| БрМЭЦМі: |
БОЮФНщЩмСЫThoughtWorksЕФЪ§зжЦНЬЈеНТдЕкШ§ИіжЇжљЁАЪ§ОнздЗўЮёЁБжаЫљдЬКЕФОпЬхФкШнЁЃ
БОЮФРДздThoughtworksЖДМћЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЪВУДЪЧЪ§ОнздЗўЮё
Ъ§ОндкЦѓвЕжаЕФДІРэЙ§ГЬЃЌФмЧхЮњЕигГЩфГіПЕЭўЖЈТЩЖдITЯЕЭГЕФгАЯьЁЃдкИїИіВПУХЗжБ№НЈЩшITЯЕЭГЁЂзщжЏФкВПДѓСПДцдкаХЯЂЭВВжЃЈsiloЃЉЕФФъДњЃЌЪ§ОнЕФВйзїгЩOLTPгІгУЯЕЭГЕФПЊЗЂЭХЖгЭЌВНПЊЗЂЃЌФЧЪБМИКѕУПИіеўИЎаХЯЂЛЏЁЂЦѓвЕаХЯЂЛЏЯЕЭГЖМЛсгавЛПщЁАБЈБэашЧѓЁБЁЃЫцКѓжкЖрзщжЏШЯЪЖЕНЭВВжЯЕЭГЕМжТаХЯЂдкзщжЏФкВЛФмРЭЈЃЌВЛФмВњЩњЖдећЬхвЕЮёСїГЬЕФЖДВьЃЌгкЪЧПЊЪМНЈЩшвдЪ§ОнВжПтЮЊДњБэЕФOLAPЯЕЭГЁЃ

етаЉЯЕЭГдкжЇГХИќИпМЖЁЂИќИДдгЕФЪ§ОнЗжЮіЕФЭЌЪБЃЌвВЖдгІЕидкзщжЏжадьОЭСЫвЛжЇзЈвЕЕФЁАЪ§ОнЭХЖгЁБЁЃетаЉШЫЪЙгУЗЧГЃзЈвЕЕФММЪѕКЭЙЄОпЖдЪ§ОнНјааЬсШЁЁЂзЊЛЛЁЂзАдиЁЂНЈСЂЪ§ОнСЂЗНЁЂЖрЮЌзъШЁЁЂЩњГЩБЈБэЁЃетаЉзЈвЕЕФММЪѕКЭЙЄОпЃЌЦеЭЈЕФШэМўПЊЗЂШЫдБВЂУЛгаеЦЮеЃЌвђДЫЖдЪ§ОнДІРэЁЂЗжЮіКЭГЪЯжЕФБфИќЖМБиаыЙщМЏЕНетИіЪ§ОнЭХЖгРДЭъГЩЁЃНсЙћЪЧЃЌЪ§ОнЭХЖгЕФbacklogРяРлЛ§СЫРДздИїИіВПУХЕФашЧѓЃЌашЧѓЕФЯьгІФмСІЯТНЕЃЌITЯЕЭГДгЩЯЯпЕНЛёЕУЪаГЁЖДВьЕФжмЦкБфГЄЁЃ
