| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫFlink
SQL ЛљБОФмСІвдМАМмЙЙдРэЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкInfoQ
ЃЌгЩAliceБрМЁЂЭЦМіЁЃ
|
|
ДѓЪ§ОнвдРыЯпМЦЫуОгЖрЃЌДѓЪ§ОндНЪЕЪБдНгаМлжЕЁЃЪ§ОнМлжЕзюДѓЛЏЕФгааЇЗНЪНОЭЪЧЭЈЙ§ЪЕЪБСїМЦЫуММЪѕЃЈFlink/Spark
ЕШЃЉПьЫйАбМЦЫуНсЙћЗДРЁИјгУЛЇЃЌЬсИпзЊЛЏТЪЃЌБЃжЄЯпЯТВњЦЗЕФе§ГЃдЫааЁЃЖј SQL ЪЧЭЈгУгябдЃЌШнвзЩЯЪжЃЌЯТУцОЭНщЩмЯТ
Flink SQL ЛљБОФмСІЁЃ
1. Get Started
Flink SQL ЪЧ Flink ИпВу APIЃЌгяЗЈзёб ANSI SQL БъзМЁЃЪОР§ШчЯТ
SELECT car_id,
MAX(speed), COUNT(speed)
FROM drive_data
WHERE speed > 90
GROUP BY TUMBLE (proctime, INTERVAL '30' SECOND),
car_id
|
Flink SQL ЪЧдк Flink Table API ЕФЛљДЁЩЯЗЂеЙЦ№РДЕФЃЌгыЩЯЪіЪОР§ЖдгІЕФ Table
API ЪОР§ШчЯТ
table.where('speed
> 90)
.window(Tumble over 30.second on 'proctime as
'w)
.groupBy('w, 'car_id)
.select('car_id, 'speed.max, 'speed.count)
|
ЩЯЪіЪОР§ЪЙгУ Scala ДњТыЃЌНсКЯвўЪНзЊЛЛКЭжазКБэЪОЕШ Scala
гяЗЈЃЌTable API ДњТыПДЦ№РДЗЧГЃНгНќ SQL БэДяЁЃ
2. МмЙЙдРэ
РЯАцБОЕФ Table API ЭЈЙ§РрЫЦСДЪНЕїгУЕФаДЗЈЃЌЙЙдьвЛПУ Table
Operator ЪїЃЌВЂЖдИїИіЪїНкЕузіДњТыЩњГЩЃЌзЊЛЏГЩ Flink ЕЭВу API ЕїгУДњТыЃЌМД DataStream/DataSet
APIЁЃ
Дг 2016 ФъПЊЪМЃЌПЊдДЩчЧјвбОгаДѓСП SQL-on-Hadoop ЕФГЩЪьНтОіЗНАИЃЌАќРЈ Apache
HiveЁЂApache ImpalaЁЂApache Drill ЕШЕШЃЌЖМвРРЕ Apache Calcite
ЬсЙЉЕФ SQL НтЮігХЛЏФмСІЃЌApache Calcite ЕБЪБвбОЪЧвЛИіЗЧГЃСїааЕФвЕНчБъзМ SQL
НтЮіКЭгХЛЏПђМмЁЃгкДЫЭЌЪБЃЌЫцзХдкЪЕЪБЗжЮіСьгђжа Flink ЕФгІгУГЁОАдіМгЃЌЖд SQL API ЕФКєЩљНЅИпЃЌгкЪЧЩчЧјПЊЪМдк
Apache Calcite ЕФЛљДЁЩЯЙЙНЈаТАцБОЕФ Table APIЃЌВЂдіМг SQL API жЇГжЁЃ
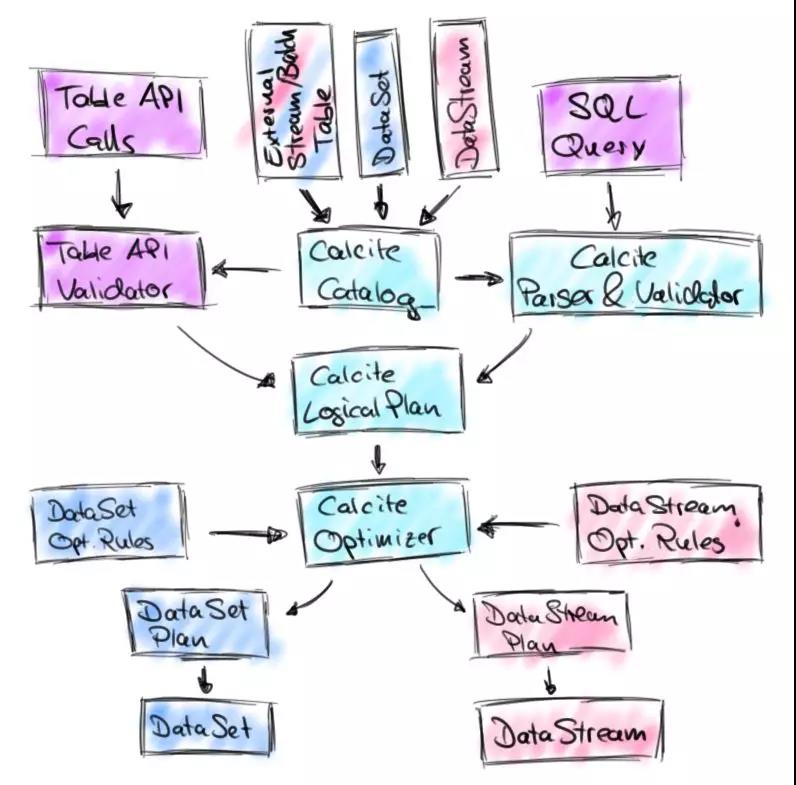
аТАцБОЕФ Table & SQL API дкдгаЕФ Table
