| БрМЭЦМі: |
БОЮФжївЊНщЩмДѓЪ§ОндквНСЦаавЕЕФЗЂеЙЧїЪЦЁЂгІгУГЁОАвдМАвНСЦаавЕНЈЩшДѓЪ§ОнЯюФПШЁЕУЕФЪевцЁЂУцСйЕФЗчЯегыгІЖдДыЪЉЁЂЯюФПММЪѕТЗЯпЕФбЁдёЁЂММЪѕФбЕугыНтОіАьЗЈЁЂШеГЃдЫЮЌЗНАИЛЙЙщФЩСЫвзВШЕНЕФПгвдМАДІРэАьЗЈЁЃ
БОЮФРДздгкtwtЩчЧј ЃЌгЩAliceБрМЁЂЭЦМіЁЃ
|
|
1 ДѓЪ§ОндквНСЦаавЕЕФЗЂеЙЧїЪЦ
ОнгаЙиЛњЙЙЭГМЦЪ§ОнЃЌзюНќМИФъШЋЧђЪ§ОнВњЩњСПбИУЭдіГЄЁЃЕН2020ФъШЋЧђЪ§ОнВњЩњСПДяЕН50.5ZBЃЌЭЌБШдіГЄ23%ЁЃдкЪ§ОнДЂСПВЛЖЯдіГЄЕФЭЦЖЏЯТЃЌДѓЪ§ОнВњвЕвВНЋЙЙНЈГіЖрВуЖрбљЕФЪаГЁИёОжЃЌОпгаЙуРЋЗЂеЙПеМфЁЃЮДРДСНФъРяЃЌДѓЪ§ОнЪаГЁНЋГЪЯжЮШВНЗЂеЙЕФЬЌЪЦЃЌдіЫйБЃГждк14%зѓгвЁЃ
НќФъРДЃЌЫцзХдЦМЦЫуЁЂДѓЪ§ОнЁЂЮяСЊЭјЁЂвЦЖЏЛЅСЊЭјЁЂШЫЙЄжЧФмЕШаТаЫММЪѕВЛЖЯгПЯжКЭГЩЪьЃЌМгЫйСЫДЋЭГвНСЦаавЕгыетаЉаТаЫММЪѕЕФШкКЯЃЌЦфжавдНЁПЕвНСЦДѓЪ§ОнЮЊДњБэЕФвНСЦаТвЕЬЌЃЌВЛЖЯЕФМЄЗЂзХвНСЦаавЕЕФЗЂеЙЁЃдкЙ§ШЅМИФъЃЌНЁПЕвНСЦДѓЪ§ОнгІгУЪаГЁЙцФЃПьЫйдіГЄЃЌДг2014ФъЕФ6.06вкдЊУЭдіЕН2018ФъЕФ56.3вкдЊЃЌФъИДКЯдіГЄТЪДяЕН74.6%ЁЃЦфжаЃЌЪ§ОнећКЯЙмРэЪаГЁЙцФЃЮЊ29.7вкдЊЃЌеМБШЮЊ52.8%ЁЃЯТЭМЪЧвНСЦаавЕДѓЪ§ОнгІгУЕФСьгђЃК
вНСЦДѓЪ§ОнЕФЧБдкМлжЕОоДѓЃЌЦфгІгУгажњгкЬсИпвНСЦЗўЮёжЪСПЁЂМѕЩйзЪдДРЫЗбЁЂгХЛЏзЪдДХфжУЁЂПижЦЦБЃааЮЊЁЂИФЩЦздЮвНЁПЕЙмРэЕШЁЃ
2 ДѓЪ§ОндквНСЦаавЕЕФгІгУГЁОА
ФПЧАЃЌвНСЦДѓЪ§ОнЕФгІгУГЁОАжївЊАќРЈСйДВОіВпжЇГжЁЂНЁПЕМАТ§ВЁЙмРэЁЂжЇИЖКЭЖЈМлЁЂвНвЉбаЗЂЁЂвНСЦЙмРэЕШЃЌЗўЮёЖдЯѓКИЧОгУёЁЂвНСЦЗўЮёЛњЙЙЁЂПЦбаЛњЙЙЁЂвНСЦБЃЯеЛњЙЙЁЂЙЋЙВНЁПЕЙмРэВПУХЕШЁЃ
гЩгкДѓЪ§ОндквНСЦЙмРэЁЂвНСЦбаОПЕШСьгђОпгаЖРЬигХЪЦЃЌдНРДдНЖрвНСЦЯрЙиЕЅЮЛгыДѓЪ§ОнЦѓвЕЁЂвНСЦаХЯЂЛЏЙЋЫОКЯзїЃЌЭЌЪБИпЕШвНбЇРрдКаЃвВЗзЗзГЩСЂДѓЪ§ОнбаОПдКЃЌгШЦфЪЧ2018Фъ4дТЃЌФГДѓбЇНЁПЕвНСЦДѓЪ§ОнЙњМвбаОПдКдкОЉГЩСЂЃЌБъжОзХвНСЦДѓЪ§ОндкИпаЃКЭвНдКСЊКЯбаОПЗНУцзпЩЯСЫаТЕФИпЖШЁЃ
вНСЦаавЕдкДѓЪ§ОнЪРНчжаеМБШДя30%вдЩЯЃЌУПФъвд48%ЕФЫйЖШдіГЄЃЌЪЧдіЫйзюПьЕФаавЕжЎвЛЃЌДг2009ФъЕН2020ФъвНСЦЪ§ОндіГЄСЫ44БЖЃЌвНСЦаавЕЪ§ОнГЪPBМЖдіГЄЃЌвЛИіШ§МзвНдКУПФъЕФвНСЦгАЯёЪ§ОнНЋдіМгЪ§ЪЎTB,ИљОнЙРЫуЃЌвЛИіжаЕШГЧЪа50ФъРлМЦЕФвНСЦЪ§ОнСПНЋДяЕН10PBМЖЁЃ
3 вНСЦаавЕНЈЩшДѓЪ§ОнЯюФПШЁЕУЕФЪевц
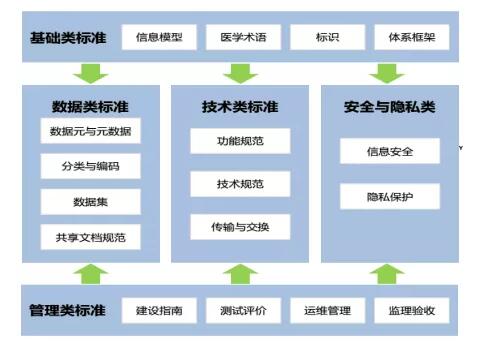
вНдКЪ§ОнЃЌАќРЈУХеяЪеЗбЁЂЕчзгВЁРњЁЂМьбщМьВщЪ§ОнКЭвНбЇгАЯёЪ§ОнЕШЃЌвНСЦЛњЙЙНЁПЕвНСЦЪ§ОнЕФЛЅСЊЛЅЭЈКЭБъзМЛЏШыПтЃЌЮДРДНЋж№ВННгШывНСЦБЃЯеЪ§ОнЁЂЛљвђВтађЪ§ОнЁЂНЁПЕжЧФмЩшБИЪ§ОнКЭЕкШ§ЗННЁПЕЙмРэЛњЙЙЪ§ОнЕШЁЃвНдКНЈЩшДѓЪ§ОнЯюФППЩЬсЙЉжкЖрШЫШКЕФОЋзМвНСЦЪ§ОнЗўЮёЃЌЮЊСйДВОіВпгыПЦбаЁЂЛљвђВтађЁЂаТвЉбаЗЂКЭНЁПЕЙмРэЕШЬсЙЉКЃСПДцДЂМАДѓЪ§ОнЗжЮіФмСІЁЃ
ДѓЪ§ОнМЋДѓЬсИпСЫСйДВОіВпЕФПЦбЇад
ДѓЪ§ОнНЋМЋДѓЬсИпвНСЦОіВпЃЌЬиБ№ЪЧСйДВОіВпЕФПЦбЇадЃЌжївЊАќРЈгУвЉЗжЮіЁЂвЉЦЗВЛСМЗДгІЁЂМВВЁВЂЗЂжЂЁЂжЮСЦСЦаЇЯрЙиадЗжЮіЁЂжЦЖЈИіадЛЏжЮСЦЗНАИЕШЃЌДѓЪ§ОнЗжЮіММЪѕНЋЪЙСйДВОіВпжЇГжЯЕЭГИќжЧФмЃЌЭЈЙ§ЭкОђвНСЦЮФЯзЪ§ОнНЈСЂвНСЦзЈМвЪ§ОнПтЃЌДгЖјИјвНЩњЬсГіеяСЦНЈвщЃЌЬсабвНЩњЗРжЙЧБдкЕФДэЮѓЃЌМѕЩйКЭНЕЕЭвНСЦЪТЙЪТЪЁЃ
ДѓЪ§ОнФмИќКУЕФЗўЮёгкЛМеп
ДѓЪ§ОнЭЈЙ§ШЋУцЗжЮіВЁШЫЬиеїЪ§ОнКЭСЦаЇЪ§ОнЃЌШЛКѓБШНЯЖржжИЩдЄДыЪЉЕФгааЇадЃЌПЩвдевЕНеыЖдЬиЖЈВЁШЫЕФзюМбжЮСЦЭООЖЁЃбаОПБэУїЃЌЖдЭЌвЛВЁШЫРДЫЕЃЌвНСЦЗўЮёЬсЙЉЗНВЛЭЌЃЌвНСЦЛЄРэЗНЗЈКЭаЇЙћВЛЭЌЃЌГЩБОЩЯвВДцдкКмДѓВювьЁЃНЋгаПЩФмМѕЩйЙ§ЖШжЮСЦЃЌвдМАжЮСЦВЛзуЁЃ
ДѓЪ§ОнДДаТвНСЦаавЕашЧѓПЊЗЂ
ЫцзХЮЂВЉЁЂЮЂаХЁЂЕчЩЬЦНЬЈЕШУННщдкPCЖЫКЭвЦЖЏЖЫЕФДДаТКЭЗЂеЙЃЌЙЋжкЗжЯэаХЯЂБфЕУИќМгБуНнздгЩЃЌЖјЙЋжкЗжЯэаХЯЂЕФжїЖЏадДйЪЙСЫЭјТчЦРТлетвЛаЮЪНЕФЗЂеЙЁЃЮЂВЉЁЂЮЂаХЦРТлАцЩЯГЩЧЇЩЯвкЕФЭјТчЦРТлаЮГЩСЫНЛЛЅадДѓЪ§ОнЃЌЦфжадЬВиСЫОоДѓЕФвНСЦаавЕашЧѓПЊЗЂМлжЕЃЌжЕЕУЙмРэепжиЪгЁЃ