ЮЂЗўЮёМмЙЙЙФРјаЁаЭЕФЁЂШЋЙІФмЕФЭХЖггЕгавЛИіЭъећЕФЗўЮёЃЈМАЦфЖдгІЕФвЕЮёЃЉЁЃетбљЕФШЋЙІФмЭХЖгВЛЙтвЊПЊЗЂКЭдЫЮЌITЯЕЭГЃЌЛЙвЊФмДгЪ§ОнжаЛёЕУЖДВьЁЊЁЊЖјЧввЊПьЃЌВЛШЛОЭЛсИњВЛЩЯЪаГЁБфЛЏЃЌЩѕжСЪЙвЛаЉживЊЕФвЕЮёГЁОАЮоЗЈЕУЕНжЇГХЁЃвђДЫЫћУЧВЛФмзјЕШвЛжЇМЏжаЪНЕФЁЂЛКТ§ЕФЪ§ОнЭХЖгРДЯьгІЫћУЧЕФашЧѓЃЌЫћУЧашвЊЪ§ОнздЗўЮёФмСІЁЃ
вЊИГФмЪ§ОнздЗўЮёЃЌЦѓвЕЕФЪ§зжЛЏЦНЬЈвЊПМТЧЁАСНИіХћШјЭХЖгЁБЕФЯТСаЫпЧѓЃК
ашвЊЖЈвхЪ§ОнСїЫЎЯпЃЌЪЙЪ§ОнФмЙЛЫГГЉЕиСїЙ§ЪеМЏЁЂзЊЛЛЁЂДцДЂЁЂЬНЫї/дЄВтЁЂПЩЪгЛЏЕШНзЖЮЃЌВњЩњвЕЮёМлжЕЁЃ
ашвЊгУЪЕЪБЕФМмЙЙКЭAPIдкЖЬЪБМфФкДІРэДѓСПЁЂЗЧНсЙЙЛЏЕФЪ§ОнЃЌДгжаЛёЕУЖДМћЃЌВЂЪЕЪБгАЯьОіВпЁЃ
ЮЊСЫЬсИпгІБфФмСІЃЌЯЕЭГжаЕФЪ§ОнВЛзіETLдЄДІРэЃЌЖјЪЧвдЁАЩњЪ§ОнЁБЕФаЮЪНЪзЯШДцШыЪ§ОнКўЃЌЕШгаСЫОпЬхЕФЮЪЬтвЊЛиД№ЪБЃЌдйШЅзщжЏКЭЩИбЁЪ§ОнЃЌДгжаевГіД№АИЁЃ
ИќНјвЛВНАбЪ§ОнАќзАГЩФмЙЉЭтШЫЪЙгУЕФЪ§ОнВњЦЗЃЌШУЕкШ§ЗНДгЪ§ОнжаЛёЕУаТЕФЖДМћгыМлжЕЁЃ
ЮЊСЫжЇГжЪ§ОнВњЦЗЕФдЫгЊЃЌашвЊЪЕЯжЯИСЃЖШЪкШЈЃЌеыЖдВЛЭЌЕФгУЛЇЩэЗнЃЌЪкШЈЗУЮЪВЛЭЌЗЖЮЇЕФЪ§ОнЁЃ
Ъ§ОнздЗўЮёНтЖС
ЯТУцЪЧThoughtWorksЕФЪ§зжЦНЬЈеНТдЕкШ§ИіжЇжљЁАЪ§ОнздЗўЮёЁБжаЫљдЬКЕФОпЬхФкШнЁЃ

Ъ§ОнСїЫЎЯпЩшМЦ
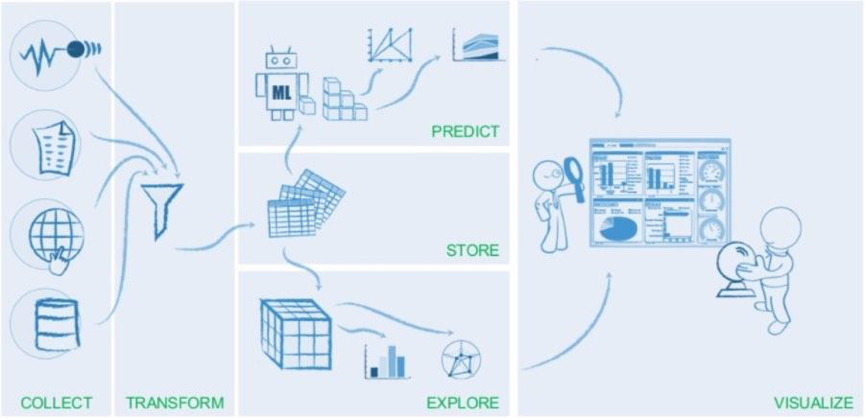
ЫљЮНСїЫЎЯпЃЌЪЧжИгУДѓЪ§ОнДДдьМлжЕЕФећИіЪ§ОнСїЁЃСїЫЎЯпДгЪ§ОнВЩМЏПЊЪМЃЌЫцКѓЪЧЪ§ОнЕФЧхЯДЛђЙ§ТЫЃЌдйШЛКѓЪЧНЋЪ§ОнНсЙЙЛЏЕНДцДЂВжПтжавдБуЗУЮЪКЭВщбЏЃЌетжЎКѓОЭПЩвдЭЈЙ§ЬНЫїЛђдЄВтЕФЗНЪНДгЪ§ОнжаевЕНвЕЮёЮЪЬтЕФД№АИЃЌВЂПЩЪгЛЏГЪЯжГіРДЁЃ
