| БрМЭЦМі: |
БОЮФжївЊНщЩмFlink
SQLЕФЩшМЦдРэвдМАЗжЯэдкАЂРяДѓЙцФЃЪЙгУжаЪеЛёЕФОбщЁЃ
БОЮФРДздгкIT168 ЃЌгЩЛ№СњЙћШэМўLindaБрМЁЂЭЦМіЁЃ |
|
АЂРяАЭАЭзд2015ФъПЊЪМЕїбаПЊдДСїМЦЫув§ЧцЃЌзюжеОіЖЈЛљгкFlinkДђдьаТвЛДњМЦЫув§ЧцЃЌеыЖдFlinkДцдкЕФВЛзуНјаагХЛЏКЭИФНјЃЌВЂНЋзюжеДњТыЙБЯзИјПЊдДЩчЧјЁЃФПЧАЮЊжЙЃЌЮвУЧвбОЯђЩчЧјЙБЯзСЫЪ§АйИіCommiterЁЃАЂРяАЭАЭНЋИУЯюФПУќУћЮЊBlinkЃЌжївЊгЩBlink
RuntimeгыFlink SQLзщГЩЁЃBlink RuntimeЪЧАЂРяАЭАЭФкВПИпЖШЖЈжЦЛЏЕФМЦЫуФкКЫЃЌFlink
SQLдђЪЧУцЯђгУЛЇЕФAPIВуЃЌЮвУЧЭъЩЦСЫВПЗжЙІФмЃЌБШШчAggЁЂJoinЁЂWindowsДІРэЕШЁЃНёФъЃЌЮвУЧвбОШЋВПХмЭЈTPCH
МАTPC-DSЕФQueryЃЌЪьЯЄЪ§ОнПтЕФШЫЖМжЊЕРЃЌетДњБэзХећИіЪ§ОнПтЛђв§ЧцЪЧвЛИіЛљБОЙІФмЭъБИЕФВњЦЗЁЃ
НгЯТРДжївЊНщЩмFlink SQLЕФЛљБОИХФюМАЪЙгУЁЃДЋЭГЕФСїЪНМЦЫув§ЧцЃЌБШШчStormЁЂSpark
StreamingЖМЛсЬсЙЉвЛаЉfunctionЛђепdatastream APIЃЌгУЛЇЭЈЙ§JavaЛђScalaаДвЕЮёТпМЃЌетжжЗНЪНЫфШЛСщЛюЃЌЕЋгавЛаЉВЛзуЃЌБШШчОпБИвЛЖЈУХМїЧвЕїгХНЯФбЃЌЫцзХАцБОЕФВЛЖЯИќаТЃЌAPIвВГіЯжСЫКмЖрВЛМцШнЕФЕиЗНЁЃ
ЮвУЧвЛжБдкЫМПМзюЪЪКЯСїМЦЫуДІРэЕФAPIЃЌКСЮовЩЮЪЃЌSQLвбОГЩЮЊДѓЪ§ОнСьгђЭЈгУЧвГЩЪьЕФгябдЃЌвђДЫЮвУЧЕФFlinkКЭBlinkОљЛљгкДЫЃЌжЎЫљвдбЁдёНЋSQLзїЮЊКЫаФAPIЃЌЪЧвђЮЊЦфОпгаМИИіЗЧГЃживЊЕФЬиЕуЃЌвЛЪЧSQLЪєгкЩшЖЈЪНгябдЃЌгУЛЇжЛвЊБэДяЧхГўашЧѓМДПЩЃЌВЛашвЊСЫНтОпЬхзіЗЈ;ЖўЪЧSQLПЩгХЛЏЃЌФкжУЖржжВщбЏгХЛЏЦїЃЌетаЉВщбЏгХЛЏЦїПЩЮЊSQLЗвыГізюгХжДааМЦЛЎ;Ш§ЪЧSQLвзгкРэНтЃЌВЛЭЌаавЕКЭСьгђЕФШЫЖМЖЎ;ЫФЪЧSQLЗЧГЃЮШЖЈЃЌдкЪ§ОнПт30ЖрФъЕФРњЪЗжаЃЌSQLБОЩэБфЛЏНЯЩйЃЌЗЧГЃЮШЖЈЁЃЕБЮвУЧЩ§МЖЛђЬцЛЛв§ЧцЪБЃЌгУЛЇЪЧЮоИажЊЕФЧвЭъШЋМцШн;зюКѓЃЌSQLОЙ§гХЛЏПЩвдЭГвЛСїКЭХњЁЃ
Й§ШЅЃЌЮвУЧМШашвЊХњФЃЪНХмШЋСПЪ§ОнЃЌвВашвЊСїФЃЪНЪЕЪБХмдіСПЪ§ОнЃЌвђДЫашвЊЭЌЪБЮЌЛЄСНИів§ЧцЃЌВЂЧвБЃГжСНЗнДњТыжЎМфЕФЭЌВНЁЃШчЙћЪЙгУSQLЃЌЮвУЧБуПЩвдвЛЗнДњТыЭЌЪБХмдкСНИіФЃЪНЯТЃЌЕЋSQLЪЧЮЊДЋЭГХњДІРэЩшМЦЕФЃЌВЂВЛФмЮЊСїДІРэЫљгУЁЃSQLЖЈвхдкБэЩЯЃЌЖјВЛЪЧСїЩЯЁЃДЋЭГSQLДІРэЕФЪ§ОнМЏБШНЯгаЯоЃЌВщбЏвЛДЮжЛЗЕЛивЛИіНсЙћЁЃЕЋЪЧЃЌСїДІРэашвЊВЛЖЯНгЪеЪ§ОнЃЌВЛЖЯЖдНсЙћНјааИќаТЃЌВЂЧвВщбЏвВВЛЛсНсЪјЃЌетЕМжТЦфашвЊЖдРњЪЗЪ§ОнВЛЖЯаое§ЁЃЫљвдЃЌSQLЕФКмЖрИХФюЮоЗЈжБНггГЩфЕНСїМЦЫуЃЌетОЭЪЧдкСїМЦЫуЩЯЖЈвхSQLЕФФбЕуЁЃ
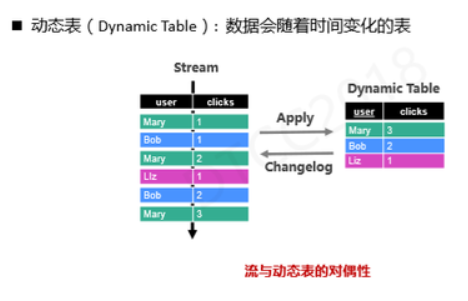 ЁЁ ЁЁ
ЮЊСЫдкСїМЦЫуЩЯЖЈвхSQLЃЌЮвУЧашвЊв§ШыМИИіИХФюЁЃМШШЛХњДІРэашвЊЖЈвхSQLБэЕФИХФюЃЌФЧдкСїМЦЫуЩЯвВашвЊБэЕФИХФюЃЌЮвУЧашвЊНЋДЋЭГОВЬЌБэРЉеЙГЩЖЏЬЌБэЃЌЫљЮНЖЏЬЌБэОЭЪЧЪ§ОнЛсЫцЪБМфЖјВЛЖЯБфЛЏЕФБэЁЃДЫЪБЃЌЮвУЧЗЂЯжСїКЭЖЏЬЌБэжЎМфгавЛжжЖдХМадЃЌвВОЭЪЧЫЕСїКЭЖЏЬЌБэПЩвдЯрЛЅзЊЛЛЁЃНЋСїЕФУПЬѕЪ§ОнВхШыЕНЪ§ОнПтжаЃЌОЭЕУЕНСЫвЛеХБэ;ЭЌЪБЮвУЧПЩвдГщШЁЖЏЬЌБэЕФchangelogЛЙддЪМСїЁЃ