зїЮЊвНСЦаавЕЃЌШчЙћФмЖдЭјЩЯвНСЦаавЕЕФЦРТлЪ§ОнНјааЪеМЏЃЌНЈСЂЭјЦРДѓЪ§ОнПтЃЌШЛКѓдйРћгУЗжДЪЁЂОлРрЁЂЧщИаЗжЮіСЫНтЯћЗбепЕФЯћЗбааЮЊЁЂМлжЕШЁЯђЁЂЦРТлжаЬхЯжЕФаТЯћЗбашЧѓЃЌвдДЫРДИФНјКЭДДаТВњЦЗЃЌжЦЖЉКЯРэЕФМлИёМАЬсИпЗўЮёжЪСПЃЌДгжаЛёШЁИќДѓЕФЪевцЃЌжЛвЊвНСЦаавЕЦѓвЕЦНЪБЩЦгкЛ§РлКЭдЫгУздЖЏЛЏЙЄОпЪеМЏЁЂЭкОђЁЂЭГМЦКЭЗжЮіетаЉЪ§ОнЃЌЮЊЮвЫљгУЃЌЖМЛсгааЇЕиАяжњздМКЬсИпЪаГЁОКељСІКЭЪевцФмСІЃЌгЎЕУСМКУЕФаЇвцЁЃ
4 вНСЦаавЕНЈЩшДѓЪ§ОнЯюФПУцСйЕФЗчЯегыгІЖдДыЪЉ
вНСЦЪ§ОнАВШЋЙиЯЕЕНЛМепвўЫНЁЂММЪѕбаЗЂЕШживЊЁЂУєИаСьгђЃЌвЛЕЉЗЂЩњЪ§ОнаЙТЖНЋЖдЛМепШКЬхЁЂЩчЛсЮШЖЈФЫжСЙњМвАВШЋдьГЩбЯжигАЯьЁЃвђДЫЃЌзіКУвНСЦЪ§ОнЕФАВШЋЗРЛЄгыжЮРэжСЙиживЊЁЃ
1ЁЂ СйДВбаОПЪ§ОнАВШЋЗчЯеЁЃСйДВбаОПЪ§ОнвЛАуЪЧжИгЩвНдКЁЂбЇЪѕбаОПЛњЙЙКЭвНСЦЦѓвЕЗЂЦ№ЕФЃЌжївЊгУгквЉЮяЁЂвНСЦЦїаЕЁЂвНСЦеяЖЯЕФПЦбЇбаОПЃЌЫљЩцМАЕФЛљБОШЫПкбЇзЪСЯЁЂеяЖЯаХЯЂЁЂВЁР§МАЛМепБЈИцЕШЪ§ОнаХЯЂЁЃВЮгыСйДВбаОПЕФвНЛММАгаЙиаХЯЂЃЌдкЭЈЙ§зЈЯпЁЂЛЅСЊЭјЯпТЗЕШЭООЖНјааДЋЪфЪБЃЌЛђЪЧдквНСЦЛњЙЙНјааДцДЂКЭЪЙгУЕШЙ§ГЬжаЃЌЖМУцСйзХжюЖрЪ§ОнАВШЋЗчЯеЁЃСэЭтЛЙДцдкдЖГЬвНСЦЪ§ОнАВШЋКЭвНСЦжааФЪ§ОнАВШЋЮЪЬтЃЌеыЖдетаЉЮЪЬташвЊДгЖрЗНУцНјааЙмПиЃК
1) АќРЈвНСЦНЁПЕДѓЪ§ОндкЪЙгУЕФЙ§ГЬжаЃЌЩцМАЕНИіШЫвўЫНЪ§ОнЕФЗжЮіРћгУЁЂСїЭЈЕШЖМгІЪмЕНбЯИёЙмПиЃЌЮоТлДгИіШЫНЧЖШЛЙЪЧЪЙгУепНЧЖШЃЌЖМашвЊЛёЕУЪкШЈаэПЩЁЃ
2) ЙЙНЈвдЛМепЮЊжааФЕФвНСЦЪ§ОнАВШЋЗРЛЄЬхЯЕЁЃЯжгаЕФвўЫНАВШЋЗРЛЄЃЌДѓЖржЛЪЧзЂжиЭбУєКЭФфУћБЃЛЄЃЌВЛЪЧШЋЗНЮЛЬхЯЕЁЃашвЊМгЧПЙЙНЈвдЛМепЮЊжааФЕФИіШЫвНСЦаХЯЂЗчЯеЦРЙРКЭЗРЛЄЬхЯЕЃЌИВИЧаХЯЂТМШыЁЂИіШЫвўЫНЙмРэЁЂМгУмДцДЂЁЂЗУЮЪПижЦЕШЖрИіЛЗНкЁЃ
3) МгЧПИіШЫаХЯЂБЃЛЄСЂЗЈЁЃвЛЗНУцЃЌЙЋУёвЊгаГфЗжШЯжЊЃЌгІЕБбЇЛсЖдздЩэвўЫНЕФБЃЛЄЁЃСэвЛЗНУцЃЌЖдЮЅЗЈааЮЊвЊгазуЙЛЕФГЭжЮЃЌДђЛїИіШЫаХЯЂЕФВЛЕБаЙТЖКЭЗЧЗЈРћгУЁЃ
2ЁЂвНСЦЪ§ОнБъзМЛЏНЈЩшЪЧвНСЦДѓЪ§ОнНЈЩшЕФЛљДЁЙЄзїЃЌЮЊСЫЪЙДѓЪ§ОнНЈЩшИќКУЕФТњзуСйДВвЕЮёКЭЮЊЛМепЗўЮёЕФашЧѓЃЌЪЕЯжЪ§ОнЭГвЛЕФБъзМЛЏКЭЙцЗЖЛЏЁЃвНСЦЪ§ОнБъзМЛЏНЈЩшЙ§ГЬжагіЕНвдЯТЗчЯеКЭФбЕуФкШнЃЌЗжЯэИјДѓМвЃК1)Ъ§ОнБъзМЛЏЩцМАЖрИігІгУЯЕЭГЃЌаЕїНгПкИФдьНјЖШКЭНгПкжЪСПАбПиФбЖШДѓЃЌашвЊаЕїКУдКЗНШЗШЯИФдьЕФНгПкЫЋЗНЧЉзжКѓжДааЁЃ2)Ъ§ОнБъзМЛЏвдЯћЯЂЗНЯЕЭГЮЊНЈЩшЦ№ЕуЃЌЪеМЏИїЯћЯЂЗНЯЕЭГЖдЪ§ОнБъзМЛЏашЧѓЃЌЯШНЈСЂЪ§ОнЛљБОМЏКЭдЄСєВПЗжРЉГфзжЖЮЃЌБмУтНгПкИФдьЗДИДаоИФЃЌЬсИпНгПкЮШЖЈадЃЛ3)Ъ§ОнБъзМЛЏШЗШЯвЕЮёСїГЬЃЌЭЈжЊЯрЙиПЦЪвЮЌЛЄЪ§ОнвЊЧѓЃЌИјГіБиЬюзжЖЮМАвЕЮёСїГЬЃЌвдУтЮЌЛЄЪ§ОнДэЮѓЛђПеШБЖјгАЯьЯћЯЂЯЕЭГЪ§ОнЮЪЬтЁЃ
5 вНСЦаавЕНЈЩшДѓЪ§ОнЯюФПММЪѕТЗЯпЕФбЁдё
ДѓЪ§ОнЯЕЭГзюЛљБОЕФзщМўЪЧДІРэПђМмЃЌДІРэПђМмКЭДІРэв§ЧцИКд№ЖдЪ§ОнЯЕЭГжаЕФЪ§ОнНјааМЦЫуЃЌвРОнЫљвЊДІРэЕФЪ§ОнРраЭКЭЪ§ОнзДЬЌЗжРрЃЌвЛаЉЯЕЭГПЩвдгУХњДІРэЗНЪНДІРэЪ§ОнЃЌвЛаЉЯЕЭГПЩвдгУСїЗНЪНДІРэСЌајВЛЖЯСїШыЯЕЭГЕФЪ§ОнЃЌСэЭтЛЙгавЛаЉЯЕЭГПЩвдЭЌЪБДІРэетСНРрЪ§ОнЁЃЯТУцЪЧСїДІРэгыХњДІРэЕФЖдБШЭМЃК
Apache HadoopЪЧвЛжжзЈгУгкХњДІРэЕФДІРэПђМмЁЃApache HadoopМАЦфMapReduceДІРэв§ЧцзюЪЪКЯДІРэЖдЪБМфвЊЧѓВЛИпЕФЗЧГЃДѓЙцФЃЪ§ОнМЏЁЃЭЈЙ§ЗЧГЃЕЭГЩБОЕФзщМўМДПЩДюНЈЭъећЙІФмЕФHadoopМЏШКЃЌЪЙЕУетвЛСЎМлЧвИпаЇЕФДІРэММЪѕПЩвдСщЛюгІгУдкКмЖрАИР§жаЁЃ
Apache StormЪЧвЛжжВржигкМЋЕЭбгГйЕФСїДІРэПђМмЃЌвВаэЪЧвЊЧѓНќЪЕЪБДІРэЕФЙЄзїИКдиЕФзюМббЁдёЁЃИУММЪѕПЩДІРэЗЧГЃДѓСПЕФЪ§ОнЃЌЭЈЙ§БШЦфЫћНтОіЗНАИИќЕЭЕФбгГйЬсЙЉНсЙћЁЃ
