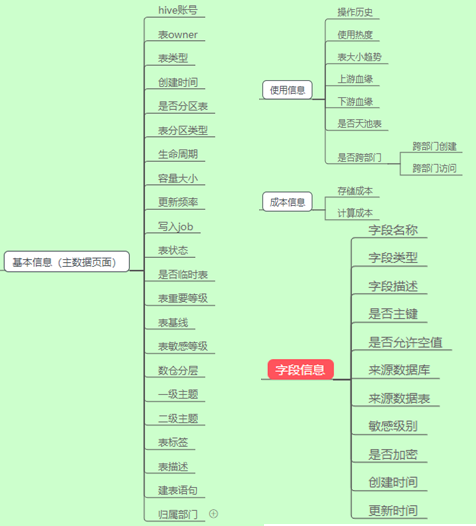
| БрМЭЦМі: |
БОЮФжївЊНщЩмЕФЪЧЪ§ОнжЮРэЕФЫМТЗвдМАЗНАИЪЕЪЉЃЌЪ§ОнзЪВњЙмРэЦНЬЈЕФШ§ДѓЙІФмФЃПщМђЮіЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкаЏГЬММЪѕ ЃЌгЩAliceБрМЁЂЭЦМіЁЃ
|
|
вЛЁЂБГОА
Ъ§ОнЕФживЊадВЛбдЖјгїЁЃУПИіЪ§ОнЙЄГЬЪІУПЬьЛсВњЩњДѓСПЪ§ОнЃЌЕЋетаЉЪ§ОнеМгУЕФГЩБОЁЂДјРДЕФМлжЕЁЂжЪСПШчКЮЃЌвдМАдкБЃжЄАВШЋЕФЧАЬсЯТЪЧЗёФмЙЛИќИпаЇЕиЪЙгУЃЌЪЧУПИіЙЋЫОдкДѓЪ§ОнЗЂеЙЕНвЛЖЈНзЖЮКѓЖМЛсгіЕНЕФЮЪЬтЁЃЖјаЏГЬгЩгкЩцМАЕФвЕЮёЯпЖрЃЌЪ§ВжЭХЖгЖрЃЌЪ§ОнАВШЋИпаЇЕиСїЭЈвВЪЧвЛИіжЮРэФбЕуЁЃ
ЖўЁЂжЮРэЫМТЗ
КЮЮЊЪ§ОнжЮРэЃПЪ§ОнжЮРэКЭжкЖраТаЫбЇПЦвЛбљЃЌвВгаКмЖржжЖЈвхЁЃIBMШЯЮЊЃЌЪ§ОнжЮРэЪЧИљОнЦѓвЕЕФЪ§ОнЙмПиеўВпЃЌРћгУзщжЏШЫдБЁЂСїГЬКЭММЪѕЕФЯрЛЅазїЃЌЪЙЦѓвЕФмЙЛНЋЁАЪ§ОнзїЮЊзЪВњЁБРДЙмРэКЭгІгУЁЃИљОнВЎЩКЭЖХВЈЗђЕФЖЈвхЃЌЪ§ОнжЮРэЪЧвЛИіЙизЂгкЙмРэаХЯЂЕФжЪСПЁЂвЛжТадЁЂПЩгУадЁЂАВШЋадКЭПЩЕУадЕФЙ§ГЬЁЃетИіЙ§ГЬгыЪ§ОнЕФгЕгаКЭЙмРэЕФжАд№НєУмЯрЙиЁЃ
ЭЈГЃШЯЮЊЃЌЪ§ОнжЮРэЪЧЮЇШЦЪ§ОнзЪВњеЙПЊЕФвЛЯЕСаЙЄзїЃЌвдЗўЮёзщжЏИїВуОіВпЮЊФПБъЃЌЪЧЪ§ОнЙмРэММЪѕЁЂЙ§ГЬЁЂБъзМКЭеўВпЕФМЏКЯЁЃ
