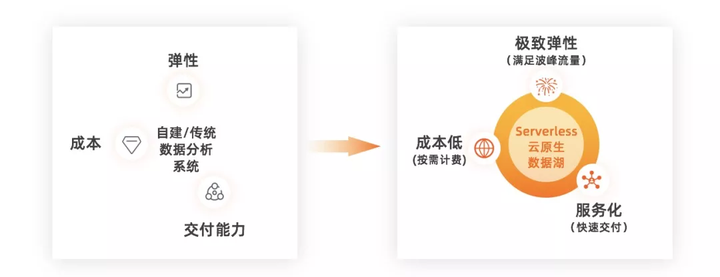
| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫЪ§ОнКўЕФЛњгігыЬєеНЁЂШчКЮЙмРэгыЙЙНЈЪ§ОнКўЃПдЦдЩњЪ§ОнКўЦНЬЈашДђЭЈдЦЛљДЁЩшЪЉЁЂServerless
SparkЗўЮёЕФММЪѕЬєеНЁЂServerless SQLЗўЮёЕФММЪѕЬєеНМАдЦдЩњЪ§ОнКўЖЫЕНЖЫзюМбЪЕМљЁЃЯЃЭћФмЙЛЖдДѓМвгаЫљЦєЗЂКЭАяжњЁЃ
БОЮФРДздгкжЊКѕЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
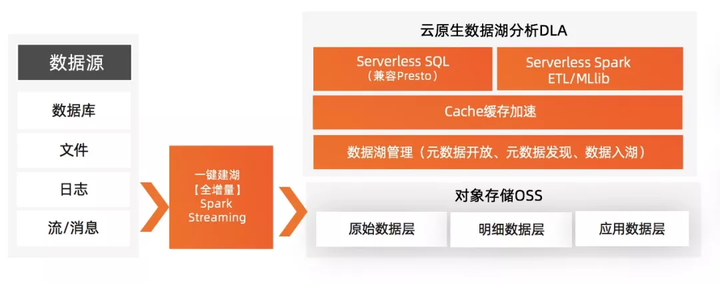
МђНщЃКЪ§ОнКўПЩвдКмКУЕиАяжњЦѓвЕгІЖдЕБЧАЪ§ОнГЁОАдНРДдНЖрЁЂЪ§ОнНсЙЙдНРДдНИДдгЁЂЪ§ОнДІРэашЧѓдНРДдНЖрбљЛЏЕФЮЪЬтЁЃАЂРядЦДг2018ФъЦ№ОЭПЊЪМВМОжЪ§ОнКўЃЌЭЦГіСЫдЦдЩњЪ§ОнКўЗжЮіData
Lake AnalyticsЃЈDLAЃЉЃЌДгЪ§ОнКўЙмРэЃЈАяжњПЭЛЇИпаЇЙмРэЙЙНЈЪ§ОнКўЃЉЃЌServerless
SparkЃЈЬсЙЉИпадМлБШЕФДѓЙцФЃМЦЫуЃЉЃЌServerless SQLЃЈЬсЙЉИпадМлБШЕФдкЯпНЛЛЅЪНЗжЮіЃЉШ§ИіЗНУцАяжњПЭЛЇЭкОђЪ§ОнМлжЕЁЃБОЮФЗжЯэЯрЙиММЪѕЬєеНМАНтОіЗНАИЁЃ
вЛ Ъ§ОнКўЕФЛњгігыЬєеН
Ъ§ОнКўПЩвдКмКУЕиАяжњЦѓвЕгІЖдЕБЧАЪ§ОнГЁОАдНРДдНЖрЁЂЪ§ОнНсЙЙдНРДдНИДдгЁЂЪ§ОнДІРэЕФашЧѓдНРДдНЖрбљЛЏЕФЮЪЬтЁЃGartner
2020ФъЗЂВМЕФБЈИцЯдЪОФПЧАвбОга39%ЕФгУЛЇдкЪЙгУЪ§ОнКўЃЌ34%ЕФгУЛЇПМТЧдк1ФъФкЪЙгУЪ§ОнКўЁЃ
Дг2018ФъЦ№ЃЌАЂРядЦОЭПЊЪМВМОжЪ§ОнКўЃЌЭЦГіСЫдЦдЩњЪ§ОнКўЗжЮіData Lake AnalyticsЃЈМђГЦЃКDLAЃЉВњЦЗЃЌНсКЯЖдЯѓДцДЂOSSвЛЦ№ЃЌДгЕЏадРЉеЙЁЂАДашИЖЗбЁЂЗўЮёЛЏЕШЗНУцДђдьгаОКељСІЕФВњЦЗЁЃЭЈЙ§ВЩгУДцДЂМЦЫуЗжРыФЃЪНЃЌДцДЂКЭМЦЫуЭъШЋАДашИЖЗбЃЌгУЛЇжЛашвЊЮЊЪЕМЪВњЩњМлжЕЕФМЦЫуТђЕЅЃЛDLAЩюЖШЖЈжЦдЦдЩњЕЏадФмСІЃЌЪЕЯжзївЕМЖЕЏадЃЌвЛЗжжгПЩЕЏ300ИіНкЕуЁЃдЦдЩњЪ§ОнКўЗжЮіDLAДгГЩБОЁЂЕЏадЁЂНЛИЖФмСІЗНУцЯрЖдДЋЭГЪ§ОнЗжЮіЗНАИЃЌЛёЕУСЫНЯДѓЕФЬсЩ§ЁЃ
дкдЦЩЯвВвбОгаЪ§ЧЇМвЦѓвЕЪЙгУЪ§ОнКўЗўЮёТњзуЪ§ОнгІгУЃЌШчгбУЫ+ ЕФU-DOPЪ§ОнПЊЗХЦНЬЈИљОнгбУЫ+ЖрФъГСЕэЕФДѓЪ§ОнСьгђОбщЃЌаЮГЩСЫвдAPPЁЂWEBЁЂаЁГЬађЁЂЙуИцгЊЯњЁЂЩчЛсЛЏЗжЯэКЭЭЦЫЭЮЊЛљДЁЕФЖрЖЫжїЬтЪ§ОнЕФВЩМЏКЭДІРэФмСІЃЌЮЊПЭЛЇаЮГЩЙцЗЖЛЏЕФЖрЖЫЪ§ОнзЪВњЁЃгШЦфЪЧРћгУСЫЪ§ОнКўЕФЕЏадФмСІЃЌгІЖдСЫЫЋЪЎвЛЗхжЕЦкМфDAUБЉеЧЕФвЕЮёБфЛЏЃЌР§ШчЃЌЭЈЙ§ЪЕЪЉЗжЮіЫбЫїЙиМќДЪЕФБфЛЏЃЌИФБфЪзвГЙуИцЭЦМіаХЯЂЃЌЖдЛюдОгУЛЇКЭЯТЕЅгУЛЇЗжВЛЭЌЧўЕРЕФЗжЮіЪсРэЃЌМАЪБЕїећгХЛнВпТдЃЌвдЮќв§ИќЖрЕФПЭЛЇаТЙКМАИДЙКЕШЁЃ
Ъ§ОнПтгыДѓЪ§ОнвЛЬхЛЏЧїЪЦдкМгЧПЃЌДЋЭГЕФЪ§ОнПтЪЙгУепгыDBAЃЌвВПЩвдЪЙгУМАЮЌЛЄДѓЪ§ОнЯЕЭГЃЌвЛЬхЛЏНтОіДѓЪ§ОнЕФЮЪЬтЁЃОпЬхдкDLAЬхЯждкЪ§ОнПтЕФЪ§ОнЮоЗьгыДѓЪ§ОнНсКЯЃЌБШШчDLAЬсЙЉЕФвЛМќШыКўНЈВжЕФЙІФмЃЛDLA
