| БрМЭЦМі: |
| БОЮФжївЊНщЩмСЫЪ§ОнжаЬЈЖЅВуЩшМЦЁЂДгжаМфМўЙЄОпЕНЦНЬЈЁЂЕфаЭАИР§ЗжЮіЕШЯрЙиФкШнЁЃ
БОЮФРДздИіШЫЭМЪщЙнЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
ЕМгя
ФПЧАЁАжаЬЈЁБЕФИХФюКмЛ№ЃЌАќРЈЪ§ОнжаЬЈЁЂAIжаЬЈЁЂвЕЮёжаЬЈЁЂММЪѕжаЬЈЕШЁЃЮЊЪВУДЮвУЧвЊдкЪ§ОнжаЬЈЧАМгЩЯЁАУєНнЁБФиЃПСЫНтЮвУЧЕФХѓгбЖМжЊЕРЮвЫљдкЕФЭХЖгЪЧвЫаХУєНнДѓЪ§ОнЭХЖгЃЌЮвУЧГЋЕМЁАУєНнЦНУёЛЏЁБЃЌАбУєНнЫМЯыШкШыЕНЯЕЭГНЈЩшжаЃЌВЂЧвбаЗЂСЫЫФИіПЊдДЦНЬЈЃКDBusЁЂWormholeЁЂMoonboxЁЂDavinciЁЃвЫаХЕФЪ§ОнжаЬЈЪЧгЩЮвУЧУєНнДѓЪ§ОнЭХЖгЛљгкЫФДѓПЊдДЦНЬЈПЊЗЂНЈЩшЕФЃЌвђДЫЮвУЧНЋвЫаХЕФЪ§ОнжаЬЈГЦжЎЮЊЁАУєНнЪ§ОнжаЬЈЁБЁЃ
БОДЮЗжЯэЗжЮЊШ§ИіВПЗжЃК
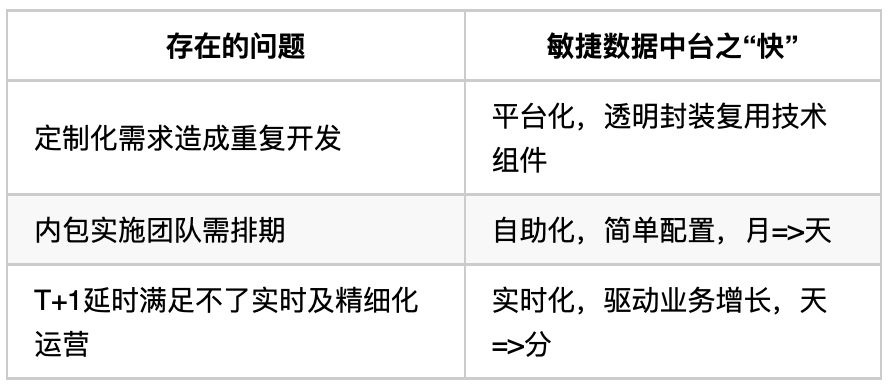
вЫаХУєНнЪ§ОнжаЬЈЕФЖЅВуЩшМЦЁЃЪ§ОнжаЬЈЪЧвЛИіЙЋЫОМЖЕФЦНЬЈЯЕЭГЃЌЫљвдВЛФмжЛДгММЪѕВуУцШЅЩшМЦЃЌЛЙвЊПМТЧАќРЈСїГЬЁЂБъзМЛЏЕШдкФкЕФЖЅВуЩшМЦЁЃ
ДгжаМфМўЙЄОпЕНЦНЬЈНщЩмвЫаХЪЧШчКЮЩшМЦНЈЩшУєНнЪ§ОнжаЬЈЕФЁЃ
НсКЯЕфаЭАИР§НщЩмвЫаХУєНнЪ§ОнжаЬЈжЇГжФФаЉЪ§ОнЗНУцЕФгІгУКЭЪЕМљЁЃ
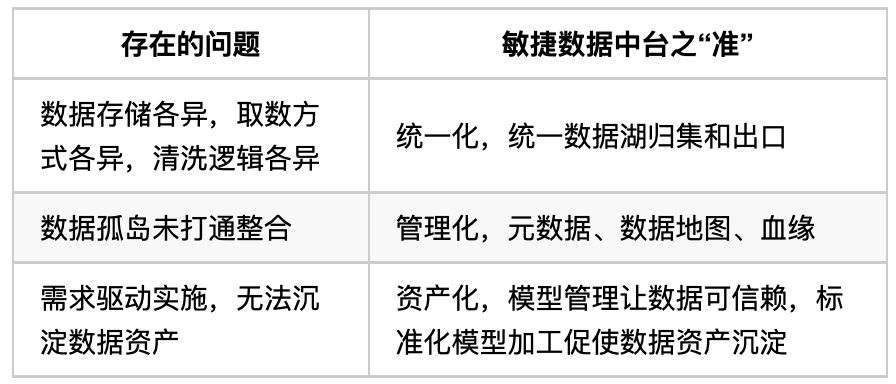
вЫаХЪ§ОнжаЬЈЖЅВуЩшМЦ
ЬиЕуКЭашЧѓ
ЙигкЪ§ОнжаЬЈЕФНЈЩшЃЌФПЧАВЂУЛгавЛИіБъзМЕФНтОіЗНАИЃЌвВУЛгавЛИіЪ§ОнжаЬЈФмЪЪгУгкЫљгаЕФЙЋЫОЃЌУПИіЙЋЫОЖМгІИУНсКЯздМКЕФвЕЮёЙцФЃМАЪ§ОнашЧѓЯжзДРДбаЗЂЪЪКЯздМКЙЋЫОЕФЪ§ОнжаЬЈЁЃ
дкНщЩмвЫаХУєНнЪ§ОнжаЬЈЕФЖЅВуЩшМЦжЎЧАЃЌЮвУЧЯШРДСЫНтЦфБГОАЃК
вЕЮёАхПщКЭвЕЮёЬѕЯпжкЖрЁЃвЫаХЕФвЕЮёДѓЬхПЩЗжЮЊЫФДѓАхПщЃКЦеЛнН№ШкАхПщЁЂВЦИЛЙмРэАхПщЁЂзЪВњЙмРэАхПщЁЂН№ШкПЦММАхПщЃЌгЕгаНќАйЬѕвЕЮёЯпКЭВњЦЗЯпЁЃ
ММЪѕбЁаЭжкЖрЁЃВЛЭЌвЕЮёЗНгаВЛЭЌЕФЪ§ОнашЧѓЃЌММЪѕбЁаЭЪБвРОнетаЉПЭЙлашЧѓМАжїЙлЦЋКУЃЌЛсбЁдёВЛЭЌЕФЪ§ОнзщМўЃЌАќРЈ
ЃКMySQLЁЂOracleЁЂHBaseЁЂKUDUЁЂCassandraЁЂElasticsearchЁЂMongoDBЁЂHiveЁЂSparkЁЂPrestoЁЂImpalaЁЂClickhouseЕШЁЃ
Ъ§ОнашЧѓЖрбљЁЃвЕЮёЯпЖрбљЃЌЕМжТЪ§ОнашЧѓЖрбљЃЌАќРЈЃКБЈБэЁЂПЩЪгЛЏЁЂЗўЮёЁЂЭЦЫЭЁЂЧЈвЦЁЂЭЌВНЁЂЪ§ОнгІгУЕШЁЃ
Ъ§ОнашЧѓЖрБфЁЃЮЊЫГгІЛЅСЊЭјЕФПьЫйБфЛЏЃЌвЕЮёЗНЕФЪ§ОнашЧѓвВЪЧЖрБфЕФЃЌОГЃгажмМЖВњГіЪ§ОнашЧѓКЭЪ§ОнгІгУЁЃ
Ъ§ОнЙмРэПМТЧЁЃвЊЧѓЪ§ОндЊаХЯЂПЩВщЃЌЪ§ОнЖЈвхКЭСїГЬБъзМЛЏЃЌЪ§ОнЙмРэПЩПиЕШЁЃ
Ъ§ОнАВШЋПМТЧЁЃвЫаХзїЮЊвЛМвЭЌЪБгЕгаЛЅСЊЭјЪєадКЭН№ШкЪєадЕФЙЋЫОЃЌЖдЪ§ОнАВШЋКЭШЈЯоЕФвЊЧѓКмИпЃЌЮвУЧдкЪ§ОнАВШЋЗНУцзіСЫКмЖрЙЄзїЃЌАќРЈЃКЖрМЖЪ§ОнАВШЋВпТдЁЂЪ§ОнСДТЗПЩзЗЫнЁЂУєИаЪ§ОнВЛПЩаЙТЖЕШЁЃ
Ъ§ОнШЈЯоПМТЧЁЃдкЪ§ОнШЈЯоЗНУцЕФЙЄзїАќРЈЃКБэМЖЁЂСаМЖЁЂааМЖЪ§ОнШЈЯоЃЌзщжЏМмЙЙЁЂНЧЩЋЁЂШЈЯоВпТдздЖЏЛЏЁЃ
Ъ§ОнГЩБОПМТЧЁЃАќРЈМЏШКГЩБОЁЂдЫЮЌГЩБОЁЂШЫСІГЩБОЁЂЪБМфГЩБОЁЂЗчЯеГЩБОЕШЁЃ
ЖЈЮЛ
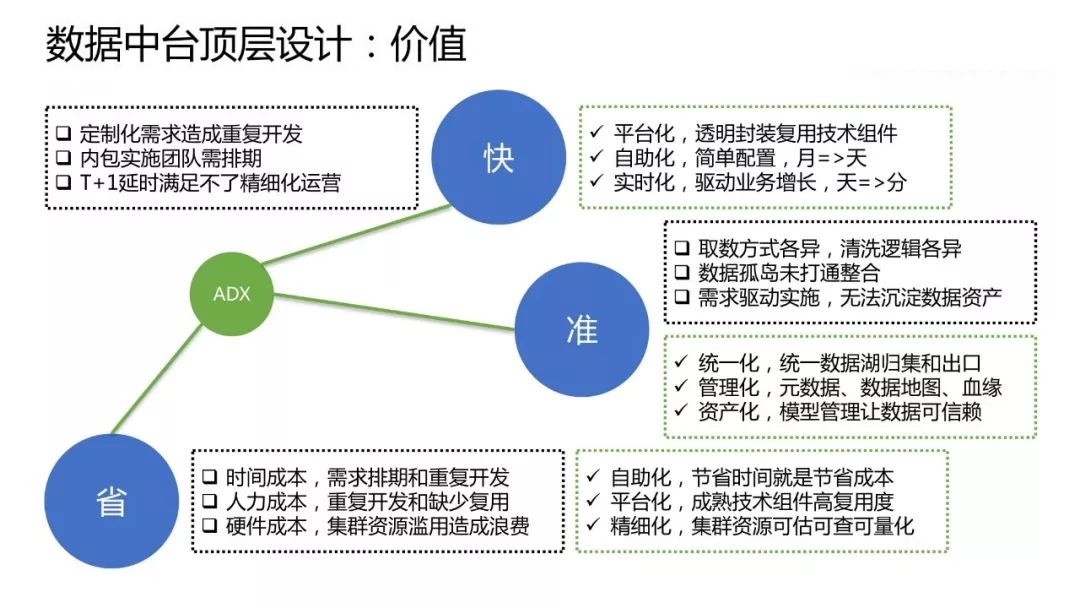
ЙигкЪ§ОнжаЬЈЕФЖЈЮЛЃЌУПИіЙЋЫОЖМВЛЬЋвЛбљЁЃгаЕФЙЋЫОвЕЮёБШНЯзЈзЂЃЌжЛгавЛЬѕвЕЮёЯпЃЌФЧЫќдкНЈЩшЪ§ОнжаЬЈЕФЪБКђЃЌПЩФмашвЊвЛИіДЙжБЕФЦНЬЈЃЌжБДяЧАЯпЃЌИќКУЕижЇГжЧАЯпЕФдЫзїЁЃ
ЧАЮФЬсЕНвЫаХвЕЮёЯпКмЖрЃЌЧвдкжкЖрвЕЮёжаУЛгавЛИіжїЬхвЕЮёЃЌетОЭЯрЕБгкЫљгавЕЮёЯпЖМЪЧжїЬхЁЃЛљгкетбљЕФБГОАЃЌЮвУЧашвЊвЛИіЦНЬЈЛЏЕФЪ§ОнжаЬЈЃЌРДжЇГХЫљгавЕЮёЯпЕФашЧѓКЭдЫзїЁЃ
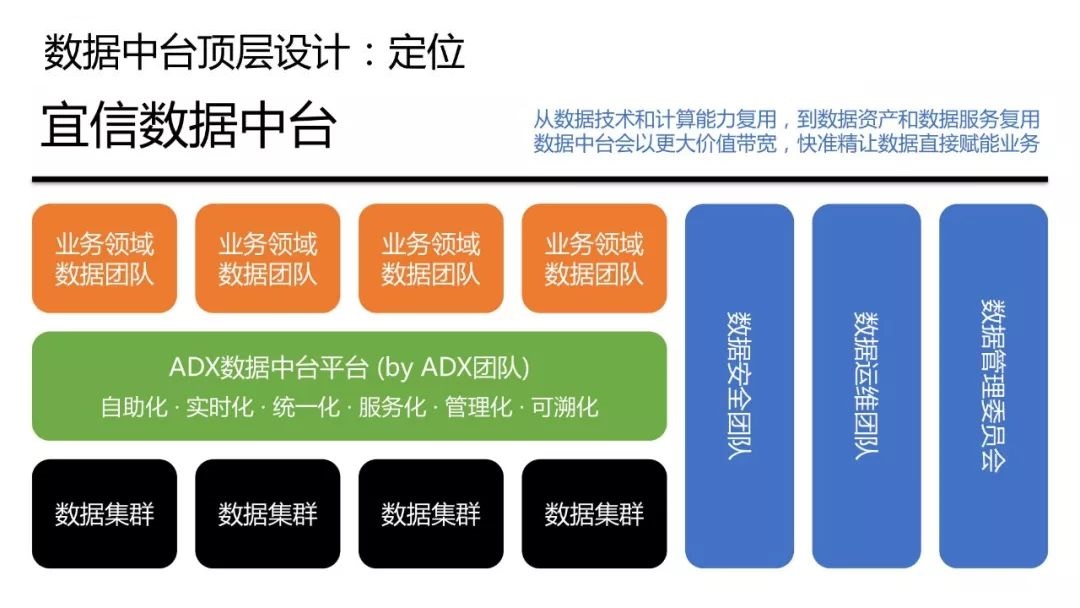
ШчЩЯЭМЫљЪОЃЌТЬЩЋЕФВПЗжЪЧвЫаХУєНнЪ§ОнжаЬЈЃЌЮвУЧГЦжЎЮЊЁАADXЪ§ОнжаЬЈЦНЬЈЁБЃЌЁАAЁБМДЁАAgileЃЈУєНнЃЉЁБЃЌжЎЫљвдГЦЮЊЁАЦНЬЈЁБЃЌЪЧвђЮЊЮвУЧЯЃЭћНЋЦфДђдьГЩвЛИіЗўЮёгкШЋвЕЮёЯпЕФЦНЬЈЯЕЭГЃЌжњСІвЕЮёЗЂеЙЁЃ
УєНнЪ§ОнжаЬЈДІгкжаМфЮЛжУЃЌзюЕзЯТЪЧИїжжЪ§ОнМЏШКЃЌзюЩЯЖЫЪЧИїИівЕЮёСьгђЪ§ОнЭХЖгЁЃЪ§ОнжаЬЈЭЈЙ§ећКЯДІРэЪ§ОнМЏШКЕФЪ§ОнЃЌЮЊвЕЮёСьгђЪ§ОнЭХЖгЬсЙЉзджњЛЏЁЂЪЕЪБЛЏЁЂЭГвЛЛЏЁЂЗўЮёЛЏЁЂЙмРэЛЏЁЂПЩЫнЛЏЕФЪ§ОнЗўЮёЁЃ
