЕУїЃЌЪ§ОнВПУХБШНЯЙизЂаТЕФЪ§ОнВњЦЗДјИјвЕЮёЕФМлжЕЃЌШДКіТдСЫвбОДцдкЕФВњЦЗЛђепБЈБэЪЧЗёЛЙДцдкМлжЕЃЌзюжеЕМжТЕЭМлжЕЕФгІгУШдШЛдкДѓСПЯћКФзЪдДЁЃ
ЕкШ§ЃЌбЬДбЪНЕФПЊЗЂФЃЪНЁЃ
бЬДбЪНЕФПЊЗЂВЛНіЛсДјРДбаЗЂаЇТЪЕЭЕФЮЪЬтЃЌЭЌЪБвђЮЊЪ§ОнжиИДМгЙЄЃЌЛЙЛсДцдкзЪдДРЫЗбЕФЮЪЬтЁЃЮвУЧРДЫувЛБЪеЫЃЌвЛеХ
500T ЕФБэЃЌМгЙЄетеХБэЃЌМЦЫуШЮЮёашвЊИпЗхЦкЯћКФ 300CoreЃЌелКЯ 7 ЬЈЗўЮёЦїЃЈАДеевЛЬЈЗўЮёЦїПЩЗжХф
CPU 40Core МЦЫуЃЉЃЌдйМгЩЯДцДЂХЬЕФГЩБО (АДее 0.7 дЊ /TB* ЬьМЦЫу)ЃЌвЛФъашвЊЯћКФ
40WЁЃЖјетеХБэУПИДгУвЛДЮЃЌОЭПЩвдНкЪЁ 40W ЕФГЩБОЁЃЫљвдЭЈЙ§ФЃаЭИДгУЃЌЛЙПЩвдЪЕЯжЪЁЧЎЕФФПЕФЁЃ
ЕкЫФЃЌЪ§ОнЧуаБЁЃ
ФуПЯЖЈЬ§ЫЕЙ§ФОЭАаЇгІАЩЃПвЛИіФОЭАзАЖрЩйЫЎЃЌжївЊШЁОігкзюЖЬЕФФЧПщАхЁЃЖдгквЛИіЗжВМЪНВЂааМЦЫуПђМмРДЫЕЃЌетИіаЇгІЭЌбљДцдкЁЃЖдгк
Spark МЦЫув§ЧцРДЫЕЃЌЫќПЩвдНЋКЃСПЕФЪ§ОнЧаЗжГЩВЛЭЌЕФЗжЦЌЃЈPartitionЃЉЃЌЗжХфЕНВЛЭЌЛњЦїдЫааЕФШЮЮёжаЃЌНјааВЂааМЦЫуЃЌДгЖјЪЕЯжМЦЫуФмСІЫЎЦНРЉеЙЁЃЕЋЪЧећИіШЮЮёЕФдЫааЪБГЄЃЌЦфЪЕШЁОігкдЫаазюГЄЕФФЧИіШЮЮёЁЃвђЮЊУПИіЗжЦЌЕФЪ§ОнСППЩФмВЛЭЌЃЌУПИіШЮЮёашвЊЕФзЪдДвВВЛЯрЭЌЁЃгЩгкВЛЭЌЕФШЮЮёВЛФмЗжХфВЛЭЌЕФзЪдДЃЌЫљвдЃЌзмШЮЮёЯћКФзЪдД
=max{ЕЅИіШЮЮёЯћКФЕФзЪдД} * ШЮЮёЪ§СПЁЃетбљвЛРДЃЌЪ§ОнСПаЁЕФШЮЮёЛсЯћКФИќЖрЕФзЪдДЃЌОЭЛсдьГЩзЪдДЕФРЫЗбЁЃ
ЕкЮхЃЌЪ§ОнЮДЩшжУЩњУќжмЦкЁЃ
вЛАудЪМЪ§ОнКЭУїЯИЪ§ОнЃЌЛсБЃСєЭъећЕФРњЪЗЪ§ОнЁЃЖјдкЛузмВуЁЂМЏЪаВуЛђепгІгУВуЃЌПМТЧЕНДцДЂГЩБОЃЌЪ§ОнНЈвщАДееЩњУќжмЦкРДЙмРэЃЌЭЈГЃБЃСєМИЬьЕФПьееЛђепЗжЧјЁЃШчЙћДцдкДѓБэУЛгаЩшжУЩњУќжмЦкЃЌОЭЛсРЫЗбДцДЂзЪдДЁЃ
ЕкСљЃЌЕїЖШжмЦкВЛКЯРэЁЃ
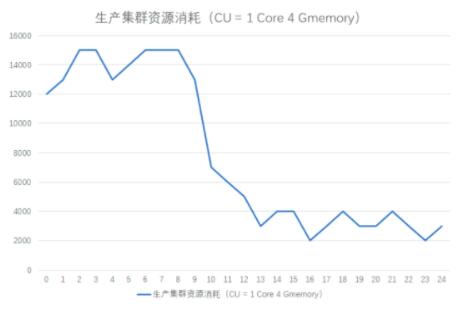
ЭЈЙ§етеХЭМФуПЩвдПДЕНЃЌДѓЪ§ОнШЮЮёЕФзЪдДЯћКФгаКмУїЯдЕФИпЗхКЭЕЭЙШаЇгІЃЌвЛАуЭэЩЯ 12 ЕуЕНЕкЖўЬьЕФ
9 ЕуЪЧИпЗхЦкЃЌ9 ЕуЕНЭэЩЯ 12 ЕуЃЌЪЧЕЭЙШЦкЁЃЫфШЛШЮЮёгаУїЯдЕФИпЗхЕЭЙШаЇгІЃЌЕЋЪЧЗўЮёЦїзЪдДВЛЪЧЕЏадЕФЃЌЫљвдОЭЛсГіЯжЗўЮёЦїдкЕЭЙШЦкБШНЯПеЯаЃЌдкИпЗхЦкБШНЯЗБУІЕФЧщПіЃЌећИіМЏШКЕФзЪдДХфжУШЁОігкИпЗхЦкЕФШЮЮёЯћКФЁЃЫљвдЃЌАбвЛаЉВЛБивЊдкИпЗхЦкФкдЫааШЮЮёЧЈвЦЕНЕЭЙШЦкдЫааЃЌвВПЩвдНкЪЁзЪдДЕФЯћКФЁЃ
ЕкЦпЃЌШЮЮёВЮЪ§ХфжУЁЃ
ШЮЮёВЮЪ§ХфжУЕФВЛКЯРэЃЌЭљЭљвВЛсРЫЗбзЪдДЁЃБШШчдк Spark жаЃЌExecutor ФкДцЩшжУЕФЙ§ДѓЃЛCPU
ЩшжУЕФЙ§ЖрЃЛЛЙга Spark УЛгаПЊЦєЖЏЬЌзЪдДЗжХфВпТдЃЌвЛаЉвбОдЫааЭъ Task ЕФ Executor
ВЛФмЪЭЗХЃЌГжајеМгУзЪдДЃЌгШЦфЪЧгіЕНЪ§ОнЧуаБЕФЧщПіЃЌзЪдДРЫЗбЛсИќМгУїЯдЁЃ
ЕкАЫЃЌЪ§ОнЮДбЙЫѕЁЃ
Hadoop ЕФ HDFS ЮЊСЫЪЕЯжИпПЩгУЃЌФЌШЯЪ§ОнДцДЂ 3 ИББОЃЌЫљвдДѓЪ§ОнЕФЮяРэДцДЂСПЯћКФЪЧБШНЯДѓЕФЁЃгШЦфЪЧЖдгквЛаЉдЪМЪ§ОнВуКЭУїЯИЪ§ОнВуЕФДѓБэЃЌЖЏщќ
500 Жр TЃЌелКЯЮяРэДцДЂашвЊ 1.5PЃЈШ§ИББОЃЌЫљвдЪЕМЪЮяРэДцДЂ 5003ЃЉЃЌДѓдМашвЊ 16 ЬЈЮяРэЗўЮёЦїЃЈвЛЬЈЗўЮёЦїПЩЗжХфДцДЂАДее
128T МЦЫуЃЉЃЌШчЙћВЛЦєгУбЙЫѕЃЌДцДЂзЪдДГЩБОЛсКмИпЁЃСэЭтЃЌдк Hive Лђеп Spark МЦЫуЙ§ГЬжаЃЌжаМфНсЙћвВашвЊбЙЫѕЃЌПЩвдНЕЕЭЭјТчДЋЪфСПЃЌЬсИп
