| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫFlinkЕФШнДэЛњжЦзДЬЌЕФвЛжТадЁЂCheckpointдРэЁЂSavepointдРэЁЂcheckpointКЭsavepointЕФЧјБ№ЁЂKafka+Flink+Kafka
ЪЕЯжЖЫЕНЖЫбЯИёвЛДЮЕШЯрЙиФкШнЁЃ
БОЮФРДздcsdnЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂзДЬЌЕФвЛжТад
ЕБдкЗжВМЪНЯЕЭГжав§ШызДЬЌЪБЃЌздШЛвВв§ШыСЫвЛжТадЮЪЬтЁЃ
вЛжТадЪЕМЪЩЯЪЧ"е§ШЗадМЖБ№"ЕФСэвЛжжЫЕЗЈЃЌвВОЭЪЧЫЕдкГЩЙІДІРэЙЪеЯВЂЛжИДжЎКѓЕУЕНЕФНсЙћЃЌгыУЛгаЗЂЩњШЮКЮЙЪеЯЪБЕУЕНЕФНсЙћЯрБШЃЌЧАепЕНЕзгаЖре§ШЗЃПОйР§РДЫЕЃЌМйЩшвЊЖдзюНќвЛаЁЪБЕЧТМЕФгУЛЇМЦЪ§ЁЃдкЯЕЭГОРњЙЪеЯжЎКѓЃЌМЦЪ§НсЙћЪЧЖрЩйЃПШчЙћгаЦЋВюЃЌЪЧгаТЉЕєЕФМЦЪ§ЛЙЪЧжиИДМЦЪ§ЃП
вЛжТадМЖБ№
дкСїДІРэжаЃЌвЛжТадПЩвдЗжЮЊ3ИіМЖБ№:
at-most-once(зюЖрвЛДЮ):
етЦфЪЕЪЧУЛгае§ШЗадБЃеЯЕФЮЏЭёЫЕЗЈЁЊЁЊЙЪеЯЗЂЩњжЎКѓЃЌМЦЪ§НсЙћПЩФмЖЊЪЇЁЃ
at-least-once(жСЩйвЛДЮ):
етБэЪОМЦЪ§НсЙћПЩФмДѓгке§ШЗжЕЃЌЕЋОјВЛЛсаЁгке§ШЗжЕЁЃвВОЭЪЧЫЕЃЌМЦЪ§ГЬађдкЗЂЩњЙЪеЯКѓПЩФмЖрЫуЃЌЕЋЪЧОјВЛЛсЩйЫуЁЃ
exactly-once(бЯИёвЛДЮ):
етжИЕФЪЧЯЕЭГБЃжЄдкЗЂЩњЙЪеЯКѓЕУЕНЕФМЦЪ§НсЙћгые§ШЗжЕвЛжТ.МШВЛЖрЫувВВЛЩйЫу
дјОЃЌat-least-onceЗЧГЃСїааЁЃЕквЛДњСїДІРэЦї(ШчStormКЭSamza)ИеЮЪЪРЪБжЛБЃжЄat-least-onceЃЌдвђгаЖў:
БЃжЄexactly-onceЕФЯЕЭГЪЕЯжЦ№РДИќИДдгЁЃетдкЛљДЁМмЙЙВу(ОіЖЈЪВУДДњБэе§ШЗЃЌвдМАexactly-onceЕФЗЖЮЇЪЧЪВУД)КЭЪЕЯжВуЖМКмгаЬєеНад
СїДІРэЯЕЭГЕФдчЦкгУЛЇдИвтНгЪмПђМмЕФОжЯоадЃЌВЂдкгІгУВуЯыАьЗЈУжВЙ(Р§ШчЪЙгІгУГЬађОпгаУнЕШадЃЌЛђепгУХњСПМЦЫуВудйзівЛБщМЦЫу)ЁЃ
зюЯШБЃжЄexactly-onceЕФЯЕЭГ(Storm TridentКЭSpark Streaming)дкадФмКЭБэЯжСІетСНИіЗНУцИЖГіСЫКмДѓЕФДњМлЁЃЮЊСЫБЃжЄexactly-onceЃЌетаЉЯЕЭГЮоЗЈЕЅЖРЕиЖдУПЬѕМЧТМдЫгУгІгУТпМЃЌЖјЪЧЭЌЪБДІРэЖрЬѕ(вЛХњ)МЧТМЃЌБЃжЄЖдУПвЛХњЕФДІРэвЊУДШЋВПГЩЙІЃЌвЊУДШЋВПЪЇАмЁЃетОЭЕМжТдкЕУЕННсЙћЧАЃЌБиаыЕШД§вЛХњМЧТМДІРэНсЪјЁЃвђДЫЃЌгУЛЇОГЃВЛЕУВЛЪЙгУСНИіСїДІРэПђМм(вЛИігУРДБЃжЄexactly-onceЃЌСэвЛИігУРДЖдУПИідЊЫизіЕЭбгГйДІРэ)ЃЌНсЙћЪЙЛљДЁЩшЪЉИќМгИДдгЁЃдјОЃЌгУЛЇВЛЕУВЛдкБЃжЄexactly-onceгыЛёЕУЕЭбгГйКЭаЇТЪжЎМфШЈКтРћБзЁЃFlinkБмУтСЫетжжШЈКтЁЃ
