| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫдЊЪ§ОнЙмРэУцСйЕФЬєеНЁЂдЦдЩњЪ§ОнКўЕФдЊЪ§ОнЙмРэМмЙЙЁЂдЊЪ§ОнЙмРэКЫаФММЪѕНтЮіМАдЦдЩњЪ§ОнКўзюМбЪЕМљЁЃЯЃЭћФмЙЛЖдДѓМвгаЫљЦєЗЂКЭАяжњЁЃ
БОЮФРДздгкжЊКѕЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
БГОА
Ъ§ОнКўЕБЧАдкЙњФкЭтЪЧБШНЯШШЕФЗНАИЃЌMarketsandMarketsЪаГЁЕїбаЯдЪОдЄМЦЪ§ОнКўЪаГЁЙцФЃдк2024ФъЛсДг2019ФъЕФ79вкУРН№діГЄЕН201вкУРН№ЁЃвЛаЉЦѓвЕвбОЙЙНЈСЫздМКЕФдЦдЩњЪ§ОнКўЗНАИЃЌгааЇНтОіСЫвЕЮёЭДЕуЃЛЛЙгаКмЖрЦѓвЕдкЙЙНЈЛђепМЦЛЎЙЙНЈздМКЕФЪ§ОнКўЃЌGartner
2020ФъЗЂВМЕФБЈИцЯдЪОФПЧАвбОга39%ЕФгУЛЇдкЪЙгУЪ§ОнКўЃЌ34%ЕФгУЛЇПМТЧдк1ФъФкЪЙгУЪ§ОнКўЁЃЫцзХЖдЯѓДцДЂЕШдЦдЩњДцДЂММЪѕЕФГЩЪьЃЌвЛПЊЪМДѓМвЛсЯШАбНсЙЙЛЏЁЂАыНсЙЙЛЏЁЂЭМЦЌЁЂЪгЦЕЕШЪ§ОнДцДЂдкЖдЯѓДцДЂжаЁЃЕБашвЊЖдетаЉЪ§ОнНјааЗжЮіЪБЃЌЗЂЯжШБЩйУцЯђЗжЮіЕФЪ§ОнЙмРэЪгЭМЃЌдкетбљЕФБГОАЯТвЕНчдкУцЯђдЦдЩњЪ§ОнКўЕФдЊЪ§ОнЙмРэММЪѕНјааСЫЙуЗКЕФЬНЫїКЭТфЕиЁЃ
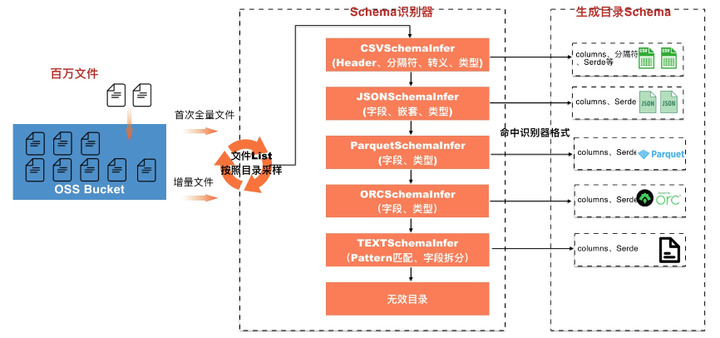
вЛЁЂдЊЪ§ОнЙмРэУцСйЕФЬєеН
1ЁЂЪВУДЪЧЪ§ОнКў
WikipediaЩЯЫЕЪ§ОнКўЪЧвЛРрДцДЂЪ§ОнздШЛ/дЪМИёЪНЕФЯЕЭГЛђДцДЂЃЌЭЈГЃЪЧЖдЯѓПщЛђепЮФМўЃЌАќРЈдЪМЯЕЭГЫљВњЩњЕФдЪМЪ§ОнПНБДвдМАЮЊСЫИїРрШЮЮёЖјВњЩњЕФзЊЛЛЪ§ОнЃЌАќРЈРДздгкЙиЯЕаЭЪ§ОнПтжаЕФНсЙЙЛЏЪ§ОнЃЈааКЭСаЃЉЁЂАыНсЙЙЛЏЪ§ОнЃЈШчCSVЁЂШежОЁЂXMLЁЂJSONЃЉЁЂЗЧНсЙЙЛЏЪ§ОнЃЈШчemailЁЂЮФЕЕЁЂPDFЁЂЭМЯёЁЂвєЦЕЁЂЪгЦЕЃЉЁЃ
ДгЩЯУцПЩвдзмНсГіЪ§ОнКўОпгавдЯТЬиадЃК
Ъ§ОнРДдДЃКдЪМЪ§ОнЁЂзЊЛЛЪ§Он
Ъ§ОнРраЭЃКНсЙЙЛЏЪ§ОнЁЂАыНсЙЙЛЏЪ§ОнЁЂЗЧНсЙЙЛЏЪ§ОнЁЂЖўНјжЦ
Ъ§ОнКўДцДЂЃКПЩРЉеЙЕФКЃСПЪ§ОнДцДЂЗўЮё
2ЁЂЪ§ОнКўЗжЮіЗНАИМмЙЙ
