| 编辑推荐: |
本文主要介绍了云原生数据湖构建、分析与开发治理最佳实践及案例分享。希望能够对大家有所启发和帮助。
本文来自于知乎,由火龙果软件Linda编辑、推荐。 |
|
最近几年数据湖热度很高,当搞大数据的同学聚在一起时候,经常会谈到这方面的话题,可能有的同学说“我们在做
Hudi 数据湖,你们用 Delta 还是 Iceberg?”,也会有同学说“我在阿里云上搞了一个OSS数据湖”、“什么,你们数据湖用
HDFS?”、“我们在阿里云上搞 JindoFS,优化数据湖”、“最近搞了个湖仓一体”等等的讨论。
数据湖的相关讨论可以说是千人千面,每一个技术同学面对数据湖的时候,根据自己不同的工作背景,都可能有自己不同的理解,那么,数据湖到底意味着什么呢?可以先了解一下数据湖的三要素。
数据湖核心三要素 :
1、包罗万象的数据
不是指数据库,也不是数据仓库;
而是指各种数据,包罗万象。非结构化数据、半结构化数据和结构化数据。
2、理想的存储
HDFS? 不是。
对象存储?It depends。
实际上,公共云对象存储才是。
为什么?海量,弹性;分层、归档,低成本;安全,合规。
3、开放的计算
数据广泛可触达,充分挖掘价值。
丰富和开放的计算,不止 BI,AI。
针对计算场景的优化、加速,性能不打折扣。
那么到底什么是云原生数据湖呢?
从理念上来讲,就是按照云原生的理念构建出来的数据湖存储系统。运用数据湖构建产品快速搭建出来的,基于oss对象存储系统挖出来的数据湖。然后基于这样的诉求,我们可以做BI和AI的分析。那么我们以阿里云上的云原生数据湖为例,可以看下云原生数据湖的上云途径。

可以看到,我们可以利用阿里云数据湖构建Data Lake Formation 、统一的对象存储OSS快速搭建出一个数据湖。
那么利用这个数据湖,我们可以用数据集成DateHub和 Data Lake Formation 提供的数据入湖的手段,把各种数据源做数据入湖的处理。那么我们最主要的业务目的是什么?是利用上面各种开放丰富的计算来做分析。
我们提供了阿里云自研的MaxCompute这种分析产品,还有E-MapReduce这个开源大数据全家桶的分析产品,来做BI的分析。我们可以利用阿里云的PAI、EMR
DateScience 这种AI的套件来做AI的智能分析。
