| БрМЭЦМі: |
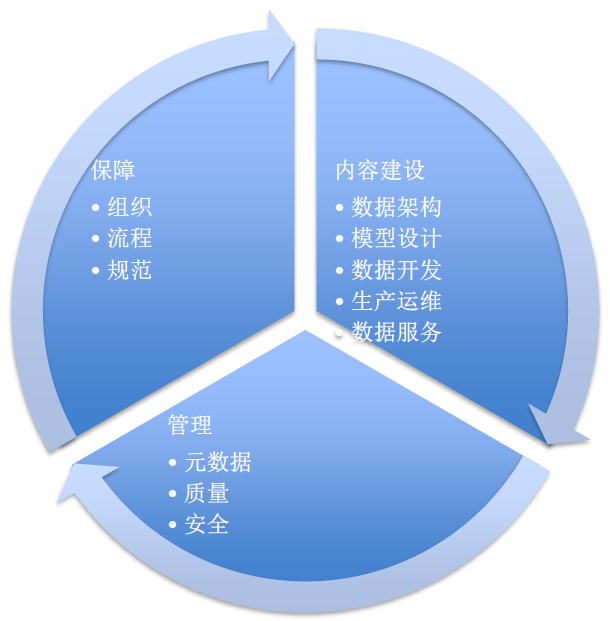
БОЮФжївЊДгзмЬхЫМТЗЁЂФЃаЭЩшМЦЁЂЪ§ОнМмЙЙЁЂЪ§ОнжЮРэЫФИіЗНУцНщЩмСЫШчКЮРћгУДѓЪ§ОнЦНЬЈЕФЬиадЃЌЙЙНЈИќЬљКЯДѓЪ§ОнгІгУЕФЪ§ОнВжПтЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкCSDN ЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
ЕМЖСЃКЫцзХЛЅСЊЭјЙцФЃВЛЖЯЕФРЉДѓЃЌЪ§ОнвВдкБЌеЈЪНЕидіГЄЃЌИїжжНсЙЙЛЏЁЂАыНсЙЙЛЏЁЂЗЧНсЙЙЛЏЪ§ОнЕФВњЩњЃЌдНРДдНЖрЕФЦѓвЕПЊЪМдкДѓЪ§ОнЦНЬЈЯТНјааЪ§ОнДІРэЁЃБОЮФжївЊДгзмЬхЫМТЗЁЂФЃаЭЩшМЦЁЂЪ§ОнМмЙЙЁЂЪ§ОнжЮРэЫФИіЗНУцНщЩмСЫШчКЮРћгУДѓЪ§ОнЦНЬЈЕФЬиадЃЌЙЙНЈИќЬљКЯДѓЪ§ОнгІгУЕФЪ§ОнВжПтЁЃ
змЬхЫМТЗ
ЫцзХЛЅСЊЭјЙцФЃВЛЖЯЕФРЉДѓЃЌЪ§ОнвВдкБЌеЈЪНЕидіГЄЃЌИїжжНсЙЙЛЏЁЂАыНсЙЙЛЏЁЂЗЧНсЙЙЛЏЪ§ОнВЛЖЯЕиВњЩњЁЃаТЛЗОГЯТЕФЪ§ОнгІгУГЪЯжвЕЮёБфЛЏПьЁЂЪ§ОнРДдДЖрЁЂЯЕЭГёюКЯЖрЁЂгІгУЩюЖШЩюЕШЬиеїЁЃ
ФЧУДЛљгкетаЉЬиеїЃЌИУШчКЮЙЙНЈЪ§ОнВжПтФиЃПБЪепШЯЮЊгІИУДгЮШЖЈЁЂПЩаХЁЂЗсИЛЁЂЭИУїЫФИіЙиМќДЪШыЪжЁЃ

ЦфжаЃЌЮШЖЈвЊЧѓЪ§ОнЕФВњГіЮШЖЈЁЂгаБЃеЯЃЛПЩаХвтЮЖзХЪ§ОнЕФжЪСПвЊзуЙЛИпЃЛЗсИЛЪЧжИЪ§ОнКИЧЕФвЕЮёУцвЊзуЙЛЗсИЛЃЛЭИУївЊЧѓЪ§ОнЙЙГЩСїГЬЬхЯЕЪЧЭИУїЃЌШУгУЛЇЗХаФЪЙгУЁЃ
