| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫДЋЭГЦѓвЕЪ§ОнЦНЬЈЕФбнНјЁЂЦѓвЕЪ§ОнЦНЬЈЕФЪЇАмЁЂЗДЫМЕЅЬхМмЙЙЕФФЃЪНМАУцЯђгђЕФЪ§ОнМмЙЙЕШЁЃЯЃЭћФмЙЛЖдДѓМвгаЫљЦєЗЂКЭАяжњЁЃ
БОЮФРДздгкжЊКѕЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
2019ФъЮвгыThoughtWorksЕФZhamak DehghaniКЯзїЃЌЬсГівЛИіЗжВМЪНЪ§ОнЦНЬЈМмЙЙData
MeshЕФМмЙЙЫМЯыКЭЩшМЦЃЌВЂдкецЪЕПЭЛЇЦѓвЕжаВЮгыЪЕЪЉЃЌБОЮФЪЧЖдетвЛЫМЯыКЭЩшМЦЕФзмНсЃЌВЮПМздЁЖHow
to Move Beyond a Monolithic Data Lake to a Distributed
Data MeshЁЗКЭЪЕМљжаЕФЩюШыЫМПМЁЃ
ДЋЭГЪ§ОнЦНЬЈИФдьЁЂжЮРэЁЂЛљДЁЩшЪЉЁЂЪ§ОнФмСІЕФЙЙНЈЗНЪНПЩФмашвЊЛљгквЛИіЭъШЋВЛЭЌгквдЭљЕФТпМЃЌМДЦѓвЕЪ§ОнЦНЬЈЃЈData
PlatformЃЉе§дкНјШывЛИіЗЖР§БфИяЃЈParadigm ShiftЃЉЕФНзЖЮЁЃ
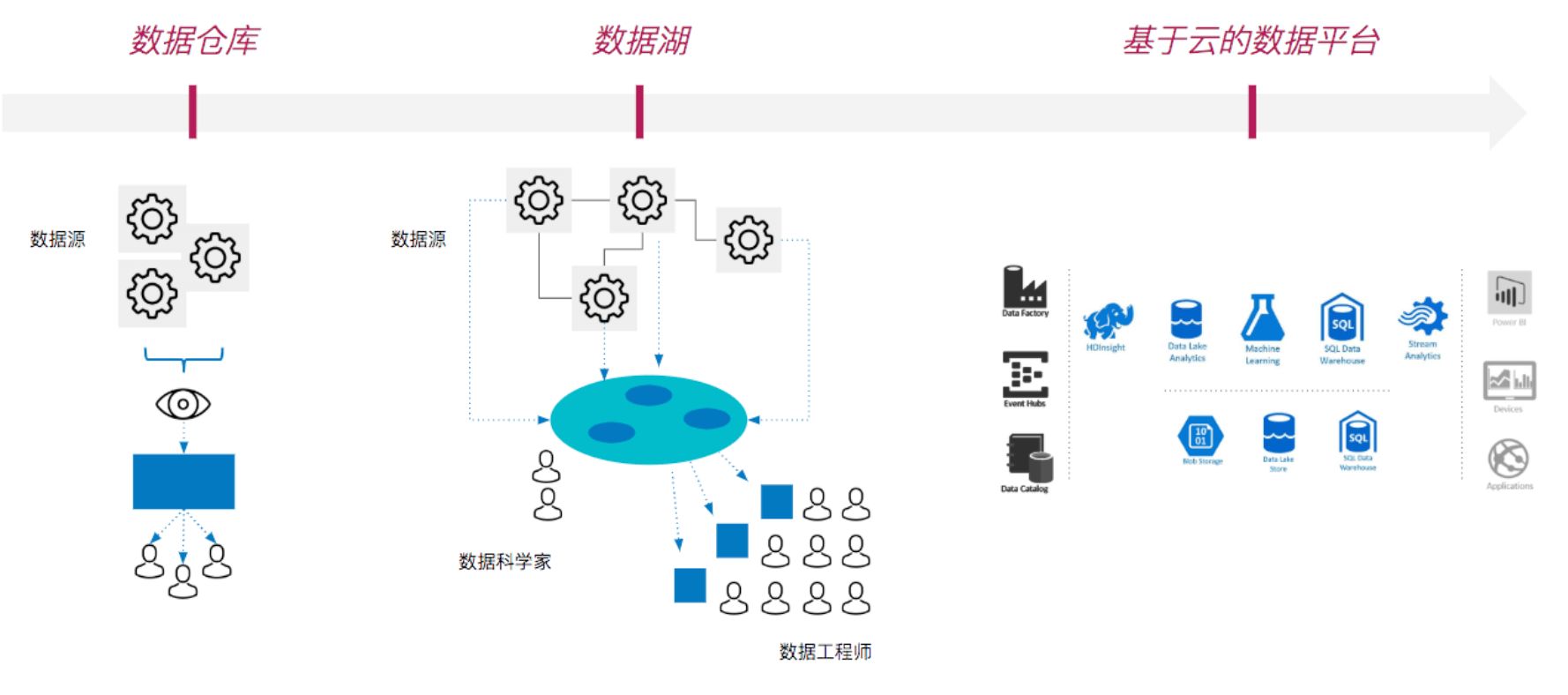
ДЋЭГЦѓвЕЪ§ОнЦНЬЈЕФбнНј
ДЋЭГЦѓвЕЪ§ОнЦНЬЈЕФбнНјжївЊгаШ§ИіживЊНзЖЮЃК
ЕквЛНзЖЮЃЌЛљгкЦѓвЕМЖЪ§ОнВжПтЕФBIФмСІЃЛ
ЕкЖўНзЖЮЃЌвдЪ§ОнКўЮЊДњБэЕФДѓЪ§ОнЩњЬЌЯЕЭГЃЛ
ЕкШ§НзЖЮЃЌЛљгкдЦЕФЪ§ОнЦНЬЈЃЌврЮЊЕБЧАжїСїЕФЛьКЯЪЕМљФЃЪНЃЌАќКЌЪЕЪБЪ§ОнСїДІРэМмЙЙЁЂећКЯХњСПгыСїДІРэЕФПђМмЁЂвдМАНсКЯдЦЖЫДцДЂЁЂСїЫЎЯпЁЂвдМАЛњЦїбЇЯАФмСІЁЃ
ЦѓвЕЪ§ОнЦНЬЈЕФЪЇАм
NewVantage PartnersЙЋЫОДг2012ФъЦ№ЃЌУцЯђВЦИЛ1000ЦѓвЕЙмРэВуЕїбаДѓЪ§ОнКЭAIдкЦфЦѓвЕФкЕФЪЕЪЉЧщПіЃЌИУБЈИц2019ФъНвЪОСЫећИіЦѓвЕЪ§ОнЦНЬЈСьгђЕФОНЦШЁЊЁЊОЁЙмдкДѓЪ§ОнКЭAIСьгђЭЖШыГЌЙ§5вкУРдЊЕФЙЋЫОНЯЩЯвЛФъдіГЄСЫ66%ЃЌдк65МвЪмЗУЦѓвЕРяЛигІЁИЮДФмЛђЩадчЬхЯжПЩСПЛЏвЕЮёНсЙћЁЙЕФЦѓвЕдіМгСЫ41%ЁЃ