злЩЯЃЌЪ§ОнжЮРэРыВЛПЊЪ§ОнзЪВњЕФГСЕэЃЌжЛгаЖдЪ§ОнгаКъЙлЕиАбПиЁЂУїЯИЕиЬНОПЃЌВХФмЬљКЯЪ§ОнЬиадНјаажЮРэЁЃЫљвдвЊНјааМЏЭХВуУцЕФЪ§ОнжЮРэЃЌОЭашвЊМЏЭХВуУцЕФЪ§ОнзЪВњЦНЬЈЁЃаЏГЬЪ§ОнзЪВњЙмРэЦНЬЈЃЈДѓгэЃЉгІдЫЖјЩњЁЃаЏГЬЪ§ОнжЮРэЬхЯЕЕФФПБъЪЧПЩвдШУУПвЛЮЛЪ§ОнЩњВњепЖдИїздгЕгаЕФЪ§ОнНјааГЃЬЌЛЏжЮРэЁЃЖјФПЧАНзЖЮЪ§ОнжЮРэЕФКЫаФФПБъОЭЪЧЬсЩ§Ъ§ОнМлжЕЁЂЬсИпЪ§ОнжЪСПЁЂДйНјЪ§ОнСїЭЈЁЃ
Ъ§ОнМлжЕЃКЪзЯШвЊжЮРэЕФОЭЪЧЕЭМлжЕЩѕжСЮоМлжЕЕФЪ§ОнЃЌР§ШчГЄЦкЮоЗУЮЪЁЂЩњУќжмЦкЙ§ГЄЕФЪ§ОнЁЃЦфДЮМЦЫузЪдДЯћКФНЯЖрЕФЪ§ОнвЊНјааЙщвђЗжЮіЃЌеыЖдадгХЛЏЁЃ
Ъ§ОнжЪСПЃКЭъЩЦБэЕФдЊЪ§ОнаХЯЂАќРЈд№ШЮШЫЁЂЪ§ВжЗжВуЁЂжїЬтЁЂживЊЕШМЖКЭУєИаЕШМЖЃЌХфжУЪ§ОнжЪСПМрПиЃЌжиЕужЮРэЮоШЫЮЌЛЄЕФЪ§ОнЁЃ
Ъ§ОнСїЭЈЃКБЃеЯАВШЋЕФЧАЬсЯТЃЌЬсИпШЈЯоЩѓХњаЇТЪЃЌДйНјЪ§ОнСїзЊЁЃ
Ш§ЁЂЗНАИЪЕЪЉ
3.1 дЊЪ§ОнНЈЩш
Ъ§ОнжЮРэЕФЪзвЊЙЄзїЪЧДюНЈдЊЪ§ОнЪ§ВжЁЃдЊЪ§ОнвЛАуЗжЮЊЫФРрЃКММЪѕдЊЪ§ОнЁЂВйзїдЊЪ§ОнЁЂЙмРэдЊЪ§ОнКЭвЕЮёдЊЪ§ОнЃЌЗжБ№УшЪіСЫЪ§ОнЕФЮяРэЛЏЁЂДІРэЙ§ГЬЁЂЙмРэЙ§ГЬМАЪ§ОнЖЈвхЁЃ
ММЪѕдЊЪ§ОнЃКДцДЂЯрЙиЪ§ОнЃЌАќРЈБэЕФдЊЪ§ОнЁЂзжЖЮдЊЪ§ОнЕШЁЃ
ВйзїдЊЪ§ОнЃКETLЯрЙиЪ§ОнЃЌАќРЈЕїЖШдЊЪ§ОнЁЂжДаадЊЪ§ОнЁЂЕїЖШжЎМфЕФбЊдЕдЊЪ§ОнЕШЁЃ
ЙмРэдЊЪ§ОнЃКАќРЈЙмРэепаХЯЂЁЂМрПиШежОЁЂЙмРэШежОЁЂЙмРэГЩаЇЕШЁЃ
