| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫHDFSЁЂYARNЁЂMapReduceЁЂДюНЈHadoopЕШЯрЙиФкШнЁЃ
БОЮФРДздВЉПЭдАЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
Hadoop
HadoopЪЧвЛПюПЊдДЕФДѓЪ§ОнЭЈгУДІРэЦНЬЈЃЌЦфЬсЙЉСЫ3ИізщМўЃЌЗжБ№ЪЧHDFSЗжВМЪНЮФМўЯЕЭГЁЂYARNЗжВМЪНзЪдДЕїЖШЁЂMapReduceЗжВМЪНРыЯпМЦЫуЁЃ
MapReduceЪЪКЯДѓЙцФЃЕФЪ§ОнЭЌЪБЖдЪЕЪБадвЊЧѓВЛИпЕФГЁОАЃЌВЛЪЪКЯДѓСПЕФаЁЮФМўвдМАЦЕЗБаоИФЕФЮФМўЁЃ
HadoopЕФЬиЕу
1.ЫЎЦНРЉеЙЃКHadoopМЏШКПЩвдДяЕНЩЯЧЇИіНкЕуЃЌЭЌЪБФмЙЛЖЏЬЌЕФаТдіКЭЩОГ§НкЕуЃЌФмЙЛДцДЂКЭДІРэPBМЖЕФЪ§ОнСПЁЃ
2.ЕЭГЩБОЃКВЛашвЊвРРЕЛњЦїЕФадФмЃЌжЛашвЊЦеЭЈЕФPCЛњОЭФмдЫааЁЃ
ФПЧАвЛАуЛсЪЙгУHDFSзїЮЊЮФМўДцДЂЃЌЪЙгУYARNЖдзЪдДНјааЙмРэЁЃ
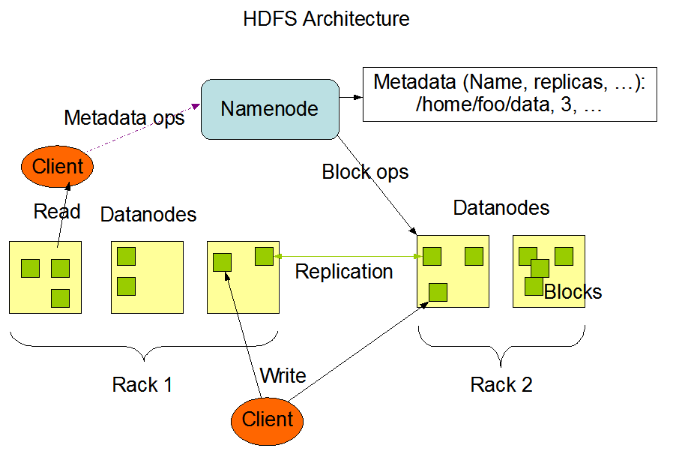
1.HDFS
HDFSЪЧЗжВМЪНЮФМўЯЕЭГЃЌПЩвдДцДЂКЃСПЕФЮФМўЁЃ
HDFSгЩNameNodeЁЂDataNodeЁЂSecondaryNameNodeНкЕузщГЩЁЃ
1.1 ЙигкBlockЪ§ОнПщ
BlockЪЧHDFSжазюаЁЕФДцДЂЕЅдЊЃЌУПИіBlockЕФДѓаЁФЌШЯЮЊ128MЁЃ
вЛИіДѓЮФМўЛсБЛВ№ЗжГЩЖрИіBlockНјааДцДЂЃЌШчЙћвЛИіЮФМўЕФДѓаЁаЁгкBlockЕФДѓаЁЃЌФЧУДBlockЪЕМЪеМгУЕФДѓаЁЮЊЮФМўБОЩэЕФДѓаЁЁЃ
УПИіBlockЖМЛсдкВЛЭЌЕФDataNodeНкЕужаДцдкБИЗнЁЃ
1.2 DataNodeНкЕу
DataNodeНкЕугУгкБЃДцBlockЃЌЭЌЪБИКд№Ъ§ОнЕФЖСаДКЭИДжЦВйзїЁЃ
DataNodeНкЕуЦєЖЏЪБЛсЯђNameNodeНкЕуЛуБЈЕБЧАДцДЂЕФBlockаХЯЂЁЃ
1.3 NameNodeНкЕу
NameNodeНкЕугУгкДцДЂЮФМўЕФдЊаХЯЂЁЂЮФМўгыBlockКЭDataNodeЕФЙиЯЕЁЃ
NameNodeдЫааЪБЕФЫљгаЪ§ОнЖМБЃДцдкФкДцЕБжаЃЌвђДЫећИіHDFSПЩДцДЂЕФЮФМўЪ§СПЪмЯогкNameNodeНкЕуЕФФкДцДѓаЁЁЃ
NameNodeНкЕужаЕФЪ§ОнЛсЖЈЪББЃДцЕНДХХЬЮФМўЕБжаЃЈжЛгаЮФМўЕФдЊаХЯЂЃЉЃЌЕЋВЛБЃДцЮФМўгыBlockКЭDataNodeЕФЙиЯЕЃЌетВПЗжЪ§ОнгЩDataNodeЦєЖЏЪБЩЯБЈКЭдЫааЪБЮЌЛЄЁЃ