дкбаОПЦѓвЕЪ§ОнЦНЬЈЯюФПЪЇАмАИР§жаЮвУЧЗЂЯжШчЯТЫФИіКЫаФдвђЃК
ЦєЖЏФбЃКШБЩйгУР§жЇГжЃЌЮоЗЈЛёЕУвЕЮёжЇГжЃЛГЄЪБМфЕФЪ§ОнКўЩшМЦгыММЪѕЦРЙРЃЛашвЊЭГвЛзщжЏФкЖрИівЕЮёЛђММЪѕВПУХЃЛ
Ъ§ОндДФбвдЙцФЃЛЏЃКШБЩйЪжЖЮЖдДэзлИДдгЕФдДЪ§ОнЯЕЭГНјааЪшПЃгыЙмРэЃЛФбвдИњЩЯВЛЖЯдіГЄЕФЪ§ОндДЯЕЭГЙцФЃЃЛ
Ъ§ОнЪЙгУФбвдЙцФЃЛЏЃКЪ§ОнЦНЬЈЯюФПИњВЛЩЯЦѓвЕДДаТвЊЧѓЃЛгУР§Й§еЃЌФбвдТњзуЙцФЃЛЏашЧѓЃЛЦНЬЈФмСІИњВЛЩЯДэзлИДдгЕФгУР§ашЧѓЃЛ
ФбвдЪЕЯжЪ§ОнЩЬвЕЛЏЃКМЋИпЕФПЊЗЂКЭдЫгЊГЩБОЃЛФбвдНЋЪ§ОнЦНЬЈеце§зЊЛЏЮЊЩЬвЕОКељСІЃЛФбвдаЮГЩДДаТЮФЛЏЁЃ
ШчЙћЮвУЧАбЦѓвЕЪ§ОнЦНЬЈЕФГЩЙІвЊЫиМЏжадкЃКдкДэзлИДдгЕФЦѓвЕММЪѕЛЗОГжаПьЫйЦєЖЏЃЛЙцФЃЛЏЕив§ШыИпМлжЕЕФаТЪ§ОндДКЭЪЙгУГЁОАЃЛОЁдчЪЕЯжЪ§ОнЖдећИіЦѓвЕЩЬвЕЯЕЭГЕФМлжЕЃЈЖдФкЛђЖдЭтЃЉЁЃ
ФЧУДЃЌЮвУЧашвЊдѕбљвЛжжММЪѕМмЙЙЫМЯыЃП
ЗДЫМЕЅЬхМмЙЙЕФФЃЪН
ЦѓвЕЪ§ОнЦНЬЈДгЕквЛЕНЕкШ§ИіНзЖЮЕФбнНјЙ§ГЬжаЃЌЮовЛР§ЭтЕибгајзХвЛИіЕЅЬхМмЙЙЃЈMonolithic ArchitectureЃЉЕФКЫаФФЃЪНЃЌжЛЪЧетИіМмЙЙЕФБэЯжаЮЪНДгвЛИібЯИёЛЎЗжЕФЪ§ОнВжПтЁЂБфГЩБЛзЈвЕЛЏКЭЩёУиЛЏЪ§ОнКўЁЂзюжезЊЛЏГЩвЛИіЖржжЪЕМљФЃЪНЕФЛьКЯЁЃ
дкЪ§ОнЕФВњГігыЯћЗбжЎМфЃЌзмгавЛИіХгШЛДѓЮяЁЊЁЊ
дкЗжВМдкЦѓвЕЮоЪ§НЧТфЃЌдкИїжжЩЯЯТЮФжаЪеМЏЪ§ОнЃЛ
ЖдЪ§ОнНјааЧхЯДЁЂРЉГфЁЂКЭзЊЛЛЃЛ