ЃЈЭМЦЌРДздЃКtuplejump Inc.ЃЉ
вЛЬѕдЫзЊСМКУЕФЪ§ОнСїЫЎЯпЃЌФмгааЇДІРэвЦЖЏ/ЮяСЊЭјЕШаТММЪѕжЦдьГіЕФМЋЦфДѓСПЕФЪ§ОнЃЌЫѕЖЬЪ§ОнДгЛёШЁЕНВњЩњЖДМћЕФЗДРЁжмЦкЃЌВЂвдПЊЗЂепгбКУЕФЗНЪНЭъГЩЪ§ОнИїИіЛЗНкЕФДІРэЃЌИГФмвЛЬхЛЏЭХЖгЁЃ
Ъ§ОнСїЫЎЯпЕФЪЕЯжгаСНжжПЩФмЕФЗНЪНЁЃвЛжжЗНЪНЪЧдкИїИіЛЗНкВЩгУИїжжЬиЖЈЕФЙЄОпЃЌР§ШчЧАУцНщЩмЕФЪ§ОнСїЫЎЯпЃЌИїИіЛЗНкЖМПЩвдгУПЊдДЕФЙЄОпРДЪЕЯжЁЃЕБШЛЃЌбЁдёетжжЗНЪНвВВЂЗЧУЛгаЬєеНЃКзщжЏБиаыздМКБраДКЭЮЌЛЄЁАНКЫЎДњТыЁБЃЌАбИїжжзЈгУЙЄОпзщКЯГЩвЛИіФкОлЕФећЬхЁЃЖдзщжЏЕФММЪѕФмСІгаНЯИпЕФвЊЧѓЁЃ
ЃЈЭМЦЌРДздЃКtuplejump Inc.ЃЉ
Г§СЫЛљгкПЊдДШэМўЪЕЯжздМКЕФЪ§ОнСїЫЎЯпЃЌвВПЩвдПМТЧВЩгУдЦЩЯЕФЪ§ОнСїЫЎЯпPaaSЗўЮёЃЌР§ШчDatabricksЁЂAWS
Data PipelineЁЂAzure Data FactoryЕШЁЃетИіЗНЪНЕФгХЕуЪЧЖдММЪѕФмСІвЊЧѓНЯЕЭЃЌШБЕудђЪЧдьГЩЖдЬиЖЈдЦЦНЬЈ/PaaSЬсЙЉЩЬЕФвРРЕЁЃ
ЪЕЪБМмЙЙКЭAPI
ЪЕЪБЕФЪ§ОнМмЙЙКЭAPIжЇГжЖЬЪБМфФкДІРэДѓСПЁЂЗЧНсЙЙЛЏЕФЪ§ОнЃЌДгжаЛёЕУЖДМћЃЌВЂЁАЪЕЪБЁБгАЯьОіВпЁЃе§ШчMike
BarlowЫљЫЕЃКЁАетЪЧЙигкдке§ШЗЪБМфзіГіИќКУОіЖЈВЂВЩШЁааЖЏЕФФмСІЃЌР§ШчдкЙЫПЭЫЂПЈЕФЪБКђЪЖБ№аХгУПЈЦлеЉЃЌЛђепЕБЙЫПЭдкХХЖгНсеЫЕФЪБКђИјИігХЛнЃЌЛђепЕБгУЛЇдкдФЖСФГЦЊЮФеТЕФЪБКђЭЦЫЭФГИіЙуИцЁЃЁБ
