| 编辑推荐: |
本文主要介绍了为什么有消息系统、Kafka核心概念、集群架构
、数据高性能、日志分段保存、二分查找定位数据、高并发网络设计、冗余副本保证高可用等相关内容。
本文来自数据仓库与Python大数据,由火龙果软件Anna编辑、推荐。 |
|
1、为什么有消息系统
解耦合
异步处理 例如电商平台,秒杀活动。
一般流程会分为:
1: 风险控制、2:库存锁定、3:生成订单、4:短信通知、5:更新数据通过消息系统将秒杀活动业务拆分开,将不急需处理的业务放在后面慢慢处理;流程改为:
1:风险控制、2:库存锁定、3:消息系统、4:生成订单、5:短信通知、6:更新数据
流量的控制
3.1 网关在接受到请求后,就把请求放入到消息队列里面 3.2 后端的服务从消息队列里面获取到请求,完成后续的秒杀处理流程。然后再给用户返回结果。
优点:控制了流量
缺点:会让流程变慢
2、Kafka核心概念
生产者:Producer 往Kafka集群生成数据
消费者:Consumer 往Kafka里面去获取数据,处理数据、消费数据Kafka的数据是由消费者自己去拉去
Kafka里面的数据
主题:topic
分区:partition
默认一个topic有一个分区(partition),自己可设置多个分区(分区分散存储在服务器不同节点上)
解决了一个海量数据如何存储的问题
例如:有2T的数据,一台服务器有1T,一个topic可以分多个区,分别存储在多台服务器上,解决海量数据存储问题
3、Kafka的集群架构
Kafka集群中,一个kafka服务器就是一个broker Topic只是逻辑上的概念,partition在磁盘上就体现为一个目录Consumer
Group:消费组
消费数据的时候,都必须指定一个group id,指定一个组的id假定程序A和程序B指定的group
id号一样,那么两个程序就属于同一个消费组
特殊:
比如,有一个主题topicA
程序A去消费了这个topicA,那么程序B就不能再去消费topicA(程序A和程序B属于一个消费组)
再比如程序A已经消费了topicA里面的数据,现在还是重新再次消费topicA的数据,是不可以的,但是重新指定一个group
id号以后,可以消费。
不同消费组之间没有影响。消费组需自定义,消费者名称程序自动生成(独一无二)。
Controller:Kafka节点里面的一个主节点。借助zookeeper
4、Kafka磁盘顺序写保证写数据性能
kafka写数据:
顺序写,往磁盘上写数据时,就是追加数据,
没有随机写的操作。
经验:
如果一个服务器磁盘达到一定的个数,磁盘也达到一定转数,往磁盘里面顺序写(追加写)数据的速度和写内存的速度差不多.
生产者生产消息,经过kafka服务先写到os cache 内存中,然后经过sync顺序写到磁盘上
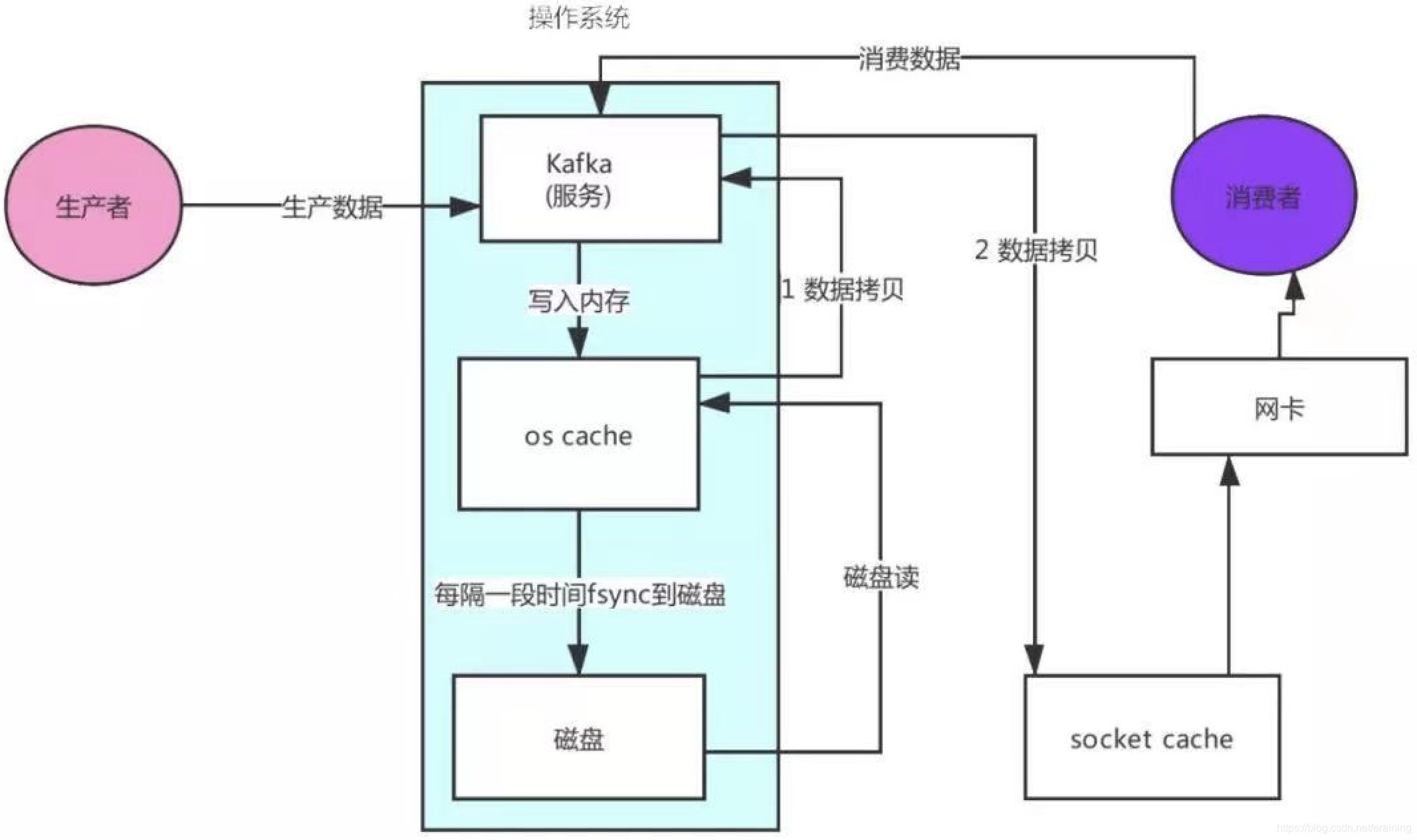
5、Kafka零拷贝机制保证读数据高性能
消费者读取数据流程:
消费者发送请求给kafka服务
kafka服务去os cache缓存读取数据(缓存没有就去磁盘读取数据)
从磁盘读取了数据到os cache缓存中
os cache复制数据到kafka应用程序中
kafka将数据(复制)发送到socket cache中
socket cache通过网卡传输给消费者
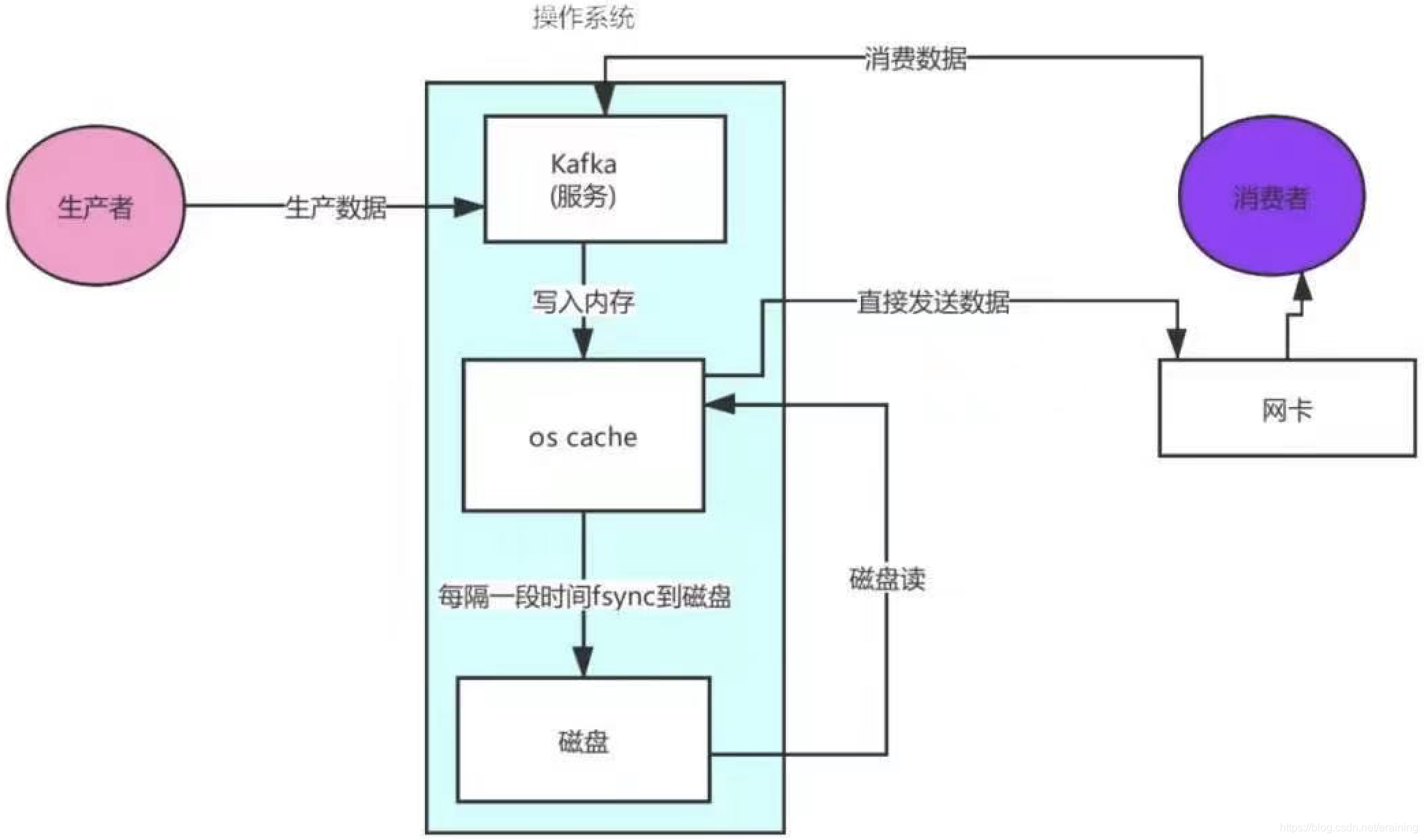
kafka linux sendfile技术 — 零拷贝
1.消费者发送请求给kafka服务
2.kafka服务去os cache缓存读取数据(缓存没有就去磁盘读取数据)
3.从磁盘读取了数据到os cache缓存中
4.os cache直接将数据发送给网卡
5.通过网卡将数据传输给消费者
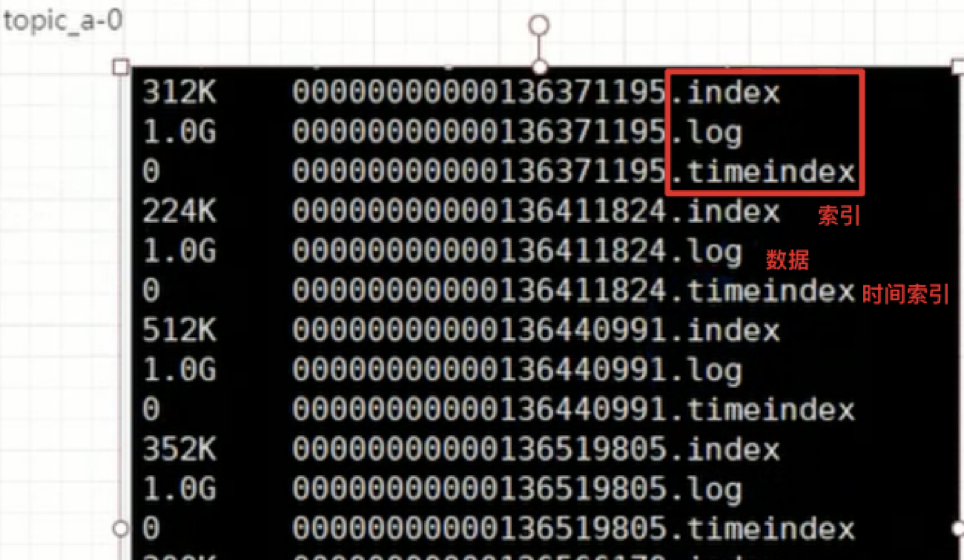
6、Kafka日志分段保存
Kafka中一个主题,一般会设置分区;
比如创建了一个topic_a,然后创建的时候指定了这个主题有三个分区。其实在三台服务器上,会创建三个目录。
服务器1(kafka1)
创建目录topic_a-0
目录下面是我们文件(存储数据),kafka数据就是message,数据存储在log文件里。
.log结尾的就是日志文件,在kafka中把数据文件就叫做日志文件
。
一个分区下面默认有n多个日志文件(分段存储),一个日志文件默认1G。
服务器2(kafka2):
创建目录topic_a-1:
服务器3(kafka3):
创建目录topic_a-2:
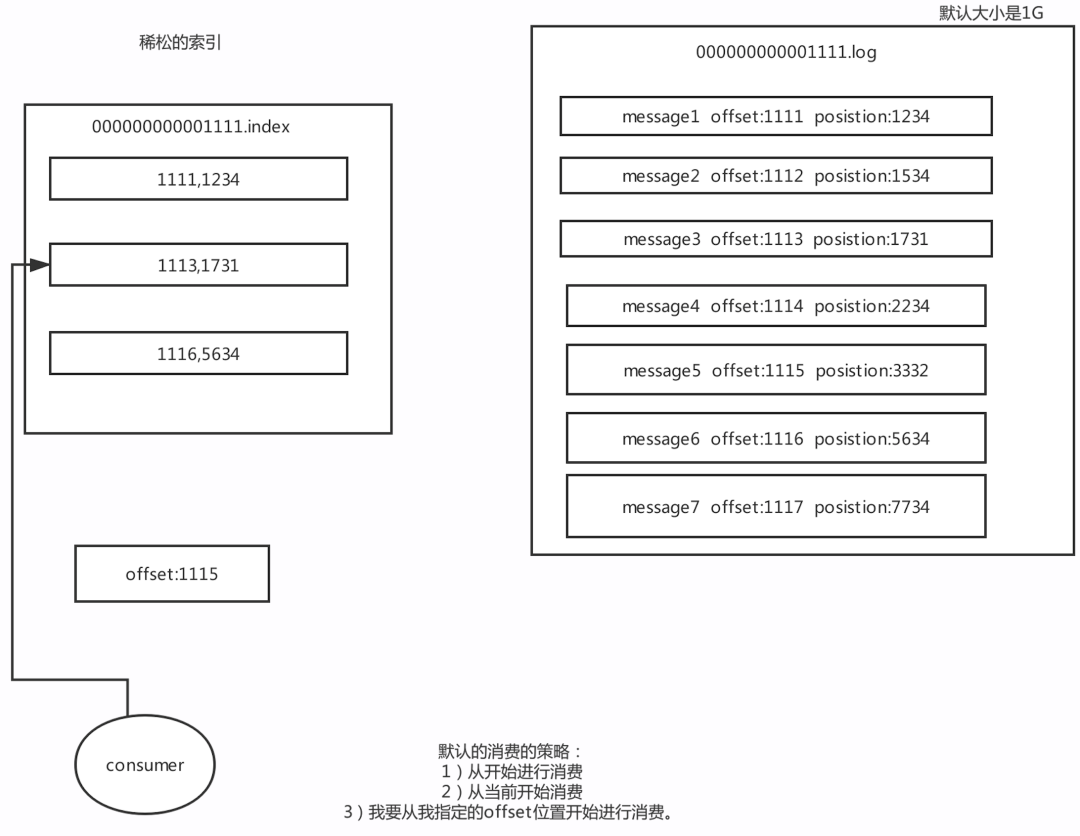
7、Kafka二分查找定位数据
Kafka里面每一条消息,都有自己的offset(相对偏移量),存在物理磁盘上面,在
position Position:物理位置(磁盘上面哪个地方)