ЮЊЪ§ОнЕФЯћЗбЗНЃЌР§ШчБЈБэЁЂЗжЮіЁЂвдМАЛњЦїбЇЯАЦНЬЈЬсЙЉЪЕЪБЛђХњСПЕФЪ§ОнМЏЁЃ
етжжЕЅЬхЪНЕФМмЙЙЫМЯыдкгІгУдкЙЙНЈЦѓвЕЪ§ОнЦНЬЈЪБЃЌздШЛГіЯжСЫЩЯЮФЫљЪіЕФОоДѓЬєеНЁЊЁЊФбвдЦєЖЏЁЂФбвдЙцФЃЛЏЁЂвдМАФбвдЩЬвЕЛЏЁЃзюжеНсЙћЃЌЪЧДѓЖрЦѓвЕЪ§ОнЦНЬЈЯюФПдкОРњСЫШ§ЕНЮхФъЕФОоДѓЭЖШыКѓЃЌФбвдЛёЕУдЄЦкЪевцЁЃ
дкЦѓвЕгІгУМмЙЙСьгђЃЌЮЂЗўЮёЃЈMicroservicesЃЉМмЙЙЕФГіЯжПЩвдБЛШЯЮЊЪЧЖдЕЅЬхМмЙЙЕФЗДЫМЃЌвдЮЂЗўЮёЮЊДњБэЕФЗжВМЪНМмЙЙгЕгагХЪЦЃК
ГЌДѓЙцФЃгІгУЕФГжајЙЙНЈКЭНЛИЖФмСІЃЛ
ИпвЕЮёИДдгЖШвЕЮёЩЯЯТЮФжаИќИпЯИСЃЖШЕФвЕЮёРЉеЙЃЛ
ЖРСЂВПЪ№ДјРДЕФИќИпПЩгУадЃЛ
ПЩбнНјЕФММЪѕеЛЁЃ
ЕЅЬхЪНМмЙЙгХЪЦдкгкНсЙЙМђЕЅЁЂЪ§ОнвЛжТадИпЁЂГжајВПЪ№ФбЖШЕЭЃЌетвЛЙЙМмздШЛШѕЛЏСЫЭХЖгЖдЦЕЗБВПЪ№ЁЂЭХЖгСщЛюадЁЂГжајНЛИЖЁЂвдМАММЪѕеЎЙмРэЕФашвЊЁЃ
дкЦѓвЕгІгУМмЙЙЕФЩЯЯТЮФжаЃЌММЪѕЭХЖгдкбЁдёЮЂЗўЮёМмЙЙЛђЕЅЬхЪНМмЙЙЪБЫљПМТЧЕФЃЌЪЧЃК
гІгУЪЧЗёгЕгавЛИіХгДѓЕФДњТыЬхЯЕЭЌЪБгжашвЊГжајНЛИЖЃЛ
вЕЮёТпМЪЧЗёПЩФмЦЕЗБГіЯжИќЯИСЃЖШЕФРЉеЙЃЛ
вЕЮёРЉеЙЪЧЗёЖдгІгУЕФПЩгУадгаМЋИпашЧѓЃЛ
ММЪѕеЎЪЧЗёашвЊИќМЄНјЕФЙмРэЃЛ
ММЪѕбЁаЭЪЧЗёашвЊбнНјЁЃ
етаЉЮЪЬтЕФД№АИШчЙћЖМЪЧЁИЪЧЁЙЃЌФЧУДЭХЖгОЭгаРэгЩзЊЯђЗжВМЪНМмЙЙЁЃ
ШчЙћЮвУЧЛиЕНЦѓвЕЪ§ОнЦНЬЈЕФЩЯЯТЮФжаРДЗДЫМетЮхИіЮЪЬтЃК
ФПЧАЦѓвЕЙуЗКЪЙгУЕЅЬхЪНМмЙЙЃЌЪ§ОнЕФГСЕэЁЂДІРэЁЂКЭЪЙгУЛљБОДцдкгкДэзлИДдгЕФдДЯЕЭГЃЈSource SystemsЃЉжаЃЌЦфДњТыЬхЯЕвЛЖЈЪЧХгДѓЕФЃЛ