DataNodeНкЕуЛсЖЈЦкЯђNameNodeНкЕуЗЂЫЭаФЬјЧыЧѓЃЌвЛЕЉNameNodeНкЕудквЛЖЈЕФЪБМфФкУЛгаЪеЕНDataNodeНкЕуЗЂЫЭЕФаФЬјдђШЯЮЊЦфвбОхДЛњЃЌВЛЛсдйИјИУDataNodeНкЕуЗжХфШЮКЮЕФIOЧыЧѓЁЃ
УПИіBlockдкNameNodeжаЖМЖдгІвЛЬѕМЧТМЃЌШчЙћЪЧДѓСПЕФаЁЮФМўНЋЛсЯћКФДѓСПФкДцЃЌвђДЫHDFSЪЪКЯДцДЂДѓЮФМўЁЃ
1.4 SecondaryNameNode
SecondaryNameNodeНкЕуЛсЖЈЪБгыNameNodeНкЕуНјааЭЌВНЃЈHAЃЉ
ЭљHDFSаДШыЮФМўЕФСїГЬ
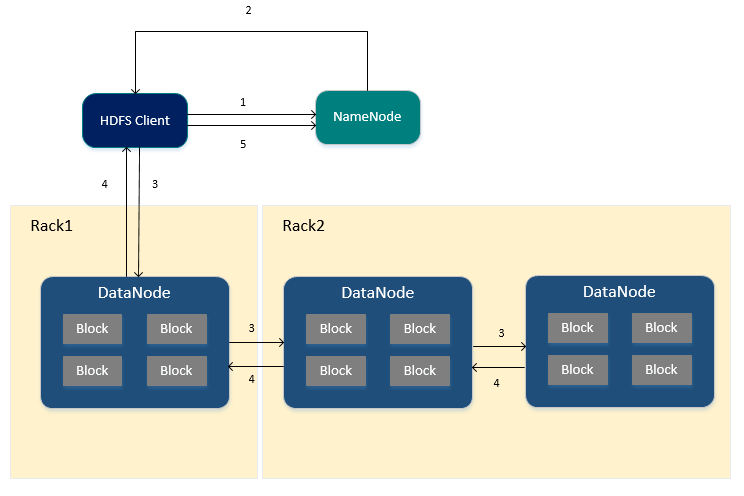
1.HDFS ClientЯђNameNodeНкЕуЩъЧыаДШыЮФМўЁЃ
2.NameNodeНкЕуИљОнЮФМўЕФДѓаЁЃЌЗЕЛиЮФМўвЊаДШыЕФBlockIdвдМАDataNodeНкЕуСаБэЃЌЭЌЪБДцДЂЮФМўЕФдЊаХЯЂвдМАЮФМўгыBlockКЭDataNodeНкЕужЎМфЕФЙиЯЕЁЃ
3.HDFS ClientНгЪеЕНNameNodeНкЕуЕФЗЕЛижЎКѓЃЌЛсНЋЪ§ОнвРДЮаДШыЕНжИЖЈЕФDataNodeНкЕуЕБжаЃЌУПИіDataNodeНкЕуНгЪеЕНЪ§ОнжЎКѓЛсАбЪ§ОнаДШыЕНДХХЬЮФМўЃЌШЛКѓНЋЪ§ОнЭЌВНИјЦфЫћЕФDataNodeНкЕуНјааБИЗнЃЈБИЗнЪ§-1ИіDataNodeНкЕуЃЉ
4.дкНјааБИЗнЕФЙ§ГЬжаЃЌУПвЛИіDataNodeНкЕуНгЪеЕНЪ§ОнКѓЖМЛсЯђЧАвЛИіDataNodeНкЕуНјааЯьгІЃЌзюжеЕквЛИіDataNodeНкЕуЗЕЛиHDFS
ClientГЩЙІЁЃ
5.ЕБHDFS ClientНгЪеЕНDataNodeНкЕуЕФЯьгІКѓЃЌЛсЯђNameNodeНкЕуЗЂЫЭзюжеШЗШЯЧыЧѓЃЌДЫЪБNameNodeНкЕуВХЛсЬсНЛЮФМўЁЃ
дкНјааБИЗнЕФЙ§ГЬжаЃЌШчЙћФГИіDataNodeНкЕуаДШыЪЇАмЃЌNameNodeНкЕуЛсжиаТбАевDataNodeНкЕуМЬајИДжЦЃЌвдБЃжЄЪ§ОнЕФПЩППадЁЃ
жЛгаЕБЯђNameNodeНкЕуЗЂЫЭзюжеШЗШЯЧыЧѓКѓЮФМўВХПЩМћЃЌШчЙћдкЗЂЫЭзюжеШЗШЯЧыЧѓЧАNameNodeОЭвбОхДЛњЃЌФЧУДЮФМўНЋЛсЖЊЪЇЁЃ
ДгHDFSЖСШЁЮФМўЕФСїГЬ
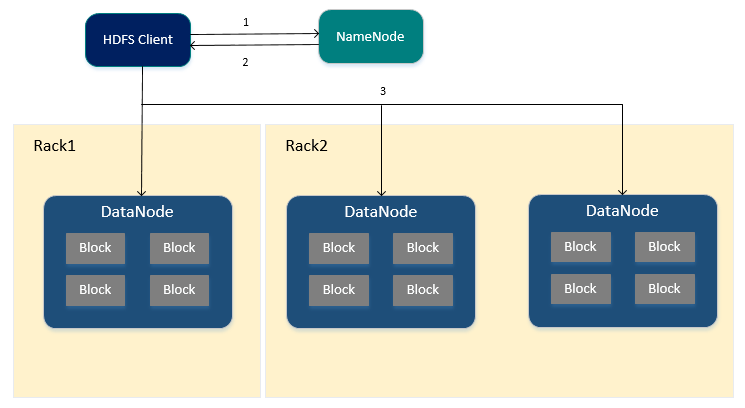
1.HDFS ClientЯђNameNodeНкЕуЩъЧыЖСШЁЮФМўЁЃ
2.NameNodeНкЕуЗЕЛиЮФМўЫљгаЖдгІЕФBlockIdвдМАетаЉBlockIdЫљдкЕФDataNodeНкЕуСаБэЃЈАќРЈБИЗнНкЕуЃЉ
3.HDFS ClientЛсгХЯШДгБОЕиЕФDataNodeжаНјааЖСШЁBlockЃЌЗёдђЭЈЙ§ЭјТчДгБИЗнНкЕужаНјааЖСШЁЁЃ
