| БрМЭЦМі: |
БОЮФжївЊНщЩмЪВУДЪЧЪ§ОнжЪСПЙмРэЃЌЪ§ОнжЪСПЮЪЬтгаФФаЉЃЌЪ§ОнжЪСПЮЪЬтИљвђЗжЮіЃЌжЦЖЈНтОіЗНАИЃЌ
ЖдЪ§ОнжЪСПНјааМрПиЃЌЪ§ОнжЪСПЦНЬЈЕФЪЕЯжКЭзюМбЪЕМљЃЌзюКѓЬИЬИЦНЬЈЮДРДЕФбнНјЗНЯђЁЃ
БОЮФРДздгкCSDN ЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂЪВУДЪЧЪ§ОнжЪСПЙмРэЃП
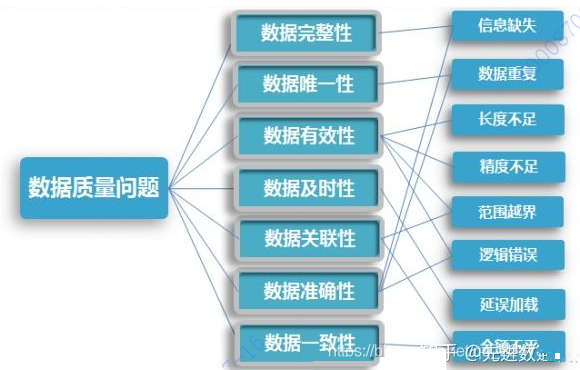
Ъ§ОнжЪСПЙмРэЪЧжИЖдЪ§ОнДгВњЩњЁЂЛёШЁЁЂДцДЂЁЂЙВЯэЁЂЮЌЛЄЁЂгІгУЕШИїИіНзЖЮПЩФмв§ЗЂЕФИїРрЪ§ОнжЪСПЮЪЬтЃЌНјааЪЖБ№ЁЂЖШСПЁЂМрПиЁЂдЄОЏЕШвЛЯЕСаЙмРэЛюЖЏЃЌВЂЭЈЙ§ИФЩЦКЭЬсИпзщжЏЕФЙмРэЫЎЦНЪЙЪ§ОнжЪСПЛёЕУНјвЛВНЬсИпЁЃ
ЁАЪ§ОнжЪСПЙмРэЪЧЖдЪ§ОнДгМЦЛЎЁЂЛёШЁЁЂДцДЂЁЂЙВЯэЁЂЮЌЛЄЁЂгІгУЁЂЯћЭіЩњУќжмЦкЕФУПИіНзЖЮРяПЩФмв§ЗЂЕФЪ§ОнжЪСПЮЪЬтЃЌНјааЪЖБ№ЁЂЖШСПЁЂМрПиЁЂдЄОЏЕШвЛЯЕСаЙмРэЛюЖЏЃЌВЂЭЈЙ§ИФЩЦКЭЬсИпзщжЏЕФЙмРэЫЎЦНЪЙЕУЪ§ОнжЪСПЛёЕУНјвЛВНЬсИпЁЃЪ§ОнжЪСПЙмРэЕФжеМЋФПБъЪЧЭЈЙ§ПЩППЕФЪ§ОнЬсЩ§Ъ§ОндкЪЙгУжаЕФМлжЕЃЌВЂзюжеЮЊЦѓвЕгЎЕУОМУаЇвцЁЃЁБЁЊЁЊвдЩЯФкШнеЊздАйЖШАйПЦЁЃ
БЪепЙлЕуЃКЁАЪ§ОнжЪСПЙмРэВЛЕЅДПЪЧвЛИіИХФюЃЌвВВЛЕЅДПЪЧвЛЯюММЪѕЁЂвВВЛЕЅДПЪЧвЛИіЯЕЭГЃЌИќВЛЕЅДПЪЧвЛЬзЙмРэСїГЬЃЌЪ§ОнжЪСПЙмРэЪЧвЛИіМЏЗНЗЈТлЁЂММЪѕЁЂвЕЮёКЭЙмРэЮЊвЛЬхЕФНтОіЗНАИЁЃЭЈЙ§гааЇЕФЪ§ОнжЪСППижЦЪжЖЮЃЌНјааЪ§ОнЕФЙмРэКЭПижЦЃЌЯћГ§Ъ§ОнжЪСПЮЪЬтНјЖјЬсЩ§ЦѓвЕЪ§ОнБфЯжЕФФмСІЁЃдкЪ§ОнжЮРэЙ§ГЬжаЃЌвЛЧавЕЮёЁЂММЪѕКЭЙмРэЛюЖЏЖМЮЇШЦетИіФПБъКЭПЊеЙЁБЁЃ
Ъ§ОнжЪСПЙмРэЕФФПЕФЃП
НтОіЦѓвЕФкВПЪ§ОнЪЙгУЙ§ГЬжагіЕНЕФЪ§ОнжЪСПЮЪЬтЃЌЬсЩ§Ъ§ОнЕФЭъећадЁЂзМШЗадКЭецЪЕадЃЌЮЊЦѓвЕЕФШеГЃОгЊЁЂОЋзМгЊЯњЁЂЙмРэОіВпЁЂЗчЯеЙмПиЕШЬсЙЉМсЪЕЁЂПЩППЕФЪ§ОнЛљДЁЁЃ
ЖўЁЂЪ§ОнжЪСПЮЪЬтгаФФаЉЃП
Ъ§ОнецЪЕадЃКЪ§ОнБиаыецЪЕзМШЗЕФЗДгГПЭЙлЕФЪЕЬхДцдкЛђецЪЕЕФвЕЮёЃЌецЪЕПЩППЕФдЪМЭГМЦЪ§ОнЪЧЦѓвЕЭГМЦЙЄзїЕФСщЛъЃЌЪЧвЛЧаЙмРэЙЄзїЕФЛљДЁЃЌЪЧОгЊепНјаае§ШЗОгЊОіВпБиВЛПЩЩйЕФЕквЛЪжзЪСЯЁЃ
Ъ§ОнзМШЗадЃКзМШЗадвВНаПЩППадЃЌзжЖЮжЕ ДэЮѓЁЂШБЪЇЃЌПежЕЁЃГЩМЈЕЅжаЗжЪ§ГіЯжИКЪ§ЛђЖЉЕЅжаГіЯжДэЮѓЕФТђМваХЯЂЕШЁЃЪЧгУгкЗжЮіКЭЪЖБ№ФФаЉЪЧВЛзМШЗЕФЛђЮоаЇЕФЪ§ОнЃЌВЛПЩППЕФЪ§ОнПЩФмЛсЕМжТбЯжиЕФЮЪЬтЃЌЛсдьГЩгаШБЯнЕФЗНЗЈКЭдуИтЕФОіВпЁЃ
Ъ§ОнЮЈвЛадЃКгУгкЪЖБ№КЭЖШСПжиИДЪ§ОнЁЂШпгрЪ§ОнЁЃжиИДЪ§ОнЪЧЕМжТвЕЮёЮоЗЈаЭЌЁЂСїГЬЮоЗЈзЗЫнЕФживЊвђЫиЃЌвВЪЧЪ§ОнжЮРэашвЊНтОіЕФзюЛљБОЕФЪ§ОнЮЪЬтЁЃ
Ъ§ОнЭъећадЃКЪ§ОнЭъећадЮЪЬтАќРЈЃКФЃаЭЩшМЦВЛЭъећЃЌР§ШчЃКЮЈвЛаддМЪјВЛЭъећЁЂВЮееВЛЭъећЃЛЪ§ОнЬѕФПВЛЭъећЃЌР§ШчЃКЪ§ОнМЧТМЬѕЪ§ЃЌЖЊЪЇЛђВЛПЩгУЃЛЪ§ОнЪєадВЛЭъећЃЌР§ШчЃКЪ§ОнЪєадПежЕЁЃВЛЭъећЕФЪ§ОнЫљФмНшМјЕФМлжЕОЭЛсДѓДѓНЕЕЭЃЌвВЪЧЪ§ОнжЪСПЮЪЬтзюЮЊЛљДЁКЭГЃМћЕФвЛРрЮЪЬтЁЃ
Ъ§ОнвЛжТадЃКЖрдДЪ§ОнЕФЪ§ОнФЃаЭВЛвЛжТЃЌР§ШчЃКУќУћВЛвЛжТЁЂЪ§ОнНсЙЙВЛвЛжТЁЂдМЪјЙцдђВЛвЛжТЁЃгУЛЇIDБиаыБЃГжЭЌвЛжжРраЭЃЌЧвГЄЖШвВвЊБЃГжвЛжТЁЃЪ§ОнЪЕЬхВЛвЛжТЃЌР§ШчЃКН№ЖюВЛЦНЁЂЃЈЪ§ОнСПЬѕЪ§ЃЉЪ§ОнБрТыВЛвЛжТЁЂУќУћМАКЌвхВЛвЛжТЁЂЗжРрВуДЮВЛвЛжТЁЂЩњУќжмЦкВЛвЛжТЁЃЯрЭЌЕФЪ§ОнгаЖрИіИББОЕФЧщПіЯТЕФЪ§ОнВЛвЛжТЁЂЪ§ОнФкШнГхЭЛЕФЮЪЬтЁЃ
Ъ§ОнЙиСЊадЃКЪ§ОнЙиСЊадЮЪЬтЪЧжИДцдкЪ§ОнЙиСЊЕФЪ§ОнЙиЯЕШБЪЇЛђДэЮѓЃЌР§ШчЃККЏЪ§ЙиЯЕЁЂЯрЙиЯЕЪ§ЁЂжїЭтМќЙиЯЕЁЂЫїв§ЙиЯЕЕШЁЃДцдкЪ§ОнЙиСЊадЮЪЬтЃЌЛсжБНггАЯьЪ§ОнЗжЮіЕФНсЙћЃЌНјЖјгАЯьЙмРэОіВпЁЃ
Ъ§ОнМАЪБадЃКЪ§ОнЕФМАЪБад(In-time)ЪЧжИФмЗёдкашвЊЕФЪБКђЛёЕНЪ§ОнЃЌЪ§ОнЕФМАЪБадгыЦѓвЕЕФЪ§ОнДІРэЫйЖШМАаЇТЪгажБНгЕФЙиЯЕЃЌЪЧгАЯьвЕЮёДІРэКЭЙмРэаЇТЪЕФЙиМќжИБъЁЃ
Ш§ЁЂЪ§ОнжЪСПЮЪЬтИљвђЗжЮі
ЫЕЕНЪ§ОнжЪСПЮЪЬтЕФдвђЃЌзіЙ§BIЛђЪ§ВжЯюФПЕФаЁЛяАщПЯЖЈЖМжЊЕРЃЌетЪЧвЛИівЕЮёКЭММЪѕОГЃГЖРДГЖШЅЁЂЛЅЯрЭЦкУЕФЮЪЬтЁЃдкКмЖрЧщПіЯТЃЌЦѓвЕЖМЛсАбЪ§ОнжЪСПЮЪЬтЭЦИјММЪѕВПУХЃЌШУММЪѕВПУХШЅВщевКЭДІРэЁЃЕЋЪЧЦѓвЕЕФЪ§ОнжЪСПЮЪЬтецЕФЖМЪЧММЪѕв§Ц№ЕФТ№ЃЌММЪѕВПУХШЫвЛЖЈЛсЫЕЃКЁАетИіЙјЮвВЛБГЃЁЁБ