гвБпШ§ИіРЖЩЋЕФАхПщЗжБ№ЪЧЪ§ОнЙмРэЮЏдБЛсЁЂЪ§ОндЫЮЌЭХЖгКЭЪ§ОнАВШЋЭХЖгЁЃЧАЮФЬсЕНвЫаХЖдЪ§ОнАВШЋЕФвЊЧѓЗЧГЃИпЃЌЫљвдЩшжУСЫзЈУХЕФЪ§ОнАВШЋЭХЖгРДЙцЛЎЙЋЫОЪ§ОнАВШЋЕФСїГЬКЭВпТдЃЛЪ§ОнЙмРэЮЏдБЛсИКд№Ъ§ОнЕФБъзМЛЏЁЂСїГЬЛЏЃЌВЙЦыММЪѕаЭЧ§ЖЏЕФЪ§ОнжаЬЈЕФЭЦЖЏаЇТЪЃЌБЃжЄгааЇГСЕэКЭГЪЯжЪ§ОнзЪВњЁЃ
ЮвУЧЖдвЫаХУєНнЪ§ОнжаЬЈЕФЖЈЮЛЪЧЃКДгЪ§ОнММЪѕКЭМЦЫуФмСІИДгУЃЌЕНЪ§ОнзЪВњКЭЪ§ОнЗўЮёИДгУЃЌУєНнЪ§ОнжаЬЈЛсвдИќДѓМлжЕДјПэЃЌПьЁЂзМЁЂОЋШУЪ§ОнжБНгИГФмвЕЮёЁЃ
МлжЕ
вЫаХУєНнЪ§ОнжаЬЈЕФМлжЕМЏжаБэЯжЮЊШ§ИіЗНУцЃКПьЁЂзМЁЂЪЁЁЃ
ФЃПщМмЙЙЮЌЖШ

ШчЭМЫљЪОЃЌвЫаХУєНнЪ§ОнжаЬЈЕФНЈЩшвВЪЧЛљгкЁАаЁЧАЬЈЃЌДѓжаЬЈЁБЕФЙВЪЖЁЃећИіжаМфВПЗжЖМЪєгкУєНнЪ§ОнжаЬЈАќКЌЕФФкШнЃЌзѓБпТЬЩЋВПЗжЪЧЛљгкЪ§ОнЮЌЖШРДПДећИіжаЬЈЃЌгвБпРЖЩЋВПЗждђЪЧЛљгкЦНЬЈЮЌЖШРДПДжаЬЈЁЃ
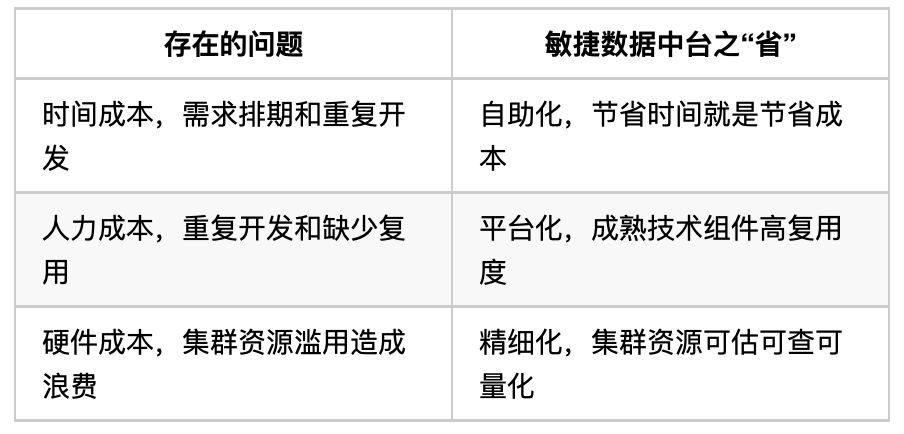
Ъ§ОнЮЌЖШЁЃИїжжФкВПЪ§ОнЁЂЭтВПЪ§ОнЯШЙщМЏЕНЪ§ОндДВуЃЌдйвдЭГвЛЛЏЁЂЪЕЪБЛЏЁЂБъзМЛЏЁЂАВШЋЛЏЕШЗНЪНДцДЂЦ№РДаЮГЩЪ§ОнКўВуЃЌЪ§ОнКўЖдетаЉдЪМЪ§ОнНјааДІРэКЭЬхЯЕЛЏЙщРрЃЌзЊЛЏЮЊЪ§ОнзЪВњЃЛЪ§ОнзЪВњВуАќРЈЪ§ВжЬхЯЕЁЂжИБъЬхЯЕЁЂБъЧЉЬхЯЕЁЂЬиеїЬхЯЕЁЂжїЪ§ОнЕШЃЛзюКѓНЋГСЕэЕФетаЉПЩИДгУЕФЪ§ОнзЪВњЬсЙЉИјЪ§ОнгІгУВуЃЌЙЉBIЁЂAIЁЂЪ§ОнВњЦЗгІгУЁЃ
ЦНЬЈЮЌЖШЁЃУПИіРЖЩЋЕФЗНПђЖМДњБэвЛИіММЪѕФЃПщЃЌећИівЫаХУєНнЪ§ОнжаЬЈОЭЪЧгЩетаЉММЪѕФЃПщзщКЯЖјГЩЁЃЦфжаDataHubЪ§ОнЪрХІЃЌПЩвдАяжњгУЛЇЭъГЩзджњЪ§ОнЩъЧыЁЂЗЂВМЁЂЭбУєЁЂЧхЯДКЭЗўЮёЕШЃЛDataWorksЪ§ОнЙЄЗЛЃЌПЩвдЖдЪ§ОнНјаазджњВщбЏЁЂзївЕЁЂПЩЪгЛЏЕШДІРэЃЛЛЙгаDataStarЪ§ОнФЃаЭЁЂDataTagЪ§ОнБъЧЉЁЂDataMgt
Ъ§ОнЙмРэЁЂADXMgt жаЬЈЙмРэЕШЁЃ
жЕЕУвЛЬсЕФЪЧЃЌетаЉФЃПщЖМВЛЪЧДг0ПЊЗЂЕФЃЌЖјЪЧЛљгкЮвУЧвбгаЕФПЊдДЙЄОпЁЃЪзЯШЃЌЛљгкГЩЪьЕФжаМфМўЙЄОпРДНјааПЊЗЂЃЌПЩвдНкдМПЊЗЂЕФЪБМфКЭГЩБОЃЛЦфДЮЃЌПЊдДЙЄОпГЩЮЊв§ЧцЃЌПЩвдЙВЭЌКЯСІжЇГХИќДѓЕФвЛеОЪНЦНЬЈЁЃ
Ъ§ОнФмСІЮЌЖШ
НЋЩЯЪіМмЙЙФЃПщжиаТАДееФмСІЮЌЖШЛЎЗжЃЌПЩвдЗжГЩШєИЩВуЃЌУПвЛВуЖМАќКЌШєИЩФмСІЁЃШчЭМЫљЪОЃЌПЩвдЧхЮњЕиПДЕННЈЩшЪ§ОнжаЬЈашвЊОпБИФФаЉЪ§ОнФмСІЃЌетаЉФмСІЖМЖдгІФФаЉЙІФмФЃПщЃЌЗжБ№ФмНтОіЪВУДЮЪЬтЁЃДЫДІВЛдйеЙПЊзИЪіЁЃ
ДгжаМфМўЙЄОпЕНЦНЬЈ
ABDзмРР

жаМфМўЙЄОпжИDBusЁЂWormholeЁЂMoonboxЁЂDavinciЫФДѓПЊдДЦНЬЈЃЌЫќУЧДгУєНнДѓЪ§ОнЃЈABDЃЌAgile
BigDataЃЉРэФюжаГщЯѓЖјГіЃЌзщГЩABDЦНЬЈеЛЃЌУєНнЪ§ОнжаЬЈдђБЛЮвУЧГЦЮЊADXЃЈAgile Data
X PlatformЃЉЁЃвВОЭЪЧЫЕЮвУЧОРњСЫДгABDЕНADXЕФЙ§ГЬЁЃ
вЛПЊЪМЃЌЛљгкЖдвЕЮёашЧѓЙВадЕФГщЯѓКЭзмНсЃЌЮвУЧЗѕЛЏГіШєИЩИіЭЈгУЕФжаМфМўЃЌШЅНтОіИїжжИїбљЕФЮЪЬтЁЃЕБГіЯжИќЮЊИДдгЕФашЧѓЃЌЮвУЧГЂЪдНЋетаЉЭЈгУЕФжаМфМўНјаазщКЯдЫгУЁЃЪЕМљжаЃЌЮвУЧЗЂЯжОГЃЛсЪЙгУЕНФГаЉЬиЖЈЕФзщКЯЃЌЭЌЪБЃЌДггУЛЇНЧЖШРДПДЃЌЫћУЧИќЯЃЭћФмЪЕЯжзджњЛЏЃЌжБНгФУЙ§РДОЭФмгУЃЌЖјВЛЪЧУПДЮЖМвЊздМКШЅбЁдёКЭзщКЯЁЃЛљгкетСНЕуЃЌЮвУЧЖдетМИИіПЊдДЙЄОпНјааСЫЗтзАЁЃ
1ЁЂABD-DBus
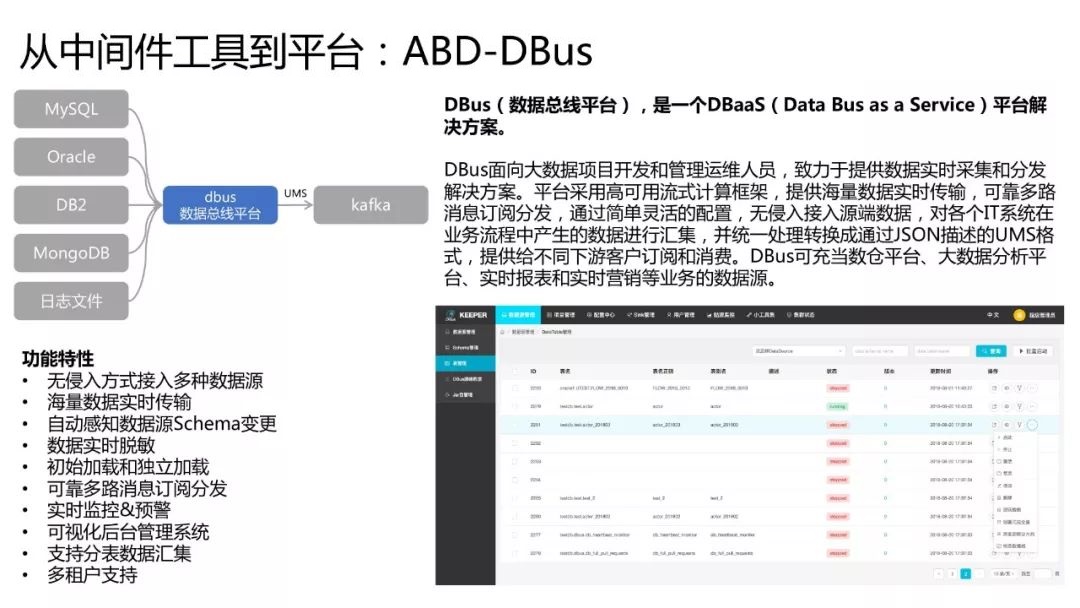
DBusЃЈЪ§ОнзмЯпЦНЬЈЃЉЃЌЪЧвЛИіDBaaSЃЈData Bus as a ServiceЃЉЦНЬЈНтОіЗНАИЁЃ
DBusУцЯђДѓЪ§ОнЯюФППЊЗЂКЭЙмРэдЫЮЌШЫдБЃЌжТСІгкЬсЙЉЪ§ОнЪЕЪБВЩМЏКЭЗжЗЂНтОіЗНАИЁЃЦНЬЈВЩгУИпПЩгУСїЪНМЦЫуПђМмЃЌЬсЙЉКЃСПЪ§ОнЪЕЪБДЋЪфЃЌПЩППЖрТЗЯћЯЂЖЉдФЗжЗЂЃЌЭЈЙ§МђЕЅСщЛюЕФХфжУЃЌЮоЧжШыНгШыдДЖЫЪ§ОнЃЌЖдИїИіITЯЕЭГдквЕЮёСїГЬжаВњЩњЕФЪ§ОнНјааЛуМЏЃЌВЂЭГвЛДІРэзЊЛЛГЩЭЈЙ§JSONУшЪіЕФUMSИёЪНЃЌЬсЙЉИјВЛЭЌЯТгЮПЭЛЇЖЉдФКЭЯћЗбЁЃDBusПЩГфЕБЪ§ВжЦНЬЈЁЂДѓЪ§ОнЗжЮіЦНЬЈЁЂЪЕЪББЈБэКЭЪЕЪБгЊЯњЕШвЕЮёЕФЪ§ОндДЁЃ
ПЊдДЕижЗЃКhttps://github.com/BriData