也就是说一条消息就有两个位置:
offset:相对偏移量(相对位置)
position:磁盘物理位置
稀疏索引:
Kafka中采用了稀疏索引的方式读取索引,kafka每当写入了4k大小的日志(.log),就往index里写入一个记录索引。
其中会采用二分查找
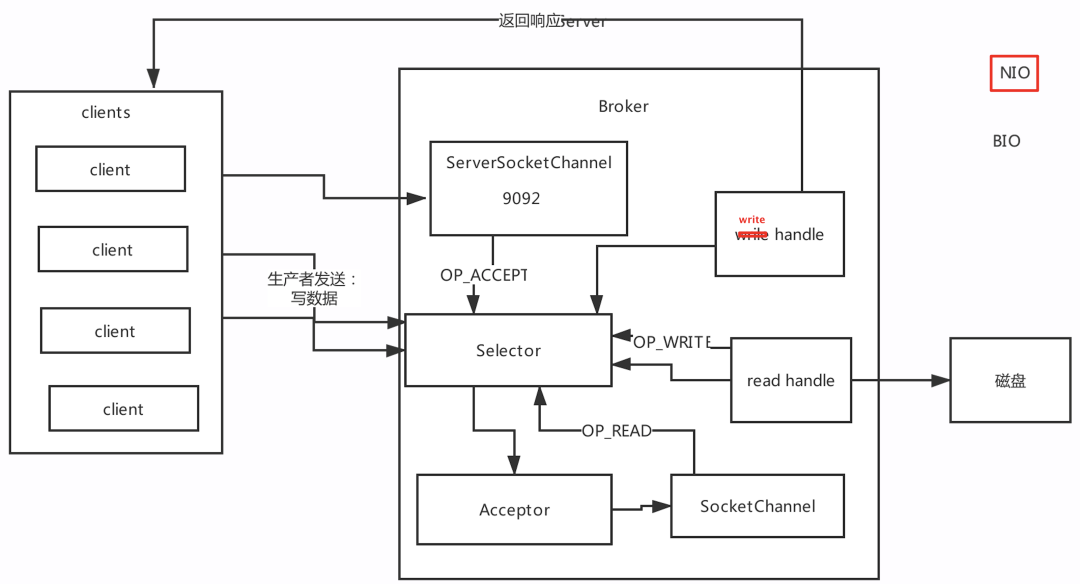
8、高并发网络设计(先了解NIO)
网络设计部分是kafka中设计最好的一个部分,这也是保证Kafka高并发、高性能的原因,对kafka进行调优,就得对kafka原理比较了解,尤其是网络设计部分
Reactor网络设计模式1:
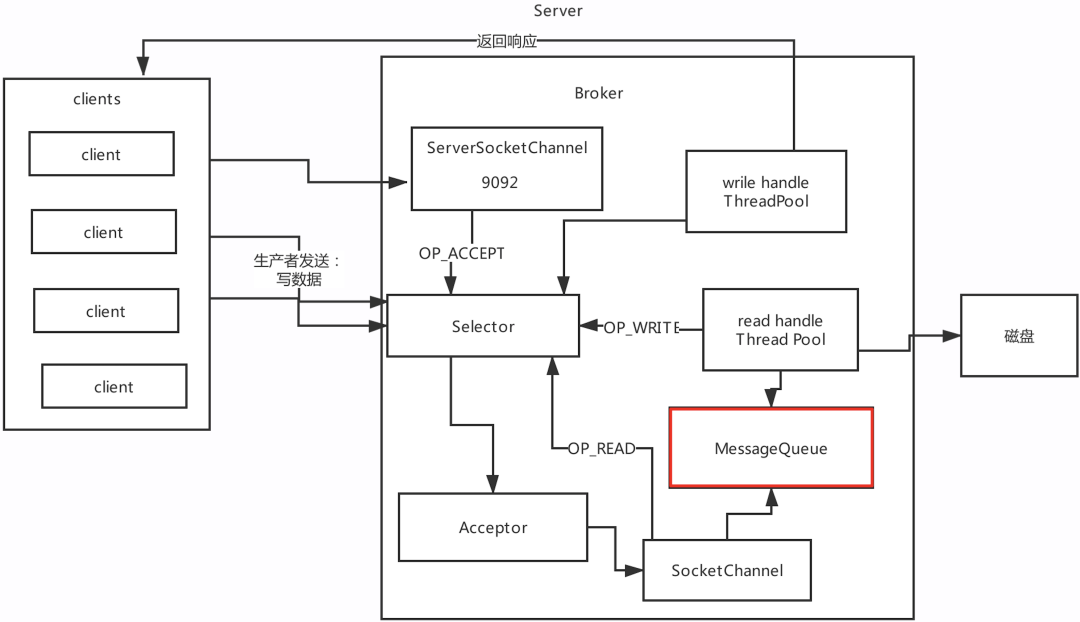
Reactor网络设计模式2:
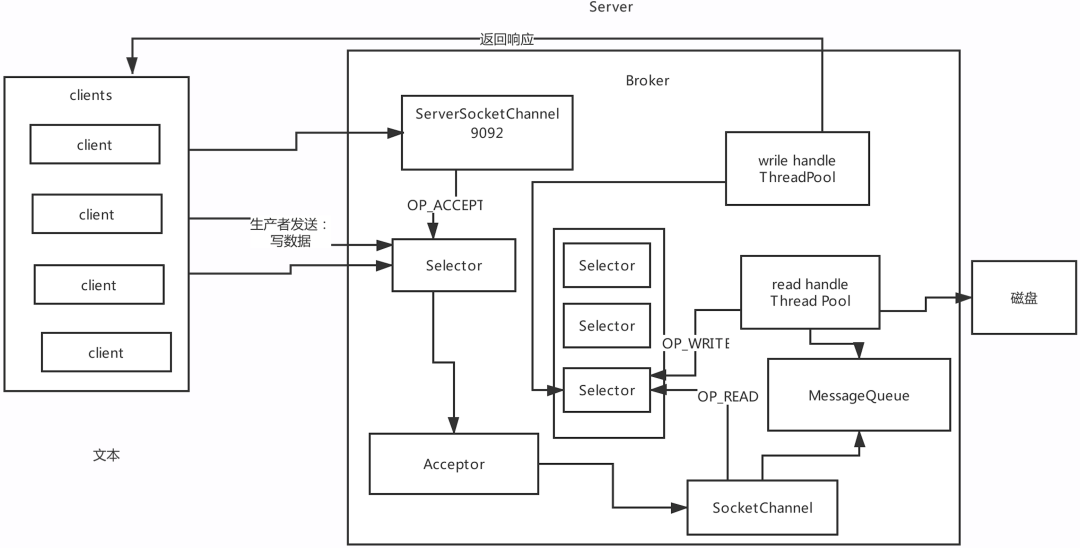
Reactor网络设计模式3:
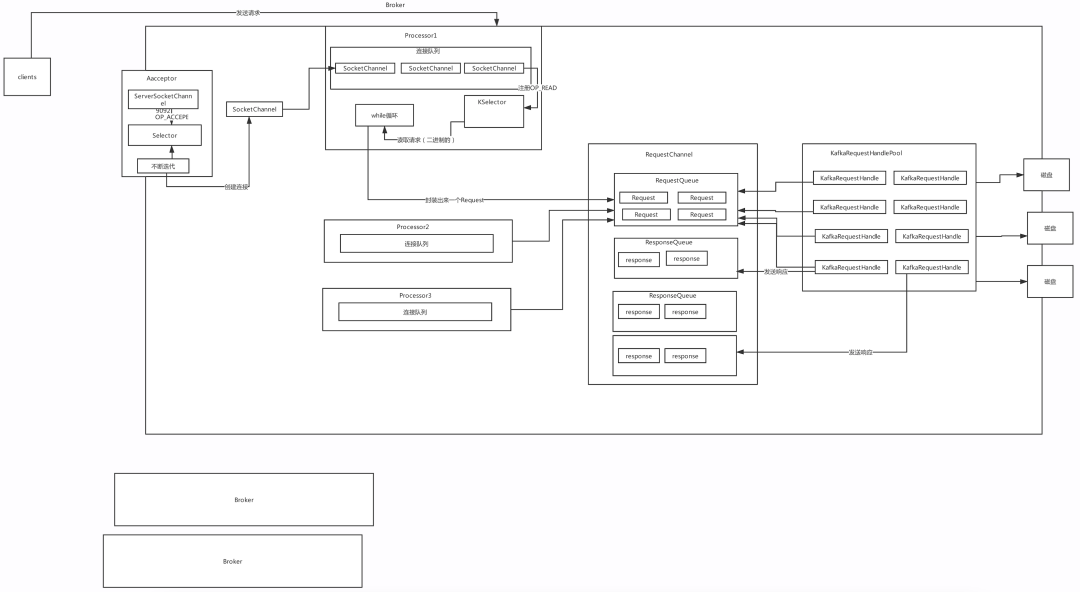
Kafka超高并发网络设计:
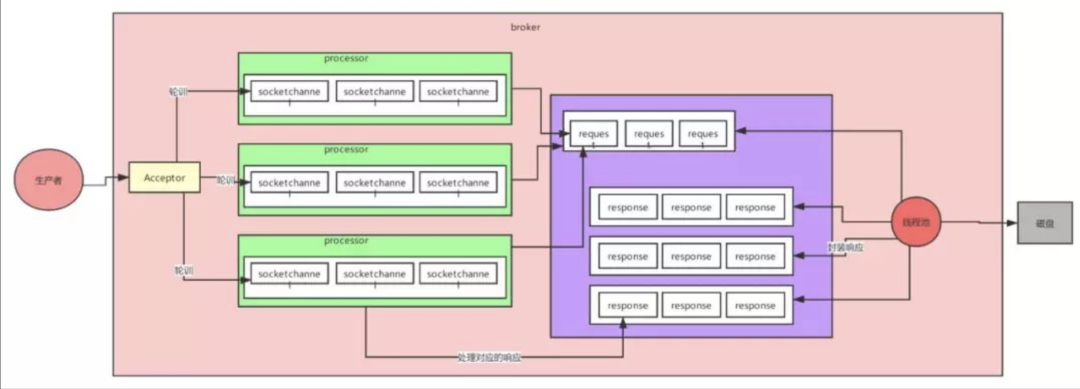
9、Kafka冗余副本保证高可用
在kafka里面分区是有副本的,注:0.8以前是没有副本机制的。创建主题时,可以指定分区,也可以指定副本个数。副本是有角色的:
leader partition:
1、写数据、读数据操作都是从leader partition去操作的。
2、会维护一个ISR(in-sync- replica )列表,但是会根据一定的规则删除ISR列表里面的值
生产者发送来一个消息,消息首先要写入到leader partition中 写完了以后,还要把消息写入到ISR列表里面的其它分区,写完后才算这个消息提交
follower partition:从leader partition同步数据。
10、优秀架构思考-总结
Kafka — 高并发、高可用、高性能
高可用:
多副本机制
高并发:网络架构设计
三层架构:多selector -> 多线程 -> 队列的设计(NIO)
高性能:
写数据:
把数据先写入到OS Cache
写到磁盘上面是顺序写,性能很高
读数据:
根据稀疏索引,快速定位到要消费的数据
零拷贝机制
减少数据的拷贝
减少了应用程序与操作系统上下文切换
11、Kafka生产环境搭建
11.1 需求场景分析
| 电商平台,需要每天10亿请求都要发送到Kafka集群上面。二八反正,一般评估出来问题都不大。
10亿请求 -> 24 过来的,一般情况下,每天的12:00 到早上8:00 这段时间其实是没有多大的数据量的。80%的请求是用的另外16小时的处理的。
16个小时处理 -> 8亿的请求。
16 * 0.2 = 3个小时 处理了8亿请求的80%的数据 |
也就是说6亿的数据是靠3个小时处理完的。
我们简单的算一下高峰期时候的qps
6亿/3小时 =5.5万/s qps=5.5万
| 10亿请求 * 50kb
= 46T 每天需要存储46T的数据 |
一般情况下,我们都会设置两个副本 46T * 2 = 92T
Kafka里面的数据是有保留的时间周期,保留最近3天的数据。
92T * 3天 = 276T
我这儿说的是50kb不是说一条消息就是50kb不是(把日志合并了,多条日志合并在一起),通常情况下,一条消息就几b,也有可能就是几百字节。
11.2 物理机数量评估
1)首先分析一下是需要虚拟机还是物理机 像Kafka mysql
hadoop这些集群搭建的时候,我们生产里面都是使用物理机。
2)高峰期需要处理的请求总的请求每秒5.5万个,其实一两台物理机绝对是可以抗住的。一般情况下,我们评估机器的时候,是按照高峰期的4倍的去评估。
如果是4倍的话,大概我们集群的能力要准备到 20万qps。这样子的集群才是比较安全的集群。大概就需要5台物理机。每台承受4万请求。
场景总结:
搞定10亿请求,高峰期5.5万的qps,276T的数据,需要5台物理机。
11.3 磁盘选择
搞定10亿请求,高峰期5.5万的qps,276T的数据,需要5台物理机。
1)SSD固态硬盘,还是需要普通的机械硬盘
SSD硬盘:性能比较好,但是价格贵
SAS盘:某方面性能不是很好,但是比较便宜。
SSD硬盘性能比较好,指的是它随机读写的性能比较好。适合MySQL这样集群。但是其实他的顺序写的性能跟SAS盘差不多。
kafka的理解:
就是用的顺序写。所以我们就用普通的【机械硬盘】就可以了。
2)需要我们评估每台服务器需要多少块磁盘 5台服务器,一共需要276T
,大约每台服务器 需要存储60T的数据。
我们公司里面服务器的配置用的是 11块硬盘,每个硬盘 7T。
11 * 7T = 77T
场景总结:
搞定10亿请求,需要5台物理机,11(SAS) * 7T