ЦфЪЕЃЌгАЯьЪ§ОнжЪСПЕФвђЫижївЊОЭММЪѕЁЂвЕЮёЁЂЙмРэШ§ИіЗНУцЃЌЯТУцЮвУЧОЭРДДгетШ§ЗНУцЗжЮіЯТВњЩњЪ§ОнжЪСПЮЪЬтЖМгаФФаЉдвђЁЃ
1ЁЂММЪѕЗНУц

Ъ§ОнФЃаЭЩшМЦЕФжЪСПЮЪЬтЃЌР§ШчЃКЪ§ОнПтБэНсЙЙЁЂЪ§ОнПтдМЪјЬѕМўЁЂЪ§ОнаЃбщЙцдђЕФЩшМЦПЊЗЂВЛКЯРэЃЌдьГЩЪ§ОнТМШыЮоЗЈаЃбщЛђаЃбщВЛЕБЃЌв§Ц№Ъ§ОнжиИДЁЂВЛЭъећЁЂВЛзМШЗЁЃ
Ъ§ОндДДцдкЪ§ОнжЪСПЮЪЬтЃЌР§ШчЃКгааЉЪ§ОнЪЧДгЩњВњЯЕЭГВЩМЏЙ§РДЕФЃЌдкЩњВњЯЕЭГжаетаЉЪ§ОнОЭДцдкжиИДЁЂВЛЭъећЁЂВЛзМШЗЕШЮЪЬтЃЌЖјВЩМЏЙ§ГЬгаУЛгаЖдетаЉЮЪЬтзіЧхЯДДІРэЃЌетжжЧщПівВБШНЯГЃМћЁЃ
Ъ§ОнВЩМЏЙ§ГЬжЪСПЮЪЬтЃЌ Р§ШчЃКВЩМЏЕуЁЂВЩМЏЦЕТЪЁЂВЩМЏФкШнЁЂгГЩфЙиЯЕЕШВЩМЏВЮЪ§КЭСїГЬЩшжУЕФВЛе§ШЗЃЌЪ§ОнВЩМЏНгПкаЇТЪЕЭЃЌЕМжТЕФЪ§ОнВЩМЏЪЇАмЁЂЪ§ОнЖЊЪЇЁЂЪ§ОнгГЩфКЭзЊЛЛЪЇАмЁЃ
Ъ§ОнДЋЪфЙ§ГЬЕФЮЪЬтЃЌР§ШчЃКЪ§ОнНгПкБОЩэДцдкЮЪЬтЁЂЪ§ОнНгПкВЮЪ§ХфжУДэЮѓЁЂЭјТчВЛПЩППЕШЖМЛсдьГЩЪ§ОнДЋЪфЙ§ГЬжаЕФЗЂЩњЪ§ОнжЪСПЮЪЬтЁЃ
Ъ§ОнзАдиЙ§ГЬЕФЮЪЬтЃЌР§ШчЃКЪ§ОнЧхЯДЙцдђЁЂЪ§ОнзЊЛЛЙцдђЁЂЪ§ОнзАдиЙцдђХфжУгаЮЪЬтЁЃ
Ъ§ОнДцДЂЕФжЪСПЮЪЬтЃЌР§ШчЃКЪ§ОнДцДЂЩшМЦВЛКЯРэЃЌЪ§ОнЕФДцДЂФмСІгаЯоЃЌШЫЮЊКѓЬЈЕїећЪ§ОнЃЌв§Ц№ЕФЪ§ОнЖЊЪЇЁЂЪ§ОнЮоаЇЁЂЪ§ОнЪЇецЁЂМЧТМжиИДЁЃ
вЕЮёЯЕЭГИїздЮЊеўЃЌбЬДбЪННЈЩшЃЌЯЕЭГжЎМфЕФЪ§ОнВЛвЛжТЮЪЬтбЯжиЁЃ
2ЁЂвЕЮёЗНУц
вЕЮёашЧѓВЛЧхЮњЃЌР§ШчЃКЪ§ОнЕФвЕЮёУшЪіЁЂвЕЮёЙцдђВЛЧхЮњЃЌЕМжТММЪѕЮоЗЈЙЙНЈГіКЯРэЁЂе§ШЗЕФЪ§ОнФЃаЭЁЃ
вЕЮёашЧѓЕФБфИќЃЌетИіЮЪЬтЦфЪЕЪЧЖдЪ§ОнжЪСПгАЯьЗЧГЃДѓЕФЃЌашЧѓвЛБфЃЌЪ§ОнФЃаЭЩшМЦЁЂЪ§ОнТМШыЁЂЪ§ОнВЩМЏЁЂЪ§ОнДЋЪфЁЂЪ§ОнзАдиЁЂЪ§ОнДцДЂЕШЛЗНкЖМЛсЪмЕНгАЯьЃЌЩдгаВЛЩїОЭЛсЕМжТЪ§ОнжЪСПЮЪЬтЕФЗЂЩњЁЃ
вЕЮёЖЫЪ§ОнЪфШыВЛЙцЗЖЃЌГЃМћЕФЪ§ОнТМШыЮЪЬтЃЌШчЃКДѓаЁаДЁЂШЋАыНЧЁЂЬиЪтзжЗћЕШвЛВЛаЁаФОЭЛсТМДэЁЃШЫЙЄТМШыЕФЪ§ОнжЪСПгыТМЪ§ОнЕФвЕЮёШЫдБУмЧаЯрЙиЃЌТМЪ§ОнЕФШЫЙЄзїбЯНїЁЂШЯецЃЌЪ§ОнжЪСПОЭЯрЖдНЯКУЃЌЗДжЎОЭНЯВюЁЃ
Ъ§ОнзїМйЃЌЖдЃЌФуУЛПДДэЃЌОЭЪЧЪ§ОнзїМйЃЁВйзїШЫдБЮЊСЫЬсИпЛђНЕЕЭПМКЫжИБъЃЌЖдвЛаЉЪ§ОнНјааДІРэЃЌЪЙЕУЪ§ОнецЪЕадЮоЗЈБЃжЄЁЃ
3ЁЂЙмРэЗНУц
ШЯжЊЮЪЬтЁЃЦѓвЕЙмРэШБЗІЪ§ОнЫМЮЌЃЌУЛгаШЯЪЖЕНЪ§ОнжЪСПЕФживЊадЃЌжиЯЕЭГЖјЧсЪ§ОнЃЌШЯЮЊЯЕЭГЪЧЭђФмЕФЃЌЪ§ОнжЪСПВюаЉвВУЛЙиЯЕЁЃ
УЛгаУїШЗЪ§ОнЙщПкЙмРэВПУХЛђИкЮЛЃЌШБЗІЪ§ОнШЯд№ЛњжЦЃЌГіЯжЪ§ОнжЪСПЮЪЬтевВЛЕНИКд№ШЫЁЃ
ШБЗІЪ§ОнЙцЛЎЃЌУЛгаУїШЗЕФЪ§ОнжЪСПФПБъЃЌУЛгажЦЖЈЪ§ОнжЪСПЯрЙиЕФеўВпКЭжЦЖШЁЃ
Ъ§ОнЪфШыЙцЗЖВЛЭГвЛЃЌВЛЭЌЕФвЕЮёВПУХЁЂВЛЭЌЕФЪБМфЁЂЩѕжСдкДІРэЯрЭЌвЕЮёЕФЪБКђЃЌгЩгкЪ§ОнЪфШыЙцЗЖВЛЭЌЃЌдьГЩЪ§ОнГхЭЛЛђУЌЖмЁЃ
ШБЗІгааЇЕФЪ§ОнжЪСПЮЪЬтДІРэЛњжЦЃЌЪ§ОнжЪСПЮЪЬтДгЗЂЯжЁЂжИХЩЁЂДІРэЁЂгХЛЏУЛгавЛИіЭГвЛЕФСїГЬКЭжЦЖШжЇГХЃЌЪ§ОнжЪСПЮЪЬтЮоЗЈБеЛЗЁЃ
ШБЗІгааЇЕФЪ§ОнЙмПиЛњжЦЃЌЖдРњЪЗЪ§ОнжЪСПМьВщЁЂаТдіЪ§ОнжЪСПаЃбщУЛгаУїШЗКЭгааЇЕФПижЦДыЪЉЃЌГіЯжЪ§ОнжЪСПЮЪЬтЮоЗЈПМКЫЁЃ
аЁНсЃКгАЯьЪ§ОнжЪСПЕФвђЫиЃЌПЩвдзмНсЮЊСНРрЃЌПЭЙлвђЫиКЭжїЙлвђЫиЁЃПЭЙлвђЫиЃКдкЪ§ОнИїЛЗНкСїзЊжаЃЌгЩгкЯЕЭГвьГЃКЭСїГЬЩшжУВЛЕБЕШвђЫиЃЌДгЖјв§Ц№ЕФЪ§ОнжЪСПЮЪЬтЁЃжїЙлвђЫиЃКдкЪ§ОнИїЛЗНкДІРэжаЃЌгЩгкШЫдБЫижЪЕЭКЭЙмРэШБЯнЕШвђЫиЃЌДгЖјВйзїВЛЕБЖјв§Ц№ЕФЪ§ОнжЪСПЮЪЬтЁЃ
ЫФЁЂЪ§ОнжЪСПЙмРэЕФЗНЗЈТл(жЦЖЈНтОіЗНАИ)
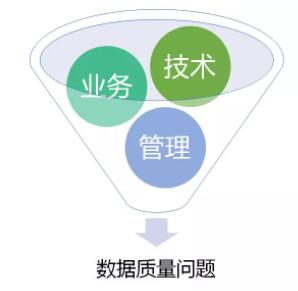
Ъ§ОнЪЧЪ§зжЛЏЪБДњЦѓвЕЕФживЊзЪВњЃЌЪ§ОнПЩвдвдВњЦЗЛђЗўЮёЕФаЮЬЌЮЊЦѓвЕДДдьМлжЕЁЃМШШЛЪ§ОнПЩвдЪЧВњЦЗЁЂПЩвдЪЧЗўЮёЃЌФЧЮЪЬтОЭМђЕЅСЫЁЃЫфШЛЪ§ОнжЪСПЙмРэУЛгаГЩЪьЗНЗЈТлжЇГХЃЌЕЋЪЧВњЦЗКЭЗўЮёЕФжЪСПЙмРэЬхЯЕШДвбЗЧГЃЕФГЩЪьСЫЃЌКЮВЛГЂЪдгУВњЦЗКЭЗўЮёЕФжЪСПЙмРэЬхЯЕРДЙмРэЪ§ОнжЪСПЃПЃЁФЧЙњМЪЩЯзюШЈЭўЕФжЪСПЙмРэЬхЯЕIOS9001ЪЧЗёвВЪЪгУгкЦѓвЕЕФЪ§ОнжЪСПЙмРэФиЃП
ЯТЭМЪЧISO9001ЛљгкPDCAЕФжЪСПЙмРэКЫаФЫМЯыЃЌЦфжиЕуЧПЕївдПЭЛЇЮЊЙизЂНЙЕуЁЂСьЕМзїгУЁЂШЋдБВЮгыЁЂЙ§ГЬЗНЗЈЁЂГжајИФНјЁЂбжЄОіВпКЭЙиЯЕЙмРэЁЃ