FlinkЕФвЛИіжиДѓМлжЕдкгкЃЌЫќМШБЃжЄСЫexactly-onceЃЌгжОпгаЕЭбгГйКЭИпЭЬЭТЕФДІРэФмСІЁЃ
ДгИљБОЩЯЫЕЃЌFlinkЭЈЙ§ЪЙздЩэТњзуЫљгаашЧѓРДБмУтШЈКтЃЌЫќЪЧвЕНчЕФвЛДЮвтвхжиДѓЕФММЪѕЗЩдОЁЃ
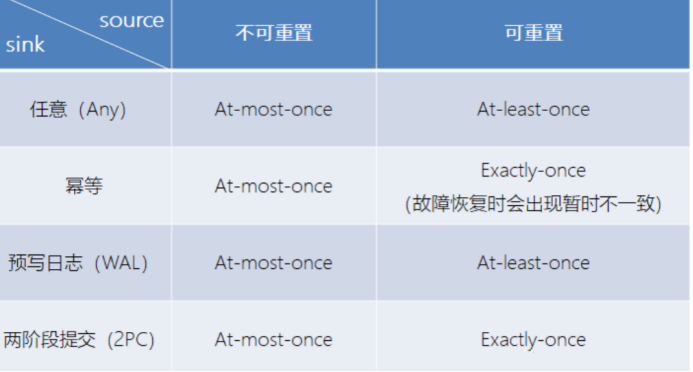
ЖЫЕНЖЫЕФзДЬЌвЛжТад
ФПЧАЮвУЧПДЕНЕФвЛжТадБЃжЄЖМЪЧгЩСїДІРэЦїЪЕЯжЕФЃЌвВОЭЪЧЫЕЖМЪЧдк Flink СїДІРэЦїФкВПБЃжЄЕФЃЛЖјдкецЪЕгІгУжаЃЌСїДІРэгІгУГ§СЫСїДІРэЦївдЭтЛЙАќКЌСЫЪ§ОндДЃЈР§Шч
KafkaЃЉКЭЪфГіЕНГжОУЛЏЯЕЭГЁЃ
ЖЫЕНЖЫЕФвЛжТадБЃжЄЃЌвтЮЖзХНсЙћЕФе§ШЗадЙсДЉСЫећИіСїДІРэгІгУЕФЪМжеЃЛУПвЛИізщМўЖМБЃжЄСЫЫќздМКЕФвЛжТадЃЌећИіЖЫЕНЖЫЕФвЛжТадМЖБ№ШЁОігкЫљгазщМўжавЛжТадзюШѕЕФзщМўЁЃ
ОпЬхЛЎЗжШчЯТ:
sourceЖЫ
ашвЊЭтВПдДПЩжиЩшЪ§ОнЕФЖСШЁЮЛжУ.ФПЧАЮвУЧЪЙгУЕФKafka SourceОпгаетжжЬиад: ЖСШЁЪ§ОнЕФЪБКђПЩвджИЖЈoffset
flinkФкВП
вРРЕcheckpointЛњжЦ
sinkЖЫ
ашвЊБЃжЄДгЙЪеЯЛжИДЪБЃЌЪ§ОнВЛЛсжиИДаДШыЭтВПЯЕЭГ. га2жжЪЕЯжаЮЪН:
a)УнЕШЃЈIdempotentЃЉаДШы
ЫљЮНУнЕШВйзїЃЌЪЧЫЕвЛИіВйзїЃЌПЩвджиИДжДааКмЖрДЮЃЌЕЋжЛЕМжТвЛДЮНсЙћИќИФЃЌвВОЭЪЧЫЕЃЌКѓУцдйжиИДжДааОЭВЛЦ№зїгУСЫЁЃ
b)ЪТЮёадЃЈTransactionalЃЉаДШы
ашвЊЙЙНЈЪТЮёРДаДШыЭтВПЯЕЭГЃЌЙЙНЈЕФЪТЮёЖдгІзХ checkpointЃЌЕШЕН
checkpoint еце§ЭъГЩЕФЪБКђЃЌВХАбЫљгаЖдгІЕФНсЙћаДШы sink ЯЕЭГжаЁЃЖдгкЪТЮёадаДШыЃЌОпЬхгжгаСНжжЪЕЯжЗНЪНЃКдЄаДШежОЃЈWALЃЉКЭСННзЖЮЬсНЛЃЈ2PCЃЉ
ЖўЁЂCheckpointдРэ
FlinkОпЬхШчКЮБЃжЄexactly-onceФи? ЫќЪЙгУвЛжжБЛГЦЮЊ"МьВщЕу"ЃЈcheckpointЃЉЕФЬиадЃЌдкГіЯжЙЪеЯЪБНЋЯЕЭГжижУЛие§ШЗзДЬЌЁЃЯТУцЭЈЙ§МђЕЅЕФРрБШРДНтЪЭМьВщЕуЕФзїгУЁЃ
МйЩшФуКЭСНЮЛХѓгбе§дкЪ§ЯюСДЩЯгаЖрЩйПХжщзгЃЌШчЯТЭМЫљЪОЁЃФуФѓзЁжщзгЃЌБпЪ§БпВІЃЌУПВІЙ§вЛПХжщзгОЭИјзмЪ§МгвЛЁЃФуЕФХѓгбвВетбљЪ§ЫћУЧЪжжаЕФжщзгЁЃЕБФуЗжЩёЭќМЧЪ§ЕНФФРяЪБЃЌдѕУДАьФи?