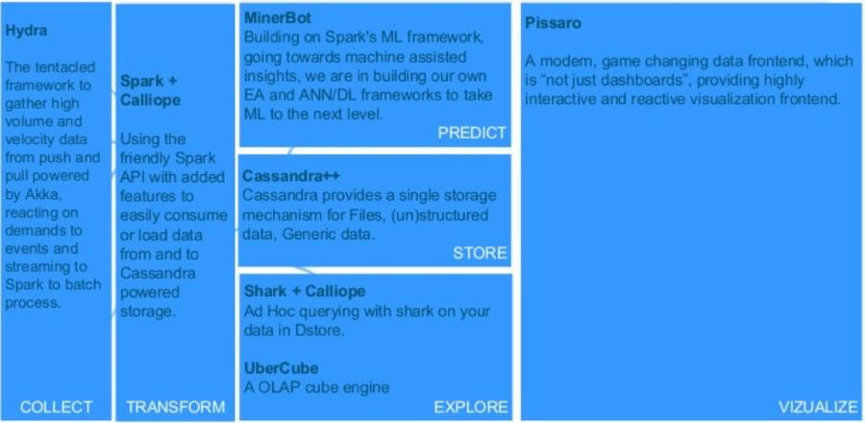
дкClouderaЕФвЛЦЊЮФеТжаНщЩмСЫЪЕЪБЪ§ОнДІРэЕФ4ИіМмЙЙФЃЪНЃЌећИіСїЫЎЯпМмЙЙдкFlume/KafkaЛљДЁЩЯЃК
1.Ъ§ОнСїЮќЪеЃКЕЭбгГйНЋЪТМўГжОУЛЏЕНHDFSЁЂHBaseЁЂSolrЕШДцДЂЛњжЦ
2.НќЪЕЪБЃЈ100КСУывдЯТЃЉЕФЪТМўДІРэЃКЪ§ОнЕНДяЪБСЂМДВЩШЁОЏИцЁЂБъМЧЁЂзЊЛЛЁЂЙ§ТЫЕШГѕВНааЖЏ
3.НќЪЕЪБЕФЪТМўЗжЦЌДІРэЃКгыЧАвЛИіФЃЪНРрЫЦЃЌЕЋЪЧЯШЖдЪ§ОнЗжЦЌ
4.ИДдгЖјСщЛюЕФОлКЯЛђЛњЦїбЇЯАЭиЦЫЃЌЪЙгУSpark
Ъ§ОнКўЩшМЦ
Ъ§ОнКўИХФюзюГѕЬсГіЪЧдк2014ФъForbesЕФвЛЦЊЮФеТжаЁЃЫќЕФИХФюЪЧЃКВЛЖдЪ§ОнзіЬсЧАЕФЁАгХЛЏЁБДІРэЃЌЖјЪЧжБНгАбЩњЪ§ОнДцДЂдкШнвзЛёЕУЕФЁЂБувЫЕФДцДЂЛЗОГжаЃЛЕШгаСЫОпЬхЕФЮЪЬтвЊЛиД№ЪБЃЌдйШЅзщжЏКЭЩИбЁЪ§ОнЃЌДгжаевГіД№АИЁЃАДееThoughtWorksММЪѕРзДяЕФЖЈвхЃЌЪ§ОнКўжаЕФЪ§ОнгІИУЪЧВЛПЩаоИФЃЈimmutableЃЉЕФЁЃ

Ъ§ОнКўЪдЭМНтОіЪ§ОнВжПтМИЗНУцЕФЮЪЬтЃК
дЄЯШЕФETLДІРэжеЙщЛсЫ№ЪЇаХЯЂЃЌШчЙћЪТКѓВХЗЂЯжашвЊЩњЪ§ОнжаЕФФГаЉаХЯЂЁЂЕЋЪЧетаЉаХЯЂгжУЛгаЭЈЙ§ETLНјШыЪ§ОнВжПтЃЌФЧУДаХЯЂОЭЮоЗЈбАЛиСЫЁЃ
ETLЕФБраДЯрЕБТщЗГЁЃЪ§ОнВжПтЕФschemaЗЂЩњИФБфЃЌETLвВвЊИњзХИФБфЃЛгІгУГЬађЕФschemaЗЂЩњИФБфЃЌETLвВвЊИњзХИФБфЁЃвђДЫЪ§ОнВжПтЭЈГЃгЩвЛИіЕЅЖРЕФЭХЖгИКд№ЃЌгкЪЧаЮГЩвЛИіЙІФмЭХЖгЃЌЯьгІЫйЖШТ§ЁЃ