API ЛљДЁЩЯЃЌгЩ Calcite ЬсЙЉ SQL НтЮіКЭгХЛЏФмСІЃЌНЋ Table API ЕїгУКЭ SQL
ВщбЏЭГвЛзЊЛЛГЩ Calcite ТпМжДааМЦЛЎЃЈCalcite RelNode ЪїЃЉЃЌВЂЖдДЫНјаагХЛЏКЭДњТыЩњГЩЃЌзюжеЭЌбљзЊЛЏГЩ
Flink DataStream/DataSet API ЕїгУДњТыЁЃ
3. DDL & DML
ЭъећЕФ SQL гяЗЈгЩ DDLЃЈdata definition languageЃЉКЭ
DMLЃЈdata manipulation languageЃЉСНВПЗжзщГЩЁЃFlink SQL ФПЧАжЛжЇГж
DML гяЗЈЃЌЖјАќКЌЪ§ОнСїЖЈвхЕФ DDL гяЗЈШдашЭЈЙ§ДњТыЪЕЯжЁЃ
ЙњФкИїДѓЙЋгадЦГЇЩЬжаЃЌЛЊЮЊдЦКЭАЂРядЦЖМЬсЙЉСЫЛљгк Flink SQL ЕФЪЕЪБСїМЦЫуЗўЮёЃЌИїздЖЈвхСЫвЛЬз
DDL гяЗЈЃЌгяЗЈДѓЭЌаЁвьЁЃвдЛЊЮЊдЦЮЊР§ЃЌЪ§ОнСїЖЈвхвдCREATE STREAMЮЊЙиМќзжЃЌОпЬхЕФ DDL
аДЗЈЪОР§ШчЯТ
CREATE SOURCE
STREAM driver_behavior (car_id STRING, speed INT,
collect_time LONG)
WITH (
type = "kafka",
kafka_bootstrap_servers = "10.10.10.10:3456,10.10.10.20:3456",
kafka_group_id = "group1",
kafka_topic = "topic1",
encode = "csv",
field_delimiter = ","
) TIMESTAMP BY collect_time.ROWTIME;
CREATE SINK STREAM over_speed_warning (message
STRING)
WITH (
type = "smn",
region = "cn-north-1",
topic_urn = "urn:smn:cn-north-1:38834633fd6f4bae813031b5985dbdea:warning",
message_subject = "title",
message_column = "message"
);
|
DDL жаАќКЌЪфШыЪ§ОнСїКЭЪфГіЪ§ОнСїЖЈвхЃЌУшЪіЪЕЪБСїМЦЫуЕФЪ§ОнЩЯЯТгЮЩњЬЌзщМўЃЌдкЩЯЪіР§згжаЃЌЪфШыСїЃЈSOURCE
STREAMЃЉРраЭЪЧ KafkaЃЌWITHзгОфУшЪіСЫ Kafka ЯћЗбепЯрЙиХфжУЁЃЪфГіСїЃЈSINK
STREAMЃЉРраЭЪЧ SMNЃЌЪЧЛЊЮЊдЦЯћЯЂЭЈжЊЗўЮёЕФЫѕаДЃЌгУгкЖЬаХКЭгЪМўЭЈжЊЁЃ
Ъ§ОнДг Kafka СїШыЃЌЯђ SMN ЗўЮёСїГіЃЌЖјжаМфЕФЪ§ОнДІРэТпМгЩ
DML ЪЕЯжЃЌОпЬхЕФ DML аДЗЈЪОР§ШчЯТ
INSERT INTO over_speed_warning
SELECT "your car speed (" || CAST(speed
as CHAR(20)) || ") exceeds the maximum speed."