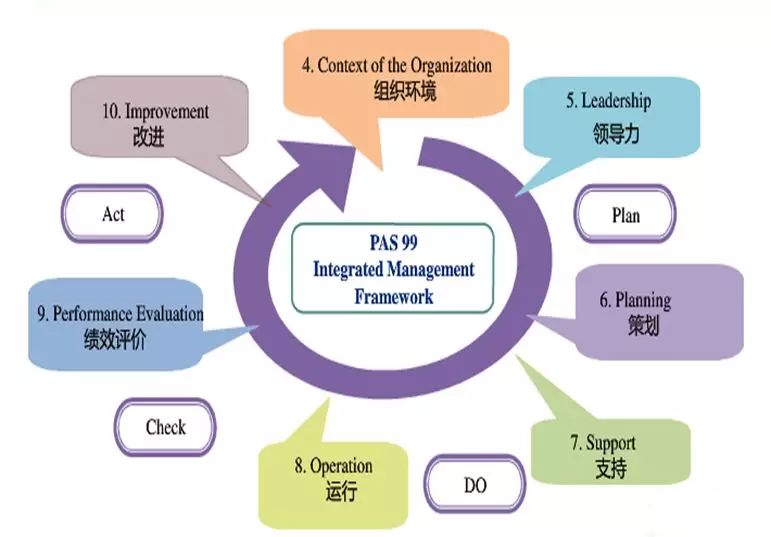
вРОнISO9001вдМАЦѓвЕдкЪ§ОнжЮРэЗНУцЕФЯрЙиОбщЃЌБЪепШЯЮЊЦѓвЕЪ§ОнжЪСПЙмРэгІДгвдЯТМИИіЗНУцзХЪжЃК
1ЁЂзщжЏЛЗОГ
ЮвУЧдкЪ§ОнжЮРэПђМмЁЂжїЪ§ОнЙмРэЁЂЪ§ОнБъзМЙмРэЕШеТНкЃЌЖМЬсЕНСЫзщжЏЛњЙЙЕФЩшжУЃЌетРядйДЮЧПЕївЛИіЧПгаСІЕФЪ§ОнЙмРэзщжЏЕФНЈЩшЪЧЪ§ОнжЮРэЯюФПГЩЙІЕФзюИљБОЕФБЃжЄЁЃЦфзївЕЪЧСНИіВуУцЃКвЛЪЧдкжЦЖШВуУцЃЌжЦЖЈЦѓвЕЪ§ОнжЮРэЕФЯрЙижЦЖШКЭСїГЬЃЌВЂдкЦѓвЕФкЭЦЙуЃЌШкШыЦѓвЕЮФЛЏЁЃЖўЪЧдкжДааВуУцЃЌЮЊИїЯювЕЮёгІгУЬсЙЉИпПЩППЕФЪ§ОнЁЃ
2ЁЂЪ§ОнжЪСПЙмРэЗНеы
ЮЊСЫИФНјКЭЬсИпЪ§ОнжЪСПЃЌБиаыДгВњЩњЪ§ОнЕФдДЭЗПЊЪМзЅЦ№ЃЌДгЙмРэШыЪжЃЌЖдЪ§ОндЫааЕФШЋЙ§ГЬНјааМрПиЃЌЧПЛЏШЋУцЪ§ОнжЪСПЙмРэЕФЫМЯыЙлФюЃЌАбетвЛЙлФюЩјЭИЕНЪ§ОнЩњУќжмЦкЕФШЋЙ§ГЬЁЃЪ§ОнжЪСПЮЪЬтЪЧгАЯьЯЕЭГдЫааЁЂвЕЮёаЇТЪЁЂОіВпФмСІЕФживЊвђЫиЃЌдкЪ§зжЛЏЪБДњЃЌЪ§ОнжЪСПЮЪЬтгАЯьЕФВЛНіНіЪЧаХЯЂЛЏНЈЩшЕФГЩАмЃЌИќЪЧгАЯьЦѓвЕНЕБОдіаЇЁЂвЕЮёДДаТЕФКЫаФвЊЫиЃЌЖдгкЪ§ОнжЪСПЮЪЬтЕФЙмРэЃЌЩюЖШжДааЕФзмЬхВпТдЁАРЌЛјНјЃЌРЌЛјГіЃЈgarbage inЃЌgarbage outЃЉЁБЃЌВЩгУЪТЧАдЄЗРПижЦЁЂЪТжаЙ§ГЬПижЦЁЂЪТКѓМрЖНПижЦЕФЗНЪННјааЪ§ОнжЪСПЮЪЬтЕФЙмРэКЭПижЦЃЌГжајЬсЩ§ЦѓвЕЪ§ОнжЪСПЫЎЦНЁЃ
3ЁЂЪ§ОнжЪСПЮЪЬтЗжЮі
ЙигкжЪСПЮЪЬтЕФЗжЮіЃЌБЪепЭЦМіВЩгУОЕфЕФСљЮїИёТъЃЈЫѕаДЃК6Ів Лђ 6SigmaЃЉЃЌСљЮїИёТъЪЧвЛжжИФЩЦЦѓвЕжЪСПСїГЬЙмРэЕФММЪѕЃЌвдЁАСуШБЯнЁБЕФЭъУРЩЬвЕзЗЧѓЃЌвдПЭЛЇЮЊЕМЯђЃЌвдвЕНчзюМбЮЊФПБъЃЌвдЪ§ОнЮЊЛљДЁЃЌвдЪТЪЕЮЊвРОнЃЌвдСїГЬМЈаЇКЭВЦЮёЦРМлЮЊНсЙћЃЌГжајИФНјЦѓвЕОгЊЙмРэЕФЫМЯыЗНЗЈЁЂЪЕМљЛюЖЏКЭЮФЛЏРэФюЁЃСљЮїИёТъжиЕуЧПЕїжЪСПЕФГжајИФНјЃЌЖдгкЪ§ОнжЪСПЮЪЬтЕФЗжЮіКЭЙмРэЃЌИУЗНЗЈвРШЛЪЪгУЁЃ
ИљОнСљЮїИёТъЕФDMAICФЃаЭЃЌЮвУЧПЩвдНЋЪ§ОнжЪСПЗжЮіЖЈвхЮЊСљИіНзЖЮЃК
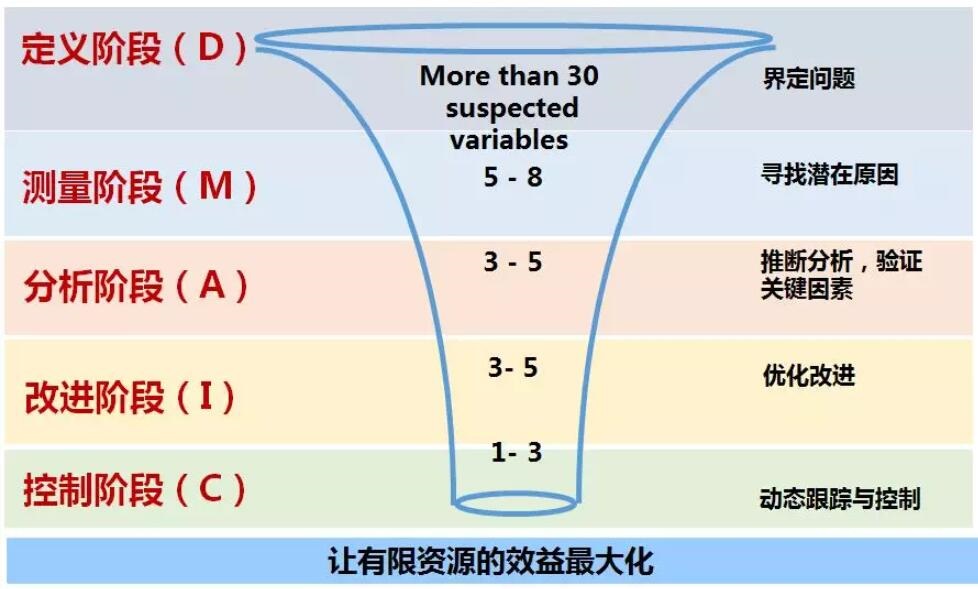
ЃЈ1ЃЉЖЈвхНзЖЮЃЈDНзЖЮЃЉЁЃНчЖЈЪ§ОнжЪСПжЮРэЕФЗЖЮЇЃЌВЂНЋЪ§ОнжЪСПИФНјЕФЗНЯђКЭФкШнНчЖЈдкКЯРэЕФЗЖЮЇФкЁЃЭЈЙ§ЪЙгУжїЪ§ОнЪЖБ№ЗЈЁЂзЈМваЁзщЗЈЁЂЮЪОэЕїВщЗЈЁЂТЉЖЗЗЈЕШЗНЗЈЃЌЖЈвхГіЪ§ОнжЮРэЕФЖдЯѓКЭЗЖЮЇЁЃЦѓвЕЪ§ОнжЪСПжЮРэЖдЯѓвЛАужївЊАќРЈСНРрЪ§ОнЃКвЛРрЪЧВйзїаЭЪ§ОнЃЌР§ШчЃКжїЪ§ОнЁЂВЮееЪ§ОнКЭНЛвзЪ§ОнЁЃСэвЛРрЪЧЗжЮіаЭЪ§ОнЃЌР§ШчЃКжїЬтЪ§ОнЁЂжИБъЪ§ОнЕШЁЃзЂЃКИљОнБЪепОбщвдМА80/20ЗЈдђЃЌЦѓвЕЕФЪ§ОнжЪЮЪЬт80%ЪЧгЩгкЙмРэВЛЕБЛђвЕЮёВйзїВЛЙцЗЖв§Ц№ЕФЃЌВЮПМЃКЁЖжїЪ§ОнЕФ3ДѓЬиЕуЁЂ4ИіГЌдНКЭШ§Иі80/20ддђЁЗЁЃ
ЃЈ2ЃЉВтСПНзЖЮЃЈMНзЖЮЃЉЁЃдкЖЈвхГіЪ§ОнжЮРэЖдЯѓКЭФкШнКѓЃЌашвЊбЁШЁвдЯТШєИЩИіжИБъРДзїЮЊЪ§ОнжЪСПЦРМлжИБъЃЌНЈСЂЪ§ОнжЪСПЦРЙРФЃаЭЃЌЖдЦѓвЕЕФЪ§ОнНјааЦРЙРКЭВтСПЁЃГЃгУЕФЪ§ОнжЪСПЦРМлжИБъОЭЪЧЮвУЧЩЯЪіЬсЕНЕФЃКЪ§ОнЮЈвЛадЁЂЪ§ОнЭъећадЁЂЪ§ОнзМШЗадЁЂЪ§ОнвЛжТадЁЂЪ§ОнЙиСЊадЁЂЪ§ОнМАЪБадЕШЁЃ
ЃЈ3ЃЉЗжЮіНзЖЮЃЈAНзЖЮЃЉЁЃЛљгкЪ§ОнжЪСПЦРЙРФЃаЭЃЌжДааЪ§ОнжЪСПЗжЮіШЮЮёЃЌЭЈЙ§Ъ§ОнЗжЮіЃЌевЕНЗЂЩњЪ§ОнжЪСПЮЪЬтЕФжиджЧјЃЌШЗЖЈГігАЯьЪ§ОнжЪСПЕФЙиМќвђЫиЁЃЪ§ОнжЮРэКЭДѓЪ§ОнЗжЮіЪЧУмВЛПЩЗжЕФЃЌЪ§ОнжЮРэЕФФПБъЪЧЬсЩ§Ъ§ОнжЪСПДгЖјЬсИпЪ§ОнЗжЮіЕФзМШЗадЃЌЖјДѓЪ§ОнЗжЮіММЪѕвВПЩЗДЯђзїгУгкЪ§ОнжЮРэЃЌЭЈЙ§ДѓЪ§ОнЗжЮіЫуЗЈКЭДѓЪ§ОнПЩЪгЛЏММЪѕЃЌФмЙЛИќзМШЗЁЂИќжБЙлЕФЖЈЮЛЕНЗЂЩњЪ§ОнжЪСПЮЪЬтЕФжЂНсЫљдкЁЃИУНзЖЮПЩвдгУЕФДѓЪ§ОнММЪѕАќРЈЃКЛиЙщЗжЮіЁЂвђзгЗжЮіЁЂгуЙЧЭМЗжЮіЁЂХСРлЭаЗжЮіЁЂОиеѓЪ§ОнЗжЮіЕШЁЃ
ЃЈ4ЃЉИФНјНзЖЮЃЈI НзЖЮЃЉЁЃЭЈЙ§жЦЖЈИФНјЙмРэКЭвЕЮёСїГЬЁЂгХЛЏЪ§ОнжЪСПЕФЗНАИЃЌЯћГ§Ъ§ОнжЪСПЮЪЬтЛђНЋЪ§ОнжЪСПЮЪЬтДјРДЕФгАЯьНЕЕЭЕНзюаЁГЬЖШЁЃЮвУЧвЛжБдкЧПЕїЪ§ОнжЪСПЕФгХЛЏКЭЬсЩ§ЃЌОјВЛЕЅЕЅЪЧММЪѕЮЪЬтЃЌгІДгЙмРэКЭвЕЮёШыЪжЃЌевГіЪ§ОнжЪСПЮЪЬтЗЂЩњЕФИљвђЃЌдйЖджЂЯТвЉЁЃЭЌЪБЃЌЪ§ОнжЪСПЙмРэЪЧвЛИіГжајгХЛЏЕФЙ§ГЬЃЌашвЊЦѓвЕШЋдБВЮгыЃЌВЂж№ВНХрбјЦ№ШЋдБЕФЪ§ОнжЪСПвтЪЖКЭЪ§ОнЫМЮЌЁЃИУЙ§ГЬжївЊгУЕНЗНЗЈЃКСїГЬдйдьЁЂМЈаЇМЄРјЕШЁЃ