Ъ§ОнДДаТЕФБОжЪОЭЪЧИќЯИСЃЖШвЕЮёЕФЗЂЯжЁЂЪЕЯжЁЂКЭЙцФЃЛЏЃЌЪ§ОнЪЙгУГЁОАвЛЖЈЗЂЩњЦЕЗБЕФЯИСЃЖШРЉеЙЃЛ
гЩгкЩЬвЕКЭЗЈЙцЛЗОГЕФВЛЭЌЃЌЪ§ОнГЁОАЕФЪЙгУгаМЋИпЕФЖРСЂадЃЌдкЕивЕЮёашвЊЪ§ОнЦНЬЈИљОнашЧѓЬсЙЉЮШЖЈЧвЖРЬиЕФЪ§ОнЗўЮёЃЛ
Ъ§ОнЦНЬЈУцЯђЕФЭљЭљОЭЪЧвЛИіХгДѓЕФММЪѕеЎЃЌЪ§ОнЦНЬЈБиаыКЭММЪѕеЎЙмРэМЏжадквЛЦ№ПМТЧЃЛ
дкдЦЦНЬЈКЭПЊдДЪ§ОнЙЄОпХюВЊбнНјЕФНёЬьЃЌЦѓвЕашвЊИќПьЕив§НјаТЕФЪ§ОнЙЄОпКЭЛљДЁЩшЪЉЃЌЦфММЪѕеЛашвЊИќПьЕФбнНјЁЃ
ДгетЮхИіЗДЫМЮвУЧПЩвдДѓЕЈЕФЬсГіЃЌЕЅЬхЪНЦѓвЕЪ§ОнЦНЬЈБиШЛашвЊЯђОпгаЮЂЗўЮёЬиадЕФЗжВМЪНЪ§ОнЦНЬЈбнНјЁЃ
ЪВУДЪЧЗжВМЪНЪ§ОнЦНЬЈData MeshЃП
вЛИіЗжВМЪНЪ§ОнЦНЬЈЕФКЫаФЪЧвЛзщгУУцЯђгђЕФЪ§ОнЛђMLВњЦЗЁЂгУздЗўЮёЕФЗНЪНЪЙгУЪ§ОнММЪѕЩшЪЉЬсЙЉЕФЪ§ОнСїЫЎЯпЃЈЧхЯДЁЂзщКЯЁЂЗсИЛЕШЃЉЛђКЯЙцЃЈЪ§ОнМјШЈЁЂвўЫНЁЂАВШЋЕШЃЉЕФЙЋЙВЗўЮёЁЂВЂНгЪмЪ§ОнВњЦЗЫМЮЌЕФЩшМЦКЭЙмРэЃЌвдМАКЭЦѓвЕНЛИЖЛљДЁЩшЪЉЩюЖШМЏГЩЁЃ
ЦфФПЕФЃЌЪЧАяжњЦѓвЕЃК
дкКЯЙцЕФЛљДЁЩЯЛёЕУЙцФЃЛЏЕФЪ§ОнФмСІНЛИЖЃЛ
НЋЙцФЃЛЏЕФЪ§ОнФмСІв§ШыЕНВЛЭЌвЕЮёГЁОАЃЛ
БЃГжЪ§ОнЕФжЪСПЁЂКЯЙцЁЂвдМААВШЋадЃЛ
БЃГжММЪѕеЛЕФЖрбљадЃЌЮќв§Ъ§ОнСьгђаТЕФММЪѕПђМмКЭЪ§ОнШЫВХЁЃ
вЛИіОпгаЗжВМЪНЬиЕуЕФЦѓвЕЪ§ОнЦНЬЈЃЌгІИУОпБИвдЯТЫФИіЬиЕуЃК
УцЯђгђЕФЪ§ОнМмЙЙ
УцЯђгђЃЈDomain-orientedЃЉЕФЪ§ОнЛђMLВњЦЗЪЧЗжВМЪНЪ§ОнЦНЬЈзюаЁЕФЁИвЕЮёЕЅдЊЁЙЃЌЫќУЧЯрЛЅКЯзїГаЕЃСЫОјДѓВПЗжЦНЬЈПЩМћЕФМлжЕЁЃвЛИіЕфаЭЕФЪ§ОнЛђMLВњЦЗЕФМмЙЙАќКЌвдЯТЫФИізщМўЃК
