| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫДѓЪ§ОнМрПиЬхЯЕЁЂМмЙЙЩшМЦЁЂTelegrafЁЂInfluxDBМАGrafanaЕШЁЃЯЃЭћФмЙЛЖдДѓМвгаЫљЦєЗЂКЭАяжњЁЃ
БОЮФРДздгкМђЪщЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
злЪі
ШежОКЭМрПиПЊЗЂШЫдБЙЄзїжаБиВЛПЩЩйЕФСНжЛблОІЃЌШежОЪЧЮЊСЫПьЫйЖЈЮЛХХВщЙЪеЯЃЌМрПиЪЧЮЊСЫЗЂЯжЧБдкЮЪЬтВЂФмМАЪБИцОЏЃЌЪЧЙЪеЯеяЖЯКЭЗжЮіЕФживЊИЈжњРћЦїЃЌЭЌбљМрПиЯЕЭГЖдДѓЪ§ОнЦНЬЈживЊадВЛбдЖјгїЁЃдкЗЂЩњЪТЙЪжЎЧАОЭФмдЄОЏЃЌзюДѓЯоЖШНЕЕЭЯЕЭГЙЪеЯТЪЃЌЪЧМрПиЕФжеМЋФПБъКЭМлжЕЬхЯжЁЃБОЮФжМдкАяжњДѓМвСЫНтМрПиЯЕЭГЃЌВЂФмПьЫйДюНЈЙЋЫОЕФМрПиЦНЬЈЁЃ
МрПиЬхЯЕ
МрПиСЃЖШЁЂМрПижИБъЭъећадЁЂМрПиЪЕЪБадЪЧЦРМлМрПиЯЕЭГЕФШ§вЊЫиЁЃДгЗжВуЬхЯЕПЩвдАбМрПиЯЕЭГЗжЮЊШ§ИіВуДЮЃК
вЕЮёВуЃКвЕЮёЯЕЭГБОжЪФПЕФЪЧЮЊСЫДяГЩвЕЮёФПБъЃЌвђДЫМрПивЕЮёЯЕЭГЪЧЗёе§ГЃзюгааЇЕФЗНЪНЪЧДгЪ§ОнЩЯМрПивЕЮёФПБъЪЧЗёДяГЩЁЃЖдвЕЮёдЫгЊЪ§ОнНјааМрПиЃЌПЩМАЪБЗЂЯжГЬађbugЛђвЕЮёТпМЩшМЦШБЯнЃЌБШШчзЂВсЪЇАмТЪЁЂЕЧТМЪЇАмТЪЁЂИЖПюЪЇАмТЪЕШЁЃвЕЮёЯЕЭГЕФЖрбљадОіЖЈСЫгІгЩИїИівЕЮёЯЕЭГЪЕЯжМрПижИБъПЊЗЂЁЃ