ШчЙћЯюСДЩЯгаКмЖржщзгЃЌФуЯдШЛВЛЯыДгЭЗдйЪ§вЛБщЃЌгШЦфЪЧЕБШ§ШЫЕФЫйЖШВЛвЛбљШДгжЪдЭМКЯзїЕФЪБКђЃЌИќЪЧШчДЫ(БШШчЯыМЧТМЧАвЛЗжжгШ§ШЫвЛЙВЪ§СЫЖрЩйПХжщзгЃЌЛиЯывЛЯТвЛЗжжгЙіЖЏДАПк)ЁЃ
гкЪЧЃЌФуЯыСЫвЛИіИќКУЕФАьЗЈ: дкЯюСДЩЯУПИєвЛЖЮОЭЫЩЫЩЕиЯЕЩЯвЛИљгаЩЋЦЄНюЃЌНЋжщзгЗжИєПЊ;
ЕБжщзгБЛВІЖЏЕФЪБКђЃЌЦЄНювВПЩвдБЛВІЖЏ; ШЛКѓЃЌФуАВХХвЛИіжњЪжЃЌШУЫћдкФуКЭХѓгбВІЕНЦЄНюЪБМЧТМзмЪ§ЁЃгУетжжЗНЗЈЃЌЕБгаШЫЪ§ДэЪБЃЌОЭВЛБиДгЭЗПЊЪМЪ§ЁЃЯрЗДЃЌФуЯђЦфЫћШЫЗЂГіДэЮѓОЏЪОЃЌШЛКѓФуУЧЖМДгЩЯвЛИљЦЄНюДІПЊЪМжиЪ§ЃЌжњЪждђЛсИцЫпУПИіШЫжиЪ§ЪБЕФЦ№ЪМЪ§жЕЃЌР§ШчдкЗлЩЋЦЄНюДІЕФЪ§жЕЪЧЖрЩйЁЃ
FlinkМьВщЕуЕФзїгУОЭРрЫЦгкЦЄНюБъМЧЁЃЪ§жщзгетИіРрБШЕФЙиМќЕуЪЧ: ЖдгкжИЖЈЕФЦЄНюЖјбдЃЌжщзгЕФЯрЖдЮЛжУЪЧШЗЖЈЕФ;
етШУЦЄНюГЩЮЊжиаТМЦЪ§ЕФВЮПМЕуЁЃзмзДЬЌ(жщзгЕФзмЪ§)дкУППХжщзгБЛВІЖЏжЎКѓИќаТвЛДЮЃЌжњЪждђЛсБЃДцгыУПИљЦЄНюЖдгІЕФМьВщЕузДЬЌЃЌШчЕБгіЕНЗлЩЋЦЄНюЪБвЛЙВЪ§СЫЖрЩйжщзгЃЌЕБгіЕНГШЩЋЦЄНюЪБгжЪЧЖрЩйЁЃЕБЮЪЬтГіЯжЪБЃЌетжжЗНЗЈЪЙЕУжиаТМЦЪ§БфЕУМђЕЅЁЃ
FlinkЕФМьВщЕуЫуЗЈ
checkpointЛњжЦЪЧFlinkПЩППадЕФЛљЪЏЃЌПЩвдБЃжЄFlinkМЏШКдкФГИіЫузгвђЮЊФГаЉдвђ(Шч
вьГЃЭЫГі)ГіЯжЙЪеЯЪБЃЌФмЙЛНЋећИігІгУСїЭМЕФзДЬЌЛжИДЕНЙЪеЯжЎЧАЕФФГвЛзДЬЌЃЌБЃжЄгІгУСїЭМзДЬЌЕФвЛжТад.