ЮвУЧжЎЫљвдбЁдёЛљгкДѓЪ§ОнЦНЬЈЙЙНЈЪ§ОнВжПтЃЌЪЧгЩДѓЪ§ОнЦНЬЈЗсИЛЕФЬиеїОіЖЈЕФЃК

ЧПДѓЕФМЦЫуКЭДцДЂФмСІЃЌЪЙЕУИќБтЦНЛЏЕФЪ§ОнСїГЬЩшМЦГЩЮЊПЩФмЃЌМђЛЏМЦЫуЙ§ГЬ
ЖрбљЕФБрГЬНгПкКЭПђМмЃЌЗсИЛСЫЪ§ОнМгЙЄЕФЪжЖЮ
ЗсИЛЕФЪ§ОнВЩМЏЭЈЕРЃЌФмЙЛЪЕЯжЗЧНсЙЙЛЏЪ§ОнКЭАыНсЙЙЛЏЪ§ОнЕФВЩМЏ
ИїжжАВШЋКЭЙмРэДыЪЉЃЌБЃеЯСЫЦНЬЈЕФПЩгУад
ВжПтМмЙЙЩшМЦддђжївЊАќРЈвдЯТЫФЕуЃК

ЕквЛздЯТЖјЩЯНсКЯздЩЯЖјЯТЕФЗНЪНЃЌБЃеЯЪ§ОнЫбМЏЕФШЋУцадЃЛ
ЕкЖўИпШнДэадЃЌЫцзХЯЕЭГёюКЯЖШЕФдіМгЃЌШЮКЮвЛИіЯЕЭГГіЯжЮЪЬтЖМЛсЖдЪ§ВжЗўЮёВњЩњгАЯьЃЌвђДЫдкЪ§ВжЙЙНЈЪБЃЌИпШнДэадЪЧБиВЛПЩЩйЕФвђЫиЃЛ
ЕкШ§Ъ§ОнжЪСПМрПиашвЊЙсДЉећИіЪ§ОнСїГЬЃЌКСВЛПфеХЕиЫЕЃЌЪ§ОнжЪСПМрПиЯћКФЕФзЪдДПЩвдЕШЭЌгкЪ§ОнВжПтЙЙНЈЕФзЪдДЃЛ
ЕкЫФЮоашЕЃаФЪ§ОнШпгрЃЌГфЗжРћгУДцДЂЛЛвзгУЁЃ
ФЃаЭЩшМЦ
ЙЙНЈЪ§ВжЕФЪзвЊВНжшОЭЪЧНјааФЃаЭЩшМЦЁЃ
ЮЌЖШНЈФЃЛђЪЕЬхЙиЯЕНЈФЃ
ГЃМћЕФФЃаЭЩшМЦЫМТЗАќРЈЮЌЖШНЈФЃКЭЪЕЬхЙиЯЕНЈФЃЁЃЮЌЖШНЈФЃЪЕЪЉМђЕЅЃЌБугкЪЕЪБЪ§ОнЗжЮіЃЌЪЪгУгквЕЮёЗжЮіБЈБэКЭBIЃЛЪЕЬхЙиЯЕНЈФЃНсЙЙНЯИДдгЃЌЕЋЫќБугкжїЬхЪ§ОнДђЭЈЃЌЪЪКЯИДдгЪ§ОнФкШнЕФЩюЖШЭкОђЁЃ