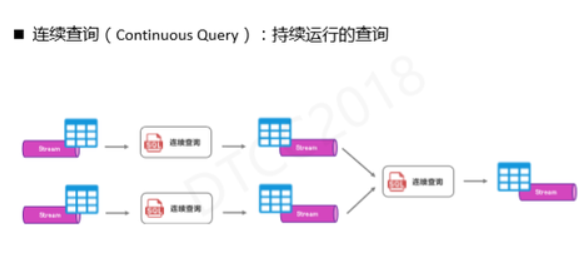
ДгСїМЦЫуЕНSQLЃЌЮвУЧПЩвдАбЫќПДГЩЪЧСЌајВщбЏЁЃСЌајВщбЏЧјБ№гкДЋЭГЕФХњДІРэВщбЏЃЌашвЊдДдДВЛЖЯЕиНгЪеЪ§ОнЃЌУПЪеЕНвЛЬѕаТЪ§ОнОЭЛсИќаТНсЙћЧвНсЙћвВЪЧвЛеХЖЏЬЌБэЃЌФЧНсЙћЕФЖЏЬЌБэгжПЩвдзїЮЊЯТвЛИіВщбЏЕФЪфШыЃЌДгЖјДЎЦ№ећИіСїМЦЫуЁЃ
ЛљгкЩЯЪіСНИіИХФюЃЌЮвУЧПЩвддкSQLЩЯЖЈвхСїМЦЫуЁЃЕЋЪЧЃЌСїМЦЫужаЕФЪ§ОнашвЊВЛЖЯаое§КЭИќаТЃЌвђДЫетаЉЪ§ОнЯТЗЂКѓПЩФмЕМжТзюжеНсЙћЕФДэЮѓЃЌЮвУЧашвЊАбетаЉДэЮѓЪ§ОнНјаааое§ЃЌетОЭЩцМАЕНСїМЦЫужавЛИіЗЧГЃживЊЕФИХФюЁЊЁЊRetractionЁЃ
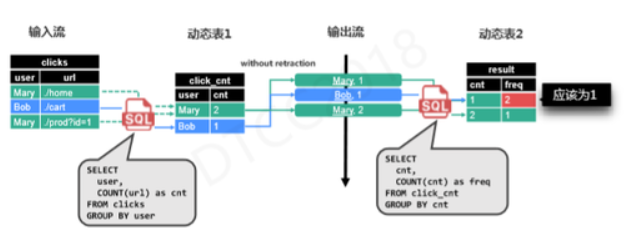
ЮЊСЫНтЪЭДЫИХФюЃЌЮвУЧОйвЛИіМђЕЅЕФР§згЃЌЩЯЭМЫљЪОгавЛИіЕуЛїЪфШыСїЃЌЫќОпБИСНИізжЖЮЃКuserКЭurlЃЌОЙ§ЕквЛИіВщбЏИљОнгУЛЇНјааЗжзщЃЌЭГМЦУПИігУЛЇЕФЕуЛїДЮЪ§;НјШыЕкЖўИіВщбЏЃЌИљОнЕуЛїДЮЪ§НјааЗжзщЃЌЭГМЦУПИіДЮЪ§ЕФОпЬхЕуЛїШЫЪ§ЁЃзюжеЃЌЮвУЧЛсЪеЕНСНЬѕМЧТМЃЌЕуЛїДЮЪ§ЫљЖдгІЕФШЫЪ§ЁЃДгНсЙћУїЯдПЩвдПДГіМЦЫугаЮѓЃЌMaryЕФЪ§ОнВЂУЛгаКЯВЂМЦЪ§ЃЌетОЭашвЊв§Шыаое§ЕФИХФюЁЃ
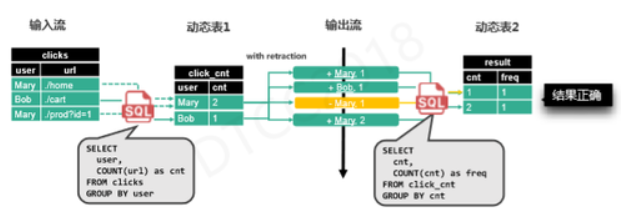