вЛзщPolyglotЪ§ОнНгПкЃЈЕМШыЛђЕМГіЃЉЃЛ
вЛИіОпгаСьгђЬиЕуЕФБпНчЃЛ
вЛзщФкжУЕФЪ§ОнСїЫЎЯпЃЛ
вЛзщСЌНгЛљДЁЩшЪЉПижЦНгПкЃЈШчШежОЃЉЁЃ
УПвЛИіЪ§ОнЛђMLВњЦЗЖМОпгаЖРСЂЕФСщЛюММЪѕеЛбЁдёЁЂПЩЗЂЯжЁЂПЩбАжЗЁЂздНтЪЭЁЂКЯЙцЁЂАВШЋЁЂПЩЙмРэЁЂПЩРЉеЙЁЂвдМАЯрЛЅдЫгЊадЁЃШЮКЮвЛИіУцЯђгђЕФЪ§ОнЛђMLВњЦЗЖМгавдЯТЬиЕуЃК
жЇГжвЛИіЖЫЕНЖЫЕФгУР§ЃЈUse CaseЃЉЃЛ
СЌНгЪ§ОнЩњВњЃЈProductionЃЉКЭЯћЗбЃЈConsumptionЃЉСНЖЫЃЛ
дкЩњВњКЭЯћЗбСНЖЫЪЧвЛЯЕСаФмСІзщГЩЕФМлжЕСДЃЌВЂОпгаЙцФЃЛЏЕФЬиадЃЛ
Ъ§ОнЩњВњКЭЯћЗбЗНЪНЪЧВЛЖЯБфЛЏЕФЃЛ
ЙигкШчКЮЪЙгУетаЉВњЦЗЃЌашвЊИФБфЯжгаЪ§ОнЩњВњКЭЯћЗбЕФЗНЪНЃЛ
гаПЩФмИљОнашвЊСбБфЛђжиаТзщКЯЃЛ
етжжЗжВМЪНМмЙЙБЃжЄЦѓвЕдкИќИДдгЖрБфЕФвЕЮёГЁОАжаЛёЕУзюДѓСщЛюЖШЧвПЩРЉеЙЕФЪ§ОнФмСІЁЃ
здЗўЮёЕФЦНЬЈЛљДЁЩшЪЉ
Ъ§ОнФмСІЕФЙЙНЈЪЧвЛЯюИДдгЕФЙЄГЬЪЕМљЃЌЗжВМЪНЪ§ОнЦНЬЈЕФСэвЛИіживЊЬиадЪЧНЋзюОпЦеБщДњБэадЕФЛљДЁЩшЪЉЪЙгУааЮЊНјааздЖЏЛЏЁЂжааФЛЏЁЂКЭЙцФЃЛЏЁЃЮвУЧбЁШЁвдЯТЦпЯюзюживЊЕФЪ§ОнЛљДЁЩшЪЉФмСІзїЮЊЦѓвЕЕФгХбЁЃК
Ъ§ОнПьееData SnapshottingЃЛ
дДЪ§ОнУшЪіSelf-describing Library;
дЪМИББОRaw CopyЃЛ
Ъ§ОнВњЦЗФЃАхData Product TemplateЃЛ
Ъ§ОнИёЪНзЊЛЛData Format ConversionЃЛ
Ъ§ОнСїЫЎЯпФЃАхData Pipeline TemplatesЃЛ
ШежОКЭзЗзйLogging & TraceabilityЁЃ