Shuffer (дк Hive Лђеп Spark МЦЫуЙ§ГЬжаЃЌЪ§ОндкВЛЭЌНкЕужЎМфЕФДЋЪфЙ§ГЬ) адФмЁЃФуПДЃЌЮвЮЊФуСаОйСЫ
8 ИіЕфаЭЕФГЩБОЯнкхЃЌФЧФуПЩФмЛсЮЪСЫЃЌРЯЪІЃЌЮввбОжаеаСЫЃЌИУдѕУДАьФиЃП Б№МБЃЌНгЯТРДЮвУЧОЭПДвЛПДЃЌШчКЮНјааОЋЯИЛЏЕФГЩБОЙмРэЁЃ
ШчКЮЪЕЯжОЋЯИЛЏГЩБОЙмРэЃП
ЮвШЯЮЊЃЌГЩБОжЮРэгІИУзёбШЋОжХЬЕуЁЂЗЂЯжЮЪЬтЁЂжЮРэгХЛЏКЭаЇЙћЦРЙРЫФИіВНжшЁЃ
ШЋОжзЪВњХЬЕу
ОЋЯИЛЏГЩБОЙмРэЕФЕквЛВНЃЌОЭЪЧвЊЖдЪ§ОнжаЬЈжаЃЌЫљгаЕФЪ§ОнНјаавЛДЮШЋУцХЬЕуЃЌЛљгкдЊЪ§ОнжааФЬсЙЉЕФЪ§ОнбЊдЕЃЌНЈСЂШЋСДТЗЕФЪ§ОнзЪВњЪгЭМЁЃ
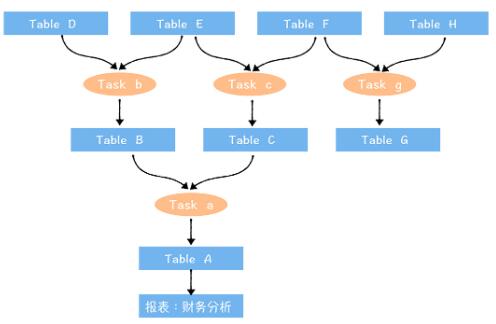
ДгетИіЭМжаФуПЩвдПДЕНЃЌШЋСДТЗЪ§ОнзЪВњЪгЭМЕФЯТгЮФЉЖЫЙиСЊЕНСЫЪ§ОнгІгУЃЈБЈБэЃКВЦЮёЗжЮіЃЉЃЌЖјЩЯгЮЕФЦ№ЕуЪЧИеНјШыЪ§ОнжаЬЈЕФдЪМЪ§ОнЁЃЪ§ОнжЎМфЭЈЙ§ШЮЮёНјааСЌНгЁЃНгЯТРДЃЌЮвУЧвЊМЦЫуШЋСДТЗЪ§ОнзЪВњЪгЭМжаЃЌФЉЖЫЪ§ОнЕФГЩБОКЭМлжЕЃЈФЉЖЫЪ§ОнОЭЪЧМгЙЄСДТЗзюЯТгЮЕФБэЃЌР§ШчЭМжа
TableAЃЌTable GЃЉЁЃЮЊЪВУДвЛЖЈвЊДгФЉЖЫПЊЪМФиЃП вђЮЊжаМфЪ§ОнЃЌдкМЦЫуМлжЕЕФЪБКђЃЌЛЙвЊПМТЧЯТгЮБэБЛЪЙгУЕФЧщПіЃЌБШНЯФбМЦЫуЧхГўЃЌЫљвдЮвУЧбЁдёДгФЉЖЫЪ§ОнПЊЪМЁЃетгыЮвУЧЯТЯпБэЕФЫГађвВЪЧвЛжТЕФЃЌШчЙћЪ§ОнЕФМлжЕКмЕЭЃЌГЩБОКмИпЃЌЮвУЧвВЪЧДгФЉЖЫЪ§ОнПЊЪМЯТЯпЕФЁЃ
ФЧУДЪ§ОнГЩБОИУШчКЮМЦЫуФиЃП
ЮвУЧвЊЖдЩЯЭМжаВЦЮёЗжЮіБЈБэКЫЫуГЩБОЃЌетИіБЈБэЩЯгЮСДТЗжаЩцМАЕН aЃЌbЃЌcЃЌ3 ИіШЮЮёЃЌAЃЌBЃЌCЃЌDЃЌEЃЌFЃЌ
6 еХБэЃЌФЧУДЃК
етеХБЈБэЕФГЩБО =3 ИіШЮЮёМгЙЄЯћКФЕФМЦЫузЪдДГЩБО +6 еХБэЯћКФЕФДцДЂзЪдДЕФГЩБОЁЃ
СэЭтЃЌашвЊзЂвтЕФЪЧЃЌШчЙћвЛИіБэБЛЖрИіЯТгЮгІгУИДгУЃЌФЧетИіБэЕФДцДЂзЪдДГЩБОвдМАВњГіШЮЮёЯћКФЕФГЩБОЃЌашвЊЗжЬЏИјЖрИігІгУЁЃ
ФЧМлжЕгжИУШчКЮМЦЫуФиЃП
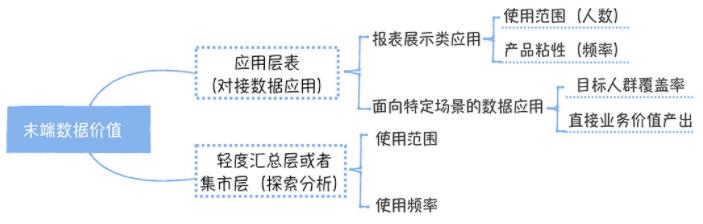
ЮвУЧРДЗжЮівЛЯТетеХЭМЁЃШчЙћФЉЖЫЪ§ОнЪЧвЛеХгІгУВуЕФБэЃЌЫќЖдНгЕФЪЧвЛИіЪ§ОнБЈБэЃЌФЧКтСПетИіЪ§ОнЕФМлжЕЃЌжївЊЪЧПДБЈБэЕФЪЙгУЗЖЮЇКЭЪЙгУЦЕТЪЁЃдкМЦЫуЪЙгУЗЖЮЇЪБЃЌЭЈГЃгУжмЛюРДЦРЙРЃЌЭЌЪБЛЙвЊПМТЧВЛЭЌЙмРэМЖБ№ЕФШЫШЈжиЃЌЖдгкРЯАхЃЌЫћвЛИіШЫЕФШЈжиПЩвдЯрЕБгк
1000 ИіЦеЭЈдБЙЄЁЃжЎЫљвдетбљЩшМЦЃЌЪЧПМТЧЕНЙмРэМЖБ№дНИпЃЌзіГіЕФЩЬвЕОіВпгАЯьОЭдНДѓЃЌздШЛетИіМлжЕвВОЭдНДѓЁЃЪЙгУЦЕТЪвЛАуЪЙгУЕЅИігУЛЇУПжмВщПДБЈБэЕФДЮЪ§РДКтСПЃЌДЮЪ§дНИпЃЌЫЕУїБЈБэМлжЕдНДѓЁЃШчЙћФЉЖЫЪ§ОнЖдНгЕФВЛЪЧвЛИіЪ§ОнБЈБэЃЌЖјЪЧУцЯђЬиЖЈГЁОАЕФЪ§ОнгІгУЃЈБШШчЮвжЎЧАЬсЕНЙ§ЕФЙЉгІСДЗжЮіОіВпЯЕЭГЃЌЫќУцЯђЕФШЫШКжївЊЪЧЙЉгІСДВПУХЃЉЁЃКтСПетРрВњЦЗЕФМлжЕЃЌжївЊПМТЧФПБъШЫШКЕФИВИЧТЪКЭжБНгвЕЮёМлжЕВњГіЁЃЪВУДЪЧжБНгвЕЮёМлжЕВњГіФиЃПЃЌдкЙЉгІСДОіВпЯЕЭГжаЃЌОЭЪЧЭЈЙ§ЯЕЭГздЖЏЩњГЩЕФВЩЙКЖЉЕЅеМЫљгаВЩЙКЖЉЕЅЕФБШР§ЁЃГ§ДЫжЎЭтЃЌФЉЖЫЪ§ОнЃЌПЩФмЛЙЪЧвЛеХМЏЪаВуЕФБэЃЌЫќжївЊгУгкЬсЙЉИјЗжЮіЪІзіЬНЫїЪНВщбЏЁЃетРрБэЕФМлжЕжївЊПДЫќБЛФФаЉЗжЮіЪІЪЙгУЃЌЪЙгУЦЕТЪШчКЮЁЃЭЌбљЃЌдкЪЙгУЗЖЮЇЦРЙРЪБЃЌвЊЖдЗжЮіЪІАДееМЖБ№НјааМгШЈЁЃ
ЗЂЯжЮЪЬт