ЕБЪ§ОнКўжЛЪЧзїЮЊДцДЂЕФЪБКђМмЙЙМмЙЙБШНЯЧхЮњЃЌдкЛљгкЪ§ОнКўДцДЂЙЙНЈЗжЮіЦНЬЈЙ§ГЬжаЃЌвЕНчНјааСЫДѓСПЕФЪЕМљЃЌЛљБОЕФМмЙЙШчЯТЃК
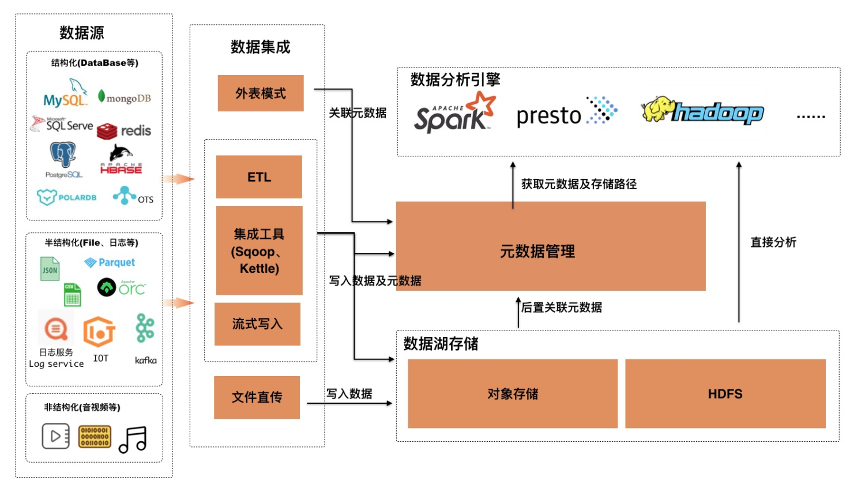
жївЊАќРЈЮхИіФЃПщЃК
Ъ§ОндДЃКдЪМЪ§ОнДцДЂФЃПщЃЌАќРЈНсЙЙЛЏЪ§Он(DatabaseЕШ)ЁЂАыНсЙЙЛЏ(FileЁЂШежОЕШ)ЁЂЗЧНсЙЙЛЏ(вєЪгЦЕЕШ)
Ъ§ОнМЏГЩЃКЮЊСЫНЋЪ§ОнЭГвЛЕНЪ§ОнКўДцДЂМАЙмРэЃЌФПЧАЪ§ОнМЏГЩжївЊЗжЮЊШ§жжаЮЬЌЁЃЕквЛжжЮЊжБНгЭЈЙ§ЭтБэЕФЗНЪНЙиСЊдЊЪ§ОнЃЛЕкЖўжжЮЊЛљгкETLЁЂМЏГЩЙЄОпЁЂСїЪНаДШыФЃЪНЃЌетжжЗНЪНжБНгДІРэЪ§ОнФмЙЛИажЊSchemaЃЌдкаДШыЪ§ОнЕФЙ§ГЬжаЭЌЪБДДНЈдЊЪ§ОнЃЛЕкШ§жжЮЊЮФМўжБНгЩЯДЋЪ§ОнКўДцДЂЃЌашвЊЪТКѓвьВНЙЙНЈдЊЪ§Он
Ъ§ОнКўДцДЂЃКФПЧАвЕНчжївЊЪЙгУЖдЯѓДцДЂвдМАздНЈHDFSМЏШК
дЊЪ§ОнЙмРэЃКдЊЪ§ОнЙмРэЃЌзїЮЊСЌНгЪ§ОнМЏГЩЁЂДцДЂКЭЗжЮів§ЧцЕФзмЯп
Ъ§ОнЗжЮів§ЧцЃКФПЧАгаЗсИЛЕФЗжЮів§ЧцЃЌБШШчSparkЁЂHadoopЁЂPrestoЕШЃЌЫћУЧЭЈГЃЭЈЙ§ЖдНгдЊЪ§ОнРДЛёЕУЪ§ОнЕФSchemaМАТЗОЖЃЛЭЌЪББШШчSparkвВжЇГжжБНгЗжЮіДцДЂТЗОЖЃЌдкЗжЮіЙ§ГЬжаНјаадЊЪ§ОнЕФЭЦЖЯ
ЮвУЧПЩвдПДЕНдЊЪ§ОнЙмРэЪЧЪ§ОнКўЗжЮіЦНЬЈМмЙЙЕФзмЯпЃЌУцЯђЪ§ОнЩњЬЌвЊжЇГжЗсИЛЕФЪ§ОнМЏГЩЙЄОпЖдНгЃЌУцЯђЪ§ОнКўДцДЂвЊНјааЭъЩЦЕФЪ§ОнЙмРэЃЌУцЯђЗжЮів§ЧцвЊФмЙЛЬсЙЉПЩППЕФдЊЪ§ОнЗўЮёЁЃ
3ЁЂдЊЪ§ОнЙмРэУцСйЕФЬєеН
дЊЪ§ОнЙмРэШчДЫживЊЃЌЕЋЪЧЕБЧАПЊдДЕФЗНАИВЛЙЛГЩЪьЃЌОГЃЛсЬ§ЕНДѓМвЙигкдЊЪ§ОнЙмРэЯрЙиЕФЬжТлЃЌБШШчЃК
га10РДИіЪ§ОнДцДЂЯЕЭГЃЌУПжжЖМШЅЖдНгЪЪХфЃЌУПДЮЖМвЊХфжУеЫУмЁЂТЗОЖЃЌецТщЗГЃЌгаУЛгаЭГвЛЕФЪгЭМЃП
вЛИіга200ИізжЖЮЕФCSVЮФМўЃЌЪжЖЏаДГі200ИізжЖЮЕФDDLецЕФКУРлЃПJSONЬэМгСЫзжЖЮУПДЮЖМашвЊЪжЖЏДІРэЯТТ№ЃП
ЮвЕФвЕЮёЪ§ОнЃЌЪЧЗёгаБЛЦфЫћЭЌбЇЩОПтХмТЗЕФЗчЯеЃП
ЗжЧјЬЋЖрСЫЃЌУПДЮЗжЮідкЖСШЁЗжЧјЩЯОгШЛеМгУСЫФЧУДЖрЪБМфЃП
.....