Serverless SQLМцШнMySQLавщМАВПЗжгяЗЈЁЃ
DLA ServerlessВњЦЗаЮЬЌЃЌПЊЗЂепжЛашвЊЪЙгУЦНЬЈНгПкМДПЩЃЌШчЪЙгУDLA SQLЕФJDBCНгПкЬсНЛSQLЃЌЪЙгУDLA
SparkЕФOpenAPIЬсНЛSparkзївЕЁЃПЊЗЂепжЛашвЊЙизЂвЕЮёТпМБОЩэЃЌВЛашвЊЙиаФЦНЬЈЕФИДдгТпМЁЃдРДЪЙгУПЊдДзщМўгіЕНЕФКмЖрЭДЕуЖМПЩвдгШаЖјНтЃК
ШыУХУХМїИп
HadoopЩњЬЌЭљЭљашвЊЖрИізщМўЭЌЪБЪЙгУЃЌБШШчYarnЁЂHDFSЁЂSparkЁЂHiveЁЂKerberosЁЂZookeeperЕШЕШЁЃПЊЗЂепашвЊСЫНтЫљгазщМўЃЌвђЮЊПЊЗЂЙ§ГЬжаетаЉзщМўЭљЭљЖМЛсНгДЅЕНЁЃ
ПЊЗЂЮЌЛЄРЇФб
ПЊЗЂепдкПЊЗЂЙ§ГЬжаЛсгіЕНИїИізщМўДјРДЕФЪЙгУЮЪЬтЃЌПЊЗЂепашвЊСЫНтЫљгаетаЉзщМўвдгІЖдетаЉЮЪЬтЁЃетаЉМгжиСЫПЊЗЂепЕФЪЙгУИКЕЃЁЃ
ЮШЖЈадФбвдБЃеЯ
ПЊдДзщМўБОЩэЖМБиаыОЙ§ЯИжТЕФЕїВЮВЂМгЩЯКЯЪЪЕФгВМўзЪдДХфжУЃЌВХФмСМКУдЫааЃЌВЂЧвашвЊаоИДВЛЩйBUGЃЌГіЯжЮЪЬтУЛгаЖЕЕзЁЃ
ШБЗІЪЪгІдЦЕФадФмгХЛЏ
дЦЩЯЕФOSSЁЂPolarDBЕШзщМўЖМЪЧдЦдЩњЕФзщМўЃЌПЊдДзщМўЖдетВПЗжЕФИФдьЪЪгІВЛзуЃЌУЛгаГфЗжЭкОђГіИќИпЕФадФмЁЃ
DLAДгЪ§ОнКўЙмРэЃЈАяжњПЭЛЇИпаЇЙмРэЙЙНЈЪ§ОнКўЃЉЃЌServerless SparkЃЈЬсЙЉИпадМлБШЕФДѓЙцФЃМЦЫуЃЉЃЌServerless
SQLЃЈЬсЙЉИпадМлБШЕФдкЯпНЛЛЅЪНЗжЮіЃЉШ§ИіЗНУцАяжњПЭЛЇЭкОђЪ§ОнМлжЕЁЃећЬхМмЙЙШчЯТЫљЪОЁЃНгЯТРДЃЌБОЮФНЋДгетШ§ИіЗНУцЃЌЗжБ№НВЪіЯрЙиММЪѕЬєеНвдМАНтОіЗНАИЁЃ
Жў ШчКЮЙмРэгыЙЙНЈЪ§ОнКўЃП
Ъ§ОнКўжаЪ§ОнФбвдЙмРэжївЊЬхЯждкСНИіЗНУцЃК
вбОдкЪ§ОнКўДцДЂOSSЩЯУцЕФЪ§ОнШчКЮИпаЇЕФЙЙНЈдЊЪ§ОнЁЃ
ЗЧOSSЪ§ОнШчКЮИпаЇЕФШыКўНЈВжЁЃ
Ъ§ОнКўЙмРэЯрЙиЕФжївЊЙІФмАќРЈдЊЪ§ОнЙмРэЁЂдЊЪ§ОнЗЂЯжЁЂЪ§ОнПтШыКўНЈВжЁЂЪЕЪБЪ§ОнШыКўЁЃНгЯТРДжиЕуНщЩмЁАКЃСПЮФМўдЊЪ§ОнздЖЏЙЙНЈММЪѕЁБКЭЁАШыКўНЈВжЪ§ОнЙмРэММЪѕЁБСНИіЙиМќММЪѕЁЃ
1 КЃСПЮФМўдЊЪ§ОнздЖЏЙЙНЈММЪѕ
ЕБвдOSSзїЮЊЪ§ОнКўДцДЂЃЌДцДЂЕФЪ§ОнЮФМўОпгавдЯТМИИіЬиадЃК
ИёЪНЗсИЛЃКАќРЈCSVЁЂTextЁЂJSONЁЂParquetЁЂOrcЁЂAvroЁЂhudiЁЂDelta
LakeЕШИёЪНЃЌЦфжаCSVЁЂTextгжАќКЌЖржжздЖЈвхЕФЗжИєЗћЕШЁЃ
ЮФМўЪ§дкАйЭђМЖБ№ЃКOSSЕФРЉеЙадМАадМлБШНЯКУЃЌгУЛЇДцДЂдкOSSЕФЮФМўЛсЪЧАйЭђМЖБ№ЁЃ
ЮФМўЖЏЬЌЩЯДЋЃКДцДЂдкOSSЩЯУцЪ§ОнЮФМўОпгаЖЏЬЌГжајЩЯДЋЕФЬиадЃЌаТЕФЮФМўШчКЮПьЫйдіСПаоИФдЊЪ§ОнЁЃ
ЮЊСЫИпаЇЕФЮЊOSSЩЯУцЕФКЃСПЪ§ОнЙЙНЈдЊЪ§ОнЃЌАЂРядЦDLAЬсГіВЂЪЕЯжСЫЁАКЃСПЮФМўдЊЪ§ОнздЖЏЙЙНЈММЪѕЁБЁЃОпЬхММЪѕШчЯТЭМЫљЪОЃЌКЫаФНтОіСЫЃКЭђБэЭђЗжЧјЪЖБ№ЁЂдіСПИажЊИќаТдЊЪ§ОнСНИіЮЪЬтЁЃ
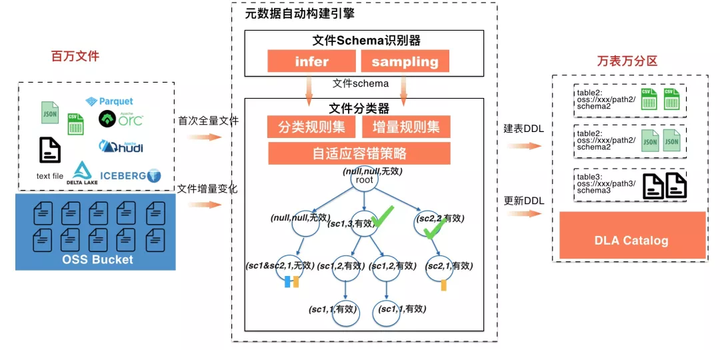
ЭђБэЭђЗжЧјЪЖБ№