ШчЭМЫљЪОЃЌDBusПЩвдЮоЧжШыЕиЖдНгИїжжЪ§ОнПтЕФЪ§ОндДЃЌЪЕЪБГщШЁдіСПЪ§ОнЃЌзіЭГвЛЧхЯДКЭДІРэЃЌВЂвдUMSЕФИёЪНДцДЂЕНKafkaжаЁЃ
DBusЕФЙІФмЛЙАќРЈХњСПГщШЁЁЂМрПиЁЂЗжЗЂЁЂЖрзтЛЇЃЌвдМАХфжУЧхЮњЙцдђЕШЃЌОпЬхЙІФмЬиадШчЭМЫљЪОЁЃ
ЩЯЭМгвЯТНЧеЙЪОЕФЪЧDBusЕФвЛИіНиЭМЃЌгУЛЇдкDBusЩЯПЩвдЭЈЙ§вЛИіПЩЪгЛЏвГУцЃЌРШЁдіСПЪ§ОнЃЌХфжУШежОКЭЧхЯДЗНЪНЃЌЭъГЩЪЕЪБЪ§ОнГщШЁЕШЙЄзїЁЃ
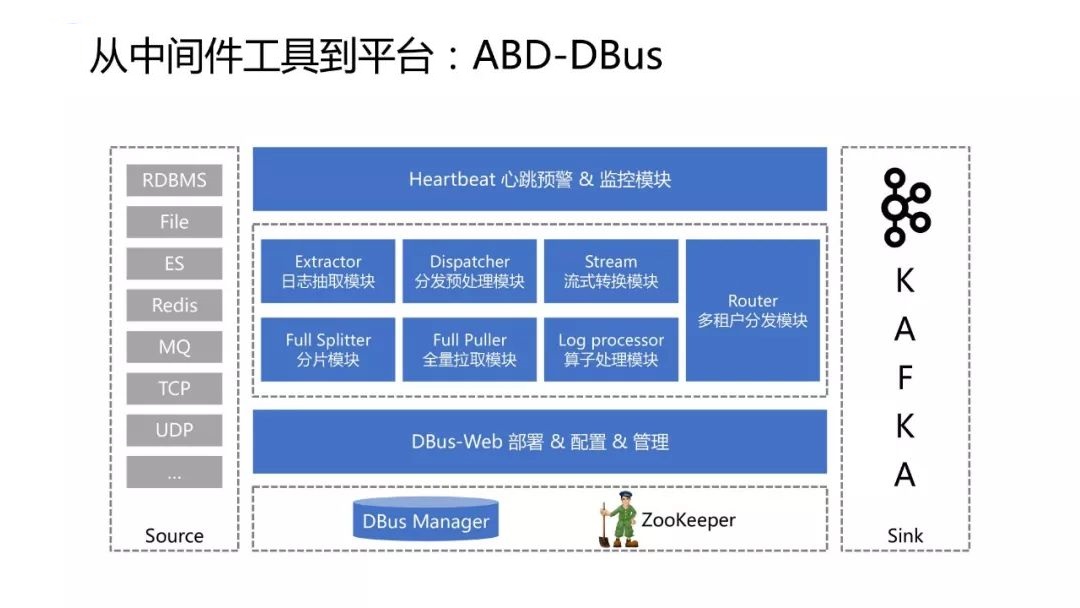
ДгШчЩЯМмЙЙЭМПЩвдПДЕНDBusАќРЈШєИЩВЛЭЌЕФДІРэФЃПщЃЌжЇГжВЛЭЌЕФЙІФмЁЃЃЈGitHubгаОпЬхНщЩмЃЌДЫДІВЛзїеЙПЊЁЃЃЉ
2ЁЂABD-Wormhole
WormholeЃЈСїЪНДІРэЦНЬЈЃЉЃЌЪЧвЛИіSPaaSЃЈStream Processing as a ServiceЃЉЦНЬЈНтОіЗНАИЁЃ
WormholeУцЯђДѓЪ§ОнЯюФППЊЗЂКЭЙмРэдЫЮЌШЫдБЃЌжТСІгкЬсЙЉЪ§ОнСїЪНЛЏДІРэНтОіЗНАИЁЃЦНЬЈзЈзЂгкМђЛЏКЭЭГвЛПЊЗЂЙмРэСїГЬЃЌЬсЙЉПЩЪгЛЏЕФВйзїНчУцЃЌЛљгкХфжУКЭSQLЕФвЕЮёПЊЗЂЗНЪНЃЌЦСБЮЕзВуММЪѕЪЕЯжЯИНкЃЌМЋДѓЕФНЕЕЭСЫПЊЗЂУХМїЃЌЪЙЕУДѓЪ§ОнСїЪНДІРэЯюФПЕФПЊЗЂКЭЙмРэБфЕУИќМгЧсСПУєНнЁЂПЩПиПЩППЁЃ
ПЊдДЕижЗ
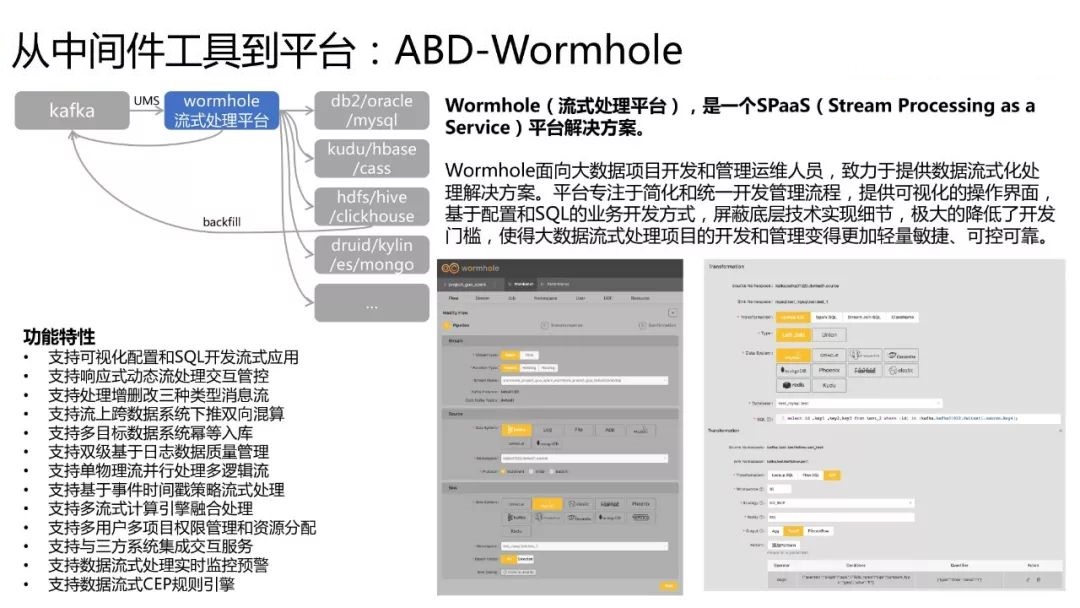
DBusНЋЪЕЪБЪ§ОнвдUMSЕФИёЪНДцДЂЕНKafkaжаЃЌЮвУЧвЊЪЙгУетаЉЪЕЪБЕФСїЪНЪ§ОнЃЌОЭвЊгУЕНWormholeетИіЙЄОпЁЃ
WormholeжЇГжХфжУСїЪНЛЏЕФДІРэТпМЃЌЭЌЪБПЩвдАбДІРэЭъжЎКѓЕФЪ§ОнаДЕНВЛЭЌЕФЪ§ОнДцДЂжаЁЃЩЯЭМжаеЙЪОСЫКмЖрWormholeЕФЙІФмЬиадЃЌЮвУЧЛЙдкПЊЗЂИќЖраТЕФЙІФмЁЃ
ЩЯЭМгвЯТНЧЪЧWormholeЕФвЛИіЙЄзїНиЭМЃЌWormholeзїЮЊСїЪНЦНЬЈЃЌздМКВЛжиаТПЊЗЂСїЪНДІРэв§ЧцЃЌЫќжївЊвРРЕSpark
Streaming КЭFlink Streaming етСНжжСїЪНМЦЫув§ЧцЁЃгУЛЇПЩвдбЁдёЦфжавЛИіСїЪНМЦЫув§ЧцЃЌБШШчSparkЃЌХфжУСїЪНДІРэТпМЃЌШЗЖЈLookupПтЕФЗНЪНЃЌВЂЭЈЙ§аДSQLРДБэДяетИіТпМЁЃШчЙћЩцМАCEPЃЌЕБШЛОЭЪЧЛљгкFlinkЁЃ
гЩДЫПЩвдПДГіЃЌЪЙгУWormholeЕФУХМїОЭЪЧХфжУМгЩЯSQLЁЃетвВЗћКЯЮвУЧвЛжББќГаЕФРэФюЃЌМДгУУєНнЛЏЕФЗНЪНжЇГжгУЛЇзджњЭцзЊДѓЪ§ОнЁЃ
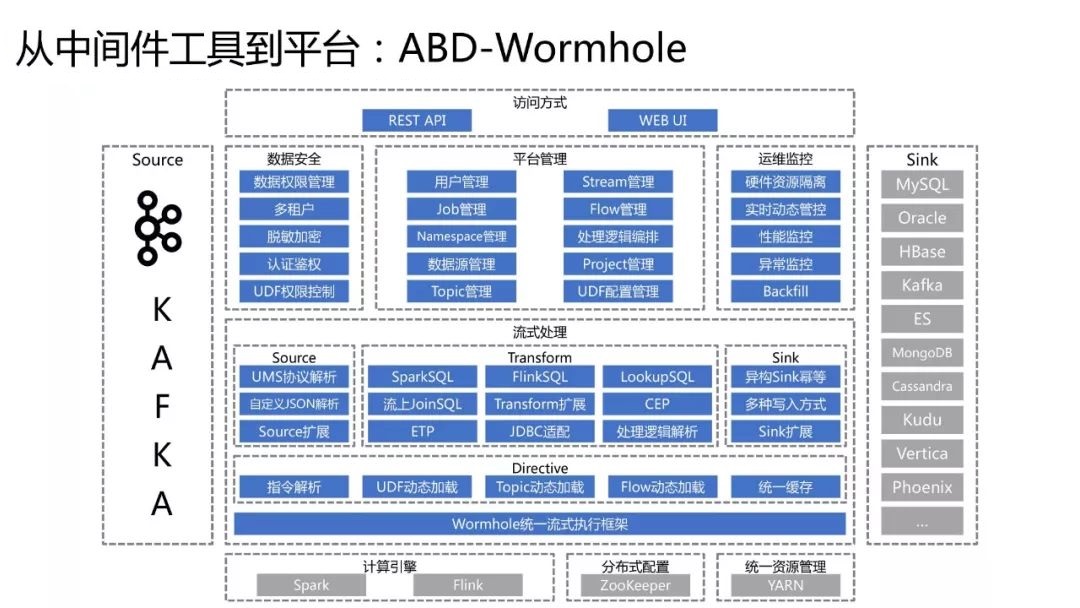
ЩЯЭМеЙЪОЕФЪЧWormholeЕФМмЙЙЭМЃЌАќКЌКмЖрЙІФмФЃПщЁЃНщЩмЦфжаЕФМИИіЙІФмЃК
WormholeжЇГжвьЙЙ SinkУнЕШЃЌФмАяжњгУЛЇНтОіЪ§ОнвЛжТадЕФЮЪЬтЁЃ
гУЙ§ Spark StreamingЕФШЫЖМжЊЕРЃЌЗЂЦ№вЛИі Spark StreamingПЩФмжЛзівЛМўЪТЧщЁЃWormholeдк
Spark StreamingЕФЮяРэМЦЫуЙмЕРжаГщЯѓГівЛВуЁАТпМЕФFlowЁБЕФИХФюЃЌОЭЪЧДгЪВУДЕиЗНЕНЪВУДЕиЗНЁЂжаМфзіЪВУДЪТЃЌетЪЧвЛИіЁАТпМЕФFlowЁБЁЃзіСЫетжжНтёюКЭГщЯѓжЎКѓЃЌWormholeжЇГждквЛИіЮяРэЕФ
Spark StreamingЙмЕРжаЭЌЪБХмЖрИіВЛЭЌвЕЮёТпМЕФFlowЁЃЫљвдРэТлЩЯНВЃЌБШШчга1000ИіВЛЭЌЕФ
SourceБэЃЌОЙ§1000ИіВЛЭЌЕФСїЪНДІРэЃЌзюКѓвЊЕУГі1000ИіВЛЭЌЕФНсЙћБэЃЌПЩвджЛдкWormholeжаЗЂЦ№вЛИіSpark
Streaming ЃЌдкРяУцХм1000ИіТпМЕФFlowРДЪЕЯжЁЃЕБШЛетбљзіЕФЛАПЩФмЛсЕМжТУПИіFlowбгГйМгДѓЃЌвђЮЊЖММЗдкЭЌвЛИіЙмЕРРяЃЌЕЋетРяЕФЩшжУЪЧКмСщЛюЕФЃЌЮвПЩвдШУФГвЛИіFlowЖРеМвЛИіVIPЕФ
StreamЃЌШчЙћгааЉFlowСїСПКмаЁЃЌЛђепбгГйЖдЦфгАЯьВЛФЧУДДѓЕФЛАЃЌПЩвдШУЫќУЧЙВЯэвЛИіStreamЁЃСщЛюадЪЧWormholeвЛИіКмДѓЕФЬиЕуЁЃ
WormholeгаздМКЕФвЛЬзжИСюКЭЗДРЁЬхЯЕЃЌгУЛЇВЛгУжиЦєЛђЭЃжЙСїЃЌОЭПЩвдЖЏЬЌЕидкЯпИќИФТпМЃЌВЂЧвЪЕЪБФУЕНзївЕКЭЗДРЁНсЙћЕШЁЃ
3ЁЂABD-Moonbox
MoonboxЃЈМЦЫуЗўЮёЦНЬЈЃЉЃЌЪЧвЛИіDVtaaSЃЈData Virtualization as a
ServiceЃЉЦНЬЈНтОіЗНАИЁЃ
MoonboxУцЯђЪ§ОнВжПтЙЄГЬЪІ/Ъ§ОнЗжЮіЪІ/Ъ§ОнПЦбЇМвЕШЃЌ ЛљгкЪ§ОнащФтЛЏЩшМЦЫМЯыЃЌжТСІгкЬсЙЉХњСПМЦЫуЗўЮёНтОіЗНАИЁЃMoonboxИКд№ЦСБЮЕзВуЪ§ОндДЕФЮяРэКЭЪЙгУЯИНкЃЌЮЊгУЛЇДјРДащФтЪ§ОнПтАуЪЙгУЬхбщЃЌгУЛЇжЛашЭЈЙ§ЭГвЛSQLгябдЃЌМДПЩЭИУїЪЕЯжПчвьЙЙЪ§ОнЯЕЭГЛьЫуКЭаДГіЁЃДЫЭтMoonboxЛЙЬсЙЉЪ§ОнЗўЮёЁЂЪ§ОнЙмРэЁЂЪ§ОнЙЄОпЁЂЪ§ОнПЊЗЂЕШЛљДЁжЇГжЃЌПЩжЇГХИќМгУєНнКЭСщЛюЕФЪ§ОнгІгУМмЙЙКЭТпМЪ§ВжЪЕМљЁЃ