4ЁЂвЕНчЪ§ОнКўдЊЪ§ОнЙмРэЯжзД
ЩЯУцетаЉЪЧДѓМвдкЖдЪ§ОнКўНјааЙмРэЗжЮіЪБгіЕНЕФЕфаЭЮЪЬтЁЃетаЉЮЪЬтЦфЪЕЖМПЩвдЭЈЙ§ЭъЩЦЕФдЊЪ§ОнЙмРэЯЕЭГРДНтОіЃЌДгдЊЪ§ОнЙмРэЕФЪгНЧПЩвдзмНсЮЊЃК
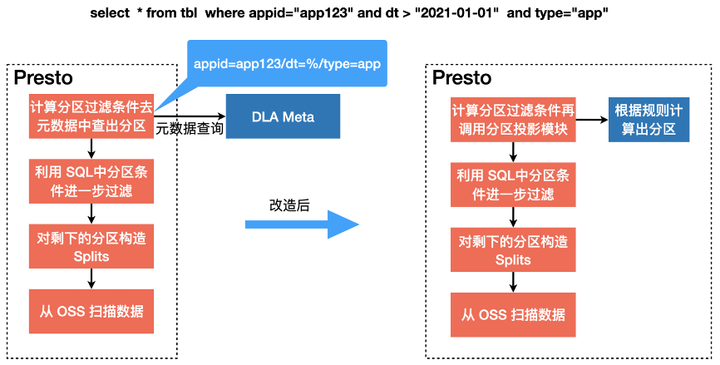
ШчКЮЙЙНЈЪ§ОнЕФЭГвЛЙмРэЪгЭМЃКУцЯђЖржжЪ§ОндДашвЊгавЛЬзЭГвЛЕФЪ§ОнЙмРэФЃаЭЃЌБШШчЭЈЙ§JDBCСЌНгЪ§ОнПтЁЂЭЈЙ§дЦеЫКХЪкШЈЙмРэЖдЯѓДцДЂЮФМўЁЂвЛЬзSerdeЙмРэДІРэВЛЭЌЕФЪ§ОнИёЪНДІРэЗНЪНЕШЁЃ
ШчКЮЙЙНЈЖрзтЛЇЕФШЈЯоЙмРэЃКШчЙћШЋгђЪ§ОнЖМЪЙгУЪ§ОнКўЗНАИЙмРэЃЌЦѓвЕЖрВПУХбаЗЂШЫдБЙВЭЌЪЙгУЪ§ОнКўЭкОђМлжЕЃЌЕЋЪЧШБЩйгааЇЕФЪ§ОнзтЛЇМАШЈЯоИєРыЃЌЛсВњЩњЪ§ОнЗчЯеЃЛ
ШчКЮздЖЏЛЏЕФЙЙНЈдЊЪ§ОнЃКЭЈЙ§ETLФЃЪНЕФЪ§ОнМЏГЩЙЄОпаДШыЪ§ОнКўДцДЂЪБЃЌЖдгІЙЄОпжЊЕРЪ§ОнSchemaПЩвджїЖЏНЈдЊЪ§ОнЃЌетбљОЭашвЊдЊЪ§ОнЗўЮёгаЭъЩЦЕФПЊЗХНгПкЁЃЕЋЪЧдкФГаЉГЁОАЪ§ОнЮФМўжБНгЩЯДЋЕНOSSДцДЂЃЌЧвЮФМўСПОоДѓЁЂЪ§ОнЖЏЬЌдіГЄБфЛЏЃЛетжжЧщПіашвЊгавЛЬзБЛЖЏЭЦЖЯЬсШЁдЊЪ§ОнЕФЗўЮёЃЌзіЕНSchemaИажЊвдМАдіСПЪЖБ№ЁЃ
ШчКЮЬсЙЉУцЯђЗжЮіЕФгХЛЏФмСІЃКБШШчКЃСПЗжЧјЕФИпаЇМгдиЕШЁЃ
еыЖдетаЉЮЪЬтвЕНчдкзіСЫДѓСПЕФЬНЫїКЭЪЕМљЃК
Hive MetastoreЃКдкHadoopЩњЬЌЮЊСЫЙЙНЈЭГвЛЕФЙмРэЪгЭМЃЌгУЛЇЛсдкздМКЕФHadoopМЏШКДюНЈHMSЗўЮёЁЃ
AWS Glue MetaЃКЬсЙЉЖрзтЛЇЕФЭГвЛЪ§ОнКўдЊЪ§ОнЙмРэЗўЮёЃЌХфЬзServerlessЕФдЊЪ§ОнХРШЁММЪѕЩњГЩдЊЪ§ОнЁЃЯрЙиЙІФмЪеЗбЁЃ
Aliyun DLA Meta: MetaМцШнHive MetastoreЃЌжЇГждЦЩЯ15+жжЪ§ОнЪ§ОндДЃЈOSSЁЂHDFSЁЂDBЁЂDWЃЉЕФЭГвЛЪгЭМЃЌЬсЙЉПЊЗХЕФдЊЪ§ОнЗУЮЪЗўЮёЃЌв§ШыЖрзтЛЇЁЂдЊЪ§ОнЗЂЯжЁЂЖдНгHUDIЕШФмСІЁЃDLA
MetaзЗЧѓБпМЪГЩБОЮЊ0ЃЌУтЗбЬсЙЉЪЙгУЁЃЯТУцвВНЋжиЕуНщЩмDLA MetaЕФЯрЙиММЪѕЪЕЯжЁЃ
ЖўЁЂдЦдЩњЪ§ОнКўЕФдЊЪ§ОнЙмРэМмЙЙ
ЮЊСЫНтОіЩЯУцетаЉЬєеНЃЌАЂРядЦдЦдЩњЪ§ОнКўЗжЮіЗўЮёDLAЕФдЊЪ§ОнЙмРэЃЌжЇГжЭГвЛЕФЖрзтЛЇдЊЪ§ОнЙмРэЪгЭМЃЛЪ§ОнФЃаЭМцШнHive