Ъ§ОнВжПтЕФЗжЮіашвЊзЈУХЕФММФмЃЌДѓВПЗжгІгУГЬађПЊЗЂепВЛеЦЮеЃЌдйЖШЧПЛЏСЫЪ§ОнВжПтзЈУХЭХЖгЃЛЖјЪ§ОнВжПтЭХЖгЦфЪЕРывЕЮёКмдЖЃЌВЂВЛФмПьЫйзМШЗЕиЯьгІвЕЮёЖдЪ§ОнЗжЮіЕФашЧѓЁЃ
дкЪ§ОнКўИХФюБГКѓЪЧПЕЭўЗЈдђЕФЬхЯжЃКЪ§ОнФмСІгывЕЮёашЧѓЖдЦыЁЃЫќвЊНтОіЕФКЫаФЮЪЬтЪЧзЈУХЕФЪ§ОнВжПтЭХЖгГЩЮЊЯьгІСІЦПОБЁЃЕБITФмСІгывЕЮёашЧѓзщКЯаЮГЩвЛЬхЛЏЭХЖгвдКѓЃЌЪ§ОнЕФВњЩњЗНВЛдйМйЩшЮДРДвЊНтОіЪВУДЮЪЬтЃЌвђДЫвВВЛЖдЪ§ОнзідЄДІРэЃЌжЛЪЧжБНгДцДЂЩњЪ§ОнЃЛЪ§ОнЕФЪЙгУЗНвдЭЈгУБрГЬгябдЃЈР§ШчJavaЛђPythonЃЉРДВйзїЪ§ОнЃЌДгЖјЮоашвРРЕзЈУХЕФЁЂМЏжаЪНЕФЪ§ОнЭХЖгЁЃ
Ъ§ОнКўЪЕЪЉЕФЕквЛВНЪЧАбЩњЪ§ОнДцДЂдкСЎМлЕФДцДЂНщжЪЃЈПЩФмЪЧHDFSЃЌвВПЩФмЪЧS3ЃЌЛђепFTPЕШЃЉЁЃЖдгкУПЗнЩњЪ§ОнЃЌгІИУгавЛЗндЊЪ§ОнУшЪіЦфРДдДЁЂгУЭОЁЂКЭФФаЉЪ§ОнЯрЙиЕШЕШЁЃдЊЪ§ОндЪаэећИізщжЏВщПДКЭЫбЫїЃЌШУУПИівЛЬхЛЏЭХЖгФмЙЛзджњЪНбАевздМКашвЊЕФЪ§ОнЁЃШЮКЮЭХЖгЖМПЩвддкЩњЪ§ОнЕФЛљДЁЩЯПЊЗЂздМКЕФЮЂЗўЮёЃЌЮЂЗўЮёДІРэжЎКѓЕФЪ§ОнПЩвдзїЮЊСэвЛЗнЩњЪ§ОнЛиЕНЪ§ОнКўЁЃЮЌЛЄЪ§ОнКўЕФЭХЖгжЛзіКмЩйЕФЛљДЁЩшЪЉЙЄзїЃЌЩњЪ§ОнЕФЪфШыКЭЪЙгУЖМгЩгывЕЮёЧПЙиСЊЕФПЊЗЂЭХЖгРДНјааЁЃДЋЭГЪ§ОнВжПтЕФЖрЮЌЗжЮіЁЂБЈБэЕШЙІФмЭЌбљПЩвдзїЮЊвЛИіЗўЮёНгШыЪ§ОнКўЁЃ