ЛњМмИажЊ
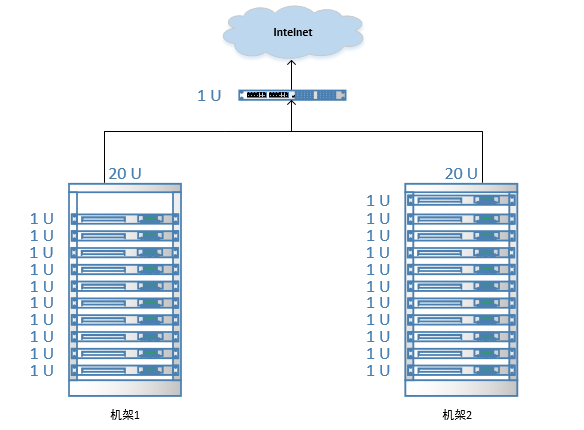
ЗжВМЪНМЏШКжаЭЈГЃЛсАќКЌЗЧГЃЖрЕФЛњЦїЃЌгЩгкЪмЕНЛњМмВлЮЛКЭНЛЛЛЛњЭјПкЕФЯожЦЃЌЭЈГЃДѓаЭЕФЗжВМЪНМЏШКЖМЛсПчКУМИИіЛњМмЃЌгЩЖрИіЛњМмЩЯЕФЛњЦїЙВЭЌзщГЩвЛИіЗжВМЪНМЏШКЁЃ
ЛњМмФкЕФЛњЦїжЎМфЕФЭјТчЫйЖШЭЈГЃИпгкПчЛњМмЛњЦїжЎМфЕФЭјТчЫйЖШЃЌВЂЧвЛњМмжЎМфЛњЦїЕФЭјТчЭЈаХЭЈГЃЛсЪмЕНЩЯВуНЛЛЛЛњЭјТчДјПэЕФЯожЦЁЃ
HadoopФЌШЯУЛгаПЊЦєЛњМмИажЊЙІФмЃЌФЌШЯЧщПіЯТУПИіBlockЖМЪЧЫцЛњЗжХфDataNodeНкЕуЃЌЕБHadoopПЊЦєЛњМмИажЊЙІФмКѓЃЌФЧУДЕБNameNodeНкЕуЦєЖЏЪБЃЌЛсНЋЛњЦїгыЛњМмжЎМфЕФЙиЯЕБЃДцдкФкДцжаЃЌЕБHDFS
ClientЩъЧыаДШыЮФМўЪБЃЌФмЙЛИљОндЄЯШЖЈвхЕФЛњМмЙиЯЕКЯРэЕФЗжХфDataNodeЁЃ
ЛњМмИажЊФЌШЯЖдBlockЕФ3ИіБИЗнЕФДцЗХВпТд
Ек1ИіBlockБИЗнДцЗХдкгыHDFS ClientЭЌвЛИіНкЕуЕФDataNodeНкЕужаЃЈШєHDFS
ClientВЛдкМЏШКЗЖЮЇФкдђЫцЛњбЁШЁЃЉ
Ек2ИіBlockБИЗнДцЗХдкгыЕквЛИіНкЕуВЛЭЌЛњМмЯТЕФНкЕужаЁЃ
Ек3ИіBlockБИЗнДцЗХдкгыЕк2ИіБИЗнЫљдкНкЕуЕФЛњМмЯТЕФСэвЛИіНкЕужаЃЌШчЙћЛЙгаИќЖрЕФИББОдђЫцЛњДцЗХдкМЏШКЕФНкЕужаЁЃ
ЪЙгУДЫВпТдПЩвдБЃжЄЖдЮФМўЕФЗУЮЪФмЙЛгХЯШдкБОЛњМмЯТевЕНЃЌВЂЧвШчЙћећИіЛњМмЩЯЗЂЩњСЫвьГЃвВПЩвддкСэЭтЕФЛњМмЩЯевЕНИУBlockЕФБИЗнЁЃ
2 YARN
YARNЪЧЗжВМЪНзЪдДЕїЖШПђМмЃЌгЩResourceMangerЁЂNodeManagerвдМАApplicationMasterзщГЩЁЃ
2.1 ResourceManager
ResourceManagerЪЧМЏШКЕФзЪдДЙмРэепЃЌИКд№МЏШКжазЪдДЕФЗжХфвдМАЕїЖШЃЌЭЌЪБЙмРэИїИіNodeManagerЃЌЭЌЪБИКд№ДІРэПЭЛЇЖЫЕФШЮЮёЧыЧѓЁЃ
2.2 NodeManager
NodeManagerЪЧНкЕуЕФЙмРэепЃЌИКд№ДІРэРДздResourceManagerКЭApplicationMasterЕФЧыЧѓЁЃ
2.3 ApplicationMaster
ApplicationMasterгУгкМЦЫуШЮЮёЫљашвЊЕФзЪдДЁЃ
2.4 ШЮЮёдЫаадкYARNЕФСїГЬ
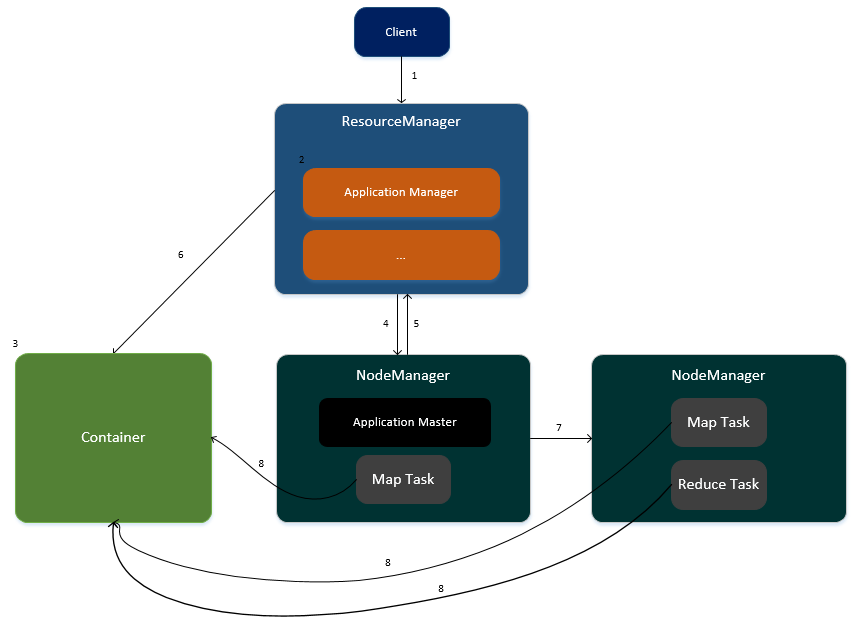
