| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫгІгУГЁОАЁЂKafka
ЭиЦЫЭМЃЈЖрИББОЛњжЦЃЉЁЂKafka КЫаФзщМўЁЂЗўЮёжЮРэЁЂKafka ЮЊЪВУДетУДПьЕШЯрЙиФкШнЁЃ
БОЮФРДзддЦМгЩчЧј ЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂгІгУГЁОА
вьВННтЙЙЃКдкЩЯЯТгЮУЛгаЧПвРРЕЕФвЕЮёЙиЯЕЛђеыЖдЕЅДЮЧыЧѓВЛашвЊСЂПЬДІРэЕФвЕЮё
ЯЕЭГЛКГхЃКгаРћгкНтОіЗўЮёЯЕЭГЕФЭЬЭТСПВЛвЛжТЕФЧщПіЃЌгШЦфЖдДІРэЫйЖШНЯТ§ЕФЗўЮёРДЫЕЦ№ЕНЛКГхзїгУ
ЯћЗхзїгУЃКЖдгкЖЬЪБМфХМЯжЕФМЋЖЫСїСПЃЌЖдКѓЖЫЕФЗўЮёПЩвдЦєЖЏБЃЛЄзїгУ
Ъ§ОнСїДІРэЃКМЏГЩ spark зіЪЕЪБЪ§ОнСїДІРэ
ЖўЁЂKafka ЭиЦЫЭМЃЈЖрИББОЛњжЦЃЉ
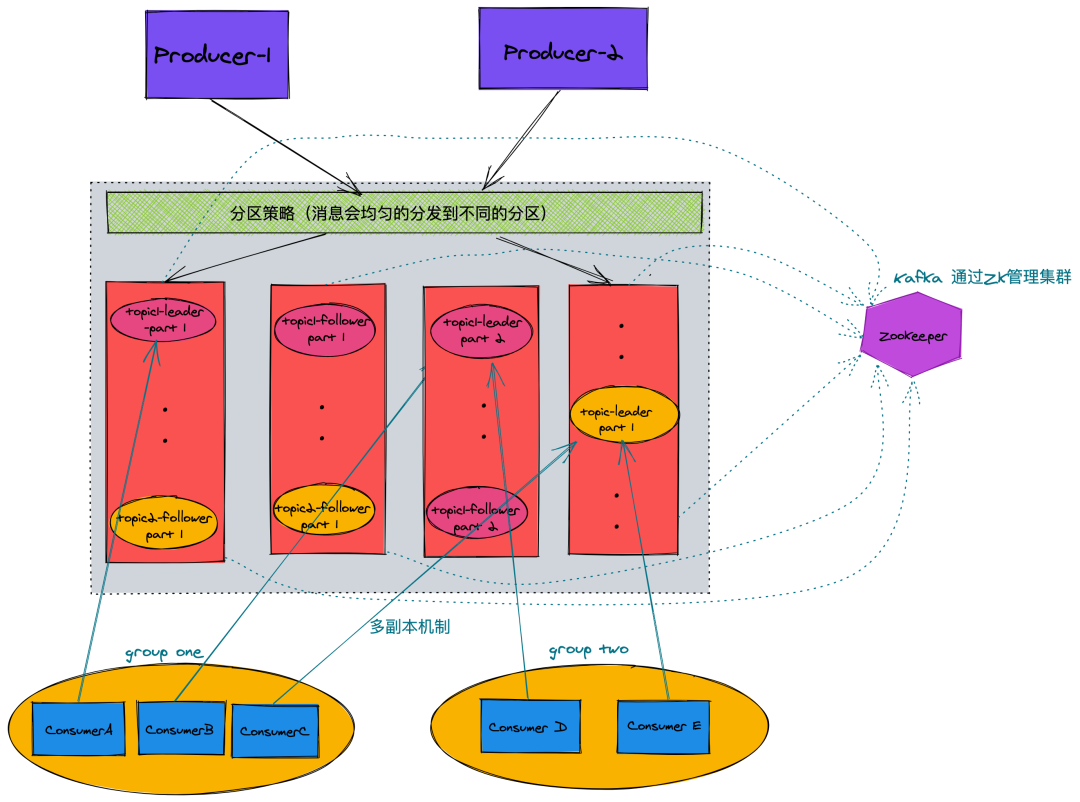
гЩЩЯЭМЮвУЧПЩвдЗЂЯж Kafka ЪЧЗжВМЪНЃЌЖдгкУПвЛИіЗжЧјЖМДцдкЖрИББОЃЌЭЌЪБећИіМЏШКЕФЙмРэЖМЭЈЙ§ zookeeper
ЙмРэЁЃ
Ш§ЁЂKafka КЫаФзщМў
1. broker
Kafka ЗўЮёЦїЃЌИКд№ЯћЯЂДцДЂКЭзЊЗЂЃЛвЛИі broker ОЭДњБэвЛИі kafka НкЕуЁЃвЛИі broker
ПЩвдАќКЌЖрИі topicЁЃ
2. topic
ЯћЯЂРрБ№ЃЌKafka АДее topic РДЗжРрЯћЯЂЁЃ