ШЋОжХЬЕуЃЌЮЊЮвУЧЗЂЯжЮЪЬтЬсЙЉСЫЪ§ОнжЇГХЃЌЖјФуашвЊжиЕуЙизЂЯТУцШ§РрЮЪЬтЃК
ГжајВњЩњГЩБОЃЌЕЋЪЧвбОУЛгаЪЙгУЕФФЉЖЫЪ§ОнЃЈЁАУЛгаЪЙгУЁБвЛАужИ 30 ЬьФкУЛгаЗУЮЪЃЉЃЛ
Ъ§ОнгІгУМлжЕКмЕЭЃЌГЩБОШДКмИпЃЌетаЉЪ§ОнгІгУЩЯгЮСДТЗЩЯЕФЫљгаЯрЙиЪ§ОнЃЛ
ИпЗхЦкИпЯћКФЕФЪ§ОнЁЃ
ФЧУДЮЊЪВУДФувЊЙизЂетШ§РрЪ§ОнФиЃП
ЦфЪЕЕквЛРрОЭЪЧУЛгаЪЙгУЃЌЕЋвЛжБдкЯћКФГЩБОЕФБэЃЌЖдгІЕФОЭЪЧЮвЬсЕНЕФЯнкх 1ЁЃ
ЕкЖўРрЦфЪЕОЭЪЧЕЭМлжЕВњГіЃЌИпГЩБОЕФЪ§ОнгІгУЃЌЖдгІЕФЪЧЯнкх 2ЁЃ
ЕкШ§РрИпГЩБОЕФЪ§ОнЃЌЖдгІЕФОЭЪЧЯнкх 4ЁЋ8ЁЃ
жЮРэгХЛЏ
еыЖдетШ§РрЮЪЬтЃЌЮвУЧашвЊжЦЖЉЯргІЕФВпТдЁЃЖдгкЕквЛРрЮЪЬтЃЌгІИУЖдБэНјааЯТЯпЁЃ Ъ§ОнЯТЯпвЊНїЩїЃЌФуПЩвдВЮПМетеХЪ§ОнЯТЯпЕФжДааЙ§ГЬЭМЃК
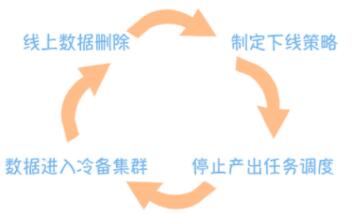
ФЉЖЫЪ§ОнЩОГ§КѓЃЌдЯШФЉЖЫЪ§ОнЕФЩЯгЮЪ§ОнЛсГЩЮЊаТЕФФЉЖЫЪ§ОнЃЌЭЌбљЛЙвЊАДЗЂЯжЮЪЬтЕНжЮРэгХЛЏНјаажиИДЃЌжБЕНЫљгаЕФФЉЖЫЪ§ОнЖМВЛТњзуЯТЯпВпТдЮЊжЙЁЃЖдЕкЖўРрЮЪЬтЃЌЮвУЧашвЊАДеегІгУСЃЖШЦРЙРгІгУЪЧЗёЛЙгаДцдкЕФБивЊЁЃЖдгкБЈБэЃЌПЩвдАДее
30 ЬьФкУЛгаЗУЮЪЕФгІгУздЖЏЯТЯпЕФВпТдЃЌЯШЖдБЈБэНјааЯњЛйЃЌШЛКѓЖдБЈБэЩЯгЮЕФБэНјааЯТЯпЃЌШчЙћИУБэЛЙБЛЦфЫћЕФгІгУв§гУЃЌОЭВЛФмЯТЯпЁЃЯТЯпВНжшПЩвдВЮПМЧАУцЕФЯТЯпВНжшЁЃЕкШ§РрЮЪЬтЃЌжївЊЪЧеыЖдИпЯћКФЕФЪ§ОнЃЌгжОпЬхЗжЮЊВњГіЪ§ОнЕФШЮЮёИпЯћКФКЭЪ§ОнДцДЂИпЯћКФЁЃЖдгкВњГіШЮЮёИпЯћКФЃЌЪзЯШвЊПМТЧЪЧВЛЪЧЪ§ОнЧуаБЁЃОпЬхдѕУДХаЖЯФиЃПЦфЪЕФуПЩвдЭЈЙ§
MR Лђеп Spark ШежОжаЃЌShuffer ЕФЪ§ОнСПНјааХаЖЯЁЃШчЙћгаФГвЛИі Task Ъ§ОнСПЗЧГЃДѓЃЌЦфЫћЕФКмЩйЃЌОЭПЩвдХаЖЈГіЯжСЫЪ§ОнЧуаБЁЃ
жЮРэаЇЙћЦРЙР
ЯждкЃЌЭЈЙ§ЮвНщЩмЕФетМИИіЗНЗЈЃЌФувбОФмЙЛНкЪЁДѓСПЕФзЪдДЯћКФЃЌФЧШчКЮСПЛЏЮвУЧЕФжЮРэГЩЙћФиЃПЮхИізжЃКЪЁСЫЖрЩйЧЎЁЃВЛЙ§ЃЌШчЙћжБНгФУЗўЮёЦїЕФЪ§СПРДКтСПЃЌЦфЪЕВЂВЛФмецЪЕЕиЗДгІжЮРэаЇЙћЃЌвђЮЊЛЙвЊПМТЧвЕЮёдіГЄЕФдвђЁЃвЕЮёВЛЪЧЭЃжЙВЛЖЏЕФЃЌЫљвдФуПЩвдЮЇШЦШЮЮёКЭЪ§ОнЕФГЩБОПМТЧетбљМИЕуЃК
ЯТЯпСЫЖрЩйШЮЮёКЭЪ§ОнЃЛетаЉШЮЮёУПШеЯћКФСЫЖрЩйзЪдДЃЛЪ§ОнеМгУСЫЖрЩйДцДЂПеМфЁЃФУетаЉзЪдДРДМЦЫуГЩБОЃЌетбљОЭФмЙЛЫуГіРДЪЁСЫЖрЩйЧЎЁЃЮвЛЙЪЧФУБОНкПЮПЊЪМЕФР§згРДПДЃЌШЮЮё
A дЫааЪБГЄ 3 ИіаЁЪБЃЌдкдЫааЙ§ГЬжаЃЌЙВЯћКФ 5384503 cpu*sЃЌ37007892 GB
*s, МйЩшЮвУЧ 1 Иі CU ЃЈ1 cpuЃЌ 4g memeoryЃЉвЛФъЪЧ 1300 дЊГЩБОЃЌелКЯУПЬьЮЊ
3.5 дЊЃЈМЦЫуЙЋЪНЮЊ 1300/365ЃЉЁЃ
Ъ§ОнЗўЮёЕФЮЪЬт
ЗўЮёЛЏдквЕЮёЯЕЭГжаЬсЕФБШНЯЖрЃЌЫќЪЧвЕЮёЯЕЭГЛЏЗБЮЊМђЃЌЪЕЯжвЕЮёВ№ЗжЕФБиОжЎТЗЃЈЬиБ№ЪЧетМИФъЮЂЗўЮёЕФИХФюЩюШыШЫаФЃЉЁЃФЧЖдгкЪ§ОнжаЬЈЃЌЗўЮёЛЏвтЮЖзХЪВУДФиЃПЪ§ОнЗўЮёЕНЕзНтОіСЫЪВУДЮЪЬтЃП
ЮвЯраХКмЖрШЫЛсгаетбљЕФвЩЮЪЁЃЗўЮёЛЏЃКВЛЭЌЯЕЭГжЎМфЭЈЙ§ЗўЮёЗНЪННЛЛЅЃЌЗўЮёЭЈГЃвд API НгПкаЮЪНДцдкЁЃЕБШЛЃЌЙигкЪ§ОнЗўЮёЕФЁАСЯЁБКмЖрЃЌаХЯЂБШНЯУмМЏЃЌЫљвдЮвЛсгУСННВЕФЪБМфАяФуИуЧхГўетВПЗжФкШнЃЌНёЬьдлУЧЯШРДДгЮЪЬтШыЪжЃЌПДвЛПДЪ§ОнЗўЮёНтОіСЫЪВУДЮЪЬтЃЌДђЯћФуЁАЮЊЪВУДвЊгаЪ§ОнЗўЮёЁБетбљЕФвЩЮЪЁЃдкЮвПДРДЃЌвЊЯыИуЧхГўЪ§ОнЗўЮёНтОіСЫЪВУДЮЪЬтЃЌОЭвЊЯШжЊЕРЃЌУЛгаЪ§ОнЗўЮёЃЌЮвУЧдкШеГЃЪ§ОнНЈЩшжаДцдкФФаЉЭДЕуЁЃ