вЕЮёдЊЪ§ОнЃКАќРЈЪ§ОнБъзМЁЂЪ§ОнжЪСПЁЂЪ§ОнжИБъЁЂЪ§ОнзжЕфЁЂЪ§ОнДњТыЁЂЪ§ОнАВШЋЕШЁЃ
ЯжНзЖЮзюЮЊЗсИЛЕФЪ§ОнЪЧММЪѕдЊЪ§ОнКЭВйзїдЊЪ§ОнЃЌ гаСЫетаЉдЊЪ§ОнОЭПЩвдЖдМЦЫу/ДцДЂГЩБОЁЂдЊЪ§ОнЭъећЖШЁЂЪ§ОнжЪСПМрПиЕФИВИЧТЪ/ЭЈЙ§ТЪЁЂСйЪББэЁЂЮоШЫЮЌЛЄБэЕШНјааЭГМЦЗжЮіЃЌНјЖјЭЦНјЯрЙизЈЯюжЮРэЁЃ
3.2 зЈЯюжЮРэ
3.2.1 ГЩБОжЮРэ
ДѓЖрЪ§ЕФЪ§ОнЙЄГЬЪІЙизЂЕФЪЧашЧѓНЛИЖЃЌЖдДцДЂЁЂМЦЫуГЩБОШЯЪЖВЛзуЁЃФПЧАМЏЭХДѓЪ§ОнМЏШКМЦЫуГЩБОКЭДцДЂГЩБОБШР§ЪЧ4ЃК6ЃЌЭЈЙ§ГѕВНжЮРэЃЌПЩНкдМФъГЩБОЪ§ЧЇЭђдЊЁЃдкДѓгэЃЈЪ§ОнзЪВњЙмРэЦНЬЈЃЉЩЯПЩвджБЙлЕиПДЕНУПИідБЙЄгЕгаЕФHiveБэЪ§ЁЂШеОљДцДЂГЩБОЁЂШеОљМЦЫуГЩБОКЭдкЭъГЩЪ§ОнжЮРэКѓдЄМЦНкЪЁЕФФъГЩБОЁЃ
3.2.1.1 МЦЫуГЩБО
МЦЫуГЩБОжївЊРДздгкCPUзЪдДЕФЯћКФЃЌИљОнУПИіЕїЖШШЮЮёЖдCPUКЫЪ§КЭЪБМфЕФеМгУЧщПіЙРЫуГіГЩБОЁЃCPUЕФдЫааГЩБОИљОнМЏШКЕФдЫгЊЧщПіЃЌМЦЮЊ10дЊ/1M
VCSЃЈУПИіCPUКЫеМгУЕФУыЪ§ЃЉЁЃ
МЦЫузЪдДжївЊЯћКФдкETLЕїЖШКЭAdhocВщбЏЃЌгЩДЫЮвУЧЖдЕфаЭЕЭаЇSQLНјааСЫЙщвђЗжЮіЁЃбЁдёВПЗжBUзїЮЊЪдЕуЃЌеыЖдЕЅДЮЯћКФДѓгк10дЊЕФИпЯћКФЕїЖШНјаагХЛЏЁЃЫфШЛМЏЭХФкетаЉИпЯћКФЕїЖШеМБШ1%ЃЌЕЋЪЧеМОнСЫЧЇЭђСПМЖЕФФъМЦЫуГЩБОЁЃ

Бэ1ЃКИпЯћКФЮЪЬтЙщвђМАНтОіЗНАИ