гУЛЇOSSЩЯУцЕФЮФМўЪ§СПЛсЕНАйЭђМЖБ№ЃЌетаЉЮФМўВЛНіИёЪНВЛЭЌЃЌБШШчJSONЁЂCSVЁЂTextЕШЃЌЖјЧвЭЌвЛжжИёЪНгЩгквЕЮёЪєадВЛЭЌОпЬхЕФSchemaзжЖЮвВВЛвЛбљЁЃИУММЪѕЭЈЙ§ЮФМўSchemaЪЖБ№ЦїДюХфЮФМўЗжРрЦїжЇГжздЖЏЩњГЩЭђБэЭђЗжЧјЁЃЦфжаЮФМўSchemaЪЖБ№ЦїБШШчеыЖдJSONЕЅЮФМўЪЖБ№ЕН0.15sЁЂCSVЕЅЮФМўЪЖБ№0.2sЃЌДюХфПЩВхАЮЕФжЧФмВЩбљВпТдМАЗжВМЪНВпТдЃЌАйЭђЮФМўЕФSchemaЪЖБ№ПЩвдЕНЗжжгМЖБ№ЁЃЮФМўЗжРрЦїЭЈЙ§ЪїЕФНсЙЙНјааОлКЯЁЂМєжІЁЂбЙЫѕЃЌАйЭђМЖБ№ЮФМўЕФЗжРрЪЖБ№ашвЊ290msзѓгвЁЃ
діСПИажЊИќаТ
ЛЇЛсЭљOSSЩЯУцГжајВЛЖЯЕФЩЯДЋЮФМўЃЌдЊЪ§ОнздЖЏЙЙНЈМШвЊАбЪєгквбОДДНЈБэЕФЮФМўSchemaБфЛЏИќаТЕНвбгаЕФБэЃЌЭЌЪБЖдЖРСЂаТдіЕФЮФМўДДНЈаТЕФБэЁЃетРявЛЗНУцЁАЮФМўSchemaЪЖБ№ЦїЁБЭЈЙ§ЛёШЁOSSЩЯУцЮФМўЕФдіМгЁЂЩОГ§БфЛЏЖдБфЛЏЕФЮФМўНјааЪЖБ№ЃЌЭЌЪБЁАЮФМўЗжРрЦїЁБЖдаТдіЕФЮФМўSchemaКЭвбОДДНЈЕФБэНјааЖдБ№ЩњГЩБфЛЏВпТдЃЌФПЧАжЇГждіМгЗжЧјЁЂдіМгзжЖЮЁЂзжЖЮВЛИќИФЁЂВЛИажЊЮФМўЩОГ§4жжВпТдЃЌКѓајПЩвдГжајЬэМгаТЕФВпТдЁЃ
2 ШыКўНЈВжЪ§ОнзщжЏММЪѕ
АбDataBaseМАЯћЯЂШежОЗўЮёЕФЪ§ОнЭГвЛДцДЂЕНЪ§ОнКўДцДЂOSSНјааЙмРэЃЌФмЙЛТњзуМЦЫуМгЫйЁЂЙЙНЈЪ§ВжЙщЕЕЁЂРфШШЗжРыЕШвЕЮёашЧѓЁЃDLAЕФШыКўНЈВжЪ§ОнзщжЏММЪѕАќРЈШ§жжЪ§ОнзщжЏЙмРэФЃЪНЃКОЕЯёФЃЪНЁЂЗжЧјФЃЪНЁЂдіСПФЃЪНЃЌШ§жжФЃЪНФмЙЛДюХфгбКУжЇГжетаЉвЕЮёГЁОАЁЃ
ОЕЯёФЃЪН
УПДЮШЋСПЭЌВНдДПтвЛИіDatabaseЯТУцЫљгаБэЕФЪ§ОнЕНЪ§ОнКўДцДЂOSSжЎЩЯЃЌЭЌВНЦкМфПЩвдзіЕНдДПтИКдидіМгПижЦдк10%вдФкЁЃетРяжївЊЪЙгУСЫШЋОжЭГвЛЪ§ОнЗжЦЌЕїЖШЫуЗЈЁЃБЃГжЪ§ОнКўЕФЪ§ОнКЭдДПтвЛжТЁЃ
ЗжЧјФЃЪН
УцЖдЙщЕЕГЁОАжЇГжАДЬьШЋСПМАдіСПЭЌВНдДПтЪ§ОнЕНЪ§ОнКўЃЌВЂвдЪБМфЗжЧјЕФЗНЪННјаазщжЏЃЌЗНБуЙщЕЕЙмРэЁЃетжжФЃЪНФмЙЛзіЕНаЁЪБМЖБ№ЕФЪБМфбгГйЁЃ
діСПФЃЪН
етжжФЃЪНЭЈЙ§ааСаЛьДцММЪѕЁЂcommitlogМАindexЙмРэММЪѕЃЌПЩвдзіЕНT+10minЕФЪ§ОнШыКўЁЃЦфжаЭЈЙ§deltaЕФдіСПЮФМўМАвьВНcompactionММЪѕНтОіСЫаЁЮФМўЮЪЬтЃЛЭЈЙ§deltaдіСПЮФМўМАЫїв§ММЪѕПЩвджЇГжDatabaseГЁОАИќаТЁЂЩОГ§ШежОЕФдіСПЪЕЪБаДШыЃЛЭЈЙ§commitlogЕФЗНЪНМЧТМЗжЧјЮФМўЕФгГЩфЃЌНтОіАйЭђЗжЧјдкДЋЭГCatalogЙмРэФЃЪНадФмТ§ЕФЮЪЬтЁЃ
Ш§ дЦдЩњЪ§ОнКўЦНЬЈашДђЭЈдЦЛљДЁЩшЪЉ
DLAећЬхЪЧвЛИіЖрзтЛЇЕФМмЙЙЃЌЗжRegionВПЪ№ЃЌУПИіRegionЕФгУЛЇЙВЯэвЛЬзПижЦТпМЁЃащФтМЏШКVCЪЧТпМЕФИєРыЕЅдЊЁЃЦНЬЈжЇГж
Serverless SparkЁЂServerless SQLЕШв§ЧцЃЌДђдьдЦдЩњЗўЮёЁЃ
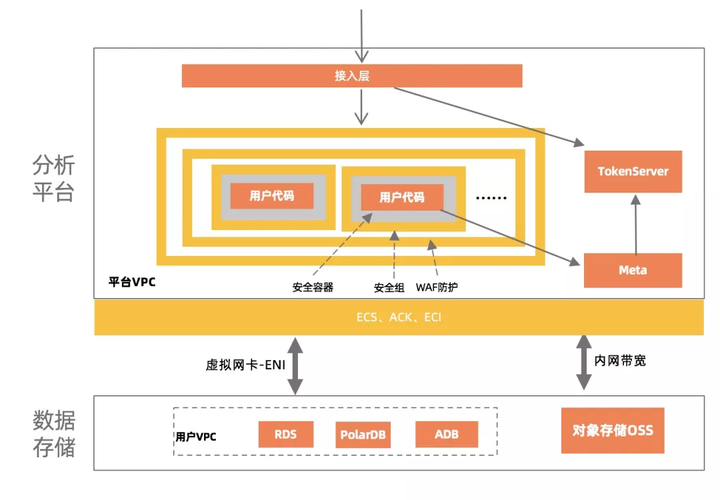
ШчЩЯЭМЫљЪОЃЌЦНЬЈжївЊУцСйЕФЬєеНгаЃКзЪдДИпаЇЙЉИјЁЂАВШЋЗРЛЄЁЂЗУЮЪЪ§ОндДЕФДјПэБЃеЯЁЃ
1 зЪдДИпаЇЙЉИј