ШчЩЯЭМЫљЪОЃЌОЙ§аое§жЎКѓЃЌОЙ§ЕкЖўИіВщбЏЪБЃЌMaryЕФзмВщбЏДЮЪ§ЛсБЛКЯВЂМЦЫуЃЌMary 1ЕФНсЙћЛсБЛИцжЊГЗЛиЃЌДгЖјЪфГіе§ШЗЕФНсЙћЃЌетОЭЪЧв§ШыRetractionЕФзїгУЁЃдкећИіЙ§ГЬжаЃЌЪЧЗёДЅЗЂRetractionвдМАЗЂЫЭЗНЪНОљгЩгХЛЏЦїОіЖЈЃЌгУЛЇЖдећИіЙ§ГЬЪЧЮоИажЊЕФЁЃ
дкДЫЛљДЁЩЯЃЌЮвУЧЗЂЯжЪРНчВЛашвЊЫљЮНЕФStream SQLгяЗЈЃЌБъзМЕФANSI SQLОЭПЩгУРДЖЈвхСїМЦЫуЃЌFlink
SQLОЭЪЧБъзМЕФANSI SQLгяЗЈЁЃЦфВПЗжКЫаФЙІФмШчЯТЃКDDLгУРДЖЈвхЪ§ОндДБэЁЂЪ§ОнНсЙЙБэ;UDFЁЂUDTFЁЂUDAFгУЛЇздЖЈвхКЏЪ§ЃЌПЩвдЖЈжЦЛЏгУЛЇИДдгЕФвЕЮёашЧѓ;JOINЪЧвЛИіБШНЯИДдгЕФЙІФмЃЌАќРЈСїгыСїжЎМфЕФJoinЃЌСїгыБэжЎМфЕФJoinвдМАWindows
JoinЕШ;ОлКЯЙІФмАќРЈРрЫЦGroup AGGЃЌWindoes AggвдМАOver AggЕШЁЃ

НгЯТРДЮвЛсНсКЯЪЕР§ЖдКЫаФЙІФмНјааНщЩмЁЃЪзЯШЪЧзАдиЪ§ОнЃЌашвЊcreate tableгяЗЈЁЃШчЩЯЭМЫљЪОЃЌЮвУЧЯШЖЈвхвЛеХclicksБэЃЌШЛКѓЖЈвхБэЕФschemaЁЂuserЁЂcTimeвдМАurlЃЌwithРяЪЧБэЕФвЛЯЕСаЪєадЃЌЫќЪЧвЛИіРДздkafkaЕФШежОБэЃЌЮвУЧПЩвдгУSELECT
* FROM clicksВщбЏзЊдиБэРяУцЕФЪ§ОнЁЃ

ШчЙћвЊНЋЩЯЪіВщбЏЪ§ОнаДЕНФГИіБэжаЃЌЮвУЧашвЊгУcreate tableЖЈвхНсЙћБэЃЌгяЗЈЭЌЩЯЃЌДДНЈвЛеХ
last_clicks НсЙћБэЃЌжїМќЪЧuserЃЌЭЈЙ§INSERT INTO гяЗЈНЋЩЯЪіВщбЏЪ§ОнВхШыMysqlБэжаЁЃ