ЖдгкAdhocВщбЏЖјбдЃЌ1%ГЌЙ§30дЊ/ДЮЃЌ13%ГЌЙ§0.3дЊ/ДЮЁЃНіет14%ЕФВщбЏОЭеМОнСЫГЌвЛАыЕФЫуСІГЩБОЁЃГ§СЫТпМЁЂвЕЮёЁЂЗжЧјВуУцЕФгХЛЏЃЌММЪѕВЮЪ§гХЛЏвВНјааШЋУцЭЦЙуЁЃР§ШчГЃМћЕФМИРрMRгХЛЏЃК
1ЃЉКЯВЂаЁЮФМўЃКХфжУMapЪфШыКЯВЂЁЂMap/ReduceЪфГіКЯВЂЁЃ
2ЃЉКЯРэПижЦreducerЪ§СП
ВЮЪ§1ЃКhive.exec.reducers.bytes.per.reducerЃЈФЌШЯ1GЃЉ
ВЮЪ§2ЃКhive.exec.reducers.maxЃЈФЌШЯЮЊ999ЃЉ
reducerЕФМЦЫуЙЋЪНЮЊЃКminЃЈВЮЪ§2ЃЌзмЪфШыЪ§ОнСП/ВЮЪ§1ЃЉЃЌвВПЩвдЭЈЙ§ЩшжУmapred.reduce.tasksжБНгПижЦreducerИіЪ§ЁЃ
3ЃЉЪЙгУЯрЭЌЕФСЌНгМќЃКЕБЖд 3 еХЛђИќЖрБэНјаа join ЪБЃЌШчЙћ on ЬѕМўЪЙгУЯрЭЌзжЖЮЃЌЛсКЯВЂЮЊвЛИі
MapReduce JobЁЃ
4ЃЉSMBЃЈsort merge bucket joinЃЉЃКгУгкСНеХДѓБэНјааjoinЃЌЕЋашвЊдЄЯШИјУПеХДѓБэЛљгкjoinЕФзжЖЮНЈСЂЭАЁЃ
set hive.enforce.bucketing = true; --ЦєгУЭАБэ
set hive.optimize.bucketmapjoin = true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
ЛЙгаНЋЪ§ОнЧуаБЕФвьГЃжЕДђЩЂЛђЕЅЖРДІРэЁЂЦєгУбЙЫѕЁЂЪИСПЛЏжДааЕШЁЃ
3.2.1.2 ДцДЂГЩБО
ДцДЂГЩБОжиЕужЮРэГЄЦкЮоЗУЮЪЪ§ОнКЭгУЛЇааЮЊЪ§ОнЃЈUBTЃЉЃЌЦфДЮЭГвЛБэДцДЂИёЪНЮЊORCЃЌВЩгУРфШШДцДЂЁЂECДцДЂЃЌзюКѓЧхРэжиИДЕФДѓЮФМўКЭвЕЮёВЛдйашвЊЕФЪ§ОнЁЃЭЈЙ§етаЉжЮРэЪжЖЮЃЌаТдіДцДЂашЧѓЫѕМѕ50%ЃЌеМзмДцДЂЕФ20%ЁЃ