дкЪЕЪЉЪ§ОнКўЕФЪБКђЃЌгавЛжжГЃМћЕФЗДФЃЪНЃКЦѓвЕгаСЫвЛИіУћвхЩЯЕФЪ§ОнКўЃЈР§ШчвЛИіЗЧГЃДѓЕФHDFSЃЉЃЌЕЋЪЧЪ§ОнжЛНјВЛГіЃЌГЩСЫЁАЪ§ОнФрегЁБЃЈЛђЪ§ОнФЙЕиЃЉЁЃдкетжжЧщПіЯТЃЌОЁЙмЪ§ОнКўЕФДцДЂзіЕУКмАєЃЌЕЋЪЧзщжЏВЂУЛгаКмКУЕиЯћЛЏетаЉЪ§ОнЃЈПЩФмЪЧвђЮЊЪ§ОнПЦбЇМвВЛОпБИЗжЮіЩњЪ§ОнЕФММЪѕФмСІЃЌЖјЪЧИќЯАЙпгкДЋЭГЕФЁЂЛљгкЪ§ОнВжПтЕФЗжЮіЗНЪНЃЉЃЌДгЖјВЛФмКмКУЕиЖвЯжЪ§ОнКўЕФМлжЕЁЃ
Ъ§ОнМДВњЦЗ
Ъ§ОнВњЦЗЪЧжИНЋЦѓвЕвбОгЕгаЛђФмЙЛВЩМЏЕФЪ§ОнзЪВњЃЌзЊБфГЩФмАяжњгУЛЇНтОіОпЬхЮЪЬтЕФВњЦЗЁЃForbesСаОйСЫМИРржЕЕУЙизЂЕФЪ§ОнВњЦЗЃК
гУгкbenchmarkЕФЪ§Он
гУгкЭЦМіЯЕЭГЕФЪ§Он
гУгкдЄВтЕФЪ§Он
Ъ§ОнВњЦЗЪЧЪ§ОнзЪВњБфЯжЕФПьЫйЭООЖЁЃвђЮЊЪ§ОнВњЦЗгаМИИігХЪЦЃКПЊЗЂПьЃЌВЛашвЊПЊЗЂГіЭъећЕФФЃаЭЃЌжЛвЊзіКУЪ§ОнећРэОЭПЩвдЖдЭтЬсЙЉЃЛЙЫПЭУцПэЃЌвЛЗнЪ§ОнПЩвдВњЩњЖржжгУЭОЃЛЪ§ОнПЩвддйЖШМгЙЄЁЃЪ§ОнВњЦЗИјЦѓвЕДДдьЕФЪевцМШПЩвдЪЧжБНгЕФЃЈгУЛЇЯывЊЗУЮЪЪ§ОнЛђЗжЮіЪБЪеЗбЃЉвВПЩвдЪЧМфНгЕФЃЈЬсЩ§ЙЫПЭжвГЯЖШЁЂНкЪЁГЩБОЁЂЛђдіМгЧўЕРзЊЛЏТЪЃЉЁЃ
дкЪЕЯжЪ§ОнВњЦЗЕФЪБКђЃЌВЛНівЊАбЪ§ОнДђАќЃЌИќживЊЕФЪЧЬсЙЉЪ§ОнжЎМфЕФЙиСЊЁЃЪ§ОнВњЦЗЕФЙЉгІепашвЊЬсГіЖДМћЁЂжИЕМгУЛЇзіОіВпЃЌЖјВЛНіНіЪЧЬсЙЉЪ§ОнЕуЁЃЪ§ОнВњЦЗашвЊПМТЧгУЛЇЕФГЁОАКЭЬхбщЃЌВЂдкЪЙгУЙ§ГЬжаВЛЖЯбнНјЁЃ
ЯИСЃЖШЪкШЈ