ПЊдДЕижЗ

Ъ§ОнДгDBusЙ§РДЃЌОЙ§WormholeЕФСїЪНДІРэЃЌПЩФмТфЕНВЛЭЌЕФЪ§ОнДцДЂжаЃЌЮвУЧашвЊЖдетаЉЪ§ОнНјааЛьЫуЃЌMoonboxжЇГжЖрдДвьЙЙЯЕЭГЮоЗьЛьЫуЁЃЩЯЭМеЙЪОСЫMoonboxЕФЙІФмЬиадЁЃ
ЦНЪБЫљЫЕЕФМДЯЏВщбЏВЂУЛгаеце§зіЕНЁАМДЯЏЁБЃЌвђЮЊашвЊгУЛЇЯШЪжЙЄЕиАбЪ§ОнЕМЕНHiveдйзіМЦЫуЃЌетЪЧвЛИідЄжУЕФЙЄзїЁЃMoonboxВЛашвЊЪТЯШАбЪ§ОнЕМЕНвЛИіЕиЗНШЅЃЌзіЕНСЫеце§ЕФМДЯЏВщбЏЁЃЪ§ОнПЩвдЩЂТфЕНВЛЭЌЕФДцДЂжаЃЌЕБгУЛЇгаашЧѓЪБЃЌ
жЛашаДвЛИіSQLЃЌMoonboxПЩвдздЖЏВ№ЗжетИіSQLЃЌДгЖјЕУжЊФФаЉБэдкФФРяЃЌШЛКѓЙцЛЎSQLЕФжДааМЦЛЎЃЌзюжеФУЕННсЙћЁЃ
MoonboxЖдЭтЬсЙЉБъзМЕФRESTЁЂAPIЁЂJDBCЁЂODBCЕШЃЌвђДЫвВПЩвдНЋжЎПДГЩвЛИіащФтЪ§ОнПтЁЃ
ЩЯЭМеЙЪОЕФЪЧMoonboxЕФМмЙЙЭМЁЃПЩвдПДЕНMoonboxЕФМЦЫув§ЧцВПЗжвВЪЧЛљгкSparkв§ЧцзіЕФЃЌВЂУЛгаздбаЁЃMoonboxЖдSparkНјааРЉеЙКЭгХЛЏЃЌдіМгСЫКмЖрЦѓвЕМЖЕФЪ§ОнПтФмСІЃЌБШШчгУЛЇЁЂзтЛЇЁЂШЈЯоЁЂ
РрДцДЂЙ§ГЬЕШЁЃ
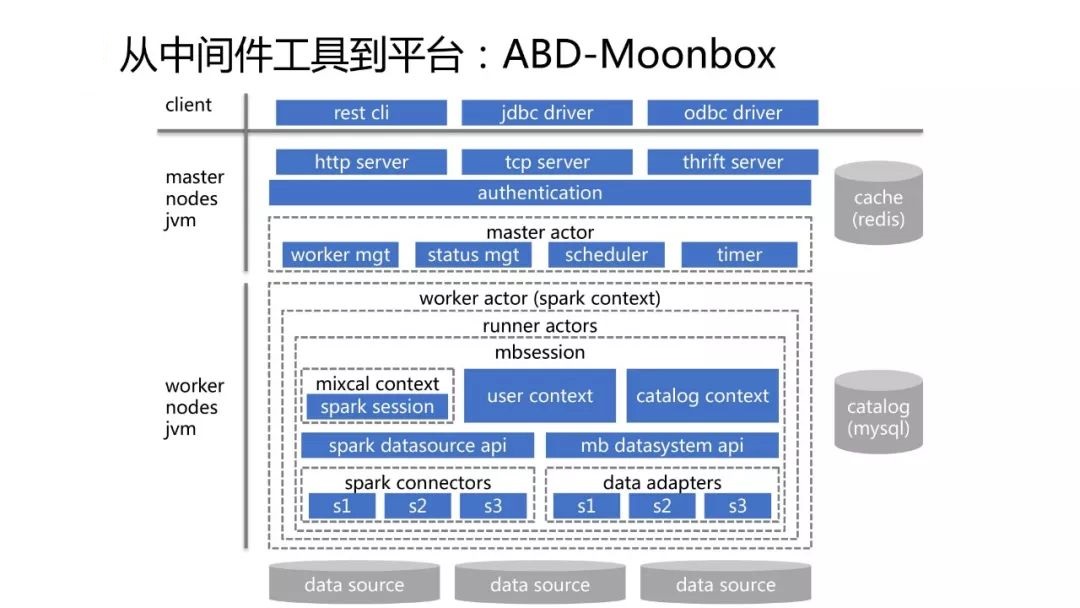
ДгЩЯЭМПДЃЌMoonboxећИіЗўЮёЖЫЪЧвЛИіЗжВМЪНЕФМмЙЙЃЌЫљвдЫќвВЪЧИпПЩгУЕФЁЃ
4ЁЂABD-Davinci
DavinciЃЈПЩЪггІгУЦНЬЈЃЉЃЌЪЧвЛИіDVaaSЃЈData Visualization as a ServiceЃЉЦНЬЈНтОіЗНАИЁЃ
DavinciУцЯђвЕЮёШЫдБ/Ъ§ОнЙЄГЬЪІ/Ъ§ОнЗжЮіЪІ/Ъ§ОнПЦбЇМвЃЌжТСІгкЬсЙЉвЛеОЪНЪ§ОнПЩЪгЛЏНтОіЗНАИЁЃМШПЩзїЮЊЙЋгадЦ/ЫНгадЦЖРСЂВПЪ№ЪЙгУЃЌвВПЩзїЮЊПЩЪгЛЏВхМўМЏГЩЕНШ§ЗНЯЕЭГЁЃгУЛЇжЛашдкПЩЪгЛЏUIЩЯМђЕЅХфжУМДПЩЗўЮёЖржжЪ§ОнПЩЪгЛЏгІгУЃЌВЂжЇГжИпМЖНЛЛЅ/аавЕЗжЮі/ФЃЪНЬНЫї/ЩчНЛжЧФмЕШПЩЪгЛЏЙІФмЁЃ
ПЊдДЕижЗ

DavinciЪЧвЛИіПЩЪгЛЏЙЄОпЃЌЫљОпБИЕФЙІФмЬиадШчЭМЫљЪОЁЃ
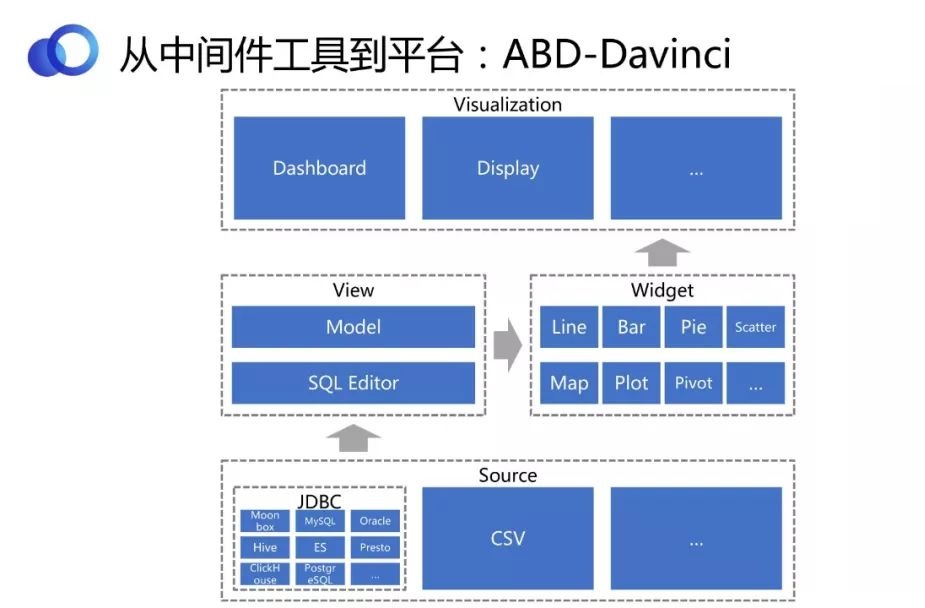
ДгЩшМЦВуУцРДПДЃЌDavinciгаздМКЕФЭъБИКЭвЛжТадЕФФкдкТпМЁЃАќРЈSourceЁЂViewЁЂWidgetЃЌжЇГжИїжжЪ§ОнПЩЪгЛЏгІгУЁЃ
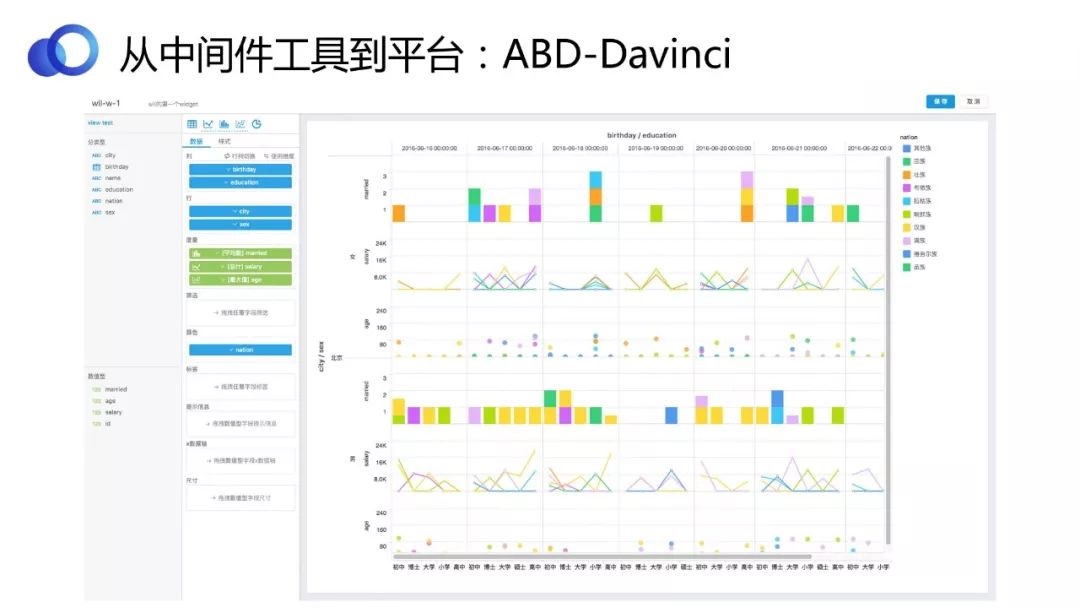
DavinciЪЧвЛИіИЛПЭЛЇЖЫЕФгІгУЃЌЫљвджївЊЛЙЪЧПДЫќЧАЖЫЕФЪЙгУЬхбщЁЂЗсИЛадКЭвзгУадЕШЁЃDavinciжЇГжЭМБэЧ§ЖЏКЭЭИЪгЧ§ЖЏСНжжФЃЪНБрМWidgetЁЃЩЯЭМЪЧвЛИіЭИЪгЧ§ЖЏЕФаЇЙћбљР§ЃЌПЩвдПДЕНКсзнзјБъЖМЪЧЭИЪгЕФЃЌЫќУЧЛсНЋећИіЭМЧаГЩВЛЭЌЕФЕЅдЊИёЃЌУПИіЕЅдЊИёРяПЩвдбЁдёВЛЭЌЕФЭМЁЃ
ABDМмЙЙ
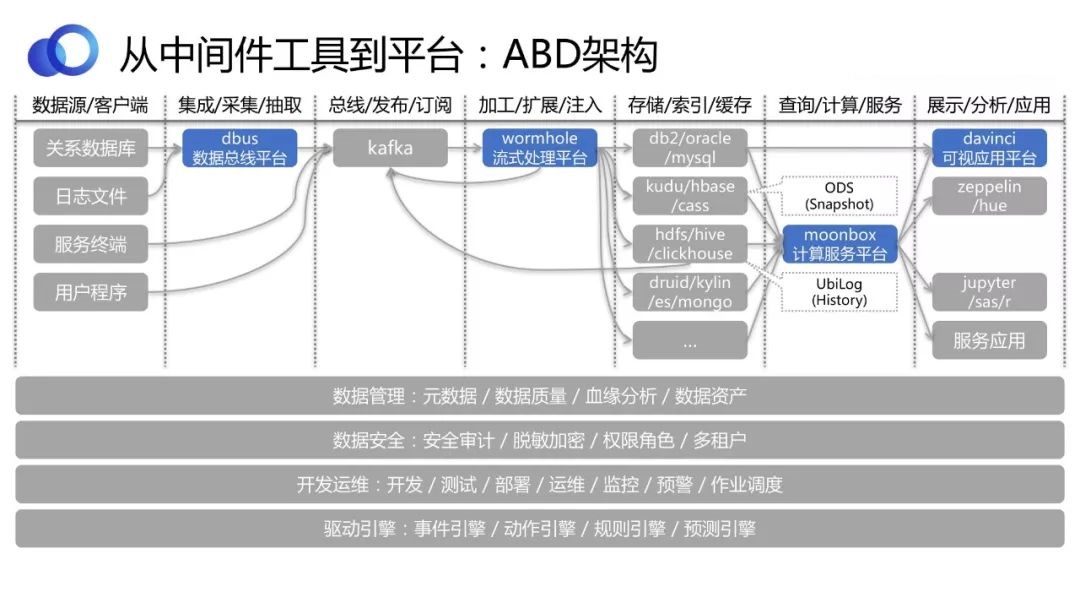
дкABDЪБДњЃЌЮвУЧЭЈЙ§DIYзщКЯЫФИіПЊдДЙЄОпРДжЇГжИїжжИїбљЕФЪ§ОнгІгУашЧѓЁЃШчЩЯЭМЫљЪОЃЌНЋећИіЖЫЕНЖЫЕФСїГЬДЎЦ№РДЃЌетИіМмЙЙЭМеЙЪОСЫЮвУЧЁАгаЪегаЗХАбећИіСДТЗДђЭЈЁБЕФРэФюЁЃ
ЪеЁЃБШШчВЩМЏЁЂМмЙЙЁЂСїзЊЁЂзЂШыЁЂМЦЫуЗўЮёВщбЏЕШЙІФмЃЌашвЊЪеСВМЏКЯГЩвЛИіЦНЬЈЁЃ
ЗХЁЃУцЖдИДдгЕФвЕЮёЛЗОГЃЌЪ§ОндДвВЪЧИїжжИїбљЕФЮоЗЈЭГвЛЃЌКмФбгавЛИіДцДЂЛђЪ§ОнЯЕЭГПЩвдТњзуЫљгаЕФашЧѓЃЌЪЙЕУДѓМвВЛдйашвЊбЁаЭЁЃвђДЫетвЛПщЕФЪЕМљЪЧПЊЗХЕФЃЌДѓМвПЩвдзджїбЁдёПЊдДЙЄОпКЭзщМўРДЪЪХфКЭМцШнЁЃ
ADXзмРР
ЗЂеЙЕНвЛЖЈНзЖЮЪБЃЌЮвУЧашвЊвЛИівЛеОЪНЕФЦНЬЈЃЌАбЛљДЁзщМўЗтзАЦ№РДЃЌЪЙЕУгУЛЇПЩвддкетИіЦНЬЈЩЯИќМђЕЅЕиЭъГЩЪ§ОнЯрЙиЕФЙЄзїЃЌгкЪЧНјШыСЫADXЪ§ОнжаЬЈНЈЩшНзЖЮЁЃ

ЩЯЭМЪЧADX змРРЃЌЯрЕБгквЛИівЛМЖЙІФмВЫЕЅЁЃгУЛЇЕЧТМЕНЦНЬЈЃЌПЩвдзівдЯТЪТЧщЃК
ЯюФППДАхЃКПЩвдПДЕНЫљдкЯюФПЕФПДАхЃЌАќРЈНЁПЕЧщПіЕШИїЗНУцЕФЭГМЦЧщПіЁЃ
ЯюФПЙмРэЃКПЩвдзіЯюФПЯрЙиЕФЙмРэЃЌАќРЈзЪВњЙмРэЁЂШЈЯоЙмРэЁЂЩѓХњЙмРэЕШЁЃ
Ъ§ОнЙмРэЃКПЩвдзіЪ§ОнЗНУцЕФЙмРэЃЌБШШчВщПДдЊЪ§ОнЃЌВщПДЪ§ОнбЊдЕЕШЁЃ