Ъ§ОнНгШыЗНЪНЖрбљЃЌНгШыаЇТЪЕЭ
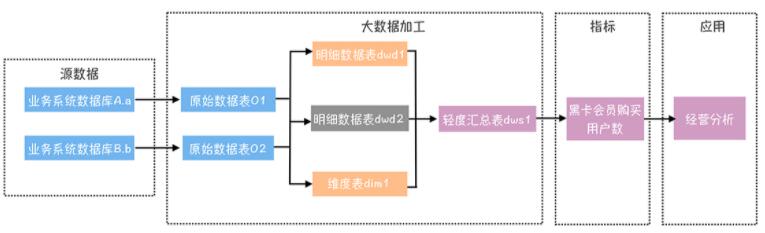
Ъ§ОнжаЬЈМгЙЄКУЕФЪ§ОнЃЌЭЈГЃЛсвд Hive БэЕФаЮЪНДцДЂдк HDFS ЩЯЁЃШчЙћЯыжБНгЭЈЙ§Ъ§ОнБЈБэЛђепЪ§ОнВњЦЗЧАЖЫеЙЯжЃЌЮЊСЫБЃжЄВщбЏЕФЫйЖШЃЌЛсАбЪ§ОнЕМГіЕНвЛИіжаМфДцДЂЩЯЃК
Ъ§ОнСПЩйЕФПЩвдгУ MySQL , Oracle ЕШ DBЃЌвђЮЊВПЪ№ЮЌЛЄЗНБуЁЂЪ§ОнСПаЁЁЂВщбЏадФмЧПЁЃБШШчЪ§ОнСПаЁгк
500W ЬѕМЧТМЃЌНЈвщЪЙгУ DB зїЮЊжаМфДцДЂЃЛ
ЩцМАДѓЪ§ОнСПЁЂЖрЮЌЖШВщбЏЕФПЩвдгУ GreenPlumЃЌЫќдкКЃСПЪ§ОнЕФ OLAPЃЈдкЯпЗжЮіДІРэЃЉГЁОАжагагХвьЕФадФмБэЯжЁЃБШШчЪ§ОнСПГЌЙ§
500W МЧТМЃЌвЊНјааЖрИіЬѕМўЕФЙ§ТЫВщбЏЃЛ
ЩцМАДѓЪ§ОнСПЕФЕЅ Key ВщбЏЃЌПЩвдгУ HBaseЁЃдкДѓЪ§ОнСПЯТЃЌHBase гЕгаВЛДэЕФЖСаДадФмЁЃБШШчГЌЙ§
500W МЧТМЃЌИљОн Key ВщбЏ Value ЕФГЁОАЁЃШчЙћашвЊгУЕНЖўМЖЫїв§ЃЌгЩгк HBase дЩњВЛжЇГжЖўМЖЫїв§ЃЌЫљвдПЩвдв§Шы
ESЃЌЛљгк ES ЙЙНЈЖўМЖЫїв§КЭ RowKeyЃЈHBase жаЕФ KeyЃЉгГЩфЙиЯЕЃЌВщбЏЪБЯШИљОнЖўМЖЫїв§дк
ES жаевЕН RowKeyЃЌШЛКѓдйИљОн RowKey ЛёШЁ HBase жаЕФ Value жЕЁЃ
вђЮЊВЛЭЌЕФжаМфДцДЂЃЌЩцМАЕФЗУЮЪ API вВВЛвЛбљЃЌЫљвдЖдЪ§ОнгІгУПЊЗЂРДЫЕЃЌУПИіЪ§ОнгІгУЖМвЊИљОнВЛЭЌЕФжаМфДцДЂЃЌПЊЗЂЖдгІЕФДњТыЃЌШчЙћЩцМАЖрИіжаМфДцДЂЃЌЛЙашвЊПЊЗЂЖрЬзДњТыЃЌЪ§ОнНгШыаЇТЪКмЕЭЁЃЖјЪ§ОнЗўЮёЮЊЪ§ОнПЊЗЂЦСБЮСЫВЛЭЌЕФжаМфДцДЂЃЌгІгУПЊЗЂЪЙгУЭГвЛЕФ
API НгПкЗУЮЪЪ§ОнЃЌДѓЗљЖШЬсИпСЫЪ§ОнгІгУЕФбаЗЂаЇТЪЁЃ
Ъ§ОнКЭНгПкУЛгаАьЗЈИДгУ
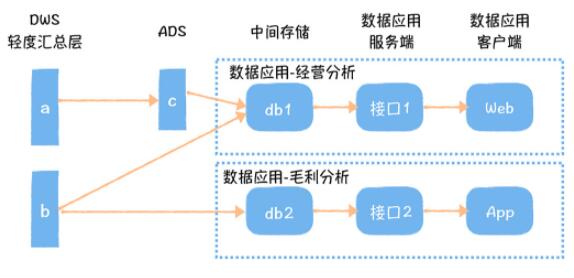
дкЩЯЭМжаЃЌЕБЮвУЧПЊЗЂЁАЪ§ОнгІгУ - ОгЊЗжЮіЁБЪБЃЌЪ§ОнПЊЗЂЛсЛљгк a БэМгЙЄ c БэЃЌШЛКѓЪ§ОнгІгУПЊЗЂЛсАб
a КЭ b ЕФЪ§ОнЕМГіЕНЁАЪ§ОнгІгУ - ОгЊЗжЮіЕФЪ§ОнПт db1ЁБжаЃЌШЛКѓПЊЗЂОгЊЗжЮіЕФЗўЮёЖЫДњТыЃЌЭЈЙ§НгПк
1 Жд web ЬсЙЉЗўЮёЁЃЕБЮвУЧгжНгЕНШЮЮёПЊЗЂЁАЪ§ОнгІгУ - УЋРћЗжЮіЁБЪБЃЌЮвУЧЭЌбљашвЊгУЕН b БэЕФЪ§ОнЃЌЫфШЛ
b ЕФЪ§ОнвбОДцдкгк db1 жаЃЌЕЋ db1 ЪЧЁАЪ§ОнгІгУ - ОгЊЗжЮіЁБЕФЪ§ОнПтЃЌЮоЗЈЙВЯэИјЁАЪ§ОнгІгУ
- УЋРћЗжЮіЁБЃЈвђЮЊВЛЭЌгІгУжЎМфЙВЯэЪ§ОнПтЃЌЛсДцдкЯрЛЅгАЯьЃЉЁЃЭЌЪБЃЌОгЊЗжЮіЕФЗўЮёЖЫНгПквВЮоЗЈжБНгИјУЋРћЗжЮігУЃЌвђЮЊНгПкЙщЪєдкОгЊЗжЮігІгУжаЃЌвбОИљОнгІгУашЧѓИпЖШЖЈжЦЛЏЁЃЫљвдЮвУЧПДЕНетбљЕФЯжЯѓЃКМДЪЙЪ§ОнжиИДЃЌВЛЭЌЪ§ОнгІгУжЎМфЃЌдкжаМфДцДЂКЭЗўЮёЖЫНгПкЩЯЃЌвВЪЧЮоЗЈИДгУЕФЁЃетжжбЬДбЪНЕФПЊЗЂФЃЪНЃЌЕМжТСЫЪ§ОнгІгУЕФбаЗЂаЇТЪЗЧГЃЕЭЁЃЖјЪ§ОнЗўЮёЃЌЪЙЪ§ОнжаЬЈБЉТЖЕФВЛдйЪЧЪ§ОнЃЌЖјЪЧНгПкЃЌНгПкВЛдйЙщЪєгкФГИіЪ§ОнгІгУЃЌЖјЪЧдкЭГвЛЕФЪ§ОнЗўЮёЩЯЁЃетОЭЪЙНгПкПЩвддкВЛЭЌЕФЪ§ОнгІгУжЎМфЙВЯэЃЌЭЌЪБвђЮЊЪ§ОнЗўЮёОпБИЯоСїЕФЙІФмЃЌЪЙНгПкБГКѓЕФЪ§ОнЙВЯэГЩЮЊПЩФмЃЌНтОіСЫВЛЭЌгІгУЙВЯэЪ§ОнЯрЛЅгАЯьЕФЮЪЬтЁЃФЧУДЕБЪ§ОнгІгУЩЯЯпжЎКѓЃЌЮвУЧОЭНјШыСЫдЫЮЌНзЖЮЃЌШчЙћетИіНзЖЮУЛгаЪ§ОнЗўЮёЕФЛАЃЌЛсГіЯжЪВУДЮЪЬтФиЃП