УПИіЦѓвЕдкЙЙНЈздМКЪ§ВжЪБЃЌгІИУИљОнвЕЮёаЮЬЌКЭашЧѓГЁОАбЁдёКЯЪЪЕФНЈФЃЗНЪНЁЃЖдгкгІгУИДдгадЦѓвЕЃЌПЩвдВЩгУЖржжНЈФЃНсКЯЕФЗНЪНЃЌР§ШчдкЛљДЁВуВЩгУЮЌЖШНЈФЃЕФЗНЪНЃЌШУЮЌЖШИќМгЧхЮњЃЛжаМфВуВЩгУЪЕЬхЙиЯЕНЈФЃЗНЪНЃЌЪЙЕУжаМфВуИќШнвзБЛЩЯВугІгУЪЙгУЁЃ
аЧаЭФЃаЭКЭбЉЛЈФЃаЭ
Г§СЫНЈФЃЗНЪНжЎЭтЃЌдкаЧаЭФЃаЭКЭбЉЛЈФЃаЭЕФбЁдёЩЯвВгаПЩФмШУЪЙгУепзѓгвЮЊФбЁЃЪТЪЕЩЯЃЌСНжжФЃаЭЪЧВЂДцЕФЃЌаЧаЭЪЧбЉЛЈФЃаЭЕФвЛжжЁЃРэТлЩЯецЪЕЪ§ОнЕФФЃаЭЖМЪЧбЉЛЈФЃаЭЃЛЪЕМЪЪ§ОнВжПтжаСНжжФЃаЭЪЧВЂДцЕФЁЃ

гЩгкаЧаЭФЃаЭЯрЖдНсЙЙМђЕЅЃЌЮвУЧПЩвддкЪ§ОнжаМфВуРћгУЪ§ОнШпгрНЋбЉЛЈФЃаЭзЊЛЛГЩаЧаЭФЃаЭЃЌДгЖјгаРћгкЪ§ОнгІгУКЭМѕЩйМЦЫузЪдДЯћКФЁЃ
Ъ§ОнЗжВу
дкШЗЖЈНЈФЃЫМТЗКЭФЃаЭРраЭжЎКѓЃЌЯТвЛВНЕФЙЄзїЪЧЪ§ОнЗжВуЁЃЪ§ОнЗжВуПЩвдЪЙЕУЪ§ОнЙЙНЈЬхЯЕИќМгЧхЮњЃЌБугкЪ§ОнЪЙгУепПьЫйЖдЪ§ОнНјааЖЈЮЛЃЛЭЌЪБЪ§ОнЗжВувВПЩвдМђЛЏЪ§ОнМгЙЄДІРэСїГЬЃЌНЕЕЭМЦЫуИДдгЖШЁЃ
ЮвУЧГЃгУЕФЪ§ОнВжПтЕФЪ§ОнЗжВуЭЈГЃЗжЮЊМЏЪаВуЁЂжаМфВуЁЂЛљДЁЪ§ОнВуЩЯЯТШ§ВуНсЙЙЁЃгЩДЋЭГЕФЖрВуНсЙЙМѕЩйЕНЩЯЯТШ§ВуНсЙЙЕФФПЕФЪЧЮЊСЫбЙЫѕећЬхЪ§ОнДІРэСїГЬЕФГЄЖШЃЌЭЌЪББтЦНЛЏЕФЪ§ОнДІРэСїГЬгажњгкЪ§ОнжЪСППижЦКЭЪ§ОндЫЮЌЁЃ

дкЩЯЯТШ§ВуЕФНсЙЙЕФгвВрЃЌЮвУЧдіМгСЫСїЪНЪ§ОнЃЌНЋЦфЬэМгГЩЪ§ОнЬхЯЕЕФвЛВПЗжЁЃетЪЧвђЮЊЕБЧАЕФЪ§ОнгІгУЗНЯђЛсдНРДдНЙизЂЪ§ОнЕФЪБаЇадЃЌдНЪЕЪБЕФЪ§ОнМлжЕЖШдНИпЁЃ
ЕЋЪЧЃЌгЩгкСїЪНЪ§ОнМЏЕФВЩМЏЁЂМгЙЄКЭЙмРэЕФГЩБОНЯИпЃЌвЛАуЖМЛсАДееашЧѓЧ§ЖЏЕФЗНЪННЈЩшЃЛДЫЭтЃЌПМТЧЕНГЩБОвђЫиЃЌСїЪНЪ§ОнЬхЯЕЕФНсЙЙИќМгБтЦНЛЏЃЌЭЈГЃВЛЛсЩшМЦжаМфВуЁЃ
ЯТУцРДОпЬхПДЯТУПвЛВуЕФзїгУЁЃ
Ъ§ОнЛљДЁВу
Ъ§ОнЛљДЁВужївЊЭъГЩЕФЙЄзїАќРЈвдЯТМИЕуЃК

Ъ§ОнВЩМЏЃКАбВЛЭЌЪ§ОндДЕФЪ§ОнЭГвЛВЩМЏЕНвЛИіЦНЬЈЩЯ
Ъ§ОнЧхЯДЃЌЧхЯДВЛЗћКЯжЪСПвЊЧѓЕФЪ§ОнЃЌБмУтдрЪ§ОнВЮгыКѓајЪ§ОнМЦЫу
Ъ§ОнЙщРрЃЌНЈСЂЪ§ОнФПТМЃЌдкЛљДЁВувЛАуАДееРДдДЯЕЭГКЭвЕЮёгђНјааЗжРр
Ъ§ОнНсЙЙЛЏЃЌЖдгкАыНсЙЙЛЏКЭЗЧНсЙЙЛЏЕФЪ§ОнЃЌНјааНсЙЙЛЏ
Ъ§ОнЙцЗЖЛЏЃЌАќРЈЙцЗЖЮЌЖШБъЪЖЁЂЭГвЛМЦСПЕЅЮЛЕШЙцЗЖЛЏВйзї
Ъ§ОнжаМфВу
Ъ§ОнжаМфВузюЮЊживЊЕФФПБъОЭЪЧАбЭЌвЛЪЕЬхВЛЭЌРДдДЕФЪ§ОнДђЭЈЦ№РДЃЌетЪЧвђЮЊЕБЧАвЕЮёаЮЬЌЯТЃЌЭЌвЛЪЕЬхЕФЪ§ОнПЩФмЗжЩЂдкВЛЭЌЕФЯЕЭГКЭРДдДЃЌЧветаЉЪ§ОнЖдЭЌвЛЪЕЬхЕФБъЪЖЗћПЩФмВЛЭЌЁЃ
ДЫЭтЃЌЪ§ОнжаМфВуЛЙПЩвдДгааЮЊжаГщЯѓЙиЯЕЁЃДгааЮЊжаГщЯѓГіРДЕФЛљДЁЙиЯЕЃЌЛсЪЧЮДРДЩЯВугІгУвЛИіКмживЊЕФЪ§ОнвРРЕЁЃР§ШчГщЯѓГіЕФаЫШЄЁЂЦЋКУЁЂЯАЙпЕШЙиЯЕЪ§ОнЪЧЭЦМіЁЂИіадЛЏЕФЛљДЁЩњВњзЪСЯЁЃ

дкжаМфВуЃЌЮЊСЫБЃжЄжїЬтЕФЭъећадЛђЬсИпЪ§ОнЕФвзгУадЃЌОГЃЛсНјааЪЪЕБЕФЪ§ОнШпгрЁЃБШШчФГвЛЪЕЪТЪ§ОнКЭСНИіжїЬтЯрЙиЕЋздЩэгжУЛгаГЩЮЊЖРСЂжїЬтЃЌдђЛсЗХдкСНИіжїЬтПтжаЃЛЮЊСЫЬсИпЕЅЪ§ОнБэЕФИДгУадКЭМѕЩйМЦЫуЙиСЊЃЌЭЈГЃЛсдкЪТЪЕБэжаШпгрВПЗжЮЌЖШаХЯЂЁЃ