Ъ§ОнЩъЧыЃКЯюФПХфжУКУСЫЃЌЪ§ОнвВСЫНтСЫЃЌПЩвдзіЪЕМЪЙЄзїСЫЁЃЛљгкАВШЋКЭШЈЯоПМТЧЃЌВЂВЛЪЧЫЖМПЩвдШЅгУЗХдкРяУцЕФЪ§ОнЃЌвђДЫЪзЯШвЊзіЪ§ОнЩъЧыЁЃгвБпРЖЩЋФЃПщЪЧБОДЮЗжЯэНЋжиЕуНщЩмЕФADXЪ§ОнжаЬЈЕФЮхДѓЙІФмФЃПщЁЃЪ§ОнЩъЧыИќЖрЪЧгЩDataHubЪ§ОнЪрХІРДЪЕЯжЕФЃЌЫќжЇГжзджњЩъЧыЁЂЗЂВМЁЂБъзМЛЏЁЂЧхЯДЁЂЭбУєЕШЁЃ
МДЯЏВщбЏЁЂХњСПзївЕЁЂСїЪНзївЕЪЧЛљгкDataWorksЪ§ОнЙЄЗЛЪЕЯжЕФЁЃ
Ъ§ОнФЃаЭЪЧЛљгкDataStarетИіФЃаЭЙмРэЦНЬЈРДЪЕЯжЕФЁЃ
гІгУЪаГЁЃЌАќРЈЪ§ОнПЩЪгЛЏЃЈЪ§ОнМгЙЄЭъжЎКѓПЩвдХфжУзюжееЙЯжбљЪНЮЊЭМЛђвЧБэАхЕШЃЌетРяПЩФмгУЕНDavinciЃЉЃЛБъЧЉЛЯёЁЂааЮЊЗжЮіЕШГЃМћЗжЮіЗНЗЈЃЛжЧФмЙЄОпЯфЃЈАяжњЪ§ОнПЦбЇМвИќКУЕизіЪ§ОнМЏЗжЮіЁЂЭкОђКЭЫуЗЈФЃаЭЕФЙЄзїЃЉвдМАжЧФмЗўЮёЁЂжЧФмЖдЛАЃЈБШШчжЧФмСФЬьЛњЦїШЫЃЉЕШЁЃ
1ЁЂADX-DataHubЪ§ОнЪрХІ
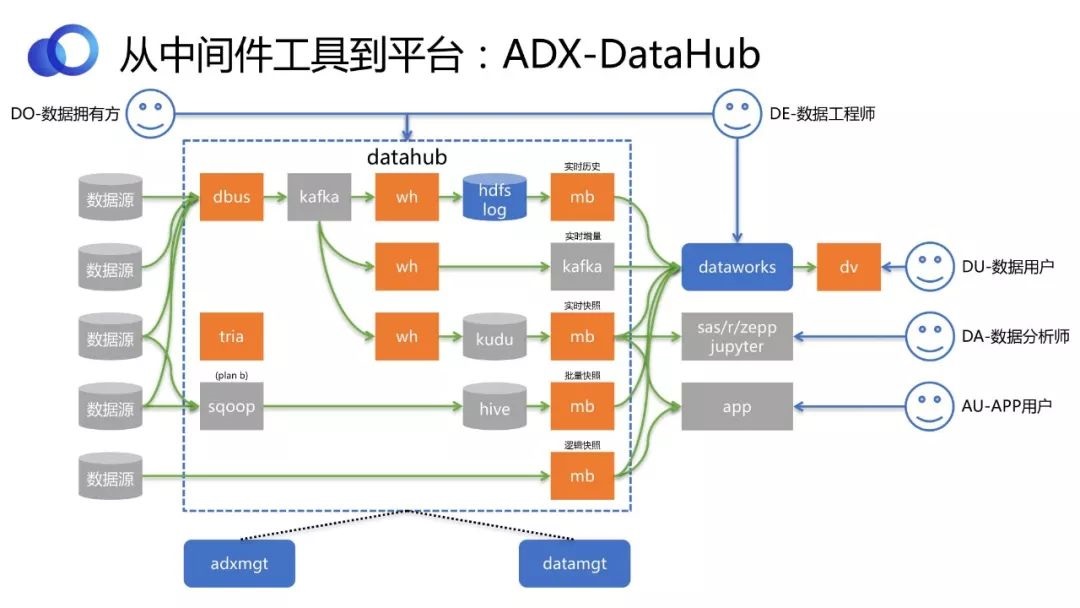
ЩЯЭМРЖЩЋащЯпПђЯдЪОЕФЪЧ DataHubЕФСїГЬМмЙЙЃЌГШЩЋЗНПщЪЧЮвУЧЕФПЊдДЙЄОпЃЌЦфжаЁАtriaЁБДњБэTriangleЃЌЪЧвЫаХСэвЛИіЭХЖгбаЗЂЕФзївЕЕїЖШЙЄОпЁЃDataHubВЛЪЧМђЕЅЕиЗтзАСЫСДТЗЃЌЖјЪЧЪЙЕУгУЛЇПЩвддквЛИіИќИпЕФlevelЩЯЕУЕНИќКУЕФЗўЮёЁЃБШШчгУЛЇашвЊФГвЛРњЪЗЪБПЬОЋШЗЕНУыЕФПьееЃЌЛђепЯЃЭћФУЕНвЛИіЪЕЪБдіСПЪ§ОнШЅзіСїЪНДІРэЃЌDataHubЖМПЩвдЬсЙЉЁЃ
ЫќЪЧдѕУДзіЕНЕФФиЃПЭЈЙ§НЋПЊдДЙЄОпв§ЧцЛЏЃЌШЛКѓНјааећКЯЁЃОйИіР§згЃКВЛЭЌЪ§ОндДЃЌЭЈЙ§DBusЪЕЪБГщШЁГіРДЃЌОЙ§WormholeСїЪНДІРэКѓТфЕН
HDFS LogЪ§ОнКўжаЃЌЮвУЧАбЫљгаЪЕЪБдіСПЪ§ОнЖМДцДЂдкетРяУцЃЌетОЭвтЮЖзХЮвУЧПЩвдДгжаФУЕНЫљгаЕФРњЪЗБфИќЪ§ОнЃЌЖјЧветаЉЪ§ОнЛЙЪЧЪЕЪБЭЌВНЕФЁЃдйЭЈЙ§MoonboxдкЩЯУцЖЈвхвЛаЉТпМЃЌЕБгУЛЇЬсГіЯывЊФГвЛРњЪЗЪБПЬЕФПьееЛђепдіСПЪ§ОнЃЌОЭПЩвдМДЪБМЦЫуВЂЬсЙЉЁЃШчЙћЯызіЪЕЪББЈБэЃЌашвЊАбЪ§ОнЪЕЪБПьееЮЌЛЄЕНвЛИіДцДЂРяЃЌетРяЮвУЧбЁдёKuduЁЃ
СїЪНДІРэгаКмЖрКУДІЃЌЭЌЪБвВгаЖЬАхЃЌБШШчдЫЮЌГЩБОНЯИпЁЂЮШЖЈадНЯВюЕШЁЃПМТЧЕНетаЉЮЪЬтЃЌЮвУЧдкDataHubжаЩшжУСЫSqoopзїЮЊPlan
BЁЃШчЙћЪЕЪБетЬѕЯпЭэЩЯГіЯжЮЪЬтЃЌПЩвдздЖЏЧаЛЛЕНPlan BЃЌЭЈЙ§ДЋЭГЕФSqoopШЅжЇГжЕкЖўЬьT+1ЕФБЈБэЁЃЕШЮвУЧевЕНВЂНтОіЮЪЬтжЎКѓЃЌPlan
BОЭЛсЧаЛЛЕНднЭЃзДЬЌЁЃ
МйЩшгУЛЇздМКгаЪ§ОндДЃЌЗХдкElasticsearch ЛђепMongoРяЃЌвВЯЃЭћЭЈЙ§DataHubЗЂВМГіШЅЙВЯэИјЦфЫћШЫЪЙгУЁЃЮвУЧВЛгІИУАбElasticsearch
Ъ§ОнЛђMongoЪ§ОнЮяРэЕиПНБДЕНвЛИіЕиЗНЃЌвђЮЊЪзЯШетаЉЪ§ОнЪЧNoSQLЕФЃЌЪ§ОнСПБШНЯДѓЃЛЦфДЮгУЛЇПЩФмЯЃЭћБ№ШЫЭЈЙ§ФЃК§ВщбЏЕФЗНЪНШЅЪЙгУElasticsearch
Ъ§ОнЃЌФЧПЩФмМЬајНЋЪ§ОнЗХдкElasticsearch РяИќКУЁЃетЪБЮвУЧзіЕФЪЧЭЈЙ§MoonboxНјаавЛИіТпМЕФЗЂВМЃЌЕЋгУЛЇВЛИажЊетИіЙ§ГЬЁЃ
злЩЯПЩвдПДГіЃЌDataHubЪЧдкФкВПАбМИИіПЊдДЦНЬЈГЃгУЕФФЃЪННјаагаЛњећКЯКЭЗтзАЃЌЖдЭтЬсЙЉвЛжТадЁЂБуНнЕФЪ§ОнЛёШЁЁЂЗЂВМЕШЗўЮёЁЃЦфЪЙгУЗНвВПЩвдЪЧИїжжВЛЭЌЕФНЧЩЋЃК
Ъ§ОнгЕгаЗНПЩвддкетРязіЪ§ОнЩѓХњЃЛ
Ъ§ОнЙЄГЬЪІПЩвдЩъЧыЪ§ОнЃЌЩъЧыЭъКѓПЩвддкетРяЖдЪ§ОнНјааМгЙЄЃЛ
APPгУЛЇПЩвдВщПДDavinciБЈБэЃЛ
Ъ§ОнЗжЮіЪІПЩвджБНггУздМКЕФЙЄОпШЅНгDataHubГіРДЕФЪ§ОнЃЌШЛКѓзіЪ§ОнЗжЮіЃЛ
Ъ§ОнгУЛЇПЩФмЯЃЭћздМКзівЛИіЪ§ОнВњЦЗЃЌDataHubПЩвдЮЊЫћЬсЙЉНгПкЁЃ
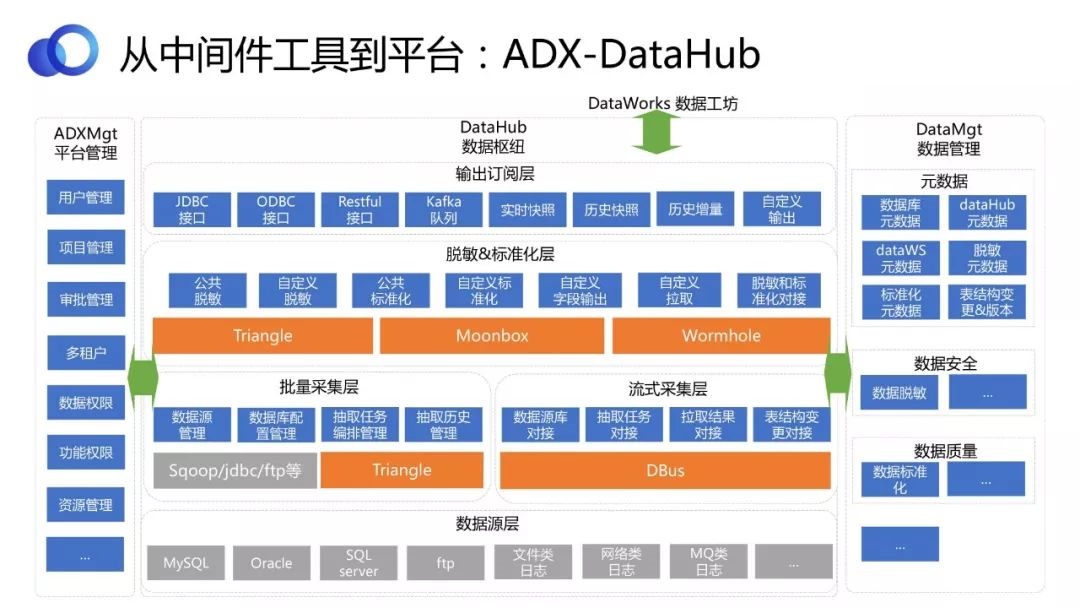
ШчЭМЃЌНЋDataHubДђПЊЃЌРДПДЦфМмЙЙЩшМЦЁЃДгЙІФмФЃПщНЧЖШРДПДЃЌDataHubЛљгкВЛЭЌПЊдДзщМўЃЌЪЕЯжВЛЭЌЙІФмЁЃАќРЈХњСПВЩМЏЁЂСїЪНВЩМЏЁЂЭбУєЁЂБъзМЛЏЕШЃЌЛЙПЩвдЛљгкВЛЭЌЕФавщЪфГіЖЉдФЁЃ
DataHubгыЦфЫћМИИізщМўжЎМфЕФЙиЯЕвВЪЧЗЧГЃНєУмЕФЁЃЫќЪфГіЕФЪ§ОнИјDataWorksЪЙгУЃЌЭЌЪБЫќгжвРРЕжаЬЈЙмРэЁЂЪ§ОнЙмРэРДТњзуЦфашЧѓЁЃ
2ЁЂADX-DataLakeЪЕЪБЪ§ОнКў
ЙувхЕФЪ§ОнКўЃЌОЭЪЧАбЫљгаЪ§ОнЖМЗХдквЛЦ№ЃЌЯШвдДцДЂКЭЙщМЏЮЊжїЃЌЪЙгУЕФЪБКђдйИљОнВЛЭЌЪ§ОнЬсЙЉВЛЭЌЪЙгУЗНЪНЁЃ
ЮвУЧетРяЬсЕНЕФЪЧвЛИіЯСвхЕФЪ§ОнКўЃЌжЛжЇГжНсЙЙЛЏЪ§ОндДКЭздШЛгябдЮФБОетСНжжРраЭЕФЪ§ОнЙщМЏЃЌВЂЧвгаЭГвЛЕФЗНЪНДцДЂЁЃ