ШчЙћЯыАбжаМфДІРэНсЙћЭЌЪБаДШыЖрИіДцДЂЃЌБШШчАбЪ§ОнДІРэНсЙћЭЌЪБаДЕНMysqlКЭHBaseЃЌШчЩЯЪЙгУCREATE
VIEW ЖЈвхвЛИіРДздЬдБІЕФЕуЛїМЧТМЃЌЭЌЪБСЌајаДЖрИіINSERT INTOЕНMysqlКЭHBaseЁЃ
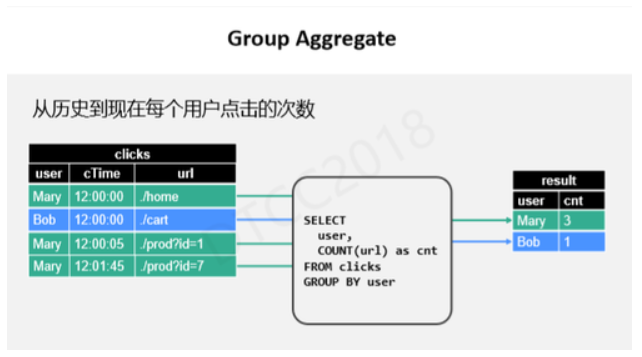
НгЯТРДЪЧGroup AggregateЃЌвВОЭЪЧЮоЯоСїСПОлКЯЁЃЫљЮНЮоЯоСїСПОлКЯжИДгРњЪЗПЊЪМЕНЯждкЕФЫљгагУЛЇЕуЛїЪ§ОнЃЌШчЩЯВщбЏеЙЪОЕФЪЧИљОнгУЛЇЗжзщЃЌШЛКѓЭГМЦЕуЛїДЮЪ§ЁЃШчЙћРДСЫвЛЬѕMary1ЕФЪ§ОнЃЌЮвУЧОЭЯШВхШыИУЪ§ОнЃЌКѓајШчЙћMaryдйДЮНјааЕуЛїЃЌЮвУЧОЭдкдЪ§ОнЛљДЁЩЯНјаааоИФИќаТЃЌвдДЫРрЭЦЁЃ
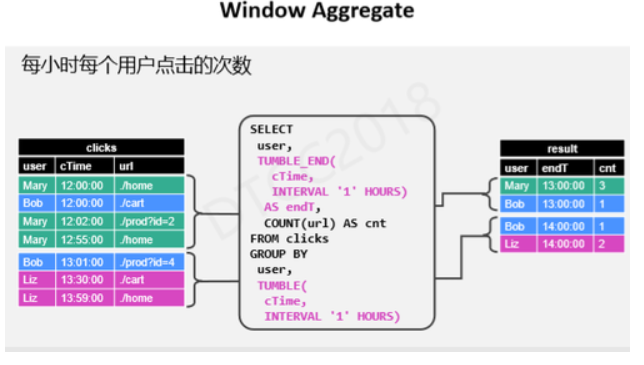
Window AggregateЪЧЖЈвхдкДАПкЩЯЕФОлКЯЃЌгаБ№гкЩЯЪіЮоЯоСїОлКЯЃЌЫќЕФдРэЪЧЪЧУПИіДАПкЖдгІЪфГівЛИіНсЙћЃЌБШШчУПаЁЪБУПИігУЛЇЕФЕуЛїДЮЪ§ЃЌашвЊдкgroup
byЕФНсЙћЩЯМгЩЯendTЪ§ОнЃЌвВОЭЪЧДАПкБъЪЖЁЃ
 ЁЁЁЁ ЁЁЁЁ
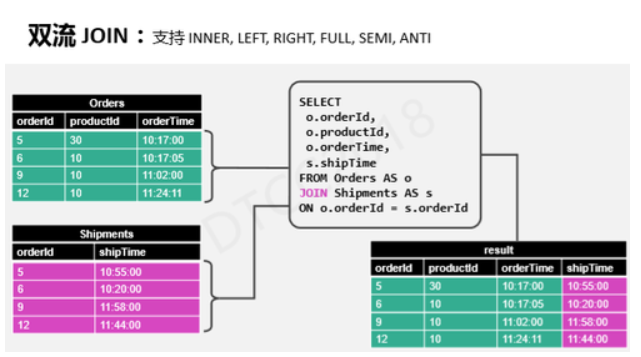
НгЯТРДНщЩмЫЋСїjoinЃЌФПЧАЮвУЧжЇГжINNER, LEFT, RIGHT,
FULL, SEMI, ANTIЕШJoinРраЭЃЌОйР§ЫЕУїЫЋСїJoinЕФжївЊЪЙгУГЁОАЃЌБШШчАбжїСїДђГЩПэБэЃЌВЂВЙЩЯЖюЭтзжЖЮЕШЁЃШчЩЯЭМЫљЪОЃЌЮвУЧашвЊНЋЖЉЕЅКЭЮяСїБэаХЯЂНјааJoinВйзїЃЌдкJoinЕФЮяРэЪЕЯжЩЯЛсгаСНЗнзДЬЌЃЌгУРДДцДЂСНЬѕСїЕНФПЧАЮЊжЙЪеЕНЕФЫљгаРњЪЗЪ§Он,ЬдЬЛњжЦЪБМфЩшЖЈЮЊвЛЬьАывЛДЮЁЃСНепжаШЮКЮвЛЗНаХЯЂбгГйЖМЛсЯШдкБэжаЕШД§ЃЌжБЕНЭЌвЛИіЖЉЕЅЕФаХЯЂгыЮяСїЙиСЊжЎКѓВХЛсЭЈЙ§JoinЪфГіЁЃ