гІгУВуЃКЖдгІгУЕФећЬхдЫаазДПіНјааСЫНтЁЂАбПиЃЌШчЙћНЋгІгУЕБГЩКкКазгЃЌПЊЗЂЁЂдЫЮЌОЭЮоДгжЊЯўгІгУЕБЧАзДЬЌЃЌВЛФмМАЪБЗЂЯжЧБдкЙЪеЯЁЃгІгУМрПиВЛгІОжЯогквЕЮёЯЕЭГЃЌЛЙАќРЈИїжжжаМфМўЁЂМЦЫув§ЧцЃЌШчSparkЁЂJstormЁЂredisЁЂzookeeperЁЂkafkaЕШЁЃГЃгУМрПиЪ§ОнЃКJVMЖбФкДцЁЂGCЁЂCPUЪЙгУТЪЁЂЯпГЬЪ§ЁЂTPSЁЂЭЬЭТСПЕШЁЃвЛАуЭЈЙ§ГщЯѓГіЕФЭГвЛжИБъЪеМЏзщМўЃЌЪеМЏгІгУМЖжИБъЃЌБШШчВЛЙмЪЧжЇИЖЯЕЭГЛЙЪЧНЛвзЯЕЭГЃЌЖМвЊМрПиjvmФкДцЪЙгУЁЃ
ЯЕЭГВуЃКЪЕЪБеЦЮеЗўЮёЦїЙЄзїзДЬЌЃЌСєвтадФмЁЂФкДцЯћКФЁЂШнСПКЭећЬхЯЕЭГНЁПЕзДЬЌЃЌБЃжЄЗўЮёЦїЮШЖЈдЫааЁЃМрПижИБъЃКФкДцЁЂДХХЬЁЂCPUЁЂЭјТчСїСПЁЂЯЕЭГНјГЬЕШЯЕЭГМЖадФмжИБъ
МмЙЙЩшМЦ
ЙЄгћЩЦЦфЪТБиЯШРћЦфЦїЃЌИљОнЖдЯжгаМрПиВњЦЗЕФЕїбаЃЌвдМАЮвУЧЖдМрПиЕФЗжВуНщЩмЁЂЫљашНтОіЕФЮЪЬтЃЌПЩвдЗЂЯжМрПиЯЕЭГДгЪеМЏЕНЗжЮіЕФСїГЬМмЙЙЃКВЩМЏЃДцДЂЃеЙЪОЃИцОЏЃК
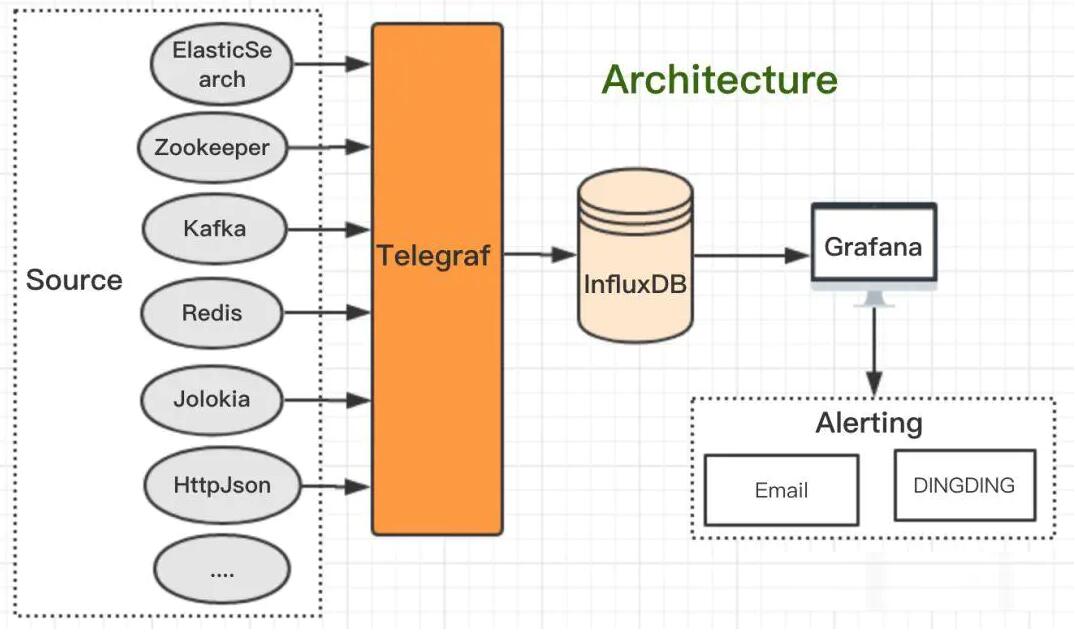
TelegrafЃКВхМўЛЏЕФжИБъЪеМЏКЭжИБъБЈИцЗўЮёЃЌФмЖЈжЦЛЏПЊЗЂВЂЧсЫЩЬэМгЫљашВхМўЁЃвбОФкжУСЫКмЖрГЃгУЗўЮёЕФВхМўЃЌетвВЪЧЮвУЧбЁдёtelegrafЕФдвђжЎвЛЃЌВЛгУдйжиИДдьТжзг
InfluxDBЃКИпадФмЕФВМЪНЪБМфађСажИБъЪ§ОнПтЁЃМрПижИБъЪеМЏЪЧЗЧГЃЦЕЗБЕФЃЌЗёдђОЭЪЇШЅСЫЪЕЪБадЃЌИпЦЕЪеМЏЕФНсЙћОЭЪЧДѓЪ§ОнСПЃЌвВвЊЖдЪБМфађСаНјааЗжЮіЃЌInfluxDBОЭФмТњзуетжжгІгУГЁОА
GrafanaЃКЪБМфађСаЗжЮіКЭМрПиЕФПЊЗХЦНЬЈЃЌжЇГжЖржжЪ§ОндД(InfluxDBЁЂOpenTSDBЪБМфађСаЪ§ОнПт)ЁЂЗсИЛЕФеЙЯжаЮЪНЁЂжЇГжemail/dingdingБЈОЏ
Telegraf