вВОЭЪЧЫЕЮвУЧЕФЪЕЪБЪ§ОнКўМгСЫЯожЦЃЌЙЋЫОЫљгаНсЙЙЛЏЪ§ОндДКЭздШЛгябдЮФБОЛсЭГвЛЪЕЪБЛузмЮЊUbiLogЃЌВЂгЩADX-DataHubЭГвЛЖдЭтЬсЙЉЗУЮЪЁЃUbiLogЕФЗУЮЪКЭЪЙгУжЛФмЭЈЙ§ADXЬсЙЉЕФФмСІЪфГіЃЌвђДЫШЗБЃСЫЖрзтЛЇЁЂАВШЋЁЂШЈЯоЙмПиЁЃ

3ЁЂADX-DataWorksЪ§ОнЙЄЗЛ
жївЊЕФЪ§ОнМгЙЄЖМЪЧдкDataWorksзджњЭъГЩЕФЁЃ

ШчЭМРДПДDataWorksЕФЙЄзїСїГЬЁЃЪзЯШDataHubЪ§ОнГіРДжЎКѓЃЌDataWorksБиаыШЅНгDataHubЕФЪ§ОнЁЃDataWorksжЇГжЪЕЪББЈБэЃЌЮвУЧФкВПЪЙгУЕФЪЧKuduЃЌЫљвдАбетИіФЃЪНЙЬЛЏЯТРДЃЌгУЛЇОЭВЛгУздМКШЅбЁаЭЃЌжБНгдкЩЯУцаДздМКЕФТпМОЭПЩвдСЫЁЃБШШчгавЛИіЪЕЪБDMЛђХњСПDMЃЌЮвУЧОѕЕУетЪЧвЛИіКмКУЕФЪ§ОнзЪВњЃЌгаИДгУМлжЕЃЌЯЃЭћБ№ЕФвЕЮёФмИДгУетИіЪ§ОнЃЌЮвУЧОЭПЩвдЭЈЙ§DataHubАбЫќЗЂВМГіШЅЃЌБ№ЕФвЕЮёОЭПЩвдЩъЧыЪЙгУЁЃ
ЫљвдDataHubКЭDataWorksЕШзщМўЗтзАЖјГЩЕФЪ§ОнжаЬЈПЩвдДяЕНЪ§ОнЙВЯэКЭЪ§ОндЫгЊЕФаЇЙћЁЃжаЬЈФкВПАќКЌKuduЁЂKafkaЁЂHiveЁЂMySQLЕШЪ§ОнПтзщМўЃЌЕЋЪЧгУЛЇВЛашвЊздМКШЅбЁаЭЃЌЮвУЧвбОзіГіСЫзюМббЁдёЃЌВЂНЋЦфЗтзАГЩвЛИіПЩжБНгЪЙгУЕФЦНЬЈЁЃ
ЩЯЭМзѓВргавЛИіЪ§ОнНЈФЃЪІЕФНЧЩЋЃЌЫћдкDataStarжазіФЃаЭЙмРэКЭПЊЗЂНЈЩшЃЌдкDataWorksжажївЊЪЧИКд№ТпМКЭФЃаЭЕФДДНЈЃЛЪ§ОнЙЄГЬЪІВЛгУЖрЫЕЃЌЪЧзюГЃМћЕФЪЙгУDataWorksЕФНЧЩЋЃЛжеЖЫгУЛЇПЩвджБНгЪЙгУDavinciЁЃ
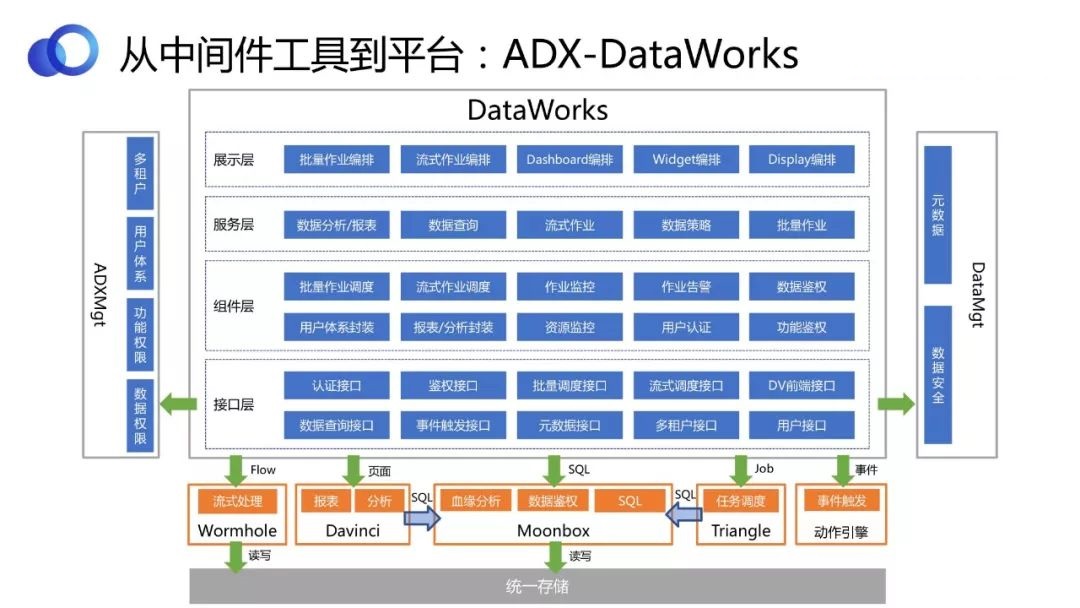
ШчЭМЃЌНЋDataWorksДђПЊРДПДЫќЕФМмЙЙЃЌЭЌбљDataWorksвВЪЧЭЈЙ§ВЛЭЌЕФФЃПщРДжЇГжИїжжВЛЭЌЕФЙІФмЁЃЙигкетВПЗжФкШнвдКѓЛсгаИќЖрЕФЮФеТКЭЗжЯэЃЌДЫДІВЛЯъЯИНщЩмЁЃ
4ЁЂDX-DataStarЪ§ОнФЃаЭ
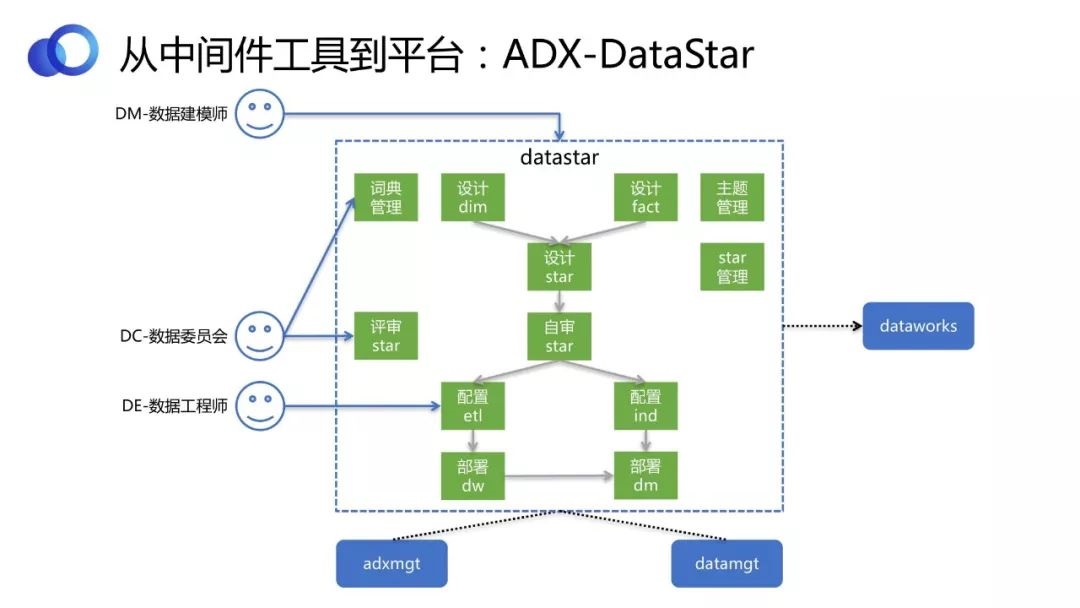
DataStarИњЪ§ОнжИБъФЃаЭЛђЪ§ОнзЪВњЯрЙиЃЌУПИіЙЋЫОЖМгаздМКФкВПЕФЪ§ОнНЈФЃСїГЬКЭЙЄОпЁЃDataStarПЩвдЗжЮЊСНИіВПЗжЃК
ФЃаЭЩшМЦЁЂЙмРэДДНЈЁЃЖдФЃаЭЩњУќжмЦкЕФЙмРэКЭЙЄвеСїГЬЕФГСЕэЁЃ
ДгDWЃЈЪ§ВжЃЉВуЕНDMЃЈЪ§ОнМЏЪаЃЉВуЃЌжЇГжХфжУЛЏЕФЗНЪНЃЌздЖЏдкЕзЯТЩњГЩЖдгІSQLТпМЃЌЖјВЛашвЊгУЛЇздМКШЅаДЁЃ
DataStarЪЧDWВуЕФЪТЪЕКЭЮЌЖШБэзщГЩЕФаЧаЭФЃаЭЃЌПЩвдзюКѓГСЕэЯТРДЁЃЕЋЮвУЧШЯЮЊЃЌДгDWВуЕНDMВуЛђAPPВуЃЌВЛашвЊаДSQLПЊЗЂСЫЃЌжЛашвЊЭЈЙ§бЁЮЌЖШКЭХфжУжИБъЕФЗНЪНЃЌОЭПЩвдздЖЏПЩЪгЛЏХфжУГіРДЁЃ
етбљЕФЛАЖдЪЙгУШЫЕФвЊЧѓОЭЗЂЩњСЫИФБфЃЌашвЊвЛИіНЈФЃЪІЛђепвЕЮёШЫдБРДзіетИіЪТЧщЃЌИјЫћвЛИіЛљДЁЪ§ОнВуЃЌЫћИљОнздМКЕФашЧѓРДХфжУЯывЊЕФжИБъЁЃећИіЙ§ГЬЃЌЪ§ОнЪЕЪЉШЫдБжЛашвЊЙизЂODSВуЕНDWВуОЭПЩвдСЫЁЃ
5ЁЂADXMgt/DataMgtжаЬЈЙмРэ/Ъ§ОнЙмРэ

жаЬЈЙмРэФЃПщжївЊЙизЂзтЛЇЙмРэЁЂЯюФПЙмРэЁЂзЪдДЙмРэЁЂШЈЯоЙмРэЁЂЩѓХњЙмРэЕШЁЃЪ§ОнЙмРэФЃПщжївЊЙизЂЪ§ОнЙмРэВуЛђЪ§ОнжЮРэВуЕФЛАЬтЁЃетСНИіФЃПщДгВЛЭЌЕФЮЌЖШЖджаМфЕФШ§ИіжївЊзщМўЬсЙЉжЇГжКЭВњЩњЙцдђжЦдМЁЃ
ADXМмЙЙ
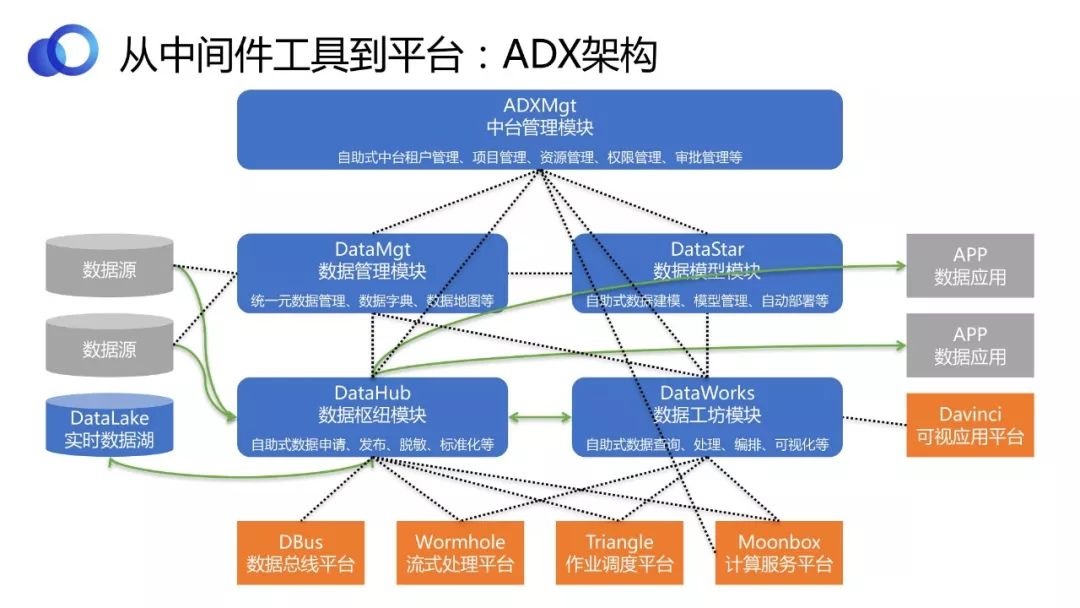
ADXЪ§ОнжаЬЈЦНЬЈМИИіФЃПщжЎМфЕФЙиСЊШчЭМЫљЪОЁЃзюЕзЯТЪЧЮхИіПЊдДЙЄОпЃЌУПИіФЃПщЖМЪЧЖдетЮхИіПЊдДЙЄОпЕФгаЛњећКЯКЭЗтзАЁЃДгЭМжаПЩвдПДГіИїзщМўжЎМфЕФЙиСЊЗЧГЃНєУмЃЌЦфжаКкЩЋащЯпДњБэЕФЪЧвРРЕЙиЯЕЃЌТЬЩЋЯпЬѕДњБэЕФЪЧЪ§ОнСїзЊЕФЙиЯЕЁЃ
ЕфаЭАИР§ЗжЮі
ШчЩЯЫљЪіЃЌЮвУЧЛљгкМИИіПЊдДЙЄОпНјаагаЛњећКЯКЭЗтзАЃЌДђдьСЫвЛИіИќМгЯжДњЛЏЁЂзджњЛЏЁЂЭъБИЕФвЛеОЪНЪ§ОнжаЬЈЦНЬЈЁЃФЧетИіЦНЬЈЪЧШчКЮЗЂЛгЦфзїгУЃЌЮЊвЕЮёЬсЙЉЗўЮёЕФФиЃПБОНкНЋСаОйЮхИіЕфаЭАИР§ЁЃ
АИР§1 ЁЊ зджњЪЕЪББЈБэ
ЁОГЁОАЁП
вЕЮёСьгђзщЪ§ОнЭХЖгашвЊНєМБжЦзївЛХњБЈБэЃЌВЛЯЃЭћХХЦкЃЌЯЃЭћПЩвдзджњЭъГЩЃЌВЂЧвВПЗжБЈБэашвЊT+0ЪБаЇадЁЃ
ЁОЬєеНЁП
вЕЮёзщЪ§ОнЭХЖгЙЄГЬФмСІгаЯоЃЌжЛЛсМђЕЅSQLЃЌжЎЧАвЊУДзЊИјBIХХЦкЃЌвЊУДЭЈЙ§ЙЄОпжБСЌвЕЮёБИПтжЦзїБЈБэЃЌвЊУДЭЈЙ§ExcelжЦзїЁЃ