MetastoreЃЛЬсЙЉАЂРядЦOpenAPIЁЂClientЁЂJDBCШ§жжПЊЗХФЃЪНЃЛЭЌЪБЬсЙЉдЊЪ§ОнздЖЏЗЂЯжЗўЮёвЛМќвьВНЙЙНЈдЊЪ§ОнЁЃЯТУцЪЧИїИіФЃПщЕФНщЩмЃК

ЭГвЛдЊЪ§ОнЪгЭМЃКжЇГж15+жаЪ§ОндДЃЌOSSЁЂHDFSЁЂDBЁЂDWЕШЃЛВЂМцШнHive MetastoreЕФЪ§ОнФЃаЭЃЌБШШчSchemaЁЂViewЁЂUDFЁЂTableЁЂPartitionЁЂSerdeЕШЃЌгбКУЖдНгSparkЁЂHadoopЁЂHudiЕШЩњЬЌЃЛ
ЗсИЛЕФПЊЗХФЃЪНЃКжЇГжАЂРядЦOpenAPiЁЂClientЁЂJDBCШ§жжНгПкПЊЗХФЃЪНЃЌЗНБуЩњЬЌЙЄОпМАвЕЮёМЏГЩDLA
MetaЃЌБШШчПЩвдПЊЗЂSqoopдЊЪ§ОнВхМўЖдНгOpenAPIЃЌЭЌВНЪ§ОнЪБЙЙНЈдЊЪ§ОнЃЛФПЧАПЊдДApache
HudiжЇГжЭЈЙ§JDBCЗНЪНЖдНгDLA MetaЃЛDLAФкжУЕФServerless SparkЁЂPrestoЁЂHudiжЇГжЭЈЙ§ClientФЃЪНЖдНгDLA
MetaЃЛ
жЇГжЖрзтЛЇМАШЈЯоПижЦЃКЛљгкUIDЕФЖрзтЛЇЛњжЦНјааШЈЯоЕФИєРыЃЌЭЈЙ§GRANT&REVOKEНјааеЫКХМфЕФШЈЯоЙмРэЁЃ
жЇГжЫЎЦНРЉеЙЃКЮЊСЫТњзуКЃСПдЊЪ§ОнЕФЙмРэЃЌЗўЮёБОЩэЪЧПЩвдЫЎЦНРЉеЙЃЌЭЌЪБЕзВуЪЙгУRDS&PolarDBЕФПтБэВ№ЗжММЪѕЃЌжЇГжДцДЂЕФРЉеЙЁЃ
дЊЪ§ОнЗЂЯжЗўЮёЃКЕБЪ§ОнШыКўЪБУЛгаЙиСЊдЊЪ§ОнЃЌПЩвдЭЈЙ§дЊЪ§ОнЗЂЯжЗўЮёвЛМќздЖЏЙиСЊдЊЪ§ОнЁЃ
ПЩвдПДГідкЖдНгЖржжЪ§ОндДвдМАЪ§ОнМЏГЩЗНЪНЗНУцЬсЙЉСЫгбКУЕФПЊЗХадЃЌФПЧАApache HudiдЩњЖдНгСЫDLA
MetaЃЛдкЗжЮіЩњЬЌЗНУцжЇГжвЕНчЭЈгУЕФЪ§ОнФЃаЭБъзМ(Hive Metastore)ЃЛЭЌЪБЗўЮёБОЩэОпБИЖрзтЛЇЁЂПЩРЉеЙЕФФмСІТњзуЦѓвЕМЖЕФашЧѓЁЃ
Ш§ЁЂдЊЪ§ОнЙмРэКЫаФММЪѕНтЮі
ЯТУцжївЊНщЩмDLA MetaЙигкдЊЪ§ОнЖрзтЛЇЁЂдЊЪ§ОнЗЂЯжЁЂКЃСПЗжЧјЙмРэШ§ЗНУцЕФММЪѕЪЕМљЃЌетМИПщвВЪЧФПЧАвЕНчКЫаФЙизЂКЭЬНЫїЕФЮЪЬтЁЃ
1ЁЂдЊЪ§ОнЖрзтЛЇЙмРэ
дкДѓЪ§ОнЬхЯЕжаЃЌЪЙгУHive MetaStore ЃЈЯТУцМђГЦHMSЃЉзїЮЊдЊЪ§ОнЗўЮёЪЧЗЧГЃЦеБщЕФЪЙгУЗНЗЈЁЃDLA
зїЮЊЖрзтЛЇЕФВњЦЗЃЌЦфжавЛИіБШНЯживЊЕФЙІФмОЭЪЧашвЊЖдВЛЭЌгУЛЇЕФдЊЪ§ОнНјааИєРыЃЌЖјЧвашвЊгЕгаЭъећЕФШЈЯоЬхЯЕЃЛHMS
БОЩэЪЧВЛжЇГжЖрзтЛЇКЭШЈЯоЬхЯЕЁЃАЂРядЦDLA жиаДСЫвЛЬзMeta ЗўЮёЃЌЦфКЫаФФПБъЪЧМцШн HMSЁЂжЇГжЖрзтЛЇЁЂжЇГжЭъећЕФШЈЯоЬхЯЕЁЂЭЌЪБжЇГжДцДЂИїжжЪ§ОндДЕФдЊЪ§ОнЁЃ