ВЛжЊЕРЪ§ОнБЛФФаЉгІгУЗУЮЪ
ОйИіР§згЃЌФГИіММЪѕШЫдБЫ§ЭЛШЛНгЕНСЫвЛЖбЕчЛАБЈОЏЃКгаДѓСПЕФШЮЮёГіЯжвьГЃЃЈЖдгІЩЯЭМжаКьЩЋБэЕФВњГіШЮЮёЃЉЁЃОЙ§НєеХЕФЖЈЮЛКѓЃЌЫ§ШЗШЯЮЪЬтРДдДгквЕЮёЯЕЭГЕФдДЪ§ОнПтЃЌвВОЭЪЧЫЕЃЌвђЮЊвЛДЮЪ§ОнПтЕФБэНсЙЙБфИќЃЌЕМжТЪ§ОнжаЬЈжаЃЌдЪМЪ§ОнЧхЯДГіЯжвьГЃЃЌДгЖјгАЯьСЫЯТгЮЕФЖрИіШЮЮёЁЃетЪБЃЌАкдкЫ§УцЧАЕФЃЌЪЧвЛЖбашвЊЛжИДжиХмЕФШЮЮёЁЃПЩЪЧЖгСазЪдДгаЯоЃЌЕНЕзЯШЛжИДФФвЛИіФиЃП
ФФИіШЮЮёзюжеЛсгАЯьЕНРЯАхЕкЖўЬьвЊПДЕФБЈБэФиЃПЫфШЛЪ§ОнбЊдЕНЈСЂСЫБэгыБэжЎМфЕФСДТЗЙиЯЕЃЌЕЋЪЧдкБэЕФФЉЖЫЃЌЮвУЧШДВЛжЊЕРетИіБэБЛФФаЉгІгУЗУЮЪЃЌЫљвдгІгУЕНБэЕФСДТЗЙиЯЕЪЧЖЯЕФЁЃЕБФГИіШЮЮёвьГЃЪБЃЌЮвУЧЮоЗЈПьЫйХаЖЯГіетИіШЮЮёгАЯьСЫФФаЉЪ§ОнгІгУЃЌДгЖјвВЮоЗЈИљОнгАЯьЗЖЮЇОіЖЈЛжИДЕФгХЯШМЖЃЌзюжеПЩФмЕМжТживЊЕФБЈБэУЛгаЛжИДЃЌВЛживЊЕФБЈБэШДБЛгХЯШЛжИДСЫЁЃЭЌбљЃЌдкГЩБОжЮРэжаЃЌЮввВЬсЕНЃЌвђЮЊУЛгагІгУКЭЪ§ОнЕФСДТЗЙиЯЕЃЌЮвУЧВЛИвУГШЛЯТЯпЪ§ОнЁЃЖјЪ§ОнЗўЮёДђЭЈСЫЪ§ОнКЭгІгУЕФЗУЮЪСДТЗЃЌНЈСЂСЫДгЪ§ОнгІгУЕНЪ§ОнжаЬЈЪ§ОнЕФШЋСДТЗЪ§ОнбЊдЕЙиЯЕЃЌетОЭЕШгкЮвУЧдкУдЙЌжаФУЕНСЫвЛИіЕиЭМЃЌЕБШЮКЮвЛИіШЮЮёГіЯжЮЪЬтЃЌЮвУЧЖМПЩвдЫГзХЕиЭМЃЌевЕНетИіЙЪеЯгАЯьСЫФФаЉгІгУЃЌДгЖјеыЖдживЊгІгУМгЫйЛжИДЫйЖШЁЃЭЌбљЃЌЮвУЧвВПЩвдЗХаФЕФЯТЯпЪ§ОнжаЬЈжаШЮвтвЛеХБэЁЃГ§СЫВЛжЊЕРЪ§ОнБЛФФаЉЯТгЮгІгУЪЙгУЃЌдкдЫЮЌНзЖЮЃЌЮвУЧЛЙОГЃУцСйзХЪ§ОнБэЦЕЗБжиЙЙЃЌЖјетвВаэЪЧЪ§ОнгІгУПЊЗЂзюПЩХТЕФиЌУЮСЫЁЃ
Ъ§ОнВПУХзжЖЮБфИќЕМжТгІгУБфИќ
Ъ§ОнжаЬЈЕзВуФЃаЭЕФзжЖЮБфИќЪЧБШНЯЦЕЗБЕФвЛИіЪТЧщЃЌвђЮЊБОЩэЛузмВуЕФФЃаЭвВдкЫцзХашЧѓВЛЖЯгХЛЏЁЃЁАЪ§ОнгІгУ
- ОгЊЗжЮіЁБЪЙгУСЫЪ§ОнжаЬЈЕФ ads_mamager_1d етеХБэЕФ c зжЖЮЃЌШчЙћЮвУЧЖдетеХБэНјааСЫжиЙЙЃЌЗУЮЪзжЖЮашвЊЬцЛЛГЩ
e зжЖЮЃЌДЫЪБашвЊЪ§ОнгІгУаоИФДњТыЁЃетжжвђЮЊЪ§ОнжаЬЈЕФЪ§ОнБфИќЕМжТгІгУашвЊжиаТЩЯЯпЕФЪТЧщЃЌЪЧЗЧГЃВЛКЯРэЕФЃЌВЛЕЋЛсдіМггІгУПЊЗЂЖюЭтЕФЙЄзїСПЃЌвВЛсЭЯРлЪ§ОнБфИќЕФНјЖШЁЃгаСЫЪ§ОнЗўЮёЃЌОЭЛсАбЪ§ОнгІгУКЭжаЬЈЪ§ОнНјааНтёюЃЌЕБжаЬЈЪ§ОнБэНсЙЙБфИќЪБЃЌЮвУЧжЛашвЊаоИФвЛЯТЪ§ОнЗўЮёЩЯНгПкВЮЪ§КЭЪ§ОнзжЖЮЕФгГЩфЙиЯЕОЭПЩвдСЫЁЃВЛашвЊдйаоИФДњТыЃЌжиаТЩЯЯпЪ§ОнгІгУЁЃ
Ъ§ОнЗўЮёгІИУОпБИЕФЦпДѓЙІФм
ФЧУДЮЊСЫШУФуИќКУЕиРэНтЪ§ОнЗўЮёЕФЙІФмЃЌЮвРДНВИіаЁЙЪЪТЁЃФуПЯЖЈШЅЙ§ВЫФёцфеОШЁПьЕнАЩЃПМйЩшгавЛИіКмДѓЕФВЫФёцфеОЃЌРяУцгаКмЖрзщЛѕМмЃЌУПИіЛѕМмЧАЖМгавЛаЉЙЄзїШЫдБАяжњЮвУЧШЁПьЕнЃЌЭЌЪБвВгаКмЖрЖгЮщХХЖгЁЃШЁПьЕнЃЌвЊЯШдМЖЈКУНгПкЃЈБШШчЭГвЛЪЙгУЪеЛѕТыРДШЁЛѕЃЉЁЃШЛКѓЃЌЮЊСЫБЃжЄВЛЭЌЖгЮщЖМФмШЁЕНПьЕнЃЌЮвУЧвЊЖдУПИіЖгЮщзівЛаЉЯоСїЃЈБШШчвЛИіЖгЮщвЛДЮжЛФмШЁвЛИіШЫЃЉЁЃдкФуШЁзпПьЕнЪБЃЌцфеОЛсМЧТМЪЧЫШЁзпСЫФФИіПьЕнЃЌЗНБуКѓајзЗВщЁЃетЖЮЪБМфЃЌВЫФёцфеОЗўЮёПЊЪМЩ§МЖЃЌВЛНіПЩвдШЁПьЕнЃЌЛЙЬсЙЉПьЕнЫЭЛѕЩЯУХЕФЗўЮёЁЃГ§ДЫжЎЭтЃЌВЛЭЌжжРрЕФПьЕнЖдгІЕФЛѕМмвВБфЕУВЛЭЌЃЌБШШчЩњЯЪЪГЦЗЃЌЛѕМмЪЧРфВиБљЯфЃЌЮФМўЁЂаХЗтЃЌЛѕМмОЭЪЧЮФМўЙёЁЃЖдгкШЁПьЕнЕФШЫРДЫЕЃЌШчЙћЫћТђСЫЩњЯЪЃЌгжТђСЫаХЗтЃЌФЧЫћвЊХХКУМИИіЖгЮщЃЌПЯЖЈВЛЗНБуЁЃЫљвдЃЌвЛАуРДНВЃЌШЁПьЕнЕФШЫзюКУжЛдквЛИіЖгЮщХХЖгЃЌЖјцфеОЙЄзїШЫдБАяЫћвЛДЮАбЖрИіЛѕМмЕФПьЕнЖМШЁЙ§РДЁЃПЩцфеОЕФЛѕМмЪЕдкЪЧЬЋЖрСЫЃЌЮЊСЫЗНБуУПИіШЁПьЕнЕФаЁЛяАщЖМФмПьЫйевЕНУПИіЛѕМмвдМАЖгЮщЃЌцфеОЬсЙЉСЫвЛИіЕМРРЁЃгыДЫЭЌЪБЃЌЮЊСЫВЛШУЙЄзїШЫдБГіДэЃЌцфеОЕФЙЄзїШЫдББиаыОЙ§бЯИёЕФВтЪдЃЌВХФмЩЯИкЁЃНВЭъетИіЙЪЪТжЎКѓЃЌЮвУЧНгзХЛиЕНЪ§ОнЗўЮёЕФетАЫДѓЙІФмЩЯРДЁЃдкШЁПьЕнЕФетИіР§згжаЃЌФуПЩвдАбЪ§ОнЗўЮёПДГЩЪЧвЛИіВЫФёцфеОЃЌЙЄзїШЫдБПДГЩЪЧ
API НтёюПтЃЌЛѕМмПЩвдПДзїЪЧжаМфДцДЂЃЌПьЕндђПЩвдШЯЮЊЪЧЪ§ОнЁЃФЧУДЖдгІЕНЦпИіЙІФмЃЌОЭЪЧЃК
НгПкЙцЗЖЛЏЖЈвхЃЌПЩвдПДГЩЪЧШЁПьЕндМЖЈЕФЪеЛѕТыЃЌЛљгкЭГвЛЕФЪеЛѕТыШЁзпПьЕнЃЛЪ§ОнЭјЙиЃЌПЩвдПДГЩЪЧЮвУЧЖдУПИіЛѕМмЧАЕФЖгЮщНјааЯоСїЃЌШЗБЃУПИіЖгЮщЖМФмШЁзпПьЕнЃЛСДТЗЙиЯЕЕФЮЌЛЄЃЌПЩвдПДзїЪЧцфеОЛсМЧТМЫШЁзпСЫЪВУДПьЕнЃЛЪ§ОнНЛИЖЃЌПЩвдПДзїцфеОЭЌЪБЬсЙЉШЁПьЕнКЭЫЭЛѕЩЯУХЗўЮёЃЛЬсЙЉЖрбљжаМфДцДЂЃЌПЩвдПДГЩгаВЛЭЌРраЭЕФЛѕМмЃЛТпМФЃаЭЃЌПЩвдПДГЩЪЧвЛИіЙЄзїШЫдБЃЌПЩвдШЁЖрИіЛѕМмЕФПьЕнЃЛAPI
НгПкЃЌПЩвдПДзїЪЧцфеОЕФВЛЭЌЛѕМмЕФВЛЭЌЖгЮщЕМРРЁЃ
ЕквЛИіЪЧНгПкЙцЗЖЛЏЖЈвхЁЃ
НгПкЙцЗЖЛЏЖЈвхОЭЪЧШЁПьЕнЪБЮвУЧдМЖЈЕФШЁМўТыЁЃЪ§ОнЗўЮёЃЌЖдИїИіЪ§ОнгІгУЦСБЮСЫВЛЭЌЕФжаМфДцДЂЃЌЬсЙЉЕФЪЧЭГвЛЕФ
APIЁЃ
ЕкЖўЃЌЪ§ОнЭјЙиЁЃзїЮЊЭјЙиЗўЮёЃЌЪ§ОнЗўЮёБиаывЊОпБИШЯжЄЁЂШЈЯоЁЂЯоСїЁЂМрПиЫФДѓЙІФмЃЌетЪЧЪ§ОнКЭНгПкИДгУЕФЧАЬсЁЃетОЭИњЮвУЧдкВЫФёцфеОЧАШЁПьЕнЃЌвЊЖдУПИіЖгЮщЕФШЫНјааШЯжЄЁЂЯоСївЛИіЕРРэЁЃЮвЯъЯИНщЩмвЛЯТЁЃЪзЯШЪЧШЯжЄЃЌЮЊСЫНтОіНгПкАВШЋЕФЮЪЬтЃЌЪ§ОнЗўЮёЪзЯШЛсЮЊУПИізЂВсЕФгІгУЗжХфвЛЖд
accesskey КЭ secretkeyЃЌгІгУУПДЮЕїгУ API НгПкЃЌЖМБиаыаЏДј acesskey
КЭ secretkeyЁЃГ§ДЫжЎЭтЃЌЖдгкУПИівбЗЂВМЕФ APIЃЌAPI ИКд№ШЫПЩвдЖдгІгУНјааЪкШЈЃЌжЛгагаШЈЯоЕФгІгУВХПЩвдЕїгУИУНгПкЁЃЭЌЪБЃЌAPI
НгПкЕФИКд№ШЫПЩвдЖдгІгУНјааЯоСїЃЈР§ШчЯожЦУПУы QPS ВЛГЌЙ§ 200ЃЉЃЌШчЙћГЌЙ§ЩшЖЈЕФуажЕЃЌОЭЛсДЅЗЂШлЖЯЃЌЯожЦНгПкЕФЗУЮЪЦЕТЪЁЃашвЊФузЂвтЕФЪЧЃЌЖдгкНгПкИДгУРДЫЕЃЌЯоСїЙІФмЗЧГЃБивЊЃЌЗёдђЛсдьГЩВЛЭЌгІгУжЎМфЕФЯрЛЅгАЯьЁЃЕБШЛЃЌЪ§ОнЗўЮёЛЙвЊЬсЙЉНгПкЯрЙиЕФМрПиЃЌБШШчНгПкЕФ
90% ЕФЧыЧѓЯьгІЪБМфЁЂНгПкЕїгУДЮЪ§ЁЂЪЇАмДЮЪ§ЕШЯрЙиЕФМрПиЃЌСэЭтЃЌЖдгкГЄЪБМфУЛгаЕїгУЕФ API ЃЌгІИУгшвдЯТЯпЁЃетбљзіЕФКУДІЪЧЗРжЙУЛгУЕФНгПкЖюЭтеМгУзЪдДЁЃ
ЕкШ§ЃЌШЋСДТЗДђЭЈЁЃ
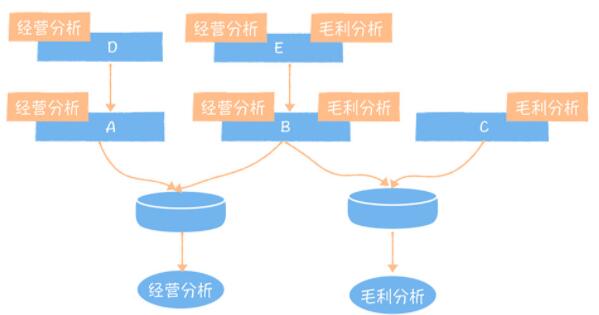
Ъ§ОнЗўЮёЛЙБиаыИКд№ЮЌЛЄЪ§ОнФЃаЭЕНЪ§ОнгІгУЕФСДТЗЙиЯЕЁЃдкЩЯЭМжаЃЌОгЊЗжЮіЪЧвЛИіЪ§ОнгІгУЃЌечУРРіЪЧЪ§ОнгІгУЕФПЊЗЂЃЌЕБЫ§ЯывЊЗУЮЪЪ§ОнЗўЮёжаЕФФГИіНгПкЛёШЁБэ
A КЭ B ЕФЪ§ОнЪБЃЌЫ§ашвЊЯђНгПкЕФЗЂВМепТэЫЇЫЇЩъЧыЪкгшШЈЯоЁЃШЛКѓОгЊЗжЮіОЭПЩвдЭЈЙ§НгПкЛёШЁЕНЪ§ОнЁЃЭЌЪБЃЌЪ§ОнЗўЮёЛсАбОгЊЗжЮіКЭБэ