我们刚才说了这个计算是非常开放以及丰富的,如果你在阿里云上有一个自建的Hadoop,或是CDH这种集群,同样可以对接到数据湖,然后进行分析。战略上面我们还合作了大量的第三方产品,比如Databricks数据洞察,同样可以对接到数据湖进行分析。
接下来,我们再来看一下数据湖的构建和分析的过程,我们提供了怎样的支持。以下讲的是数据湖构建,我们专门提供了这样的一个数据湖构建产品Data
Lake Formation。
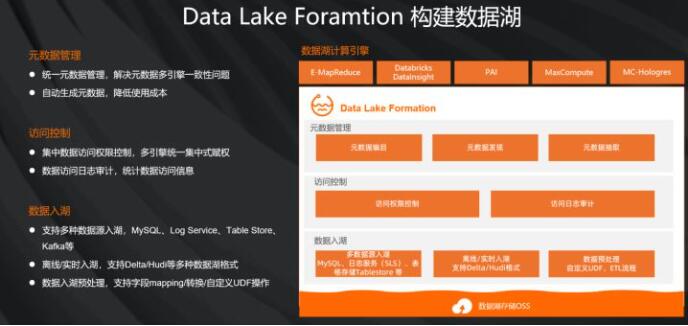
它的核心就是维护数据湖的元数据,数据湖不光是包括数据本身,还包括数据的元数据。数据的元数据是在Data
Lake Formation中,统一管理和存储的。好处是避免了各个计算产品自己来维护文件的元数据所带来的不一致性。统一集中来管理的话,我们还可以做集中的访问控制上的权限或日志审计。Data
Lake Formation对接的各种数据源,比如MySQL、Kafka等,提供了离线和实时入湖的方式。目前我们对接的数据湖的格式,有Delta和Hudi。
接下来重点讲解一下,我们在分析产品上,利用开源大数据分析的套件E-MapReduce来做数据湖分析。
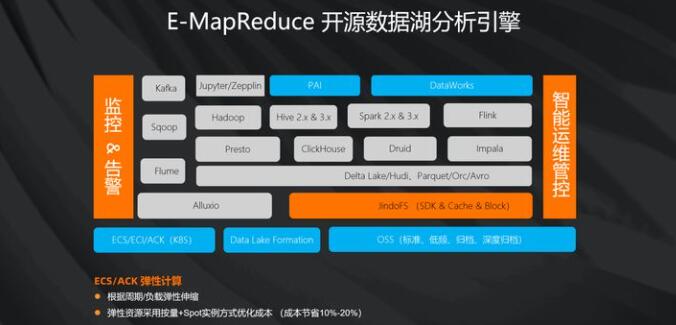
EMR其实是一个开源大数据全家桶的产品,以上只是列出了数据湖分析上的相关支持。在分析引擎和OSS数据湖之间,我们还提供了数据湖加速的支持。我们有了Alluxio这种开源的加速器,同时也有自研的JindoFS加速器。JindoFS对OSS数据湖我们提供了全面对接开源分析引擎的支持。
整个EMR的产品可以run在ACK上,也可以run在ECS上面,利用ECS和ACK的弹性伸缩的能力,我们让整个数据湖分析变得低成本。
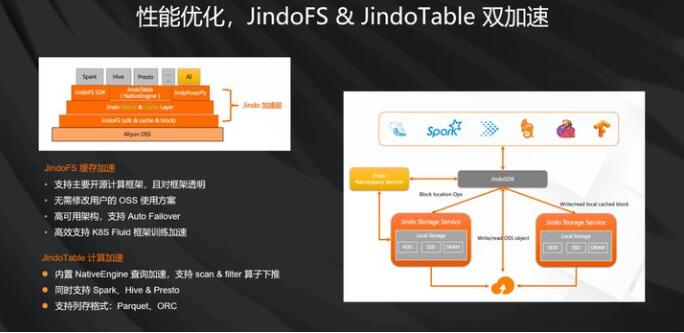
刚才提到,在EMR产品套件中,有了数据湖加速的这一层次,接下来重点讲一下JindoFS和JindoTable双加速的能力。
JindoFS主要是在文件系统层面,利用计算侧的磁盘资源,对远端的OSS数据做缓存加速,从而大幅度提升Hive、Spark、Presto的分析处理能力。JindoTable和JindoFS相当于是相互配合,它主要是在表分区这个层次上面,去做缓存去做加速。然后对Parquet、ORC这种格式做了Native的优化,从而更进一步提升了上面提到的分析引擎的处理能力。

