| БрМЭЦМі: |
БОЮФжївЊДгдЦЩЯМмЙЙДѓЪ§ОнЦНЬЈЕФЬєеНКЭЛњгіЃЌдЦдЩњЪ§ОнКўМмЙЙШ§ДѓддђЃЌЬкбЖдЦЪ§ОнКўВњЦЗМмЙЙЁЂгІгУГЁОАЫФИіЗНУцНјааНщЩмЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДзд дЦМгЩчЧј ЃЌгЩAliceБрМЁЂЭЦМіЁЃ |
|
вЛЁЂдЦЩЯМмЙЙДѓЪ§ОнЦНЬЈЕФЬєеНКЭЛњгі
бЁдё Cloud ЛЙЪЧ Local ЕФжюЖрЬжТлКЭЪЕМљжаЃЌГЩБОвЛжБЪЧШЦВЛПЊЕФЛАЬтЁЃЁАЙЋгадЦЬЋЙѓСЫЃЌвЛФъЛњЦїОЭЙЛЭаЙмШ§ЮхФъСЫЁБЃЌетЛљБОЩЯЪЧИеПЊЪМНгДЅЙЋгадЦЕФЦѓвЕЃЌдкНјааСЫЯъЯИМлИёЖдБШКѓЕФЕквЛНсТлЃЌвВвђДЫЕМжТЙњФкжаДѓаЭЙЋЫОКмЩйбЁдёЙЋгадЦЁЃЗДЙлЙњЭтКмЖржаДѓаЭЦѓвЕЃЈР§ШчnetflixЃЌpinterestЃЉЃЌЛЙгаЬхСПНЯДѓЕФжаЙњГіКЃЙЋЫОЃЈШчShareitЃЌmobvistaЃЉЛсЧуЯђбЁдёЙЋгадЦЁЃЪВУДдвђЕМжТСЫетбљЕФВювьФиЃПКЫаФВювьОЭдкгкдЦдЩњММЪѕЕФЦеМАКЭТфЕиЁЃОпЬхЕНЪ§ОнЦНЬЈВювьЕФКЫаФОЭЪЧдЦдЩњЪ§ОнКўМмЙЙМЋДѓЕФНЕЕЭСЫЦѓвЕЕФЩЯдЦГЩБОЃЌПЩвдДяЕНБШ
Local ИќЕЭЕФ IT ГЩБОЃЌЭЌЪБЯэЪмЙЋгадЦЕФИїжжКУДІЁЃ
1. ЬєеН
ЁЄжБНгЧЈвЦ local ДѓЪ§ОнЦНЬЈЃЈДцЫуёюКЯЧвЙЬЖЈЙцФЃЃЉДцдкЯТУцЮЪЬтЃК
ЁЄРћгУТЪЕЭ/ЪБаЇадВюЃКдЄСєзЪдДЬЋЖрРћгУТЪЕЭЃЌМЏШКЙцФЃЙ§аЁЪ§ОнЩњВњЪБаЇадВюЃЛ
ЁЄСщЛюадВюЃККмФбПьЫйгІЖдЖрБфЕФ adhoc ашЧѓ /backfill ЕШРраЭШЮЮёЃЛМЏШКЩ§МЖРЇФбЃЌЧЈвЦЪ§ОнЃЛ
ЁЄГЩБОИпЃКЛљгк hdfs ЕФДцДЂЙцФЃИњМЦЫуЙцФЃВЛЦЅХфЃЌДѓСПРЫЗбЃЛдЦжїЛњБОЩэаЁЪБМлИёИпЃЛhdfs ЮЌЛЄГЩБОИпЃЛ