Apache SamzaЪЧвЛжжгыApache KafkaЯћЯЂЯЕЭГНєУмАѓЖЈЕФСїДІРэПђМмЁЃЫфШЛKafkaПЩгУгкКмЖрСїДІРэЯЕЭГЃЌЕЋАДееЩшМЦЃЌSamzaПЩвдИќКУЕиЗЂЛгKafkaЖРЬиЕФМмЙЙгХЪЦКЭБЃеЯЁЃИУММЪѕПЩЭЈЙ§KafkaЬсЙЉШнДэЁЂЛКГхЃЌвдМАзДЬЌДцДЂЁЃ
Apache FlinkЪЧвЛжжПЩвдДІРэХњДІРэШЮЮёЕФСїДІРэПђМмЁЃИУММЪѕПЩНЋХњДІРэЪ§ОнЪгзїОпБИгаЯоБпНчЕФЪ§ОнСїЃЌНшДЫНЋХњДІРэШЮЮёзїЮЊСїДІРэЕФзгМЏМгвдДІРэЁЃFlinkЪЧвЛИіаТаЫЕФЯюФПДцдквЛЖЈЕФОжЯоадЁЃ
Apache SparkЪЧвЛжжАќКЌСїДІРэФмСІЕФЯТвЛДњХњДІРэПђМмЁЃгыHadoopЕФMapReduceв§ЧцЛљгкИїжжЯрЭЌддђПЊЗЂЖјРДЕФSparkжївЊВржигкЭЈЙ§ЭъЩЦЕФФкДцМЦЫуКЭДІРэгХЛЏЛњжЦМгПьХњДІРэЙЄзїИКдиЕФдЫааЫйЖШЁЃSparkЪЧЖрбљЛЏЙЄзїИКдиДІРэШЮЮёЕФзюМббЁдёЁЃSparkХњДІРэФмСІвдИќИпФкДцеМгУЮЊДњМлЬсЙЉСЫЮогыТзБШЕФЫйЖШгХЪЦЁЃЖдгкжиЪгЭЬЭТТЪЖјЗЧбгГйЕФЙЄзїИКдиЃЌдђБШНЯЪЪКЯЪЙгУSpark
StreamingзїЮЊСїДІРэНтОіЗНАИЁЃ
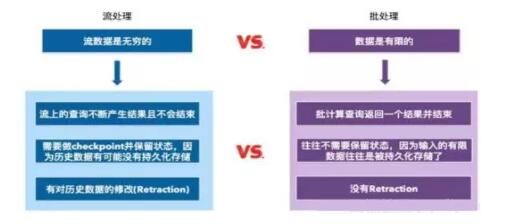
ОЙ§ЖдМИжжДѓЪ§ОнДІРэПђМмКЭДІРэв§ЧцЕФБШНЯЃЌНсКЯвНдКЯжгагІгУЯЕЭГЕФНЈЩшЧщПіКЭЪ§ОнСПЕФЙцФЃвдМАЪ§ОнРраЭЕФИДдгЖШЃЈвНСЦЪ§ОнАќРЈНсЙЙЛЏКЭЗЧНсЙЙЛЏЛЙгаАыНсЙЙЛЏЪ§ОнЃЌЪ§ОнРраЭЖржжЖрбљЃЌгаЕФЪ§ОнЪЪКЯХњДІРэЃЌЖјгаЕФЪ§ОнЪЪКЯСїДІРэЃЉЃЌЫљвдбЁгУПЊдДДѓЪ§ОнМмЙЙЕФApache
SparkНЈЩшвНдКДѓЪ§ОнЗжЮіЦНЬЈЁЃ
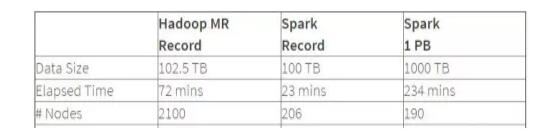
ЩЯУцЪЧHadoopКЭSparkЕФДІРэадФмЖдБШЭМЃЌДгЭМжаПЩвдПДГіХХађ100TBЕФЪ§ОнЃЈ1ЭђвкЬѕЪ§ОнЃЉЃЌSparkжЛгУСЫHadoopЫљгУ1/10ЕФМЦЫузЪдДЃЌКФЪБжЛгаHadoopЕФ1/3ЁЃ
HadoopЕФДІРэв§ЧцMapReduceжЛЬсЙЉСНИіВйзїMapКЭReduceЃЌБэДяСІЧЗШБЃЛвЛИіJobжЛгаMapКЭReduceСНИіНзЖЮЮоЗЈТњзуИДдгЕФМЦЫуашвЊЃЌJobжЎМфЕФвРРЕЙиЯЕЪЧгЩПЊЗЂепздМКЙмРэЕФЃЛReduceTaskашвЊЕШД§ЫљгаMapTaskЖМЭъГЩКѓВХПЩвдПЊЪМЃЌЪБбгИпжЛЪЪгУBatchЪ§ОнДІРэЃЌЖдгкНЛЛЅЪНЪ§ОнДІРэЃЌЪЕЪБЪ§ОнДІРэЕФжЇГжВЛЙЛЁЃвђДЫMapReduceаЇТЪЯрЖдНЯЕЭЃЌЫљвдЮвУЧбЁдёИќгааЇТЪЃЌЫйЖШИќПьЕФФкДцМЖМЦЫуЕФSparkРДЙЙНЈвНСЦДѓЪ§ОнЗжЮіЦНЬЈЁЃ
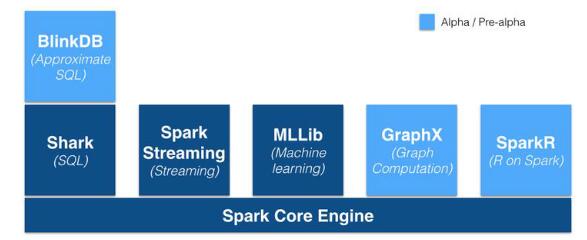
SparkЕФгХЪЦВЛНіЬхЯждкадФмЬсЩ§ЩЯЕФЃЌSparkПђМмЮЊХњДІРэЃЌНЛЛЅЪНЃЌСїЪНЃЌЛњЦїбЇЯАЃЌЭММЦЫуЬсЙЉСЫЭГвЛЕФЪ§ОнДІРэЦНЬЈЃЌетЯрЖдгкЪЙгУHadoopгаКмДѓгХЪЦЁЃ
ЬсЕНSparkВЛЕУЫЕвЛЯТRDDЃЌRDDЃЈResilient Distributed DatasetЃЉЃЌRDDОЭЪЧвЛИіВЛПЩБфЕФДјЗжЧјЕФМЧТММЏКЯЃЌRDDвВЪЧSparkжаЕФБрГЬФЃаЭЁЃSparkЬсЙЉСЫRDDЩЯЕФСНРрВйзїЃЌзЊЛЛКЭЖЏзїЁЃзЊЛЛЪЧгУРДЖЈвхвЛИіаТЕФRDDАќРЈmap,
flatMap, filterЕШЃЌЖЏзїЪЧЗЕЛивЛИіНсЙћАќРЈcollect, reduceЕШЁЃ
SparkЛљгкRDDЕФГщЯѓЃЌЪЕЯжЪ§ОнДІРэТпМЕФДњТыЗЧГЃМђЖЬЃЛЬсЙЉКмЖрзЊЛЛКЭЖЏзїЃЌКмЖрЛљБОВйзїШчJoinЃЌGroupByвбОдкRDDзЊЛЛКЭЖЏзїжаЪЕЯжЃЛвЛИіJobПЩвдАќКЌRDDЕФЖрИізЊЛЛВйзїЃЌдкЕїЖШЪБПЩвдЩњГЩЖрИіНзЖЮЃЈStageЃЉЃЌЖјЧвШчЙћЖрИіmapВйзїЕФRDDЕФЗжЧјВЛБфЃЌЪЧПЩвдЗХдкЭЌвЛИіTaskжаНјааЃЛжаМфНсЙћЗХдкФкДцжаЃЌФкДцЗХВЛЯТСЫЛсаДШыБОЕиДХХЬЃЛЭЈЙ§НЋСїВ№ГЩаЁЕФbatchЬсЙЉDiscretized
StreamДІРэСїЪ§ОнЁЃ
вНСЦаавЕЪ§ОнСПЗЧГЃДѓЃЌУПШедіСПЪ§ОнвВКмДѓЃЌЪ§ОнРраЭИДдгЃЌбЁдёЭЈгУадИќЧПЁЂдЫЫуаЇТЪИќИпЕФSparkМмЙЙРДЙЙНЈвНСЦДѓЪ§ОнЗжЮіЦНЬЈЃЌПЩвдИќКУЕФЗўЮёгквНСЦаавЕЁЂЗўЮёгкЛМепЁЃ
6 вНСЦаавЕНЈЩшДѓЪ§ОнЯюФПЕФММЪѕФбЕугыНтОіАьЗЈ
БОЯюФПвдЮРНЁЮЏИјГіЕФвНдКаХЯЂЛЏНЈЩшЕФвЊЧѓКЭЯрЙиЪ§ОнФЃаЭЮЊЛљДЁЃЌНсКЯвНдКЕФвЕЮёСїГЬЖдЯжгавЕЮёНјааЪсРэЃЌШЗЖЈвЕЮёжаЕФЮЪЬтаЮГЩзмЬхЩшМЦЃЛжЦЖЈЪ§ОнБъзМЁЂНгПкБъзМЁЂЯћЯЂБъзМЁЂЮФЕЕБъзМКЭЗўЮёБъзМЃЛИљОнзмЬхЩшМЦКЭБъзМЙцЗЖЭЌВННјааДѓЪ§ОнЦНЬЈЪЕЪЉЁЃ
БОЯюФПЛљгкЛМепОЭеяЙ§ГЬНЈСЂФЃаЭЃЌИУФЃаЭЪЧДгЛМепШыдКЕНГідКЙ§ГЬжаЫљВњЩњЕФЯрЙиЪ§ОнЃЌжївЊАќРЈЛМепЕФМьВщаХЯЂЃЌЭМЯёађСаБэЕФЩњГЩЃЌЯЕЭГЭМЯёМЧТМЃЌЛМепЬиеїЪ§ОнЁЂВЁжжЪ§ОнЁЂжЮСЦЗНАИгыЗбгУЪ§ОнЁЂжЮСЦзДЬЌЪ§ОнМАдкИУЙ§ГЬжаВњЩњЕФЙмРэРрЪ§ОнЁЃ