Ъ§ОнРДдДПЩФмРДздвьЙЙЪ§ОнПтЃЌУЛгаКмКУЕФЦНЬЈжЇГжзджњЕМЪ§ЁЃ
ЖдЪ§ОнЪБаЇадвЊЧѓКмИпЃЌашвЊСїЩЯзіЪ§ОнДІРэТпМЁЃ
ЁОЗНАИЁП

гУADXЪ§ОнжаЬЈНтОізджњЪЕЪББЈБэЕФЮЪЬтЁЃ
Ъ§ОнЙЄГЬЪІЕЧТМЦНЬЈЃЌДДНЈаТЕФЯюФПЃЌЩъЧыЪ§ОнзЪдДЁЃ
Ъ§ОнЙЄГЬЪІЭЈЙ§дЊЪ§ОнВщевбЁГіБэЃЌбЁдёDataWorksЗНЪНЪЙгУЃЌЬюаДЦфЫћаХЯЂЃЌЩъЧыетаЉашвЊгУЕНЕФБэЁЃБШШчЮвашвЊгУЕН100еХБэЃЌЦфжа70еХЪЧЭЈЙ§T+1ЕФЗНЪНЪЙгУЃЌ30еХЪЧЭЈЙ§ЪЕЪБЗНЪНЪЙгУЁЃ
ФЌШЯжаЬЈЛсзіБъзМЛЏЭбУєМгУмВпТдЃЌЪеЕНетаЉЩъЧыжЎКѓЃЌжаЬЈЙмРэдБЛсАДВпТдвРДЮНјааЩѓХњЁЃ
ЩѓХњЭЈЙ§КѓЃЌжаЬЈЛсздЖЏзМБИКЭЪфГіЫљЩъЧыЕФЪ§ОнзЪдДЃЌЪ§ОнЙЄГЬЪІПЩвддЫгУФУЕНЕФЪ§ОнзЪдДНјаазджњВщбЏЁЂПЊЗЂЁЂХфжУЁЂSQLБрХХЁЂХњСПЛђСїЪНДІРэЁЂХфжУDVЕШЁЃ
зюКѓНЋзджњБЈБэЛђвЧБэАхЬсНЛИјгУЛЇЪЙгУЁЃ
ЁОзмНсЁП
ИїИіНЧЩЋЭЈЙ§вЛеОЪНЪ§ОнжаЬЈНЛЛЅЃЌЭГвЛСїГЬЃЌЫљгаЖЏзїЖММЧТМдкАИЃЌПЩВщбЏЁЃ
ЦНЬЈШЋзджњФмСІЃЌДѓДѓЬсИпСЫвЕЮёЪ§зжЛЏЧ§ЖЏНјГЬЃЌЮоашХХЦкЕШД§ЃЌОЙ§ЖЬднХрбЕЃЌШЫОљ 3-5ШеПЩвдзджњЭъГЩвЛеХЪЕЪББЈБэЃЌЪЕЪББЈБэВЛдйЧѓШЫЁЃ
ЦНЬЈжЇГжШЫдБвВЮоашЙ§ЖрВЮгыЃЌВЛдйГЩЮЊНјЖШЦПОБЁЃ
ЁОФмСІЁП
етИіГЁОАашвЊгУЕНКмЖрЪ§ОнФмСІЃЌАќРЈЃКМДЯЏВщбЏФмСІЁЂХњСПДІРэФмСІЁЂЪЕЪБДІРэФмСІЁЂБЈБэПДАхФмСІЁЂЪ§ОнШЈЯоФмСІЁЂЪ§ОнАВШЋФмСІЁЂЪ§ОнЙмРэФмСІЁЂзтЛЇЙмРэФмСІЁЂЯюФПЙмРэФмСІЁЂзївЕЙмРэФмСІЁЂзЪдДЙмРэФмСІЁЃ
АИР§2 ЁЊ азїФЃаЭжИБъ
ЁОГЁОАЁП
вЕЮёЯпашвЊДђдьздМКЕФЛљДЁЪ§ОнМЏЪаЃЌвдЙВЯэИјЦфЫћвЕЮёЛђепЧАЯпЯЕЭГЪЙгУЁЃ
ЁОЬєеНЁП
ШчКЮгааЇНЈЩшЪ§ОнФЃаЭКЭЙмРэЪ§ОнФЃаЭЁЃ
ШчКЮМШжЇГжздМКСьгђФкЪ§ОнФЃаЭНЈЩшЃЌЭЌЪБвВжЇГжЪ§ОнФЃаЭЕФЙВЯэЁЃ
Ъ§ОнЕФЙВЯэЗЂВМШчКЮДгСїГЬЩЯЙЬЛЏЁЂВЂЪЕЯжММЪѕАВШЋЭГвЛЙмПиЁЃ
ШчКЮдЫгЊЪ§ОнвдШЗБЃгааЇЪ§ОнзЪВњГСЕэКЭЙмРэЁЃ
ЁОЗНАИЁП
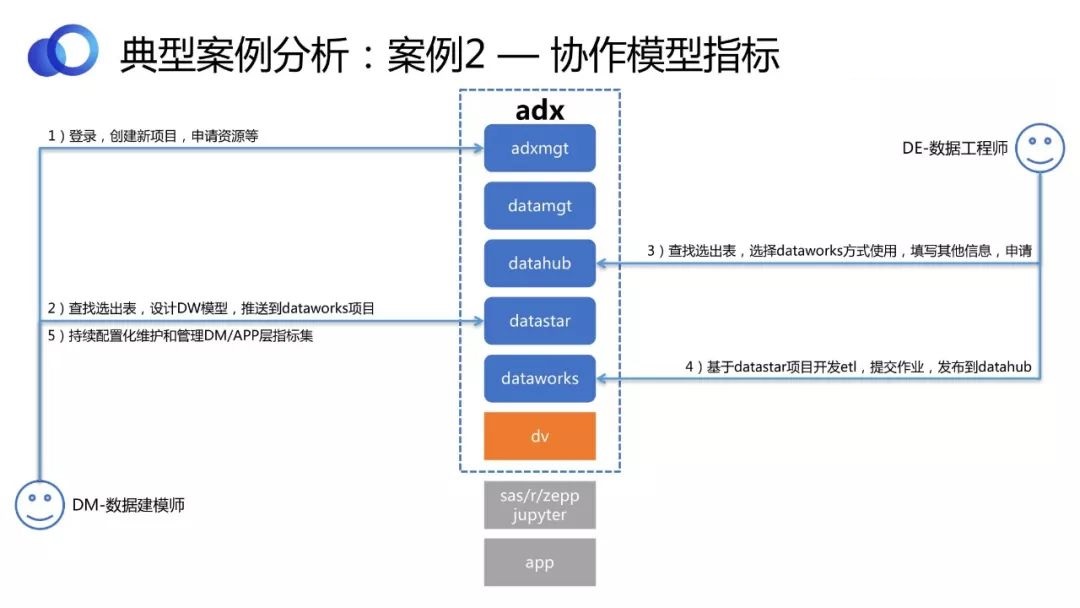
гУADXЪ§ОнжаЬЈНтОіазїФЃаЭжИБъЕФЮЪЬтЁЃ
Ъ§ОнНЈФЃЪІЕЧТМЦНЬЈЃЌДДНЈаТЯюФПЃЌЩъЧызЪдДЁЃШЛКѓВщевбЁГіБэЃЌЩшМЦвЛИіЛђШєИЩИіЮЌЖШБэЕФDWФЃаЭЃЌЭЦЫЭЕНDataWorksЯюФПЁЃ
Ъ§ОнЙЄГЬЪІбЁдёашвЊЕФSourceБэЃЌЛљгкDataStarЯюФПЭъГЩДгODSЕНDWжЎЧАЕФETL ПЊЗЂЃЌШЛКѓЬсНЛзївЕЃЌЗЂВМЕНDataHubХмЦ№РДЁЃ
Ъ§ОнНЈФЃЪІГжајПЩЪгЛЏХфжУЮЌЛЄКЭЙмРэDW/APPВужИБъМЏЃЌАќРЈЮЌЖШЕФОлКЯЁЂМЦЫуЕШЁЃ
ЁОзмНсЁП
етЪЧвЛИіЕфаЭЕФЪ§ОнзЪВњЙмРэЁЂЪ§ОнзЪВњдЫгЊЕФАИР§ЃЌЭЈЙ§ЭГвЛЕФазїЛЏЕФФЃаЭжИБъЙмРэЃЌШЗБЃСЫФЃаЭПЩЮЌЛЄЁЂжИБъПЩХфжУЁЂжЪСППЩзЗЫнЁЃ
DataStarвВжЇГжвЛжТадЮЌЖШЙВЯэЁЂЪ§ОнДЪЕфБъзМЛЏЁЂвЕЮёЯпЪсРэЕШЃЌПЩвдНјвЛВНШсаджЇГжЙЋЫОЭГвЛЪ§ОнЛљДЁВуЕФНЈЩшКЭГСЕэЁЃ
ЁОФмСІЁП БОАИР§ашвЊЕФФмСІАќРЈЃКЪ§ОнЗўЮёФмСІЁЂМДЯЏВщбЏФмСІЁЂХњСПДІРэФмСІЁЂЪ§ОнШЈЯоФмСІЁЂЪ§ОнАВШЋФмСІЁЂЪ§ОнЙмРэФмСІЁЂЪ§ОнзЪВњФмСІЁЂзтЛЇЙмРэФмСІЁЂЯюФПЙмРэФмСІЁЂзївЕЙмРэФмСІЁЂзЪдДЙмРэФмСІЁЃ
АИР§3 ЁЊ УєНнЗжЮіЭкОђ
ЁОГЁОАЁП
вЕЮёСьгђзщЪ§ОнЗжЮіЭХЖгашвЊзджњЕФНјааПьЫйЪ§ОнЗжЮіЭкОђЁЃ
ЁОЬєеНЁП
ЗжЮіЭХЖгЪЙгУЙЄОпИївьЃЌШчSASЁЂRЁЂPythonЁЂSQLЕШЁЃ
ЗжЮіЭХЖгЭљЭљашвЊдЪМЪ§ОнНјааЗжЮіЃЈЗЧЭбУєЃЉЃЌВЂЧвашвЊШЋРњЪЗЪ§ОнЁЃ
ЗжЮіЭХЖгЯЃЭћПЩвдПьЫйФУЕНЫљашЪ§ОнЃЈЭљЭљВЂВЛжЊЕРашвЊЪВУДЪ§ОнЃЉЃЌВЂУєНнИпаЇзЈзЂгкЪ§ОнЗжЮіБОЩэЁЃ
ЁОЗНАИЁП
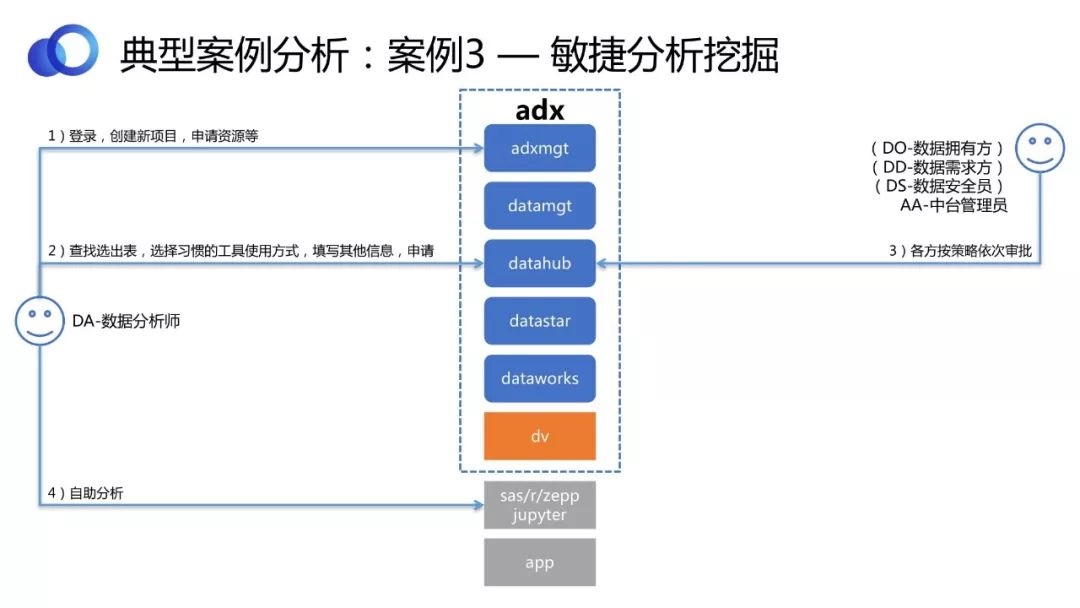
гУADXЪ§ОнжаЬЈНтОіУєНнЗжЮіЭкОђЕФЮЪЬтЁЃ
Ъ§ОнЗжЮіЪІЕЧТМЦНЬЈЃЌДДНЈаТЯюФПЃЌЩъЧызЪдДЁЃИљОнашЧѓВщевбЁГіБэЃЌбЁдёЯАЙпЕФЙЄОпЪЙгУЗНЗЈЃЌЬюаДЦфЫћаХЯЂЃЌЩъЧыЪЙгУЁЃ
ИїЗНАДееВпТдвРДЮЩѓХњЁЃ
ЩѓХњЭЈЙ§КѓЃЌЪ§ОнЗжЮіЪІЛёЕУзЪдДЃЌРћгУЙЄОпНјаазджњЗжЮіЁЃ
ЁОзмНсЁП
MoonboxБОЩэЪЧЪ§ОнащФтЛЏНтОіЗНАИЃЌКмЪЪКЯНјааИїжжвьЙЙЪ§ОндДЕФМДЯЏЪ§ОнЖСШЁКЭМЦЫуЃЌПЩвдНкЪЁЪ§ОнЗжЮіЪІКмЖрЪ§ОнЙЄГЬЗНУцЕФЙЄзїЁЃ