ЁЄадФмВюЃКЭГвЛЪЕР§РраЭЃЌВЛФмКмКУгХЛЏВЛЭЌМЦЫуИКдивЊЧѓЃЌБШШч shuffle БОЕиДХХЬ iops ЕШЕШЃЛ
ЁЄПЩППадФбвдБЃеЯЃКШнджвдМАРћгУЖр azЃЈПЩгУЧјЃЉМЦЫузЪдДФбЃЌhdfs Жр az ВПЪ№ЃЌПч az СїСПЪєгкНєШБаЭзЪдДЃЌЭЈГЃБШНЯНєеХЁЃ
2. ЛњгіЃКЙЋгадЦЙВЯэОМУ
ЁЄЕЏадМЦЫуЃКГфЗжРћгУЕЏадМЦЫуФмЙЛДѓЗљЖШНЕЕЭГЩБОЃЌгШЦфЪЧРћгУИќЕЭМлЕФ spot ЛњЦїЃЛ
ЁЄЖдЯѓДцДЂЃКдЦЗўЮёЖдЯѓДцДЂЕУвцгк EC БрТыЃЌвдМАВЛашвЊдЄСєДцДЂЃЌЮоашзЈвЕШЫдБПЊЗЂдЫЮЌЕШЕШЬиадЃЌЯрБШгк
hdfs га 1:5 ЕН 1:10 ЕФГЩБОгХЪЦЃЌВЂЧвгаКмКУЕФПч az ЭјТчДјПэжЇГХЃЛ
ЁЄЖрбљадЃКРћгУИќМгЗсИЛЕФЪЕР§РраЭЮЊВЛЭЌ workload ЬсЙЉЯргІЕФадФмЬсЩ§ЁЃ
ШчКЮБмУтжБНгЧЈвЦ local ДѓЪ§ОнМмЙЙЕНдЦЩЯДјРДЕФЮЪЬтЃЌГфЗжРћгУЙЋгадЦЬиадЃЌе§ШЗЕФДюНЈ/ЪЙгУдЦдЩњДѓЪ§ОнЦНЬЈЃЌЬсСЖГіСЫдЦдЩњЪ§ОнКўМмЙЙЃЌЪЧЮвУЧбаОПЕФжиЕуЁЃ
ЖўЁЂдЦдЩњЪ§ОнКўМмЙЙШ§Дѓддђ
дЦдЩњЪ§ОнКўМмЙЙЕФКЫаФРэФюЪЧЕЭГЩБОЃЌВЂЧвзЗЧѓВЛЫзЕФадФмЁЃзлКЯЙЋгадЦЩЯЕФЛњгіЃЌЮвУЧЬсГідЦдЩњЪ§ОнКўМмЙЙШ§ДѓддђЃКДцЫуЗжРыВЩгУЖдЯѓДцДЂНЕЕЭДцДЂГЩБОЁЂГфЗжРћгУдЦЩЯЕЏадзЪдДНЕЕЭМЦЫуГЩБОЁЂЭЈЙ§ЛКДцМАНЈФЃИяаТЕШвЛаЉСаВЙГЅМмЙЙРДЬсЩ§адФмЃЌЯТУцЗжБ№ПДПДШ§ДѓддђЕФгХЪЦКЭвЊПЫЗўЕФРЇФбЁЃ
1. ЖдЯѓДцДЂ
ЁЄДцЫуЗжРыЪЧЪ§ОнКўМмЙЙжазюживЊЕФддђЃЌЪЙгУЙЋгадЦЖдЯѓДцДЂЗўЮёДњЬц hdfs гаЯТУцвЛЯЕСаКУДІЃК