дЦдЩњЦНЬЈЛљгкАЂРядЦЕФЕззљECS&ACK&ECIЃЌгыАЂРядЦIAASзЪдДДѓГиДђЭЈЃЌБОRegionПчПЩгУЧјзЪдДЕїЖШЃЌБЃеЯзЪдДЕФЙЉИјЁЃжЇГж1ЗжжгЕЏ300ИіНкЕуЃЌЕЅПЭЛЇдкДѓRegion
5wМЦЫуНкЕузЪдДЕФБЃеЯЁЃ
2 АВШЋЗРЛЄ
гУЛЇПЩвдаДШЮвтЕФДњТыЦНЬЈФкдЫааЃЌПЩФмЪЧЙЪвтЖёадЕФЙЅЛїааЮЊЃЌШчЙћУЛгаШЮКЮБЃЛЄЃЌдђЦНЬЈУцСйАВШЋЮЃЯеЁЃдкАВШЋЗНУцЃЌЮвУЧЭЈЙ§ШчЯТММЪѕБЃеЯАВШЋадЃК
вЛДЮУмдПЃКУПИіJobШЮЮёЖМЛсШЅTokenServerЩъЧыСйЪБЕФTokenЃЌJobЪЇаЇTokenЛсЙ§ЦкЃЌШчЙћДцдкЙЅЛїааЮЊЃЌдђЦНЬЈЛсжБНгШУTokenЙ§ЦкЃЌдђЗУЮЪMetaЕШЗўЮёЛсБЛОмОјЁЃ
дЄЗРDDOS&зЂШыЙЅЛїЃКЫљгаЕФЗУЮЪЦНЬЈЗўЮёЕФЧыЧѓЃЌЖМЛсЖдНгЕНАВШЋЗРЛЄжааФЃЌАВШЋЗРЛЄжааФМьВтгаШЮКЮЙЅЛїЛђепзЂШыааЮЊЃЌжБНгЙиБеЭјТчЖЫПкЁЃ
МЦЫуШнЦїИєРыЃКМЦЫуНкЕуМфВЩгУАЂРядЦздбаЕФАВШЋШнЦїЃЌШнЦїБОЩэПЩвдЪЕЯжVMЯрЭЌЕФАВШЋИєРыМЖБ№ЁЃ
АВШЋАзУћЕЅЃКгУЛЇЛЅЯржЎМфЕФЭјТчЪЧЭъШЋИєРыЕФЁЃ
ENIащФтЭјПЈЃКДђЭЈVPCашвЊХфжУздМКеЫКХЯТЕФАВШЋзщКЭащФтНЛЛЛЛњЃЈVSwitchЃЉЃЌХфжУжЎКѓНсЫуНкЕуШнЦїЛсЗжХфгУЛЇVPCЖдгІVSwitchЭјЖЮЕФЕФIPЃЌВЂЙвдигУЛЇЕФАВШЋзщЁЃ
3 ИпЭЬЭТЭјТчДјПэ
ЗУЮЪOSSЗўЮёЪЧЭЈЙ§ИпЭЬЭТЕФДјПэЗўЮёЁЃ
ЪЙгУENIММЪѕЗУЮЪздГжVPCЃЌИњдкздГжVPCФкECSЩЯВПЪ№МЦЫув§ЧцЗУЮЪздГжVPCФкЪ§ОнвЛбљЃЌДјПэЭЌбљЪЧVPCФкЭјДјПэЁЃ
ЫФ Serverless SparkЗўЮёЕФММЪѕЬєеН
Apache SparkЪЧФПЧАЩчЧјзюЮЊСїааЕФПЊдДв§ЧцЃЌВЛЕЋОпБИСїЁЂSQLЁЂЛњЦїбЇЯАвдМАЭМЕШМЦЫуФмСІЃЌвВПЩвдСЌНгЗсИЛЕФЪ§ОндДЁЃЕЋЪЧЃЌУцЖдЪ§ОнКўГЁОАЃЌДЋЭГМЏШКАцSparkЗНАИЃЌГ§СЫУцСйЧАУцЬсЕНЕФЪ§ОнЙмРэРЇФбЁЂдЫЮЌГЩБОЁЂМЦЫузЪдДЕЏадФмСІВЛзуЁЂЦѓвЕМЖФмСІШѕЕШЮЪЬтЭтЃЌЛЙУцСйЗУЮЪOSSЕФадФмВЛМбЁЂИДдгзївЕФбвдЕїЪдЕШЮЪЬтЁЃ
НшжњгкЕкЖўеТНкЬсЕНЕФЪ§ОнКўЙмРэЛњжЦЃЌПЩвдКмКУЕиНтОіЪ§ОнЙмРэФбЬтЁЃНшжњгкЕкШ§еТНкЬсЕНЕФЖрзтЛЇАВШЋЦНЬЈЃЌDLA
SparkЪЕЯжСЫШЋаТЕФдЦдЩњServerlessВњЦЗаЮЬЌЃЌКмКУЕиНтОіСЫЕЏадЮЪЬтЁЂдЫЮЌГЩБОЮЪЬтвдМАЦѓвЕМЖашЧѓЮЪЬтЁЃБОеТНкЖдSparkЗУЮЪOSSЕФадФмгХЛЏвдЖрзтЛЇUIЗўЮёзіНјвЛВНеЙПЊЁЃ
1 SparkЗУЮЪOSSгХЛЏ
ЩчЧјАцБОЕФЮЪЬт
ПЊдДАцSparkЗУЮЪOSSЪ§ОнФЌШЯВЩгУHadoop FileFormatНгПкжБНгЖдНгOSSFileSystemЪЕЯжЁЃИУЗНЗЈдкЪЕМљжаЗЂЯжДцдкадФмВюЃЌвЛжТадФбвдБЃжЄЕШЮЪЬтЁЃ
ЃЈ1ЃЉSparkЗУЮЪOSSадФмВю
КЫаФдвђдкгкOSS KVФЃаЭИњHDFSЮФМўЪїФЃаЭЕФВювьЁЃFileFormatЫуЗЈзюГѕЩшМЦЪЧЛљгкHDFSЮФМўЯЕЭГЃЌШЛЖјЖдЯѓДцДЂШчOSSЃЌЮЊСЫНтОіРЉеЙадЃЌБОжЪЩЯВЩгУЕФЪЧKVФЃаЭЁЃKVФЃаЭЯрЖдгкHDFSЮФМўЯЕЭГВювьНЯДѓЃЌБШШчRenameDirectoryНгПкЃЌдкHDFSжажЛЪЧжИеыВйзїЃЌЕЋдкKVжаЃЌашвЊНЋЫљгазгЮФМўКЭФПТМЕФKVжДааRenameЃЌадФмПЊЯњКмДѓЃЌВЂЧвБЃжЄВЛСЫдзгадЁЃHadoop