3. partition
topic ЕФЗжЧјЃЌвЛИі topic ПЩвдАќКЌЖрИі partitionЃЌtopic ЯћЯЂБЃДцдкИїИі
partition ЩЯЃЛгЩгквЛИі topic ФмБЛЗжЕНЖрИіЗжЧјЩЯЃЌИј kafka ЬсЙЉИјСЫВЂааЕФДІРэФмСІЃЌетвВе§ЪЧ
kafka ИпЭЬЭТЕФдвђжЎвЛЁЃ
partition ЮяРэЩЯгЩЖрИі segment ЮФМўзщГЩЃЌУПИі segment ДѓаЁЯрЕШЃЌЫГађЖСаДЃЈетвВЪЧ
kafka БШНЯПьЕФдвђжЎвЛЃЌВЛашвЊЫцЛњаДЃЉЁЃУПИі Segment Ъ§ОнЮФМўвдИУЖЮжазюаЁЕФ offset
ЃЌЮФМўРЉеЙУћЮЊ.logЁЃЕБВщев offset ЕФ Message ЕФЪБКђЃЌЭЈЙ§ЖўЗжВщевПьевЕН Message
ЫљДІгкЕФ Segment жаЁЃ
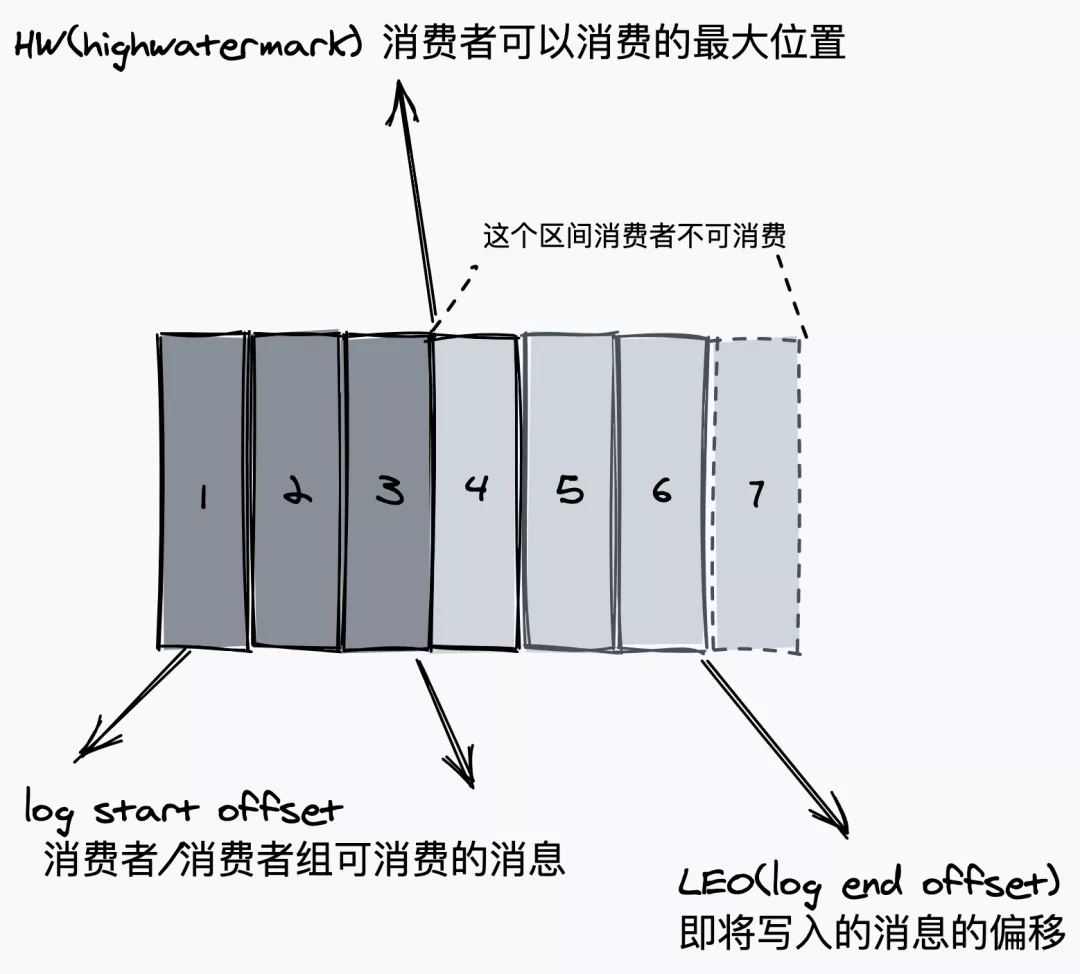
4. offset
ЯћЯЂдкШежОжаЕФЮЛжУЃЌПЩвдРэНтЪЧЯћЯЂдк partition ЩЯЕФЦЋвЦСПЃЌвВЪЧДњБэИУЯћЯЂЕФЮЈвЛађКХЁЃ
ЭЌЪБвВЪЧжїДгжЎМфЕФашвЊЭЌВНЕФаХЯЂЁЃ
.jpg)
5. Producer
ЩњВњепЃЌИКд№Яђ Kafka Broker ЗЂЯћЯЂЕФПЭЛЇЖЫЁЃ
6. Consumer
ЯћЯЂЯћепЃЌИКд№ЯћЗб Kafka Broker жаЕФЯћЯЂЁЃ
7. Consumer Group
ЯћЗбепзщЃЌУПИі Consumer БиаыЪєгквЛИі groupЃЛЃЈзЂвтЃКвЛИіЗжЧјжЛФмгЩзщФквЛИіЯћЗбепЯћЗбЃЌЯћЗбепзщжЎМфЛЅВЛгАЯьЁЃЃЉ