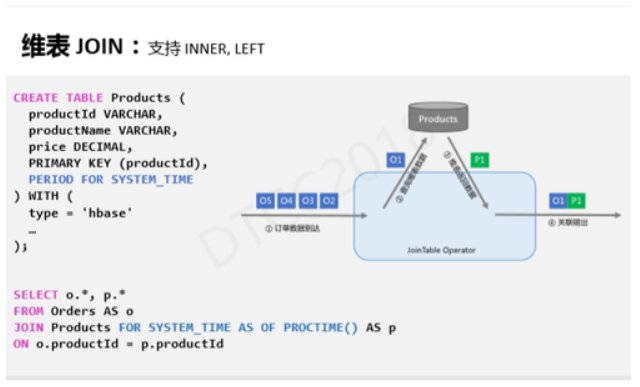
ЮЌБэJoinгыЫЋСїJoinРрЫЦЃЌФПЧАжЇГжINNER, LEFTСНжжНЛвзРраЭЁЃЮЌБэJoinЕФЪЙгУЭЌбљЮЊВЙШЋжїСїЃЌЕЋЯыВЙШЋЕФзжЖЮдкСэвЛЮЌБэжаЁЃШчЩЯЭМЫљЪОЃЌЪЙгУЪБЪзЯШашвЊЭЈЙ§CREATE
TABLE гяЗЈЖЈвхвЛеХЮЌБэЃЌДЫДІЖЈвхЕФЪЧ Products БэЃЌДцДЂгыВњЦЗЯрЙиаХЯЂЃЌВщбЏЭЌбљЪЙгУJoinгяЗЈЁЃOrderгыProductsБэЭЈЙ§Products
IDЪЕЯжJoinЁЃЙиМќзжPERIOD FOR SYSTEM_TIME ЪЧ SQL 2.11БъзМРяЕФгяЗЈЃЌвтЫМЪЧЕБЧАЙиСЊЕФProductsЪЧЕБЧАЪБПЬЕФаХЯЂЃЌЙиСЊжЎКѓВЛдйИќаТаХЯЂЁЃЩЯЭМгвВреЙЪОЕФЪЧЮЌБэJoinЮяРэжДааЕФИХФюЁЃЮвУЧПЩвдИљОнOrderШЅProductsЪ§ОнПтРяВщбЏаХЯЂЃЌзюжеProductsЮЌБэЗЕЛиЙиСЊаХЯЂЁЃ
КЫаФЙІФмШчЩЯЫљЪіЃЌНгЯТРДжївЊСФгХЛЏЁЃЮЌБэжаЃЌЖЉЕЅO1ВщбЏЪБЪЧЖТШћЕШД§IOЕФзДЬЌЃЌДЫЪБЮоТлШчКЮЕїгХадФмЃЌЭЬЭТСПКЭCPUЪЙгУТЪЖМЩЯВЛШЅЃЌвђДЫЮвУЧв§ШывьВНIOЙІФмЁЃ
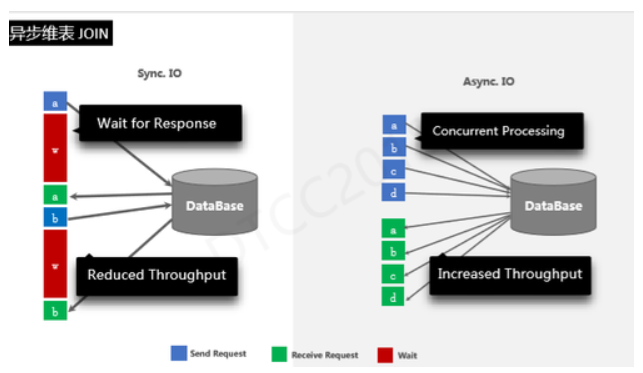
ШчЩЯзѓАыВПЗжЮЊЮДв§ШывьВНIOЪБЕФзДЬЌЃЌШчЩЯгвАыВПЗжЮЊв§ШыКѓЃЌДЫЪБШєЗЂЦ№AЧыЧѓЃЌВЛашЕШД§IOОЭПЩСЂПЬЗЂЦ№BCDВщбЏЧыЧѓЃЌШЛКѓвьВНЕШД§ЗЕЛиНсЙћЁЃЗЕЛиABCDвдКѓдйЙмРэЪфГіЃЌМЋДѓЕиЬсИпСЫећЬхадФмЁЃ
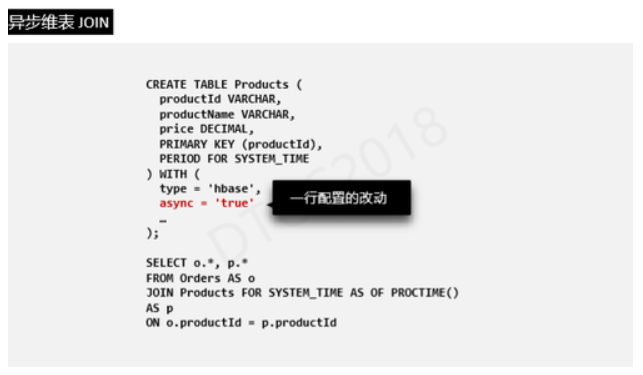