1.ПЭЛЇЖЫЯђResourceManagerЬсНЛШЮЮёЧыЧѓЁЃ
2.ResourceManagerЩњГЩвЛИіApplicationManagerНјГЬЃЌгУгкШЮЮёЕФЙмРэЁЃ
3.ApplicationManagerДДНЈвЛИіContainerШнЦїгУгкДцЗХШЮЮёЫљашвЊЕФзЪдДЁЃ
4.ApplicationManagerбАевЦфжавЛИіNodeManagerЃЌдкДЫNodeManagerжаЦєЖЏвЛИіApplicationMasterЃЌгУгкШЮЮёЕФЙмРэвдМАМрПиЁЃ
5.ApplicationMasterЯђResourceManagerНјаазЂВсЃЌВЂМЦЫуШЮЮёЫљашЕФзЪдДЛуБЈИјResourceManagerЃЈCPUгыФкДцЃЉ
6.ResourceManagerЮЊДЫШЮЮёЗжХфзЪдДЃЌзЪдДЗтзАдкContainerШнЦїжаЁЃ
7.ApplicationMasterЭЈжЊМЏШКжаЯрЙиЕФNodeManagerНјааШЮЮёЕФжДааЁЃ
8.ИїИіNodeManagerДгContainerШнЦїжаЛёШЁзЪдДВЂжДааMapЁЂReduceШЮЮёЁЃ
3 MapReduce
MapReduceЪЧЗжВМЪНРыЯпМЦЫуПђМмЃЌЦфдРэЪЧНЋЪ§ОнВ№ЗжГЩЖрЗнЃЌШЛКѓЭЈЙ§ЖрИіНкЕуВЂааДІРэЁЃ
MapReduceжДааСїГЬ
MapReduceЗжЮЊMapШЮЮёвдМАReduceШЮЮёСНВПЗжЁЃ
3.1 MapШЮЮё
1.ЖСШЁЮФМўжаЕФФкШнЃЌНтЮіГЩKey ValueЕФаЮЪН (KeyЮЊЦЋвЦСПЃЌValueЮЊУПааЕФЪ§Он)
2.жиаДmapЗНЗЈЃЌЩњГЩаТЕФKeyКЭValueЁЃ
3.ЖдЪфГіЕФKeyКЭValueНјааЗжЧјЁЃ
4.НЋЪ§ОнАДееKeyНјааЗжзщЃЌkeyЯрЭЌЕФvalueЗХЕНвЛИіМЏКЯжаЃЈЪ§ОнЛузмЃЉ
ДІРэЕФЮФМўБиаывЊдкHDFSжаЁЃ
3.2 ReduceШЮЮё
1.ЖдЖрИіMapШЮЮёЕФЪфГіЃЌАДееВЛЭЌЕФЗжЧјЃЌЭЈЙ§ЭјТчИДжЦЕНВЛЭЌЕФreduceНкЕуЁЃ
2.ЖдЖрИіMapШЮЮёЕФЪфГіНјааКЯВЂЁЂХХађЁЃ
3.НЋreduceЕФЪфГіБЃДцЕНЮФМўЃЌДцЗХдкHDFSжаЁЃ
4.ДюНЈHadoop
4.1 АВзА
1.гЩгкHadoopЪЙгУJavaгябдНјааБраДЃЌвђДЫашвЊАВзАJDKЁЃ
2.ДгCDHжаЯТдиHadoop 2.XВЂНјааНтбЙЃЌCDHЪЧCloudreaЙЋЫОЖдИїжжПЊдДПђМмЕФећКЯгыгХЛЏЃЈНЯЮШЖЈЃЉ
4.2 аоИФХфжУ
1.аоИФЛЗОГХфжУ
БрМetc/hadoop/hadoop-env.shЮФМўЃЌаоИФJAVA_HOMEХфжУЃЈДЫЮФМўЪЧHadoopЦєЖЏЪБМгдиЕФЛЗОГБфСПЃЉ
БрМ/etc/hostsЮФМўЃЌЬэМгжїЛњУћгыIPЕФгГЩфЙиЯЕЁЃ