8. Zookeeper
ЙмРэ kafka МЏШКЃЌИКд№ДцДЂСЫМЏШК brokerЁЂtopicЁЂpartition ЕШ meta
Ъ§ОнДцДЂЃЌЭЌЪБвВИКд№ broker ЙЪеЯЗЂЯжЃЌpartition leader бЁОйЃЌИКдиОљКтЕШЙІФмЁЃ
ЫФЁЂЗўЮёжЮРэ
МШШЛ Kafka ЪЧЗжВМЪНЕФЗЂВМ/ЖЉдФЯЕЭГЃЌетбљШчЙћзіЕФМЏШКжЎМфЪ§ОнЭЌВНКЭвЛжТадЃЌkafka ЪЧВЛЪЧПЯЖЈВЛЛсЖЊЯћЯЂФиЃПвдМАхДЛњЕФЪБКђШчЙћНјаа
Leader бЁОйФиЃП
1. Ъ§ОнЭЌВН
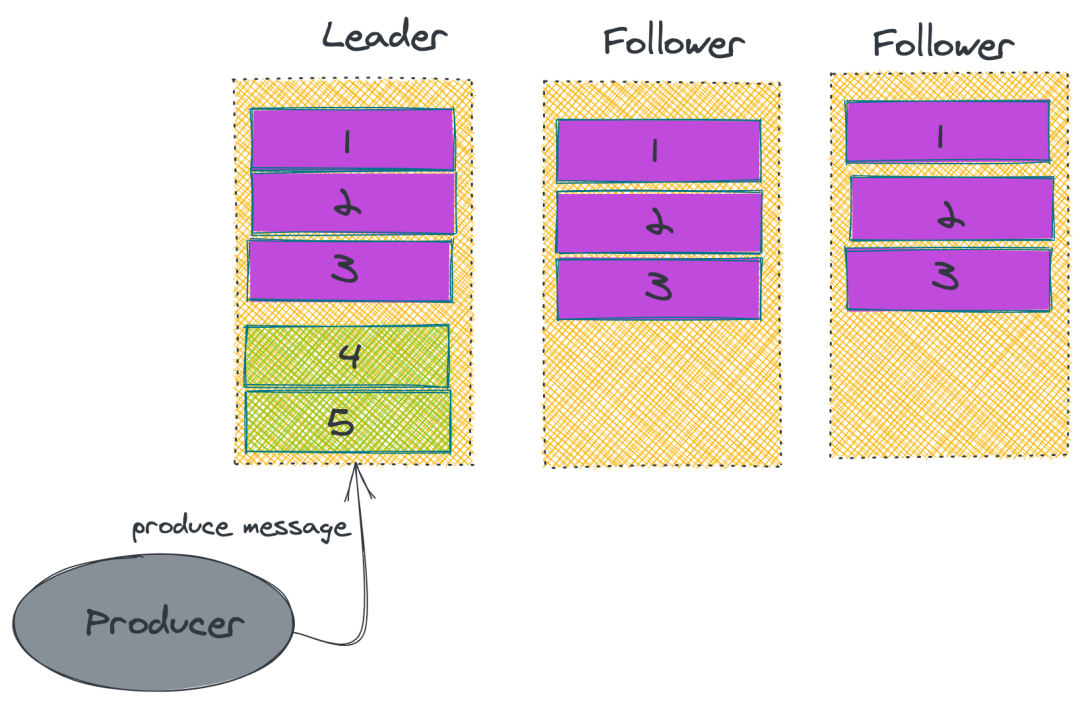
дк Kafka жаЕФ Partition гавЛИі leader гыЖрИі followerЃЌproducer
ЭљФГИі Partition жааДШыЪ§ОнЃЌЪЧжЛЛсЭљ leader жааДШыЪ§ОнЃЌШЛКѓЪ§ОнВХЛсБЛИДжЦНјЦфЫћЕФ
Replica жаЁЃЖјУПвЛИі follower ПЩвдРэНтГЩвЛИіЯћЗбепЃЌЖЈЦкШЅ leader ШЅРЯћЯЂЁЃЖјжЛгаЪ§ОнЭЌВНСЫКѓЃЌkafka
ВХЛсИјЩњВњепЗЕЛивЛИі ACK ИцжЊЯћЯЂвбОДцДЂТфЕиСЫЁЃ
2. ISR
дк Kafka жаЃЌЮЊСЫБЃжЄадФмЃЌKafka ВЛЛсВЩгУЧПвЛжТадЕФЗНЪНРДЭЌВНжїДгЕФЪ§ОнЁЃЖјЪЧЮЌЛЄСЫвЛИіЃКin-sync
Replica ЕФСаБэЃЌLeader ВЛашвЊЕШД§Ыљга Follower ЖМЭъГЩЭЌВНЃЌжЛвЊдк ISR