ШчЩЯЃЌвьВНIOЪЙгУЪБгыЮЌБэJoinжЛгавЛааХфжУИФЖЏЃЌЖдгкгУЛЇРДЫЕЃЌетИіЪЙгУЪЧЗЧГЃМђБуЕФЁЃ
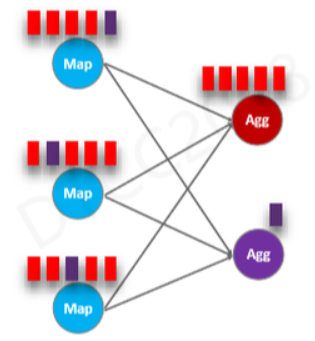
ЕкЖўИігХЛЏЪЧДѓЪ§ОнжаЕФГЃМћГЁОАЁЊЁЊЪ§ОнЧуаБЁЃШчЩЯЮЊИФНјжЎЧАЃЌКьЩЋОлКЯНкЕуГіЯжЪ§ОнЛ§бЙЯжЯѓЃЌЖјзЯЩЋНкЕуЯрЖдНЯПеЁЃ
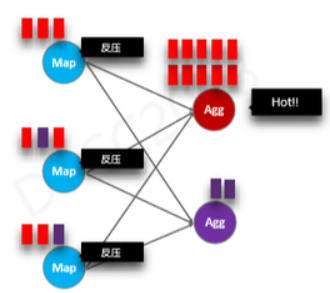
ШчЙћГжајвЛЖЮЪБМфЃЌКьЩЋОлКЯНкЕуОЭЛсБЛДђТњЃЌДгЖјБфЮЊШШЕуЃЌЫљгаЩЯгЮmapНкЕуОЭЛсЗДбЙЃЌЭЃжЙДІРэЪ§ОнНјШыЕШД§зДЬЌЃЌЖјЯТгЮЕФзЯЩЋНкЕуЛљБОДІгкПеЯазДЬЌЁЃ
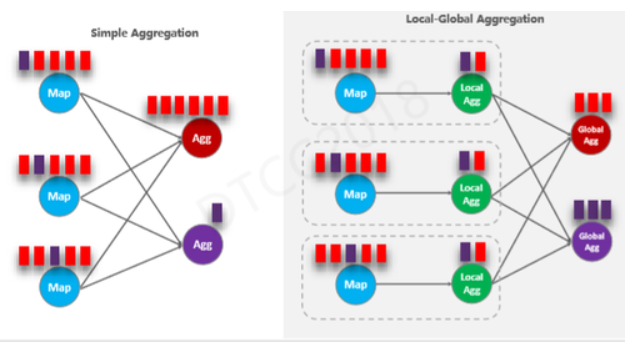
ЮвУЧв§ШыLocal-Global ОлКЯгХЛЏЁЃзѓЭМЪЧЮДгХЛЏЭиЦЫЭМЃЌгвБпЪЧв§ШыLocal-GlobalгХЛЏКѓЕФЭМЃЌЮвУЧдкMapКѓв§ШыLocal
AggНкЕуЃЌMapгыLocal AggЪЧСДдквЛЦ№ЕФвЛИіЯпГЬЃЌжЎМфЕФЪ§ОнДЋЪфУЛгаШЮКЮЭјТчПЊЯњЁЃLocal
AggПЩвдНЋЪеЕНЕФЪ§ОнАДее keyНјаадЄОлКЯЃЌШЛКѓНЋНсЙћАДее keyЗжЗЂИјЯТгЮGlobal AggНјааЛузмЁЃ
МйШчУПИіMapЕФ TPS ЪЧУПУы1ЭђЕФЪ§ОнСПЃЌШЋОжОЭ2Иі keyЃККьЩЋКЭзЯЩЋЁЃШчЙћ Local
AggОлКЯЕФМфИєЪЧУПУыжгвЛДЮЃЌФЧУДУПИіLocal AggФмНЋ1ЭђЬѕЪ§ОндЄОлКЯГЩзюЖр2Ьѕ(ШЋОжЙВ2Иі
key)ЁЃФЧУДGlobal AggУПУыжгзюЖрЪеЕНжЛЛсШ§ЬѕЯћЯЂЃЌФмгааЇНЕЕЭGlobal Agg ЕФШШЕуЁЃгХЛЏКѓЃЌЮвУЧЖдДЫНјааадФмВтЪдЃЌЗЂЯжLocal-Global
ПЩвдДјРДГЌЙ§20БЖЕФадФмЬсЩ§ЁЃвђДЫЃЌећИіЗНАИЪЧЪЎЗжгааЇЕФЁЃ
|