2.ХфжУHadoopЙЋЙВЪєадЃЈcore-site.xmlЃЉ
<configuration>
<!-- HadoopЙЄзїФПТМ,гУгкДцЗХHadoopдЫааЪБВњЩњЕФСйЪБЪ§Он -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/hadoop/hadoop-2.9.0/data </value>
</property>
<!-- NameNodeЕФЭЈаХЕижЗ,1.xФЌШЯ9000,2.xПЩвдЪЙгУ8020
-->
<property>
<name>fs.default.name</name>
<value>hdfs://192.168.1.80:8020 </value>
</property>
</configuration> |
3.ХфжУHDFSЃЈhdfs-site.xmlЃЉ
<configuration>
<!--жИЖЈblockЕФБИЗнЪ§СП(НЋblockИДжЦЕНМЏШКжаБИЗнЪ§-1ИіDataNodeНкЕужа)-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- ЙиБеHDFSЕФЗУЮЪШЈЯо -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration> |
4.ХфжУYARNЃЈyarn-site.xmlЃЉ
<configuration>
<!-- ХфжУReduceШЁЪ§ОнЕФЗНЪНЪЧshuffle(ЫцЛњ) -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> |
5.ХфжУMapReduceЃЈmapred-site.xmlЃЉ
<configuration>
<!-- ШУMapReduceШЮЮёЪЙгУYARNНјааЕїЖШ -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> |
6.ХфжУSSH
гЩгкдкЦєЖЏHDFSКЭYARNЪБЖМашвЊЖдгУЛЇЕФЩэЗнНјаабщжЄЃЌвђДЫПЩвдХфжУSSHЩшжУУтУмТыЕЧТМЁЃ
//ЩњГЩУидП
ssh-keygen -t rsa
//ИДжЦУидПЕНБОЛњ
ssh-copy-id 192.168.1.80 |
4.3 ЦєЖЏHDFS
1.ИёЪНЛЏNameNode
| bin/hdfs namenode
-format |

2.ЦєЖЏHDFS

ЦєЖЏHDFSКѓНЋЛсЦєЖЏNameNodeЁЂDataNodeЁЂSecondaryNameNodeШ§ИіНјГЬЁЃ

ЦєЖЏЪБШєГіЯжДэЮѓПЩвдНјШыlogsФПТМВщПДЯргІЕФШежОЮФМўЁЃ
3.ЗУЮЪHDFSЕФПЩЪгЛЏЙмРэНчУц
ЕБHDFSЦєЖЏЭъБЯКѓЃЌПЩвдЗУЮЪhttp://localhost:50070НјШыHDFSЕФПЩЪгЛЏЙмРэНчУцЃЌдкДЫвГУцжаПЩвдЖдећИіHDFSМЏШКНјааМрПивдМАЮФМўЕФЩЯДЋКЭЯТдиЁЃ
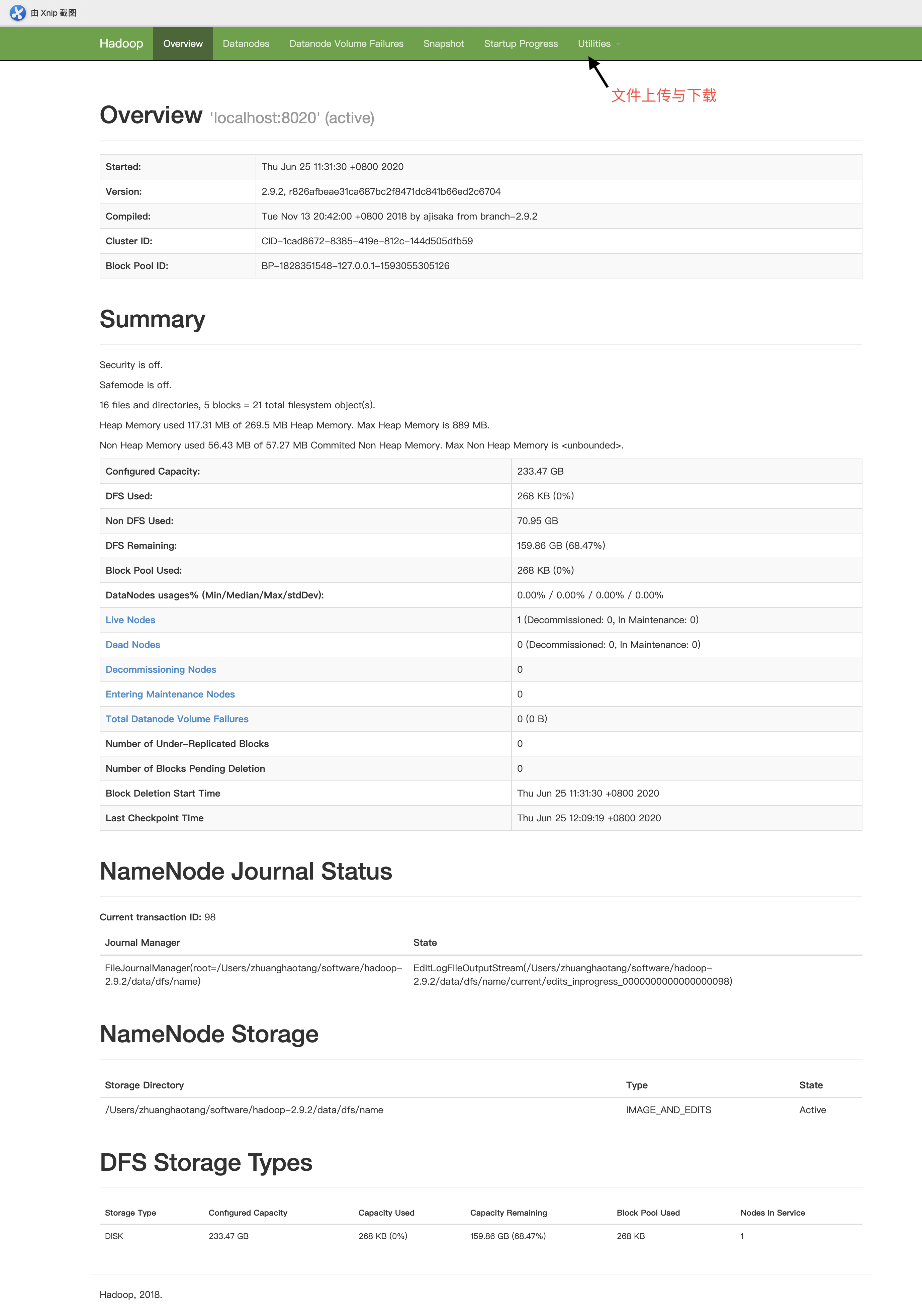