Datahub/DataLakeЬсЙЉСЫЪЕЪБЭЌВНЕФШЋдіСПЪ§ОнКўЃЌЛЙПЩвдНјааХфжУЛЏЭбУєМгУмЕШАВШЋВпТдЃЌЮЊЪ§ОнЗжЮіГЁОАЬсЙЉСЫАВШЋПЩППШЋУцЕФЪ§ОнжЇГжЁЃ
MoonboxЛЙзЈУХЬсЙЉСЫ mbpyЃЈMoonbox PythonЃЉПтЃЌвджЇГжPythonгУЛЇИќШнвзЕФдкАВШЋЙмПиЯТНјааПьЫйЮоЗьЕиЪ§ОнВщПДЁЂМДЯЏМЦЫуКЭГЃгУЫуЗЈдЫЫуЙЄзїЁЃ
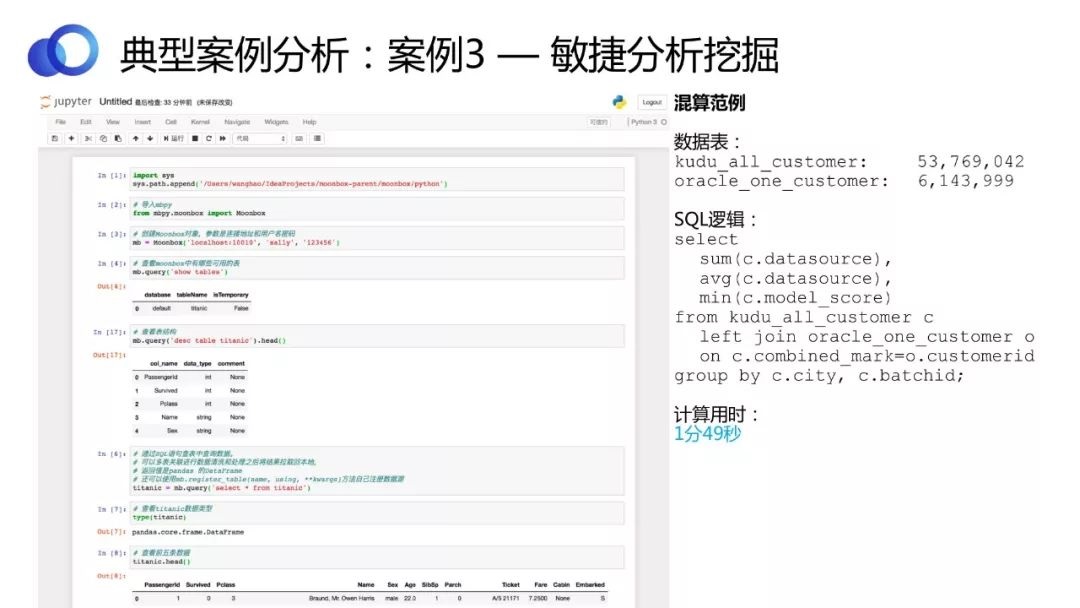
ОйИіР§згЃЌвЛИігУЛЇДђПЊJupyterЃЌimportвЛИіmbpyЕФПтАќЃЌВЂвдгУЛЇЩэЗнЕЧТМMoonboxЃЌОЭПЩвдВщПДЙмРэдБЪкШЈИјЫћЕФБэЁЃЫћПЩвддЫгУФУЕНЕФЪ§ОнКЭБэНјааЗжЮіЁЂМЦЫуЕШЃЌЖјВЛашвЊЙизЂетаЉЪ§ОнРДздФФРяЃЌетЖдгУЛЇРДЫЕЪЧвЛИіЮоЗьЕФЬхбщЁЃ
ШчЩЯЭМЃЌгаСНеХБэЃЌвЛеХБэЪЧ5000ЖрЭђЬѕЪ§ОнЃЌДцДЂдкKuduРяЃЛСэвЛеХБэЪЧ600ЭђЖрЬѕЪ§ОнЃЌДцДЂдкOracleРяЁЃЪ§ОнДцДЂдквьЙЙЕФЯЕЭГжаЃЌЧвkuduБОЩэВЛжЇГжSQLЁЃЮвУЧЭЈЙ§MoonboxжЦЖЈТпМЃЌШЯЮЊЪ§ОнЖМдквЛИіащФтЪ§ОнПтжаЃЌ
жЛгУСЫ1Зж40УыОЭМЦЫуГіНсЙћЁЃ
ЁОФмСІЁП
БОАИР§ашвЊЕФФмСІАќРЈЃКЗжЮізъШЁФмСІЁЂЪ§ОнЗўЮёФмСІЁЂЫуЗЈФЃаЭФмСІЁЂМДЯЏВщбЏФмСІЁЂЖрЮЌЗжЮіФмСІЁЂЪ§ОнШЈЯоФмСІЁЂЪ§ОнАВШЋФмСІЁЂЪ§ОнЙмРэФмСІЁЂзтЛЇЙмРэФмСІЁЂЯюФПЙмРэФмСІЁЂзЪдДЙмРэФмСІЁЃ
АИР§4 ЁЊ ЧщОАЖрЦССЊЖЏ
ЁОГЁОАЁП
ЮЊСЫжЇГжШЋЗНЮЛЕФГЁОАЛЏКЭЪ§зжЛЏЧ§ЖЏЃЌгаЪБЛсашвЊДѓжааЁжЧЖрЦССЊЖЏЃЌДѓЦСМДЮЊЗХгГДѓЦСЃЌжаЦСМДЮЊЕчФдЦСФЛЃЌаЁЦСМДЮЊЪжЛњЦСФЛЃЌжЧЦСМДЮЊСФЬьПЭЛЇЖЫЦСФЛЁЃ
ЁОЬєеНЁП
ЖрЦСгЩгкЖЈЮЛВЛЭЌЃЌеЙЪОДѓаЁВЛЭЌЃЌВйзїВЛЭЌЃЌПЩвдвЊЧѓВЛЭЌГЬЖШЕФПЩЪгЛЏКЭЖЈжЦЛЏЃЌДјРДвЛЖЈПЊЗЂСПЁЃ
ЖрЦСвВашвЊдкЪ§ОнШЈЯоВуУцБЃГжИпЖШвЛжТЁЃ
ЦфжажЧЦСИќашвЊNLPЁЂСФЬьЛњЦїШЫКЭШЮЮёЛњЦїШЫЕШжЧФмФмСІЃЌЛЙашвЊгаЖЏЬЌЩњГЩЭМБэФмСІЁЃ
ЁОЗНАИЁП
ЭЈЙ§DavinciЕФDisplayЙІФмЃЌПЩвдКмКУжЇГжХфжУЛЏТњзуДѓаЁЦСЖЈжЦЛЏашЧѓЁЃ
ЭЈЙ§DavinciЭГвЛЪ§ОнШЈЯоЬхЯЕЃЌПЩвддкЖрЦСжЎМфБЃГжвЛжТЕФЪ§ОнШЈЯоЬѕМўЁЃ
ЭЈЙ§ConvoAIЕФChatbot/NLPФмСІЃЌПЩвджЇГжжЧФмЮЂBIФмСІЃЌМДЮЊжЧЦСЁЃ
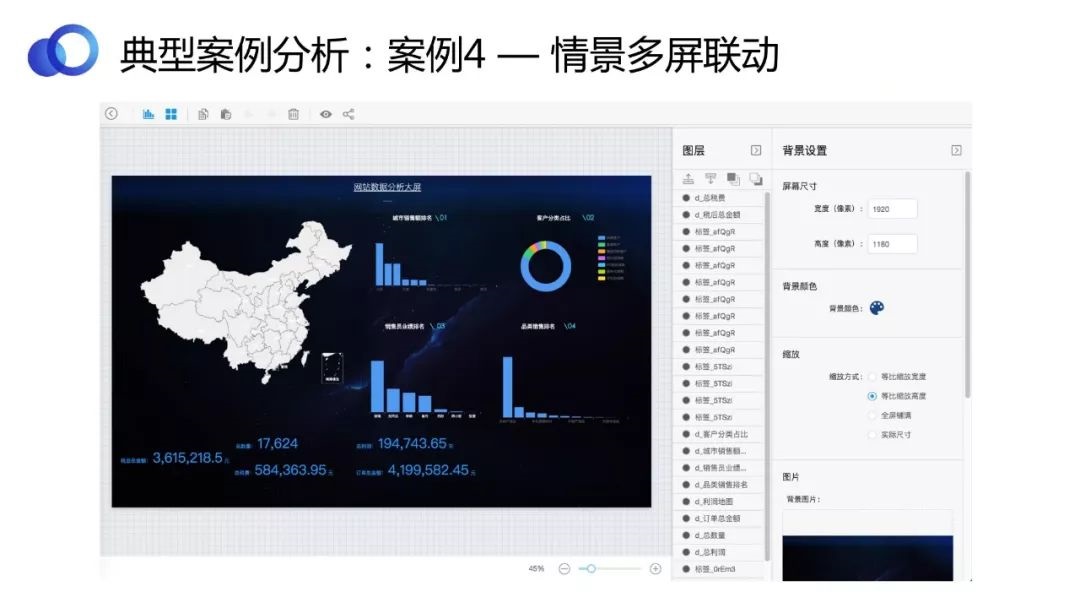
ЩЯЭМеЙЪОЕФЪЧDavinciЕФDisplayБрМвГУцЃЌПЩвдЭЈЙ§ЬєбЁВЛЭЌЕФзщМўЁЂЕїећЭИУїЖШЁЂШЮвтАкЗХЮЛжУЁЂЕїЧАОАБГОАЁЂбеЩЋЫѕЗХБШР§ЕШЃЌздгЩЕиЖЈвхЯывЊЕФеЙЪОбљЪНЁЃ
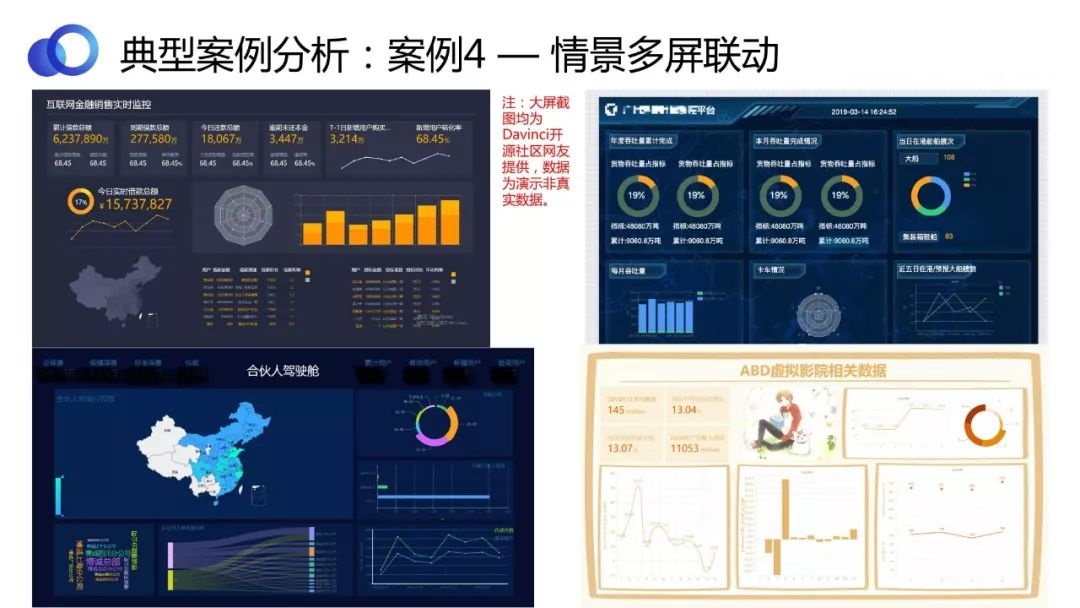
ЩЯЭМЪЧDavinciХфжУДѓЦСЕФР§згЃЌЃЈЭМЦЌРДдДгкDavinciПЊдДЩчЧјЭјгбЕФЪЕМљЃЌЪ§ОнОЙ§ДІРэЃЉЃЌПЩвдПДЕНЭЈЙ§DavinciПЩвдздМКХфжУДѓЦСЃЌВЛашвЊПЊЗЂЁЃ
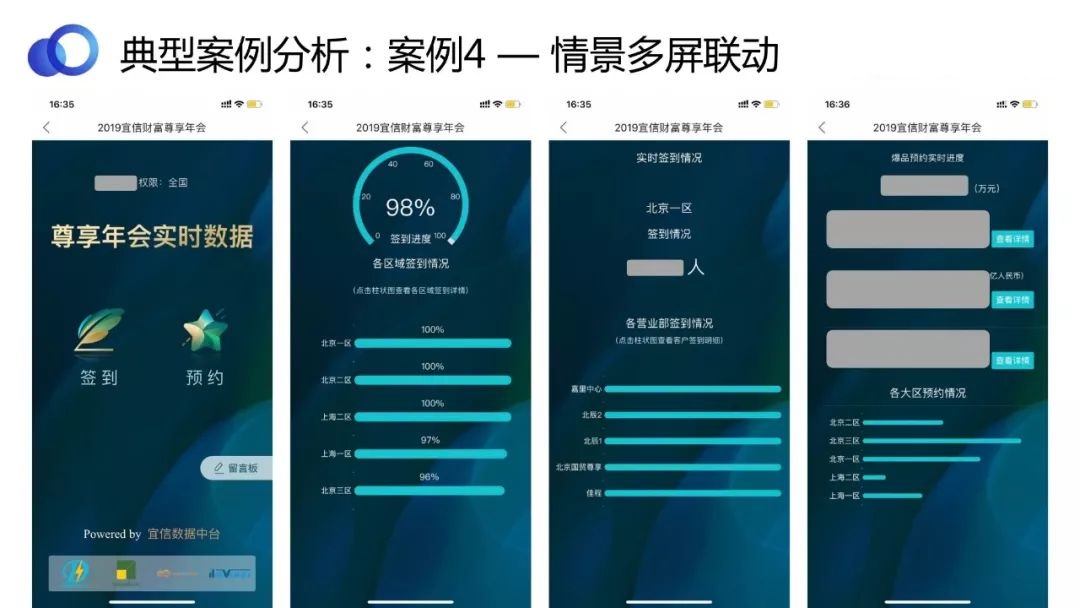
ЩЯЭМеЙЪОЕФЪЧDavinciХфжУаЁЦСЕФЪОР§ЁЃЭМЦЌРДдДгквЫаХЕФз№ЯэФъЛсЁЃЯжГЁЙЄзїШЫдБЭЈЙ§ЪжЛњВщПДЪЕЪБЪ§ОнЃЌСЫНтЯжГЁЧщПіЁЃ
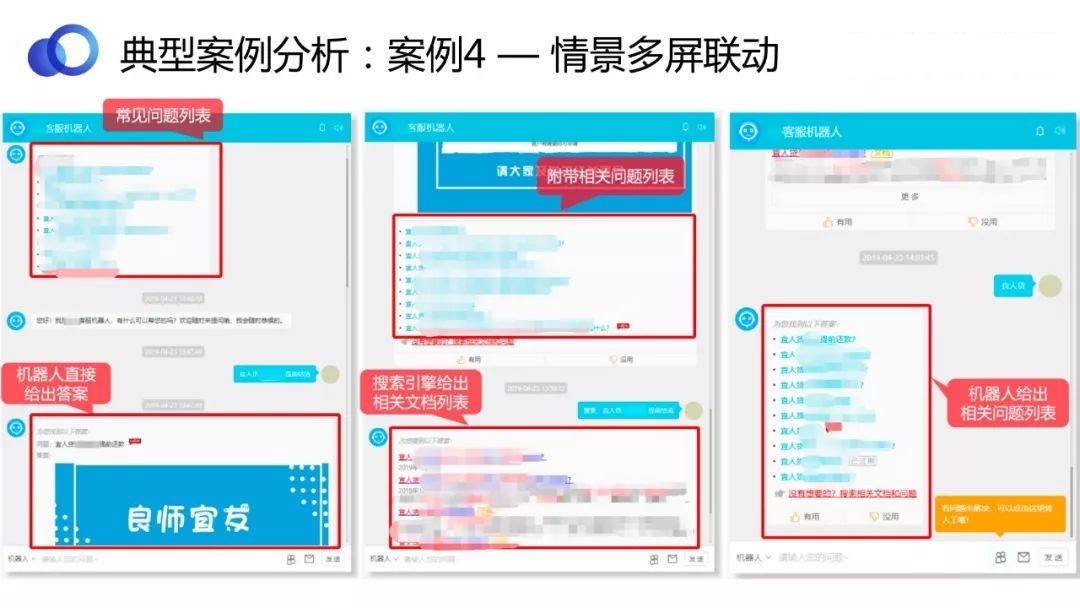
ЩЯЭМеЙЪОЕФЪЧжЧЦСЕФЪОР§ЁЃЮвУЧЙЋЫОФкВПгавЛИіЛљгкConvoAIЕФСФЬьЛњЦїШЫЃЌПЩвдЭЈЙ§вЛИіСФЬьДАПкЃЌИњгУЛЇЛЅЖЏЃЌеыЖдгУЛЇашЧѓЗЕЛиНсЙћЃЌАќРЈЭМБэЕШЁЃ
АИР§5 ЁЊ Ъ§ОнАВШЋЁЂЙмРэ
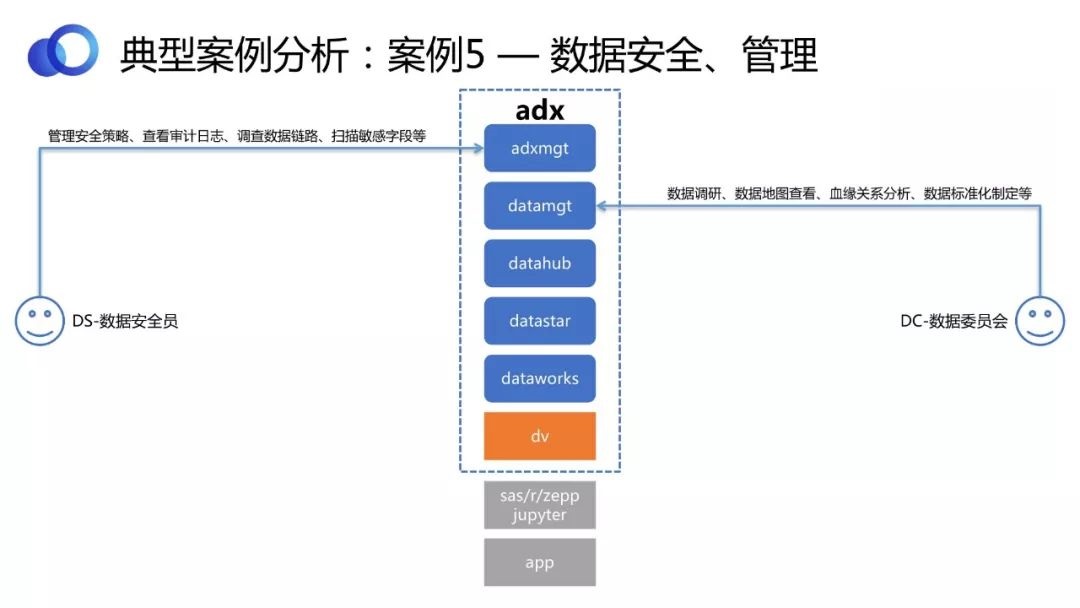
етИіАИР§БШНЯМђЕЅЃЌвЛИіЭъБИЕФЪ§ОнжаЬЈЃЌВЛНігагІгУПЭЛЇГЁОАЃЌЛЙгаЙмРэПЭЛЇГЁОАЃЌЙмРэПЭЛЇЕфаЭЕФБШШчЪ§ОнАВШЋЭХЖгКЭЪ§ОнЮЏдБЛсЁЃ
Ъ§ОнАВШЋЭХЖгашвЊЙмРэАВШЋВпТдЁЂЩЈУшУєИазжЖЮЁЂЩѓХњЪ§ОнзЪдДЩъЧыЕШЁЃвЫаХУєНнЪ§ОнжаЬЈЬсЙЉздЖЏЩЈУшЙІФмЃЌМАЪБНЋЩЈУшНсЙћЗЕЛиИјАВШЋЭХЖгШЫдБШЗШЯЁЃАВШЋЭХЖгвВПЩвдЖЈвхМИВуВЛЭЌЕФАВШЋВпТдЁЂВщПДЩѓМЦШежОЁЂЕїВщЪ§ОнСїзЊСДТЗЕШЁЃ
Ъ§ОнЮЏдБЛсашвЊзіЪ§ОнЕїбаЁЂЪ§ОнЕиЭМВщПДЁЂбЊдЕЗжЮіЁЂжЦЖЈБъзМЛЏКЭСїГЬЛЏЕФЧхЯДЙцдђЕШЁЃЫћУЧЭЌбљПЩвдЕЧТМЪ§ОнжаЬЈЃЌЭъГЩетаЉЙЄзїЁЃ
змНс
БОДЮЗжЯэжївЊНщЩмСЫвЫаХУєНнЪ§ОнжаЬЈЕФЖЅВуЩшМЦКЭЖЈЮЛЁЂФкВПЕФФЃПщМмЙЙКЭЙІФмЁЂвдМАЕфаЭгІгУГЁОАгыАИР§ЁЃ
|