ПьееЕФЪЕЯжЫуЗЈ:
a)МђЕЅЫуЗЈЈCднЭЃгІгУ, ШЛКѓПЊЪМзіМьВщЕу, дйжиаТЛжИДгІгУ
b)FlinkЕФИФНјCheckpointЫуЗЈ. FlinkЕФcheckpointЛњжЦдРэРДзд"Chandy-Lamport
algorithm"ЫуЗЈ(ЗжВМЪНПьееЫу)ЕФвЛжжБфЬх: вьВН barrier ПьееЃЈasynchronous
barrier snapshottingЃЉ
УПИіашвЊcheckpointЕФгІгУдкЦєЖЏЪБЃЌFlinkЕФJobManagerЮЊЦфДДНЈвЛИіCheckpointCoordinatorЃЌCheckpointCoordinatorШЋШЈИКд№БОгІгУЕФПьеежЦзїЁЃ
РэНтBarrier
СїЕФbarrierЪЧFlinkЕФCheckpointжаЕФвЛИіКЫаФИХФю. ЖрИіbarrierБЛВхШыЕНЪ§ОнСїжа,
ШЛКѓзїЮЊЪ§ОнСїЕФвЛВПЗжЫцзХЪ§ОнСїЖЏ(гаЕуРрЫЦгкWatermark).етаЉbarrierВЛЛсПчдНСїжаЕФЪ§Он.
УПИіbarrierЛсАбЪ§ОнСїЗжГЩСНВПЗж: вЛВПЗжЪ§ОнНјШыЕБЧАЕФПьее
, СэвЛВПЗжЪ§ОнНјШыЯТвЛИіПьее . УПИіbarrierаЏДјзХПьееЕФid. barrier ВЛЛсднЭЃЪ§ОнЕФСїЖЏ,
ЫљвдЗЧГЃЧсСПМЖ. дкСїжа, ЭЌвЛЪБМфПЩвдгаРДдДгкЖрИіВЛЭЌПьееЕФЖрИіbarrier, етИівтЮЖзХПЩвдВЂЗЂЕФГіЯжВЛЭЌЕФПьее.
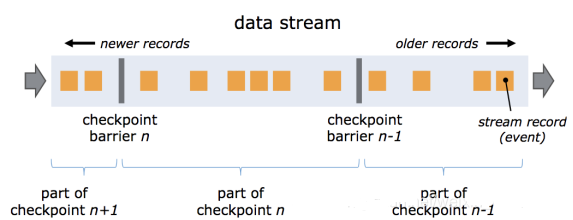
FlinkЕФМьВщЕужЦзїЙ§ГЬ
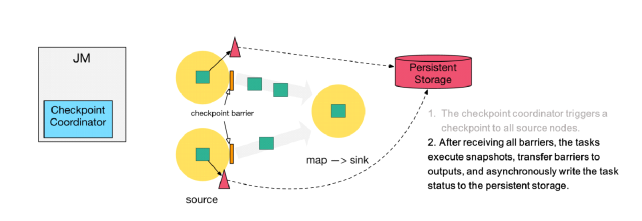
ЕквЛВН: Checkpoint Coordinator ЯђЫљга source
НкЕу trigger Checkpoint. ШЛКѓSource TaskЛсдкЪ§ОнСїжаАВВхCheckPoint
barrier
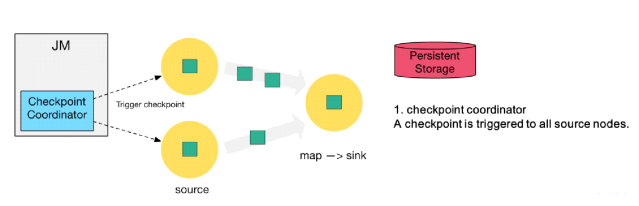
ЕкЖўВН: source НкЕуЯђЯТгЮЙуВЅ barrierЃЌетИі barrier
ОЭЪЧЪЕЯж Chandy-Lamport ЗжВМЪНПьееЫуЗЈЕФКЫаФЃЌЯТгЮЕФ task жЛгаЪеЕНЫљга input
ЕФ barrier ВХЛсжДааЯргІЕФ Checkpoint
ЕкШ§ВН: ЕБ task ЭъГЩ state БИЗнКѓЃЌЛсНЋБИЗнЪ§ОнЕФЕижЗЃЈstate
handleЃЉЭЈжЊИј Checkpoint coordinatorЁЃ
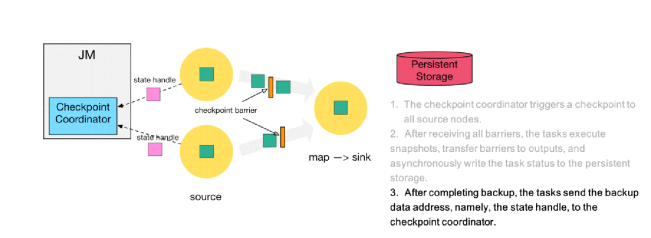