ЕБЯТдиЮФМўЪБЛсНјааЧыЧѓЕФжиЖЈЯђЃЌжиЖЈЯђЕФЕижЗЕФhostЮЊNameNodeЕФжїЛњУћЃЌвђДЫПЭЛЇЖЫБОЕиЕФhostЮФМўжаашвЊХфжУNameNodeжїЛњУћгыIPЕФгГЩфЙиЯЕЁЃ
4.4 ЦєЖЏYARN

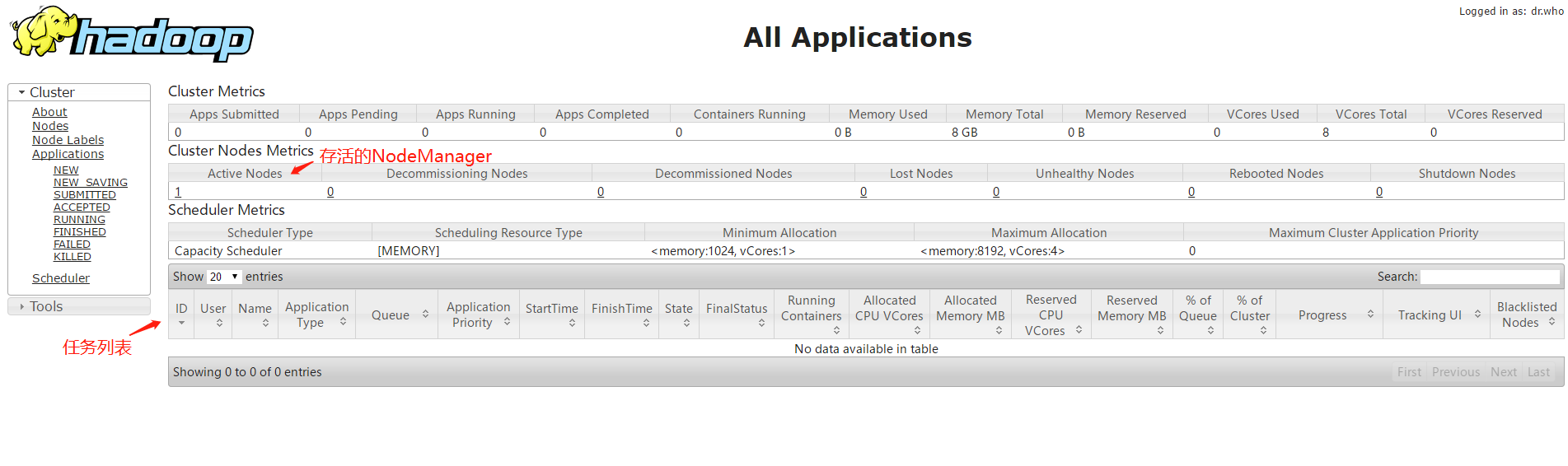
ЦєЖЏYARNКѓЃЌНЋЛсЦєЖЏResourceManagerвдМАNodeManagerНјГЬЁЃ

ПЩвдЗУЮЪhttp://localhost:8088НјШыYARNЕФПЩЪгЛЏЙмРэНчУцЃЌПЩвддкДЫвГУцжаВщПДШЮЮёЕФжДааЧщПівдМАзЪдДЕФЗжХфЁЃ
4.5 ЪЙгУShellВйзїHDFS
HDFSгыLinuxРрЫЦЃЌга/ИљФПТМЁЃ
#ЯдЪОЮФМўжаЕФФкШн
bin/hadoop fs -cat <src>
НЋБОЕижаЕФЮФМўЩЯДЋЕНHDFS
bin/hadoop fs -copyFromLocal <localsrc>
<dst>
#НЋБОЕижаЕФЮФМўЩЯДЋЕНHDFS
bin/hadoop fs -put <localsrc> <dst>
#НЋHDFSжаЕФЮФМўЯТдиЕНБОЕи
bin/hadoop fs -copyToLocal <src> <localdst>
#НЋHDFSжаЕФЮФМўЯТдиЕНБОЕи
bin/hadoop fs -get <src> <localdst>
#НЋБОЕижаЕФЮФМўМєЧаЕНHDFSжа
bin/hadoop fs -moveFromLocal <localsrc>
<dst>
#НЋHDFSжаЕФЮФМўМєЧаЕНБОЕижа
bin/hadoop fs -moveToLocal <src> <localdst>
#дкHDFSФкЖдЮФМўНјаавЦЖЏ
bin/hadoop fs -mv <src> <dst>
#дкHDFSФкЖдЮФМўНјааИДжЦ
bin/hadoop fs -cp <src> <dst>
#ЩОГ§HDFSжаЕФЮФМў
bin/hadoop fs -rm <src>
#ДДНЈФПТМ
bin/hadoop fs -mkdir <path>
#ВщбЏжИЖЈТЗОЖЯТЮФМўЕФИіЪ§
bin/hadoop fs -count <path>
#ЯдЪОжИЖЈФПТМЯТЕФФкШн
bin/hadoop fs -ls <path> |
4.6 ЪЙгУJAVAВйзїHDFS
/**
* @Auther: ZHUANGHAOTANG
* @Date: 2018/11/6 11:49
* @Description:
*/
public class HDFSUtils {
private static Logger logger = LoggerFactory.getLogger(HDFSUtils.class);
/**
* NameNode URL
*/
private static final String NAMENODE_URL = "192.168.1.80:8020";
/**
* HDFSЮФМўЯЕЭГСЌНгЖдЯѓ
*/
private static FileSystem fs = null;