ЃЈ5ЃЉПижЦНзЖЮ(CНзЖЮЃЉЁЃЙЬЛЏЪ§ОнБъзМЃЌгХЛЏЪ§ОнЙмРэСїГЬЃЌВЂЭЈЙ§Ъ§ОнЙмРэКЭМрПиЪжЖЮЃЌШЗБЃСїГЬИФНјГЩЙћЃЌЬсЩ§Ъ§ОнжЪСПЁЃ жївЊЗНЗЈгаЃКБъзМЛЏЁЂГЬађЛЏЁЂжЦЖШЛЏЕШЁЃ
ЮхЁЂЪ§ОнжЪСПМрПи(ЪТЧАдЄЗРПижЦЁЂЪТжаЙ§ГЬПижЦКЭЪТКѓМрЖНПижЦ)ЃК
5ЁЂЪ§ОнШЋжмЦкЙмРэ
Ъ§ОнЕФЩњУќжмЦкДгЪ§ОнЙцЛЎПЊЪМЃЌжаМфЪЧвЛИіАќРЈЩшМЦЁЂДДНЈЁЂДІРэЁЂВПЪ№ЁЂгІгУЁЂМрПиЁЂДцЕЕЁЂЯњЛйетМИИіНзЖЮВЂВЛЖЯбЛЗЕФЙ§ГЬЁЃЦѓвЕЕФЪ§ОнжЪСПЙмРэгІЙсДЉЪ§ОнЩњУќжмЦкЕФШЋЙ§ГЬЃЌИВИЧЪ§ОнБъзМЕФЙцЛЎЩшМЦЁЂЪ§ОнЕФНЈФЃЁЂЪ§ОнжЪСПЕФМрПиЁЂЪ§ОнЮЪЬтеяЖЯЁЂЪ§ОнЧхЯДЁЂгХЛЏЭъЩЦЕШЗНУцЁЃ
ЃЈ1ЃЉЪ§ОнЙцЛЎЁЃДгЦѓвЕеНТдЕФНЧЖШВЛЖЯЭъЩЦЦѓвЕЪ§ОнФЃаЭЕФЙцЛЎЃЌАбЪ§ОнжЪСПЙмРэШкШыЕНЦѓвЕеНТджаЃЌНЈСЂЪ§ОнжЮРэЬхЯЕЃЌВЂШкШыЦѓвЕЮФЛЏжаЁЃ
ЃЈ2ЃЉЪ§ОнЩшМЦЁЃЭЦЖЏЪ§ОнБъзМЛЏжЦЖЈКЭЙсГЙжДааЃЌИљОнЪ§ОнБъзМЛЏвЊЧѓЭГвЛНЈФЃЙмРэЃЌЭГвЛЪ§ОнЗжРрЁЂЪ§ОнБрТыЁЂЪ§ОнДцДЂНсЙЙЃЌЮЊЪ§ОнЕФМЏГЩЁЂНЛЛЛЁЂЙВЯэЁЂгІгУЕьЖЈЛљДЁЁЃ
ЃЈ3ЃЉЪ§ОнДДНЈЁЃРћгУЪ§ОнФЃаЭБЃжЄЪ§ОнНсЙЙЭъећЁЂвЛжТЃЌжДааЪ§ОнБъзМЁЂЙцЗЖЪ§ОнЮЌЛЄЙ§ГЬЃЌМгШыЪ§ОнжЪСПМьВщЃЌДгдДЭЗЯЕЭГБЃжЄЪ§ОнЕФе§ШЗадЁЂЭъећадЁЂЮЈвЛадЁЃ
ЃЈ4ЃЉЪ§ОнЪЙгУЁЃРћгУдЊЪ§ОнМрПиЪ§ОнЪЙгУЃЛРћгУЪ§ОнБъзМБЃжЄЪ§Оне§ШЗЃЛРћгУЪ§ОнжЪСПМьВщМгЙЄе§ШЗЁЃдЊЪ§ОнЬсЙЉИїЯЕЭГЭГвЛЕФЪ§ОнФЃаЭНјааЪЙгУЃЌМрПиЪ§ОнЕФРДдДШЅЯђЃЌЬсЙЉШЋЯЂЕФЪ§ОнЕиЭМжЇГжЃЛЦѓвЕДгММЪѕЁЂЙмРэЁЂвЕЮёШ§ИіЗНУцНјааЙцЗЖЃЌбЯИёжДааЪ§ОнБъзМЃЌБЃжЄЪ§ОнЪфШыЖЫЕФе§ШЗадЃЛЪ§ОнжЪСПЬсЙЉСЫЪТЧАдЄЗРЁЂЪТжадЄОЏЁЂЪТКѓВЙОШЕФШ§ИіЗНУцДыЪЉЃЌаЮГЩЭъећЕФЪ§ОнжЮРэЬхЯЕЁЃ
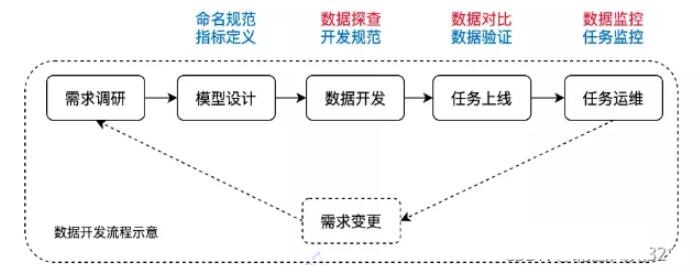
ЩЯЭМеЙЪОСЫдкЪ§ОнПЊЗЂЕФСїГЬжаЃЌЪ§ОнжЪСПЦНЬЈПЩвдЬсЙЉФФаЉЙІФмЃК
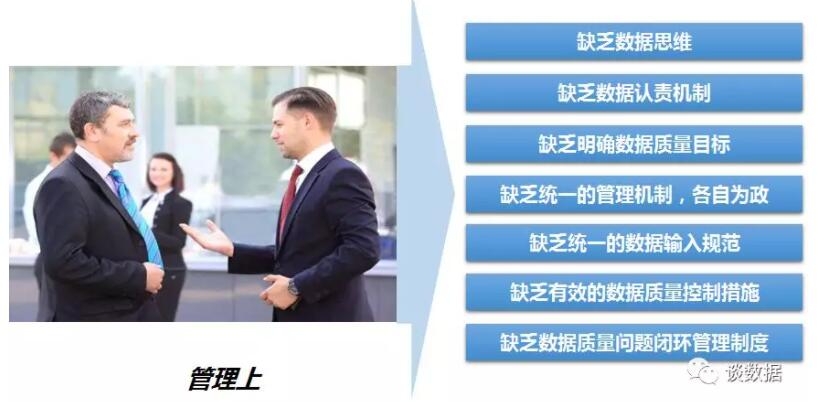
Ъ§ОнЬНВщЃКПЩвдИљОнИїжжЮЌЖШРДВщПДЪ§ОнУїЯИКЭЗжВМЧщПіЁЃ
Ъ§ОнЖдБШЃКПЊЗЂЭЌбЇПЩФмОГЃЛсЗЂЯжЯпЩЯБэКЭВтЪдБэВЛвЛжТЃЌЫљвдЮвУЧдкШЮЮёЩЯЯпЕФЛЗНкЬсЙЉСЫЪ§ОнЖдБШЕФЙІФмЁЃ
ШЮЮёМрПиЃКМрПиЯпЩЯЪ§ОнЃЌЬсЙЉБЈОЏКЭШлЖЯЙІФмЁЃ
Ъ§ОнжЪСПЦНЬЈзюгаДњБэадЕФЙІФмЪЧЃКЖдЪ§ОнПЊЗЂЦНЬЈВњГіЕФ Hive БэЪ§ОнНјаажїМќжиИДМьВтЃЌШчЙћДцдкжиИДдђНјааБЈОЏЁЃ
Ъ§ОнжЪСПМрПизюгагУЕФГЁОАЪЧЗРжЙЪ§ОнЮЪЬтТћбгЕНЯТгЮЁЃОйИіР§згЃКЪ§ОнШЮЮёВњГівЛеХ Hive БэЃЌИУБэПЩФмЛсЭЌВНвЛаЉаХЯЂЕН Hive metastoreЃЈHMSЃЉЁЃHMS ЕФжїДгМмЙЙПЩФмДцдквЛЖЈЕФбгГйЃЌМйЩш HMS ГіЯжЮЪЬтЃЌЯТгЮШЮЮёПЩФмЛсЖСЕНдрЪ§ОнЃЌетЪБШчЙћЮвУЧЪЙгУЪ§ОнжЪСПМрПиЃЌОЭФмМАЪБЗЂЯжЮЪЬтЃЌзшжЙЯТгЮШЮЮёдЫааЁЃ
1ЁЂЪТЧАдЄЗРПижЦЃКНЈСЂЪ§ОнБъзМЛЏФЃаЭЁЂЙцдђ
ЭГвЛжИБъЖЈвх
ЭГвЛжИБъПкОЖ
ЭГвЛЭтВПЪ§ОнЪфГіЙщПк
вЛЁЂдДЖЫЙмПи
дДЖЫБфЖЏЃЌБиаыЬсЧАЭЈжЊЪ§ВжВрЁЃ
гаЬѕМўЕФЛАЃЌЪЙгУЙЄОпМрПидДЖЫжиЕуФкШнЕФБфЖЏЁЃ
НЈСЂЪ§ОнБъзМЛЏФЃаЭЃЌЖдУПИіЪ§ОндЊЫиЕФвЕЮёУшЪіЁЂЪ§ОнНсЙЙЁЂвЕЮёЙцдђЁЂжЪСПЙцдђЁЂЙмРэЙцдђЁЂВЩМЏЙцдђНјааЧхЮњЕФЖЈвхЃЌвдЩЯЕФЪ§ОнжЪСПЕФаЃбщЙцдђЁЂВЩМЏЙцдђБОЩэвВЪЧвЛжжЪ§ОнЃЌдкдЊЪ§ОнжаЖЈвхЁЃУцЖдХгДѓЕФЪ§ОнжжРрКЭНсЙЙЃЌШчЙћУЛгадЊЪ§ОнРДУшЪіетаЉЪ§ОнЃЌЪЙгУепЮоЗЈзМШЗЕиЛёШЁЫљашаХЯЂЁЃе§ЪЧЭЈЙ§дЊЪ§ОнЃЌЪЙЕУЪ§ОнВХПЩвдБЛРэНтЁЂЪЙгУЃЌВХЛсВњЩњМлжЕЁЃЙЙНЈЪ§ОнЗжРрКЭБрТыЬхЯЕЃЌаЮГЩЦѓвЕЪ§ОнзЪдДФПТМЃЌШУгУЛЇФмЙЛЧсЫЩЕиВщевКЭЖЈЮЛЕНЯрЙиЕФЪ§ОнЁЃЪЕМљИцЫпЮвУЧзіКУдЊЪ§ОнЙмРэЃЌЪЧдЄЗРЪ§ОнжЪСПЮЪЬтЕФЛљДЁЁЃ
Ъ§ОнжЪСПЮЪЬтЕФдЄЗРПижЦзюгааЇЕФЗНЗЈОЭЪЧевГіЗЂЩњЪ§ОнжЪСПЮЪЬтЕФИљБОдвђВЂВЩШЁЯрЙиЕФВпТдНјааНтОіЁЃ
1ЃЉШЗЖЈИљБОдвђЃКШЗЖЈв§Ц№Ъ§ОнжЪСПЮЪЬтЕФЯрЙивђЫиЃЌВЂЧјЗжЫќУЧЕФгХЯШДЮађЃЌвдМАЮЊНтОіетаЉЮЪЬтаЮГЩОпЬхЕФНЈвщЁЃ
2ЃЉжЦЖЈКЭЪЕЪЉИФНјЗНАИЃКзюжеШЗЖЈЙигкааЖЏЕФОпЬхНЈвщКЭДыЪЉЃЌЛљгкетаЉНЈвщжЦЖЈВЂЧвжДааЬсИпЗНАИЃЌдЄЗРЮДРДЪ§ОнжЪСПЮЪЬтЕФЗЂЩњЁЃ
2ЁЂЪТжаЙ§ГЬПижЦ: ETLЙмРэКЭМрПи