ЖрзтЛЇЪЕЯж
ЮЊСЫЪЕЯжЖрзтЛЇЙІФмЃЌЮвУЧАбУПеХПтЕФдЊЪ§ОнКЭАЂРядЦЕФUID НјааЙиСЊЃЌЖјБэЕФдЊЪ§ОнгжЪЧКЭПтЕФдЊаХЯЂЙиСЊЕФЁЃЫљвдЛљгкетжжЩшМЦУПеХПтЁЂУПеХБэЖМЪЧПЩвдЖдгІЕНОпЬхЕФгУЛЇЁЃЕБгУЛЇЧыЧѓдЊЪ§ОнЕФЪБКђЃЌГ§СЫашвЊДЋНјПтУћКЭБэУћЃЌЛЙашвЊНЋЧыЧѓЕФАЂРядЦUID
ДјНјРДЃЌдйНсКЯЩЯЪіЙиСЊЙиЯЕОЭПЩвдФУЕНЯргІгУЛЇЕФдЊЪ§ОнЁЃУПИідЊЪ§ОнЕФAPI ЖМгавЛИіUID ВЮЪ§ЃЌБШШчШчЙћЮвУЧашвЊЭЈЙ§getTable
ЛёШЁФГИігУЛЇЕФБэаХЯЂЃЌећИіСїГЬШчЯТЃК
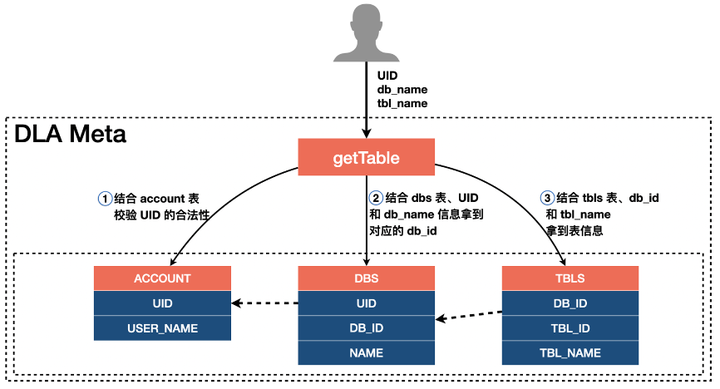
ЩЯУцЕФACCOUNT ЪЧDLA жаДцДЂгУЛЇеЫЛЇаХЯЂЕФБэЃЛDBS КЭTBLS ЪЧгУгкДцДЂдЊЪ§ОнЕФБэЁЃащЯпДњБэЫћУЧжЎМфЕФЙиСЊЙиЯЕЁЃ
ШЈЯоЬхЯЕ
ЮвУЧжЊЕРЃЌвЛАуДѓаЭЕФЦѓвЕЛсДцдкЖрИіВЛЭЌВПУХЃЌЛђепвЛИіБШНЯДѓЕФВПУХашвЊЧјЗжГіВЛЭЌЕФгУЛЇЃЌетаЉгУЛЇжЎМфгжашвЊЙВЯэвЛаЉзЪдДЁЃЮЊСЫНтОіетИіЮЪЬтЃЌDLA
НЋАЂРядЦUID зїЮЊжїеЫКХЃЌDLA userName зїЮЊзгеЫКХРДЧјБ№УПИігУЛЇЃЌЭЌвЛИіАЂРядЦUID
ЯТУцЕФВЛЭЌзггУЛЇЗУЮЪЕФзЪдДЪЧгаЯожЦЕФЃЌБШШчжїеЫКХгУЛЇПЩвдПДЕНЫљгаЕФдЊЪ§ОнЃЛЖјвЛАугУЛЇжЛФмПДЕНвЛВПЗжЁЃЮЊСЫНтОіетИіЮЪЬтЃЌDLA
Meta ЪЕЯжСЫвЛЬзЭъећЕФШЈЯоЬхЯЕЃЌгУЛЇПЩвдЭЈЙ§GRANT/REVOKE ЖдгУЛЇНјааЯрЙиЕФШЈЯоВйзїЁЃ
DLA Meta жаЫљгаЖдЭтЕФдЊЪ§ОнAPI ЖМЪЧгаШЈЯоаЃбщЕФЃЌБШШчCreate Database
ЪЧашвЊгаШЋОжЕФCreate ЛђAll ШЈЯоЕФЁЃжЛгаШЈЯоаЃбщЭЈЙ§ВХПЩвдНјааЯТвЛВНЕФВйзїЁЃФПЧАDLA Meta
ШЈЯоПижЦСЃЖШЪЧзіЕНБэМЖБ№ЕФЃЌПЩвдЖдгУЛЇЪкгшБэМЖБ№ЕФШЈЯоЃЛЕБШЛЃЌСаСЃЖШЁЂЗжЧјСЃЖШЕФШЈЯоЮвУЧвВЪЧПЩвдзіЕНЕФЃЌФПЧАЛЙдкЙцЛЎжаЁЃЯТУцЪЧЮвУЧШЈЯоаЃбщЕФДІРэСїГЬЃК
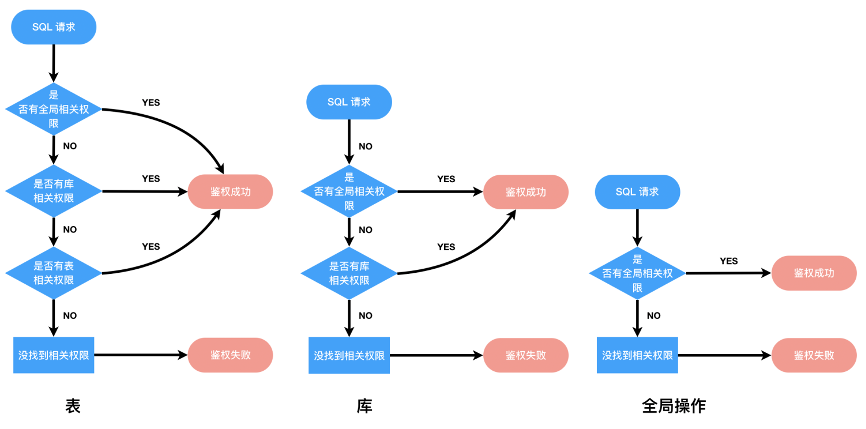
гЩгкDLA PrestoПЩвдМцШнMySQL ШЈЯоВйзїЯрЙиЃЌЮЊСЫНЕЕЭгУЛЇЕФЪЙгУГЩБОЃЌЕБЧАDLA Meta
ЕФШЈЯоЪЧгыMySQL ШЈЯоЪЧМцШнЕФЃЌЫљвдШчЙћФуЖдMySQL ЕФШЈЯоЬхЯЕБШНЯСЫНтЃЌФЧУДетаЉжЊЪЖЪЧПЩвджБНгдЫгУЕНDLA
ЕФЁЃ
2ЁЂдЊЪ§ОнЗЂЯжSchemaЭЦЖЯММЪѕ
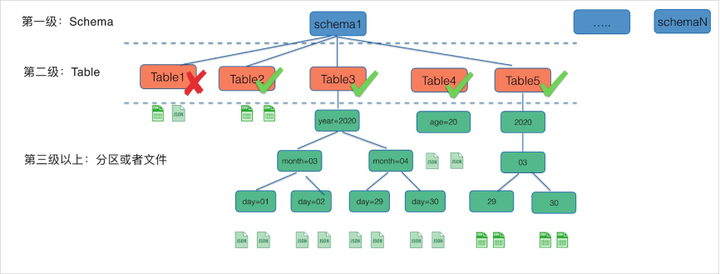