11.4 内存评估
搞定10亿请求,需要5台物理机,11(SAS) * 7T
我们发现kafka读写数据的流程 都是基于os cache,换句话说假设咱们的os
cashe无限大那么整个kafka是不是相当于就是基于内存去操作,如果是基于内存去操作,性能肯定很好。内存是有限的。1)
尽可能多的内存资源要给 os cache 2) Kafka的代码用 核心的代码用的是scala写的,客户端的代码java写的。都是基于jvm。所以我们还要给一部分的内存给jvm。Kafka的设计,没有把很多数据结构都放在jvm里面。所以我们的这个jvm不需要太大的内存。根据经验,给个10G就可以了。
| NameNode:
jvm里面还放了元数据(几十G),JVM一定要给得很大。比如给个100G。 |
假设我们这个10请求的这个项目,一共会有100个topic。
100 topic * 5 partition * 2 = 1000 partition
一个partition其实就是物理机上面的一个目录,这个目录下面会有很多个.log的文件。
.log就是存储数据文件,默认情况下一个.log文件的大小是1G。
我们如果要保证 1000个partition 的最新的.log 文件的数据 如果都在内存里面,这个时候性能就是最好。1000
* 1G = 1000G内存.
我们只需要把当前最新的这个log 保证里面的25%的最新的数据在内存里面。
250M * 1000 = 0.25 G* 1000 =250G的内存。
250内存 / 5 = 50G内存
50G+10G = 60G内存
64G的内存,另外的4G,操作系统本生是不是也需要内存。
其实Kafka的jvm也可以不用给到10G这么多。
评估出来64G是可以的。
当然如果能给到128G的内存的服务器,那就最好。
我刚刚评估的时候用的都是一个topic是5个partition,但是如果是数据量比较大的topic,可能会有10个partition。
总结:
搞定10亿请求,需要5台物理机,11(SAS) * 7T ,需要64G的内存(128G更好)
11.5 CPU压力评估
评估一下每台服务器需要多少cpu core(资源很有限)
我们评估需要多少个cpu ,依据就是看我们的服务里面有多少线程去跑。
线程就是依托cpu 去运行的。
如果我们的线程比较多,但是cpu core比较少,这样的话,我们的机器负载就会很高,性能不就不好。
评估一下,kafka的一台服务器 启动以后会有多少线程?
Acceptor线程 1
processor线程 3 6~9个线程
处理请求线程 8个 32个线程
定时清理的线程,拉取数据的线程,定时检查ISR列表的机制 等等。
所以大概一个Kafka的服务启动起来以后,会有一百多个线程。
cpu core = 4个,一遍来说,几十个线程,就肯定把cpu 打满了。
cpu core = 8个,应该很轻松的能支持几十个线程。
如果我们的线程是100多个,或者差不多200个,那么8 个 cpu core是搞不定的。
所以我们这儿建议:
CPU core = 16个。如果可以的话,能有32个cpu core 那就最好。
结论:
kafka集群,最低也要给16个cpu core,如果能给到32 cpu core那就更好。
2cpu * 8 =16 cpu core
4cpu * 8 = 32 cpu core
总结:
搞定10亿请求,需要5台物理机,11(SAS) * 7T ,需要64G的内存(128G更好),需要16个cpu
core(32个更好)
11.6 网络需求评估
评估我们需要什么样网卡?
一般要么是千兆的网卡(1G/s),还有的就是万兆的网卡(10G/s)
高峰期的时候 每秒会有5.5万的请求涌入,5.5/5
= 大约是每台服务器会有1万个请求涌入。
我们之前说的,
10000 * 50kb = 488M 也就是每条服务器,每秒要接受488M的数据。数据还要有副本,副本之间的同步
也是走的网络的请求。 488 * 2 = 976m/s
说明一下:
很多公司的数据,一个请求里面是没有50kb这么大的,我们公司是因为主机在生产端封装了数据
然后把多条数据合并在一起了,所以我们的一个请求才会有这么大。
说明一下:
一般情况下,网卡的带宽是达不到极限的,如果是千兆的网卡,我们能用的一般就是700M左右。
但是如果最好的情况,我们还是使用万兆的网卡。
如果使用的是万兆的,那就是很轻松。
|
11.7 集群规划
请求量
规划物理机的个数
分析磁盘的个数,选择使用什么样的磁盘
内存
cpu core
网卡
就是告诉大家,以后要是公司里面有什么需求,进行资源的评估,服务器的评估,大家按照我的思路去评估。
一条消息的大小 50kb -> 1kb 500byte 1M
ip 主机名
192.168.0.100 hadoop1