ЪТжаЪ§ОнжЪСПЕФПижЦЃЌМДдкЪ§ОнЕФЮЌЛЄКЭЪЙгУЙ§ГЬжаШЅМрПиКЭДІРэЪ§ОнжЪСПЁЃЭЈЙ§НЈСЂЪ§ОнжЪСПЕФСїГЬЛЏПижЦЬхЯЕЃЌЖдЪ§ОнЕФаТНЈЁЂБфИќЁЂВЩМЏЁЂМгЙЄЁЂзАдиЁЂгІгУЕШИїИіЛЗНкНјааСїГЬЛЏПижЦЁЃЪ§ОнжЪСПЕФЙ§ГЬПижЦЃЌвЊзіКУСНИіЧПЛЏЃК

ЃЈ1ЃЉЧПЛЏЪ§ОнЕФБъзМЛЏЩњВњЃЌДгЪ§ОнЕФдДЭЗПижЦКУЪ§ОнжЪСПЃЌИУЙ§ГЬПЩвдВЩгУЯЕЭГздЖЏЛЏаЃбщКЭШЫЙЄИЩдЄЩѓКЫЯрНсКЯЕФЗНЪННјааЙмРэЃЌЪ§ОнЕФаТдіКЭБфИќвЛЗНУцЭЈЙ§ЯЕЭГНјааЪ§ОнаЃбщЃЌЖдгкВЛЗћКЯжЪСПЙцдђЕФЪ§ОнВЛдЪаэБЃГжЃЌСэвЛЗНУцВЩМЏСїГЬЧ§ЖЏЕФЪ§ОнЙмРэФЃЪНЃЌЪ§ОнЕФаТдіКЭБфИќВйзїЖМашвЊШЫЙЄНјааЩѓКЫЃЌжЛгаЩѓКЫЭЈЙ§ВХФмЩњаЇЁЃ
ЃЈ2ЃЉЧПЛЏЪ§ОнжЪСПдЄОЏЛњжЦЃЌЖдгкЪ§ОнжЪСПБпНчФЃК§ЕФЪ§ОнВЩгУЪ§ОнжЪСПдЄОЏЛњжЦЁЃЪ§ОндЄОЏЛњжЦЪЧЖдЪ§ОнЯрЫЦадКЭЪ§ОнЙиСЊаджИБъЕФживЊПижЦЗНЗЈЁЃеыЖдД§ЙмРэЕФЪ§ОндЊЫиЃЌХфжУЪ§ОнЯрЫЦадЫуЗЈЛђЪ§ОнЙиСЊадЫуЗЈЃЌдкЪ§ОнаТдіЁЂБфИќЁЂДІРэЁЂгІгУЕШЛЗНкЕїгУдЄжУЕФЪ§ОнжЪСПЫуЗЈЃЌНјааЯрЪЖЖШЛђЙиСЊадЗжЮіЃЌВЂИјГіЪ§ОнЗжЮіЕФНсЙћЁЃЪ§ОндЄОЏЛњжЦГЃгУдквЕЮёЛюЖЏЕФНЛвзЗчЯеПижЦЕШГЁОАЁЃ
2.1ЁЂETLЙмРэКЭМрПи
ETLЛљБОЩЯОЭЪЧМИИіЮЌЖШ
1ЁЂETLШЮЮёдЫааЕФЧщПі
ШчЙћЪЧздбаПђМмЕФЛАЃЌПЩвддкУПИіВНжшМгИіAOPзівЛаЉШежОЕФДђгЁЃЌШчЙћЪЧДПhiveЕФЛАЃЌПЩвдПДyarnвГУц
ЩѕжСздМКЕїгУapiПДЃКhttps://www.cnblogs.com/yurunmiao/p/4224137.htmlЃЈHive SQLдЫаазДЬЌМрПиЃЈHiveSQLMonitorЃЉЃЉ
2ЁЂETLШЮЮёПЊЪМЃЌНсЪјКЭЯћКФЪБМфЃЈЧсСПЃЌЪЪжаЃЌжиСПЃЉ
3ЁЂETLЕФживЊМЖБ№ЃЈЪЧЗёЩцМАзЪВњЯрЙиЃЌЪЧЗёЪЧЩЯгЮШЮЮёЃЉ
4ЁЂETLГЩЙІЪЇАмЕФЗжЮіЃЈетИівЛАуЕїЖШПђМмЖМЛсжЊЕРЃЌжЛЪЧвЊПМТЧШчКЮАбЯћЯЂећКЯЕНвЛЦ№ЃЌаДШыЭЌвЛИіЕиЗНЃЉ
5ЁЂЕЅЖРЖдФГаЉРраЭЕФETLзіЪЕЪБМЧТМЃЈБШШчsparkШЮЮёЃЌПЩвддкХмЭъФГвЛИіВНжшЃЌЭљkafkaЭЦЫЭвЛЬѕХмЪ§ОнЕФЯћЯЂЃЌетбљОЭПЩвдЯрЖдЪЕЪБЕФМрПиЕНвЛаЉДњТыаДГЩЕФETLЕФШежОЧщПіЃЌЕБГЄЪБМфУЛгаЪеЕНИУШЮЮёЕФЯћЯЂЕФЪБКђЃЌОЭПЩвдзівЛаЉБЈОЏЃЉ
3ЁЂЪТКѓМрЖНПижЦ: МрПижИБъ
3.1ЁЂЪ§ОнжЪСПМрПи--МрПижИБъ
вЛЁЂдДЖЫЙмПи
дДЖЫБфЖЏЃЌБиаыЬсЧАЭЈжЊЪ§ВжВрЁЃ
гаЬѕМўЕФЛАЃЌЪЙгУЙЄОпМрПидДЖЫжиЕуФкШнЕФБфЖЏЁЃ
ЖўЁЂЪ§ВжМрПиЙмРэ
ЖдвбгаЙцЗЖУЛгаЙсГЙЕФИјгшОЏИцЃКНЈФЃЙцЗЖЁЂПЊЗЂЙцЗЖЁЂЩЯЯпЙцЗЖ
ЪЙгУЙЄОпМгЧПЪ§ОнжЪСПМрПиЃЌЗЂЯжЮЪЬтМАЪБЭЈжЊЁЂИцОЏЁЃ
НЈСЂЪ§ОнжЪСПНтОіЛњжЦЃЌд№ШЮЕНШЫЁЃ
ЖЈЦкИДХЬ
живЊГЃМћЮЪЬтШыИцОЏЙцдђ
дДЖЫЪ§ОнжЪСПЮЪЬтЃЌаЕїдДЖЫНтОі
ДцДЂФЃаЭЁЂETLПЊЗЂЁЂЩЯЯпСїГЬЕШв§Ц№ЕФЮЪЬтЃЌашвЊжЦЖЈКЯЪЪЕФНтОіЗНАИ
ЖўЁЂЪ§ОнМрПи
ЮвУЧЖдгкЕФМрПижИБъЪЧетбљЕФЃЌЪ§ОнЛЙдкЪ§ВжВуУцЕФЪБКђЃЌЦфЪЕФмЙЛМрПиЕФЮЌЖШВЛЖр
1ЁЂЛљгкБэ
ЭГМЦCountЛђепБэЪЕМЪеМгУЕФДХХЬПеМфЃЌPVЃЈМгgroupЬѕМўЃЉЃЌUVЃЈМгgroupЬѕМўШЅжиЃЉПЩвдЬсЙЉМИжжФЌШЯБЈОЏЙцдђИљОнЦНОљжЕЃЌЩЯвЛДЮЕФжЕЃЌЛђеп7ЬьЧАЕФжЕЃЌгыБОДЮЕФжЕзіБШНЯЃЌРДЩшЖЈЪЧЗёБЈОЏЃЌШЛКѓдйЬсЙЉздЖЈвхsqlБЈОЏЙІФм
ЛљБОЩЯОЭЪЧcountзмЬѕЪ§ЃЌPVЃЌUVЃЌЛЗБШЃЌЪ§ОнЦЅХфТЪЃЈjoinЕФГЁОАЯТЃЌЛсВЛЛсЖЊЪ§ОнЃЉЃЌЛђепОлКЯКѓЕФЭЗВПЪ§ОнЕФЖдБШ
2ЁЂЛљгкзжЖЮ
ФЌШЯЬсЙЉжиИДжЕаЃбщЃЌзжЖЮШБЪЇТЪЃЈЮЊnullЛђепПезжЗћДЎЕФБШР§ЃЉДђЗжЃЌвВПЩвдздЖЈвхЃЌШчЙћЪЧЪ§жЕРраЭПЩвдМЦЫуЦНОљжЕЃЌзюДѓ/зюаЁЃЌжаЮЛЪ§ЃЌЫФЗжЮЛЪ§ЕШжИБъ
3ЁЂЦЋЯђВњЦЗ
ВЛЭЌВњЦЗЖдЪ§ОнЗжЮіОЭЛсгаВЛЭЌЕФвЊЧѓЃЌЖјЧвЖМВЛЬЋвЛбљЃЌБШШчСєДцЃЌЛёПЭАЁЃЌгУЛЇааЮЊЯВЛЖАЁЃЌетИіОЭЗЧГЃЕФЗБЖрСЫЃЌЛЙЪЧИљОнВњЦЗЛђепЗжЮіЕФОбщРДзіздЖЈвхАЩ
ЖЈЦкПЊеЙЪ§ОнжЪСПЕФМьВщКЭЧхЯДЙЄзїгІзїЮЊЦѓвЕЪ§ОнжЪСПжЮРэЕФГЃЬЌЙЄзїРДзЅЁЃ
1ЃЉЩшжУЪ§ОнжЪСПЙцдђЁЃЛљгкЪ§ОнЕФдЊФЃаЭХфжУЪ§ОнжЪСПЙцдђЃЌМДеыЖдВЛЭЌЕФЪ§ОнЖдЯѓЃЌХфжУЯргІЕФЪ§ОнжЪСПжИБъЃЌВЛЯогкЃКЪ§ОнЮЈвЛадЁЂЪ§ОнзМШЗадЁЂЪ§ОнЭъећадЁЂЪ§ОнвЛжТадЁЂЪ§ОнЙиСЊадЁЂЪ§ОнМАЪБадЕШЁЃ
2ЃЉЩшжУЪ§ОнМьВщШЮЮёЁЃЩшжУГЩЪжЖЏжДааЛђЖЈЦкздЖЏжДааЕФЯЕЭГШЮЮёЃЌЭЈЙ§жДааМьВщШЮЮёЖдДцСПЪ§ОнНјааМьВщЃЌаЮГЩЪ§ОнжЪСПЮЪЬтЧхЕЅЁЃ