жаЕФ Follower ЭъГЩЪ§ОнЭЌВНОЭПЩвдЗЂЫЭ ACK ИјЩњВњепМДПЩШЯЮЊЯћЯЂЭЌВНЭъГЩЁЃЭЌЪБШчЙћЗЂЯж
ISR РяУцФГвЛИі follower ТфКѓЬЋЖрЕФЛАЃЌОЭЛсАбЫќЬоГ§ЁЃ
ОпЬхСїГЬШчЯТЃК
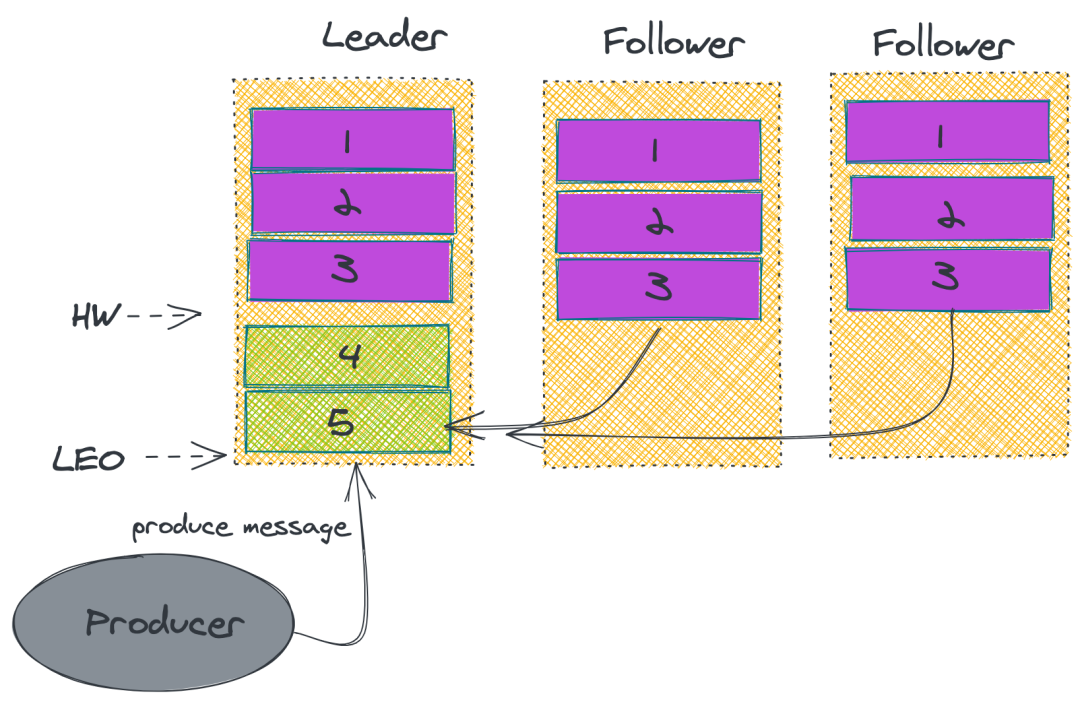
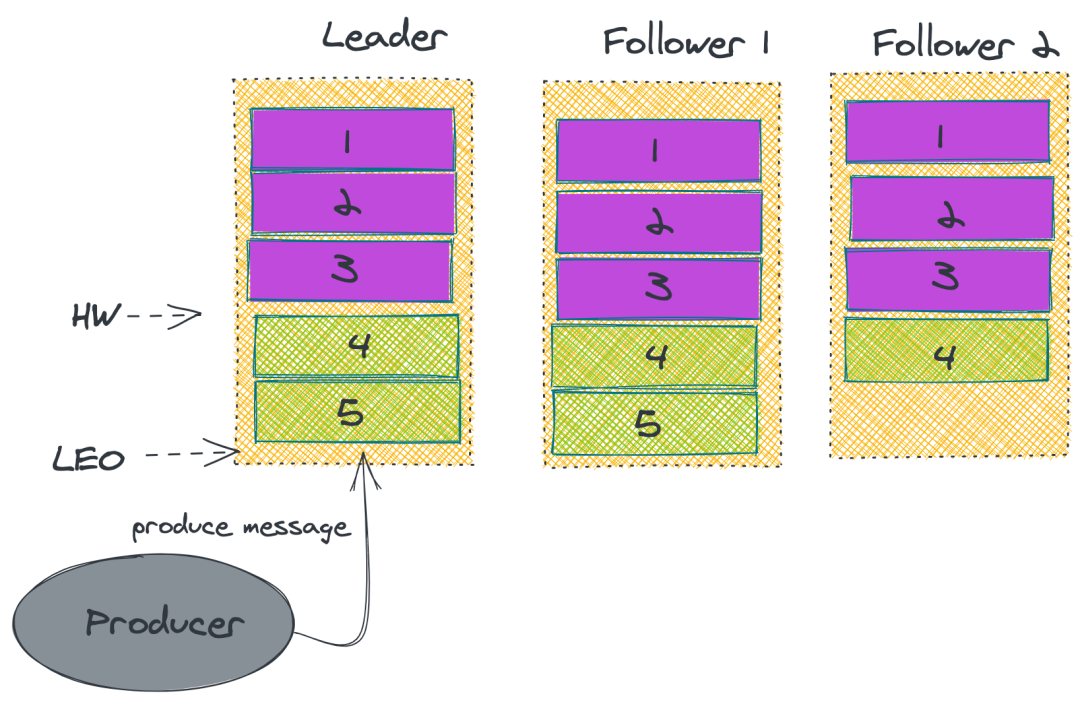
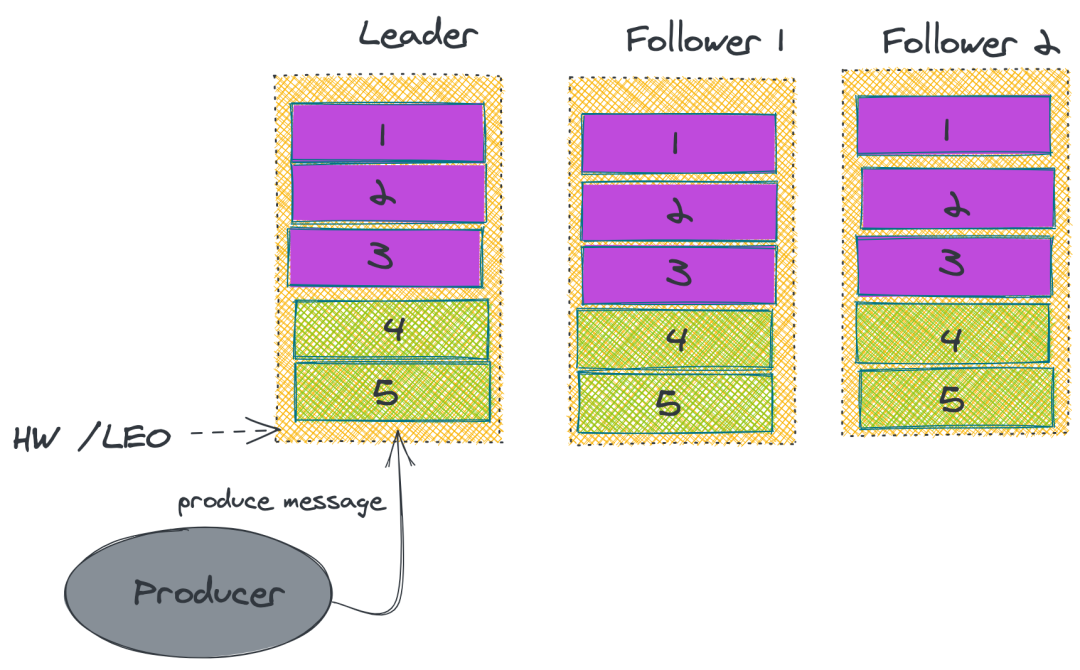
ЩЯЪіЕФзіЗЈВЂЮоЗЈБЃжЄ Kafka вЛЖЈВЛЖЊЯћЯЂЁЃЫфШЛ Kafka ЭЈЙ§ЖрИББОЛњжЦжазюДѓЯоЖШБЃжЄЯћЯЂВЛЛсЖЊЪЇЃЌЕЋЪЧШчЙћЪ§ОнвбОаДШыЯЕЭГ
page cache жаЕЋЪЧЛЙУЛРДЕУМАЫЂШыДХХЬЃЌДЫЪБЭЛШЛЛњЦїхДЛњЛђепЕєЕчЃЌФЧЯћЯЂздШЛЖјШЛЕиОЭЛсЖЊЪЇЁЃ
3. Kafka ЙЪеЯЛжИД
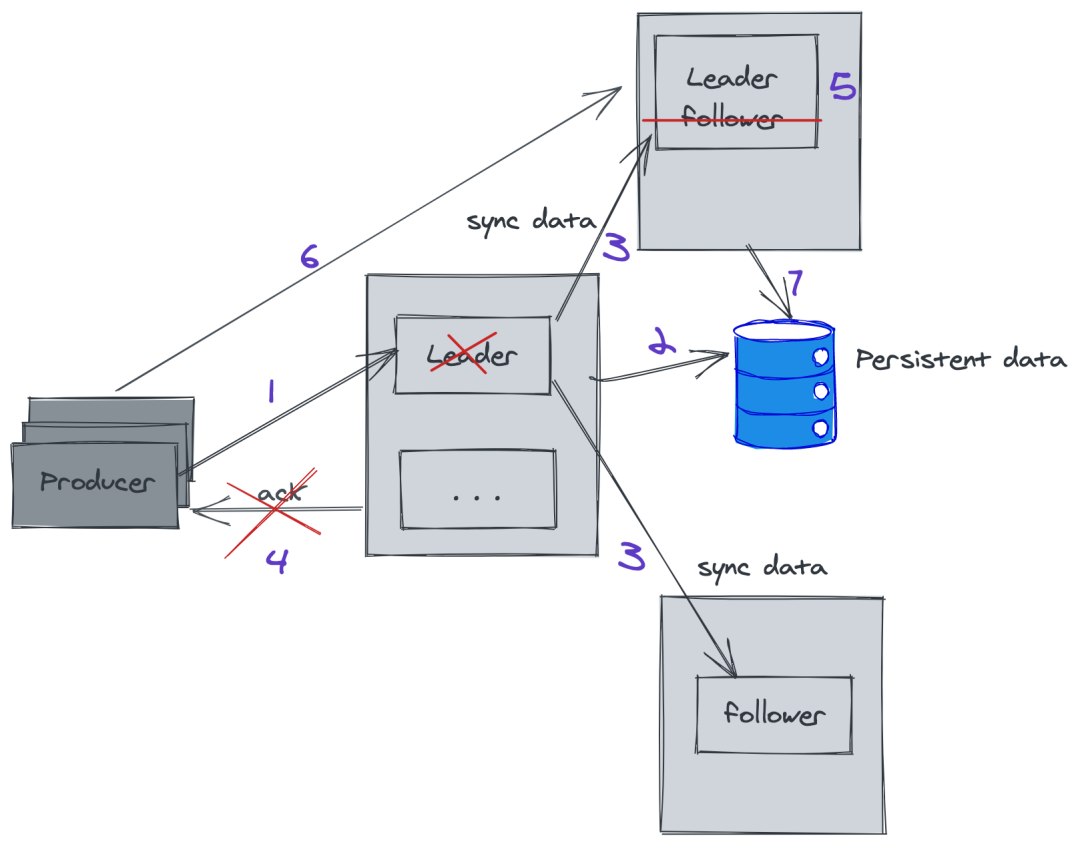
Kafka ЭЈЙ§ Zookeeper СЌзјМЏШКЕФЙмРэЃЌЫљвдетРяЕФбЁОйЛњжЦВЩгУЕФЪЧZabЃЈzookeeper
ЪЙгУЃЉЁЃ
ЩњВњепЗЂЩњЯћЯЂИј leader ЃЌетИіЪБКђ leader ЭъГЩЪ§ОнДцДЂЃЌЭЛШЛЗЂЩњЙЪеЯЃЌУЛгаИј producer
ЗЕЛи ackЃЛ
ЭЈЙ§ ZK бЁОйЃЌЦфжавЛИі follower ГЩЮЊ leader ЃЌетИіЪБКђ producer жиаТЧыЧѓаТЕФ
leaderЃЌВЂДцДЂЪ§ОнЁЃ