ЕБЪ§ОнвдВњЦЗЛђЗўЮёЕФаЮЪНЖдЭтЬсЙЉЃЌЦѓвЕПЩФмашвЊеыЖдВЛЭЌЕФгУЛЇЩэЗнЃЌЪкШЈЗУЮЪВЛЭЌЗЖЮЇЕФЪ§ОнЃЌЖдгІВЛЭЌЕФЗўЮёЫЎЦНКЭВЛЭЌЕФАВШЋМЖБ№ЁЃвЛаЉЕфаЭЕФЯИСЃЖШЪкШЈЕФГЁОАПЩФмАќРЈЃКЦѓвЕФкВПКЭЭтВПгУЛЇФмЙЛЗУЮЪЕФЪ§ОнЗЖЮЇВЛЭЌЃЛЙЉгІСДЩЯВЛЭЌЛЗНкЕФКЯзїЛяАщФмЙЛЗУЮЪЕФЪ§ОнЗЖЮЇВЛЭЌЃЛИЖЗбгыУтЗбЕФгУЛЇФмЙЛЗУЮЪЕФЪ§ОнЗЖЮЇВЛЭЌЃЛВЛЭЌЛсдБМЖБ№ФмЙЛЗУЮЪЕФЪ§ОнЗЖЮЇВЛЭЌЕШЕШЁЃ
дЪаэЗУЮЪЕФЪ§ОнЗЖЮЇЪєгкЪ§ОнВњЦЗ/ЗўЮёздЩэЕФвЕЮёЙцдђЁЃЁЖЮЂЗўЮёЩшМЦЁЗЕФЕк9еТНЈвщЃЌЁА[ЗўЮё]ЭјЙиПЩвдЬсЙЉЯрЕБгааЇЕФДжСЃЖШЕФЩэЗнбщжЄЁЁВЛЙ§ЃЌБШдЪаэЃЈЛђНћжЙЃЉЕФЬиЖЈзЪдДЛђЖЫЕуИќЯИСЃЖШЕФЗУЮЪПижЦЃЌПЩвдСєИјЮЂЗўЮёБОЩэРДДІРэЁБЁЃ
аЁНс
ЮЊСЫМгЫйЁАЙЙНЈ-ЖШСП-бЇЯАЁБЕФОЋвцДДвЕбЛЗЃЌвЕЮёгыITЙВЭЌзщГЩЕФвЛЬхЛЏЭХЖгВЛФмвРРЕгкМЏжаЪНЕФЪ§ОнЭХЖгРДЛёЕУЖдвЕЮёЕФЖДВьЁЃЫћУЧашвЊЙцЛЎЪЪвЫздМКЕФЪ§ОнСїЫЎЯпЃЌдкБивЊЪБв§ШыЪЕЪБЪ§ОнМмЙЙКЭAPIЃЌгУЪ§ОнКўРДжЇГХздЗўЮёЕФЪ§ОнВйзїЃЌДгЖјИќПьЁЂИќзМШЗЕиДгЪ§ОнжаЛёЕУЖДВьЃЌгАЯьвЕЮёОіВпЁЃИќНјвЛВНЃЌЪ§ОнБОЩэвВПЩвдзїЮЊВњЦЗЖдФкВПгУЛЇФЫжСЭтВПгУЛЇЬсЙЉЗўЮёЃЌВЂЭЈЙ§ЯИСЃЖШЪкШЈЬхЯжЗўЮёЕФВювьЛЏКЭАВШЋадашЧѓЁЃЭЈЙ§НЈЩшЁАЪ§ОнздЗўЮёЁБетИіжЇжљЃЌЦѓвЕНЋеце§ФмЙЛХЬЛюЪ§ОнзЪВњЃЌЪЙЦфдкДДаТЕФЪ§зжЛЏвЕЮёжаЗЂЛгИќДѓЕФМлжЕЃЌетЪЧЦѓвЕЪ§зжЛЏТУГЬЕФЕкШ§ВНЁЃ |