ЁЄдЦЗўЮёЖдЯѓДцДЂЕУвцгк EC БрТыЃЌвдМАВЛашвЊдЄСєДцДЂЃЌЮоашзЈвЕШЫдБПЊЗЂдЫЮЌЕШЕШЬиадЃЌЯрБШгк hdfs
га 1:5 ЕН 1:10 ЕФГЩБОгХЪЦЁЃ
ЁЄЖдЯѓДцДЂгаКмКУЕФ sla БЃеЯ 4 Иі 9 ЕФПЩгУадЃЌЖдБШ hdfs вЊЛЈВЛЩйСІЦјВХФмзіЕН 3 Иі9ЃЛЖдЯѓДцДЂга
11 Иі 9 ЕФГжОУЛЏБЃеЯЃЌЖдБШ hdfs МДЪЙШ§ИББОШдгаНЯИпЖЊЪ§ОнПЩФмадЁЃ
ЁЄЖдЯѓДцДЂга hdfs ВЛОпгаЕФЬиадЃКЖрАцБОЁЂЪ§ОнЩњУќжмЦкЙмРэЁЂПч region БИЗнЁЂЪТМўЧ§ЖЏЁЂЗУЮЪЗНИЖЗбЕШЕШЁЃ
ЁЄНтОіМЦЫузЪдДгыДцДЂзЪдДВЛЦЅХфЃЌЭЈГЃашЧѓЕФ hdfs ДцДЂзЪдДЪЧМЦЫуМЏШКЕФСНБЖвдЩЯЁЃ
ЁЄИїжжИКдиЕФДѓЪ§ОнМЏШКЙВЯэвЛЗнЪ§ОнЃЌМѕЩйЪ§ОнЭЌВНИДдгадКЭНЕЕЭГЩБОЁЃ
ЖдЯѓДцДЂгажюЖрКУДІЃЌЕЋЪЧжБНгАбЖдЯѓДцДЂгУгкДѓЪ§ОнЃЌашвЊзЈвЕЕФЙЋгадЦКЭДѓЪ§ОнБГОАжЊЪЖРДНтОіЃЌБШШчЮѓгУОЭгаПЩФмЛсГіЯжвдЯТЧщПіЃК
ЁЄЖдЯѓДцДЂУЛга rename гявхЃЌЛсЕМжТЗжВМЪНШЮЮё commit адФмКмВюЃЌЭЈГЃЛсЕМжТШЮЮёЪБГЄЗБЖЩѕжСИќГЄЁЃ
ЁЄЖдЯѓДцДЂДѓЖрЖМЪЧзюжевЛжТадЃЌзюжевЛжТадЕМжТШЮЮёЦЕЗБЪЇАмЃЌЩѕжСЖСШЁЪ§ОнДэЮѓЕШбЯжиКѓЙћЁЃ
ЁЄЖдЯѓДцДЂ list адФмЖМВЛЬЋКУЃЌЕМжТЗжЮі/НЈВжШЮЮёКФЪБдіМгЁЃ
2. ЕЏадМЦЫу
ГфЗжРћгУЕЏадМЦЫузЪдДЃЌФмЙЛДѓДѓМѕЩйМЏШКПеЯаЪБЦкЕФГЩБОРЫЗбЃЌВЂЧвФмЙЛПьЫйЯьгІИїжжСйЪБашЧѓ /backfill
ашЧѓЁЃ