A КЭ B ЕФЗУЮЪЙиЯЕЃЌЭЦЫЭИјЪ§ОнжаЬЈЕФдЊЪ§ОнжааФЁЃНгзХдЊЪ§ОнжааФБэ AЁЂB вдМА A КЭ B ЕФЩЯгЮЫљгаЕФБэЃЈЭМжа
D КЭ EЃЉЩЯЃЌОЭЛсгаОгЊЗжЮіЪ§ОнгІгУЕФБъЧЉЁЃЕББэ D ЕФВњГіШЮЮёвьГЃЪБЃЌТэЫЇЫЇПЩвдЭЈЙ§дЊЪ§ОнжааФЃЌПьЫйХаЖЯГіИУШЮЮёгАЯьСЫОгЊЗжЮіЪ§ОнВњЦЗЕФЪ§ОнВњГіЁЃЭЌЪБЃЌЕБТэЫЇЫЇЯывЊЯТЯпБэ
D ЪБЃЌвВПЩвдЭЈЙ§етеХБэЪЧЗёгаБъЧЉЃЌПьЫйХаЖЯетИіБэЯТгЮЪЧЗёЛЙгагІгУЗУЮЪЁЃЕБТэЫЇЫЇШЁЯћ API НгПкЪкШЈЪБЃЌдЊЪ§ОнжааФЭЌЪБЛсЧхРэБэЕФЯрЙиБъЧЉЁЃашвЊЬиБ№ЬсЕНЕФЪЧЃЌвЛИіЪ§ОнгІгУЭљЭљЩцМАКмЖрвГУцЃЌШчЙћЮвУЧдкгАЯьЗжЮіЪБЃЌжЛЗжЮіЕНгІгУЃЌПЩФмСЃЖШЛЙЪЧЬЋДжСЫЃЌашвЊЕНИќЯИМЖБ№ЕФвГУцЕФСЃЖШЃЌБШШчвЛИіШЮЮёвьГЃЃЌЮвВЛЙтвЊжЊЕРЪЧФФИіЪ§ОнВњЦЗЃЌЛЙБиаыЕУжЊЕРЪЧФФИіЪ§ОнВњЦЗЕФФФИівГУцЁЃДЫЪБЃЌЮвУЧдкНгПкЪкШЈЪБЃЌПЩвдБъзЂвГУцУћГЦЁЃ
ЕкЫФЃЌЭЦКЭРЕФЪ§ОнНЛИЖЗНЪНЁЃЯраХФуЬ§ЕНЕФЪ§ОнЗўЮёЃЌЖМЪЧвд API НгПкЕФаЮЪНЖдЭтЬсЙЉЗўЮёЃЌЕЋЪЧвЕЮёЪЕМЪГЁОАжаЃЌЙт
API ЛЙВЛЙЛЕФЁЃЮвАб API ЗНЪНГЦЮЊРЕФЗНЪНЃЌЖјЪЕМЪвЕЮёжаЭЌбљЛЙашвЊЭЦЕФГЁОАЁЃБШШчдкЪЕЪБжБВЅГЁОАжаЃЌЩЬМвашвЊЕквЛЪБМфЛёЕУЙигкЛюЖЏЕФЯњЪлЪ§ОнЃЌДЫЪБОЭашвЊЪ§ОнЗўЮёОпБИЭЦЕФФмСІЃЌЮвАбЫќГЦЮЊЪ§ОнЕФЫЭЛѕЩЯУХЗўЮёЁЃЪ§ОнЗўЮёНЋЪ§ОнЪЕЪБаДШыЕНвЛИі
Kafka жаЃЌШЛКѓгІгУЭЈЙ§ЖЉдФ Kafka ЕФ TopicЃЌПЩвдЛёЕУЪЕЪБЪ§ОнЕФЭЦЫЭЁЃ
ЕкЮхЃЌРћгУжаМфДцДЂЃЌМгЫйЪ§ОнВщбЏЁЃЪ§ОнжаЬЈжаЪ§Онвд Hive БэЕФаЮЪНДцдкЃЌЛљгк Hive ЛђепЪЧ
Spark МЦЫув§ЧцЃЌВЂВЛФмТњзуЪ§ОнВњЦЗЕЭбгГйЃЌИпВЂЗЂЕФЗУЮЪвЊЧѓЃЌЫљвдЃЌвЛАузіЗЈЪЧНЋЪ§ОнДг Hive
БэЕМГіЕНвЛИіжаМфДцДЂЃЌгЩжаМфДцДЂЬсЙЉЪЕЪБВщбЏЕФФмСІЁЃЪ§ОнЗўЮёашвЊИљОнгІгУГЁОАжЇГжЖржжжаМфДцДЂЃЌЮвСаОйСЫвЛаЉГЃгУЕФжаМфДцДЂвдМАетаЉДцДЂЪЪгУЕФГЁОАЃЌЯЃЭћФуФмИљОнЪЕМЪГЁОАбЁдёЪЪКЯЕФжаМфДцДЂЁЃ

ЕкСљЃЌТпМФЃаЭЃЌЪЕЯжЪ§ОнЕФИДгУЁЃ
дкЧАУцШЁПьЕнЕФГЁОАжаЃЌУПвЛИіЛѕМмвЛВІЙЄзїШЫдБЃЌЦфЪЕЖдШЁПьЕнЕФШЫВЂВЛгбКУЃЌЫљвдзюКУЕФОЭЪЧвЛИіШЫАяЮвУЧАбЫљгаЕФПьЕнЖМШЁСЫЁЃетОЭгаЕуЖљРрЫЦЪ§ОнЗўЮёжаТпМФЃаЭЕФИХФюСЫЁЃЮвУЧПЩвддкЪ§ОнЗўЮёжаЖЈвхТпМФЃаЭЃЌШЛКѓЛљгкТпМФЃаЭЗЂВМ
APIЃЌТпМФЃаЭЕФБГКѓЪЕМЪЪЧЖрИіЮяРэБэЃЌДггУЛЇЕФЪгНЧЃЌвЛИіНгПкОЭПЩвдЗУЮЪЖреХВЛЭЌЕФЮяРэБэСЫЁЃТпМФЃаЭПЩвдРрБШЮЊЪ§ОнПтжаЪгЭМЕФИХФюЃЌЯрБШгкЮяРэФЃаЭЃЌТпМФЃаЭжЛЖЈвхСЫБэКЭзжЖЮЕФгГЩфЙиЯЕЃЌЪ§ОнЪЧдкВщбЏЪБЖЏЬЌМЦЫуЕФЁЃТпМФЃаЭПЩвдПДзїЪЧЯрЭЌжїМќЕФЮяРэФЃаЭзщГЩЕФДѓПэБэЁЃТпМФЃаЭЕФДцдкЃЌНтОіСЫЪ§ОнИДгУЕФЮЪЬтЃЌЯрЭЌЕФЮяРэФЃаЭжЎЩЯЃЌгІгУПЩвдИљОнздМКЕФашЧѓЃЌЙЙНЈГіВЛЭЌЕФТпМФЃаЭЃЌУПИігІгУПДЕНВЛЭЌЕФСаЁЃ
ЕкЦпЃЌЙЙНЈ API МЏЪаЃЌЪЕЯжНгПкИДгУЁЃЮЊСЫЪЕЯжНгПкЕФИДгУЃЌЮвУЧашвЊЙЙНЈ API ЕФМЏЪаЃЌгІгУПЊЗЂепПЩвджБНгдк
API МЏЪаЗЂЯжвбгаЕФЪ§ОнНгПкЃЌжБНгЩъЧыИУНгПкЕФ API ШЈЯоЃЌМДПЩЗУЮЪИУЪ§ОнЃЌВЛашвЊжиИДПЊЗЂЁЃашвЊЬиБ№жИГіЕФЪЧЃЌЪ§ОнЗўЮёЭЈЙ§дЊЪ§ОнжааФЃЌПЩвдЛёЕУНгПкЗУЮЪЕФБэЙиСЊСЫФФаЉжИБъЁЃЪЙгУепПЩвдЛљгкжИБъЕФзщКЯЃЌЩИбЁНгПкЃЌетбљОЭПЩвдИљОнЯывЊЕФЪ§ОнЃЌВщевПЩвдЬсЙЉетаЉЪ§ОнЕФНгПкЃЌаЮГЩСЫвЛИіБеЛЗЁЃ