192.168.0.101 hadoop2
192.168.0.102 hadoop3
主机的规划:
kafka集群架构的时候:
主从式的架构:
controller -> 通过zk集群来管理整个集群的元数据。
zookeeper集群
hadoop1 hadoop2 hadoop3
kafka集群
理论上来讲,我们不应该把kafka的服务于zk的服务安装在一起。
但是我们这儿服务器有限。
所以我们kafka集群也是安装在hadoop1 haadoop2 hadoop3
11.8 zookeeper集群搭建
11.9 核心参数详解
11.10 集群压力测试
12、kafka运维
12.1 常见运维工具介绍
KafkaManager — 页面管理工具
12.2 常见运维命令
场景一: topic数据量太大,要增加topic数
一开始创建主题的时候,数据量不大,给的分区数不多。
kafka-topics.sh --create --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181
--replication-factor 1 --partitions 1 --topic test6
kafka-topics.sh --alter --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181
--partitions 3 --topic test6
broker id:
hadoop1:0
hadoop2:1
hadoop3:2
假设一个partition有三个副本:
partition0:
a,b,c
a:leader partition
b,c:follower partition
ISR:{a,b,c}
如果一个follower分区 超过10秒 没有向leader partition去拉取数据,那么这个分区就从ISR列表里面移除。
leader patition ->
场景二:核心topic增加副本因子
如果对核心业务数据需要增加副本因子
vim test.json脚本,将下面一行json脚本保存
{“version”:1,“partitions”:[{“topic”:“test6”,“partition”:0,“replicas”:[0,1,2]},{“topic”:“test6”,“partition”:1,“replicas”:[0,1,2]},{“topic”:“test6”,“partition”:2,“replicas”:[0,1,2]}]}
执行上面json脚本:
kafka-reassign-partitions.sh --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181
--reassignment-json-file test.json --execute
场景三: 负载不均衡的topic,手动迁移
vi topics-to-move.json
{“topics”: [{“topic”: “test01”}, {“topic”: “test02”}],
“version”: 1} // 把你所有的topic都写在这里
kafka-reassgin-partitions.sh --zookeeper hadoop1:2181,hadoop2:2181,hadoop3:2181
--topics-to-move-json-file topics-to-move.json --broker-list
“5,6” --generate
// 把你所有的包括新加入的broker机器都写在这里,就会说是把所有的partition均匀的分散在各个broker上,包括新进来的broker
此时会生成一个迁移方案,可以保存到一个文件里去:expand-cluster-reassignment.json
kafka-reassign-partitions.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
--reassignment-json-file expand-cluster-reassignment.json
--execute
kafka-reassign-partitions.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181
--reassignment-json-file expand-cluster-reassignment.json
--verify
这种数据迁移操作一定要在晚上低峰的时候来做,因为他会在机器之间迁移数据,非常的占用带宽资源