FileOutputFormatдкаДШыЪ§ОнЕФЪБКђЯШаДЕНСйЪБФПТМЃЌзюКѓаДШызюжеФПТМЃЌСйЪБФПТМЕНзюжеФПТМЕФЙ§ГЬжаашвЊзіЮФМўЪїКЯВЂЃЌКЯВЂЙ§ГЬжагаДѓСПRenameВйзїЁЃ
ЃЈ2ЃЉвЛжТадФбБЃжЄ
FileFormat v1ЫуЗЈжаЃЌКЯВЂЮФМўЪїВйзїШЋВПдкAppMasterЕЅЕужДааЃЌаЇТЪЗЧГЃЕЭЃЌгШЦфЪЧЖЏЬЌЗжЧјГЁОАЁЃЮЊСЫНтОіAppMasterЕЅЕуЃЌЩчЧјЬсЙЉСЫЫуЗЈ2ЃЌЦфКЫаФЫМТЗЪЧНЋКЯВЂЙ§ГЬВЂааЕНTaskжажДааЃЌдкадФмЩЯЛсгавЛЖЈЕФЬсИпЃЌЕЋЪЧЃЌШчЙћJobжДааЪЇАмЃЌВПЗжГЩЙІЕФTaskЛсНЋЪ§ОнаДШызюжеЪ§ОнФПТМЃЌЕМжТдрЪ§ОнЮЪЬтЁЃ
Spark OSSЗУЮЪгХЛЏ
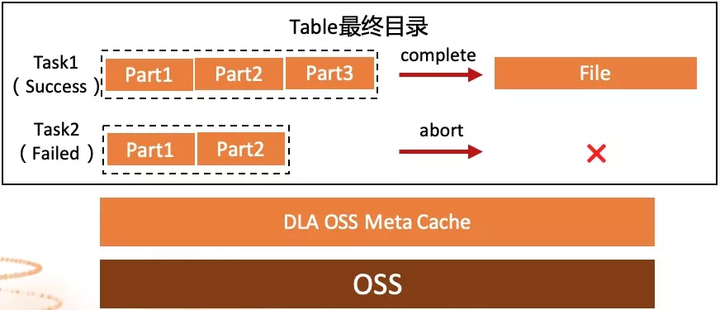
ЃЈ1ЃЉЛљгкMultipartUploadЕФFileOutputFormatЪЕЯж
еыЖдSparkЗУЮЪOSSЕФЬиЕуЃЌЮвУЧШЋаТЪЕЯжСЫHadoop FileOutputFormatНгПкЃЌШчЩЯЭМЫљЪОЁЃЫуЗЈЕФИФНјжиЕудкгХЛЏКЯВЂВйзїЃЌКЯВЂЕФКЫаФЪЧНтОіЮФМўКЮЪБПЩМћЕФЮЪЬтЁЃOSSЬсЙЉMultipartUploadНгПкЃЌвВОЭЪЧЖЯЕуајДЋЙІФмЃЌЮФМўПЩвдЗжЦЌЩЯДЋЃЌЩЯДЋУЛгаНсЪјЃЌЗжЦЌЮФМўЪЧВЛПЩМћЕФЁЃНшжњИУЬиадЃЌЮвУЧПЩвдШУTaskжБНгНЋЪ§ОнаДШыЕНзюжеФПТМЃЌжЛгазївЕГЩЙІВХШУЮФМўзюжеПЩМћЃЌИУЗНЗЈВЛгУЯШаДШыСйЪБФПТМЃЌвВОЭДѓДѓМѕЩйСЫдЊЪ§ОнЕФВйзїЁЃЖдгкжДааЪЇАмЕФTaskаДШыЕФСйЪБЗжЦЌЃЌЮвУЧдкзївЕНсЪјЪБЃЌжДааAbortВйзїЃЌОЭПЩвдНЋЦфЩОГ§ЃЌетвВОЭНЕЕЭСЫПеМфеМгУЁЃ
еыЖдSparkЕфаЭETL Benchmark TerasortЃЌдк1TBЪфШыЪ§ОнСПЕФЧщПіЯТЃЌDLA
FileOutputFormatжДааЪБМфЫѕЖЬ62%ЃЌадФмЬсЩ§163%ЁЃЖјеыЖдЖЏЬЌЗжЧјГЁОАЃЌЩчЧјЫуЗЈ1дЫааЪЇАмЃЌЫуЗЈ2ПЩвджДааГЩЙІЃЌDLA
FileOutputFormatЫуЗЈЯрБШЫуЗЈ2адФмЛЙвЊНјвЛВНЬсЩ§124%ЁЃ
ЃЈ2ЃЉOSSдЊЪ§ОнCache
SparkЖСШЁOSSЕФЙ§ГЬжаЃЌдкResolveRelationНзЖЮЃЌSparkЛсБщРњOSSЕФФПТМЃЌНтЮіБэНсЙЙКЭЗжЧјНсЙЙЃЌвдМАНтЮіSchemaЃЌИУЙ§ГЬжаЭЌбљЛсгаДѓСПдЊЪ§ОнВйзїЃЌВЂЧвЭЌвЛИіOSS
ЖдЯѓЕФдЊЪ§ОнЛсБЛЗУЮЪЖрДЮЁЃеыЖдИУЮЪЬтЃЌЮвУЧЪЕЯжСЫЖдOSSдЊЪ§ОнЕФЛКДцЃЌЕквЛДЮЗУЮЪЕНЕФOSSЖдЯѓдЊЪ§ОнОЭЛсБЛЛКДцЕНБОЕиЃЌКѓајШчЙћЗУЮЪИУЖдЯѓжБНгЖСШЁБОЕиЛКДцЁЃетжжЗНЪНПЩвдзюДѓЯоЖШНЕЕЭЖдOSSдЊЪ§ОнЕФЗУЮЪЁЃCacheЛњжЦПЩвдШУResolveRelationга1БЖзѓгвЕФадФмЬсЩ§ЃЌеыЖдЕфаЭЕФSparkВщбЏГЁОАЃЌИУЛњжЦећЬхПЩвдЬсЩ§60%ЕФадФмЁЃ
2 ЖрзтЛЇUIЗўЮё
UIЗўЮёЖдгкПЊЗЂепРДЫЕжСЙиживЊЃЌПЊЗЂШЫдБвРРЕUIЗўЮёНјаазївЕЕїЪдЃЌвдМАЩњВњзївЕЕФЮЪЬтХХВщЁЃКУЕФUIЗўЮёПЩвдКмКУЕиМгЫйбаЗЂаЇТЪЁЃ
HistoryServerЕФЭДЕу
SparkЩчЧјЬсЙЉHistoryServerЬсЙЉЖдSparkРњЪЗзївЕЕФUIКЭШежОЗўЮёЃЌдкЪЕМЪгІгУжагіЕНжюЖрЭДЕуЃЌЕфаЭШчЯТЃК
ЃЈ1ЃЉEventlogПеМфПЊЯњДѓ