дЊЪ§ОнЗЂЯжЕФЖЈЮЛЃКЮЊOSSЕШДцДЂЩЯУцЕФЪ§ОнЮФМўздЖЏЗЂЯжКЭЙЙНЈБэЁЂзжЖЮЁЂЗжЧјЃЌВЂИажЊаТдіБэ&зжЖЮ&ЗжЧјЕШдЊЪ§ОнаХЯЂЃЌЗНБуМЦЫугыЗжЮіЁЃ
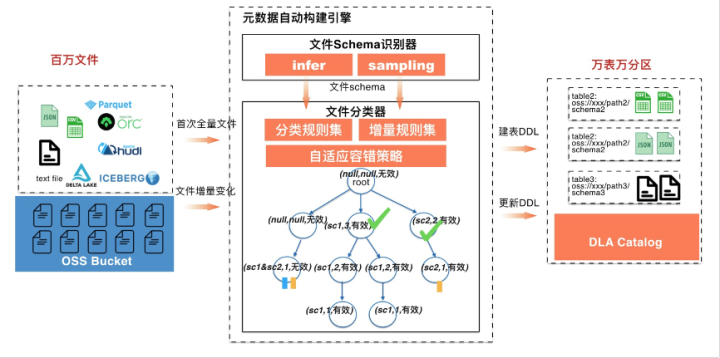
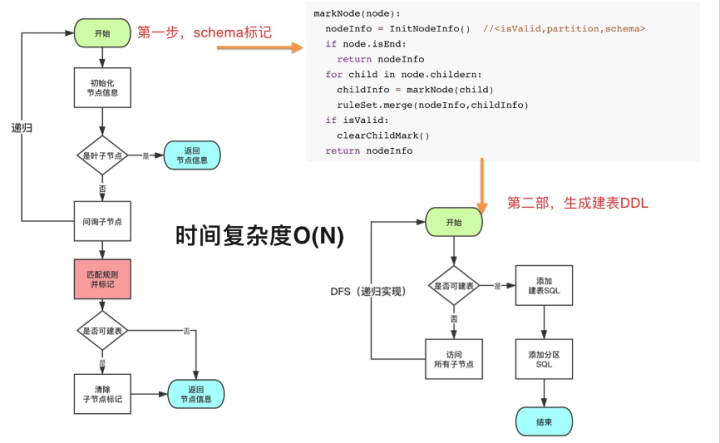
ДгЩЯЭМПЩвдПДГіЃЌдЊЪ§ОнЗЂЯжЕФЪфШыЪЧвЛИіИИФПТМЃЌЯТУцПЩвдАќКЌАйЭђМЖБ№OSSЕФЮФМўЃЌЭЌЪБетаЉЮФМўЛЙдкдіСПЕФЬэМгЁЃЪфГіЮЊИљОнSchemaаХЯЂНјааОлКЯЩњГЩЪ§ФПЮЊЭђМЖБ№ЕФБэЃЌвдМАЕЅБэЭђМЖБ№ЗжЧјЁЃдЊЪ§ОнздЖЏЗЂЯжв§ЧцжївЊАќРЈЮФМўSchemaЪЖБ№ЦїЁЂЮФМўБэЗжРрЦїЁЂMetaЭЌВНШ§ПщЃЌЯТУцжиЕуНщЩмSchemaЪЖБ№ЦїЁЂвдМАЮФМўБэЗжРрЦїЁЃ
ЮФМўSchemaЪЖБ№ЦїЃКетИіФЃПщжївЊгУРДЭЦЖЯOSSЩЯУцЮФМўЕФИёЪНМАзжЖЮЁЃЖдгквЛИіЮФМўЭъШЋУЛгаSchemaаХЯЂЧщПіЯТЃЌЪзЯШашвЊЭЦЖЯГіЪЧЪВУДИёЪНЃЌШЛКѓЛЙашвЊЭЦЖЯГіОпЬхЕФзжЖЮЁЃећИіФЃПщАќРЈЮФМўВЩбљЁЂSchemaЪЖБ№ЦїСНПщЁЃВтЪдБэУїЕЅИіЮФМўЕФSchemaЬНВташвЊ150msзѓгвЃЌШчЙћЖдЫљгаЕФЮФМўНјааШЋСПЕФЪЖБ№ЃЌећИіаЇТЪЛсБШНЯЕЭЃЌDLA
дЊЪ§ОнЗЂЯжгавЛЬзВЩбљЕФММЪѕЃЌМѕЩйЮФМўЪЖБ№ЕФЪ§СПЁЃОпЬхЕФSchemaЪЖБ№ЦїгЩвЛзщSchemaЭЦЖЯЕФВпТдзщГЩЃЌУцЖдвЛИіУЛгаШЮКЮЯШбщаХЯЂЕФЮФМўЃЌЭЈЙ§ж№ИіЦЅХфCSVЁЂJSONЁЂParquetЕШЭЦЖЯЦїЕФЗНЪНРДНјааЪЖБ№ЃЌУПжжЭЦЖЯЦїдкаЇТЪКЭзМШЗадЩЯУцзіСЫДѓСПгХЛЏЃЌБШШчCSVФкВПАќКЌСЫ30+жжИљОнБэЭЗЁЂЗжИєЗћЁЂзЊвхЁЂв§гУзщКЯЕФВпТдЃЌЭЌЪБзжЖЮЕФЪЖБ№ЪЙгУЪ§ОнааВЩбљЕФЗНЪНБЃжЄзМШЗТЪЕФЧщПіЯТЃЌМѕЩйдЖГЬIOЖСШЁЁЃ
ЮФМўЗжРрЦїЃКгЩгкЮФМўдкOSSЩЯУцЪЧАДееФПТМДцДЂЕФЃЌЕБЭЈЙ§SchemaЪЖБ№ЦїЪЖБ№ГіСЫвЖзгНкЕуФПТМЯТУцЕФSchemaЧщПіКѓЃЌШчЙћУПИівЖзгНкЕуФПТМДДНЈвЛеХБэЃЌБэЛсКмЖрЃЌЙмРэИДдгЧвФбвдЗжЮіЁЃвђДЫашвЊгавЛЬзЮФМўЗжРрЦїРДОлКЯЩњГЩзюжеЕФБэЁЃЧвжЇГждіСПЮФМўЕФSchemaБфИќЃЌБШШчЬэМгзжЖЮЁЂЬэМгЗжЧјЕШЁЃЯТУцЪЧећИіЗжРрЫуЗЈЙ§ГЬЃЌИљОнФПТМЪїаЮЕФНсЙЙЃЌЕквЛВНЯШЩюЖШБщРњВЂНсКЯЁАЮФМўSchemaЪЖБ№ЦїЁБдкУПИіНкЕуОлКЯзгНкЕуЕФSchemaЪЧЗёМцШнЃЌШчЙћМцШндђАбзгФПТМЯђЩЯКЯВЂЮЊЗжЧјЃЌШчЙћВЛМцШндђУПИізгФПТМДДНЈвЛеХБэЁЃОЙ§ЕквЛВНКѓУПИіНкЕуЪЧЗёПЩвдДДНЈБэЁЂЗжЧјаХЯЂЃЌвдМАКЯВЂКѓЕФSchemaЖМЛсДцДЂдкНкЕуЩЯУцЃЛЕкЖўВНдйДЮБщРњПЩвдЩњГЩЖдгІЕФMetaДДНЈЪТМўЁЃ