–generate: 根据给予的Topic列表和Broker列表生成迁移计划。generate并不会真正进行消息迁移,而是将消息迁移计划计算出来,供execute命令使用。
–execute: 根据给予的消息迁移计划进行迁移。
–verify: 检查消息是否已经迁移完成。
场景四:如果某个broker leader partition过多
正常情况下,我们的leader partition在服务器之间是负载均衡。
hadoop1 4
hadoop2 1
hadoop3 1
现在各个业务方可以自行申请创建topic,分区数量都是自动分配和后续动态调整的,
kafka本身会自动把leader partition均匀分散在各个机器上,这样可以保证每台机器的读写吞吐量都是均匀的
但是也有例外,那就是如果某些broker宕机,会导致leader partition过于集中在其他少部分几台broker上,
这会导致少数几台broker的读写请求压力过高,其他宕机的broker重启之后都是folloer partition,读写请求很低,
造成集群负载不均衡有一个参数,auto.leader.rebalance.enable,默认是true,
每隔300秒(leader.imbalance.check.interval.seconds)检查leader负载是否平衡
如果一台broker上的不均衡的leader超过了10%,leader.imbalance.per.broker.percentage,
就会对这个broker进行选举
配置参数:
auto.leader.rebalance.enable 默认是true
leader.imbalance.per.broker.percentage: 每个broker允许的不平衡的leader的比率。如果每个broker超过了这个值,控制器会触发leader的平衡。这个值表示百分比。10%
leader.imbalance.check.interval.seconds:默认值300秒
13、Kafka生产者
13.1 消费者发送消息原理
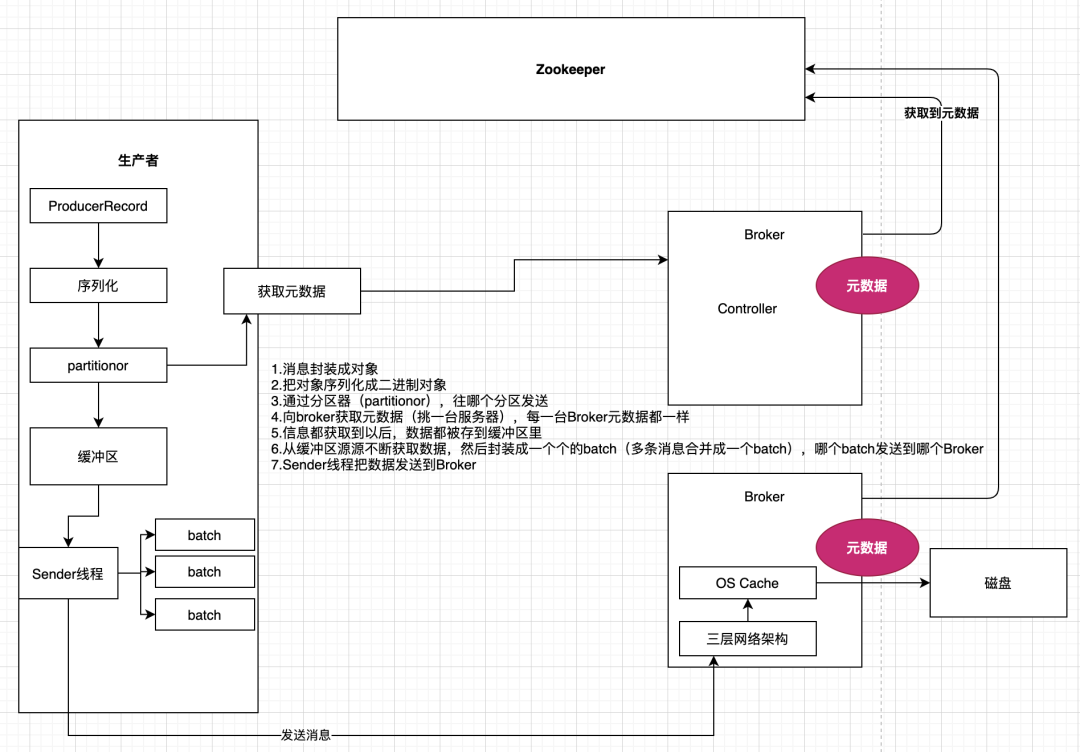
13.2 消费者发送消息原理—基础案例演示
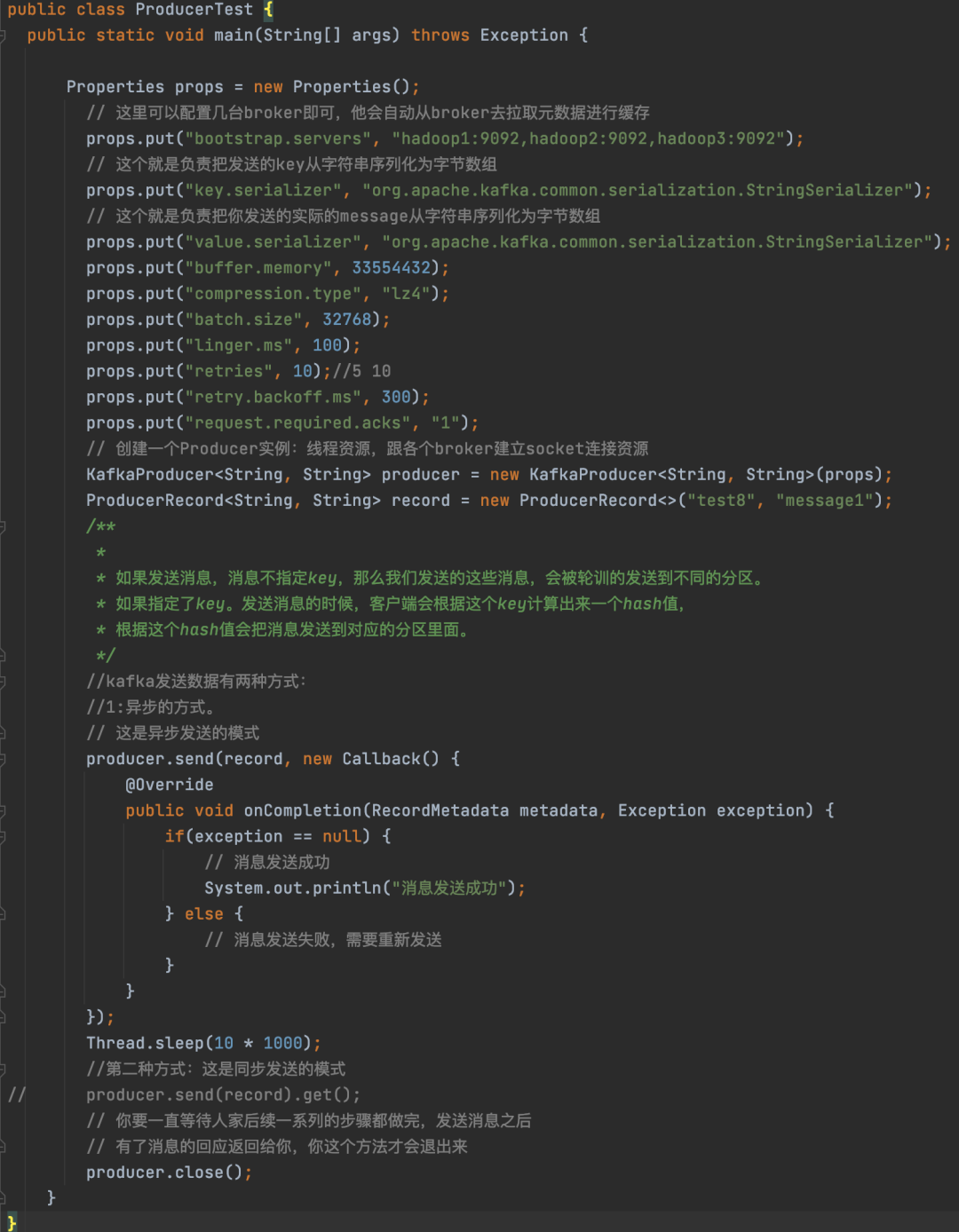
13.3 如何提升吞吐量
如何提升吞吐量:
参数一:buffer.memory:
设置发送消息的缓冲区,默认值是33554432,就是32MB
参数二:compression.type:
默认是none,不压缩,但是也可以使用lz4压缩,效率还是不错的,压缩之后可以减小数据量,提升吞吐量,但是会加大producer端的cpu开销
参数三:batch.size:
设置batch的大小,如果batch太小,会导致频繁网络请求,吞吐量下降;
如果batch太大,会导致一条消息需要等待很久才能被发送出去,而且会让内存缓冲区有很大压力,过多数据缓冲在内存里,默认值是:16384,就是16kb,也就是一个batch满了16kb就发送出去,一般在实际生产环境,这个batch的值可以增大一些来提升吞吐量,如果一个批次设置大了,会有延迟。一般根据一条消息大小来设置。
如果我们消息比较少。配合使用的参数linger.ms,这个值默认是0,意思就是消息必须立即被发送,但是这是不对的,一般设置一个100毫秒之类的,这样的话就是说,这个消息被发送出去后进入一个batch,如果100毫秒内,这个batch满了16kb,自然就会发送出去。
13.4 如何处理异常
1、LeaderNotAvailableException:
这个就是如果某台机器挂了,此时leader副本不可用,会导致你写入失败,要等待其他follower副本切换为leader副本之后,才能继续写入,此时可以重试发送即可;如果说你平时重启kafka的broker进程,肯定会导致leader切换,一定会导致你写入报错,是LeaderNotAvailableException。
2、NotControllerException:
这个也是同理,如果说Controller所在Broker挂了,那么此时会有问题,需要等待Controller重新选举,此时也是一样就是重试即可。
3、NetworkException:网络异常 timeout
a. 配置retries参数,他会自动重试的
b. 但是如果重试几次之后还是不行,就会提供Exception给我们来处理了,我们获取到异常以后,再对这个消息进行单独处理。我们会有备用的链路。发送不成功的消息发送到Redis或者写到文件系统中,甚至是丢弃。
13.5 重试机制
重试会带来一些问题:
消息会重复
有的时候一些leader切换之类的问题,需要进行重试,设置retries即可,但是消息重试会导致,重复发送的问题,比如说网络抖动一下导致他以为没成功,就重试了,其实人家都成功了.