1ЃЉНќ30ЬьЮоЗУЮЪБэЕФГЩБОеМОнзмДцДЂЕФ20%ЃЌЦфжа99%ЪЧСйЪББэЁЃетаЉЮоЗУЮЪБэгЩBUФкВПНјааШЗШЯЧхРэЃЌвЛаЉШежОБэЛђепМЏЭХЕФгУЛЇааЮЊЪ§ОнЕШашвЊГЄЦкБЃДцЕФЛсМгШыАзУћЕЅЃЌУЛгаМгШыАзУћЕЅЕФБэЛсздЖЏЩОГ§ЁЃ
2ЃЉгУЛЇааЮЊЪ§ОнжЎЧАШЋСДТЗБЃДцСЫШ§ФъЕФРњЪЗЃЌЭЈЙ§ж№НЅЫѕЖЬећИіСїГЬЪ§ОнЕФЩњУќжмЦкДяЕНЫѕМѕГЩБОЕФФПЕФЁЃЮЊСЫзіЕНжЮРэЙ§ГЬжаЯТгЮЮоИажЊЃЌНЋдБэИФЮЊБИЗнБэдйДДНЈвЛИідБэБэУћЕФЪгЭМЃЌж№НЅЫѕЖЬЪгЭМПЩЖСЕФЪБМфЗЖЮЇЃЌД§ЯТгЮЪЙгУЮовьГЃжЎКѓПЩНЋБИЗнБэЕФЩњУќжмЦкЫѕЖЬЁЃетИігХЛЏНкЪЁСЫДѓСПДцДЂГЩБОЁЃ
3ЃЉгЩгкРњЪЗвХСєЮЪЬтЃЌжЎЧАБэЕФЪ§ОнИёЪНЮДЭъШЋЭГвЛЁЃRCFileеМБШ13.46%ЃЌAvroеМБШ1.99%ЃЌбЙЫѕБэеМБШ5.4%ЃЌЗЧНсЙЙЛЏЪ§ОнеМБШ24.15%ЁЃЫљвдНЋетаЉБэзЊЛЏЮЊORCИёЪНЃЌЭЌЪБЬсЩ§МЦЫуаЇТЪКЭДцДЂФмСІЁЃ
4ЃЉНЋВЛГЃгУЕЋашвЊБЃДцЕФЪ§ОнНјааРфДцДЂЁЃРфДцДЂЕФГЩБОЮЊШШДцДЂЕФ40%ЃЌЪЙгУECММЪѕПЩНјвЛВНбЙЫѕЕН20%ЁЃЕЋЪЧРфДцДЂЛсгАЯьВщбЏЕФадФмЃЌашвЊИљОнЪ§ОнЕФЪЙгУГЁОАзлКЯПМТЧЁЃетИігХЛЏвВНкЪЁСЫВЛаЁЕФДцДЂГЩБОЁЃ
3.2.2 жЪСПЙцЗЖ
ЪзЯШЭъЩЦБэЕФдЊЪ§ОнаХЯЂЃЌХфжУЪ§ОнжЪСПМрПиЃЈDQCЃЉЃЌЦфДЮжиЕужЮРэЮоШЫЮЌЛЄЕФБэКЭСйЪББэЁЃ
1ЃЉЭъЩЦдЊЪ§ОнаХЯЂЃК
БэЕФдЊЪ§ОнаХЯЂ
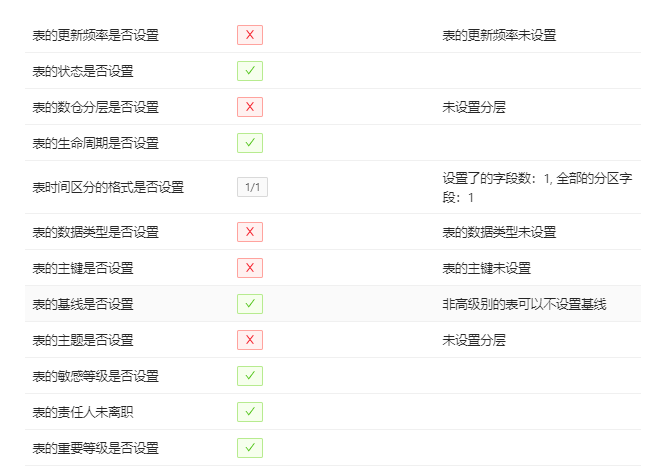