除了性能优化,我们知道数据湖还需要做成本优化,因为里面保存了大量的数据。JindoTable和JindoFS同样互相配合,我们做了分层和归档。利用OSS的基础能力,我们维护数据的热度、冷度,然后通过Jindo的相关命令,可以对数据进行缓存、归档和分层这些功能。利用分层的能力,我们可以看到假定一个用户,如果它有10PB的数据,以HDFS这种方式来做存储方案,成本会达到上百万。但如果我们换用OSS数据湖的方案,我们可以把大量的冷数据放在归档,整个存储成本可以大幅度降低。
接下来,我们来看一个数据湖的最佳实践。来源于上海数禾科技的大数据架构师程俊杰先生的一篇在阿里云社区分享的案例文章。以下经过他的同意,对他的文章进行了一些摘要和加工。
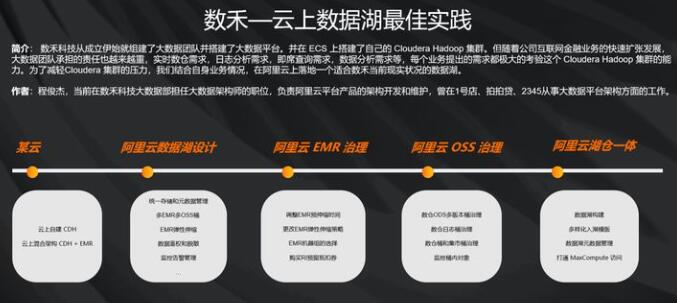
上海数禾科技在某云上面使用的是CDH+EMR,云上混合的架构。它迁移到阿里云之后,是按照数据湖的理念做的设计,充分考虑到他们不同的业务需求,以及权限控制和脱敏相关的部分。
经过过去的一年,他们在成功地迁移到阿里云数据湖架构上之后,又做了EMR的治理和OSS的治理,这些治理方面的经验在文章里面都做了大量的分享。最近他们又升级到了湖仓一体的架构,把元数据用Data
Lake Formation来统一管理,然后组合使用EMR和MaxCompute等多个阿里云计算产品来对数据湖进行分析。

以上是数禾在阿里云上面的数据湖架构,我们可以看到它在OSS的数据湖上面,其实有多个Bucket。在这上面,利用JindoFS提供的OSS透明的缓存加速能力,然后有多个EMR集群分别去按照不同的业务诉求来做分析。面对这么多集群,他们的调度是用的目前比较流行的大数据调度平台Airflow。
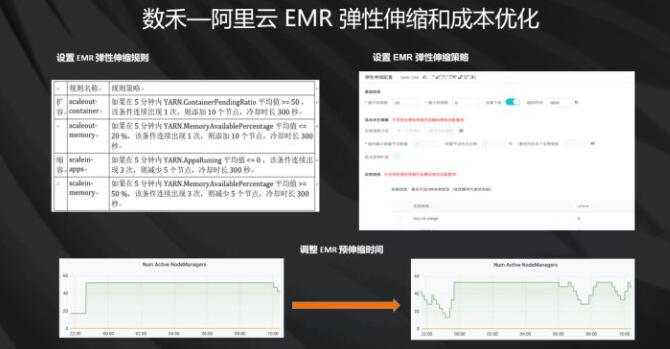
刚才提到,数据湖的一个非常大的价值是把存储成本和计算成本降下来。计算成本其实主要是靠弹性伸缩来降。在EMR里面,可以去设置弹性伸缩策略和弹性伸缩规则。弹性伸缩规则结合YARN的调度能力,可以看到什么时候该扩集群,什么时候该缩集群。包括提前伸缩的时间都可以做设置,真正的做到需要多少,就用多少。把计算成本降到最低。这个跟好几年前做的Hadoop集群实战,是完全不一样的。

以上主要介绍了如何构建云原生数据湖,那么如此多的数据结构化、半结构化、非结构化的存储在你的数据库和数据仓库里,这么多的数据应该如何来管?先来看一看企业在管理数据的过程中又面临哪些问题?
1、数据孤岛:
数据不集中,重复存储,重复计算
数据上云门槛高,数据存储成本高
2、数据开发和运维成本高:
自研数据平台难度大,成本高
开源工具扩展性,稳定性难以保证
数据质量,运维成本难以匹配业务快速增长需求
3、数据共享应用不易
数仓中的数据对各类BI或应用不便
数据存储分散,分布在数仓,数据湖,数据库中
数据难以共享和统一管理
4、大规模数据难以治理
随着数据规模的不断增大,数据治理越发难以进行,数据质量、监控、安全逐渐成为瓶颈
针对这些问题,阿里云的DataWorks产品提供了一站式的数据开发治理的能力。
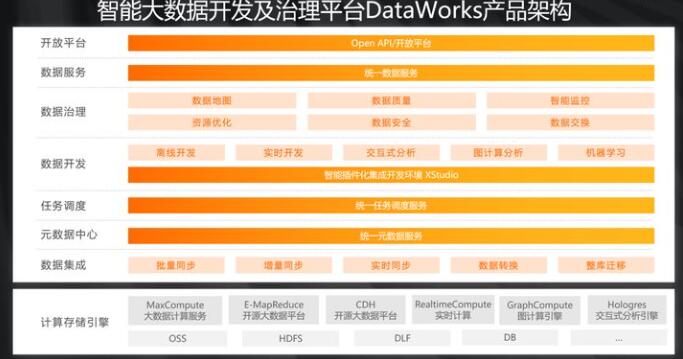
它构建于不同的计算和存储引擎之上,包括阿里云自研的大数据服务MaxCompute,开源的大数据平台EMR/CDH,支持实时计算、图计算,交互式分析。它构建在OSS
、HDFS、DLF之上湖仓一体的体系下,为大家提供实时离线的数据集成、数据开发,并且通过统一的调度任务和统一的元数据服务,为大家提供了各种各样的数据治理的能力。包括数据质量,智能监控,数据地图,数据安全,资源优化等。通过统一的元数据服务,为企业提供从数据平台到业务系统最后一公里的能力。
最后我们可以通过open API把我们整个平台开放给客户,也就是说您可以在不看到DataWorks界面的情况下,深度集成整个DataWorks的产品能力。
那这样一款产品它哪些核心能力呢?可以概括为以下几点:
数据集成
数据开发
数据治理
数据服务
首先,它通过数据集成实现了数据的入仓入湖。第二,数据在进入了我们的系统之后,数据开发它会通过支持多引擎的能力对这些数据进行精细化的处理和开发。第三,数据治理在基于多引擎湖仓一体的体系上提供统统一的元数据服务,使您对您的数据可以实现更易用和可用性。最后,通过数据服务使这些数据可以一站式的直达到你的系统中。

我们首先来看一下数据集成,我们这里一共提供了50多种不同类型数据之间的相互的同步,比如说关系型数据库、大数据存储、消息队列以及非结构化的数据,而且同时我们提供了离线和实时的入仓和入湖。
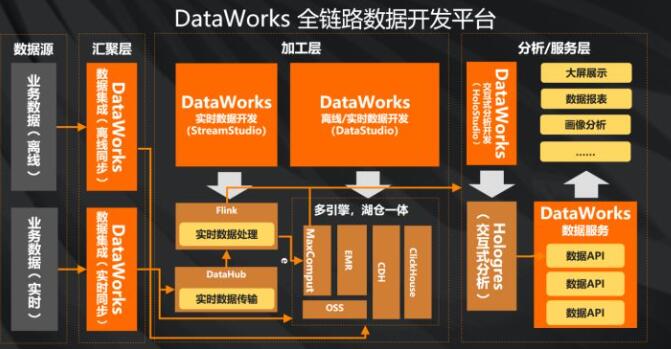
当我们的业务数据通过数据集成进入到我们的计算和存储引擎之后,DataWorks提供实时离线的开发,通过支持多引擎的能力以及跨引擎之间的相互调度的能力,根据各种引擎的性能,你可以选择最优的最合适你的调度引擎,把它们集合成一个整体,对这些数据进行处理和开发。最后这些数据通过我们的数据服务提供给各种BI的分析的工具来展示数据报表和图像的分析。