ЫцзХЦНЬЈЕФж№НЅГЩЪьЃЌВЛЭЌаавЕбЁдёЪВУДбљЕФЛљДЁЩшЪЉЃЌШчКЮЪЕЯжЃЌЖМПЩФмЗЂЩњБфЛЏЃЌЦѓвЕашвЊИљОнздЩэЧщПібЁдёзюОпгаЙцФЃадКЭМлжЕЕФФмСІНјааЭЖзЪЁЃетаЉФмСІЛљгкЪ§ОнЛљДЁЩшЪЉздЗўЮёЦНЬЈЁЂЭЈЙ§ПижЦНгПкЙЉИјИјЖРСЂЕФЪ§ОнЛђMLВњЦЗЃЌзюжеЪЕЯжЛљДЁЩшЪЉФмСІЕФздЖЏЛЏКЭЙцФЃЛЏЁЃ
Ъ§ОнВњЦЗЫМЮЌ
Ъ§ОнЛђMLВњЦЗжЇГжвЛИіЖЫЕНЖЫЕФгУР§ЃЌЧвгЕгаЩњВњКЭЯћЗбСНЖЫЃЌетбљЕФЬиадКЭгІгУСьгђЕФВњЦЗЪЕМљРрЫЦЃЌЪ§ОнВњЦЗЫМЮЌЬсГіСЫвЛИіЁИЪ§ОнВњЦЗОРэЁЙЕФИХФюЃЌЦфжАд№АќРЈЃК
ЙмРэгУР§ЃЌВЛЖЯЗЂЯжФЧаЉЙцФЃЛЏЕФЪЙгУГЁОАЃЌаое§ЯжгагУР§ЃЌСЌНгЪ§ОнЩњВњКЭЯћЗбСНЖЫЃЛ
ЙмРэМлжЕСДЃЌОіЖЈЪ§ОнВњЦЗЫљашвЊЕФКЫаФФмСІЃЌКЭММЪѕМмЙЙЪІЩшМЦНтОіЗНАИЃЛ
дкЦѓвЕЖДВьЪ§ОнЩњВњКЭЯћЗбЕФааЮЊЃЌЙФРје§ЯђааЮЊЃЈР§ШчЙФРјЪ§ОнЗЂЯжData DiscoveryЃЉЃЌаое§ФЧаЉВЛЗћКЯЪ§ОнЦНЬЈЫМЯыЕФааЮЊЃЌВЛЖЯЬсИпЪЙгУТЪЃЈAdoption
RateЃЉЃЛ
бнНјЪ§ОнВњЦЗЕФЩшМЦЁЃ
ЭЌЪБЃЌЛЙгаШ§ИіЗНЯђЕФВњЦЗЫМЮЌашвЊЫМПМ.
ЪзЯШЃЌЪ§ОнЦНЬЈжаСНИіЛљДЁЩшЪЉЃЈЪ§ОнЛљДЁЩшЪЉКЭMLЛљДЁЩшЪЉЃЉЕФНЈЩшашвЊЭЈЙ§ВњЦЗЙмРэЕФЗНЪННјааЙЙНЈЃЌдвђгаШчЯТМИЕуЃК
ЛљДЁЩшЪЉЕФНЈЩшЗЖЮЇКЭЫГађЃЌгЩЦфжЇГжЕФЪ§ОнЛђMLВњЦЗЪЧЗёгаЙцФЃЛЏЕФЪЙгУашвЊОіЖЈЃЛ
ЖдЛљДЁЩшЪЉЕФЪЙгУЗНЪНвВВЂЗЧгРКуВЛБфЃЌвЛЗНУцРДздгкЪЙгУепЃЈЪ§ОнЛђMLВњЦЗЃЉБОЩэЕФашЧѓБфЛЏЃЌСэЭтвЛЗНУцдђРДздгкЙЄОпМЏБОЩэЕФПьЫйбнНјЃЈРДздгкПЊдДЩчЧјЛђдЦЃЉЃЌЦНЬЈашвЊВЛЖЯбАевИќКУЕФЗНЪНТњзуВЛЖЯБфЛЏЕФашЧѓЃЛ
ЪЙгУаТЕФЛљДЁЩшЪЉЙЄОпЭЌЪБВњЩњаТЕФааЮЊКЭСїГЬЁЃ
вдЩЯМИЕудвђОіЖЈСЫЪ§ОнЛђMLЛљДЁЩшЪЉЗНЯђЕФВњЦЗОРэвдЯТжАд№ЃК