ФПЧАЭГМЦЕНЕФБэКЭзжЖЮЕФдЊЪ§ОнаХЯЂМћЩЯЭМЃЌДгжабЁШЁСЫ12ИіживЊжИБъзїЮЊЭъећадЮЌЖШЕФЭГМЦЃЌШчЯТЭМЁЃРњЪЗБэЕФЭъећадвВЛсАДееЩшЖЈЕФНижЙЪБМфНјааХњСПВЙГфЃЌЭЌЪБаТНЈе§ЪНБэбЯИёАДееЭъећадЕФЙцЗЖНЈСЂЃЌЗёдђЮоЗЈДДНЈЁЃ
2ЃЉХфжУDQCЃКддђЩЯУПИіе§ЪНЪЙгУЕФБэЖМашвЊХфжУDQCаЃбщЃЌБШШчБЃжЄЕїЖШЭъГЩКѓЕФЪ§ОнвЊДѓгквЛЖЈЪ§СПЃЌНёЬьКЭзђЬьЕФЪ§ОнВЈЖЏвЊдквЛЖЈЕФЗЖЮЇЃЌФГаЉЧщОГЯТашвЊжїМќЮЈвЛЃЌЛђепздЖЈвхаЃбщЙцдђЁЃаЃбщЙцдђЗжЮЊЧПЙцдђЁЂШѕЙцдђЁЃЧПЙцдђЛсШлЖЯЯТгЮЃЌЗРжЙДэЮѓЪ§ОнгАЯьЕНЯТгЮЕФЪЙгУЃЌЖдЩњВњдьГЩВЛПЩФцЕФгАЯьЁЃШѕЙцдђЛсДЅЗЂгЪМўОЏИцЁЃ
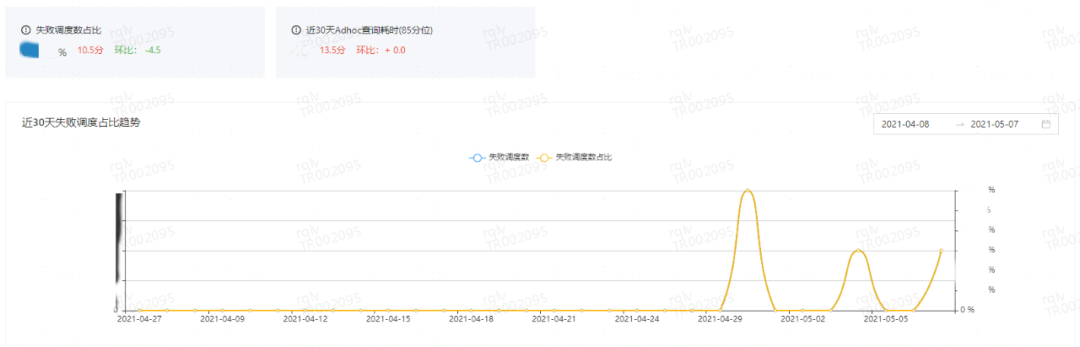
3ЃЉЮоШЫЮЌЛЄБэжЮРэЃКвђЮЊРыжАзЊИкЕШдвђЃЌгааЉБэЕФд№ШЮШЫШБЪЇЃЌИјЯТгЮЪЙгУдьГЩСЫвЛаЉРЇФбЁЃЮвУЧЪзЯШНЋЮоШЫЮЌЛЄБэЕФУїЯИПЊЗХИјИїBUЃЌЭЦЖЏBUВЙШЋд№ШЮШЫаХЯЂЁЃКѓЦкПЊЗЂСЫзЪдДзЊвЦЯЕЭГЃЌРыжАЛђзЊИкЧАЛсНЋд№ШЮШЫУћЯТЕФзЪдДНјаавЛМќзЊвЦЁЃ
4ЃЉСйЪББэжЮРэЃКСйЪББэЪ§СПеМзмБэЪ§СПЕФБШР§НЯИпЃЌашвЊНјаажЮРэЁЃЮвУЧУїШЗСЫСйЪББэЕФЪЙгУЙцЗЖЃЌжЛЪЧзїЮЊСйЪБЪЙгУЃЌЦпЬьКѓздЖЏЩОГ§ЁЃПЩвдгУРДНјааЬНЫїадЗжЮіЁЂХХеЯЃЌЕЋЪЧВЛПЩгУгкБЈБэвРРЕЁЂЕїЖШвРРЕЁЂЪ§ОнДЋЪфЁЃЕїЖШШЮЮёжаВњЩњЕФжаМфБэашвЊдкШЮЮёНсЪјКѓЩОГ§ЁЃ
3.2.3 Ъ§ОнСїЭЈ