1) ЛМепЬиеїЪ§ОнЃКЛМепЬиеїЪ§ОнжївЊгаЯжВЁЪЗЁЂМьВщМьбщРрЪ§ОнЁЃКИЧСЫМВВЁЕФжївЊжЂзДЁЂЬхеїЁЂЗЂВЁЙ§ГЬЁЂМьВщЁЂеяЖЯЁЂжЮСЦМАМШЭљМВВЁаХЯЂЁЂВЛСМЪШКУЩѕжСжАвЕЁЃ
2) ВЁжжЪ§ОнЃКМДЛМепМВВЁЕФеяЖЯНсЙћЃЌвЛАугаЕквЛеяЖЯЁЂЕкЖўеяЖЯЁЂЕкШ§еяЖЯЕШЁЃФПЧАЪЙгУICD-10НјааМВВЁЕФЗжРргыБрТы
ЁЃ
3) жЮСЦЗНАИгыЗбгУЪ§Он:ИљОнеяЖЯНсЙћЮЊЛМепЬсЙЉЕФжЮСЦЗНАИгыЗбгУЪ§ОнжївЊАќРЈвЉЦЗЁЂМьВщЁЂМьбщЁЂЪжЪѕЁЂЛЄРэЁЂжЮСЦ6ДѓРрЃЌДЫЭтЗбгУЪ§ОнЛЙгаВФСЯЗбЁЂДВЮЛЗбЁЂЛЄРэЗбЁЂЛЛвЉЗбгУЕШЁЃ
4) жЮСЦзДЬЌЪ§Он:жЮСЦзДЬЌЪ§ОнМДЛМепГідКЪБЕФжЮСЦНсТлЃЌвЛАуЗжЮЊжЮгњЁЂКУзЊЁЂЮДгњЁЂЫРЭі4РрЁЃ
5) ЙмРэРрЪ§Он:Г§ЛМепОЭвНЙ§ГЬВњЩњЕФЗўЮёгквНдКЙмРэЕФЪ§ОнЭтЃЌЛЙАќРЈвНдКдЫгЊКЭЙмРэЯЕЭГжаЕФЪ§ОнЃЌШчЮязЪЯЕЭГЁЂВЦЮёЯЕЭГЁЂМЈаЇПМКЫЯЕЭГЕШВњЩњЕФЪ§ОнЁЃ
вНСЦДѓЪ§ОнЗжЮіЦНЬЈгЩЪ§ОнЛёШЁЁЂЪ§ОнећКЯЃЌЪ§ОнМгЙЄКЭЪ§ОнеЙЯжЫФИіФЃПщзщГЩЁЃвНСЦДѓЪ§ОнДІРэФЃаЭШчЯТЭМЃК
1) Ъ§ОнЛёШЁЃКдкетИіНзЖЮвЊЛиД№вдЯТМИИіЮЪЬтЃЌАќРЈвЊЪеМЏФФаЉЪ§ОнЃЌФФаЉЪ§ОнЪЧЖдгкеНТдадЕФОіВпЛђЯИНкОіВпгаАяжњЕФЃЌФФаЉЪ§ОнЗжЮіГіРДЕФНсЙћЪЧгаМлжЕЕФЃЌФФаЉЪ§ОнЕУГіЕФаХЯЂЖдгквЛИіСйДВеяСЦЪЧгаАяжњЃЌФФаЉЪ§ОнФмИќКУЕФЪЕЯжИЈжњеяСЦФПБъЕШЁЃ
2) Ъ§ОнећКЯЃКЮЊСЫЕУЕНИќМгОЋШЗЕФНсЙћЃЌдкДѓЪ§ОнЗжЮіЕФЙ§ГЬЕБжаЃЌЪ§ОнећКЯЪЧЙиМќЕФЛЗНкЃЌЪ§ОнећКЯЪЧНЋДгвНдКаХЯЂЦНЬЈГщШЁЕФвЕЮёЪ§ОнАДееЭГвЛЕФДцДЂКЭЖЈвхНјааМЏГЩЁЃвНдКаХЯЂЛЏОЙ§ЖрФъЕФЗЂеЙЃЌЛ§РлСЫКмЖрЛљДЁадКЭСуЩЂЕФвЕЮёЪ§ОнЁЃЕЋЪЧЪ§ОнЗжЩЂдкСйДВЁЂИЈжњЁЂЙмРэЕШВЛЭЌВПУХЃЌжТЪЙЪ§ОнВщбЏЗУЮЪРЇФбЃЌвНдКЙмРэВуШЫдБЮоЗЈжБНгВщдФЪ§ОнКЭЖдЪ§ОнНјааЗжЮіРћгУЃЌЪ§ОнећКЯашвЊзлКЯВЛЭЌИёЪНЁЂВЛЭЌвЕЮёЯЕЭГЕФЪ§ОнЁЃ
3) Ъ§ОнМгЙЄЃКвНдКдгаЕФвЕЮёЪ§ОнБиаыОЙ§БъзМЛЏДІРэКѓВХФмЙЛЧЈШыДѓЪ§ОнЦНЬЈЁЃгЩгквНдКЕФДѓЪ§ОнРДздИїИіВЛЭЌЕФвЕЮёЯЕЭГЃЌЪ§ОнИёЪНКЭБъзМВЛЭГвЛЃЌКмФбЖдЪ§ОнНјааЭГвЛЕФЙмРэКЭРћгУЁЃвЛАуДѓЪ§ОнЦНЬЈЕФНЈЩшЖМЛсеыЖдНсЙЙЛЏКЭЗЧНсЙЙЛЏЪ§ОнНЈСЂВЛЭЌЕФжїЫїв§Ъ§ОнЃЌШЛКѓЖддДЪ§ОнНјааЧхЯДКѓЕМШыЪ§ОнМЏЁЃгЕгаЛђДДдьвЛИіИЩОЛЁЂНсЙЙСМКУЕФЪ§ОнМЏЪЧБиаыЕФЁЃЪЙгУЪ§ОнЧхЯДШэМўЙЄОпПЩвдАяжњЯИЛЏЪ§ОнВЂНЋЦфжиЫмЮЊПЩгУЕФЪ§ОнМЏЁЃ
4) Ъ§ОнеЙЯжЃКЪ§ОнеЙЯжМДЪ§ОнПЩЪгЛЏЃЌЮЊЗНБувНЛЄШЫдБЁЂЛМепКЭЙмРэШЫдБРэНтКЭдФЖСЪ§ОнЃЌЖјВЩгУЯрЙиММЪѕАДвЕЮёЙцдђНјааЕФЪ§ОнзЊЛЛЁЃетОЭвЊЧѓвНдКЯрЙиЕФвЕЮёЙцдђЖМЪЧвбОШЗЖЈКУЕФЃЌетаЉвЕЮёЙцдђПЩвдАяжњЪ§ОнЗжЮідБЦРЙРЫћУЧЕФЙЄзїЃЌНЋЪ§ОнНјааЗжЮіЕУГігаМлжЕЕФНсЙћЁЃ
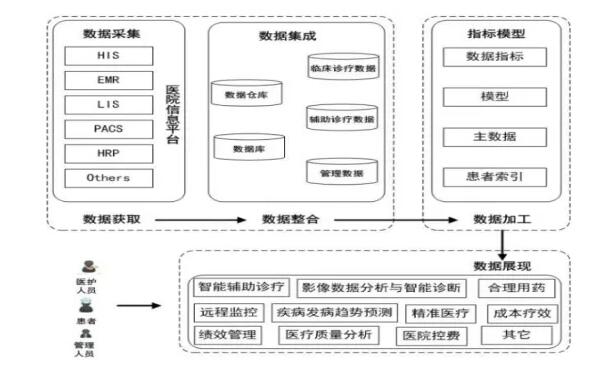
вНСЦДѓЪ§ОнЯюФПНЈЩшЙ§ГЬжаЕФММЪѕФбЕуЃК
Ъ§ОнБъзМЛЏЪЧЪ§ОнВЩМЏКЭЪ§ОнЗжЮіЕФЛљДЁЃЌвНдКдкаХЯЂЛЏНЈЩшЙ§ГЬжаШБЗІЭЈгУЕФЪ§ОнБъзМЁЂММЪѕБъзМЁЂЙмРэБъзМКЭвЕЮёБъзМЃЌЮДаЮГЩБъзМЛЏЕФЕзВуаХЯЂМмЙЙЁЃдкНјааЪ§ОнВЩМЏжЎЧАЪзЯШвЊЖдвНдКЯжгаЪ§ОнАДвдЯТБъзМНјааЙщРрЁЂГщШЁЁЂећКЯЁЂЮЊЕкЖўНзЖЮЕФЪ§ОнМгЙЄЬсЙЉБъзМЛЏЕФЪ§ОнЁЃ
вНСЦДѓЪ§ОнБъзМЛЏгыећКЯЁЃНЋВЛЭЌПЦЪвЃЌВЛЭЌвЕЮёЯЕЭГЕФЗЧНсЙЙЛЏЁЂСуТвЕФЪ§ОнећКЯГЩгаРћгУМлжЕЕФЪ§ОнЃЛЖдДѓЪ§ОнНјааЙ§ТЫЃЌЩшМЦдрЪ§ОнЙ§ТЫЙцдђЃЛЪ§ОнвЛжТадМьВщЃЌЮоаЇжЕКЭШБЪЇжЕДІРэЁЃдквНСЦДѓЪ§ОнЕФгІгУЕФЭЌЪБЃЌЛЙДцдкЪ§ОнЕФГщШЁЁЂДцДЂЁЂЧхЯДЁЂећКЯЁЂЭкОђЁЂЗжЮіЁЂеЙЯжЕШЮЪЬташвЊНтОіЁЃ
ЯТЭМЪЧНјааЪ§ОнЗжЮіЕФВНжшЃК
ЕквЛВНДгећЬхЩЯЖдЫљвЊНјааЪ§ОнЗжЮіЕФЖдЯёНјааЩшМЦЃЌЕкЖўДЮДгММЪѕЪЕЯжЯИНкЩЯЖдЪ§ОнЗжЮіЖдЯёНјааЪЕЯжЁЃ
НЋдЪМЪ§ОнзЊЛЏЮЊжаМфЪ§ОнЃЌвђЮЊКЃСПЕФдЪМЪ§ОнЪЧУЛгаЧхЯДЕФЗЧНсЙЙЛЏЪ§ОнЃЌвђДЫашвЊгУHDFSНјааДцДЂЃЌЪЙгУSparkНјааЧхЯДбЙЫѕБрТыЃЌЕУЕННсЙЙЛЏЕФжаМфЪ§ОнЃЌжаМфЪ§ОнЪЧНјааЪ§ОнЗжЮіЕФФПБъЪ§ОнЃЌжаМфЪ§ОндкСПЩЯБШдЪМЪ§ОнвЊаЁЃЌЕЋЕЅЛњШдШЛФбвдДІРэЃЌвђДЫвЊгУHDFSДцДЂЃЌгУSpark/HiveНјааНјвЛВНДІРэЃЌЕУЕНаЁЪ§ОнКѓдкНјааНЈФЃЁЂЗжЮіЃЌВЂНЋЗжЮіНсЙћПЩЪгЛЏЁЃ