ЮхЁЂKafka ЮЊЪВУДетУДПь
1. ЫГађаДДХХЬ
Kafka ВЩгУСЫЫГађаДДХХЬЃЌЖјгЩгкЫГађаДДХХЬЯрЖдЫцЛњаДЃЌМѕЩйСЫбАЕижЗЕФКФЗбЪБМфЁЃЃЈдк Kafka
ЕФУПвЛИіЗжЧјРяУцЯћЯЂЪЧгаађЕФЃЉ
2. Page Cache
Kafka дк OS ЯЕЭГЗНУцЪЙгУСЫ Page Cache ЖјВЛЪЧЮвУЧЦНГЃЫљгУЕФ BufferЁЃPage
Cache ЦфЪЕВЛФАЩњЃЌвВВЛЪЧЪВУДаТЯЪЪТЮяЁЃ

ЮвУЧдк linux ЩЯВщПДФкДцЕФЪБКђЃЌОГЃПЩвдПДЕН buff/cacheЃЌСНепЖМЪЧгУРДМгЫй IO
ЖСаДгУЕФЃЌЖј cache ЪЧзїгУгкЖСЃЌвВОЭЪЧЫЕЃЌДХХЬЕФФкШнПЩвдЖСЕН cache РяУцЃЌетбљгІгУГЬађЖСДХХЬОЭЗЧГЃПьЃЛЖј
buff ЪЧзїгУгкаДЃЌЮвУЧПЊЗЂаДДХХЬЖМЪЧЃЌвЛАуШчЙћаДШывЛИі buff РяУцдй flush ОЭЗЧГЃПьЁЃЖј
kafka е§ЪЧАбетСНепЗЂЛгЕНСЫМЋжТЃКKafka ЫфШЛЪЧ scala аДЕФЃЌЕЋЪЧвРОЩдк Java ЕФащФтЛњЩЯдЫааЃЌОЁЙмШчДЫЃЌkafka
ЫќЛЙЪЧОЁСПБмПЊСЫ JVM ЕФЯожЦЃЌЫќРћгУСЫ Page cache РДДцДЂЃЌетбљЖуПЊСЫЪ§Ондк JVM
вђЮЊ GC ЖјЗЂЩњЕФ STWЁЃСэвЛЗНУцвВЪЧ Page Cache ЪЙЕУЫќЪЕЯжСЫСуПНБДЃЌОпЬхЯТУцЛсНВЁЃ
3. СуПНБД
ЮоТлЪЧгХауЕФ Netty ЛЙЪЧЦфЫћгХауЕФ Java ПђМмЃЌЛљБОЖМдкСуПНБДМѕЩйСЫ CPU ЕФЩЯЯТЮФЧаЛЛКЭДХХЬЕФ