Spot МлИёЭЈГЃФмЕНШ§елЩѕжСвЛелЃЌШчКЮГфЗжРћгУ Spot МЦЫузЪдДЃЌгжВЛжСгкБЛЛиЪеЕМжТШЮЮёЪЇАмЪЧдЦдЩњЪ§ОнЦНЬЈЕФвЛДѓЬєеНЁЃ
ДѓЪ§ОнМЦЫуВЂЗЧЪЧЮозДЬЌЕФЃЌshuffle ЮФМў/Ъ§ОнКмДѓГЬЖШЩЯзшШћСЫМЏШКЕФЕЏадЫѕШнЃЌШчКЮНтОі shuffle
ХХВМЃЌДяГЩзюИпаЇТЪЕФМЏШКЫѕШнжСЙиживЊЁЃЭЌЪБМЏШКРЉШнШчКЮТњзуВЈЖЏадКмДѓЕФДѓЪ§ОнМЦЫуашЧѓвВЪЧвЛИіЦРМлдЦдЩњЪ§ОнЦНЬЈадФмЕФживЊжИБъЁЃ
yarn ЕФећЬхЩшМЦИќЪЪКЯ local Ъ§ОнЦНЬЈЕФЙЬЖЈМЏШКЙцФЃЃЌШчКЮРћгУ k8s РДДяЕНИпаЇЕФзЪдДЕїЖШВпТдЪЧдЦдЩњЪ§ОнКўЕФСэвЛИіКЫаФФбЕуЁЃ
3. адФмЬсЩ§ЃКЛКДцМгЫйКЭНЈФЃИяаТ
дЦдЩњЪ§ОнКўВЩгУЖдЯѓДцДЂДњЬц hdfsЃЌЫ№ЪЇЕєСЫ hdfs ЕФ locality ЕФгХЪЦЃЌашвЊзівЛЖЈЕФВЙГЅМмЙЙЁЃ
Ъ§ОнЧуаБЖрФъРДвЛжБЪЧЪ§ОнЙЄГЬЕФЫоЕаЃЌЖддЦдЩњЪ§ОнКўМмЙЙЖјбдШДЪЧИіКУЯћЯЂЃЛЪ§Он scan НзЖЮЃЌЪ§ОнШШЖШЕФОоДѓВювьПЩвдгУКмЩйЕФЛКДцРДЧЫЖЏДяЕНКмКУЕФМгЫйаЇЙћЃЌЯТУцЪЧв§гУзд
snowflake ЕФТлЮФЃЌread-only ЕФЧыЧѓЕФЛКДцУќжаТЪИпДя 80%ЁЃ
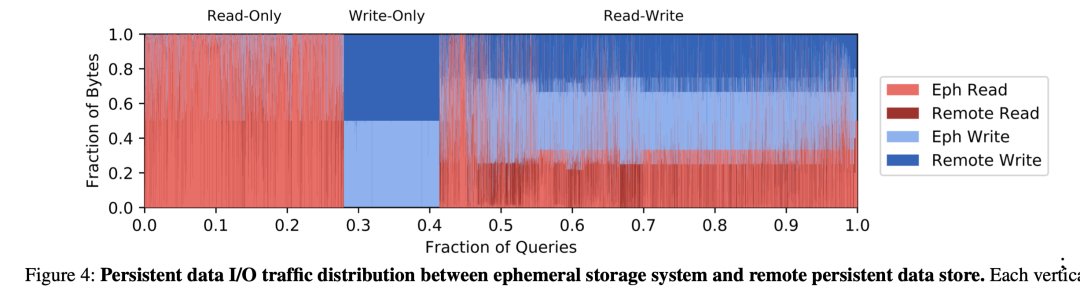
Г§СЫЛКДцМгЫйЃЌМѕЩйЪ§ОнЮФМўЕФЩЈУшСПдкЪ§ОнКўМмЙЙЯТИќживЊЃЌШчКЮзіКУЪ§ОнХХВМашвЊаТвЛДњЕФНЈФЃММЪѕЁЃГ§СЫЗжЧјЃЌЗжЭАЕШДЋЭГММЪѕЃЌЯЁЪшЫїв§дкЪ§ОнКўАчбнЗЧГЃживЊЕФзїгУЁЃap
Яђ tp ДцДЂИёЪНЩшМЦЕФППТЃДѓДѓМгЫйСЫЗжЮіадФмЃЌПЩвдПДЕН clickhouse ЕШИпадФмЪ§ВжЯЕЭГЖМЛсв§ШыЯЁЪшЫїв§ММЪѕЃЌдкВЛдѕУДдіМгДцДЂЕФЛљДЁЩЯДѓДѓЬсЩ§СЫВщбЏадФмЁЃ