вЊШЗБЃвНСЦДѓЪ§ОнРћгУЙ§ГЬжаЃЌВЛБЛЭтНчЧдШЁКЭаоИФЃЌвЊНЈСЂЯргІЕФЪ§ОнМгУмММЪѕКЭЪ§ОнЗУЮЪЪкШЈЛњжЦЕШЁЃЪ§ОнМгУмВЩгУssl
vpnММЪѕМгУмЃЌБЃеЯЪ§ОнЕФДЋЪфАВШЋКЭФкШнАВШЋЃЌЪ§ОнЕФЗУЮЪвЊЪЕЯжЫЋвђзгШЯжЄЃЌеЪКХУмТыМгзЈгУУмдПЕФЗНЪНЁЃ
7 ДѓЪ§ОнЦНЬЈЕФЯЕЭГгыЙІФмВтЪд
ВтЪдбщЪеЕФФПЕФКЭЬєеНЃК
ЯЕЭГВтЪдбщЪеЪЧвЛИіЯюФПЪЕЪЉНсЪјЕФБъжОЃЌЯЕЭГВтЪдбщЪеЭъГЩКѓЯюФПДгЪЕЪЉНзЖЮНјШыЮЌБЃНзЖЮЃЌВтЪдНЈЩшЭъЙЄЕФвНСЦДѓЪ§ОнЦНЬЈдкНЈЩшФПБъКЭЙІФмЩЯЪЧЗёТњзувЊЧѓЃЌВтЪдбщЪеЕФФкШнАќРЈЃКЙІФмЯюВтЪдЁЂвЕЮёСїГЬВтЪдЁЂШнДэВтЪдЁЂАВШЋадВтЪдЁЂадФмВтЪдЁЂвзгУадВтЪдЁЂЪЪгІадВтЪдКЭЮФЕЕВтЪдЃЌВтЪдбщЪеАДЙњМвБъзМвЊЧѓКЭЙцЗЖНјааЃЌЖдВтЪдУЛгаЭЈЙ§ЕФФкШнашАДЙњМвБъзМвЊЧѓНјааећИФЃЌећИФКѓдйВтЪджБЕНЭъШЋЭЈЙ§ВтЪдбщЪеЮЊжЙЁЃ
ВтЪдбщЪеВЮПМЗНАИЃК
бщЪеБъзМАќРЈ ЁЖGB/T 16260-1996 аХЯЂММЪѕ/ШэМўВњЦЗЦРМл/жЪСПЬиадМАЦфЪЙгУжИФЯЁЗЃЌЁЖGB/T
17544-1998ШэМўАќжЪСПвЊЧѓКЭВтЪдЁЗЃЌЁЖGB/T 15532-2008 МЦЫуЛњШэМўВтЪдЙцЗЖЁЗЁЃ
бщЪеЯюФПЃК
AЃЉЯЕЭГЙІФмЯюВтЪдЃК ЖдШэМўашЧѓЙцИёЫЕУїЪщжаЕФЫљгаЙІФмЯюНјааВтЪдЁЃ
BЃЉЯЕЭГвЕЮёСїГЬВтЪдЃК ЖдШэМўЯюФПЕФЕфаЭвЕЮёСїГЬНјааВтЪдЁЃ
CЃЉЯЕЭГШнДэВтЪдЕФМьВтФкШнАќРЈЃК
1ЃЉ ШэМўЖдгУЛЇГЃМћЕФЮѓВйзїЪЧЗёФмНјааЬсЪОЃЛ
2ЃЉ ШэМўЖдгУЛЇЕФВйзїДэЮѓКЭШэМўДэЮѓЃЌЪЧЗёгазМШЗЁЂЧхЮњЕФЬсЪОЃЛ
3ЃЉ ШэМўЖдживЊЪ§ОнЕФЩОГ§ЪЧЗёгаОЏИцКЭШЗШЯЬсЪОЃЛ
4ЃЉ ШэМўЪЧЗёФмХаЖЯЪ§ОнЕФгааЇадЃЌЦСБЮгУЛЇЕФДэЮѓЪфШыЃЌЪЖБ№ЗЧЗЈжЕЃЌВЂгаЯргІЕФДэЮѓЬсЪОЁЃ
DЃЉЯЕЭГАВШЋадВтЪдЕФМьВтФкШнАќРЈЃК
1ЃЉШэМўжаЕФУмдПЪЧЗёвдУмЮФЗНЪНДцДЂЃЛ
2ЃЉШэМўЪЧЗёгаСєКлЙІФмЃЌМДЪЧЗёБЃДцгагУЛЇЕФВйзїШежОЃЛ
3ЃЉШэМўжаИїжжгУЛЇЕФШЈЯоЗжХфЪЧЗёКЯРэЃЛ
EЃЉЯЕЭГадФмВтЪдЃК ЖдШэМўашЧѓЙцИёЫЕУїЪщжаУїШЗЕФШэМўадФмНјааВтЪдЃЌВтЪдЕФзМдђЪЧвЊТњзуЙцИёЫЕУїЪщжаЕФИїЯюадФмжИБъЁЃ
FЃЉЯЕЭГвзгУадВтЪдФкШнАќРЈЃК
1ЃЉШэМўЕФгУЛЇНчУцЪЧЗёгбКУЃЌЪЧЗёГіЯжжагЂЮФЛьдгЕФНчУцЃЛ
2ЃЉШэМўжаЕФЬсЪОаХЯЂЪЧЗёЧхГўЃЌвзРэНтЃЌЪЧЗёДцдкдЪМЕФгЂЮФЬсЪОЃЛ
3ЃЉШэМўжаИїИіФЃПщЕФНчУцЗчИёЪЧЗёвЛжТЃЛ
4ЃЉШэМўжаЕФВщбЏНсЙћЕФЪфГіЗНЪНЪЧЗёБШНЯжБЙлЃЌКЯРэЃЌВЂЧвФмжЇГжЖржжЪфГіБЃДцИёЪНЁЃ
GЃЉЯЕЭГЪЪгІадВтЪдЃК ВЮеегУЛЇЕФШэЁЂгВМўЪЙгУЛЗОГКЭашЧѓЙцИёЫЕУїЪщжаЕФЙцЖЈЃЌСаГіПЊЗЂЕФШэМўашвЊТњзуЕФШэЁЂгВМўЛЗОГЃЌЖдУПИіЛЗОГНјааВтЪдЁЃ
HЃЉЯЕЭГЮФЕЕВтЪдЃК
гУЛЇЮФЕЕАќРЈЃКАВзАЪжВсЁЂВйзїЪжВсКЭЮЌЛЄЪжВсЃЌЖдгУЛЇЮФЕЕВтЪдЕФФкШнАќРЈЃК
1) ВйзїЁЂЮЌЛЄЮФЕЕЪЧЗёЦыШЋЁЂЪЧЗёАќКЌВњЦЗЪЙгУЕФаХЯЂКЭЫљгаЕФЙІФмФЃПщЃЛ
2) гУЛЇЮФЕЕЪЧЗёШнвзРэНтЃЌЪЧЗёЪЙгУЪЪЕБЕФЪѕгяЃЌЭМаЮБэЪОЃЌЯъЯИНтЪЭРДБэДя
3) гУЛЇЮФЕЕУшЪіЕФаХЯЂЪЧЗёе§ШЗЃЌЪЧЗёУЛгаЦчвхКЭДэЮѓЕФБэДяЃЛ
4) гУЛЇЮФЕЕЖджївЊЙІФмКЭЙиМќВйзїЪЧЗёЬсЙЉгІгУЪЕР§ЃЛ
5) гУЛЇЮФЕЕЪЧЗёгаЯъЯИЕФФПТМБэКЭЫїв§БэЃЛ
ЕНДЫЃЌвдЩЯЯЕЭГВтЪдбщЪевЊЧѓШЋВПТњзуЃЌЯЕЭГВтЪдбщЪеЭъГЩЁЃ
8 вНСЦаавЕЪЕЪЉДѓЪ§ОнЯюФПШеГЃдЫЮЌЗНАИ
вНСЦДѓЪ§ОнЯюФПОЙ§ЯЕЭГЪддЫааКЭзюжебщЪеКѓОЭНјШыдЫЮЌНзЖЮСЫЃЌ ЯюФПЫљЩцМАЕНЕФгВМўЩшБИАДГЇЩЬЕФЙцЖЈНјааБЃаоЃЈвЛАуЪЧШ§ФъЃЉЁЂШэМўВњЦЗАДКЯЭЌдМЖЈНјааБЃаоЁЃ
ГЁОАУшЪіЃК ДЫДЮДѓЪ§ОнЯюФПЕФЪЕЪЉАќРЈЛљгкsparkПЊЗЂЕФвНСЦДѓЪ§ОнЗжЮіЯЕЭГЃЌвдМАЮЊДѓЪ§ОнЗжЮіЯЕЭГзіжЇГХЕФЗўЮёЦїЁЂДцДЂЁЂЭјТчМААВШЋЩшБИЕШвбОДгЪЕЪЉНјШыдЫЮЌНзЖЮЁЃ
дЫЮЌЙЄзїашЧѓЗжЮіЃК вЛСїЕФдЫЮЌЗўЮёЬхбщРДздгквдгУЛЇЗўЮёЮЊКЫаФЕФВпТдЃЌШчКЮБЃеЯвНСЦДѓЪ§ОнЗжЮіЯЕЭГЮШЖЈЕФдЫааЪЧдЫЮЌЙЄзїЕФжиЕуЃЌОЙ§гыгУЛЇЕФЙЕЭЈШЗЖЈСЫШчЯТЕФгУЛЇашЧѓЃК