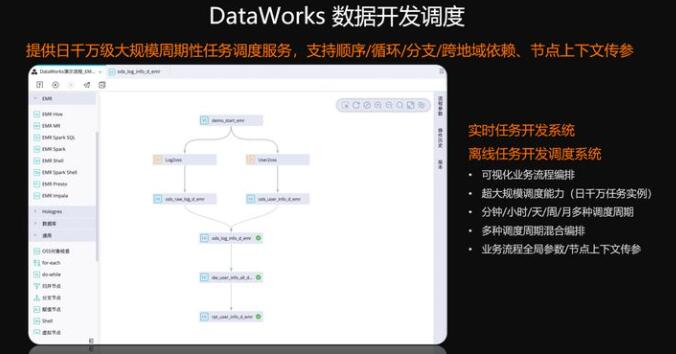
上图也是一个简单的基于EMR的数据开发的调度的价格图。我们可以看到它可以支持EMR的不同类型的作业,同时我们还支持一系列的逻辑业务节点,通过支持这些逻辑业务节点,我们可以支持循环、顺序、分支、跨地域、依赖等等,并且提供这种按日的千万级的大规模的调度来符合企业这种复杂的逻辑业务结构。
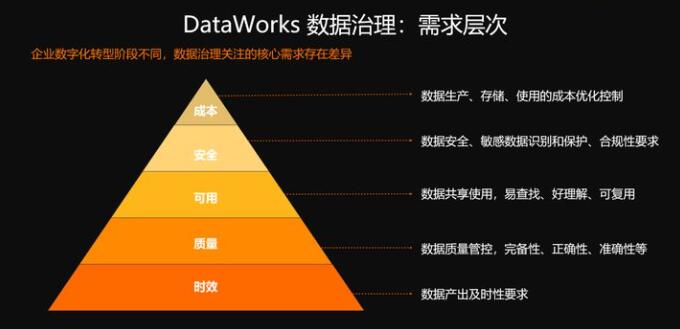
这些数据经过了精密的数据开发的基础上,随着企业业务的不断发展,数字化转型的不同阶段,那么大家对数据治理也呈现了不同层次的不同类型的需求,我们在数据实时的正确产生的基础上,我们对于数据整个的共享性、易用性,好理解,数据安全,敏感数据识别等等,以及你的成本优化,都有了一些更高层次的需求。
那么DataWorks在各种各样的数据治理的需求方面,又提供了哪些能力来可以帮助你的企业管理数据、治理数据呢?

首先在时效性方面,我们有一个全方位的运维和智能监控系统,并且通过各式各样的比如说短信、邮件、钉钉、电话来以及移动运维对你进行及时的告警,使您可以在任何地方的任何时间,只要打开你的手机,就可以对你的线上任务进行及时的处理。
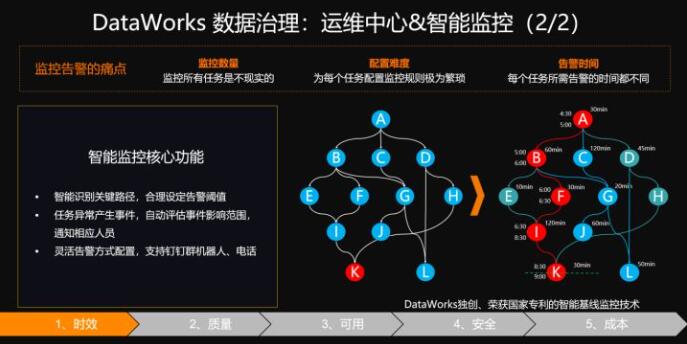
以上可以看到,这是一款DataWorks独创的,并且已经获得了国家专利的智能基线监控技术。可以看到上图的K节点,你只要关心你整个数据最后产出的节点,而无需关注它的上游节点,DataWorks会非常智能的帮你搜索遍历它的上游节点,并且找出它的关键路径,在关键路上的每一个节点设置相应的智能监控和告警,这样就可以提前的发现问题,及时干预。
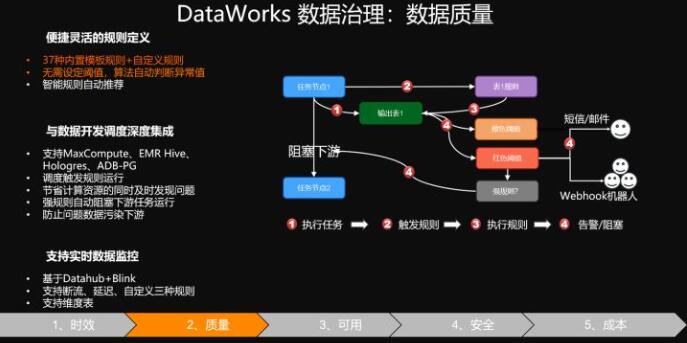
我们这里提供30多种的内置模板,并且提供自定义模板的设置,可以让你对你的任何一张报表根据你的规则设置它的校验规则,同时它跟刚才的数据开发流程其实是紧密结合的,也就是说你在你的任意一个业务节点,对你的任意的一张表可以设置相应的规则,当你的任务会调度到这个节点的时候,这个规则也同时被触发。你也可以根据不同的级别来设置各种各样的报警,甚至去阻塞下游业务,这样就可以防止脏数据的产生。