HistoryServerвРРЕSparkв§ЧцНЋдЫаажаЕФEventаХЯЂШЋВПМЧТМЕНFileSystemжаЃЌШЛКѓКѓЬЈЛиЗХВЂЛцГіUIвГУцЁЃЖдгкИДдгзївЕКЭГЄзївЕEventlogСПНЯДѓЃЌПЩвдДяЕНАйGBЩѕжСTBМЖБ№ЁЃ
ЃЈ2ЃЉИДдгзївЕКЭГЄзївЕВЛжЇГж
ИДдгзївЕЛђепГЄзївЕЕФEventlogКмДѓЃЌHistoryServerЛсНтЮіЪЇАмЃЌЩѕжСOOMЁЃдйМгЩЯПеМфПЊЯњДѓЕФдвђЃЌгУЛЇвЛАуЖМжЛФмЙиБеEventlogЁЃ
ЃЈ3ЃЉReplayаЇТЪВюЃЌбгГйИп
HistoryServerВЩгУКѓЬЈReplay EventlogЕФЗНЪНЛЙдSpark UIЃЌЯрЕБгкАбSparkв§ЧцЕФЪТМўШЋВПжиЗХвЛБщЃЌПЊЯњДѓЃЌЛсгабгГйЁЃЬиБ№ЪЧзївЕНЯЖрЛђепНЯИДдгЕФЧщПіЯТЃЌбгГйПЩДяЗжжгЩѕжСЪЎЗжжгМЖБ№ЁЃ
DLAЖрзтЛЇSparkUI
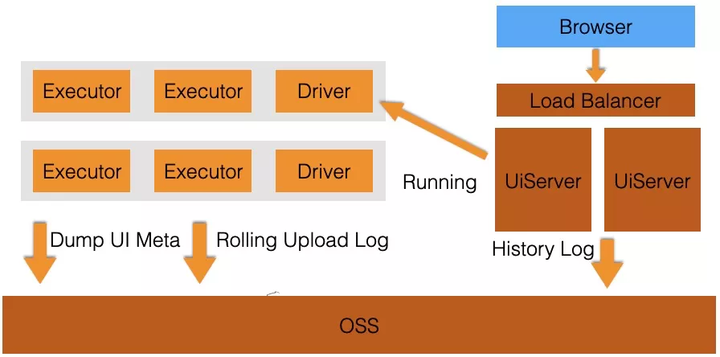
SparkUIЗўЮёЪЧDLAЦНЬЈздбаЕФЖрзтЛЇUIЗўЮёЃЌеыЖдЩчЧјЗНАИзіСЫЩюЖШгХЛЏЃК
ЃЈ1ЃЉШЅEventlog
DLA SparkШЅЕєСЫEventlogвРРЕЃЌдкзївЕНсЪјЕФЪБКђЃЌSpark DriverжЛЪЧdump
UIЕФMetaЕНOSSЃЌБЃДцзївЕНсЪјЧАЕФвГУцдЊаХЯЂЁЃетВПЗжаХЯЂжЛЪЧЯрЖдгкEventlogРДЫЕЃЌЛсДѓДѓМѕЩйЃЌМДЪЙЗЧГЃИДдгЕФзївЕвВжЛгаMBМЖБ№ЁЃUiServerЖСШЁOSSЩЯЕФUI
MetaЃЌНЋЦфЗДађСаЛЏГіРДМДПЩеЙЪОSparkUIвГУцЁЃ
ЃЈ2ЃЉUIServerЫЎЦНРЉеЙ
UIServerжївЊИКд№НтЮіРњЪЗUI MetaКЭЬсЙЉStderrКЭStdoutШежОЗўЮёЃЌЪЧЧсСПЛЏЃЌЮозДЬЌЕФЃЌПЩвдЪЕЯжЫЎЦНРЉеЙЃЌНјЖјжЇГжЭђМЖБ№ПЭЛЇЭЌЪБдкЯпЗўЮёЁЃUIServer
URLВЩгУМгУмtokenзїЮЊВЮЪ§ЃЌtokenДњБэЕФгУЛЇЩэЗнЃЌзївЕidЃЌUIServerОнДЫЪЕЯжЖрзтЛЇЗўЮёЛЏЁЃ
ЃЈ3ЃЉБОЕиШежОздЖЏЙіЖЏ
ЖдгкГЄзївЕЖјбдЃЌStderrЛђепStdoutаХЯЂЛсЫцзХЪБМфдіМгРлЛ§ЃЌзюжеЩѕжСПЩФмДђБЌДХХЬЁЃDLA
SparkАВШЋШнЦїФкжУКѓЬЈНјГЬЃЌЪЕЯжШежОЙіЖЏЃЌБЃДцзюгаМлжЕЕФзюНќвЛЖЮЪБМфЕФШежОЁЃ
Юх Serverless SQLЗўЮёЕФММЪѕЬєеН
DLA Serverless SQLЪЧЛљгкФПЧАЭаЙмгкLinuxЛљН№ЛсжЎЯТЕФPrestoDBДђдьЕФдЦдЩњЪ§ОнКўв§ЧцЃЌAlibabaЭЌЪБвВЪЧPrestoЛљН№ЛсГЩдБжЎвЛЃЌвЛжБдкЙБЯзгХЛЏPrestoЁЃPrestoDBв§ЧцБОЩэОпгагХауЕФЬиадЃК
ШЋФкДцМЦЫуДјРДЕФМЋжТЫйЖШЁЃ
жЇГжЭъећSQLгявхДјРДЕФЧПДѓБэДяСІЁЃ
взгУЕФВхМўЛњжЦЪЙЕУЮвУЧПЩвдЖдШЮКЮЪ§ОндДНјааЙиСЊВщбЏЁЃ
ЧПДѓЕФЩчЧјЪЙЕУЮвУЧЪЙгУжЎКѓУЛгаКѓЙЫжЎгЧЁЃ
ВЛЙ§ЩчЧјPrestoDBЪЧЕЅзтЛЇЕФвЛИів§ЧцЃЌЫќМйЖЈФуЪЧдквЛИіЙЋЫОФкВПЪЙгУЃЌвђДЫЫуСІИєРыЁЂИпПЩгУЕШЕШЗНУцУЛгаЙ§ЖрЭЖШыЃЌетЪЙЕУвЊжБНгЪЙгУЫќРДзїЮЊдЦдЩњЗўЮёЕФв§ЧцДцдкМИИіЮЪЬтЃК
вЛИігУЛЇШчЙћЬсНЛДѓСПДѓВщбЏНЋПЩФмеМгУМЏШКЫљгазЪдДЃЌЕМжТЦфЫќгУЛЇЮоЗЈЪЙгУЁЃ
ЕЅCoordinatorЪЙЕУећИіЗўЮёЕФПЩгУадЮоЗЈЕУЕНБЃжЄЁЃ
ЮвУЧзіСЫвЛЯЕСаЕФгХЛЏЁЂИФдьЪЙЕУЫќПЩвддЦдЩњЕФаЮЬЌЗўЮёЫљгаЕФгУЛЇЃЌНёЬьзХжиНщЩмЖрзтЛЇИєРыММЪѕвдМАЖрCoordinatorСНИіжївЊЕФЬиадЁЃ