Ъ§ОнМЏЪаВу
Ъ§ОнМЏЪаВуЪЧЩЯЯТШ§ВуМмЙЙЕФзюЩЯВуЃЌЭЈГЃЪЧгЩашЧѓГЁОАЧ§ЖЏНЈЩшЕФЃЌВЂЧвИїМЏЪаМфДЙжБЙЙдьЁЃ

дкЪ§ОнМЏЪаВуЃЌЮвУЧПЩвдЩюЖШЭкОђЪ§ОнМлжЕЁЃжЕЕУзЂвтЕФЪЧЃЌЪ§ОнМЏЪаВуашвЊФмЙЛПьЫйЪдДэЁЃЃЈСЫНтИќЖрЪ§ОнВжПтНЈЩшФкШнЃЌЛЖгЕуЛїдФЖСЃК6000зжЯъНтЪ§ОнВжПтНЈЩшЗНЗЈЃЉ
Ъ§ОнМмЙЙ
Ъ§ОнМмЙЙАќРЈЪ§ОнећКЯЁЂЪ§ОнЬхЯЕЁЂЪ§ОнЗўЮёШ§ВПЗжЃК
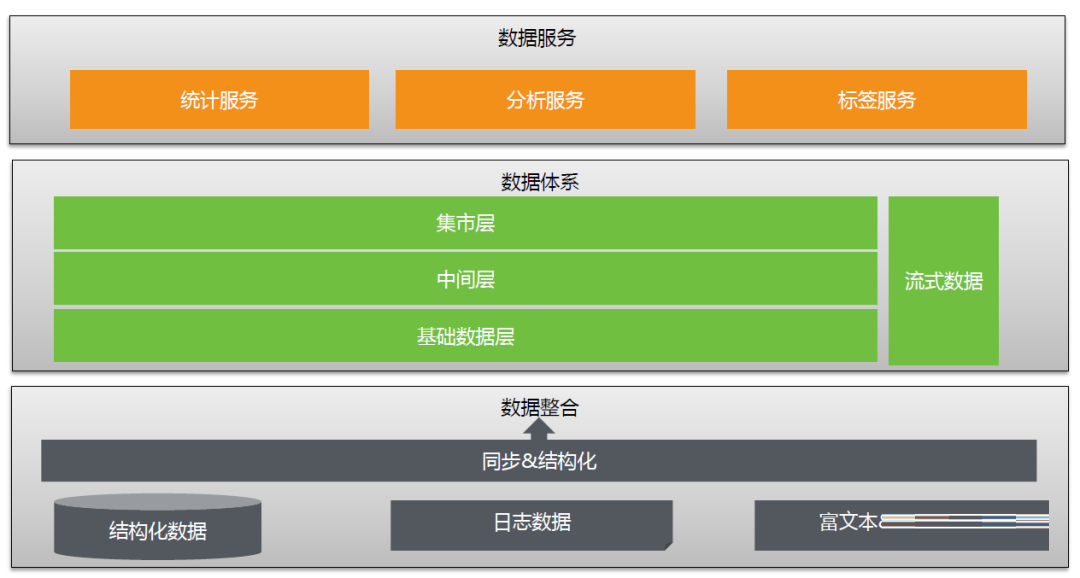
ЦфжаЃЌЪ§ОнећКЯгжПЩвдЗжЮЊНсЙЙЛЏЁЂАыНсЙЙЛЏЁЂЗЧНсЙЙЛЏШ§РрЁЃ
Ъ§ОнећКЯ
НсЙЙЛЏЪ§ОнВЩМЏгжПЩЯИЗжЮЊШЋСПВЩМЏЁЂдіСПВЩМЏЁЂЪЕЪБВЩМЏШ§РрЁЃШ§жжВЩМЏЗНЪНЕФИїздЬиЕуКЭЪЪгІГЁКЯШчЯТЭМЫљЪОЃЌЦфжаШЋСПВЩМЏЕФЗНЪНзюЮЊМђЕЅЃЛЪЕЪБВЩМЏЕФВЩМЏжЪСПзюФбПижЦЁЃ
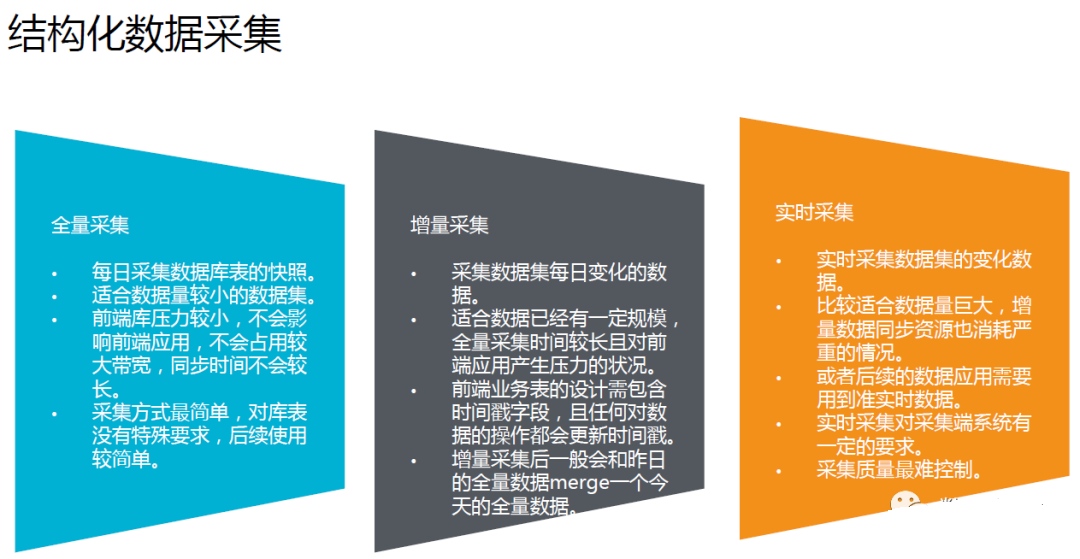
дкДЋЭГЕФМмЙЙжаЃЌШежОЕФНсЙЙЛЏДІРэЪЧЗХдкЪ§ВжЬхЯЕжЎЭтЕФЁЃдкДѓЪ§ОнЦНЬЈВжПтМмЙЙжаЃЌШежОдкВЩМЏЕНЦНЬЈжЎЧАВЛзіНсЙЙЛЏДІРэЃЛдкДѓЪ§ОнЦНЬЈЩЯАДааЗћЗжИюУПЬѕШежОЃЌећЬѕШежОДцДЂдквЛИіЪ§ОнБэзжЖЮЃЛКѓајЃЌЭЈЙ§UDFЛђMRМЦЫуПђМмЪЕЯжШежОНсЙЙЛЏЁЃ