Ш§ЁЂЬкбЖдЦЪ§ОнКўВњЦЗМмЙЙ
1. ЬкбЖдЦЪ§ОнКўВњЦЗ
вЊНтОіЪ§ОнКўМмЙЙШ§ДѓддђжаЕФжюЖрЮЪЬтЃЌДг 0 ДђдьдЦдЩњЪ§ОнКўЃЌашвЊКмЖрзЈвЕЕФЙЋгадЦБГОАКЭЪ§ОнКўММЪѕФмСІЃЌЬкбЖдЦЮЊДЫЭЦГіСНПюЪ§ОнКўВњЦЗЃЌБугкПЭЛЇЪ§ОнЦНЬЈМмЙЙЩ§МЖЁЃ
ЬкбЖдЦЪ§ОнКўМЦЫуЃЈData Lake ComputeЃЌDLCЃЉЁО1ЁПЬсЙЉСЫУєНнИпаЇЕФЪ§ОнКўЗжЮігыМЦЫуЗўЮёЁЃИУЗўЮёВЩгУЮоЗўЮёЦїМмЙЙЃЈServerlessЃЉЩшМЦЃЌгУЛЇЮоашЙизЂЕзВуМмЙЙЛђЮЌЛЄМЦЫузЪдДЃЌЪЙгУБъзМ
SQL МДПЩЭъГЩЖдЯѓДцДЂЗўЮёЃЈCOSЃЉМАЦфЫћдЦЖЫЪ§ОнЩшЪЉЕФСЊКЯЗжЮіМЦЫуЁЃНшжњИУЗўЮёЃЌгУЛЇЮоашНјааДЋЭГЕФЪ§ОнЗжВуНЈФЃЃЌДѓЗљЫѕМѕСЫКЃСПЪ§ОнЗжЮіЕФзМБИЪБМфЃЌгааЇЬсЩ§СЫЦѓвЕЪ§ОнУєНнЖШЁЃ
ЁО1ЁПDLCЃК
https://cloud.tencent.com/product/dlc?!version=2&!preview=
ЬкбЖдЦЪ§ОнКўЙЙНЈЃЈData Lake FormationЃЌDLFЃЉЁО2ЁПЬсЙЉСЫЪ§ОнКўЕФПьЫйЙЙНЈЃЌгыКўЩЯдЊЪ§ОнЙмРэЗўЮёЃЌАяжњгУЛЇПьЫйИпаЇЕФЙЙНЈЦѓвЕЪ§ОнКўММЪѕМмЙЙЃЌАќРЈЭГвЛдЊЪ§ОнЙмРэЁЂЖрдДЪ§ОнШыКўЁЂШЮЮёБрХХЁЂШЈЯоЙмРэЕШЪ§ОнКўЙЙНЈЙЄОпЁЃНшжњЪ§ОнКўЙЙНЈЃЌгУЛЇПЩвдМЋДѓЕФЬсИпЪ§ОнШыКўзМБИЕФаЇТЪЃЌЗНБуЕФЙмРэЩЂТфИїДІЕФЙТЕКЪ§ОнЁЃ
ЁО2ЁПDLFЃК
https://cloud.tencent.com/product/dlf?!version=2&!preview=
СНПюЪ§ОнКўВњЦЗЙІФмЖЈЮЛВювьШчЯТЭМЫљЪОЃК

2. еЙЭћЪ§ОнКўНтОіЗНАИ