goгябдБраДЕФВхМўЛЏжИБъЪеМЏagentЃЌБрвыГЩвЛИіУЛгаЭтВПвРРЕЕФЖўНјжЦЮФМўЃЌАВзАВПЪ№КмБуНнЃЌжБНгЯТдиЁЂНтбЙОЭааЃЌФЌШЯХфжУЮФМўдк$TELEGRAF_HOME/etc/telegraf/telegraf.confФПТМЯТЁЃtelegrafВхМўЗжЮЊСНДѓРрЃКinputЁЂoutputЁЃ
inputЃКЪеМЏinputsХфжУЕФЫљгажИБъЃЌвбФкжУЕФinputВхМўЃКelasticsearchЁЂredisЁЂjolokiaЕШЁЃвВПЩжБНгЪеМЏдЫааagent
serverЕФИїжжжИБъЃЌБШШчФкДцЁЂcpuЁЂДХХЬЁЂДХХЬIOЁЂНјГЬЁЂswapЕШЁЃinputХфжУЖМКмМђУївзгУЃЌвЛАужЛашХфжУЗўЮёIPЕижЗОЭПЩвдЃЌШчredisжИБъЪеМЏХфжУЃК
ШчЙћУЛгаФкжУЪеМЏВхМўЃЌгаСНжжЪЕЯжЗНАИЃК 
ПЊЗЂinputВхМўЃЌЕЋеташвЊгаGOгябдЛљДЁ
Ншжњгкhttpjson inputВхМўЃЌИУВхМўЧыЧѓhttp urlЃЌЗЕЛиjsonИёЪНЁЃurlХфжУЮЊздЖЈвхжИБъЪеМЏЗўЮёЃЌдкжИБъЪеМЏЗўЮёФкЪЕЯжжИБъЪеМЏЙІФмЃЌШЛКѓжИБъЗтзАГЩjsonЗЕЛиЛђжИБъЪ§ОнжБНгдкЗўЮёФкШыПтЁЃЮвУЧМрПиKettle
CarteЁЂsparkЁЂjstormЕШгУЕФетжжЪЕЯжЫМТЗЁЃ
outputЃКНЋЪеМЏЕНЕФЖШСПЪ§ОнађСаЛЏДцДЂЃЌTelegrafжИБъгЩЫФИіВПЗжзщГЩЃКЖШСПЁЂБъЧЉЁЂзжЖЮЁЂЪБМфДСЁЃжЇГжвдЯТДцДЂНсЙЙЃКInfluxDBЁЂGraphiteЁЂJSONЃЌБШШчЖШСПЪфГіЕНInfluxDBЕФХфжУЃК 
urlsЃКInfluxDBЖЫПк
databaseЃКДцДЂЕФЪ§ОнПт
retention_policyЃКЪ§ОнБЃСєВпТд
ЕїЖШЦЕТЪЃКЫљгажИБъЪеМЏЦЕТЪЪЧвЛбљЕФЃЌдкХфжУЮФМўagentЯюЯТХфжУЃК

ЗўЮёЦєЖЏЃК

--configЃКХфжУЮФМў?