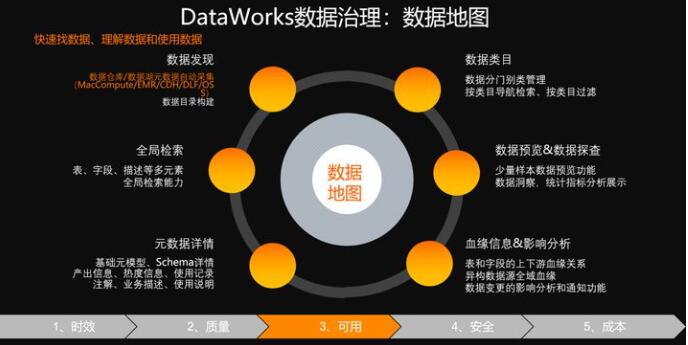
数据在已经以高质量、高效生成的基础上,DataWorks提供对湖仓一体不同引擎的元数据的统一的采集以及管理。基于这些统一采集管理的原数据,就可以提供全域数据的检索,数据详情的分析、数据的热度、数据的产出信息以及非常精确的血缘关系。基于这样血缘关系,你可以对数据进行溯源以及进行各种各样的数据分析,你的数据就会变得更好理解,更好用更好查找。

我们除此以外还提供了一个全链路的数据安全的保护。数据安全领域我们提供了租户隔离Role Base的权限管理,操作行为的日志,并且跟开源的Kerberos/LDAP是打通的。除此以外,对整个数据的开发链路其实也是有一个全链路的安全保障的,从数据传输开始,比如说我们可以对数据传输数据源的访问进行控制,在数据存储的过程中可以进行存储加密,数据的备份和恢复,在数据处理的过程中可以进行更细力度安全管控,随后的数据交换数据下载,然后会进行相应的接口的鉴权,以及进行数据脱敏的处理。

企业的资产随着数据量的逐渐的增大,那么企业对资产的管控也需要需要有越来越高的需求。DataWorks在基于以前数仓的基础上,也逐渐的把它拓展到刚才我们讲的整个的数据湖场景,它可以基于湖仓一体,逐步把整个企业全域的资源盘点和规划,优化给到客户,使成本得到非常精良的控制。
下面我们以EMR为例子,看一下在EMR这个产品上,到底是怎样深度结合,进行全域的数据开发和治理的。
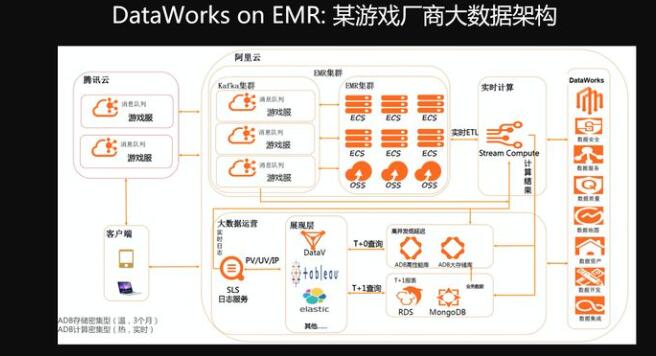
某一个游戏厂商,它的数据进入了阿里云的整个系统之后,进入EMR集群先进行消息队列,然后进入EMR集群进行相应的计算和处理,通过实时计算、交互式分析,最后给到用户大数据的BI的展现。
我们可以看到在整个链路过程中,DataWorks会与整个我们链路的各种各样的数据存储和计算引擎进行深度的结合,在全链路去cover整个数据开发和治理的过程。
以上是一个简单的demo,大家可以看到DataWorks在EMR上,我们是怎样进行集成的。
最后总结一下,DataWorks在湖仓一体的基础上,支持多引擎,提供一个全域的数据开发和治理的平台。通过这款产品可以帮助企业最终实现您的一切业务数据化,一切数据业务化的功能。
|