дкБЪепПДРДЃЌШежОНсЙЙдНЙцЗЖЃЌНтЮіГЩБОдНЕЭЁЃдкШежОНсЙЙЛЏЕФЙ§ГЬжаЃЌВЂВЛвЛЖЈашвЊЭъШЋЦНЦЬЪ§ОнФкШнЃЌжЛашНсЙЙЛЏГіживЊГЃгУзжЖЮЃЛЭЌЪБЃЌЮЊСЫБЃеЯРЉеЙадЃЌПЩвдРћгУЪ§ОнШпгрБЃДцдЪМЗћКЯзжЖЮЃЈШчuseragentзжЖЮЃЉЁЃ
ЗЧНсЙЙЛЏЕФЪ§ОнашвЊНсЙЙЛЏВХФмЪЙгУЁЃЗЧНсЙЙЛЏЪ§ОнЬиеїЬсШЁАќРЈгявєзЊЮФБОЁЂЭМЦЌЪЖБ№ЁЂздШЛгябдДІРэЁЂЭМЦЌДяБъЁЂЪгЦЕЪЖБ№ЕШЗНЪНЁЃ

ОЁЙмФПЧАЪ§ВжМмЙЙЬхЯЕжаВЂВЛАќКЌЗЧНсЙЙЛЏЪ§ОнЬиеїЬсШЁВйзїЃЌЕЋдкЮДРДЃЌетНЋГЩЮЊПЩФмЁЃ
Ъ§ОнЗўЮёЛЏ
Ъ§ОнЗўЮёЛЏАќРЈЭГМЦЗўЮёЁЂЗжЮіЗўЮёКЭБъЧЉЗўЮёЃК

ЭГМЦЗўЮёжївЊЪЧЦЋДЋЭГЕФБЈБэЗўЮёЃЌРћгУДѓЪ§ОнЦНЬЈНЋЪ§ОнМгЙЄКѓЕФНсЙћЗХШыЙиЯЕаЭЪ§ОнПтжаЃЌЙЉЧАЖЫЕФБЈБэЯЕЭГЛђвЕЮёЯЕЭГВщбЏЁЃ
ЗжЮіЗўЮёгУРДЬсЙЉУїЯИЕФЪТЪЕЪ§ОнЃЌРћгУДѓЪ§ОнЦНЬЈЕФЪЕЪБМЦЫуФмСІЃЌдЪаэВйзїШЫдБзджїСщЛюЕФНјааИїжжЮЌЖШЕФНЛВцзщКЯВщбЏЁЃЗжЮіЗўЮёЕФФмСІРрЫЦгкДЋЭГcubeЬсЙЉЕФФкШнЃЌЕЋЪЧдкДѓЪ§ОнЦНЬЈЯТВЛашвЊдЄЯШНЈКУcubeЃЌИќСщЛюЁЂИќНкЪЁГЩБОЁЃ
БъЧЉЗўЮёЃЌДѓЪ§ОнЕФгІгУГЁОАЯТЃЌОГЃЛсЖджїЬхНјааЬиеїПЬЛЃЌБШШчПЭЛЇЕФЯћЗбФмСІЁЂаЫШЄЯАЙпЁЂЮяРэЬиеїЕШЕШЃЌетаЉЪ§ОнЭЈЙ§ДђБъЧЉзЊЛЛГЩKVЕФЪ§ОнЗўЮёЃЌгУгкЧАЖЫгІгУВщбЏЁЃЃЈСЫНтИќЖрЪ§ОнЗўЮёЛЏЕФФкШнЃЌЛЖгЕуЛїдФЖСЃКПьЪжДѓЪ§ОнЦНЬЈЗўЮёЛЏЪЕМљЃЉ
МмЙЙЩшМЦжавЛаЉЪЕгУЕФЕу