IOЁЃЕБШЛ Kafka вВВЛР§ЭтЁЃСуПНБДЕФИХФюОпЬхетРяВЛзїЬЋЯъЯИЕФИДЪіЃЌДѓжТЕиИјДѓМвНВвЛЯТетИіИХФюЁЃ
ДЋЭГЕФвЛДЮгІгУГЬЧыЧѓЪ§ОнЕФЙ§ГЬЃК
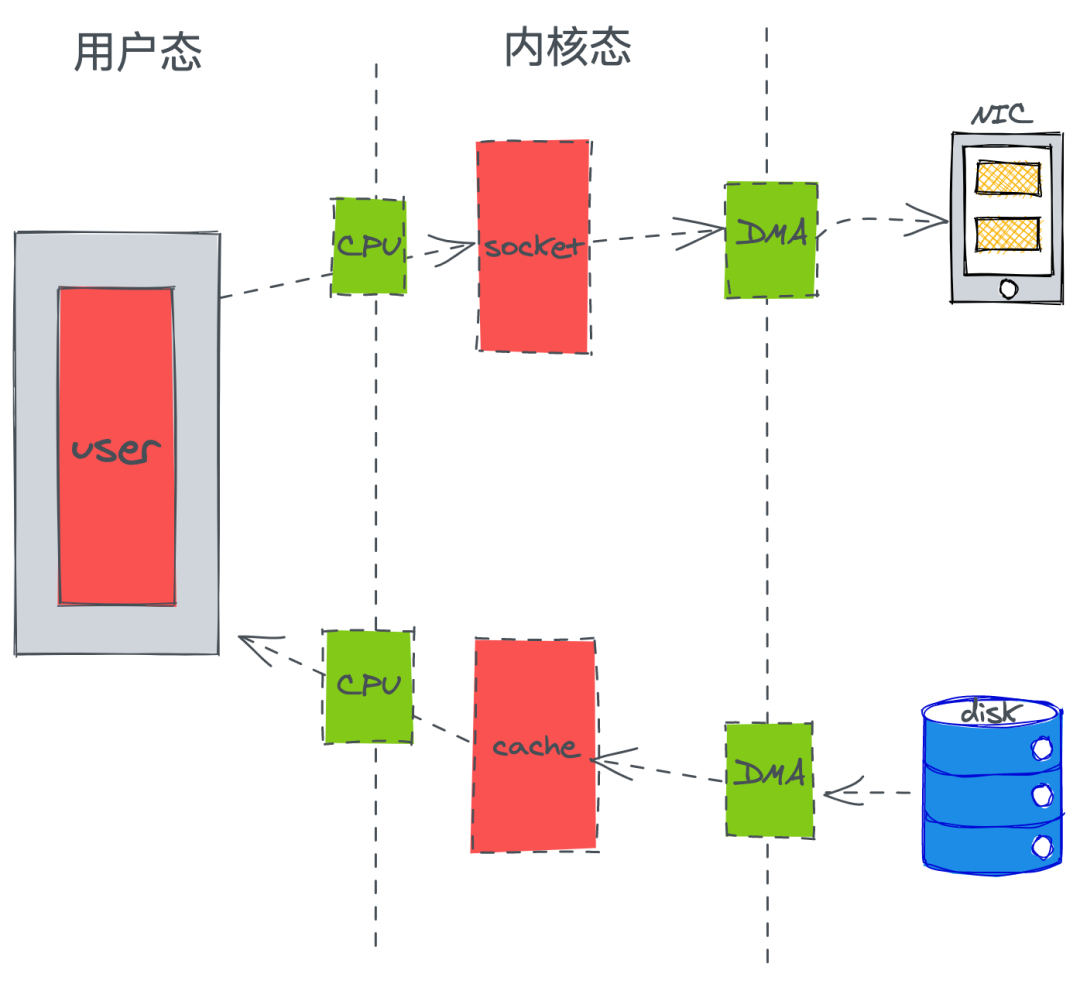
етРяДѓжТПЩвдЗЂДЋЭГЕФЗНЪНЗЂЩњСЫ4ДЮПНБДЃЌ2ДЮ DMA КЭ2ДЮ CPUЃЌЖј CPU ЗЂЩњСЫ4ДЮЕФЧаЛЛЁЃЃЈDMA
МђЕЅРэНтОЭЪЧЃЌдкНјаа I/O ЩшБИКЭФкДцЕФЪ§ОнДЋЪфЕФЪБКђЃЌЪ§ОнАсдЫЕФЙЄзїШЋВПНЛИј DMA ПижЦЦїЃЌЖј
CPU ВЛдйВЮгыШЮКЮгыЪ§ОнАсдЫЯрЙиЕФЪТЧщЃЉ
4. СуПНБДЕФЗНЪН
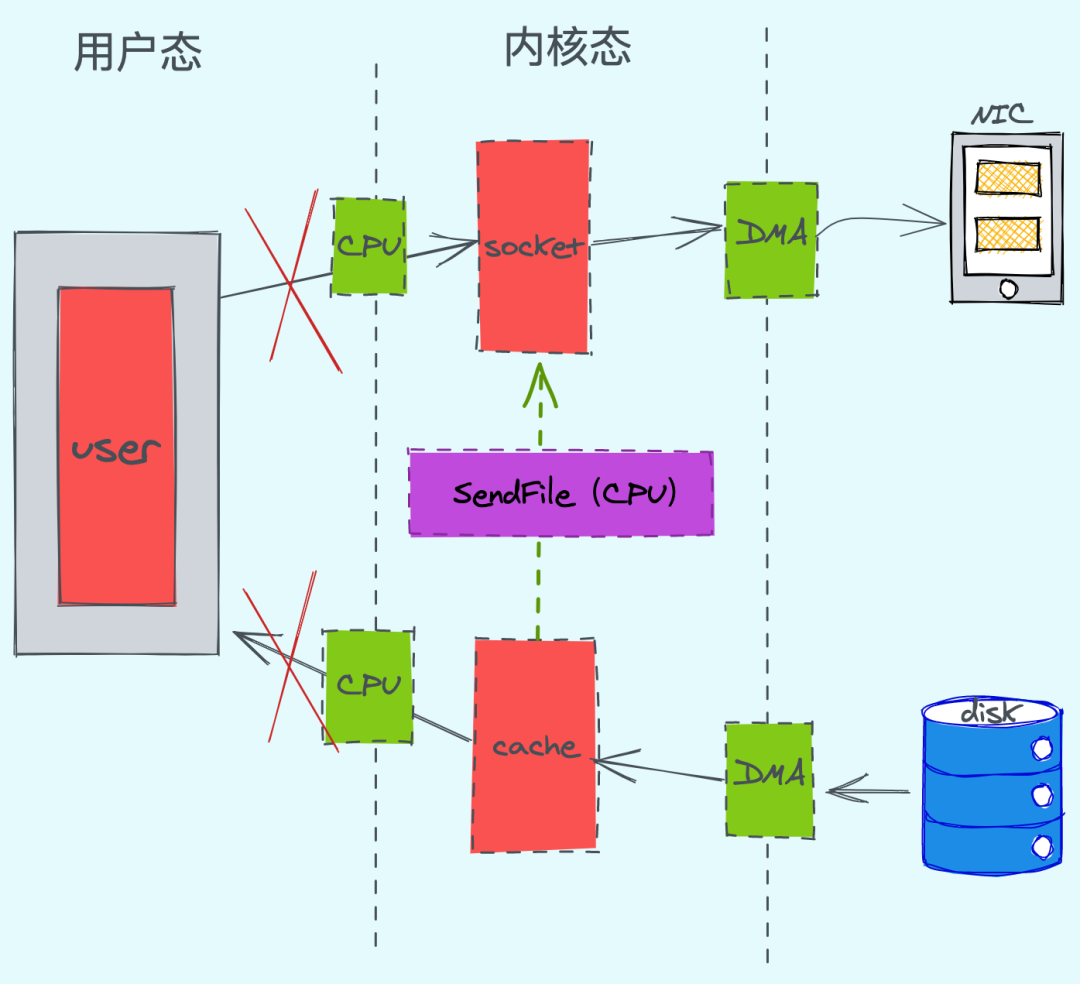
ЭЈЙ§гХЛЏЮвУЧПЩвдЗЂЯжЃЌCPU жЛЗЂЩњСЫ2ДЮЕФЩЯЯТЮФЧаЛЛКЭ3ДЮЪ§ОнПНБДЁЃЃЈlinux ЯЕЭГЬсЙЉСЫЯЕЭГЪТЙЪЕїгУКЏЪ§ЁАsendfile()ЁБЃЌетбљЯЕЭГЕїгУЃЌПЩвджБНгАбФкКЫЛКГхЧјРяЕФЪ§ОнПНБДЕН
socket ЛКГхЧјРяЃЌВЛдйПНБДЕНгУЛЇЬЌЃЉ
5. ЗжЧјЗжЖЮ
ЮвУЧЩЯУцвВНщЩмЙ§ЃЌkafka ВЩШЁСЫЗжЧјЕФФЃЪНЃЌЖјУПвЛИіЗжЧјгжЖдгІЕНвЛИіЮяРэЗжЖЮЃЌВщевЕФЪБКђПЩвдИљОнЖўЗжВщевПьЫйЖЈЮЛЁЃетбљВЛНіЬсЙЉСЫЪ§ОнЖСЕФВщбЏаЇТЪЃЌвВЬсЙЉСЫВЂааВйзїЕФЗНЪНЁЃ