1ЃЎ ЬсИпдЫЮЌЙЄзїаЇТЪЃЌдЫЮЌЕФМАЪБадЃЌзМШЗадЁЃ
2ЃЎ дЫЮЌШЫдБМЈаЇПМКЫЃЌгаРћгкЬсИпдЫЮЌЙЄзїаЇТЪЃЌгаРћгкдЫЮЌЙЄзїЕФДДаТЃЌгаРћгкЬсИпЙЄзїЕФЛ§МЋадКЭжїЖЏадЁЃ
3ЃЎ бВМьЪЧдЫЮЌЙЄзїЕФШеГЃФкШнЁЃШЗШЯЩшБИЕФбВМьжмЦкЃЌНЈСЂВЂжДаагІгУЯЕЭГбВМьжЦЖШЃЌжЦЖЈбВМьЙЄзїСїГЬЕЅЃЌАДСїГЬАДЪБАДвЊЧѓЖдЩшБИНјаабВМьЁЃ
дЫЮЌЗНАИЕФжЦЖЈЃК дЫЮЌЗНАИАќРЈзщжЏМмЙЙЃЌдЫЮЌвЊЧѓЃЌдЫЮЌЗНЪНЃЌЙмРэжЦЖШЙВЫФИіЗНУцЁЃ
зщжЏМмЙЙЃК вдзмОРэЧЃЭЗЃЌЯТЩшдЫгЊВПЁЂЪаГЁВПКЭММЪѕВПЃЛдкдЫгЊВПЯТЩшШЫЪТЁЂааеўЁЂЩЬЮёЁЂВЩЙКЁЂВЦЮёЕШВПУХЃЛдкЪаГЁВПЯТЩшЯњЪлВПЁЂЪаГЁВПЁЂВњЦЗВПКЭПЭЗўВПЃЛдкММЪѕВПЯТЩшЯЕЭГМЏГЩВПЁЂдЫЮЌЙмРэВПЁЂЪлЧАЗНАИВПЕШВПУХЁЃ
дЫЮЌвЊЧѓЃК ИљОнГіЯжЮЪЬтЕФНєМБГЬЖШЃЌШЗЖЈЗЧГЃбЯжиЁЂбЯжиКЭвЛАуШ§ИіЕШМЖЁЃИљОнЮЪЬтЕФНєМБГЬЖШШЗШЯЯьгІЪБМфЃЌ2ИіаЁЪБвдФкЁЂ4аЁЪБвдФкЁЂ8аЁЪБвдФкЃЌ
дЫЮЌжЇГжЕФЗНЪНАќРЈЯжГЁжЇГжЁЂЕчЛАгЪМўжЇГжКЭдЖГЬажњжЇГжЁЃ
дЫЮЌЗНЪНЃК ИљОндЫЮЌЙЄзїЕФашЧѓКЭдЫЮЌЯьгІЪБМфвЊЧѓОіЖЈНЈЩшЭъећЕФдЫЮЌМЦЛЎВЂШЗЖЈЗўЮёЕФБъзМЃЌвдЯжГЁШэгВМўбВМьЮЊжїЃЌдіЧПдЫЮЌМЦЛЎЕФжДааСІЃЌЯТУцЪЧдЫЮЌЙЄзїСїГЬЃК
НЈЩшЭъећЕФдЫЮЌМЦЛЎЃКдкећИідЫЮЌЙ§ГЬжаЃЌМЦЛЎЪЧећИіЙЄзїСїГЬЕФКЫаФЃЌАДееМЦЛЎЯШааЕФддђЃЌвРОнБОФъЖШЙЄзїМЦЛЎжЦЖЈЗжЯюЙЄзїМЦЛЎКЭЪБМфЮЌЖШМЦЛЎЃЌВЂАДСїГЬЁЂАДМЦЛЎНјааЪЕЪЉКЭБЃеЯЁЃ
ЯжГЁбВМьЕФживЊадЃКЯжГЁбВМьМЦЛЎЪЧдЫЮЌЙЄзїМЦЛЎЕФжиЕуЃЌЭЈЙ§ЯжГЁбВМьФмЙЛЗЂЯжЯЕЭГБЁШѕЛЗНкЁЂЙиМќвЕЮёНкЕуЁЂДцдкЕФвўЛМЃЌгШЦфЪЧЖджЦЖЈгІМБдЄАИМАБИЦЗБИМўМЦЛЎжСЙиживЊЁЃ
жДааСІЕФживЊадЃКдЫЮЌМЦЛЎЕФжДааЪЧдЫЮЌЙЄзїЕФжиЕуЃЌдкдЫЮЌМЦЛЎжДааЙ§ГЬжаЃЌгІбЯИёАДееСїГЬЙцЗЖПЊеЙдЫЮЌЃЌВЂзЂжиПижЦвдНЕЕЭдЫЮЌЗчЯеЁЃеыЖддЫЮЌжДааЧщПіЃЌгІЖЈЦкЯђгУЛЇНјааЗДРЁЁЃ
ЗўЮёБъзМЃКЧЉЖЉЪлКѓЗўЮёГаХЕКЏгыгУЛЇдМЖЈЗўЮёМЖБ№ЃЌЖдгкЫљГаХЕЕФЗўЮёМЖБ№АќРЈЬсЙЉЕФзЪдДЃЈБИЦЗКЭБИМўЕШЃЉЁЂЬсЙЉЕФЗНАИгІбЯИёАДдМЖЈжДааЃЛ
ЙмРэжЦЖШЃК АќРЈдЫЮЌЙЄзїСїГЬЙмРэЃЌЛњЗПЛЗОГбВМьжЦЖШЃЌЗўЮёЦїЁЂДцДЂЁЂЭјТчМААВШЋЩшБИЕШбВМьжЦЖШЃЌгІгУЯЕЭГбВМьжЦЖШЕШЯрЙиФкШнЁЃ
9 вНСЦаавЕЪЕЪЉДѓЪ§ОнЯюФПвзВШЕНЕФПгвдМАДІРэАьЗЈ
дквНдКДѓЪ§ОнЯЕЭГЪЕЪЉЕФЙ§ГЬжаГіЯжСЫвдЯТДэЮѓМАДІРэАьЗЈдкДЫДІзівЛИізмНсНіЙЉДѓМвВЮПМЁЃ
1ЁЂspark thriftserverБЈвдЯТДэЮѓЃЌЦфЫћжюШч hive/sparksql
ЕШЗНЪНОље§ГЃ
ERROR
ActorSystemImpl: Uncaught fatal error from thread
[ sparkDriverActorSystem - akka .actor . default-dispatcher-379]
shutting down ActorSystem [ sparkDriverActorSystem
]
java.lang.OutOfMemoryError:
Java heap space
|
двђЃКthriftserverЕФЖбФкДцВЛзу
НтОіАьЗЈЃКжиЦєthriftserverЃЌВЂЕїДѓexecutor-memoryФкДцЃЈВЛФмГЌЙ§sparkзмЪЃгрФкДцЃЌШчГЌЙ§ЃЌПЩЕїДѓspark-env.shжаЕФSPARK_WORKER_MEMORYВЮЪ§ЃЌВЂжиЦєsparkМЏШКЁЃ
| start-thriftserver.sh
--master spark://masterip:7077 --executor - memory
2g -- total- executor - cores 4 --executor-cores
1 --hiveconf hive.server2.thrift.port=10050 --conf
spark . dynamicAllocation . enabled = false |
ШчЙћЕїДѓСЫexecutorЕФФкДц,вРОЩБЈДЫДэЮѓ,заЯИЗжЮіЗЂЯжгІИУВЛЪЧexecutorФкДцВЛзу,ЖјЪЧ
drive rФкДцВЛзу,дк standalone ФЃЪНЯТФЌШЯИјdriver 1GФкДц,ЕБЮвУЧЬсНЛгІгУЦєЖЏdriverЪБ,ШчЙћЖСШЁЪ§ОнЬЋДѓ,driver
ОЭПЩФмБЈФкДцВЛзуЁЃдкspark-defaults .confжаЕїДѓdriverВЮЪ§ spark.driver.memory
2g ЭЌЪБдк spark-env.sh жаЭЌбљЩшжУ export SPARK _ DRIVER _
MEMORY = 2g
2ЁЂCaused by: java.lang.OutOfMemoryError:
GC overhead limit exceeded**** JDK6 аТдіДэЮѓРраЭЁЃЕБGCЮЊЪЭЗХКмаЁПеМфеМгУДѓСПЪБМфЪБХзГіЁЃдкJVMжадіМгИУбЁЯю