дкМмЙЙЩшМЦжагавЛаЉЪЕгУЕФЕуЃЌетРяИјДѓМвЗжЯэвЛЯТЃК

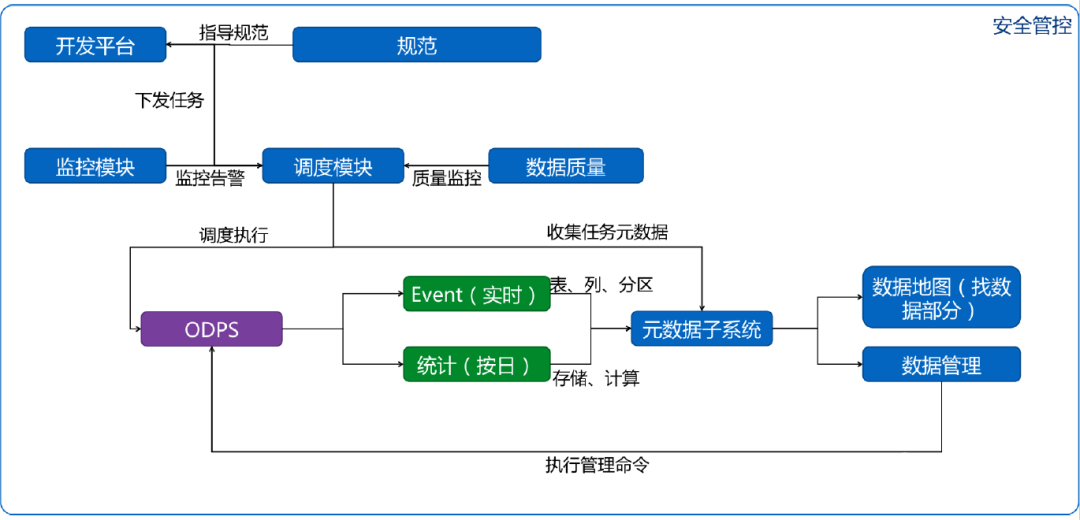
ЕквЛЃЌЭЈЙ§ЧЩгУащФтНкЕуЪЕЯжЖрЯЕЭГЪ§ОндДЭЌВНЃЌЪЕЯжПчЯЕЭГМфЕФЪ§ОнДЋЪфЃЌЪЕЯжЖргІгУМфЪ§ОнНЛЛЅЁЃЭЈЙ§ЧЩгУащФтНкЕуМѕЩйдЫЮЌШЫдБдкЪЕМЪГіЯжЮЪЬтЪБЕФдЫЮЌГЩБОЁЃ
ЕкЖўЃЌВЩгУЧПжЦЗжЧјЃЌдкЫљгаЕФБэЖМЩЯЖММгЩЯЪБМфЗжЧјЁЃЭЈЙ§ЗжЧјЃЌБЃжЄУПИіШЮЮёЖМФмЙЛЖРСЂжиХмЃЌЖјВЛВњЩњЪ§ОнжЪСПЮЪЬтЃЌНЕЕЭСЫЪ§ОнаоИДГЩБОЃЛДЫЭтЭЈЙ§ЗжЧјВУМєЃЌЛЙПЩвдНЕЕЭМЦЫуГЩБОЁЃ
ЕкШ§ЃЌгІгУМЦЫуПђМмЭъГЩШежОНсЙЙЛЏЁЂЭЌРрЪ§ОнМЦЫуЙ§ГЬЕШВйзїЃЌМѕЧсСЫПЊЗЂШЫдБЕФИКЕЃЃЌЭЌЪБИќШнвзЮЌЛЄЁЃ
ЕкЫФЃЌгХЛЏЙиМќТЗОЖЁЃгХЛЏЙиМќТЗОЖжаКФЪБзюГЄЕФШЮЮёЪЧзюгааЇЕФБЃеЯЪ§ОнВњГіЪБМфЕФЪжЖЮЁЃЃЈСЫНтИќЖрЪ§ОнВжПтМмЙЙЩшМЦЗНЗЈЃЌЛЖгЕуЛїдФЖСЃКЭђзжГЄЮФЯъНтЪ§ОнВжПтМмЙЙКЭНЈЩшЗНЗЈТлЃЉ
Ъ§ОнжЮРэ
Ъ§ОнжЮРэЕФФкШнжївЊЬхЯждкШ§ИіЗНУцЃК
БЃеЯЬхЯЕЃКПЊеЙЪ§ОнжЮРэзщжЏНЈЩшЃЌВЂНЈСЂХфЬзЕФСїГЬКЭБъзМЙцЗЖ
ФкШнНЈЩшЃКАќРЈЪ§ОнМмЙЙЖЅВуЙцЛЎЩшМЦЁЂЪ§ОнФЃаЭБъзМЩшМЦЁЂЪ§ОнПЊЗЂЁЂЩњВњдЫгЊЮЌЛЄЁЂЪ§ОнЙВЯэЗўЮё
ЙмРэЬхЯЕЃКЪ§ОнжЮРэКЭЪ§ОнАВШЋЪЧКЫаФжиЕу
Ъ§ОнжЮРэВЛЪЧЖРСЂгкЯЕЭГжЎЭтЕФБЃеЯЃЌЫќгІИУЙсДЉдкЪ§ВжМмЙЙФкВПКЭЪ§ОнДІРэЕФСїГЬжЎжаЁЃЃЈСЫНтИќЖрЪ§ОнжЮРэЕФФкШнЃЌЛЖгЕуЛїдФЖСЃКЯъНтЪ§ОнжЮРэОХДѓКЫаФСьгђЃЌвдвјаавЕЮЊР§ЃЉ