ЮДРДЃЌЬкбЖдЦЪ§ОнКўНтОіЗНАИНЈЩшНЋвдЖдЯѓДцДЂ COS ЮЊЪ§ОнКўДцДЂЃЌвдШнЦїЗўЮёЮЊдЦдЩњзЪдДЕїЖШЃЌвдЪ§ОнКўЙЙНЈ
DLF ЮЊЭГвЛдЊЪ§ОнХІДјЃЌЙЙНЈЬкбЖдЦЩЯЕФЪ§ВжНЈФЃЁЂЪ§ОнЗжЮіЁЂЛњЦїбЇЯАЕФЪ§ОнКўНтОіЗНАИЁЃ
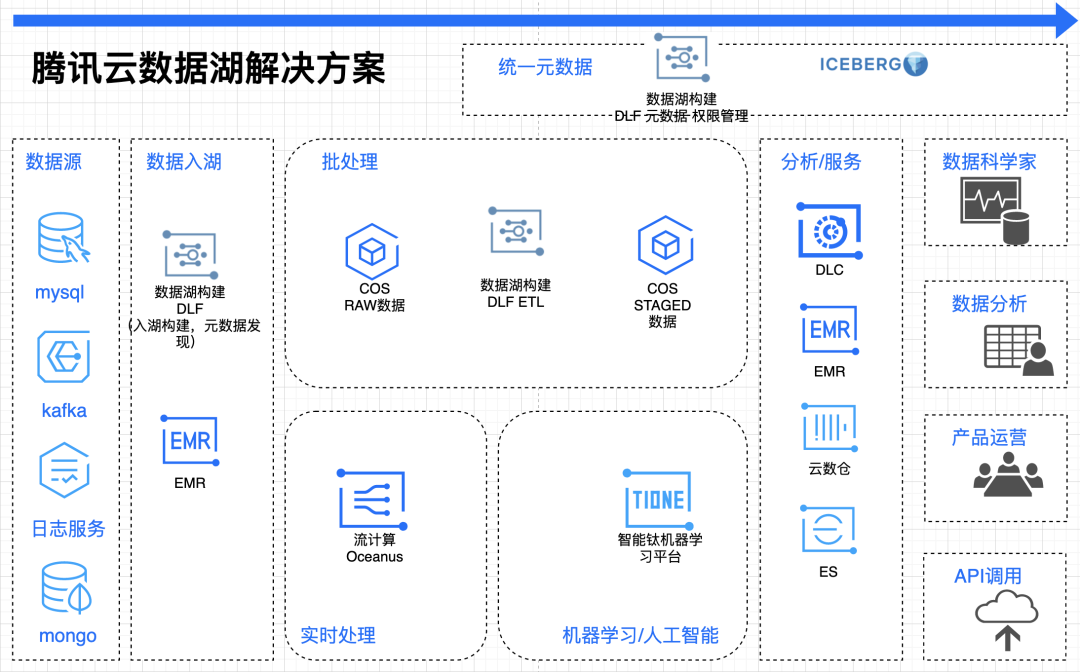
ЫФЁЂгІгУГЁОА
1. Ъ§ОнШыКўЙЙНЈ
ПьЫйЙЙНЈЪ§ОнКўЃЌвдМАдкИїжжЪ§ОнжЎМфЭЌВНКЭДІРэЪ§ОнЃЌЮЊИпадФмЗжЮіЪ§ОнМЦЫузїЪ§ОнзМБИЁЃ
2. Ъ§ОнЗжЮі
гУЛЇПЩжБНгВщбЏКЭМЦЫу COS ЭАжаЕФЪ§ОнЃЌЖјЮоашНЋЪ§ОнОлКЯЛђМгдиЕНЪ§ОнКўМЦЫужаЁЃЪ§ОнКўМЦЫуФмЙЛДІРэЗЧНсЙЙЛЏЁЂАыНсЙЙЛЏКЭНсЙЙЛЏЕФЪ§ОнМЏЃЌИёЪНАќРЈ
CSVЁЂJSONЁЂAvroЁЂParquetЁЂORC ЕШЁЃПЩвдНЋЪ§ОнКўМЦЫуМЏГЩЕНЪ§ОнПЩЪгЛЏгІгУжаЃЌЩњГЩЪ§ОнБЈБэЃЌЧсЫЩЪЕЯжЪ§ОнПЩЪгЛЏЁЃ
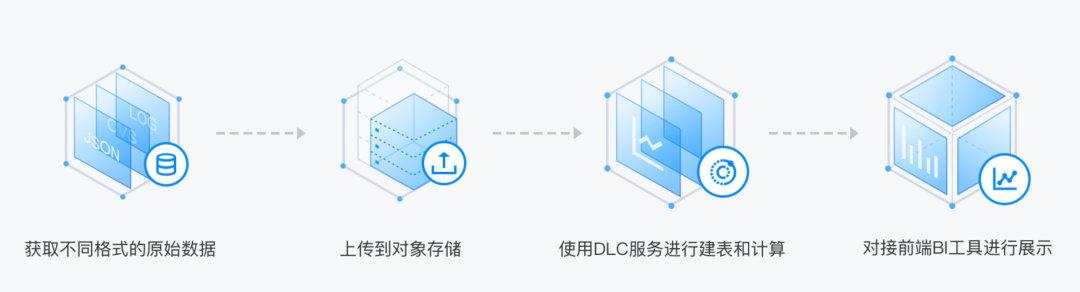
3. СЊАюЗжЮі
Ъ§ОнКўМЦЫужЇГжЖдЖрдДвьЙЙЪ§ОнНјааСЊКЯВщбЏЗжЮіЃЌАќРЈЖдЯѓДцДЂЁЂдЦЪ§ОнПтЁЂДѓЪ§ОнЗўЮёЕШЁЃгУЛЇЭЈЙ§ЭГвЛЕФЪ§ОнЪгЭМЃЌЪЙгУБъзМЕФ
SQL МДПЩЪЕЯжЖрдДЪ§ОнСЊКЯВщбЏЗжЮіЁЃЮоашвРРЕЪ§ОнЙЄГЬЭХЖгНјааДЋЭГЪ§ОнЗжВуНЈФЃЕФ ETL ВйзїЃЌвВЮоашМгдиЪ§ОнЁЃ
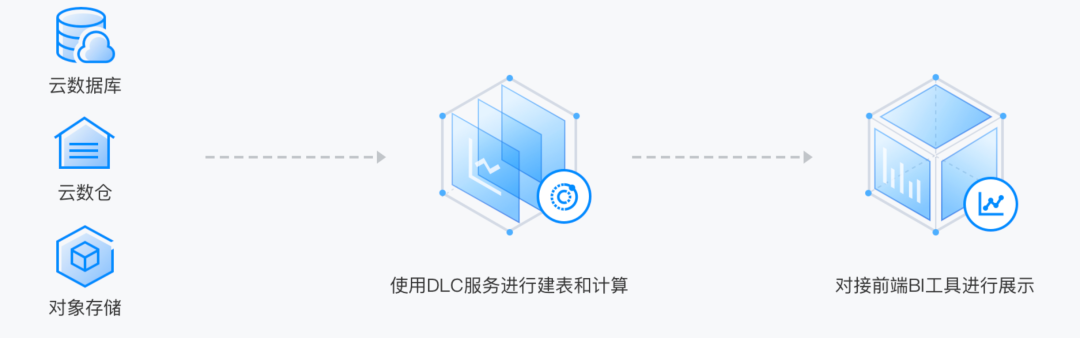
4. ЭГвЛдЊЪ§Он
гаЭГвЛММЪѕдЊЪ§ОнЙмРэЫпЧѓЃЌЯЃЭћЭГвЛЙмРэЗжЩЂдкИїДІЕФЪ§ОндДЃЌВЂНЈСЂЦѓвЕМЖШЈЯоЙмРэЃЌДгЖјдкИїжжЗжЮіМЦЫув§ЧцЩЯЪЙгУЃЌЖјЮоашдкЪ§ОнЙТЕКжЎМфвЦЖЏЪ§ОнЁЃ
|