етжжЭЈгУЕФЫуЗЈПЩвдЪЖБ№ШЮвтФПТМАкЗХЃЌЕЋЪЧгЩгкУцЯђКЃСПЗжЧјЕФГЁОАЃЌЪТЯШВЛжЊЕРЗжЧјФПТМЪЧЗёПЩвдОлКЯЃЌетбљУПИіФПТМЖМашвЊВЩбљЪЖБ№ЃЌЧвдкОлКЯЪБШчЙћФГИіЗжЧјКЭЦфЫћЗжЧјМцШнЖШДяВЛЕНвЊЧѓЃЌЛсВ№ЗжЩњГЩДѓСПЕФБэЃЌдкетжжГЁОАЯТадФмвЛАуЁЃШчЙћгУЛЇЕФOSSФПТМНсЙЙАДееЕфаЭЕФЪ§ВжНсЙЙЃЌПтЁЂБэЁЂЗжЧјФЃЪНЙцЛЎЃЌФЧУДдкЗжЧјЪЖБ№МАБэЪЖБ№ЩЯУцЛсгаЙЬЖЈЕФЙцдђЃЌетбљПЩвдЖдЩЯУцЕФЫуЗЈБщРњЙ§ГЬМєжІЃЌЗжЧјМфЕФВЩбљТЪНјвЛВНМѕЩйЃЌЧвШнДэТЪИќИпЁЃЪ§ВжФЃЪНЕФФПТМЙцЛЎашвЊШчЯТЃК
3ЁЂКЃСПЗжЧјДІРэММЪѕ
ЗжЧјЭЖгА
дкДѓЪ§ОнГЁОАжаЃЌЗжЧјЪЧгУгкЬсЩ§адФмЗЧГЃГЃМћЕФЗНЗЈЃЌКЯРэЛЎЗжЗжЧјгаРћгкМЦЫув§ЧцЙ§ТЫЕєДѓСПЮогУЕФЪ§ОнДгЖјЬсЩ§МЦЫуадФмЁЃЕЋЪЧШчЙћЗжЧјЗЧГЃЖрЃЌБШШчЕЅБэЪ§АйЭђЕФЗжЧјЃЌФЧУДМЦЫув§ЧцДгдЊЪ§ОнЗўЮёВщбЏЗжЧјЫљашвЊЕФЪБМфОЭЛсЩЯЩ§ЃЌДгЖјЪЙЕУВщбЏЕФећЬхЪБМфБфГЄЁЃБШШчЮвУЧПЭЛЇгаеХБэга130ЖрЭђЗжЧјЃЌвЛИіМђЕЅЕФЗжЧјЙ§ТЫВщбЏдЊЪ§ОнЗУЮЪетПщОЭЛЈСЫ4УывдЩЯЕФЪБМфЃЌЖјЪЃЯТЕФМЦЫуЪБМфШДВЛЕН1УыЃЁ
еыЖдетИіЮЪЬтЃЌЮвУЧЩшМЦПЊЗЂГіСЫвЛжжНазіЁАЗжЧјгГЩфЁБЕФЙІФмЃЌЗжЧјгГЩфШУгУЛЇжИЖЈЗжЧјЕФЙцдђЃЌШЛКѓОпЬхУПИіSQLВщбЏЕФЗжЧјЛсжБНгЭЈЙ§SQLгяОфжаЕФВщбЏЬѕМўНсКЯгУЛЇДДНЈБэЪБКђжИЖЈЕФЙцдђжБНгдкМЦЫув§ЧцжаМЦЫуГіРДЃЌДгЖјВЛгУШЅВщбЏЭтВПЕФдЊЪ§ОнЃЌБмУтдЊЪ§ОнБЌеЈДјРДЕФадФмЮЪЬтЁЃОВтЪдЃЌЩЯЪіГЁОАЯТЃЌРћгУЗжЧјЭЖгАЩњГЩЗжЧјашвЊЕФЪБМфНЕЮЊ1УывдЯТЃЌДѓДѓЬсЩ§ВщбЏаЇТЪЁЃ
ЛљгкOSSЕФMetatableММЪѕ
ПЩвдПДЕНDLAЕФЗжЧјЭЖгАММЪѕНЕЕЭСЫКЃСПЗжЧјЧщПіЯТЃЌЗУЮЪMetaЗўЮёЕФЪБМфПЊЯњЃЌИУММЪѕЭЈЙ§МЦЫуВрМЦЫуЗжЧјЕФЗНЗЈРДЙцБмЕєКЃСПЗжЧјЕФЗУЮЪЁЃDLAФПЧАЛљгкApache