6. Ъ§ОнбЙЫѕ
Kafka ЖдЪ§ОнЬсЙЉСЫЃКGzip КЭ Snappy бЙЫѕавщЕШбЙЫѕавщЃЌЖдЯћЯЂНсЙЙЬхНјааСЫбЙЫѕЃЌвЛЗНУцМѕЩйСЫДјПэЃЌвВМѕЩйСЫЪ§ОнДЋЪфЕФЯћКФЁЃ
СљЁЂKafka АВзА
1. АВзАJDK
гЩгкЪЙгУбЙЫѕАќЛЙашвЊздМКХфжУЛЗОГБфСПЃЌЫљвдетРяЭЦМіжБНггУ yum
АВзАЃЌЪьЯЄВщПДФПЧА Java ЕФАцБОЃК
АВзАФуЯывЊЕФАцБОЃЌетРяЮвЪЧ1.8
| yum install java-1.8.0-openjdk-devel.x86_64 |
ВщПДЪЧЗёАВзАГЩЙІ
2. АВзАZookeeper
ЪзЯШашвЊШЅЙйЭјЯТдиАВзААќЃЌШЛКѓНтбЙ
| tar -zxvf zookeeper-3.4.9.tar.gz |
вЊзіЕФОЭЪЧНЋетИіЮФМўИДжЦвЛЗнЃЌВЂУќУћЮЊЃКzoo.cfgЃЌШЛКѓдк zoo.cfg жааоИФздМКЕФХфжУМДПЩ
cp zoo_sample.cfg
zoo.cfg
vim zoo.cfg |
жївЊХфжУНтЪЭШчЯТЃК
# zookeeperФкВПЕФЛљБОЕЅЮЛЃЌЕЅЮЛЪЧКСУыЃЌетИіБэЪОвЛИіtickTimeЮЊ2000КСУыЃЌдкzookeeperЕФЦфЫћХфжУжаЃЌЖМЪЧЛљгкtickTimeРДзіЛЛЫуЕФ
tickTime=2000
# МЏШКжаЕФfollowerЗўЮёЦї(F)гыleaderЗўЮёЦї(L)жЎМф ГѕЪМСЌНг ЪБФмШнШЬЕФзюЖраФЬјЪ§ЃЈtickTimeЕФЪ§СПЃЉЁЃ
initLimit=10