消息乱序
消息重试是可能导致消息的乱序的,因为可能排在你后面的消息都发送出去了。
所以可以使用"max.in.flight.requests.per.connection"参数设置为1,
这样可以保证producer同一时间只能发送一条消息。
两次重试的间隔默认是100毫秒,用"retry.backoff.ms"来进行设置
基本上在开发过程中,靠重试机制基本就可以搞定95%的异常问题。
13.6 ACK参数详解
producer端设置的
request.required.acks=0;
只要请求已发送出去,就算是发送完了,不关心有没有写成功。
性能很好,如果是对一些日志进行分析,可以承受丢数据的情况,用这个参数,性能会很好。
request.required.acks=1;
发送一条消息,当leader partition写入成功以后,才算写入成功。
不过这种方式也有丢数据的可能。
request.required.acks=-1;
需要ISR列表里面,所有副本都写完以后,这条消息才算写入成功。
ISR:1个副本。1 leader partition 1 follower partition
kafka服务端:
min.insync.replicas:1, 如果我们不设置的话,默认这个值是1
一个leader partition会维护一个ISR列表,这个值就是限制ISR列表里面
至少得有几个副本,比如这个值是2,那么当ISR列表里面只有一个副本的时候。
往这个分区插入数据的时候会报错。
设计一个不丢数据的方案:
数据不丢失的方案:
1)分区副本 >=2
2)acks = -1
3)min.insync.replicas >=2
还有可能就是发送有异常:对异常进行处理
13.7 自定义分区
分区:
1、没有设置key
我们的消息就会被轮训的发送到不同的分区。
2、设置了key
kafka自带的分区器,会根据key计算出来一个hash值,这个hash值会对应某一个分区。
如果key相同的,那么hash值必然相同,key相同的值,必然是会被发送到同一个分区。
但是有些比较特殊的时候,我们就需要自定义分区
public class HotDataPartitioner implements Partitioner
{
private Random random;
@Override
public void configure(Map<String, ?> configs)
{
random = new Random();
}
@Override
public int partition(String topic, Object keyObj,
byte[] keyBytes, Object value, byte[] valueBytes,
Cluster cluster) {
String key = (String)keyObj;
List partitionInfoList = cluster.availablePartitionsForTopic(topic);
//获取到分区的个数 0,1,2
int partitionCount = partitionInfoList.size();
//最后一个分区
int hotDataPartition = partitionCount - 1;
return !key.contains(“hot_data”) ? random.nextInt(partitionCount
- 1) : hotDataPartition;
}
}
如何使用:
配置上这个类即可:props.put(”partitioner.class”, “com.zhss.HotDataPartitioner”);
13.8 综合案例演示
需求分析:
电商背景 -》 二手的电商平台
【欢乐送】的项目,用户购买了东西以后会有【星星】,用星星去换物品。一块钱一个星星。
订单系统(消息的生产),发送一条消息(支付订单,取消订单) -> Kafka <- 会员系统,从kafak里面去消费数据,找到对应用户消费的金额
然后给该用户更新星星的数量。
分析一下:
发送消息的时候,可以指定key,也可以不指定key.
1)如果不指定key
zhangsan ->下订单 -> 100 -> +100
zhangsan -> 取消订单 -> -100 -> -100
会员系统消费数据的时候,有可能先消费到的是 取消订单的数据。
2)如果指定key,key -> hash(数字) -> 对应分区号 -> 发送到对应的分区里面。
如果key相同的 -> 数据肯定会被发送到同一个分区(有序的)
这个项目需要指定key,把用户的id指定为key.
14、Kafka消费者
14.1 消费组概念
groupid相同就属于同一个消费组
1)每个consumer都要属于一个consumer.group,就是一个消费组,topic的一个分区只会分配给
一个消费组下的一个consumer来处理,每个consumer可能会分配多个分区,也有可能某个consumer没有分配到任何分区
2)如果想要实现一个广播的效果,那只需要使用不同的group id去消费就可以。
topicA:
partition0、partition1
groupA:
consumer1:消费 partition0
consuemr2:消费 partition1
consuemr3:消费不到数据
groupB:
consuemr3:消费到partition0和partition1
3)如果consumer group中某个消费者挂了,此时会自动把分配给他的分区交给其他的消费者,如果他又重启了,那么又会把一些分区重新交还给他
14.2 基础案例演示
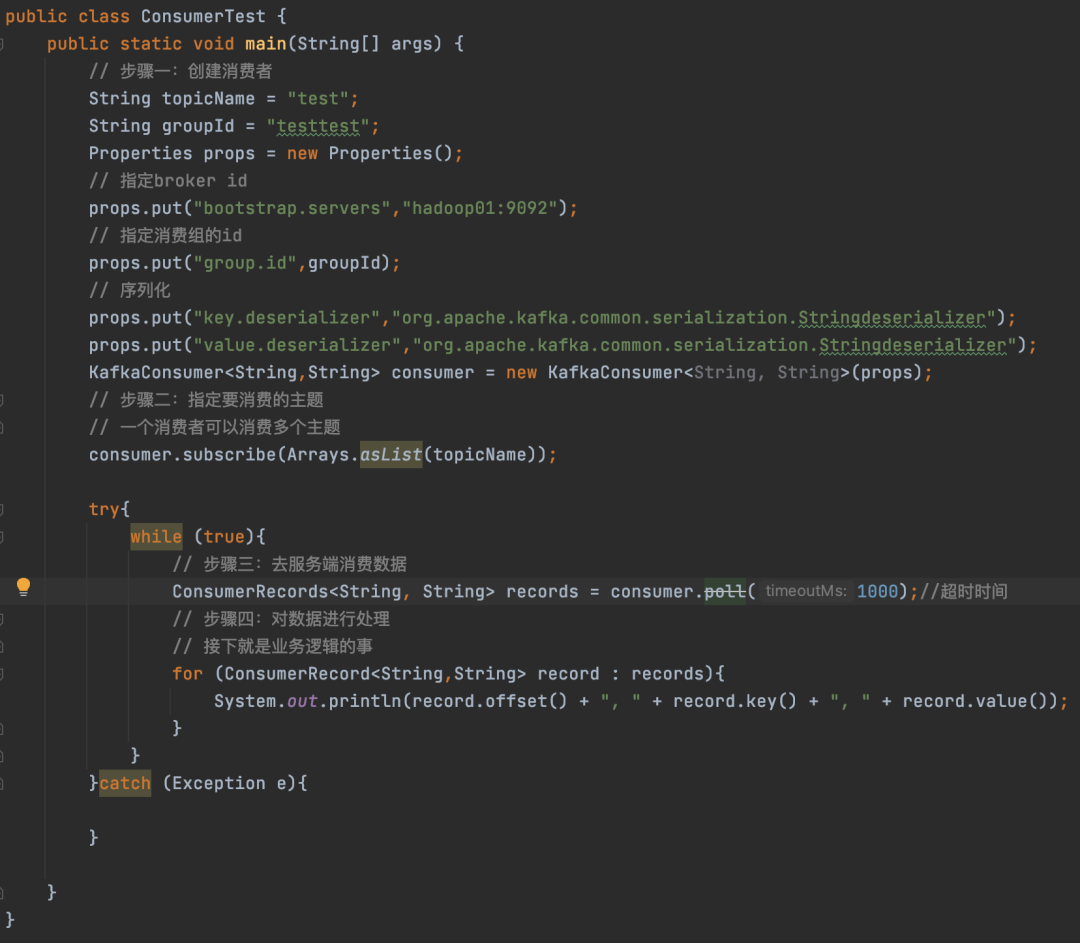
14.3 偏移量管理
每个consumer内存里数据结构保存对每个topic的每个分区的消费offset,定期会提交offset,老版本是写入zk,但是那样高并发请求zk是不合理的架构设计,zk是做分布式系统的协调的,轻量级的元数据存储,不能负责高并发读写,作为数据存储
现在新的版本提交offset发送给kafka内部topic:__consumer_offsets,提交过去的时候,
key是group.id+topic+分区号,value就是当前offset的值,每隔一段时间,kafka内部会对这个topic进行compact(合并),也就是每个group.id+topic+分区号就保留最新数据。
__consumer_offsets可能会接收高并发的请求,所以默认分区50个(leader partitiron
-> 50 kafka),这样如果你的kafka部署了一个大的集群,比如有50台机器,就可以用50台机器来抗offset提交的请求压力.