-XX : -UseGCOverheadLimit ЙиБеЯожЦGCЕФдЫааЪБМфЃЈФЌШЯЦєгУ ЃЉ дк spark-defaults.confжадіМгвдЯТВЮЪ§
spark.executo r. extraJavaOptions -XX: -UseGCOverheadLimit
spark . driver . extraJavaOptions -XX : -UseGCOverheadLimit
3ЁЂspark ДэЮѓУшЪіЃКorg.apache.hadoop.ipc.RemoteException(org
. apache . hadoop . ipc . StandbyException): Operation
category READ is not supported in state standby двђЃКNNжїДгЧаЛЛЪБ,sparkБЈЩЯЪіДэЮѓ,ОЗжЮі
spark-defaults.conf ХфжУВЮЪ§ spark.eventLog.dir аДЫРСЫЦфжавЛИіNNЕФIP,ЕМжТжїДгЧаЛЛЪБЃЌЮоЗЈЖСШежОЁЃСэЭтЃЌИњгІгУГЬађЪЙгУЕФcheckpointвВгаЙиЯЕ,ЪзДЮЦєЖЏгІгУГЬађЪБ,ДДНЈСЫвЛИіаТЕФ
sparkcontext ,ЖјИУ sparkcontext АѓЖЈСЫОпЬхЕФNN ip, ЭљКѓУПДЮГЬађжиЦє,гЩгкгІгУДњТыЁО
StreamingContext .getOrCreate (checkpointDirectory
, functionToCreateContext _)ЁП НЋДгвбга checkpoint ФПТМЕМШыcheckpoint
Ъ§ОнРДжиаТДДНЈ StreamingContext ЪЕР§ЁЃШчЙћ checkpointDirectory
ДцдкЃЌФЧУД context НЋЕМШы checkpoint Ъ§ОнЁЃШчЙћФПТМВЛДцдкЃЌКЏЪ§ functionToCreateContext
НЋБЛЕїгУВЂДДНЈаТЕФ contextЁЃЙЪГіЯжЩЯЪівьГЃЁЃНтОіАьЗЈЃК
1ЁЂНЋФГИіNNЙЬЖЈIPИФГЩnameserviceЖдгІЕФжЕ
2ЁЂЧхПегІгУГЬађЕФcheckpointШежО 3ЁЂжиЦєгІгУКѓ,ЧаЛЛNN,sparkгІгУе§ГЃ
4ЁЂЛёШЁУПДЮФкДцGCаХЯЂ
spark-defaults.confжадіМгЃК
| spark.executor.extraJavaOptions
-XX : +PrintGC -XX: +PrintGCDetails -XX: +PrintGCTimeStamps
-XX:+PrintGCDateStamps -XX: +PrintGCApplicationStoppedTime
-XX: +PrintHeapAtGC -XX:+PrintGCApplicationConcurrentTime
-Xloggc: gc.log |
5ЁЂtimeout,БЈДэЃК
17/10/18
17:33:46 WARN TaskSetManager: Lost task 1393.0
in stage 382.0 ( TID 223626, test-ssps-s-04
) : ExecutorLostFailure (executor 0 exited caused
by one of the running tasks )
Reason:Executor heartbeat timed
out after 173568 ms
17/10/18 17:34:02 WARN NettyRpcEndpointRef:
Error sending message [message = KillExecutors
(app-20171017115441-0012,List(8))] in 2 attempts
org.apache.spark.rpc.RpcTimeoutException
: Futures timed out after [120 seconds]. This
timeout is controlled by spark.rpc.askTimeout
at org.apache.spark.rpc.RpcTimeout.org$apache$spark$
rpc$ RpcTimeout $$ createRpcTimeoutException
(RpcTimeout.scala:48)
|
ЭјТчЛђgcв§Ц№,workerЛђexecutorУЛНгЪеЕНexecutorЛђtaskЕФаФЬјЗДРЁЁЃ
ЬсИп spark.network.timeout ЕФжЕЃЌИљОнЧщПіИФГЩ300(5min)ЛђИќИпЁЃ
ФЌШЯЮЊ 120(120s),ХфжУЫљгаЭјТчДЋЪфЕФбгЪБ
spark.network.timeout 300000
6ЁЂЭЈЙ§sparkthriftserverЖСШЁlzoЮФМўБЈДэЃК
| ClassNotFoundException: Class com.hadoop.compression.lzo.LzoCodec
not found |
дкspark-env.shжадіМгШчЯТХфжУЃК
export
LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/hadoop/hadoop-2.2.0/lib/native
export SPARK_LIBRARY_PATH=$SPARK_LIBRARY_PATH:/home/hadoop/hadoop-2.2.0/lib/native
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/home/hadoop/hadoop-
2.2.0 /share / hadoop /yarn /: / home / hadoop
/hadoop-2.2.0/share/hadoop/yarn/lib/:/home/hadoop/hadoop-
2.2.0 /share / hadoop /common /:/ home/hadoop
/ hadoop-2.2.0/share/hadoop/common/lib/:/home/hadoop/hadoop-
2.2.0/share /hadoop / hdfs/: /home / hadoop
/ hadoop-2.2.0/share/hadoop/hdfs/lib/:/home/hadoop/hadoop-2.2.0