3ЃЉГіОпЪ§ОнжЪСПЮЪЬтБЈИцЁЃИљОнЪ§ОнжЪСПЮЪЬтЧхЕЅЛузмаЮГЩЪ§ОнжЪСПБЈИцЃЌЪ§ОнжЪСПБЈИцжЇГжВщбЏЁЂЯТдиЕШВйзїЁЃ
4ЃЉжЦЖЈКЭЪЕЪЉЪ§ОнжЪСПИФНјЗНАИЃЌНјааЪ§ОнжЪСПЮЪЬтЕФДІРэЁЃ
5ЃЉЦРЙРгыПМКЫЁЃЭЈЙ§ЖЈЦкЖдЯЕЭГПЊеЙШЋУцЕФЪ§ОнжЪСПзДПіЦРЙРЃЌДгЮЪЬтТЪЁЂНтОіТЪЁЂНтОіЪБаЇЕШЗНУцНЈСЂЦРМлжИБъНјааећИФЦРЙРЃЌИљОнећИФгХЛЏНсЙћЃЌНјааЪЪЕБЕФМЈаЇПМКЫЁЃ
БЪепЙлЕуЃКЪ§ОнжЮРэЕФЁАГЃЬЌЛЏЁБВХЪЧЪ§ОнжЪСПЮЪЬтЕФзюКУНтОіЗНЪНЃЌЖјвЊЪЕЯжГЃЬЌЛЏжЮРэОЭашвЊИФБфдРДЕФЦѓвЕзщжЏаЮЪНЁЂЙмРэСїГЬЁЂзЊБфЙлФюЃЌвдЪЪгІетжжБфЛЏЁЃЪ§ОнжЮРэЕФЁАГЃЬЌЛЏЁБвЊОЕУЦ№елЬкЃЌЫљвдЧЇЭђВЛФмРЯзіаЉжиаТЗЂУїТжзгЕФ~ЧщЃЁ
СљЁЂОРе§Ъ§ОнЮЪЬт
ЦѓвЕЛЙашвЊВЛЪБНјаажїЖЏЕФЪ§ОнЧхРэКЭДІРэВЙОШЃЌвдОРе§ЯжгаЕФЪ§ОнЮЪЬтЁЃ
ОРе§Ъ§ОнЮЪЬтЩцМАЪ§ОнЕФЩњВњЗНЁЂЯћЗбЗНЃЌетвЛВНжшашвЊЦѓвЕЪ§ОнЛЗОГжаЕФЧАжаКѓЬЈЙВЭЌПЊеЙЪ§ОнОРДэЁЃЪ§ОнжЪСПЙмРэЗНАИвЊгыЦѓвЕЕФЬиЖЈЕФвЕЮёФПБъНєУмЦЅХфЃЌЪЙИїЗНЖдЪ§ОнжЪСПЙмРэФПБъКЭОРе§ЗНАИДяГЩЙВЪЖЃЌетЖдЪ§ОнжЪСПФПБъЕФзюжеДяГЩжСЙиживЊЁЃ
НЈСЂЪ§ОнжЪСПНтОіЛњжЦЃЌд№ШЮЕНШЫЁЃ
ЦпЁЂжЪСППМКЫЬхЯЕKPI
ЖдвбгаЙцЗЖУЛгаЙсГЙЕФИјгшОЏИцЃКНЈФЃЙцЗЖЁЂПЊЗЂЙцЗЖЁЂЩЯЯпЙцЗЖ
ЪЙгУЙЄОпМгЧПЪ§ОнжЪСПМрПиЃЌЗЂЯжЮЪЬтМАЪБЭЈжЊЁЂИцОЏЁЃ
Ъ§ОнжЪСППМКЫНЈСЂЪ§ОнжЪСПKPIЃЌЭЈЙ§зЈЯюПМКЫМЦЗжЕФЗНЪНЖдИїЦѓвЕИївЕЮёгђЁЂИїВПУХЕФЪ§ОнжЪСПЙмРэЧщПіНјааЦРЙРЁЃ
вдЪ§ОнжЪСПЕФЦРЙРНсЙћЮЊвРОнЃЌВЂНЋЮЪЬтЪ§ОнЙщНсЕНЯргІЕФЗжРрЃЌВЂАДЫљдкЗжРрЕФШЈжЕНјааСПЛЏЁЃзмНсЗЂЩњЪ§ОнжЪСПЮЪЬтЕФЙцТЩЃЌРћгУЪ§ОнжЪСПЙмРэЙЄОпЖЈЦкЖдЪ§ОнжЪСПНјааМрПиКЭВтСПЃЌМАЪБЗЂЯжДцдкЕФЪ§ОнжЪСПЮЪЬтЃЌВЂЖНДйТфЪЕИФе§ЁЃ
ПМКЫЪЕааНБГЭНсКЯжЦЃЌУПДЮИљОнИївЕЮёгђЁЂИїВПУХЪ§ОнжЪСПKPIЕФМьКЫЧщПіЃЌЗжБ№ИјгшЯргІЕФНБЗЃЗжжЕЃЌзїЮЊИївЕЮёгђЁЂИїВПУХФъжеПМКЫЕФФкШнЃЌВЂНЋЪ§ОнжЪСПзЈЯюПМКЫНсЙћФЩШыЖдгкШЫдБЁЂВПУХЕФећЬхМЈаЇПМКЫЬхЯЕжаЁЃ
ЭЈЙ§ЦРМлЯрЙиЪ§ОнжЪСПKPIЫЎЦНЃЌЖНДйИїЗНдкШеГЃЙЄзїжажиЪгЪ§ОнжЪСПЃЌдкЗЂЯжЮЪЬтЪБФмЙЛзЗИљЫндДЕижїЖЏНтОіЃЌЖдгкИпЫЎЦНЕФЪ§ОнжЪСПЙЄзїГЩЙћНјааМЄРјЁЂБэеУЃЌЬсЩ§ЦѓвЕЕФЪ§ОнжЪСПЙмРэвтЪЖЁЃ
змНс
Ъ§ОнжЪСПЙмРэЪЧЦѓвЕЪ§ОнжЮРэвЛИіживЊЕФзщГЩВПЗжЃЌЦѓвЕЪ§ОнжЮРэЕФЫљгаЙЄзїЖМЪЧЮЇШЦЬсЩ§Ъ§ОнжЪСПФПБъЖјПЊеЙЕФЁЃвЊзіКУЪ§ОнжЪСПЕФЙмРэЃЌгІзЅзЁгАЯьЪ§ОнжЪСПЕФЙиМќвђЫиЃЌЩшжУжЪСПЙмРэЕуЛђжЪСППижЦЕуЃЌДгЪ§ОнЕФдДЭЗзЅЦ№ЃЌДгИљБОЩЯНтОіЪ§ОнжЪСПЮЪЬтЁЃЖдгкЪ§ОнжЪСПЮЪЬтВЩгУСПЛЏЙмРэЛњжЦЃЌЗжЕШМЖКЭгХЯШМЖНјааЙмРэЃЌбЯжиЕФЪ§ОнжЪСПЮЪЬтЛђЪ§ОнжЪСПЪТМўПЩвдЩ§МЖЮЊЙЪеЯЃЌВЂЖдЙЪеЯНјааЖЈвхЁЂЕШМЖЛЎЗжЁЂдЄжУДІРэЗНАИКЭReviewЁЃСПЛЏЕФЪ§ОнжЪСПЪЙЕУЮвУЧПЩвдЭЈЙ§ЭГМЦЙ§ГЬПижЦЖдЪ§ОнжЪСПНјааМрВтЁЃвЛЕЉЗЂЯжвьГЃжЕЛђепЪ§ОнжЪСПЕФЭЛШЛЖёЛЏЃЌБуИљОнЪ§ОнВњЩњЕФТпМЫГЬйУўЙЯевЕНВњЩњЪ§ОнЕФвЕЮёЛЗНкЃЌШЛКѓВЩгУСљЮїИёТъСїГЬИФЩЦжаЕФОЕфЗжЮіЗНЗЈЖдвЕЮёНјааЭъЩЦЃЌеце§ЕФзіЕНгаЕФЗХЪИЁЃ Л№ЩНв§ЧцСїХњЪ§ОнжЪСПНтОіЗНАИКЭзюМбЪЕМљ
Ъ§ОнжЪСПЬєеН
ФПЧАЮвУЧЕФЪ§ОнжЪСПЬєеНгаФФаЉЃППЩвдЭЈЙ§МИИігУЛЇ case СЫНтвЛЯТЁЃ
User Story 1
ФГСїСПМЖВњЦЗЩЬвЕЛЏЯЕЭГЃЌM МЖШежОЬѕЪ§/УыЃЛЯЃЭћУыМЖМрПиШежОбгГйЁЂЙиМќзжЖЮПежЕЃЌT+1 МьВтШежОВЈЖЏТЪЁЃ
User Story 2
ФГФкВПвЕЮёЯЕЭГЃЌШежОДцДЂ ESЃЛЯЃЭћУП 5 ЗжжгМьВтЩЯвЛжмЦкШежОВЈЖЏЧщПіЁЃ
User Story 3
ФГФкВПжИБъЦНЬЈЃЌвЕЮёЪ§ОнгЩ Hive ЖЈЦкЭЌВНЕН ClickHouseЃЛЯЃЭћУПДЮЭЌВНШЮЮёКѓМьВщ Hive гы ClickHouse жаЕФжИБъЪЧЗёвЛжТЁЃ
ЭЈЙ§ЩЯУцЕФНщЩмЃЌДѓМвгІИУвВДѓжТЧхГўСЫЕБЧАЪ§ОнжЪСПашвЊНтОіЕФЮЪЬтЁЃПЩФмгааЉЭЌбЇЛсЫЕЃЌЪ§ОнжЪСПЦНЬЈЮввВзіЙ§ЃЌЮЪЬтЙщзмЦ№РДвВВЛИДдгЃЌзмЖјбджЎОЭЪЧЖдЪ§ОнНјааИїжжМЦЫуЃЌЖдБШМЦЫуРДЕФуажЕМДПЩЃЌвЛАужБНгвРРЕгк Spark в§ЧцЛђеп Hive в§ЧцМЦЫуМДПЩЁЃШЗЪЕЃЌЦфЪЕетвВЪЧЮвУЧЪ§ОнжЪСПзюПЊЪМЕФбљзгЁЃФЧЮЊЪВУДЛсбнЛЏЕНФПЧАетбљЃЌЮвУЧУцСйСЫвЛаЉЪВУДЮЪЬтЃП
ЪзЯШЪЧГЁОАашЧѓЗЧГЃИДдгЃК