ЕкЫФВН: ЯТгЮЕФ sink НкЕуЪеМЏЦыЩЯгЮСНИі input ЕФ barrier
жЎКѓЃЌЛсжДааБОЕиПьееЃЌетРяЬиЕиеЙЪОСЫ RocksDB incremental Checkpoint
ЕФСїГЬЃЌЪзЯШ RocksDB ЛсШЋСПЫЂЪ§ОнЕНДХХЬЩЯЃЈКьЩЋДѓШ§НЧБэЪОЃЉЃЌШЛКѓ Flink ПђМмЛсДгжабЁдёУЛгаЩЯДЋЕФЮФМўНјааГжОУЛЏБИЗнЃЈзЯЩЋаЁШ§НЧЃЉЁЃ

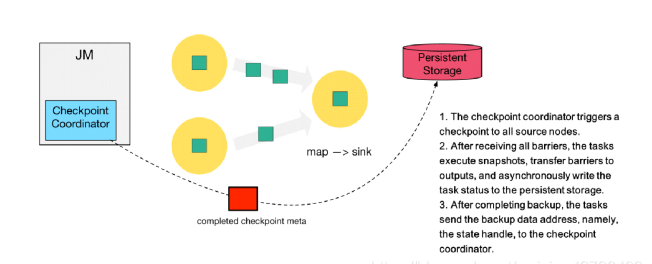
ЕкЮхВН: ЭЌбљЕФЃЌsink НкЕудкЭъГЩздМКЕФ Checkpoint
жЎКѓЃЌЛсНЋ state handle ЗЕЛиЭЈжЊ CoordinatorЁЃ

ЕкСљВН: зюКѓЃЌЕБ Checkpoint coordinator ЪеМЏЦыЫљга
task ЕФ state handleЃЌОЭШЯЮЊетвЛДЮЕФ Checkpoint ШЋОжЭъГЩСЫЃЌЯђГжОУЛЏДцДЂжадйБИЗнвЛИі
Checkpoint meta ЮФМўЁЃ
бЯИёвЛДЮгявх: barrierЖдЦы
дкЖрВЂааЖШЯТ, ШчЙћвЊЪЕЯжбЯИёвЛДЮ, дђвЊжДааbarrierЖдЦы.
ЕБ job graph жаЕФУПИі operator НгЪеЕНbarriers
ЪБЃЌЫќОЭЛсМЧТМЯТЦфзДЬЌЁЃгЕгаСНИіЪфШыСїЕФ OperatorsЃЈР§Шч CoProcessFunctionЃЉЛсжДааbarrier
ЖдЦыЃЈbarrier alignmentЃЉвдБуЕБЧАПьееФмЙЛАќКЌЯћЗбСНИіЪфШыСї barrier жЎЧАЃЈЕЋВЛГЌЙ§ЃЉЕФЫљга
events ЖјВњЩњЕФзДЬЌЁЃ
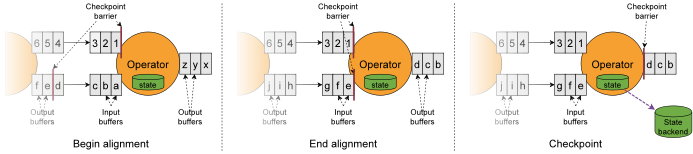
1.ЕБoperatorЪеЕНЪ§зжСїЕФbarrier nЪБ, ЫќОЭВЛФмДІРэ(ЕЋЪЧПЩвдНгЪе)РДздИУСїЕФШЮКЮЪ§ОнМЧТМЃЌжБЕНЫќДгзжФИСїЫљгаЪфШыНгЪеЕН
barrier n ЮЊжЙЁЃЗёдђЃЌЫќЛсЛьКЯЪєгкПьее n ЕФМЧТМКЭЪєгкПьее n + 1 ЕФМЧТМЁЃ
2.НгЪеЕН barrier n ЕФСї(Ъ§зжСї)днЪББЛИщжУЁЃДгетаЉСїНгЪеЕФМЧТМШыЪфШыЛКГхЧј,
ВЛЛсБЛДІРэЁЃ
3.ЭМвЛжаЕФ Checkpoint barrier nжЎКѓЕФЪ§Он
123вбНсЕНДяСЫЫузг, ДцШыЕНЪфШыЛКГхЧјУЛгаБЛДІРэ, жЛгаЕШЕНзжФИСїЕФCheckpoint barrier
nЕНДяжЎКѓВХЛсПЊЪМДІРэ.