Ъ§ОнжЪСП
БЃеЯЪ§ОнжЪСПЃЌПЩвдДгЪТЧАЁЂЪТжаЁЂЪТКѓШыЪжЃК
ЪТЧАЃЌЮвУЧПЩвдЭЈЙ§жЦЖЈУПЗнЪ§ОнЕФЪ§ОнжЪСПМрПиЙцдђЃЌдНживЊЕФЪ§ОнЖдгІЕФМрПиЙцдђгІИУдНЖрЁЃ
ЪТжаЃЌЭЈЙ§МрПиКЭгАЯьЪ§ОнЩњВњЙ§ГЬЃЌЖдВЛЗћКЯжЪСПвЊЧѓЕФЪ§ОнНјааИЩдЄЃЌЪЙЦфВЛгАЯьЯТСїЪ§ОнЕФжЪСПЁЃ
ЪТКѓЃЌЭЈЙ§ЖдЪ§ОнжЪСПЧщПіНјааЗжЮіКЭДђЗжЃЌНЋвЛаЉВЛзуКЭИФНјЗДРЁЪ§ОнМрПиЬхЯЕЃЌЭЦЖЏећЬхЕФЪ§ОнжЪСПЬсЩ§ЁЃЃЈСЫНтИќЖрЪ§ОнжЪСПЕФФкШнЃЌЛЖгЧыЕуЛїдФЖСЃКЦѓвЕЪ§ОнжЪСПЙмРэЕФКЫаФвЊЫиКЭММЪѕТЗЯпЃЈPPTЃЉЃЉ
Ъ§ОнЩњУќжмЦкЙмРэ
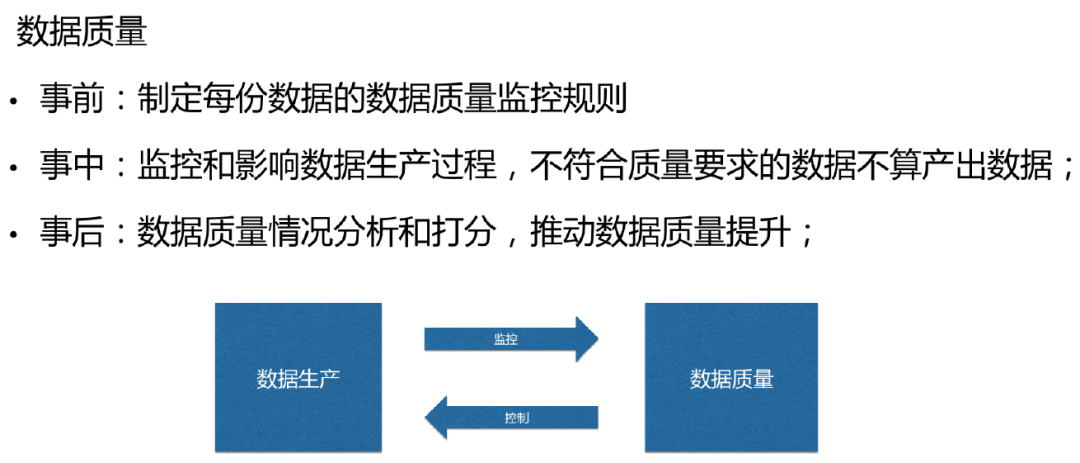
ГігкГЩБОЕШвђЫиЕФПМТЧЃЌдкДѓЪ§ОнЦНЬЈЩЯвРШЛашвЊЖдЪ§ОнЩњУќжмЦкНјааЙмРэЁЃИљОнЪЙгУЦЕТЪНЋЪ§ОнЗжЮЊБљЁЂРфЁЂЮТЁЂШШЫФРрЁЃвЛИіКЯРэЕФЪ§ОнЩњУќжмЦкЙмРэвЊБЃжЄЮТШШЪ§ОнеМећИіЪ§ОнЬхЯЕДѓВПЗжЃЛЭЌЪБЮЊСЫБЃеЯЪ§ОнзЪВњЕФЭъећадЃЌЖдгкживЊЕФЛљДЁЪ§ОнЛсГЄОУБЃСєЁЃ
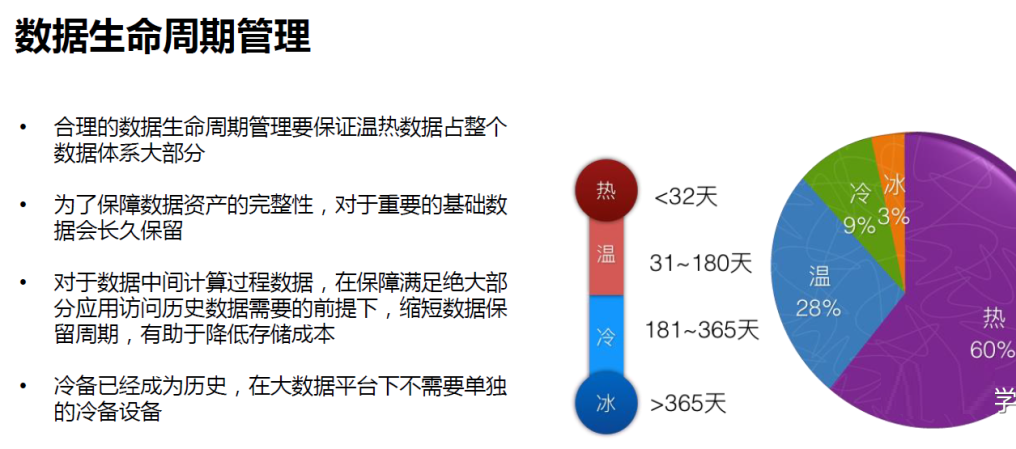
ЖдгкЪ§ОнжаМфМЦЫуЙ§ГЬЪ§ОнЃЌдкБЃеЯТњзуОјДѓВПЗжгІгУЗУЮЪРњЪЗЪ§ОнашвЊЕФЧАЬсЯТЃЌЫѕЖЬЪ§ОнБЃСєжмЦкЃЌгажњгкНЕЕЭДцДЂГЩБОЃЛзюКѓвЛЕужЕЕУзЂвтЕФЪЧЃЌРфБИвбОГЩЮЊРњЪЗЃЌдкДѓЪ§ОнЦНЬЈЯТВЛашвЊЕЅЖРЕФРфБИЩшБИЁЃ |