#syncLimitЃКМЏШКжаЕФfollowerЗўЮёЦї(F)гыleaderЗўЮёЦї(L)жЎМф ЧыЧѓКЭгІД№
жЎМфФмШнШЬЕФзюЖраФЬјЪ§ЃЈtickTimeЕФЪ§СПЃЉ
syncLimit=5
# Ъ§ОнДцЗХЮФМўМаЃЌzookeeperдЫааЙ§ГЬжагаСНИіЪ§ОнашвЊДцДЂЃЌвЛИіЪЧПьееЪ§ОнЃЈГжОУЛЏЪ§ОнЃЉСэвЛИіЪЧЪТЮёШежО
dataDir=/tmp/zookeeper
## ПЭЛЇЖЫЗУЮЪЖЫПк
clientPort=2181 |
ХфжУЛЗОГБфСП
vim ~/.bash_profile
export ZK=/usr/local/src/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZK/bin
export PATH
// ЦєЖЏ
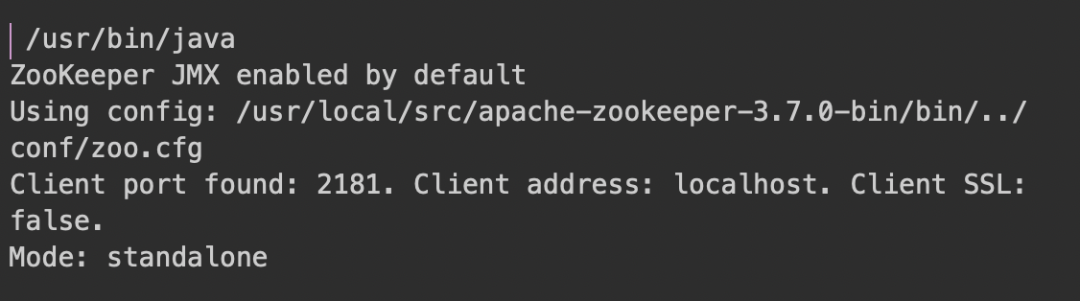
zkServer.sh start |
ЯТУцФмПДЦєЖЏГЩЙІ

3. АВзА Kafka
ЯТди
Kafka
АВзА Kafka
| tar -xzvf kafka_2.12-2.0.0.tgz
|
ХфжУЛЗОГБфСП
export ZK=/usr/local/src/apache
-zookeeper-3.7.0-bin
export PATH= $PATH:$ZK/bin
export KAFKA= /usr/local/src/kafka
export PATH= $PATH:$KAFKA/bin |
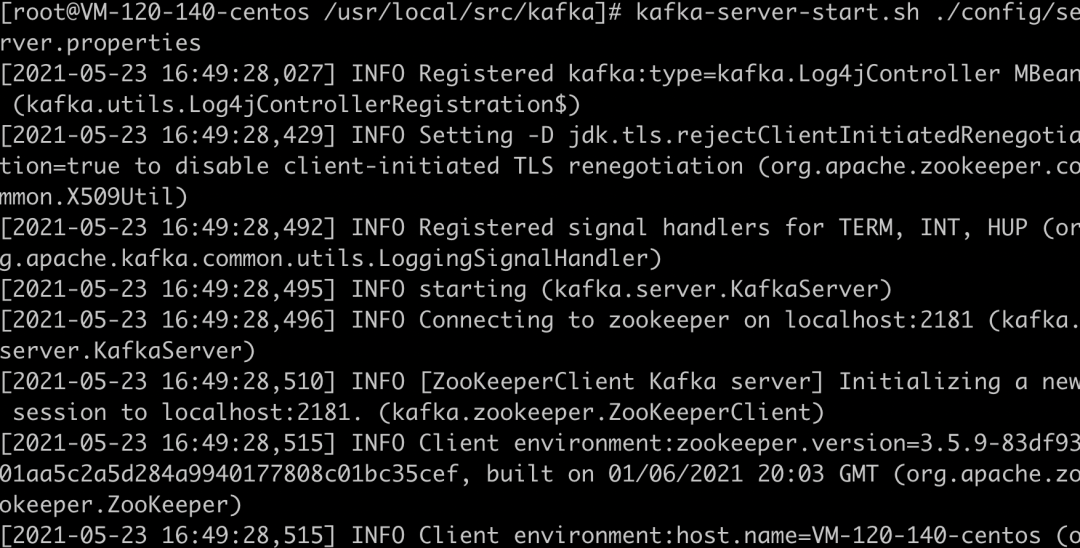
ЦєЖЏ Kafka
nohup kafka-server-start.sh здМКЕФХфжУЮФМўТЗОЖ/server.properties
& |
|