4.вЛЕЉзюКѓЫљгаЪфШыСїЖМНгЪеЕН barrier nЃЌOperator
ОЭЛсАбЛКГхЧјжа pending ЕФЪфГіЪ§ОнЗЂГіШЅЃЌШЛКѓАб CheckPoint barrier n
НгзХЭљЯТгЮЗЂЫЭЁЃетРяЛЙЛсЖдздЩэНјааПьееЁЃ
жСЩйвЛДЮгявх: barrierВЛЖдЦы
ЧАУцНщЩмСЫbarrierЖдЦы, ШчЙћbarrierВЛЖдЦыЛсдѕУДбљ?
ЛсжиИДЯћЗб, ОЭЪЧжСЩйвЛДЮгявх.

МйЩшВЛЖдЦы, дкзжФИСїЕФCheckpoint barrier nЕНДяЧА,
вбОДІРэСЫ1 2 3. ЕШзжФИСїCheckpoint barrier nЕНДяжЎКѓ, ЛсзіCheckpoint
n. МйЩшетИіЪБКђГЬађвьГЃДэЮѓСЫ, дђжиаТЦєЖЏЕФЪБКђЛсCheckpoint nжЎКѓЕФЪ§ОнжиаТМЦЫу.
1 2 3 ЛсБЛдйДЮБЛМЦЫу, Ыљвд123ГіЯжСЫжиИДМЦЫу.
Ш§ЁЂSavepointдРэ
Flink ЛЙЬсЙЉСЫПЩвдздЖЈвхЕФОЕЯёБЃДцЙІФмЃЌОЭЪЧБЃДцЕуЃЈsavepointsЃЉ
ддђЩЯЃЌДДНЈБЃДцЕуЪЙгУЕФЫуЗЈгыМьВщЕуЭъШЋЯрЭЌЃЌвђДЫБЃДцЕуПЩвдШЯЮЊОЭЪЧОпгавЛаЉЖюЭтдЊЪ§ОнЕФМьВщЕу
FlinkВЛЛсздЖЏДДНЈБЃДцЕуЃЌвђДЫгУЛЇЃЈЛђЭтВПЕїЖШГЬађЃЉБиаыУїШЗЕиДЅЗЂДДНЈВйзї
БЃДцЕуЪЧвЛИіЧПДѓЕФЙІФмЁЃГ§СЫЙЪеЯЛжИДЭтЃЌБЃДцЕуПЩвдгУгкЃКгаМЦЛЎЕФЪжЖЏБИЗнЃЌИќаТгІгУГЬађЃЌАцБОЧЈвЦЃЌднЭЃКЭжиЦєгІгУЃЌЕШЕШ
ЫФЁЂcheckpointКЭsavepointЕФЧјБ№

ЮхЁЂKafka+Flink+Kafka ЪЕЯжЖЫЕНЖЫбЯИёвЛДЮ
ЮвУЧжЊЕРЃЌЖЫЕНЖЫЕФзДЬЌвЛжТадЕФЪЕЯжЃЌашвЊУПвЛИізщМўЖМЪЕЯжЃЌЖдгкFlink + KafkaЕФЪ§ОнЙмЕРЯЕЭГЃЈKafkaНјЁЂKafkaГіЃЉЖјбдЃЌИїзщМўдѕбљБЃжЄexactly-onceгявхФиЃП
ФкВП ЁЊЁЊ РћгУcheckpointЛњжЦЃЌАбзДЬЌДцХЬЃЌЗЂЩњЙЪеЯЕФЪБКђПЩвдЛжИДЃЌБЃжЄВПЕФзДЬЌвЛжТад
source ЁЊЁЊ kafka consumerзїЮЊsourceЃЌПЩвдНЋЦЋвЦСПБЃДцЯТРДЃЌШчЙћКѓајШЮЮёГіЯжСЫЙЪеЯЃЌЛжИДЕФЪБКђПЩвдгЩСЌНгЦїжижУЦЋвЦСПЃЌжиаТЯћЗбЪ§ОнЃЌБЃжЄвЛжТад
sink ЁЊЁЊ kafka producerзїЮЊsinkЃЌВЩгУСННзЖЮЬсНЛ sinkЃЌашвЊЪЕЯжвЛИіTwoPhaseCommitSinkFunction
ФкВПЕФcheckpointЛњжЦЮвУЧвбОгаСЫСЫНтЃЌФЧsourceКЭsinkОпЬхгжЪЧдѕбљдЫааЕФФиЃПНгЯТРДЮвУЧж№ВНзівЛИіЗжЮіЁЃ
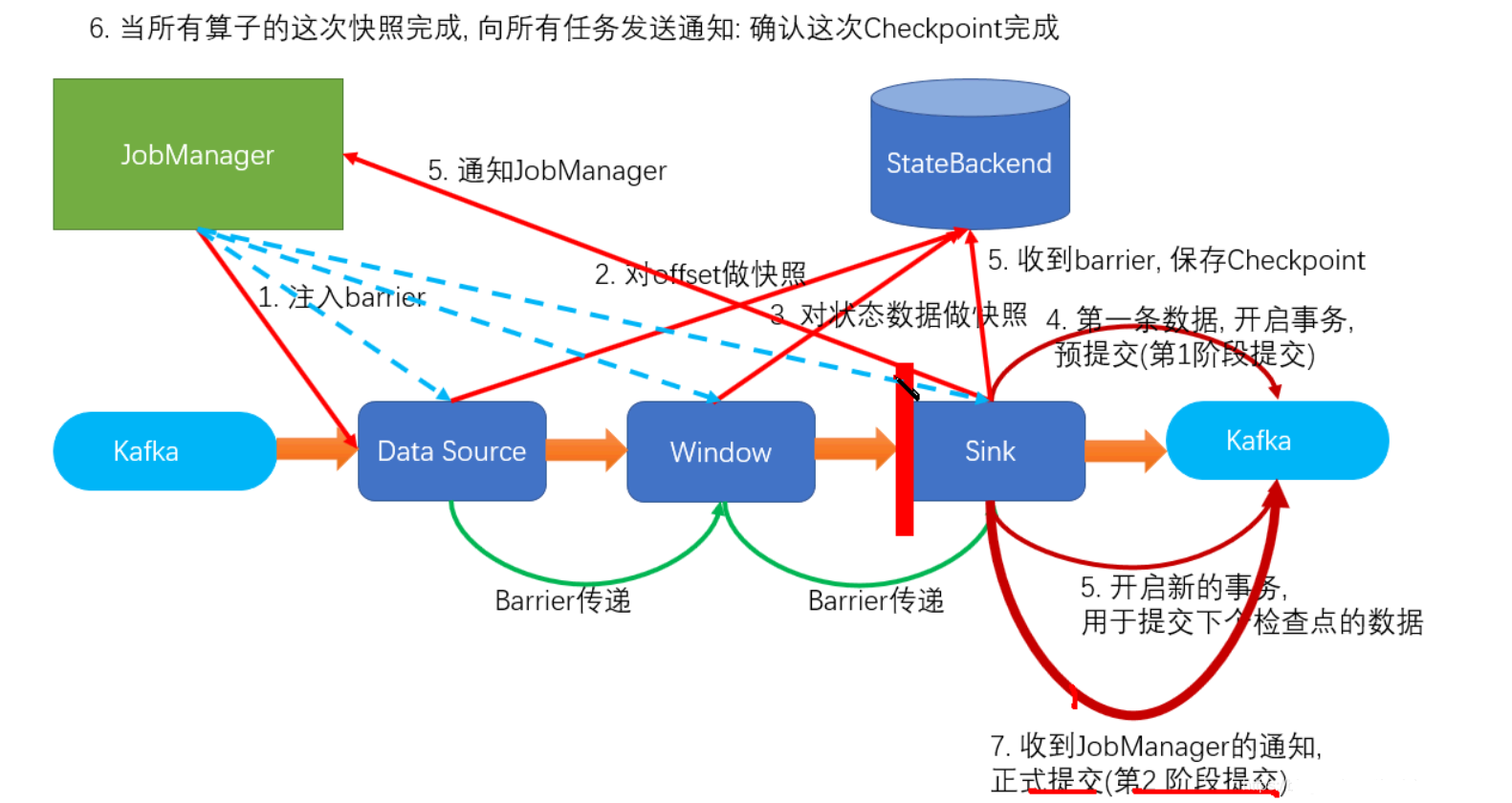
ОпЬхЕФСННзЖЮЬсНЛВНжшзмНсШчЯТЃК