--config-directoryЃКХфжУЮФМўФПТМЃЌШчЙћгаЖрИіХфжУЮФМўЪБЪЙгУ
InfluxDB
InfluxDBЪЧЮЊЪБМфађСаЙЙНЈЕФИпадФмЪ§ОнДцДЂЃЌЬсЙЉРрSQLЕФВщбЏгябдЁЂЬиЖЈЗжЮіЪБМфађСаЕФЙІФмЁЃЭЈЙ§ЩшжУЪ§ОнБЃСєВпТдЃЌздЖЏДгЯЕЭГжаЩОГ§Й§ЦкЪ§ОнЃЌЪЭЗХДцДЂПеМфЁЃЩчЧјАцжЛжЇГжЕЅЬЈЗўЮёЦїЃЌЛсгаЕЅЕуЙЪеЯЗчЯеЃЌЩЬвЕАцАцжЇГжИпПЩгУЃЌЖдЮвУЧРДЫЕЃЌЕЅЛњInfluxDBвбОФмТњзуашЧѓЁЃбЁдёInfluxDBЕФдвђЃК
InflluxDBЪЧгУGOаДЕФЃЌБрвыКѓЪЧвЛИіЭъШЋЮовРРЕЕФЖўНјжЦЮФМўЃЌАВзАВПЪ№ЗЧГЃБуНнЃЌНтбЙЫѕАќМДПЩ
ИпадФмЪБМфађСазЈгаЪ§ОнПтЃЌЖдЪБМфађСаЕФДцДЂКЭВщбЏЖМзіСЫгХЛЏ
РрSQLВщбЏгябдЃЌНЕЕЭЪЙгУУХМї
Ъ§ОнБЃСєВпТдПЩвдгааЇЕФздЖЏЧхРэЙ§ЦкЪ§Он
InfluxDBЕФЪ§ОнЪЧвдshard groupsаЮЪНДцДЂЃЌжИЖЈЪБМфМфИєЕФЪ§ОнДцДЂЕНвЛИіshard
groupsРяЃЌетИіЪБМфМфИєГЦЮЊshardGroupDurationЁЃ
ЗўЮёЦєЖЏЃК 
influxНјШыshellУќСюаа: 
ГЃгУУќСюЃК
show databasesЃКВщПДЫљгаЪ§ОнПт
use db_nameЃКНјШыЪ§ОнПт
show?measurementsЃКЯдЪОЪ§ОнПтЯТЫљгаЖШСП
select *?from cpu limit 10ЃКВщбЏвЛИіЖШСПЕФЪ§Он
TelegrafФЌШЯЪЧНЋЪеМЏЕФЪ§ОнГжОУЛЏЕНtelegrafетИіЪ§ОнПтЯТЃЌУПИіinputЖдгІвЛИіЖШСПБэЃЌБШШчzookeeperЕФжИБъЪ§ОнОЭдкzookeeperетИіЖШСПЯТЃК

ВщбЏЪ§ОнБЃСєВпТдЃК 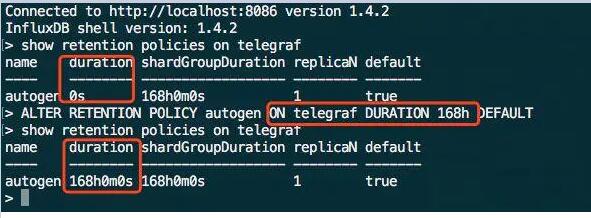
durationЃКЪ§ОнБЃСєЪБМфЃЌ0БэЪОЮоЯожЦЃЌInfluxDBФЌШЯ30ЗжжгМьВщвЛДЮБЃСєВпТдЁЃALTER
RETENTIONгяОфаоИФБЃСє7ЬьЪ§ОнЁЃ
replicaNЃКУПИіЖШСПдкМЏШКРяЕФИББОЪ§ЃЌИББОБЃжЄЪ§ОнИпПЩгУадЃЌЩчЧјАц(ЕЅНкЕу)ВЛжЇГжИББОЪ§ЩшжУ
Java ClientЃК