/ share / hadoop / mapreduce /:/ home / hadoop
/ hadoop-2.2.0/share/hadoop/mapreduce/lib/:/home/hadoop/hadoop-2.2.0
/ share / hadoop /tools / lib /:/ home / hadoop
/ spark-1.6.1-bin-2.2.0 /lib /
|
ВЂЗжЗЂЕНИїНкЕуЃЌжиЦєspark thrift serverжДаае§ГЃ
7ЁЂspark workerжаЗЂВМexecutorЦЕЗББЈДэ,ЯнШыЫРбЛЗЃЈаТНЈ->ЪЇАм->аТНЈ->ЪЇАм.....ЃЉ
workШежОЃК
Asked
to launch executor app-20171024225907-0018/77347
for org.apache.spark.sql.hive.thriftserver.HiveThriftServer2
worker.ExecutorRunner (Logging.scala:logInfo(58))
- Launch command: "/ home / hadoop / jdk1.7.0_09
/ bin / java" ......
Executor app-20171024225907-0018/77345
finished with state EXITED message Command exited
with code 53 exitStatus 53
executorШежОЃК
ERROR [main] storage.DiskBlockManager
(Logging.scala:logError(95)) - Failed to create
local dir in . Ignoring this directory.
java.io.IOException: Failed
to create a temp directory (under ) after 10
attempts!
|
дйПДХфжУЮФМўspark-env.shЃК
export SPARK_LOCAL_DIRS=/data/spark/data
ЩшжУСЫsparkБОЕиФПТМЃЌЕЋЛњЦїЩЯВЂУЛгаДДНЈИУФПТМЃЌЫљвдв§ЗЂДэЮѓЁЃ
./drun "mkdir -p /data/spark/data"
./drun "chown -R hadoop:hadoop /data/spark"
ДДНЈКѓЃЌжиЦєworkerЮДдйГіЯжДэЮѓЁЃ
8ЁЂspark workerвьГЃЭЫГіЃК
workerжаШежОЃК
17/10/25
11:59:58 INFO worker.Worker: Master with url
spark: // 10.10.10.82:7077 requested this worker
to reconnect.
17/10/25 11:59:58 INFO worker.Worker:
Not spawning another attempt to register with
the master, since there is an attempt scheduled
already.
17/10/25 11:59:59 INFO worker.Worker:
Successfully registered with master spark: //
10.10.10.82:7077
17/10/25 12:00:05 INFO worker.ExecutorRunner:
Killing process!
17/10/25 12:00:05 INFO util.ShutdownHookManager:
Shutdown hook called
17/10/25 12:00:06 INFO util.ShutdownHookManager:
Deleting directory /data/spark /data / spark-ab442bb5-62e6-4567-bc7c-8d00534ba1a3
|
НќЦкЃЌЦЕЗБГіЯжworkerвьГЃЭЫГіЧщПіЃЌДгworkerШежОПДЕНЃЌmasterвЊЧѓжиаТСЌНгВЂзЂВсЃЌзЂВсКѓЃЌworkerМЬајСЌНгmaster,ВЂЗДРЁСЫвЛИіДэЮѓаХЯЂЃК
| ERROR worker.Worker:
Worker registration failed: Duplicate worker IDжЎКѓОЭЭЛШЛЩБЕєЫљгаExecutorШЛКѓЭЫГіworkerЁЃ |
ГіЯжИУЮЪЬтЕФЛњЦїФкДцЖМЪЧ16g(ЦфЫћ32gНкЕу,УЛгаГіЯжworkerЭЫГіЮЪЬт)ЁЃдйВщПДИУРрНкЕуyarnЕФ
ХфжУЃЌЗЂЯжЗжХфyarnЕФзЪдДЪЧ15g,ЛГвЩЮЪЬтНкЕуyarnКЭsparkЭЌДІИпЗхЦкЃЌЕМжТsparkЗжХфВЛЕНзЪдДЭЫГіЁЃ
ЮЊВщПДЮЪЬтЪБМфЕуЃЌНкЕужаyarnзЪдДЪЙгУЧщПіЃЌжЛФмЕНactive rmжаВщПДrmШежОЃЌзюКѓПДЕННкЕужадк
11:46:22 ЕН 11:59:18ЃЌЮЪЬтНкЕуyarnеМгУзЪдДвЛжБдкЁЃШчДЫЃЌШЗЪЕЪЧИУЮЪЬтЫљжТЃЌНЋyarnзЪдДЕїећжС12g/10g,КѓајдйМЬајЙлВьУЛгаЗЂЯжДЫЮЪЬтСЫЁЃ
змНс
вНСЦаавЕЭЈЙ§ЪЕЪЉДѓЪ§ОнЯюФПЃЌПЩЬсЙЉжкЖрШЫШКЕФОЋзМвНСЦЪ§ОнЗўЮёЃЌЮЊСйДВОіВпгыПЦбаЁЂЛљвђВтађЁЂаТвЉбаЗЂКЭНЁПЕЙмРэЕШЬсЙЉКЃСПДцДЂМАДѓЪ§ОнЗжЮіФмСІЁЃДѓЪ§ОнЗжЮіММЪѕЪЙСйДВОіВпжЇГжЯЕЭГИќжЧФмЃЌЭЈЙ§ЭкОђвНСЦЮФЯзЪ§ОнНЈСЂвНСЦзЈМвЪ§ОнПтЃЌДгЖјИјвНЩњЬсГіеяСЦНЈвщЃЌЬсабвНЩњЗРжЙЧБдкЕФДэЮѓЃЌМѕЩйКЭНЕЕЭвНСЦЪТЙЪТЪЁЃДѓЪ§ОнЭЈЙ§ШЋУцЗжЮіВЁШЫЬиеїЪ§ОнКЭСЦаЇЪ§ОнЃЌШЛКѓБШНЯЖржжИЩдЄДыЪЉЕФгааЇадЃЌМѕЩйЙ§ЖШжЮСЦЃЌвдМАжЮСЦВЛзуЃЌевЕНеыЖдЬиЖЈВЁШЫЕФзюМбжЮСЦЭООЖЁЃ |