ОіЖЈЫљЯНЛљДЁЩшЪЉНЈЩшЕФТЗЯпЭМЃЛ
СЫНтЪЙгУепЕФашЧѓБфЛЏЁЂНєИњПЊдДЩчЧјЛђдЦЖЫЙЄОпЕФБфЛЏЃЌАДееашвЊбнНјММЪѕеЛЃЛ
ЖдаТЕФСїГЬКЭЙЄОпдкзщжЏФкНјааЕМШы, ЬсИпЛљДЁЩшЪЉЕФЪЙгУТЪЁЃ
ЦфДЮЃЌЗжВМЪНЪ§ОнЦНЬЈЕФЙЙНЈБиШЛЬєеНЯжгаЮЇШЦдкЕЅЬхЪНМмЙЙЯЕЭГЕФITзщжЏМмЙЙЁЊЁЊЪ§ОнЕФЩњВњЁЂДцДЂЁЂДІРэЁЂКЭЪЙгУЖМБЛЙЬЛЏдкУПИіЕЅЬхЯЕЭГжаЃЌЦфзщжЏФЃЪНвВвЛЖЈЪЧЗжЩЂдкУПИіЯЕЭГжаЕФЁЃетвтЮЖзХЦНЬЈМЖЕФзщжЏзЊаЭЃЌашвЊдкЪ§ОнЦНЬЈЕФЛљДЁЩЯЖЈвхвЛИіЦНЬЈМЖЕФВњЦЗИКд№ШЫЃЌЦфжАд№АќРЈЃК
ЖДВьгђвдМАБпНчЃЌЦНКтЖрИігђЩЯЯТЮФЕФГхЭЛЮЪЬтЃЌгУИпГщЯѓЕФгябдЯђВЛЭЌгђЕФЪ§ОнЩњВњепКЭЯћЗбепНтЪЭЃЛ
ВЛЖЯЯђвЕЮёВПУХКЭЙмРэВуУшЪіЪ§ОнЦНЬЈЕФвЕЮёМлжЕЃЛ
УцЖдвЛИіИпФкОлЁЂЕЭёюКЯЕФЦНЬЈЃЌНЈСЂБивЊЕФБъзМЁЂЙЄзїЗНЪНЁЂЙЕЭЈддђЕШЃЛ
ЩшЖЈЪ§ОнЦНЬЈВњЦЗОРэЃЈЪ§Он/MLВњЦЗЗНЯђЛђЛљДЁЩшЪЉЗНЯђЃЉМЖЕФKPIЃЌИКд№ЦфГЩГЄЁЃ
зюКѓЃЌдкЮвУЧЕФЪЕМљжаЗЂЯжЃЌЗжВМЪНЪ§ОнЦНЬЈЕФЗНЪННЋЬєеНаэЖрЯжгаВПУХЕФЙЄзїЗНЪНЃЌЬиБ№ЪЧаХЯЂАВШЋЁЂЦѓвЕЛљДЁЩшЪЉжЇГжЁЂКЯЙцЁЂЕкШ§ЗНЪ§ОнЬсЙЉЩЬЕШЁЃЮвУЧашвЛИізщжЏМЖБ№аЕїепЕФДцдкЃЌЦфжАд№АќРЈЃК
аЕїЦфЫћВПУХЃЌБивЊЪБГщЕїШЫдБЛЅЯрзЄГЁвдНтОіФІВСЕФЮЪЬтЃЛ
дкВЛЭЌВПУХжааћДЋЗжВМЪНЪ§ОнЦНЬЈЖдгкЦѓвЕЯђЪ§ОнзЊаЭЕФМлжЕЃЛ
ЖдЕкШ§ЗНЪ§ОнЬсЙЉЩЬЬсГіаТЕФвЊЧѓЃЌПЩФмЩцМАЕкШ§ЗНЕФЦНЬЈЪЙгУГЁОАЁЃ
ЮвУЧШЯЮЊЃЌетЫФРрВњЦЗЙмРэРрИкЮЛЃЌЪЧЦѓвЕЭЈЙ§ЗжВМЪНЪ§ОнЦНЬЈНјааЦѓвЕЪ§ОнеНТдзЊаЭЕФЛљДЁЁЃ
ЛљгкГжајМЏГЩЕФНЛИЖЛљДЁЩшЪЉ