消费者 -> broker端的数据
message -> 磁盘 -> offset 顺序递增
从哪儿开始消费? -> offset
消费者(offset)
14.4 偏移量监控工具介绍
web页面管理的一个管理软件(kafka Manager)
修改bin/kafka-run-class.sh脚本,第一行增加JMX_PORT=9988
重启kafka进程
另一个软件:主要监控的consumer的偏移量。就是一个jar包
java -cp KafkaOffsetMonitor-assembly-0.3.0-SNAPSHOT.jar
com.quantifind.kafka.offsetapp.OffsetGetterWeb
–offsetStorage kafka \(根据版本:偏移量存在kafka就填kafka,存在zookeeper就填zookeeper)
–zk hadoop1:2181
–port 9004
–refresh 15.seconds
–retain 2.days
写了一段程序 ,消费kafka里面的数据(consumer,处理数据 -> 业务代码) ->
Kafka
如何去判断你的这段代码真的是实时的去消费的呢?
延迟几亿条数据 -> 阈值(20万条的时候 发送一个告警。)
14.5 消费异常感知
heartbeat.interval.ms:
consumer心跳时间间隔,必须得与coordinator保持心跳才能知道consumer是否故障了,
然后如果故障之后,就会通过心跳下发rebalance的指令给其他的consumer通知他们进行rebalance的操作
session.timeout.ms:
kafka多长时间感知不到一个consumer就认为他故障了,默认是10秒
max.poll.interval.ms:
如果在两次poll操作之间,超过了这个时间,那么就会认为这个consume处理能力太弱了,会被踢出消费组,分区分配给别人去消费,一般来说结合业务处理的性能来设置就可以了。
14.6 核心参数解释
fetch.max.bytes:
获取一条消息最大的字节数,一般建议设置大一些,默认是1M
其实我们在之前多个地方都见到过这个类似的参数,意思就是说一条信息最大能多大?
1. Producer
发送的数据,一条消息最大多大, -> 10M
2. Broker
存储数据,一条消息最大能接受多大 -> 10M
3. Consumer
max.poll.records:
一次poll返回消息的最大条数,默认是500条
connection.max.idle.ms:
consumer跟broker的socket连接如果空闲超过了一定的时间,此时就会自动回收连接,但是下次消费就要重新建立socket连接,这个建议设置为-1,不要去回收
enable.auto.commit:
开启自动提交偏移量
auto.commit.interval.ms:
每隔多久提交一次偏移量,默认值5000毫秒
_consumer_offset
auto.offset.reset:
earliest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
topica -> partition0:1000
partitino1:2000
latest
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
none
topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
14.7 综合案例演示
引入案例:二手电商平台(欢乐送),根据用户消费的金额,对用户星星进行累计。
订单系统(生产者) -> Kafka集群里面发送了消息。
会员系统(消费者) -> Kafak集群里面消费消息,对消息进行处理。
14.8 group coordinator原理
面试题:消费者是如何实现rebalance的? — 根据coordinator实现
1.什么是coordinator
2.每个consumer group都会选择一个broker作为自己的coordinator,他是负责监控这个消费组里的各个消费者的心跳,以及判断是否宕机,然后开启rebalance的
如何选择coordinator机器
首先对groupId进行hash(数字),接着对__consumer_offsets的分区数量取模,默认是50,_consumer_offsets的分区数可以通过offsets.topic.num.partitions来设置,找到分区以后,这个分区所在的broker机器就是coordinator机器。
比如说:groupId,“myconsumer_group” -> hash值(数字)->
对50取模 -> 8
__consumer_offsets 这个主题的8号分区在哪台broker上面,那一台就是coordinator
就知道这个consumer group下的所有的消费者提交offset的时候是往哪个分区去提交offset,
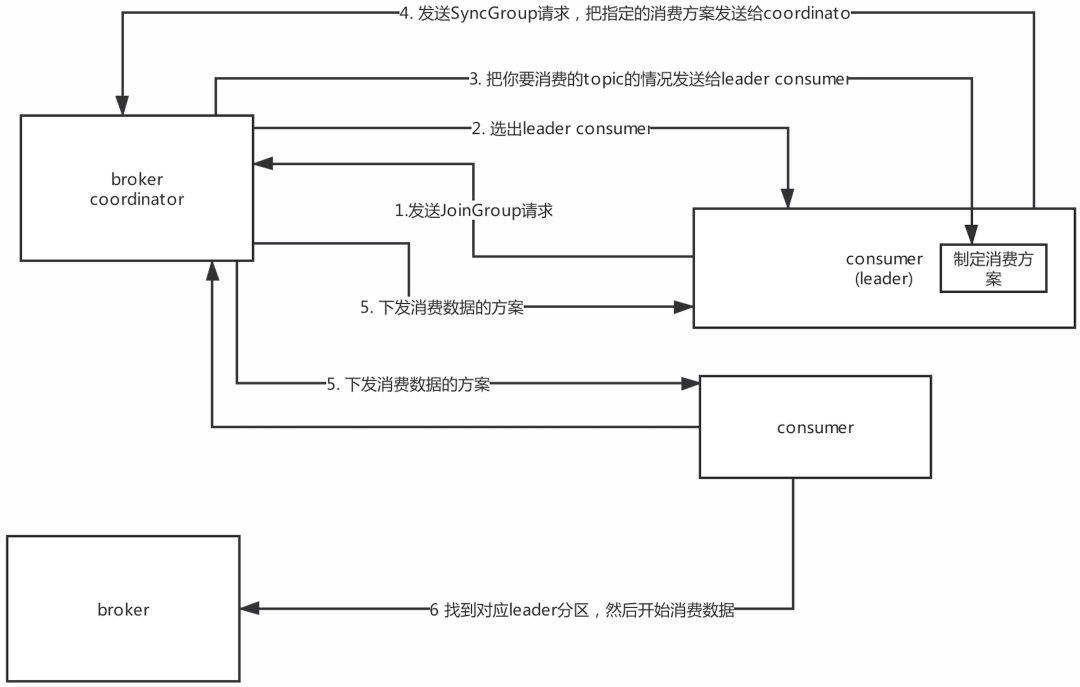
3.运行流程
1)每个consumer都发送JoinGroup请求到Coordinator,
2)然后Coordinator从一个consumer group中选择一个consumer作为leader,
3)把consumer group情况发送给这个leader,
4)接着这个leader会负责制定消费方案,
5)通过SyncGroup发给Coordinator
6)接着Coordinator就把消费方案下发给各个consumer,他们会从指定的分区的
leader broker开始进行socket连接以及消费消息
14.9 rebalance策略
consumer group靠coordinator实现了Rebalance