ЪзЯШЮвУЧПДвЛЯТDLA Serverless SQLЕФећЬхМмЙЙЃК
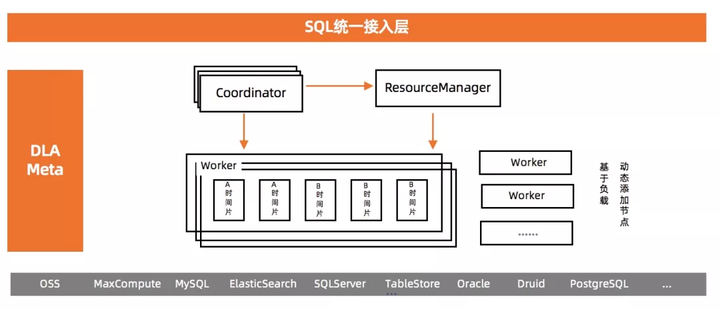
ЮвУЧдкКЫаФЕФPrestoDBМЏШКжмБпНЈЩшСЫжюШчНгШыВуЁЂЭГвЛдЊЪ§ОнЕШЕШЗўЮёРДЪЙЕУгУЛЇПЩвдгУЕУЮШЖЈЁЂгУЕУБуРћЃЌЯТУцЮвУЧНЋдкЖрзтЛЇИєРыММЪѕКЭЖрCoordinatorММЪѕЕФНщЩмжаЯъЯИЦЪЮіЁЃ
1 ЖрзтЛЇИєРыММЪѕ
PrestoDBдЩњЪЧгазЪдДзщЕФжЇГжЃЌЫќПЩвджЇГждкВЛЭЌзЪдДзщМфзівЛЖЈГЬЖШЕФCPUЁЂФкДцЕФЯожЦЃЌЕЋЪЧЫќгавЛаЉЮЪЬтЪЙЕУЮвУЧЮоЗЈЛљгкЫќРДЪЕЯжМЦЫуСІЕФИєРыЃК
ШЋОжЕїЖШВуУцЃКМДЪЙвЛИізтЛЇЪЙгУСЫЙ§ЖрЕФМЦЫуСІзЪдДвВВЛЛсМАЪББЛГЭЗЃЃЌжЛгааТВщбЏЛсБЛBlockЁЃ
WorkerЕїЖШВуУцЃКЫљгазтЛЇЕФSplitЪЧдкЭЌвЛИіЖгСаРяУцНјааЕїЖШЃЌвЛИізтЛЇШчЙћгаЙ§ЖрSplitЛсгАЯьЦфЫќзтЛЇЁЃ
ЮвУЧЕФМЦЫуСІЖрзтЛЇЗНАИШчЯТЃК
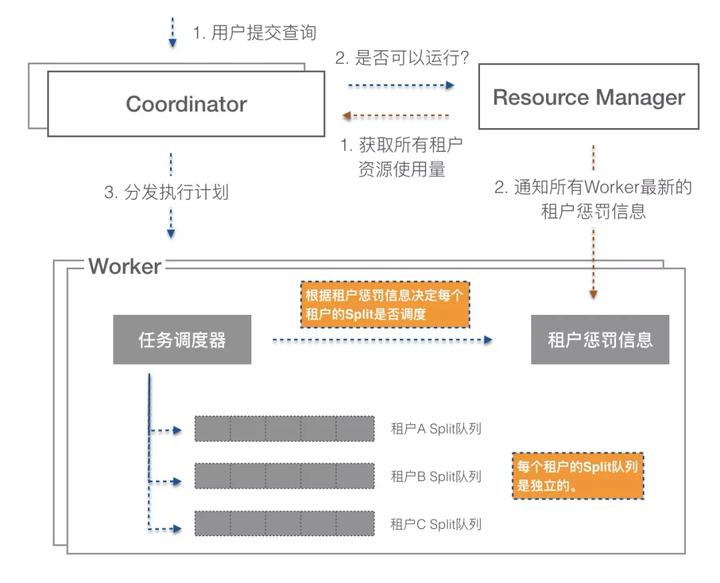
ЮвУЧдкМЏШКжав§ШыСЫвЛИіResourceManagerЕФФЃПщгУгкДгЫљгаЕФCoordinatorЪеМЏЫљгазтЛЇЕФзЪдДЪЙгУаХЯЂЃЌResourceManagerАбЪеМЏЕНЕФзЪдДЪЙгУаХЯЂИњЮвУЧдЄЩшЕФМЦЫуСІЕФуажЕНјааЖдБШЃЌМЦЫуГіФФаЉзтЛЇгІИУБЛГЭЗЃЃЌШЛКѓАбетИіГЭЗЃаХЯЂЭЈжЊЕНЫљгаЕФWorkerЁЃWorkerдкНјааЕїЖШЕФЪБКђЛсВЮееResourceManagerЭЈжЊЙ§РДЕФГЭЗЃаХЯЂОіЖЈФФаЉзтЛЇЕФВщбЏЕУЕНЕїЖШЃЌФФаЉзтЛЇЕФВщбЏВЛНјааЕїЖШЁЃетбљВЛЭЌЕФзтЛЇжЎМфЫуСІОЭЛсЕУЕНИєРыЃЌЮвУЧВтЪдСЫШчЙћгавЛИізтЛЇЙ§СПЪЙгУзЪдДЃЌЫќЛсдкзюГЄ1.3УыжЎФкЕУЕНГЭЗЃЃЌДгЖјЪЭЗХзЪдДИјЦфЫќзтЛЇЃЌЖјЩчЧјФЌШЯАцБОЕФЁАГЭЗЃЁБвЊЕШЕНзтЛЇЫљгаЕФВщбЏжДааЭъГЩВХЛсЕНРДЁЃжЛгадЊЪ§ОнКЭМЦЫуСІЕУЕНИєРыЃЌЮвУЧВХФмЗХаФгУвЛИіМЏШКРДЗўЮёЮвУЧЫљгаЕФгУЛЇЁЃ
2 Multi-CoordinatorММЪѕ
ЩчЧјАцБОЕФPrestoРяУцЃЌCoordinatorЪЧвЛИіЕЅЕуЃЌЫќЛсДјРДСНИіЗНУцЕФЮЪЬтЃК
ПЩгУадвўЛМ: вЛЕЉCoordinatorхДЛњЁЂећИіМЏШКНЋВЛПЩгУДя5ЕН10ЗжжгЁЃ
ЮоЗЈЪЕЯжЮоЗьЩ§МЖЃЌЩ§МЖЙ§ГЬжагАЯьЫљгагУЛЇЕФВщбЏЪЙгУЁЃ
ЮвУЧВЩШЁСЫШчЯТЕФМмЙЙЗНАИЃК
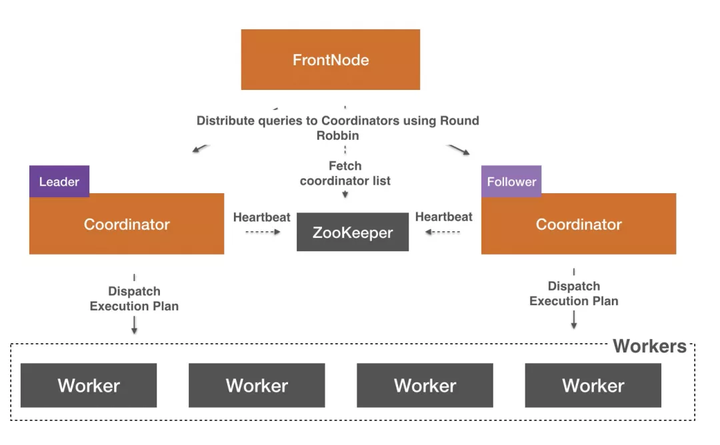
ЪзЯШЮвУЧдкPrestoЕФCoordinatorжЎЩЯЗХжУСЫвЛИіаТЕФFrontNodeФЃПщЃЌШУгУЛЇСЌНгЕНетИіФЃПщЃЌЖјВЛЪЧжБНгСЌНгЕНЮвУЧЕзВуЕФCoordinatorЃЌетбљЮвУЧЕзВуЕНЕзгаЖрЩйИіCoordinatorЃЌЯждкФФИіCoordinatorдкИјгУЛЇЬсЙЉЗўЮёЖМЖдгУЛЇЭъШЋЭИУїЃЌетбљМмЙЙЩЯОЭБШНЯСщЛюЃЌДгЖјЗНБуЮвУЧдкЕзВуЖдCoordinatorНјааРЉеЙЁЃ
FrontNodeдкНгЪеЕНгУЛЇЕФВщбЏжЎКѓЛсАбЧыЧѓАДееRound RobinЕФЗНЪНЗЂЫЭИјЕзВуЕФЖрИіCoordinatorЃЌетбљЖрИіCoordinatorОЭПЩвдЗжЕЃбЙСІЃЌЕЋЪЧећИіМЏШКЛЙЪЧгавЛаЉШЋОжЕФЪТЧщвЊгаЕЅИіCoordinatorРДзіЃЌБШШчPrestoЕФWorkerзДЬЌМрПиЁЂOOM