Ъ§ОнСїЭЈжївЊЙизЂЕФЪЧЙВЯэЪ§ОнЁЃгаСНИіРДдДЃКПчBUКЯзїЕФЯюФПЃЌжаЬЈЬсЙЉЕФЗўЮёгкШЋвЕЮёЕФЪ§ОнБШШчЃКЭГвЛЖЉЕЅЪ§ОнЕШЁЃжиЕужЮРэЕФЪЧПчBUКЯзїЕФЯюФПжагЩгкзщжЏМмЙЙЕФИФБфЁЂЯюФПзщБфЖЏЁЂЪ§ОндДБфИќЕШдвђВњЩњЕФШЈЯоЭтвчЁЃ
ЯжНзЖЮЕФжЮРэПМТЧСНИіЗНУцЃКМШвЊдіМгBUжЎМфЕФЪ§ОнСїЭЈадЁЂЬсИпЪ§ОнМлжЕЃЌгжвЊМАЪБжЮРэШЈЯоЭтвчЁЂУєИаЪ§ОнаЙТЖЁЃвзгУадгыАВШЋаджЎМфЕФЦНКтДцдквЛЖЈЬєеНЁЃЮЊДЫЮвУЧЩЯЯпМЖСЊЩѓХњЙІФмЁЃЖдгкЩшжУМЖСЊЩѓХњЕФБэЃЌЦфЯТгЮБэЕФШЈЯоЩѓХњашвЊЩЯгЮБэownerЙВЭЌВЮгыЃЌНјвЛВНМгЧПСЫЪ§ОнАВШЋадЁЃЭЌЪБЩЯЯпСЫЛљгкУмМЖЕФВювьЛЏЩѓХњСїГЬЁЃЖдгкИпУмБэДгбЯАбПиЃЌЕЭУмБэдђОЁСПМђЛЏЩѓХњСїГЬЃЌЗНБуЪ§ОнПьЫйСїЭЈЁЃ
ЫФЁЂЦНЬЈЛЏгыГЃЬЌЛЏ
Ъ§ОнзЪВњЙмРэЦНЬЈФПЧАгаШ§ДѓЙІФмФЃПщЃЌЗжБ№ЪЧзЪВњХЬЕуЁЂжЮРэЙЄОпЁЂНЁПЕЗжЮіЁЃШ§ИіФЃПщЕФЙиЯЕШчЯТЭМЫљЪОЃК
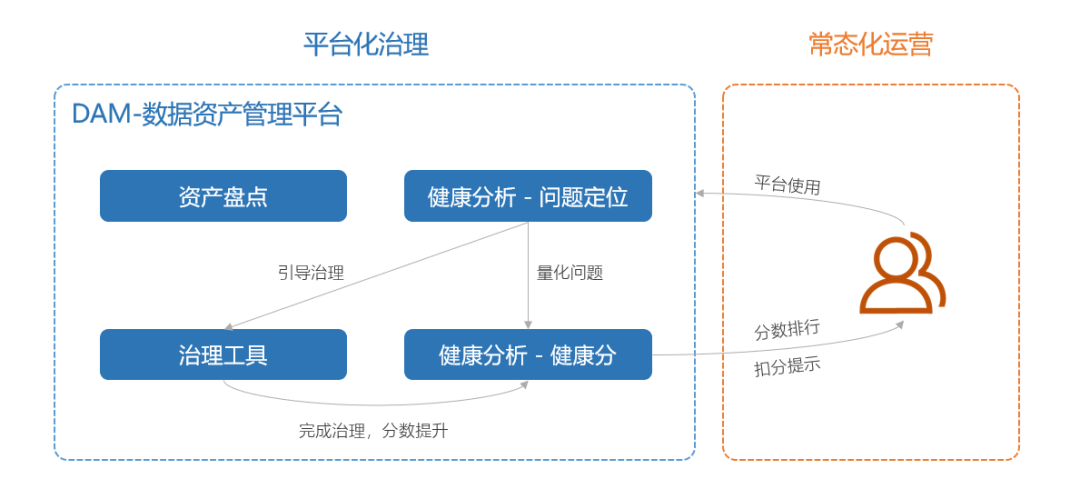
ЦфжазЪВњХЬЕужївЊЪЧзЪВњЪ§ОнПДАхЃЌАќКЌМЏЭХЁЂBUзщжЏКЭИіШЫЕФзЪВњИХРРЃЌГЩБОЗжЮіЃЌжЪСПКЭЪ§ОнЙВЯэЯрЙижИБъЁЃ
ЕкЖўИіФЃПщЪЧЪ§ОнжЮРэЁЃЪ§ОнЪєжїПЩвддкЁАЮвЕФЙЄзїЬЈЁБЖдгаЮЪЬтЕФЪ§ОнНјааБуНнЕижЮРэЁЃашвЊжЮРэЕФЪ§ОнЖМЛсвдЮЪЬтБъЧЉЕФаЮЪННјааЗжРреЙЪОЁЃ