这里有三种rebalance的策略:range、round-robin、sticky
比如我们消费的一个主题有12个分区:
p0,p1,p2,p3,p4,p5,p6,p7,p8,p9,p10,p11
假设我们的消费者组里面有三个消费者
1.range策略
range策略就是按照partiton的序号范围
p0~3 consumer1
p4~7 consumer2
p8~11 consumer3
默认就是这个策略;
2.round-robin策略
就是轮询分配
consumer1:0,3,6,9
consumer2:1,4,7,10
consumer3:2,5,8,11
但是前面的这两个方案有个问题:
12 -> 2 每个消费者会消费6个分区
假设consuemr1挂了:p0-5分配给consumer2,p6-11分配给consumer3
这样的话,原本在consumer2上的的p6,p7分区就被分配到了 consumer3上。
3.sticky策略
最新的一个sticky策略,就是说尽可能保证在rebalance的时候,让原本属于这个consumer
的分区还是属于他们,然后把多余的分区再均匀分配过去,这样尽可能维持原来的分区分配的策略
consumer1:0-3
consumer2: 4-7
consumer3: 8-11
假设consumer3挂了
consumer1:0-3,+8,9
consumer2: 4-7,+10,11
15、Broker管理
15.1 Leo、hw含义
Kafka的核心原理
如何去评估一个集群资源
搭建了一套kafka集群 -》 介绍了简单的一些运维管理的操作。
生产者(使用,核心的参数)
消费者(原理,使用的,核心参数)
broker内部的一些原理
核心的概念:LEO,HW
LEO:是跟offset偏移量有关系。
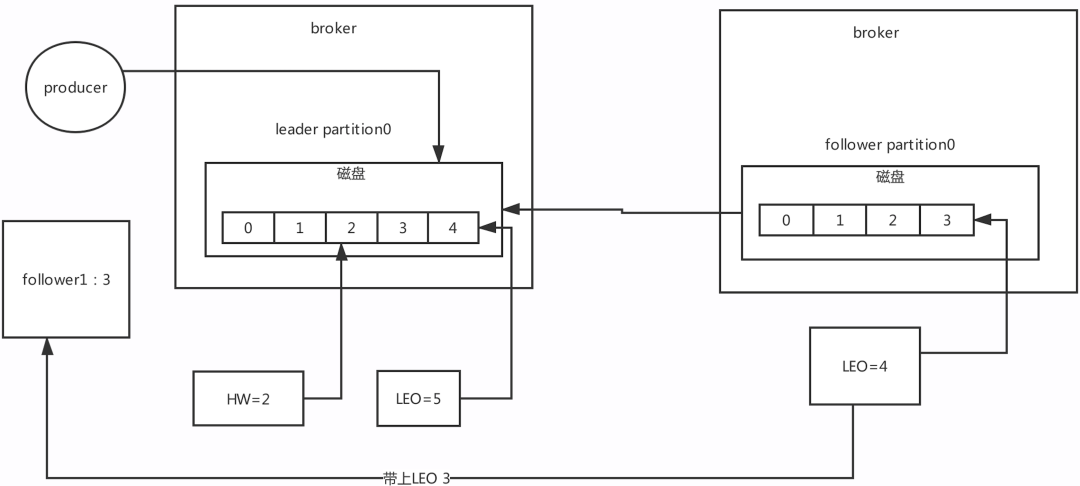
LEO:
在kafka里面,无论leader partition还是follower
partition统一都称作副本(replica)。
| 每次partition接收到一条消息,都会更新自己的LEO,也就是log
end offset,LEO其实就是最新的offset + 1 |
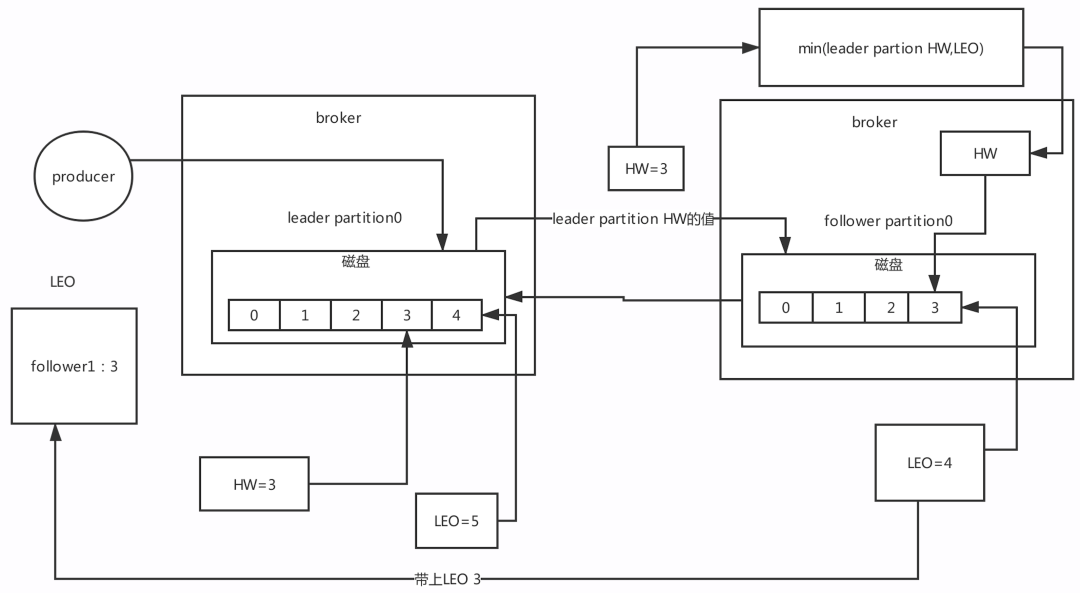
HW:高水位
LEO有一个很重要的功能就是更新HW,如果follower和leader的LEO同步了,此时HW就可以更新
HW之前的数据对消费者是可见,消息属于commit状态。HW之后的消息消费者消费不到。
15.2 Leo更新
15.3 hw更新
15.4 controller如何管理整个集群
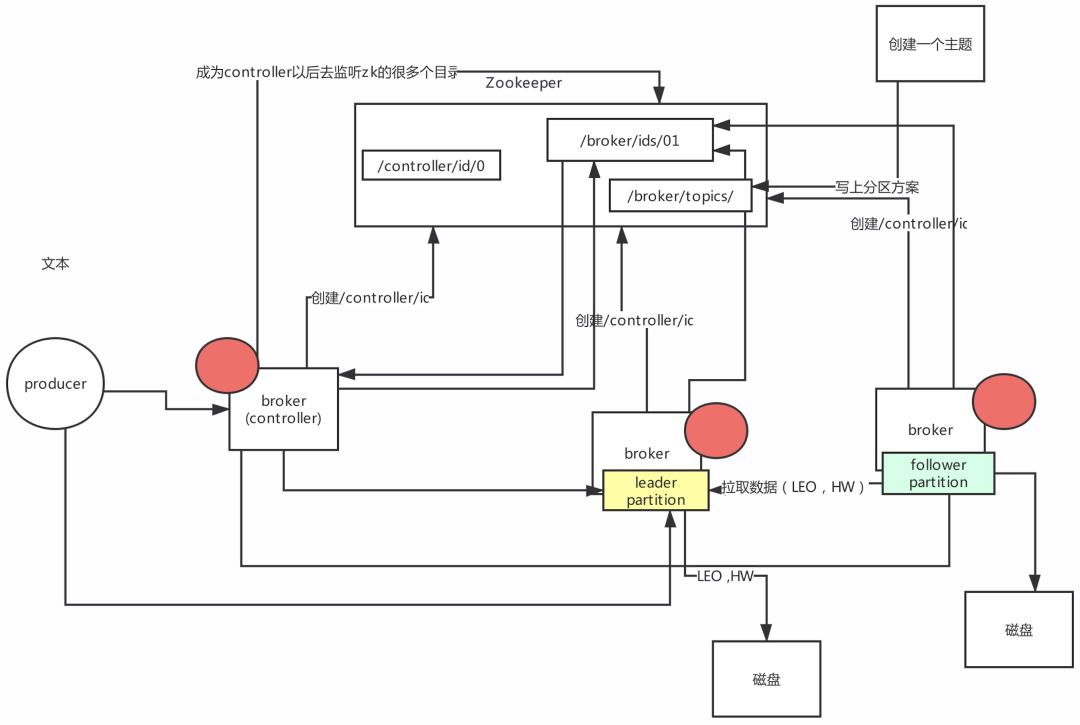
1: 竞争controller的
/controller/id
2:controller服务监听的目录:
/broker/ids/ 用来感知 broker上下线
/broker/topics/ 创建主题,我们当时创建主题命令,提供的参数,ZK地址。
/admin/reassign_partitions 分区重分配
15.5 延时任务
kafka的延迟调度机制(扩展知识)
我们先看一下kafka里面哪些地方需要有任务要进行延迟调度。
第一类延时的任务:
比如说producer的acks=-1,必须等待leader和follower都写完才能返回响应。
有一个超时时间,默认是30秒(request.timeout.ms)。
所以需要在写入一条数据到leader磁盘之后,就必须有一个延时任务,到期时间是30秒延时任务
放到DelayedOperationPurgatory(延时管理器)中。
假如在30秒之前如果所有follower都写入副本到本地磁盘了,那么这个任务就会被自动触发苏醒,就可以返回响应结果给客户端了,
否则的话,这个延时任务自己指定了最多是30秒到期,如果到了超时时间都没等到,就直接超时返回异常。
第二类延时的任务:
follower往leader拉取消息的时候,如果发现是空的,此时会创建一个延时拉取任务
延时时间到了之后(比如到了100ms),就给follower返回一个空的数据,然后follower再次发送请求读取消息,
但是如果延时的过程中(还没到100ms),leader写入了消息,这个任务就会自动苏醒,自动执行拉取任务。
海量的延时任务,需要去调度。
15.6 时间轮机制
什么会有要设计时间轮?
Kafka内部有很多延时任务,没有基于JDK Timer来实现,那个插入和删除任务的时间复杂度是O(nlogn),
而是基于了自己写的时间轮来实现的,时间复杂度是O(1),依靠时间轮机制,延时任务插入和删除,O(1)
时间轮是什么?
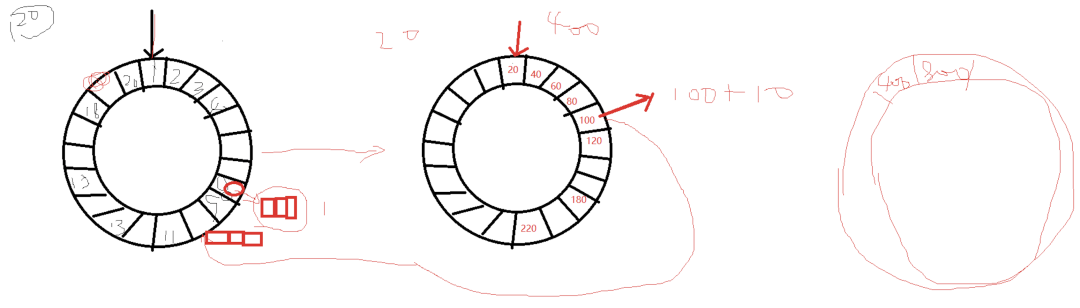
其实时间轮说白其实就是一个数组。
tickMs:时间轮间隔 1ms
wheelSize:时间轮大小 20
interval:timckMS * whellSize,一个时间轮的总的时间跨度。20ms
currentTime:当时时间的指针。
a:因为时间轮是一个数组,所以要获取里面数据的时候,靠的是index,时间复杂度是O(1)
b:数组某个位置上对应的任务,用的是双向链表存储的,往双向链表里面插入,删除任务,时间复杂度也是O(1)
举例:插入一个8ms以后要执行的任务
19ms
3.多层级的时间轮
比如:要插入一个110毫秒以后运行的任务。
tickMs:时间轮间隔 20ms
wheelSize:时间轮大小 20
interval:timckMS * whellSize,一个时间轮的总的时间跨度。20ms
currentTime:当时时间的指针。
第一层时间轮:1ms * 20
第二层时间轮:20ms * 20
第三层时间轮:400ms * 20
|