ЗжВМЪНЪ§ОнЦНЬЈЕФзюжеФПЕФЪЧдкЦѓвЕеце§аЮГЩОпБИСщЛюадЁЂЙцФЃЛЏЁЂвдМАбнНјадЕФЪ§ОнФмСІЦНЬЈЃЌетОЭашвЊКЭЦѓвЕЯжгаЕФГжајМЏГЩЛљДЁЩшЪЉНјааећКЯЃЌећКЯГЁОААќКЌЃК
ЗжВМдкУПИіЪ§ОнЛђMLВњЦЗжаЪ§ОнСїЫЎЯпЕФЙЙНЈжЪСППЩвдгаЭГвЛЕФНЛИЖЛљДЁЩшЪЉНјааЙмРэвдМАПЩЪгЛЏЃЛ
ЫљгаздЗўЮёЪ§ОнЛљДЁЩшЪЉЩЯЕФФмСІПЩвдЭЈЙ§ЦѓвЕЯжгаГжајМЏГЩЦНЬЈНјаажЪСППижЦЃЛ
ОпЬхЪ§ОнЛђMLВњЦЗЬсЙЉФмСІПЩвдЭЈЙ§ЯжгаГжајМЏГЩЦНЬЈНјаажЪСПБЃжЄЁЃ
ЕНДЫЃЌЮвУЧНщЩмСЫЗжВМЪНЪ§ОнЦНЬЈЕФЫФИіживЊзщГЩВПЗжЃЌЫќУЧЗжБ№ЪЧЃК
ОпгаСьгђЬиеїЕФЪ§ОнЛђMLВњЦЗЃЛ
здЗўЮёЕФЪ§ОнЛљДЁЩшЪЉЃЛ
ОпгаВњЦЗЫМЮЌЬиадЕФЙмРэЗНЪНКЭНЧЩЋЃЛ
ЛљгкГжајМЏГЩЕФНЛИЖЛљДЁЩшЪЉЁЃ
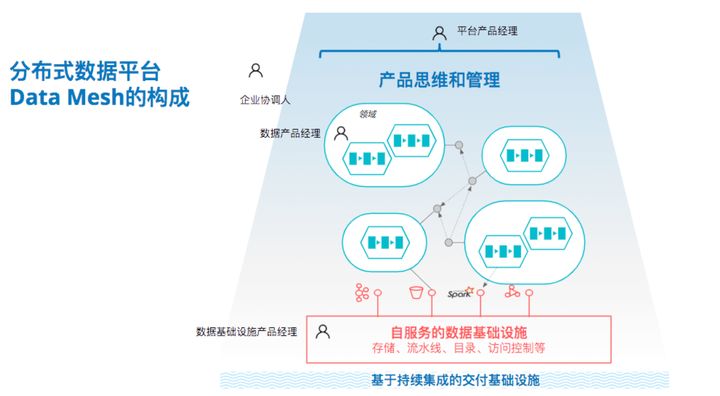
аДдкзюКѓ
ЦѓвЕЪ§ОнЦНЬЈЕФбнНјОРњСЫДгЪ§ОнВжПтЁЂЕНЪ§ОнКўЁЂдйЕНдЦЕФЙ§ГЬЃЌдкЙ§ШЅЕФЮхФъРяЃЌКФЗбОозЪНЈЩшЕФЪ§ОнЦНЬЈФбвдЛёЕУдЄЦкЪевцЃЌЮвУЧШЯЮЊЃЌвдЮЂЗўЮёЃЈMicroservicesЃЉЮЊДњБэЕФЗжВМЪНМмЙЙЃЈDistributed
ArchitrectureЃЉЫМЯыЃЌе§дкШЁДњвЛЬхЪНМмЙЙЃЈMonolithic ArchitectureЃЉдкЪ§ОнСьгђе§дкв§ЗЂвЛДЮЗЖЪНБфИяЁЃ
ЛЅСЊЭјИяаТе§дкГЩЮЊГЃЬЌЃЌЦѓвЕе§дкЯђЯТвЛДњЁЂМДЪ§ОнЦѓвЕНјаабнНјЃЌЮвУЧашвЊаТЕФМмЙЙЫМЯыЁЂММЪѕЪЕЯжЁЂКЭзщжЏНсЙЙЁЃдкетИіБГОАЯТЃЌЮвУЧЬсГіСЫвЛИіЗжВМЪНЪ§ОнЦНЬЈData
MeshЕФИХФюЁЂМмЙЙЩшМЦЁЂвдМАжЮРэЗНЪНЃЌЫќЕФФПБъЪЧАяжњЦѓвЕЛёЕУгыЪБОуНјЕФЁЂСщЛюЧвЙцФЃЛЏЕФЁЂУцЯђвЕЮёСьгђЕФЙуЗКЪ§ОнФмСІЃЌАяжњЦѓвЕЪЕЯжЪ§ОнзЊаЭЁЃ
|