ЕквЛЬѕЪ§ОнРДСЫжЎКѓЃЌПЊЦєвЛИі kafka ЕФЪТЮёЃЈtransactionЃЉЃЌе§ГЃаДШы kafka ЗжЧјШежОЕЋБъМЧЮЊЮДЬсНЛЃЌетОЭЪЧЁАдЄЬсНЛЁБ
jobmanager ДЅЗЂ checkpoint ВйзїЃЌbarrier Дг source ПЊЪМЯђЯТДЋЕнЃЌгіЕН
barrier ЕФЫузгНЋзДЬЌДцШызДЬЌКѓЖЫЃЌВЂЭЈжЊ jobmanagerr
sink СЌНгЦїЪеЕН barrierЃЌБЃДцЕБЧАзДЬЌЃЌДцШы checkpointЃЌЭЈжЊ jobmanagerЃЌВЂПЊЦєЯТвЛНзЖЮЕФЪТЮёЃЌгУгкЬсНЛЯТИіМьВщЕуЕФЪ§Он
jobmanager ЪеЕНЫљгаШЮЮёЕФЭЈжЊЃЌЗЂГіШЗШЯаХЯЂЃЌБэЪО checkpoint ЭъГЩ
sink ШЮЮёЪеЕН jobmanager ЕФШЗШЯаХЯЂЃЌе§ЪНЬсНЛетЖЮЪБМфЕФЪ§Он
ЭтВПkafkaЙиБеЪТЮёЃЌЬсНЛЕФЪ§ОнПЩвде§ГЃЯћЗбСЫ
СљЁЂдкДњТыжаВтЪдCheckpoint
package com.flink.charpter07.state;
import org.apache.flink.api .common.functions.FlatMapFunction;
import org.apache.flink.api .common.functions.MapFunction;
import org.apache.flink.api .common.serialization.SimpleStringSchema;
import org.apache.flink.api .java.tuple.Tuple2;
import org.apache.flink.runtime .state.filesystem.FsStateBackend;
import org.apache.flink.streaming .api.CheckpointingMode;
import org.apache.flink.streaming .api.environment.CheckpointConfig;
import org.apache.flink.streaming .api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming .connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.streaming .connectors.kafka.FlinkKafkaProducer;
import org.apache.flink.util.Collector;
import java.io.IOException;
import java.util.Properties;
public class S04_CheckPoint {
public static void main(String[] args) throws
IOException {
StreamExecutionEnvironment env = StreamExecutionEnvironment.
getExecutionEnvironment();
env.setParallelism(2);
Properties properties = new Properties();
properties.setProperty ("bootstrap.servers", "hadoop162:9092,
hadoop163:9092");
properties.setProperty ("group.id", "S04_CheckPoint");