HudiЪЕЯжDLA LakehouseЃЌЬсЙЉИпаЇЕФКўВжЁЃЦфжадкКЃСПЗжЧјДІРэетПщЃЌApache HudiНЋБэЕФКЃСПЗжЧјгГЩфаХЯЂДцДЂдквЛИіOSSЩЯУцЕФObjectРяУцЃЌетбљЭЈЙ§ЖСШЁШєИЩИіObjectЮФМўПЩвдЛёШЁЫљгаЕФЗжЧјаХЯЂЃЌЙцБмЗУЮЪMetaЗўЮёЕФПЊЯњЁЃЯТУцНщЩмDLA
LakehouseЛљгкHudiЕФMetatableММЪѕЃК
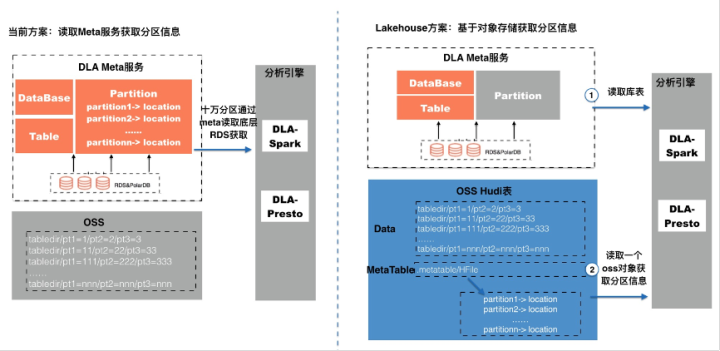
ДгЩЯЭМПЩвдПДЕНDLA MetaжаЛсДцДЂПтЁЂБэЁЂЗжЧјЕФаХЯЂЃЌЪЙгУЕБЧАЗНАИOSSЩЯУцЗжЧјФПТМЖдгІЕФЗжЧјаХЯЂЛсДцДЂдкDLA
MetaЗўЮёжаЃЌЕБЗжЮів§ЧцЗУЮЪетеХБэЕФЪБКђЃЌЛсЭЈЙ§DLA MetaЗўЮёЖСШЁДѓСПЕФЗжЧјаХЯЂЃЌетаЉЗжЧјаХЯЂЛсДгЕзВуЕФRDSжаЖСГіЃЌетбљЛсгавЛЖЈЕФЗУЮЪПЊЯњЁЃШчЙћЪЙгУЕНDLA
LakehouseЗНАИЃЌПЩвдНЋДѓСПЕФЗжЧјгГЩфаХЯЂЕЅЖРДцДЂдкЛљгкOSSЖдЯѓЕФHudi MetatableжаЃЌMetatableЕзВуЛљгкHFileжЇГжИќаТЩОГ§ЃЌЭЈЙ§KVДцДЂЗНЪНЬсИпЗжЧјВщбЏаЇТЪЁЃетбљЗжЮів§ЧцдкЗУЮЪЗжЧјБэЕФЪБКђЃЌПЩвджЛдкMetaжаЖСШЁПтЁЂБэЧсСПЕФаХЯЂЃЌЗжЧјаХЯЂПЩвдЭЈЙ§ЖСШЁOSSЕФЖдЯѓЛёШЁЁЃФПЧАИУЗНАИЛЙдкЙцЛЎжаЃЌDLAЯпЩЯЛЙВЛжЇГжЁЃ
ЫФЁЂдЦдЩњЪ§ОнКўзюМбЪЕМљ
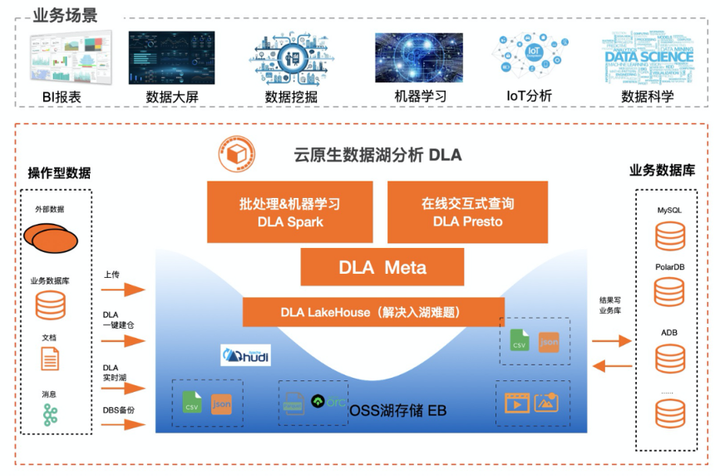
зюМбЪЕМљЃЌвдDLAЮЊР§згЁЃDLAжТСІгкАяжњПЭЛЇЙЙНЈЕЭГЩБОЁЂМђЕЅвзгУЁЂЕЏадЕФЪ§ОнЦНЬЈЃЌБШДЋЭГHadoopжСЩйНкдМ50%ЕФГЩБОЁЃЦфжаDLA
MetaжЇГждЦЩЯ15+жжЪ§ОнЪ§ОндДЃЈOSSЁЂHDFSЁЂDBЁЂDWЃЉЕФЭГвЛЪгЭМЃЌв§ШыЖрзтЛЇЁЂдЊЪ§ОнЗЂЯжЃЌзЗЧѓБпМЪГЩБОЮЊ0ЃЌУтЗбЬсЙЉЪЙгУЁЃDLA
LakehouseЛљгкApache HudiЪЕЯжЃЌжївЊФПБъЪЧЬсЙЉИпаЇЕФКўВжЃЌжЇГжCDCМАЯћЯЂЕФдіСПаДШыЃЌФПЧАетПщдкМгНєВњЦЗЛЏжаЁЃDLA
Serverless PrestoЪЧЛљгкApache PrestoDBбаЗЂЕФЃЌжївЊЪЧзіСЊАюНЛЛЅЪНВщбЏгыЧсСПМЖETLЁЃDLAжЇГжSparkжївЊЪЧЮЊдкКўЩЯзіДѓЙцФЃЕФETLЃЌВЂжЇГжСїМЦЫуЁЂЛњЦїбЇЯАЃЛБШДЋЭГздНЈSparkгазХ300%ЕФадМлБШЬсЩ§ЃЌДгECSздНЈSparkЛђепHiveХњДІРэЧЈвЦЕНDLA
SparkПЩвдНкдМ50%ЕФГЩБОЁЃЛљгкDLAЕФвЛЬхЛЏЪ§ОнДІРэЗНАИЃЌПЩвджЇГжBIБЈБэЁЂЪ§ОнДѓЦСЁЂЪ§ОнЭкОђЁЂЛњЦїбЇЯАЁЂIOTЗжЮіЁЂЪ§ОнПЦбЇЕШЖржжвЕЮёГЁОАЁЃ
|