Java ClientЖдhttp apiНјааСЫЗтзАЃЌЕзВугУRetrofitПђМмНјааhttpЧыЧѓЃЌЪЧЯпГЬАВШЋЕФЃЌжЛашдквЛИігІгУжаДДНЈвЛИіInfluxDB
ClientЖдЯѓЁЃ
clientЕФаДВйзїжЇГжbatchЃЌЦфЪЕЯждРэЃК
1ЁЂДДНЈКѓЬЈЕЅЯпГЬЖЈЪБЕїЖШШЮЮёЃЌЯпГЬУПИєвЛЖЈЪБМфЗЂЫЭЧыЧѓЃК 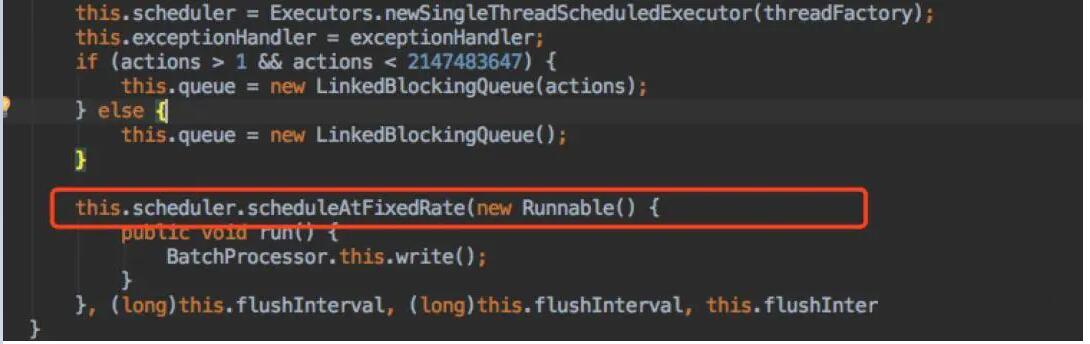
2ЁЂУПДЮwriterЪБЃЌАбЧыЧѓЗХЕНBlockingQueueЖгСаРяЃЌШчЙћЖгСаДѓгкbatchЪ§ЃЌОЭЦєЖЏЯпГЬЗЂЫЭЧыЧѓЃК

Client ApiЪЙгУР§зг:
1ЁЂДДНЈЪ§ОнПтСЌНгЃК
InfluxDB influxDB= InfluxDBFactory.connect(url, user,
password);
urlЃКInfluxDBЕФЕижЗКЭЖЫПкЃЌБШШч http://localhost:8086
user/passwordЃКInfluxDBЕФгУЛЇУћ/УмТы
2ЁЂЩшжУЗУЮЪЕФЪ§ОнПтЃК
influxDB.setDatabase(database);
3ЁЂЪ§ОнаДШыЃК
Point.Builder builder = Point.measurement(measurement);
builder.tag(tags);
builder.fields(fields);
influxDB.write(builder.build());
Grafana
GrafanaЪЧвЛИіжИБъВщбЏЁЂПЩЪгЛЏЁЂМрПиЕФПЊдДгІгУЃЌгазХЗЧГЃЦЏССЕФЭМБэКЭВМОжеЙЪОЃЌЙІФмЦыШЋЕФЖШСПвЧБэХЬКЭЭМаЮБрМЦїЃЌжЇГжGraphiteЁЂzabbixЁЂInfluxDBЁЂPrometheusКЭOpenTSDBзїЮЊЪ§ОндДЁЃ
GrafanaжївЊЬиадЃК
СщЛюЗсИЛЕФЭМаЮЛЏзщМўЃЌАќРЈШШСІЭМЁЂжБЗНЭМЁЂЕиЭМЕШ
дкЭЌвЛdashboardФкПЩвдЛьКЯЖржжеЙЪОзщМў
ПЊдДЩчЧјгаДѓСПЕФВхМўПЩЙЉбЁдёЃЌАќРЈЪ§ОндДВхМўЁЂЭМаЮВхМўЁЂЭЈжЊВхМў
ПЩвддкЭЌвЛИіЪгЭМРяЪЙгУЖрИіВЛЭЌЪ§ОндД
МђЕЅЪЙгУНщЩмЃК
АВзАЃК
ЯТди&НтбЙЖўНјжЦАќ
ХфжУЃК
ХфжУЮФМўЃК$GRAFANA_HOME$/conf
ХфжУЖЫПкКХЁЂEmailЁЂЕЧТМгУЛЇ
start:
УќСюЃК/opt/grafana/bin/grafana-server start
ЗУЮЪ:
http://ip:port
|