KillerЕШЕШЃЌвђДЫЮвУЧв§ШыСЫвЛИіZookeeperРДзіCoordinatorбЁжїЕФЪТЧщЃЌбЁжїжЎКѓжїCoordinatorЕФжАд№ЛсИњЩчЧјЕФPrestoРрЫЦЃКзіШЋОжЕФWorkerзДЬЌМрПиЁЂOOM
KillerвдМАжДааЗжХфИјЫќЕФВщбЏЃЛДгCoordinatorЕФжАд№дђБШНЯЧсСПМЖ: жЛИКд№жДааЗжХфИјЫќЕФВщбЏЁЃ
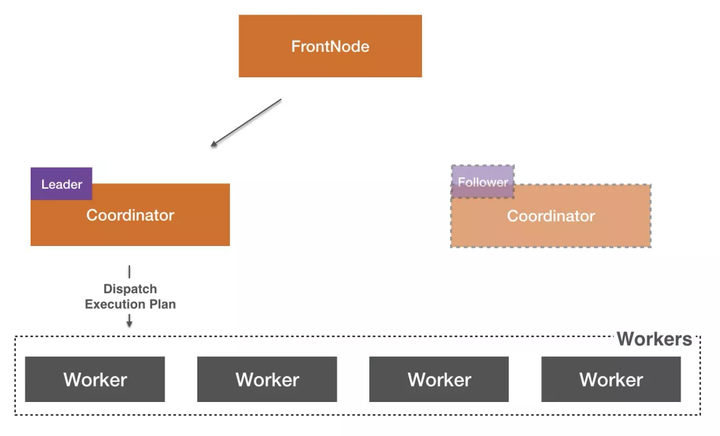
ШчЙћЦфжавЛИіCoordinatorвђЮЊШЮКЮЮЪЬтхДЛњЃЌZookeeperЛсдкУыМЖЗЂЯжетИіЮЪЬтВЂжиаТбЁжїЃЌгУЛЇЪмЕНгАЯьЕФВщбЏжЛвЊжиЪдМДПЩЁЃЖјЧвЮвУЧе§дкзіЕФвЛИіГЂЪдЪЧзіВщбЏЕФздЖЏжиЪдЃЌЖдгкШЗЖЈЪЧЯЕЭГдвђдьГЩЕФЪЇАмЮвУЧзіздЖЏжиЪдЃЌетбљвЛИіCoordinatorЖдгУЛЇЕФгАЯьНЋЛсКмаЁЁЃ
ЖјгаСЫЖрCoordinatorЕФМмЙЙЃЌЮвУЧвЊЪЕЯжЮоЗьЩ§МЖОЭЗЧГЃМђЕЅСЫЃЌЮвУЧдкЩ§МЖЕФЪБКђжЛвЊжїЖЏАбФГИіCoordinator/WorkerДгМЏШКжаеЊГ§ЃЌНјааЩ§МЖЃЌЩ§МЖЭъГЩдйМгШыМЏШКЃЌПЭЛЇПЩвдКСВЛИажЊЃЌвђЮЊдкЩ§МЖЙ§ГЬжаЪМжегавЛИіе§ГЃЙЄзїЕФМЏШКдкИјгУЛЇЬсЙЉЗўЮё,
БШШчЮвУЧдкЩ§МЖДгCoordinatorЕФЪБКђЃЌећИіМЏШКЧщПіШчЯТЃК
ЭЈЙ§жюШчЖрзтЛЇИєРыММЪѕЁЂЖрCoordinatorМмЙЙЕШЕШгХЛЏЃЌЮвУЧЛљгкPrestoDBДђдьСЫПЩвдЗўЮёЫљгаЕФгУЛЇЕФАЂРядЦдЦдЩњЪ§ОнКўServerless
SQLв§ЧцЁЃ
Сљ дЦдЩњЪ§ОнКўЖЫЕНЖЫзюМбЪЕМљ
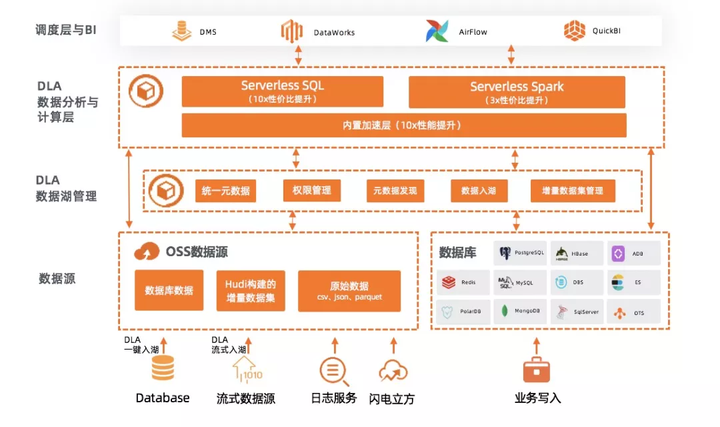
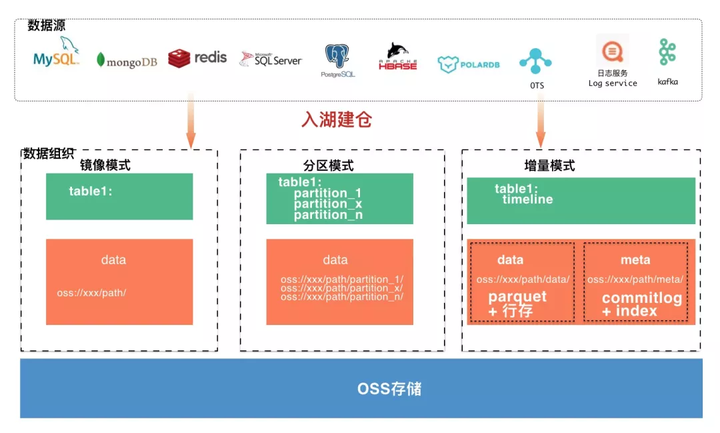
ШчЩЯЭМЗНАИЫљЪОЃЌDLAЬсЙЉСЫЖЫЕНЖЫЕФЗНАИЃЌУцЖдOSSЪ§ОнПЊЗХадДјРДЕФЙмРэМАШыКўРЇФбЃЌDLAЪ§ОнКўЙмРэЃЌАяжњФњвЛеОЪНЙЙНЈАВШЋЪ§ОнКўЁЃ
ЬсЙЉЭГвЛПЊЗХЕФMetaЗўЮёЖдOSSЪ§ОнНјааЙмРэЃЌжЇГжПтБэШЈЯоЁЃ
РћгУдЊЪ§ОнХРШЁЙІФмЃЌПЩвдвЛМќДДНЈOSSЩЯЕФдЊЪ§ОнаХЯЂЃЌЧсЫЩздЖЏЪЖБ№CSV/JSON/ParquetЕШИёЪНЃЌНЈСЂКУПтБэаХЯЂЃЌЗНБуКѓајМЦЫув§ЧцЪЙгУЁЃ
вЛМќНЋRDS/PolarDB/MongoDBЕШЪ§ОнПтЕФЪ§ОнЭЌВНЕНOSSДцДЂЕБжаЃЌДюНЈРфШШЪ§ОнЗжВуЕФвЕЮёМмЙЙЃЌЖдЖрдДКЃСПЪ§ОнНјааЪ§ОнЖДВьЗжЮіЁЃ
жЇГжСїЪНЙЙНЈHudiИёЪНЃЌТњзуT+10ЗжжгЕФбгГйвЊЧѓЃЌМЋДѓЬсЩ§ЗжЮіЕФЖЫЕНЖЫЕФбгГйЁЃ
ServerlessЛЏSQLЗжЮіЃЌАяжњФњМДПЊМДгУЪ§ОнКўЁЃгУЛЇЮоашЙКТђШЮКЮзЪдДЃЌМДПЩдЫааБъзМЕФSQLгяЗЈВщбЏЪ§ОнЁЃ
жЇГжЖдЪ§ОнКўДцДЂOSS CacheМгЫйЃЌЬсЩ§10БЖЕФадФмЁЃ
жЇГжRDSЁЂPolarDBЁЂADBЁЂMongoDBЪ§ОнЪЎжжЪ§ОндДЕФЗжЮіЁЃ
ЖдБШДЋЭГЕФPrestoЁЂImpalaЗНАИЬсЩ§10xЕФадМлБШЬсЩ§ЁЃ
ServerlessЛЏSparkМЦЫуЃЌАяжњФњзджїЭцзЊЪ§ОнКўЁЃгУЛЇЮоашЙКТђШЮКЮзЪдДЃЌМДПЩЪЙгУдЦдЩњЕФSparkЗўЮёЃЌжЇГжOSS
Ъ§PBЕФЪ§ОнЧхЯДЁЂЛњЦїбЇЯАЁЂгУЛЇПЩБрГЬЃЌЭцзЊЪ§ОнКўЁЃ
УПЗжжгПЩЕЏГі500ИіНкЕуВЮгыМЦЫуЁЃ
ЖдБШДЋЭГЕФздНЈSparkЗНАИЬсЩ§3xЕФадМлБШЬсЩ§ЁЃ
|