properties.setProperty ("auto.offset.reset", "latest");
env.setStateBackend(new FsStateBackend ("hdfs://hadoop162:8020/ flink/checkpoints/fs"));
//ЩшжУcheckpointЕФЪБМфМфИє
env.enableCheckpointing(2000);
//ЩшжУФЃЪНЮЊОЋзМвЛДЮ(ФЌШЯжЕ)
env.getCheckpointConfig().setCheckpointingMode
(CheckpointingMode.EXACTLY_ONCE);
//ЩшжУcheckpointжЎМфЕФЪБМфМфИє
env.getCheckpointConfig( ).setMinPauseBetweenCheckpoints(1000);
//checkpointБиаыдквЛЗжжгФкЭъГЩЃЌЗёдђБЛХзЦњ
env.getCheckpointConfig( ).setCheckpointTimeout(60000);
//ЭЌвЛЪБМфжЛдЪаэвЛИіcheckpoint
env.getCheckpointConfig( ).setMaxConcurrentCheckpoints(1);
//ПЊЦєдкjobжажежЙКѓШЮШЛБЃСєЕФexternalized checkpoints
env.getCheckpointConfig( ).enableExternalizedCheckpoints
(CheckpointConfig .ExternalizedCheckpointCleanup
.RETAIN_ON_CANCELLATION);
env.addSource(new FlinkKafkaConsumer<String>
("test10",new SimpleStringSchema(
),properties))
.flatMap(new FlatMapFunction<String, Tuple2<String,Long>>()
{
@Override
public void flatMap(String value, Collector<Tuple2< String,Long>>
out) throws Exception {
for (String word : value.split(" "))
{
out.collect(Tuple2.of(word,1l));
}
}
})
.keyBy(t->t.f0)
.sum(1)
//.map(t->"("+t.f0+":"+t.f1+")")
.map(new MapFunction<Tuple2<String, Long>,
String>() {
@Override
public String map(Tuple2<String, Long>
value) throws Exception {
StringBuffer bs = new StringBuffer();
bs.append("(").append(value.f0).append(" :").append(value.f1).append(")");
return bs.toString();
}
})
.addSink(new FlinkKafkaProducer<String>
("hadoop162:9092","test11",new
SimpleStringSchema()));
try {
env.execute();
} catch (Exception e) {
e.printStackTrace();
}
}
}
|
|