static {
Configuration conf = new Configuration();
try {
fs = FileSystem.get(URI.create(NAMENODE_URL),
conf);
} catch (IOException e) {
logger.info("ГѕЪМЛЏHDFSСЌНгЪЇАмЃК{}", e);
}
}
/**
* ДДНЈФПТМ
*/
public static void mkdir(String dir) throws Exception
{
dir = NAMENODE_URL + dir;
if (!fs.exists(new Path(dir))) {
fs.mkdirs(new Path(dir));
}
}
/**
* ЩОГ§ФПТМЛђЮФМў
*/
public static void delete(String dir) throws Exception
{
dir = NAMENODE_URL + dir;
fs.delete(new Path(dir), true);
}
/**
* БщРњжИЖЈТЗОЖЯТЕФФПТМКЭЮФМў
*/
public static List<String> listAll(String
dir) throws Exception {
List<String> names = new ArrayList<>();
dir = NAMENODE_URL + dir;
FileStatus[] files = fs.listStatus(new Path(dir));
for (FileStatus file : files) {
if (file.isFile()) { //ЮФМў
names.add(file.getPath().toString());
} else if (file.isDirectory()) { //ФПТМ
names.add(file.getPath().toString());
} else if (file.isSymlink()) { //ШэЛђгВСДНг
names.add(file.getPath().toString());
}
}
return names;
}
/**
* ЩЯДЋЕБЧАЗўЮёЦїЕФЮФМўЕНHDFSжа
*/
public static void uploadLocalFileToHDFS(String
localFile, String hdfsFile) throws Exception {
hdfsFile = NAMENODE_URL + hdfsFile;
Path src = new Path(localFile);
Path dst = new Path(hdfsFile);
fs.copyFromLocalFile(src, dst);
}
/**
* ЭЈЙ§СїЩЯДЋЮФМў
*/
public static void uploadFile(String hdfsPath,
InputStream inputStream) throws Exception {
hdfsPath = NAMENODE_URL + hdfsPath;
FSDataOutputStream os = fs.create(new Path(hdfsPath));
BufferedInputStream bufferedInputStream = new