РыЯпМрПиВЛдйЖрЫЕСЫЃЌДѓМвЖМЪьЯЄЃЌжївЊЪЧВЛЭЌДцДЂЕФЪ§ОнжЪСПМрПиЃЌБШШч Hive Лђеп ClickHouse ЁЃ
зжНкЬјЖЏФкВПЕФЙуИцЯЕЭГЖдЪБаЇадКЭзМШЗадвЊЧѓКмИпЃЌгУЙуИцЭЌбЇЕФЛАЫЕЃЌШчЙћгУЮЂХњЯЕЭГ 10 min ВХзівЛДЮМьВтЃЌПЩФмЯпЩЯЫ№ЪЇОЭЩЯАйЭђСЫЩѕжСЧЇЭђСЫЁЃЫљвдЙуИцЯЕЭГЭЌбЇЖдЪЕЪБадвЊЧѓЯрЖдНЯИпЁЃ
СэЭтвЛИіЪЧИДдгЭиЦЫЧщПіЯТЕФСїЪНбгГйМрПиЁЃ
зюКѓЪЧЮЂХњЃЌжИвЛЖЮЪБМфФкЕФЖЈЪБЕїЖШЃЌгааЉ Kafka ЕМШы ES ЕФСїЪНГЁОАЃЌашвЊУПИєМИЗжжгЖдБШЯТЧАвЛжмЦкЁЃ
ДЫЭтЃЌзжНкЬјЖЏИїжжВњЦЗЛсВњГіКЃСПЕФШежОЪ§ОнЃЌЮвУЧашвЊгУгаЯоЕФзЪдДРДТњзуДѓМвЖджЪСПМрПиЕФашЧѓЁЃ
УцСйетаЉЬєеНЃЌЮвУЧЕФНтОіЗНАИЪЧЪВУДЃП
СїХњЪ§ОнжЪСПНтОіЗНАИ
ВњЦЗЙІФмМмЙЙ
Л№ЩНв§ЧцСїХњЪ§ОнжЪСПНтОіЗНАИга 4 ИіДѓЕФЙІФмЃК
РыЯпЪ§ОнжЪСПМрПиЃКНтОіХњКЭЮЂХњМрПиГЁОАЃЌжЇГж HiveЁЂClickHouseЁЂES ЕШЖржжЪ§ОндДЃЌВЂгазжЖЮЁЂЮЈвЛадЕШЖржжМрПиЮЌЖШЃЌдЪаэЭЈЙ§ SQL здЖЈвхЮЌЖШОлКЯНјааМрПиЁЃ
СїЪНЪ§ОнжЪСПМрПиЃКНтОіСїЪНМрПиГЁОАЃЌжЇГж Kafka/BMQ ЕШЪ§ОндДЁЃ
Ъ§ОнЬНВщЃКНтОіЪ§ОнПЊЗЂжЎЧАЖдЪ§ОнФкШнДцвЩЮЪЬтЃЌжЇГж Hive Ъ§ОндДЁЃ
Ъ§ОнЖдБШЃКНтОіаТОЩБэЪ§ОнвЛжТадЮЪЬтЃЌжЇГж Hive/Hive SQL Ъ§ОндДЁЃ
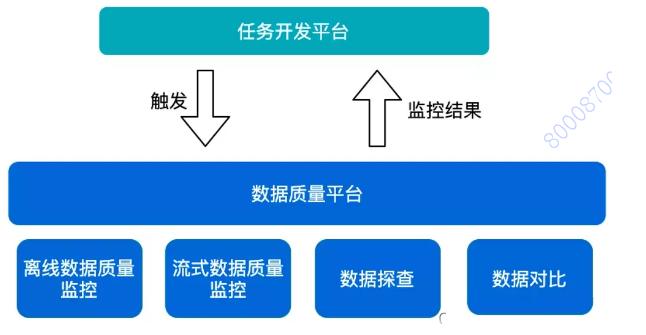
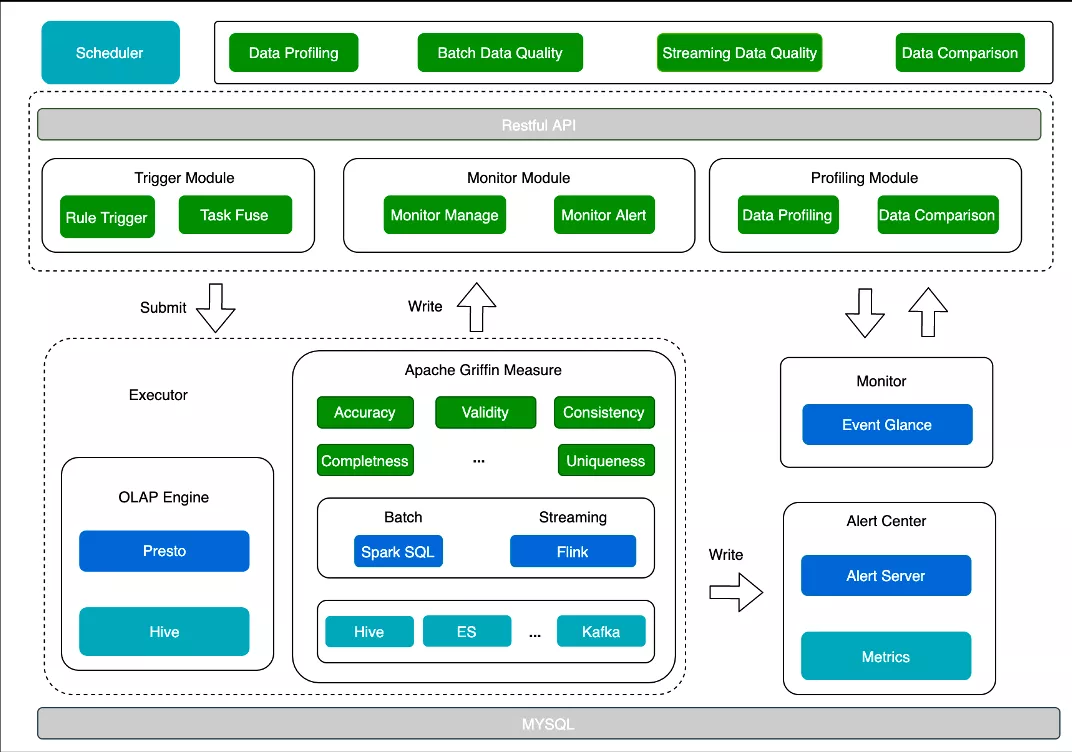
ЩЯЭМЪЧЪ§ОнжЪСПЦНЬЈЕФЯЕЭГМмЙЙЭМЃЌжївЊЗжЮЊ 5 ИіВПЗжЃК
SchedulerЃКЭтВПЕїЖШЦїЃЌДЅЗЂРыЯпМрПиЁЃжївЊЗжСНжжРраЭЃК
ЖдЭтЬсЙЉ API ЕїгУШЮЮёЃЛ
ЖЈЪБЕїЖШЃЌЭЈЙ§ calljob ЕїгУЪ§ОнЁЃ
BackendЃККѓЖЫЗўЮёЃЌЦЋЗўЮёВуЃЌДІРэвЕЮёТпМЁЃжївЊИКд№ЃК
жЪСПЦНЬЈКЭЭтВПЕФНЛЛЅЃЌЫљга API ЯьгІЖМЪЧЭЈЙ§етвЛВуНјааЃЛ
ШЮЮёЬсНЛЃКгУЛЇдкжЪСПЦНЬЈХфжУЕФЙцдђЛсЗХЕНвЕЮёДцДЂЃЌScheduler БЛЕїгУКѓЃЌBackend ЛсНЋШЮЮёЯрЙиЕФВЮЪ§ХфжУНјааШЮЮёЬсНЛЃЛ
ЛёШЁжЪСПМрПиЕФНсЙћВЂНјааХаЖЯЃЌШЛКѓКЭЭтВПЯЕЭГНјааНЛЛЅЃЌдкашвЊЪБЗЂЫЭОЏБЈЭЈжЊгУЛЇЁЃ
ExecutorЃКЦНЬЈКЫаФЕФШЮЮёжДааФЃПщЃЌМЏГЩСЫвЛаЉв§ЧцЃЌР§ШчЪ§ОнЬНВщЪЙгУ OLAP в§ЧцЁЃжЪСПМрПиВПЗжЪЙгУ Griffin ЕФ Measure НјааЪ§ОнЭГМЦЁЃ
MonitorЃКЪЧвЛИіЯрЖдЖРСЂЕФФЃПщЃЌжївЊНјаазДЬЌЗўЮёЕФСїзЊЃЌЬсЙЉжиИДБЈОЏЕШЙІФмЁЃ
Alert CenterЃКжЪСПЦНЬЈЧПвРРЕгкИУЦНЬЈЁЃЫќЪЧЭтВПБЈОЏЗўЮёЃЌНгЪеИїжжБЈОЏЪТМўЁЃ
РыЯпЪ§ОнМьВтСїГЬ
ЯТУцПДвЛЯТРыЯпЪ§ОнЕФМьВтСїГЬ
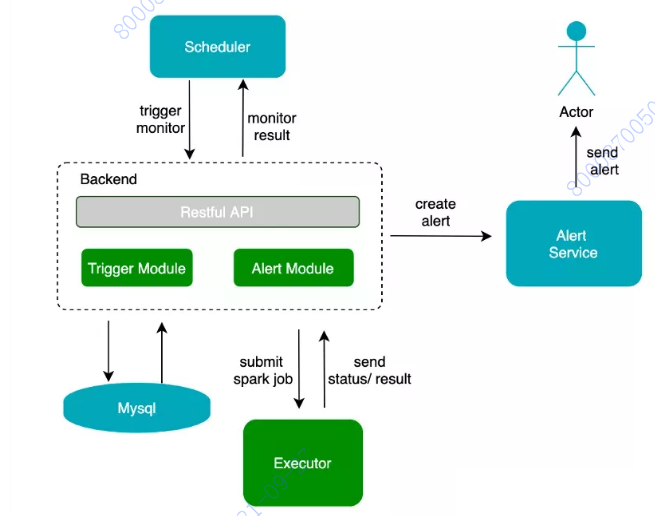
РыЯпЪ§ОнЕФМрПиЁЂЬНВщЁЂЖдБШЕФжДааСїГЬвЛжТЃЌжївЊЗжЮЊ 4 ВНЃК
МрПиДЅЗЂЃКЕїЖШЯЕЭГЕїгУжЪСПФЃПщ Backend APIЃЛ
зївЕЬсНЛЃКBackend вд Cluster ФЃЪНЬсНЛ Spark зївЕжС YarnЃЛ
НсЙћЛиДЋЃКзївЕНсЪј (ГЩЙІЁЂЪЇАм)ЃЌDriver НЋНсЙћ sync жС BackendЃЛ
ЯћЯЂДЅЗЂЃКBackend ИљОнНсЙћДЅЗЂЯргІЖЏзї (Р§ШчЃКБЈОЏЁЂЯћЯЂЬсЪО)ЁЃ
ЮвУЧзмНсСЫвЛЯТЪ§ОнжЪСПЦНЬЈЕФгХЪЦЃК
ЕїЖШЯЕЭГЕЭёюКЯЃКЪ§ОнжЪСПЦНЬЈУЛгаКЭЕїЖШЯЕЭГЧПАѓЖЈЃЌвЛАуПЩвдгУвЕЮёЯЕЭГЕФ API ЪЕЯжЛЅЯрЕїгУЁЃ
ЪТМўДЅЗЂИпаЇЃЌBackend ЫЎЦНРЉеЙФмСІЧПЃКBackend ЪЧЮозДЬЌЕФЪЕР§ЗўЮёЃЌШчЙћжЪСПМрПиЕФвЕЮёЯЕЭГНЯЖрЃЌBackend ПЩвдВЩгУЫЎЦНРЉеЙЕФЗНЪНВПЪ№ЃЌНгЪеЧыЧѓВЂЬсНЛзївЕЁЃ
УЛга Quota ЯожЦЃКЦНЬЈБОЩэУЛгаЮЌЛЄЪ§ОнжЪСПМрПиЕЅЖРашвЊЕФзЪдДЖгСаЃЌЖјЪЧАбетИіШЈЯоПЊЗХИјгУЛЇЃЌгУЫћУЧздЩэЕФзЪдДзізЪдДМрПиЁЃетбљОЭАб Quota ЮЪЬтзЊЛЛГЩСЫгУЛЇзЪдДЮЪЬтЁЃ
ЕБШЛШЮКЮвЛИіЙЄОпЖМВЛПЩФмЪЧЭъУРЕФЃЌЪ§ОнжЪСПЦНЬЈднЪБЛЙгавЛаЉД§ЬсЩ§ЕФЕиЗНЃК
ЗЧ CPU УмМЏаЭВщбЏНЯжиЃКећИіЦНЬЈЕФЩшМЦЪЧвдШЮЮёЬсНЛЕФЗНЪНЭъГЩРыЯпГЁОАЕФашЧѓЁЃЕЋЪЧКѓРДЮвУЧЗЂЯжЦфЪЕВЛашвЊЦєЖЏ Spark ЕФзївЕШдШЛЛсЦєЖЏвЛИі Spark зївЕЃЌШч ES SQL ВщбЏЃЌетИіВщбЏЪЧКмжиЕФЁЃ
вРРЕ Yarn зіЕїЖШЮШЖЈадВЛИпЃКЦНЬЈЩЯЕФШЮЮёдкзЪдДВЛГфзуЛђБЛМЗеМЕФЧщПіЯТЃЌЛсГіЯжШЮЮёдЫааЛђЕїгУКмТ§ЁЃ
СїЪНМрПижДаа