Ъ§ОнЗўЮёЯЕЭГМмЙЙЩшМЦ
ДѓВПЗжЙЋЫОдкЪЕЯжЪ§ОнЗўЮёЪБЃЌжївЊВЩгУСЫдЦдЩњЁЂТпМФЃаЭКЭЪ§ОнздЖЏЕМГіШ§ИіЙиМќЩшМЦЃЌЙигкетВПЗжФкШнЃЌЮвЯЃЭћФуФмЭЈЙ§бЇЯАЃЌдкЪЕМЪЙЄзїжаПЩвдНшМјЮвУЧЕФЗНЪНЭъГЩЪ§ОнЗўЮёЕФЩшМЦЃЌЛђепдкбЁдёЩЬвЕЛЏВњЦЗЪБЃЌИјФувЛИіМмЙЙбЁаЭЗНУцЕФВЮПМЁЃ
дЦдЩњ
дЦдЩњЕФКЫаФгХЪЦдкгкУПИіЗўЮёжСЩйгаСНИіИББОЃЌЪЕЯжСЫЗўЮёЕФИпПЩгУЃЌЭЌЪБИљОнЗУЮЪСПДѓаЁЃЌЗўЮёЕФИББОЪ§СППЩвдЖЏЬЌЕїећЃЌЛљгкЗўЮёЗЂЯжЃЌПЩвдЪЕЯжЖдПЭЛЇЖЫЭИУїЕФЕЏадЩьЫѕЁЃЗўЮёжЎМфЛљгкШнЦїЪЕЯжСЫзЪдДИєРыЃЌБмУтСЫЗўЮёжЎМфЕФЯрЛЅгАЯьЁЃетаЉЬиадЗЧГЃЪЪгУгкЬсЙЉИпВЂЗЂЁЂЕЭбгГйЃЌдкЯпЪ§ОнВщбЏЕФЪ§ОнЗўЮёЁЃ
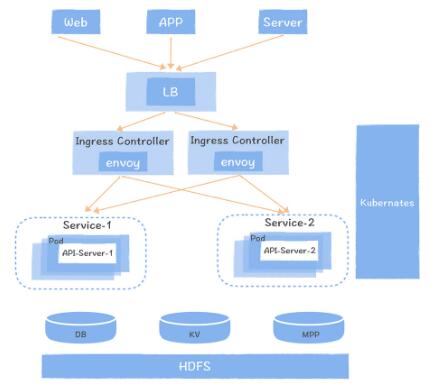
ЩЯЭМЪЧЪ§ОнЗўЮёЕФВПЪ№МмЙЙЃЌдкетИіЭМжаЃЌУПИівбОЗЂВМЩЯЯпЕФ API НгПкЖМЖдгІСЫвЛИі Kubernates
ЕФ ServiceЃЌУПИі Service гаЖрИіИББОЕФ Pod зщГЩЃЌУПИі API НгПкЗУЮЪКѓЖЫДцДЂв§ЧцЕФДњТыдЫаадк
Pod ЖдгІЕФШнЦїжаЃЌЫцзХ API НгПкЕїгУСПЕФБфЛЏЃЌPod ПЩвдЖЏЬЌЕФДДНЈКЭЯњЛйЁЃEnvoy ЪЧЗўЮёЭјЙиЃЌПЩвдНЋ
Http ЧыЧѓИКдиОљКтЕН Service ЕФЖрИі Pod ЩЯЁЃIngress Controller
ПЩвдВщПД Kubernates жаУПИі Service ЕФ Pod БфЛЏЃЌЖЏЬЌЕиНЋ Pod IP аДЛиЕН
EnvoyЃЌДгЖјЪЕЯжЖЏЬЌЕФЗўЮёЗЂЯжЁЃЧАЖЫЕФ APPЃЌWeb ЛђепЪЧвЕЮёЯЕЭГЕФ Server ЖЫЃЌЭЈЙ§вЛИі
4 ВуЕФИКдиОљКт LB НгШыЕН EnvoyЁЃЛљгкдЦдЩњЕФЩшМЦЃЌНтОіСЫЪ§ОнЗўЮёВЛЭЌНгПкжЎМфзЪдДИєРыЕФЮЪЬтЃЌЭЌЪБПЩвдЛљгкЧыЧѓСПЪЕЯжЖЏЬЌЕФЫЎЦНРЉеЙЁЃЭЌЪБНшжњ
Envoy ЪЕЯжСЫЯоСїЁЂШлЖЯЕФЙІФмЁЃФувВПЩвдНшМјЮвУЧЕФЗНАИЃЌЪЕЯжддЩњЕФЪ§ОнЗўЮёЩшМЦЁЃ
ТпМФЃаЭ
ЯрНЯгкЮяРэФЃаЭЃЌТпМФЃаЭВЂУЛгаБЃДцЪЕМЪЕФЪ§ОнЃЌЖјжЛЪЧАќРЈСЫТпМФЃаЭКЭЮяРэФЃаЭЕФгГЩфЙиЯЕЃЌЪ§ОндкУПДЮВщбЏЪБЖЏЬЌЩњГЩЁЃТпМФЃаЭЕФЩшМЦЃЌНтОіСЫВЛЭЌНгПкЃЌЖдгкЭЌвЛЗнЪ§ОнЃЌашвЊжЛПДЕНздМКашвЊЕФЪ§ОнЕФашЧѓЁЃЯТЭМЪЧЭјвзЪ§ОнЗўЮёТпМФЃаЭЕФЯЕЭГЩшМЦЭМЁЃ
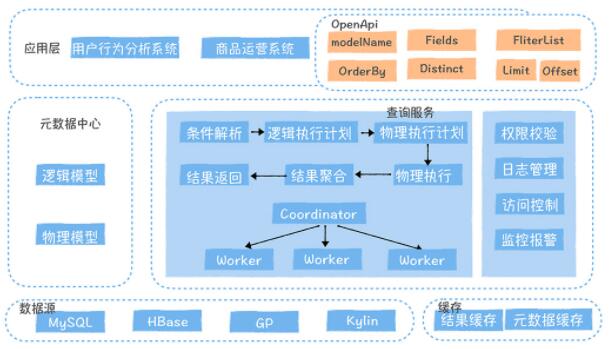
НгПкЗЂВМепдкЪ§ОнЗўЮёжабЁдёжїМќЯрЭЌЕФЖреХЮяРэБэЙЙНЈвЛИіТпМФЃаЭЃЌШЛКѓЛљгкТпМФЃаЭЗЂВМНгПкЁЃAPI
ЗўЮёНгЕНВщбЏЧыЧѓКѓЃЌИљОнТпМФЃаЭКЭЮяРэФЃаЭзжЖЮЕФгГЩфЙиЯЕЃЌНЋТпМжДааМЦЛЎВ№НтЮЊУцЯђЮяРэФЃаЭЕФЮяРэжДааМЦЛЎЃЌВЂЯТЗЂЖрИіЮяРэФЃаЭЩЯШЅжДааЃЌзюКѓЖджДааЕФНсЙћНјааОлКЯЃЌЗЕЛиИјПЭЛЇЖЫЁЃвЛИіТпМФЃаЭЙиСЊЕФЮяРэФЃаЭПЩвдЗжВМдкВЛЭЌЕФВщбЏв§ЧцЩЯЃЌЕЋЪЧетжжЧщПіЯТЃЌПМТЧадФмвђЫиЃЌжЛжЇГжЛљгкжїМќЕФЩИбЁЁЃ
Ъ§ОнздЖЏЕМГі
Ъ§ОнЗўЮёбЁдёЕФЪЧЪ§ОнжаЬЈЕФвЛеХБэЃЌШЛКѓНЋЪ§ОнЕМГіЕНжаМфДцДЂжаЃЌЖдЭтЬсЙЉ
API ЁЃФЧЪ§ОнЪВУДЪБКђЕМГіЕНжаМфДцДЂжаФиЃП вЊЕШЪ§ОнВњГіЭъГЩЁЃЫљвддкгУЛЇбЁдёСЫвЛеХЪ§ОнжаЬЈЕФБэЃЌЖЈвхКУБэЕФжаМфДцДЂКѓЃЌЪ§ОнЗўЮёЛсздЖЏЩњГЩвЛИіЪ§ОнЕМГіШЮЮёЃЌЭЌЪБНЈСЂЕНетИіЪ§ОнжаЬЈБэЕФВњГіШЮЮёЕФвРРЕЙиЯЕЃЌЕШЕНУПДЮЕїЖШВњГіШЮЮёНсЪјЃЌОЭЛсДЅЗЂЪ§ОнЕМГіЗўЮёЃЌНЋЪ§ОнЕМГіЕНжаМфДцДЂжаЃЌДЫЪБ
API НгПкОЭПЩвдВщбЏЕНзюаТЕФЪ§ОнЁЃ

|