ЕкШ§ИіФЃПщЪЧЪ§ОнНЁПЕЗжЮіЁЃЗжЮЊзЪдДРћгУЁЂЙмРэЙцЗЖЁЂГЩЙћНЛИЖЁЂЪ§ОнАВШЋЫФИіЮЌЖШЖдЪ§ОнЕФНЁПЕзДЬЌНјааЭГМЦЁЃBUФкВПЯывЊЬсжЪНЕБОЁЂЬсИпПЊЗЂаЇТЪЃЌНЁПЕЗжЛсЪЧвЛИізюжБЙлЕФжИБъЁЃШчЙћгаBUЪшгкЪ§ОнжЮРэЃЌФЧУДЯргІЕФНЁПЕЗжКЭBUжЎМфЕФХХУћОЭЛсЯТНЕЃЌвдДЫРДДйНјГЃЬЌЛЏжЮРэЁЃЯТЭМЮЊЪ§ОнНЁПЕЗжзмРРЁЃ
зЪдДРћгУЃКПМВьНќ7ЬьCPUРыЩЂЯЕЪ§ЁЂИпЯћКФЕїЖШГЩБОЯЕЪ§МАНќ45ЬьЮоЗУЮЪБэГЩБОеМБШЁЃ
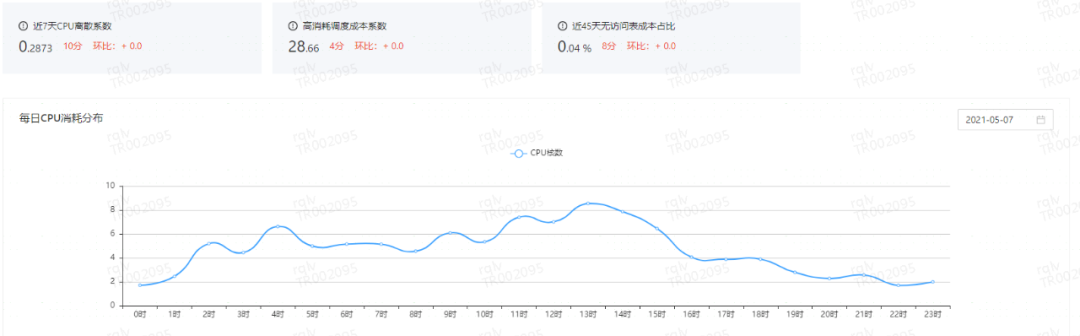
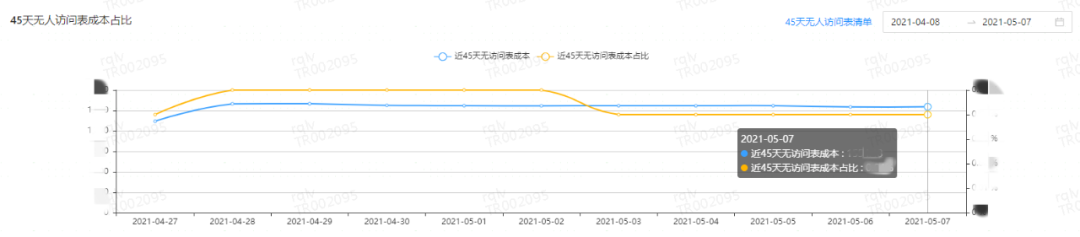
зЪдДРћгУНЁПЕЗж
ЙмРэЙцЗЖЃКПМВьБэЕФдЊЪ§ОнЃЈЪ§ВжЗжВуЁЂд№ШЮШЫЁЂживЊЕШМЖЁЂЛљЯпЁЂУєИаЕШМЖКЭжїЬтЕШЃЉЭъећадЁЃ
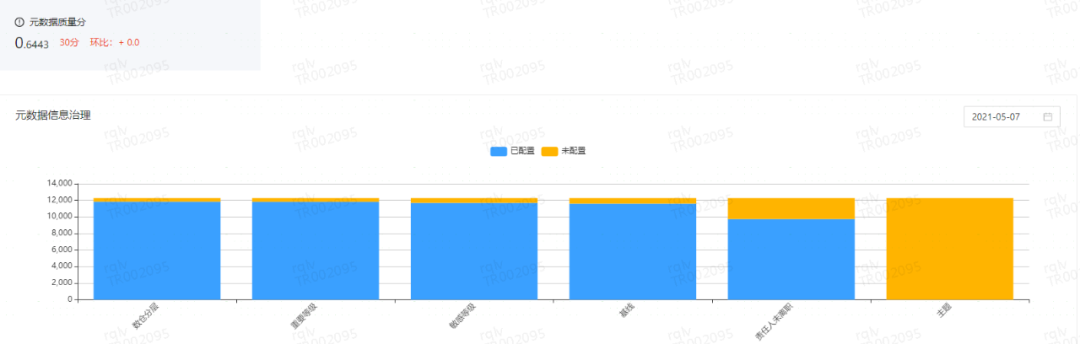
ЙмРэЙцЗЖНЁПЕЗж
ГЩЙћНЛИЖЃКПМВьЪЇАмЕїЖШеМБШКЭВщбЏЪБГЄЁЃ

ГЩЙћНЛИЖНЁПЕЗж
Ъ§ОнАВШЋЃКжиЕуПМВьЖдУєИаЪ§ОнЕФЪЙгУЪЧЗёДцдкЗчЯеЁЃ
ЮхЁЂзмНс
Ъ§ОнжЮРэЪЧвЛИіБШНЯПэЗКЕФИХФюЃЌУПИіЙЋЫОашвЊжЮРэЕФЪ§ОнВЛвЛбљЃЌВЂЧвЭЌвЛЙЋЫОВЛЭЌЕФЗЂеЙНзЖЮжЮРэЕФФкШнвВВЛвЛбљЁЃашвЊОіВпВуИљОнЪ§ОнЬхЯЕЗЂеЙЕФНзЖЮШЗЖЈБОНзЖЮжЮРэЕФКЫаФФПБъЃЌвдДЫРДеЙПЊжЮРэЁЃ
ЯжНзЖЮЮвУЧеыЖдЪ§ОнЕФГЩБОЁЂжЪСПЁЂСїЭЈШ§ИіЮЌЖШЕФжиЕуЮЪЬтНјааСЫжЮРэЁЃЯТНзЖЮНЋЛсгаИќИпЕФжЮРэвЊЧѓЁЃЭЌЪБгЩгкЪ§ОндкВЛЖЯВњЩњЃЌжЮРэвВВЛЪЧвЛРЭгРвнЕФЃЌЫљвдНшжњЦНЬЈШУУПИіЪ§ОнЩњВњепПЩвдБуНнЕиНјааГЃЬЌЛЏжЮРэЪЧБиОжЎТЗЁЃ |