ЖдгкСїЪНЪ§ОнЕФМрПиЃЌЮвУЧбЁдёСЫ Flink в§ЧцЃЌвђЮЊСїЪНЪ§ОнВЛЭЌгкРыЯпЪ§ОнЃЌВЛФмгУПьееЕФЗНЪНЕЭГЩБОФУЕНЙ§ГЬЁЃЫљвдЮвУЧвЊвРРЕвЛаЉЭтВПЕФЪБађЪ§ОнПтдйМгЙцдђв§ЧцРДеЙЪОЖдЪ§ОнЕФМрПиЁЃ
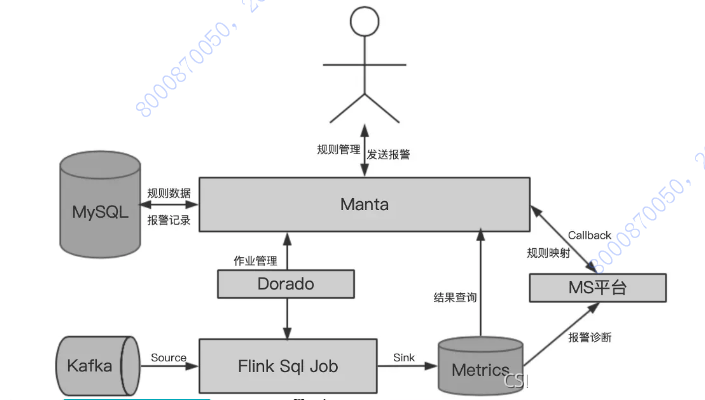
ЦНЬЈЩЯСїЪНЪ§ОнМрПиЕФСїГЬЮЊЃК
ИљОнЙцдђЖЈвхЃЌДДНЈ Flink зївЕЃЛ
ИљОнБЈОЏЬѕМўЃЌзЂВс Bosun БЈОЏЪТМўЃЛ
Flink зївЕЯћЗб Kafka Ъ§ОнЃЌМЦЫуМрПижИБъаД MetricsЃЛ
Bosun Лљгк Metrics ЕФЪБађЪ§ОнЃЌЖЈЪБМьВтЃЌДЅЗЂБЈОЏЃЛ
Backend НгЪеБЈОЏЛиЕїЃЌДІРэБЈОЏЗЂЫЭТпМЁЃ
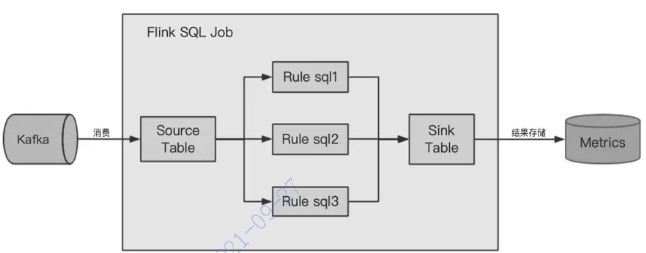
СїЪНМрПижЇГжГщбљ & ЕЅ Topic Жр Rule гХЛЏ
Kafka Ъ§ОнГщбљ
вЛАуСїЪНЪ§ОнЕФЮЪЬтЖМЪЧЭЈгУадЮЪЬтЃЌПЩвдЭЈЙ§Ъ§ОнВЩбљЗЂЯжЮЪЬтЁЃвђДЫЮвУЧПЊЗЂСЫЪ§ОнВЩбљЕФЙІФмЃЌМѕЩйЪ§ОнзЪдДЕФеМБШЯћКФЁЃFlink Kafka Connector жЇГжГщбљЃЌПЩжБНгВйзї kafka topic ЕФ offset РДДяЕНГщбљЕФФПЕФЁЃБШШчЃЌЮвУЧАДее 1% ЕФБШР§НјааГщбљЃЌдРДЩЯ W Иі partition ЕФ TopicЃЌЮвУЧжЛашвЊ ** ИіЛњЦїОЭПЩвджЇГХЁЃ
ЕЅ Topic Жр Rule гХЛЏ
зюдчЕФЪБКђЮвУЧЪЧЖдвЛИі Topic ЖЈвхвЛИі RuleЃЌШЛКѓПЊЦєвЛИі Flink ШЮЮёНјааЯћЗбЃЌжДаа RuleЁЃКѓРДЮвУЧЗЂЯжвЛаЉЙиМќЕФЪ§ОнашвЊЖдЖрИіЮЌЖШНјааМрПиЃЌвВОЭЪЧвЊЖЈвхЖрИіЮЌЖШЕФ RuleЃЌЖдУПвЛЬѕ Rule ЖМПЊШЮЮёШЅЯћЗбЪЧЗЧГЃКФзЪдДЕФЃЌЫљвдЮвУЧРћгУМрПиВЛЪЧ CPU УмМЏаЭзївЕЕФЬиадЃЌИДгУЖСШЁВПЗжЃЌЕЅ slot жажДааЖрИі RuleЃЌЖд Topic МЖБ№НјааЕЅвЛЯћЗбЃЌдквЛИіШЮЮёжаАбЯрЙи Rule ЖМжДааЭъЁЃ
ЮДРДбнНјЗНЯђ
БОЮФНщЩмСЫЪ§ОнжЪСПЦНЬЈЕФЪЕЯжКЭзюМбЪЕМљЃЌзюКѓЬИЬИЦНЬЈЮДРДЕФбнНјЗНЯђЁЃ
ЕзВув§ЧцЭГвЛЃЌСїХњвЛЬхЃКФПЧАЦНЬЈЕФРыЯпШЮЮёДѓВПЗжЪЧЛљгк Spark ЭъГЩЕФЃЌСїЪНЪ§ОнВЩгУСЫ Flink ДІРэЃЌOLAP в§Чцгжв§НјСЫ prestoЃЌЕМжТетЬзЯЕЭГМмЙЙЕФдЫЮЌГЩБОБШНЯИпЁЃЮвУЧПДЕН Flink ФПЧАЕФ presto ФмСІКЭ Flinkbatch ЕФФмСІвВдкВЛЖЯЗЂеЙЃЌвђДЫЮвУЧКѓајЛсГЂЪдЧавЛаЉШЮЮёЃЌзіЕНеце§втвхЩЯЕФЭГвЛв§ЧцЁЃ
жЧФмЃКв§ШыЫуЗЈНјааЪ§ОнЧ§ЖЏЁЃПМТЧв§Шы ML ЗНЗЈИЈжњуажЕбЁШЁЛђепжЧФмБЈОЏЃЌИљОнЪ§ОнЕШМЖздЖЏЭЦМіжЪСПЙцдђЁЃОйМИИіР§згЃЌБШШчЮвУЧПЩвдЛљгкЪБађЫуЗЈжЧФмЕФВЈЖЏТЪМрПиРДНтОіНкМйШеСїСПИпЗхКЭЦНГЃЕФгВЙцдђуажЕЕФЬсЩ§ЁЃ
БуНнЃКOLAP ЖдадФмЬсЩ§БШНЯЯджјЃЌЕЋЪЧФПЧАЮвУЧжЛгУдкСЫЪ§ОнЬНВщЙІФмЩЯЁЃКѓајПЩвдНЋ OLAP в§ЧцгІгУгкжЪСПМьВтЁЂЪ§ОнОнЬНВщЁЂЪ§ОнЖдБШгІгУгыЪ§ОнПЊЗЂСїГЬЁЃ
гХЛЏЃКБШШчЭЈЙ§ЕЅвЛ JobЃЌЭЌЪБдЫааЖрИіМрПиЃЌНЋМрПиКЭЪ§ОнЬНВщНсКЯЁЃЮвУЧЯждкдкГЂЪдНЋЪ§ОнжЪСПЕФЙцдђЩњГЩКЭЪ§ОнЬНВщзіНсКЯЃЌзіЕНЫљМћМДЫљЕУЕФЪ§ОнКЭЙцдђЕФЖдгІЙиЯЕЁЃ
Q&A
QЃКЪ§ОнжЪСПЮЪЬтЕФХХВщКмЖрЪБКђЪБМфГЩБОЗЧГЃИпЃЌФуУЧдкЪ§ОнжЪСПЮЪЬтЕФЙщвђЗжЮіЩЯгазіЪВУДЙЄзїТ№ЃП
AЃКетИіЮЪЬтЪЧЗЧГЃКЫаФЕФЭДЕуЁЃетРяПЩвдНщЩмЯТФПЧАЮвУЧЕФЫМТЗЃКСЊКЯзжНкЬјЖЏЫуЗЈЕФЭЌбЇзіЪ§ОнЯТзъЃЌвВОЭЪЧЖдЪ§ОнСДТЗЕФУПвЛеХБэЖМНјааЪ§ОнЬНВщЁЃШчЙћЗЂЯжжЪСПЮЪЬтЃЌЭЈЙ§вЛаЉРрЫЦгкбЊдЕКЭзжЖЮЕФЙиЯЕевЕНЪ§ОнЩЯгЮЕФзжЖЮЁЃФПЧАЮвУЧдкзіЕФЛЙЪЧетбљЦЋЬНВщ+СїГЬЕФЗНЪНШЅОЁПьСЫНтЩЯгЮЪ§ОнЃЌЙщвђЗжЮіетВПЗжднЪБЛЙУЛгаЪВУДНјеЙЁЃ
QЃКЪ§ОнжЪСПБеЛЗЪЧШчКЮзіЕФЃКБШШчЪ§ОнжЪСПЮЪЬтгЩЫРДНтОіЃПЪ§ОнжЪСПШчКЮКтСПЃП
AЃКЪ§ОнжЪСПЮЪЬтЫРДНтОіЃПЫдкЙизЂЪ§ОнжЪСПЃЌЫШЅ push ЭЦНјЃЌЫПЊЗЂСЫЪ§ОнЃЌЫШЅНтОіЪ§ОнжЪСПЮЪЬтЁЃетЪЧвЛИіазїЩЯЕФЮЪЬтЁЃ
ШчКЮКтСПЪ§ОнжЪСПЃПЮвУЧФкВПгавЛаЉПЩжЮРэЕФжИБъЃЌБШШчБЈОЏСПЁЂКЫаФШЮКЮЕФБЈОЏТЪЕШЁЃ
QЃКШчКЮБЃжЄЖЫЕНЖЫЪ§ОнвЛжТадЃП
AЃКЖЫЕНЖЫЪ§ОнвЛжТадВЛЪЧвЛИіЕЅвЛЕФЙЄОпФмНтОіЕФЃЌПЩФмашвЊвЛаЉЗНАИЃЌБШШчЃКДгЖЫЩЯЩЯБЈЕФЪ§ОнЃЌНсКЯТёЕуЯЕЭГзіЪ§ОнаЃбщЃЌдкЗЂАцЕФЪБКђШЗЖЈЪ§ОнЪЧзМШЗЕФЁЃЕЋЪЧЮвШЯЮЊЖЫЕНЖЫЪ§ОнвЛжТадФПЧАећИіаавЕЖМЛЙзіЕФБШНЯЧЗШБЃЌвЕЮёЖЫШчЙћГіЯжСЫЮЪЬтЃЌЪЧКмФбХХВщЕФЁЃШчЙћЖдЪ§ОнСДТЗЕФУПвЛВуЖМзіМрПиЃЌПЩФмЮЪЬтХХВщЦ№РДЛсЯрЖдМђЕЅвЛаЉЃЌЕЋетжжзіЗЈДњМлгжБШНЯДѓЁЃ
|