FROM (
SELECT car_id, MAX(speed) AS speed, COUNT(speed)
AS overspeed_count
FROM driver_behavior
WHERE speed > 90
GROUP BY TUMBLE (collect_time, INTERVAL '30' SECOND),
car_id
)
WHERE overspeed_count >= 3;
|
вдЩЯ DML гяОфЃЌУшЪіСЫдк 30 УыФкГЕСОРлМЦГЌЫйШ§ДЮЪБЃЌЯђзїЮЊЪфГіСїЕФЯТгЮ SMN зщМўЪфГіИцОЏЯћЯЂЁЃDML
гяОфжаINSERT INTOЙиМќзжКѓНєНгзХЪфГіСїУћЃЌЖјFROMЙиМќзжКѓНєНгзХЪфШыСїУћЃЌSELECT
згОфБэДяЪфГіЕФФкШнЃЌWHEREзгОфБэДяЪфГіашвЊТњзуЕФЙ§ТЫЬѕМўЁЃЩЯЪіР§згЪЙгУЕНСЫ SQL згВщбЏЃЌЭтВуFROMКѓИњзХвЛећИіSELECTзгОфЃЌЮЊСЫЗНБуРэНтЃЌЮвУЧвВПЩвдАбзгВщбЏгяЗЈзЊЛЏГЩЕШМлЕФСйЪБСїЖЈвхБэДяЃЌдкЛЊЮЊдЦЪЕЪБСїМЦЫуЗўЮёЕФ
DDL гяЗЈжажЇГжСЫетжжЬиадЃЌгыЩЯЪі DML аДЗЈЕШМлЕФЪОР§ШчЯТ
CREATE TEMP STREAM
over_speed_info (car_id STRING, speed INT, overspeed_count
INT);
INSERT INTO over_speed_info
SELECT car_id, MAX(speed) AS speed, COUNT(speed)
AS overspeed_count
FROM driver_behavior
WHERE speed > 90
GROUP BY TUMBLE (collect_time, INTERVAL '30' SECOND),
car_id;
INSERT INTO over_speed_warning
SELECT "your car speed (" || CAST(speed
as CHAR(20)) || ") exceeds the maximum speed."
FROM over_speed_info
WHERE overspeed_count >= 3;
|
ЭЈЙ§TEMP STREAM гяЗЈЖЈвхСйЪБСїЃЌПЩвдНЋДјгазгВщбЏЕФ SQL
гяЗЈЦНЦЬБэДяЃЌДЎНгЪ§ОнСїТпМЃЌИќШнвзРэНтЁЃ
4. гяЗЈ
Flink SQL ЕФКЫаФВПЗжЪЧ DML гяЗЈЃЌЛљДЁЕФ DML гяЗЈАќКЌЕбПЈЖћЛ§ЃЈЕЅБэЧщПіЯТжЛга
Scan ВйзїЃЉЁЂбЁдёЃЈFilterЃЉКЭЭЖгАЃЈProjectionЃЉШ§ИіЪ§ОнВйзїВПЗжЃЌШ§епЗжБ№ЖдгІFROMзгОфЁЂWHERE
згОфКЭSELECTзгОфЃЌетШ§ИіВПЗжЕФЫГађДњБэСЫ DML гяОфЕФТпМжДааЫГађЁЃНЯЮЊНјНзЕФгяЗЈАќКЌОлКЯЁЂДАПкКЭСЌНгЃЈJOINЃЉЕШГЃгУгяЗЈЃЌвдМАХХађЁЂЯожЦКЭМЏКЯЕШЗЧГЃгУгяЗЈЁЃЯТБэМђЕЅСаОй
Flink SQL ЛљДЁКЭГЃгУЕФНјНз DML гяЗЈОфЪНВЂМгвдЫЕУїЃЌЦфЫћгяЗЈдЊЫиКЭФкНЈКЏЪ§ЕШЯъЯИФкШнЃЌПЩВЮПМFlink
SQLЮФЕЕ
ЛљДЁгяЗЈ

ОлКЯгяЗЈ

СЌНггяЗЈ

5. ГЁОА
ФПЧА Flink SQL ЕФгІгУЙуЗКЃЌПЩвдгУдк IoTЁЂГЕСЊЭјЁЂжЧЛлГЧЪаЁЂШежОЗжЮіЁЂETLЁЂЪЕЪБДѓЦСЁЂЪЕЪБИцОЏЁЂЪЕЪБЭЦМіЕШЕШЁЃдк
IoT КЭГЕСЊЭјЕШаавЕЖд Flink гаИќИпЕФвЊЧѓЃЌШчЪБМфЕиРэКЏЪ§ЁЂCEP SQLЁЂStreamingML
ЕШЃЌИїИідЦГЇЩЬЖМгаВЛЭЌГЬЖШЕФЪЕЯжЃЌЛЊЮЊдЦЪЕЪБСїМЦЫудкетЗНУцЬиадзюЮЊЗсИЛЁЃ |