BufferedInputStream(inputStream);
byte[] data = new byte[1024];
int len;
while ((len = bufferedInputStream.read(data))
!= -1) {
if (len == data.length) {
os.write(data);
} else { //зюКѓвЛДЮЖСШЁ
byte[] lastData = new byte[len];
System.arraycopy(data, 0, lastData, 0, len);
os.write(lastData);
}
}
inputStream.close();
bufferedInputStream.close();
os.close();
}
/**
* ДгHDFSжаЯТдиЮФМў
*/
public static byte[] readFile(String hdfsFile)
throws Exception {
hdfsFile = NAMENODE_URL + hdfsFile;
Path path = new Path(hdfsFile);
if (fs.exists(path)) {
FSDataInputStream is = fs.open(path);
FileStatus stat = fs.getFileStatus(path);
byte[] data = new byte[(int) stat.getLen()];
is.readFully(0, data);
is.close();
return data;
} else {
throw new Exception("File Not Found In HDFS");
}
}
} |
4.7 жДаавЛИіMapReduceШЮЮё
HadoopЬсЙЉСЫhadoop-mapreduce-examples-2.9.0.jarЃЌЦфЗтзАСЫКмЖрШЮЮёМЦЫуЕФЗНЗЈЃЌгУЛЇПЩвджБНгНјааЕїгУЁЃ
#ЪЙгУhadoop jarУќСюРДжДааJARАќ
hadoop jar |
#ЪЙгУhadoop jarУќСюРДжДааJARАќ
hadoop jar
1.ДДНЈвЛИіЮФМўЭЌЪБНЋДЫЮФМўЩЯДЋЕНHDFSжа
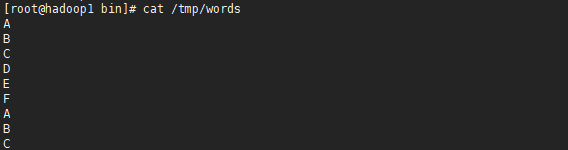
2.ЪЙгУHadoopЬсЙЉЕФhadoop-mapreduce-examples-2.9.0.jarжДааwordcountДЪЦЕЭГМЦЙІФм
| bin/hadoop jar
/usr/hadoop/hadoop-2.0.0/share/hadoop/mapreduce/hadoop -mapreduce-examples-2.9.0.jar
wordcount /words /result |

3.дкYARNЕФПЩЪгЛЏЙмРэНчУцжаПЩвдВщПДШЮЮёЕФжДааЧщПі
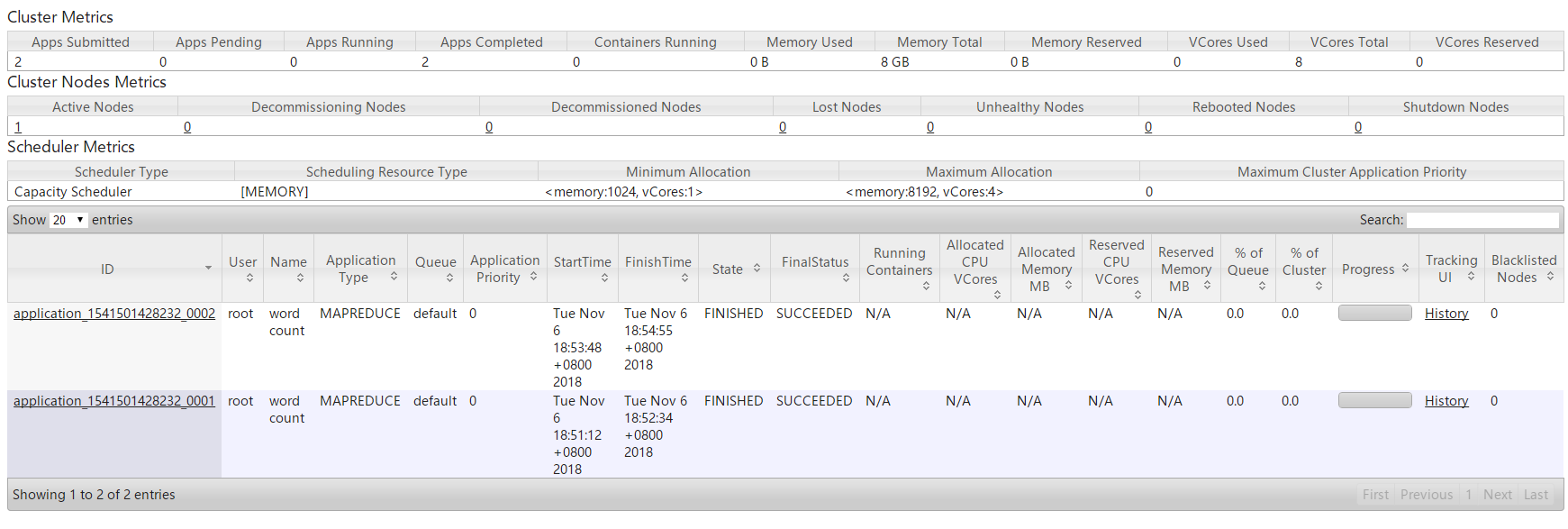
4.ЕБШЮЮёжДааЭъБЯКѓПЩвдВщПДШЮЮёЕФжДааНсЙћ

ШЮЮёЕФжДааНсЙћНЋЛсБЃДцЕНHDFSЕФЮФМўжаЁЃ |









